
Detection of Plausibility and Error Reasons in Finite Element Simulations with Deep Learning Networks

Abstract
1. Introduction
1.1. State of the Art
1.2. Methodical Background
1.3. Research Gap
- RQ1: Is there a multilabel classification framework capable of predicting the specific sources of errors for different FE simulations?
- RQ2: In combination with the classification model, which CNN architecture is particularly suitable for detecting the causes of errors?
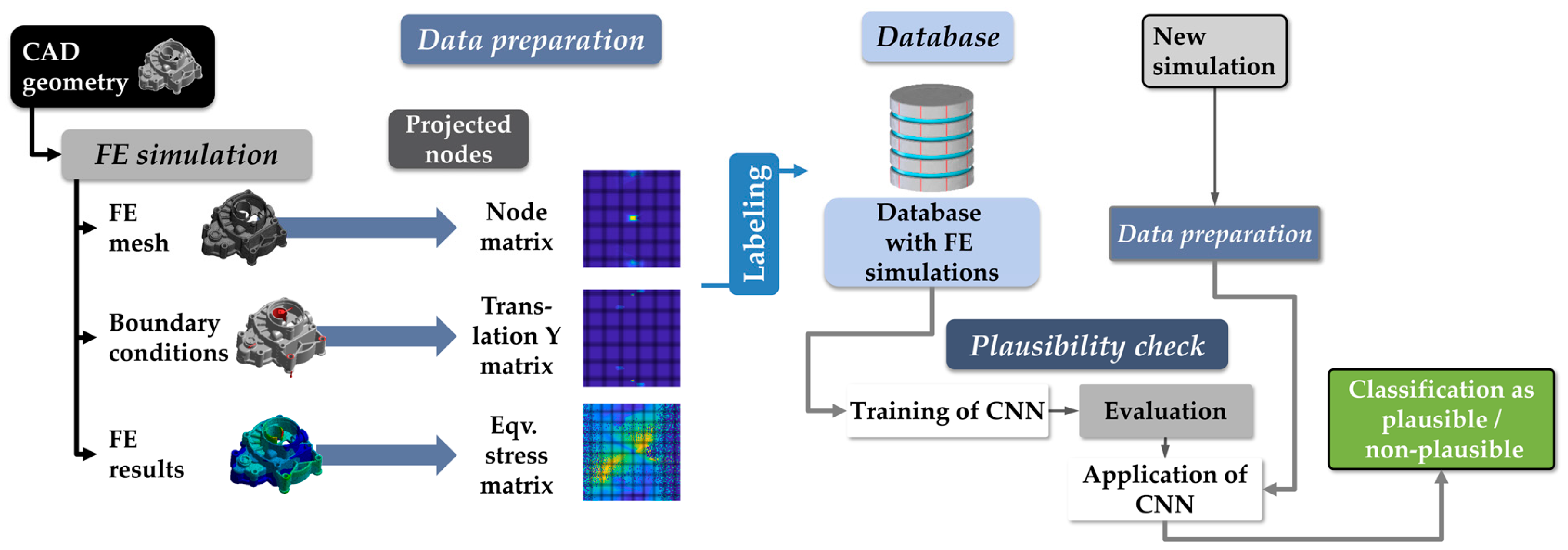
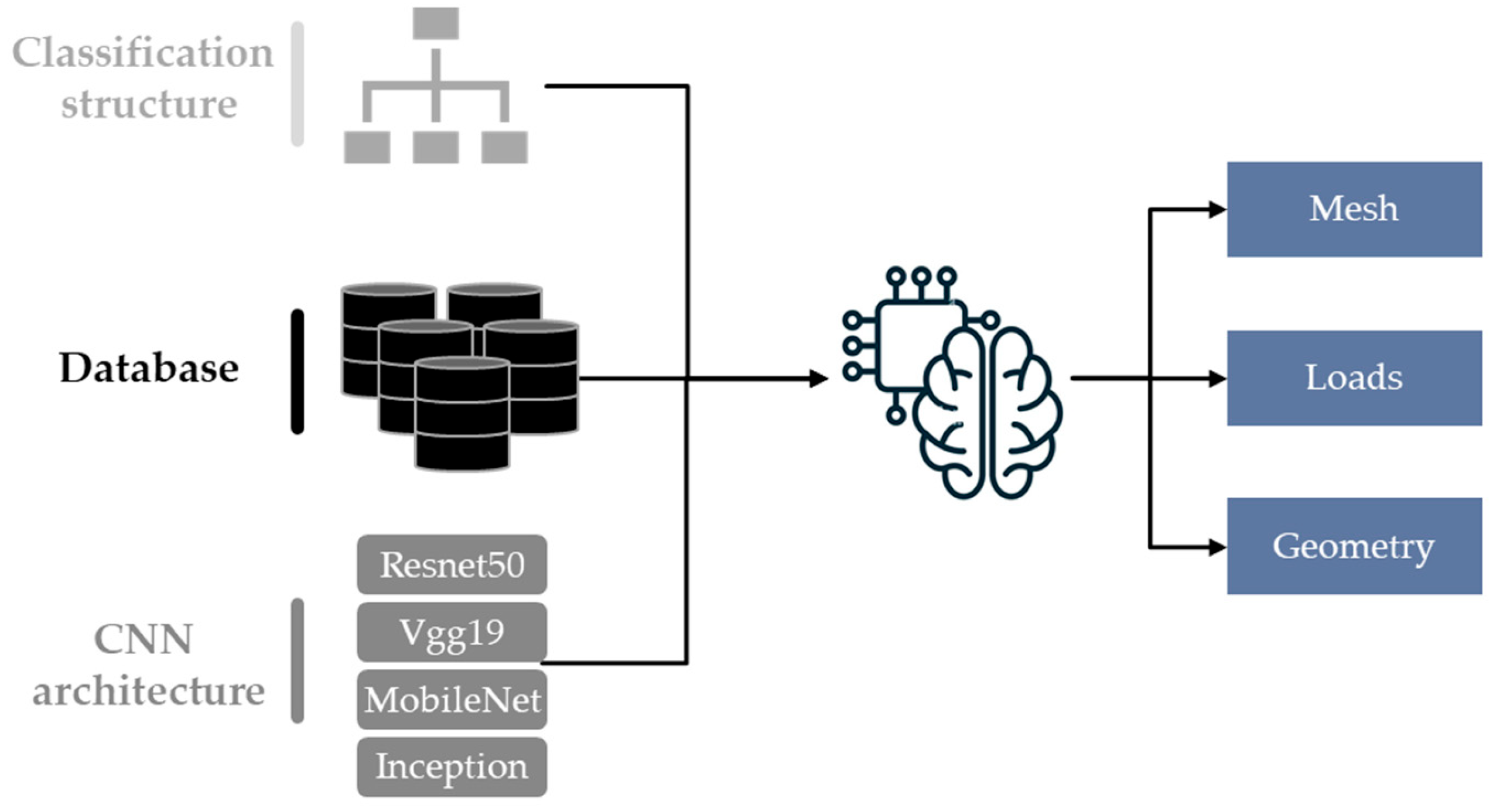
2. Methodical Approach
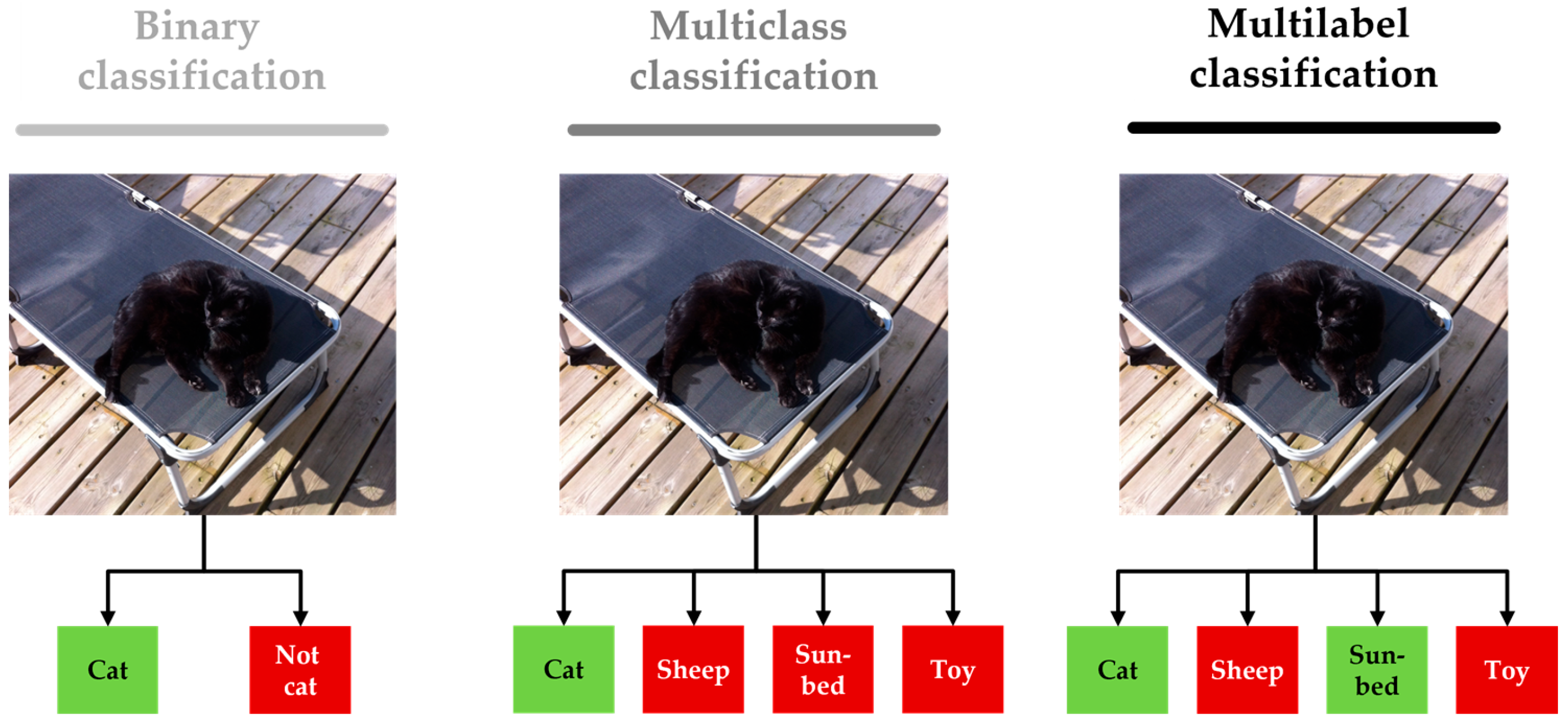
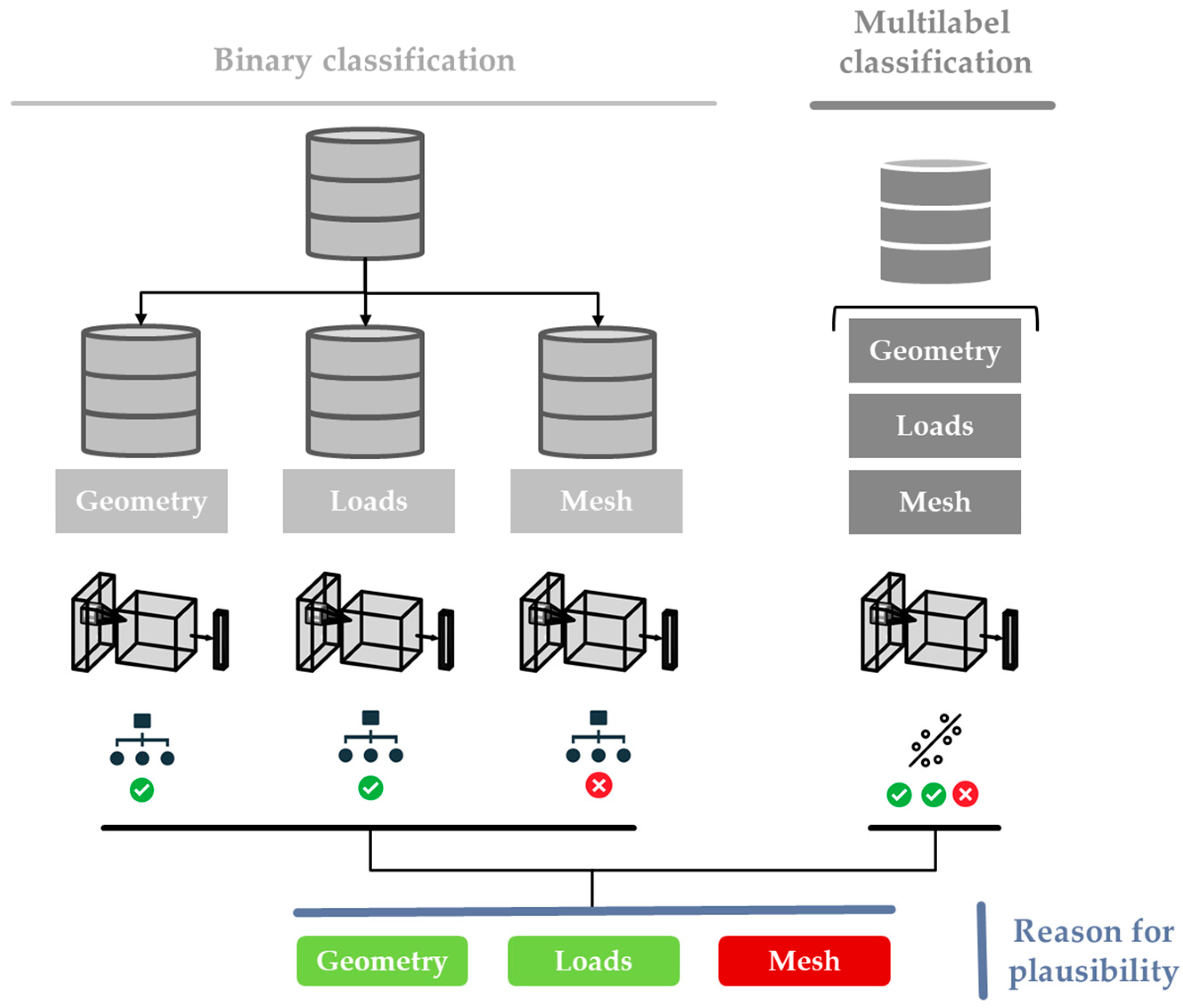
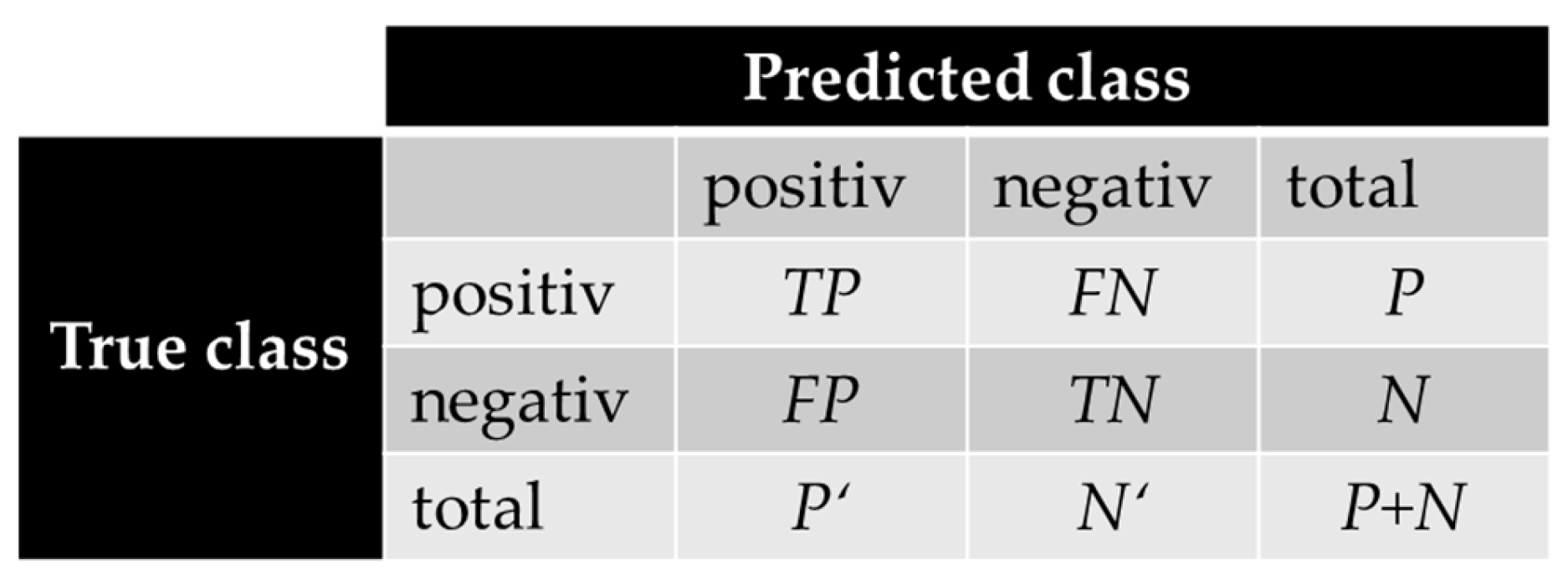
2.1. Classification Structure
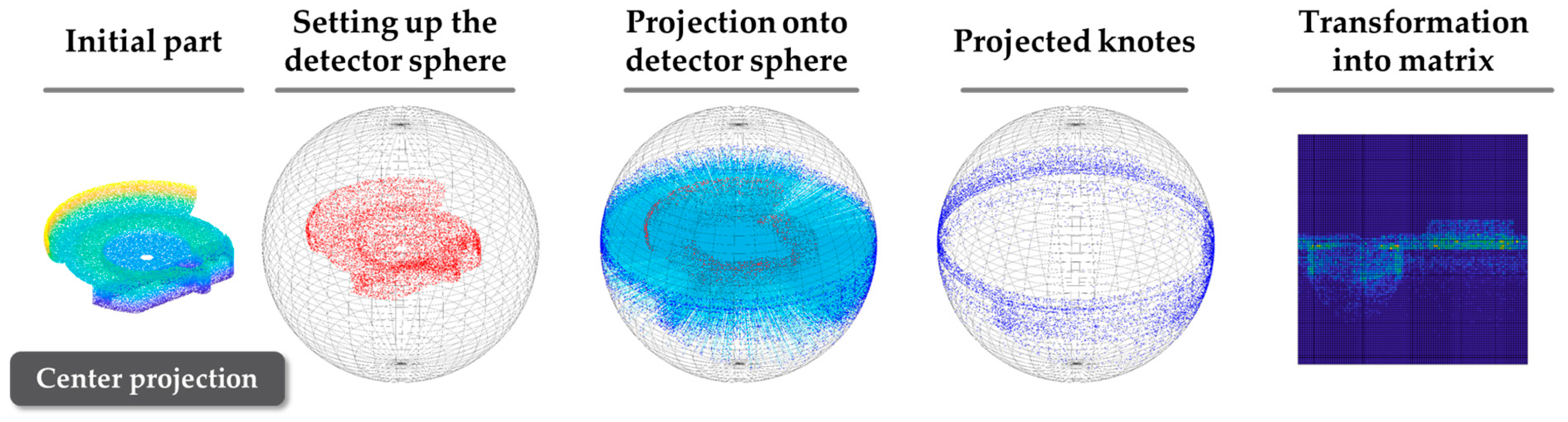
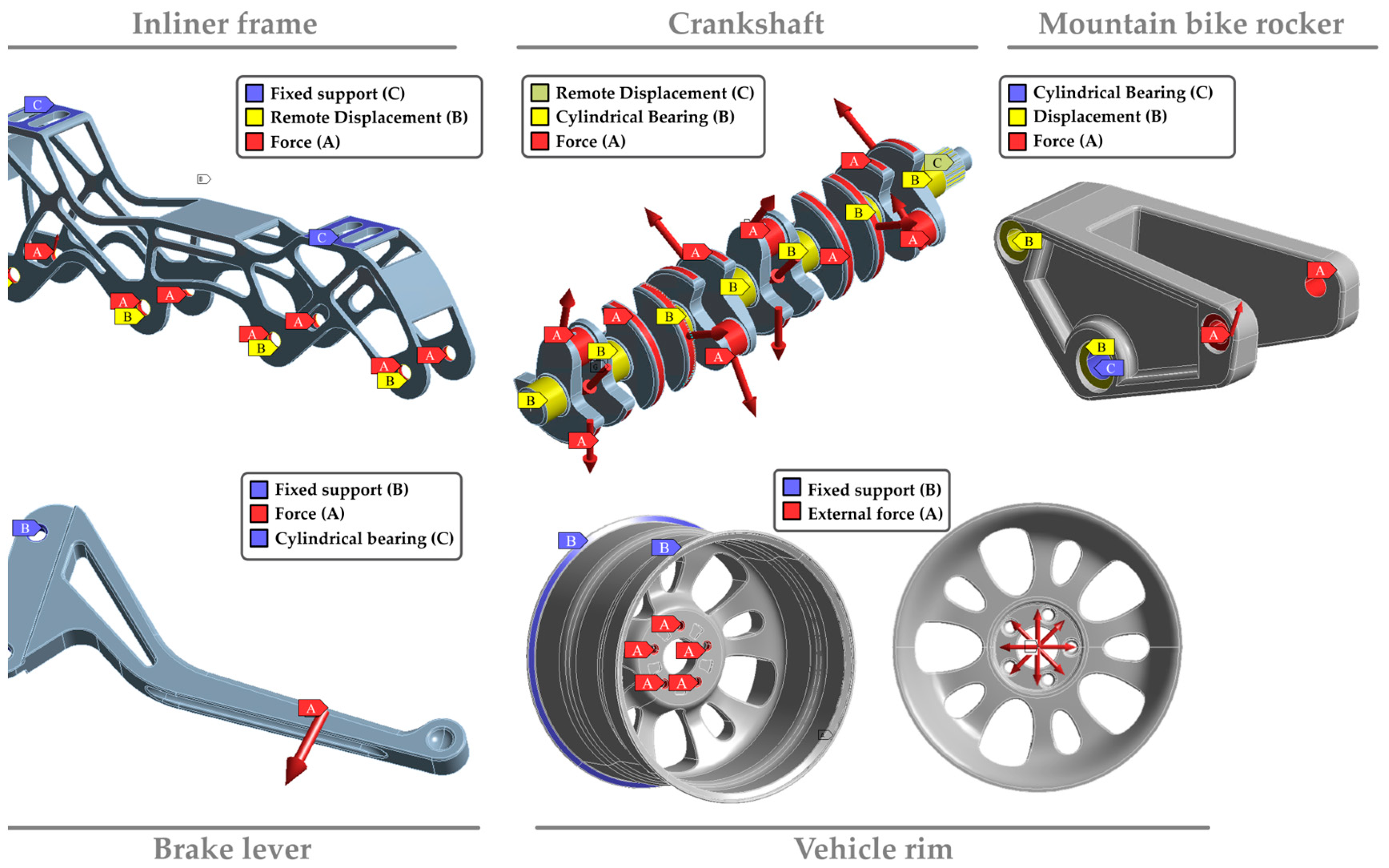
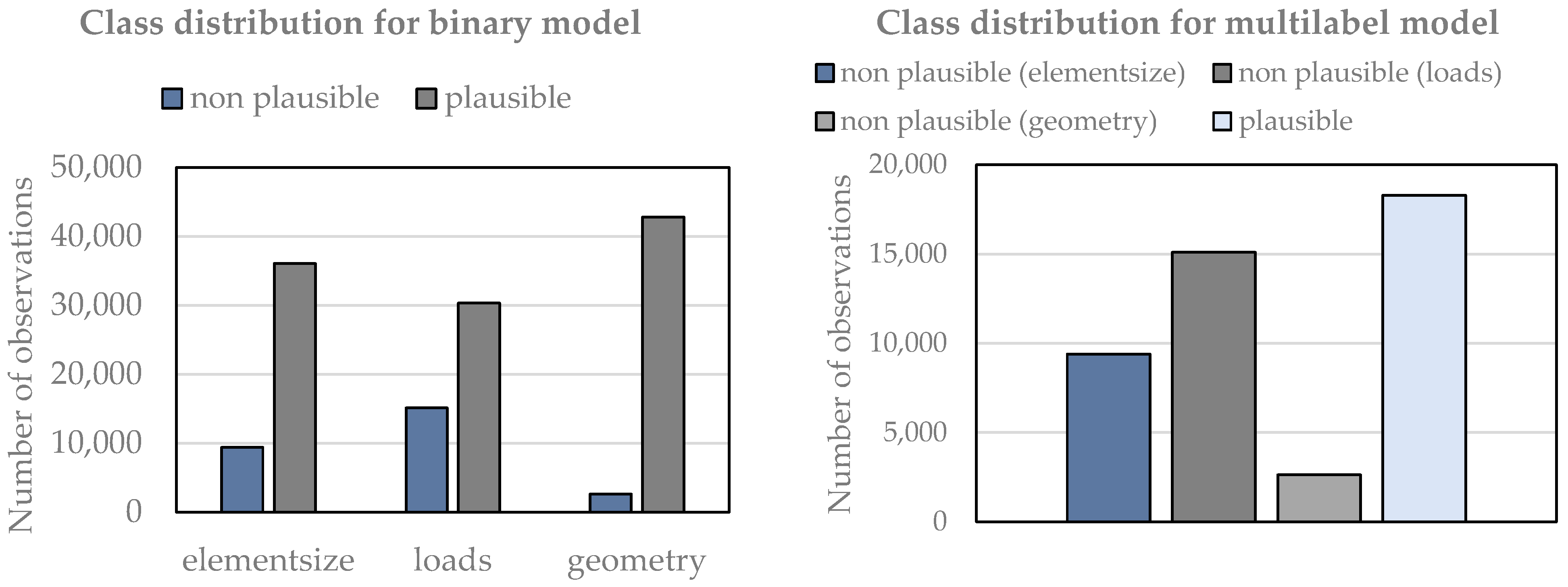
2.2. Database
Dataset Preparation
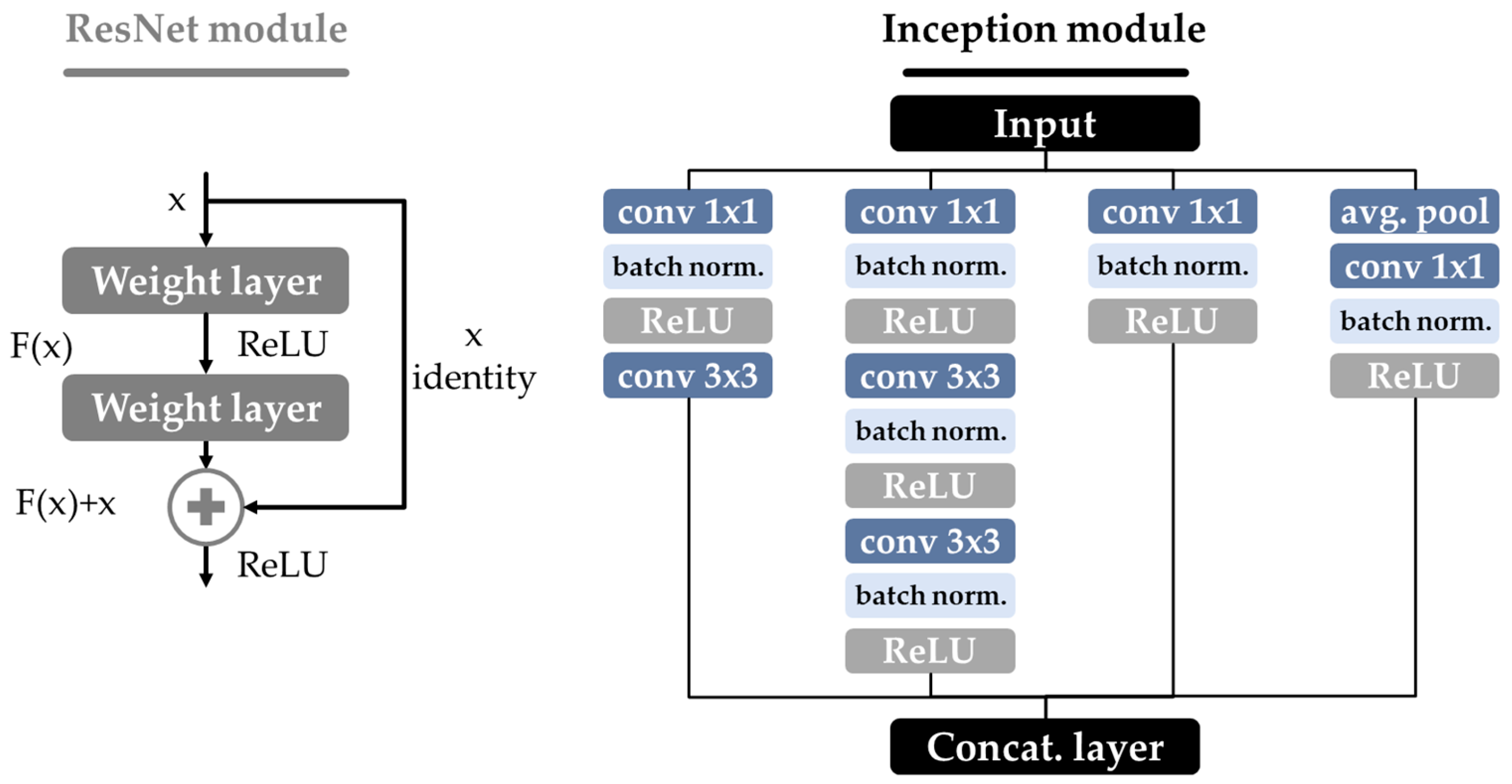
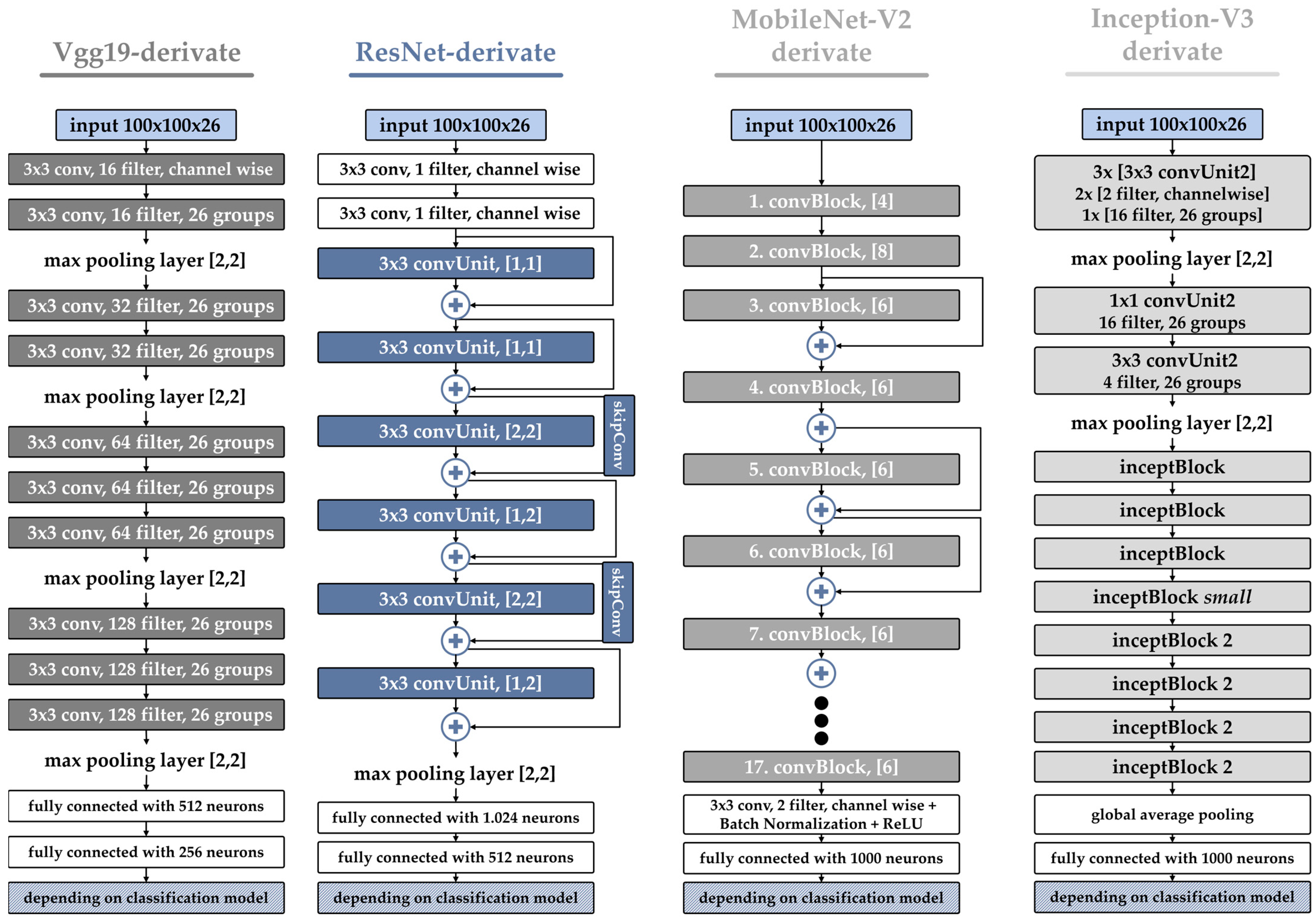
2.3. CNN Architecture
3. Result Comparison
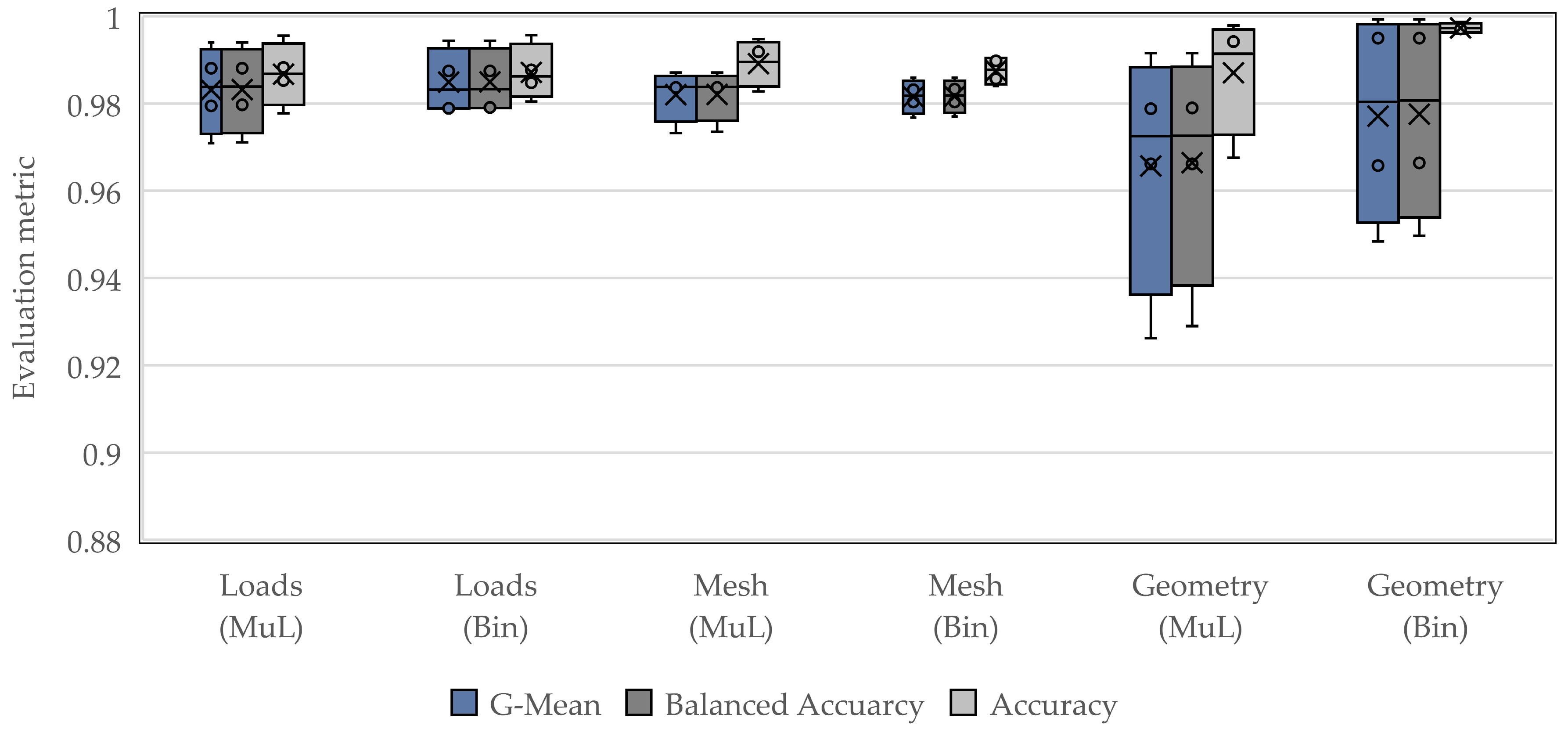
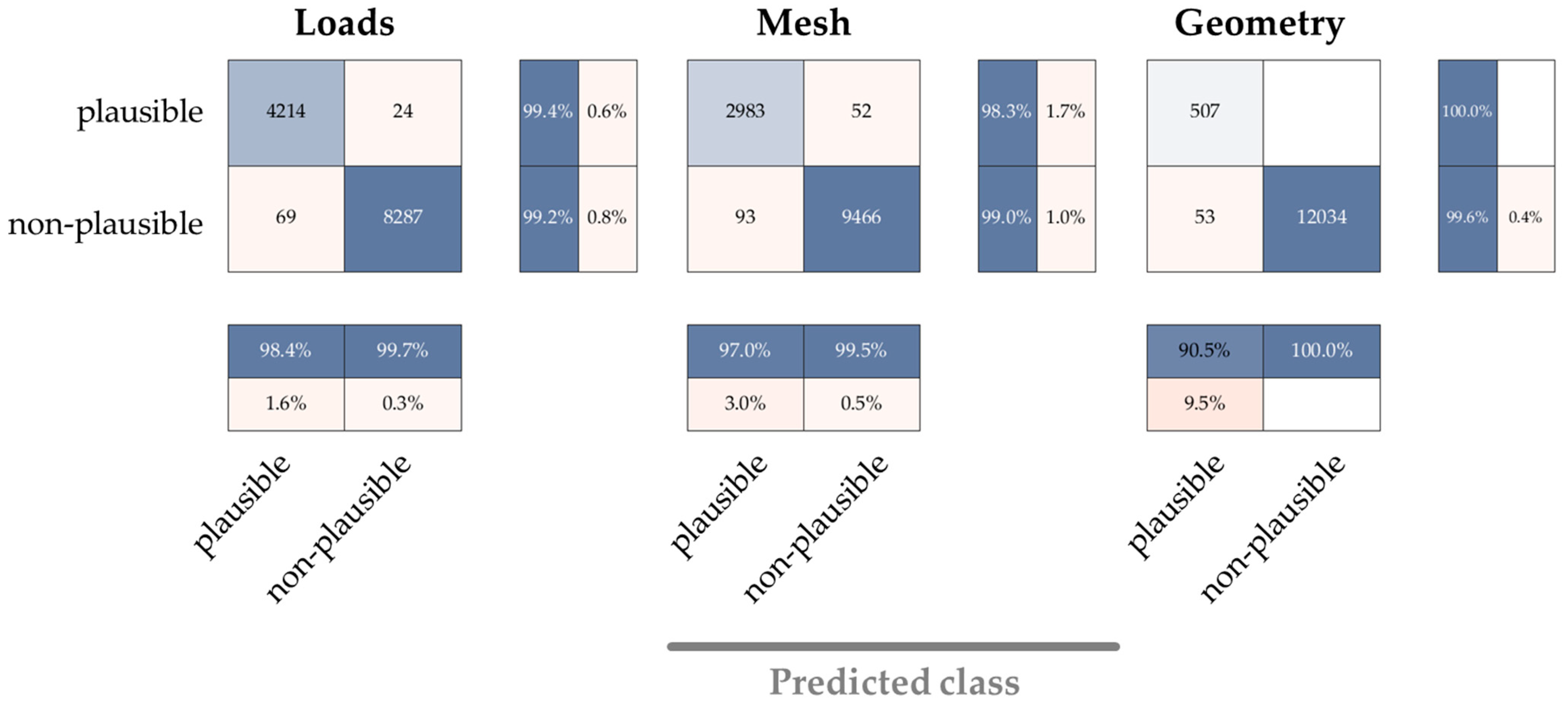
3.1. Classification Approach
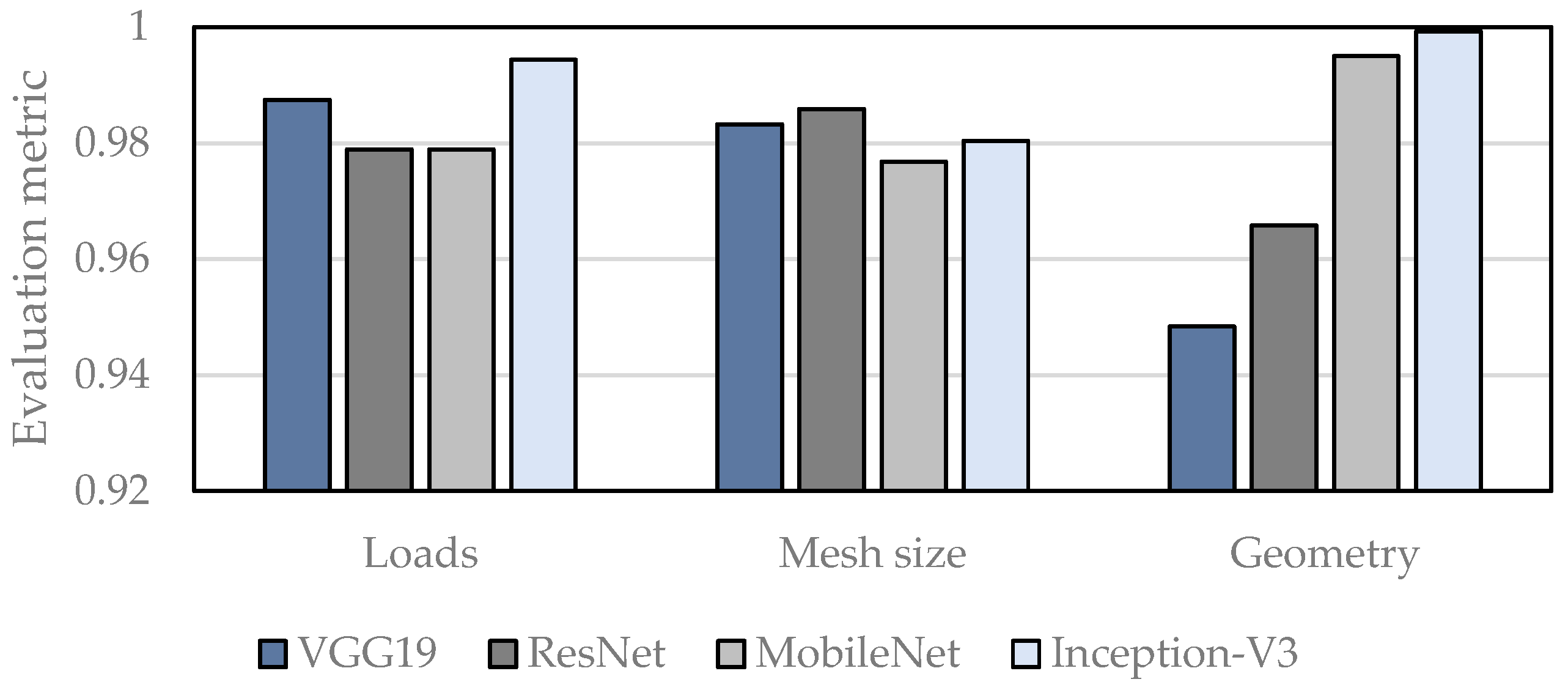
3.2. CNN Architecture
4. Discussion
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

| Dataset Binary | Evaluation Metric | |||
|---|---|---|---|---|
| Loads | Mesh Size | Geometry | ||
| Vgg19 | 0.9875 | 0.9832 | 0.9484 | G-Mean |
| 0.9875 | 0.9833 | 0.9497 | Balanced Accuracy | |
| 0.9877 | 0.9906 | 0.9960 | Accuracy | |
| ResNet | 0.9789 | 0.9859 | 0.9658 | G-Mean |
| 0.9791 | 0.9859 | 0.9664 | Balanced Accuracy | |
| 0.9848 | 0.9898 | 0.9971 | Accuracy | |
| MobileNet-V2 | 0.9789 | 0.9768 | 0.9950 | G-Mean |
| 0.9789 | 0.9770 | 0.9950 | Balanced Accuracy | |
| 0.9805 | 0.9857 | 0.9976 | Accuracy | |
| Inception-V3 | 0.9944 | 0.9804 | 0.9993 | G-Mean |
| 0.9944 | 0.9804 | 0.9993 | Balanced Accuracy | |
| 0.9957 | 0.9840 | 0.9987 | Accuracy | |
| Dataset Multilabel | Evaluation Metric | |||
|---|---|---|---|---|
| Loads | Mesh Size | Geometry | ||
| Vgg19 | 0.9709 | 0.9733 | 0.9262 | G-Mean |
| 0.9711 | 0.9735 | 0.9290 | Balanced Accuracy | |
| 0.9778 | 0.9828 | 0.9942 | Accuracy | |
| ResNet | 0.9795 | 0.9871 | 0.9662 | G-Mean |
| 0.9797 | 0.9871 | 0.9662 | Balanced Accuracy | |
| 0.9853 | 0.9919 | 0.9676 | Accuracy | |
| MobileNet-V2 | 0.9881 | 0.9840 | 0.9788 | G-Mean |
| 0.9881 | 0.9840 | 0.9790 | Balanced Accuracy | |
| 0.9883 | 0.9871 | 0.9979 | Accuracy | |
| Inception-V3 | 0.9940 | 0.9837 | 0.9916 | G-Mean |
| 0.9940 | 0.9837 | 0.9916 | Balanced Accuracy | |
| 0.9956 | 0.9948 | 0.9886 | Accuracy | |
References
- Feng, Y.; Zhao, Y.; Zheng, H.; Li, Z.; Tan, J. Data-driven product design toward intelligent manufacturing: A review. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420911257. [Google Scholar] [CrossRef]
- Briard, T.; Jean, C.; Aoussat, A.; Véron, P.; Le Cardinal, J.; Wartzack, S. Data-driven design challenges in the early stages of the product development process. Proc. Des. Soc. 2021, 1, 851–860. [Google Scholar] [CrossRef]
- Quan, H.; Li, S.; Zeng, C.; Wei, H.; Hu, J. Big Data driven Product Design: A Survey. arXiv 2021, arXiv:2109.11424. [Google Scholar]
- Iriondo, A.; Oscarsson, J.; Jeusfeld, M.A. Simulation Data Management in a Product Lifecycle Management Context. In Advances in Manufacturing Technology XXXI; IOS Press: Amsterdam, The Netherlands, 2017; pp. 476–481. [Google Scholar]
- Chari, S. Addressing Engineering Simulation Data Management (SDM) Challenges: How Engineering Enterprises Can Improve Productivity, Collaboration and Innovation; Cabot Partners Group, Inc.: Danbury, CT, USA, 2013. [Google Scholar]
- Yang, X.; Liang, J.; Liao, Y.; Liu, F.; Feng, X.; Wen, Y. Study of Universal Simulation Data Management System. In Proceedings of the 2009 International Conference on Information Technology and Computer Science, Kiev, Ukraine, 25–26 July 2009; pp. 333–338. [Google Scholar]
- Bennet, J.; Creary, L.; Englemore, R.; Melosh, R. SACON: A Knowledge-Based Consultant for Structural Analysis; Stanford Heuristic Programming Project; Stanford University—Computer Science Department: Stanford, CA, USA, 1979. [Google Scholar]
- Johansson, J. Manufacturability Analysis Using Integrated KBE, CAD and FEM. In Volume 5: 13th Design for Manufacturability and the Lifecycle Conference; 5th Symposium on International Design and Design Education; 10th International Conference on Advanced Vehicle and Tire Technologies; ASMEDC: Houston, TX, USA, 2008; pp. 191–200. [Google Scholar]
- Javadi, A.A.; Mehravar, M.; Faramarzi, A.; Ahangar-Asr, A. An artificial intelligence based finite element method. Comput. Intell. Syst. 2009, 1, 1–120. [Google Scholar]
- Lai, J.-Y.; Wang, M.-H.; Song, P.-P.; Hsu, C.-H.; Tsai, Y.-C. Recognition and decomposition of rib features in thin-shell plastic parts for finite element analysis. Comput. -Aided Des. Appl. 2018, 15, 264–279. [Google Scholar] [CrossRef]
- Song, P.-P.; Lai, J.-Y.; Tsai, Y.-C.; Hsu, C.-H. Automatic recognition and suppression of holes on mold bases for finite element applications. Eng. Comput. 2019, 35, 925–944. [Google Scholar] [CrossRef]
- Boussuge, F.; Léon, J.-C.; Hahmann, S.; Fine, L. Idealized models for FEA derived from generative modeling processes based on extrusion primitives. Eng. Comput. 2015, 31, 513–527. [Google Scholar] [CrossRef]
- Kestel, P.; Kügler, P.; Zirngibl, C.; Schleich, B.; Wartzack, S. Ontology-based approach for the provision of simulation knowledge acquired by Data and Text Mining processes. Adv. Eng. Inform. 2019, 39, 292–305. [Google Scholar] [CrossRef]
- Zimmerling, C.; Poppe, C.; Kärger, L. Virtuelle Produktentwicklung mittels Simulationsmethoden und KI. Lightweight Des. 2019, 12, 12–19. [Google Scholar] [CrossRef]
- Spruegel, T.C.; Hallmann, M.; Wartzack, S. A concept for FE plausibility checks in structural mechanics. In Proceedings of the NAFEMS World Congress, San Diego, CA, USA, 21–24 June 2015. [Google Scholar]
- Spruegel, T.C.; Bickel, S.; Schleich, B.; Wartzack, S. Approach and application to transfer heterogeneous simulation data from finite element analysis to neural networks. J. Comput. Des. Eng. 2021, 8, 298–315. [Google Scholar] [CrossRef]
- Bickel, S.; Spruegel, T.C.; Schleich, B.; Wartzack, S. How Do Digital Engineering and Included AI Based Assistance Tools Change the Product Development Process and the Involved Engineers. Proc. Int. Conf. Eng. Des. 2019, 1, 2567–2576. [Google Scholar] [CrossRef]
- Bonaccorso, G. Machine Learning Algorithms, 1st ed.; Packt Publishing Limited: Birmingham, UK, 2017. [Google Scholar]
- Mahesh, B. Machine learning algorithms—A review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar]
- Goodfellow, I.; Courville, A.; Bengio, Y. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Cleve, J.; Lämmel, U. Data Mining, 2nd ed.; De Gruyter Oldenbourg: Berlin, Germany, 2016. [Google Scholar]
- Runkler, T.A. Data Mining: Methoden und Algorithmen Intelligenter Datenanalyse, 1st ed.; mit 7 Tabellen; Vieweg + Teubner: Wiesbaden, Germany, 2010. [Google Scholar]
- Tsoumakas, G.; Katakis, I. Multi-Label Classification. Int. J. Data Warehous. Min. 2007, 3, 1–13. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef]
- Deng, L. Deep Learning: Methods and Applications. FNT Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway Networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Bickel, S.; Schleich, B.; Wartzack, S. Resnet networks for plausibility detection in finite element simulations. In Proceedings of the DS 118: Proceedings of NordDesign 2022, Copenhagen, Denmark, 16–18 August 2022; pp. 1–10. [Google Scholar]
- Opitz, H. A Classification System to Describe Workpieces; Taylor, A., Translator; Pergamon Press: New York, NY, USA, 1970. [Google Scholar]
- Murray-Smith, D.J. Testing and Validation of Computer Simulation Models: Principles, Methods and Applications, 1st ed.; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Van Basshuysen, R. Handbuch Verbrennungsmotor: Grundlagen, Komponenten, Systeme, Perspektiven, 7th ed.; mit 1804 Abbildungen und mehr als 1400 Literaturstellen; Springer Vieweg: Wiesbaden, Germany, 2015. [Google Scholar]
- Kohler, E. Verbrennungsmotoren: Motormechanik, Berechnung und Auslegung des Hubkolbenmotors, 4th ed.; Friedr. Vieweg & Sohn Verlag: Wiesbaden, Germany, 2006. [Google Scholar]
- DIN. Cycles—Safety Requirements for Bicycles—Part 4: Braking Test Methods; German Institute for Standardization e.V.: Berlin, Germany, 2014. [Google Scholar]
- Wang, L.; Chen, Y.; Wang, C.; Wang, Q. Fatigue Life Analysis of Aluminum Wheels by Simulation of Rotary Fatigue Test. SV-JME 2011, 57, 31–39. [Google Scholar] [CrossRef]
- Jape, R.K.; Jadhav, S.G.; Student, M.T. CAD modeling and FEA analysis of wheel rim for weight reduction. Int. J. Eng. Sci. Comput. 2016, 6, 7404–7411. [Google Scholar]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The Balanced Accuracy and Its Posterior Distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Washington, DC, USA, 23–26 August 2010. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Branco, P.; Torgo, L.; Ribeiro, R. A Survey of Predictive Modelling under Imbalanced Distributions. arXiv 2015, arXiv:1505.01658. [Google Scholar]
- García, V.; Mollineda, R.A.; Sánchez, J.S. Index of Balanced Accuracy: A Performance Measure for Skewed Class Distributions; Springer: Berlin/Heidelberg, Germany, 2009; pp. 441–448. [Google Scholar]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Patt. Recogn. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




| Rotatory | Non-Rotatory | |||||
|---|---|---|---|---|---|---|
| L/D < 0.5 | 0.5 < L/D < 3 | L/D ≥ 3 | A/C > 4 | A/B ≤ 3 & A/C ≥ 4 | A/B ≤ 3 | A/B ≤ 3 & A/C < 4 |
| Vehicle rim | Crankshaft | Inliner frame | Brake lever | Mountain bike rocker | ||
| Dataset | Simulation Numbers | Plausible | Non-Plausible Mesh | Non-Plausible Geometry | Non-Plausible Loads | Storage Space |
|---|---|---|---|---|---|---|
| Vehicle rim | 9968 | 3736 | 2488 | 0 | 4992 | 676 GB |
| (1816) | (80) | (792) | (1520) | (888) | 217 GB | |
| Brake lever | 9862 | 5896 | 2493 | 0 | 1987 | 574 GB |
| (1225) | (554) | (315) | (290) | (251) | 64 GB | |
| Bike rocker | 22,624 | 12,257 | 3780 | 1620 | 6776 | 2890 GB |
| Crankshaft | 8640 | 4800 | 1440 | 0 | 2880 | 6920 GB |
| Inliner frame | 8952 | 4344 | 2172 | 0 | 3252 | 1650 GB |
| Whole dataset | 63,087 | 31,667 | 13,480 | 3430 | 21,026 | 12,991 GB |
| Options | Value |
|---|---|
| Solver Type | adam |
| Mini Batchsize | 128 |
| Max. Epochs | 40 |
| Validation Frequency | 125 |
| Validation Patience | 8 |
| Shuffle | Once |
| Learning Rate Binary | MobileNet: 0.0001 ResNet: 0.000001 Vgg19: 0.00001 Inception: 0.001 |
| Learning Rate Multilabel | MobileNet: 0.0001 ResNet: 0.000001 Vgg19: 0.00001 Inception: 0.0001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bickel, S.; Goetz, S.; Wartzack, S. Detection of Plausibility and Error Reasons in Finite Element Simulations with Deep Learning Networks. Algorithms 2023, 16, 209. https://doi.org/10.3390/a16040209
Bickel S, Goetz S, Wartzack S. Detection of Plausibility and Error Reasons in Finite Element Simulations with Deep Learning Networks. Algorithms. 2023; 16(4):209. https://doi.org/10.3390/a16040209
Chicago/Turabian StyleBickel, Sebastian, Stefan Goetz, and Sandro Wartzack. 2023. "Detection of Plausibility and Error Reasons in Finite Element Simulations with Deep Learning Networks" Algorithms 16, no. 4: 209. https://doi.org/10.3390/a16040209
APA StyleBickel, S., Goetz, S., & Wartzack, S. (2023). Detection of Plausibility and Error Reasons in Finite Element Simulations with Deep Learning Networks. Algorithms, 16(4), 209. https://doi.org/10.3390/a16040209