

Model-Robust Estimation of Multiple-Group Structural Equation Models


Abstract
1. Introduction
2. Model-Robust Estimation in Structural Equation Modeling
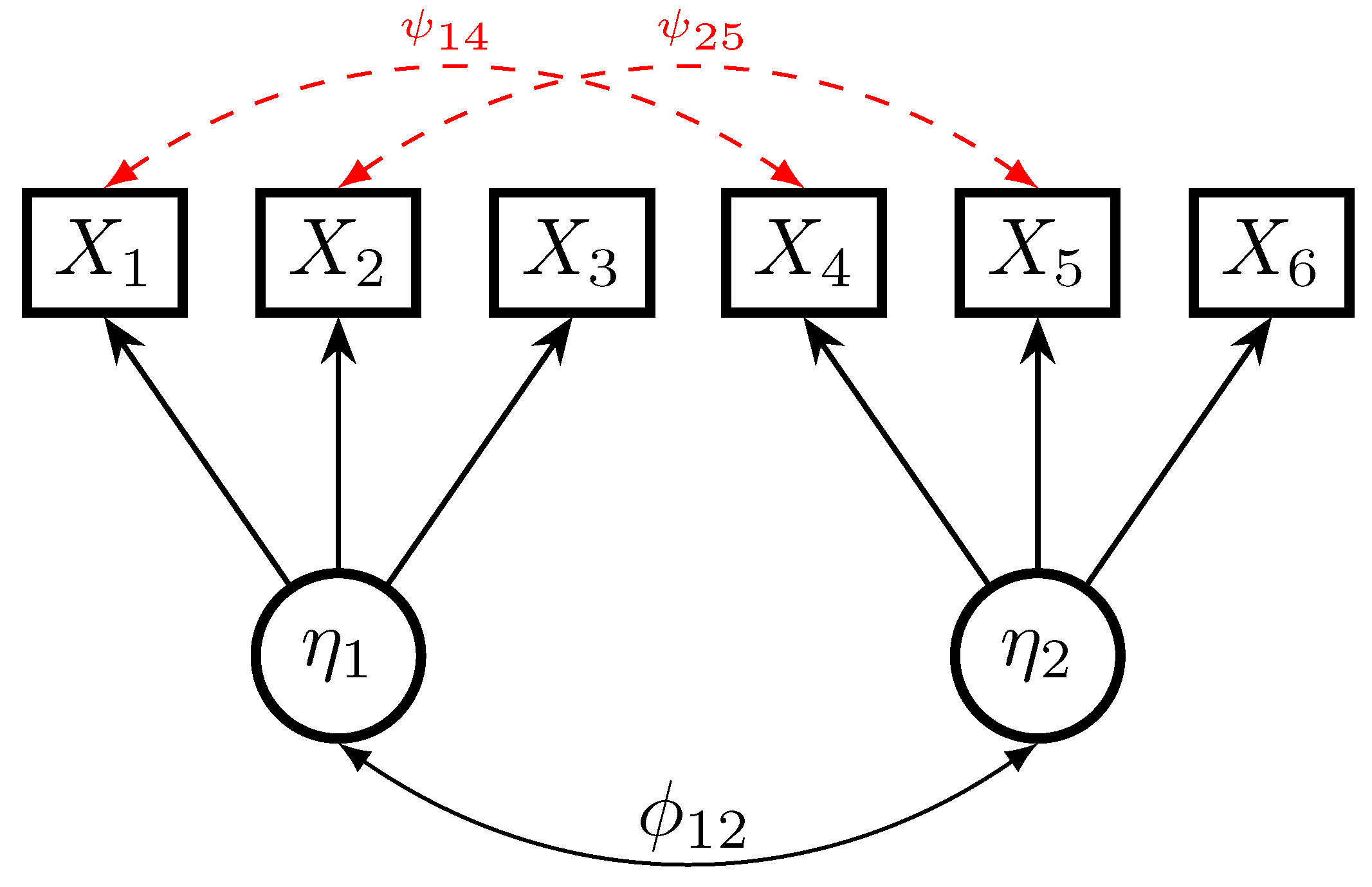
2.1. Multiple-Group Structural Equation Modeling
2.2. Robust Moment Estimation Using Robust Loss Functions
2.2.1. Bias Derivation in the Presence of Model Errors
2.2.2. Standard Error Estimation
2.3. Regularized Maximum Likelihood Estimation
3. Simulation Study 1: Unmodeled Residual Error Correlation
3.1. Method
3.2. Results
4. Focused Simulation Study 1A: Computation of Standard Errors
4.1. Method
4.2. Results
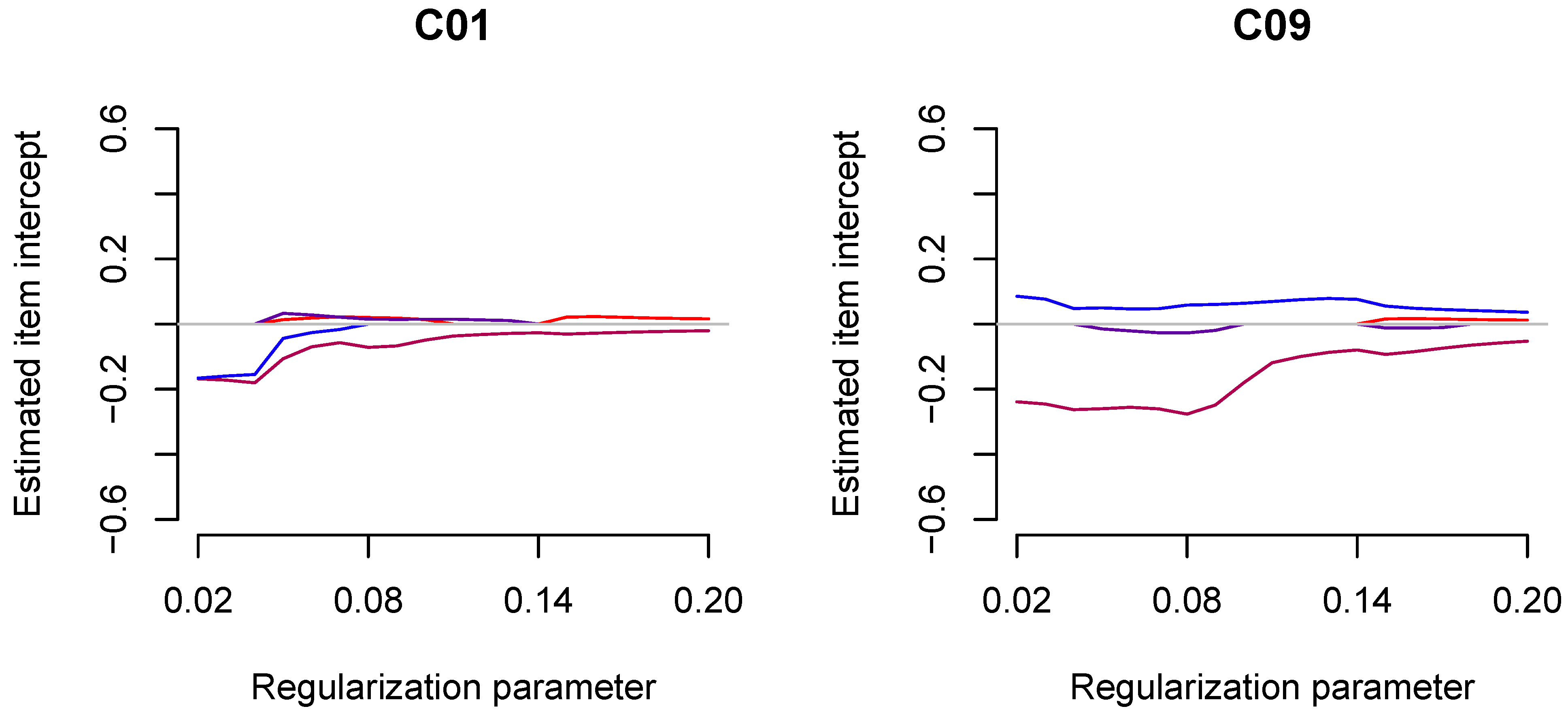
5. Simulation Study 2: Noninvariant Item Intercepts (DIF)
5.1. Method
5.2. Results
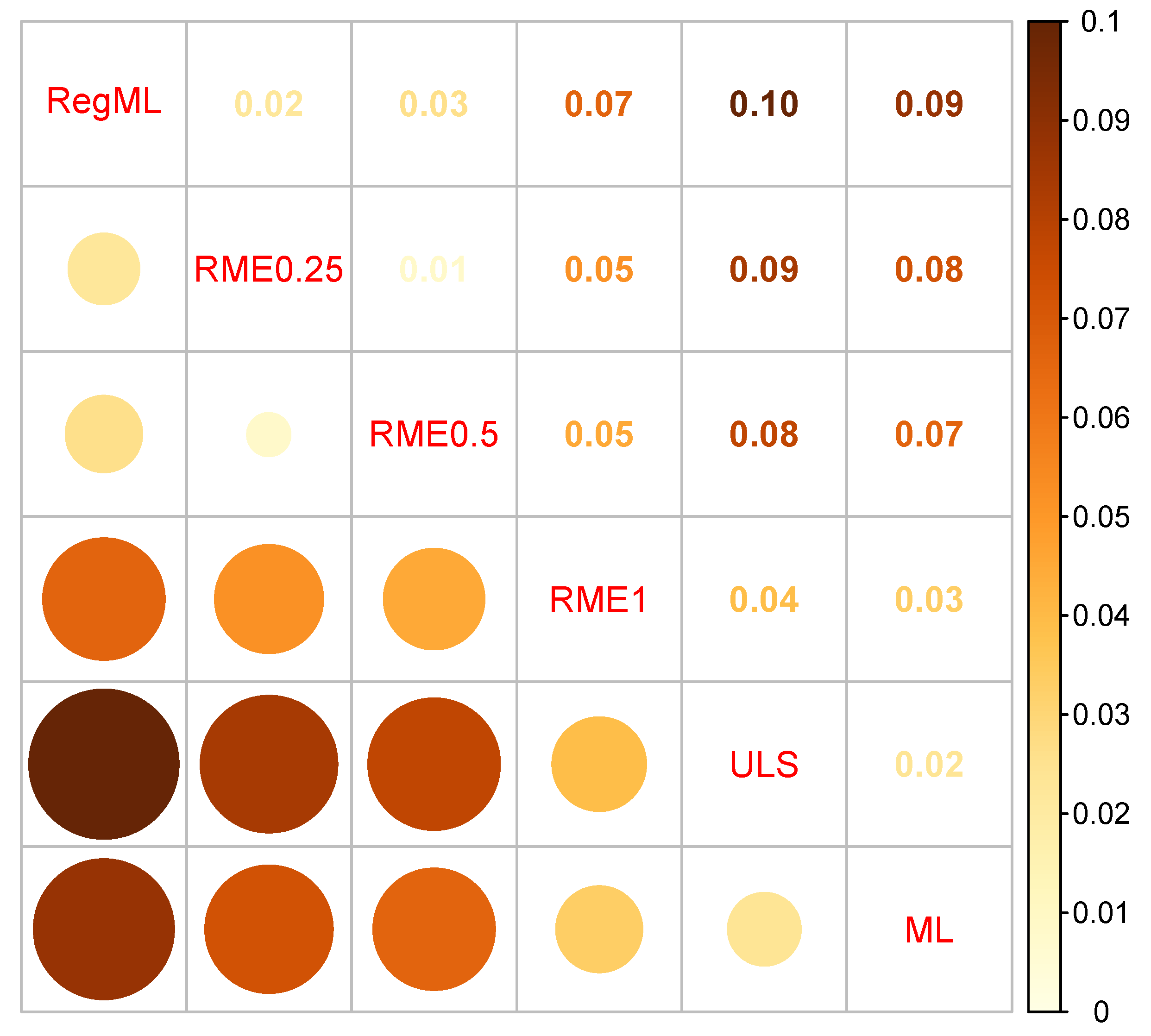
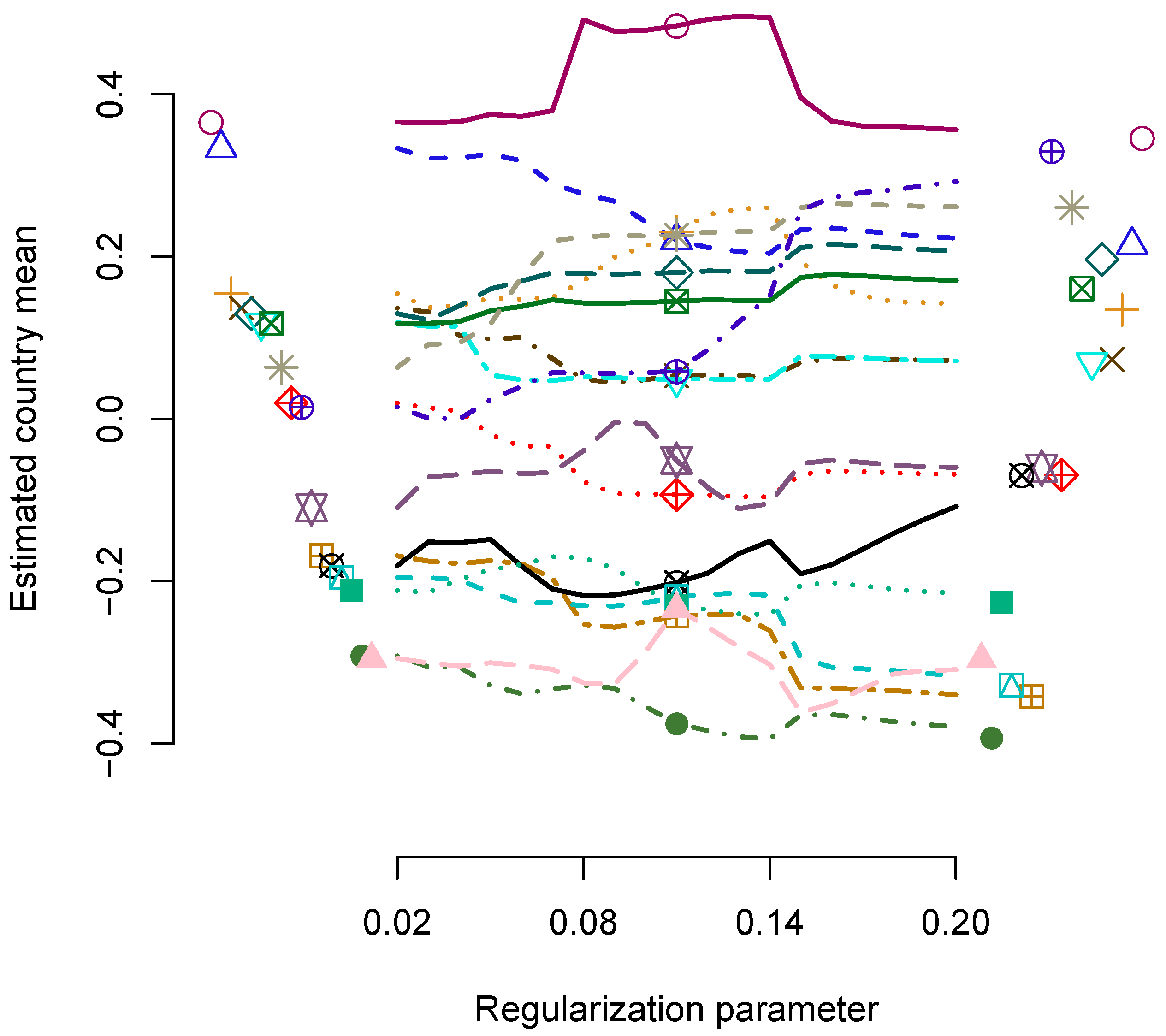
6. Empirical Example: ESS 2005 Data
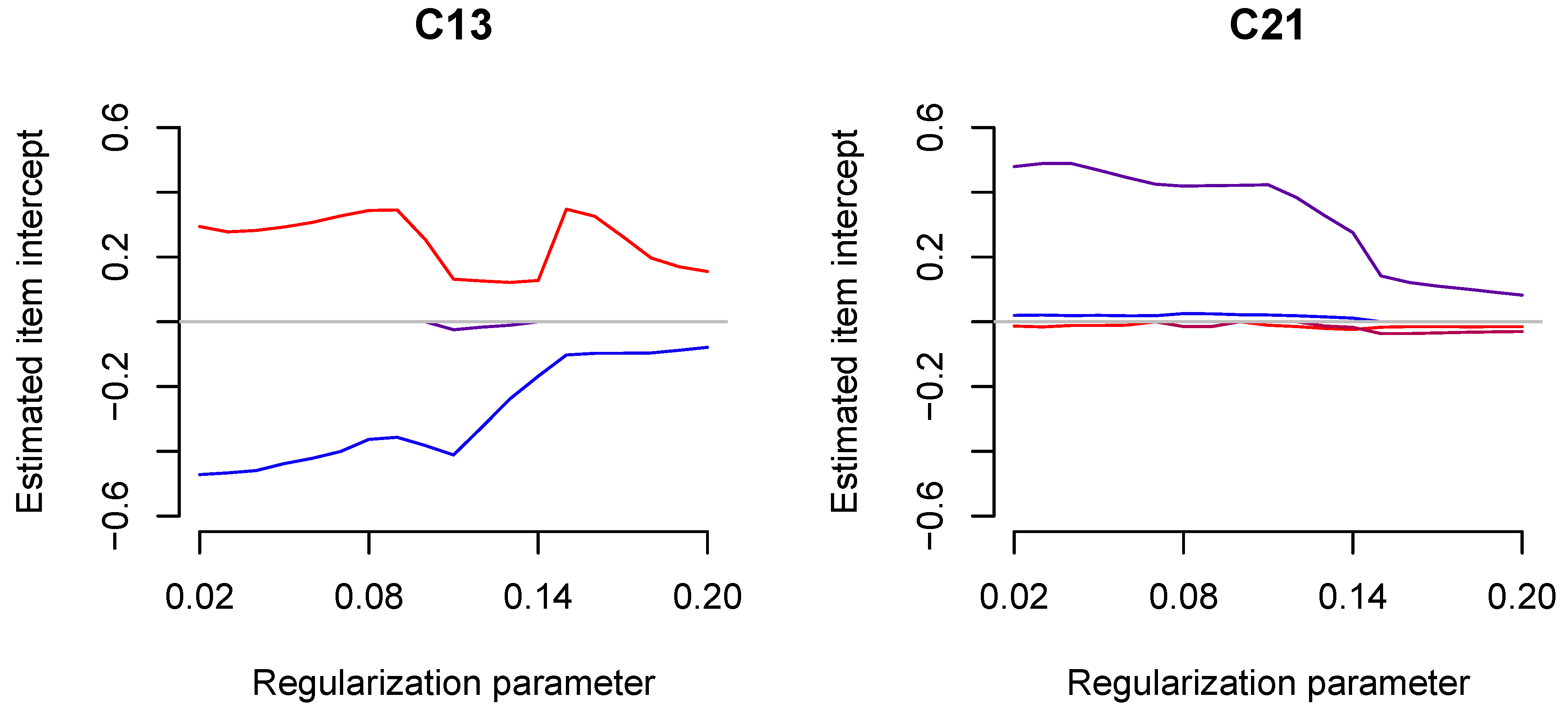
6.1. Method
6.2. Results
7. Discussion
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BIC | Bayesian information criterion |
| BS | bootstrap |
| CFA | confirmatory factor analysis |
| DF | delta formula |
| DIF | differential item functioning |
| DWLS | diagonally weighted least squares |
| ESS | European social survey |
| JK | jackknife |
| MAD | mean absolute deviation |
| ML | maximum likelihood |
| MVN | multivariate normal |
| OI | observed information |
| RegML | regularized maximum likelihood |
| RME | robust moment estimation |
| RMSE | root mean square error |
| SCAD | smoothly clipped absolute deviation |
| SEM | structural equation model |
| ULS | unweighted least squares |
References
- Bartholomew, D.J.; Knott, M.; Moustaki, I. Latent Variable Models and Factor Analysis: A Unified Approach; Wiley: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Bollen, K.A. Structural Equations with Latent Variables; John Wiley & Sons: New York, NY, USA, 1989. [Google Scholar] [CrossRef]
- Browne, M.W.; Arminger, G. Specification and estimation of mean-and covariance-structure models. In Handbook of Statistical Modeling for the Social and Behavioral Sciences; Arminger, G., Clogg, C.C., Sobel, M.E., Eds.; Springer: Boston, MA, USA, 1995; pp. 185–249. [Google Scholar] [CrossRef]
- Jöreskog, K.G.; Olsson, U.H.; Wallentin, F.Y. Multivariate Analysis with LISREL; Springer: Basel, Switzerland, 2016. [Google Scholar] [CrossRef]
- Mulaik, S.A. Foundations of Factor Analysis; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar] [CrossRef]
- Shapiro, A. Statistical inference of covariance structures. In Current Topics in the Theory and Application of Latent Variable Models; Edwards, M.C., MacCallum, R.C., Eds.; Routledge: London, UK, 2012; pp. 222–240. [Google Scholar] [CrossRef]
- Yuan, K.H.; Bentler, P.M. Structural equation modeling. In Handbook of Statistics, Vol. 26: Psychometrics; Rao, C.R., Sinharay, S., Eds.; Elsevier: Amsterdam, The Netherlands, 2007; Volume 26, pp. 297–358. [Google Scholar] [CrossRef]
- Robitzsch, A. Comparing the robustness of the structural after measurement (SAM) approach to structural equation modeling (SEM) against local model misspecifications with alternative estimation approaches. Stats 2022, 5, 631–672. [Google Scholar] [CrossRef]
- Wu, H.; Browne, M.W. Quantifying adventitious error in a covariance structure as a random effect. Psychometrika 2015, 80, 571–600. [Google Scholar] [CrossRef] [PubMed]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics; Wiley: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Maronna, R.A.; Martin, R.D.; Yohai, V.J. Robust Statistics: Theory and Methods; Wiley: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Ronchetti, E. The main contributions of robust statistics to statistical science and a new challenge. Metron 2021, 79, 127–135. [Google Scholar] [CrossRef]
- Robitzsch, A. Estimation methods of the multiple-group one-dimensional factor model: Implied identification constraints in the violation of measurement invariance. Axioms 2022, 11, 119. [Google Scholar] [CrossRef]
- Leitgöb, H.; Seddig, D.; Asparouhov, T.; Behr, D.; Davidov, E.; De Roover, K.; Jak, S.; Meitinger, K.; Menold, N.; Muthén, B.; et al. Measurement invariance in the social sciences: Historical development, methodological challenges, state of the art, and future perspectives. Soc. Sci. Res. 2023, 110, 102805. [Google Scholar] [CrossRef]
- Meredith, W. Measurement invariance, factor analysis and factorial invariance. Psychometrika 1993, 58, 525–543. [Google Scholar] [CrossRef]
- Millsap, R.E. Statistical Approaches to Measurement Invariance; Routledge: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Holland, P.W.; Wainer, H. (Eds.) Differential Item Functioning: Theory and Practice; Lawrence Erlbaum: Hillsdale, NJ, USA, 1993. [Google Scholar] [CrossRef]
- Penfield, R.D.; Camilli, G. Differential item functioning and item bias. In Handbook of Statistics, Vol. 26: Psychometrics; Rao, C.R., Sinharay, S., Eds.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 125–167. [Google Scholar] [CrossRef]
- Chen, Y.; Li, C.; Xu, G. DIF statistical inference and detection without knowing anchoring items. arXiv 2021, arXiv:2110.11112. [Google Scholar]
- Robitzsch, A. Comparing robust linking and regularized estimation for linking two groups in the 1PL and 2PL models in the presence of sparse uniform differential item functioning. Stats 2023, 6, 192–208. [Google Scholar] [CrossRef]
- Wang, W.; Liu, Y.; Liu, H. Testing differential item functioning without predefined anchor items using robust regression. J. Educ. Behav. Stat. 2022, 47, 666–692. [Google Scholar] [CrossRef]
- Boos, D.D.; Stefanski, L.A. Essential Statistical Inference; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Kolenikov, S. Biases of parameter estimates in misspecified structural equation models. Sociol. Methodol. 2011, 41, 119–157. [Google Scholar] [CrossRef]
- White, H. Maximum likelihood estimation of misspecified models. Econometrica 1982, 50, 1–25. [Google Scholar] [CrossRef]
- Browne, M.W. Generalized least squares estimators in the analysis of covariance structures. S. Afr. Stat. J. 1974, 8, 1–24. [Google Scholar] [CrossRef]
- Savalei, V. Understanding robust corrections in structural equation modeling. Struct. Equ. Model. 2014, 21, 149–160. [Google Scholar] [CrossRef]
- MacCallum, R.C.; Browne, M.W.; Cai, L. Factor analysis models as approximations. In Factor Analysis at 100; Cudeck, R., MacCallum, R.C., Eds.; Lawrence Erlbaum: Hillsdale, NJ, USA, 2007; pp. 153–175. [Google Scholar] [CrossRef]
- Siemsen, E.; Bollen, K.A. Least absolute deviation estimation in structural equation modeling. Sociol. Methods Res. 2007, 36, 227–265. [Google Scholar] [CrossRef]
- van Kesteren, E.J.; Oberski, D.L. Flexible extensions to structural equation models using computation graphs. Struct. Equ. Model. 2022, 29, 233–247. [Google Scholar] [CrossRef]
- Robitzsch, A. Lp loss functions in invariance alignment and Haberman linking with few or many groups. Stats 2020, 3, 246–283. [Google Scholar] [CrossRef]
- Kolen, M.J.; Brennan, R.L. Test Equating, Scaling, and Linking; Springer: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Asparouhov, T.; Muthén, B. Multiple-group factor analysis alignment. Struct. Equ. Model. 2014, 21, 495–508. [Google Scholar] [CrossRef]
- Muthén, B.; Asparouhov, T. IRT studies of many groups: The alignment method. Front. Psychol. 2014, 5, 978. [Google Scholar] [CrossRef]
- Pokropek, A.; Lüdtke, O.; Robitzsch, A. An extension of the invariance alignment method for scale linking. Psych. Test Assess. Model. 2020, 62, 303–334. [Google Scholar]
- Battauz, M. Regularized estimation of the nominal response model. Multivar. Behav. Res. 2020, 55, 811–824. [Google Scholar] [CrossRef]
- Oelker, M.R.; Tutz, G. A uniform framework for the combination of penalties in generalized structured models. Adv. Data Anal. Classif. 2017, 11, 97–120. [Google Scholar] [CrossRef]
- Shapiro, A. Statistical inference of moment structures. In Handbook of Latent Variable and Related Models; Lee, S.Y., Ed.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 229–260. [Google Scholar] [CrossRef]
- Fox, J.; Weisberg, S. Robust Regression in R: An Appendix to an R Companion to Applied Regression. 2010. Available online: https://bit.ly/3canwcw (accessed on 27 March 2023).
- Holland, P.W.; Welsch, R.E. Robust regression using iteratively reweighted least-squares. Commun. Stat. Theory Methods 1977, 6, 813–827. [Google Scholar] [CrossRef]
- Chatterjee, S.; Mächler, M. Robust regression: A weighted least squares approach. Commun. Stat. Theory Methods 1997, 26, 1381–1394. [Google Scholar] [CrossRef]
- Ver Hoef, J.M. Who invented the delta method? Am. Stat. 2012, 66, 124–127. [Google Scholar] [CrossRef]
- Kolenikov, S. Resampling variance estimation for complex survey data. Stata J. 2010, 10, 165–199. [Google Scholar] [CrossRef]
- Chen, J. Partially confirmatory approach to factor analysis with Bayesian learning: A LAWBL tutorial. Struct. Equ. Model. 2022, 22, 800–816. [Google Scholar] [CrossRef]
- Geminiani, E.; Marra, G.; Moustaki, I. Single- and multiple-group penalized factor analysis: A trust-region algorithm approach with integrated automatic multiple tuning parameter selection. Psychometrika 2021, 86, 65–95. [Google Scholar] [CrossRef]
- Hirose, K.; Terada, Y. Sparse and simple structure estimation via prenet penalization. Psychometrika 2022. [Google Scholar] [CrossRef]
- Huang, P.H.; Chen, H.; Weng, L.J. A penalized likelihood method for structural equation modeling. Psychometrika 2017, 82, 329–354. [Google Scholar] [CrossRef]
- Huang, P.H. lslx: Semi-confirmatory structural equation modeling via penalized likelihood. J. Stat. Softw. 2020, 93, 1–37. [Google Scholar] [CrossRef]
- Jacobucci, R.; Grimm, K.J.; McArdle, J.J. Regularized structural equation modeling. Struct. Equ. Model. 2016, 23, 555–566. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Jacobucci, R.; Ammerman, B.A. Tutorial on the use of the regsem package in R. Psych 2021, 3, 579–592. [Google Scholar] [CrossRef]
- Scharf, F.; Nestler, S. Should regularization replace simple structure rotation in exploratory factor analysis? Struct. Equ. Model. 2019, 26, 576–590. [Google Scholar] [CrossRef]
- Fan, J.; Li, R.; Zhang, C.H.; Zou, H. Statistical Foundations of Data Science; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar] [CrossRef]
- Friedrich, S.; Groll, A.; Ickstadt, K.; Kneib, T.; Pauly, M.; Rahnenführer, J.; Friede, T. Regularization approaches in clinical biostatistics: A review of methods and their applications. Stat. Methods Med. Res. 2023, 32, 425–440. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, J.; Xu, G.; Ying, Z. Statistical analysis of Q-matrix based diagnostic classification models. J. Am. Stat. Assoc. 2015, 110, 850–866. [Google Scholar] [CrossRef]
- Zhang, H.; Li, S.J.; Zhang, H.; Yang, Z.Y.; Ren, Y.Q.; Xia, L.Y.; Liang, Y. Meta-analysis based on nonconvex regularization. Sci. Rep. 2020, 10, 5755. [Google Scholar] [CrossRef]
- Tutz, G.; Gertheiss, J. Regularized regression for categorical data. Stat. Model. 2016, 16, 161–200. [Google Scholar] [CrossRef]
- Kyung, M.; Gill, J.; Ghosh, M.; Casella, G. Penalized regression, standard errors, and Bayesian lassos. Bayesian Anal. 2010, 5, 369–411. [Google Scholar] [CrossRef]
- Minnier, J.; Tian, L.; Cai, T. A perturbation method for inference on regularized regression estimates. J. Am. Stat. Assoc. 2011, 106, 1371–1382. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 11 January 2022).
- Robitzsch, A. sirt: Supplementary Item Response Theory Models; R Package Version 3.13-128. 2023. Available online: https://github.com/alexanderrobitzsch/sirt (accessed on 2 April 2023).
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar] [CrossRef]
- Knoppen, D.; Saris, W. Do we have to combine values in the Schwartz’ human values scale? A comment on the Davidov studies. Surv. Res. Methods 2009, 3, 91–103. [Google Scholar] [CrossRef]
- Beierlein, C.; Davidov, E.; Schmidt, P.; Schwartz, S.H.; Rammstedt, B. Testing the discriminant validity of Schwartz’ portrait value questionnaire items—A replication and extension of Knoppen and Saris (2009). Surv. Res. Methods 2012, 6, 25–36. [Google Scholar] [CrossRef]
- Muthén, B.; Asparouhov, T. New Methods for the Study of Measurement Invariance with Many Groups. Technical Report. 2013. Available online: https://bit.ly/3nBbr5M (accessed on 4 March 2023).
- Muthén, B.; Asparouhov, T. Recent methods for the study of measurement invariance with many groups: Alignment and random effects. Sociol. Methods Res. 2018, 47, 637–664. [Google Scholar] [CrossRef]
- Muthén, B. A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika 1984, 49, 115–132. [Google Scholar] [CrossRef]
- Robitzsch, A. On the bias in confirmatory factor analysis when treating discrete variables as ordinal instead of continuous. Axioms 2022, 11, 162. [Google Scholar] [CrossRef]
- Yuan, K.H.; Bentler, P.M.; Chan, W. Structural equation modeling with heavy tailed distributions. Psychometrika 2004, 69, 421–436. [Google Scholar] [CrossRef]
- Yuan, K.H.; Bentler, P.M. Robust procedures in structural equation modeling. In Handbook of Latent Variable and Related Models; Lee, S.Y., Ed.; Elsevier: Amsterdam, The Netherlands, 2007; pp. 367–397. [Google Scholar] [CrossRef]
- Pokropek, A.; Davidov, E.; Schmidt, P. A Monte Carlo simulation study to assess the appropriateness of traditional and newer approaches to test for measurement invariance. Struct. Equ. Model. 2019, 26, 724–744. [Google Scholar] [CrossRef]
- Rutkowski, L.; Svetina, D. Assessing the hypothesis of measurement invariance in the context of large-scale international surveys. Educ. Psychol. Meas. 2014, 74, 31–57. [Google Scholar] [CrossRef]
- Liu, X.; Wallin, G.; Chen, Y.; Moustaki, I. Rotation to sparse loadings using Lp losses and related inference problems. Psychometrika 2023. [Google Scholar] [CrossRef]
- Asparouhov, T.; Muthén, B. Penalized Structural Equation Models. Technical Report. 2023. Available online: https://bit.ly/3TlbxdC (accessed on 4 March 2023).
- Hennig, C.; Kutlukaya, M. Some thoughts about the design of loss functions. Revstat Stat. J. 2007, 5, 19–39. [Google Scholar] [CrossRef]
- Robitzsch, A.; Lüdtke, O. Why full, partial, or approximate measurement invariance are not a prerequisite for meaningful and valid group comparisons. Struct. Equ. Model. 2023. [Google Scholar]
- Stefanski, L.A.; Boos, D.D. The calculus of M-estimation. Am. Stat. 2002, 56, 29–38. [Google Scholar] [CrossRef]
- Hennig, C. How wrong models become useful-and correct models become dangerous. In Between Data Science and Applied Data Analysis. Studies in Classification, Data Analysis, and Knowledge Organization; Schader, M., Gaul, W., Vichi, M., Eds.; Springer: Berlin, Germany, 2003; pp. 235–243. [Google Scholar] [CrossRef]
- Saltelli, A.; Funtowicz, S. When all models are wrong. Issues Sci. Technol. 2014, 30, 79–85. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bias | Relative RMSE | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RME with p = | RME with p = | ||||||||||||||
| Par | N | RegML | 0.25 | 0.5 | 1 | ULS | ML | RegML | 0.25 | 0.5 | 1 | ULS | ML | ||
| 0 | 500 | −0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 102 | 102 | 101 | 101 | 100 | 101 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 102 | 101 | 101 | 100 | 100 | 100 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 103 | 100 | 100 | 100 | 100 | 100 | |||
| 0.3 | 500 | 0.02 | 0.02 | 0.02 | 0.03 | 0.07 | 0.07 | 100 | 101 | 103 | 113 | 162 | 166 | ||
| 1000 | 0.01 | 0.01 | 0.01 | 0.03 | 0.07 | 0.07 | 100 | 101 | 105 | 122 | 213 | 218 | |||
| 2500 | 0.01 | 0.01 | 0.01 | 0.03 | 0.07 | 0.07 | 100 | 101 | 108 | 144 | 318 | 328 | |||
| 0.6 | 500 | 0.01 | 0.01 | 0.01 | 0.03 | 0.15 | 0.16 | 100 | 101 | 102 | 119 | 312 | 336 | ||
| 1000 | 0.00 | 0.01 | 0.01 | 0.03 | 0.15 | 0.16 | 100 | 100 | 103 | 129 | 429 | 462 | |||
| 2500 | 0.00 | 0.01 | 0.01 | 0.03 | 0.15 | 0.16 | 100 | 100 | 105 | 152 | 672 | 722 | |||
| 0 | 500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 101 | 108 | 106 | 104 | 104 | 100 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 101 | 105 | 104 | 103 | 104 | 100 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 101 | 104 | 104 | 104 | 104 | 100 | |||
| 0.3 | 500 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.01 | 102 | 104 | 103 | 101 | 109 | 100 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.01 | 100 | 101 | 101 | 102 | 117 | 102 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.01 | 100 | 100 | 101 | 105 | 137 | 108 | |||
| 0.6 | 500 | 0.00 | 0.00 | 0.00 | 0.01 | 0.04 | 0.02 | 100 | 108 | 107 | 107 | 139 | 138 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.01 | 0.04 | 0.02 | 100 | 107 | 107 | 110 | 166 | 146 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.01 | 0.04 | 0.02 | 100 | 104 | 105 | 111 | 219 | 160 | |||
| 0 | 500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 117 | 113 | 109 | 109 | 100 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 109 | 107 | 106 | 107 | 100 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 101 | 107 | 107 | 107 | 108 | 100 | |||
| 0.3 | 500 | −0.02 | −0.01 | −0.01 | −0.01 | −0.03 | −0.02 | 107 | 110 | 107 | 105 | 116 | 100 | ||
| 1000 | −0.01 | −0.01 | −0.01 | −0.01 | −0.03 | −0.02 | 104 | 100 | 100 | 103 | 127 | 102 | |||
| 2500 | −0.01 | 0.00 | −0.01 | −0.01 | −0.03 | −0.01 | 107 | 100 | 101 | 108 | 155 | 111 | |||
| 0.6 | 500 | −0.02 | 0.00 | −0.01 | −0.01 | −0.06 | −0.03 | 105 | 102 | 100 | 100 | 139 | 136 | ||
| 1000 | −0.01 | 0.00 | 0.00 | −0.01 | −0.06 | −0.03 | 102 | 101 | 100 | 104 | 176 | 145 | |||
| 2500 | 0.00 | 0.00 | 0.00 | −0.01 | −0.06 | −0.03 | 100 | 101 | 102 | 112 | 260 | 177 | |||
| RME with p = | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.25 | 0.5 | 1 | ULS | ML | ||||||||||||||||||
| Par | N | DF | JK | BS | DF | JK | BS | DF | JK | BS | DF | JK | BS | OI | DF | JK | BS | |||||
| 0 | 500 | 95.8 | 95.1 | 95.5 | 95.5 | 94.8 | 94.9 | 95.3 | 94.4 | 95.0 | 94.9 | 94.2 | 94.6 | 95.0 | 95.1 | 94.2 | 94.6 | |||||
| 1000 | 95.2 | 94.7 | 94.9 | 95.1 | 94.6 | 94.7 | 94.8 | 94.4 | 94.7 | 94.6 | 94.2 | 94.3 | 94.7 | 94.7 | 94.4 | 94.5 | ||||||
| 2500 | 95.4 | 94.7 | 95.3 | 95.3 | 94.7 | 94.9 | 95.3 | 94.6 | 94.9 | 95.2 | 94.7 | 94.7 | 95.2 | 95.2 | 94.7 | 94.9 | ||||||
| 0.6 | 500 | 94.8 | 94.5 | 94.6 | 94.5 | 94.1 | 94.5 | 93.7 | 93.0 | 93.3 | 94.7 | 94.0 | 94.3 | 93.5 | 94.4 | 93.7 | 94.4 | |||||
| 1000 | 94.3 | 94.0 | 94.7 | 94.3 | 93.7 | 94.1 | 93.7 | 93.3 | 93.1 | 94.7 | 94.0 | 94.4 | 93.6 | 94.6 | 94.0 | 94.1 | ||||||
| 2500 | 95.1 | 94.5 | 95.0 | 95.0 | 94.3 | 94.7 | 95.0 | 94.2 | 94.1 | 95.2 | 94.5 | 94.8 | 94.3 | 95.2 | 94.3 | 94.6 | ||||||
| 0 | 500 | 95.8 | 95.4 | 96.0 | 95.6 | 95.1 | 95.9 | 95.2 | 94.5 | 95.1 | 94.7 | 94.0 | 94.3 | 95.0 | 95.1 | 93.9 | 94.7 | |||||
| 1000 | 95.2 | 94.3 | 95.6 | 95.1 | 93.9 | 95.1 | 94.6 | 93.7 | 94.4 | 94.4 | 93.4 | 93.7 | 94.6 | 94.7 | 93.8 | 93.8 | ||||||
| 2500 | 94.5 | 93.8 | 94.6 | 94.4 | 93.8 | 94.1 | 94.2 | 93.9 | 94.3 | 94.2 | 93.8 | 94.0 | 94.6 | 94.6 | 93.8 | 94.1 | ||||||
| 0.6 | 500 | 95.5 | 94.9 | 96.0 | 95.6 | 94.7 | 96.2 | 95.6 | 94.5 | 95.3 | 94.9 | 93.8 | 94.5 | 88.5 | 96.2 | 95.7 | 96.4 | |||||
| 1000 | 95.1 | 94.5 | 95.5 | 94.9 | 94.5 | 95.0 | 94.7 | 94.4 | 94.8 | 94.6 | 93.8 | 94.4 | 88.5 | 95.6 | 94.7 | 95.9 | ||||||
| 2500 | 95.1 | 94.7 | 95.2 | 95.0 | 94.7 | 94.9 | 95.3 | 94.5 | 94.9 | 95.2 | 94.3 | 94.9 | 89.0 | 95.4 | 94.5 | 95.4 | ||||||
| 0 | 500 | 96.6 | 96.2 | 97.6 | 96.4 | 95.8 | 96.9 | 95.8 | 94.8 | 95.4 | 95.1 | 94.3 | 94.4 | 95.0 | 95.0 | 94.4 | 94.9 | |||||
| 1000 | 96.1 | 95.3 | 96.7 | 95.9 | 95.1 | 95.9 | 95.5 | 94.8 | 95.3 | 95.3 | 94.6 | 94.9 | 95.1 | 95.1 | 94.7 | 94.9 | ||||||
| 2500 | 95.0 | 94.7 | 95.3 | 95.1 | 94.6 | 95.1 | 95.1 | 94.6 | 94.9 | 95.0 | 94.5 | 94.7 | 95.0 | 95.0 | 94.3 | 94.4 | ||||||
| 0.6 | 500 | 96.1 | 95.7 | 97.1 | 96.1 | 95.6 | 96.9 | 95.7 | 95.2 | 95.8 | 94.9 | 94.5 | 94.6 | 88.7 | 96.7 | 96.5 | 96.8 | |||||
| 1000 | 95.3 | 95.0 | 95.9 | 95.4 | 95.0 | 95.8 | 95.3 | 94.7 | 95.3 | 94.9 | 94.2 | 94.7 | 88.6 | 95.8 | 95.1 | 96.4 | ||||||
| 2500 | 95.1 | 94.7 | 95.0 | 95.1 | 94.6 | 95.0 | 94.9 | 94.5 | 94.8 | 95.1 | 94.5 | 94.7 | 88.8 | 95.2 | 94.8 | 95.6 | ||||||
| Bias | Relative RMSE | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RME with p = | RME with p = | ||||||||||||||
| Par | N | RegML | 0.25 | 0.5 | 1 | ULS | ML | RegML | 0.25 | 0.5 | 1 | ULS | ML | ||
| 0 | 500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 103 | 102 | 100 | 100 | 100 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 102 | 101 | 100 | 100 | 100 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 100 | 100 | 100 | 100 | 100 | |||
| 0.3 | 500 | −0.02 | −0.03 | −0.03 | −0.07 | −0.12 | −0.12 | 101 | 100 | 100 | 113 | 152 | 152 | ||
| 1000 | 0.00 | −0.01 | −0.02 | −0.06 | −0.12 | −0.12 | 100 | 103 | 106 | 140 | 231 | 230 | |||
| 2500 | 0.00 | −0.01 | −0.01 | −0.05 | −0.12 | −0.12 | 100 | 103 | 107 | 169 | 356 | 355 | |||
| 0.6 | 500 | 0.00 | −0.01 | −0.02 | −0.07 | −0.24 | −0.24 | 100 | 104 | 104 | 129 | 303 | 302 | ||
| 1000 | 0.00 | −0.01 | −0.01 | −0.06 | −0.24 | −0.24 | 100 | 102 | 103 | 144 | 435 | 433 | |||
| 2500 | 0.00 | 0.00 | −0.01 | −0.05 | −0.24 | −0.24 | 100 | 101 | 104 | 171 | 698 | 692 | |||
| 0 | 500 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 100 | 103 | 102 | 101 | 100 | 100 | ||
| 1000 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 102 | 101 | 100 | 100 | 100 | |||
| 2500 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 100 | 101 | 101 | 100 | 100 | 100 | |||
| 0.3 | 500 | −0.02 | −0.03 | −0.03 | −0.07 | −0.12 | −0.11 | 100 | 103 | 102 | 115 | 153 | 149 | ||
| 1000 | 0.00 | −0.01 | −0.02 | −0.06 | −0.12 | −0.11 | 100 | 104 | 107 | 139 | 223 | 216 | |||
| 2500 | 0.00 | −0.01 | −0.01 | −0.05 | −0.12 | −0.12 | 100 | 103 | 108 | 167 | 344 | 332 | |||
| 0.6 | 500 | 0.00 | −0.01 | −0.01 | −0.06 | −0.23 | −0.21 | 100 | 103 | 102 | 124 | 286 | 267 | ||
| 1000 | 0.00 | 0.00 | −0.01 | −0.05 | −0.23 | −0.22 | 100 | 103 | 103 | 139 | 421 | 390 | |||
| 2500 | 0.00 | −0.01 | −0.01 | −0.05 | −0.24 | −0.22 | 100 | 101 | 104 | 174 | 693 | 641 | |||
| RME with p = | |||||||
|---|---|---|---|---|---|---|---|
| Rank | CNT | RegML | 0.25 | 0.5 | 1 | ULS | ML |
| 1 | C10 | 0.37 | 0.37 | 0.37 | 0.34 | 0.34 | 0.35 |
| 2 | C21 | 0.01 | −0.01 | 0.01 | 0.18 | 0.27 | 0.33 |
| 3 | C06 | 0.06 | 0.17 | 0.19 | 0.26 | 0.25 | 0.26 |
| 4 | C03 | 0.33 | 0.33 | 0.32 | 0.25 | 0.21 | 0.21 |
| 5 | C08 | 0.13 | 0.15 | 0.16 | 0.23 | 0.23 | 0.20 |
| 6 | C12 | 0.12 | 0.14 | 0.15 | 0.20 | 0.19 | 0.16 |
| 7 | C05 | 0.15 | 0.17 | 0.17 | 0.15 | 0.11 | 0.13 |
| 8 | C16 | 0.14 | 0.05 | 0.06 | 0.09 | 0.06 | 0.07 |
| 9 | C01 | 0.12 | 0.11 | 0.10 | 0.07 | 0.08 | 0.07 |
| 10 | C14 | −0.11 | −0.10 | −0.10 | −0.09 | −0.05 | −0.06 |
| 11 | C22 | 0.02 | −0.01 | −0.02 | −0.06 | −0.08 | −0.07 |
| 12 | C15 | −0.18 | −0.17 | −0.17 | −0.16 | −0.01 | −0.07 |
| 13 | C09 | −0.21 | −0.21 | −0.21 | −0.21 | −0.19 | −0.23 |
| 14 | C13 | −0.30 | −0.30 | −0.30 | −0.32 | −0.28 | −0.30 |
| 15 | C17 | −0.20 | −0.19 | −0.21 | −0.29 | −0.36 | −0.33 |
| 16 | C25 | −0.17 | −0.18 | −0.19 | −0.29 | −0.39 | −0.34 |
| 17 | C24 | −0.29 | −0.32 | −0.34 | −0.37 | −0.38 | −0.39 |
| CNT | TR09 | TR20 | CO07 | CO16 |
|---|---|---|---|---|
| C01 | · | −0.17 | · | −0.17 |
| C03 | · | −0.32 | · | −0.26 |
| C05 | −0.50 | 0.29 | · | · |
| C06 | 0.09 | · | 0.24 | · |
| C08 | · | 0.12 | · | · |
| C09 | · | −0.24 | · | 0.09 |
| C10 | −0.47 | 0.25 | · | · |
| C12 | · | 0.05 | · | · |
| C13 | 0.29 | · | · | −0.47 |
| C14 | 0.10 | 0.31 | · | −0.42 |
| C15 | 0.42 | 0.07 | · | −0.22 |
| C16 | −0.26 | · | · | −0.13 |
| C17 | −0.52 | −0.12 | · | · |
| C21 | · | · | 0.48 | · |
| C22 | −0.14 | · | · | −0.36 |
| C24 | · | −0.32 | · | −0.17 |
| C25 | −0.52 | · | · | −0.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Robitzsch, A. Model-Robust Estimation of Multiple-Group Structural Equation Models. Algorithms 2023, 16, 210. https://doi.org/10.3390/a16040210
Robitzsch A. Model-Robust Estimation of Multiple-Group Structural Equation Models. Algorithms. 2023; 16(4):210. https://doi.org/10.3390/a16040210
Chicago/Turabian StyleRobitzsch, Alexander. 2023. "Model-Robust Estimation of Multiple-Group Structural Equation Models" Algorithms 16, no. 4: 210. https://doi.org/10.3390/a16040210
APA StyleRobitzsch, A. (2023). Model-Robust Estimation of Multiple-Group Structural Equation Models. Algorithms, 16(4), 210. https://doi.org/10.3390/a16040210