

Comparing Activation Functions in Machine Learning for Finite Element Simulations in Thermomechanical Forming


Abstract
:1. Introduction
1.1. Constitutive Behavior and Material Flow Law
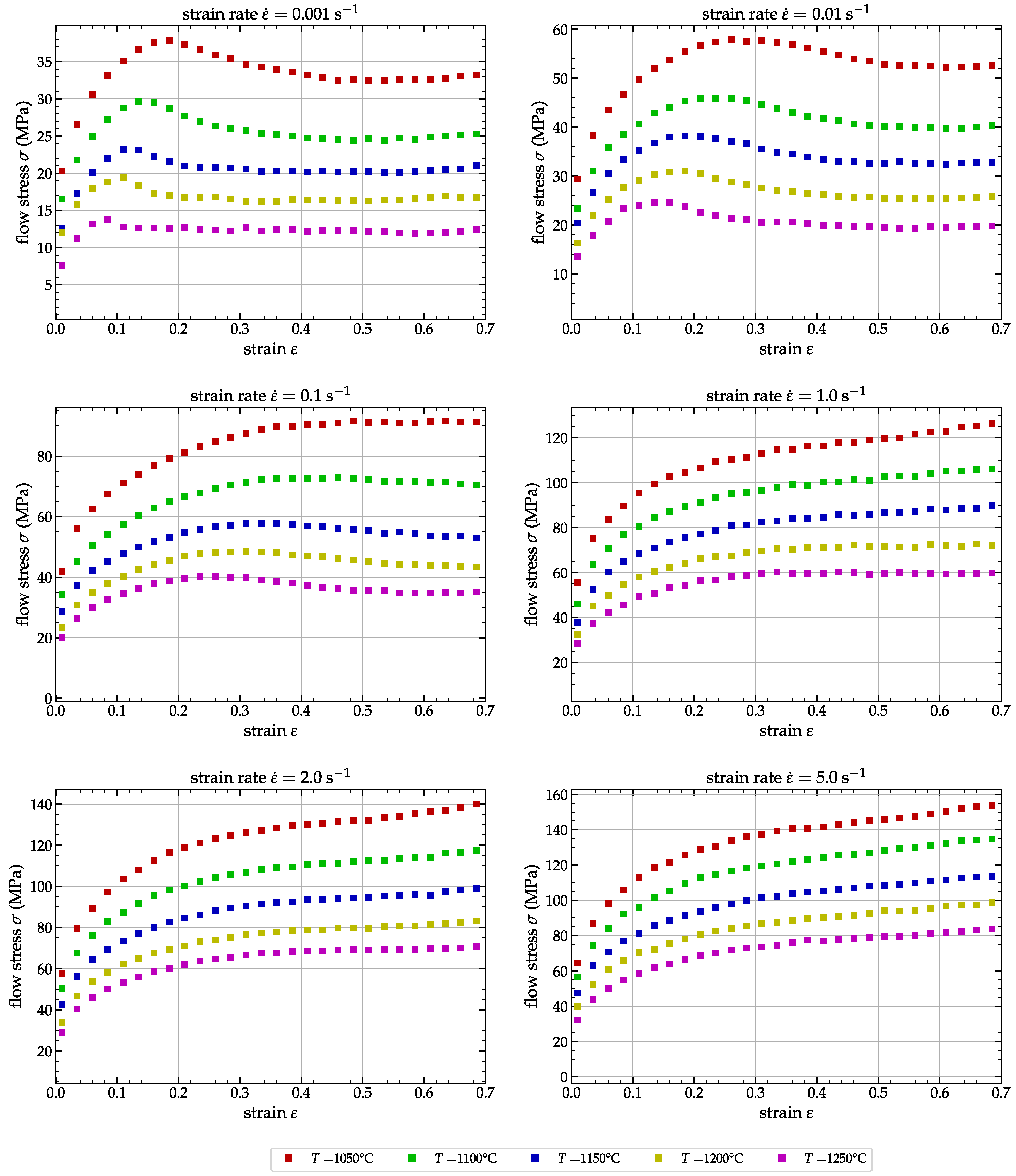
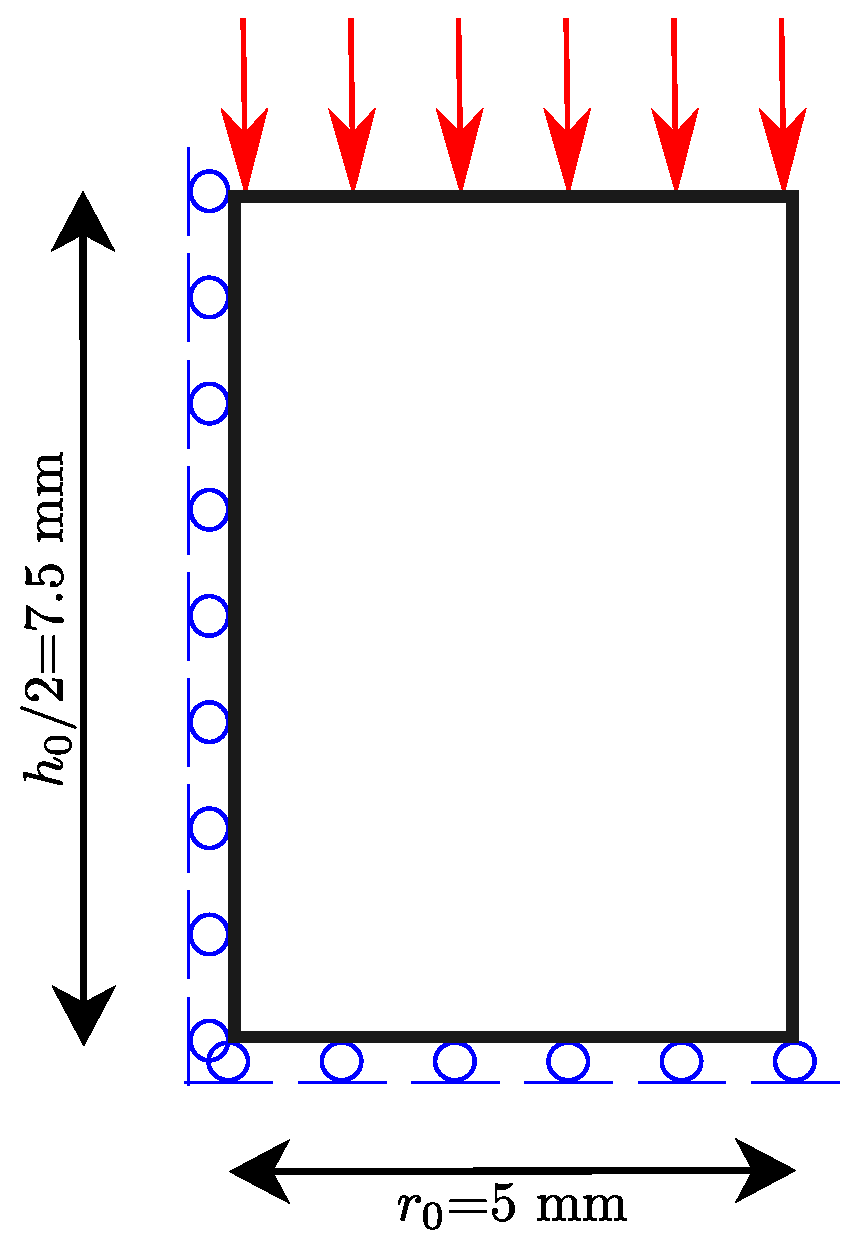
1.2. Experimental Tests and Data
2. Artificial Neural Network Flow Law
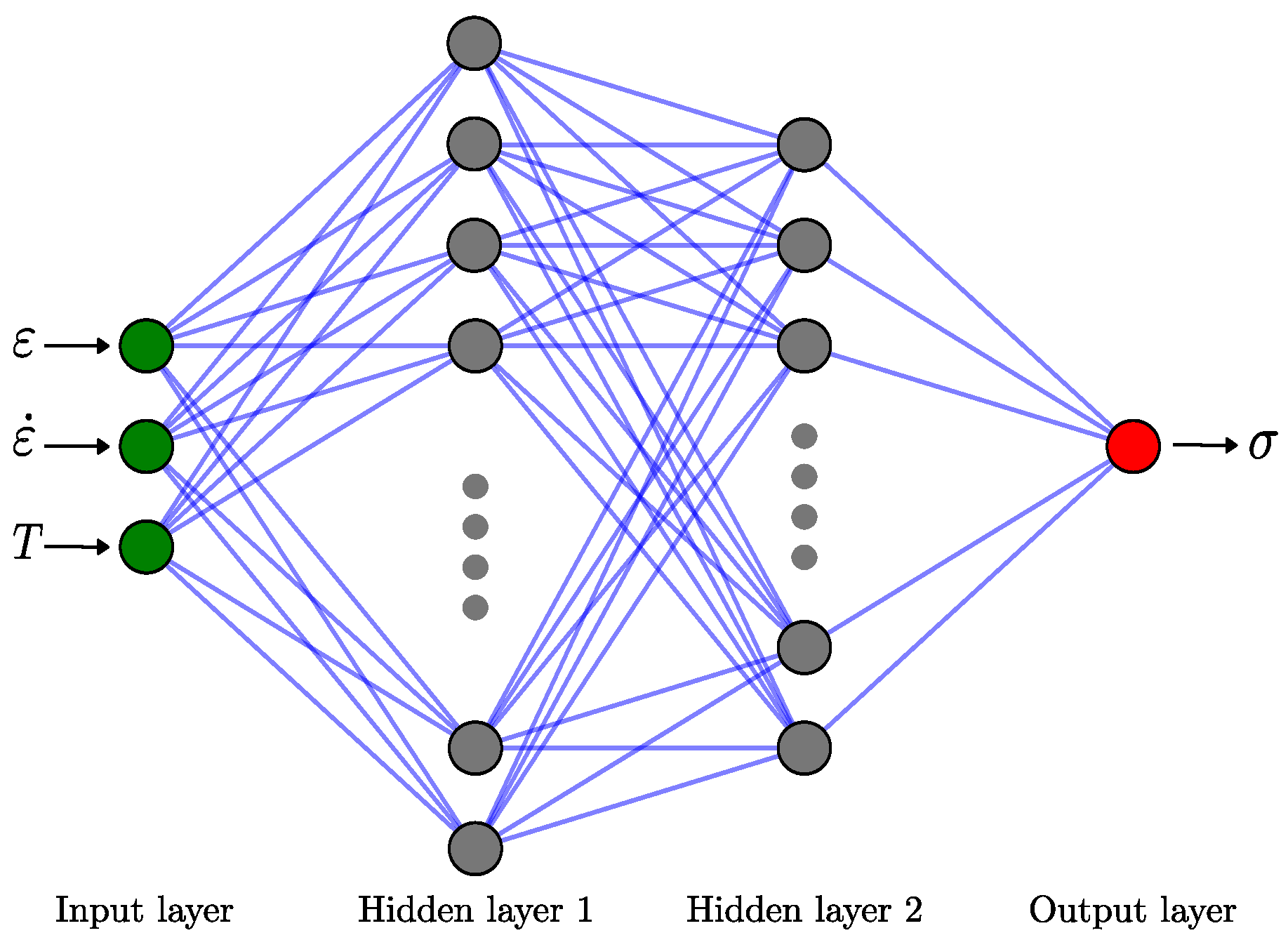
2.1. Artificial Neural Network Equations
2.1.1. Network Architecture
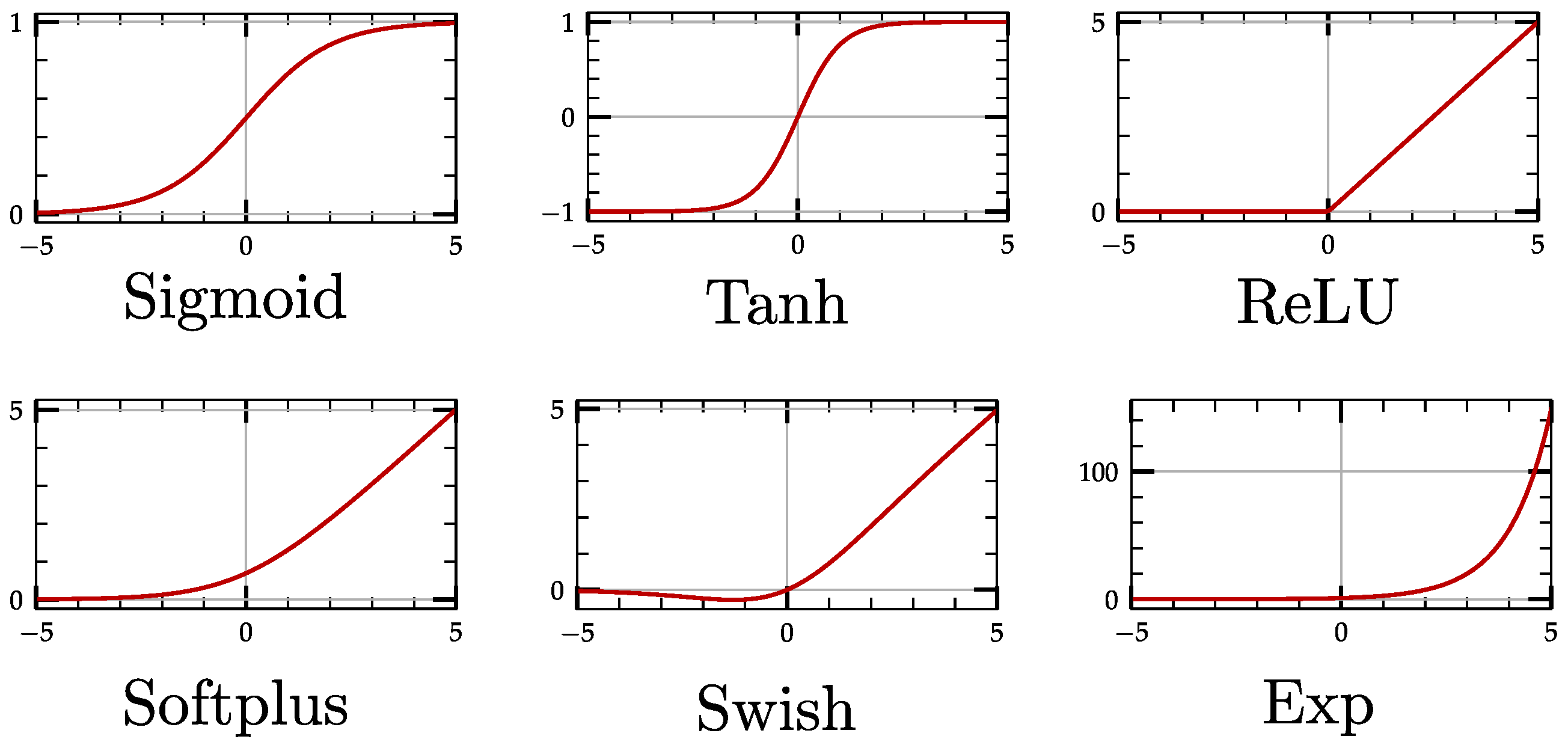
2.1.2. Activation Functions
2.1.3. Pre- and Post-Processing Architecture
2.1.4. Derivatives of the Neural Network
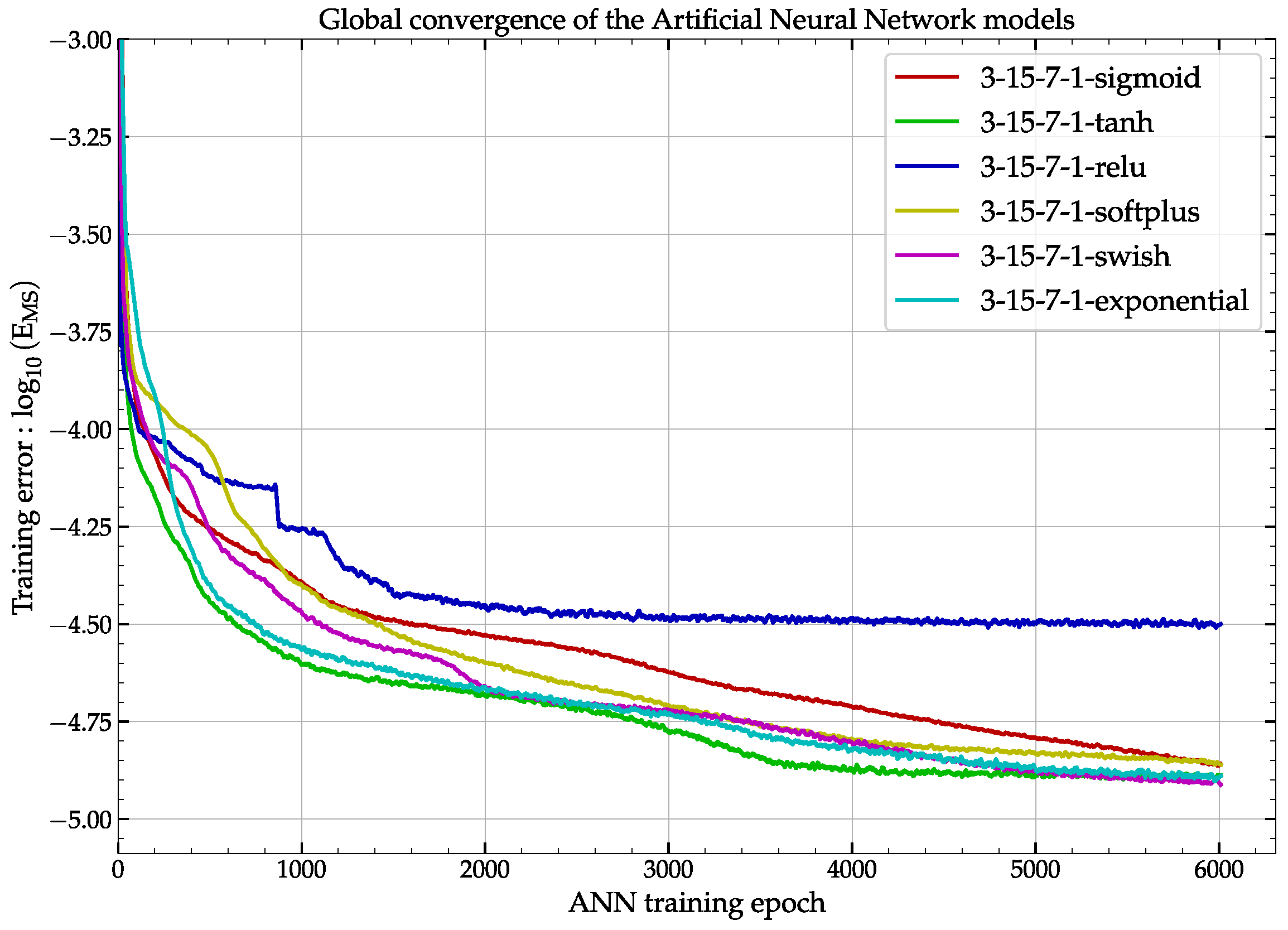
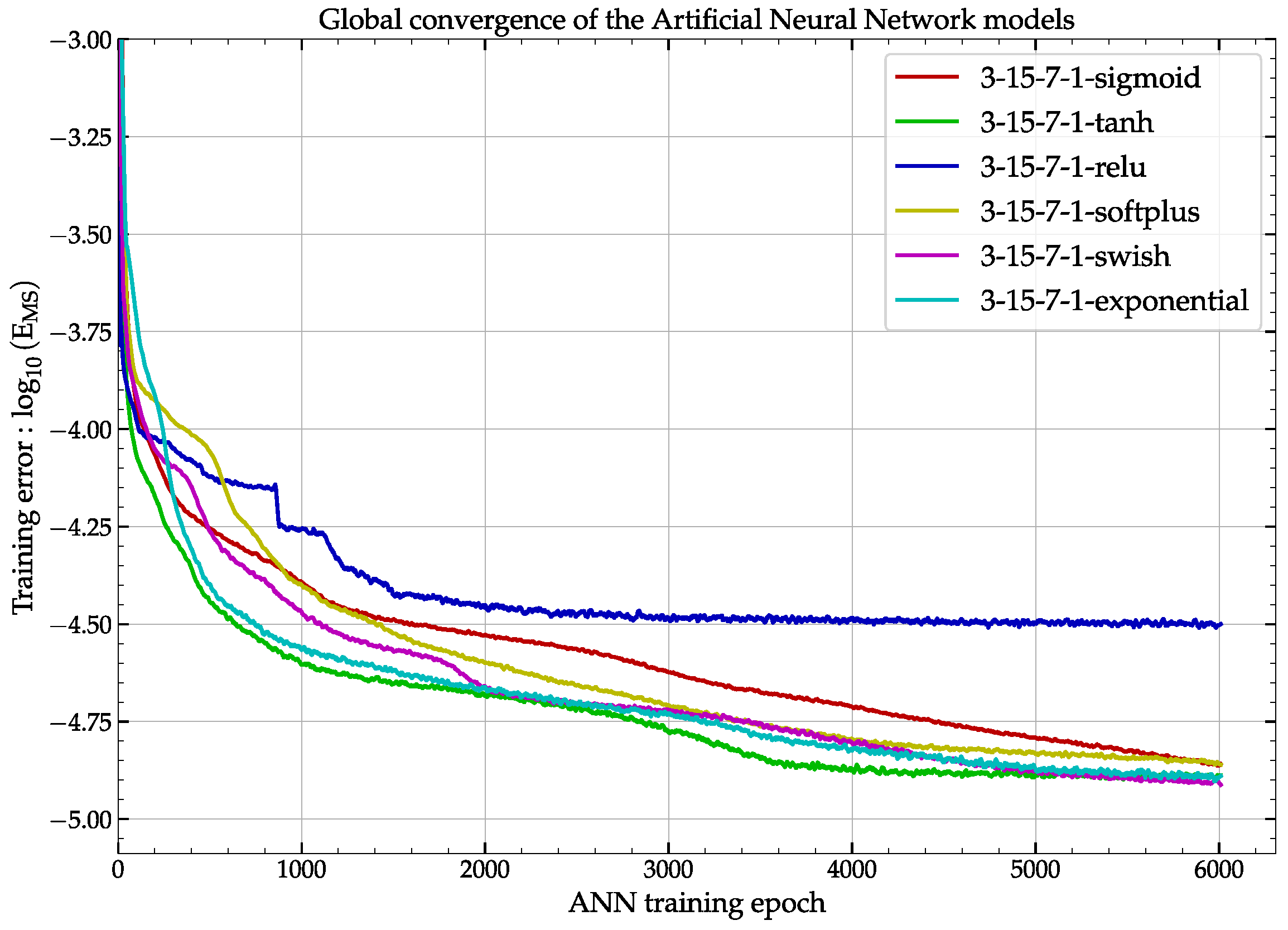
2.2. Training of the ANN on Experimental Data
3. Numerical Simulations Using the ANN Flow Law
3.1. Numerical Implementation of the ANN Flow Law
- We first use Equation (11) to compute the vector where all components of will be remapped within the range :where ⊘ is the Hadamard division operator.
- Conforming to Equation (2), we compute the vector:
- We repeat the process for the second layer, so that we compute the vectors:and:
- Then, we can compute in a single step the three derivatives from Equation (13) with the following expression:where the expression used for changes depending on the activation function used.
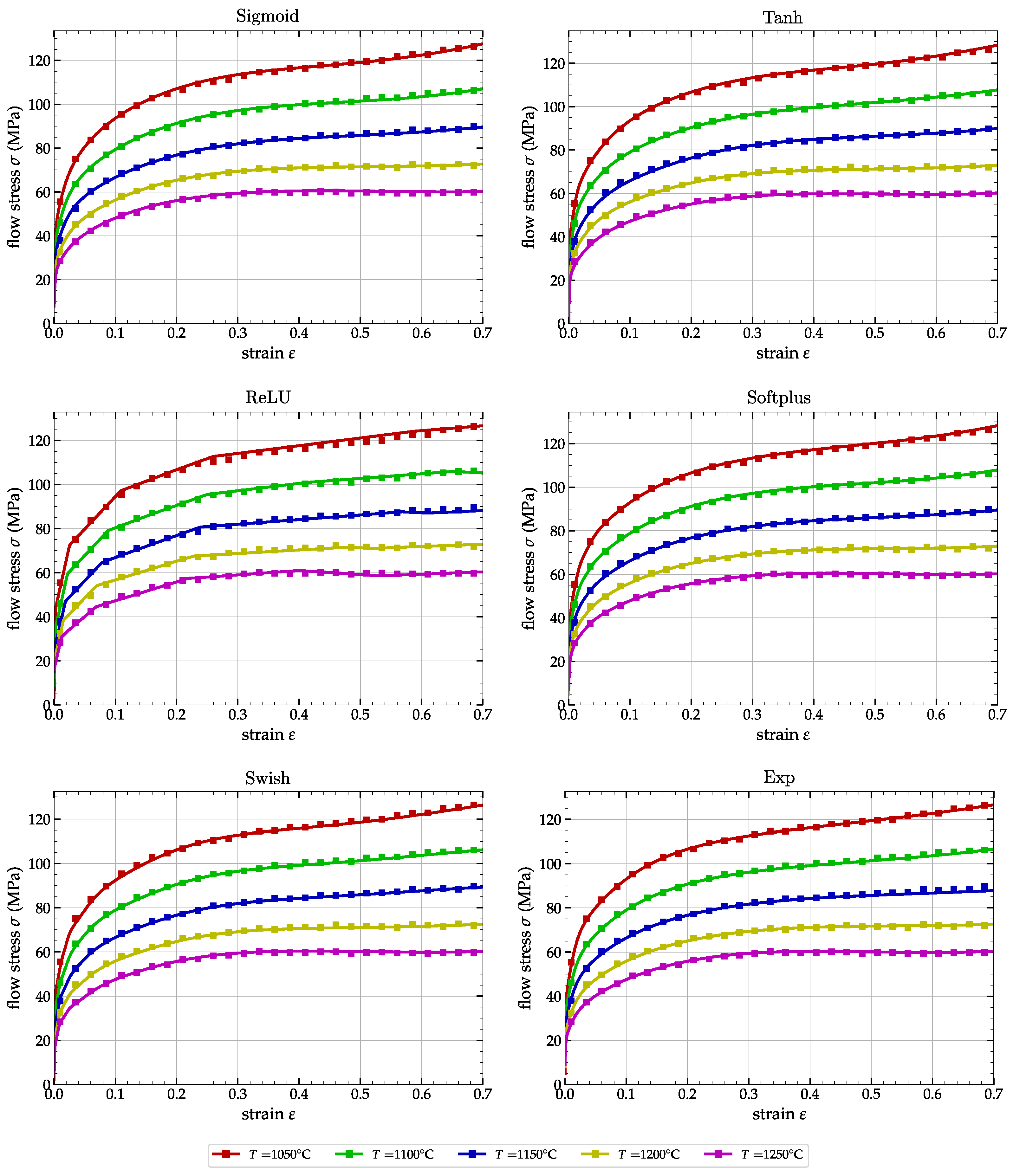
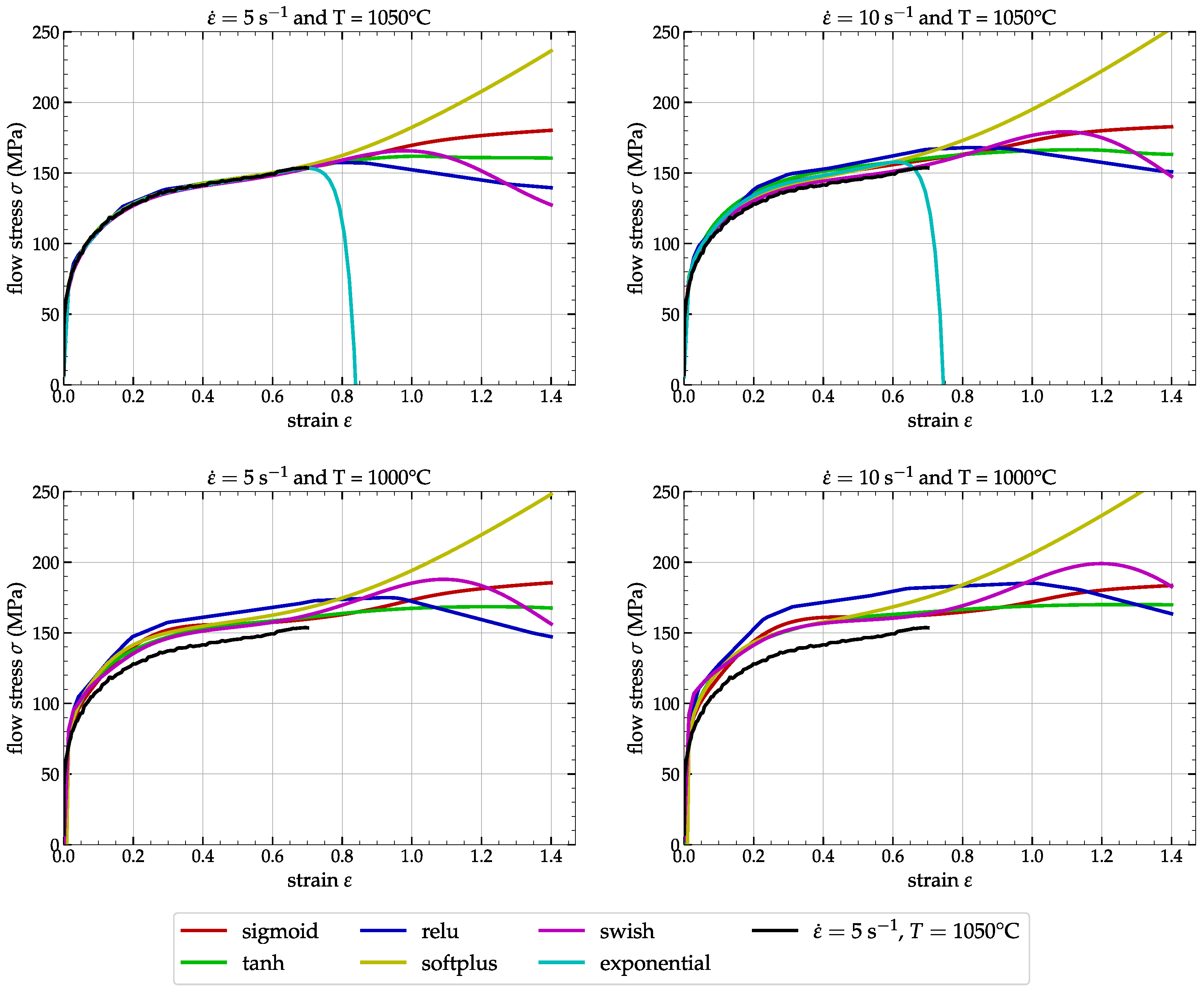
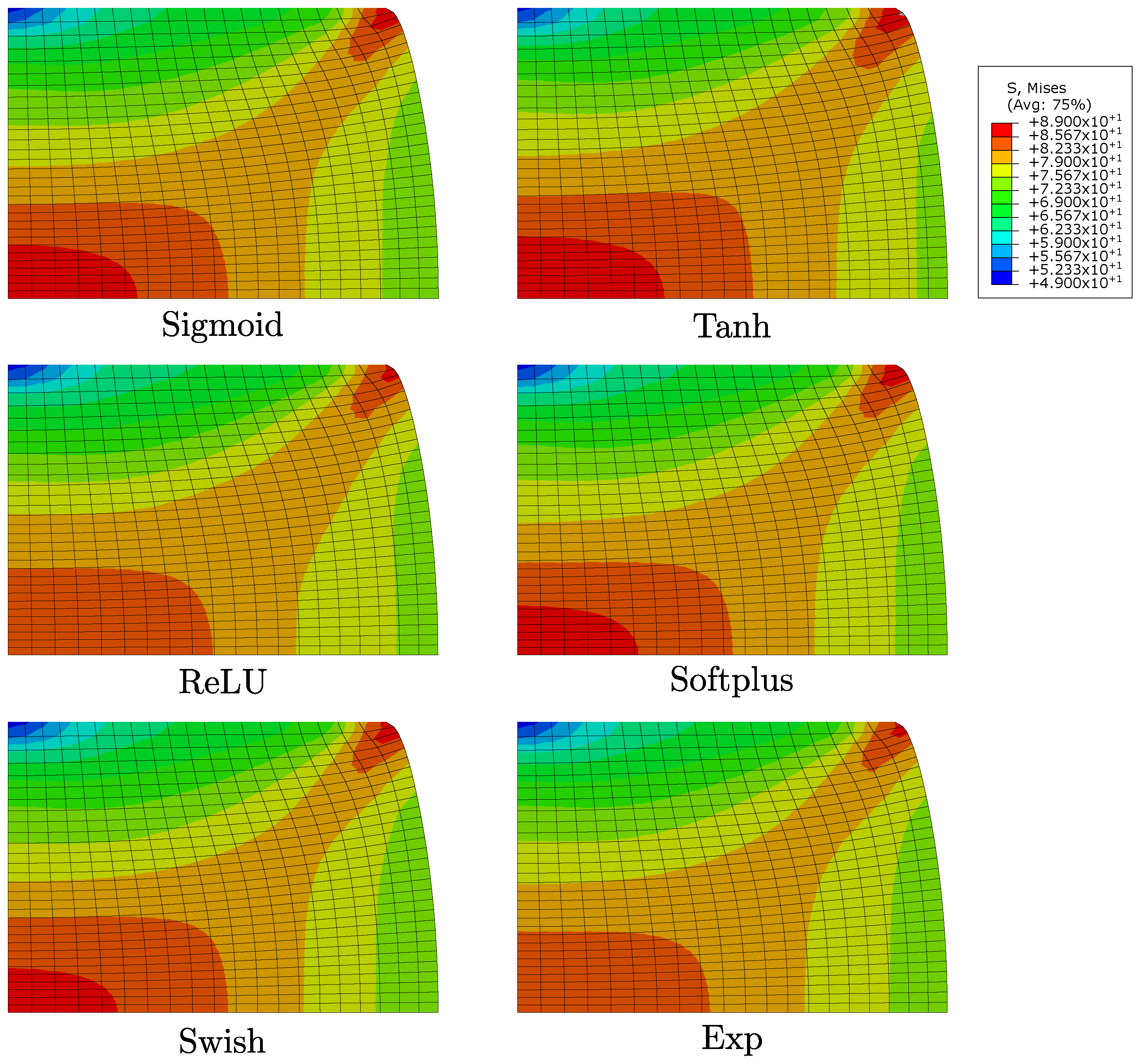
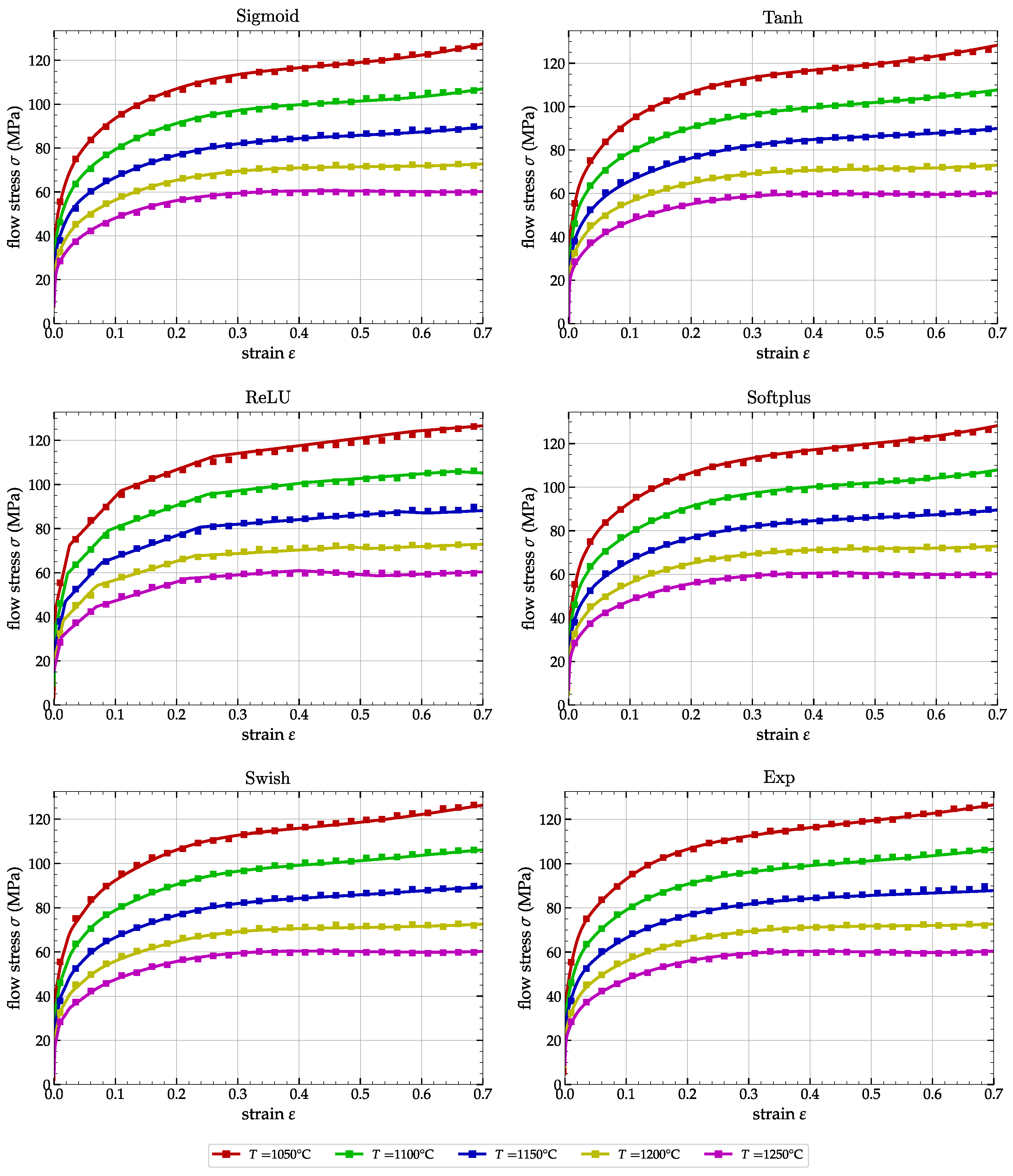
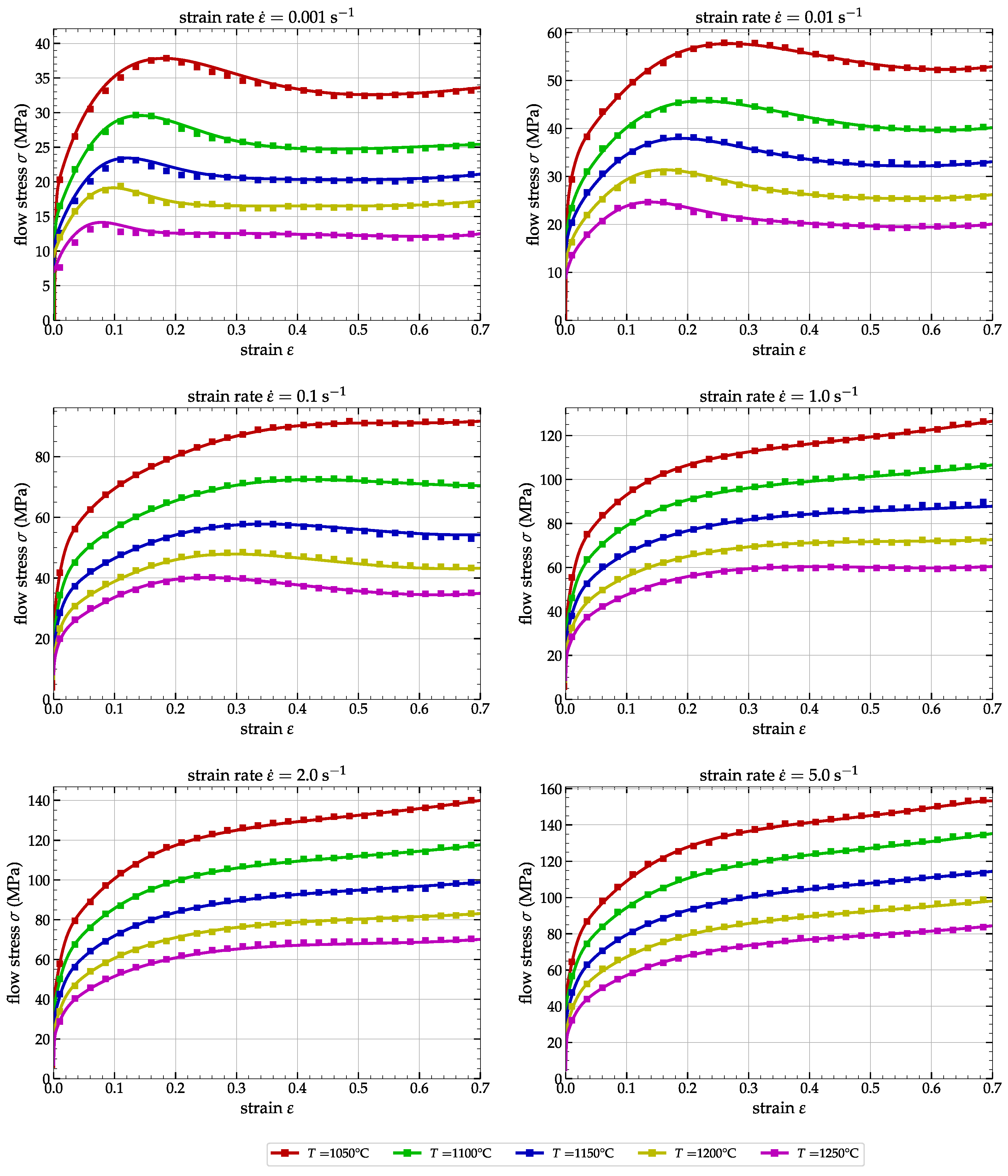
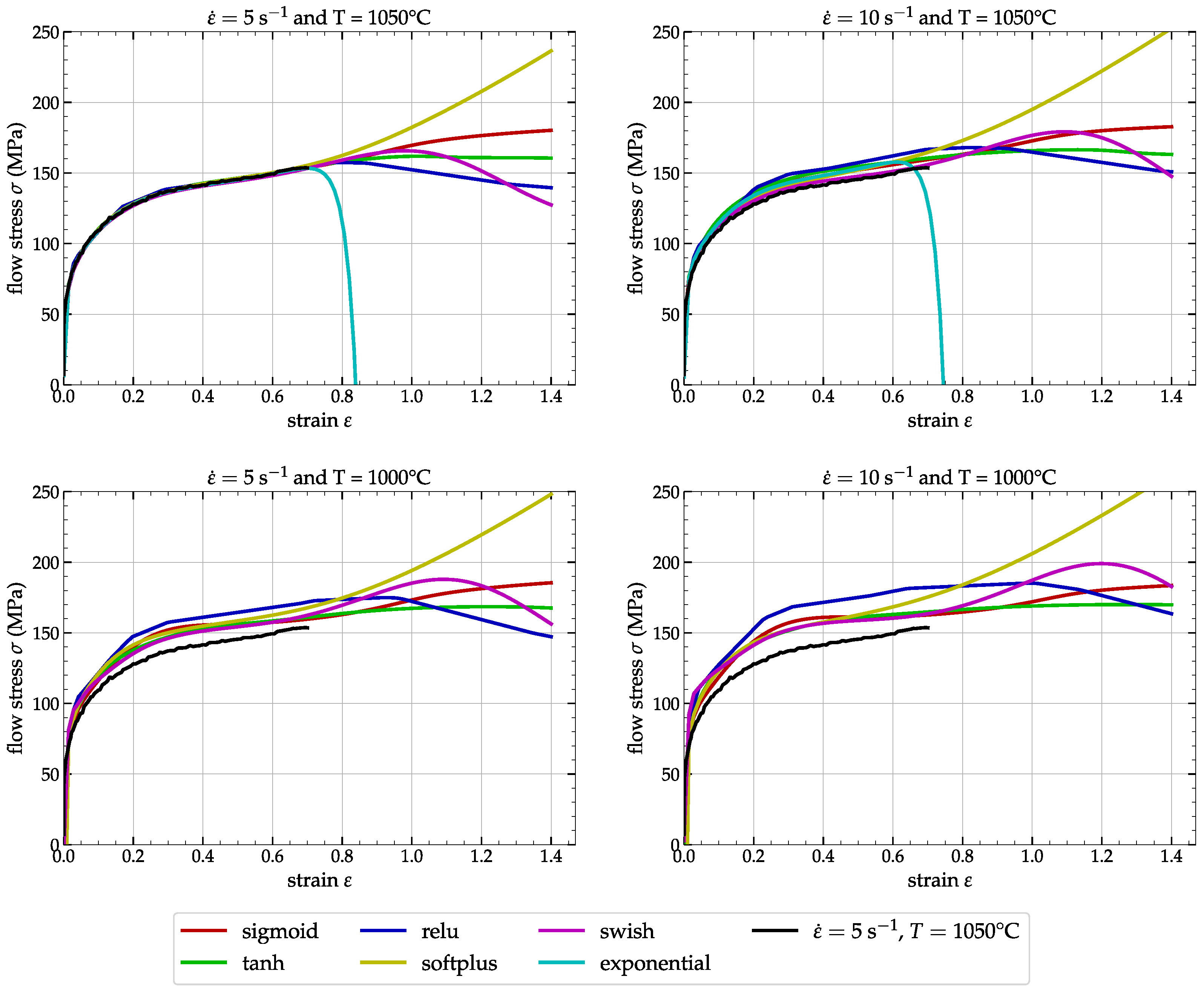
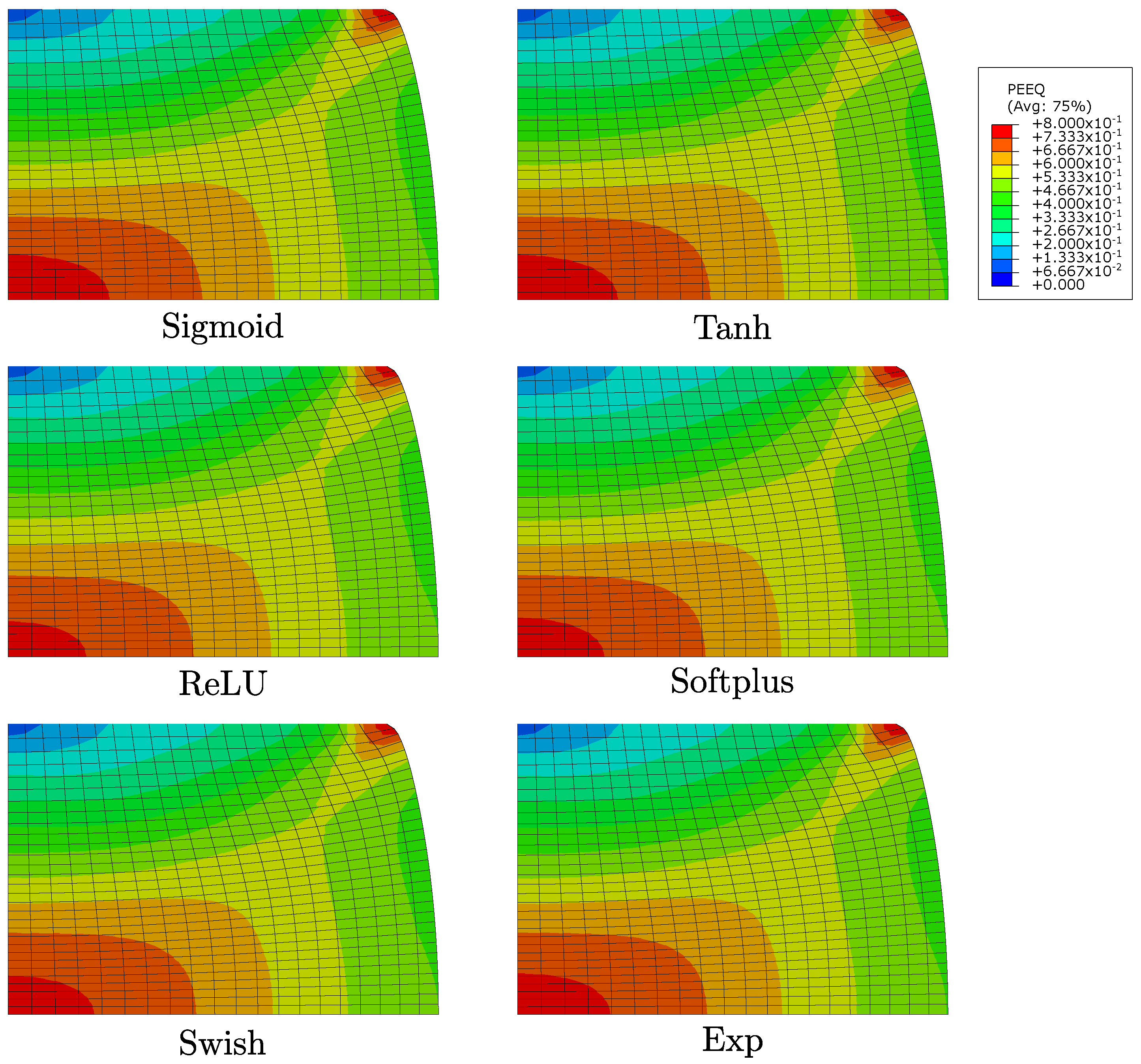
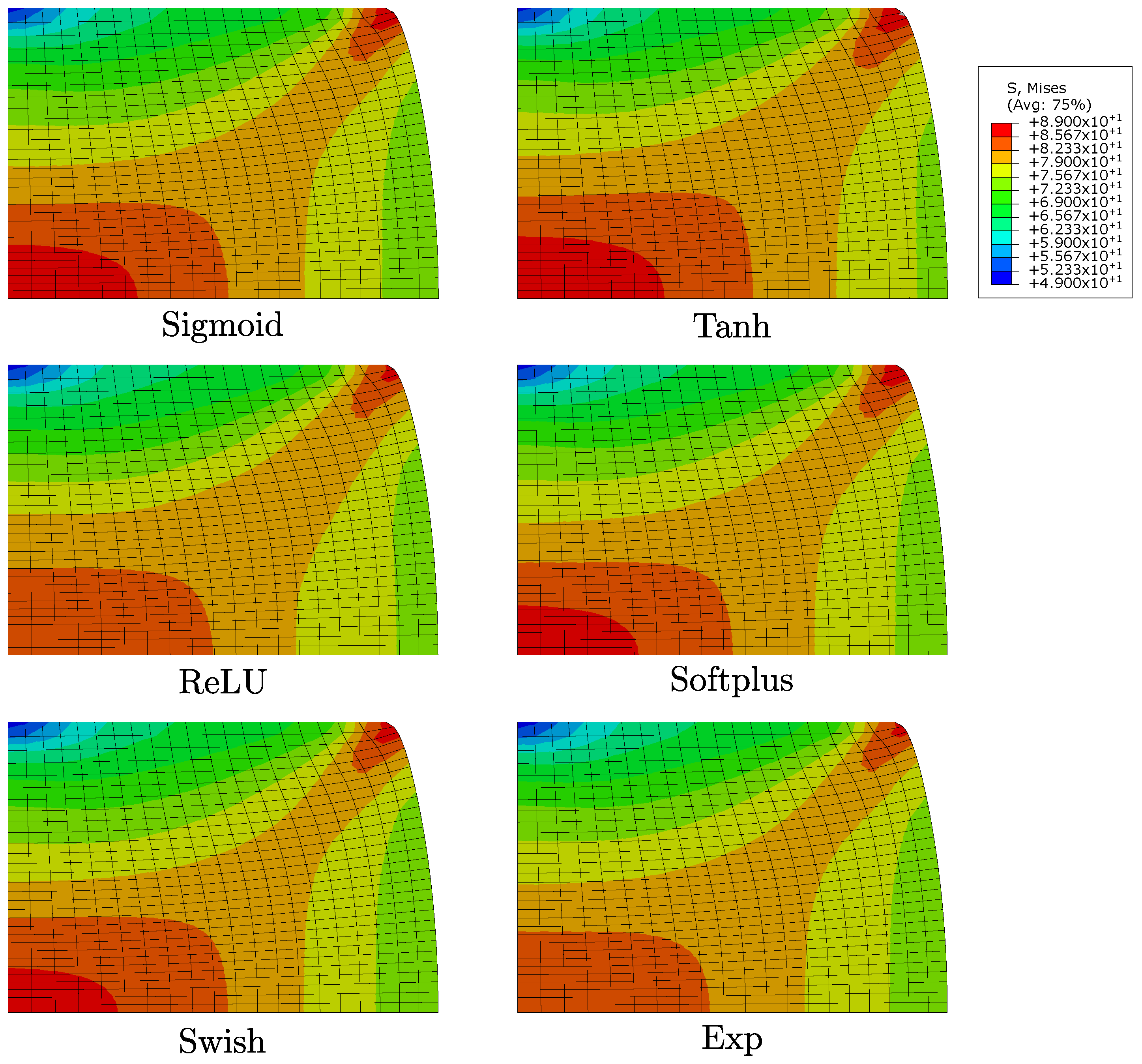
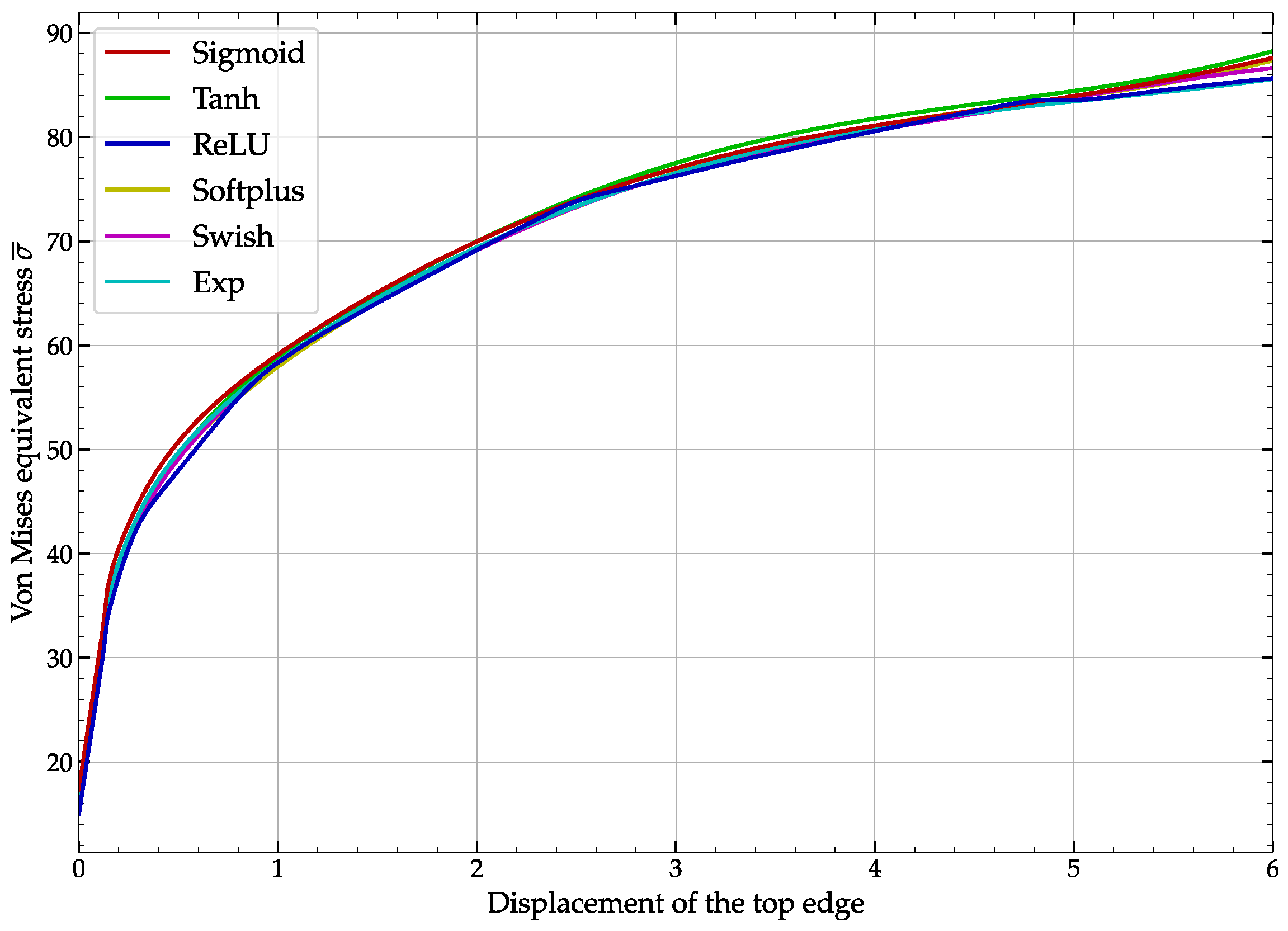
3.2. Numerical Simulations and Comparisons
4. Conclusions and Major Remarks
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial Neural Network |
| CAX4RT | Abaqus 4 nodes axis-symmetric thermomechanical element |
| CPU | Central processing unit |
| FE | Finite Element |
| UHARD | Abaqus standard user subroutine |
| VUHARD | Abaqus explicit user subroutine |
Appendix A. Python Code to Compute Stress and Derivatives

Appendix B. Fortran 77 Subroutines to Implement the ANN Flow Law



References
- Abaqus. Reference Manual; Hibbitt, Karlsson and Sorensen Inc.: Providence, RI, USA, 1989. [Google Scholar]
- Lin, Y.C.; Chen, M.S.; Zhang, J. Modeling of flow stress of 42CrMo steel under hot compression. Mater. Sci. Eng. A 2009, 499, 88–92. [Google Scholar] [CrossRef]
- Bennett, C.J.; Leen, S.B.; Williams, E.J.; Shipway, P.H.; Hyde, T.H. A critical analysis of plastic flow behaviour in axisymmetric isothermal and Gleeble compression testing. Comput. Mater. Sci. 2010, 50, 125–137. [Google Scholar] [CrossRef]
- Kumar, V. Thermo-mechanical simulation using gleeble system-advantages and limitations. J. Metall. Mater. Sci. 2016, 58, 81–88. [Google Scholar]
- Yu, D.J.; Xu, D.S.; Wang, H.; Zhao, Z.B.; Wei, G.Z.; Yang, R. Refining constitutive relation by integration of finite element simulations and Gleeble experiments. J. Mater. Sci. Technol. 2019, 35, 1039–1043. [Google Scholar] [CrossRef]
- Kolsky, H. An Investigation of the Mechanical Properties of Materials at very High Rates of Loading. Proc. Phys. Soc. Sect. B 1949, 62, 676–700. [Google Scholar] [CrossRef]
- Ponthot, J.P. Unified Stress Update Algorithms for the Numerical Simulation of Large Deformation Elasto-Plastic and Elasto-Viscoplastic Processes. Int. J. Plast. 2002, 18, 36. [Google Scholar] [CrossRef]
- Johnson, G.R.; Cook, W.H. A Constitutive Model and Data for Metals Subjected to Large Strains, High Strain Rates, and High Temperatures. In Proceedings of the 7th International Symposium on Ballistics, The Hague, The Netherlands, 19–21 April 1983; pp. 541–547. [Google Scholar]
- Zerilli, F.J.; Armstrong, R.W. Dislocation-mechanics-based constitutive relations for material dynamics calculations. J. Appl. Phys. 1987, 61, 1816–1825. [Google Scholar] [CrossRef]
- Jonas, J.; Sellars, C.; Tegart, W.M. Strength and structure under hot-working conditions. Metall. Rev. 1969, 14, 1–24. [Google Scholar] [CrossRef]
- Gao, C.Y. FE Realization of a Thermo-Visco-Plastic Constitutive Model Using VUMAT in Abaqus/Explicit Program. In Computational Mechanics; Springer: Berlin/Heidelberg, Germany, 2007; p. 301. [Google Scholar]
- Ming, L.; Pantalé, O. An Efficient and Robust VUMAT Implementation of Elastoplastic Constitutive Laws in Abaqus/Explicit Finite Element Code. Mech. Ind. 2018, 19, 308. [Google Scholar] [CrossRef]
- Liang, P.; Kong, N.; Zhang, J.; Li, H. A Modified Arrhenius-Type Constitutive Model and its Implementation by Means of the Safe Version of Newton–Raphson Method. Steel Res. Int. 2022, 94, 2200443. [Google Scholar] [CrossRef]
- Tize Mha, P.; Dhondapure, P.; Jahazi, M.; Tongne, A.; Pantalé, O. Interpolation and extrapolation performance measurement of analytical and ANN-based flow laws for hot deformation behavior of medium carbon steel. Metals 2023, 13, 633. [Google Scholar] [CrossRef]
- Pantalé, O.; Tize Mha, P.; Tongne, A. Efficient implementation of non-linear flow law using neural network into the Abaqus Explicit FEM code. Finite Elem. Anal. Des. 2022, 198, 103647. [Google Scholar] [CrossRef]
- Pantalé, O. Development and Implementation of an ANN Based Flow Law for Numerical Simulations of Thermo-Mechanical Processes at High Temperatures in FEM Software. Algorithms 2023, 16, 56. [Google Scholar] [CrossRef]
- Minsky, M.L.; Papert, S. Perceptrons; An Introduction to Computational Geometry; MIT Press: Cambridge, UK, 1969. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer Feedforward Networks Are Universal Approximators. Neural Net. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Gorji, M.B.; Mozaffar, M.; Heidenreich, J.N.; Cao, J.; Mohr, D. On the Potential of Recurrent Neural Networks for Modeling Path Dependent Plasticity. J. Mech. Phys. Solids 2020, 143, 103972. [Google Scholar] [CrossRef]
- Jamli, M.; Farid, N. The Sustainability of Neural Network Applications within Finite Element Analysis in Sheet Metal Forming: A Review. Measurement 2019, 138, 446–460. [Google Scholar] [CrossRef]
- Lin, Y.; Zhang, J.; Zhong, J. Application of Neural Networks to Predict the Elevated Temperature Flow Behavior of a Low Alloy Steel. Comput. Mater. Sci. 2008, 43, 752–758. [Google Scholar] [CrossRef]
- Stoffel, M.; Bamer, F.; Markert, B. Artificial Neural Networks and Intelligent Finite Elements in Non-Linear Structural Mechanics. Thin-Walled Struct. 2018, 131, 102–106. [Google Scholar] [CrossRef]
- Stoffel, M.; Bamer, F.; Markert, B. Neural Network Based Constitutive Modeling of Nonlinear Viscoplastic Structural Response. Mech. Res. Commun. 2019, 95, 85–88. [Google Scholar] [CrossRef]
- Ali, U.; Muhammad, W.; Brahme, A.; Skiba, O.; Inal, K. Application of Artificial Neural Networks in Micromechanics for Polycrystalline Metals. Int. J. Plast. 2019, 120, 205–219. [Google Scholar] [CrossRef]
- Wang, T.; Chen, Y.; Ouyang, B.; Zhou, X.; Hu, J.; Le, Q. Artificial neural network modified constitutive descriptions for hot deformation and kinetic models for dynamic recrystallization of novel AZE311 and AZX311 alloys. Mater. Sci. Eng. A 2021, 816, 141259. [Google Scholar] [CrossRef]
- Cheng, P.; Wang, D.; Zhou, J.; Zuo, S.; Zhang, P. Comparison of the Warm Deformation Constitutive Model of GH4169 Alloy Based on Neural Network and the Arrhenius Model. Metals 2022, 12, 1429. [Google Scholar] [CrossRef]
- Churyumov, A.Y.; Kazakova, A.A. Prediction of True Stress at Hot Deformation of High Manganese Steel by Artificial Neural Network Modeling. Materials 2023, 16, 1083. [Google Scholar] [CrossRef] [PubMed]
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Karniadakis, G.E. How important are activation functions in regression and classification? A survey, performance comparison, and future directions. J. Mach. Learn. Model. Comput. 2023, 4, 21–75. [Google Scholar] [CrossRef]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In From Natural to Artificial Neural Computation; Mira, J., Sandoval, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar]
- Dugas, C.; Bengio, Y.; Bélisle, F.; Nadeau, C.; Garcia, R. Incorporating Second-Order Functional Knowledge for Better Option Pricing. In Advances in Neural Information Processing Systems; Leen, T., Dietterich, T., Tresp, V., Eds.; MIT Press: Cambridge, UK, 2000; Volume 13. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2018, arXiv:1710.05941. [Google Scholar]
- Shen, Z.; Yang, H.; Zhang, S. Neural network approximation: Three hidden layers are enough. Neural Net. 2021, 141, 160–173. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Software. Available online: tensorflow.org (accessed on 5 July 2023).
- Kingma, D.P.; Lei, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Pantalé, O. Comparing Activation Functions in Machine Learning for Finite Element Simulations in Thermomechanical Forming: Software Source Files. Software Heritage. 2023. Available online: https://archive.softwareheritage.org/swh:1:dir:b418ca8e27d05941c826b78a3d8a13b07989baf6 (accessed on 15 November 2023).
- Koranne, S. Hierarchical data format 5: HDF5. In Handbook of Open Source Tools; Springer: Berlin/Heidelberg, Germany, 2011; pp. 191–200. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Element | C | Mn | Mo | Si | Ni | Cr | Cu |
|---|---|---|---|---|---|---|---|
| Wt % |
| Activation | CPU | (MPa) | (%) | Rank | ||||
|---|---|---|---|---|---|---|---|---|
| Sigmoid | 1:04 | 13.853 | 0.604 | 1.007 | 1.412 | 1.201 | 1.536 | 2 |
| Tanh | 1:03 | 12.890 | 0.621 | 1.035 | 1.634 | 1.390 | 1.748 | 5 |
| ReLU | 1:03 | 31.537 | 0.860 | 1.434 | 2.750 | 2.339 | 2.881 | 6 |
| Softplus | 1:04 | 13.968 | 0.600 | / | 1.617 | 1.375 | 1.724 | 4 |
| Swish | 1:04 | 12.434 | 0.619 | 1.417 | 0.720 | 1.205 | 1.546 | 3 |
| Exp | 1:03 | 12.843 | 0.688 | 1.147 | 1.176 | / | 1.362 | 1 |
| Activation | CPU (s) | /s | (MPa) | T (°C) | ||
|---|---|---|---|---|---|---|
| Sigmoid | 574 | 1,092,001 | 1902 | 0.762 | 87.6 | 1164.3 |
| Tanh | 648 | 1,096,099 | 1691 | 0.761 | 88.3 | 1164.4 |
| ReLU | 460 | 1,082,453 | 2353 | 0.750 | 85.6 | 1163.9 |
| Softplus | 906 | 1,087,812 | 1200 | 0.753 | 87.4 | 1164.1 |
| Swish | 738 | 1,082,832 | 1467 | 0.753 | 86.6 | 1164.0 |
| Exp | 540 | 1,077,954 | 1996 | 0.757 | 85.6 | 1164.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pantalé, O. Comparing Activation Functions in Machine Learning for Finite Element Simulations in Thermomechanical Forming. Algorithms 2023, 16, 537. https://doi.org/10.3390/a16120537
Pantalé O. Comparing Activation Functions in Machine Learning for Finite Element Simulations in Thermomechanical Forming. Algorithms. 2023; 16(12):537. https://doi.org/10.3390/a16120537
Chicago/Turabian StylePantalé, Olivier. 2023. "Comparing Activation Functions in Machine Learning for Finite Element Simulations in Thermomechanical Forming" Algorithms 16, no. 12: 537. https://doi.org/10.3390/a16120537
APA StylePantalé, O. (2023). Comparing Activation Functions in Machine Learning for Finite Element Simulations in Thermomechanical Forming. Algorithms, 16(12), 537. https://doi.org/10.3390/a16120537