3.1. Separability of Time Series Components
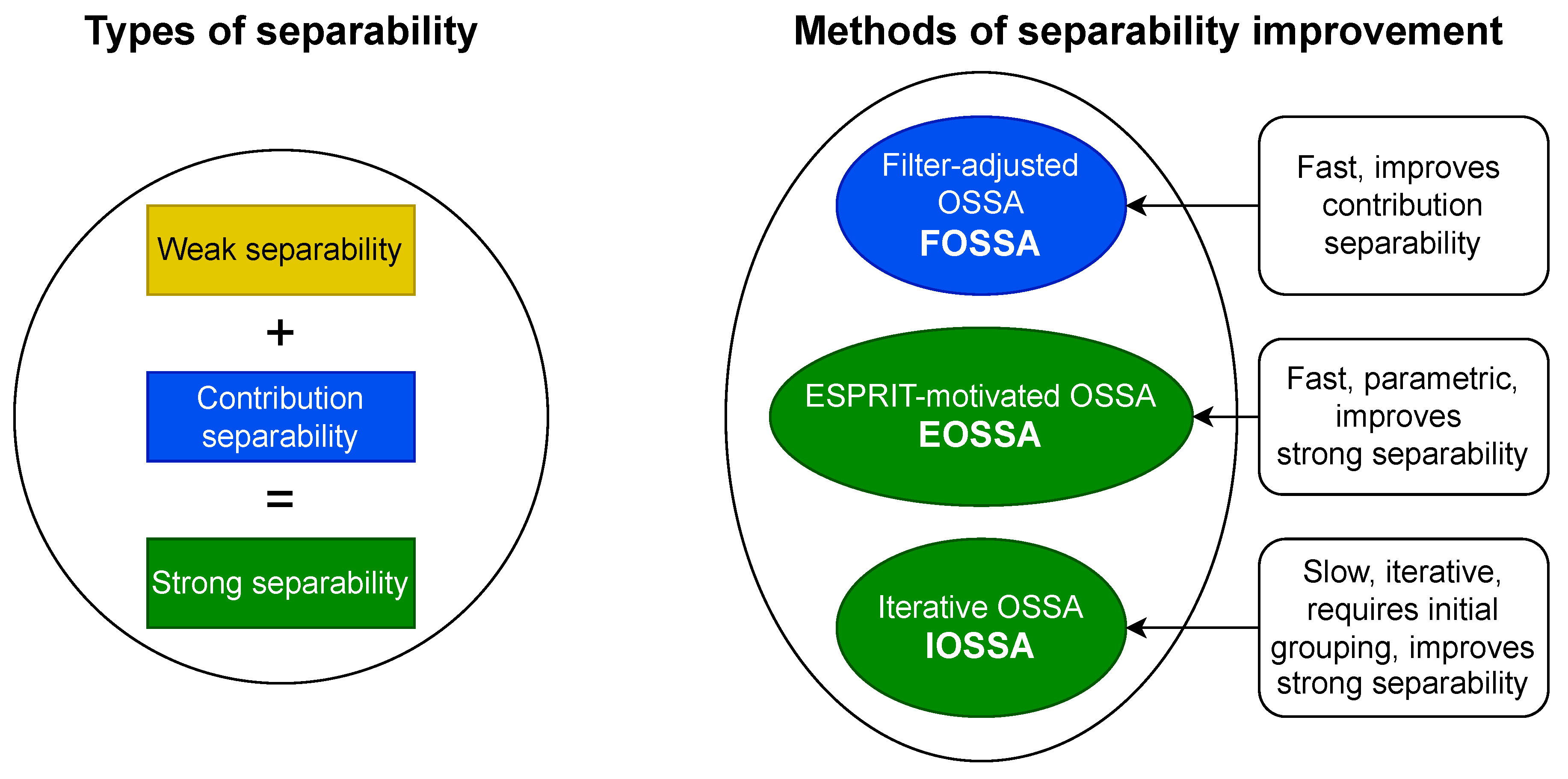
For the proper decomposition of a time series into a sum of components, these components must be separable. By separability we mean the following. Let the time series be a sum of two components in which we are interested separately. If the decomposition of the entire time series into elementary components can be divided into two parts, with one part referring to the first component and the other part referring to the second component, then by gathering these components into groups and summing them up, we will obtain exactly the components we are interested in, that is, to separate them. If the decomposition into elementary components is not unique (which is the case with singular value decomposition), then the notions of weak and strong separability arise. Weak separability is defined as the existence of a decomposition in which the components of the time series are separable. Strong separability means the separability of the components in any decomposition provided by the decomposition method in use. Therefore, the main goal in obtaining a decomposition of a time series is to achieve strong separability.
Without loss of generality, let us formalize this notion for the sum of two time series, following [
4] (Section 1.5 and Chapter 6). Let
be a time series of length
N, the window length
L be chosen and the time series
and
correspond to the trajectory matrices
and
. The SVDs of the trajectory matrices are
and
. Then
Time series and are weakly separable using SSA, if and .
Weakly separable time series and are strongly separable, if for each and .
Thus, strong separability consists of weak separability, which is related to the orthogonality of the time series components (more precisely, orthogonality of their L- and K-lagged vectors), and of different contributions of these components (that is, different contributions of elementary components produced by them). We will call the latter contribution separability. The conclusion of this is that to improve weak separability one needs to adjust the notion of orthogonality of the time series components, and to improve contribution separability, one needs to change the contributions of the components. To obtain strong separability, both weak and contribution separabilities are necessary.
3.2. Methods of Separability Improvement
The following methods are used to improve separability: FOSSA [
9], IOSSA [
9]. and EOSSA. Algorithms and implementations of the FOSSA and IOSSA methods can be found in [
13,
14]. A separate
Section 5 is devoted to EOSSA. The common part of the methods’ names is OSSA, which stands for Oblique SSA.
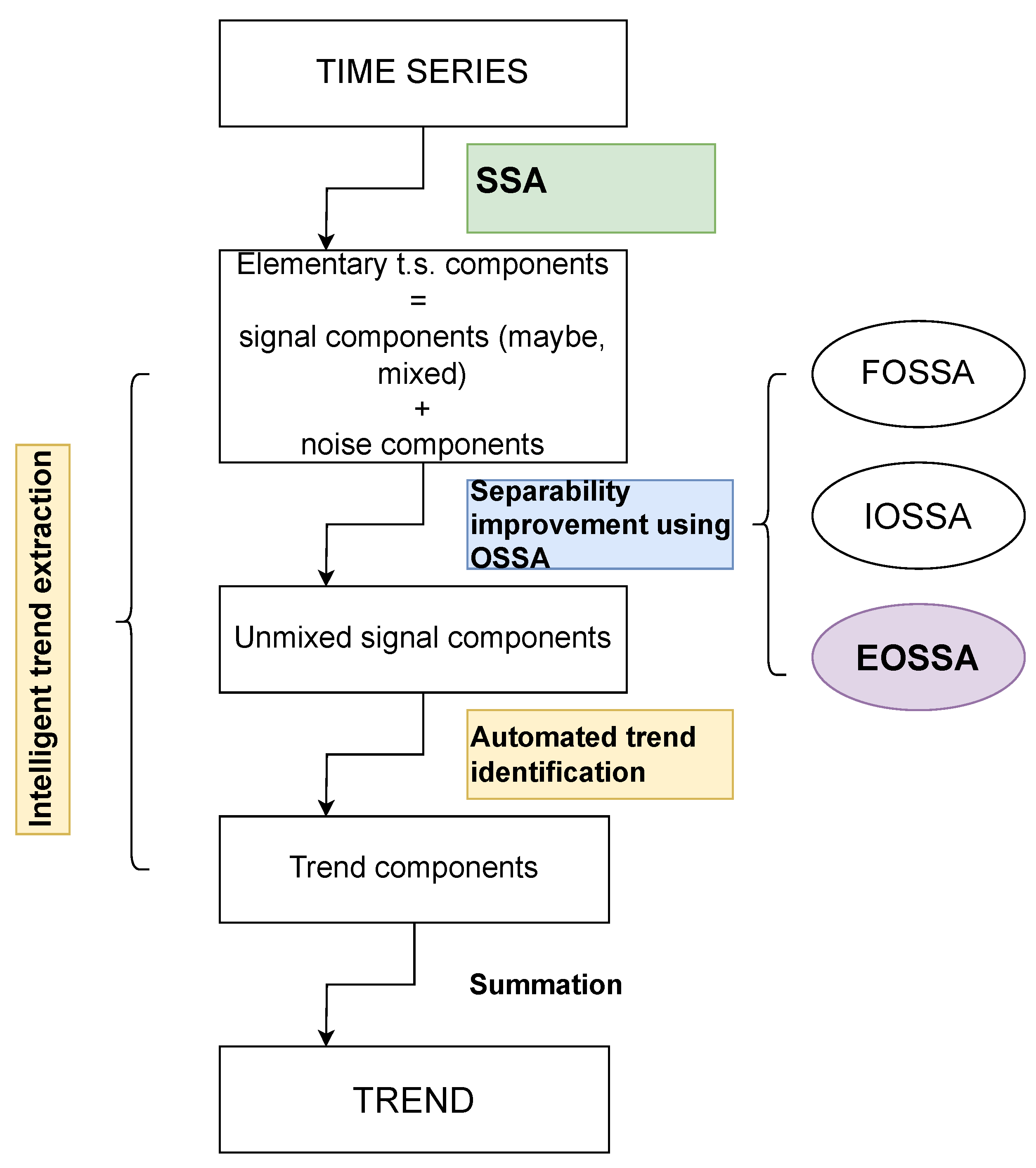
All methods are nested (that is, they are add-ons to the SVD step of Algorithm 1) and satisfy the following scheme.
Scheme of applying nested methods:
Perform the SVD step of Algorithm 1.
Select t of the SVD components, presumably related to the signal; denote their sum .
Perform re-decomposition of by one of nested methods to improve the separability of the signal components (nested decomposition).
In all algorithms for improving separability, we first select the components of the expansion to be improved. Consider the case where the leading t components are selected. The algorithms’ input is a matrix of rank t, recovered from the leading t components, not necessarily Hankel. Denote . Then the result of the algorithms is the decomposition of the matrix and of the time series generated by .
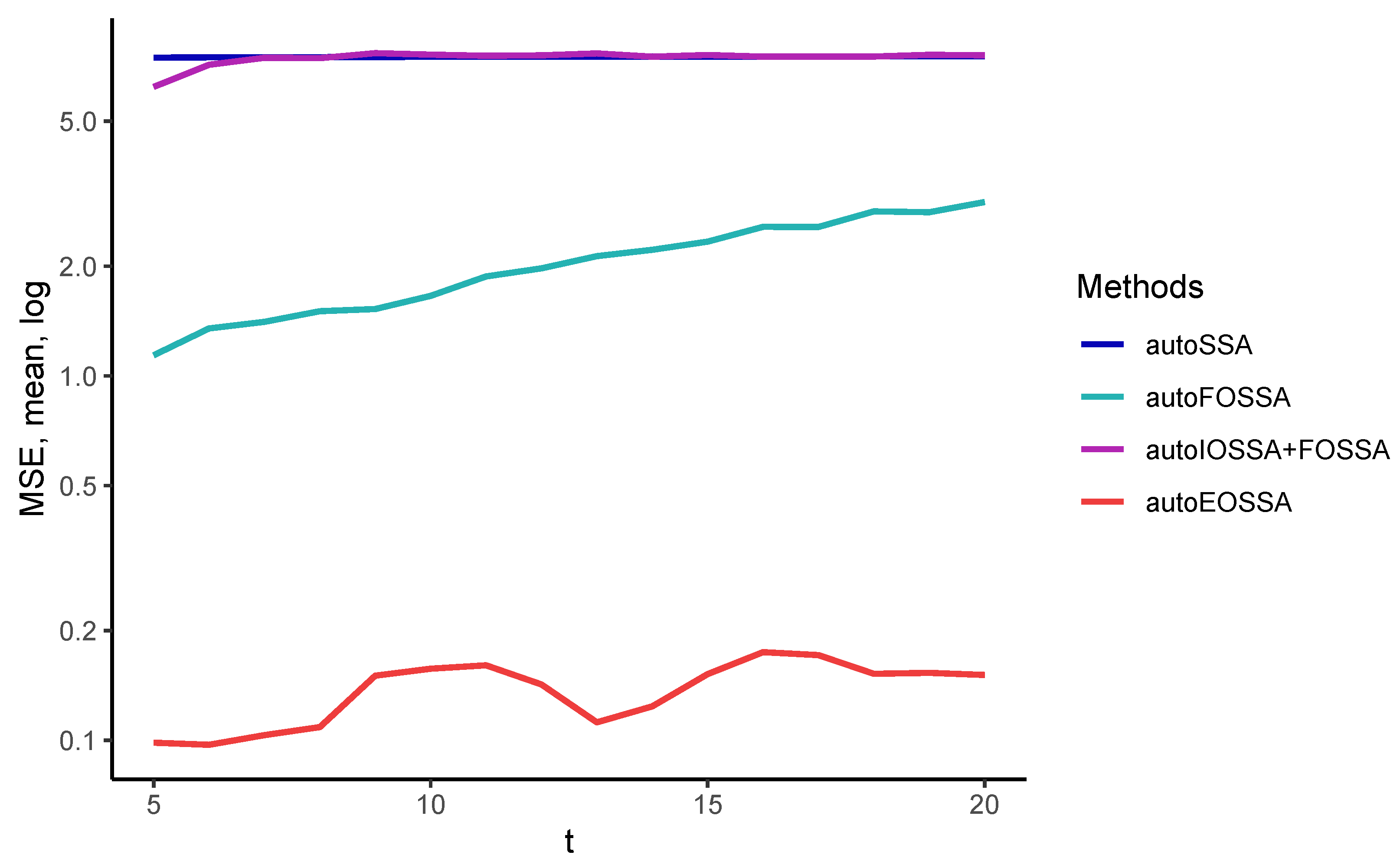
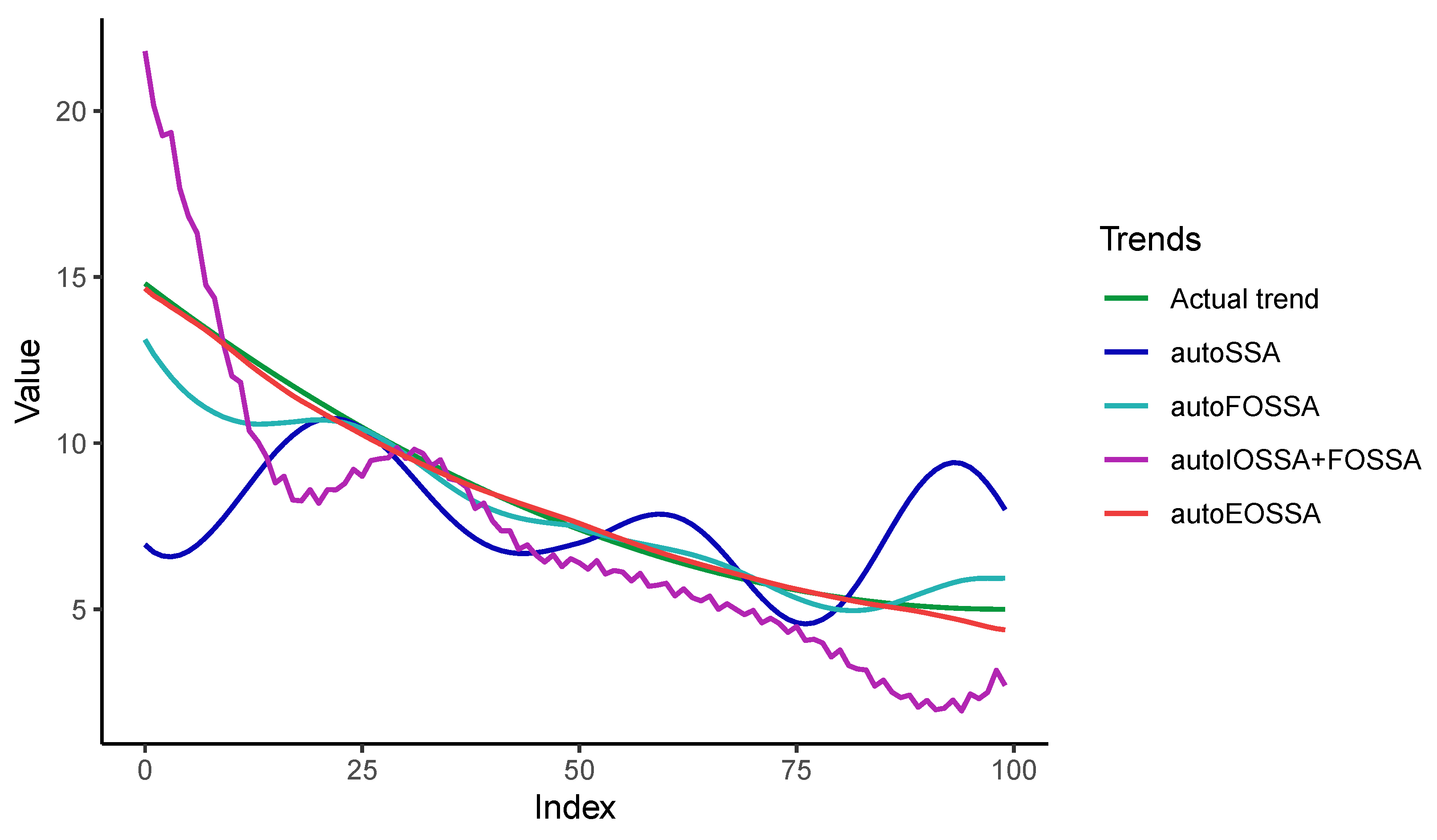
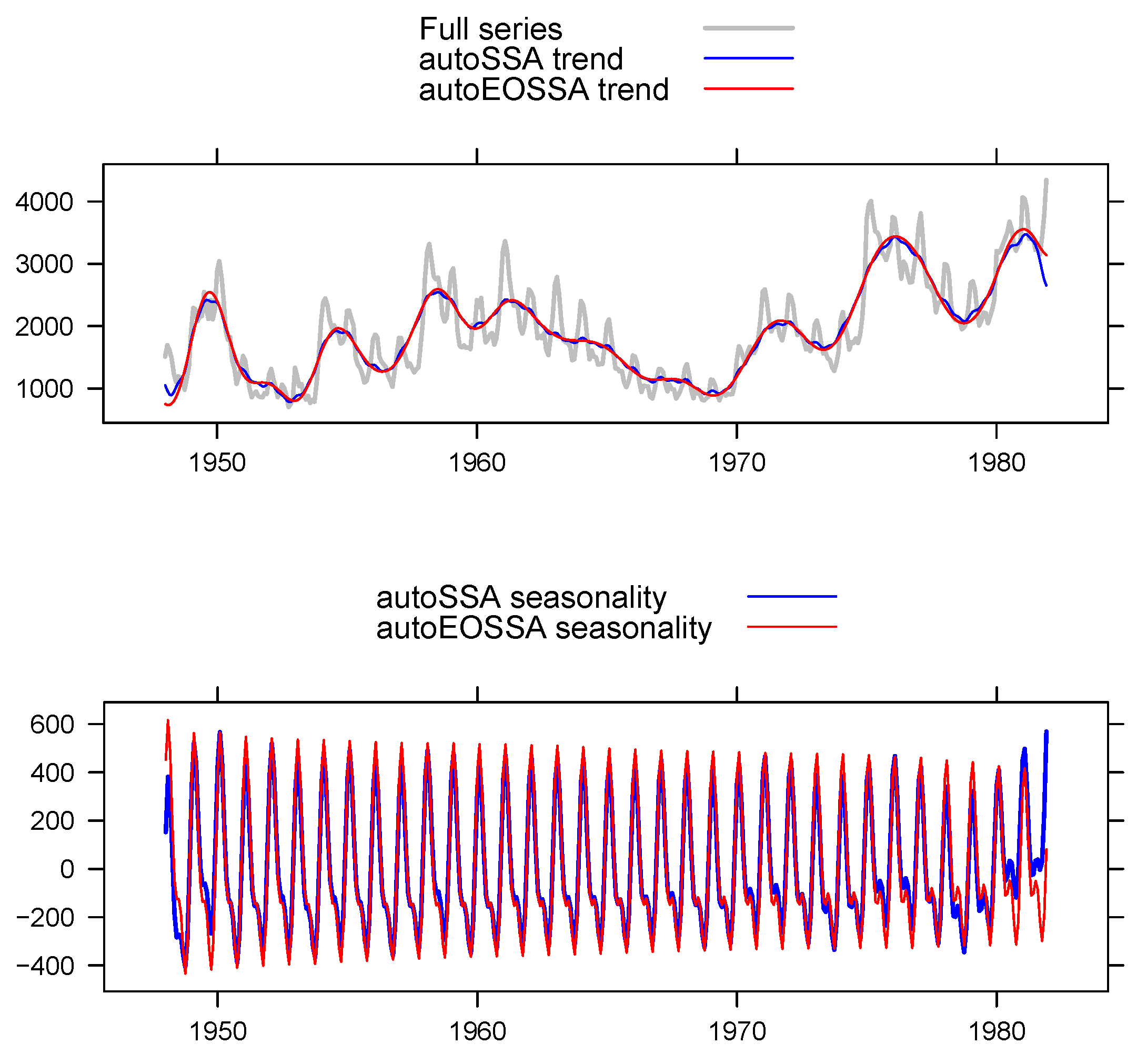
Figure 2 illustrates the relationship between the various methods of improving separability and the different types of separability, which are indicated by color. The characteristics of these methods are briefly listed. In the following paragraphs, we provide a more detailed description of each method.
The Filter-adjusted Oblique SSA (
FOSSA) [
9] method is easy to use; however, it can improve only contribution separability, that is, strong separability if the weak separability holds. The idea behind a variation of the method, called DerivSSA (this is the one we will use in this work), is to use the time series derivative (going to consecutive differences in the discrete case) that changes the component contributions. The method calculates
, whose column space belongs to the column space of
, and then constructs the SVD of the matrix
,
. The [
14] (Algorithm 2.11) provides an extended version of the algorithm that makes different contributions of the components to the time series, regardless of whether those contributions were the same or different. It is implemented in [
13] and that is what we will use. We will take the default value of
, so we will not specify it in the algorithm parameters. Thus, the only parameter of the algorithm is
t. We will write FOSSA(
t).
The Iterative Oblique SSA (
IOSSA) [
9] method can improve weak separability. It can also improve the strong separability, but the use of IOSSA is quite time-consuming, so when there is weak separability, it does not make sense to use it. The idea behind the method is to change the standard Euclidean inner product
to the oblique inner product
for a symmetric positive semi-definite matrix
. This approach allows any two non-collinear vectors to become orthogonal. It is shown in [
9] that any two sufficiently long time series governed by LRRs can be made exactly separable by choosing suitable inner products in the column and row signal spaces. The algorithm uses iterations, starting from the standard inner product, to find the appropriate matrices that specify the inner products. The detailed algorithm is given in [
14]. We will use the implementation from [
13]. The parameter of the algorithm is the initial grouping
. We will consider two types of grouping. Since our goal is trend extraction, in the first case the initial grouping consists of two groups and is set only by the first group
. Also, consider the variant with elementary grouping with
and
. Since the algorithm is iterative, it has a stopping criterion that includes the maximum number of iterations
and tolerance; the latter will be taken by default to be
and we will not specify it in the parameters. There is also a parameter
, which is responsible for improving the contribution separability; it will be taken equal to 2 by default. So, the reference to the algorithm is IOSSA(
t,
,
I) in the case of non-elementary grouping and IOSSA(
t,
) when grouping is elementary.
Note that since IOSSA(t, , I) requires an initial group of components I, it matters which decomposition of the matrix is input (the other methods do not care). Therefore, before applying IOSSA, it makes sense to apply some other method, such as FOSSA, to improve the initial decomposition and make it easier to build the initial grouping I.
The third method we will consider is the ESPRIT-motivated OSSA (
EOSSA) algorithm. This method is new, so we will provide the full algorithm and its justification in
Section 5. The method can improve strong separability. Unlike IOSSA, it is not iterative; instead, it relies on an explicit parametric form of the time series components. However, when the signal is infinite-rank time series or if the rank is overestimated, this approach may result in reduced stability. The reference to the algorithm is EOSSA(
t).
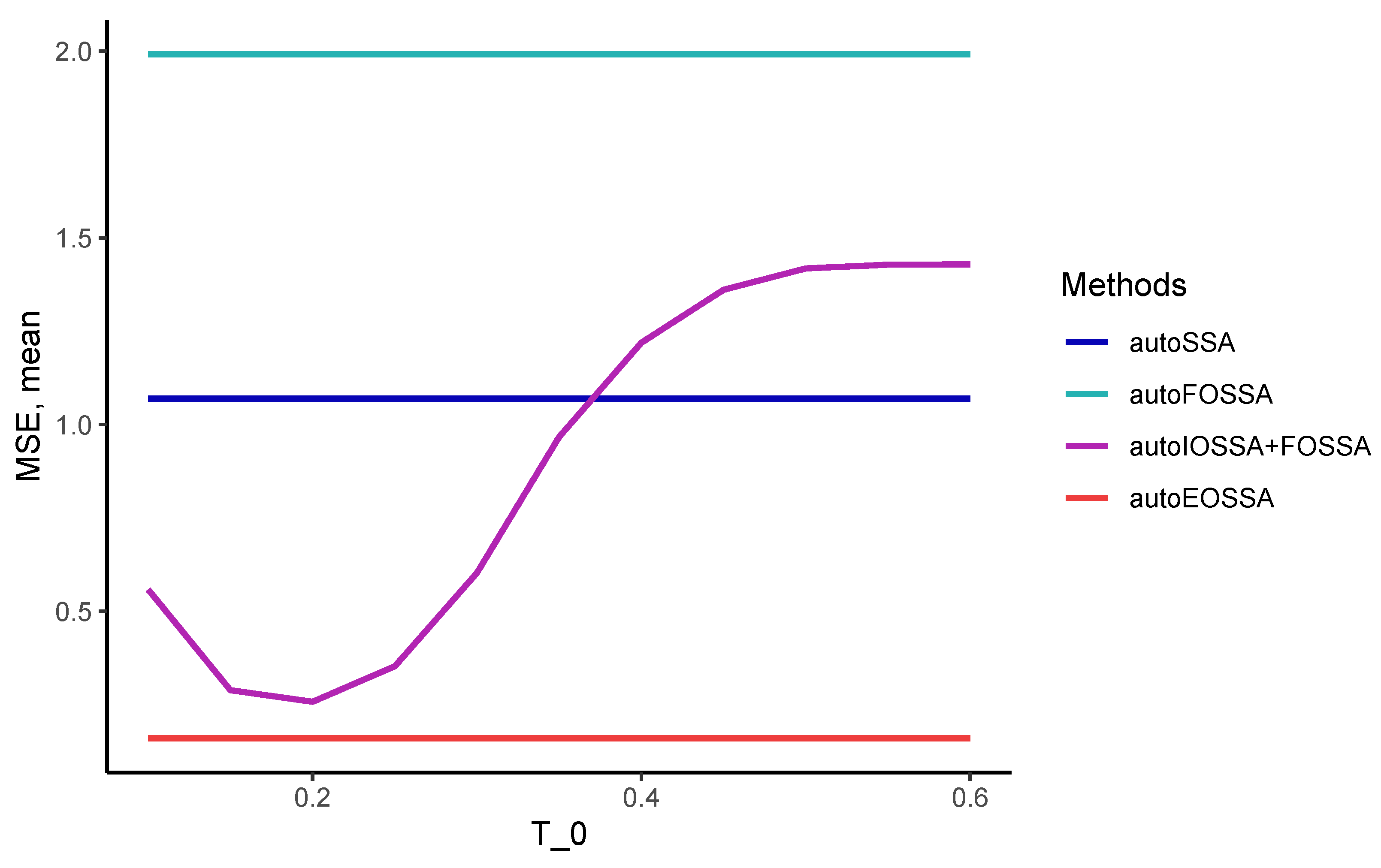
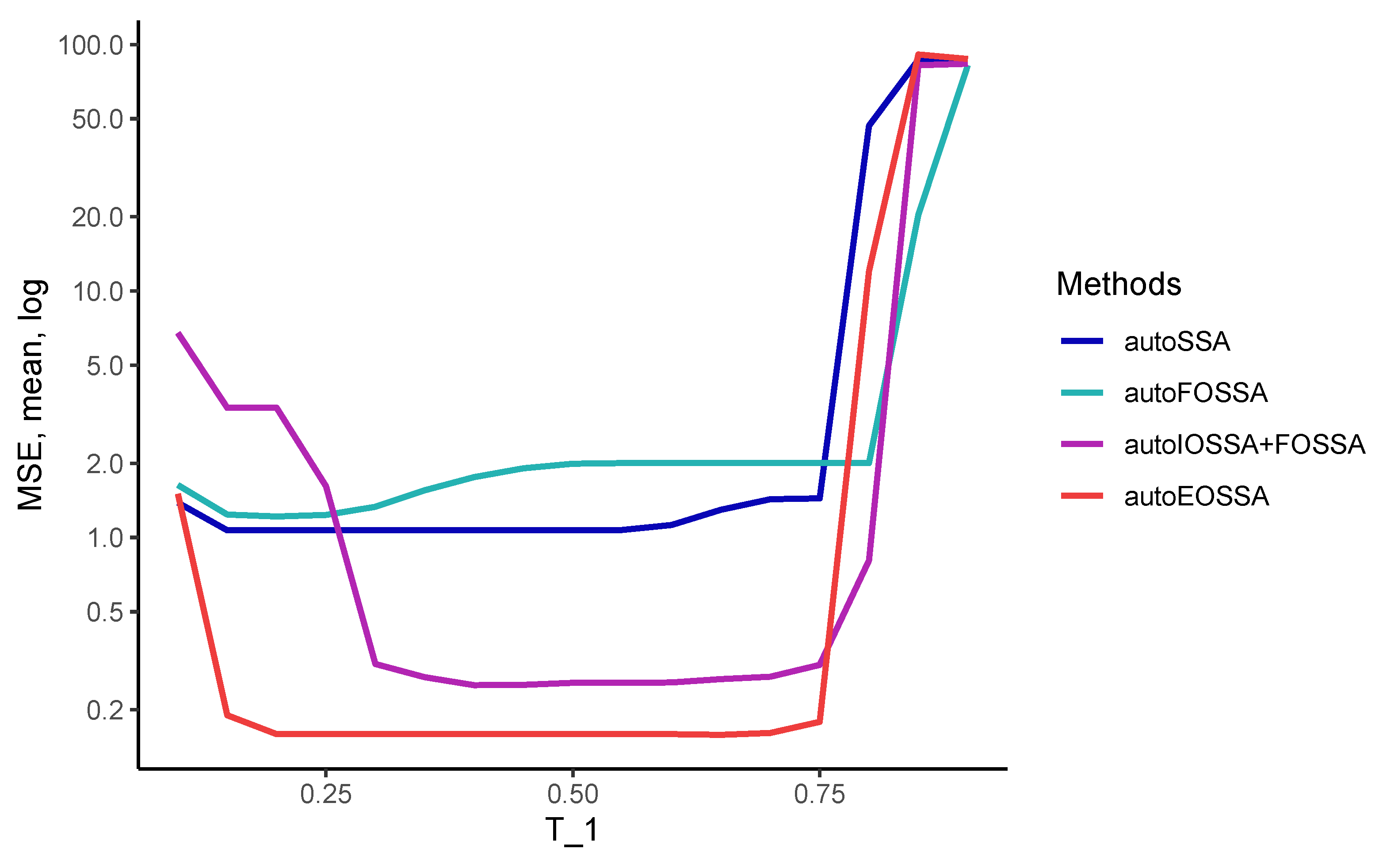
3.3. Comparison of Methods in Computational Cost
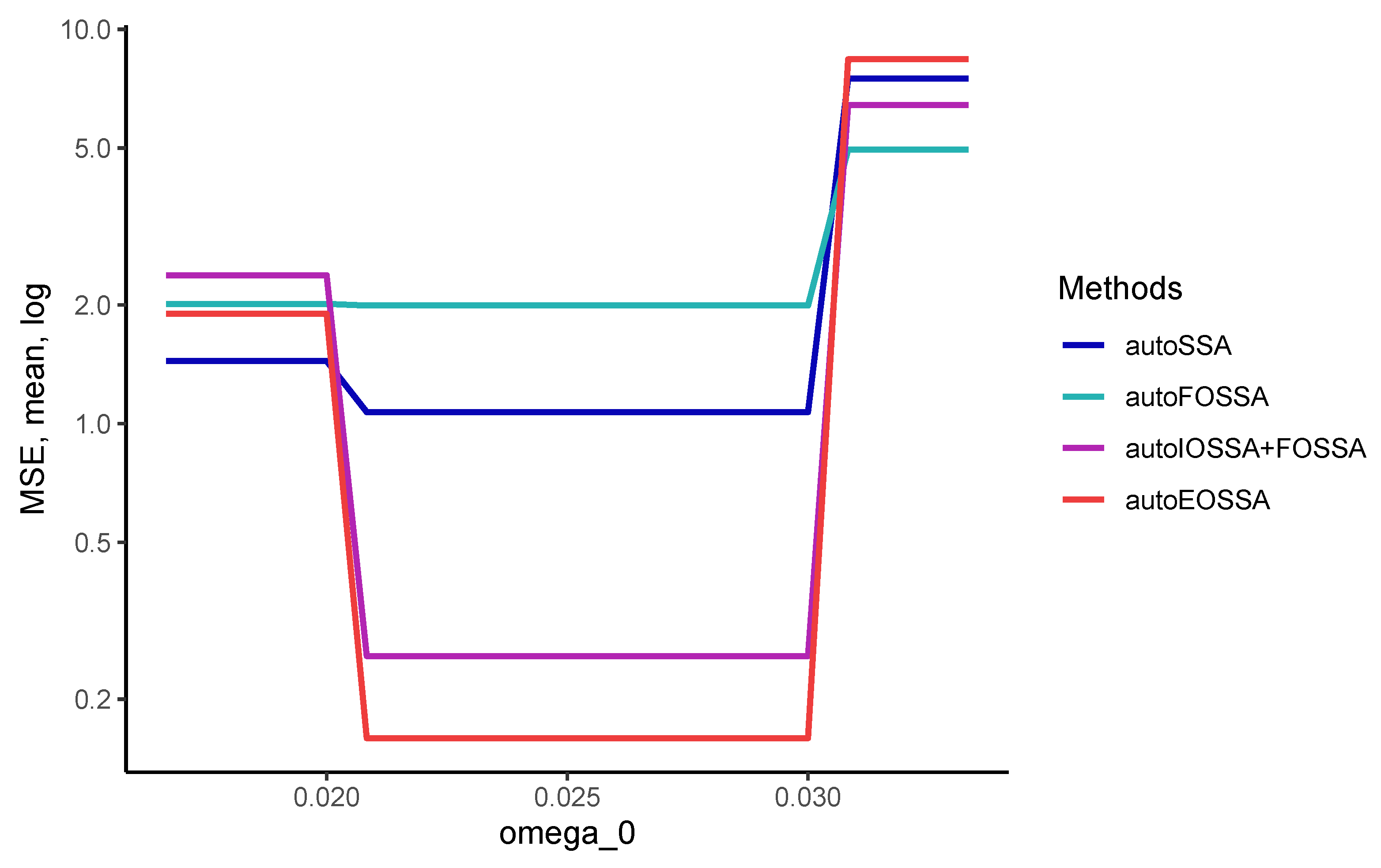
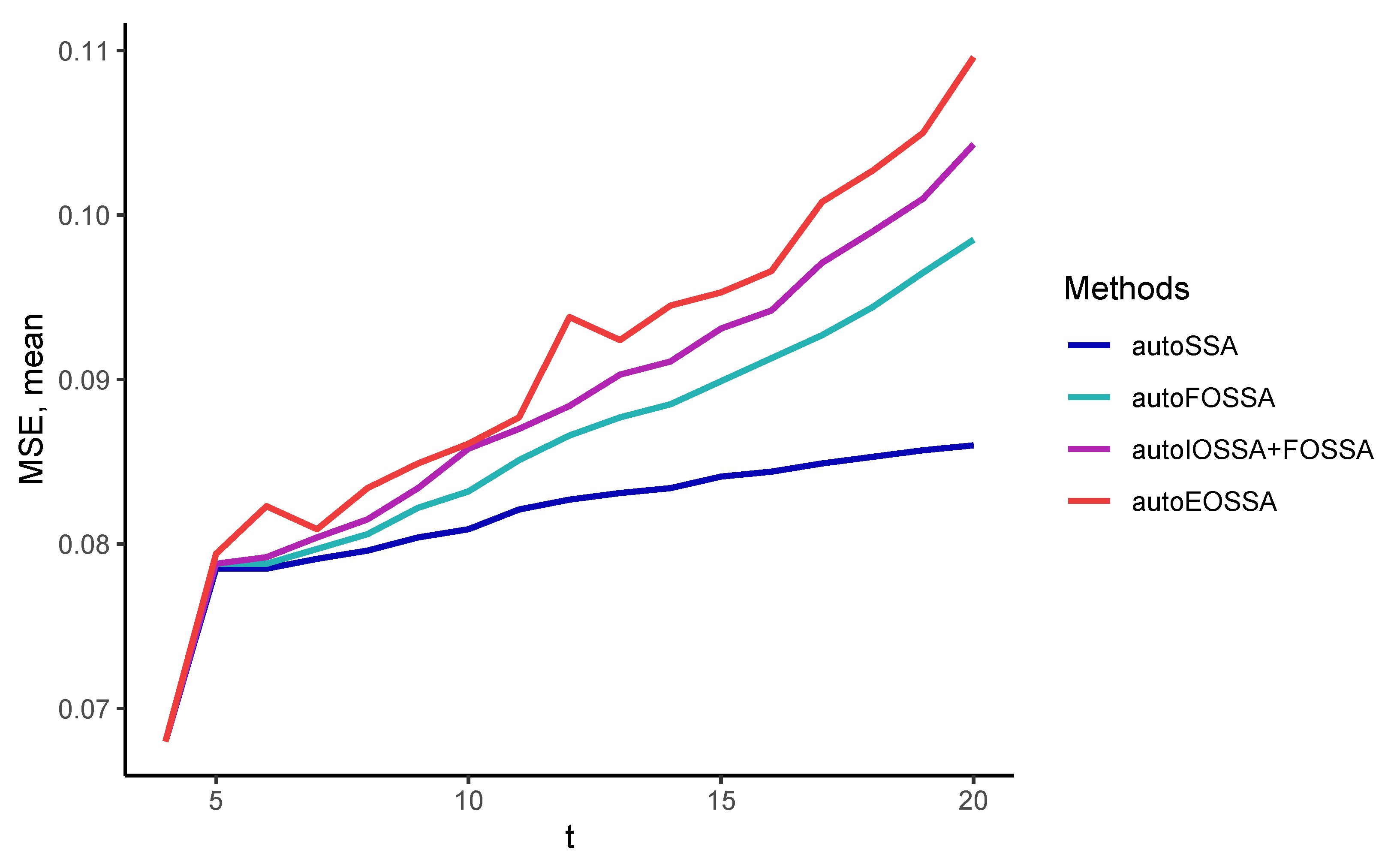
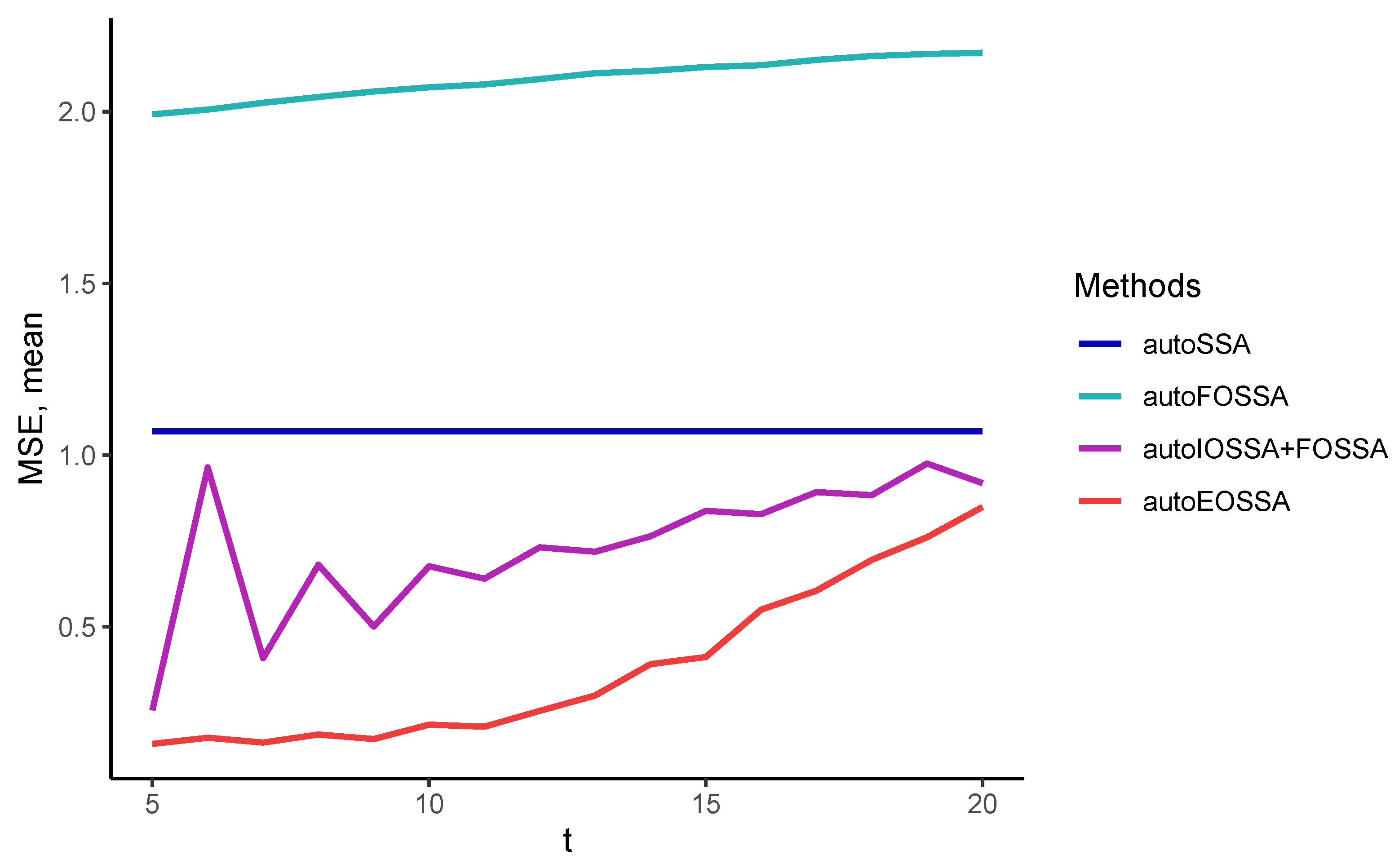
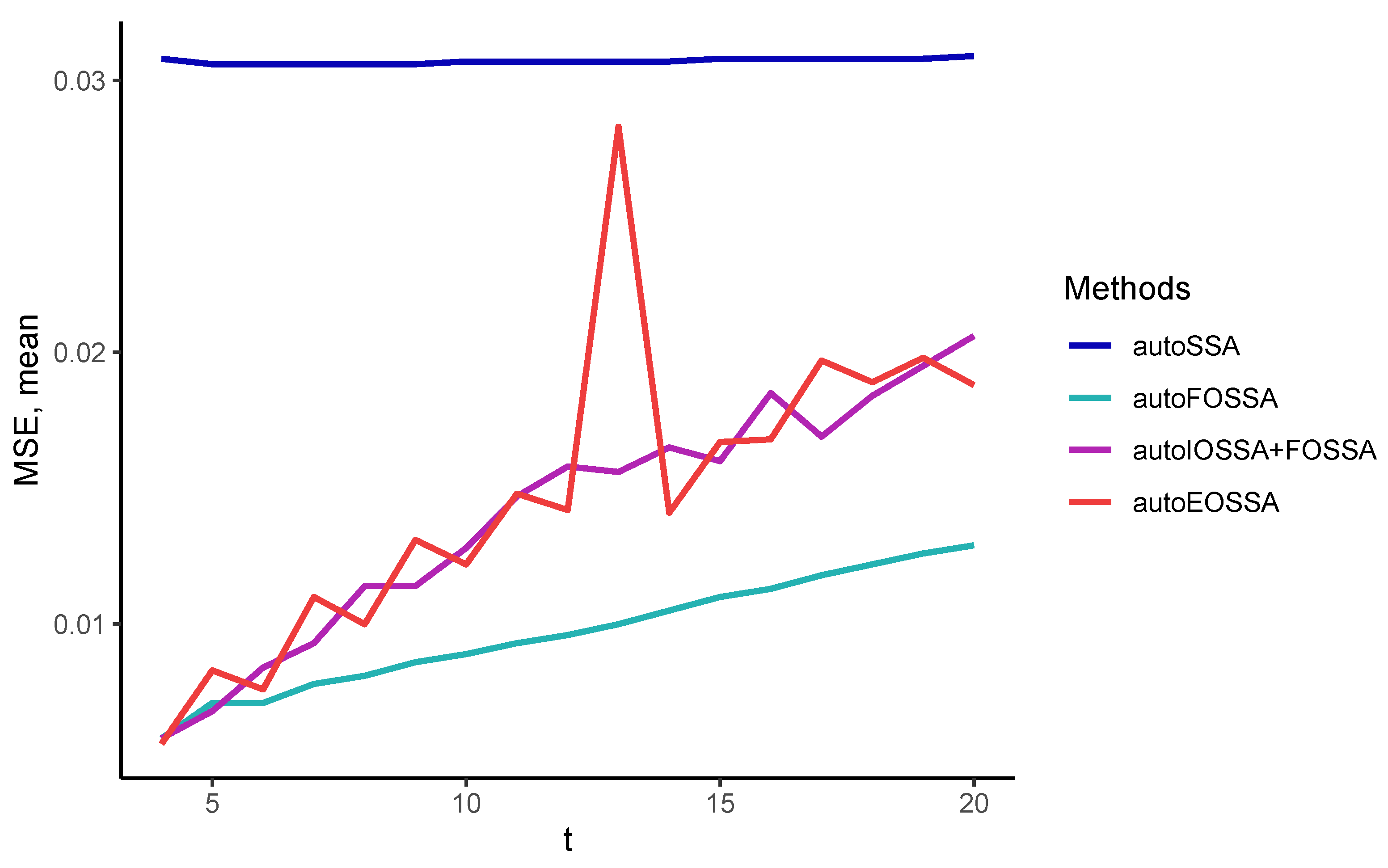
So that the results at different time series lengths do not depend on the quality of the separability of time series components, we considered signals that are discretizations of a single signal, namely, we considered time series in the form of
with standard white Gaussian noise. The rank of the signal is 5, so the number of components
t was also chosen to be 5.
The IOSSA method was given two variants as the initial grouping, the correct grouping
(true) and the incorrect one
(wrong). As one can see from
Table 1, the computational time is generally the same. IOSSA marked 10 ran with the maximum number 10 of iterations to converge. In other cases, there was only one iteration. Note that the computational time in R is unstable, since it depends on the unpredictable start of the garbage collector, but the overall picture of the computational time cost is visible.
Thus, EOSSA and FOSSA work much faster than IOSSA, but FOSSA improves only contribution separability, i.e., strong separability if weak separability holds. Since variations of OSSA are applied after SSA, the indicated computational times for OSSA are the overheads concerning the SSA computational cost (the column `SSA’). If there is no separability improving, the overhead is zero.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}