

Forgetful Forests: Data Structures for Machine Learning on Streaming Data under Concept Drift

Abstract
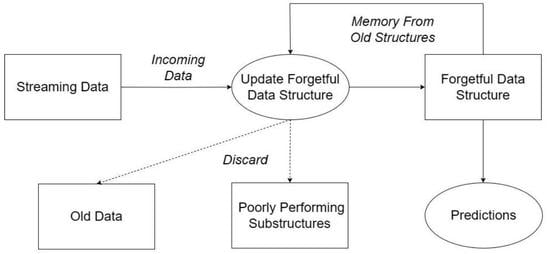
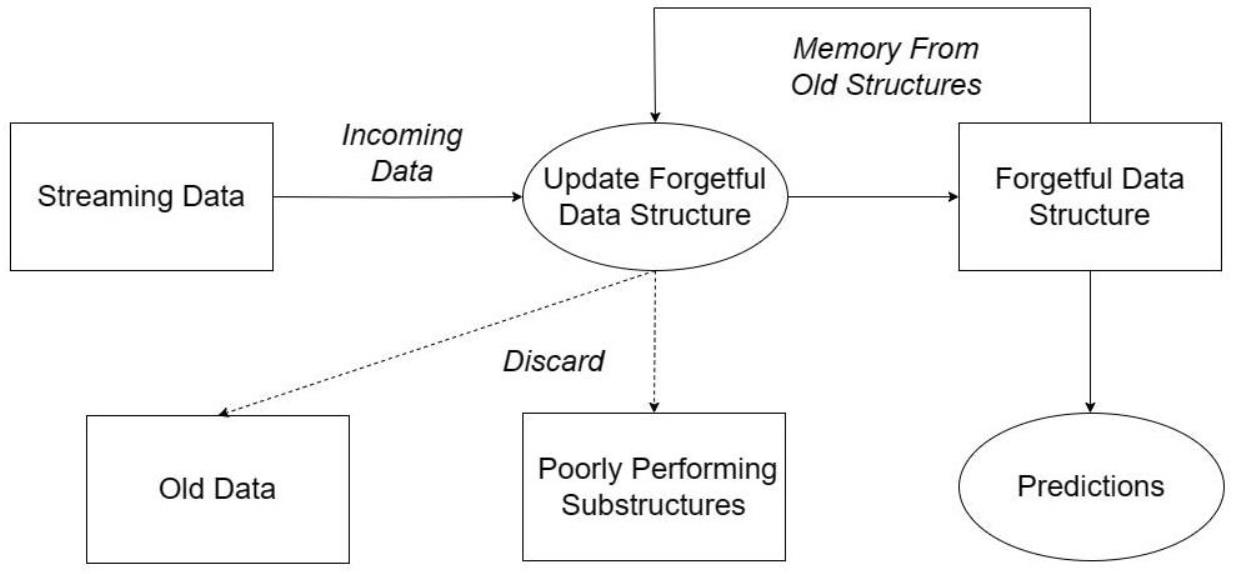{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Related Work
2.1. Hoeffding Tree
2.2. Adaptive Hoeffding Tree
2.3. iSOUP-Tree
2.4. Adaptive Random Forest
2.5. Ensemble Extreme Learning Machine
3. Forgetful Data Structures
3.1. Forgetful Decision Trees
3.2. Adaptive Calculation of Retain Size and Max Tree Height
- When accuracy increases (i.e., the more recent predictions have been more accurate than previous ones) a lot, the model can make good use of more data. We want to increase with the effect so that we discard little or no data. When the accuracy increase is mild, the model has perhaps achieved an accuracy plateau, so we increase , but only slightly.
- When accuracy changes little or not at all, we allow to slowly increase.
- When accuracy decreases, we want to decrease to forget old data, because this indicates that concept drift has happened. When concept drift is mild and accuracy decreases only a little, we want to retain more old data, so should decrease only a little. When accuracy decreases a lot, the new data may follow a completely different functional mapping from the old data, so we want to forget most of the old data, suggesting should be very small.
3.3. Forgetful Random Forest
- Only a limited number of features are considered at each split, increasing the chance of updating (rather than rebuilding) subtrees during recursion, thus saving time by avoiding the need to rebuild subtrees from scratch. The number of features considered by each decision tree is uniformly and randomly chosen within the range , where is the number of features in the dataset. Further, every node inside the same decision tree considers the same features.
- The update function for each tree will randomly and uniformly discard old data without replacement, instead of discarding data based on time of insertion. Because this strategy does not give priority to newer data, this strategy increases the diversity of the data given to the trees.
- To decrease the correlation between trees and increase the diversity in the forest, we give the user the option to choose the leveraging bagging [11] strategy to the data arriving at each random forest tree. The size of the data after bagging is times the size of original data, where is a random number with an expected value of , generated by a distribution. To avoid the performance loss resulting from too many copies of the data, we never allow to be larger than . Each data item in the expanded data is randomly and uniformly selected from the original data with replacement. We apply bagging to each decision tree inside the random forest.
4. Tuning the Values of the Hyperparameters
- The evaluation function can be a Gini Impurity [17] score or an entropy reduction coefficient. Which one is chosen does not make a material difference, so we set to entropy reduction coefficient for all datasets.
- The maximum tree height () is adaptively set based on the methods in Section 3.2 to log base 2 of . Applying other stopping criteria does not materially affect the accuracy. For that reason, we ignore other stopping criteria.
- To mitigate the inaccuracies of the initial cold start, the model will not discard any data in cold startup mode. To leave cold startup mode, the accuracy should be better than random guessing on the last of data, when is at least . adapts if it is too small, so we will set its initial value to data items.
- To avoid discarding trees too often, we will discard a tree only when we have confidence that the accuracy has changed. We observe that all datasets enjoy a good accuracy when .
- There are forgetful decision trees in each forgetful random forest. We observe that the accuracy of all datasets stops growing after both with bagging and without bagging, so we will set .
- The adaptation strategy in Section 3.2 needs an initial value for parameter , which influences the increase rate of the retained data . Too much data will be retained if the initial is large, but the accuracy will be low for lack of training data if the initial value of is small. We observe that the forgetful decision tree does well when or initially. We will use as our initial setting and use it in the experiments of Section 5 for all our algorithms, because most simulated datasets have higher accuracy at than at .
5. Results
- Previous papers [8,18] provide two different configurations for the Hoeffding tree. The configuration from [8] usually has the highest accuracy, so we will use it in the following experiment: , , and . Because the traditional Hoeffding tree cannot deal with concept drift, we set to allow the model to adapt when concept drift happens.
- The designers of the Hoeffding adaptive tree suggest six possible configurations of the Hoeffding adaptive tree, which are HAT-INC, HATEWMA, HAT-ADWIN, HAT-INC NB, HATEWMA NB, and HAT-ADWIN NB. HAT-ADWIN NB has the best accuracy, and we will use it in the following experiments. The configuration is , , , and .
- The designers provide only one configuration for the iSOUP tree [9], so we will use it in the following experiment. The configuration is , , , and .
- For the train-once model, we will train the model only once with all of the data before starting to measure accuracy and other metrics. The train-once model is never updated again. In this case, we will use a non-incremental decision tree, which is the CART algorithm [7], to fit the model. We use the setting with the best accuracy, which is , and no other restrictions.
5.1. Categorical Variables
5.2. Metrics
5.3. Datasets
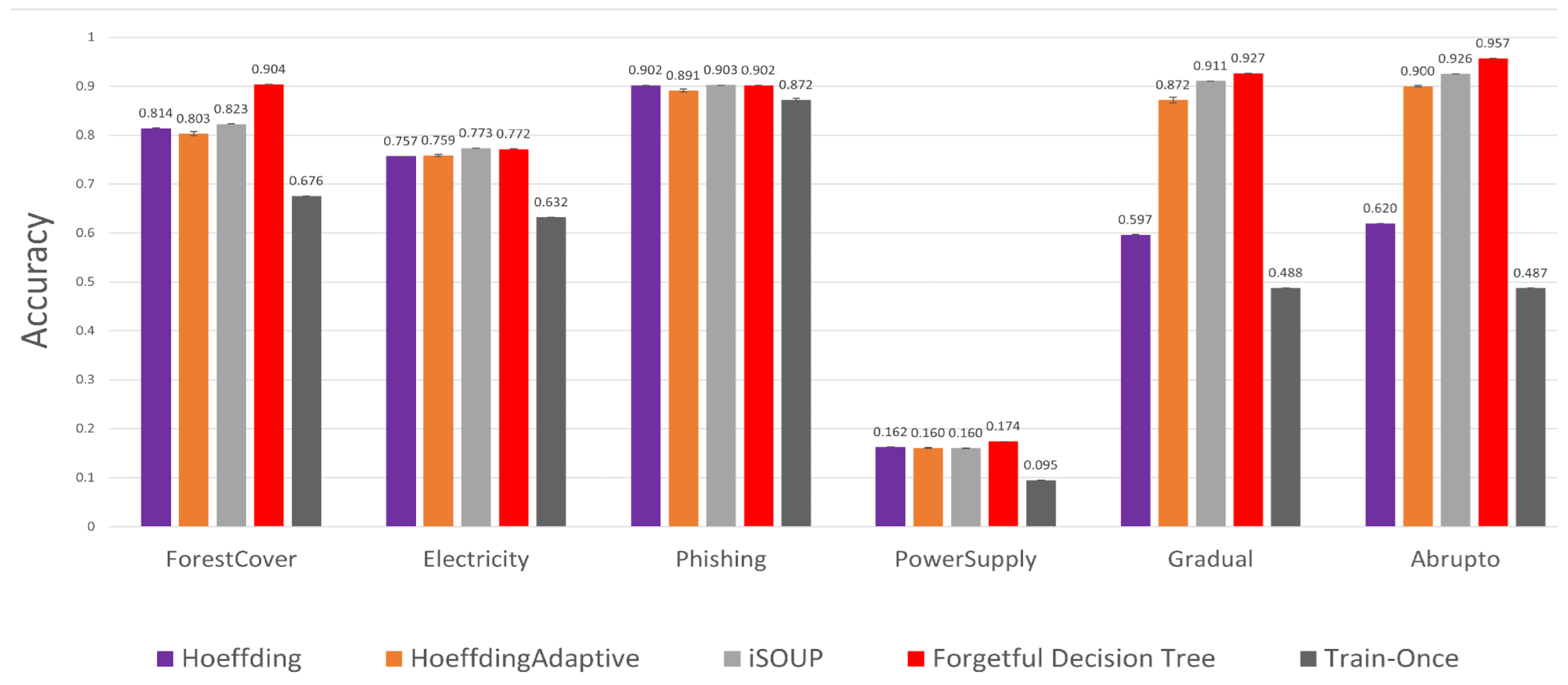
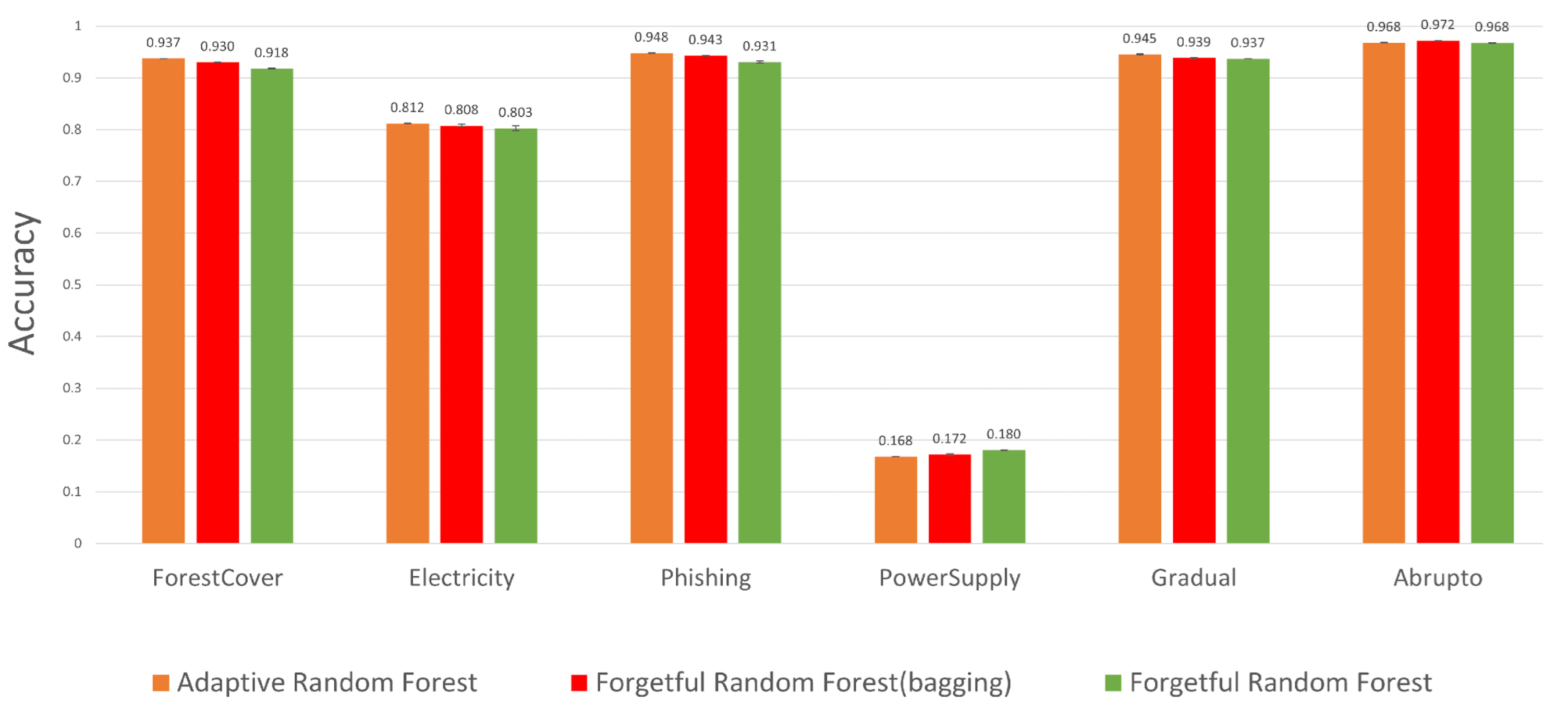
- The forest cover type (ForestCover) [20] dataset captures images of forests for each m cell determined from the US Forest Service (USFS) Region 2 Resource Information System (RIS) data. Each increment consists of 400 image observations. The task is to infer the forest type. This dataset suffers from concept drift because later increments have different mappings from input image to forest type than earlier ones. For this dataset, the accuracy first increases and then flattens out after the first data items have been observed, out of data items.
- The electricity [21] dataset describes the price and demand of electricity. The task is to forecast the price trend in the next min. Each increment consists of data from one day. This data suffers from concept drift because of market and other external influences. For this dataset, the accuracy never stabilizes, so we start measuring accuracy after the first increment, which is after the first data items have arrived, out of data items.
- Phishing [22] contains web pages accessed over time, some of which are malicious. The task is to predict which pages are malicious. Each increment consists of pages. The tactics of phishing purveyors get more sophisticated over time, so this dataset suffers from concept drift. For this dataset, the accuracy flattens out after the first data items have arrived.
- Power supply [23] contains three years of power supply records of an Italian electrical utility, comprising data items. Each data item contains two features, which are the amount of power supplied from the main grid and the amount of power transformed from other grids. Each data item is labelled with the hour of the day when it was collected (from to ). The task is to predict the label from the power measurements. Concept drift arises because of season, weather, and the differences between working days and weekends. Each increment consists of data items, and the accuracy flattens out after the first data items have arrived.
- The two synthetic datasets are from [16]. Both are time-ordered and are designed to suffer from concept drift over time. One, called Gradual, has data points. Gradual is characterized by complete label changes that happen gradually over data points at three single points, and data items between each concept drift. Another dataset, called Abrupt, has data points. It undergoes complete label changes at three single points, with data items between each concept drift. Each increment consists of data points. Unlike the datasets that were used in Section 4, these datasets contain only four features, two of which are binary classes without noise, and the other two are sparse values generated by and , where and are the uniformly generated random numbers. For both datasets, the accuracy flattens out after data items have arrived.
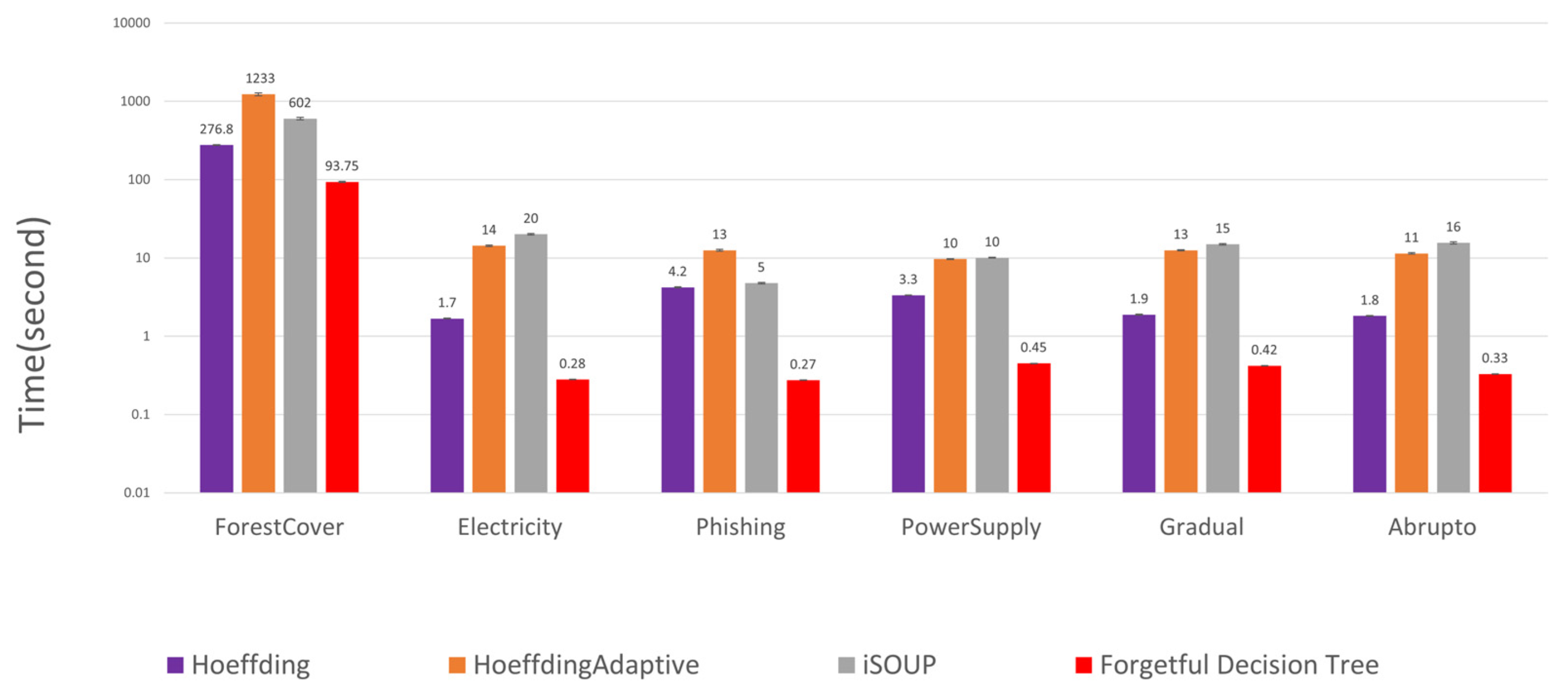
5.4. Quality and Time Performance of the Forgetful Decision Tree
5.5. Quality and Time Performance of the Forgetful Random Forest
6. Discussion and Conclusions
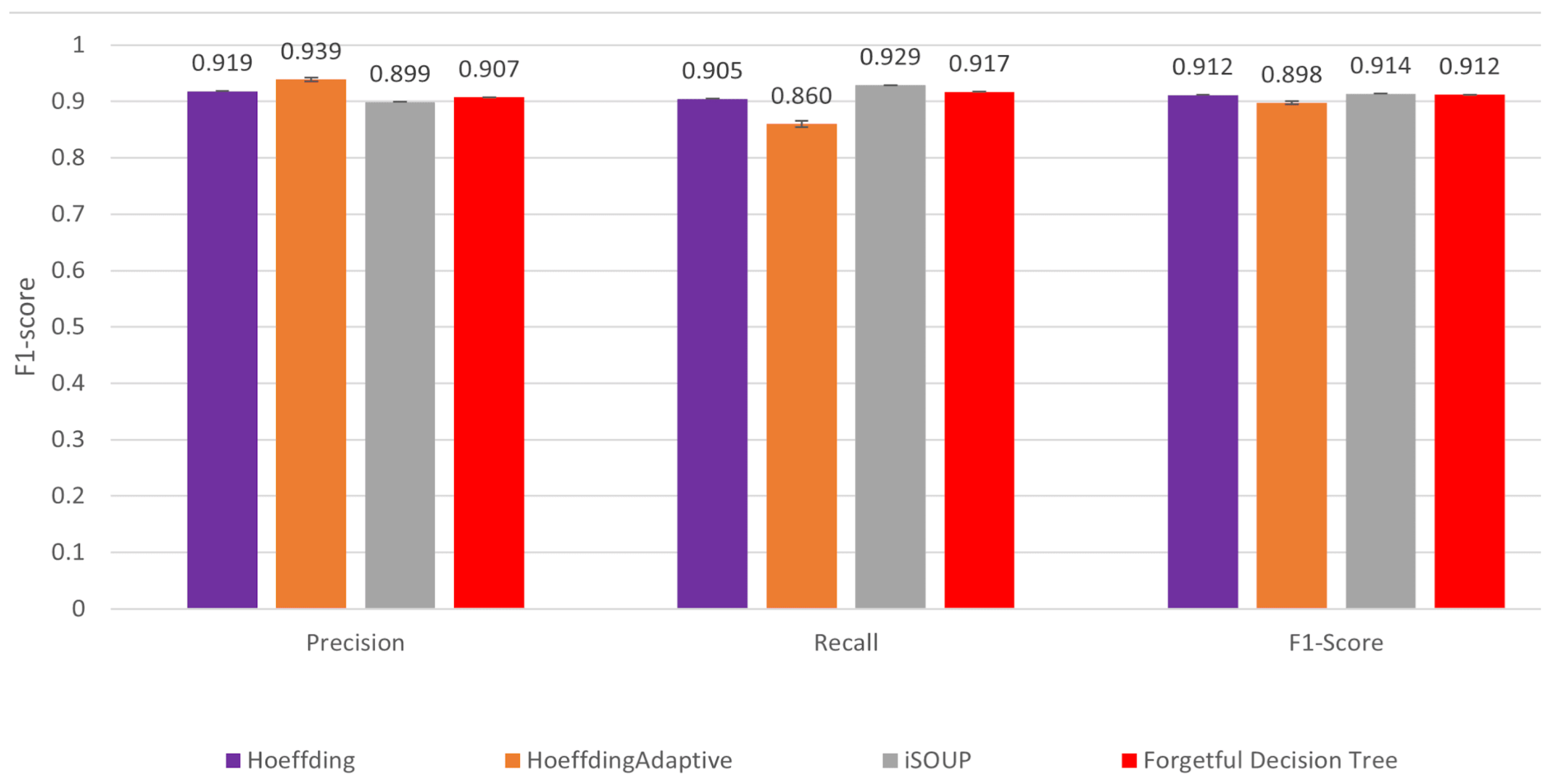
- The forgetful decision tree is at least three times faster and at least as accurate as state-of-the-art incremental decision tree algorithms for a variety of concept drift datasets. When the precision, recall, and F1 score are appropriate, the forgetful decision tree has a similar F1 score to state-of-the-art incremental decision tree algorithms.
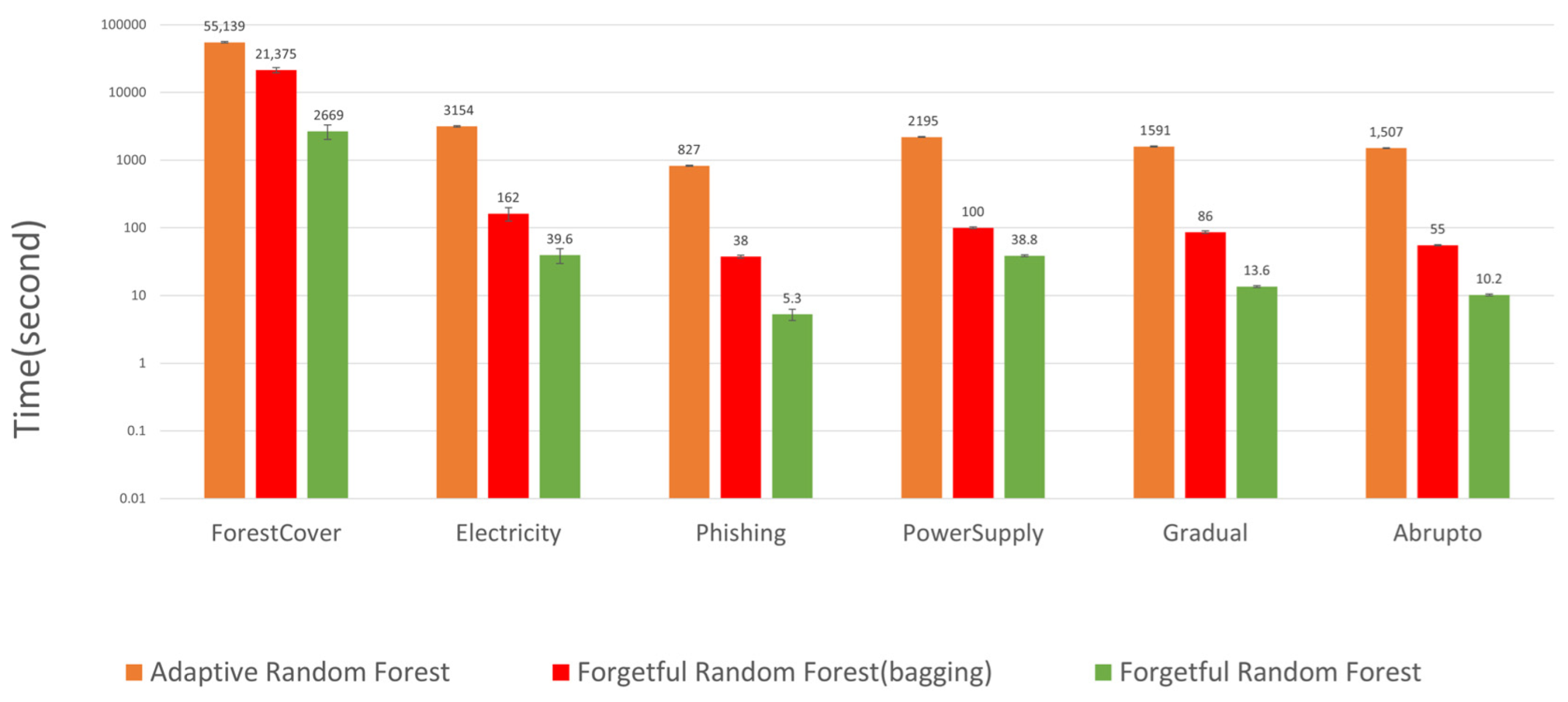
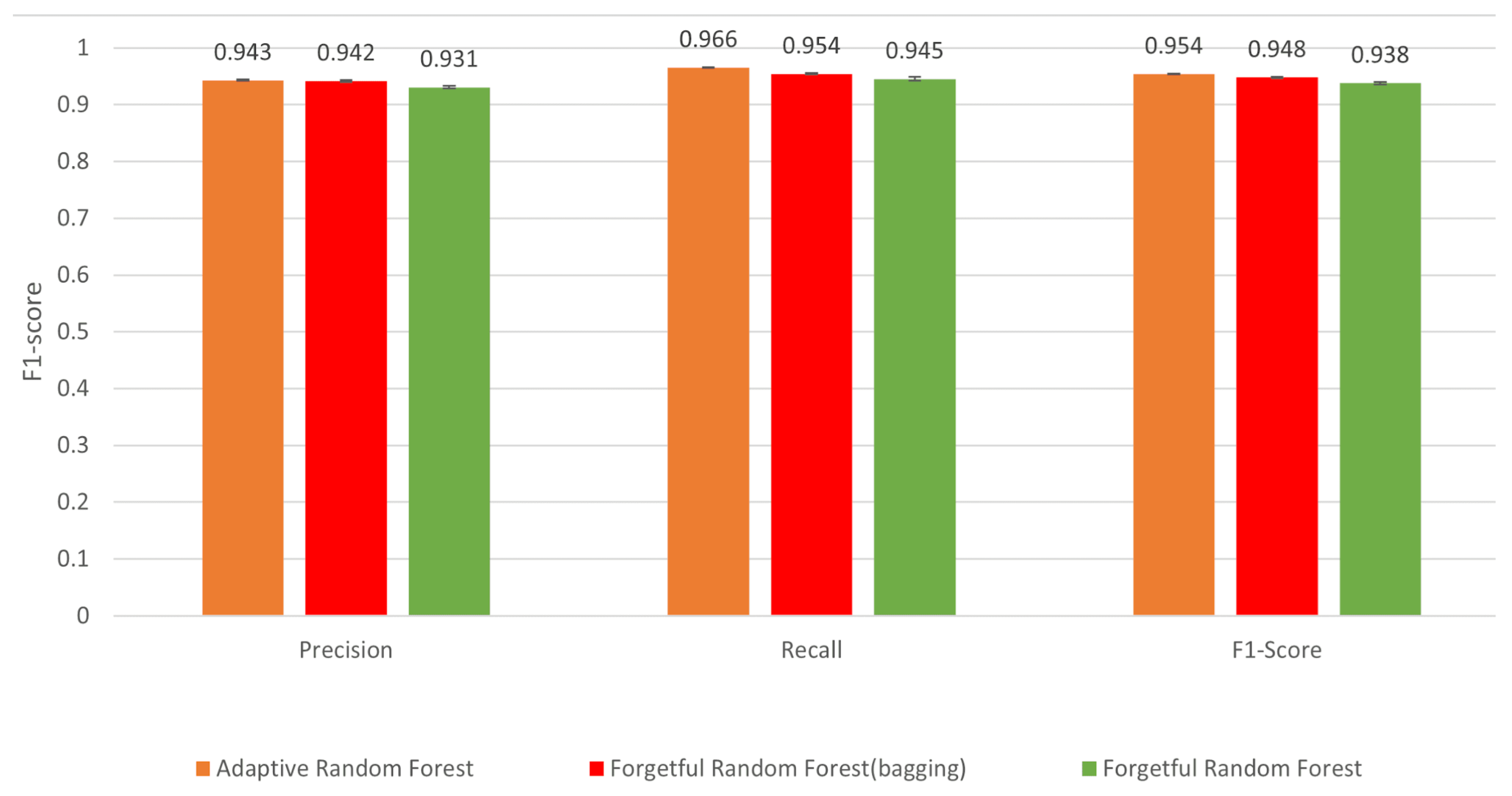
- The forgetful random forest without bagging is at least times faster than state-of-the-art incremental random forest algorithms, but is less accurate by at most .
- By contrast, the forgetful random forest with bagging has a similar accuracy to the most accurate state-of-the-art forest algorithm (adaptive random forest) and is faster.
- At a conceptual level, our experiments show that it was possible to set hyperparameter values based on changes in accuracy on synthetic data and then apply those values to real data. The main such hyperparameters are (increase rate of size of data retained), (the confidence interval that accuracy has changed), and (the number of decision trees in the forgetful random forests).
- Further our experiments show the robustness of our approach across a variety of applications where concept drift is frequent or infrequent, mild or drastic, and gradual or abrupt.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Algorithms for Forgetful Decision Trees


- The stopping criteria may combine one or more factors, such as maximum tree height, minimum samples to split, and minimum impurity decrease. If the criteria holds, then the node will not further split. In addition, if all data points in the node have the same label, that node will not be split further. controls and is computed in below.
- The evaluation function evaluates the splitting score for each feature and each splitting value. It will typically be a Gini Impurity [17] score or an entropy reduction coefficient. As we discuss below, the functions and find split points that minimize the weighted sum of scores of each subset of the data after splitting. Thus, the score must be evaluated on many split points (e.g., if the input attribute is , then possible splitting criteria could be , , …) to find the optimal splitting values.
- determines the size of and to be retained when new data for and arrives. For example, suppose . Then of the oldest of and (the data present before the incoming batch) will be discarded. The algorithm then appends and to what remains of and . All nodes in the subtrees will discard the same data items as the root node. In this way, the tree is trained with only the newest of data in the tree. Discarding old data helps to overcome concept drift, because the newer data better reflects the mapping from to after concept drift. should never be less than , to avoid forgetting any new incoming data. As mentioned above, upon initialization, new data will be continually added to the structure without forgetting until accuracy flattens out, which is controlled by . and are computed in below.
Appendix B. Ongoing Parameter Tuning
- When , the in the exponent will ensure that will be . In this way, the curves slightly upward when is equal to, or slightly higher than , but curves steeply upward when is much larger than .
- When , is equal to . In this way, is flat or curves slightly downward when is slightly lower than but curves steeply downwards when is much lower than .
- Other functions to set are possible, but this one has the following desirable properties: (i) it is continuous regardless of the values of and ; (ii) is close to 1 when is close to ; (iii) when differs from significantly in either direction, reacts strongly.
Appendix C. Algorithms for Forgetful Random Forests


Appendix D. Methods for Determining Hyperparameters
References
- Pandey, R.; Singh, N.K.; Khatri, S.K.; Verma, P. Artificial Intelligence and Machine Learning for EDGE Computing; Elsevier Inc.: Amsterdam, The Netherlands, 2022; pp. 23–32. [Google Scholar]
- Saco, A.; Sundari, P.S.; J, K.; Paul, A. An Optimized Data Analysis on a Real-Time Application of PEM Fuel Cell Design by Using Machine Learning Algorithms. Algorithms 2022, 15, 346. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Stuart Russell; Peter Norvig. Artificial Intelligence: A Modern Approach, 4th ed.; Prentice Hall: Hoboken, NJ, USA, 2020; pp. 1–36. [Google Scholar]
- Polikar, R.; Upda, L.; Upda, S.S.; Honavar, V. Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans. Syst. 2001, 31, 497–508. [Google Scholar] [CrossRef]
- Diehl, C.; Cauwenberghs, G. SVM incremental learning, adaptation and optimization. Proc. Int. Joint Conf. Neural Netw. 2003, 4, 2685–2690. [Google Scholar] [CrossRef]
- Loh, W.-Y. Classification and Regression Trees. WIREs Data Mining Knowl. Discov. 2011, 13, 14–23. [Google Scholar] [CrossRef]
- Sun, J.; Jia, H.; Hu, B.; Huang, X.; Zhang, H.; Wan, H.; Zhao, X. Speeding up Very Fast Decision Tree with Low Computational Cost. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; Volume 7, pp. 1272–1278. [Google Scholar] [CrossRef]
- Osojnik, A.; Panov, P.; Dzeroski, S. Tree-based methods for online multi-target regression. J. Intell. Inf. Syst. 2017, 50, 315–339. [Google Scholar] [CrossRef]
- Domingos, P.; Hulten, G. Mining High-Speed Data Streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; KDD’00. Association for Computing Machinery: New York, NY, USA, 2000; pp. 71–80. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability Inequalities for sums of Bounded Random Variables. In The Collected Works of Wassily Hoeffding; Springer Series in Statistics; Fisher, N.I., Sen, P.K., Eds.; Springer: New York, NY, USA, 1994. [Google Scholar]
- Bifet, A.; Gavaldà, R. Adaptive Learning from Evolving Data Streams. In Advances in Intelligent Data Analysis VIII; Adams, N.M., Robardet, C., Siebes, A., Boulicaut, J.-F., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 249–260. [Google Scholar] [CrossRef]
- Ikonomovska, E.; Gama, J.; Dzeroski, S. Learning model trees from evolving data streams. Data Min. Knowl. Discov. 2021, 23, 128–168. [Google Scholar] [CrossRef]
- Gomes, H.M.; Bifet, A.; Read, J.; Barddal, J.P.; Enembreck, F.; Pfharinger, B.; Holmes, G.; Abdessalem, T. Adaptive Random Forests for Evolving Data Stream Classification. Mach. Learn. 2017, 106, 1469–1495. [Google Scholar] [CrossRef]
- Yang, R.; Xu, S.; Feng, L. An Ensemble Extreme Learning Machine for Data Stream Classification. Algorithms 2018, 11, 107. [Google Scholar] [CrossRef]
- Lobo, J.L. Synthetic Datasets for Concept Drift Detection Purposes. Harvard Dataverse. 2020. Available online: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/5OWRGB (accessed on 25 May 2023).
- Gini, C. Concentration and Dependency Ratios; Rivista di Politica Economica: Roma, Italy, 1997; pp. 769–789. [Google Scholar]
- Hulten, G.; Spencer, L.; Pedro, M.D. Mining time-changing data streams. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 97–106. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Anderson, C.W.; Blackard, J.A.; Dean, D.J. Covertype Data Set. 1998. Available online: https://archive.ics.uci.edu/ml/datasets/Covertype (accessed on 25 May 2023).
- Harries, M.; Gama, J.; Bifet, A. Electricity. 2009. Available online: https://www.openml.org/d/151 (accessed on 25 May 2023).
- Sethi, T.S.; Kantardzic, M. On the Reliable Detection of Concept Drift from Streaming Unlabeled Data. Expert Syst. Appl. 2017, 82, 77–99. [Google Scholar] [CrossRef]
- Zhu, X. Stream Data Mining Repository. 2010. Available online: http://www.cse.fau.edu/~xqzhu/stream.html (accessed on 25 May 2023).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Z.; Sun, Y.; Shasha, D. Forgetful Forests: Data Structures for Machine Learning on Streaming Data under Concept Drift. Algorithms 2023, 16, 278. https://doi.org/10.3390/a16060278
Yuan Z, Sun Y, Shasha D. Forgetful Forests: Data Structures for Machine Learning on Streaming Data under Concept Drift. Algorithms. 2023; 16(6):278. https://doi.org/10.3390/a16060278
Chicago/Turabian StyleYuan, Zhehu, Yinqi Sun, and Dennis Shasha. 2023. "Forgetful Forests: Data Structures for Machine Learning on Streaming Data under Concept Drift" Algorithms 16, no. 6: 278. https://doi.org/10.3390/a16060278
APA StyleYuan, Z., Sun, Y., & Shasha, D. (2023). Forgetful Forests: Data Structures for Machine Learning on Streaming Data under Concept Drift. Algorithms, 16(6), 278. https://doi.org/10.3390/a16060278