
A Novel Short-Memory Sequence-Based Model for Variable-Length Reading Recognition of Multi-Type Digital Instruments in Industrial Scenarios


Abstract
1. Introduction
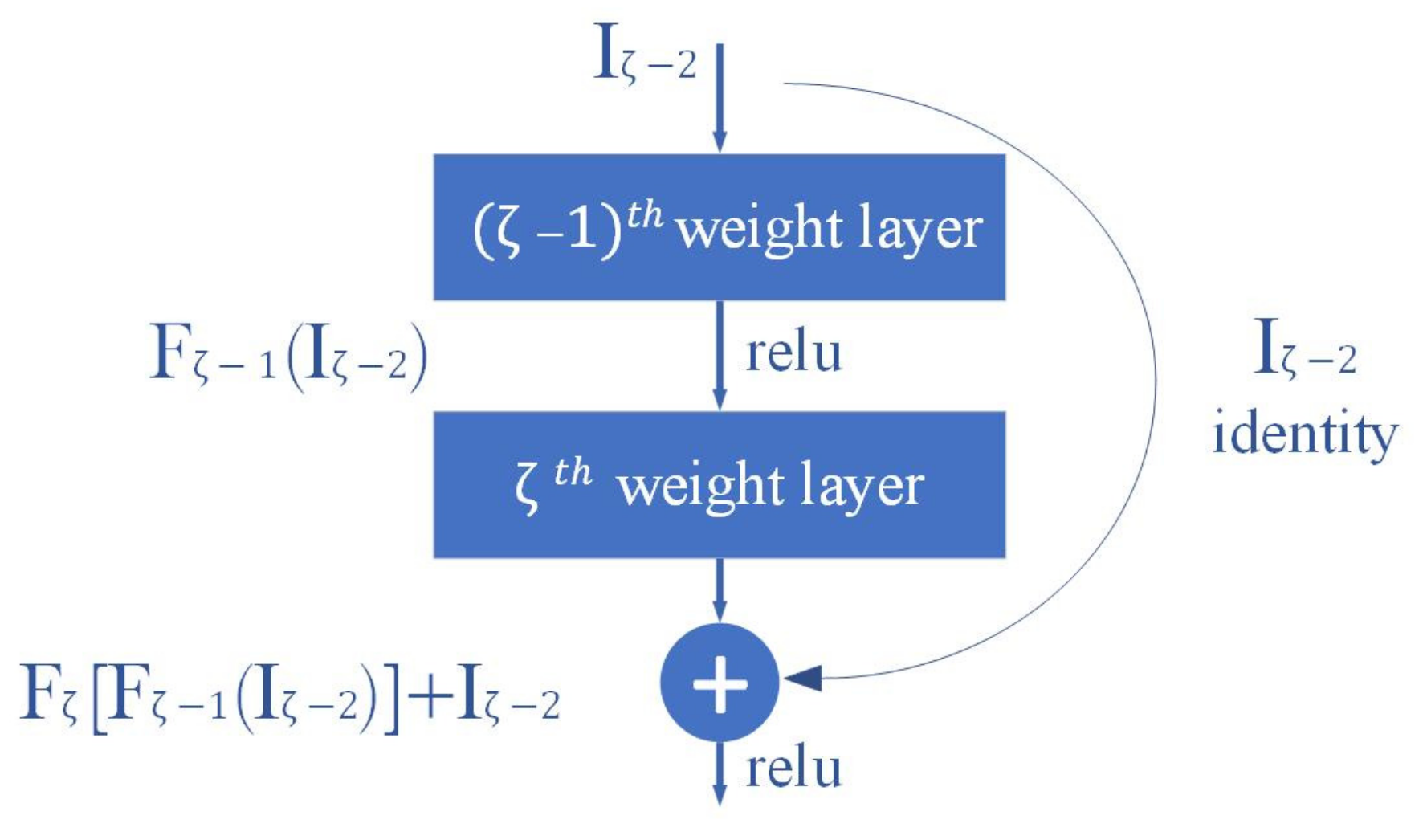
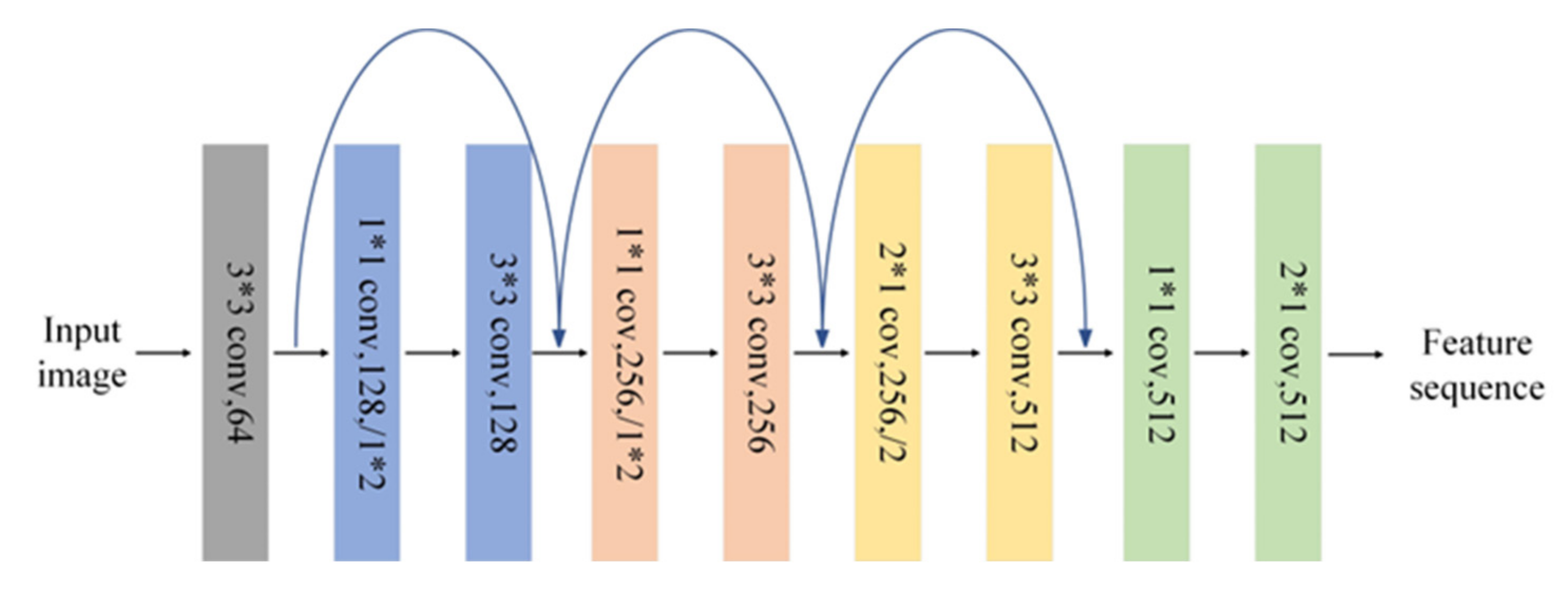
- Considering the variable font styles and variable aspect ratios of different kinds of digital instrument readings, as well as the difficulty in small characters recognition, we involve shortcut connection strategy into traditional convolutional structure to form a skip connection structure for extracting more complex and advanced character feature maps, taking advantage of the powerful high-dimensional function fitting ability of residual networks and deep network optimization capability;
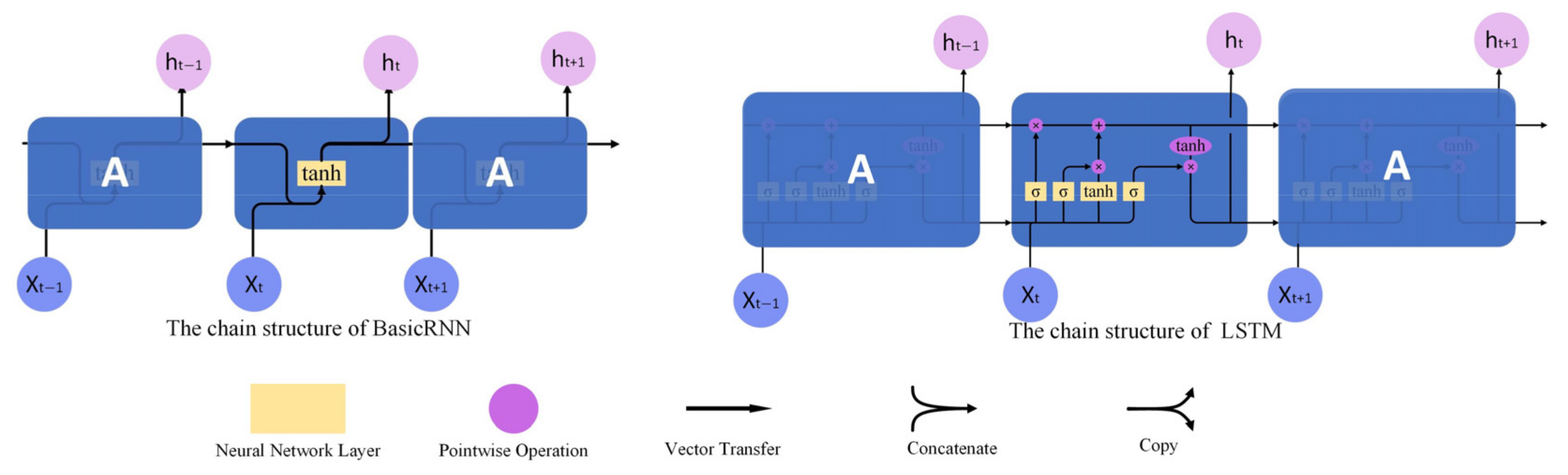
- In order to reduce the connection between the characters of the string, while emphasizing the local connections, we applied an RNN-based sequence module, which reduced the long-distance trending memory of the string and strengthen the short-distance dependencies among adjacent sequences, obviously improving the recognition accuracy and generalization of the model;
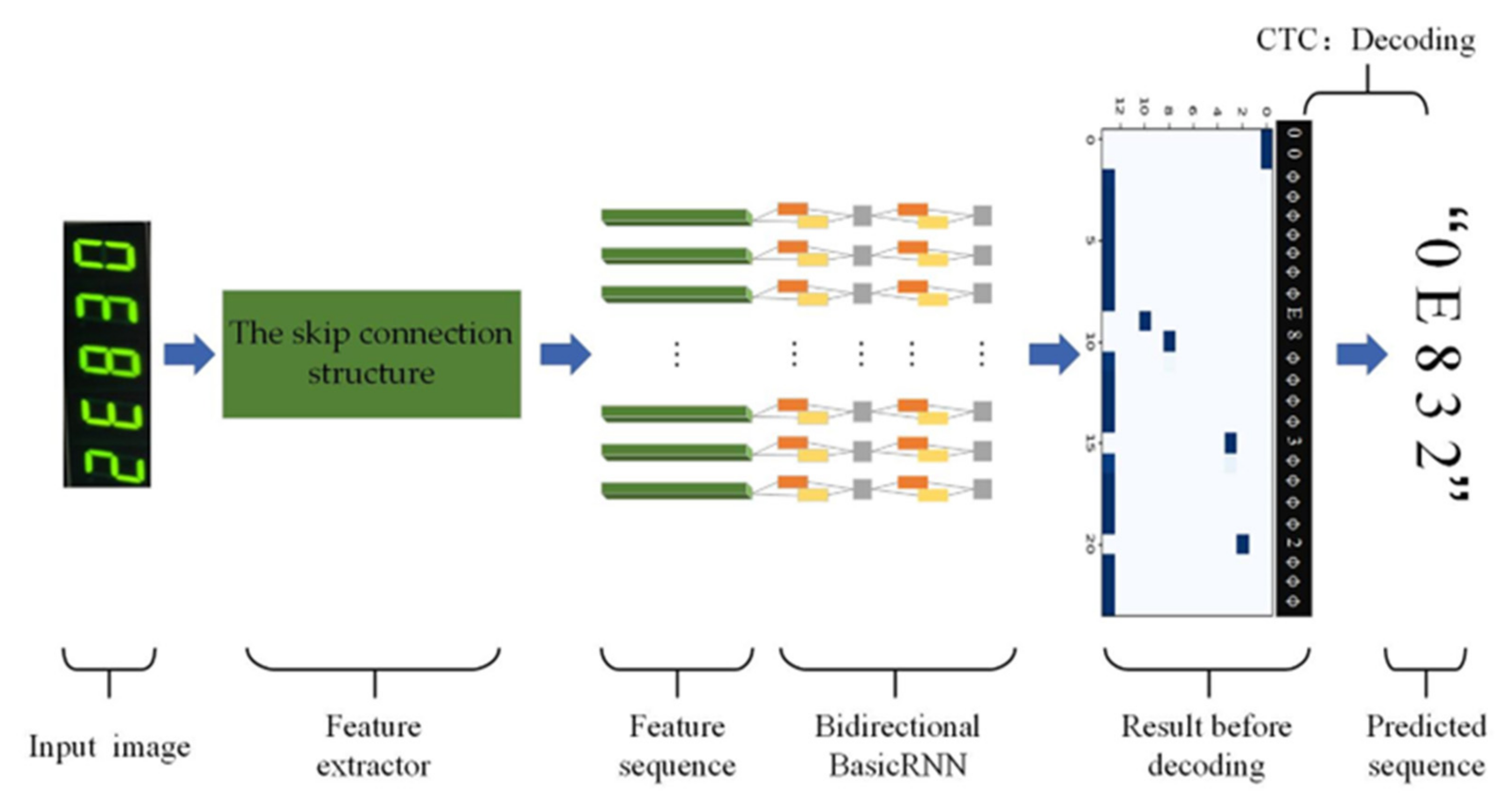
- Based on the above two innovations, we propose a novel short-memory sequence-based model, consisting of a feature extractor, an RNN-based sequence module and the CTC, which achieves promising results in the task of multi-type digital instrument reading recognition and performs robustly for invisible data.
2. Model Building
2.1. The Feature Extractor
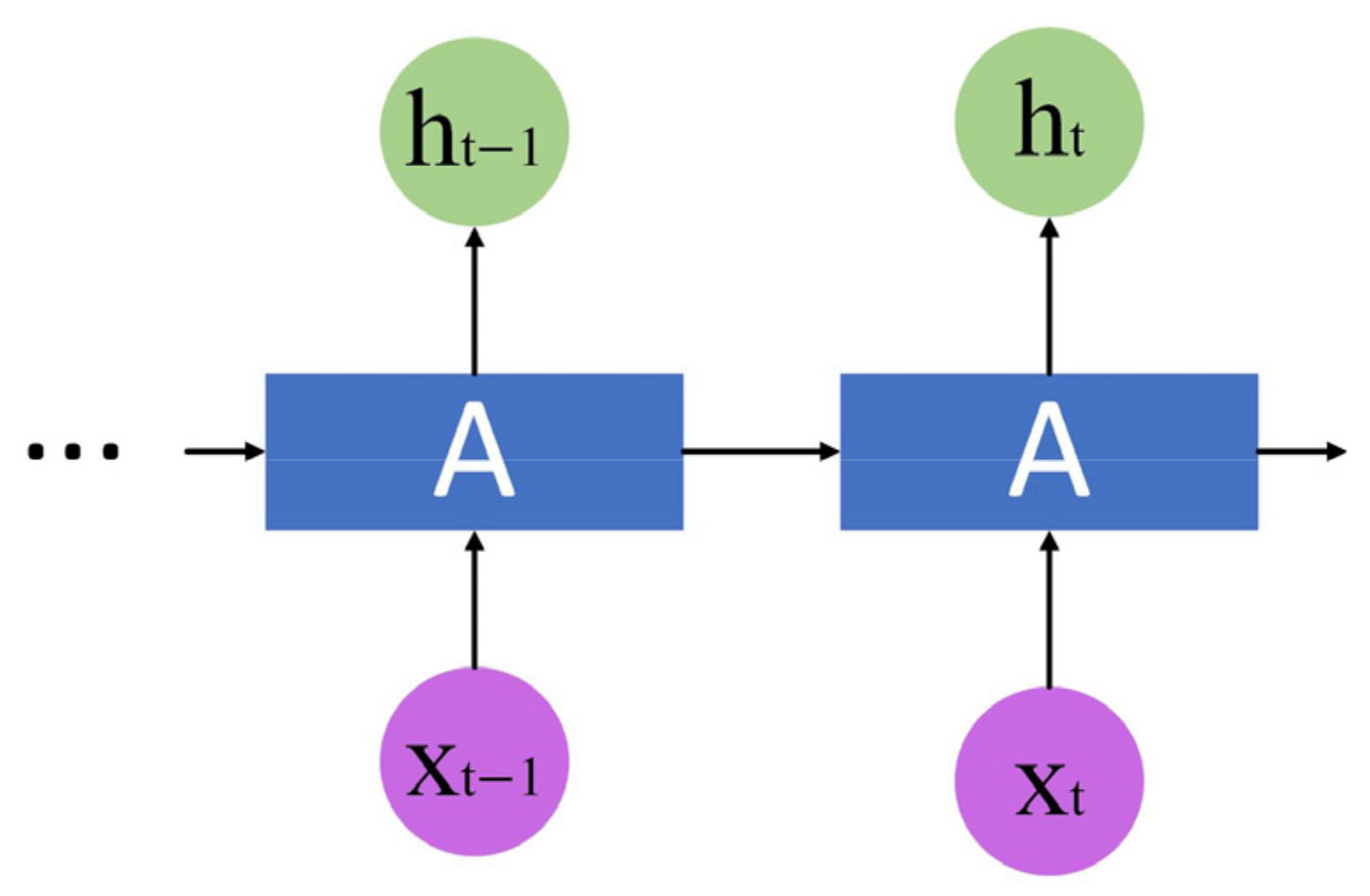
2.2. The Sequence Modeling Module
2.3. The Decoding Module: CTC
3. The Proposed Network
3.1. Architecture and Parameters of the Novel Short-Memory Sequence-Based Model
3.2. Network Training
4. Experimental Analysis
4.1. Datasets and Implementation Details
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Data Pre-Processing and Evaluation Metrics
4.2.1. Data Pre-Processing
4.2.2. Evaluation Metrics
4.3. Experimental Result and Analysis
4.3.1. The Effectiveness of the Feature Extractor in the Proposed Method
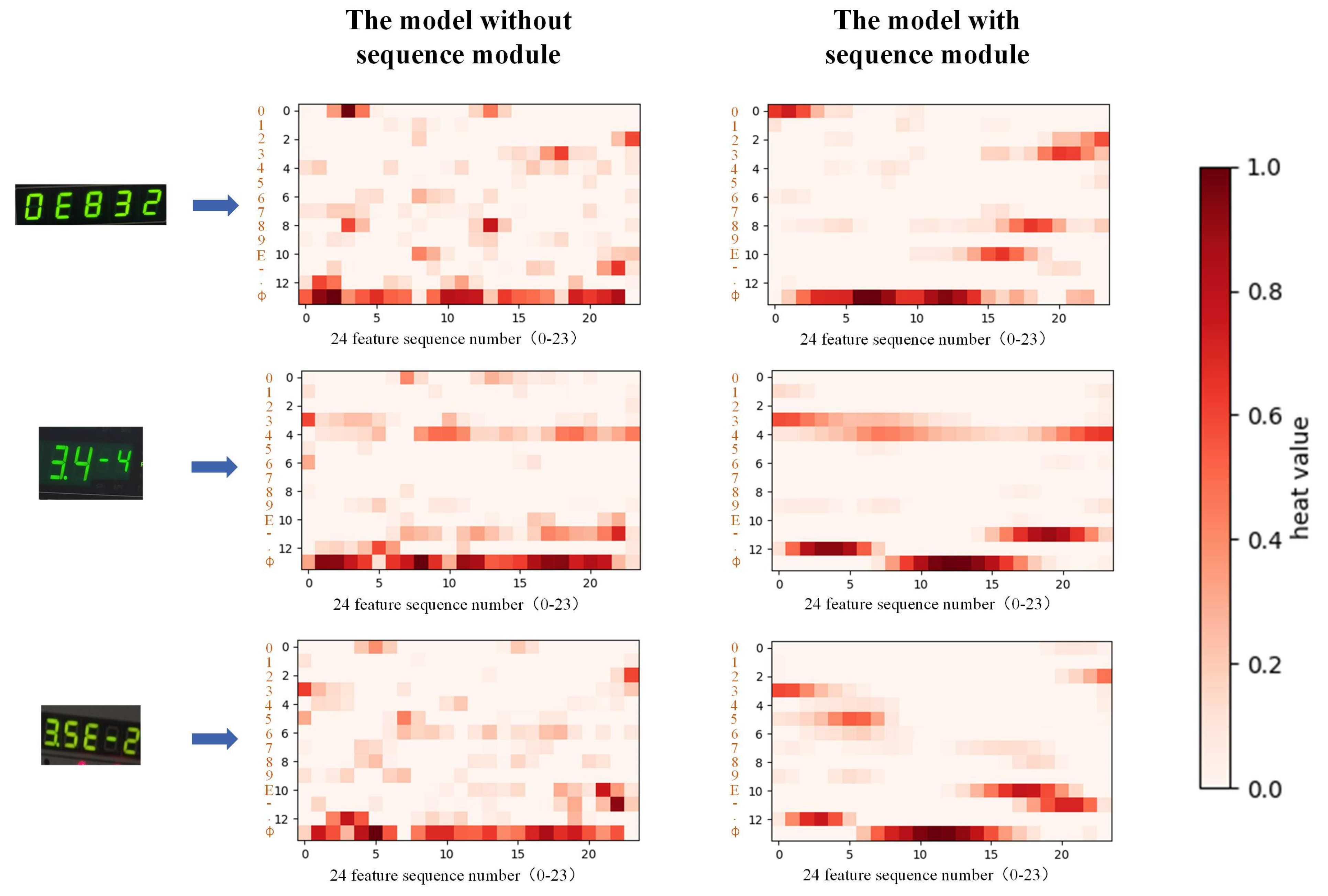
4.3.2. The Necessity of the Sequence Modeling
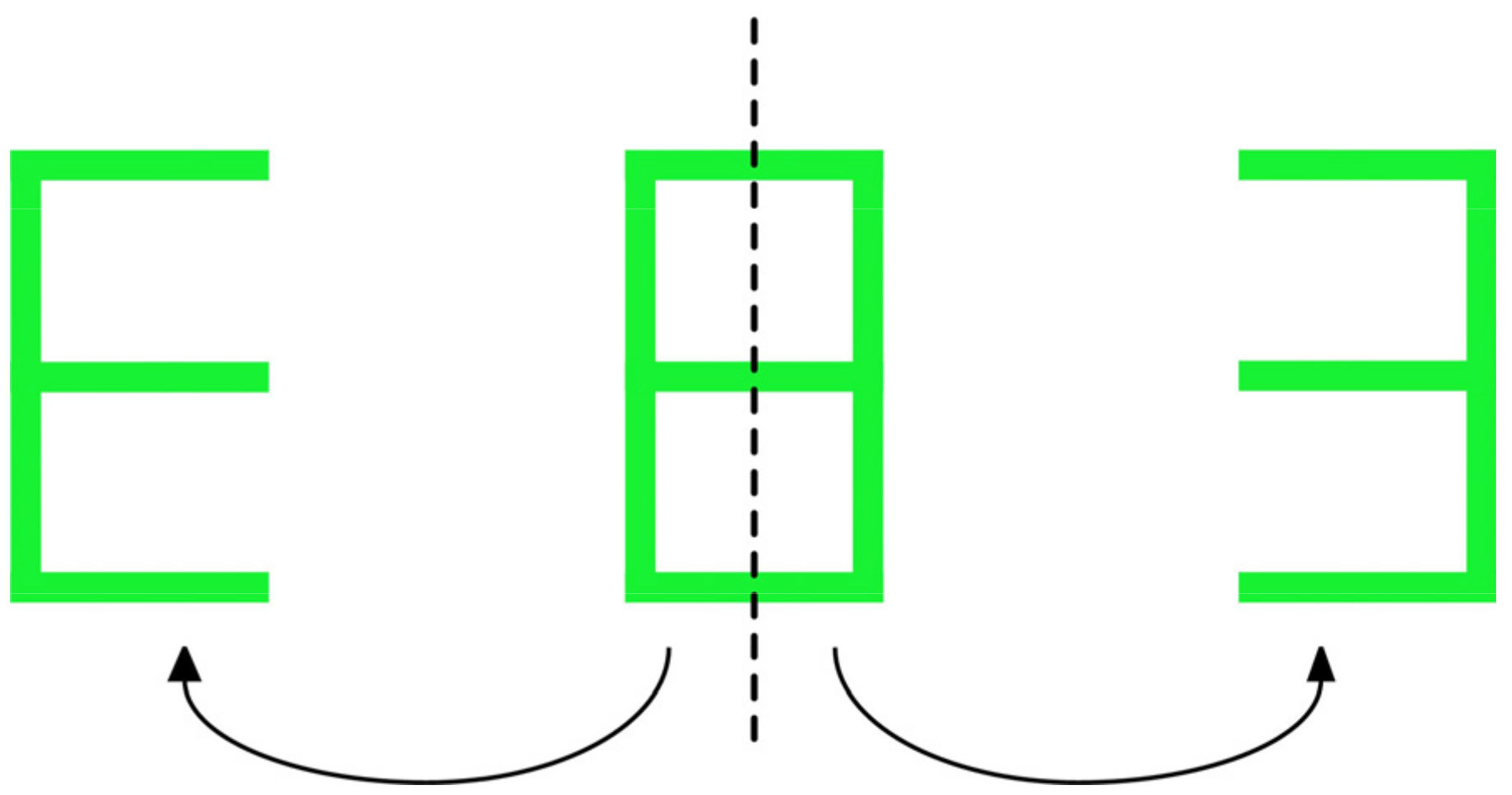
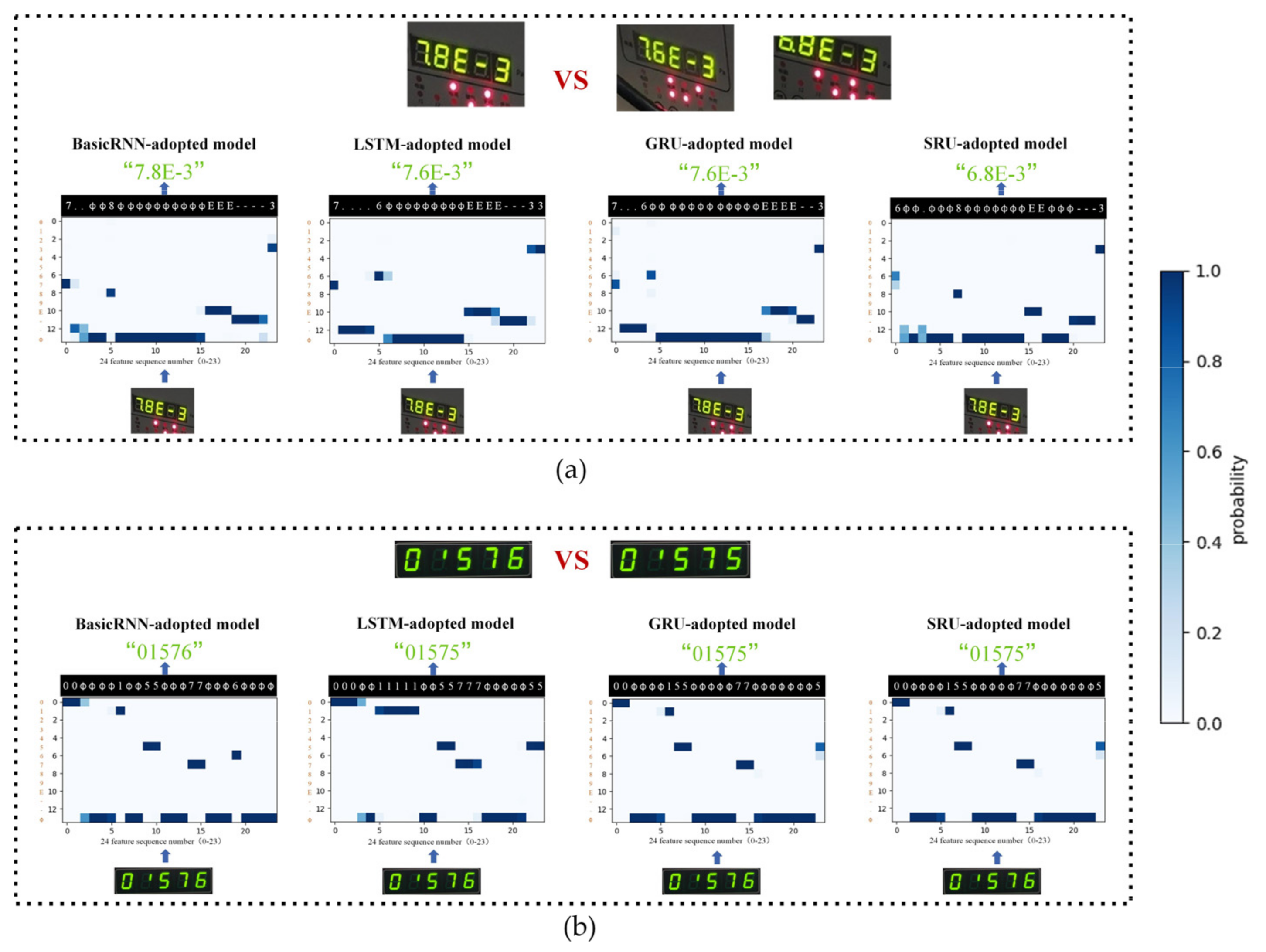
4.3.3. The Proposed Sequence Module Focuses on Short-Distance Dependencies to Improve Model Generalization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shan, F.; Sun, H.; Tang, X.; Shi, W.; Wang, X.; Li, X.; Zhang, X.; Zhang, H. Investigation on Intelligent Recognition System of Instrument Based on Multi-step Convolution Neural Network. Int. J. Comput. Commun. Eng. 2020, 9, 185–192. [Google Scholar] [CrossRef]
- Fang, J.; Guo, M.; Gu, X.S.; Wang, X.; Tan, S. Digital instrument identification based on block feature fusion SSD. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 616–620. [Google Scholar]
- Sun, H.; Shan, F.; Tang, X.; Shi, W.; Wang, X.; Li, X.; Cheng, Y.; Zhang, H. Intelligent Digital Recognition System Based on Vernier Caliper. IJCCE 2021, 10, 1–8. [Google Scholar] [CrossRef]
- Zhang, H.; Duan, H.; Zhang, S. A fast recognition method for display value of digital instrument. Comput. Eng. Appl. 2005, 41, 223–226. [Google Scholar]
- Wang, X.; Wang, J.; Wang, H. Research on Intelligent and Digital Recognition System and Character Recognition of Electrical Instruments. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018. [Google Scholar]
- Mo, W.; Pei, L.; Huang, Q.; Liao, W. Digital Multimeter Reading Recognition for Automation Verification. In Proceedings of the AIAM2020: 2nd International Conference on Artificial Intelligence and Advanced Manufacture, Manchester, UK, 15–17 October 2020. [Google Scholar]
- Zhang, J.; Zuo, L.; Gao, J.; Zhao, S. Digital instruments recognition based on PCA-BP neural network. In Proceedings of the Technology, Networking, Electronic & Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017. [Google Scholar]
- Wu, C.; Wu, Q.; Yuan, C.; Li, P.; Zhang, Y.; Xiao, Y. Multimeter digital recognition based on feature coding detection. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 14–16 October 2017. [Google Scholar]
- Liu, Z.; Luo, Z.; Gong, P.; Guo, M. The research of character recognition algorithm for the automatic verification of digital instrument. In Proceedings of the 2013 2nd International Conference on Measurement, Information and Control (ICMIC), Harbin, China, 16–18 August 2013. [Google Scholar]
- Zhang, Z.; Chen, G.; Li, J.; Ma, Y.; Ju, N. The research on digit recognition algorithm for automatic meter reading system. In Proceedings of the Intelligent Control & Automation, Jinan, China, 7–9 July 2010. [Google Scholar]
- Ma, B.; Meng, X.; Ma, X.; Li, W.; Hao, L.; Jiang, D. Digital Recognition Based on Image Device Meters. In Proceedings of the 2010 Second WRI Global Congress on Intelligent Systems, Wuhan, China, 16–17 December 2010. [Google Scholar]
- Zhou, W.; Peng, J.; Han, Y. Deep Learning-based Intelligent Reading Recognition Method of the Digital Multimeter. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 3272–3277. [Google Scholar]
- Chen, H.; Xin, W.; Bo, X. Study on digital display instrument recognition for substation based on pulse coupled neural network. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Melbourne, Australia, 17–20 October 2021. [Google Scholar]
- Peng, G.; Du, B.; Li, Z.; He, D. Machine vision-based, digital display instrument positioning and recognition. Int. J. Ind. Eng. 2022, 29, 230–243. [Google Scholar]
- Montazzolli, S.; Jung, C.R. Real-Time Brazilian License Plate Detection and Recognition Using Deep Convolutional Neural Networks. In Proceedings of the 2017 30th SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Niteroi, Brazil, 17–20 October 2017. [Google Scholar]
- Hochuli, A.G.; Oliveira, L.S.; de Souza Britto, A.; Sabourin, R. Segmentation-Free Approaches for Handwritten Numeral String Recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Lei, L.; Zhang, H.; Liu, Q.; Li, X. Research on Reading Recognition Algorithm of Industrial Instruments Based on Faster-RCNN. In Proceedings of the 2021 International Conference on Networking, Communications and Information Technology (NetCIT), Manchester, UK, 26–27 December 2021; pp. 148–153. [Google Scholar]
- Bourbakis, N.G.; Koutsougeras, C.; Jameel, A. Handwriting recognition using a reduced character method and neural nets. In Proceedings of the Nonlinear Image Processing VI, San Jose, CA, USA, 28 March 1995; Volume 2424, pp. 592–601. [Google Scholar]
- Graves, A.; SFernández Gomez, F. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; Association for Computing Machinery: New York, NY, USA, 2006. [Google Scholar]
- Sun, H.; Fu, M.; Abdussalam, A.; Huang, Z.; Sun, S.; Wang, W. License Plate Detection and Recognition Based on the YOLO Detector and CRNN-12. In Proceedings of the 4th International Conference on Signal and Information Processing, Networking and Computers (ICSINC), Qingdao, China, 23–25 May 2018; Volume 494, pp. 66–74. [Google Scholar] [CrossRef]
- Li, X.; Wen, Z.; Hua, Q. Vehicle License Plate Recognition Using Shufflenetv2 Dilated Convolution for Intelligent Transportation Applications in Urban Internet of Things. Wirel. Commun. Mob. Comput. 2022, 2022, 3627246. [Google Scholar] [CrossRef]
- Wei, D.U.; Zhuo, W.N. Uncategorized Text Verification Code Recognition Based on CTC Model. Comput. Mod. 2018, 9, 48. [Google Scholar]
- Ma, J. Neural CAPTCHA networks. Appl. Soft Comput. 2020, 97 Pt 1, 106769. [Google Scholar] [CrossRef]
- Zhan, H.; Wang, Q.; Lu, Y. Handwritten Digit String Recognition by Combination of Residual Network and RNN-CTC; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Messina, R.; Louradour, J. Segmentation-free handwritten Chinese text recognition with LSTM-RNN. In Proceedings of the International Conference on Document Analysis & Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2016. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Alsharif, O.; Pineau, J. End-to-End Text Recognition with Hybrid HMM Maxout Models. arXiv 2013, arXiv:1310.1811. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Werbos, P.J. Backpropagation through time: What it does and how to do it. Proc. IEEE 1990, 78, 1550–1560. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Lei, T.; Zhang, Y. Training RNNs as Fast as CNNs. arXiv 2017, arXiv:1709.02755. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Training Samples | Number of Testing Samples | Notes |
|---|---|---|---|
| A | 4213 | 412 | Containing 1–6 digits images, the testing data and training data are in equilibrium distribution on the kinds of strings, character fonts, character spacing and aspect ratios. |
| B | 4150 | 421 | Containing 1–6 digits images, about 23% of the reading strings in the test set were not found in the training set, while 77% pictures in testing data are quite different from training data for character fonts or character spacing and aspect ratios. |
| Layer | Input Shape | Kerner Size | Filter | Stride | Output Shape |
|---|---|---|---|---|---|
| Conv1 | (batch,100,32,1) | 3 × 3 | 64 | 2 × 2 | (batch,49,15,64) |
| MaxPool1 | (batch,49,15,64) | 2 × 2 | - | 1 × 2 | (batch,48,7,64) |
| Conv2_x | (batch,48,7,64) | 1 × 1, 128, 1 × 2 | (batch,48,4,128) | ||
| 3 × 3, 128, 1 × 1 | |||||
| Conv3_x | (batch,48,4,64) | 1 × 1, 256, 1 × 2 | (batch,48,4,128) | ||
| 3 × 3, 256, 1 × 1 | |||||
| Conv4_x | (batch,48,2,128) | 2 × 1, 512, 2 × 2 | (batch,48,4,128) | ||
| 3 × 3, 512, 1 × 1 | |||||
| Conv5 | (batch,24,1,512) | 1 × 1 | 512 | 1 × 1 | (batch,24,1,512) |
| Conv6 | (batch,24,1,512) | 2 × 1 | 512 | 1 × 1 | (batch,24,1,512) |
| Bi-BasicRNN | (batch,24,1,512) | Hidden units:256 | (batch,24,1,512) | ||
| Bi-BasicRNN | (batch,24,1,512) | Hidden units:256 | (batch,24,1,512) | ||
| CTC Layer | - | - | - | ||
| Network Model | Train on A1 Test on A2 | Train on B1 Test on B2 | ||
|---|---|---|---|---|
| The skip connection structure + CTC | 0.969 | −13 | 0.831 | −95 |
| The plain CNN structure + CTC | 0.958 | −17 | 0.740 | −143 |
| Network Model | Train on A1 Test on A2 |
|---|---|
| The model without sequence module | 0.969 |
| The model with sequence module | 0.990 |
| Network Model | Train on B1 Test on B2 | |
|---|---|---|
| The Number of Memorial Errors | ||
| The BasicRNN-adopted model | 0.897 | 6 |
| The LSTM-adopted model | 0.815 | 44 |
| The GRU-adopted model | 0.839 | 36 |
| The SRU-adopted model | 0.808 | 35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, S.; Li, X.; Yao, Y.; Yang, S. A Novel Short-Memory Sequence-Based Model for Variable-Length Reading Recognition of Multi-Type Digital Instruments in Industrial Scenarios. Algorithms 2023, 16, 192. https://doi.org/10.3390/a16040192
Wei S, Li X, Yao Y, Yang S. A Novel Short-Memory Sequence-Based Model for Variable-Length Reading Recognition of Multi-Type Digital Instruments in Industrial Scenarios. Algorithms. 2023; 16(4):192. https://doi.org/10.3390/a16040192
Chicago/Turabian StyleWei, Shenghan, Xiang Li, Yong Yao, and Suixian Yang. 2023. "A Novel Short-Memory Sequence-Based Model for Variable-Length Reading Recognition of Multi-Type Digital Instruments in Industrial Scenarios" Algorithms 16, no. 4: 192. https://doi.org/10.3390/a16040192
APA StyleWei, S., Li, X., Yao, Y., & Yang, S. (2023). A Novel Short-Memory Sequence-Based Model for Variable-Length Reading Recognition of Multi-Type Digital Instruments in Industrial Scenarios. Algorithms, 16(4), 192. https://doi.org/10.3390/a16040192