
Examination of Lemon Bruising Using Different CNN-Based Classifiers and Local Spectral-Spatial Hyperspectral Imaging

 , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Collecting the Samples
2.2. Hardware System for Data Collection
2.3. Removal of the Noisy Spectral Data
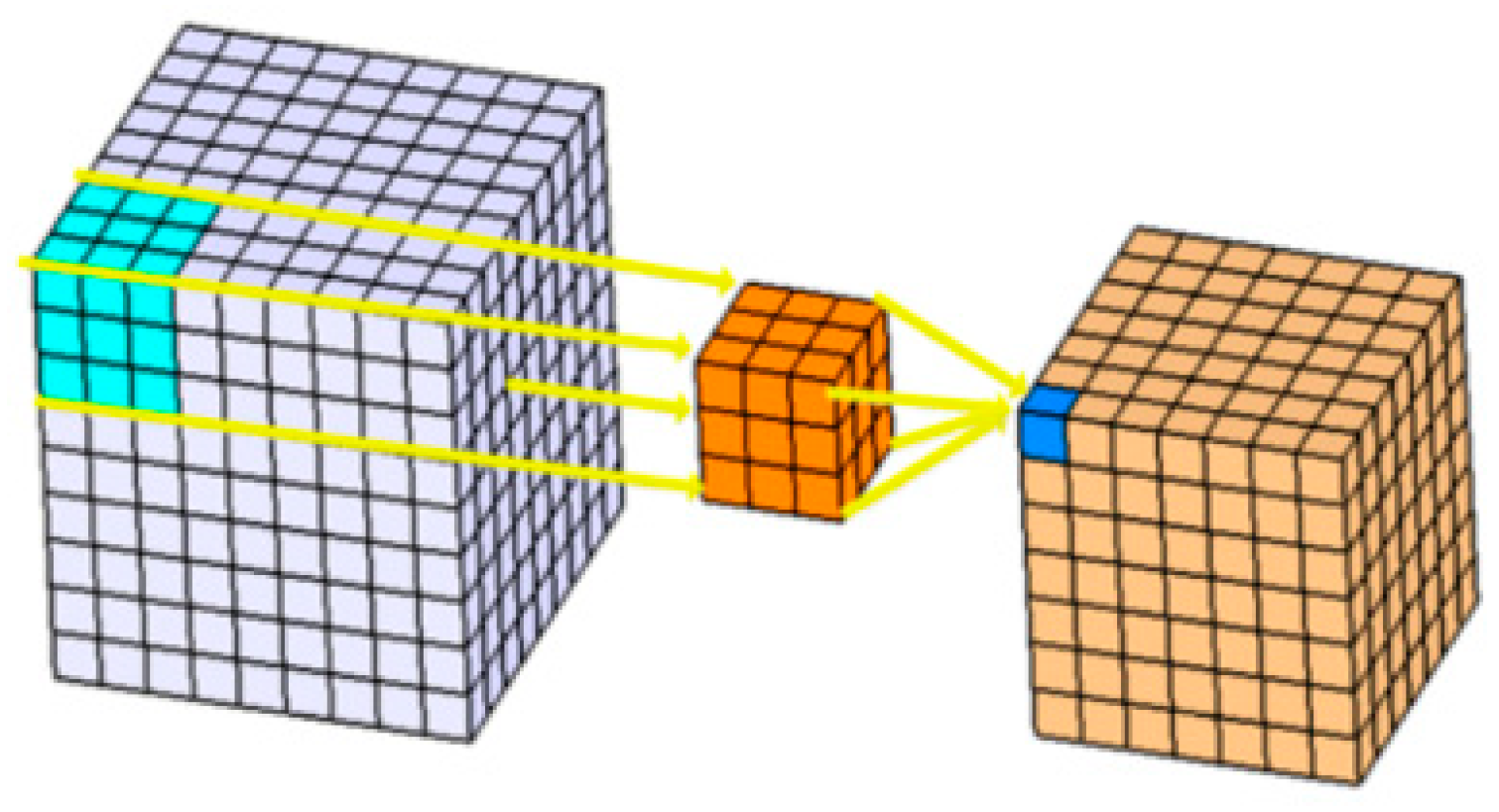
2.4. The 3-Dimensional (3D) Structure of the Hyperspectral Imaging Fruit Samples
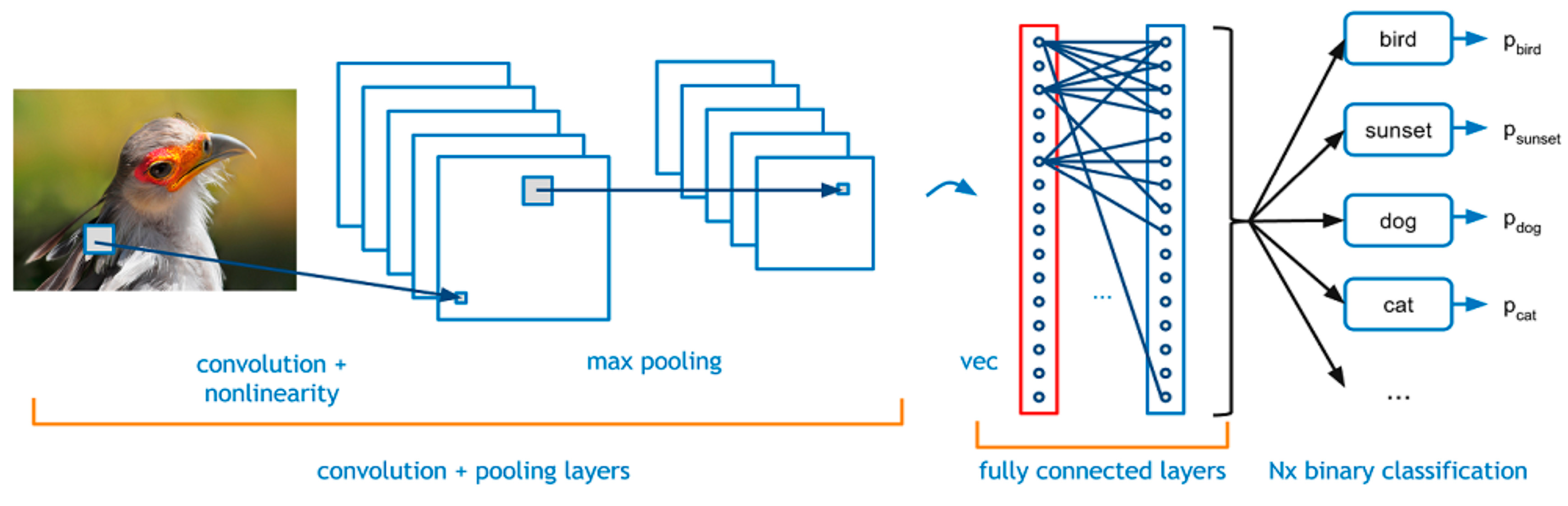
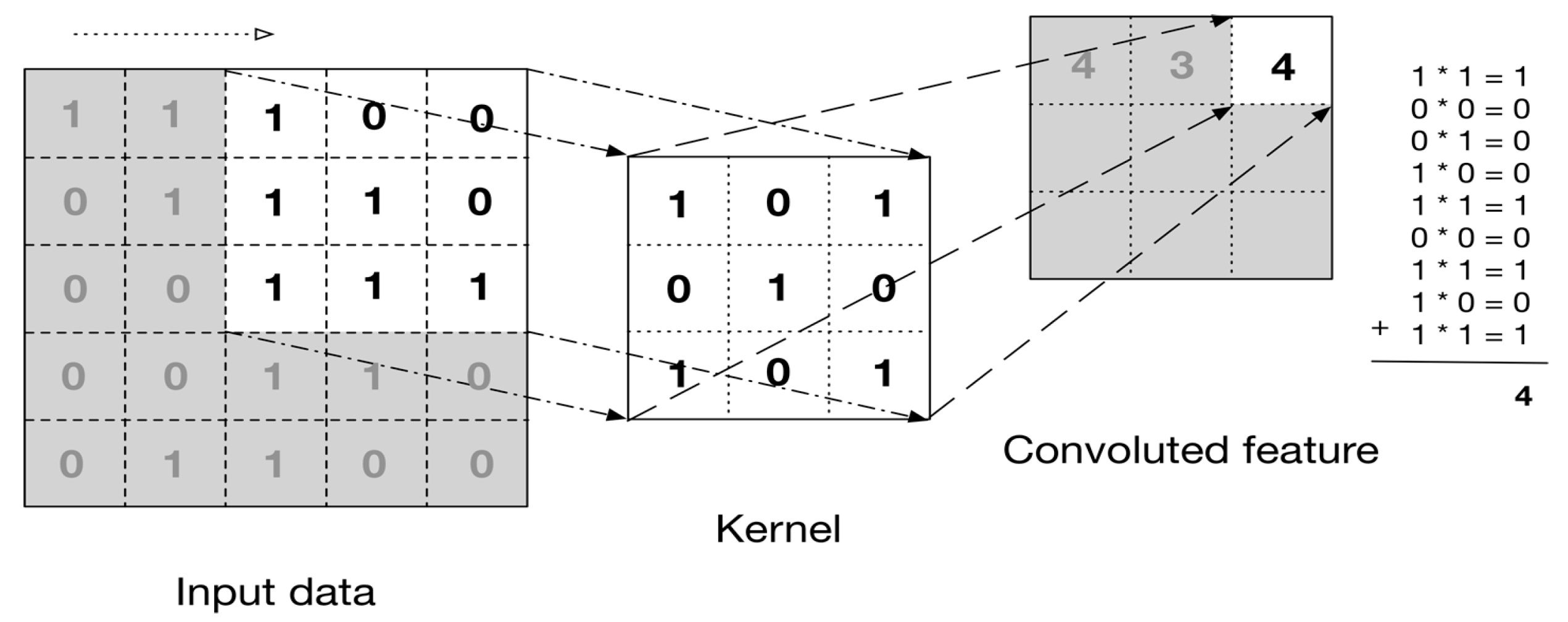
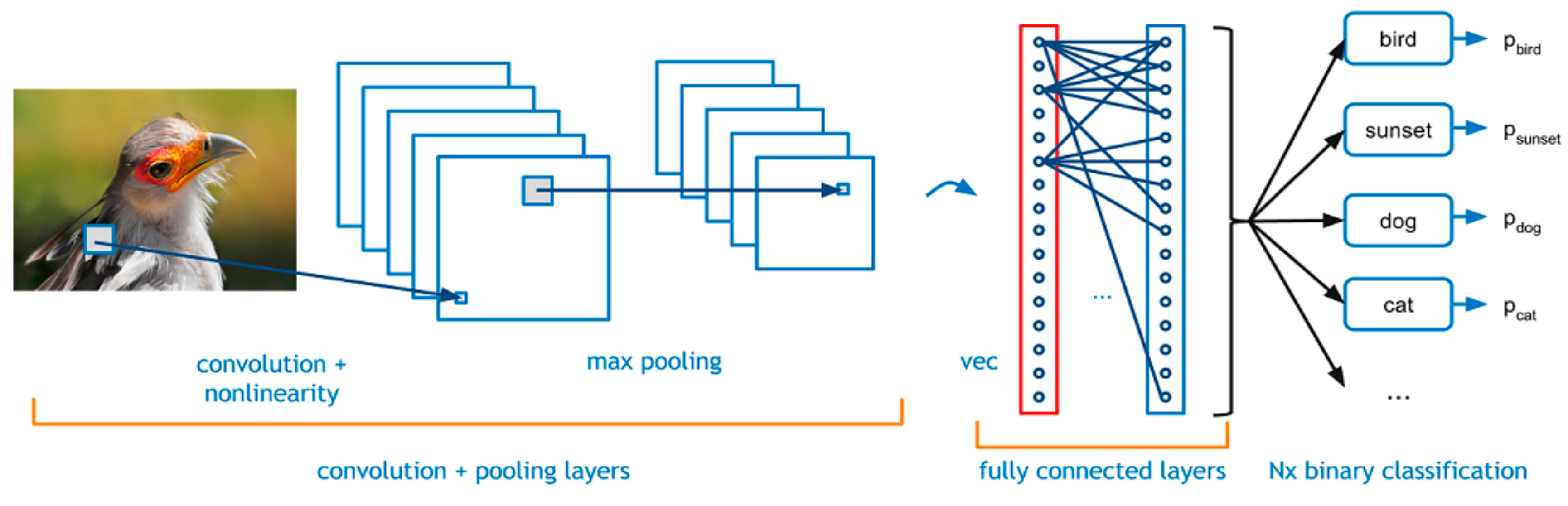
2.5. 3D-Convolutional Neural Network Classifiers
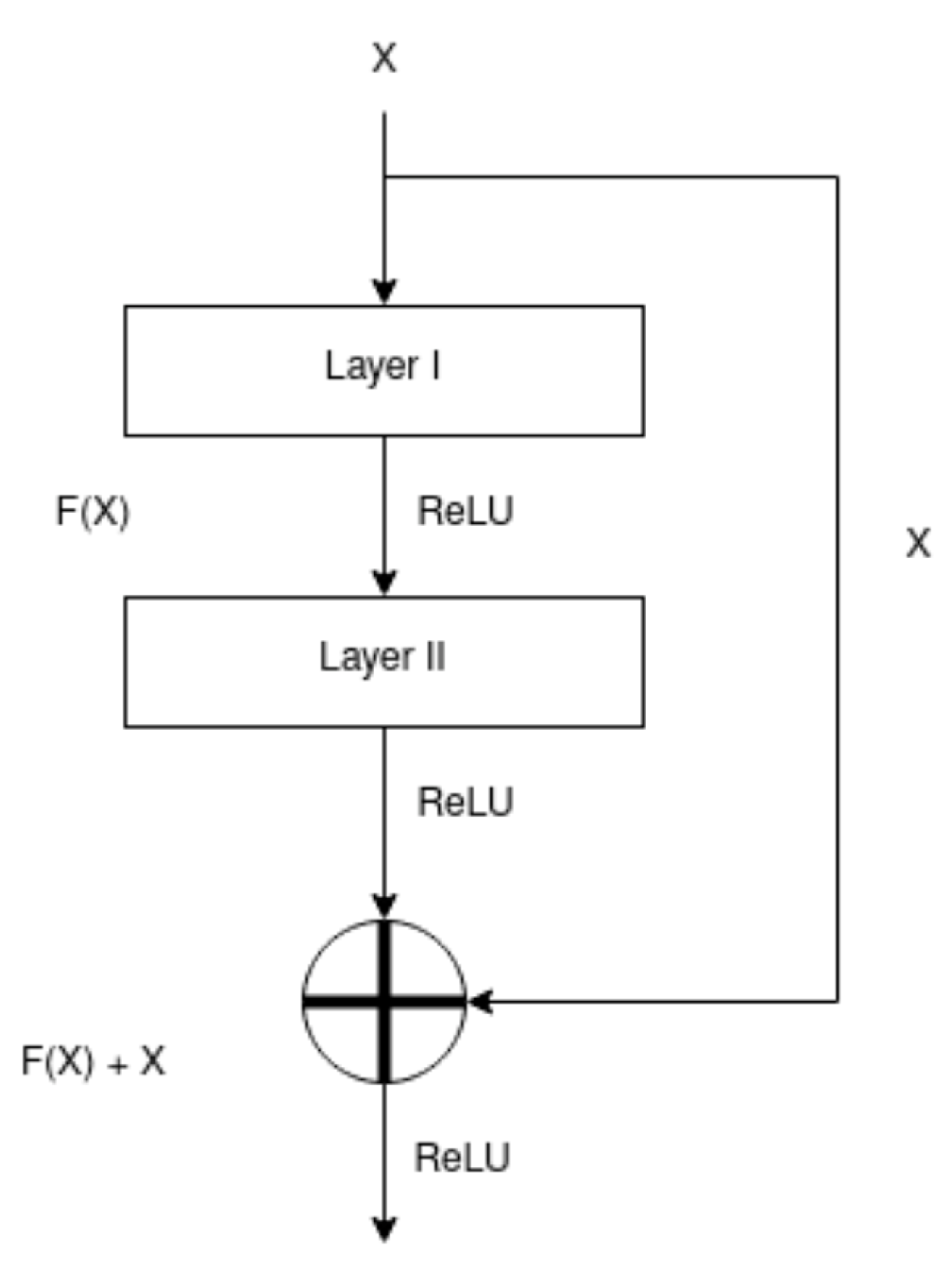
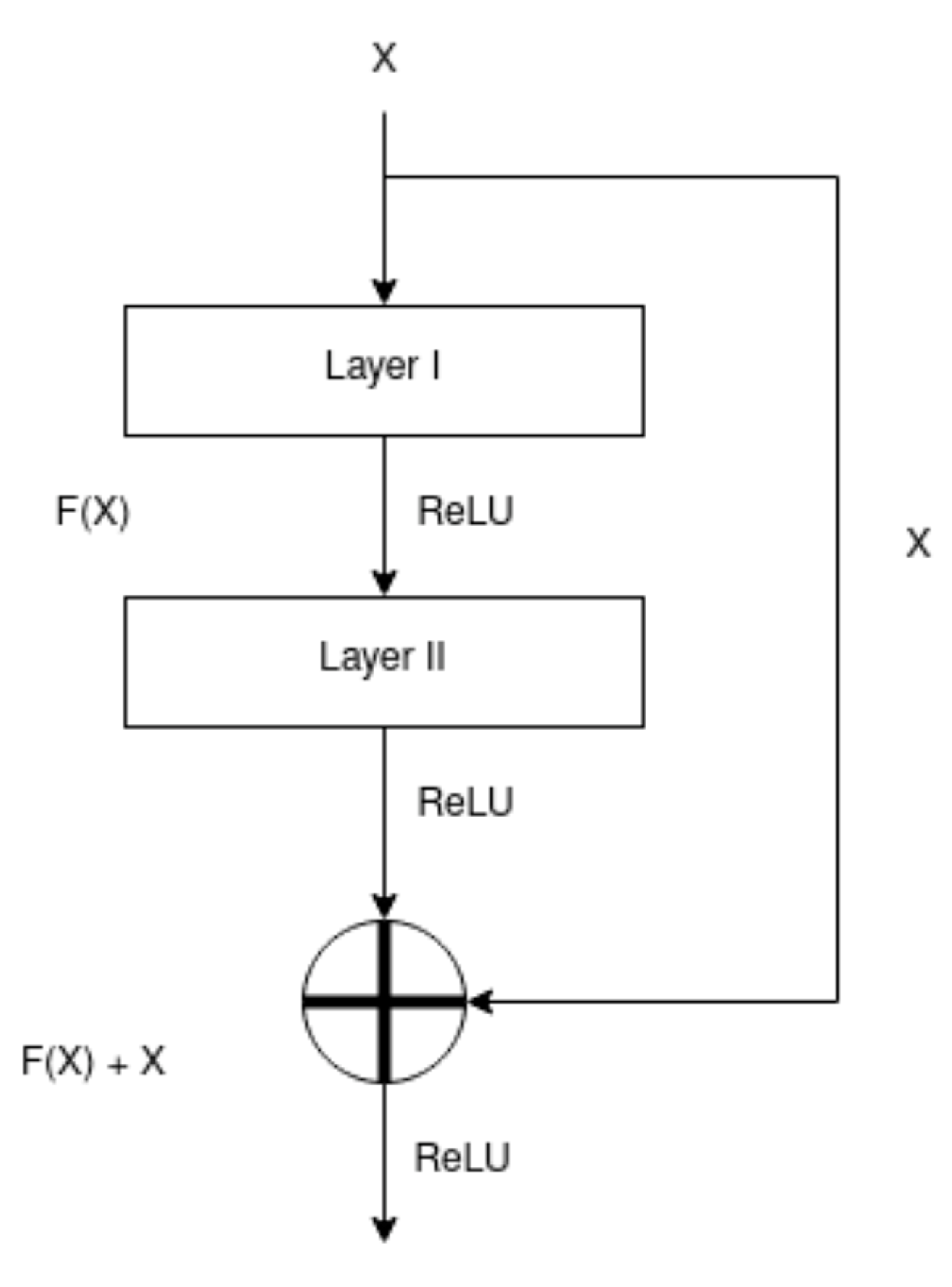
2.5.1. ResNet Architecture
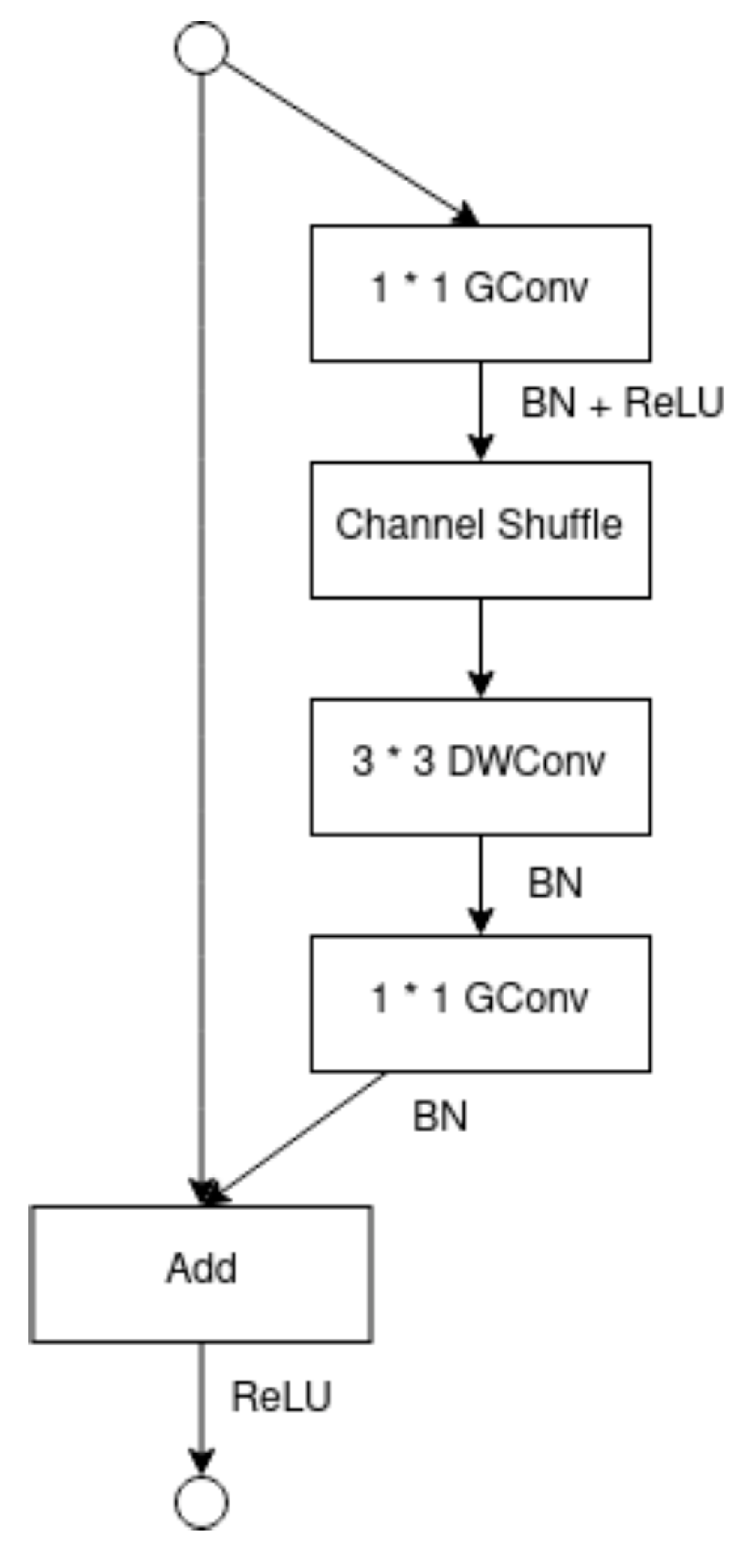
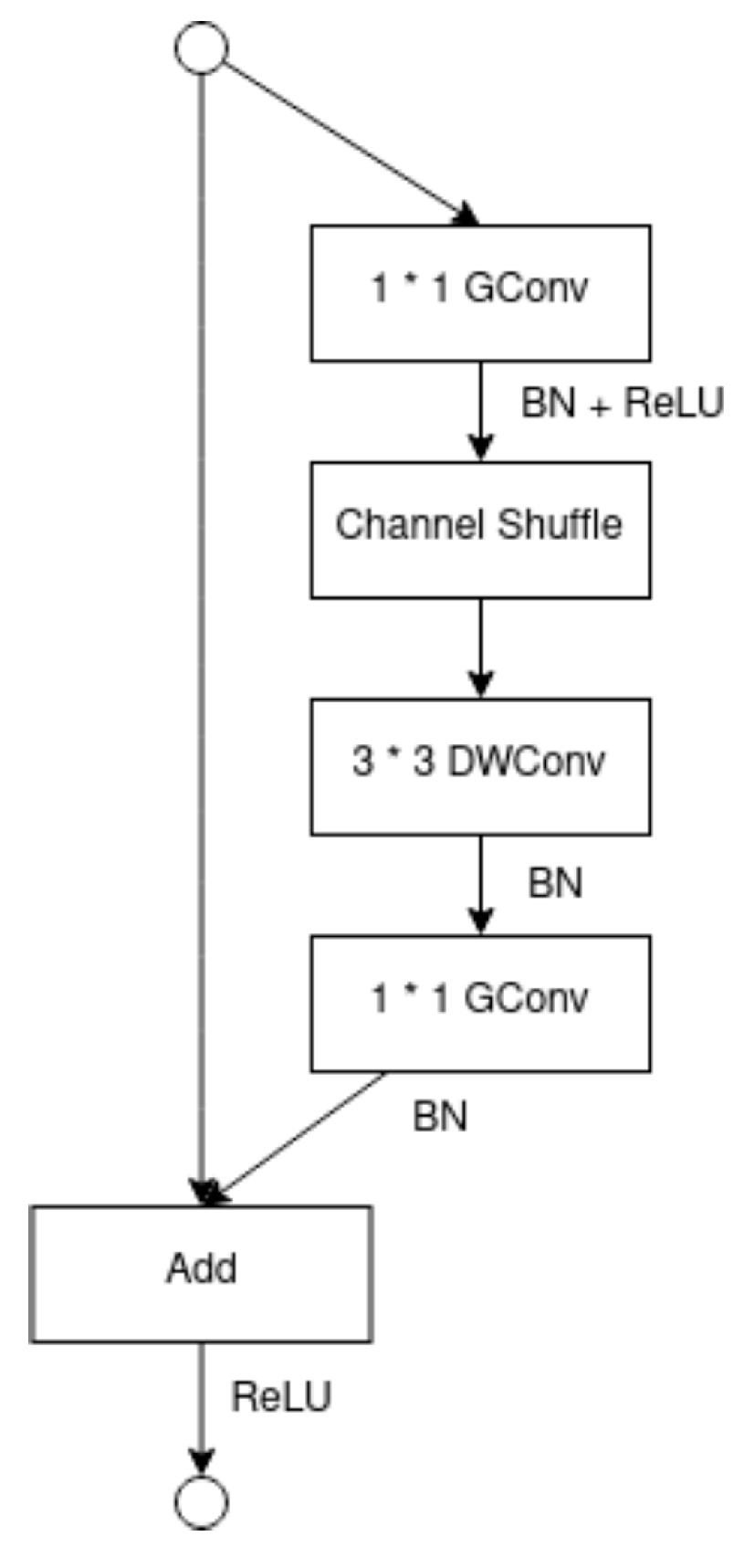
2.5.2. ShuffleNet Architecture
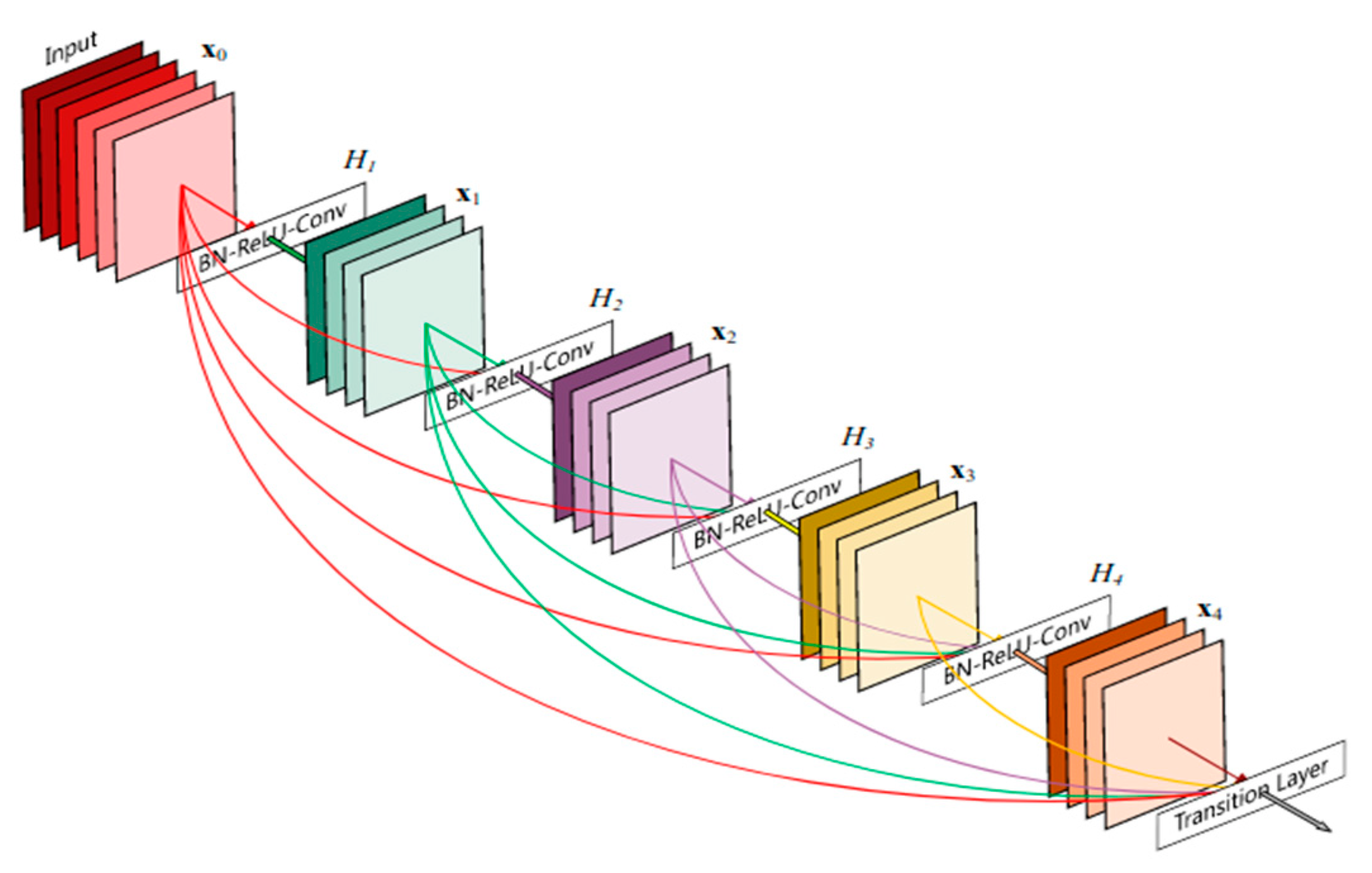
2.5.3. DenseNet Architecture
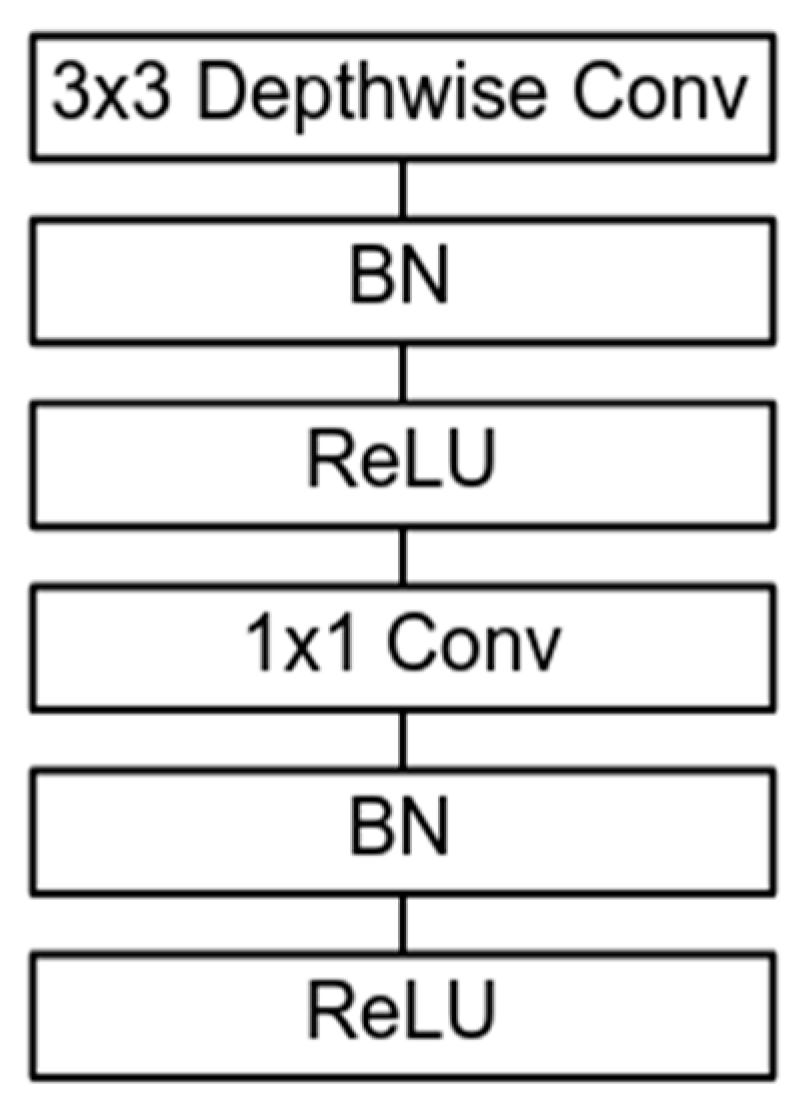
2.5.4. MobileNet Architecture
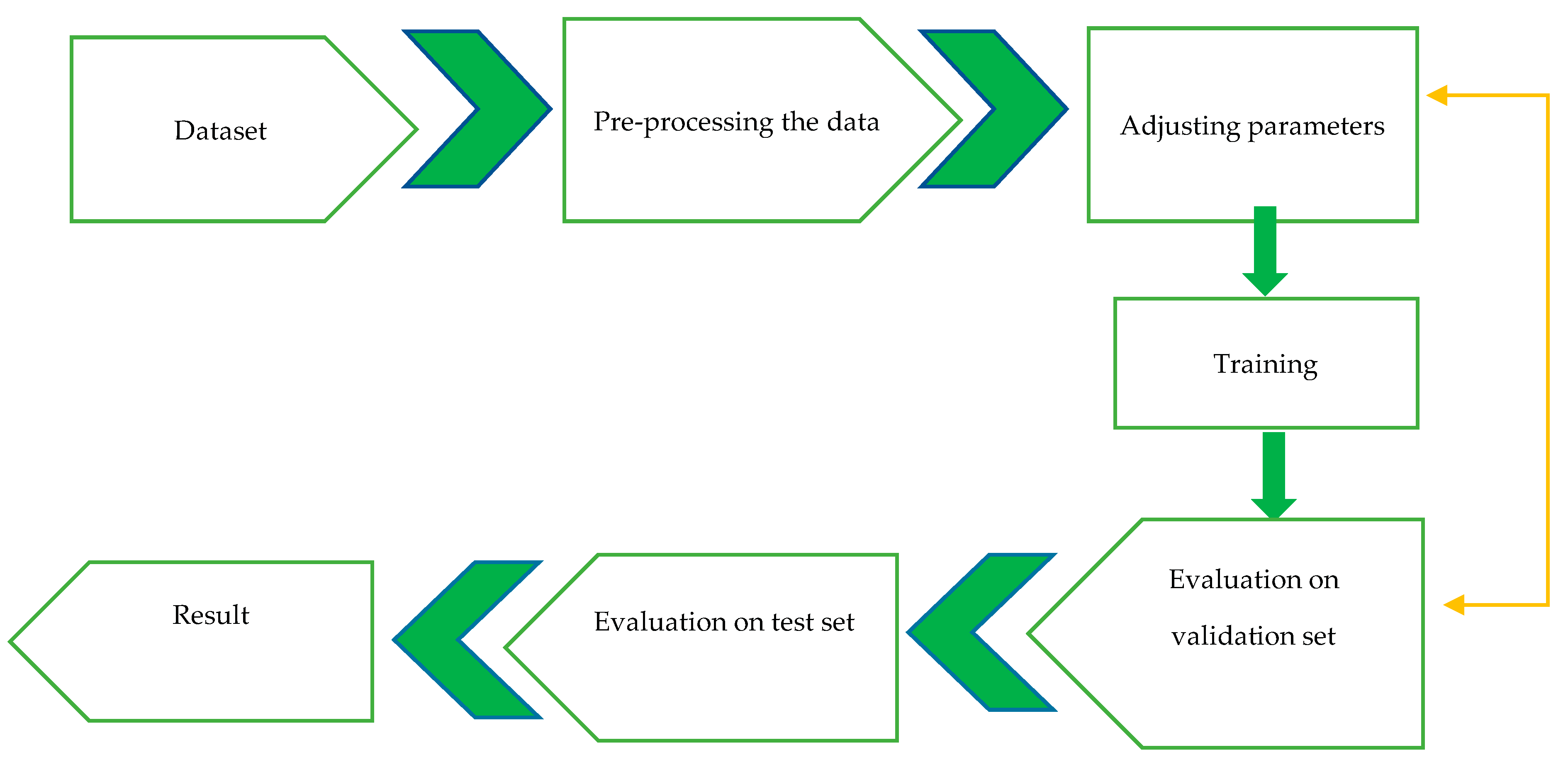
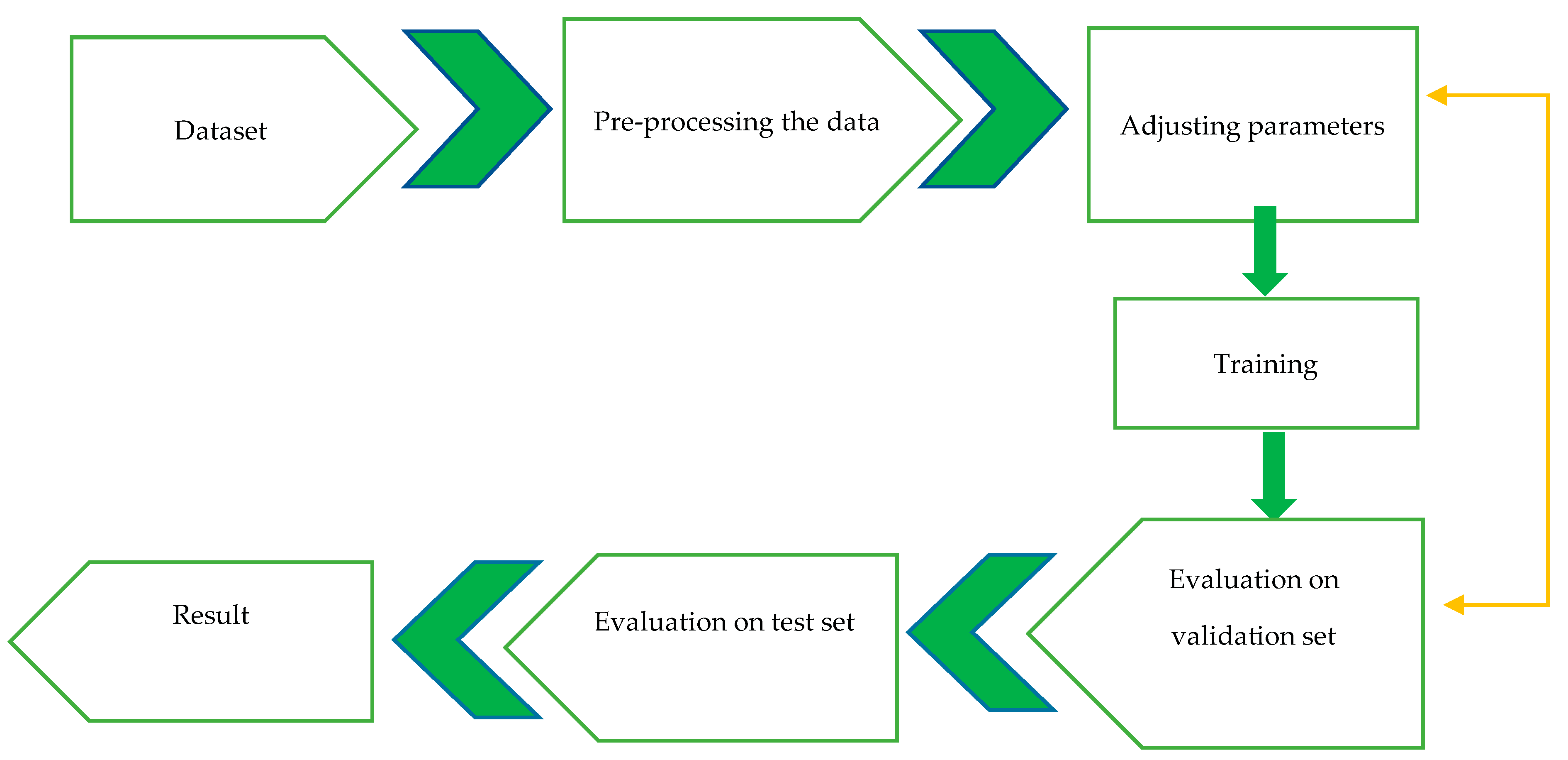
2.6. Train, Test and Validation Disjoint Sets: A Partition of the Input Dataset
3. Results
3.1. 3D-CNN Model Parameter, NN Size and Training Time
3.2. The Final Deep Network Classifiers Structure
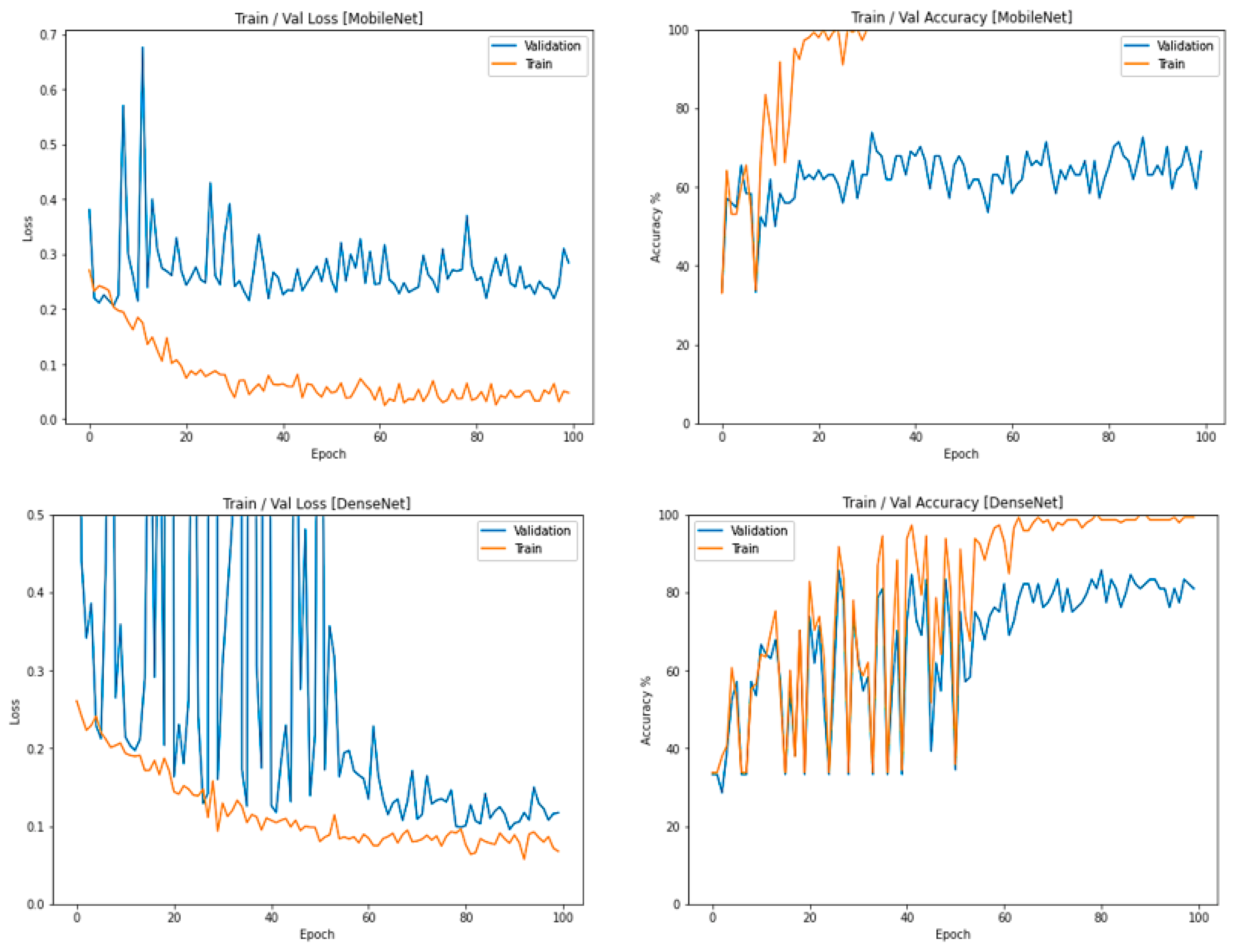
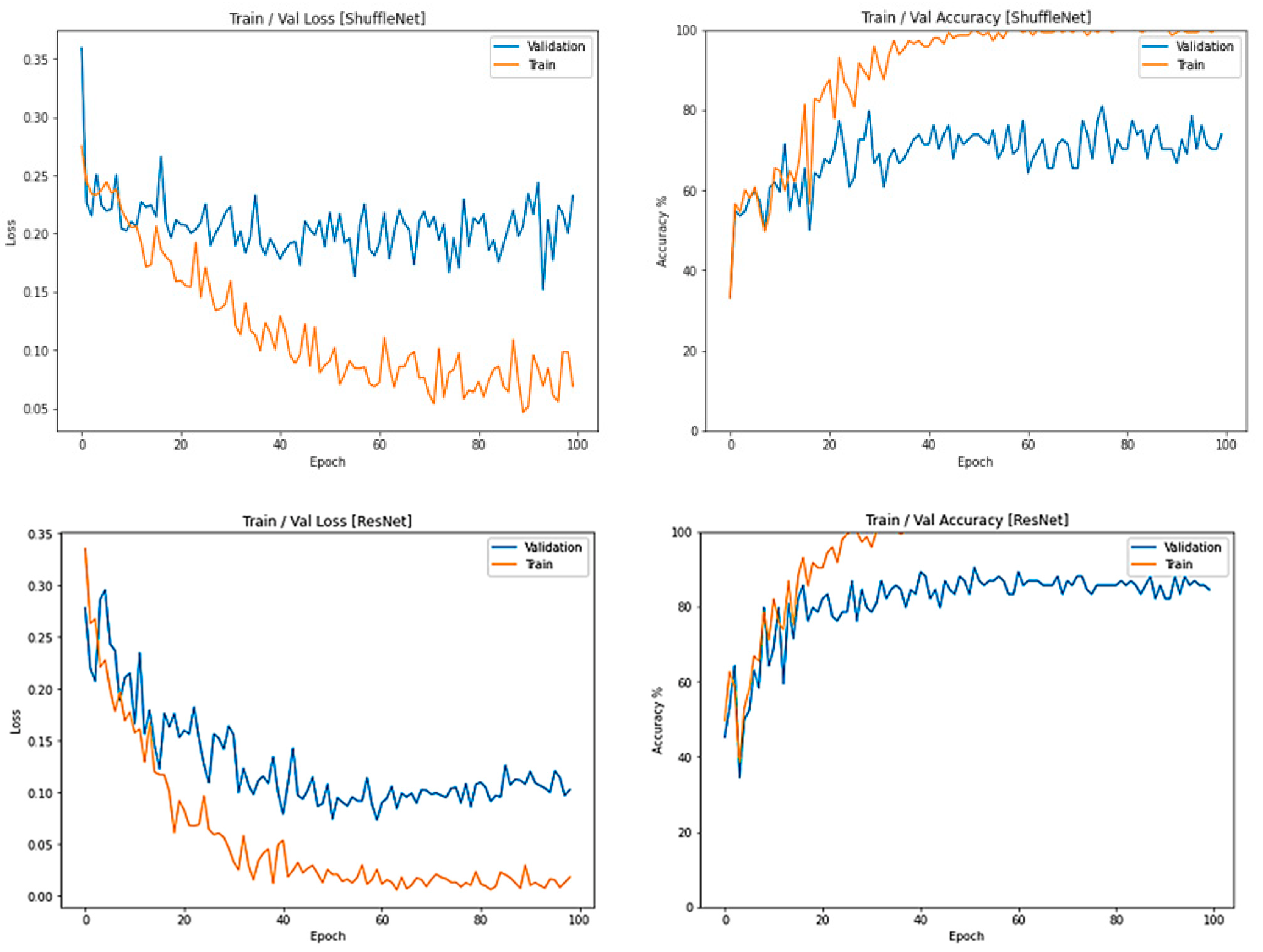
3.3. The Behavior and Performance of All Four Deep Learning Classifiers after the Training Phase: Cross Entropy (CE) Loss Function and Output Classification Accuracy (%)
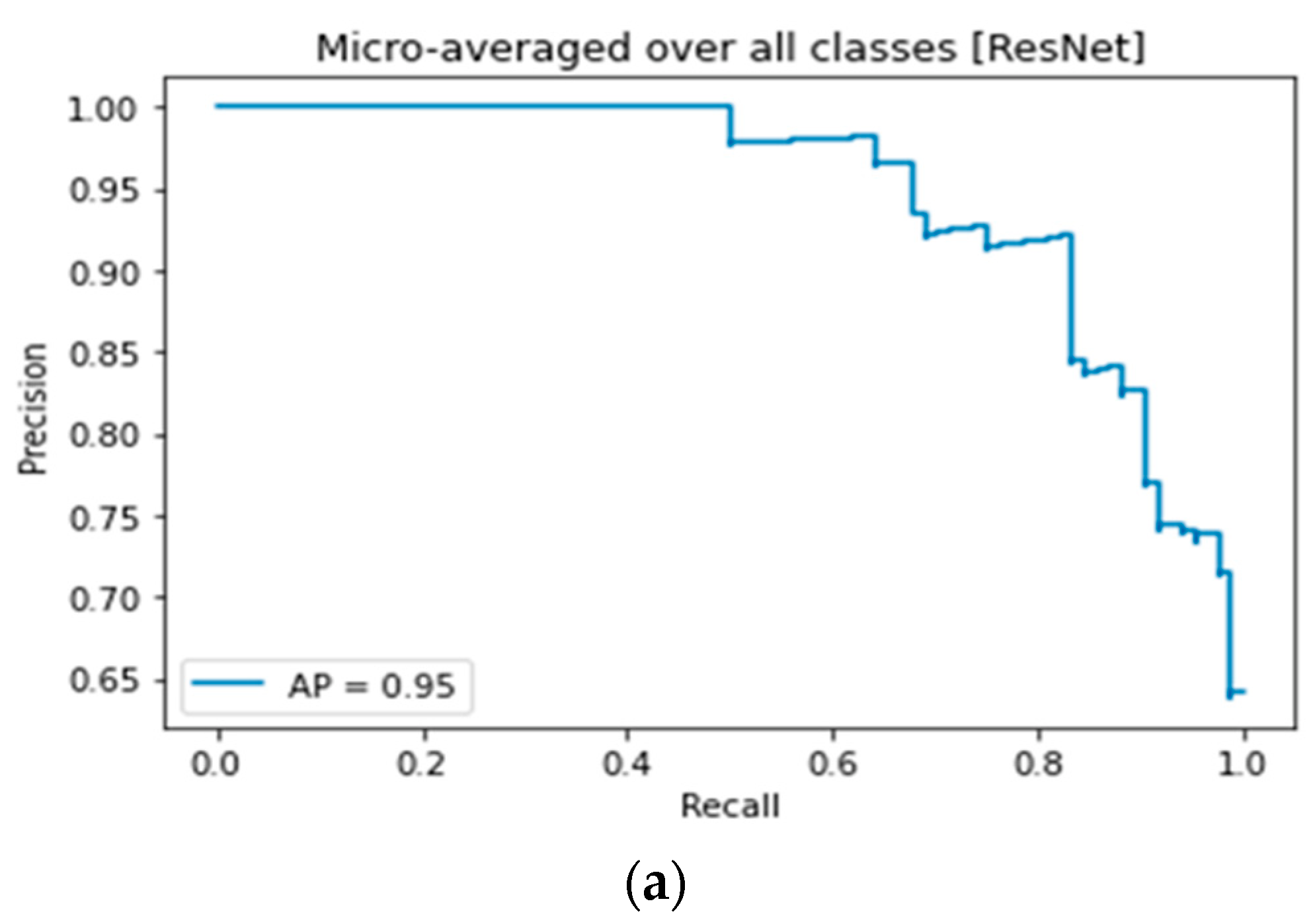
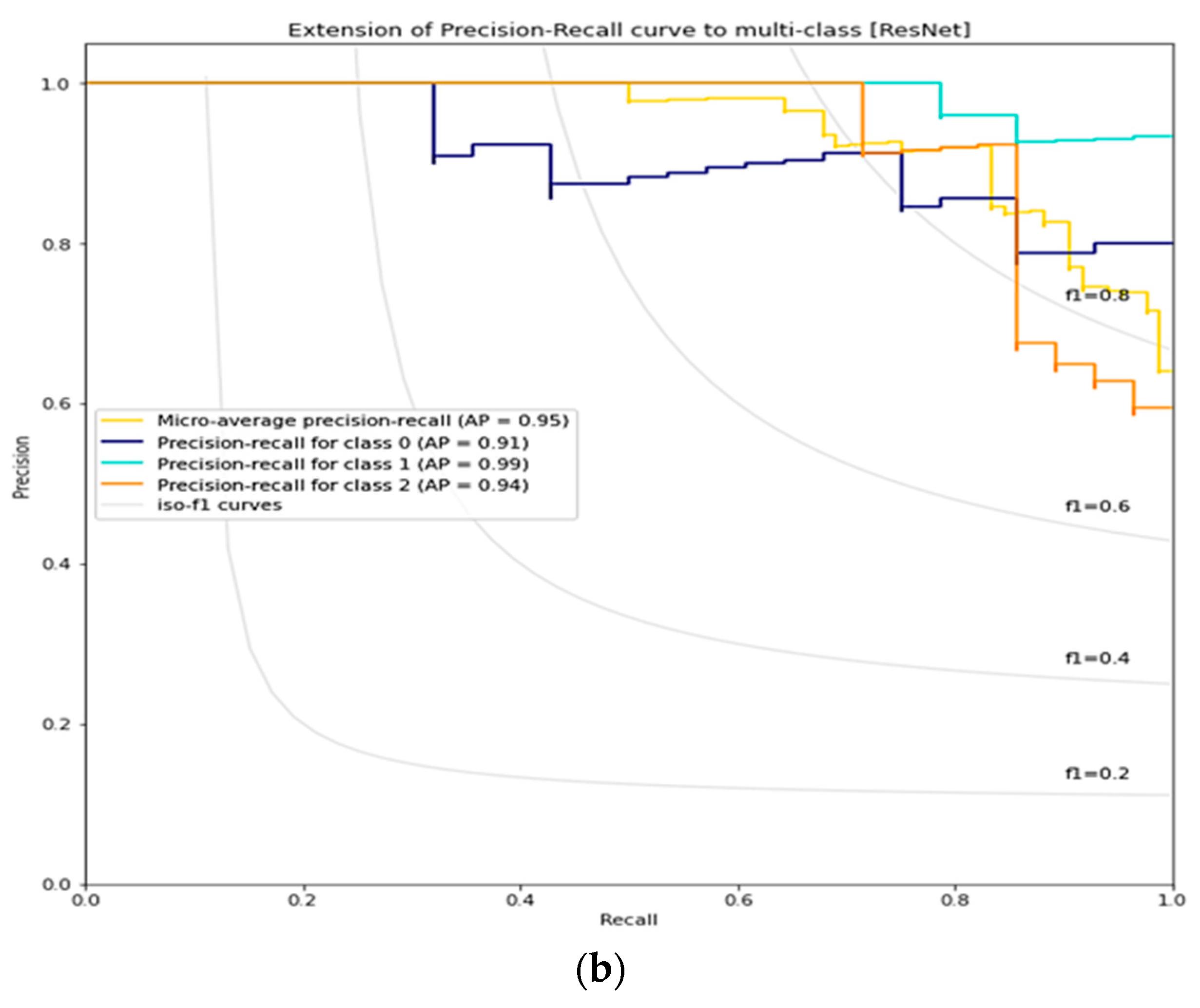
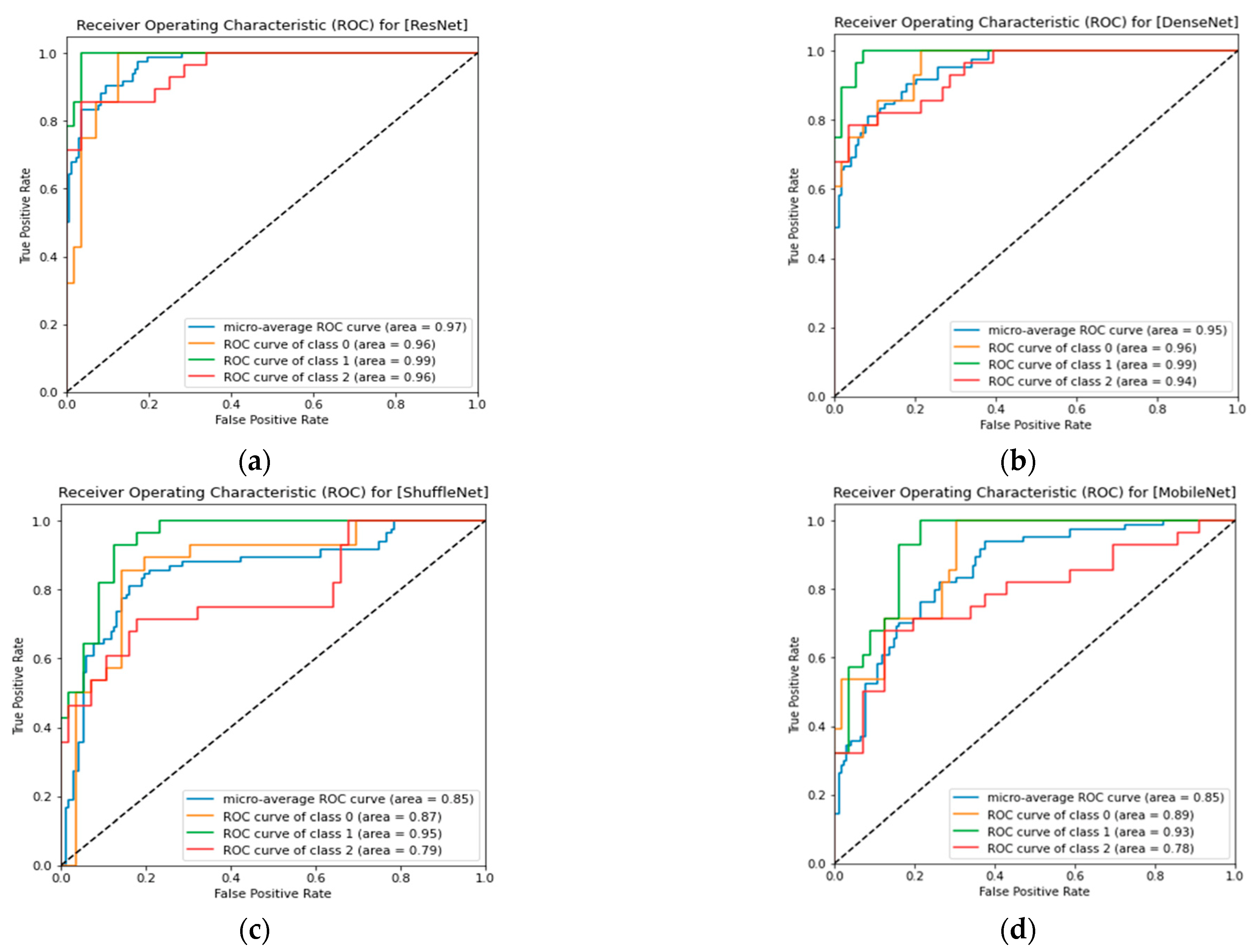
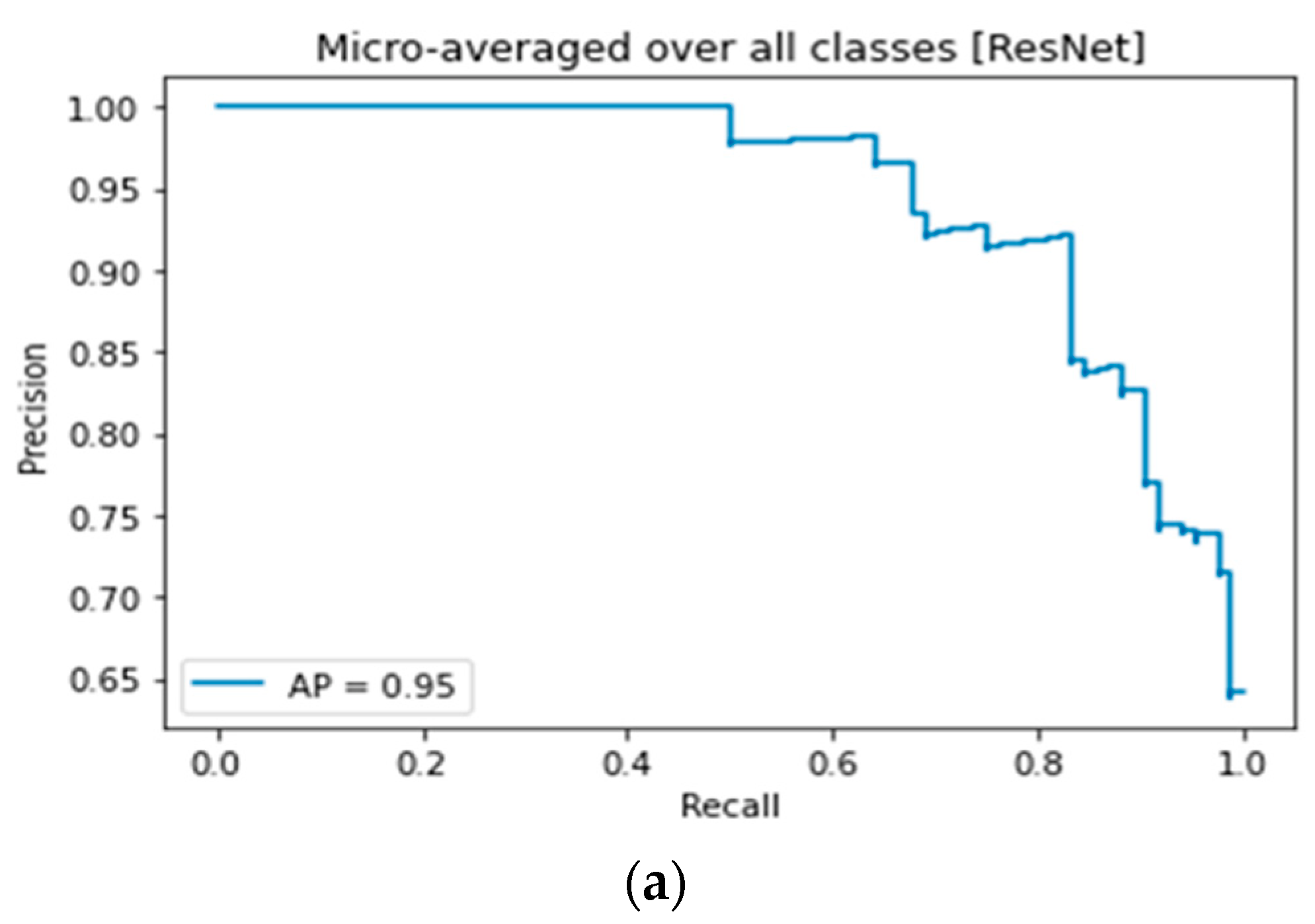
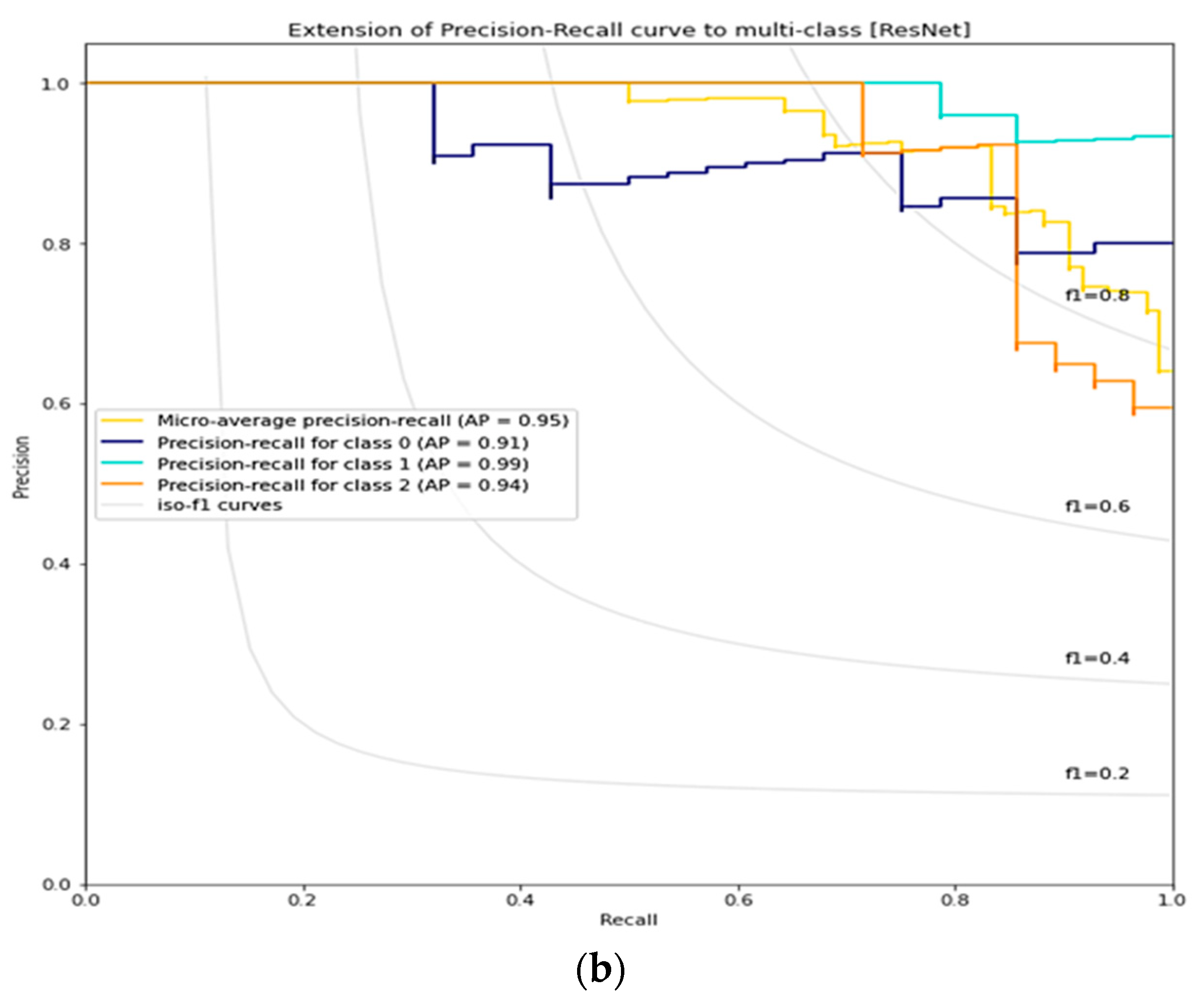
3.4. ResNet Lemon Bruising Classifier Results: Confusion Matrix and Precision-Recall Curves
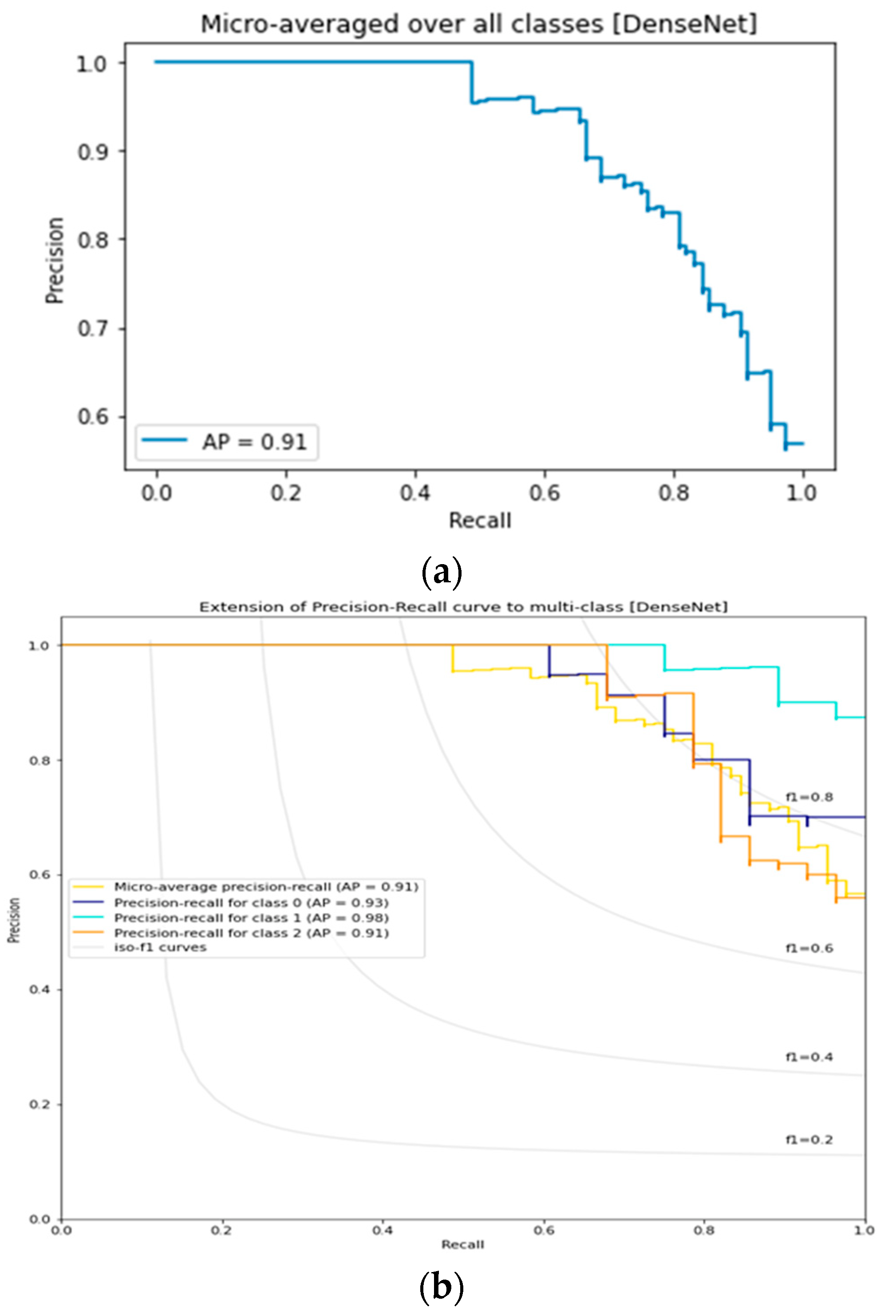
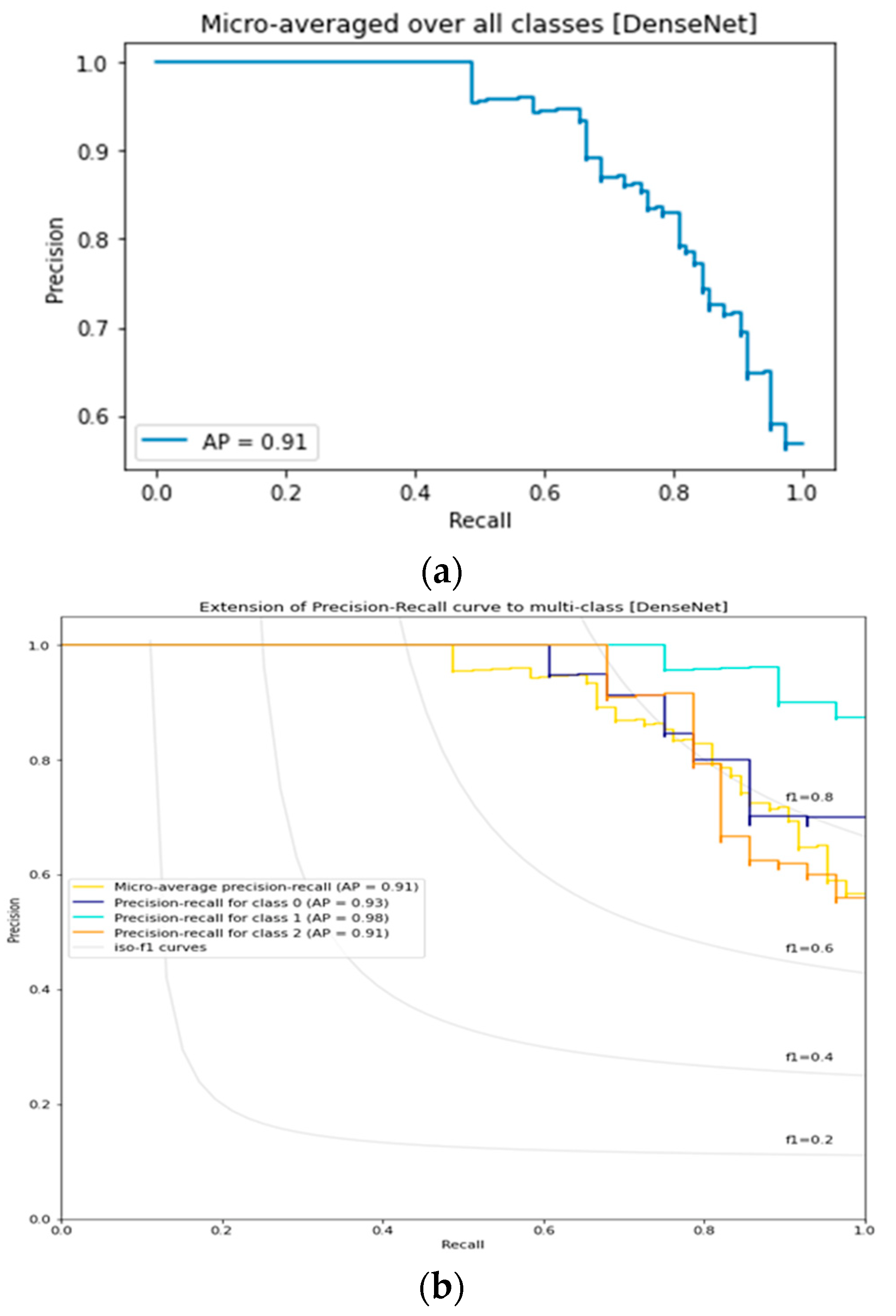
3.5. DenseNet Lemon Bruising Classifier Results: Confusion Matrix and Precision-Recall Curves
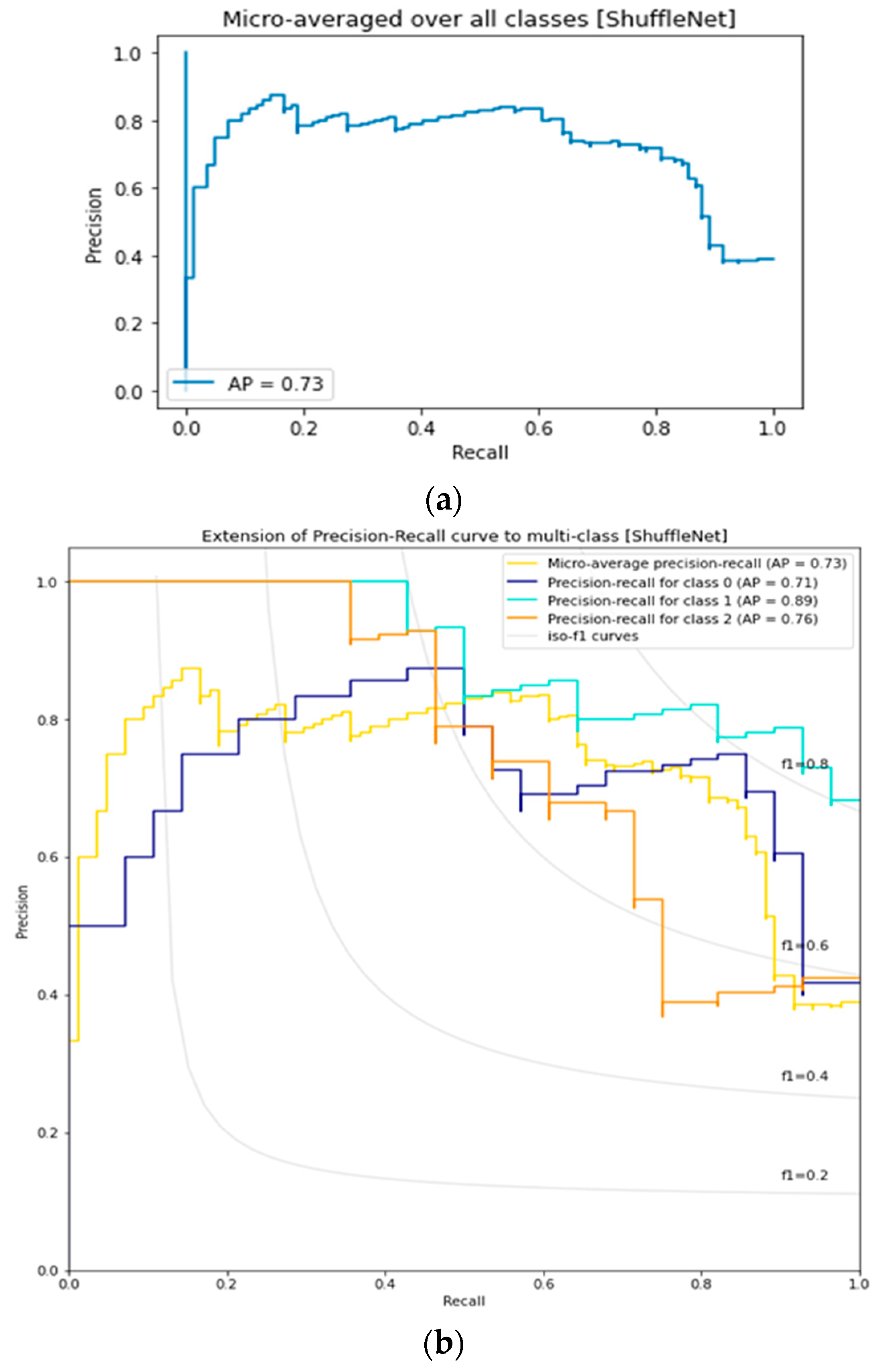
3.6. ShuffleNet Lemon Bruising Classifier Results: Confusion Matrix and Precision-Recall Curves
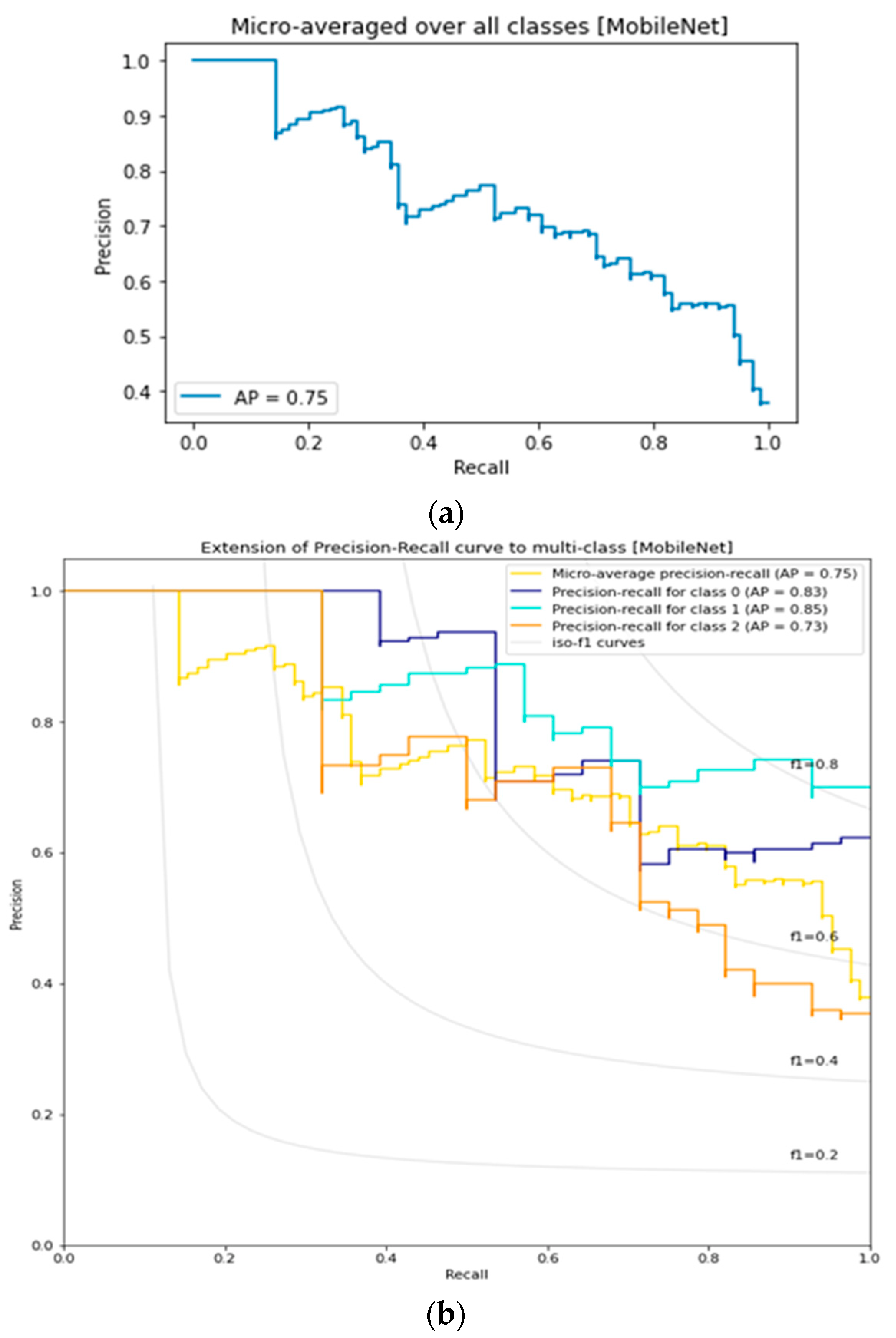
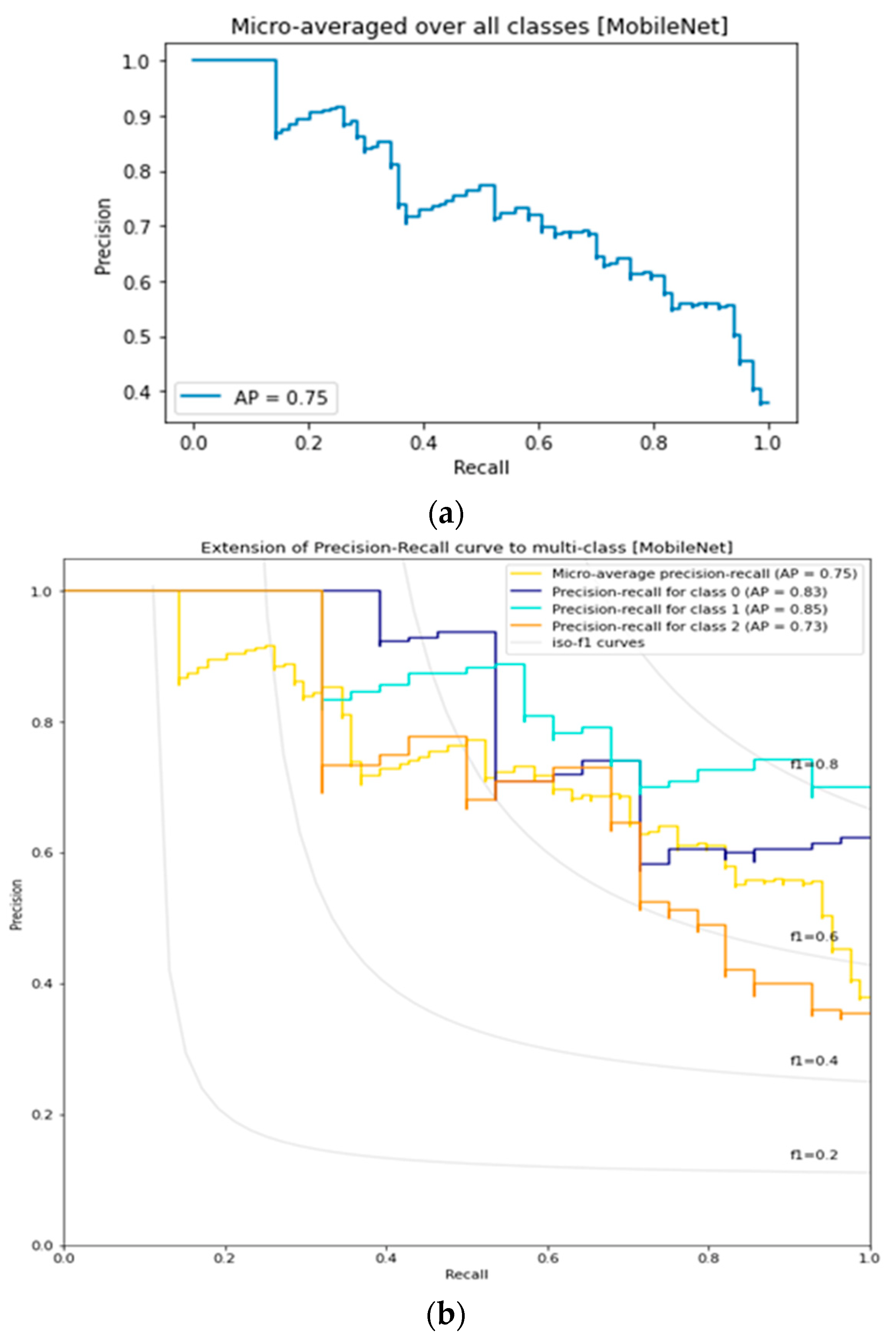
3.7. MobileNet Lemon Bruising Classifier Results: Confusion Matrix and Precision-Recall Curves
3.8. Comparison of Lemon Bruising Classification Performance over the Four Deep Learning Architectures Considered: Accuracy (%), F1-Score, and AP
4. Conclusions
- The input dataset was small and the use of specific augmentations helped in generalizing the model’s prediction. Thus, we used two kind of data augmentation in this work: RandomHorizontalFlip and Color Jitter.
- There were limitations in the case of GPU memory resources and they were solved by accumulating gradients of smaller batches. With this method, we were able to train the networks with batch size 8, which is useful in the training phase.
- Using 3D-CNN layers helps us extract useful information from the 3D structure of concatenated hyperspectral images and leverage the spatial information within nearby pixels of the images and spectrums, thus having a double spectral-spatial classification.
- The best result is achieved from models with Residual Connections such as ResNet. These connections enhance the flow of gradients in these models. As a result, the model can be deeper without suffering the degradation problems like vanishing gradients and deeper models provide higher generalization power.
- Using exponential schedulers instead of a fixed learning rate helps to dynamically adapt the learning rate based on the epoch number. Furthermore, this scheduler enhances the process of finding an optimal point on our loss function by using big steps at the start of training and reducing the step sizes as we converge in the following epochs.
- Changing the architecture of the models in order to make them more efficient, like ShuffleNet and MobileNet, will sacrifice their performance and generalization power in complex tasks like 3D-CNN classifications in favor of their simplicity.
- The easiest label to distinguish in our dataset is Class 1 (8 h after bruising). Both Class 0 (healthy, un-bruised) and Class 2 (16 h after bruising) labels are harder to distinguish and need more powerful networks like ResNet and DenseNet to be correctly classified.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rico, D.; Martin-Diana, A.B.; Barat, J.; Barry-Ryan, C. Extending and measuring the quality of fresh-cut fruit and vegetables: A review. Trends Food Sci. Technol. 2007, 18, 373–386. [Google Scholar] [CrossRef]
- Gulsen, O.; Roose, M.L. Lemons: Diversity and relationships with selected Citrus genotypes as measured with nuclear genome markers. J. Am. Soc. Hortic. Sci. 2001, 126, 309–317. [Google Scholar] [CrossRef]
- Issa, I.M.; Munishi, E.J.; Mubarack, K. Post-harvest Losses for Urban Fresh Fruits and Vegetables along the Continuum of Supply Chain Functions: Evidence from Dar es Salaam City-Tanzania. Can. Soc. Sci. 2021, 17, 75–87. [Google Scholar]
- Firdous, N. Post-harvest losses in different fresh produces and vegetables in Pakistan with particular focus on tomatoes. J. Hortic. Postharvest Res. 2021, 4, 71–86. [Google Scholar]
- Li, Z.; Thomas, C. Quantitative evaluation of mechanical damage to fresh fruits. Trends Food Sci. Technol. 2014, 35, 138–150. [Google Scholar] [CrossRef]
- Stropek, Z.; Gołacki, K. A new method for measuring impact related bruises in fruits. Postharvest Biol. Technol. 2015, 110, 131–139. [Google Scholar] [CrossRef]
- Hussein, Z.; Fawole, O.A.; Opara, U.L. Harvest and postharvest factors affecting bruise damage of fresh fruits. Hortic. Plant J. 2020, 6, 1–13. [Google Scholar] [CrossRef]
- Zhou, X.; Ampatzidis, Y.; Lee, W.S.; Zhou, C.; Agehara, S.; Schueller, J.K. Deep learning-based postharvest strawberry bruise detection under UV and incandescent light. Comput. Electron. Agric. 2022, 202, 107389. [Google Scholar] [CrossRef]
- Yin, H.; Li, B.; Zhang, F.; Su, C.-T.; Ou-Yang, A.-G. Detection of early bruises on loquat using hyperspectral imaging technology coupled with band ratio and improved Otsu method. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 283, 121775. [Google Scholar] [CrossRef]
- Guo, W.; Gao, M.; Cheng, J.; Zhou, Y.; Zhu, X. Effect of mechanical bruises on optical properties of mature peaches in the near-infrared wavelength range. Biosyst. Eng. 2021, 211, 114–124. [Google Scholar] [CrossRef]
- Huang, X.; Meng, Q.; Wu, Z.; He, F.; Tian, P.; Lin, J.; Zhu, H.; Zhou, X.; Huang, Y. Detection of early bruises in Gongcheng persimmon using hyperspectral imaging. Infrared Phys. Technol. 2022, 125, 104316. [Google Scholar] [CrossRef]
- Pourdarbani, R.; Sabzi, S.; Kalantari, D.; Paliwal, J.; Benmouna, B.; García-Mateos, G.; Molina-Martínez, J.M. Estimation of different ripening stages of Fuji apples using image processing and spectroscopy based on the majority voting method. Comput. Electron. Agric. 2020, 176, 105643. [Google Scholar] [CrossRef]
- Sabzi, S.; Pourdarbani, R.; Rohban, M.H.; García-Mateos, G.; Paliwal, J.; Molina-Martínez, J.M. Early detection of excess nitrogen consumption in cucumber plants using hyperspectral imaging based on hybrid neural networks and the imperialist competitive algorithm. Agronomy 2021, 11, 575. [Google Scholar] [CrossRef]
- Wieme, J.; Mollazade, K.; Malounas, I.; Zude-Sasse, M.; Zhao, M.; Gowen, A.; Argyropoulos, D.; Fountas, S.; Van Beek, J. Application of hyperspectral imaging systems and artificial intelligence for quality assessment of fruit, vegetables and mushrooms: A review. Biosyst. Eng. 2022, 222, 156–176. [Google Scholar] [CrossRef]
- Benmouna, B.; Pourdarbani, R.; Sabzi, S.; Fernandez-Beltran, R.; García-Mateos, G.; Molina-Martínez, J.M. Comparison of Classic Classifiers, Metaheuristic Algorithms and Convolutional Neural Networks in Hyperspectral Classification of Nitrogen Treatment in Tomato Leaves. Remote Sens. 2022, 14, 6366. [Google Scholar] [CrossRef]
- Rivera, N.V.; Gómez-Sanchis, J.; Chanona-Pérez, J.; Carrasco, J.J.; Millán-Giraldo, M.; Lorente, D.; Cubero, S.; Blasco, J. Early detection of mechanical damage in mango using NIR hyperspectral images and machine learning. Biosyst. Eng. 2014, 122, 91–98. [Google Scholar] [CrossRef]
- Munera, S.; Rodríguez-Ortega, A.; Aleixos, N.; Cubero, S.; Gómez-Sanchis, J.; Blasco, J. Detection of Invisible Damages in ‘Rojo Brillante’Persimmon Fruit at Different Stages Using Hyperspectral Imaging and Chemometrics. Foods 2021, 10, 2170. [Google Scholar] [CrossRef]
- Che, W.; Sun, L.; Zhang, Q.; Tan, W.; Ye, D.; Zhang, D.; Liu, Y. Pixel based bruise region extraction of apple using Vis-NIR hyperspectral imaging. Comput. Electron. Agric. 2018, 146, 12–21. [Google Scholar] [CrossRef]
- Fan, S.; Li, C.; Huang, W.; Chen, L. Detection of blueberry internal bruising over time using NIR hyperspectral reflectance imaging with optimum wavelengths. Postharvest Biol. Technol. 2017, 134, 55–66. [Google Scholar] [CrossRef]
- Li, X.; Liu, Y.; Jiang, X.; Wang, G. Supervised classification of slightly bruised peaches with respect to the time after bruising by using hyperspectral imaging technology. Infrared Phys. Technol. 2021, 113, 103557. [Google Scholar] [CrossRef]
- Zeng, X.; Miao, Y.; Ubaid, S.; Gao, X.; Zhuang, S. Detection and classification of bruises of pears based on thermal images. Postharvest Biol. Technol. 2020, 161, 111090. [Google Scholar] [CrossRef]
- Gai, Z.; Sun, L.; Bai, H.; Li, X.; Wang, J.; Bai, S. Convolutional neural network for apple bruise detection based on hyperspectral. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 279, 121432. [Google Scholar] [CrossRef] [PubMed]
- Dunno, K.; Stoeckley, I.; Hofmeister, M. Susceptibility of impact damage to whole apples packaged inside molded fiber and expanded polystyrene trays. Foods 2021, 10, 1980. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Huang, J.; Zhou, W.; Li, H.; Li, W. Sign language recognition using 3D convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Sabzi, S.; Abbaspour-Gilandeh, Y.; Javadikia, H. The use of soft computing to classification of some weeds based on video processing. Appl. Soft Comput. 2017, 56, 107–123. [Google Scholar] [CrossRef]
- Sabzi, S.; Pourdarbani, R.; Arribas, J.I. A computer vision system for the automatic classification of five varieties of tree leaf images. Computers 2020, 9, 6. [Google Scholar] [CrossRef]
- Waldamichael, F.G.; Debelee, T.G.; Schwenker, F.; Ayano, Y.M.; Kebede, S.R. Machine Learning in Cereal Crops Disease Detection: A Review. Algorithms 2022, 15, 75. [Google Scholar] [CrossRef]
- Pizzolante, R.; Carpentieri, B. Visualization, Band Ordering and Compression of Hyperspectral Images. Algorithms 2012, 5, 76–97. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, C.; Xu, Q.; Cheng, R.; Song, Y.; Yuan, X.; Sun, J. I3D-Shufflenet Based Human Action Recognition. Algorithms 2020, 13, 301. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | # of Total Samples (Before Augmentation) | # of Class Label 0 (Healthy, Undamaged) | # of Class Label 1 (8 h after Bruising) | # of Class Label 2 (16 h after Bruising) |
|---|---|---|---|---|
| Train | 147 | 49 | 49 | 49 |
| Test | 21 | 7 | 7 | 7 |
| Validation | 42 | 14 | 14 | 14 |
| Total | 210 | 70 | 70 | 70 |
| Model Name | Parameter Set Size (MB) | Train Time Per Epoch (seconds) |
|---|---|---|
| ResNet | 242 | 24 |
| ShuffleNet | 5 | 7 |
| DenseNet | 43 | 46 |
| MobileNet | 12 | 7 |
| Class 0 | Class 1 | Class 2 | ||
|---|---|---|---|---|
| ResNet | Class 0 | 6 | 0 | 1 |
| Class 1 | 1 | 6 | 0 | |
| Class 2 | 1 | 1 | 5 | |
| Class 0 | Class 1 | Class 2 | ||
|---|---|---|---|---|
| DenseNet | Class 0 | 5 | 1 | 1 |
| Class 1 | 0 | 7 | 0 | |
| Class 2 | 1 | 1 | 5 | |
| Class 0 | Class 1 | Class 2 | ||
|---|---|---|---|---|
| ShuffleNet | Class 0 | 6 | 1 | 0 |
| Class 1 | 0 | 7 | 0 | |
| Class 2 | 1 | 2 | 4 | |
| Class 0 | Class 1 | Class 2 | ||
|---|---|---|---|---|
| MobileNet | Class 0 | 6 | 1 | 0 |
| Class 1 | 0 | 7 | 0 | |
| Class 2 | 2 | 2 | 3 | |
| Model Name | Accuracy % | F1-Score | AP | AROC |
|---|---|---|---|---|
| ResNet | 90.47 | 0.9046 | 0.95 | 0.97 |
| DenseNet | 85.71 | 0.8547 | 0.91 | 0.95 |
| ShuffleNet | 80.95 | 0.7974 | 0.73 | 0.85 |
| MobileNet | 73.80 | 0.7147 | 0.75 | 0.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pourdarbani, R.; Sabzi, S.; Dehghankar, M.; Rohban, M.H.; Arribas, J.I. Examination of Lemon Bruising Using Different CNN-Based Classifiers and Local Spectral-Spatial Hyperspectral Imaging. Algorithms 2023, 16, 113. https://doi.org/10.3390/a16020113
Pourdarbani R, Sabzi S, Dehghankar M, Rohban MH, Arribas JI. Examination of Lemon Bruising Using Different CNN-Based Classifiers and Local Spectral-Spatial Hyperspectral Imaging. Algorithms. 2023; 16(2):113. https://doi.org/10.3390/a16020113
Chicago/Turabian StylePourdarbani, Razieh, Sajad Sabzi, Mohsen Dehghankar, Mohammad H. Rohban, and Juan I. Arribas. 2023. "Examination of Lemon Bruising Using Different CNN-Based Classifiers and Local Spectral-Spatial Hyperspectral Imaging" Algorithms 16, no. 2: 113. https://doi.org/10.3390/a16020113
APA StylePourdarbani, R., Sabzi, S., Dehghankar, M., Rohban, M. H., & Arribas, J. I. (2023). Examination of Lemon Bruising Using Different CNN-Based Classifiers and Local Spectral-Spatial Hyperspectral Imaging. Algorithms, 16(2), 113. https://doi.org/10.3390/a16020113