

eNightTrack: Restraint-Free Depth-Camera-Based Surveillance and Alarm System for Fall Prevention Using Deep Learning Tracking

 , , , and
, , , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
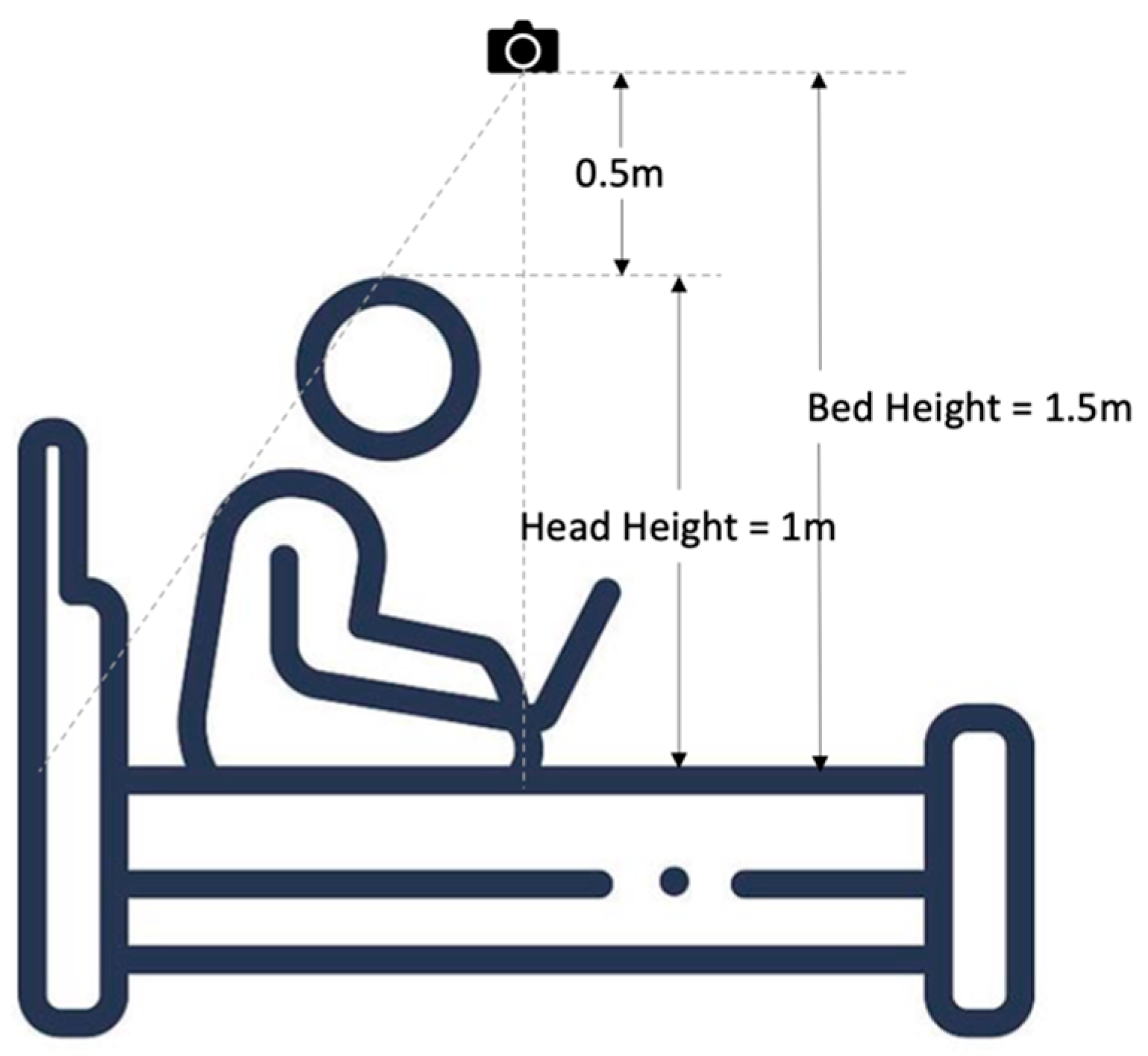
2.2. System Setup
2.3. Data Preprocessing
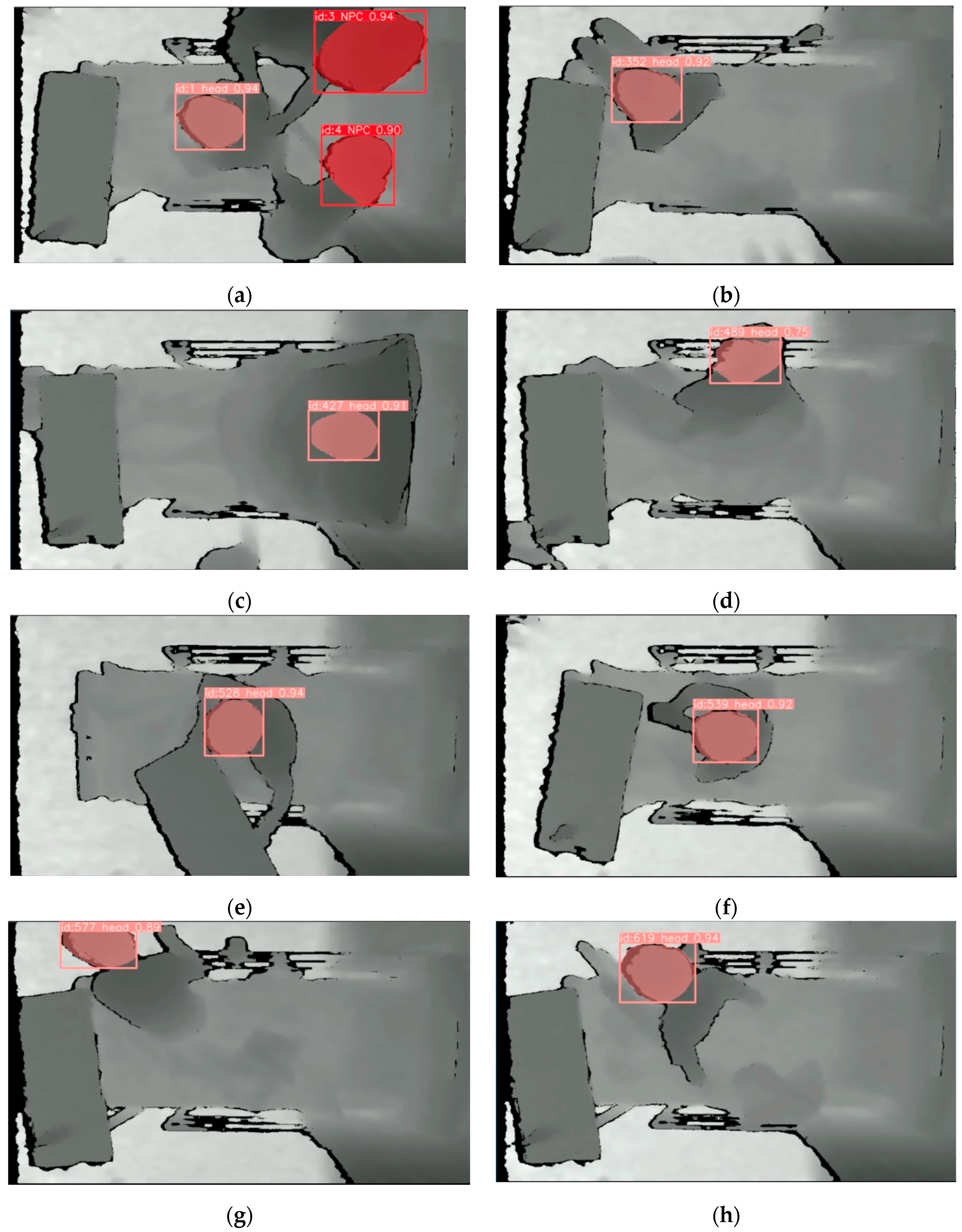
2.4. Instance Segmentation
2.5. Multi-Object Detection
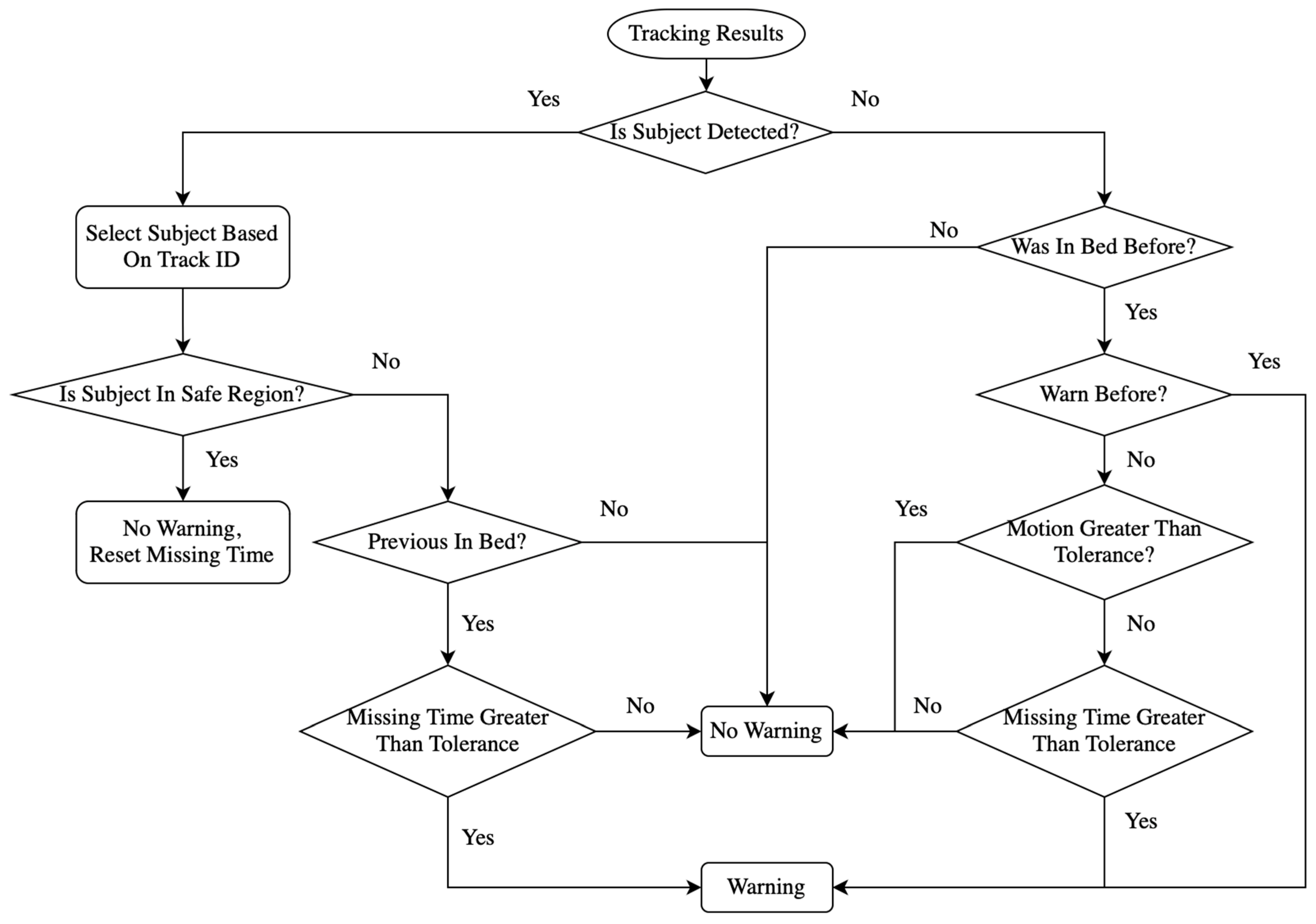
2.6. Alarm Identification
3. Results
3.1. Evaluation Metrices
3.1.1. Tracking Evaluation
3.1.2. Confusion Matrices
3.1.3. Object Detection Performance Evaluation
3.2. Performance of YOLOv8 Instance Segmentation
3.3. Comparison of Different Tracking Techniques
3.4. Performance of Alarm Algorithm
- TP: the bed-exiting scenarios are predicted with warning.
- TN: the staying-in-bed scenarios are identified as safe.
- FP: the staying-in-bed scenarios are predicted with warning.
- FN: the bed-exiting scenarios are identified as safe.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ko, A.; Van Nguyen, H.; Chan, L.; Shen, Q.; Ding, X.M.; Chan, D.L.; Chan, D.K.Y.; Brock, K.; Clemson, L. Developing a self-reported tool on fall risk based on toileting responses on in-hospital falls. Geriatr. Nurs. 2012, 33, 9–16. [Google Scholar] [CrossRef] [PubMed]
- LeLaurin, J.H.; Shorr, R.I. Preventing falls in hospitalized patients: State of the science. Clin. Geriatr. Med. 2019, 35, 273–283. [Google Scholar] [CrossRef] [PubMed]
- Gallardo, M.; Asencio, J.; Sanchez, J.; Banderas, A.; Suarez, A. Instruments for assessing the risk of falls in acute hospitalized patients: A systematic review protocol. J. Adv. Nurs. 2012, 69, 185–193. [Google Scholar] [CrossRef]
- Hignett, S.; Sands, G.; Griffiths, P. In-patient falls: What can we learn from incident reports? Age Ageing 2013, 42, 527–531. [Google Scholar] [CrossRef] [PubMed]
- Choi, Y.S.; Lawler, E.; Boenecke, C.A.; Ponatoski, E.R.; Zimring, C.M. Developing a multi-systemic fall prevention model, incorporating the physical environment, the care process and technology: A systematic review. J. Adv. Nurs. 2011, 67, 2501–2524. [Google Scholar] [CrossRef]
- Feng, Z.; Hirdes, J.P.; Smith, T.F.; Finne-Soveri, H.; Chi, I.; Du Pasquier, J.N.; Gilgen, R.; Ikegami, N.; Mor, V. Use of physical restraints and antipsychotic medications in nursing homes: A cross-national study. Int. J. Geriatr. Psychiatry A J. Psychiatry Late Life Allied Sci. 2009, 24, 1110–1118. [Google Scholar] [CrossRef] [PubMed]
- Kwok, T.; Bai, X.; Chui, M.Y.; Lai, C.K.; Ho, D.W.; Ho, F.K.; Woo, J. Effect of physical restraint reduction on older patients’ hospital length of stay. J. Am. Med. Dir. Assoc. 2012, 13, 645–650. [Google Scholar] [CrossRef] [PubMed]
- Choi, E.; Song, M. Physical restraint use in a Korean ICU. J. Clin. Nurs. 2003, 12, 651–659. [Google Scholar] [CrossRef] [PubMed]
- Capezuti, E. Minimizing the use of restrictive devices in dementia patients at risk for falling. Nurs. Clin. 2004, 39, 625–647. [Google Scholar] [CrossRef]
- Gallinagh, R.n.; Nevin, R.; Mc Ilroy, D.; Mitchell, F.; Campbell, L.; Ludwick, R.; McKenna, H. The use of physical restraints as a safety measure in the care of older people in four rehabilitation wards: Findings from an exploratory study. Int. J. Nurs. Stud. 2002, 39, 147–156. [Google Scholar] [CrossRef] [PubMed]
- Hofmann, H.; Hahn, S. Characteristics of nursing home residents and physical restraint: A systematic literature review. J. Clin. Nurs. 2014, 23, 3012–3024. [Google Scholar] [CrossRef] [PubMed]
- Lam, K.; Kwan, J.S.; Kwan, C.W.; Chong, A.M.; Lai, C.K.; Lou, V.W.; Leung, A.Y.; Liu, J.Y.; Bai, X.; Chi, I. Factors associated with the trend of physical and chemical restraint use among long-term care facility residents in Hong Kong: Data from an 11-year observational study. J. Am. Med. Dir. Assoc. 2017, 18, 1043–1048. [Google Scholar] [CrossRef]
- Lancaster, G.A.; Whittington, R.; Lane, S.; Riley, D.; Meehan, C. Does the position of restraint of disturbed psychiatric patients have any association with staff and patient injuries? J. Psychiatr. Ment. Health Nurs. 2008, 15, 306–312. [Google Scholar] [CrossRef] [PubMed]
- Andrews, G.J. Managing challenging behaviour in dementia. BMJ 2006, 332, 741. [Google Scholar] [CrossRef] [PubMed]
- Gastmans, C.; Milisen, K. Use of physical restraint in nursing homes: Clinical-ethical considerations. J. Med. Ethics 2006, 32, 148–152. [Google Scholar] [CrossRef] [PubMed]
- Ooi, C.H.; Yoon, P.S.; How, C.H.; Poon, N.Y. Managing challenging behaviours in dementia. Singap. Med. J. 2018, 59, 514. [Google Scholar] [CrossRef]
- Ackerman, M.M.; Tang, X.; Guyot-Sionnest, P. Fast and sensitive colloidal quantum dot mid-wave infrared photodetectors. ACS Nano 2018, 12, 7264–7271. [Google Scholar] [CrossRef] [PubMed]
- Massé, F.; Gonzenbach, R.R.; Arami, A.; Paraschiv-Ionescu, A.; Luft, A.R.; Aminian, K. Improving activity recognition using a wearable barometric pressure sensor in mobility-impaired stroke patients. J. Neuroeng. Rehabil. 2015, 12, 72. [Google Scholar] [CrossRef]
- Cheung, C.-W.J.; Chan, W.-H.R.; Chiu, M.-W.; Law, S.-Y.; Lee, T.-H.; Zheng, Y.-P. A three-month study of fall and physical activity levels of intellectual disability using a transfer belt-based motion recording sensor. In 6th World Congress of Biomechanics (WCB 2010), Proceedings of the in Conjunction with 14th International Conference on Biomedical Engineering (ICBME) and 5th Asia Pacific Conference on Biomechanics (APBiomech), Singapore, 1–6 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1393–1396. [Google Scholar]
- Yaacoub, J.-P.A.; Noura, M.; Noura, H.N.; Salman, O.; Yaacoub, E.; Couturier, R.; Chehab, A. Securing internet of medical things systems: Limitations, issues and recommendations. Future Gener. Comput. Syst. 2020, 105, 581–606. [Google Scholar] [CrossRef]
- Liu, B.; Cai, H.; Ju, Z.; Liu, H. RGB-D sensing based human action and interaction analysis: A survey. Pattern Recognit. 2019, 94, 1–12. [Google Scholar] [CrossRef]
- Fuertes Muñoz, G.; Mollineda, R.A.; Gallardo Casero, J.; Pla, F. A rgbd-based interactive system for gaming-driven rehabilitation of upper limbs. Sensors 2019, 19, 3478. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Cinque, L.; Del Bimbo, A.; Marini, M.R. MIFTel: A multimodal interactive framework based on temporal logic rules. Multimed. Tools Appl. 2020, 79, 13533–13558. [Google Scholar] [CrossRef]
- Cheung, J.C.-W.; So, B.P.-H.; Ho, K.H.M.; Wong, D.W.-C.; Lam, A.H.-F.; Cheung, D.S.K. Wrist accelerometry for monitoring dementia agitation behaviour in clinical settings: A scoping review. Front. Psychiatry 2022, 13, 913213. [Google Scholar] [CrossRef] [PubMed]
- Shorr, R.I.; Chandler, A.M.; Mion, L.C.; Waters, T.M.; Liu, M.; Daniels, M.J.; Kessler, L.A.; Miller, S.T. Effects of an intervention to increase bed alarm use to prevent falls in hospitalized patients: A cluster randomized trial. Ann. Intern. Med. 2012, 157, 692–699. [Google Scholar] [CrossRef] [PubMed]
- Faisal, I.A.; Purboyo, T.W.; Ansori, A.S.R. A review of accelerometer sensor and gyroscope sensor in IMU sensors on motion capture. J. Eng. Appl. Sci 2019, 15, 826–829. [Google Scholar]
- Sawane, M.; Prasad, M. MEMS piezoelectric sensor for self-powered devices: A review. Mater. Sci. Semicond. Process. 2023, 158, 107324. [Google Scholar] [CrossRef]
- Xiong, D.; Zhang, D.; Zhao, X.; Zhao, Y. Deep Learning for EMG-based Human-Machine Interaction: A Review. IEEE/CAA J. Autom. Sin. 2021, 8, 512–533. [Google Scholar] [CrossRef]
- Xue, J.; Lai, K.W.C. Dynamic gripping force estimation and reconstruction in EMG-based human-machine interaction. Biomed. Signal Process. Control 2023, 80, 104216. [Google Scholar] [CrossRef]
- Jannat, M.K.A.; Islam, M.S.; Yang, S.H.; Liu, H. Efficient Wi-Fi-Based Human Activity Recognition Using Adaptive Antenna Elimination. IEEE Access 2023, 11, 105440–105454. [Google Scholar] [CrossRef]
- Ding, J.; Wang, Y. A WiFi-Based Smart Home Fall Detection System Using Recurrent Neural Network. IEEE Trans. Consum. Electron. 2020, 66, 308–317. [Google Scholar] [CrossRef]
- Liu, H.; Gamboa, H.; Schultz, T. Sensor-Based Human Activity and Behavior Research: Where Advanced Sensing and Recognition Technologies Meet. Sensors 2023, 23, 125. [Google Scholar] [CrossRef] [PubMed]
- Xue, T.; Liu, H. Hidden Markov Model and Its Application in Human Activity Recognition and Fall Detection: A Review. In Proceedings of the Communications, Signal Processing, and Systems, Singapore, 21–22 August 2021; pp. 863–869. [Google Scholar]
- Mekruksavanich, S.; Jantawong, P.; Hnoohom, N.; Jitpattanakul, A. Automatic Fall Detection using Deep Neural Networks with Aggregated Residual Transformation. In Proceedings of the 2022 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; pp. 811–814. [Google Scholar]
- Liang, S.; Chu, T.; Lin, D.; Ning, Y.; Li, H.; Zhao, G. Pre-impact Alarm System for Fall Detection Using MEMS Sensors and HMM-based SVM Classifier. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4401–4405. [Google Scholar]
- Liu, H.; Hartmann, Y.; Schultz, T. Motion Units: Generalized Sequence Modeling of Human Activities for Sensor-Based Activity Recognition. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 1506–1510. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. High-Level Features for Human Activity Recognition and Modeling. In Proceedings of the Biomedical Engineering Systems and Technologies. BIOSTEC 2022, Vienna, Austria, 9–11 February 2022; pp. 141–163. [Google Scholar]
- Carneiro, S.A.; Silva, G.P.d.; Leite, G.V.; Moreno, R.; Guimarães, S.J.F.; Pedrini, H. Multi-Stream Deep Convolutional Network Using High-Level Features Applied to Fall Detection in Video Sequences. In Proceedings of the 2019 International Conference on Systems, Signals and Image Processing (IWSSIP), Osijek, Croatia, 5–7 June 2019; pp. 293–298. [Google Scholar]
- Kasturi, S.; Filonenko, A.; Jo, K.-H. Human fall recognition using the spatiotemporal 3d cnn. In Proceedings of the 29th International Workshop on Frontiers of Computer Vision, 2019, Yeosu, South Korea, 20–22 February 2023; pp. 1–3. [Google Scholar]
- Hasan, M.M.; Islam, M.S.; Abdullah, S. Robust Pose-Based Human Fall Detection Using Recurrent Neural Network. In Proceedings of the 2019 IEEE International Conference on Robotics, Automation, Artificial-intelligence and Internet-of-Things (RAAICON), Dhaka, Bangladesh, 29 November–1 December 2019; pp. 48–51. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Cheung, J.C.-W.; Tam, E.W.-C.; Mak, A.H.-Y.; Chan, T.T.-C.; Lai, W.P.-Y.; Zheng, Y.-P. Night-time monitoring system (eNightLog) for elderly wandering behavior. Sensors 2021, 21, 704. [Google Scholar] [CrossRef] [PubMed]
- Cheung, J.C.-W.; Tam, E.W.-C.; Mak, A.H.-Y.; Chan, T.T.-C.; Zheng, Y.-P. A night-time monitoring system (eNightLog) to prevent elderly wandering in hostels: A three-month field study. Int. J. Environ. Res. Public Health 2022, 19, 2103. [Google Scholar] [CrossRef] [PubMed]
- Tam, A.Y.-C.; So, B.P.-H.; Chan, T.T.-C.; Cheung, A.K.-Y.; Wong, D.W.-C.; Cheung, J.C.-W. A blanket accommodative sleep posture classification system using an infrared depth camera: A deep learning approach with synthetic augmentation of blanket conditions. Sensors 2021, 21, 5553. [Google Scholar] [CrossRef] [PubMed]
- Tam, A.Y.-C.; Zha, L.-W.; So, B.P.-H.; Lai, D.K.-H.; Mao, Y.-J.; Lim, H.-J.; Wong, D.W.-C.; Cheung, J.C.-W. Depth-Camera-Based Under-Blanket Sleep Posture Classification Using Anatomical Landmark-Guided Deep Learning Model. Int. J. Environ. Res. Public Health 2022, 19, 13491. [Google Scholar] [CrossRef] [PubMed]
- Lai, D.K.-H.; Zha, L.-W.; Leung, T.Y.-N.; Tam, A.Y.-C.; So, B.P.-H.; Lim, H.-J.; Cheung, D.S.K.; Wong, D.W.-C.; Cheung, J.C.-W. Dual ultra-wideband (UWB) radar-based sleep posture recognition system: Towards ubiquitous sleep monitoring. Eng. Regen. 2023, 4, 36–43. [Google Scholar] [CrossRef]
- Lai, D.K.-H.; Yu, Z.-H.; Leung, T.Y.-N.; Lim, H.-J.; Tam, A.Y.-C.; So, B.P.-H.; Mao, Y.-J.; Cheung, D.S.K.; Wong, D.W.-C.; Cheung, J.C.-W. Vision Transformers (ViT) for Blanket-Penetrating Sleep Posture Recognition Using a Triple Ultra-Wideband (UWB) Radar System. Sensors 2023, 23, 2475. [Google Scholar] [CrossRef] [PubMed]
- Shea, T.; Tam, Y.; So, P.; Chan, T.; Mak, H.; Lai, K.; Wong, M.; Zheng, Y.; Cheung, C. Multi-depth cameras system for bed exit and fall prevention of hospitalized elderly patients. Gerontechnology 2022, 21, 1. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Wong, C.; Yifu, Z.; Montes, D. Ultralytics/Yolov5: v6. 2-Yolov5 Classification Models, Apple m1, Reproducibility, Clearml and Deci. ai Integrations. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...7002879J/exportcitation (accessed on 25 August 2023).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Phon-Amnuaisuk, S.; Murata, K.T.; Pavarangkoon, P.; Yamamoto, K.; Mizuhara, T. Exploring the applications of faster R-CNN and single-shot multi-box detection in a smart nursery domain. arXiv 2018, arXiv:1808.08675. [Google Scholar]
- Lee, J.-D.; Chien, J.-C.; Hsu, Y.-T.; Wu, C.-T. Automatic Surgical Instrument Recognition—A Case of Comparison Study between the Faster R-CNN, Mask R-CNN, and Single-Shot Multi-Box Detectors. Appl. Sci. 2021, 11, 8097. [Google Scholar] [CrossRef]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 1–14. [Google Scholar] [CrossRef]
- Gong, S.; Cristani, M.; Loy, C.C.; Hospedales, T.M. The re-identification challenge. In Person Re-Identification; Gong, S., Cristani, M., Yan, S., Loy, C.C., Eds.; Springer: London, UK, 2014; pp. 1–20. [Google Scholar]
- Zhang, Y.; Wang, X.; Ye, X.; Zhang, W.; Lu, J.; Tan, X.; Ding, E.; Sun, P.; Wang, J. ByteTrackV2: 2D and 3D Multi-Object Tracking by Associating Every Detection Box. arXiv 2023, arXiv:2303.15334. [Google Scholar]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 24–28 October 2022; pp. 1–21. [Google Scholar]
- Veeramani, B.; Raymond, J.W.; Chanda, P. DeepSort: Deep convolutional networks for sorting haploid maize seeds. BMC Bioinform. 2018, 19, 289. [Google Scholar] [CrossRef] [PubMed]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lu, L.; Zhao, C.; Luo, S.; Fu, Y. A Data-Driven Human Activity Classification Method for an Intelligent Hospital Bed. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4991–4996. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Video Clips Count | Purpose of Simulation | State | Caregivers Appear? |
|---|---|---|---|---|
| Sc01 1 | 15 | Nurse helping with dressing scenario—nurse puts a safety vest on the patient. | Staying In Bed | Yes |
| Sc02 | 15 | Exiting bedside scenario—patient removes the safety vest and slips away at the side of bed. | Bed Exiting | No |
| Sc03 | 15 | Nurse changing sheets scenario—nurse changes bed sheets when the patient is on the bed. | Staying In Bed | Yes |
| Sc04 | 14 | Exiting at bed end scenario—patient exits bed at the rear end of the bed. | Bed Exiting | No |
| Sc05 | 14 | Nurse helping adjust position scenario—nurse pulls sheets up to help patient to adjust their sleeping position. | Staying In Bed | Yes |
| Sc06 | 15 | Kneeling on rear edge of bed scenario—patient kneels on the bed at the rear edge. | Bed Exiting | No |
| Sc07 | 15 | Adjusting bed level scenario—nurse/patient adjusts the level of the bed from lying to sitting and raises the level of the bed and returns it to the original position. | Staying In Bed | Yes |
| Sc08 | 16 | Picking up belongings scenario—patient leans over the bed rail to look for personal belongings at the bottom of locker. | Bed Exiting | No |
| Sc09 | 15 | Nurse helping turn scenario—nurse helps patient to turn and places a pillow for support. | Staying In Bed | Yes |
| Sc10 | 15 | Pillow mimicking scenario—patient exits bed when a supporting pillow similar to a human shape is still on the bed. | Bed Exiting | No |
| Sc11 | 15 | Changing position scenario—patient changes from a lying to sitting position. | Staying In Bed | No |
| Sc12 | 15 | Climbing exiting scenario—patient climbs over bed rails and leaves. | Bed Exiting | No |
| Sc13 | 15 | Pushing table scenario—patient pushes table towards the rear end of bed. | Staying In Bed | No |
| Sc14 | 16 | Leaning scenario—patient climbs over rail and leans their upper body out to pick up items. | Bed Exiting | No |
| Sc15 | 16 | Drinking scenario—patient searches for personal belongings on top of the locker (only reaching hand out to pick up a cup of water). | Staying In Bed | No |
| Sc16 | 16 | Sliding under the blanket scenario—patient slides under the blanket at the rear end of bed and leaves. | Bed Exiting | No |
| Sc17 | 16 | Use of urinal scenario—male patient sits near the edge of the bed and uses urinal for voiding. | Staying In Bed | No |
| Sc18 | 16 | Leaning forward scenario—patient leans forward when sitting at the edge of bed. | Bed Exiting | No |
| Sc19 | 17 | Use of bedpan scenario—patient uses bedpan in bed. | Staying In Bed | Yes |
| Sc20 | 16 | Sliding scenario—patient slides to the rear end of the bed and leaves without blanket. | Bed Exiting | No |
| Class | mAP50 |
|---|---|
| All | 98.8% |
| Medical Personnel | 98.6% |
| Patient | 99.0% |
| mAP50 | ||||||
|---|---|---|---|---|---|---|
| Class | Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Mean |
| All | 98.2% | 98.8% | 97.0% | 96.8% | 97.0% | 97.6% |
| Medical Personnel | 97.1% | 98.4% | 94.8% | 97.3% | 95.5% | 96.6% |
| Patient | 9.91% | 99.3% | 99.2% | 96.3% | 98.4% | 98.5% |
| StrongSORT | DeepSORT | ByteTrack | |
|---|---|---|---|
| Number of frames losing tracking | 21,482 | 8205 | 8205 |
| Lost-tracking rate | 23.4% | 8.9% | 8.9% |
| Total count of ID changes | 1550 | 2109 | 1697 |
| Sensitivity | Specificity | Balanced Accuracy | F1 | |
|---|---|---|---|---|
| DeepSORT | 96.8% | 62.8% | 79.8% | 82.8% |
| ByteTrack | 96.8% | 61.4% | 79.1% | 82.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, Y.-J.; Tam, A.Y.-C.; Shea, Q.T.-K.; Zheng, Y.-P.; Cheung, J.C.-W. eNightTrack: Restraint-Free Depth-Camera-Based Surveillance and Alarm System for Fall Prevention Using Deep Learning Tracking. Algorithms 2023, 16, 477. https://doi.org/10.3390/a16100477
Mao Y-J, Tam AY-C, Shea QT-K, Zheng Y-P, Cheung JC-W. eNightTrack: Restraint-Free Depth-Camera-Based Surveillance and Alarm System for Fall Prevention Using Deep Learning Tracking. Algorithms. 2023; 16(10):477. https://doi.org/10.3390/a16100477
Chicago/Turabian StyleMao, Ye-Jiao, Andy Yiu-Chau Tam, Queenie Tsung-Kwan Shea, Yong-Ping Zheng, and James Chung-Wai Cheung. 2023. "eNightTrack: Restraint-Free Depth-Camera-Based Surveillance and Alarm System for Fall Prevention Using Deep Learning Tracking" Algorithms 16, no. 10: 477. https://doi.org/10.3390/a16100477
APA StyleMao, Y.-J., Tam, A. Y.-C., Shea, Q. T.-K., Zheng, Y.-P., & Cheung, J. C.-W. (2023). eNightTrack: Restraint-Free Depth-Camera-Based Surveillance and Alarm System for Fall Prevention Using Deep Learning Tracking. Algorithms, 16(10), 477. https://doi.org/10.3390/a16100477