1. Introduction
Given a set of points
,
, a well-separated pair decomposition (WSPD) can be seen as a compressed representation for approximating
pairwise distances of
n points from
S into
space, where the dimension
d is considered a constant. The formal definition of a WSPD will be given in
Section 2. A WSPD can also be seen as a clustering approach, e.g., a WSPD is a partition of the
edges of the complete Euclidean graph into
subsets. This decomposition was first introduced in a seminal paper [
1] by Paul B. Callahan and S. Rao Kosaraju in 1995. It has been shown in [
1] that the size of a WSPD, when computed by their algorithm, is exponential in
d. Hence, it has never been used in practice for dimensions larger than three.
However, a WSPD has been shown to be useful in many different applications. It is known that a WSPD can be used to efficiently solve a number of proximity problems [
2], such as the closest pair problem, the all-nearest neighbors problem, etc. It is also known that a WSPD directly induces a
t-spanner of a point set or provides a
—approximation of the Euclidean minimum spanning tree. The authors in [
3] used a WSPD to compute approximate energy-efficient paths in radio networks. Their algorithm reduced the complexity of computing such paths to
by moving most of the computation to the preprocessing stage by precomputing a template path for each pair of sets compressing the pairwise distances.
Since a WSPD proved to be an essential decomposition for different important problems, in this paper, I investigate to what extent a WSPD can be helpful for situations where the input and the dimension d is much larger than two or three.
On the technical side, a WSPD of a set of points is represented by a sequence of pairs of sets , , called dumbbells, such that (i) for every two distinct points there exists a unique dumbbell such that ; (ii) the distances between points in and are approximately equal; (iii) the distances between points in or points in are much smaller than the distances between points in and .
As stated before, the size of a WSPD, i.e., the number of dumbbells, is known to grow exponentially with the dimension
d. Hence, instead of computing a WSPD directly on
, I first propose to transform the points in
S with a nonlinear function
,
or
, where
denotes the set of learnable function parameters. The parameters
are determined such that the function
preserves the properties of
S that are important for a WSPD, e.g., preserves pairwise distances for points in
S. If the function
manages to preserve most of the important information for a WSPD, there is hope that the WSPD computed on the mapped points
,
or
, where the size of the WSPD is
, will output “dumbbells” that are meaningful even for the original input
S. If this is the case, the reconstructed dumbbells should continue to be “dumbbell-shaped” in the original space. In practice, some of the reconstructed dumbbells can become “bad” because they do not approximate the distances in any practical sense. However, I will show that the number of “bad” dumbbells is negligible in practice. Moreover, such “bad” dumbbells can be easily refined without significantly increasing the total number of dumbbells. One tool I employ might be of independent interest: I implemented a WSPD following the nontrivial algorithm of the partial fair-split tree that guarantees the construction time of
and a WSPD of
size. To my knowledge, my implementation is the first open-source publicly available implementation of a WSPD that carefully follows the original algorithm in [
1]. The implementation of a WSPD in the ParGeo C++ library (see [
4]) uses a simple fair-split kd-tree and as such does not ensure theoretical bounds on the size of a WSPD.
Recently, there have been attempts to improve classical clustering for high-dimensional datasets. The authors in [
5] have proposed a deep embedded clustering method that simultaneously learns feature representations and cluster assignments using a nonlinear mapper
. The work of [
6,
7] proposed an interesting Maximal Coding Rate Reduction principle for determining the parameters
of the function
. The work of [
8] further developed that idea in the context of manifold clustering.
Although this work was motivated by the research above, I note that their use of a function was aimed at improving clustering in the sense that a nonlinear mapper was used as an additional mechanism to “learn” a better set of features that would enable a better clustering. In my approach, , which is represented by a neural network, is primarily used as a mapper to a very low-dimensional representation of the original dataset, since only there can a WSPD be computed efficiently.
In the rest of this paper, I will formally define a WSPD and state two important theorems. Furthermore, I will introduce two different functions for and present steps for computing a WSPD for high-dimensional data sets. Finally, I provide empirical evidence for the claim that a WSPD of size can be computed efficiently for dimensions d much larger than three.
2. Preliminaries
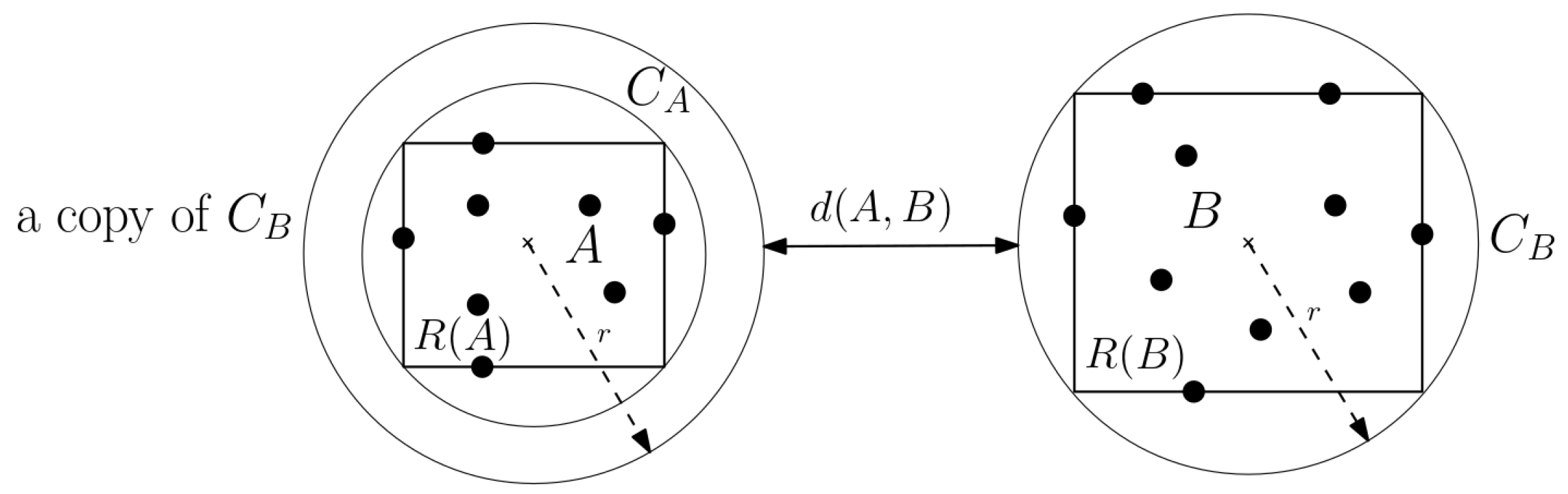
Let
S be a set of
n points in
. For any
, let
denote the minimum enclosing axis-aligned box of
A. Let
be the minimum enclosing ball of
, and let
denote the radius of
. Let
be the ball with the same center as
but with radius
r. Furthermore, for two sets
A,
, let
, and let
denote the minimum distance between
and
. For example, if the
intersects
, then
(
Figure 1).
Definition 1. A pair of sets A and B are said to be well separated (a dumbbell) if , for any given separation constant and .
Definition 2 (WSPD). A well-separated pair decomposition of , for a given , is a sequence , where , such that the following applies:
- 1.
are well separated with respect to separation constant s, for all ;
- 2.
For all , there exists a unique pair such that or .
Note that a WSPD always exists since one could use all singleton pairs , for all pairs . However, this would yield a sequence of dumbbells of size . The question is whether one could do better than that. The answer to that question was given by the following theorem.
Theorem 1 ([
1])
. Given a set S of n points in and a separation constant , a WSPD of S with amount of dumbbells can be computed in time. While Theorem 1 states that it is possible to compute only
dumbbells, for fixed dimension
d, it is still not clear how to efficiently determine the appropriate dumbbell for a given query pair
. In [
3], it has been shown that retrieving the corresponding dumbbell can be performed in
time for a fixed dimension
d.
Theorem 2 ([
3])
. Given a well-separated pair decomposition of a point set S with separation constant and fixed dimension d, I can construct a data structure in space and construction time such that for any pair of points in S I can determine the unique pair of clusters that is part of the well-separated pair decomposition with in constant time. 3. Deep Embedded WSPD
Instead of computing a WSPD of , as suggested by Theorem 1, I propose to first transform the data with a nonlinear mapping , where is chosen to be either 2 or 3, and is a set of learnable parameters. In this section, I introduce two approaches for training the neural net for embedding the point sets.
3.1. Metric Multidimensional Scaling
The most natural choice for a function
is to use metric multidimensional scaling (mMDS), which tries to preserve the pairwise distances between points, i.e., it solves the optimization problem
where
denotes the Euclidean norm and
are some given weights. For the implementation of a function
, I will use deep neural networks. The neural network approach for computing the metric MDS mapper has already been used in [
9]. Inspired by the work of [
5,
10,
11], I chose the following architecture with
five fully connected layers of the form below:
and
. Moreover, the output
,
of the
kth layer for each
is defined as follows:
where
is just another name for any
,
denotes an activation function and
are model parameters. For the activation function
, I use the hyperbolic tangent (tanh).
3.2. Autoencoder
We will also implement the function
as a stacked autoencoder, a type of neural network typically used to learn encodings of unlabeled data. It is known that such a learned data representation maintains semantically meaningful information ([
12,
13]). Moreover, it has been shown in [
14], one of the seminal papers in deep learning, that an autoencoder can be effectively used on real-world datasets as a nonlinear generalization of the widely used principal component analysis (PCA).
The fundamental concept is to use an encoder to reduce high-dimensional data to a low-dimensional space. However, this results in a loss of information in the data. The decoder then works to map the data back to its original space. The better the mapping, the less information is lost in the process. Thus, the basic idea of an autoencoder is to have an output layer with the same dimensionality as the inputs. In contrast, the number of units in the middle layer is typically much smaller compared to the inputs or outputs. Therefore, it is assumed that the middle layer units contain a reduced data representation. Since the output is supposed to approximate the input, it is hoped that the reduced representation preserves “interesting” properties of the input (e.g., pairwise distances). It is common that autoencoders have a symmetric architecture, i.e., for an odd number L, the number of units in the kth layer of an L-layer autoencoder architecture is equal to the number of units in the th layer. Moreover, the first part of the network, up to the middle layer, is called the encoder, while the part from the middle layer to the outputs is called the decoder.
We use a very similar architecture as above, namely
nine layers of the form below:
for
. The output
,
of the
kth layer for any
is computed as above using the tanh activation function. Training is conducted by minimizing the following least squares loss:
Once the autoencoder is trained on a given dataset S, the encoder part of the network is used as a nonlinear mapper , and the decoder part is discarded.
3.3. Computing WSPD in High Dimensions
Given a function , the algorithm for computing a WSPD of a high-dimensional dataset is given by the following steps:
Compute a lower-dimensional representation .
Compute a WSPD, for any given , as proposed by Theorem 1. Let , , denote the dumbbells.
Reconstruct , , in the original space. Note that not all of them are well separated, i.e., they are not dumbbells anymore.
Refine all not well-separated pairs until they become dumbbells.
We will refer to the above steps as the NN-WSPD algorithm. Note that the reconstruction step in NN-WSPD can be performed efficiently. What requires further explanation is the refine step, which guarantees that the set of computed dumbbells in
is in fact again a well separated pair decomposition of
S. Suppose
for some
i is not well separated and let
. We propose the following steps in Algorithm 1 to refine
.
| Algorithm 1 Refine(, ) |
if is not a dumbbell then Split into and ▹Assuming , otherwise split Remove from WSPD. Add and to WSPD Refine(, ) and Refine() ▹(Two recursive calls) end if
|
The complexity of the refine step depends on the recursion depth. We will experimentally demonstrate that the depth is relatively small for all the datasets that I tried in practice, introducing just a moderate number of new dumbbells.
3.4. Fast Dumbbell Retrieval in High Dimensions
As Theorem 2 stated, for any pair of points
I can determine the unique dumbbell
,
, in constant time but only if dimension
d is considered constant. The hidden constant in the running time is again exponential in
d (due to the packing argument used in [
3], Lemma 10). Hence, the only way for a pair of points
to retrieve the corresponding dumbbell
efficiently is to build and query the data structure proposed in [
3] in lower-dimensional representation
. Namely, let
, denote the dumbbells in
and
, the reconstructed and refined dumbbells in
computed by NN-WSPD. Note that
in general, since the number of reconstructed and refined dumbbells might be larger. However, let
,
, denote the corresponding dumbbells in
of the WSPD computed by NN-WSPD in
. Note that
,
is also a valid WSPD of
, and let query
denote the query call to the data structure proposed in [
3] built on that WSPD. The query algorithm for any two points
is defined in Algorithm 2.
| Algorithm 2 RetrieveDumbbell(a, b) |
Require:
, for , query
Let ,
= query ▹ Retrieve dumbbells by query from [3]
Return such that |
The run-time complexity of Algorithm 2 again depends on the number of additional dumbbells that the refine step will add.
4. Experiments
Our implementations of the neural networks are performed in PyTorch [
15], and a WSPD is implemented in C++ following the algorithm proposed in [
1]. All codes are available for testing at
https://github.com/dmatijev/high_dim_wspd.git. The experiments were conducted on Ryzen 9 3900X, with 12 cores and 64GB of DDR4 RAM with an Ubuntu 20.04 operating system.
For the training of the neural networks, I use an initial learning rate of 0.001 and a batch size of 512. All networks are trained for a number of epochs set to 500. It is essential to state that I did not put effort into fine-tuning these hyperparameters. Instead, all hyperparameters are set to achieve a reasonably good WSPD reconstruction and, to maintain fairness, are held constant across all datasets. We used Adam [
16] for first-order gradient-based optimization and the ReduceLROnPlateau callback for reducing the learning rate (dividing it by 10) when a metric, given by (
1) for mMDS NN, and (
3) in the case of autoencoder NN, has stopped improving.
4.1. Datasets
We evaluated the computation of a WSPD on artificially generated and real high-dimensional datasets. Artificially generated datasets are drawn from the following:
A uniform distribution over the hypercube;
A normal (Gaussian) distribution, with mean 0 and standard deviation 1;
A Laplace or double exponential distribution, with the position of the distribution peak at 0 and the exponential decay at 1.
For real-world datasets, I used two public scRNA-seq datasets downloaded from [
17]. scRNA-seq data are used to assess which genes are turned on in a cell and in what amount. Therefore, scRNA-data are typically used in computational biology to determine transcriptional similarities and differences within a population of cells, allowing for a better understanding of the biology of a cell. We apply the standard preprocessing to scRNA-seq data (see [
18,
19]): (a) compute the natural log-transformation of gene counts after adding a pseudo count of 1 and (b) select the top 2000 most variable genes followed by a dimensionality reduction to 100 principle components. We used two datasets of sizes
and
.
One possible motivation for a WSPD on scRNA-seq data can be found in the work of [
20]. Namely, the authors in [
20] solve the marker gene selection problem by solving a linear program (LP). For a large amount of data, the LP cannot be efficiently solved in practice. Hence, the practical approach to that issue could be to solve an LP on a subset of constraints, then define a separation oracle that iteratively introduces new constraints to the LP, if the current solution is not feasible. Following the work of [
20], the oracle could add the currently most violated constraints, i.e., pairs of points whose distance is less than a predefined constant value. Given the WSPD, one could speed up the oracle by using dumbbells as a substitute for the pairwise distances.
4.2. Measuring the Quality of a WSPD
Let , , denote the WSPD for some set of points . For and for some dumbbell i, I make the following observations:
Points within the sets
and
can be made “arbitrarily close” as compared to points in the opposite sets by choosing the appropriate separation
, i.e.,
Distances between points in the opposite sets can be made “almost equal”, by choosing the appropriate
, i.e.,
Since a WSPD is primarily concerned with compressing the quadratic space of pairwise distances into a linear space (for a fixed dimension
d), I will use Equation (
5) repeatedly in my plots in order to measure how much distances are indeed preserved within a dumbbell.
4.3. Results
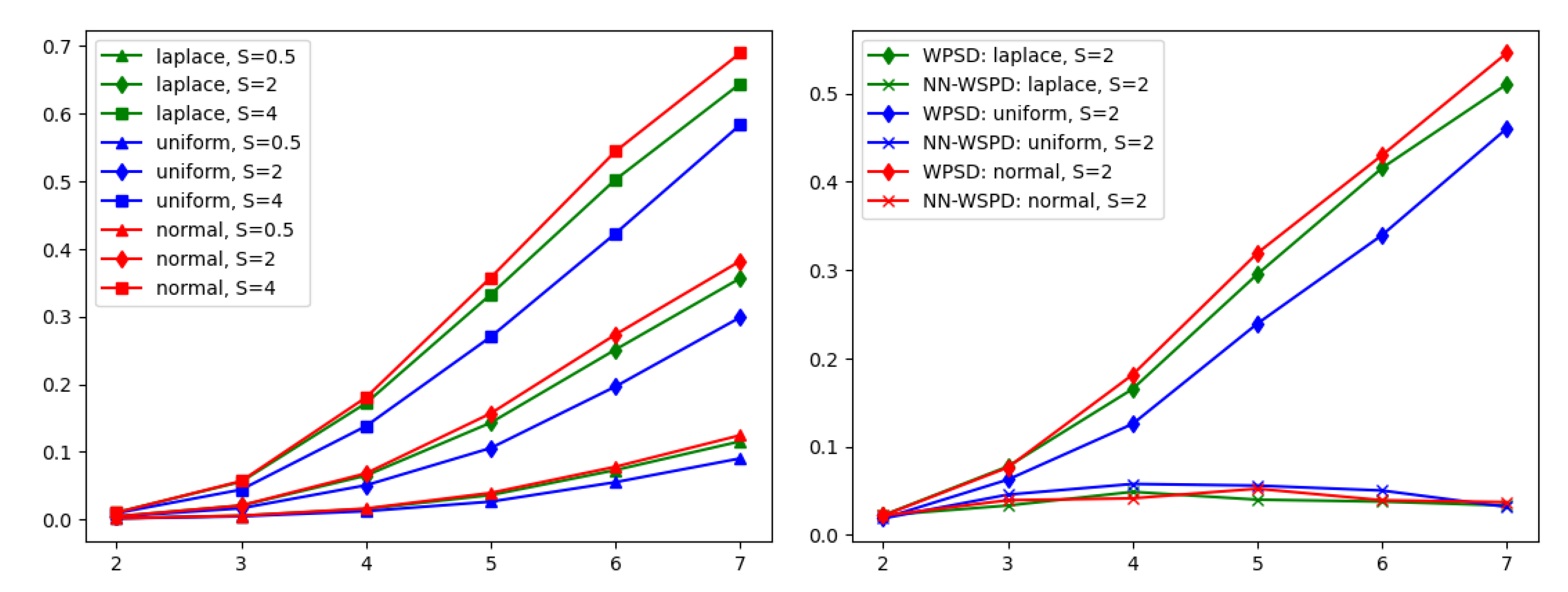
In
Figure 2 (left), synthetic datasets were used to demonstrate the dependence between the size of a WSPD and the dimension of the input data in practice. Recall that the number of dumbbells is bounded above by
(Theorem 1). In my experiments, I found that the dependence on dimension
d is indeed severe, making the WSPD algorithm proposed in [
1] unusable in practice for dimensions
or
. However, it is unclear whether the number of dumbbells is just an artifact of the construction of the WSPD algorithm or whether that number of dumbbells is indeed necessary to satisfy the properties of a WSPD given by Definition 2. Thus,
Figure 2 (right) demonstrates the total number of dumbbells when computed with the algorithm proposed in [
1] and compares it to the number of dumbbells computed with the NN-WSPD approach.
Observation: For many practical datasets, there exists a WSPD , , with for any dimension d, i.e., the hidden constant in notation is not exponential in the dimension d.
I performed numerous experiments with synthetic data and my two real datasets to support my claim.
4.3.1. Synthetic Datasets
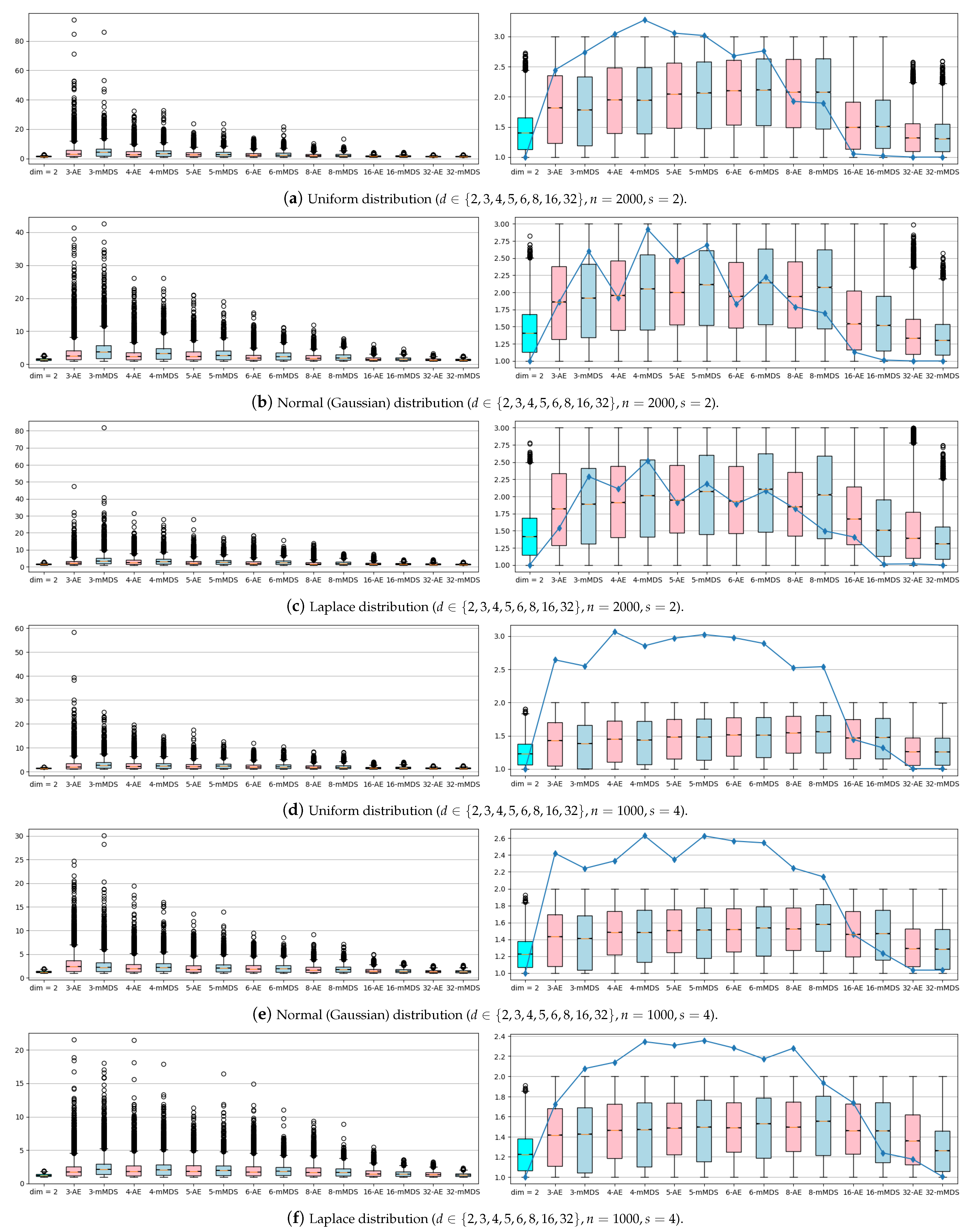
In
Figure 3, the experiments were performed with the synthetic datasets. Only for
was the standard WSPD algorithm used, and for
, NN-WSPD was used. On the boxplots in the left column, NN-WSPD was applied but without the refine step (Algorithm 1). From this one can see that many of the reconstructed dumbbells can violate the quality given by Equation (
5), which the dumbbells are supposed to guarantee. However, most dumbbells are still well separated since a lot of valuable information for a WSPD was preserved by the nonlinear mapper
. The results of the refine step (Algorithm 1) can be seen in boxplots in the right column in
Figure 3. Note that after the refine step all dumbbells are indeed dumbbells (i.e., well separated), with the overall number of dumbbells that rarely gets larger than the starting WSPD size multiplied by a factor of at most three, independent of the dimension
d. We noticed that the higher the dimension
d of the input set
S, the fewer refined dumbbells are needed. This is not that surprising bearing in mind the fact that when a Euclidean distance is defined using many coordinates there is less difference in the distances between different pairs of samples (see the curse of dimensionality phenomenon [
21]).
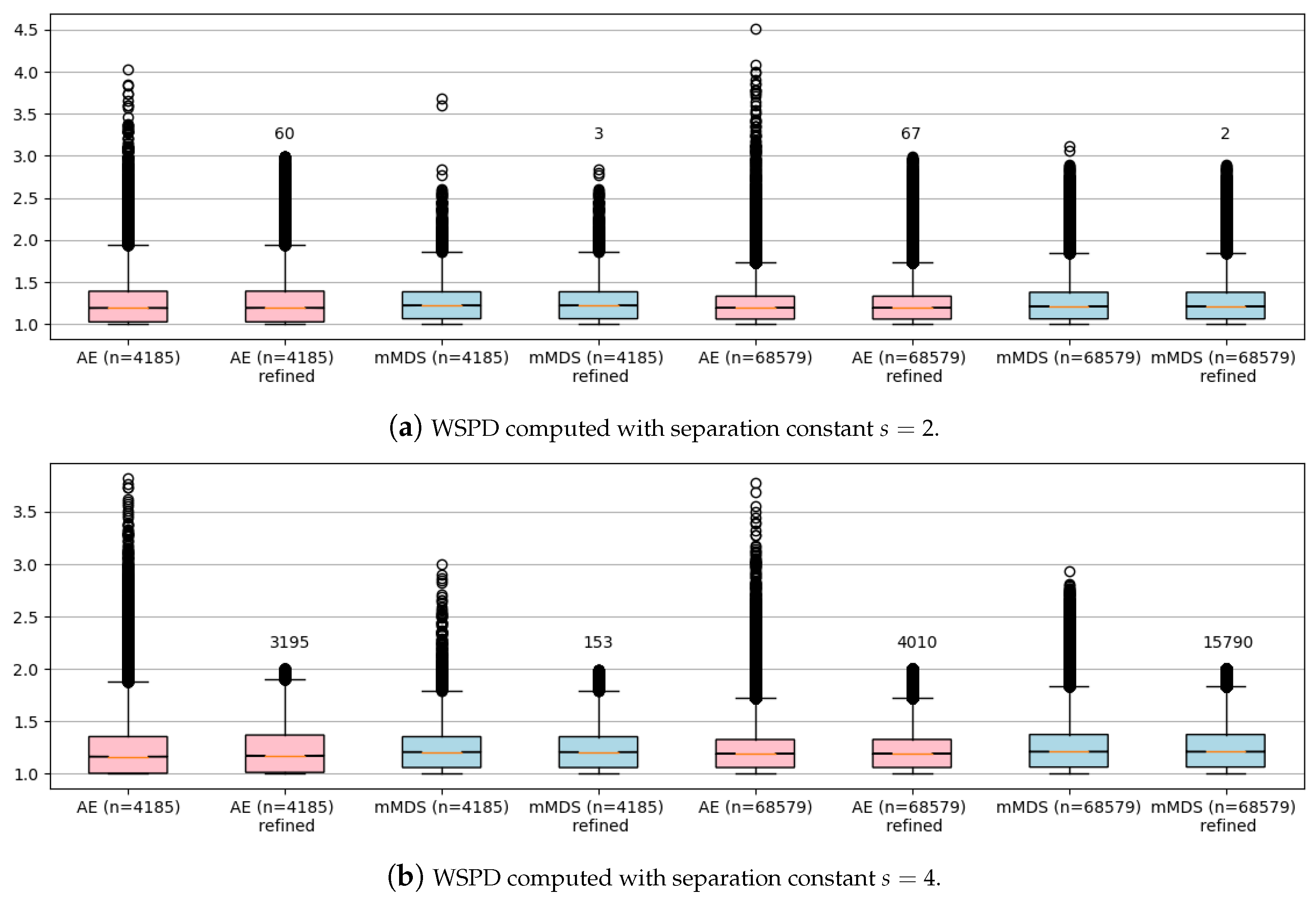
4.3.2. scRNA-Seq Datasets
I had even fewer problems computing a WSPD for my two real datasets (
and
n = 68,579) that, after being preprocessed, were given in
,
. In
Figure 4, I output boxplots for both sets before and after the refining step. Note that the number of newly added refined dumbbells is negligible, even compared to the original sets’ size. Moreover, notice that computing a WSPD directly on such a high-dimensional input (
) is very inefficient and practically of no use due to the dependence on
d. For example, I managed to compute a WSPD for dataset
in 507 s with 8,401,551 dumbbells, which is slightly above 95% of the overall size of pairwise distances, i.e., 95% of dumbbells were just singletone pairs
. In contrast, my NN-WSPD approach always outputs a WSPD with a very moderate increase in size compared to a WSPD of size
computed in the plane the points were projected to, as my experiments showed.
5. Conclusions
Well-separated pair decomposition is a well known decomposition in computational geometry. However, computational geometry as a field is concerned with algorithms that solve problems on datasets in , where the dimension d is considered a constant. In this work, I demonstrated that a WSPD of size could be computed even for high-dimensional sets, hence removing the requirement that dimension d is a constant. In my approach, I used an implementation of a nonlinear function that was based on artificial neural networks.
The past decade has seen remarkable advances in deep learning approaches based on artificial neural networks. We also witnessed a few successful applications of neural networks in discrete problems, e.g., I would like to point the reader to the surprising results presented in [
22], which introduces a new neural network architecture (Ptr-Net) and shows that it can be used to learn approximate solutions to well-known geometric problems, such as planar convex hulls, Delaunay triangulations, and the planar traveling salesperson problem.
These advances inspire us to further explore the applications of deep learning in fields such as geometry.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



