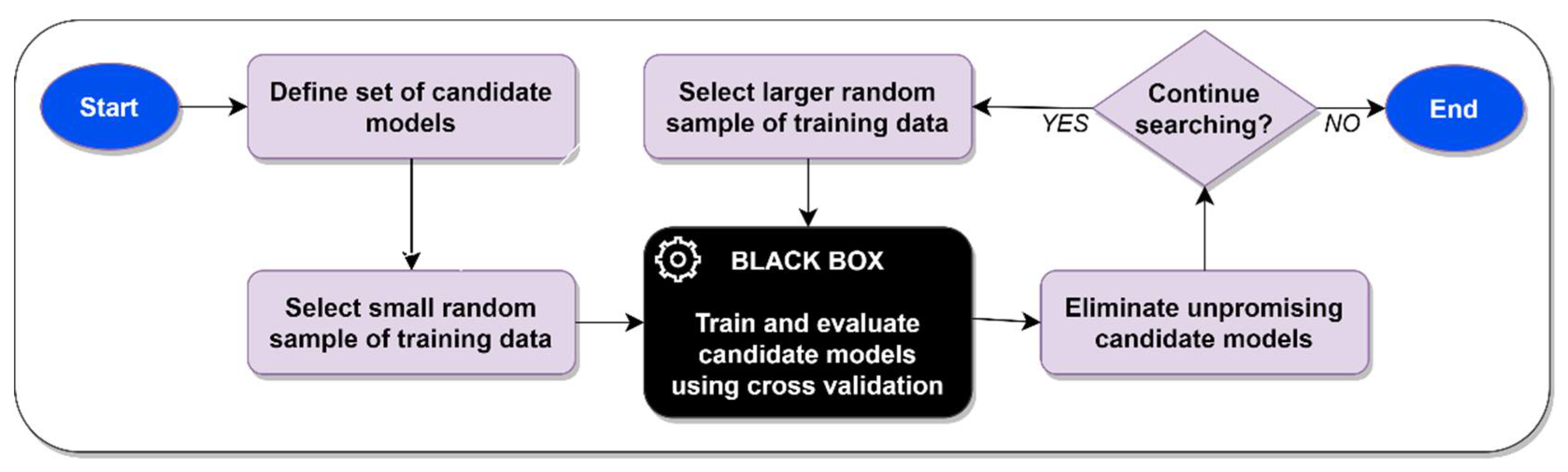
This section begins by introducing the greedy successive halving algorithm, which demonstrates how greedy cross validation can be integrated into the successive halving process. Successive halving ordinarily relies on standard cross validation, which treats ML model evaluation as an opaque “black box” process. The proposed greedy successive halving algorithm, however, relies on greedy cross validation, thus allowing the algorithm to pay attention to and benefit from the information that is generated while the ML model evaluation process is still underway. The greedy successive halving algorithm leverages this informational advantage to significantly increase the speed of the ML model selection process without sacrificing the quality of the models that are ultimately chosen.
After introducing the greedy successive halving algorithm, this section next describes the series of experiments that were conducted in order to compare the performance of the proposed algorithm against that of successive halving with standard cross validation, both in terms of wall-clock time and in the quality of the final ML models chosen by each algorithm. These experiments involve a variety of real-world datasets, a variety of machine learning algorithms (including both multiple classifiers and multiple regressors), differing numbers of folds for the cross-validation process, and differing sizes for the sets of candidate models that are considered by the competing algorithms. The results of these experiments—which reveal the overwhelming superiority of the greedy successive halving algorithm—are subsequently presented in
Section 3.
2.1. The Greedy Successive Halving Algorithm
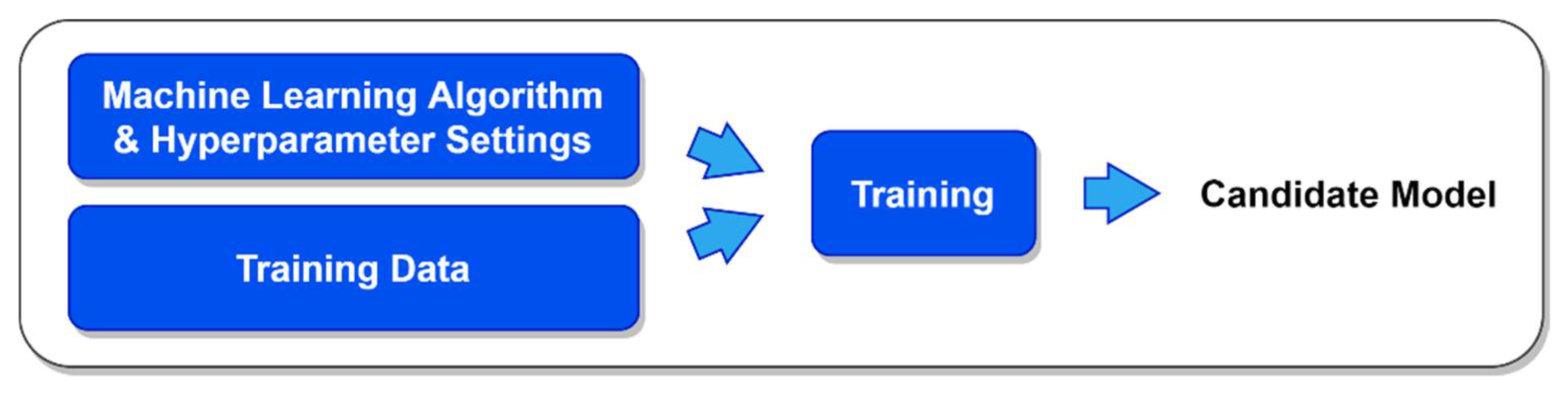
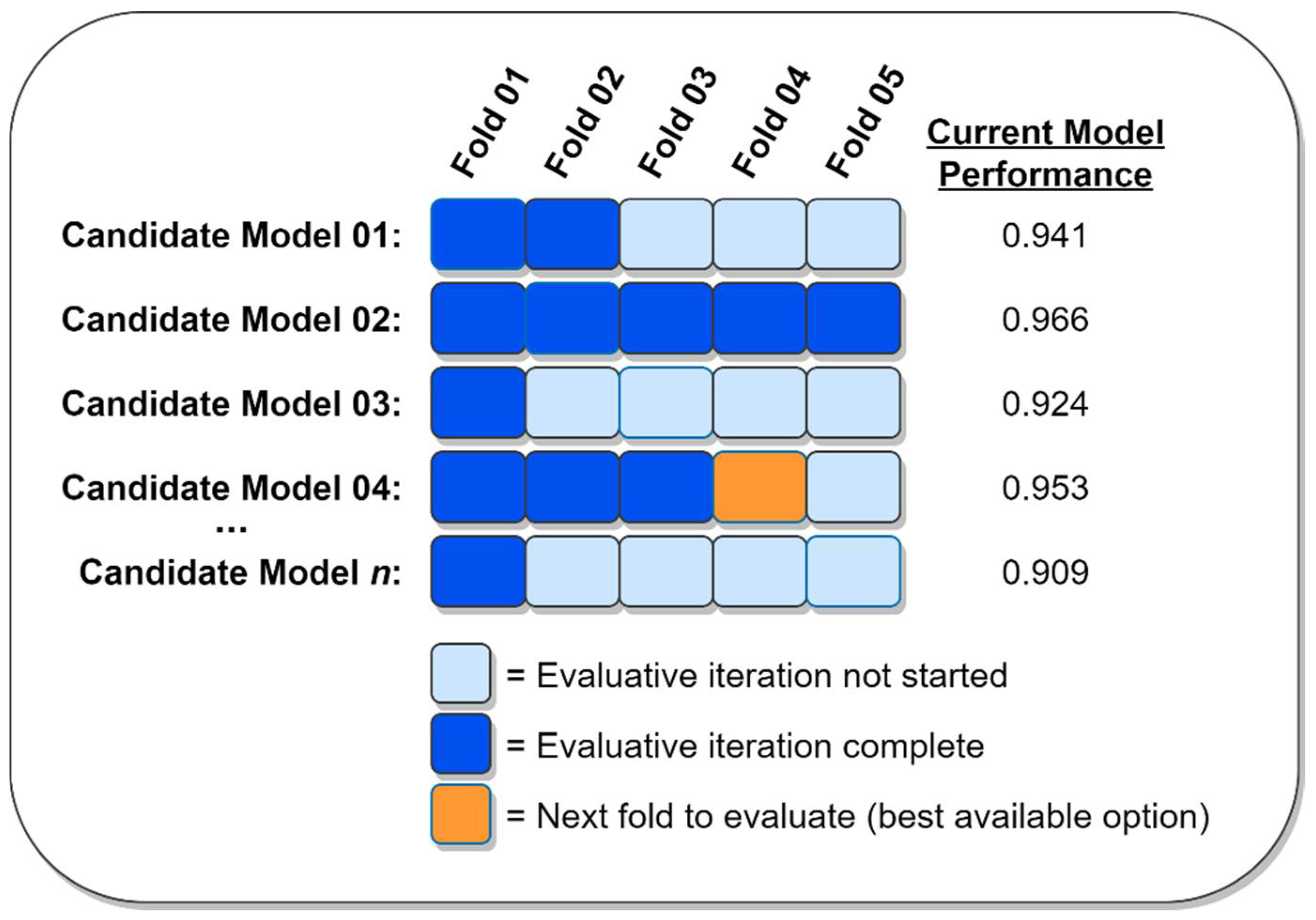
By design, standard cross validation fully evaluates each candidate ML model from start to finish and returns the model’s overall level of performance [
16]. Standard cross validation is a memoryless process insofar as it neither cares about nor pays attention to how the performance of any candidate ML model compares to that of any other model. In contrast, greedy cross validation maintains an estimate of every candidate model’s level of performance and uses that information to prioritize the evaluation of the most promising models. This means that when using greedy cross validation, the most promising models will be the earliest to be completely evaluated during the overall model evaluation process [
8]. The proposed greedy successive halving algorithm capitalizes on this difference between standard and greedy cross validation to achieve its superior performance.
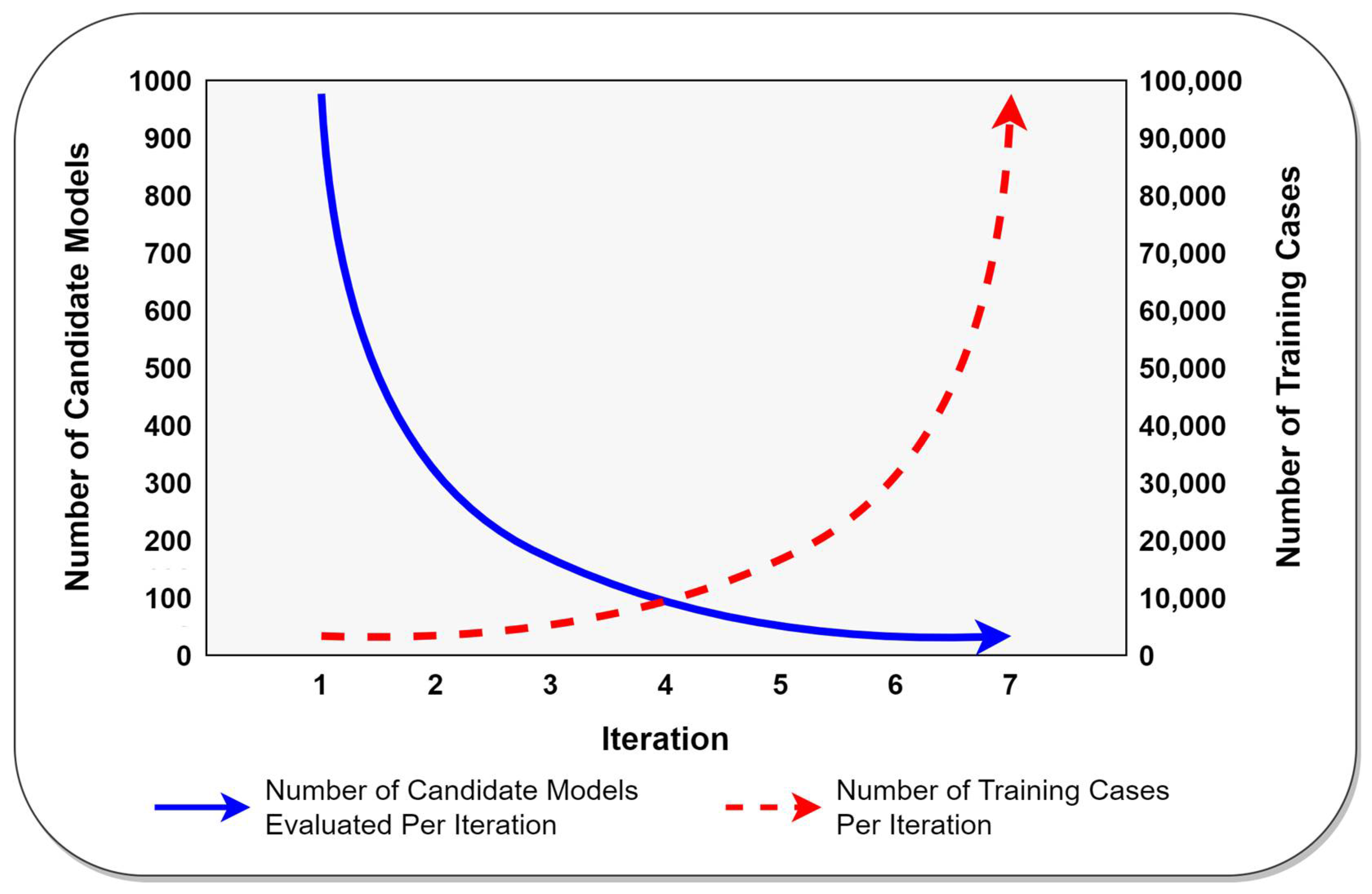
As illustrated in
Figure 2, both the number of candidate ML models and the number of training cases that will be used during each iteration of the successive halving algorithm are determined by exponential functions and can be easily calculated before the algorithm begins evaluating any ML models. Since the number of models needed for each successive halving iteration can be easily calculated in advance, the current successive halving iteration can be terminated immediately as soon as the number of ML models needed for the next iteration have been fully evaluated via greedy cross validation. Put differently, there is no need to wait until
every candidate model for the current iteration has been fully evaluated before identifying the set of best-performing models that will be used in the next iteration. Instead, by virtue of greedy cross validation’s innate prioritization of the most promising ML models, any iteration of successive halving (except the final iteration) can be concluded immediately as soon as greedy cross validation has fully evaluated a sufficient number of models to satisfy the input requirements of the next iteration. This is the key insight that endows greedy successive halving with its superior performance.
Successive halving—including greedy successive halving—is an iterative algorithm. During the first iteration, successive halving considers the complete set of candidate ML models but does so using a minimally sized random sample of the available training data. By the time successive halving reaches the final iteration, it considers only the two most promising candidate models but does so using all of the available training data. For the current study, the maximum number of training cases to use per iteration (
) was thus set equal to the total number of available training cases, while the minimum number of training cases to use per iteration (
) was set equal to
, with
being the number of folds to use during the cross-validation process. Since 5 and 10 are the two most common values of
used by AI/ML practitioners [
17], setting
guaranteed that a minimum of
cases would be used to train and evaluate each candidate model during the first iteration of the successive halving algorithm.
In successive halving, the amount by which the number of candidate models is reduced from one iteration to the next and the amount by which the number of training cases is increased from one iteration to the next both depend on exponential functions, which in turn depend on the number of successive halving iterations. Prior to calculating the parameters of the exponential functions, it is therefore necessary to calculate the number of iterations that will be needed during the successive halving process. The total number of iterations to perform (
) is a function of the minimum and maximum number of cases per iteration and a halving factor (
), as shown in Equation (1). Each successive halving iteration considers approximately
of the models from the previous iteration. For the current study, the halving factor was set equal to 3, which matches the default value used in scikit-learn’s implementation of the successive halving algorithm [
15].
Once the number of successive halving iterations is known, the number of ML models to use and the number of training cases to use for any iteration can be easily calculated using exponential functions of the form
. Specifically, for any iteration
(where
for the first iteration), the number of ML models that are needed for the next iteration (
) can be determined by Equation (2), while the number of training cases to use for the current iteration (
) can be determined by Equation (3).
As soon as the number of training cases to use for the current iteration () is known (per Equation (3)), a random sample of training cases can be drawn from the complete set of training data, which can then be randomly subdivided into k folds. Next, Equation (2) can be used to calculate the number of candidate ML models () that will be needed as input for the next iteration. If the current iteration also happens to be the algorithm’s final iteration, then will naturally be equal to 1, indicating that the single, best-performing model is to be returned. Once the value of is known, the evaluation of the candidate models for the current iteration can begin.
It is at this point that the greedy successive halving algorithm diverges from the standard successive halving algorithm. With standard successive halving, the next step would be to completely evaluate the performance of every remaining candidate ML model by using standard cross validation. After the overall performance of every remaining candidate ML model has been identified, the standard successive halving algorithm would select the
best-performing models, which would subsequently be advanced to the next iteration [
11]. Any models that did not perform sufficiently well to survive to the next iteration would be discarded. Note that with standard successive halving, every remaining candidate model must be fully evaluated before the algorithm can proceed to the next iteration.
In contrast to standard successive halving, the greedy successive halving algorithm does not require every remaining candidate ML model to be fully evaluated before it is able to proceed to the next iteration. Instead, greedy successive halving is able to advance to the next iteration as soon as it has fully evaluated just
of the remaining candidate models. This key advantage is attributable to greedy successive halving’s use of greedy cross validation, which automatically prioritizes the evaluation of the most promising ML models. A complete description of the proposed greedy successive halving algorithm is provided in Algorithm 1 below.
| Algorithm 1. ML model selection using greedy successive halving. |
| Input: M (set of candidate ML models), k (number of folds), D (training dataset), |
| h (halving factor) |
| Output: Best-performing ML model identified in M |
| |
|
|
|
|
|
| (for each halving iteration) |
| |
| : |
| |
| |
| |
| |
| |
| |
| |
| |
| (for each remaining candidate model) |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| : |
| |
| |
| |
| |
| |
|
|
2.2. Evaluative Experiments
Having presented and discussed the proposed greedy successive halving algorithm, it is now possible to describe the extensive series of experiments that were conducted in order to assess, quantify, and compare the performance of greedy successive halving against that of standard successive halving. In total, 60 experiments were carried out to rigorously evaluate the performance characteristics of the proposed greedy successive halving algorithm under a variety of different conditions. These experiments involved five different machine learning algorithms, three of which were classifiers (a Bernoulli naïve Bayes classifier, a decision tree classifier, and a deep neural network classifier) and two of which were regressors (a passive aggressive regressor and a Tweedie regressor). The versions of these algorithms found in Python’s scikit-learn library were used in the experiments to ensure replicability. These specific ML algorithms were chosen because of their widely varying approaches to machine learning [
18,
19,
20,
21] and to provide insights into the performance of greedy successive halving in scenarios involving both classification and regression tasks. Four different real-world datasets were used in conjunction with these ML algorithms, with the Wine Recognition dataset [
22] and Wisconsin Diagnostic Breast Cancer dataset [
23] serving as input for the classification algorithms and the California Housing dataset [
24] and Diabetes dataset [
25] serving as input for the regression algorithms. These datasets are all well-known among AI/ML practitioners and are freely available in the Python scikit-learn library, thus ensuring that the results of the experiments could be easily replicated. The characteristics of each of these datasets are provided in
Table 1 below.
Two possible values for the number of cross-validation folds (
) were used in the experiments, with
. These values of
were adopted because they are the most widely used among AI/ML practitioners when performing cross validation [
17]. Additionally, three different values for the number of candidate ML models (
) were also used in the experiments, with
. The set of candidate ML models was randomly generated for each experiment, with care being taken to ensure that each model’s hyperparameter settings were unique within the set. For the models involving deep neural networks, both the algorithmic hyperparameters and the structure of the neural networks (number of hidden layers, number of nodes per layer, etc.) were allowed to vary from model to model. In summary, then, 12 different experimental conditions were used for each ML algorithm, yielding an overall total of 60 unique experimental conditions (5 ML algorithms * 2 datasets per algorithm * 2 values of
* 3 different sizes for
= 60 total experiments). Each of these experiments was repeated 30 times in order to ensure that the distributions of the resulting performance metrics would be approximately Gaussian, per the Central Limit Theorem [
26].
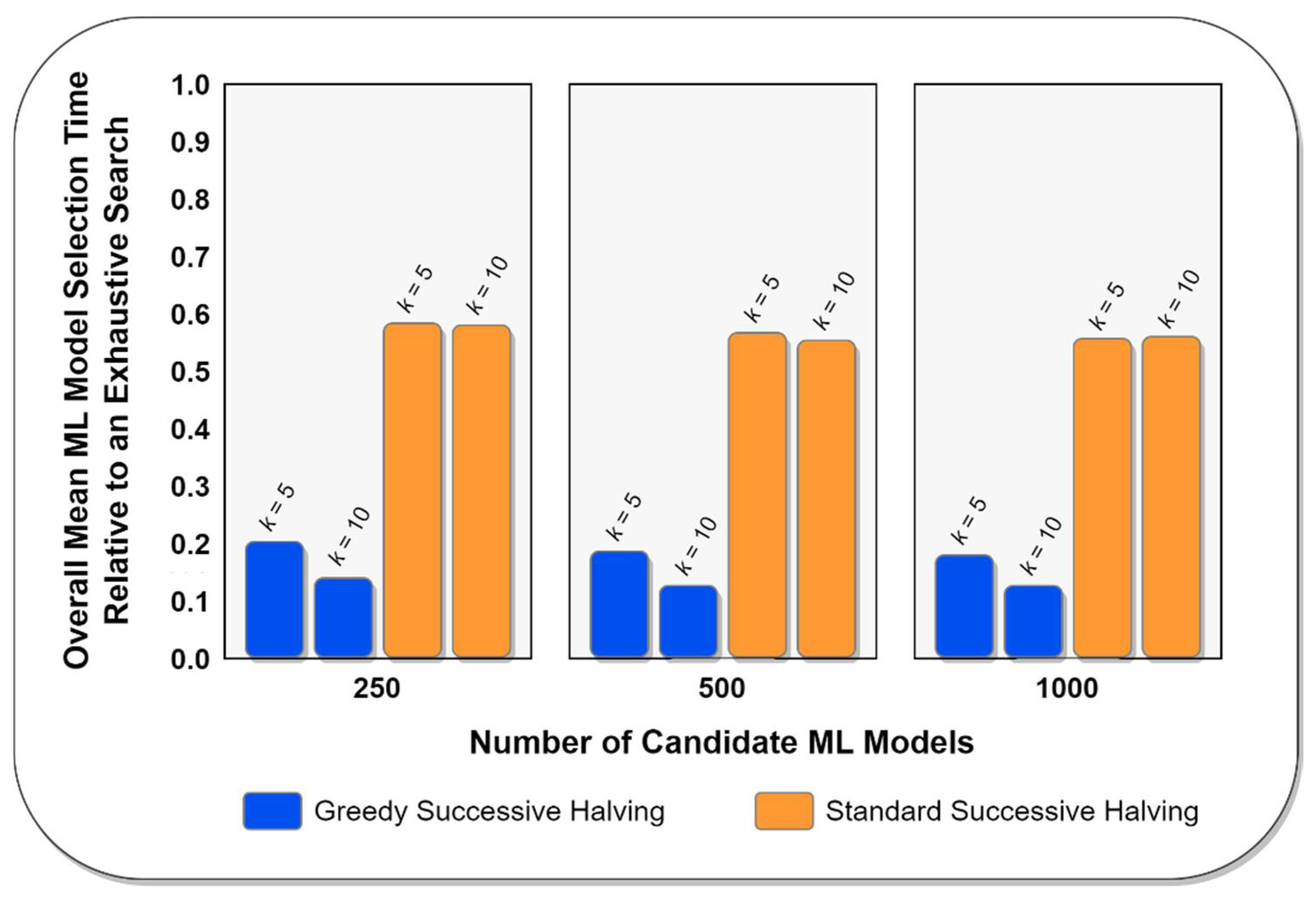
As noted above, the overall goal of the experiments was to compare the performance of the proposed greedy successive halving algorithm against that of the standard successive halving algorithm under a wide variety of different conditions. With this goal in mind, two different performance metrics were generated for each experiment: (1) the wall-clock time required by each algorithm to choose a final ML model from among the set of candidate models, and (2) the quality of the final model chosen by each algorithm. The first of these performance metrics allowed for an assessment of how quickly the competing algorithms completed the ML model selection task, while the second of these performance metrics allowed the quality of the final model chosen by the greedy successive algorithm to be compared against the quality of the final model chosen by the standard successive halving algorithm. If the greedy successive halving algorithm could be shown to select ML models of statistically comparable quality to those selected by the standard successive halving algorithm while requiring less wall-clock time to do so, then it could be reasonably concluded that the greedy successive halving algorithm is superior to the standard successive halving algorithm.
Among the classifiers, the performance of the final ML model chosen by each of the competing successive halving algorithms was measured in terms of classification accuracy, while among the regressors, the performance of the final model chosen by the competing successive halving algorithms was measured in terms of the mean absolute error (MAE) of the model’s predictions. For each experiment, a naïve, exhaustive search of all of the experiment’s candidate models was first performed using standard
k-fold cross validation without successive halving. Since an exhaustive search evaluates every possible candidate model using the complete set of training data for a given experiment, the results of the exhaustive search established a baseline wall-clock processing time for each experiment, as well as a baseline performance value for the ground truth optimal model among the set of candidate models considered during the experiment. The mean performance values for the ground truth optimal models identified during the experiments are provided in
Table 2 below. Note that the values reported for the California Housing and Diabetes datasets indicate the average MAE for the corresponding experiments’ ground truth optimal models, while the values reported for the Wine Recognition and Wisconsin Diagnostic Breast Cancer datasets indicate the average classification accuracy for the corresponding experiments’ ground truth optimal models. To better contextualize the MAE values reported in the table, it is also worthwhile to note that the raw values for the target variable in the California Housing dataset ranged from 0.15 to 5.0, while the raw values for the target variable in the Diabetes dataset ranged from 25 to 346.
After all of the experiments were complete, both the performance of the final models chosen by each variant of the successive halving algorithm and the wall-clock time required by each variant were standardized as percentages of their corresponding baseline values. For example, a standardized performance value of 1.02 for a regressor model would indicate that the mean absolute error for the chosen model was 2% greater than the ground truth optimal model, while a standardized performance value of 0.98 for a classifier model would indicate that the classification accuracy of the chosen model was 2% less than the ground truth optimal model. Similarly, a standardized time of 0.30 would indicate that a successive halving algorithm required only 30% as much wall-clock time as a corresponding exhaustive search of the same set of candidate models. Using this approach allowed the performance of the competing algorithms to be compared across experimental conditions in a statistically valid way. Finally, the standardized wall-clock times and model performance values for the standard and greedy successive halving algorithms were compared against each other using Welch’s
t-tests [
27]. Unlike most other
t-tests, Welch’s
t-tests allow the independent samples being compared to have unequal variances. Since there was no
ex ante reason to expect the distributional variances of the performance metrics generated by each competing algorithm to be equal, Welch’s
t-tests provided an appropriate statistical foundation for comparing the experimental results.
The experiments themselves were run sequentially using a fixed hardware configuration on the Google Cloud Platform [
28]. Since the hardware resources used to conduct the experiments were identical for each experimental condition, any statistically significant differences in wall-clock times or model performance values would be attributable solely to differences between the standard successive halving algorithm and the greedy successive halving algorithm. The results of the experiments are presented in the following section.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}