1. Introduction
In this paper, we consider the single-machine problem with job release times and machine unavailable periods, where machine unavailable periods are caused by flexible preventive maintenance (PM) activities. For classical single-machine scheduling problems, most research assumes that all jobs are ready for processing simultaneously or that machines are always available to simplify the complexity of scheduling problems. These two assumptions may impede many possible practical applications, and some studies have demonstrated that there is a need to consider the dynamic job release time [
1] or machine unavailable periods [
2,
3]. Both are common phenomena in the real world and are significant factors in production scheduling decisions. That is, taking into consideration jobs’ release time and machine unavailable periods, a given production scheduling problem can be solved more realistically.
For the considered problem, more precisely, there are
n jobs with different release times to the production system and waiting to be processed on a single machine without preemption. The machine is not always available; it needs to be maintained periodically to prevent its continuous working time from exceeding a specific threshold value and to initialize the machine’s status. To the best of our knowledge, there are only three studies considering dynamic job release time and machine availability constraints simultaneously for the single-machine scheduling problem. Detienne [
4] was the first to consider this type of problem and proposed a MIP model to minimize the weighted number of late jobs. In this study, the machine unavailable periods were fixed and known in advance. Cui and Lu [
5] considered the dynamic job release time for the machine availability scheduling problem. The main difference from the study of Detienne [
4] is that, when implementing PM as a decision variable in scheduling planning, it is not fixed and known. For this problem, the researchers proposed a MIP model, heuristic algorithms and the branch and bound (BAB) method to minimize the makespan. Pang et al. [
6] considered the single-machine maintenance scheduling problem with dynamic job release time, and this study was motivated by a clean operation of semiconductor manufacturing in which the machine had to stop to remove the dirt in the machine as a clean agent. For this problem, the researchers proposed a scatter simulated annealing algorithm to simultaneously minimize the total weighted tardiness and total completion time.
Our considered problem is the same as that of Cui and Lu [
5] mentioned above; the objective of Cui and Lu [
5] is to minimize the makespan, implying maximizing the throughput of the system. With the increasing importance of time-related competition and customer satisfaction, production performance based on due-dates becomes more significant. Thus, the objective we adopted is to minimize the total weighted tardiness (
TWT) for responding to the needs of on-time delivery in just-in-time (JIT) production, which is one of the important, relevant objectives for today’s manufacturing environments. Moreover, the
TWT objective has not been considered as often by researchers in this problem. This problem is also NP-hard because the special case without machine maintenance constraints, that is, the single-machine scheduling problem to minimize the total weighted tardiness has proven to be NP-hard [
7].
For the NP-hard problem considered in this paper, we propose a trajectory-based immigration strategy genetic algorithm. The main reason is that different genetic algorithms (GAs) have been implemented successfully in many complicated scheduling problems but are seldom applied to the considered problem. Additionally, an immigration strategy is one of the common ways to keep the diversity of the population and avoid local convergence. Thus, we develop a novel trajectory-based immigration strategy containing three different solution knowledge extraction matrices for collecting important information from the searched chromosomes and embed the immigration strategy into the proposed GA method to generate better immigrants. Furthermore, we develop a mixed integer programming (MIP) model to obtain benchmark solutions to evaluate the performance of the proposed GA.
The rest of this paper is as follows. In
Section 2, we review previous related studies. We define the considered problem and a mixed integer programming model to minimize the total weighted tardiness in
Section 3. In
Section 4, we describe the trajectory-based GA in this paper.
Section 5 describes the computational experiment, including the parameter settings of the GA, test data generation scheme and experimental results. In
Section 6, we discuss the results obtained. Finally,
Section 7 contains our conclusions and future research.
2. Literature Review
Regarding scheduling problems with machine availability constraints, hundreds of contributions have been developed in the literature. Most of the machine availability is caused by preventive maintenance. Preventive maintenance (PM) is designed as a prior measure to reduce the probability of failure or degradation, and activating PM tasks in scheduling problems are usually classified into two categories: (i) PM tasks are performed at a fixed interval or within a time window or (ii) PM tasks are carried out depending on certain monitored conditions.
Table 1 exhibits a brief review of work on single-machine scheduling problems with PM tasks based on the two categories. As seen from
Table 1, the previous major studies focused on the first category with different objective functions. Additionally, Ma et al. [
8] provided a detailed review and classification of papers that dealt with deterministic scheduling problems related to fixed PM tasks in different manufacturing shop floors. This information indicated increasing interest in studying this field over the past several decades.
The references most pertinent to our considered paper are Qi et al. [
9], Sbihi and Varnier [
2], and Cui and Lu [
5]. In these studies, the PM task is driven by monitoring the current machine’s working time to ensure that it does not exceed a preset critical time threshold and to initialize the status of the machine. Qi et al. [
9] proposed three heuristic algorithms and a branch and bound (BAB) method to minimize the total completion time. Sbihi and Varnier [
2] considered the two categories mentioned in
Table 1 and proposed the BAB method to minimize maximum tardiness. The two above studies assumed that all jobs were ready at time 0. Cui and Lu [
5] first considered the dynamic case of jobs’ release time in the single-machine problem. They proposed a mixed integer programming (MIP), a BAB method and a heuristic algorithm to minimize the makespan.
Another PM task motivated by the wafer cleaning operation of a semiconductor manufacturing factory was proposed by Su and Wang [
10], where a machine has to be maintained periodically so that the amount of dirt left on the machine does not exceed a preset critical dirt threshold. Su and Wang [
10] developed a MIP, a dynamic programming-based heuristic algorithm to minimize the total absolute deviation of job completion times. Later, Su et al. [
11] extended the single-machine problem to a parallel machine problem and developed a MIP model and three heuristic algorithms to minimize the number of tardy jobs. Pang et al. [
6] extended the study of Su and Wang [
10] to consider job release time and bicriteria (total weighted tardiness and job completion time). They proposed a scatter simulated annealing (SSA) algorithm to obtain nondominated solutions.
From
Table 1, it is evident that our considered problem, i.e., the dynamic single-machine scheduling problem with PM tasks, where PM tasks are driven by the threshold value of the machine’s continuous working time and the total weighted tardiness as the objective, has not been studied so far. The considered problem is NP-hard since the static single-machine problem with the objective of the total weighted tardiness, where the machine is always available, has proven to be NP-hard [
7]. For this kind of NP-hard problem, applying traditional methodologies, such as heuristic algorithms or exact algorithms, suffers either from solution effectiveness or computational efficiency. In recent years, various GAs based on global exploration and local exploitation search mechanisms, due to their flexibility, have been utilized more successfully than traditional approaches in solving NP-hard problems [
12].
Table 1.
Two categories of related studies for the considered problem.
Table 1.
Two categories of related studies for the considered problem.
| Objectives | First Category | Second Category |
|---|
| Makespan | [3,13,14,15,16] | [5] |
| Total completion time or total flow time | [14,17,18,19,20] | [9] |
| Total weighted completion time | [21,22,23,24,25] | [26] |
| Total absolute deviation of job completion times | | [10] |
| Maximum lateness | [14] | [26] |
| Maximum earliness | [27] | |
| Maximum tardiness | [2,20,28] | [2] |
| Mean lateness | [20] | |
| Mean tardiness | [20] | |
| Number of tardy jobs | [14,29,30,31] | [11] |
| Weighted number of late jobs | [4] | |
| Bicriteria (total weighted tardiness and total completion time) | | [6] |
Compared with classical scheduling problems, employing meta-heuristic algorithms to solve single-machine scheduling problems with machine unavailability constraints has been very limited, with only a few studies to date. Pang et al. [
6] considered a single-machine scheduling problem in which PM tasks are driven by the accumulated dirt and adopted the total weighted tardiness and total completion time simultaneously as an objective. The researchers proposed a scatter simulated annealing (SSA) algorithm to obtain nondominated solutions. Chen et al. [
32] developed a GA to solve a single-machine scheduling problem by minimizing total tardiness, where machine availability is measured by its reliability. Due to their success in applying meta-heuristic algorithms to solve the scheduling problem with machine availability constraints, we propose a new GA with knowledge of solution trajectory, aiming at presenting a trajectory-based immigration strategy to enhance the effectiveness of our GA.
4. The Proposed GA
GAs are well-known stochastic search algorithms to solve combinatorial optimization problems. The original idea was developed by Holland [
36]. In a GA, a population is maintained by selection, crossover and mutation operators until a stopping criterion is satisfied and an optimal/best solution is obtained. However, it is likely to be trapped in local optima [
37]. As a result, immigration strategies, such as random immigrants [
38] and elitism-based immigrants [
39], have been proposed to enhance the diversity of chromosomes in the population [
40]. In this paper, we develop a trajectory-based immigrant scheme to maintain the diversity of chromosomes in each population.
Trajectory-based immigration schemes are not like random-based immigrant or elitism-based immigrant schemes. The former (random-based immigrant scheme) randomly generated immigrants. Regarding the latter, it adopted the elite chromosome as a base to generate immigrants with better solution quality in this way. In this paper, we develop a solution-characteristic reserved technology based on solution extraction knowledge matrices to extract the relation between job and position, job and job, and from job to job for each feasible solution. The solution extraction knowledge matrices are called job-position trajectory (JPT), job-job trajectory (JJT) and from-to trajectory (FTT). Based on the information provided by the three matrices, we develop a trajectory-based immigration scheme such that the generated immigrants can gain a balance between randomness and solution quality for the GA. Next, the steps for building three trajectory matrices are described as follows.
Step 1. Generate feasible schedules randomly and obtain the corresponding TWT value , y = 1, 2, …, N. N is the number of the population.
Step 2. Calculate the mean () and standard deviation () for this group.
Step 3. Obtain a semaphore value () for each schedule by normalization, i.e., . Note that a larger signal is better to minimize the TWT.
Step 4. Initialize matrices CJP, CJJ, CFT, SJP, SJJ and SFT.
Step 5. Complete count matrix (CJP) by counting the number of jobs i occupied at position j in schedule , and in a similar fashion to complete matrices (CJJ and CFT) if job i is before job j in schedule , and if job i is from to job j (job i and j is adjacent).
Step 6. Complete semaphore matrix SJP by accumulating semaphore value () if job i occupied position j in schedule , and in a similar fashion to complete matrix SJJ if job i is before job j in schedule , and matrix SFT if from the job i is to job j.
Step 7. Obtain each element of the job-position trajectory (
JPT) matrix by the following equation:
Step 8. Obtain each element of the job-job trajectory (
JJT) matrix by the following equation:
Step 9. Obtain each element of the from-to trajectory (
FTT) matrix by the following equation:
To demonstrate the three types of trajectory forms (job-position, job-job and from-to), we use an 8-job instance in
Table 3 and generate 1000 solutions randomly, for example. Applying the above steps, the
JPT,
JJT and
FTT matrices are built, as shown in
Table 4,
Table 5 and
Table 6.
To validate whether the three matrices can help us to find good immigrants, we applied correlation analysis to realize the correlation between the objective value and matrices. The steps are described as follows:
Step 1. For instance, generate K feasible solutions (π𝑦) randomly and obtain objective values () for solution y, y = 1, 2,…, K.
Step 2. For each solution,
, obtain three feature values based on the
JPT,
JJT and
FTT matrices using the following equations:
Step 3. Obtain the mean and standard deviation of the objective value and feature values for the
K solutions using the following equations:
Step 4. Calculate the correlation values between the objective value and matrices by the following equation:
For the example of
Table 3 and based on the results in
Table 4,
Table 5 and
Table 6, we determine that the correlation values
are −0.97130, −0.88297 and −0.81809 when
K = 250. The values are negative because the objective function is minimized. To further examine the correlation between objective value and matrices, we randomly regenerate 80 instances with eight jobs and follow the procedures mentioned above to obtain the correlation values shown in
Table 7.
From
Table 7, the results achieved for the
JJT matrix are slightly worse, where the correlation value is greater than 75% in 53 cases of the 80 total instances is 66.25%, which is less than the 100% and 98.75% obtained by
JPT and
FTT, respectively. As expected, the impact of the position information for jobs on the objective function appears to be more significant than that of the precedence relationship of pairs of jobs. Overall, the majority of correlation values are greater than 75%, which indicates that the proposed matrices are highly correlated with the objective value of the schedule. That is, it is implied that we can apply the information provided by the proposed matrices to search for better solutions.
Based on this finding, we constructed the trajectory matrices of JPT, JJT and FTT from the previously explored chromosomes during the GA process. We did not discard or ignore the hidden information in them. Based on the information given by the three trajectory matrices, we developed the immigrant generation method and embedded it into the GA. Thus, the developed GA is called the trajectory-based immigration strategy GA (TISGA) in this paper. Each part of TISGA is described as follows:
4.1. Encoding Scheme
The encoding scheme is important in making a solution recognizable in applying GA. Our proposed GA is based on a permutation representation of n jobs, which is the natural representation of a solution and one of the widely used encoding schemes for single-machine scheduling problems.
4.2. Population Initialization
To generate a variety of chromosomes, i.e., the sequence of jobs, the jobs are first sorted according to the following dispatching rules, and then the rest of the chromosomes are generated randomly.
First-in, first-out (FIFO): sequence the jobs by increasing the order of their release time, i.e., . Ties are broken by the EDD rule.
Shortest processing time (SPT): sequence the jobs by increasing the order of their processing time, i.e., . Ties are broken by the FIFO rule.
Largest processing time (LPT): sequence the jobs by decreasing the order of their processing time. Ties are broken by the FIFO rule.
Weight shortest processing time (WSPT): sequence the jobs by increasing the order of the index . Ties are broken by the FIFO rule.
Earliest due date (EDD): sequence the jobs by increasing the order of their due date, i.e., . Ties are broken by the FIFO rule.
4.3. Fitness Function and Evaluation
In this study, our objective was to minimize the TWT, and it was expected that a chromosome with a smaller TWT would have a larger fitness value for survival. Thus, the fitness value of a chromosome is evaluated by the inverse of its value as follows:
,
y = 1, 2,…, population size, where fitness (
) is the fitness value for the yth chromosome;
TWT(
) is the
TWT value; and
is the smallest value (
= 0.000001), which aims to keep the denominator greater than zero. To obtain the
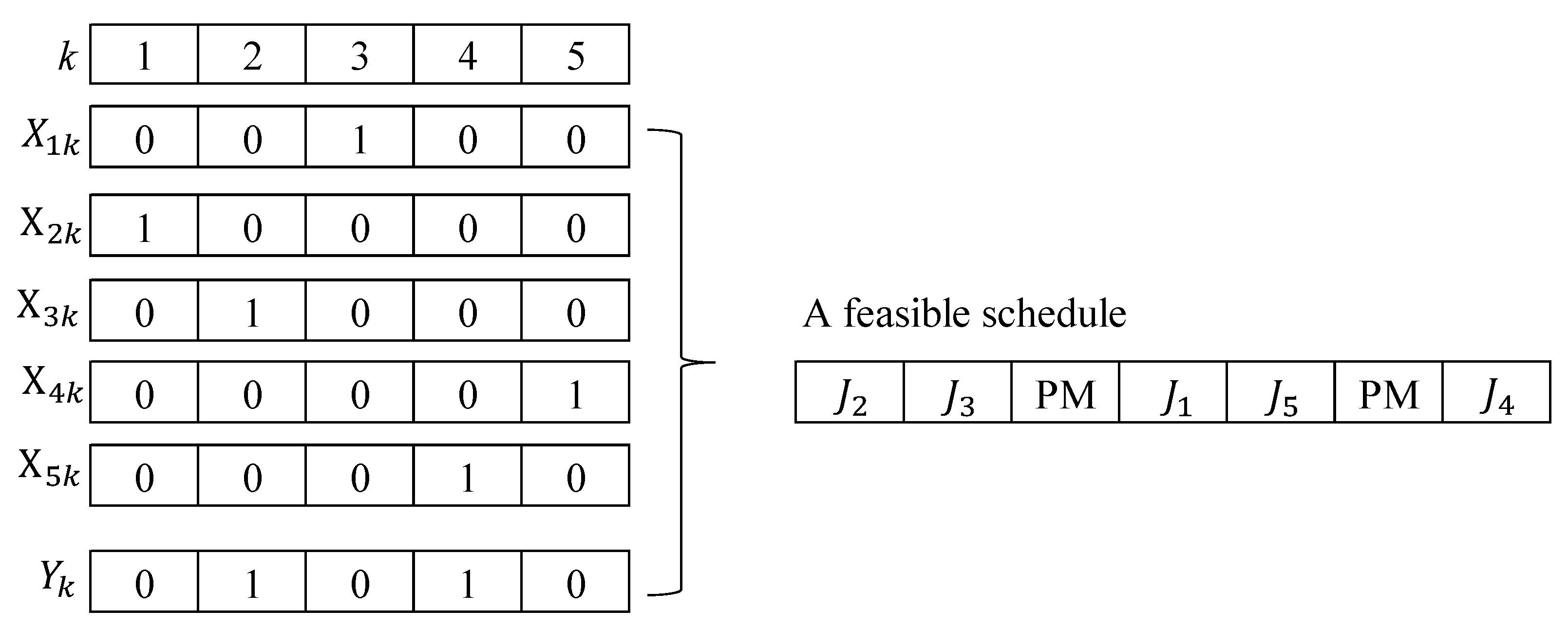
TWT value for each chromosome, we use the DP method, as mentioned above. In this decoding, the job sequence is based on the relative order in the chromosome, but when to execute PM activities depends on the proposed DP method, as mentioned above. Suppose one of the chromosomes is represented by
J1-J3-J4-J5-J2 for the 5-job instance shown in
Table 2. Using the proposed decoding method, the feasible schedule for the chromosome of
J1-J3-J4-J5-J2 is obtained, as shown in
Figure 3, where the corresponding
TWT and fitness values are 41 and 0.0244, respectively.
4.4. Crossover/Mutation
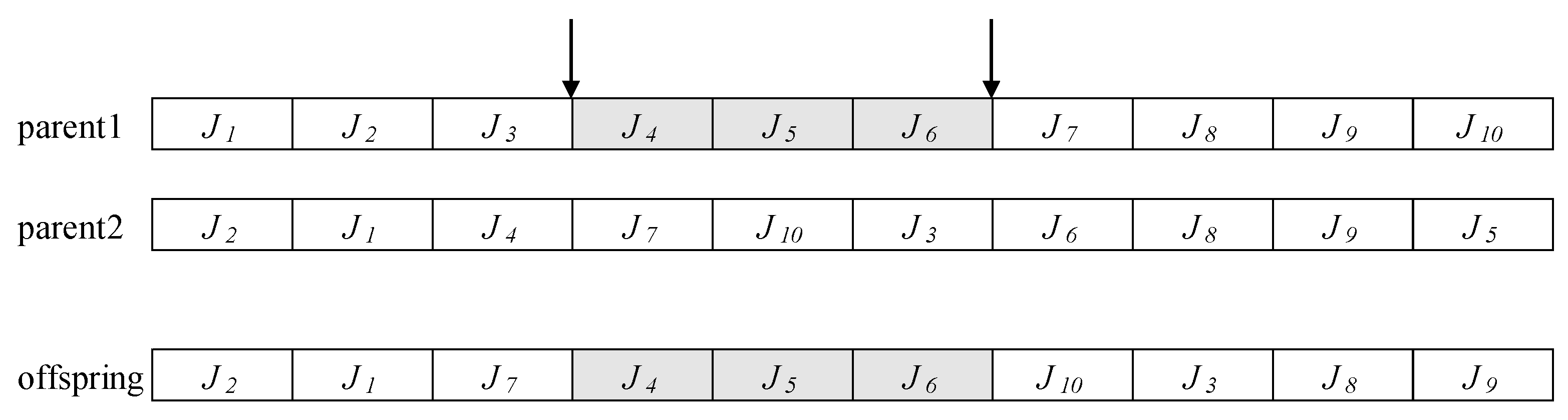
For recombination/crossover to generate offspring, we applied bias roulette wheel selection to choose parents from the pool of the population, which was the first selection operator proposed by Holland in 1975 (Goldberg, 1989). Since then, it has become a common method used in a variety of GA applications. For crossover, we consider order crossover (OX). In the OX crossover, two cutoff points from parent one are randomly selected, and the information between the two cutoff points is added to the generated offspring. The remaining jobs are filled in the order from parent 2. In this way, OX crossover always generates feasible offspring.
Figure 4 illustrates an example of an OX crossover.
For each offspring generated by OX crossover, the parent solution’s features may be randomly modified by the mutation operator. The mutation operator preserves a reasonable level of population diversity that helps the GA escape local optima. In this paper, we adopt a swap mutation. More precisely, we produced a random number from uniformly distributed between 0 and 1. If the random number is less than or equal to a given mutation probability , i.e., , then the contents of two random genes of the offspring are swapped.
4.5. Immigration
In immigrant schemes, a certain number of immigrants are generated and added to the pool of the population by replacing the worst individuals from the current generation. In this paper, we applied random immigration and trajectory-based immigration strategies addressed in this paper to create immigrants for the next population. For the trajectory-based immigration strategy, the percentage of immigrants generated from JPT, FTT and JJT is 37%, 33% and 30%, respectively, since the first two matrices have a higher correlation with the objective value mentioned above. A bias roulette wheel as the basic selection mechanism is used for producing immigrants based on the information of JPT, JJT and FTT matrices in which a job of higher has a large chance to be selected.
The pseudocode of the trajectory-based immigration procedure and immigrant-creation procedure based on
JPT,
JJT and
FTT are described in
Procedure_TBI (seen in
Figure 5),
Procedure_JPTimm,
Procedure_JJTimm and
Procedure_FTTimm. Note that the main difference among the three procedures is that the given information to generate immigrants is different, i.e., provided by either
JPT,
JJT or
FTT matrices. Here, we only use
Procedure_JPTimm as an illustration in the following (seen in
Figure 6).
It is noted that the value of k in Procedure_ begins from 0, not 1, which is the main difference between Procedure_ and the other two procedures.
4.6. New Generation
For a subsequent generation, first, we used the elitist strategy for reproduction, where 10% of the chromosomes with higher fitness values are automatically copied to the next generation. Second, the worse 10% of chromosomes are directly replaced by new chromosomes generated by “immigration” in the next generation. Finally, 80% of the chromosomes in the next generation come from crossover/mutation. If GA has no immigration scheme, then the rates for reproduction and crossover/mutation are changed to 10% and 90%, respectively.
The pseudocode for the proposed TISGA is described in
Figure 7.
5. Computational Experiment
The A comprehensive experiments are conducted; there are 23 test problem sizes n ={5, 6, 7, 8, 9, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100, 200, 300, 400, 500}. Job processing time, release time and weights are generated uniformly on the interval [2, 15], [0, 50] and [1, 10], respectively. The maximum working time limit and maintenance time are L = {15, 30} and MT = 5. Additionally, the due date of each job was generated from a uniform distribution ], where is the average processing time of all jobs, tardiness factor TF = {0.4, 0.6} and relative range factor of the due date R = {0.4, 0.6}. Ten instances were generated for each of the eight combinations of parameter values (L, TF, R), yielding 80 instances for each value of n. Our MIP model is executed by IBM ILOG CPLEX Optimization Studio Version 12.7.1, and the proposed GA is coded in C++. All tests were conducted on a PC with an Intel Xeon E-2124 3.4 GHz CPU with 32 GB of RAM.
To examine the performance of the proposed TISGA, we also proposed a basic GA without immigration and a GA with a random immigration strategy (GARI). For a fair comparison, all versions of the proposed GAs have and 100 chromosomes for and , respectively, and their parameter settings mentioned above are the same. Each version of the GA algorithm is run five times repeatedly to obtain the best result for each instance, and the computational time limit is set to CPU seconds as the stopping criterion for each version of the GAs.
First, we aim to show the efficiency of the proposed GAs. The proposed MIP model is built to find optimal solutions for small-sized problems since the considered problem here is NP-hard.
Table 8 shows the average
TWT values (Ave
TWT) and the number of optimal solutions found by each algorithm for small-sized problems. The results obtained by the GA algorithms that are worse (higher) than those obtained by the MIP model are presented in boldface. From
Table 8, even with a small increment of
n (
n = 15), it becomes impossible for the MIP model to reach optimal solutions within a reasonable computational time, where the computational time limit for the MIP model is set to 7200 s. Additionally, the three versions of the proposed GAs are almost equivalent when comparing the average
TWT value and Nopt. Regarding the average computational time shown in
Table 9, note that the computational time limit of all versions of the GAs is the same as
seconds. This experiment demonstrates that the MIP model is very expensive regarding the computational cost when
n = 15. On the other hand, the GA performances are very reliable in finding the optimal solutions in less than 0.15 s. Therefore, this experiment justified that the development of GAs can reduce the computational effort without seriously losing solution quality.
Recall that the MIP model cannot find all optimal solutions within 7200 s, and the basic GA becomes slightly worse on solution quality when n = 15. Thus, we further investigate the performances of different GAs for large-sized problems in the second experiment. Please note that the computational time limits of the GAs are the same, i.e., seconds, for each n. For comparison, we apply the relative percentage deviation (RPD) of each instance computed as follows.
, where
Min is the lowest
TWT value for a given instance obtained by any of the GA algorithms, and
TWT(A) is the
TWT value obtained for a given algorithm and instance. AveRPD refers to Average RPD.
Table 10 shows the AveRPD and the total number of best solutions (Nbest) obtained by each GA. As depicted in the table, GARI finds slightly better solutions than the basic GA; that is, 1.937% is obtained by GARI, while the basic GA gives a mean AveRPD value of 2.341%. Overall, TISGA significantly outperforms GARI and basic GA because the total number of best solutions obtained by the proposed TISGA is 1269, 136 for basic GA, and 156 for GARI among 1280 instances. The results support our inference that GAs maintain the diversity level of the population through immigration strategy to achieve a better quality of solutions. Furthermore, the proposed trajectory-based immigration strategy enhances the effectiveness of the GA method more than the random immigration strategy.
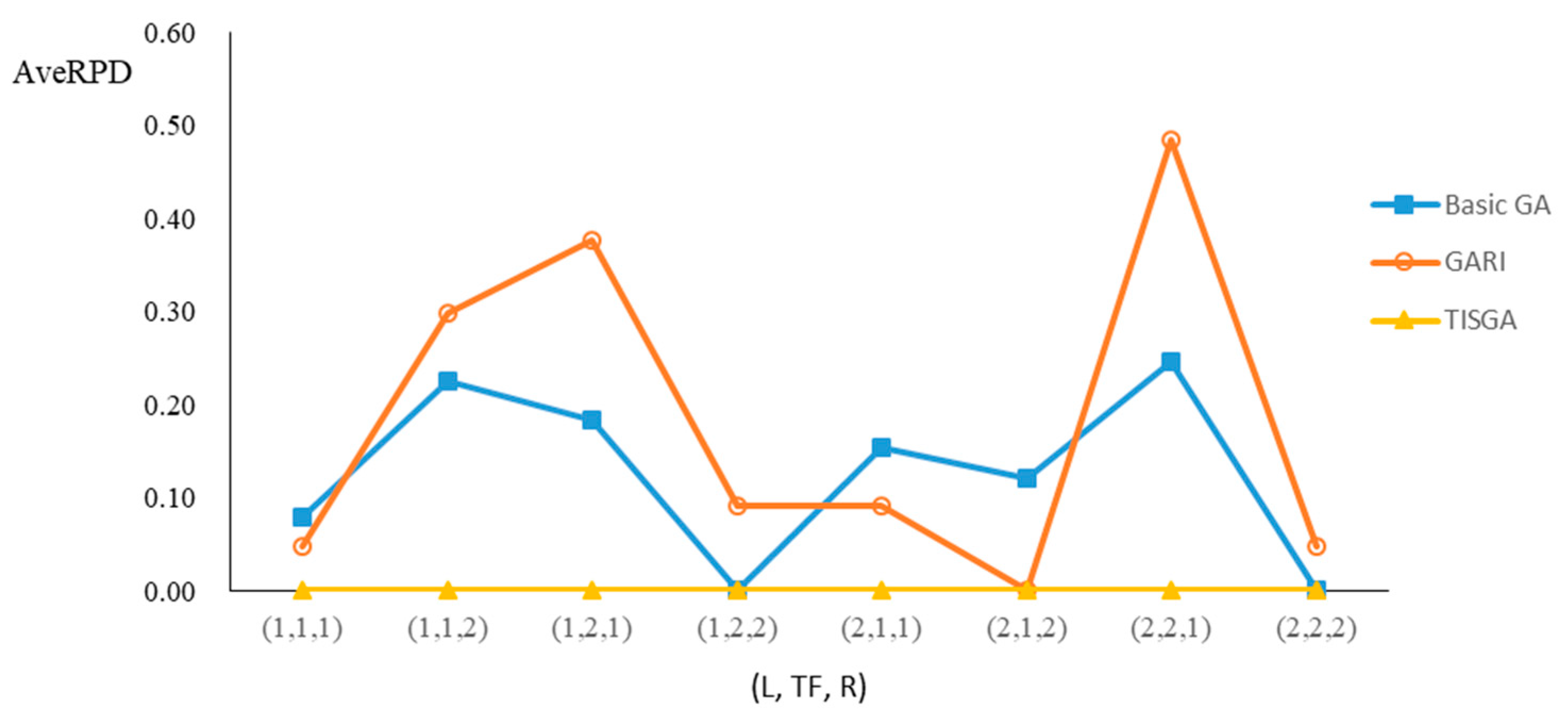
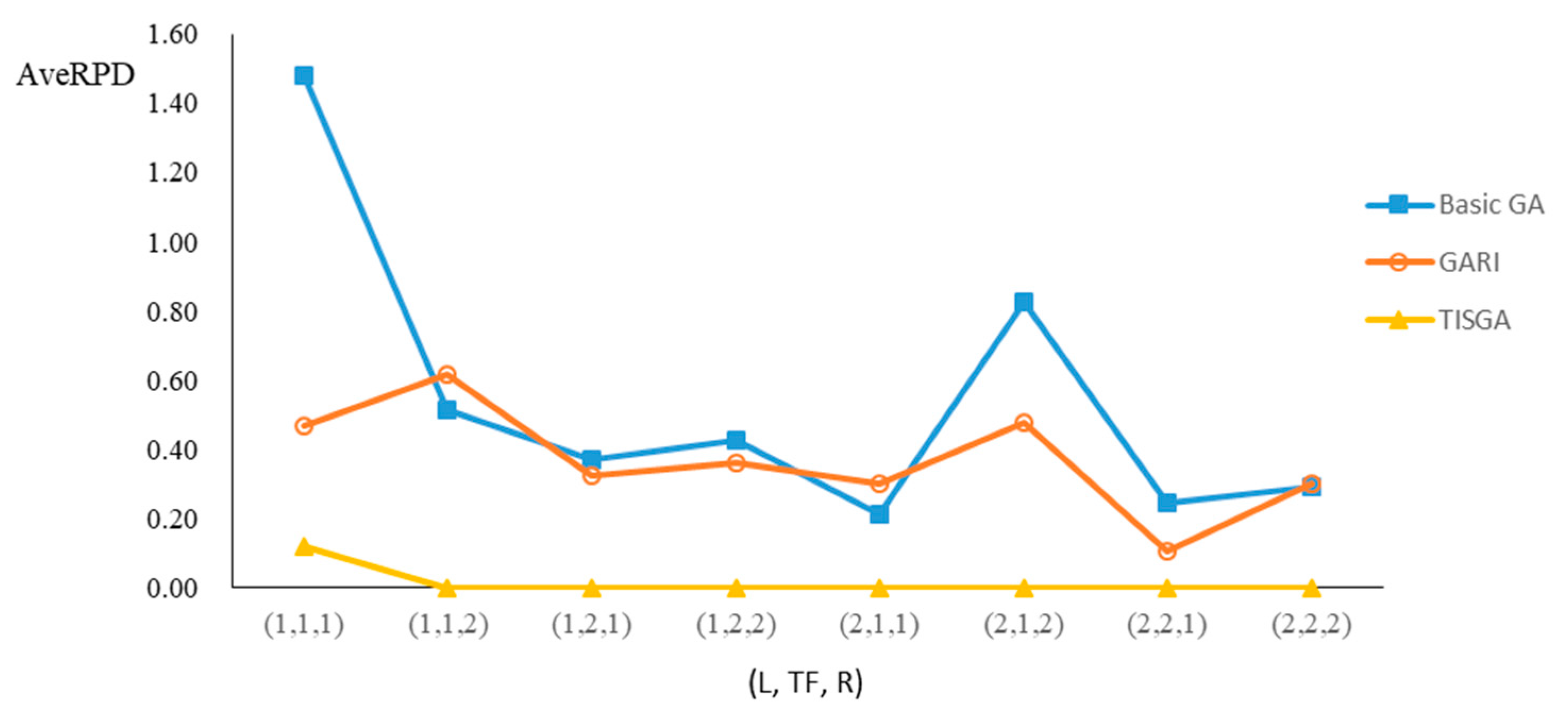
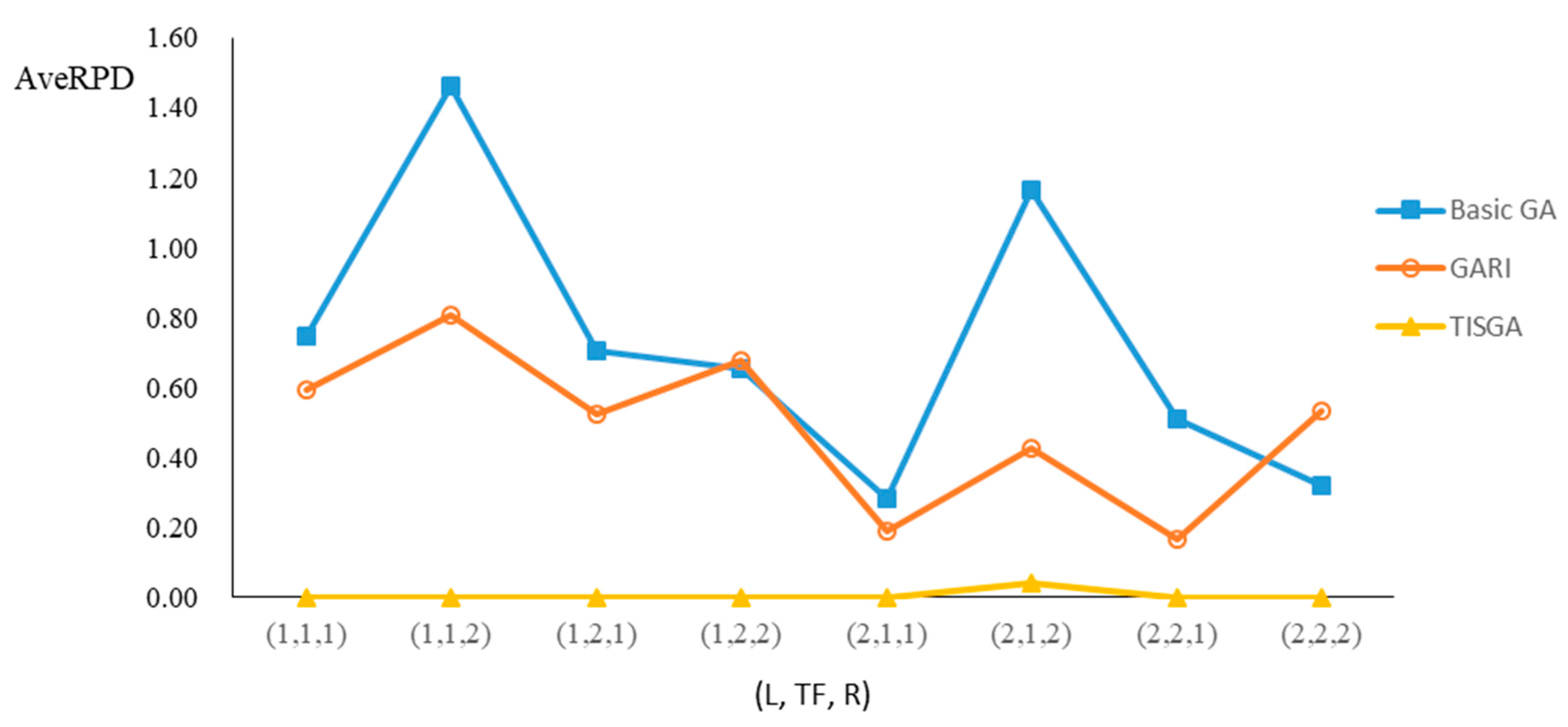
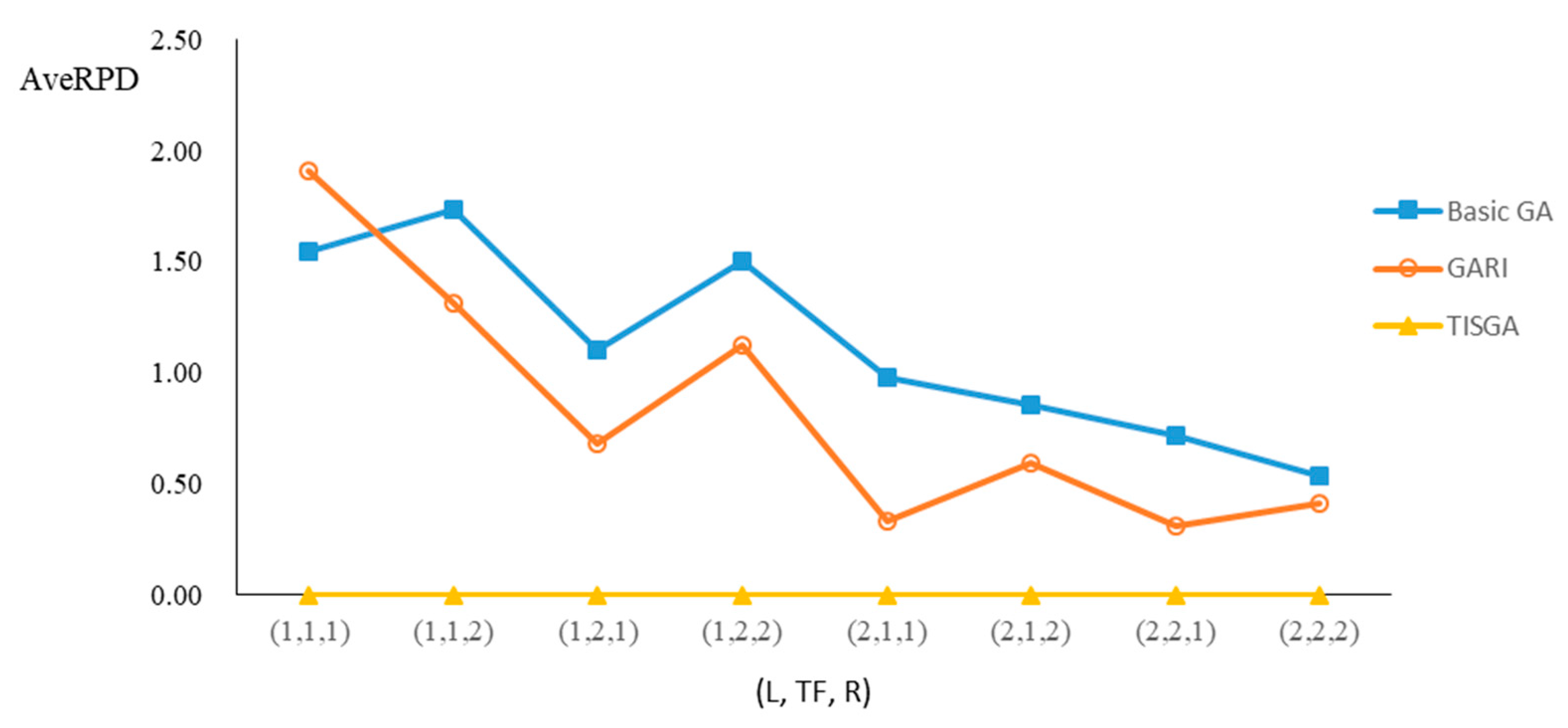
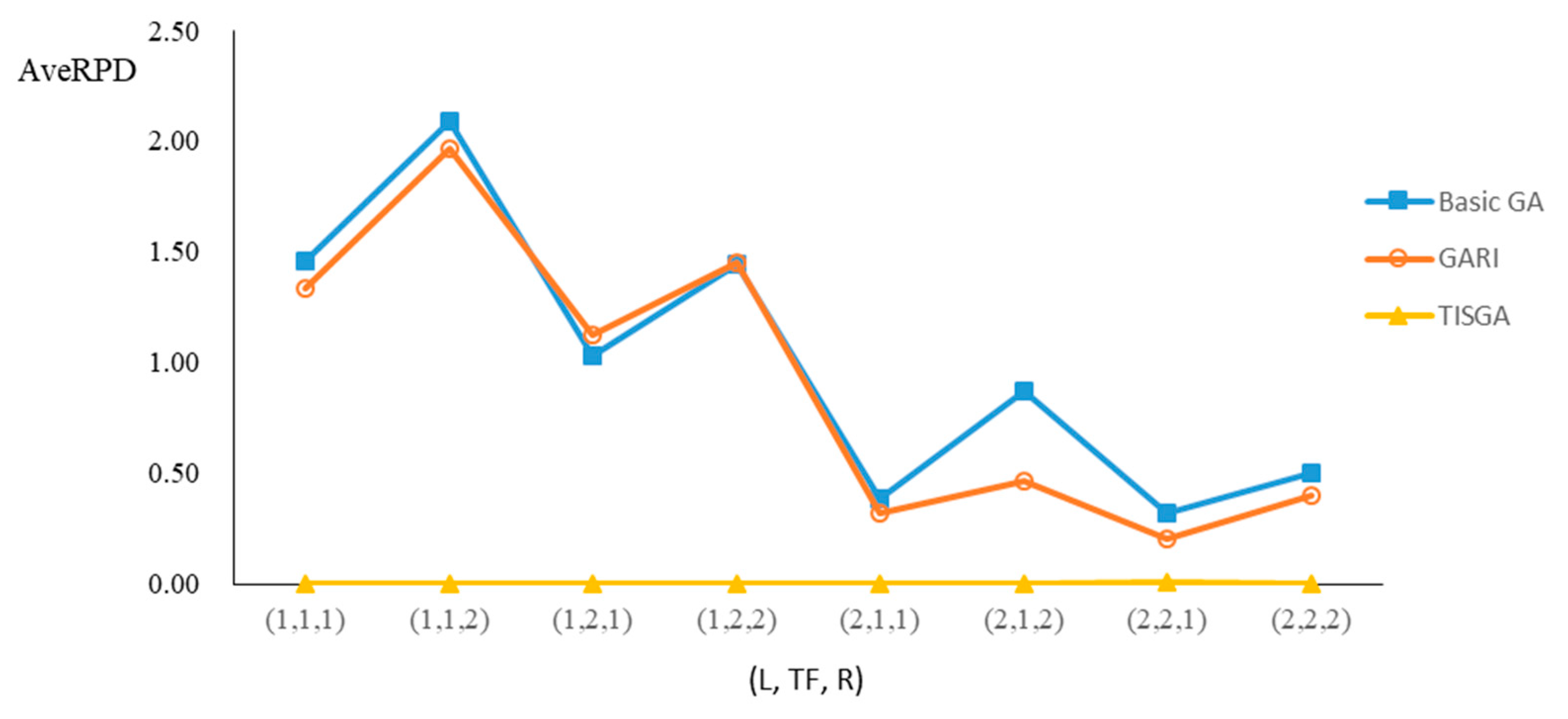
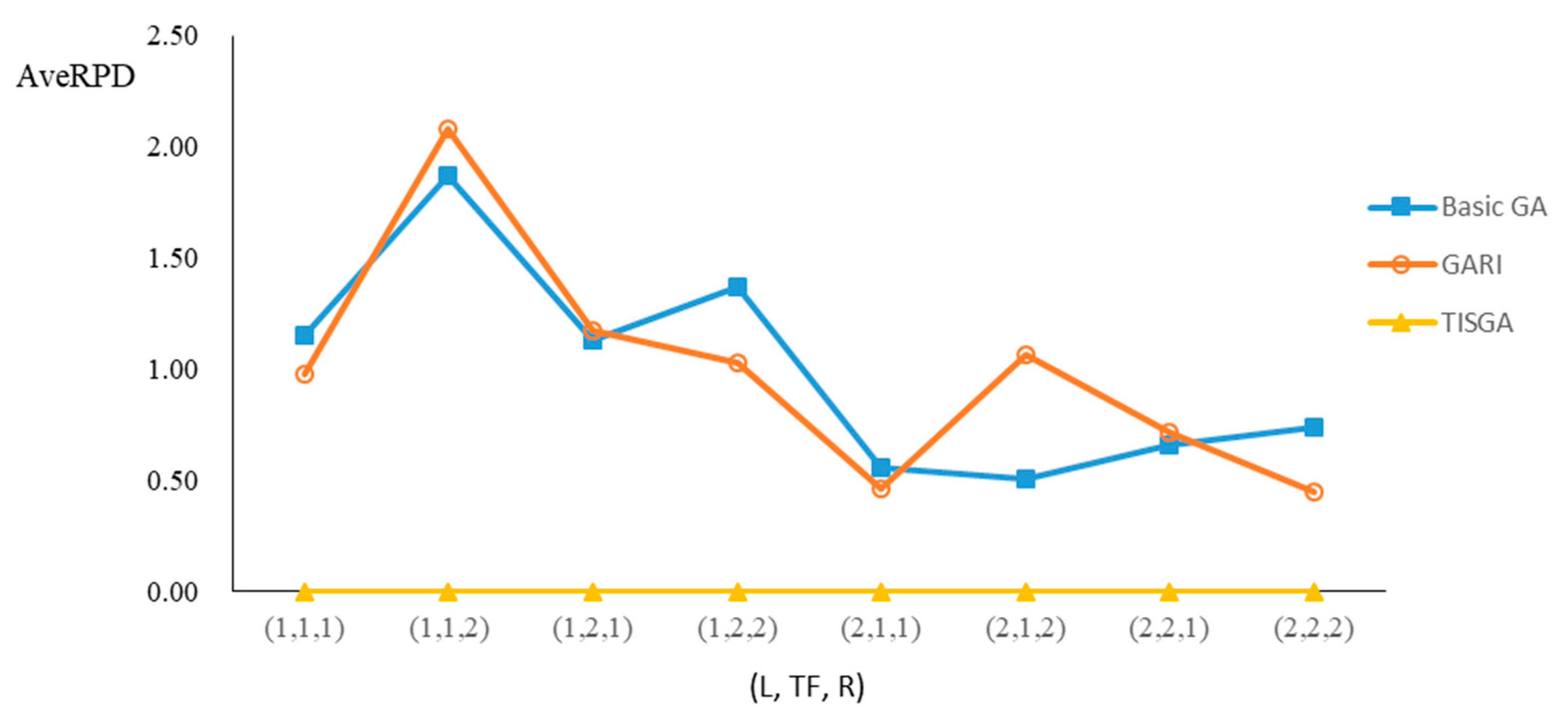
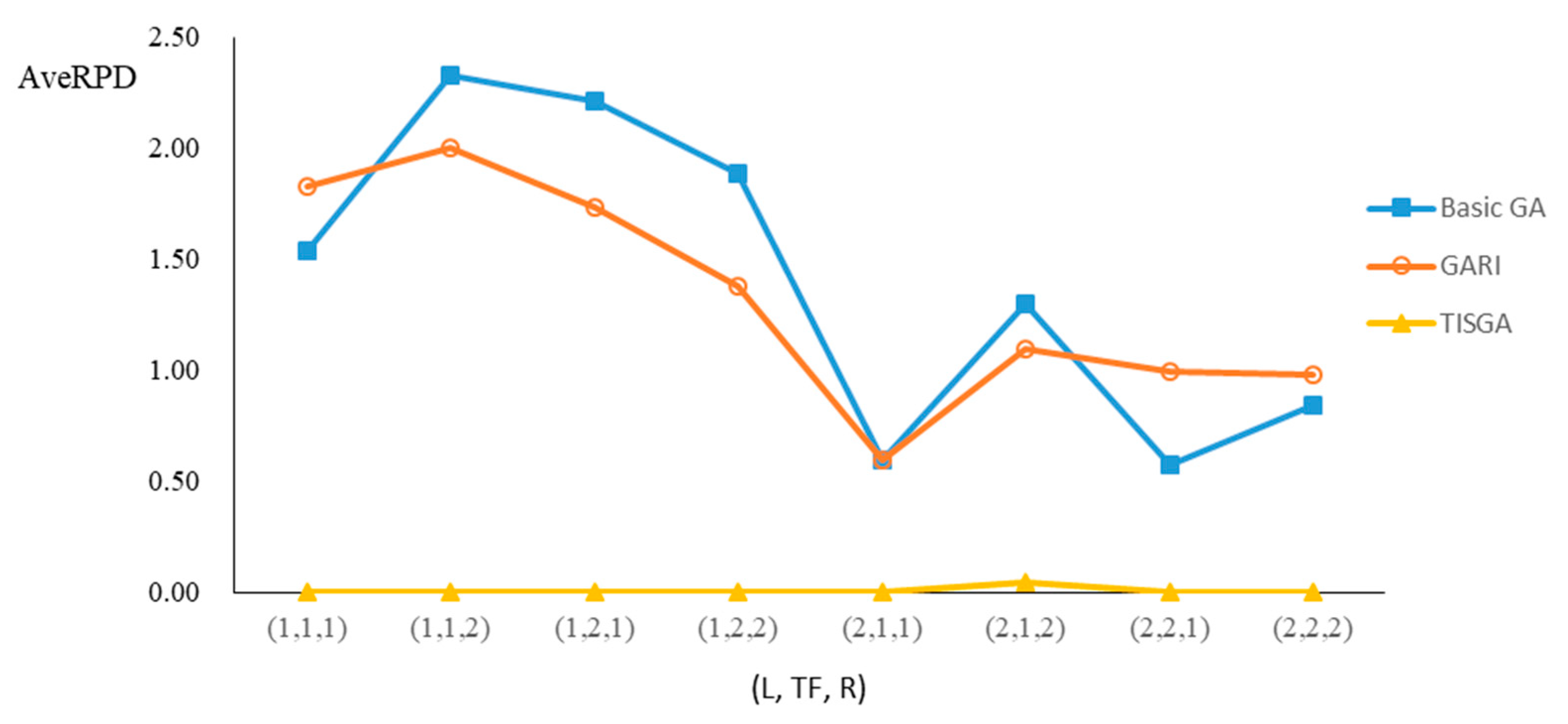
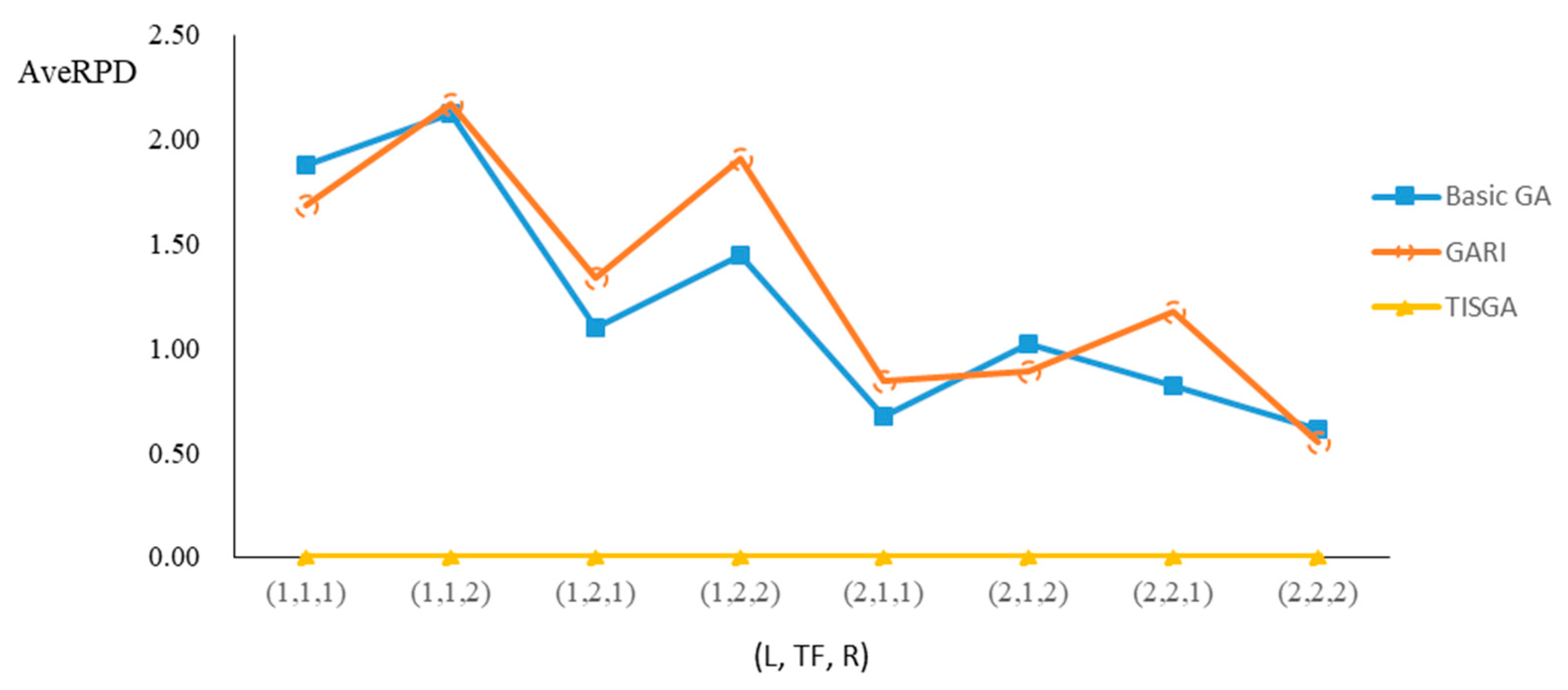
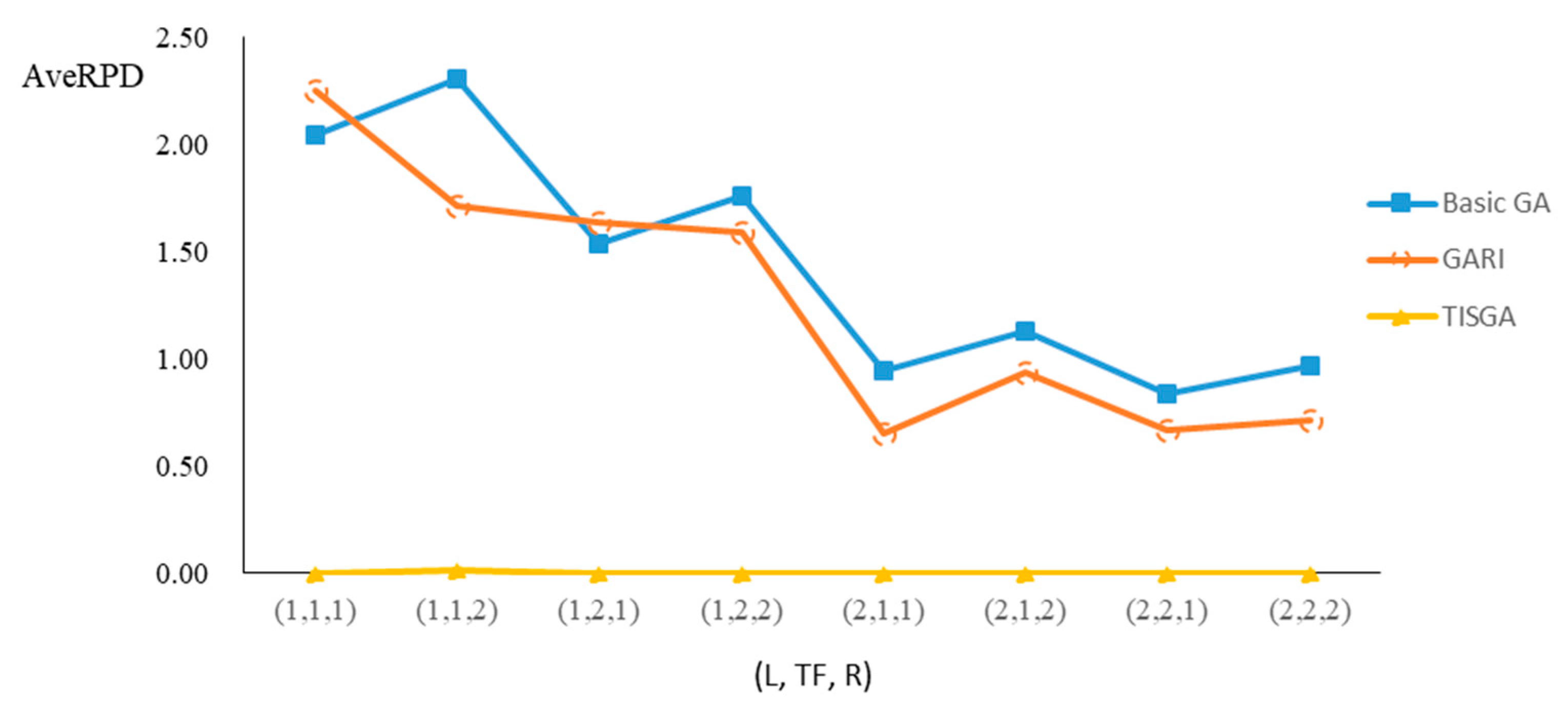
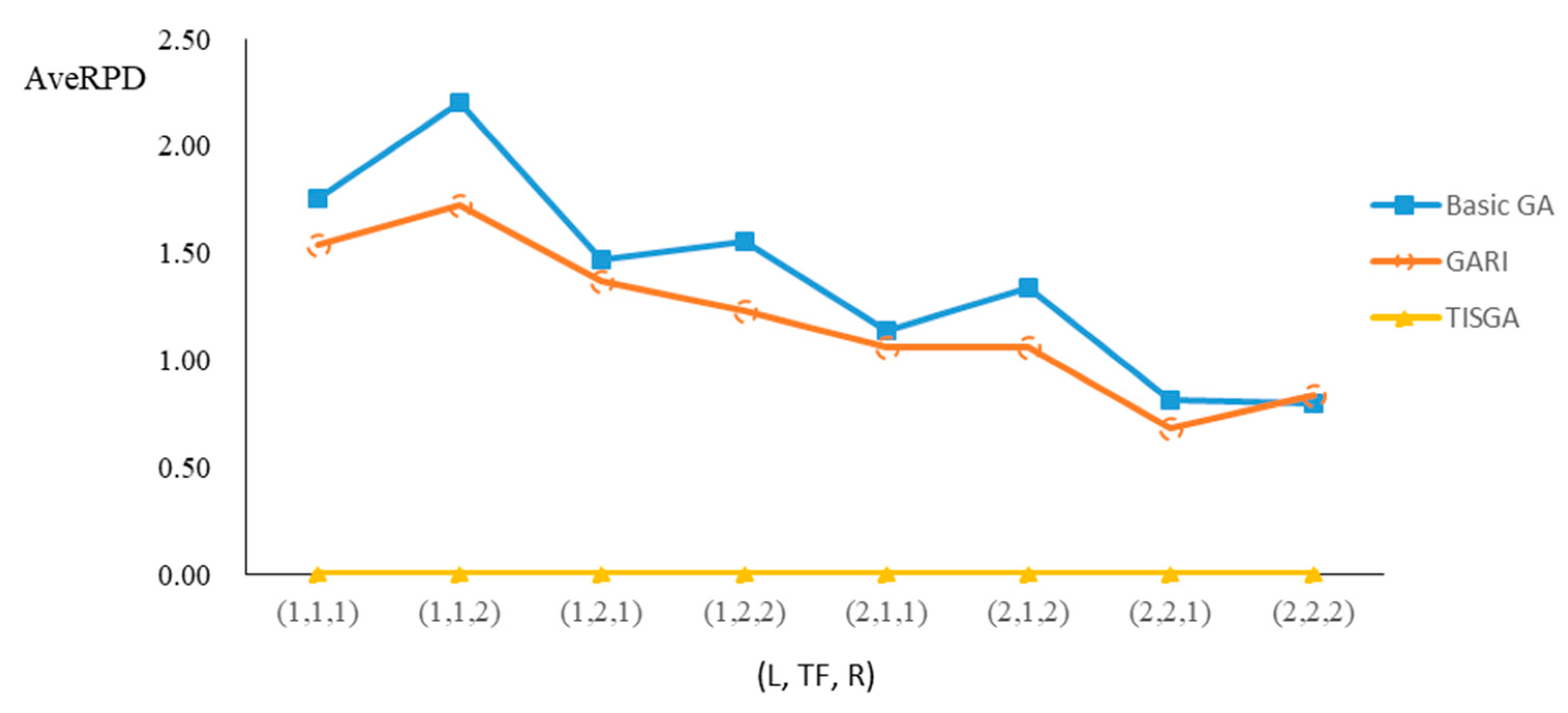
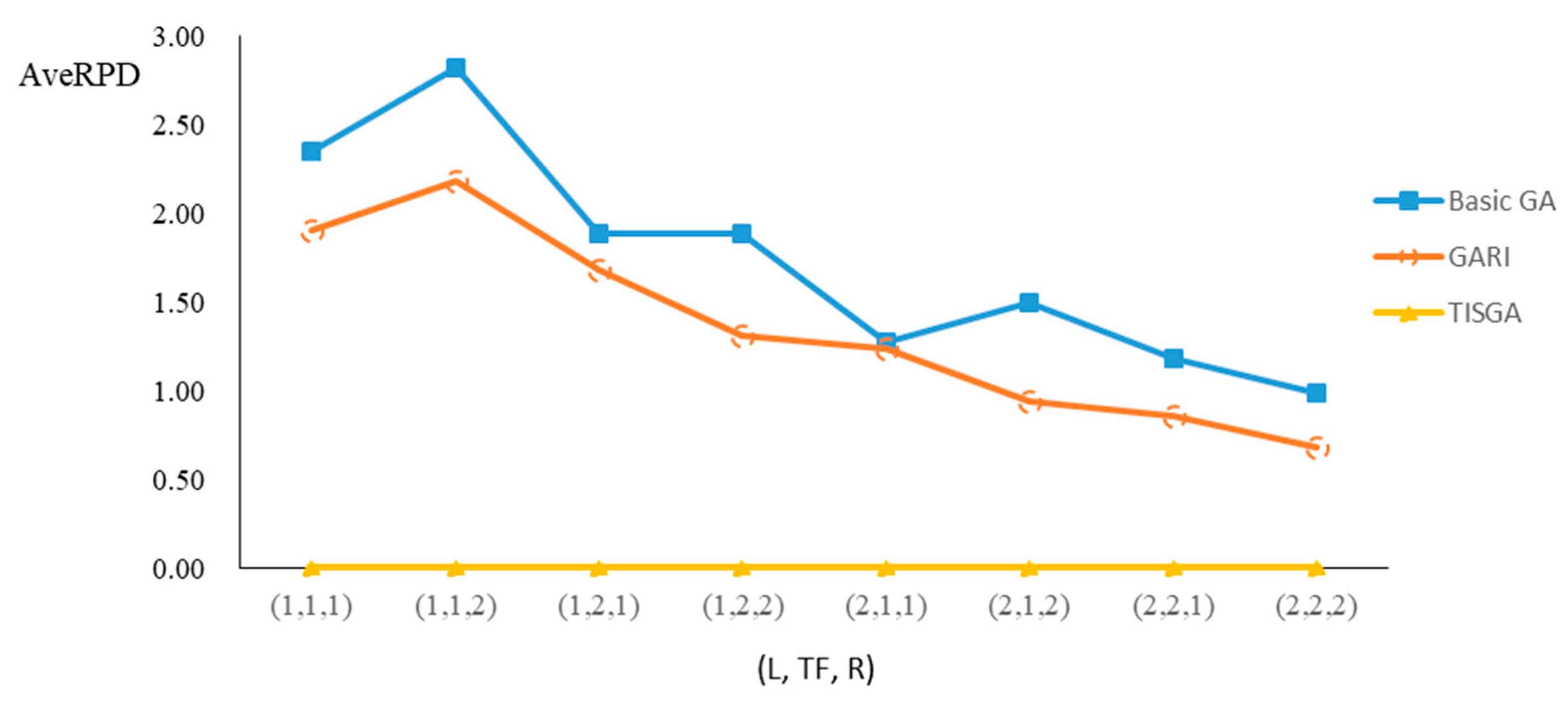
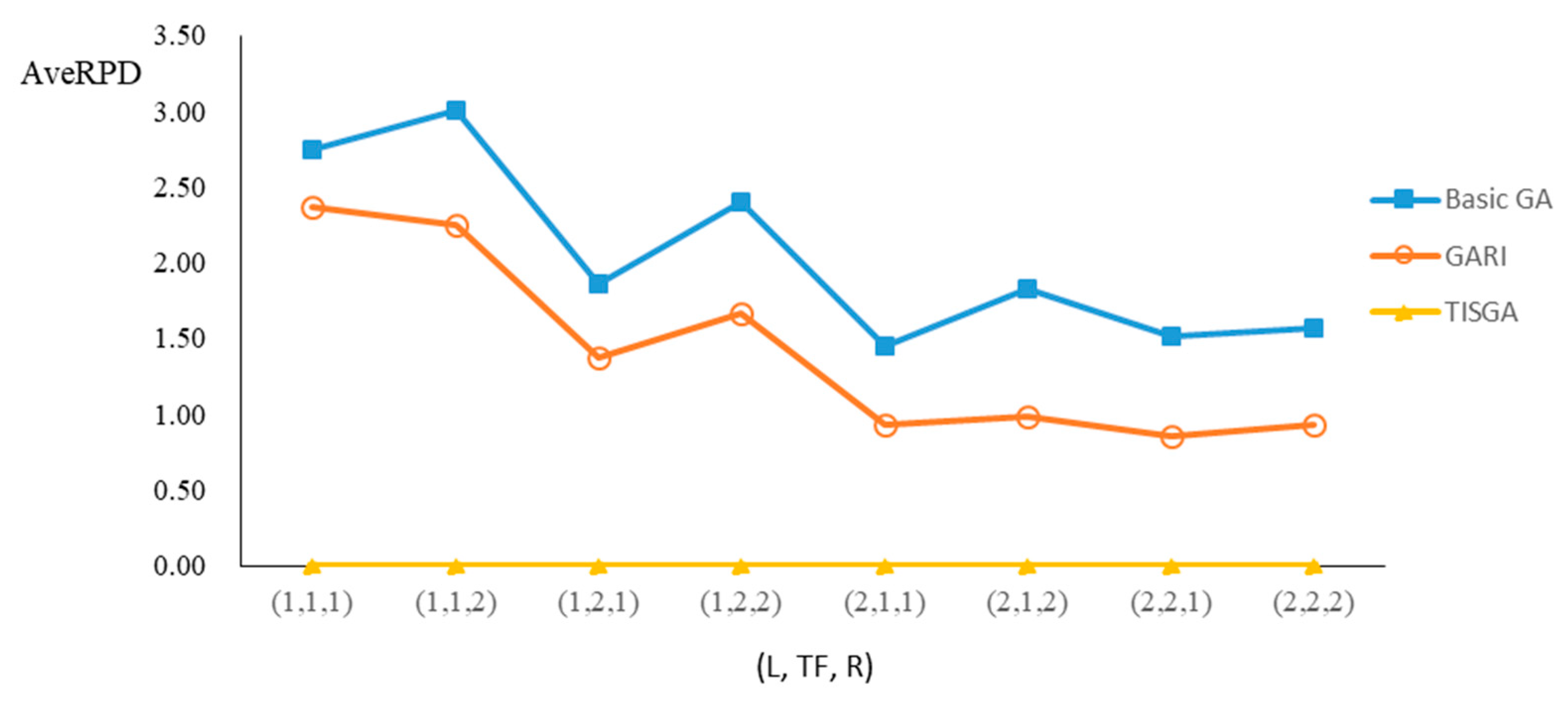
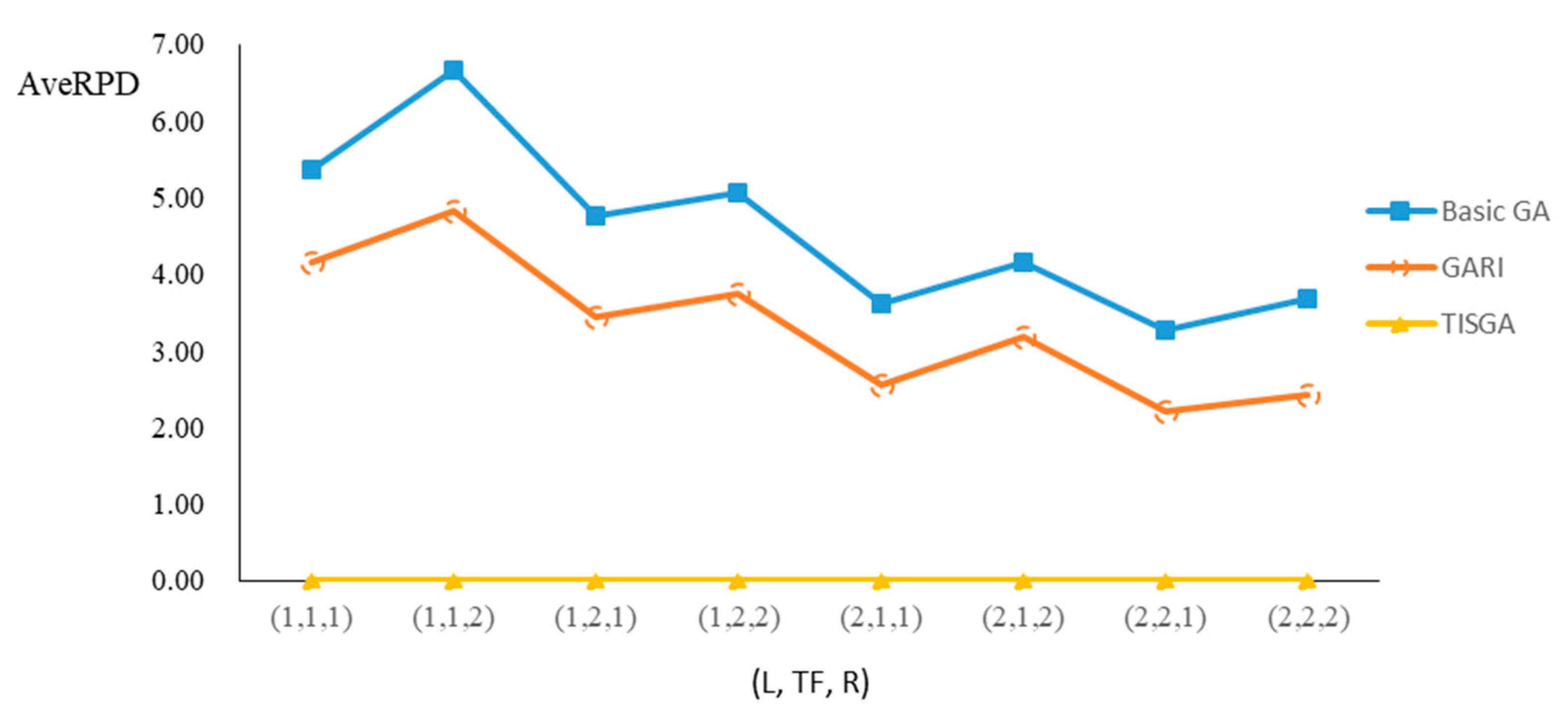
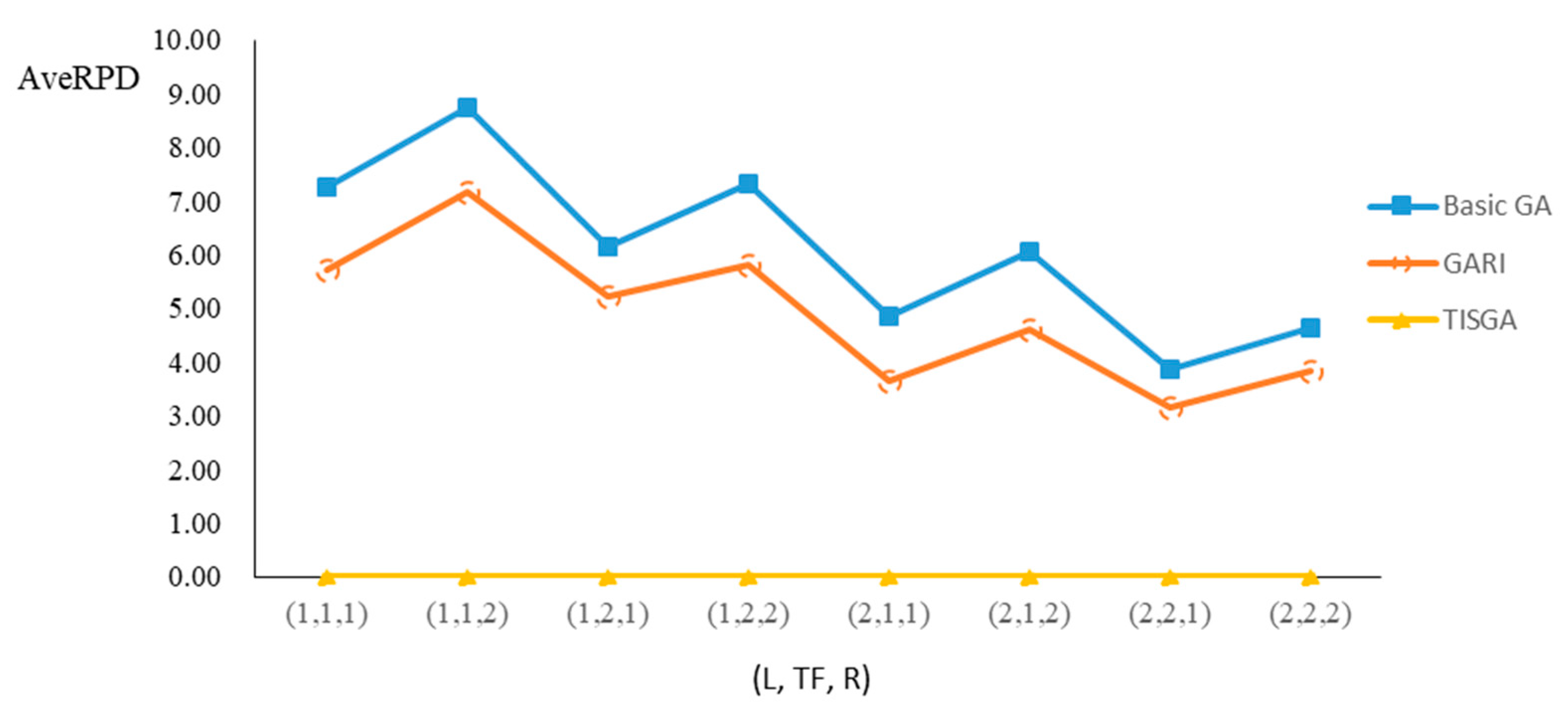
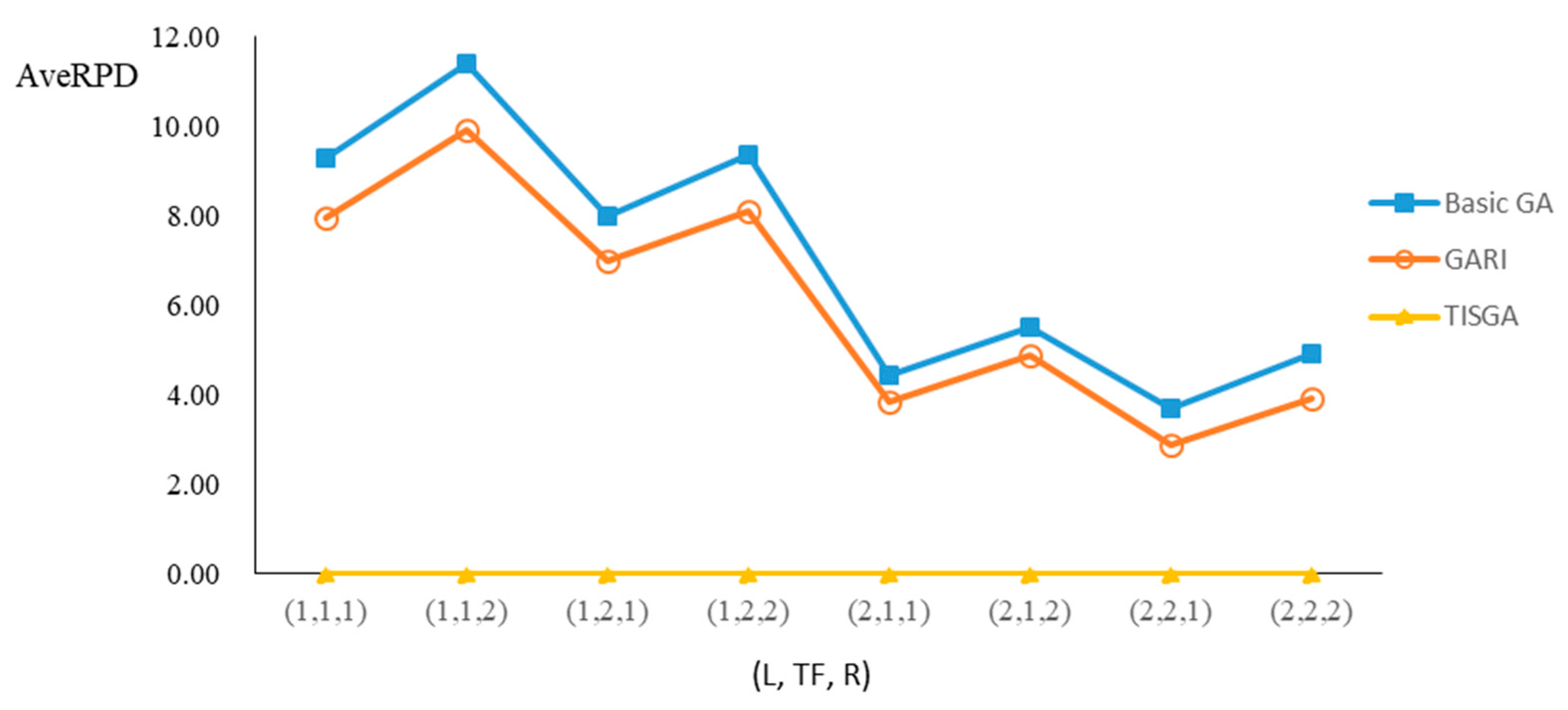
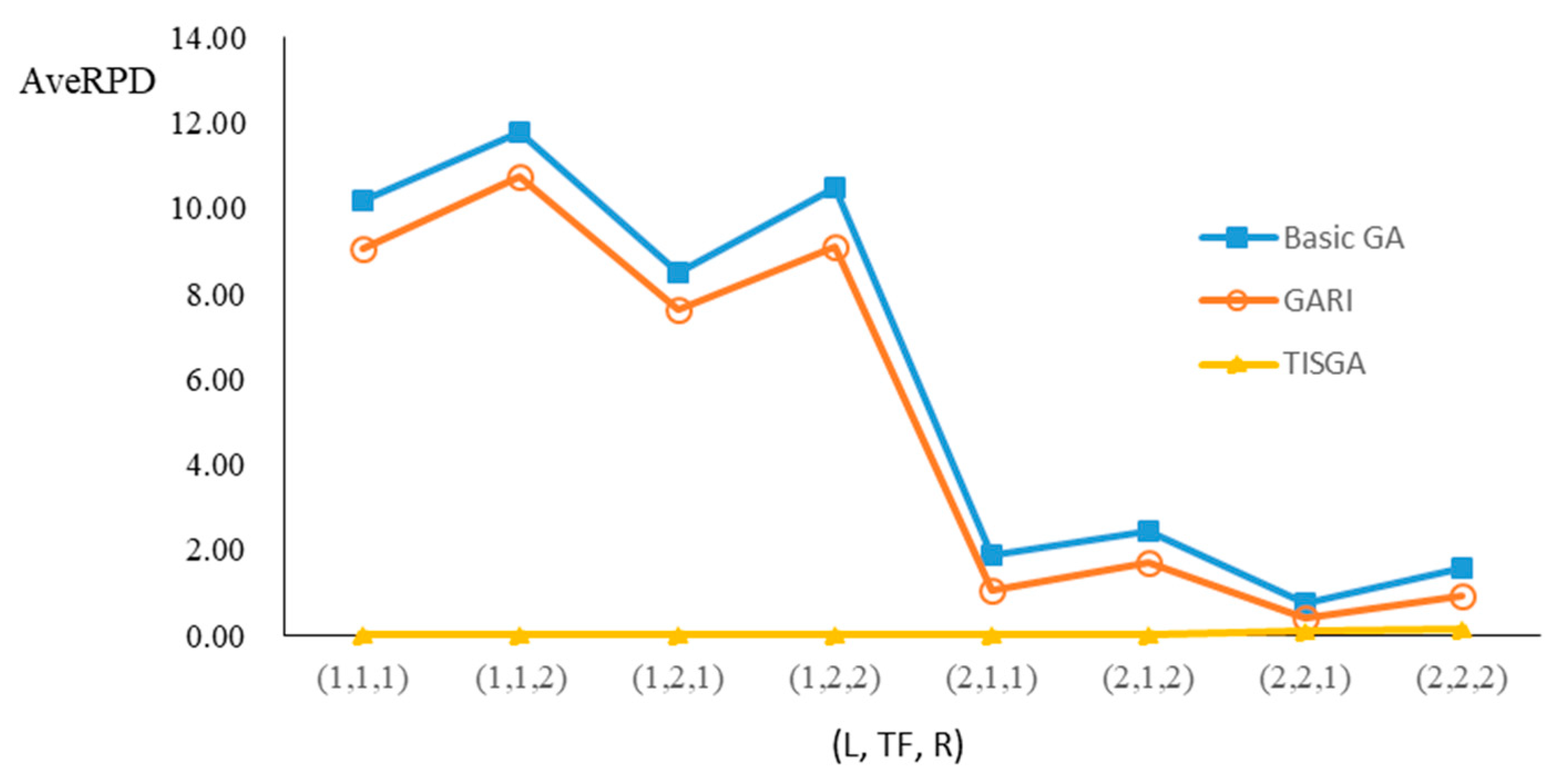
We also examined the performance of GAs under different combinations of (L, TF, R) for each problem.
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17,
Figure 18,
Figure 19,
Figure 20,
Figure 21,
Figure 22 and
Figure 23 illustrate the comparison results under eight combinations of (L, TF, R) for large-sized problems. From these figures, in some cases, GARI is worse than the basic GA; that is, the performances of GARI and the basic GA are influenced by the values of (L, TF, R). However, as the number of jobs increases, GARI becomes gradually better than the basic GA for any combination of (L, TF, R) because adding randomly generated immigrants helps increase the diversity of solutions for the GA method, especially for larger job sizes. The proposed TISGA overcomes the influence of combinations of (L, TF, R) on solutions and is robust in obtaining better solutions.
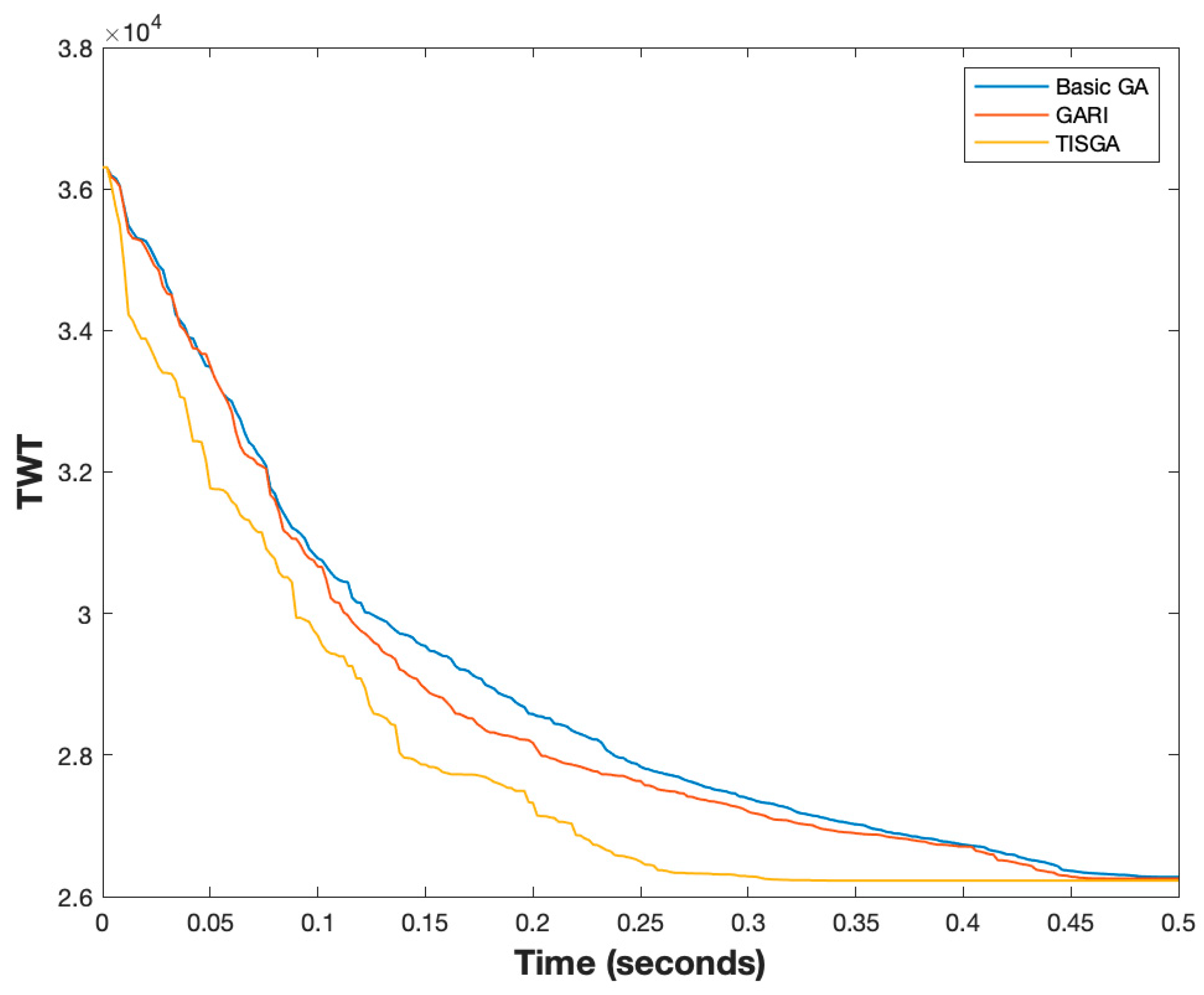
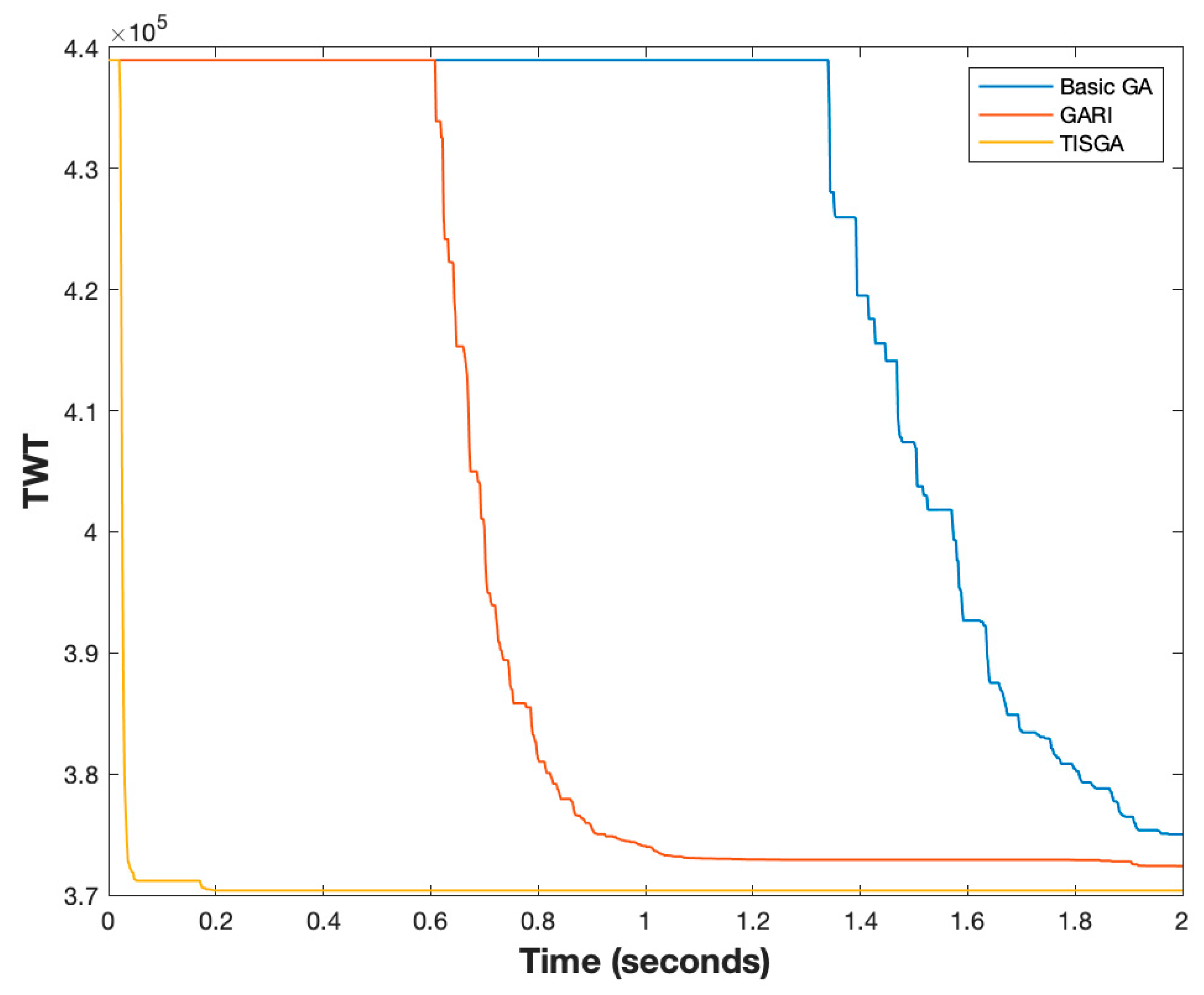
Better convergence is another important topic for designing a good GA method. Thus, we compared the convergence of the basic GA, GARI and TISGA using instances with
n = 50 and
n = 200, respectively, as shown in
Figure 21 and
Figure 22. From
Figure 24 and
Figure 25, the convergence speed in TISGA is highest among GARI and the basic GA, and the solutions obtained by TISGA require less computation time than those required by GARI and the basic GA. Through these experimental results, we conclude that coupling a GA with the trajectory-based immigration scheme accelerates the convergence speed and significantly improves the performance of the basic GA.
7. Conclusions
In this paper, we have addressed the single-machine scheduling problem with job release time and flexible preventive maintenance to minimize TWT. To the best of our knowledge, this problem with the TWT objective has not yet been addressed in the literature. For this problem, some JPT, JJT and FTT matrices are established based on the concept of the experience-driven knowledge scheme. Equipped with these matrices, we proposed a GA coupled with a trajectory-based immigration strategy, called TISGA, to generate immigrants to maintain the population diversity of a GA.
To examine the performance of TISGA, we formulated a MIP model and two GAs; one is the basic GA without an immigration strategy, and the other is GARI with a randomly generated immigration strategy. For small-sized problems, GARI and TISGA exhibited the same performances in terms of AveTWT and Nopt as compared to the MIP model. For large-sized problems, 1269 of the 1280 (99.14%) best solutions were found by TISGA, and then 12.18% and 10.63% were obtained by GARI and the basic GA, respectively. The results showed that TISGA outperformed the GARI and basic GA methods. Furthermore, our TISGA showed robust performance with respect to different values of (L, TF, R). More specifically, the results have shown that embedding the proposed trajectory-based immigration strategy in a GA has been enough to obtain excellent solutions for the problem under consideration. Consequently, further research could come in developing more efficient and advanced metaheuristics, successfully adapting the concept of an experience-driven knowledge scheme. Additionally, other potential extensions of this study, including parallel machines, job shops and sequence-dependent setup times, can be made for future research.




{kind=link}
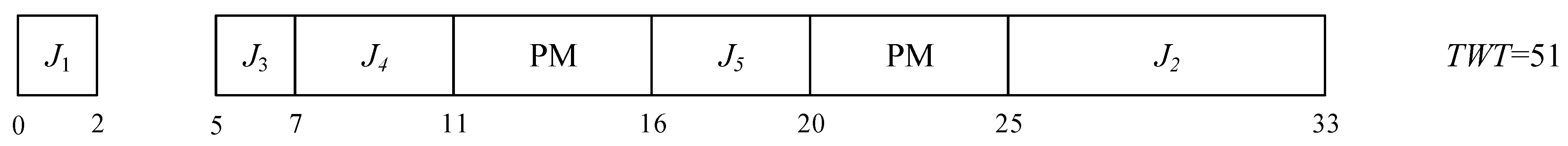{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
























