
Polychrony as Chinampas

 , ,
, ,
Abstract
1. Introduction
- Is a given vertex activated at a particular time?
- Can we reconstruct all the vertices that will change their states to activated?
2. Nonlinear Signal Flow Graphs
- Every signal has an intensity of one.
- Every vertex has a threshold intensity of two.
- If a vertex coincidentally receives signals of an intensity higher or equal to the threshold, then the vertex fires a signal through each of its outgoing edges.
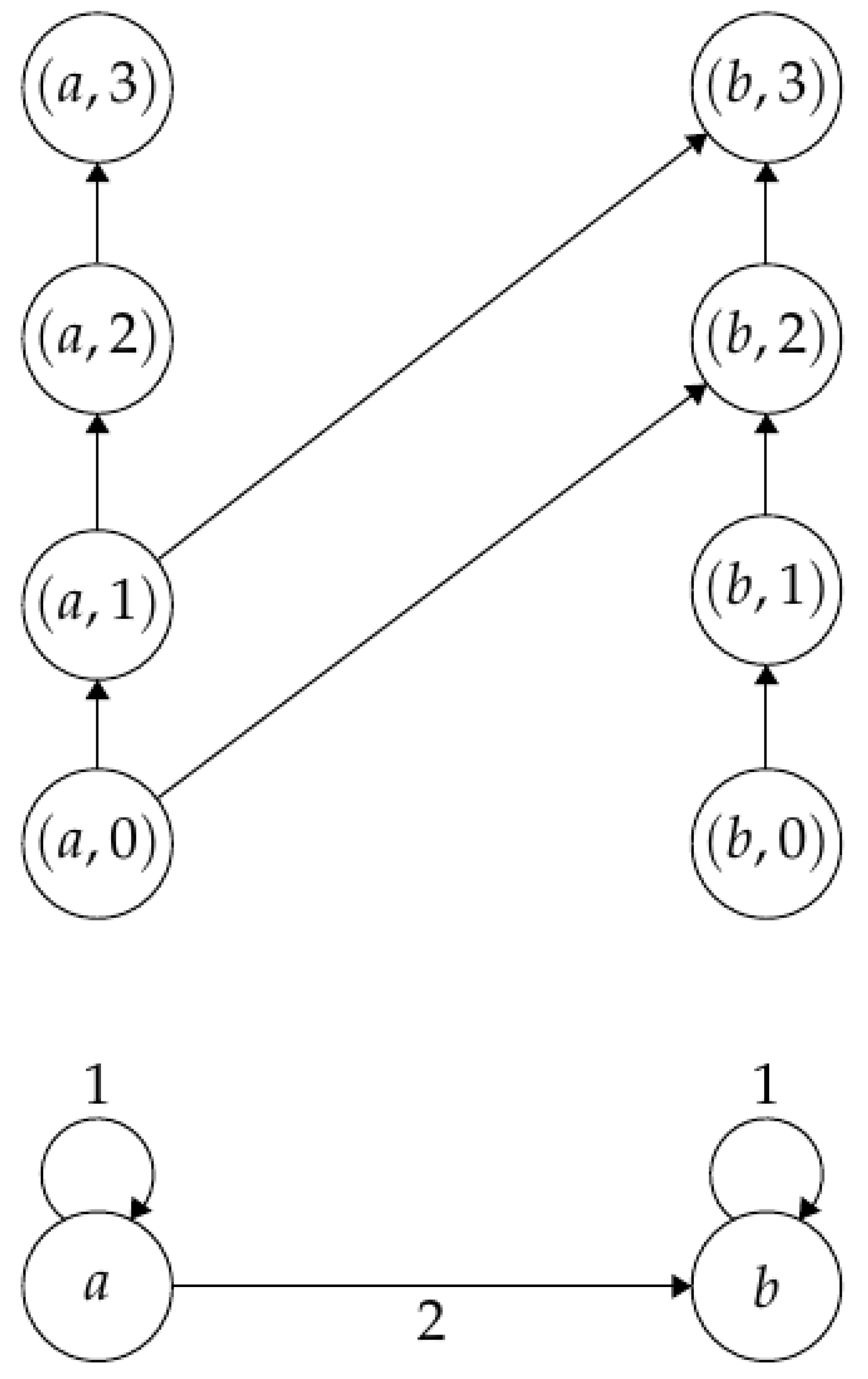
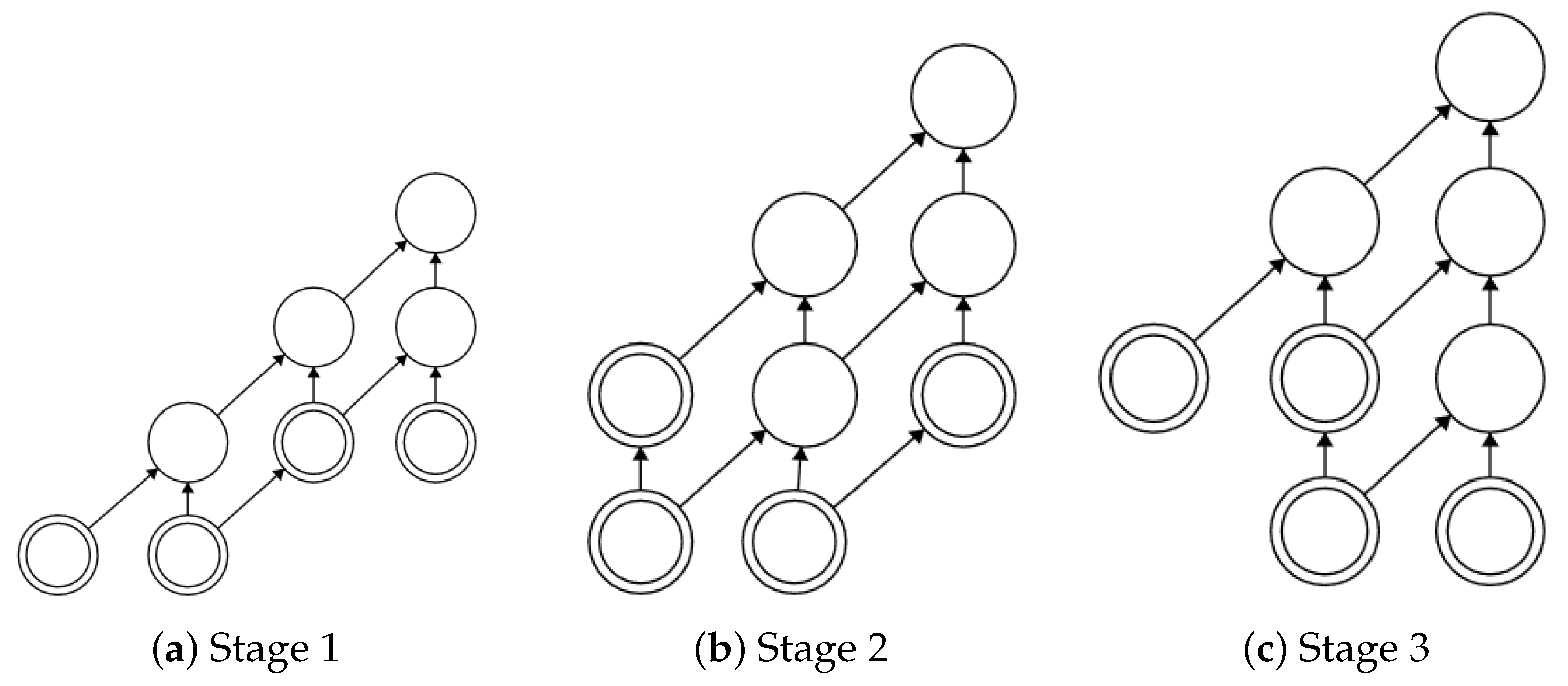
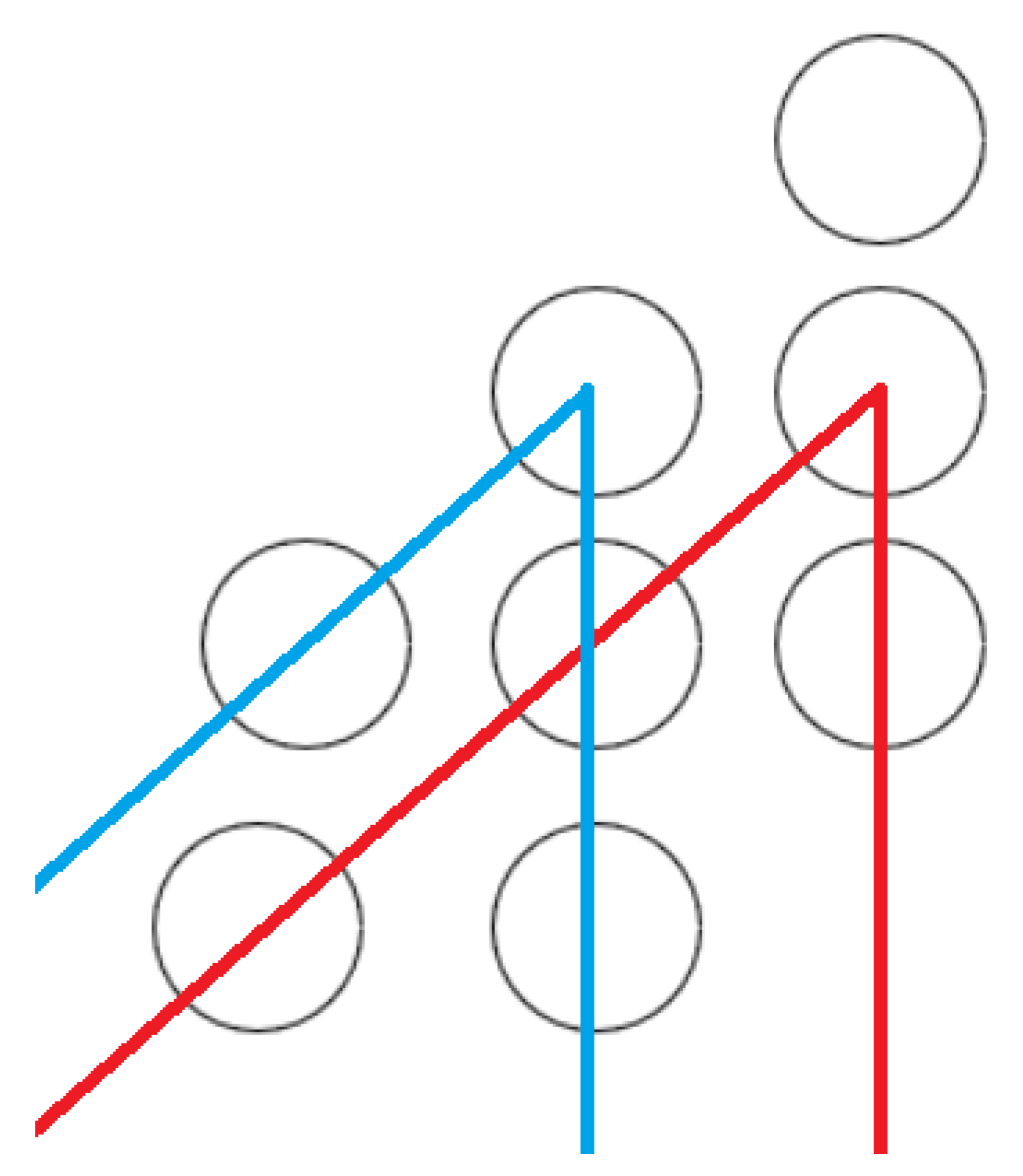
3. Base and Activation Diagrams
3.1. Base Diagram
3.2. Activation Diagram
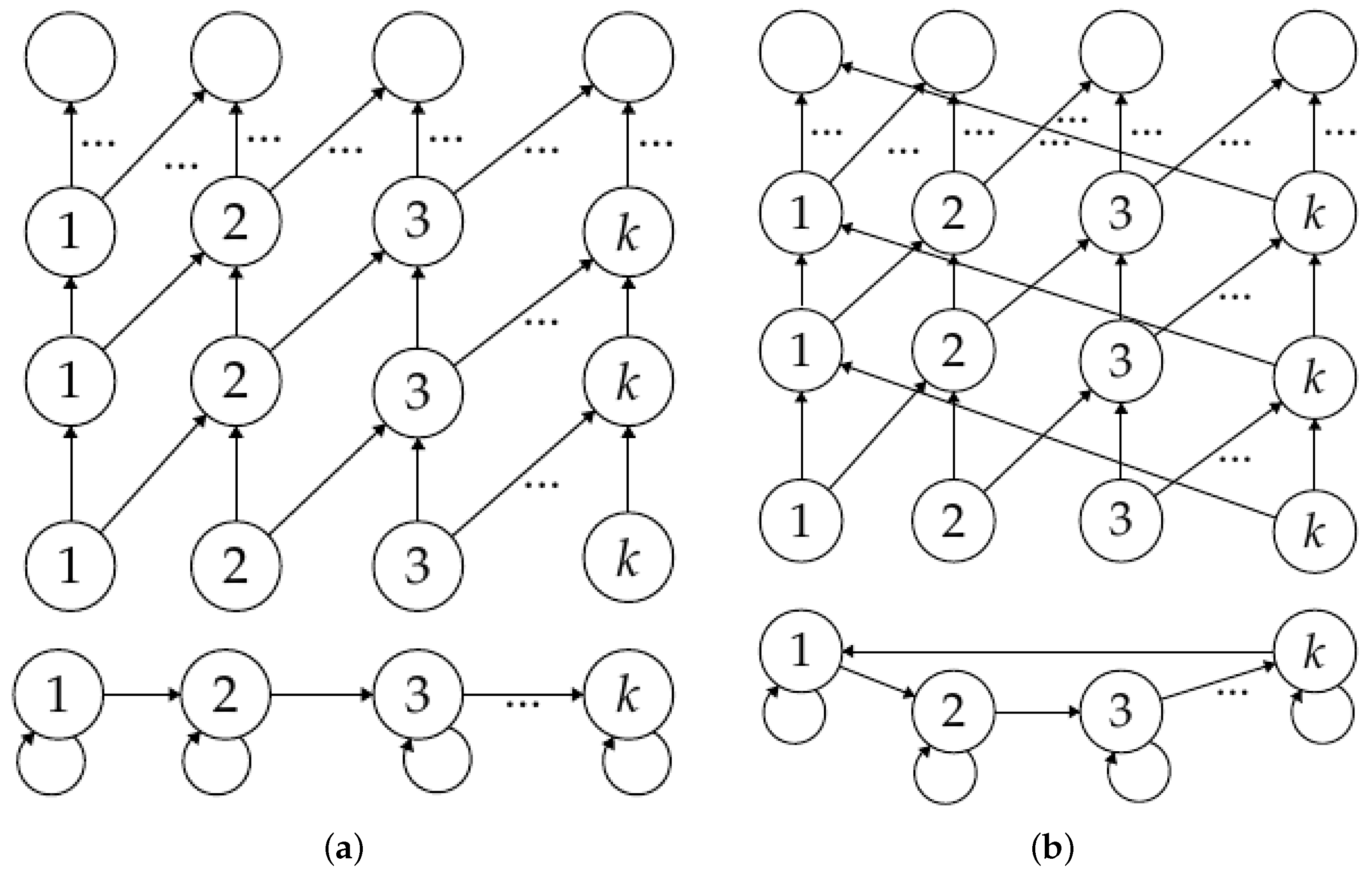
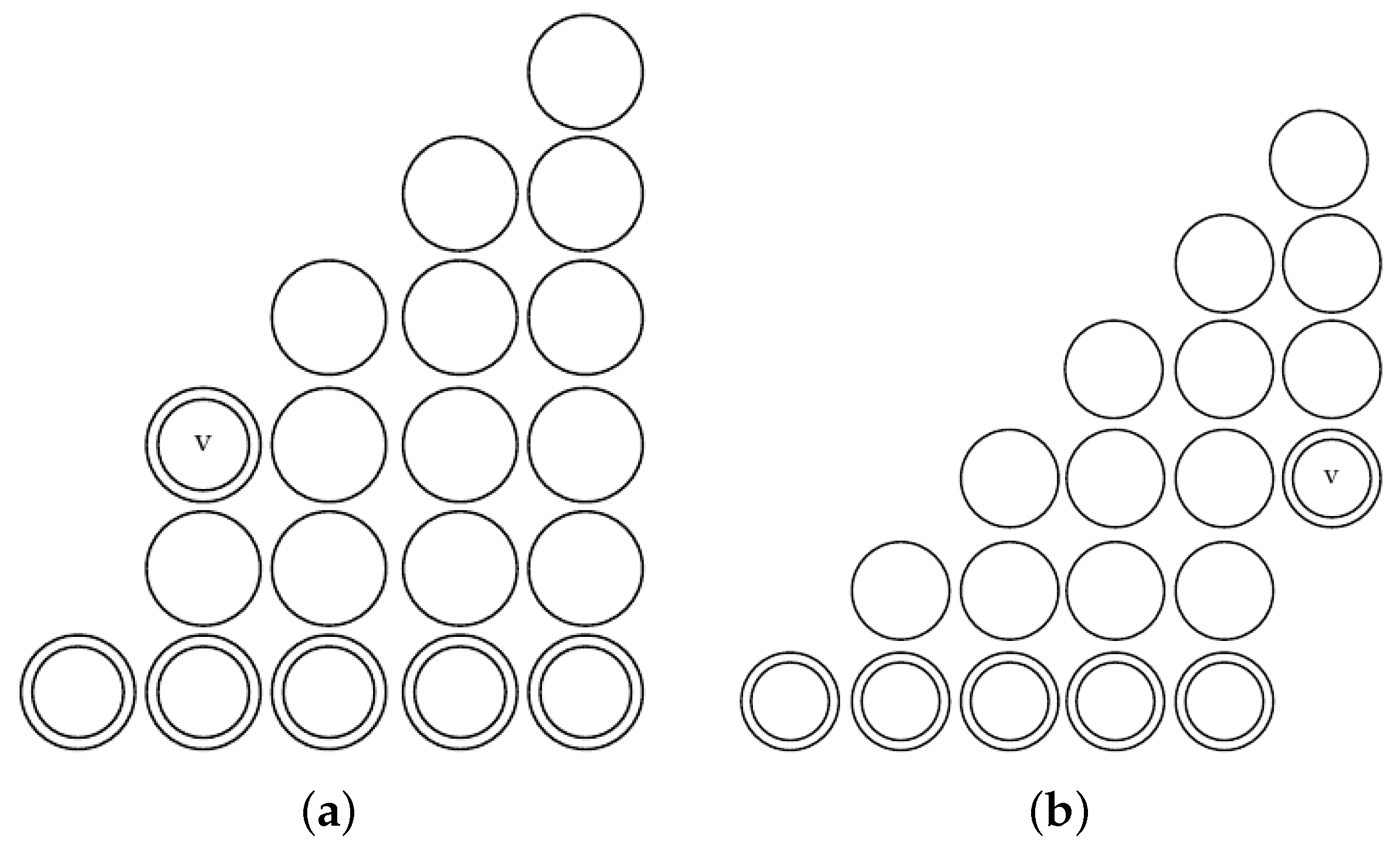
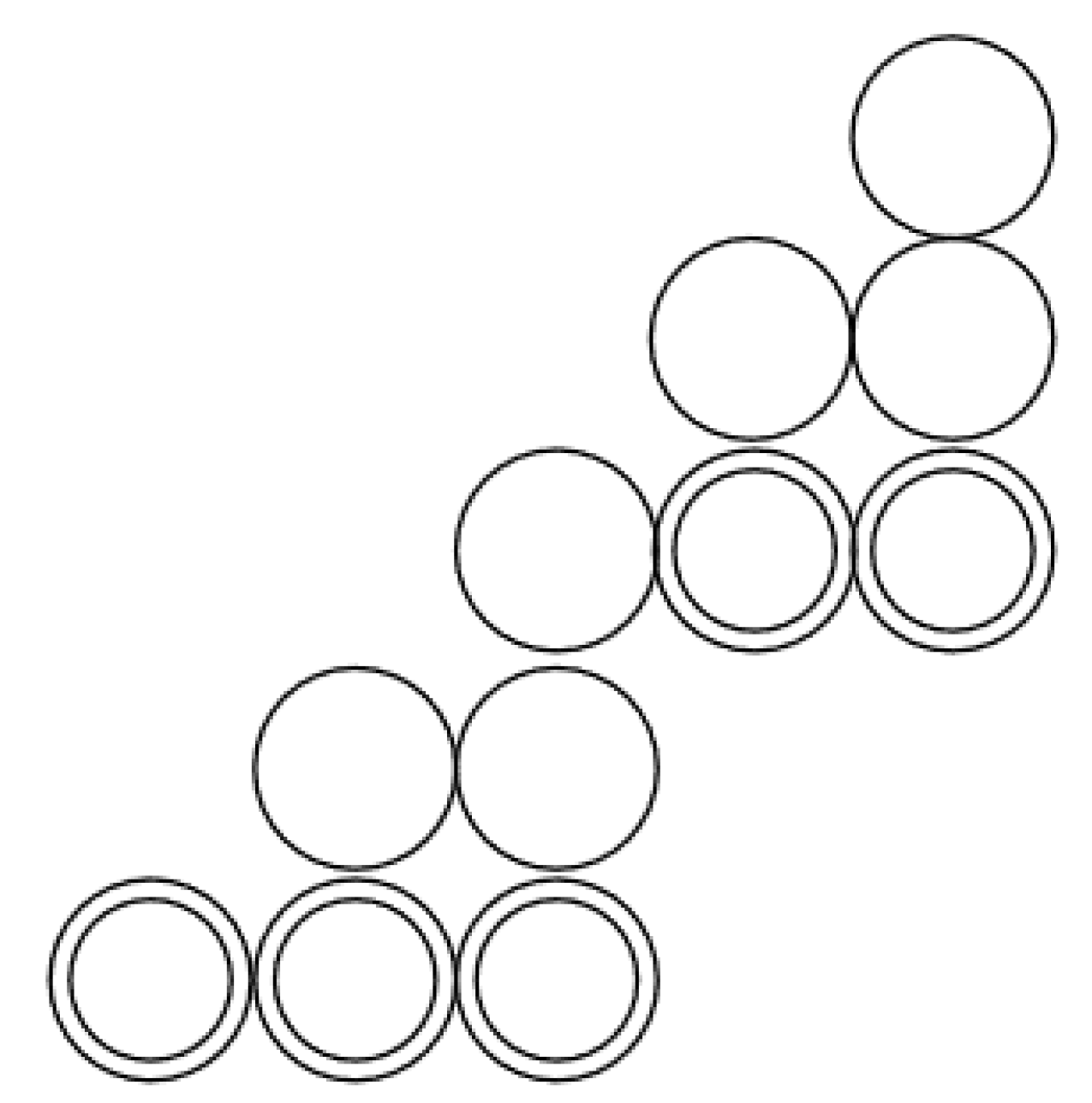
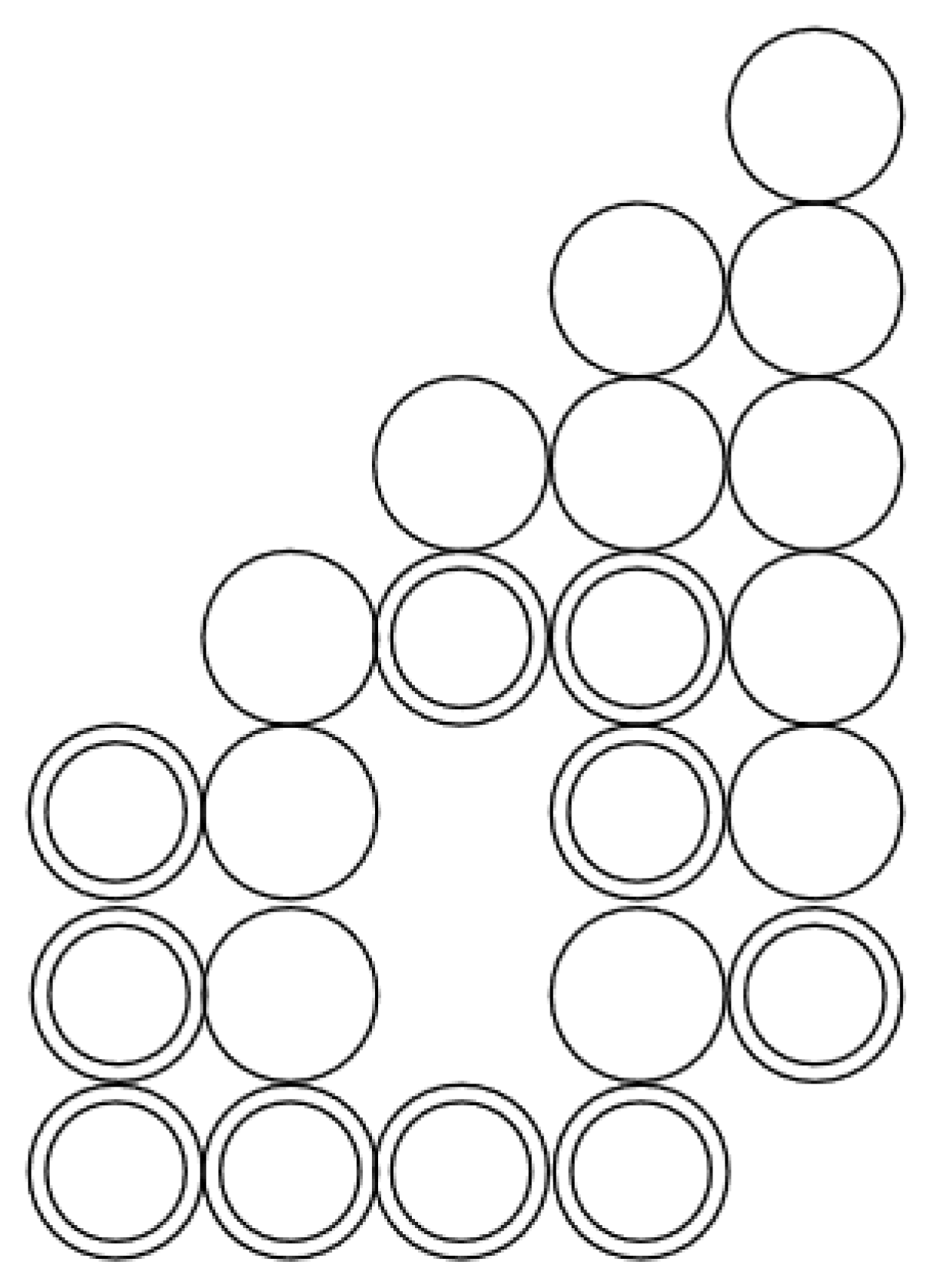
4. Chinampas
The Topological Description of a Chinampa
| Algorithm 1: Factorization via BFS |
 |
5. Cascades and Cellular Atomata
5.1. Base Diagrams as a Model of a Network
5.2. Cellular Automata
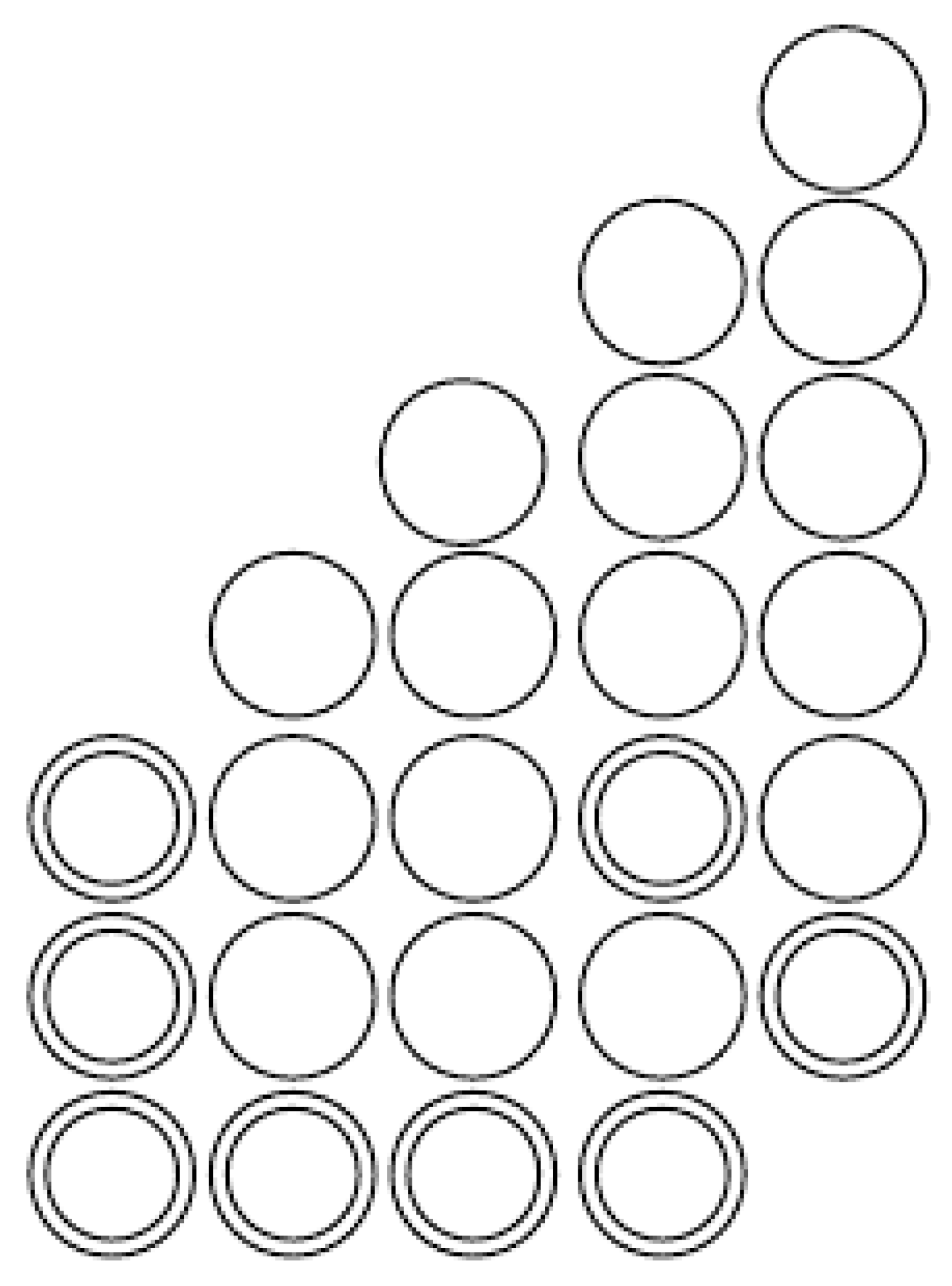
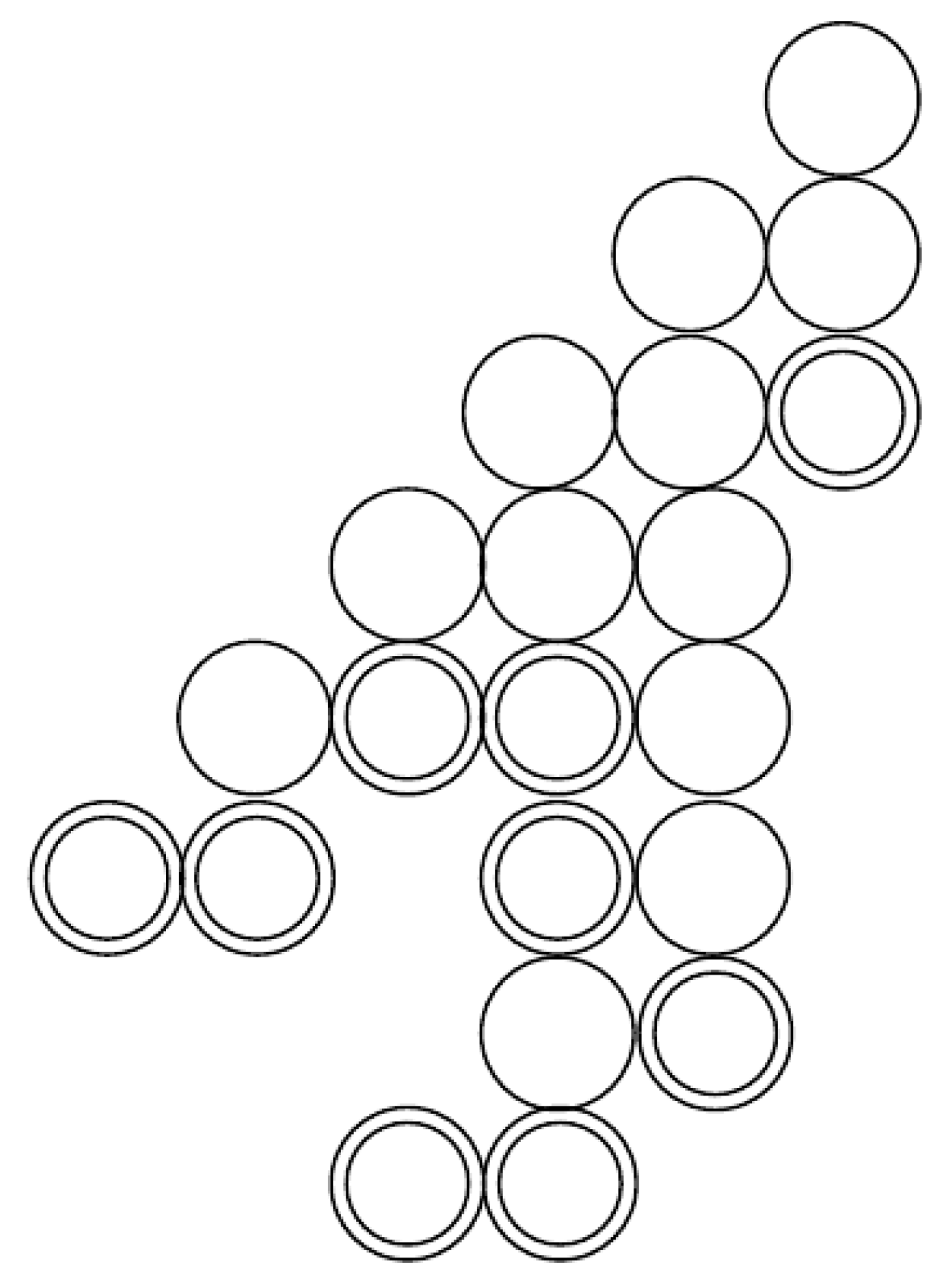
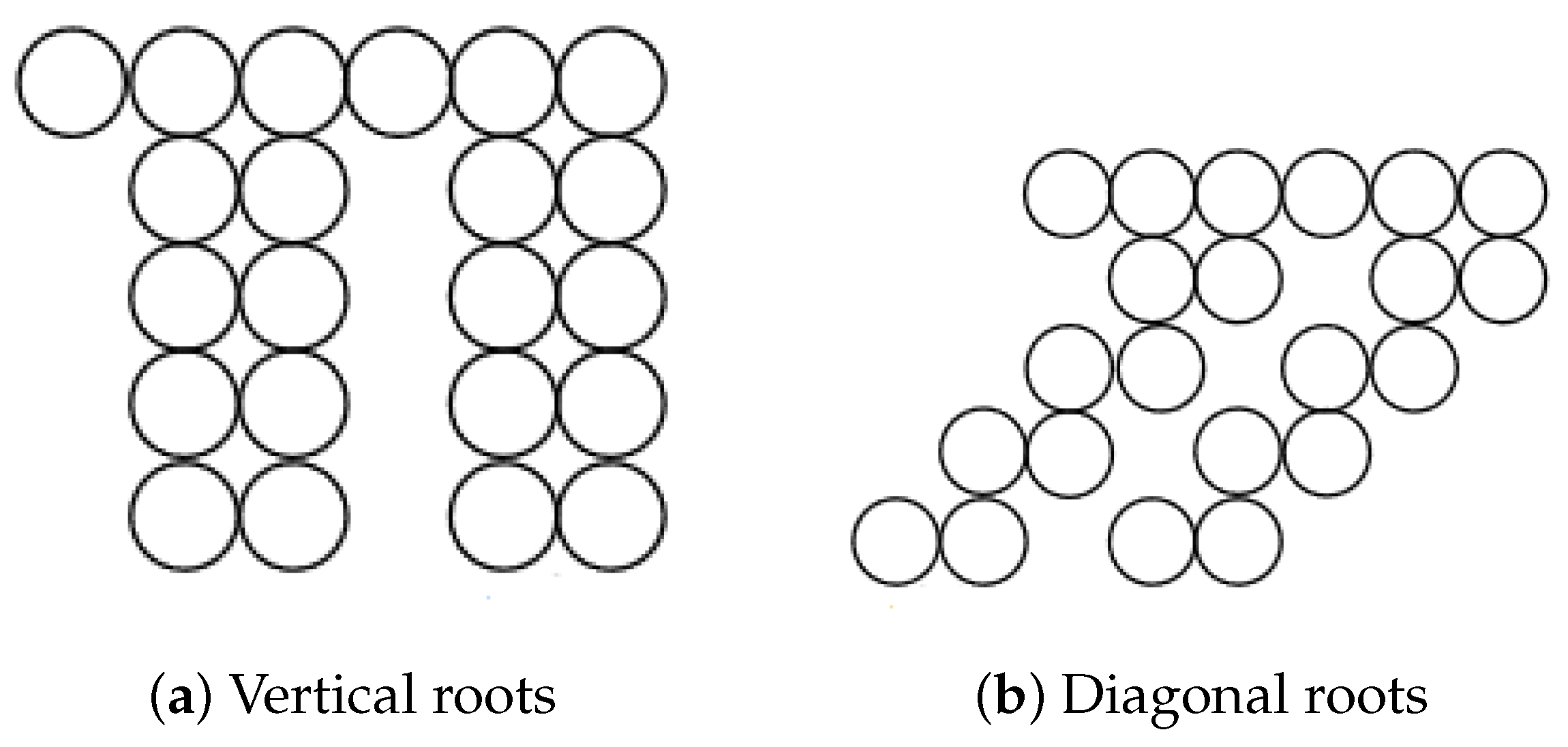
6. Combinatorial Description of Chinampas
6.1. Profit Properties
6.2. Combinatorial Description of Chinampas with Profits of Zero and One
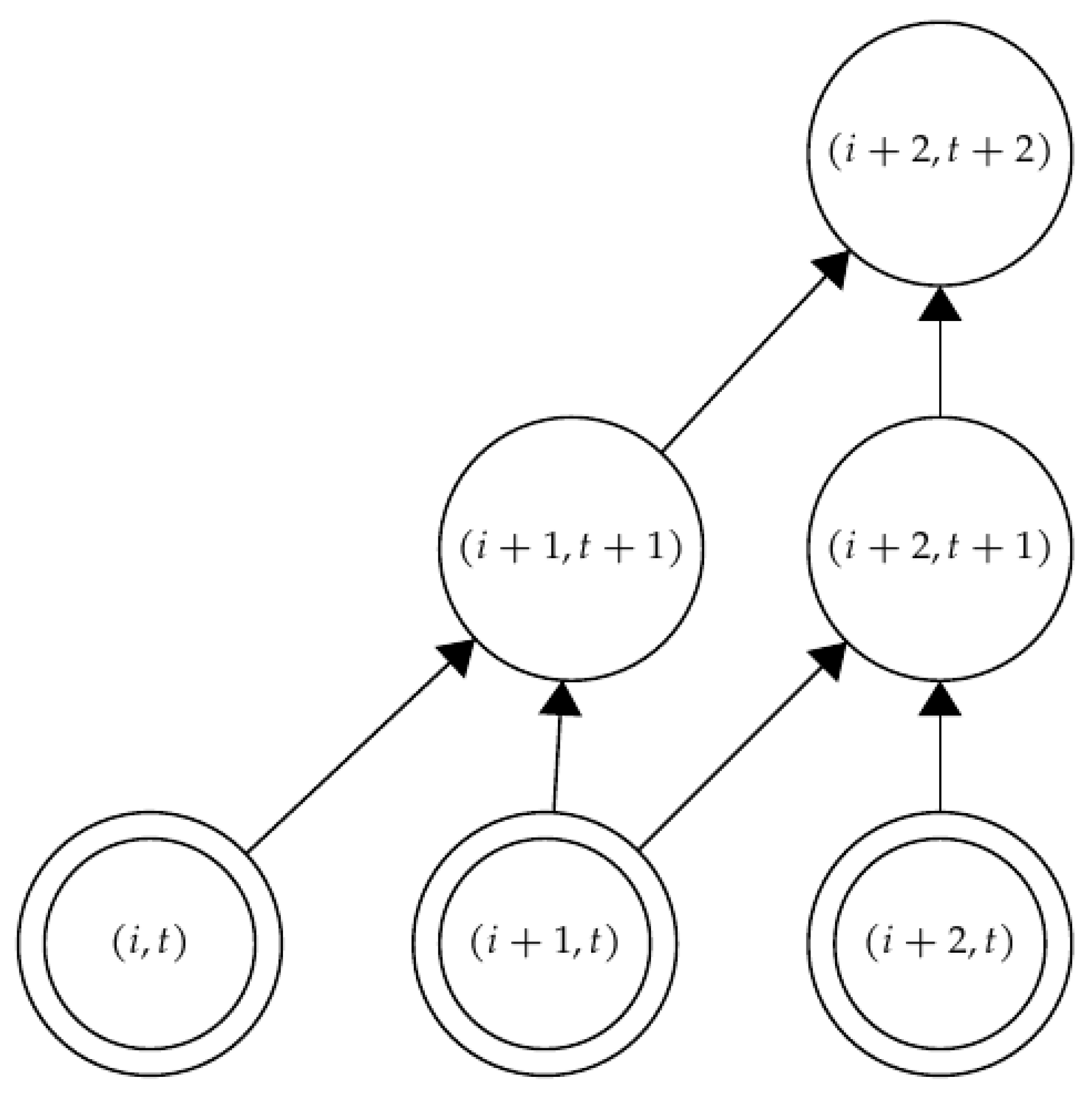
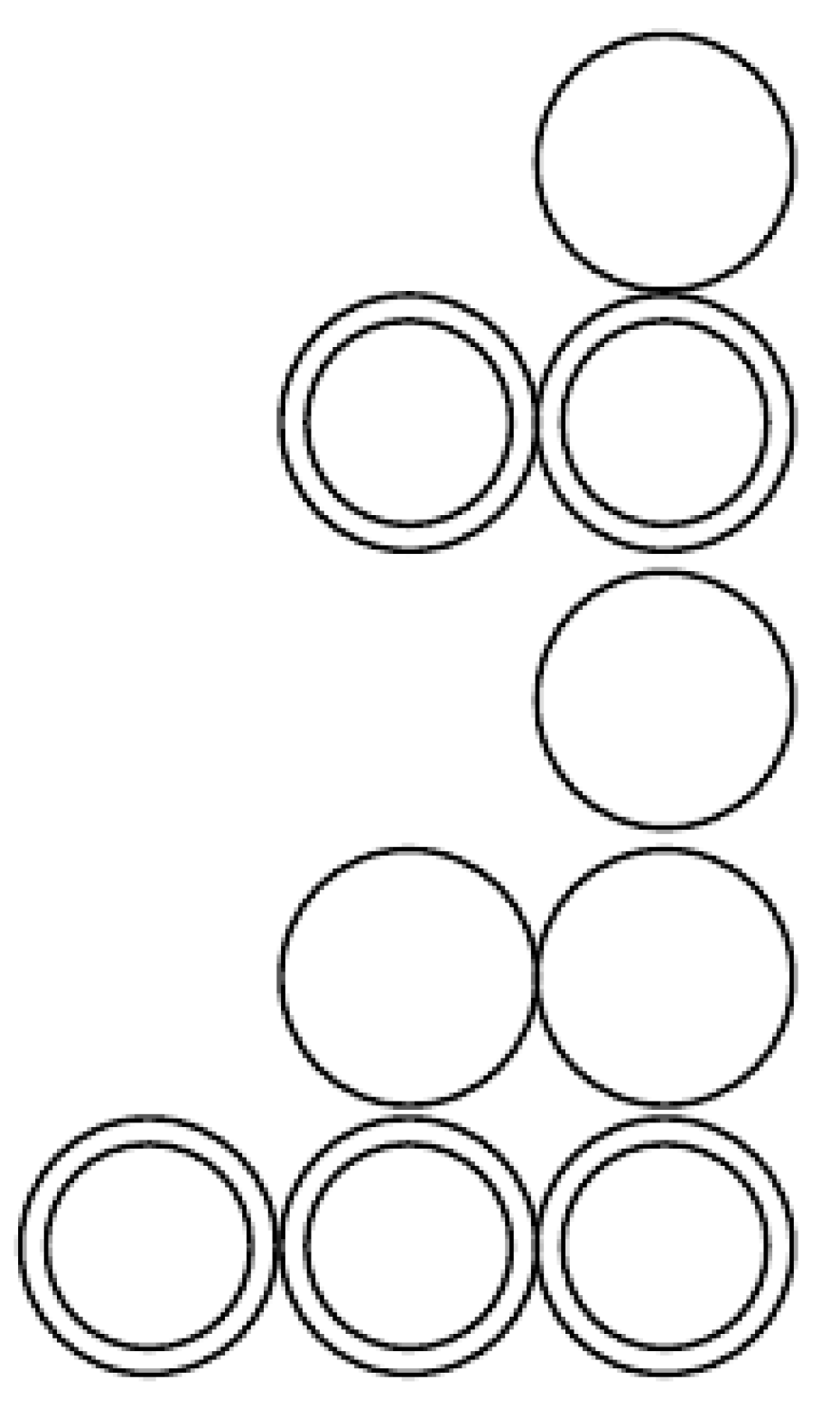
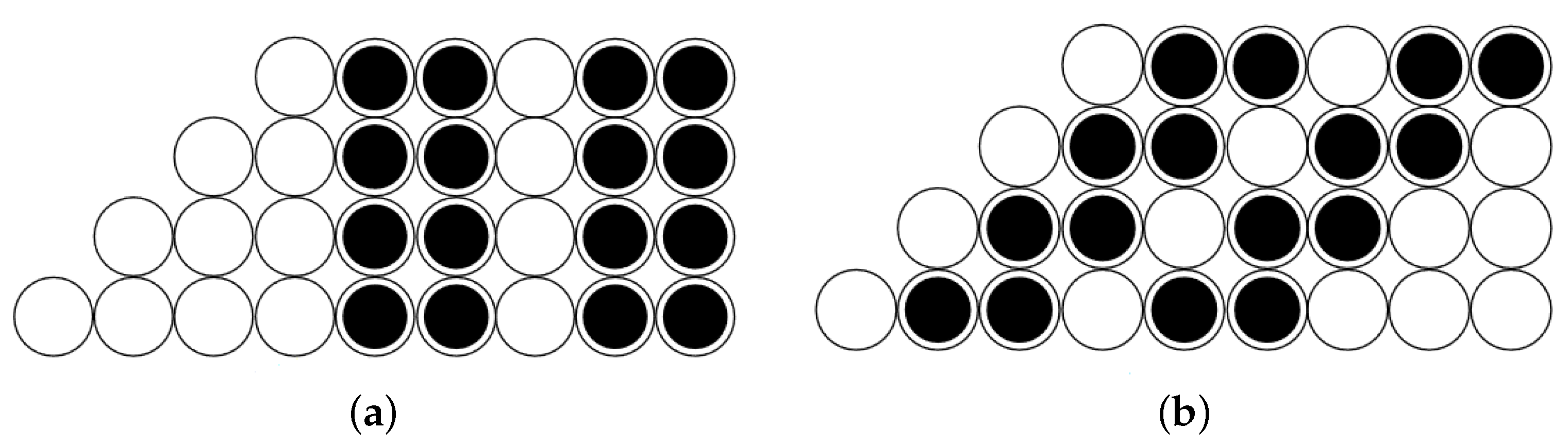
- None of the instances of are at the top. We then have subpyramids as in the previous proposition, so we count
- One instance is at the top. Then, the remaining instances can be placed in ways on the two subpyramids. However, the two subcases have terms in common, as shown in Figure 16. Thus, the correct number of combinations is .
6.3. Algorithms for Activated Vertices
Building Chinampas
| Algorithm 2: Build chinampas |
 |
| Algorithm 3: Remove duplicates |
 |
| Algorithm 4: Will_vertex_be_activated |
 |
7. Triangular Sequences
Ehrhart Series and Order Polynomials
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Izhikevich, E.M. Polychronization: Computation with spikes. Neural Comput. 2006, 18, 245–282. [Google Scholar] [CrossRef] [PubMed]
- Mason, S.J. Feedback Theory-Some Properties of Signal Flow Graphs. Proc. IRE 1953, 41, 1144–1156. [Google Scholar] [CrossRef]
- Shannon, C.E. The Theory and Design of Linear Differential Equation Machines Report to National Defense Research Council, January 1942; Wiley-IEEE Press: New York, NY, USA, 1993; Chapter 33; pp. 514–559. [Google Scholar] [CrossRef]
- Guyton, A.C.; Coleman, T.G.; Granger, H.J. Circulation: Overall Regulation. Annu. Rev. Physiol. 1972, 34, 13–44. [Google Scholar] [CrossRef]
- Guilherme, J.; Horta, N.; Franca, J. Symbolic synthesis of non-linear data converters. In Proceedings of the 1998 IEEE International Conference on Electronics, Circuits and Systems. Surfing the Waves of Science and Technology (Cat. No.98EX196), Lisboa, Portugal, 7–10 September 1998; Volume 3, pp. 219–222. [Google Scholar] [CrossRef]
- Coşkun, K.Ç.; Hassan, M.; Drechsler, R. Equivalence Checking of System-Level and SPICE-Level Models of Static Nonlinear Circuits. In Proceedings of the Design, Automation and Test in Europe Conference (DATE), Online, 17–19 April 2023; Volume 16, p. 18. [Google Scholar]
- Ersalı, C.; Hekimoğlu, B. Nonlinear model and simulation of DC-DC Buck-Boost converter using switching flow-graph method. In Proceedings of the International Informatics Congress, Kunming, China, 15–16 December 2022. [Google Scholar]
- Baran, T.A. Inversion of nonlinear and time-varying systems. In Proceedings of the IEEE Digital Signal Processing and Signal Processing Education Meeting (DSP/SPE), Sedona, AZ, USA, 4–7 January 2011; pp. 283–288. [Google Scholar] [CrossRef]
- Thorpe, S.; Delorme, A.; Rullen, R.V. Spike-based strategies for rapid processing. Neural Netw. 2001, 14, 6–7. [Google Scholar] [CrossRef]
- Indiveri, G.; Chicca, E.; Douglas, R.J. Artificial Cognitive Systems: From VLSI Networks of Spiking Neurons to Neuromorphic Cognition. Cogn. Comput. 2009, 1, 119–127. [Google Scholar] [CrossRef]
- Indiveri, G.; Linares-Barranco, B.; Legenstein, R.; Deligeorgis, G.; Prodromakis, T. Integration of nanoscale memristor synapses in neuromorphic computing architectures. Nanotechnology 2013, 24, 384010. [Google Scholar] [CrossRef]
- Mead, C. Neuromorphic electronic systems. Proc. IEEE 1990, 78, 1629–1636. [Google Scholar] [CrossRef]
- Markovic, D.; Mizrahi, A.; Querlioz, D.; Grollier, J. Physics for Neuromorphic Computing. arXiv 2020, arXiv:2003.04711. [Google Scholar] [CrossRef]
- Sushchik, M.; Rulkov, N.; Larson, L.; Tsimring, L.; Abarbanel, H.; Yao, K.; Volkovskii, A. Chaotic pulse position modulation: A robust method of communicating with chaos. IEEE Commun. Lett. 2000, 4, 128–130. [Google Scholar] [CrossRef]
- Shiu, D.S.; Kahn, J. Differential pulse-position modulation for power-efficient optical communication. IEEE Trans. Commun. 1999, 47, 1201–1210. [Google Scholar] [CrossRef]
- Nahmias, M.A.; Shastri, B.J.; Tait, A.N.; Prucnal, P.R. A Leaky Integrate-and-Fire Laser Neuron for Ultrafast Cognitive Computing. IEEE J. Sel. Top. Quantum Electron. 2013, 19, 1–12. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Barabási, A. Network Science; Cambridge University Press: Cambridge, MA, USA, 2016. [Google Scholar] [CrossRef]
- Wolfram, S. A New Kind of Science; Wolfram Media: Champaign, IL, USA, 2002. [Google Scholar]
- Gardner, M. Mathematical Games—The Fantastic Combinations of John Conway’s New Solitaire Game ‘Life’. Sci. Am. 1970, 223, 70–120. [Google Scholar] [CrossRef]
- Wilf, H.S. Generating Functionology, 3rd ed.; A. K. Peters Ltd.: Wellesley, MA, USA, 2006; p. 245. [Google Scholar] [CrossRef]
- Stanley, R.P. A chromatic-like polynomial for ordered sets. In Proceedings of the 2nd Conference on Combinatorics Mathematics Application; University of North Carolina: Chapel Hill, NC, USA, 1970; pp. 421–427. [Google Scholar]
- Beck, M.; Robins, S. Computing the Continuous Discretely. Integer-Point Enumeration in Polyhedra, with Illustrations by David Austin, 2nd ed.; Undergraduate Texts Math; Springer: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Beck, M.; Sanyal, R. Combinatorial Reciprocity Theorems. An Invitation to Enumerative Geometric Combinatorics; Grad. Stud. Math.; American Mathematical Society (AMS): Providence, RI, USA, 2018; Volume 195. [Google Scholar] [CrossRef]
- Wolfram Research, I. Mathematica, Version 12.1; Wolfram Research, Inc.: Champaign, IL, USA, 2020. [Google Scholar]
- Arciniega-Nevárez, J.A.; Berghoff, M.; Dolores-Cuenca, E.R. An algebra over the operad of posets and structural binomial identities. Boletín Soc. Mat. Mex. 2022, 29, 478. [Google Scholar] [CrossRef]
- Dolores-Cuenca, E.R. Computing Order Series/Ehrhart Polynomials of Posets with Mathematica. In The Notebook Archive; 2022. Available online: https://notebookarchive.org/2022-02-3pvm73a (accessed on 8 November 2022).
- Pauli, R.; Weidel, P.; Kunkel, S.; Morrison, A. Reproducing Polychronization: A Guide to Maximizing the Reproducibility of Spiking Network Models. Front. Neuroinform. 2018, 12, 46. [Google Scholar] [CrossRef] [PubMed]
- Oberländer, J.; Bouhadjar, Y.; Morrison, A. Learning and replaying spatiotemporal sequences: A replication study. Front. Integr. Neurosci. 2022, 16. [Google Scholar] [CrossRef] [PubMed]
- Pfeil, T.; Grübl, A.; Jeltsch, S.; Müller, E.; Müller, P.; Petrovici, M.A.; Schmuker, M.; Brüderle, D.; Schemmel, J.; Meier, K. Six networks on a universal neuromorphic computing substrate. Front. Neurosci. 2013, 7, 11. [Google Scholar] [CrossRef]
- Merolla, P.; Arthur, J.; Akopyan, F.; Imam, N.; Manohar, R.; Modha, D.S. A digital neurosynaptic core using embedded crossbar memory with 45pJ per spike in 45nm. In Proceedings of the 2011 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 19–21 September 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Seo, J.s.; Brezzo, B.; Liu, Y.; Parker, B.D.; Esser, S.K.; Montoye, R.K.; Rajendran, B.; Tierno, J.A.; Chang, L.; Modha, D.S.; et al. A 45nm CMOS neuromorphic chip with a scalable architecture for learning in networks of spiking neurons. In Proceedings of the 2011 IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 19–21 September 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Boahen, K. Neurogrid: Emulating a million neurons in the cortex. In Proceedings of the IEEE Conference on Engineering in Medicine and Biology Society, New York, NY, USA, 30 August 2006–3 September 2006; pp. 1–4. [Google Scholar] [CrossRef]
- Elnagar, S.; Thomas, M.A.; Osei-Bryson, K.M. What is Cognitive Computing? An Architecture and State of The Art. arXiv 2023, arXiv:2301.00882. [Google Scholar] [CrossRef]
- Aghnout, S.; Karimi, G.; Azghadi, M. Modeling triplet spike-timing-dependent plasticity using memristive devices. J. Comput. Electron. 2017, 16, 401–410. [Google Scholar] [CrossRef]
- Froemke, R.; Dan, Y. Spike-timing-dependent synaptic modification induced by natural spike trains. Nature 2002, 416, 433–438. [Google Scholar] [CrossRef]
- Pfister, J.P.; Gerstner, W. Triplets of Spikes in a Model of Spike Timing-Dependent Plasticity. J. Neurosci. 2006, 26, 9673–9682. [Google Scholar] [CrossRef]
- Hartley, M.; Taylor, N.; Taylor, J. Understanding spike-time-dependent plasticity: A biologically motivated computational model. Brain Inspired Cognitive Systems. Neurocomputing 2006, 69, 2005–2016. [Google Scholar] [CrossRef]
- Silva, G. The Need for the Emergence of Mathematical Neuroscience: Beyond Computation and Simulation. Front. Comput. Neurosci. 2011, 5, 51. [Google Scholar] [CrossRef]
- Štukelj, G. Significance of Neural Noise. Ph.D. Thesis, LM University, Munchen, Germany, 2020. [Google Scholar]
- Mozer, M.C.; Smolensky, P. Using Relevance to Reduce Network Size Automatically. Connect. Sci. 1989, 1, 3–16. [Google Scholar] [CrossRef]
- Janowsky, S.A. Pruning versus clipping in neural networks. Phys. Rev. A 1989, 39, 6600–6603. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Denker, J.; Solla, S. Optimal Brain Damage. In Proceedings of the Advances in Neural Information Processing Systems; Touretzky, D., Ed.; Morgan-Kaufmann: San Francisco, CA, USA, 1989; Volume 2. [Google Scholar]
- Hoefler, T.; Alistarh, D.; Ben-Nun, T.; Dryden, N.; Peste, A. Sparsity in Deep Learning: Pruning and Growth for Efficient Inference and Training in Neural Networks. J. Mach. Learn. Res. 2022, 22, 554. [Google Scholar]
- Liu, S.; Wang, Z. Ten Lessons We Have Learned in the New “Sparseland”: A Short Handbook for Sparse Neural Network Researchers. arXiv 2023, arXiv:2302.02596. [Google Scholar] [CrossRef]
- Bergeron, F.; Labelle, G.; Leroux, P. Combinatorial Species and Tree-like Structures. In Encyclopedia of Mathematics and its Applications; Cambridge University Press: Cambridge, MA, USA, 1997. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Theory | Base Diagram |
|---|---|
| External stimulated node | Primary vertex |
| Internal stimulated node | Secondary vertex |
| (Network, external stimuli) | Activation diagram (AD) |
| Cascade | AD with equal or more |
| secondary vertices than primary ones |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dolores-Cuenca, E.; Arciniega-Nevárez, J.A.; Nguyen, A.; Zou, A.Y.; Van Popering, L.; Crock, N.; Erlebacher, G.; Mendoza-Cortes, J.L. Polychrony as Chinampas. Algorithms 2023, 16, 193. https://doi.org/10.3390/a16040193
Dolores-Cuenca E, Arciniega-Nevárez JA, Nguyen A, Zou AY, Van Popering L, Crock N, Erlebacher G, Mendoza-Cortes JL. Polychrony as Chinampas. Algorithms. 2023; 16(4):193. https://doi.org/10.3390/a16040193
Chicago/Turabian StyleDolores-Cuenca, Eric, José Antonio Arciniega-Nevárez, Anh Nguyen, Amanda Yitong Zou, Luke Van Popering, Nathan Crock, Gordon Erlebacher, and Jose L. Mendoza-Cortes. 2023. "Polychrony as Chinampas" Algorithms 16, no. 4: 193. https://doi.org/10.3390/a16040193
APA StyleDolores-Cuenca, E., Arciniega-Nevárez, J. A., Nguyen, A., Zou, A. Y., Van Popering, L., Crock, N., Erlebacher, G., & Mendoza-Cortes, J. L. (2023). Polychrony as Chinampas. Algorithms, 16(4), 193. https://doi.org/10.3390/a16040193