

Deep Cross-Network Alignment with Anchor Node Pair Diverse Local Structure


Abstract
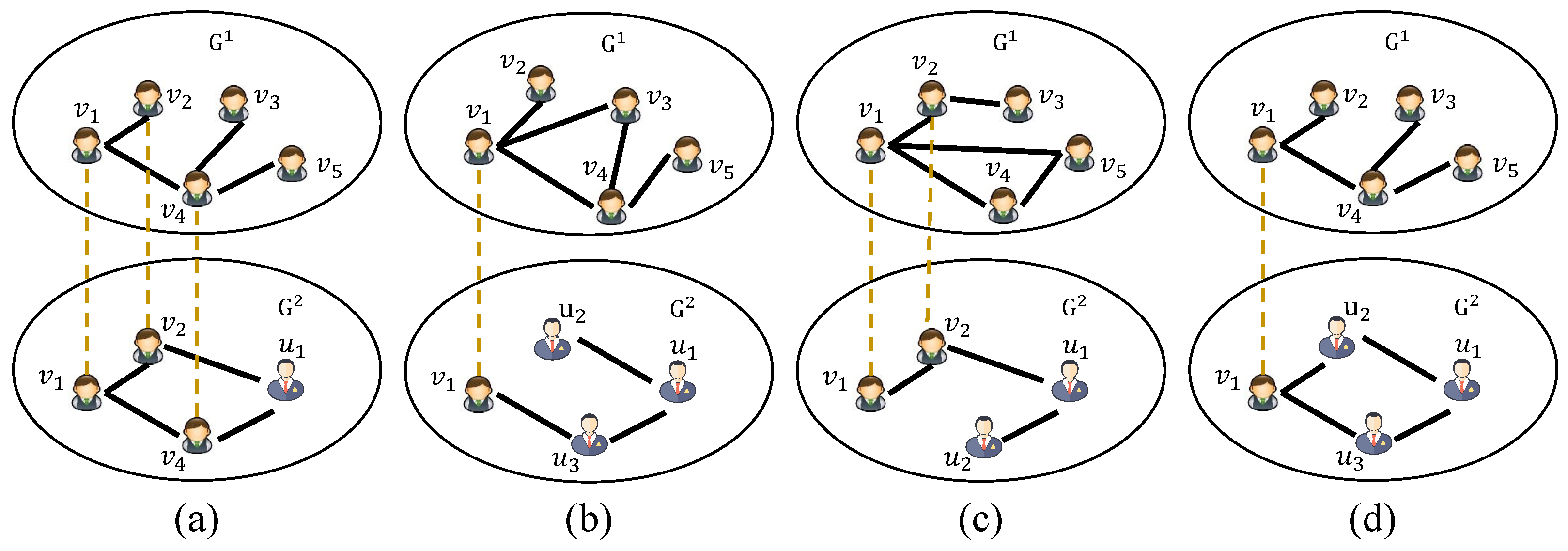
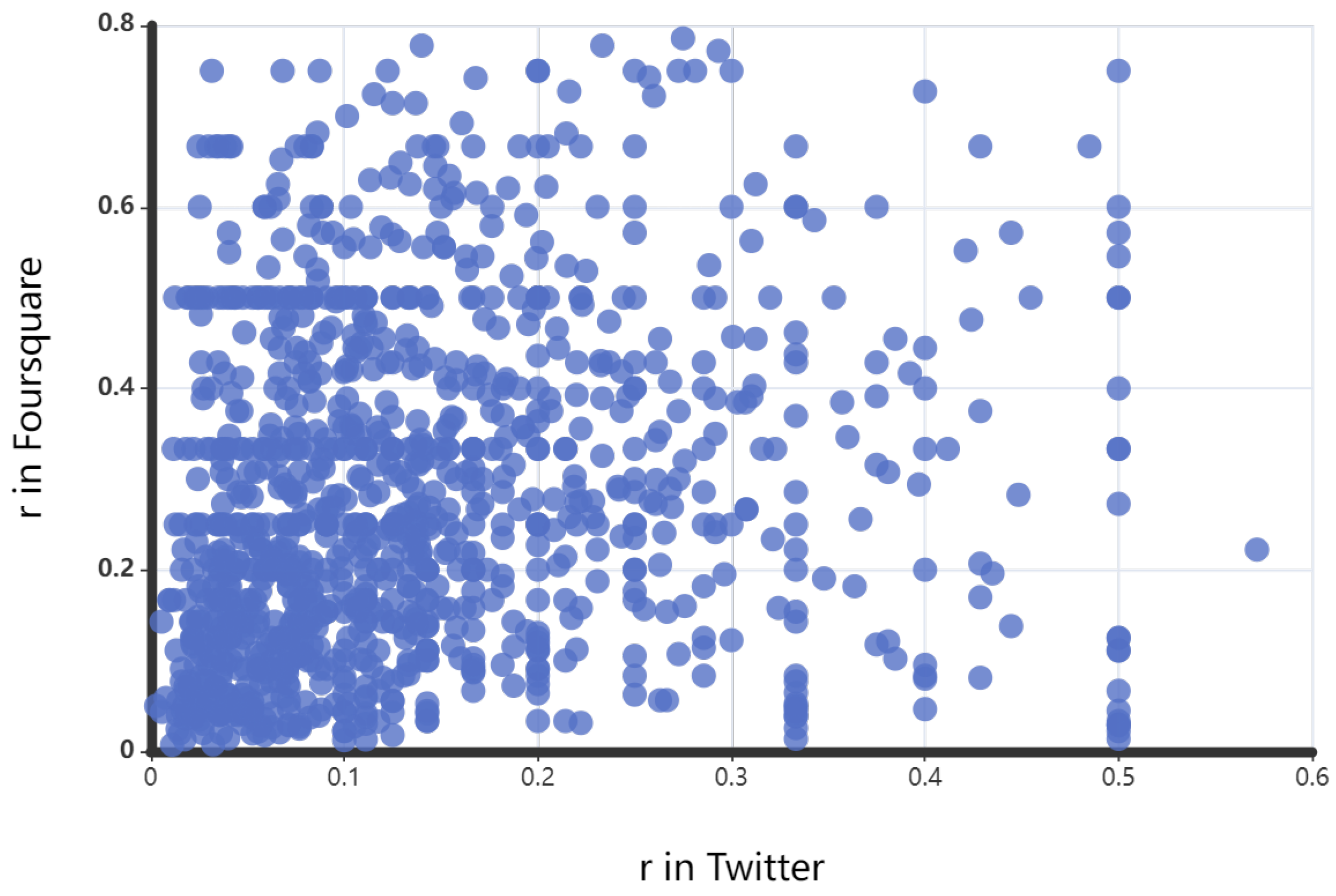
1. Introduction
- We present a masked network encoder to embed nodes in each network as a Gaussian distribution, which not only preserves the structural information but also obtains the uncertainty of node representations. Additionally, the mask mechanism could alleviate the impact of nodes that will confuse structural proximity in alignment.
- We generalize the information of labeled anchor node pairs to other node pairs by utilizing meta-learning. Additionally, a method based on meta-learning can also reduce the dependence on the number of labeled anchor nodes, where it is time-consuming to collect labeled anchor nodes.
- We propose an end-to-end framework based on a masked variational auto-encoder to address the NA task. Our solution works better than other NA methods, according to extensive experiments on both real-world and synthetic datasets.
2. Related Work
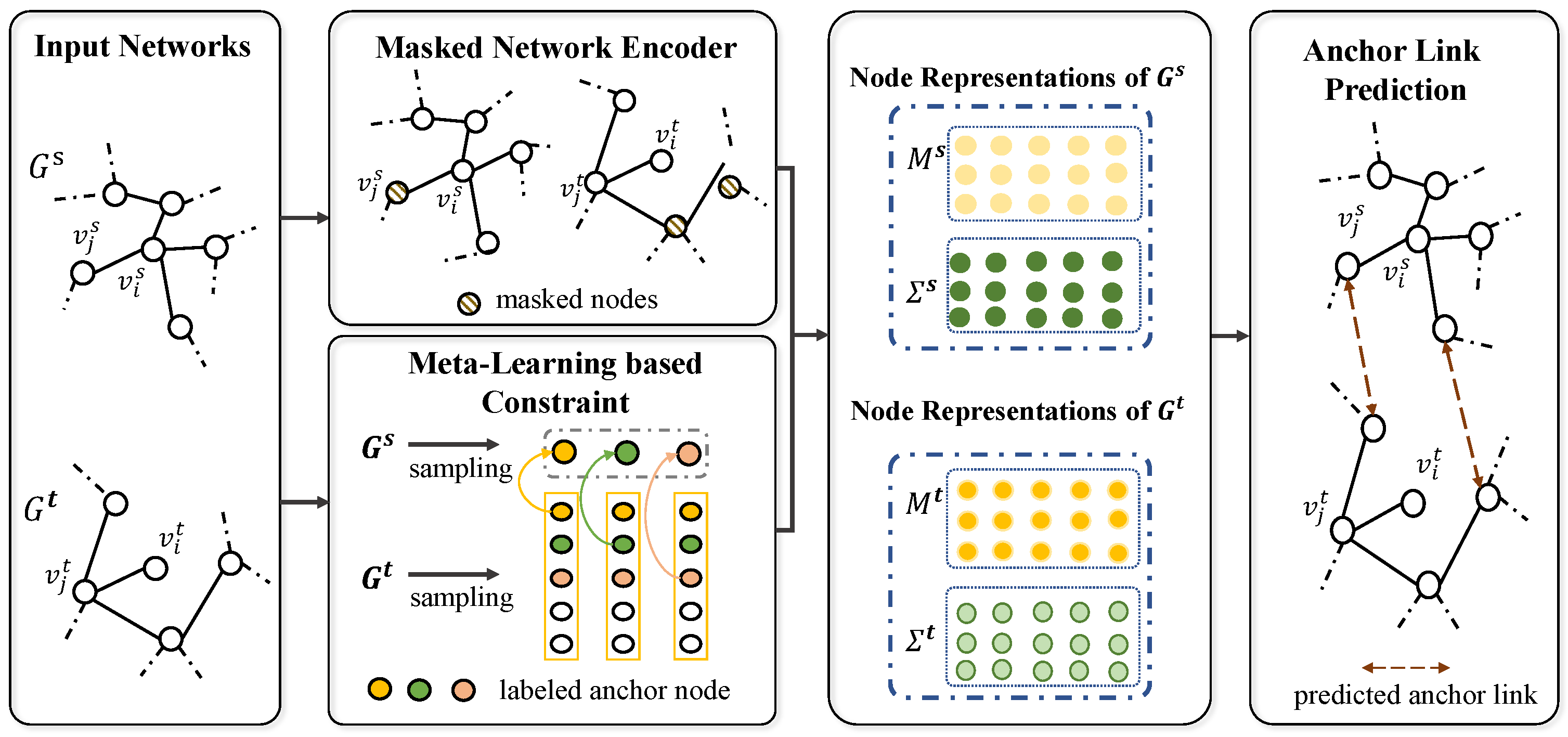
3. Method
3.1. Problem Formulation
3.2. Network Embedding with the Diverse Local Structure of Anchor Node
3.2.1. Masked Network Encoder Based on Variational Graph Convolution
3.2.2. Meta-Learning-Based Constraint
3.3. Network Alignment Based on Node Representations
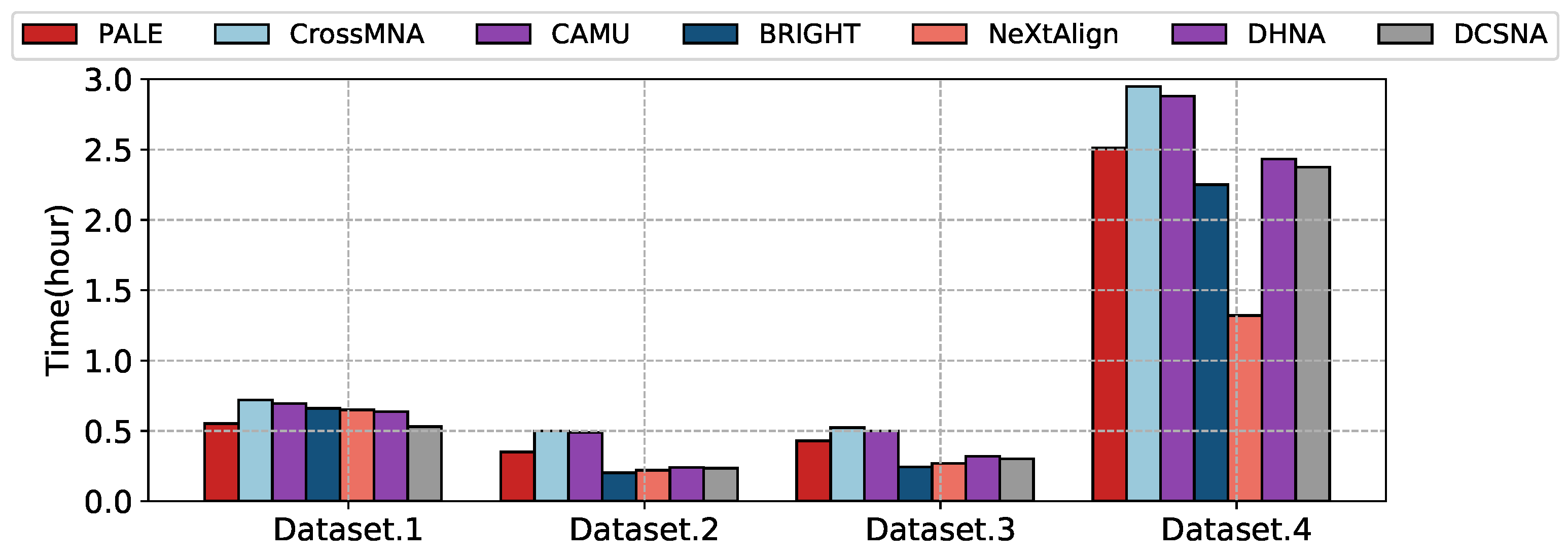
3.4. Time Complexity
4. Experiment
4.1. Datasets
- The synthetic dataset. It is constructed based on Facebook [45]. We remove nodes with degrees of less than 10 and sample two networks in accordance with the methodology described in [12], resulting in 38,344 nodes and 1,183,080 edges. It uses a distribution to determine which network each edge belongs to. Whenever , the edge is thrown away; if the edge is only preserved in the first network, ; if , only the other network retains the edge; otherwise, both networks maintain the edge. We set and denote the synthetic dataset as Dataset.4.
4.2. Baseline Methods
- PALE [12] first learns the individual embeddings of two networks by existing single network embedding methods LINE. Then, it learns a mapping function to match the latent space of the two networks and predicts anchor node pairs by calculating the distance of embeddings.
- CrossMNA [16] uses two vectors to preserve the common features of the anchor nodes in different networks (inter-vector) and the specific structural feature for a node in its selected network (intra-vector) respectively. Additionally, it uses the inter-vector to align nodes in different networks.
- CAMU [15] learns network embedding by considering network structure and node attribute information. Additionally, then it learns a mapping function to decrease the representation distribution discrepancy of different networks.
- BRIGHT [35] builds a specific unified space using labeled anchor links as landmarks using random walk with restart (RWR), and then employs a common linear layer to determine the significance of the RWR scores at various dimensions.
- NeXtAlign [46] uses a special relational graph convolutional network (RelGCN) to encode the alignment consistency.
- DHNA [31] uses a variational autoencoder to learn node embeddings, and considers the different anchor nodes’ degrees across networks.
4.3. Experimental Settings
4.3.1. Evaluation Metrics
4.3.2. Parameter Settings
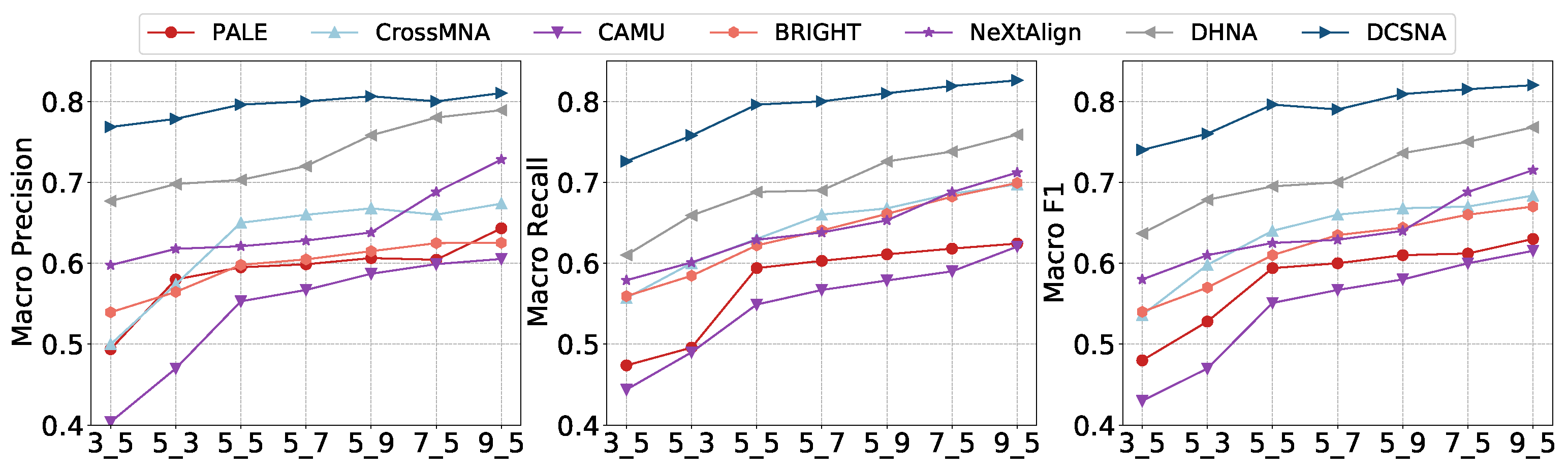
4.4. Performance Analysis
- Based on the experimental results, we find that our method DCSNA can perform better than other baseline methods in most cases, especially under the metric Macro Precision. These results demonstrate DCSNA’s superiority, which learns each node representation as a distribution and masks the nodes with a larger degree. Representing nodes as distributions let us distinguish the nodes from their neighbor nodes and reduce confusion during network alignment. This is also why embedding-based methods, such as PALE and CrossMNA, perform slightly worse, as they overly preserve the neighbor structure of nodes, making nodes and their neighbors indistinguishable. Since CAMU is to reduce the node representation distribution between two networks, it performs better than methods that only learn node representations.
- Although BRIGHT and NeXtAlign consciously distinguish anchor node pairs from their neighbors through mechanisms, such as sampling or using anchor links as landmarks, the key idea is still keeping the consistency of anchor node pairs. Therefore, they are more suitable for the situation where most anchor nodes satisfy equivalence connection status across networks.
- It is worth noting that the performance of DHNA is second only to our model in most cases. DHNA considers the degree discrepancy across nodes, i.e., non-equivalence connection status, and makes a balance between consistency and such connection status. However, it ignores another connection status.
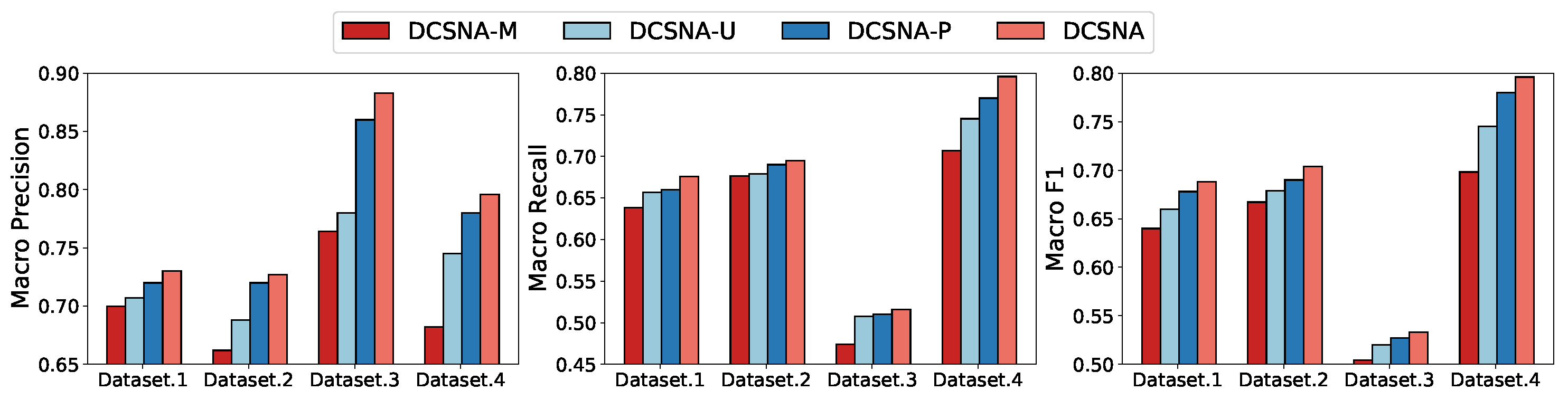
4.5. Ablation Study
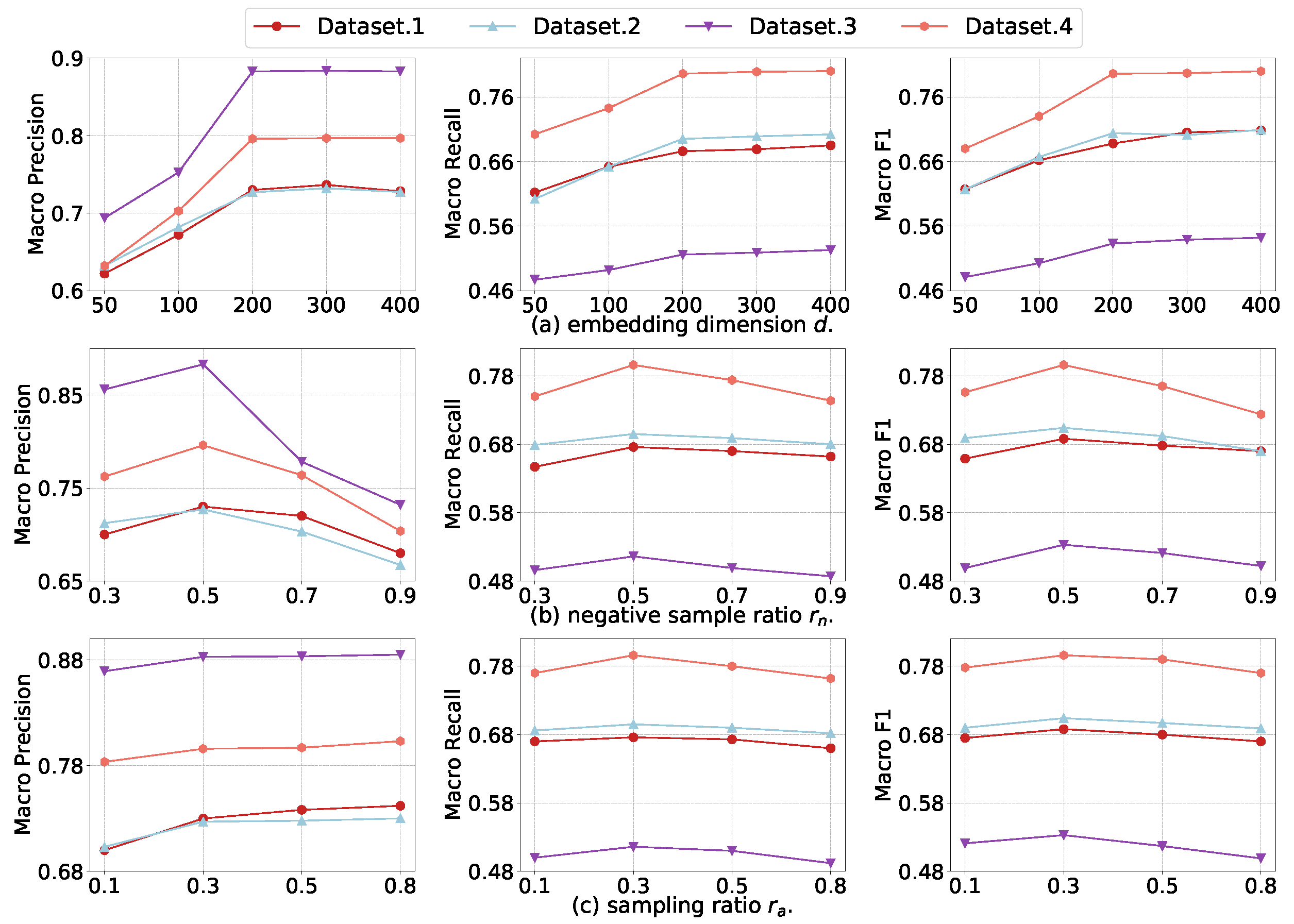
4.6. Parameter Sensitivity
- Figure 7a shows that performance improves with increasing node size d, but performance degrades when d is more than 200. The reason is that we represent each node as a distribution containing both mean and variance embedding, as the dimension d increases, the uncertainty (i.e., the information of variance embedding) will accumulate and result in the poor performance of matching potential anchor nodes.
- From Figure 7b, we can observe that our model could achieve competitive performance on different . It indicates that although the negative sampling mechanism is helpful for better training of the model, it plays a limited role. Improper determination of the number of negative samples may even reduce the accuracy of the model.
- From Figure 7c, we can observe our model can achieve competitive performance by using fewer labeled anchor nodes, which demonstrates the effectiveness of meta-learning constraint and the robustness of our model. Since the number of labeled anchor nodes is usually small in the real task, the robustness of the model can guarantee the model to be applied to the alignment task well.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shu, K.; Wang, S.; Tang, J.; Zafarani, R.; Liu, H. User identity linkage across online social networks: A review. ACM Sigkdd Explor. Newsl. 2017, 18, 5–17. [Google Scholar] [CrossRef]
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Philip, S.Y. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2016, 29, 17–37. [Google Scholar] [CrossRef]
- Zhang, J.; Philip, S.Y. Integrated anchor and social link predictions across social networks. Knowl. Inf. Syst. 2019, 60, 303–326. [Google Scholar] [CrossRef]
- Kong, X.; Zhang, J.; Yu, P.S. Inferring Anchor Links across Multiple Heterogeneous Social Networks. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (CIKM’13), Francisco, CA, USA, 27 October 2013; ACM: New York, NY, USA, 2013; pp. 179–188. [Google Scholar]
- Chen, L.J.; Gao, J. A trust-based recommendation method using network diffusion processes. Phys. A Stat. Mech. Appl. 2018, 506, 679–691. [Google Scholar] [CrossRef]
- Wang, B.; Gu, Y.; Zheng, D. Community detection in error-prone environments based on particle cooperation and competition with distance dynamics. Phys. A Stat. Mech. Appl. 2022, 607, 128178. [Google Scholar] [CrossRef]
- Wang, Q.; Xiao, Y.; Meng, D. Identification of structural key genes of mutual information gene networks of brain tumor. Phys. A Stat. Mech. Appl. 2022, 608, 128322. [Google Scholar] [CrossRef]
- Liang, B.; Wang, L.; Wang, X. OLMNE+FT: Multiplex network embedding based on overlapping links. Phys. A Stat. Mech. Appl. 2022, 596, 127116. [Google Scholar] [CrossRef]
- Jiao, P.; Tang, M.; Liu, H.; Wang, Y.; Lu, C.; Wu, H. Variational autoencoder based bipartite network embedding by integrating local and global structure. Inf. Sci. 2020, 519, 9–21. [Google Scholar] [CrossRef]
- Wu, H.; Wolter, K.; Jiao, P.; Deng, Y.; Zhao, Y.; Xu, M. EEDTO: An Energy-Efficient Dynamic Task Offloading Algorithm for Blockchain-Enabled IoT-Edge-Cloud Orchestrated Computing. IEEE Internet Things J. 2021, 8, 2163–2176. [Google Scholar] [CrossRef]
- Liu, L.; Cheung, W.K.; Li, X.; Liao, L. Aligning Users across Social Networks Using Network Embedding. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI’16), New York, NY, USA, 9–15 July 2016; pp. 1774–1780. [Google Scholar]
- Man, T.; Shen, H.; Liu, S.; Jin, X.; Cheng, X. Predict Anchor Links across Social Networks via an Embedding Approach. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI’16), New York, NY, USA, 9–15 July 2016; pp. 1823–1829. [Google Scholar]
- Chen, H.; YIN, H.; Sun, X.; Chen, T.; Gabrys, B.; Musial, K. Multi-Level Graph Convolutional Networks for Cross-Platform Anchor Link Prediction. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD’20), Long Beach, CA, USA, 6–10 July 2020; ACM: New York, NY, USA, 2020; pp. 1503–1511. [Google Scholar]
- Trung, H.T.; Toan, N.T.; Vinh, T.V.; Dat, H.T.; Thang, D.C.; Hung, N.Q.V.; Sattar, A. A comparative study on network alignment techniques. Expert Syst. Appl. 2020, 140, 112883. [Google Scholar] [CrossRef]
- Zheng, C.; Pan, L.; Wu, P. CAMU: Cycle-Consistent Adversarial Mapping Model for User Alignment across Social Networks. IEEE Trans. Cybern. 2021, 52, 10709–10720. [Google Scholar] [CrossRef]
- Chu, X.; Fan, X.; Yao, D.; Zhu, Z.; Huang, J.; Bi, J. Cross-Network Embedding for Multi-Network Alignment. In Proceedings of the The World Wide Web Conference (WWW’19), San Francisco, CA, USA, 13–17 May 2019; ACM: New York, NY, USA, 2019; pp. 273–284. [Google Scholar]
- Trung, H.T.; Van Vinh, T.; Tam, N.T.; Yin, H.; Weidlich, M.; Hung, N.Q.V. Adaptive network alignment with unsupervised and multi-order convolutional networks. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 85–96. [Google Scholar]
- Nicolau, M.; McDermott, J. Learning neural representations for network anomaly detection. IEEE Trans. Cybern. 2018, 49, 3074–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, X.; Du, X.; Zhao, J. Structure Based User Identification across Social Networks. IEEE Trans. Knowl. Data Eng. 2018, 30, 1178–1191. [Google Scholar] [CrossRef]
- Bayati, M.; Gleich, D.F.; Saberi, A.; Wang, Y. Message-passing algorithms for sparse network alignment. ACM Trans. Knowl. Discov. Data (TKDD) 2013, 7, 1–31. [Google Scholar] [CrossRef]
- Zhang, S.; Tong, H. Final: Fast attributed network alignment. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1345–1354. [Google Scholar]
- Koutra, D.; Tong, H.; Lubensky, D. Big-align: Fast bipartite graph alignment. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 389–398. [Google Scholar]
- Vijayan, V.; Milenković, T. Multiple network alignment via multiMAGNA++. IEEE/ACM Trans. Comput. Biol. Bioinform. 2017, 15, 1669–1682. [Google Scholar] [CrossRef]
- Ge, R.; Wu, Q.; Xu, J. Computational methods for protein–protein interaction network alignment. In Recent Advances in Biological Network Analysis; Springer: Berlin/Heidelberg, Germany, 2021; pp. 45–63. [Google Scholar]
- Menor-Flores, M.; Vega-Rodríguez, M.A. Decomposition-based multi-objective optimization approach for PPI network alignment. Knowl.-Based Syst. 2022, 243, 108527. [Google Scholar] [CrossRef]
- Lanrezac, A.; Laurent, B.; Santuz, H.; Férey, N.; Baaden, M. Fast and Interactive Positioning of Proteins within Membranes. Algorithms 2022, 15, 415. [Google Scholar] [CrossRef]
- Sun, M.; Zhu, H.; Xie, R.; Liu, Z. Iterative Entity Alignment Via Joint Knowledge Embeddings. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 4258–4264. [Google Scholar] [CrossRef]
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual Knowledge Graph Embeddings for Cross-Lingual Knowledge Alignment. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI’17), Melbourne, Australia, 19–25 August 2017; pp. 1511–1517. [Google Scholar]
- Zaslavskiy, M.; Bach, F.; Vert, J.P. A path following algorithm for the graph matching problem. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 2227–2242. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, L.; Liu, D. Anchor link prediction across social networks based on multiple consistency. Knowl.-Based Syst. 2022, 257, 109939. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, Q.; Wang, W.; Guo, X.; Shao, M.; Liu, H.; Liang, W.; Pan, L. Network Alignment enhanced via modeling heterogeneity of anchor nodes. Knowl.-Based Syst. 2022, 250, 109116. [Google Scholar] [CrossRef]
- Ren, J.; Zhang, Z.; Jin, J.; Zhao, X.; Wu, S.; Zhou, Y.; Shen, Y.; Che, T.; Jin, R.; Dou, D. Integrated Defense for Resilient Graph Matching. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Volume 139, pp. 8982–8997. [Google Scholar]
- Zhang, J.; Chen, B.; Wang, X.; Chen, H.; Li, C.; Jin, F.; Song, G.; Zhang, Y. MEgo2Vec: Embedding Matched Ego Networks for User Alignment Across Social Networks. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM’18), Turin, Italy, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 327–336. [Google Scholar] [CrossRef]
- Zhong, Z.; Cao, Y.; Guo, M.; Nie, Z. Colink: An Unsupervised Framework for User Identity Linkage. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 5714–5721. [Google Scholar]
- Yan, Y.; Zhang, S.; Tong, H. BRIGHT: A Bridging Algorithm for Network Alignment. In Proceedings of the Web Conference (WWW’21), Ljubljana, Slovenia, 19–23 April 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 3907–3917. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, F.; Song, X.; Song, Y.I.; Lin, C.Y.; Hon, H.W. What’s in a Name? An Unsupervised Approach to Link Users across Communities. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining (WSDM’13), Rome, Italy, 4–8 February 2013; ACM: New York, NY, USA, 2013; pp. 495–504. [Google Scholar]
- Liu, S.; Wang, S.; Zhu, F.; Zhang, J.; Krishnan, R. HYDRA: Large-Scale Social Identity Linkage via Heterogeneous Behavior Modeling. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data (SIGMOD’14), Snowbird, UT, USA, 22–27 June 2014; ACM: New York, NY, USA, 2014; pp. 51–62. [Google Scholar]
- Riederer, C.; Kim, Y.; Chaintreau, A.; Korula, N.; Lattanzi, S. Linking users across domains with location data: Theory and validation. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 707–719. [Google Scholar]
- Wang, Z.; Lv, Q.; Lan, X.; Zhang, Y. Cross-lingual Knowledge Graph Alignment via Graph Convolutional Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 349–357. [Google Scholar]
- Wang, Y.; Wang, W.; Zhen, Z.; Peng, Q.; Jiao, P.; Liang, W.; Shao, M.; Sun, Y. Geometry interaction network alignment. Neurocomputing 2022, 501, 618–628. [Google Scholar] [CrossRef]
- Zhu, D.; Cui, P.; Wang, D.; Zhu, W. Deep Variational Network Embedding in Wasserstein Space. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 2827–2836. [Google Scholar]
- Zhou, F.; Cao, C.; Zhang, K.; Trajcevski, G.; Zhong, T.; Geng, J. Meta-GNN: On Few-Shot Node Classification in Graph Meta-Learning. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM’19), Beijing China, 3–7 November 2019; pp. 2357–2360. [Google Scholar]
- Zhang, S.; Tong, H. Attributed Network Alignment: Problem Definitions and Fast Solutions. IEEE Trans. Knowl. Data Eng. 2019, 31, 1680–1692. [Google Scholar] [CrossRef]
- De Domenico, M.; Lancichinetti, A.; Arenas, A.; Rosvall, M. Identifying modular flows on multilayer networks reveals highly overlapping organization in interconnected systems. Phys. Rev. X 2015, 5, 011027. [Google Scholar] [CrossRef]
- Viswanath, B.; Mislove, A.; Cha, M.; Gummadi, K.P. On the Evolution of User Interaction in Facebook. In Proceedings of the 2nd ACM Workshop on Online Social Networks, Barcelona, Spain, 17 August 2009; pp. 37–42. [Google Scholar]
- Zhang, S.; Tong, H.; Jin, L.; Xia, Y.; Guo, Y. Balancing Consistency and Disparity in Network Alignment. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD’21), Washington, DC, USA, 24–28 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 2212–2222. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Nodes | # Edges | # Anchor Links | |
|---|---|---|---|---|
| Dataset.1 | 9872 | 39,561 | 6352 | 0.86 |
| 9916 | 44,808 | |||
| Dataset.2 | 3583 | 14,485 | 985 | 0.80 |
| 1905 | 6097 | |||
| Dataset.3 | 5120 | 164,919 | 1609 | 0.73 |
| 5313 | 76,972 | |||
| Dataset.4 | 38,310 | 591,124 | 38,287 | 0.82 |
| 38,310 | 591,694 |
| Metric | Dataset | PALE | CrossMNA | CAMU | BRIGHT | NeXtAlign | DHNA | DCSNA |
|---|---|---|---|---|---|---|---|---|
| Macro Precision | Dataset.1 | 0.617 | 0.630 | 0.663 | 0.602 | 0.710 | 0.719 | 0.730 |
| Dataset.2 | 0.589 | 0.629 | 0.654 | 0.617 | 0.649 | 0.672 | 0.727 | |
| Dataset.3 | 0.596 | 0.616 | 0.635 | 0.616 | 0.651 | 0.750 | 0.883 | |
| Dataset.4 | 0.595 | 0.650 | 0.553 | 0.598 | 0.621 | 0.703 | 0.796 | |
| Macro Recall | Dataset.1 | 0.554 | 0.620 | 0.646 | 0.626 | 0.697 | 0.662 | 0.676 |
| Dataset.2 | 0.586 | 0.618 | 0.686 | 0.554 | 0.693 | 0.677 | 0.695 | |
| Dataset.3 | 0.585 | 0.616 | 0.629 | 0.614 | 0.696 | 0.706 | 0.516 | |
| Dataset.4 | 0.594 | 0.630 | 0.549 | 0.622 | 0.629 | 0.688 | 0.796 | |
| Macro F1 | Dataset.1 | 0.583 | 0.618 | 0.655 | 0.619 | 0.703 | 0.675 | 0.688 |
| Dataset.2 | 0.585 | 0.619 | 0.670 | 0.584 | 0.670 | 0.673 | 0.704 | |
| Dataset.3 | 0.584 | 0.616 | 0.670 | 0.616 | 0.674 | 0.721 | 0.533 | |
| Dataset.4 | 0.594 | 0.640 | 0.551 | 0.610 | 0.625 | 0.695 | 0.796 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, W.; Shao, M.; Sun, Y. Deep Cross-Network Alignment with Anchor Node Pair Diverse Local Structure. Algorithms 2023, 16, 234. https://doi.org/10.3390/a16050234
Wang Y, Wang W, Shao M, Sun Y. Deep Cross-Network Alignment with Anchor Node Pair Diverse Local Structure. Algorithms. 2023; 16(5):234. https://doi.org/10.3390/a16050234
Chicago/Turabian StyleWang, Yinghui, Wenjun Wang, Minglai Shao, and Yueheng Sun. 2023. "Deep Cross-Network Alignment with Anchor Node Pair Diverse Local Structure" Algorithms 16, no. 5: 234. https://doi.org/10.3390/a16050234
APA StyleWang, Y., Wang, W., Shao, M., & Sun, Y. (2023). Deep Cross-Network Alignment with Anchor Node Pair Diverse Local Structure. Algorithms, 16(5), 234. https://doi.org/10.3390/a16050234