
Stereo 3D Object Detection Using a Feature Attention Module

Abstract
:1. Introduction
- Without the aid of lidar, stereo 3D object detection suffers performance setbacks, requiring retraining or augmentation with lidar for “new” object categories or forms, escalating equipment costs. The use of binocular vision as a cost-effective alternative necessitates addressing accuracy challenges.
- While 2D segmentation methods from images enhance detection [1,2], their efficacy dwindles for diverse objects like height limit devices [3], which can assume various forms (e.g., single pole, multipole, irregular natural obstacles). Exploring alternative solutions becomes imperative for enhancing detection efficacy.
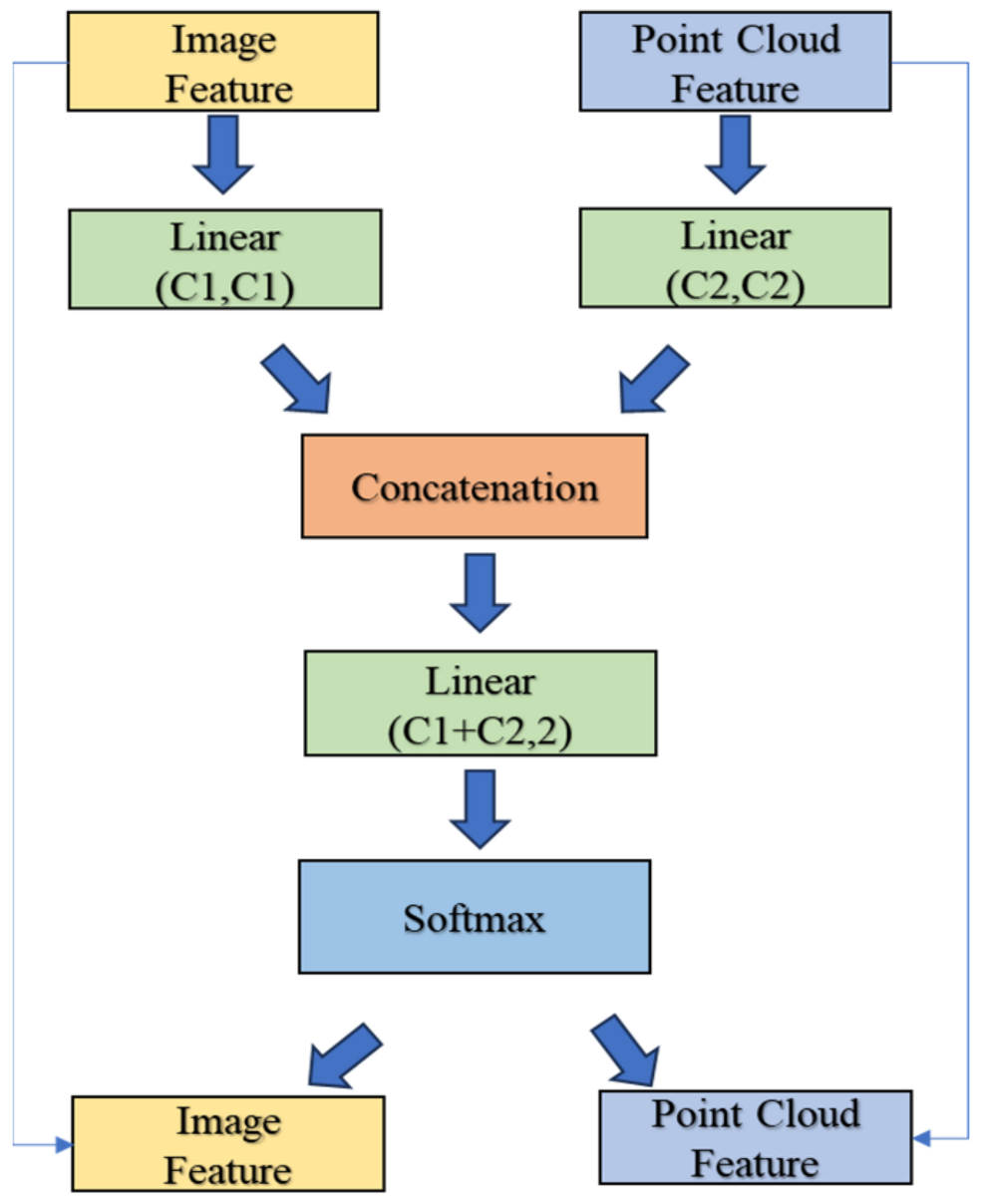
- Our proposed feature attention module aims to facilitate feature fusion by evaluating the significance of stereo point cloud and image features across diverse models. This module effectively analyzes feature weights, offering targeted insights for model enhancements.
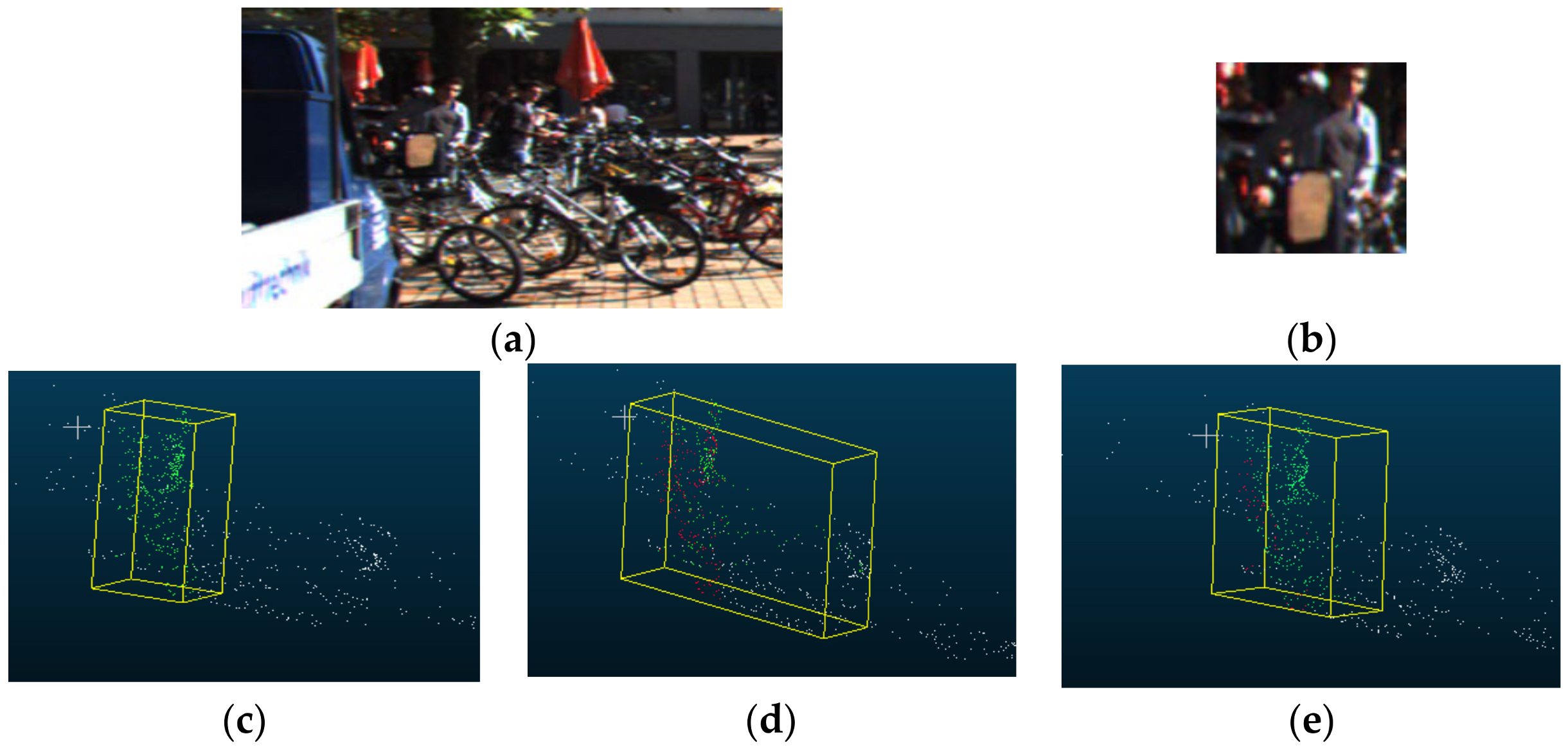
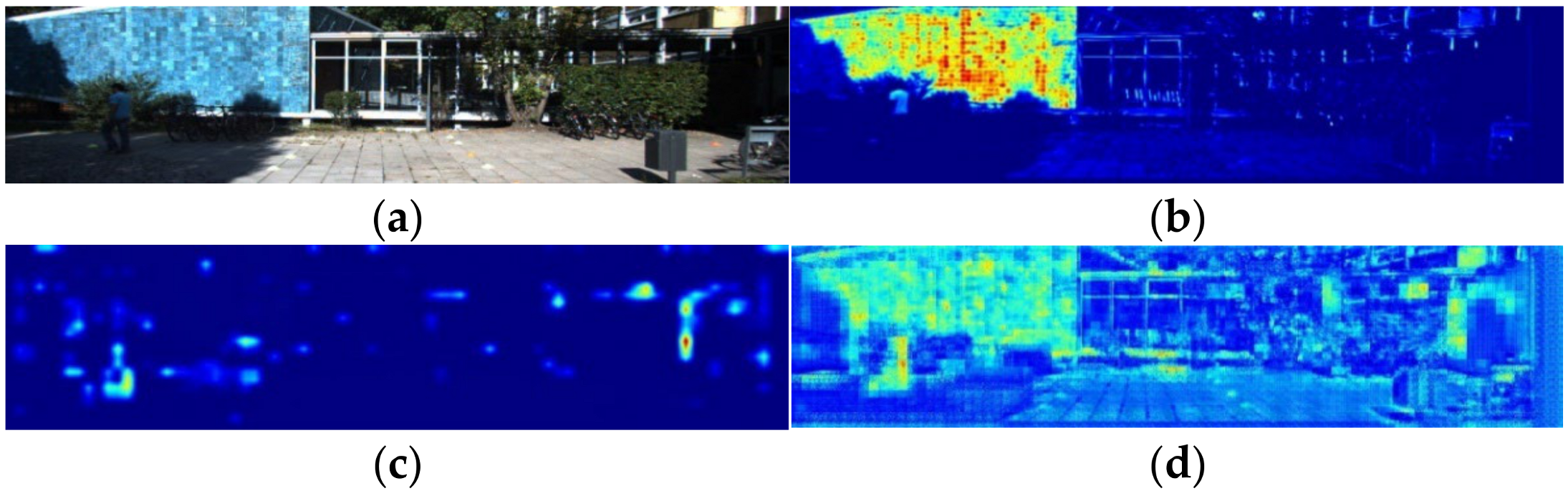
- Utilizing our feature attention module, we scrutinized the relevance of stereo point cloud and image features within the local area of the PatchNet [4] model. This analysis sheds light on the impact of image segmentation methods.
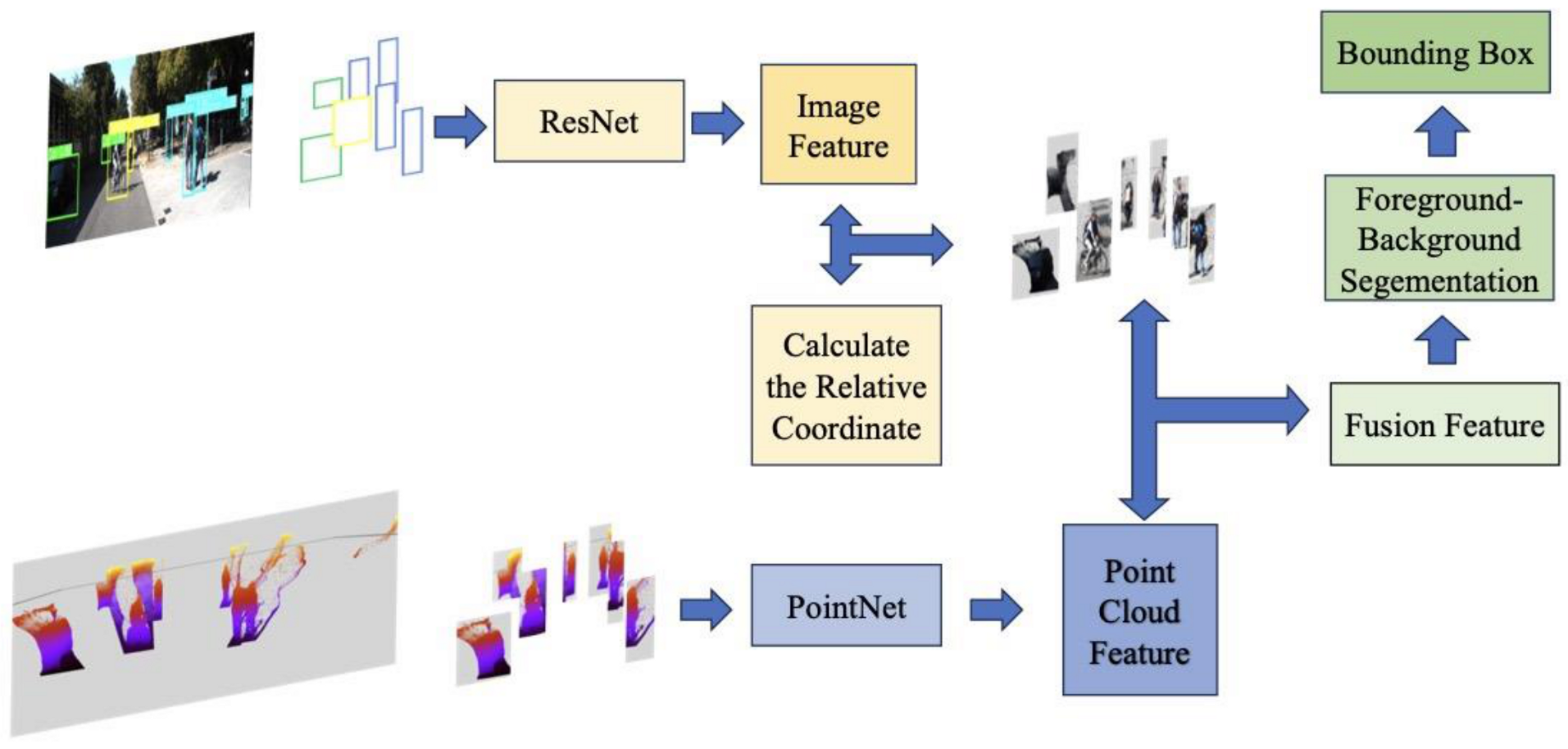
- Employing the feature attention module, we delved into the importance of point cloud and image features within the local realm of the Pseudo-Lidar FpointNet [5,6] model. Additionally, we devised a category-based feature reweighting module to address declining foreground–background segmentation accuracy.
2. Related Work
2.1. Stereo-Based 3D Object Detection
2.2. Feature Fusion Strategy for 3D Object Detection
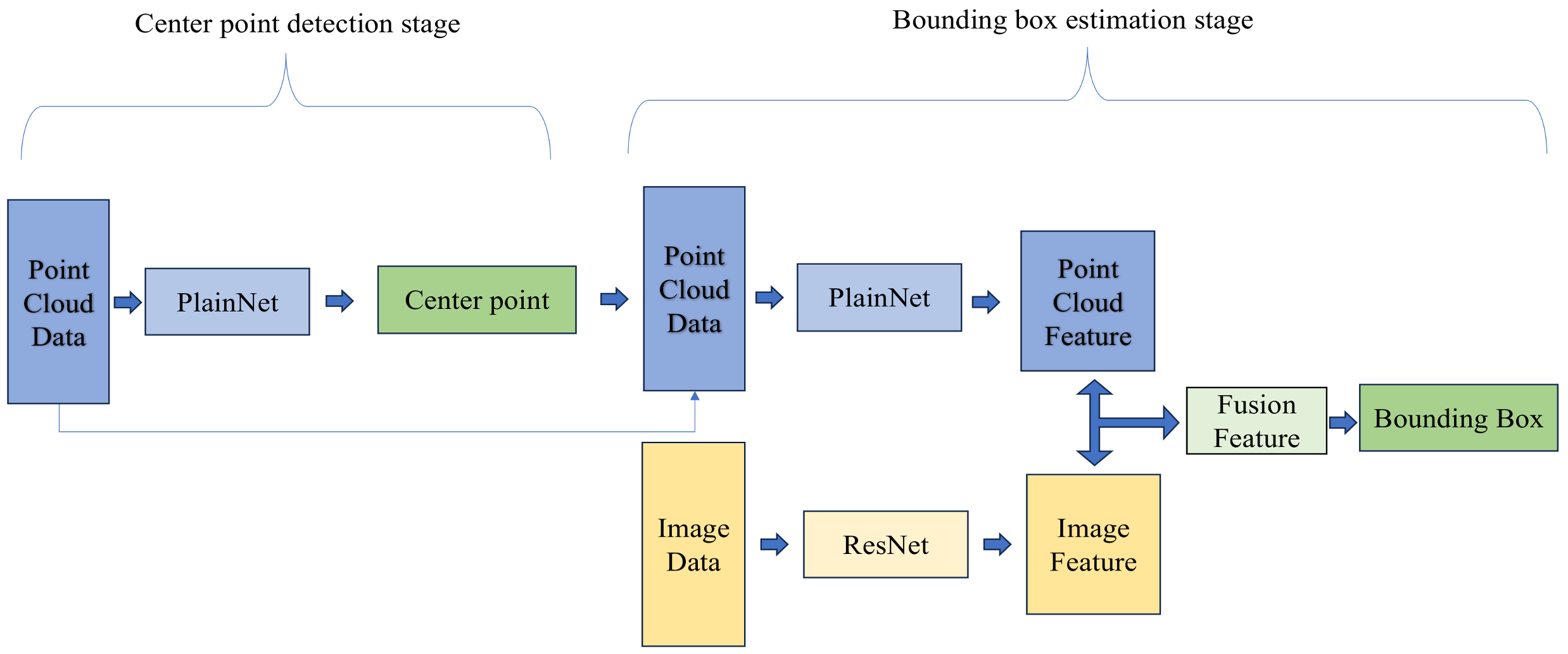
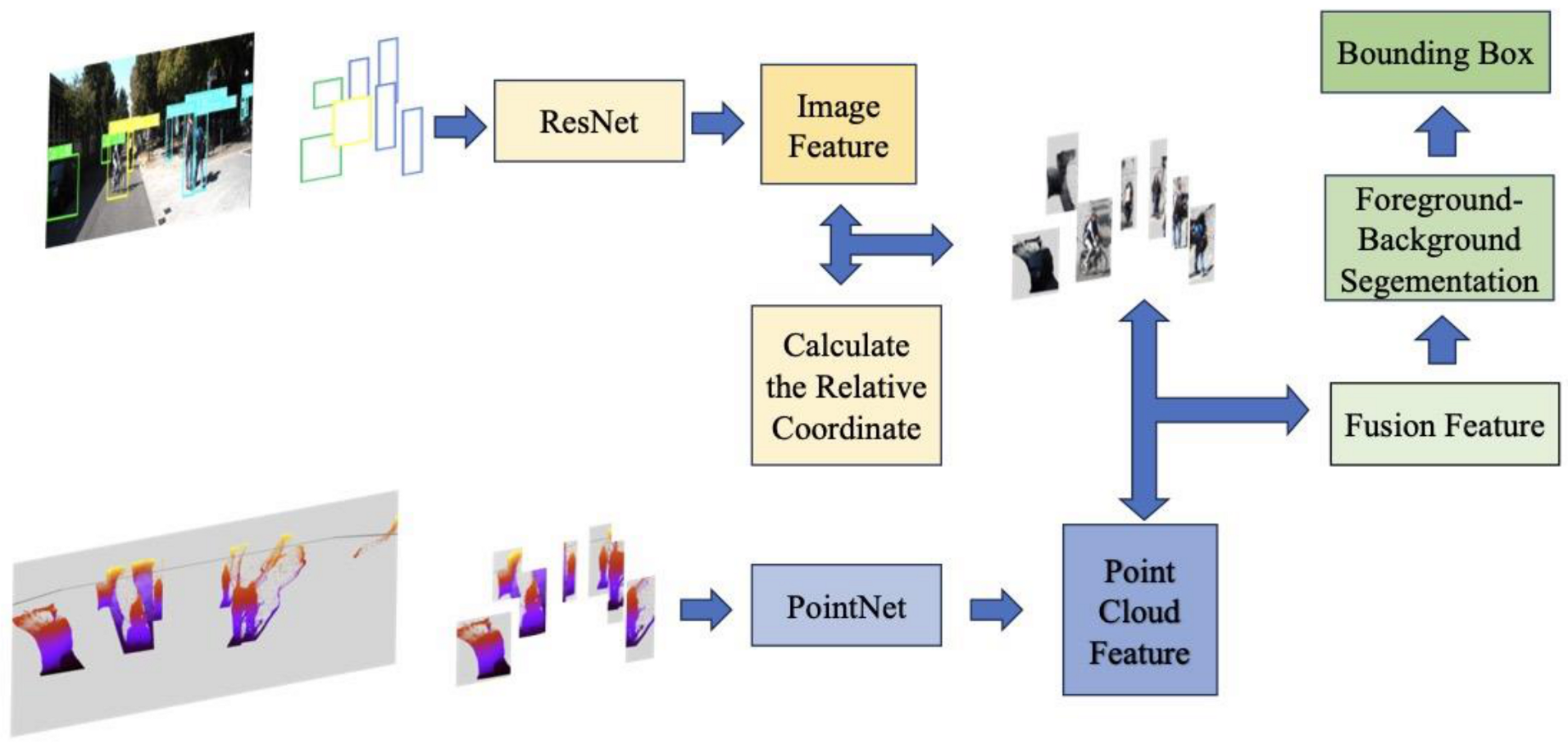
3. Methodology
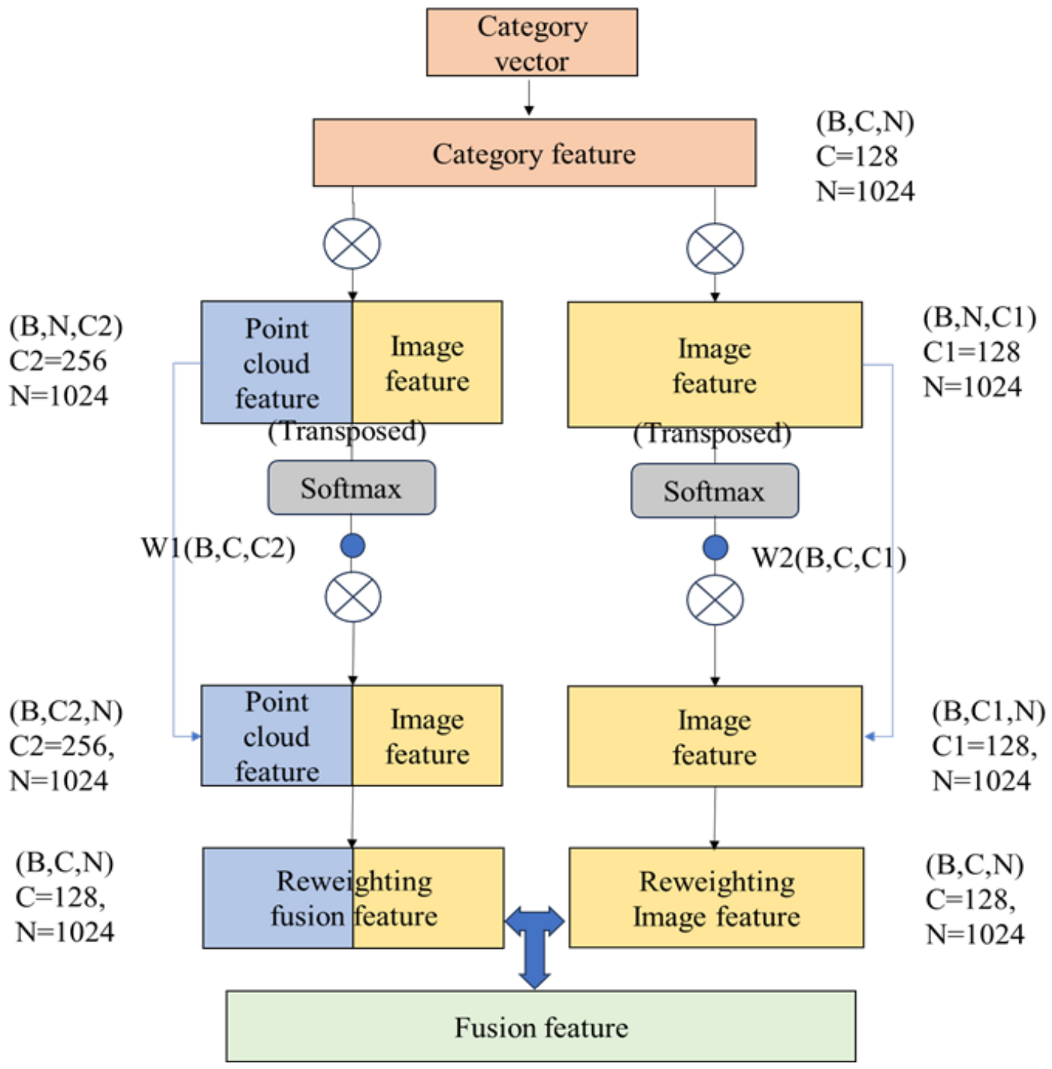
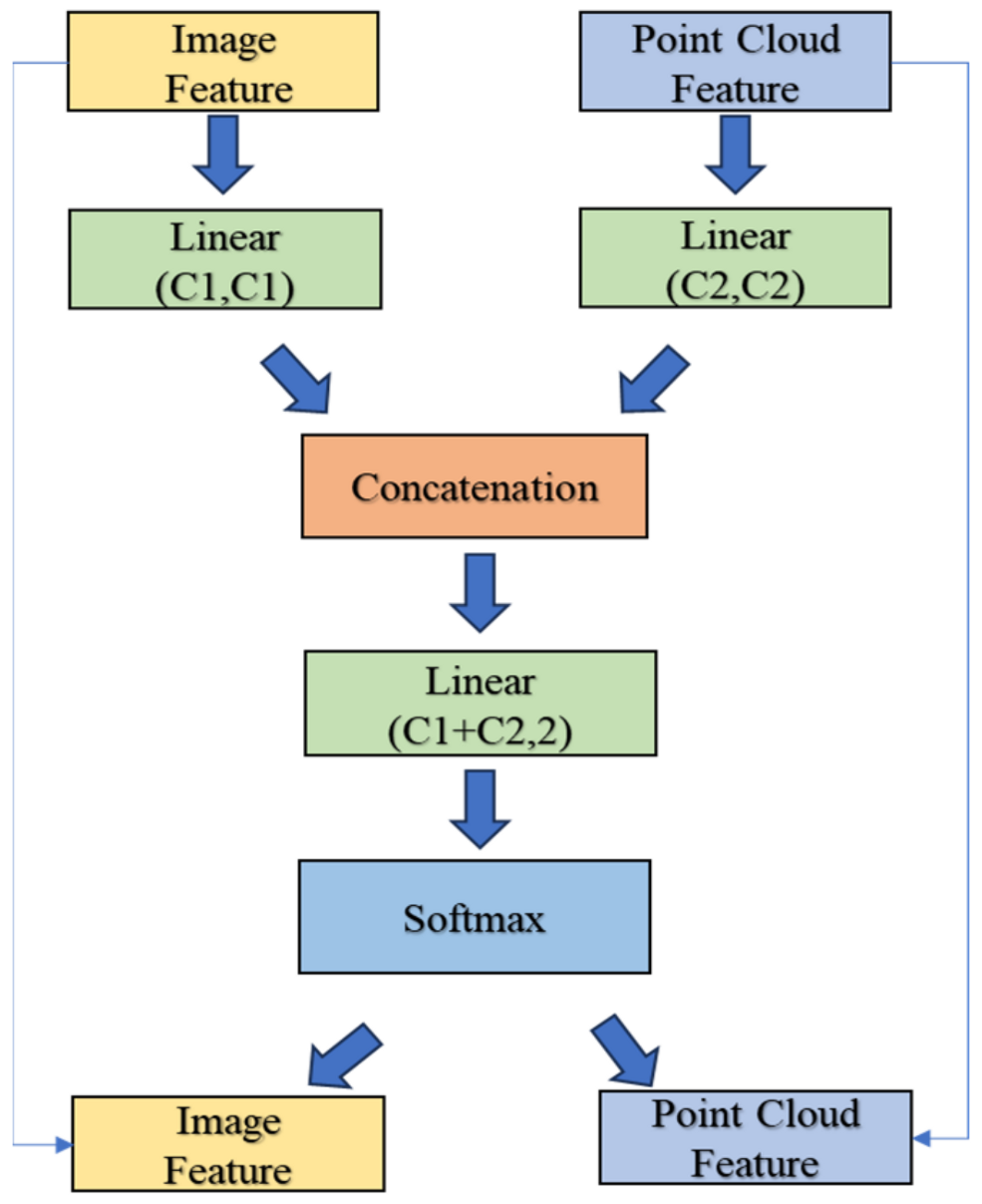
3.1. Feature Attention Module
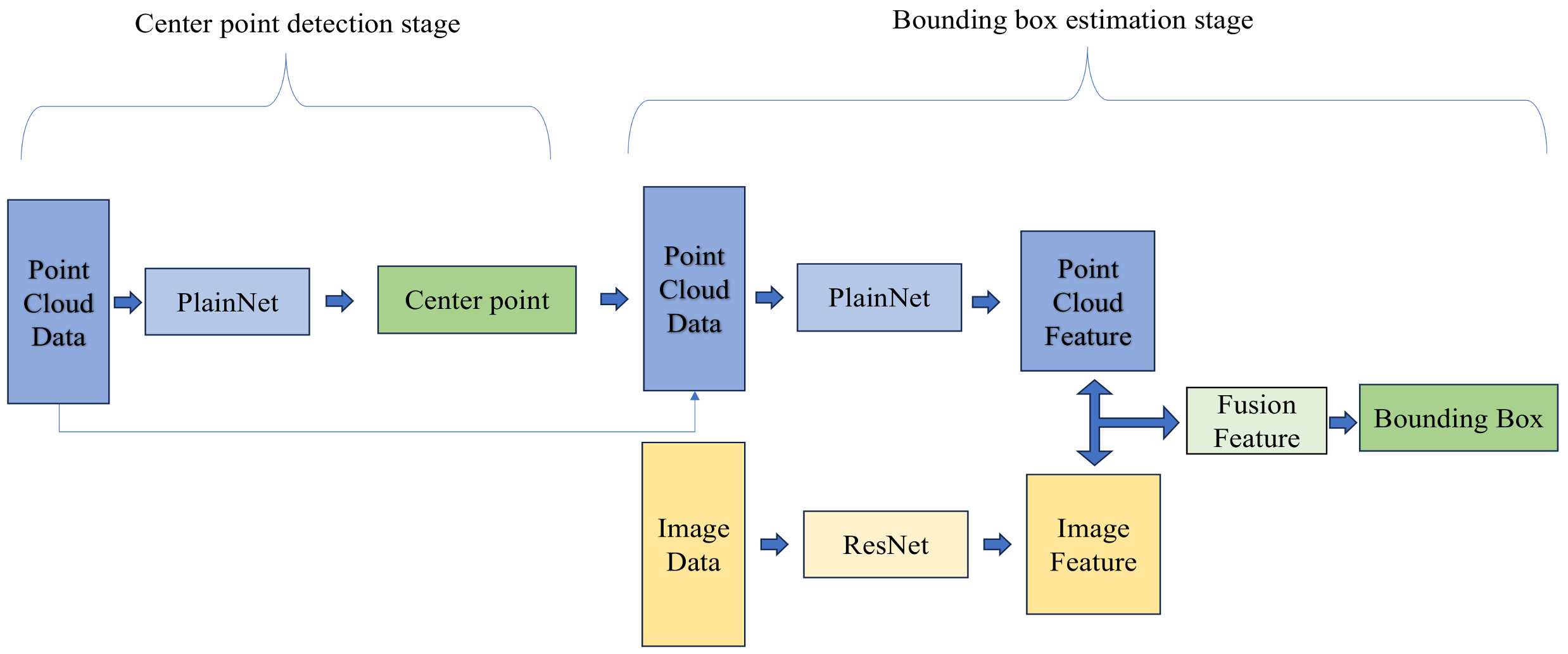
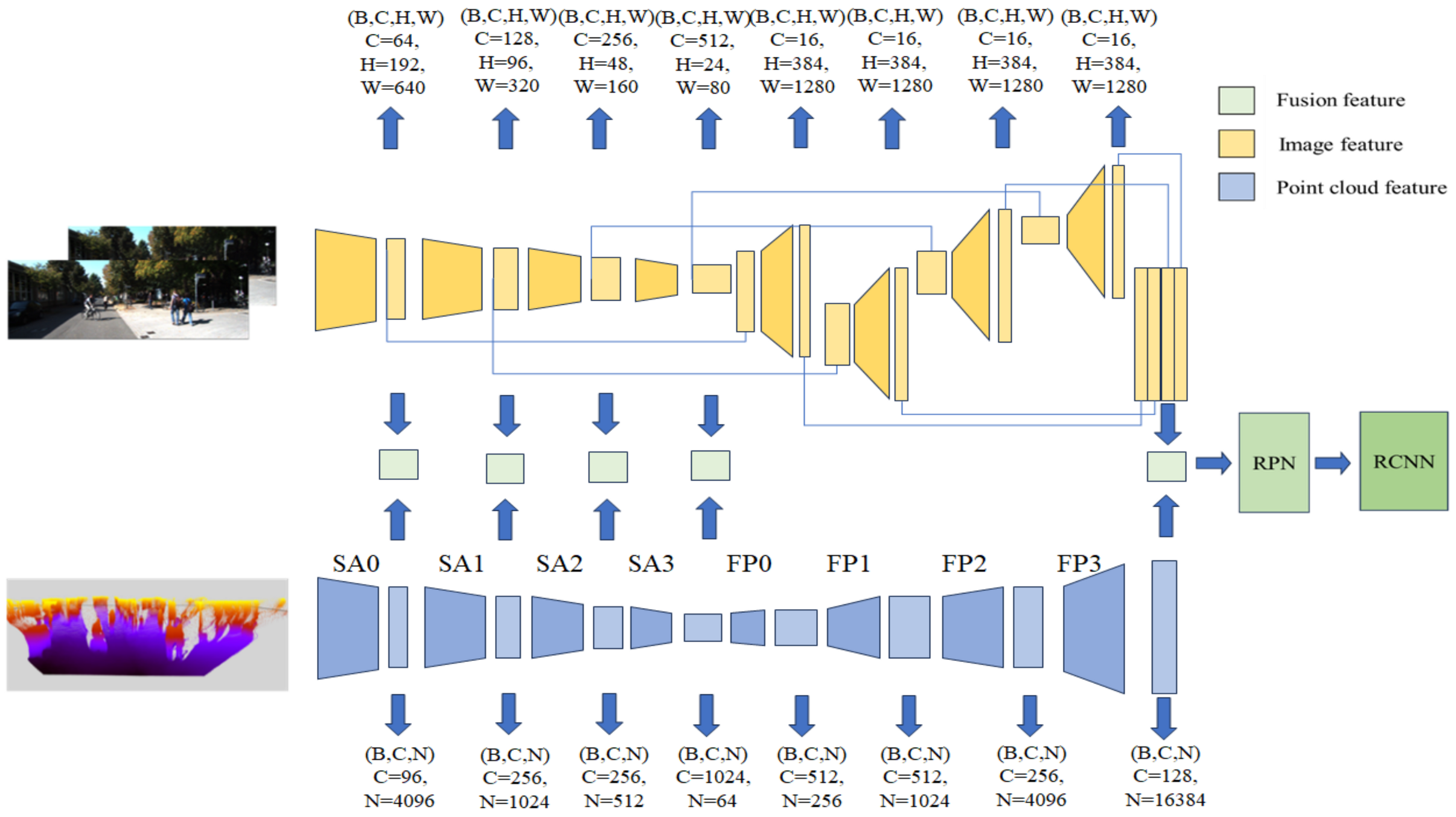
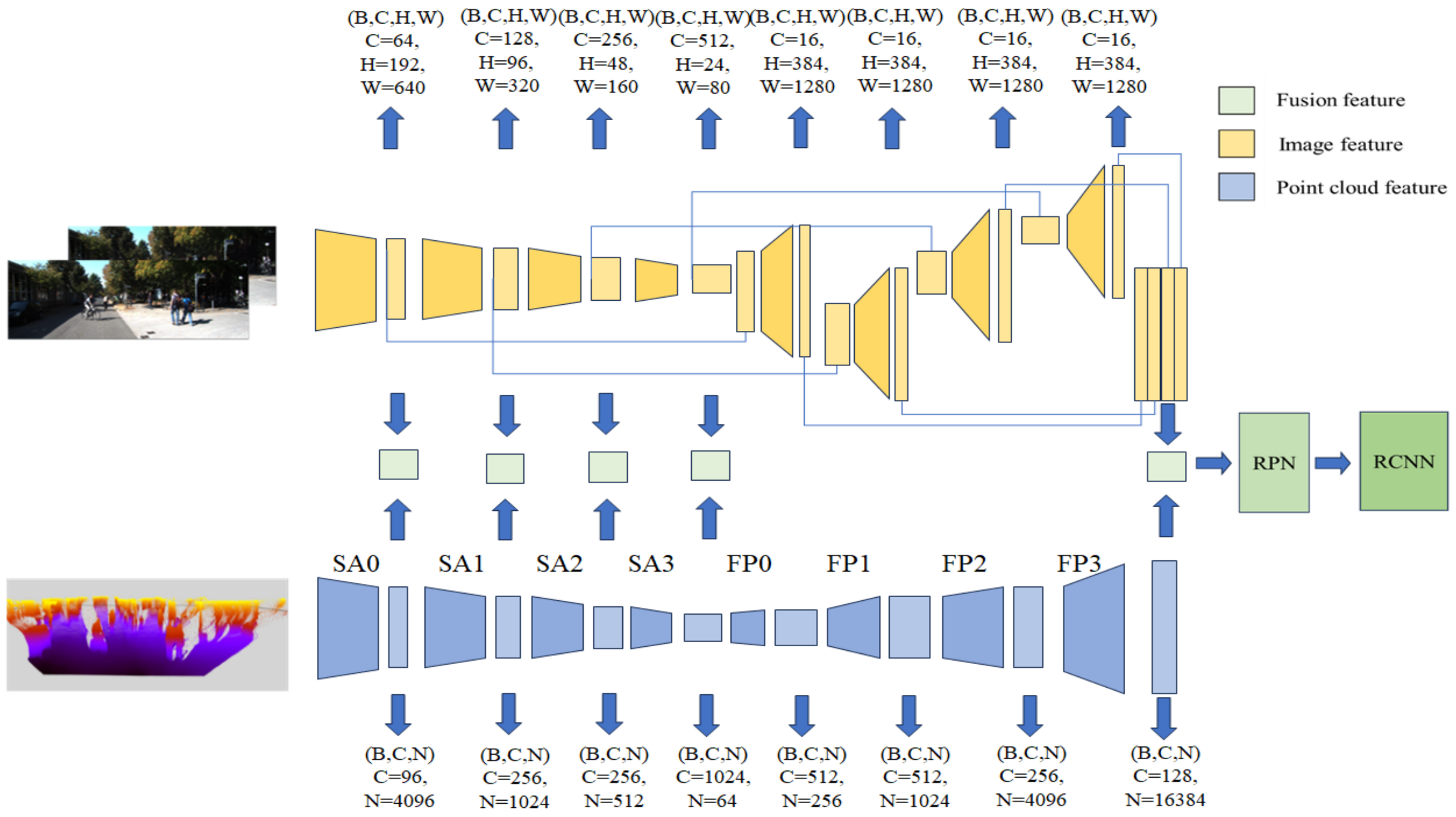
3.2. Basic Model and Feature Fusion Method
3.3. The Usage of Feature Attention Module
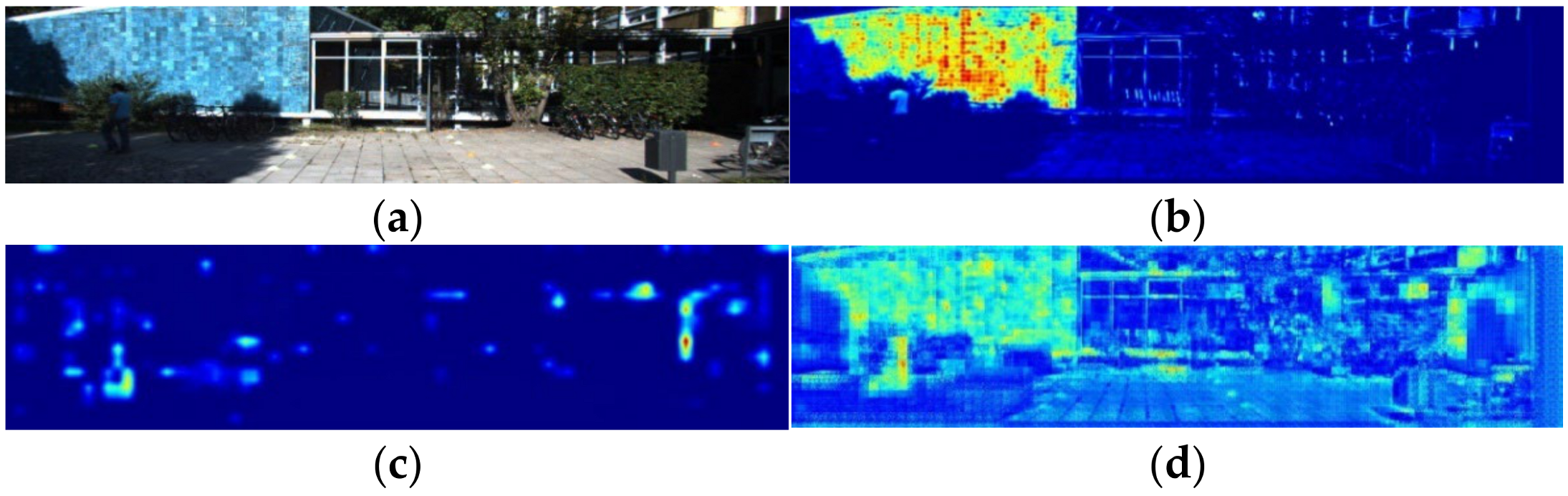
3.3.1. Interpretability of Image Segmentation with the Feature Attention Module
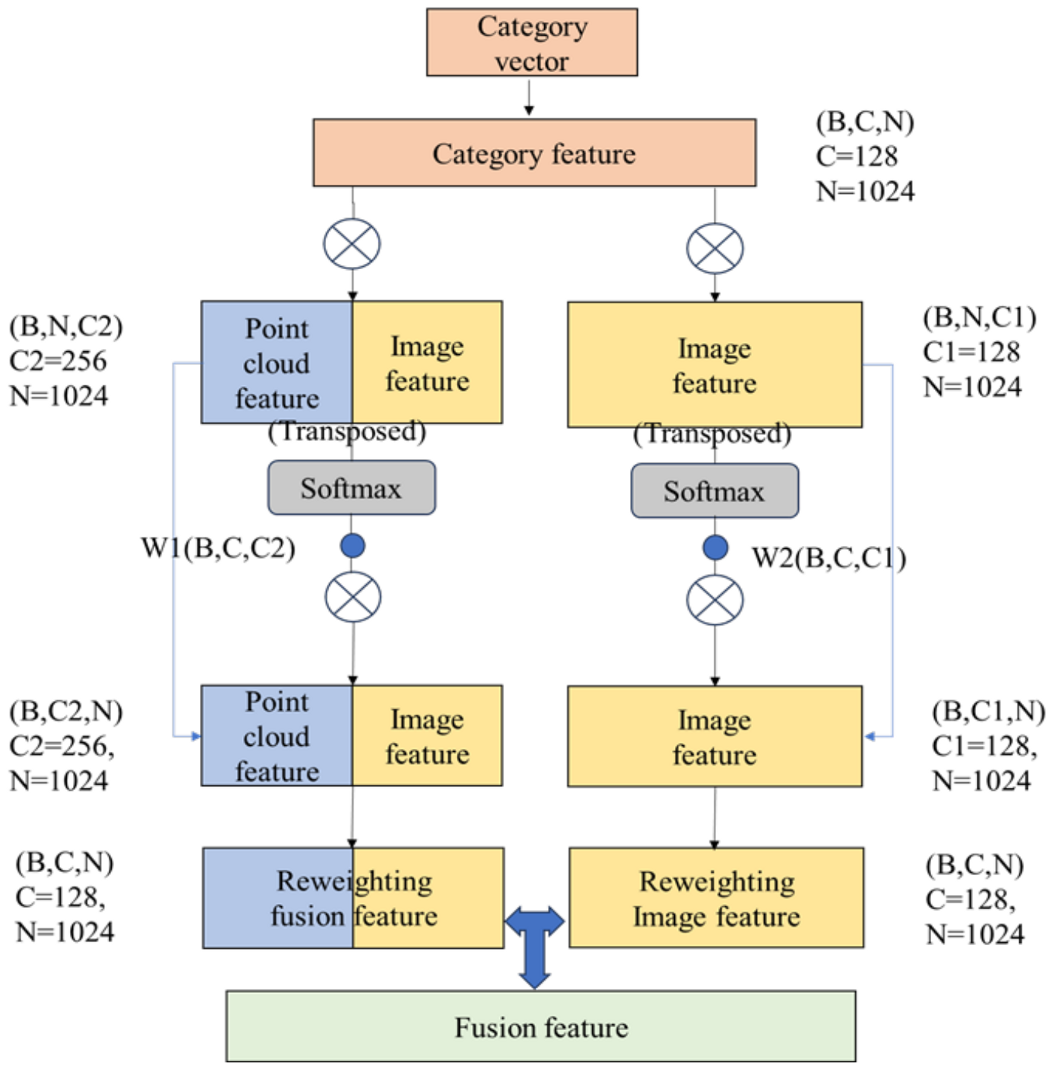
3.3.2. Design of Category Reweighting Module
3.3.3. Parameter Optimization Strategy of the Global Fusion Method
4. Experiment
4.1. Dataset
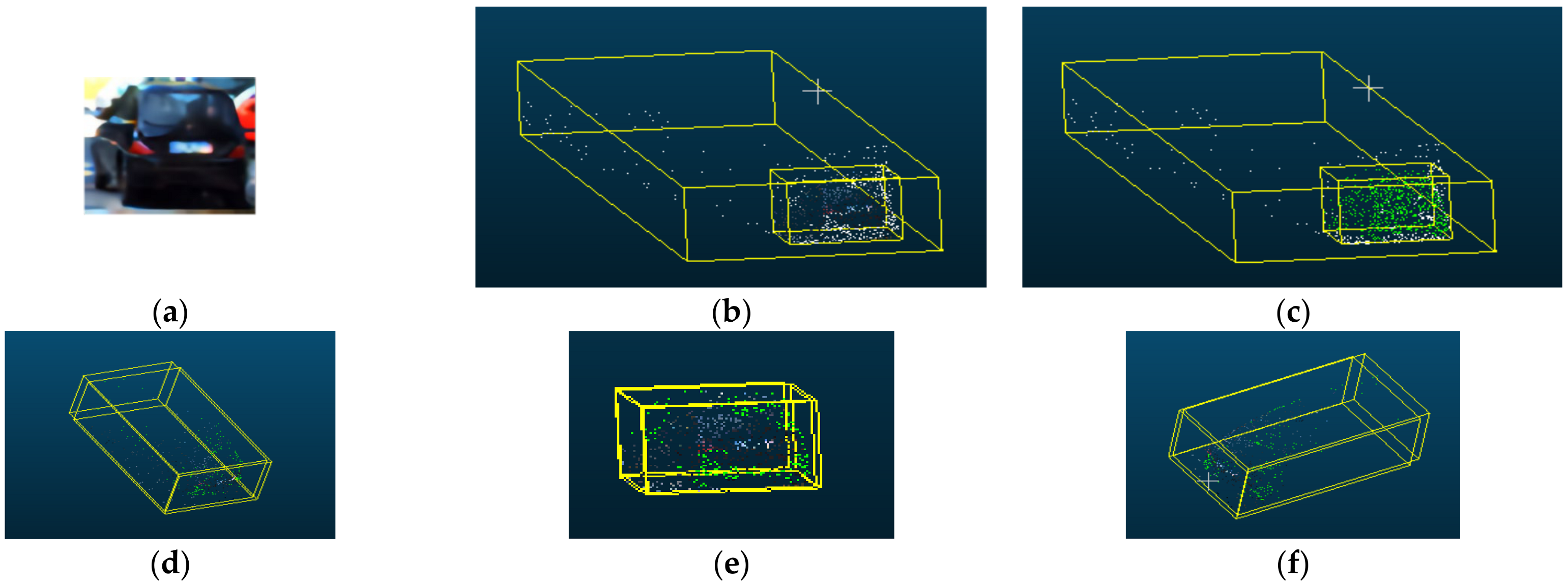
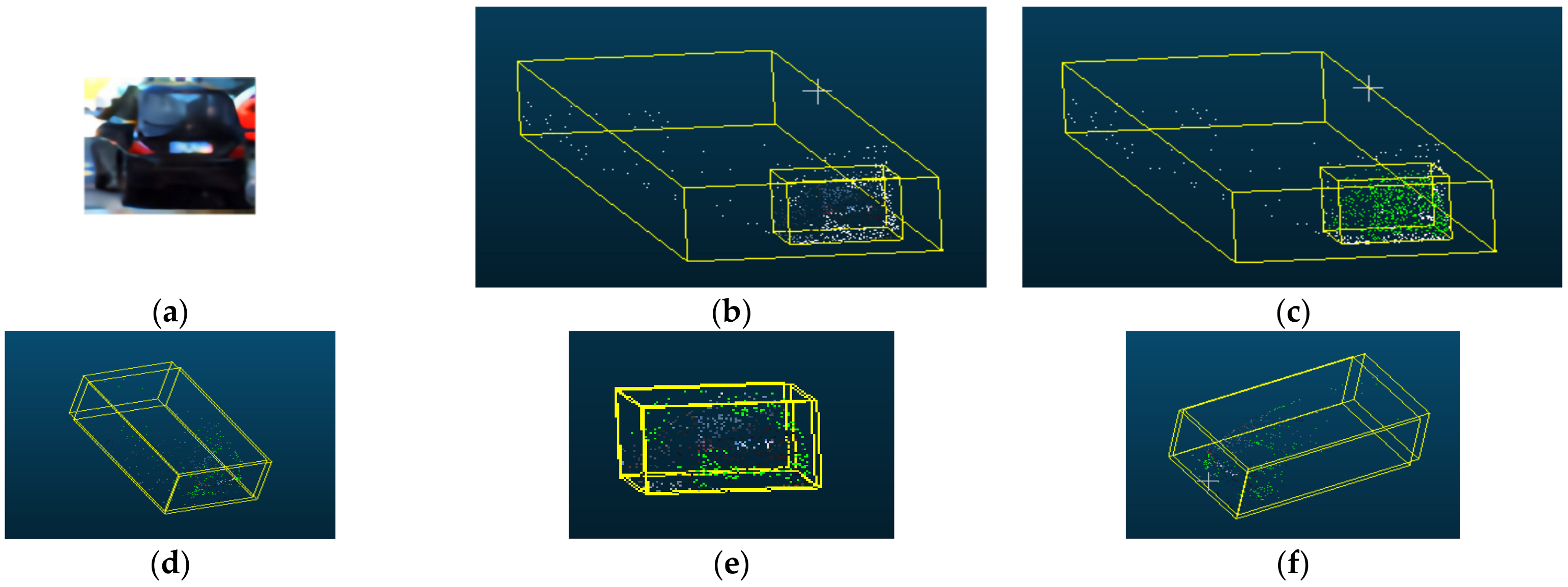
4.2. PatchNet Local Fusion and Model Interpretability
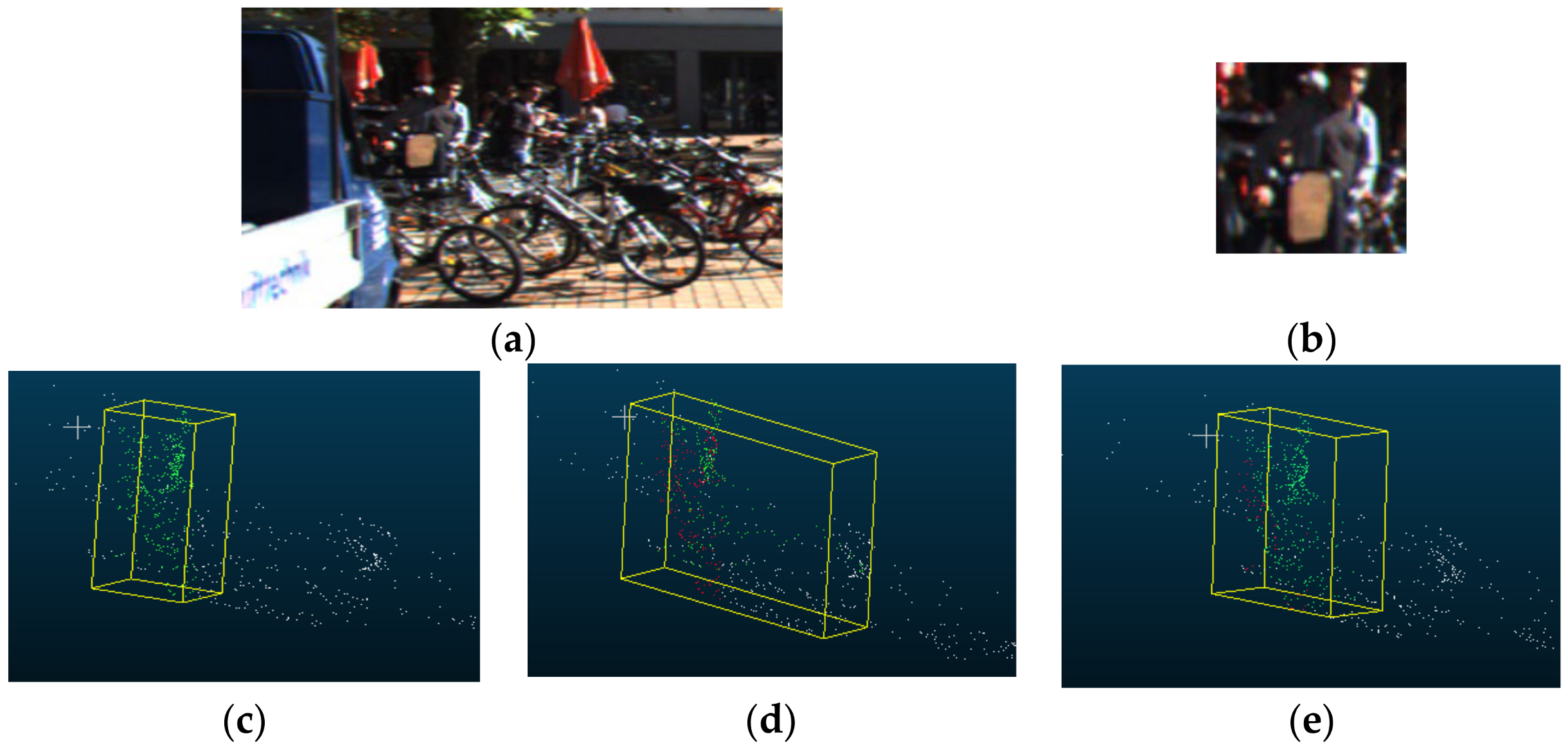
4.3. Pseudo-Lidar F-PointNet Local Fusion and Improvement Strategy
4.4. Pseudo-Lidar EPNet Global Fusion and Model Compression Strategy
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pon, A.D.; Ku, J.; Li, C.; Waslander, S.L. Object-centric stereo matching for 3d object detection. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8383–8389. [Google Scholar]
- Sun, J.; Chen, L.; Xie, Y.; Zhang, S.; Jiang, Q.; Zhou, X.; Bao, H. Disp r-cnn: Stereo 3d object detection via shape prior guided instance disparity estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10548–10557. [Google Scholar]
- Li, T.; Yang, S.; Guo, Z.; Sheng, Z. Design of Monitoring System for Height Limiting Device Based on Acceleration Sensor. In Proceedings of the 2021 International Conference on Computer Engineering and Application (ICCEA), Kunming, China, 25–27 June 2021; pp. 299–302. [Google Scholar]
- Ma, X.; Liu, S.; Xia, Z.; Zhang, H.; Zeng, X.; Ouyang, W. Rethinking pseudo-lidar representation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 311–327. [Google Scholar]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8445–8453. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3d object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 35–52. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Ma, H.; Fidler, S.; Urtasun, R. 3D Object Proposals Using Stereo Imagery for Accurate Object Class Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Xu, B.; Chen, Z. Multi-Level Fusion Based 3D Object Detection from Monocular Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; Computer Vision Foundation/IEEE Computer Society: Washington, DC, USA, 2018; pp. 2345–2353. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving. In Proceedings of the International Conference on Learning Representations, Edinburgh, UK, 4–6 September 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++ deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Garg, D.; Wang, Y.; Hariharan, B.; Campbell, M.; Weinberger, K.Q.; Chao, W.L. Wasserstein distances for stereo disparity estimation. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; pp. 22517–22529. [Google Scholar]
- Guo, X.; Shi, S.; Wang, X.; Li, H. LIGA-Stereo: Learning LiDAR Geometry Aware Representations for Stereo-based 3D Detector. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3153–3163. [Google Scholar]
- Xu, Z.; Zhang, W.; Ye, X.; Tan, X.; Yang, W.; Wen, S.; Ding, E.; Meng, A.; Huang, L. Part-Aware Adaptive Zooming Neural Network for 3D Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12557–12564. [Google Scholar]
- Qin, Z.; Wang, J.; Lu, Y. Triangulation learning network: From monocular to stereo 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7615–7623. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7644–7652. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Xie, L.; Xiang, C.; Yu, Z.; Xu, G.; Yang, Z.; Cai, D.; He, X. PI-RCNN: An Efficient Multi-Sensor 3D Object Detector with Point-Based Attentive Cont-Conv Fusion Module. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12460–12467. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Ayoub, S.; Gulzar, Y.; Reegu, F.A.; Turaev, S. Generating Image Captions Using Bahdanau Attention Mechanism and Transfer Learning. Symmetry 2022, 14, 2681. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Y.; Yang, L.; Qi, Z. CANet: Concatenated attention neural network for image restoration. IEEE Signal Process. Lett. 2020, 27, 1615–1619. [Google Scholar] [CrossRef]
- Gao, L.; Chen, L.; Liu, P.; Jiang, Y.; Li, Y.; Ning, J. Transformer-based visual object tracking via fine–coarse concatenated attention and cross concatenated MLP. Pattern Recognit. 2024, 146, 109964. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4604–4612. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 January–24 October 2020; pp. 10386–10393. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Zhang, F.; Prisacariu, V.; Yang, R.; Torr, P.H. Ga-net: Guided aggregation net for end-to-end stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 185–194. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. Dsgn: Deep stereo geometry network for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12536–12545.
- Cho, S.; Kim, H.; Kwon, J. Filter pruning via softmax attention. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3507–3511. [Google Scholar]
- Yu, F.; Huang, K.; Wang, M.; Cheng, Y.; Chu, W.; Cui, L. Width & Depth Pruning for Vision Transformers. Proc. AAAI Conf. Artif. Intell. (AAAI) 2022, 36, 3143–3151. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | PatchNet | PatchNet with Late Fusion | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Difficult | Easy | Moderate | Difficult | |
| Car | 76.90/ 68.44 | 53.00/ 41.84 | 44.09/ 33.90 | 76.39/ 65.17 | 53.21/ 41.35 | 42.92/ 33.41 |
| Pedestrian | 40.11/ 33.53 | 31.73/ 26.13 | 26.30/ 21.35 | 41.42/ 36.19 | 32.90/ 28.29 | 26.75/ 23.14 |
| Cyclist | 40.38/ 36.56 | 22.13/ 20.02 | 20.43/ 18.36 | 42.64/ 36.83 | 23.93/ 20.50 | 22.27/ 18.97 |
| Category/Feature | Point Cloud | Image |
|---|---|---|
| Car | 0.77 | 0.23 |
| Pedestrian | 0.73 | 0.27 |
| Cyclist | 0.68 | 0.31 |
| Category | Pseudo-Lidar F-PointNet | Pseudo-Lidar F-PointNet with Late Fusion | ||||
|---|---|---|---|---|---|---|
| Easy | Moderate | Difficult | Easy | Moderate | Difficult | |
| Car | 71.69/ 57.58 | 47.77/ 35.16 | 39.43/ 29.19 | 75.06/ 62.04 | 51.09/ 38.30 | 43.82/ 32.17 |
| Pedestrian | 43.63/ 33.43 | 35.01/ 25.65 | 29.37/ 21.41 | 51.58/ 42.67 | 41.55/ 33.59 | 34.40/ 27.83 |
| Cyclist | 48.31/ 40.83 | 27.67/ 23.28 | 25.60/ 21.62 | 55.20/ 47.49 | 31.03/ 26.47 | 28.72/ 24.33 |
| Category/Feature | Point Cloud | Image |
|---|---|---|
| Car | 0.67 | 0.33 |
| Pedestrian | 0.79 | 0.21 |
| Cyclist | 0.81 | 0.19 |
| Category/Feature | Point Cloud | Image | Proportion of Foreground Point Cloud |
|---|---|---|---|
| Car | 0.67 | 0.33 | 0.38 |
| Pedestrian | 0.79 | 0.21 | 0.32 |
| Cyclist | 0.81 | 0.19 | 0.24 |
| Category/Feature | Point Cloud | Image |
|---|---|---|
| Car | 0.54 | 0.56 |
| Pedestrian | 0.24 | 0.76 |
| Cyclist | 0.19 | 0.81 |
| Method | Segmentation Accuracy | Detection Accuracy | |||||
|---|---|---|---|---|---|---|---|
| Point Cloud | Image | Category Vector | Reweighting Module | Easy | Moderate | Difficult | |
| √ | √ | 0.851 | 33.43 | 25.65 | 21.41 | ||
| √ | √ | 0.840 | 42.67 | 33.59 | 27.83 | ||
| √ | √ | √ | 0.841 | 37.14 | 29.21 | 23.95 | |
| √ | √ | √ | √ | 0.851 | 44.18 | 34.97 | 29.05 |
| Method | Segmentation Accuracy | Detection Accuracy | |||||
|---|---|---|---|---|---|---|---|
| Point Cloud | Image | Category Vector | Reweighting Module | Easy | Moderate | Difficult | |
| √ | √ | 0.851 | 40.83 | 23.28 | 21.62 | ||
| √ | √ | 0.840 | 47.49 | 26.47 | 24.33 | ||
| √ | √ | √ | 0.841 | 46.61 | 25.74 | 23.50 | |
| √ | √ | √ | √ | 0.851 | 47.88 | 25.22 | 23.46 |
| Method | Segmentation Accuracy | Detection Accuracy | |||||
|---|---|---|---|---|---|---|---|
| Point Cloud | Image | Category Vector | Reweighting Module | Easy | Moderate | Difficult | |
| √ | √ | 0.843 | 48.46 | 26.96 | 25.15 | ||
| √ | √ | 0.830 | 48.56 | 26.86 | 25.24 | ||
| √ | √ | √ | 0.829 | 51.58 | 28.28 | 26.25 | |
| √ | √ | √ | √ | 0.841 | 50.24 | 27.58 | 25.61 |
| Method | Segmentation Accuracy | Detection Accuracy | |||||
|---|---|---|---|---|---|---|---|
| Point Cloud | Image | Category Vector | Reweighting Module | Easy | Moderate | Difficult | |
| √ | √ | 0.843 | 31.41 | 24.58 | 19.86 | ||
| √ | √ | 0.830 | 44.98 | 34.56 | 28.59 | ||
| √ | √ | √ | 0.829 | 40.09 | 31.23 | 25.58 | |
| √ | √ | √ | √ | 0.841 | 44.33 | 34.57 | 28.85 |
| Method | Easy | Moderate | Difficult | Fusion | Image Segmentation | Method Type |
|---|---|---|---|---|---|---|
| PSMNet + AVOD [5,13] | 27.39 | 26.00 | 20.72 | Y | N | 3D |
| DSGN [35] | 36.84 | 31.42 | 27.55 | N | N | 3D |
| PL-FP [5,6] (original paper) | 33.80 | 27.40 | 24.00 | N | N | 2D-3D |
| PL-FP [5,6] (this paper) | 33.43 | 25.65 | 21.41 | N | N | 2D-3D |
| Ours | 44.18 | 34.97 | 29.05 | Y | N | 2D-3D |
| OC-Stereo [1] | 34.80 | 29.05 | 28.06 | N | Y | 2D-3D |
| Disp-RCNN [2] | 40.43 | 33.03 | 27.05 | N | Y | 2D-3D |
| Method | Easy | Moderate | Difficult | Fusion | Image Segmentation | Method Type |
|---|---|---|---|---|---|---|
| PSMNet + AVOD [5,13] | 35.88 | 22.78 | 21.94 | Y | N | 3D |
| DSGN [35] | 35.39 | 23.16 | 22.29 | N | N | 3D |
| PL-FP [5,6] (original paper) | 41.30 | 25.20 | 24.90 | N | N | 2D-3D |
| PL-FP [5,6] (this paper) | 40.83 | 23.28 | 21.62 | N | N | 2D-3D |
| Ours | 45.88 | 25.22 | 23.46 | Y | N | 2D-3D |
| OC-Stereo [1] | 45.59 | 25.93 | 24.62 | N | Y | 2D-3D |
| Disp-RCNN [2] | 55.98 | 33.46 | 29.51 | N | Y | 2D-3D |
| Method | Easy | Moderate | Difficult |
|---|---|---|---|
| PL Point R-CNN [26] | 46.12 | 36.59 | 30.35 |
| PL EPNet [7] | 49.56 | 40.01 | 33.60 |
| Ours | 50.50 | 40.91 | 34.68 |
| Method | Easy | Moderate | Difficult | Fusion | Image Segmentation | Method Type |
|---|---|---|---|---|---|---|
| PSMNet + AVOD [5,13] | 27.39 | 26.00 | 20.72 | Y | N | 3D |
| DSGN [35] | 36.84 | 31.42 | 27.55 | N | N | 3D |
| PL-FP [5,6] | 33.80 | 27.40 | 24.00 | N | N | 2D-3D |
| Ours | 50.50 | 40.91 | 34.68 | Y | N | 3D |
| OC-Stereo [1] | 34.80 | 29.05 | 28.06 | N | Y | 2D-3D |
| Disp-RCNN [2] | 40.43 | 33.03 | 27.05 | N | Y | 2D-3D |
| Layer | Point Cloud | Image |
|---|---|---|
| The feature immediately following the 0th layer of the SA module | 0.914 | 0.086 |
| The feature immediately following the 1st layer of the SA module | 0.999 | 0.001 |
| The feature immediately following the 2nd layer of the SA module | 0.999 | 0.001 |
| The feature immediately following the 3rd layer of the SA module | 0.001 | 0.999 |
| The feature immediately following the last layer of the FP module | 0.839 | 0.161 |
| Num | Fusion Layer | Precision | Recall | Parameter | Flops | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NOT | SA0 | SA1 | SA2 | SA3 | FP | Easy | Moderate | Difficult | ||||
| 1 | √ | 46.12 | 36.59 | 30.35 | 0.512 | 3.01M | 6884 M | |||||
| 2 | √ | √ | 45.16 | 36.97 | 31.14 | 0.513 | 11.11M | 53,657 M | ||||
| 3 | √ | √ | √ | 48.20 | 38.74 | 32.70 | 0.513 | 13.54M | 123,3136 M | |||
| 4 | √ | √ | √ | √ | √ | 50.50 | 40.91 | 34.68 | 0.520 | 13.96M | 123,3304 M | |
| 5 | √ | 48.66 | 38.50 | 32.14 | 0.488 | 11.09M | 53,602 M | |||||
| 6 | √ | √ | 47.17 | 37.67 | 31.65 | 0.531 | 13.53M | 123,3080 M | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, K.; Jiang, R.; He, J. Stereo 3D Object Detection Using a Feature Attention Module. Algorithms 2023, 16, 560. https://doi.org/10.3390/a16120560
Zhao K, Jiang R, He J. Stereo 3D Object Detection Using a Feature Attention Module. Algorithms. 2023; 16(12):560. https://doi.org/10.3390/a16120560
Chicago/Turabian StyleZhao, Kexin, Rui Jiang, and Jun He. 2023. "Stereo 3D Object Detection Using a Feature Attention Module" Algorithms 16, no. 12: 560. https://doi.org/10.3390/a16120560
APA StyleZhao, K., Jiang, R., & He, J. (2023). Stereo 3D Object Detection Using a Feature Attention Module. Algorithms, 16(12), 560. https://doi.org/10.3390/a16120560