3.1. Proposed Stranded-NN Model
The authors proposed a new NN model for detecting semi-critical or critical machinery errors during operation. The proposed stranded-NN model includes a series of different NN strands (different neural networks of arbitrary depth). Each strand comprises a set of NN layers with layer depth depending on the input and specific rules. The data input of the model is a time series of sensory measurement data. The data output of the model is a set of classes that determine the criticality of the event. Our proposed model was constructed using the tensorflow keras framework [
43,
44].
Let us assume an
m number of time-series sensory machinery measurements. Given model input as a 1D array of
, where measurements are from different sensors of a specific machinery location or operation,
, where
. All measurements are entered as a chronological order stream. The stranded-NN is structured from different neural network sub-models, each capable of accepting a specific data input size of batch size
. The following equation determines each model strand depth of hidden layers
q:
where
corresponds to taking the integer part of the value
x and
m is the number of sensory batch observations. If the number of intervals collected measurements
, then the instantiated NN-strand for this case is a model of two hidden layers
of 64 and 16 perceptrons accordingly. For probing intervals of more than 32 measurements, the strand depth of
q hidden layers is according to Equation (
1). The number of neurons
per
ith layer is defined as
neurons/layer. The sum of trainable parameters
p, for each strand, is defined by Equation (
2).
where
q is the total number of hidden layers calculated by Equation (
1), and
, signifying the number of perceptrons of the first hidden layer. The input batches of each NN-strand enter its first hidden layer with the maximum number of perceptrons, and as they progress layer by layer, the number of neurons per layer is reduced by a power of two. The minimum number of neurons at the last hidden layer is always
. That means that the maximum number of classes
that can be introduced per strand can be no more than 16. For the NN-strand neurons, the ReLU activation function is used, and the soft-max activation function’s output layer applies for the detection class selection.
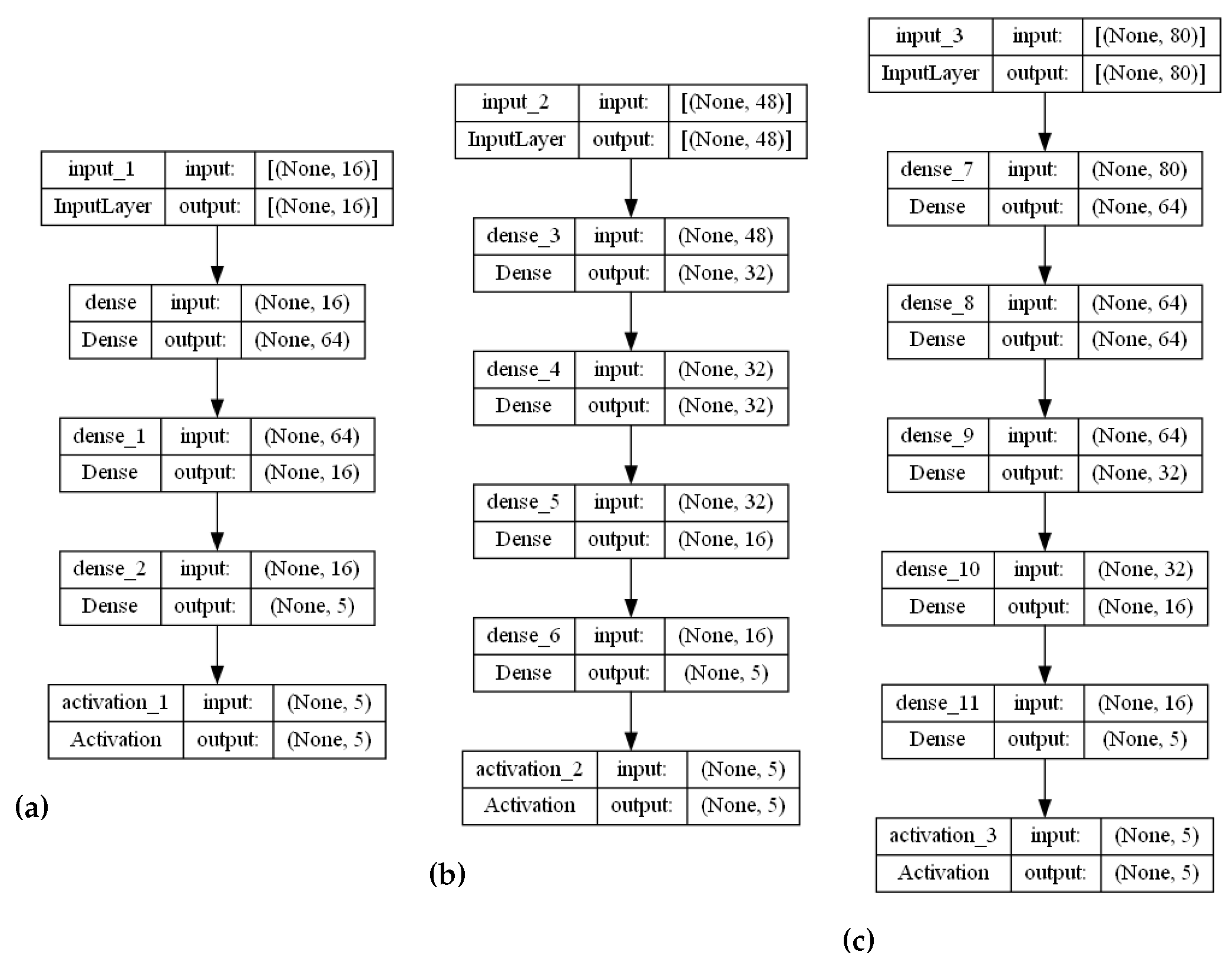
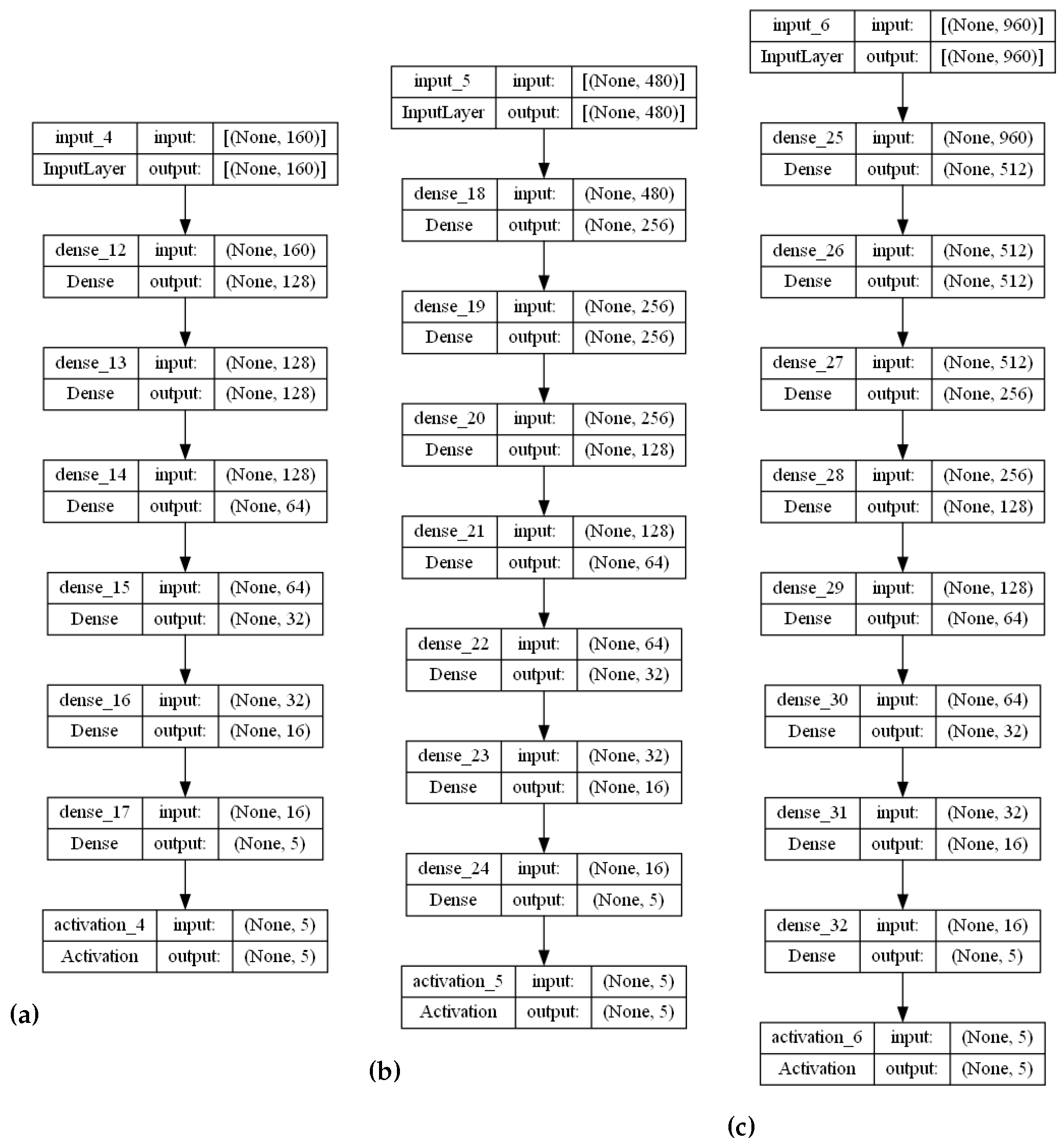
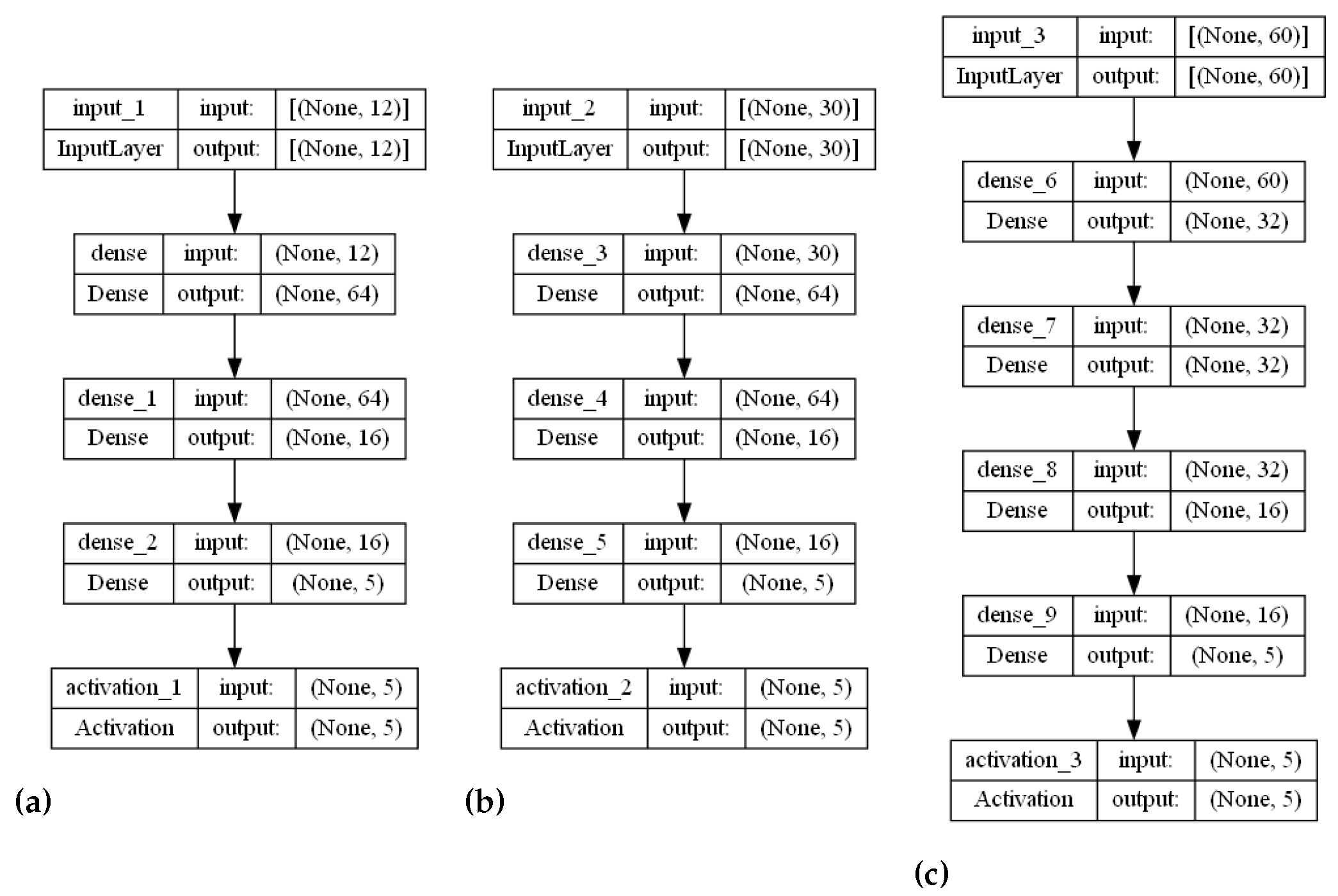
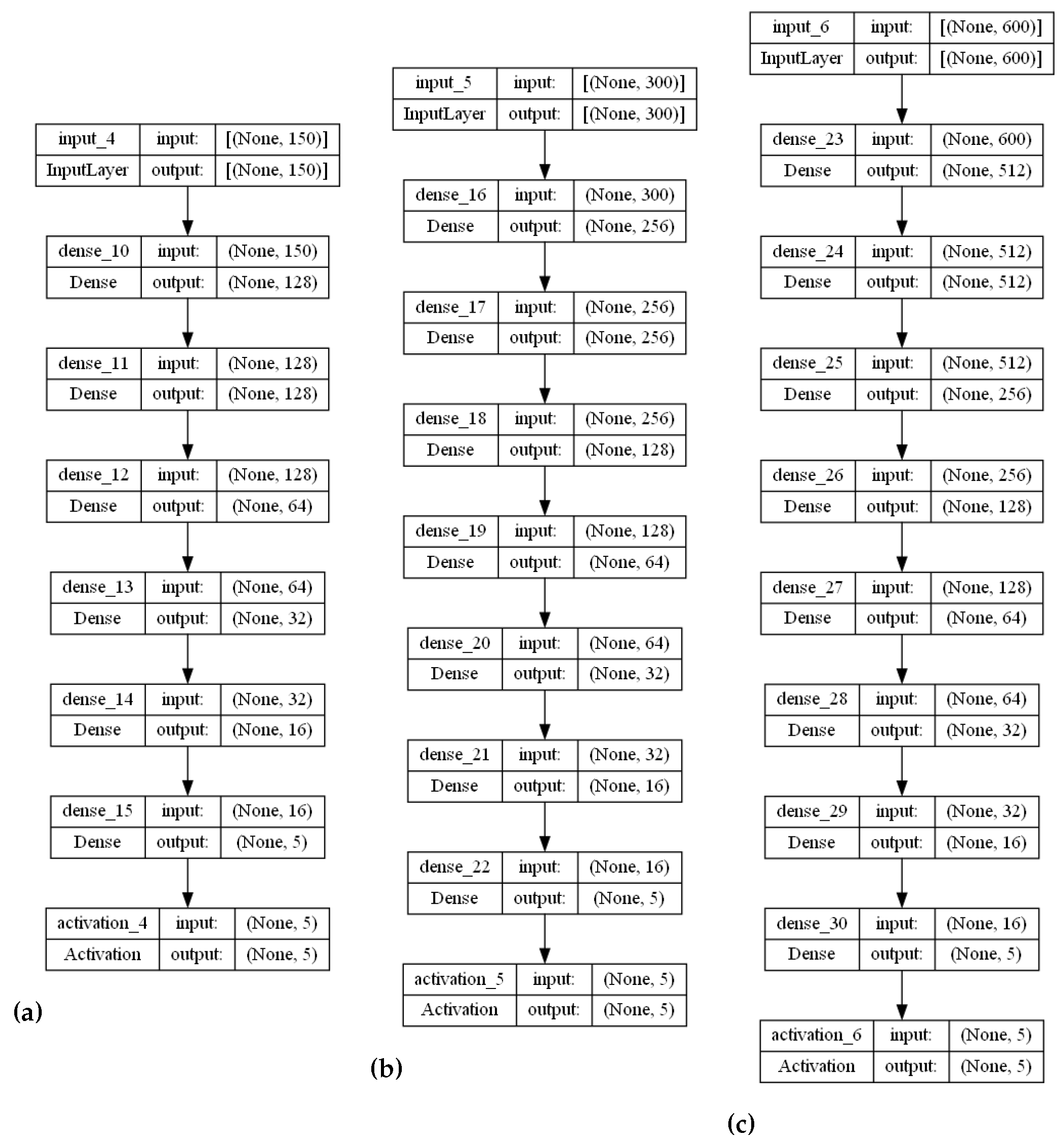
The stranded-NN model accepts different time series sensory measurements over time (m) as input. Then, according to the m value, it automatically generates fully-connected hidden layers of perceptrons. For example, let us assume that a piece of monitoring equipment has a set of temperature sensors, transmitting data every s. In order to perform real-time malfunction detection every min, a time series of sensory measurements needs to be created to form a measurement data input batch of measurement values. This batch of measurements needs to be annotated to an operational class. For the input value of , the stranded-NN algorithm generates a model of three hidden layers (, where 64, 32, 16 is the number of perceptrons for each layer. Then, the last layer is connected, collecting for the classification output i classes layer. For close-to-real-time detection of 10 min intervals, a batch of the total size of measurements data needs to be annotated (classified). For this batch input, the stranded-NN algorithm generates a model of five hidden layers , where 256, 128, 64, 32, 16 is the number of perceptrons per layer accordingly. In real-time cases where the number of monitoring equipment sensors is limited (for example, temperature sensors), small batch values (for example, ) are used. The stranded-NN algorithm cannot generate enough hidden layers for such small values. That is why a threshold value of was added in order for the stranded-NN algorithm to be able to generate at least a two hidden layer model () of 64 and 16 perceptrons per layer accordingly.
In order to eliminate degraded gradients, L1 regularization is performed over the cross entropy loss function in each hidden layer, according to Equation (
3):
where
is the modified loss function for the NN layer,
N is the number of samples,
K is the number of detection classes,
is the indicator value that the sample
n belongs to class
i,
is the probability that the strand associates the
nth input with class
i, and
is the sum of the layer absolute weight values. Parameter
is set to
as derived by experimentation for all model strands.
Table 1 summarizes the hyperparameters accessible for each strand and their tuned values.
To eliminate over-fitting issues, especially for datasets with a limited number of batch data, dropout layers can be introduced among layers as follows:
For even numbers of q, a dropout layer can be inserted after every even layer depth;
For odd numbers of q, a dropout layer can be inserted after every odd layer depth after the first hidden layer.
The use of dropout layers for the model is not obligatory. Nevertheless, in cases of over-fitting, dropouts can be set uniformly across all strands of the stranded-NN network if requested. The drop probability of each layer can be determined via fine-tuning experimentation to minimize catastrophic drops. As a guideline from the authors’ experimentation, the drop probability may be a randomly set value per layer between 0.05 and 0.1. For values above 0.1, significant losses and accuracy degradation were observed. The stranded-NN model can be used with or without including dropout layers. For big data input cases, the use of dropouts is not recommended.
To limit the number of constructed layers, as the value of batch measurements m increases, a layer limit was set, such as . The value of measurements per input batch was set as a measurements’ threshold value to cover even the cases of periodic checks. Nevertheless, it is considered a hyper-parameter by the stranded model. It can be altered if more frequent sensory probing is performed (less than 10 s) or a big set of sensory observations is collected per machinery asset (more than 128 observations per real-time interval).
During the per-strand training process of the stranded-NN model, the Adam solver was used with the categorical cross entropy as a loss function. The learning rate parameter , which defines the per-strand weight adjustments over the loss function, was initially set to for all model strands. If, while training, the strand validation loss decreases between epochs, then the is decreased by a learning rate decrease factor . This is performed until the parameter reaches the value of . Below, further decreases, triggered by validation loss decays, do not contribute significantly to the NN weights.
The stranded-NN model is a collection of NN-strands, which can be used for either training or classification based on the input measurements batch size.
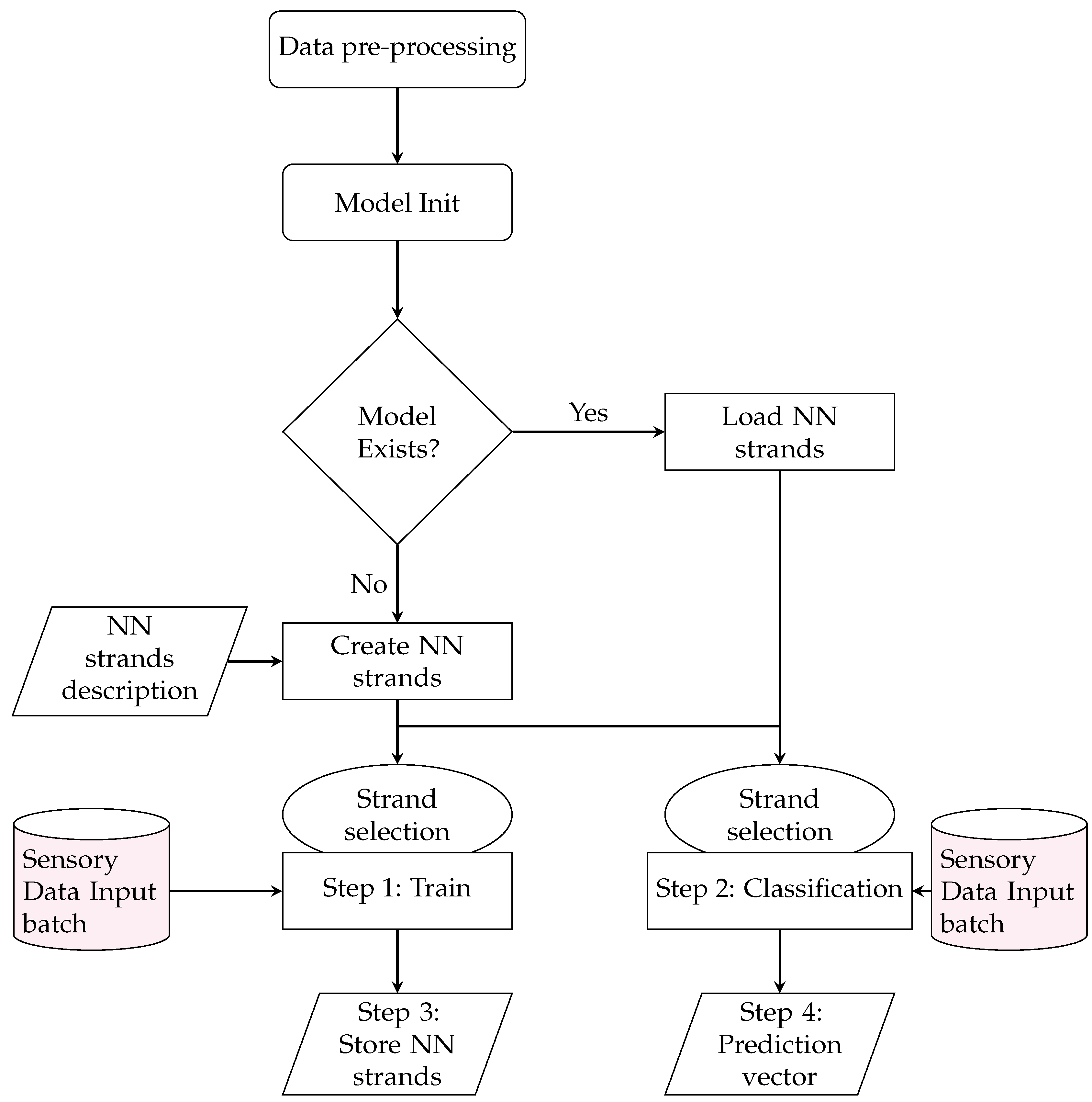
Figure 1 illustrates the stranded model training and prediction process flow. At the initialization of the NN strands, the description configuration file is parsed, and the initial NN strands are generated and attached to the model. Upon first strand creation, the model is stored with initial weights using a separate model file per NN strand using the HDF5 data format. Upon successful model storage, the model select command can select a specific NN strand of specified data input and model depth. The stranded-NN algorithmic process includes the following steps for both models training and predictions:
Data Preprocessing: The data pre-processing step includes arranging the data input streams to 1D arrays, where n is the corresponding model strand input (stranded model input batch size). The data pre-processing also includes transforming the annotated outputs to binary 1D vectors with sizes equal to the stranded model classes. After the pre-processing, the stranded model initialization occurs, which involves either the creation of the stranded model and its corresponding strands or the stranded model load (load of strands’ weights).
Step 1—Training: In this step, the selected strand is trained using the appropriate sensory batch as data input. The model uses a configurable batch size and epoch values per selected strand for the training process. The train data split ratios to validation, and testing sets are also configurable. The default value of (10% of the training dataset) was used for the validation set. The default value of (20% of the training dataset) was used for strand evaluation. The training data set input batches were also shuffled prior to training. Since the sensory measures were in chronological order for all input batches and were classified as a batch, the shuffling process did not affect the order of the time intervals (batch size) that we wanted to have a classification outcome.
Any number can be used between 20–80 epochs for the training process epochs. However, the authors selected the size of 40 epochs, 10 epochs above the learning rate reduction initialization to be considered during the training process (fine tuning of trainable parameters). Regarding the training and evaluation batch input sizes, an arbitrary number between can be selected. No significant accuracy or loss changes were detected from the batch size variations in the reported range, as reported by our experimentation.
Step 2—Classification: In this step, the classification-class selection response of the selected strand is calculated using appropriate sensory batched data as input.
Step 3—Store NN strands: Upon training, the new model strand weights are stored in the new model file in the NN-model strand directory. Additionally, the strand model evaluation results regarding loss and accuracy are stored in the stranded-NN model’s output results file.
Step 4—Prediction vector output: If requested, the predictions of the output layer can be separately stored before the appliance of the soft-max activation function. This output vector is called a regression or predictions vector. It can be used in order to have the unregulated output of the strand as an input to other algorithmic output correlation, similarity, or regression processes.
According to
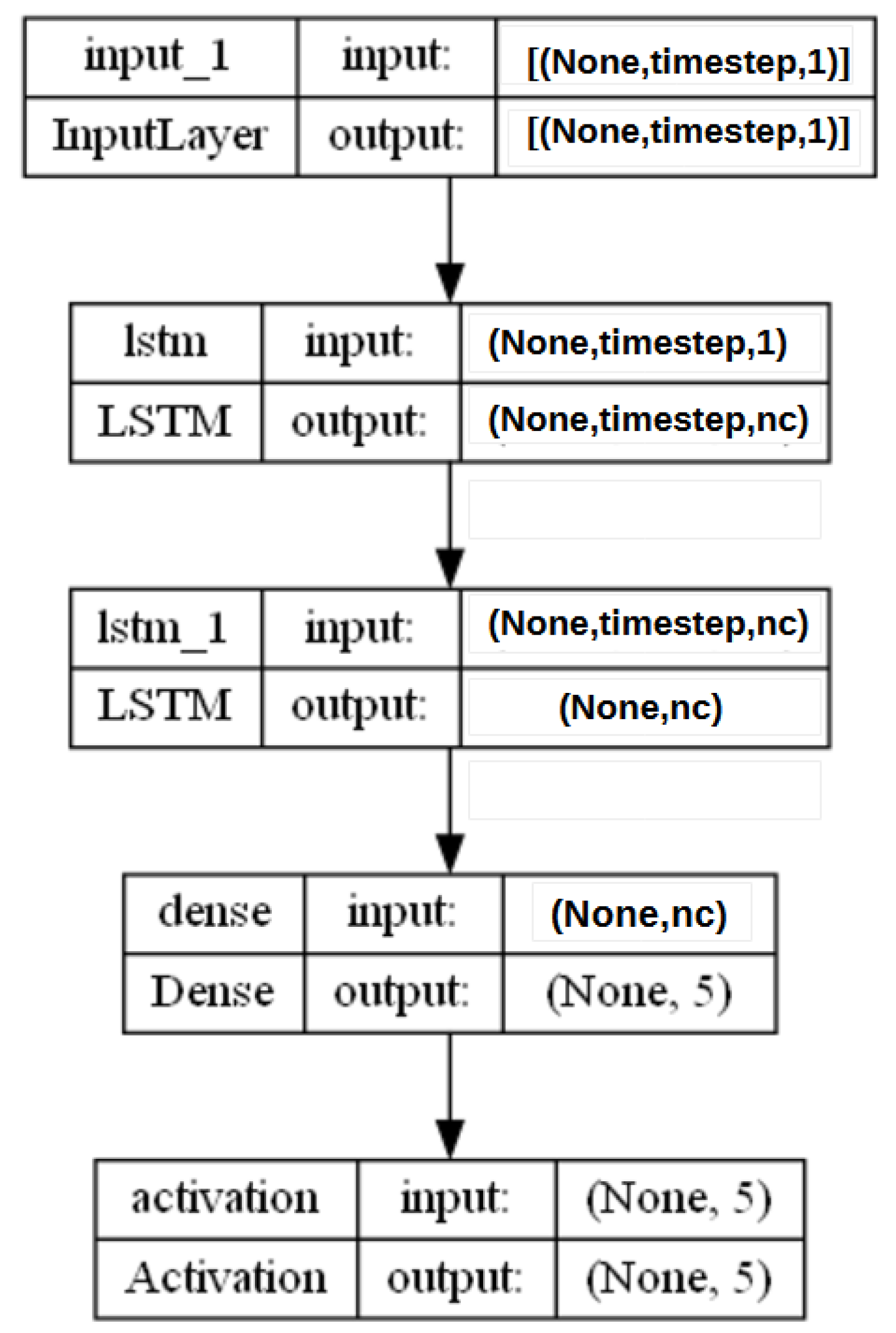
Table A1, the maximum number of trainable strand parameters is 15.3 M (4096 inputs per time interval), and the maximum size for this strand is 61.5 MB. Since multiple strands can co-exist in a stranded model, the total stranded model size varies as a cumulative sum of strands’ train parameters and sizes. The following section puts to the test the stranded-NN using two distinct evaluation IIoT scenarios. The model results are then compared to existing MLP [
19,
20,
45] and LSTM implementations [
27,
37,
46].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

