


Time-Series Forecasting of Seasonal Data Using Machine Learning Methods


Abstract
1. Introduction
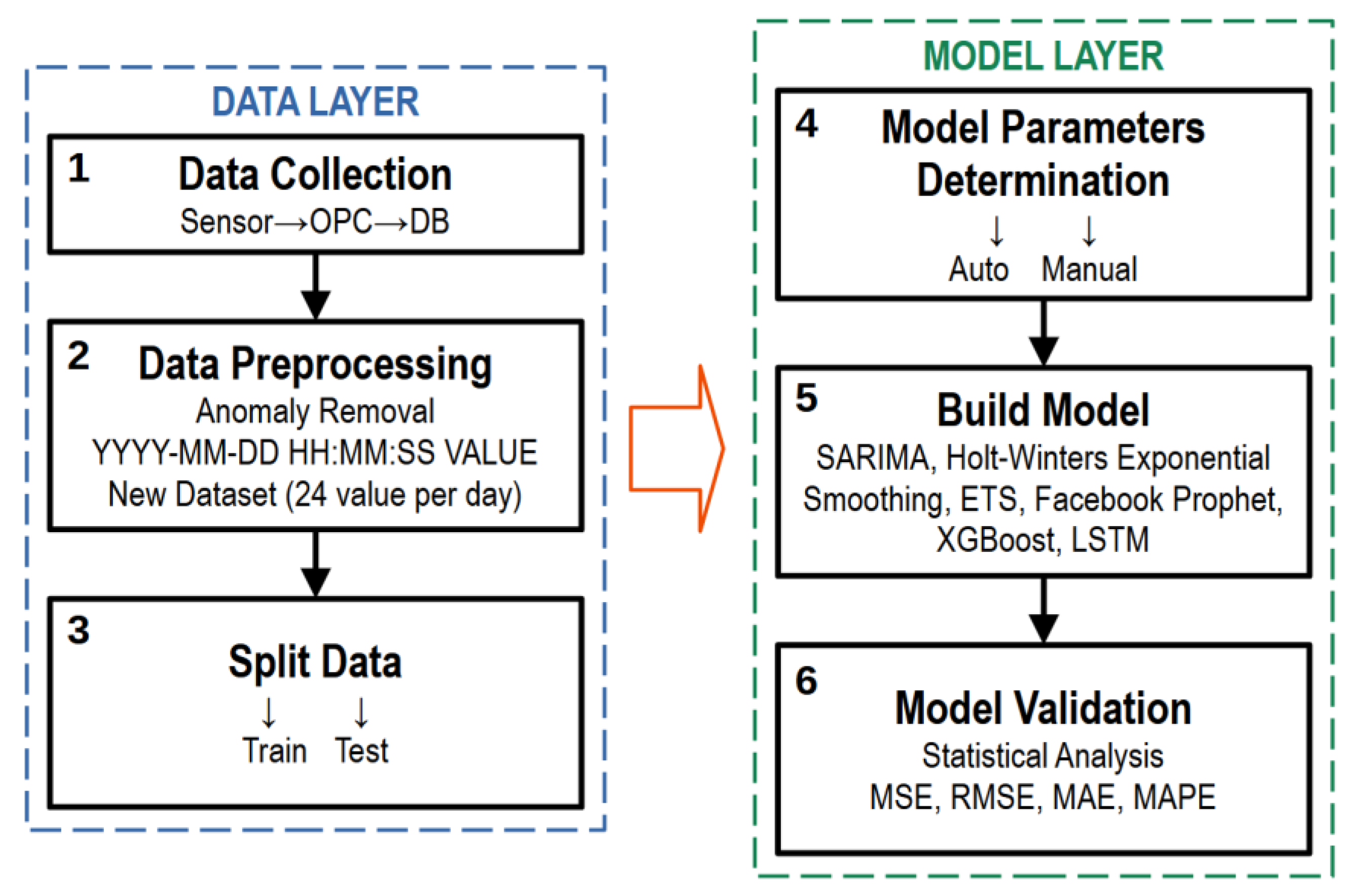
2. Methodology
2.1. The Technical Roadmap and Data Collection
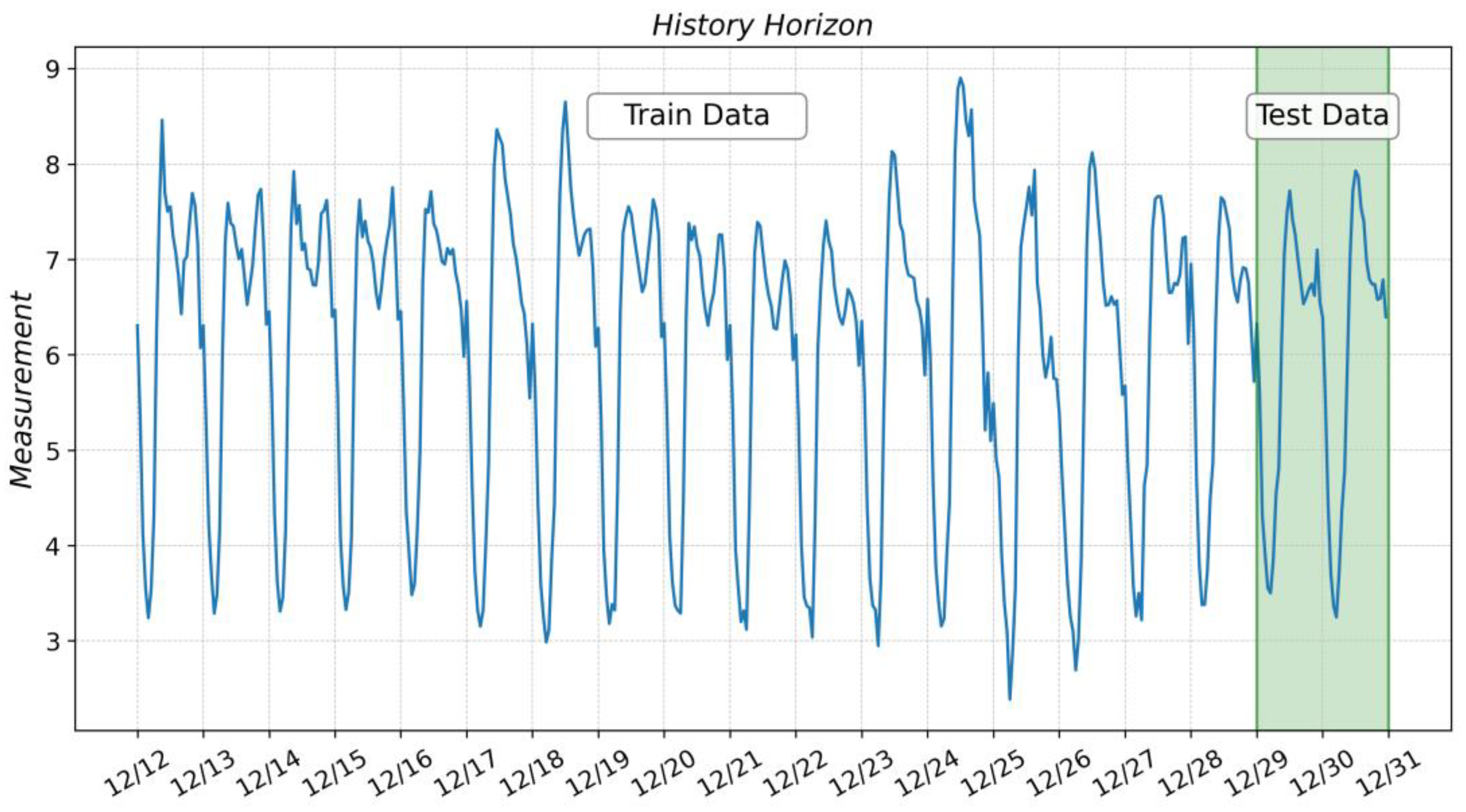
2.2. Data Preprocessing
3. Development of the Models
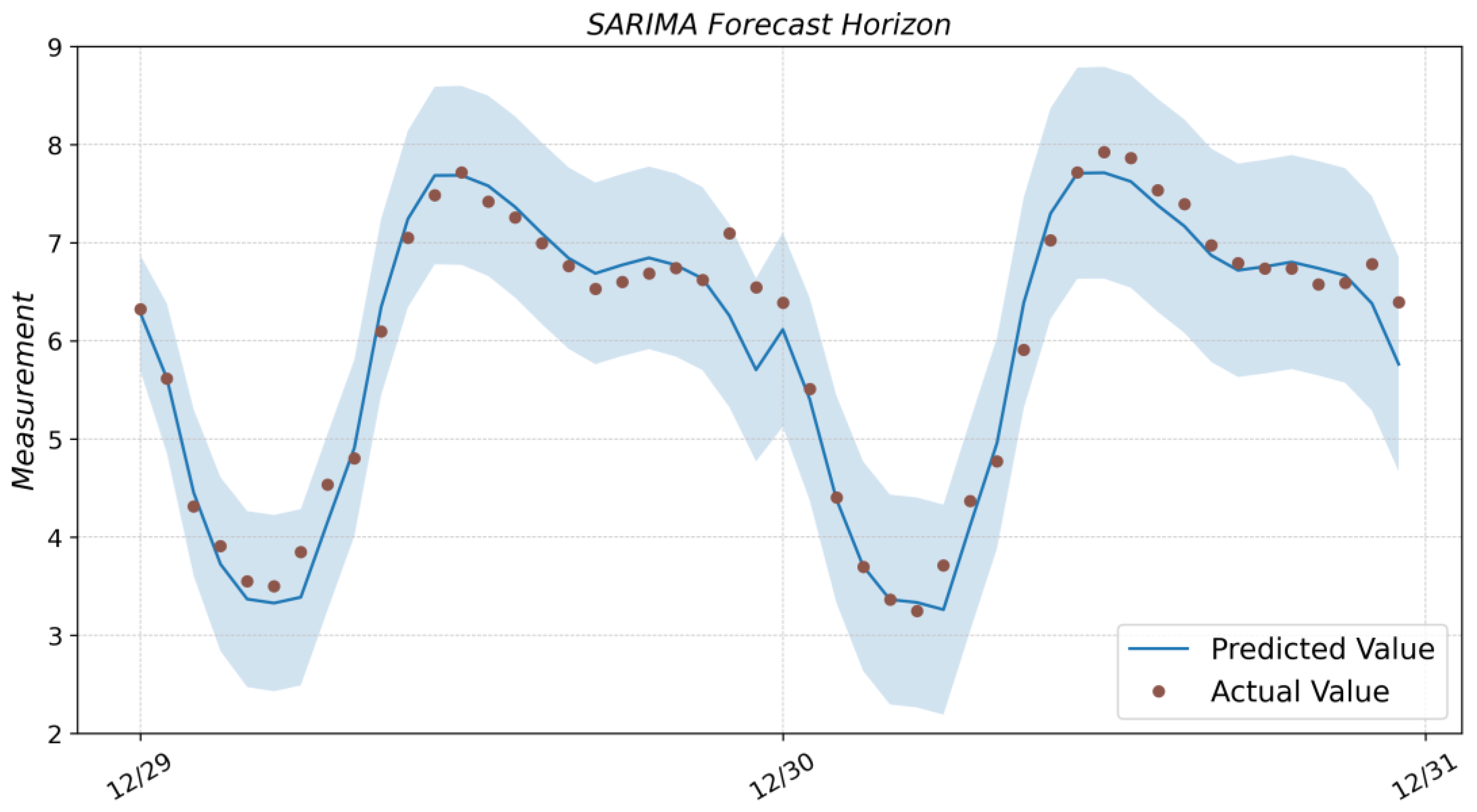
3.1. SARIMA
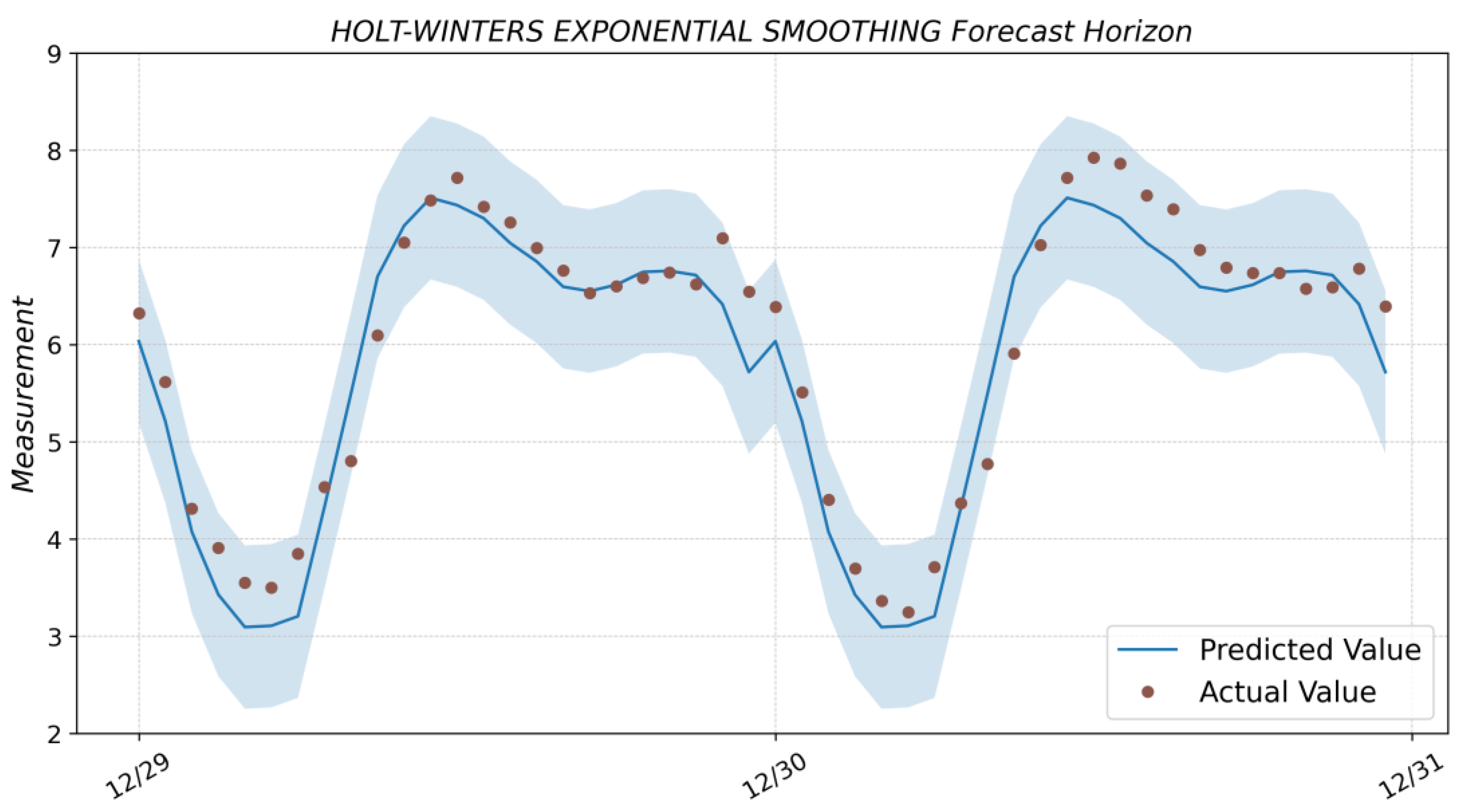
3.2. Holt-Winters Exponential Smoothing
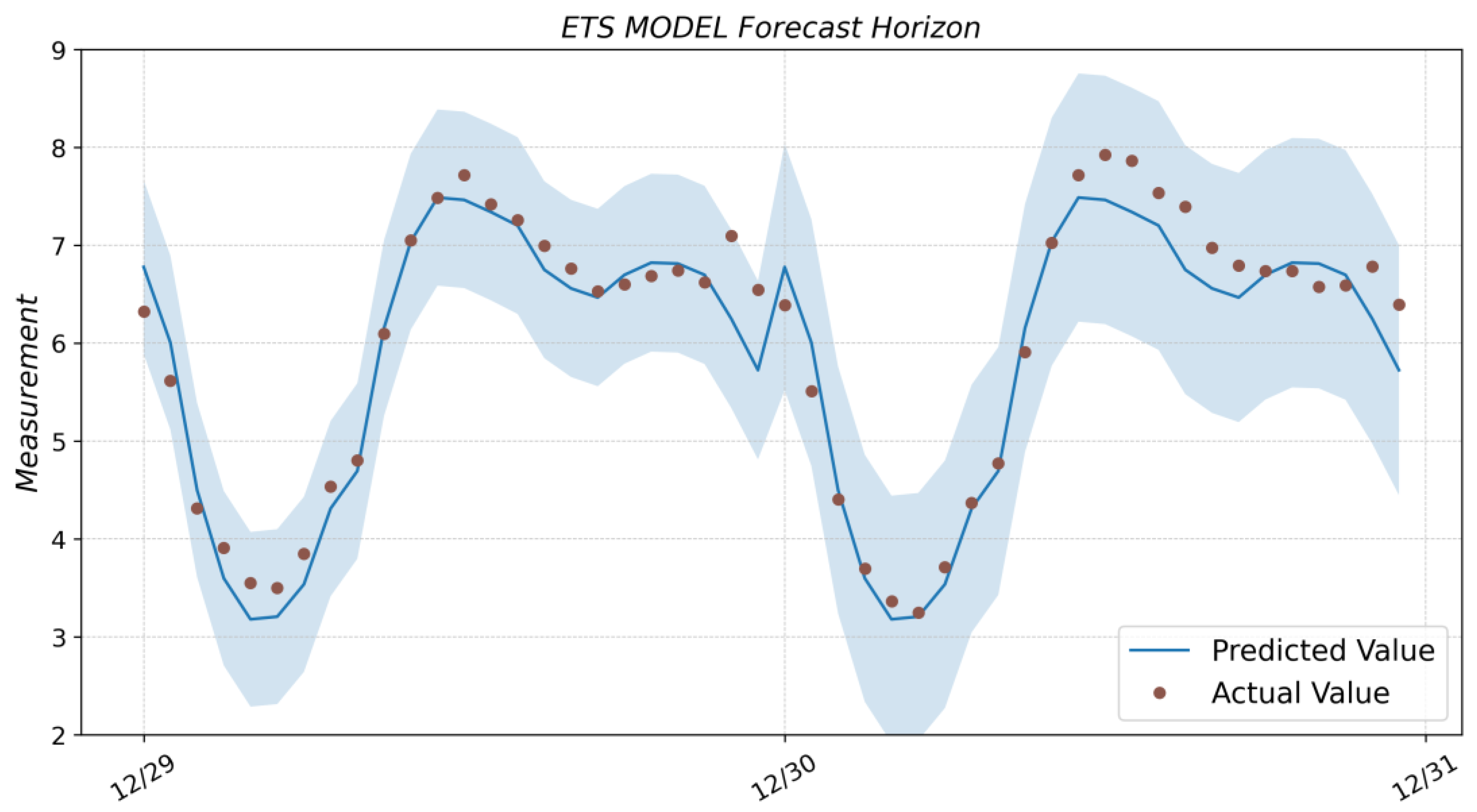
3.3. ETS
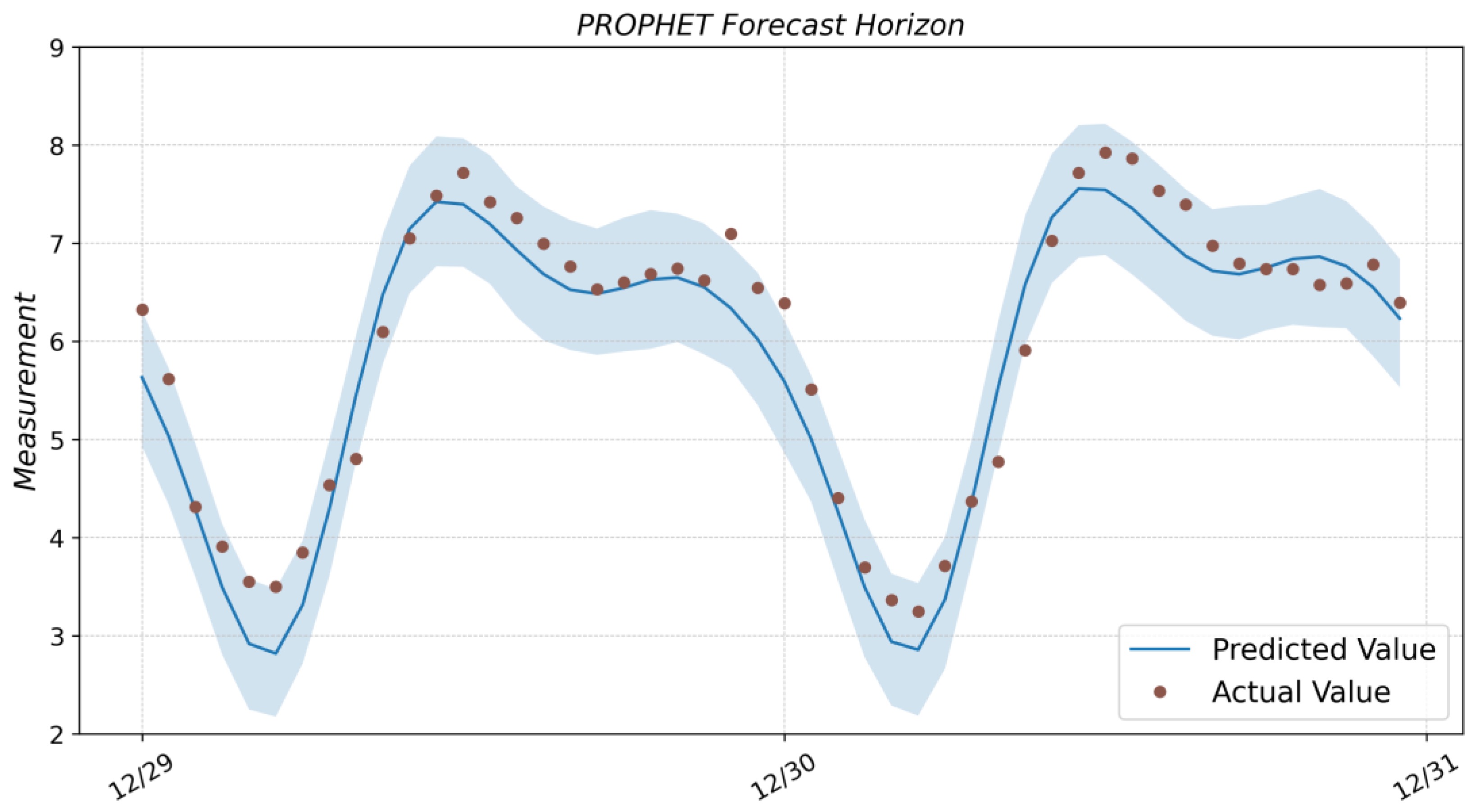
3.4. Facebook Prophet
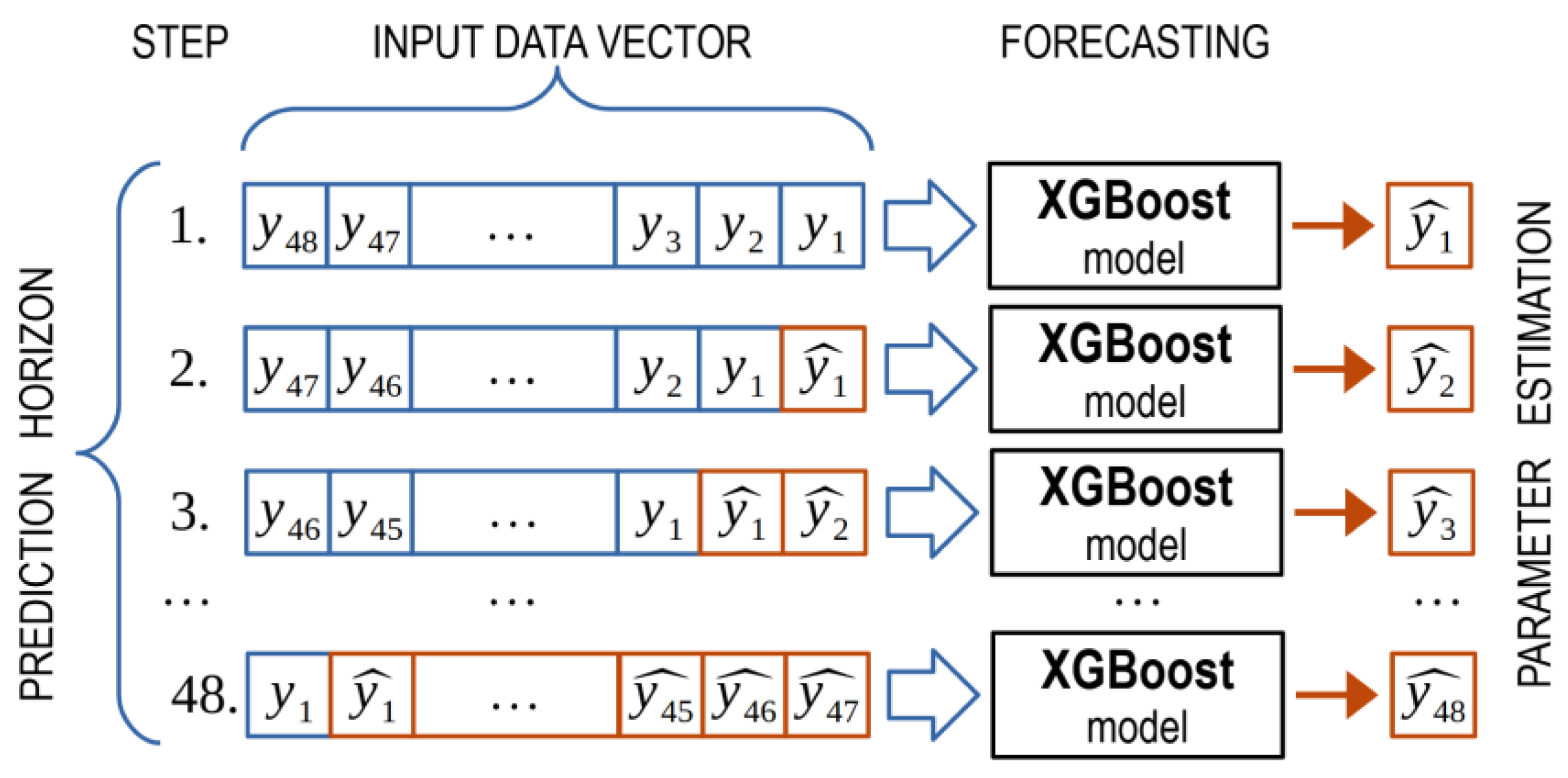
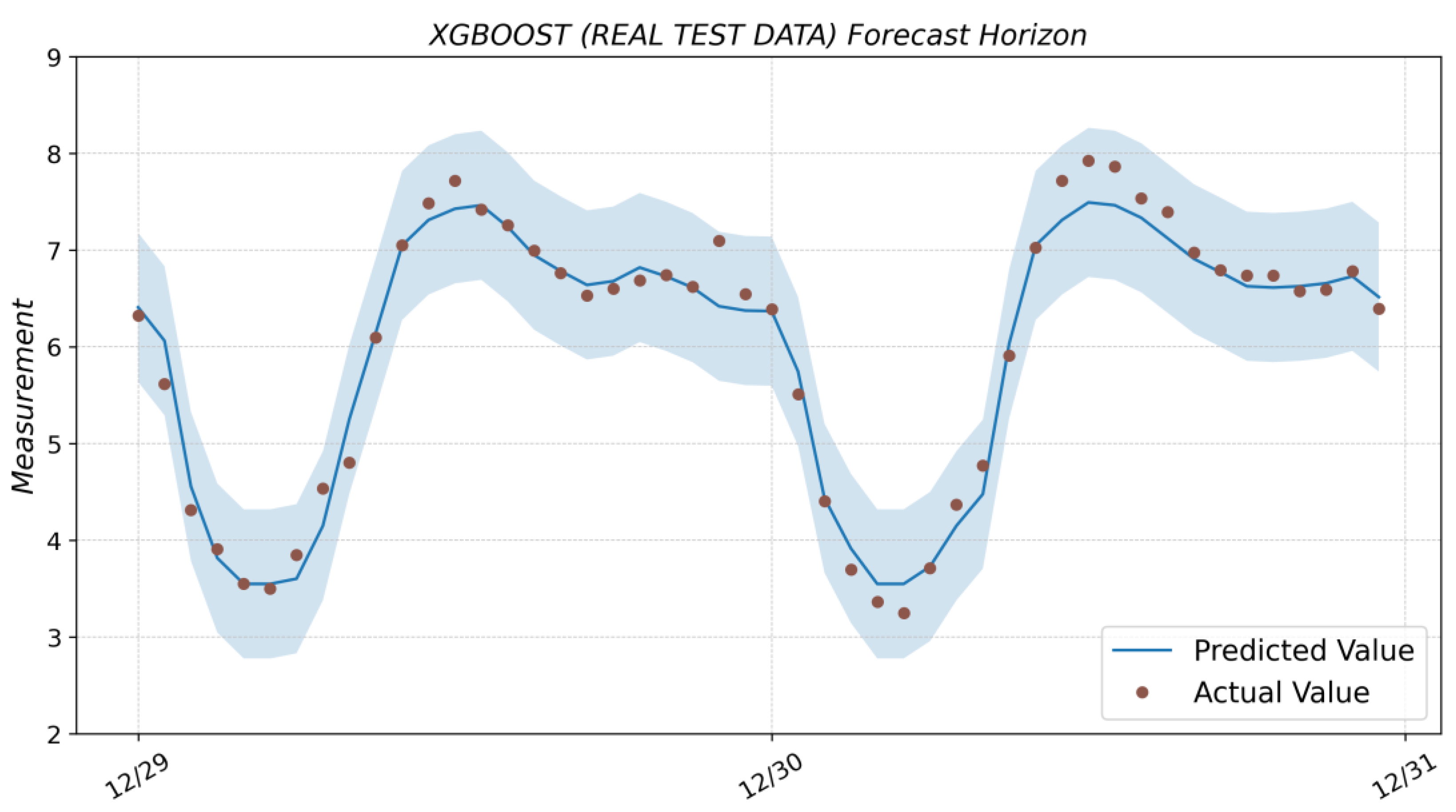
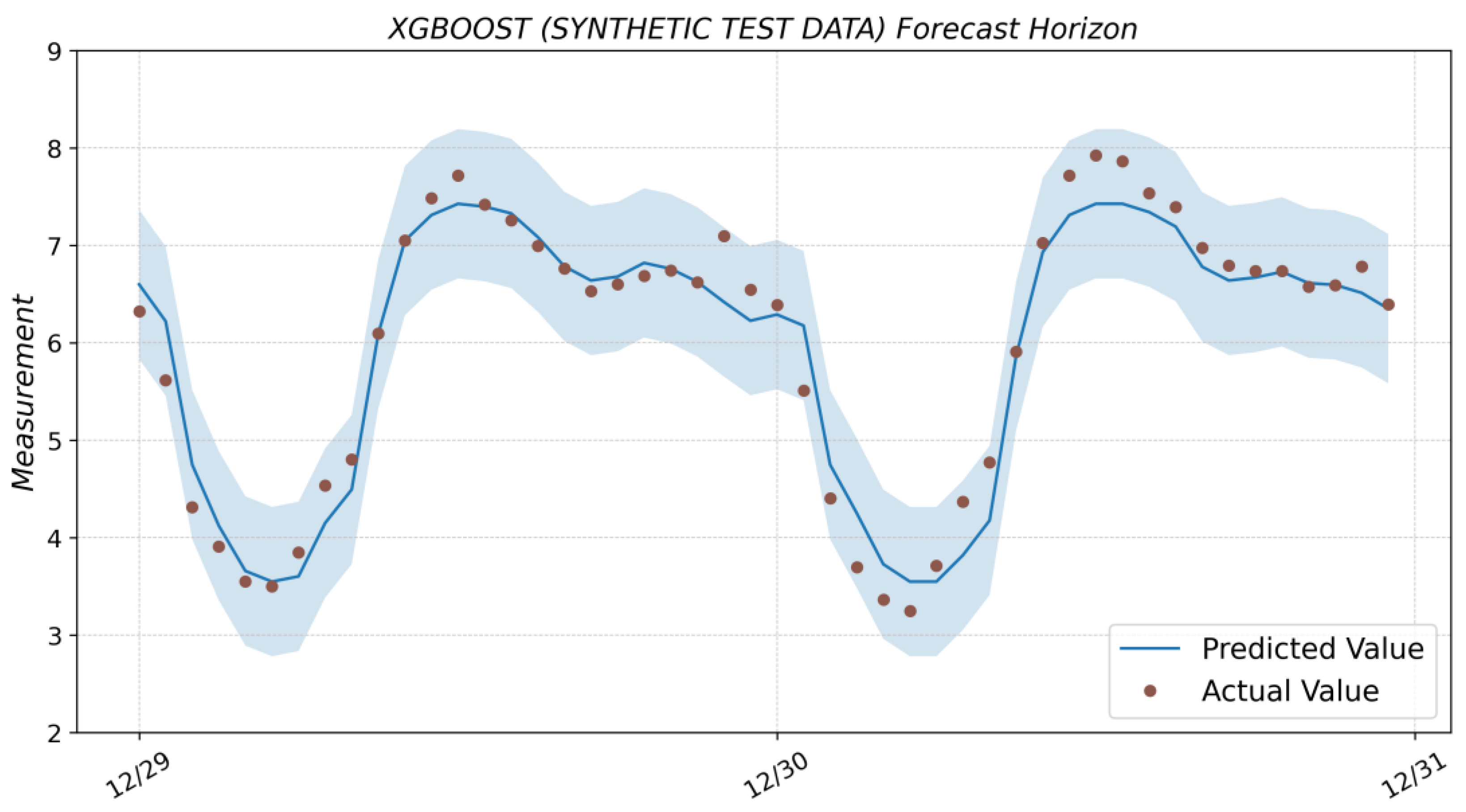
3.5. XGBoost
- max_depth = 6—maximum tree depth for base learners;
- learning_rate = 0.05—boosting learning rate (xgb’s “eta”);
- n_estimators = 5000—number of gradients boosted trees (equivalent to the number of boosting rounds);
- gamma = 0.1—minimum loss reduction required to make a further partition on a leaf node of the tree.
- To generate a forecast for 1 h ahead, the model’s input is the historical sample for the previous 48 h. The model’s output estimates the observed parameter 1 h ahead.
- One element shifts the historical sample dataset to the left, and as a result, its length is reduced by 1. An element is placed in the place of the missing element at the end of the sample—the estimate of the observed parameter obtained at the previous step. A new parameter estimate is obtained at the model’s output, corresponding to the 2-h forecast horizon.
- Iterations continue until the desired forecast horizon is obtained.
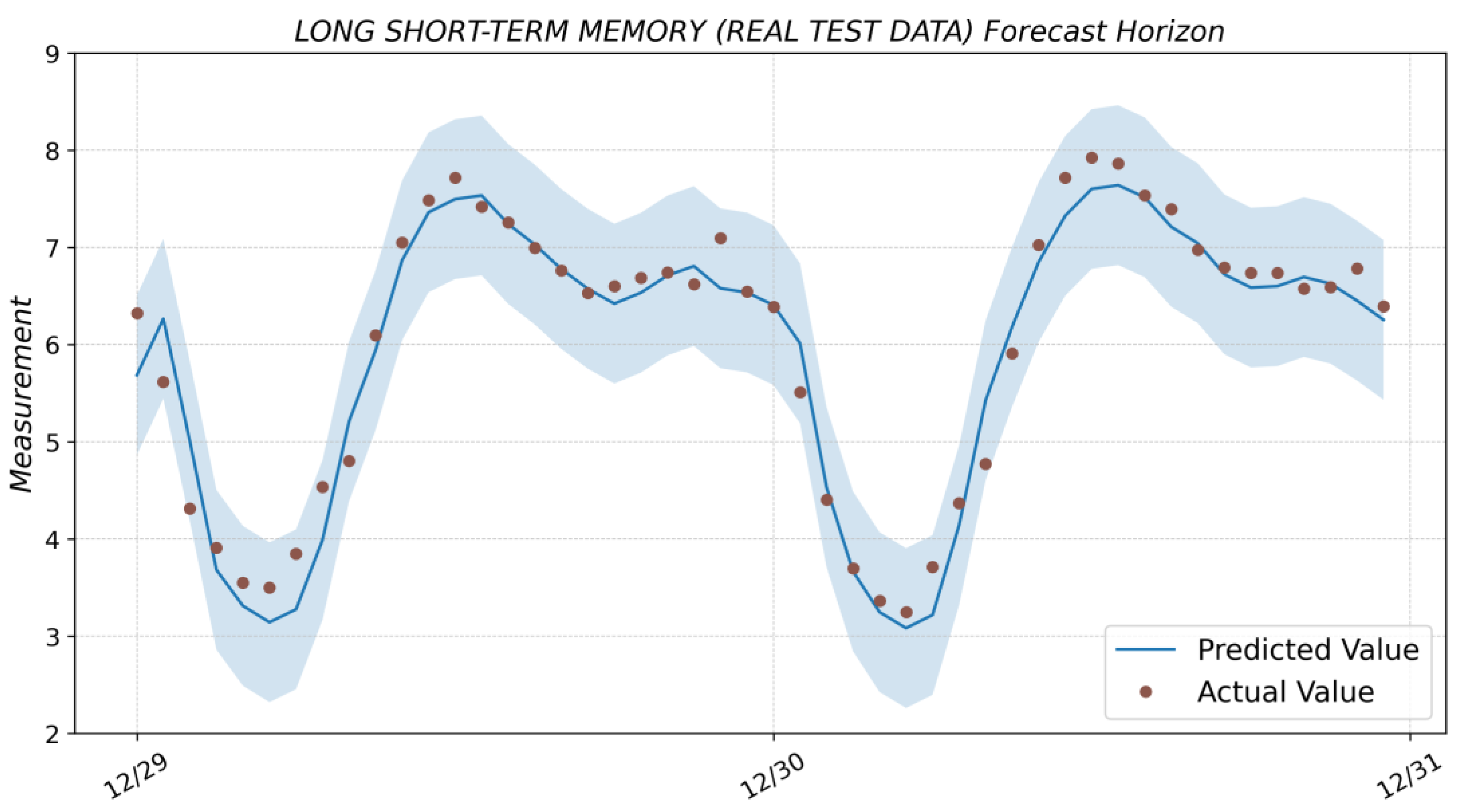
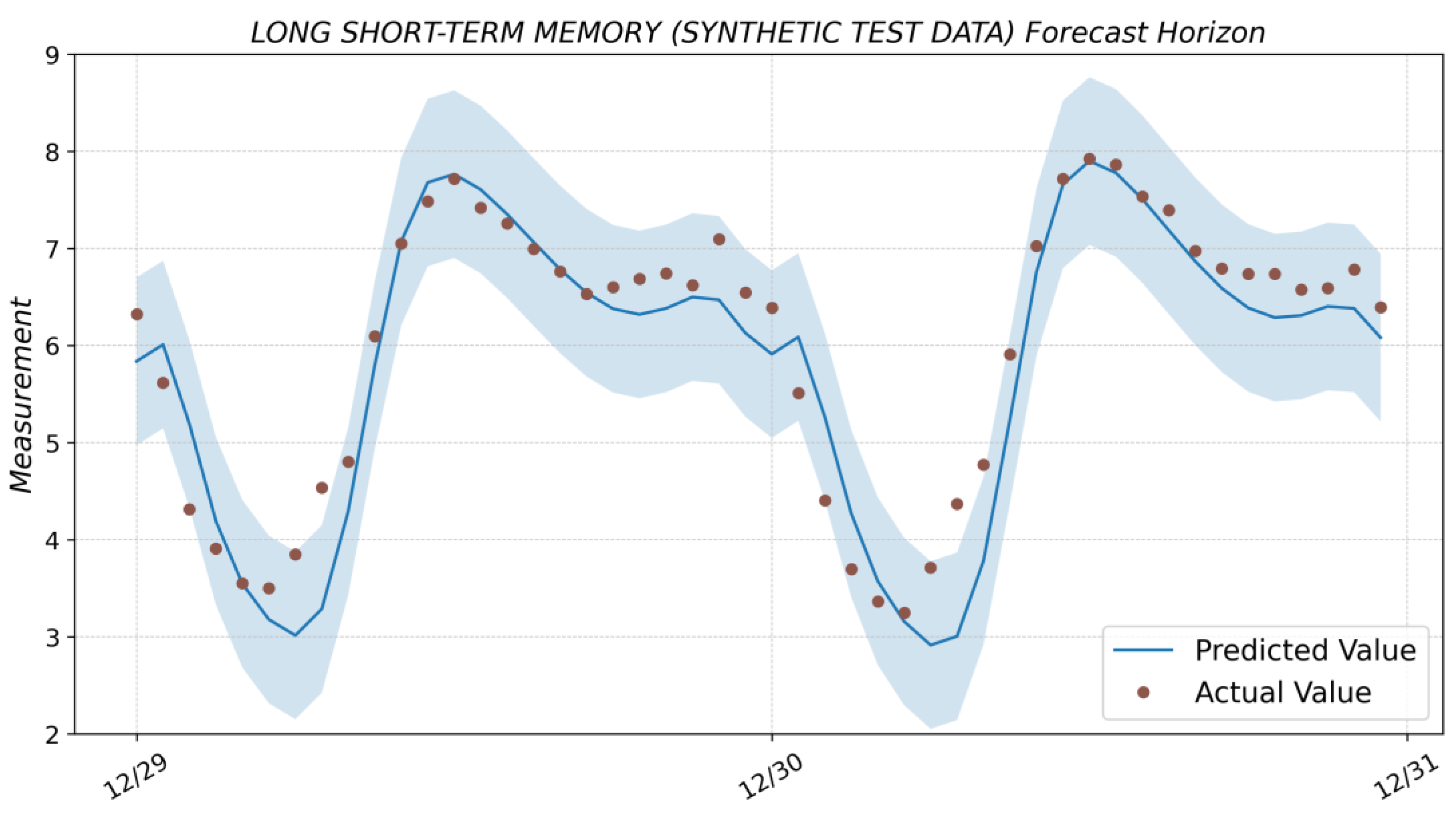
3.6. Long Short-Term Memory
- batch_size = 16—number of samples per gradient update;
- epochs = 200—number of epochs to train the model;
- units = 32—dimensionality of the output space.

4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADfuller | Augmented Dickey-Fuller |
| ANN | Artificial Neural Network |
| ARIMA | Autoregressive integrated moving average |
| DB | Data base |
| ETS | Exponential smoothing |
| LSTM | Long short-term memory |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| MSE | Mean squared error |
| OPC | Open Platform Communications |
| P.Time | Prediction time |
| R2 | Correlation coefficient |
| RMSE | Root mean squared error |
| RNN | Recurrent neural network |
| SARIMA | Seasonal autoregressive integrated moving average |
| T.Time | Training time |
Appendix A








Appendix B
| Algorithm A1: XGBoost model retraining and prediction (48 h ahead) | |
| 1 | ← The time interval for the training data |
| 2 | ← Resample and training data generation |
| 3 | |
| 4 | 6 ← Maximum tree depth for base learners |
| 5 | 0.05 ← Boosting learning rate |
| 6 | 5000 ← Number of gradients boosted trees |
| 7 | 0.1 ← Minimum loss reduction |
| 8 | ← XGBoost regressor |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | ← Training model |
| 14 | ← Prediction array initialization |
| 15 | |
| 9 | |
| 10 | |
| 11 | ← New train data |
| 12 | |
| 13 | ← Get prediction |
| 14 | ← Convert to the Pandas dataframe |
| 15 | |
| 16 | ← Add new predicted value |
| 17 | |
| 18 | ← Prediction dataset for the next 48 hrs |
References
- Nguyen, G.; Dlugolinsky, S.; Bobák, M. Machine learning and deep learning frameworks and libraries for large-scale data mining: A survey. Artif. Intell. Rev. 2019, 52, 77–124. [Google Scholar] [CrossRef]
- Makridakis, S.; Wheelwright, S.C.; Hyndman, R.J. Forecasting Methods and Applications; John Wiley and Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; John Wiley and Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J.C. A survey on data mining techniques applied to electricity-related time series forecasting. Energies 2015, 8, 13162–13193. [Google Scholar] [CrossRef]
- Fu, T.C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Torres, J.F.; Galicia, A.; Troncoso, A. A scalable approach based on deep learning for big data time series forecasting. Integr. Comput.-Aided Eng. 2018, 25, 335–348. [Google Scholar] [CrossRef]
- Liu, Z.; Jiang, P.; Zhang, L.; Niu, X. A combined forecasting model for time series: Application to short-term wind speed forecasting. Appl. Energy 2020, 259, 114137. [Google Scholar] [CrossRef]
- Torres, J.; Hadjout, D.; Sebaa, A.; Martínez-Álvarez, F.; Troncoso, A. Deep Learning for Time Series Forecasting: A Survey. Big Data 2020, 9, 3–21. [Google Scholar] [CrossRef]
- Hajirahimi, Z.; Khashei, M. Hybrid structures in time series modeling and forecasting: A review. Eng. Appl. Artif. Intell. 2019, 86, 83–106. [Google Scholar] [CrossRef]
- Gasparin, A.; Lukovic, S.; Alippi, C. Deep learning for time series forecasting: The electric load case. CAAI Trans. Intell. Technol. 2021, 7, 1–25. [Google Scholar] [CrossRef]
- Pongdatu, G.A.N.; Putra, Y.H. Time Series Forecasting using SARIMA and Holt Winter’s Exponential Smoothing. IOP Conf. Ser. Mater. Sci. Eng. 2018, 407, 012153. [Google Scholar] [CrossRef]
- Huang, W.; Li, Y.; Zhao, Y.; Zheng, L. Time Series Analysis and Prediction on Bitcoin. BCP Bus. Manag. 2022, 34, 1223–1234. [Google Scholar] [CrossRef]
- Kemalbay, G.; Korkmazoglu, O.B. Sarima-arch versus genetic programming in stock price prediction. Sigma J. Eng. Nat. Sci. 2021, 39, 110–122. [Google Scholar] [CrossRef]
- Paliari, I.; Karanikola, A.; Kotsiantis, S. A comparison of the optimized LSTM, XGBOOST and ARIMA in Time Series forecasting. In Proceedings of the 12th International Conference on Information, Intelligence, Systems & Applications (IISA), Chania Crete, Greece, 12–14 July 2021. [Google Scholar]
- Andreeski, C.; Mechkaroska, D. Modelling, Forecasting and Testing Decisions for Seasonal Time Series in Tourism. Acta Polytech. Hung. 2020, 17, 149–171. [Google Scholar] [CrossRef]
- Uğuz, S.; Büyükgökoğlan, E. A Hybrid CNN-LSTM Model for Traffic Accident Frequency Forecasting during the Tourist Season. Teh. Vjesn.–Tech. Gaz. 2022, 29, 2083–2089. [Google Scholar]
- Etuk, E. A seasonal time series model for Nigerian monthly air traffic data. IJRRAS 2013, 14, 596–602. [Google Scholar]
- Feng, T.; Tianyu, Z.; Zheng, Y.; Jianxing, Y. The comparative analysis of SARIMA, Facebook Prophet, and LSTM for road traffic injury prediction in Northeast China. Front. Public Health 2022, 10, 946563. [Google Scholar] [CrossRef]
- Zhu, X.; Helmer, E.H.; Gwenzi, D.; Collin, M. Characterization of Dry-Season Phenology in Tropical Forests by Reconstructing Cloud-Free Landsat Time Series. Remote Sens. 2021, 13, 4736. [Google Scholar] [CrossRef]
- Figueiredo, N.; Blanco, C. Water level forecasting and navigability conditions of the Tapajós River–Amazon–Brazil. La Houille Blanche 2016, 3, 53–64. [Google Scholar] [CrossRef]
- Shen, J.; Valagolam, D.; McCalla, S. Prophet forecasting model: A machine learning approach to predict the concentration of air pollutants (PM2.5, PM10, O3, NO2, SO2, CO) in Seoul, South Korea. PeerJ 2020, 8, e9961. [Google Scholar] [CrossRef]
- Hasnain, A.; Sheng, Y.; Hashmi, M.Z. Time Series Analysis and Forecasting of Air Pollutants Based on Prophet Forecasting Model in Jiangsu Province, China Citation. Front. Environ. Sci. 2022, 10, 1044. [Google Scholar] [CrossRef]
- Luo, Z.; Jia, X.; Bao, J. A Combined Model of SARIMA and Prophet Models in Forecasting AIDS Incidence in Henan Province, China. Int. J. Environ. Res. Public Health 2022, 19, 5910. [Google Scholar] [CrossRef]
- Pandit, A.; Khan, D.Z.; Hanrahan, J.G. Historical and future trends in emergency pituitary referrals: A machine learning analysis. Pituitary 2022, 25, 927–937. [Google Scholar] [CrossRef] [PubMed]
- Benkachcha, S.; Benhra, J.; El Hassani, H. Seasonal Time Series Forecasting Models based on Artificial Neural Network. Int. J. Comput. Appl. 2015, 116, 9–14. [Google Scholar]
- Palmroos, C.; Gieseler, J.; Morosan, N. Solar energetic particle time series analysis with Python. Front. Astron. Space Sci. 2022, 9, 1073578. [Google Scholar] [CrossRef]
- Wan, X.; Zou, Y.; Wang, J.; Wang, W. Prediction of shale oil production based on Prophet algorithm. J. Phys. Conf. Ser. 2021, 2009, 012056. [Google Scholar] [CrossRef]
- El-Rawy, M.; Abd-Ellah, M.K.; Fathi, H.; Abdella Ahmed, A.K. Forecasting effluent and performance of wastewater treatment plant using different machine learning techniques. J. Water Process Eng. 2021, 44, 102380. [Google Scholar] [CrossRef]
- Ding, Z.; Yu, Y.; Xia, Y. Nonlinear hysteretic parameter identification using an attention-based long short-term memory network and principal component analysis. Nonlinear Dyn 2023, 111, 4559–4576. [Google Scholar] [CrossRef]
- Yu, Y.; Liang, S.; Samali, B.; Nguyen, T.N.; Zhai, C.; Li, J.; Xie, X. Torsional capacity evaluation of RC beams using an improved bird swarm algorithm optimized 2D convolutional neural network. Eng. Struct. 2022, 273, 115066. [Google Scholar] [CrossRef]
- Taylor, S.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference, San Francisco, CA, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Rumelhart, D.; Hinton, G.; Williams, R. Long short-term memory. Naturev 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Anqi, X.; Hao, Y.; Jing, C.; Li, S.; Qian, Z. A Short-Term Wind Speed Forecasting Model Based on a Multi-Variable Long Short-Term Memory Network. Atmosphere 2021, 12, 651. [Google Scholar]
- Zemkoho, A. A Basic Time Series Forecasting Course with Python. Oper. Res. Forum 2023, 4, 2. [Google Scholar] [CrossRef]
- Plevris, V.; Solorzano, G.; Bakas, N.; Ben Seghier, M. Investigation of Performance Metrics in Regression Analysis and Machine Learning-Based Prediction Models. In 8th European Congress on Computational Methods in Applied Sciences and Engineering (ECCOMAS 2022) at Oslo; European Community on Computational Methods in Applied Sciences: Barcelona, Spain, 2022. [Google Scholar]
- Pandas—Python Data Analysis Library. Available online: https://pandas.pydata.org/ (accessed on 3 February 2023).
- Cowpertwait, P.S.P.; Metcalfe, A.V. Introductory Time Series with R; Springer: Berlin/Heidelberg, Germany, 2009; pp. 142–143. [Google Scholar]
- Introduction—Statmodels. Available online: https://www.statsmodels.org/stable/index.html/ (accessed on 3 February 2023).
- Pmdarima: ARIMA Estimators for Python. Available online: https://alkaline-ml.com/pmdarima/index.html (accessed on 3 February 2023).
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice, 3rd ed.; Otexts, Monash University: Melbourne, Australia, 2022. [Google Scholar]
- Prophet|Forecasting at Scale. Available online: https://facebook.github.io/prophet/ (accessed on 3 February 2023).
- XGBoost. Available online: https://xgboost.ai/about (accessed on 3 February 2023).
- Python API Reference—XGBoost Documentation. Available online: https://xgboost.readthedocs.io/en/stable/python/index.html (accessed on 3 February 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Timestamp | Measurement |
|---|---|---|
| 0 | 12 December 2022 00:00:00 | 6.305967 |
| 1 | 12 December 2022 01:00:00 | 5.355895 |
| 2 | 12 December 2022 02:00:00 | 4.122726 |
| 3 | 12 December 2022 03:00:00 | 3.546737 |
| … | ||
| 452 | 30 December 2022 20:00:00 | 6.578148 |
| 453 | 30 December 2022 21:00:00 | 6.591513 |
| 454 | 30 December 2022 22:00:00 | 6.785699 |
| 455 | 30 December 2022 23:00:00 | 6.396174 |
| 456 | 31 December 2022 00:00:00 | 6.322228 |
| Model | R2 | MSE | RMSE | MAE | MAPE | T.Time | P.Time |
|---|---|---|---|---|---|---|---|
| SARIMA | 0.961 | 0.076 | 0.276 | 0.198 | 0.035 | 1298.060 | 0.020 |
| Holt-Winters ES | 0.921 | 0.156 | 0.396 | 0.324 | 0.059 | 0.049 | 0.001 |
| ETS | 0.945 | 0.109 | 0.329 | 0.254 | 0.043 | 0.285 | 0.001 |
| Prophet | 0.918 | 0.162 | 0.402 | 0.331 | 0.062 | 0.881 | 0.754 |
| XGBoost (real test data) | 0.975 | 0.050 | 0.224 | 0.163 | 0.029 | 7.505 | 0.005 |
| XGBoost (synthetic test data) | 0.954 | 0.091 | 0.301 | 0.228 | 0.043 | 7.505 | 0.235 |
| LSTM (real test data) | 0.960 | 0.080 | 0.282 | 0.218 | 0.041 | 39.505 | 0.361 |
| LSTM (synthetic test data) | 0.907 | 0.184 | 0.429 | 0.322 | 0.063 | 39.505 | 3.185 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kramar, V.; Alchakov, V. Time-Series Forecasting of Seasonal Data Using Machine Learning Methods. Algorithms 2023, 16, 248. https://doi.org/10.3390/a16050248
Kramar V, Alchakov V. Time-Series Forecasting of Seasonal Data Using Machine Learning Methods. Algorithms. 2023; 16(5):248. https://doi.org/10.3390/a16050248
Chicago/Turabian StyleKramar, Vadim, and Vasiliy Alchakov. 2023. "Time-Series Forecasting of Seasonal Data Using Machine Learning Methods" Algorithms 16, no. 5: 248. https://doi.org/10.3390/a16050248
APA StyleKramar, V., & Alchakov, V. (2023). Time-Series Forecasting of Seasonal Data Using Machine Learning Methods. Algorithms, 16(5), 248. https://doi.org/10.3390/a16050248