

A Largely Unsupervised Domain-Independent Qualitative Data Extraction Approach for Empirical Agent-Based Model Development

Abstract
1. Introduction
2. Background, Materials, and Methods
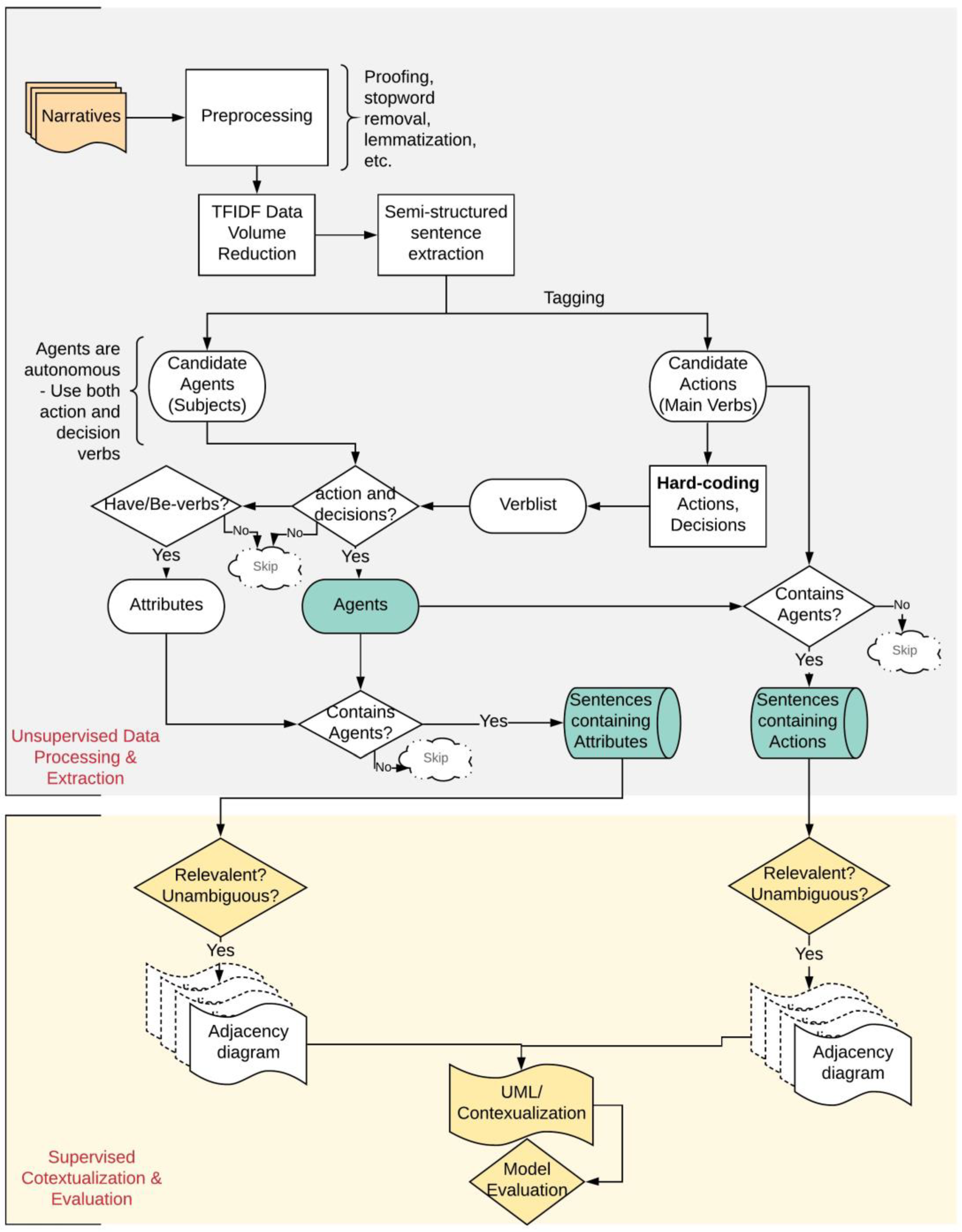
3. The Proposed Framework
- Unsupervised data processing and extraction;
- Data preprocessing (cleaning and normalization);
- Data volume reduction;
- Tagging and information extraction;
- Supervised contextualization and evaluation;
- UML/Model conceptualization;
- Model evaluation.
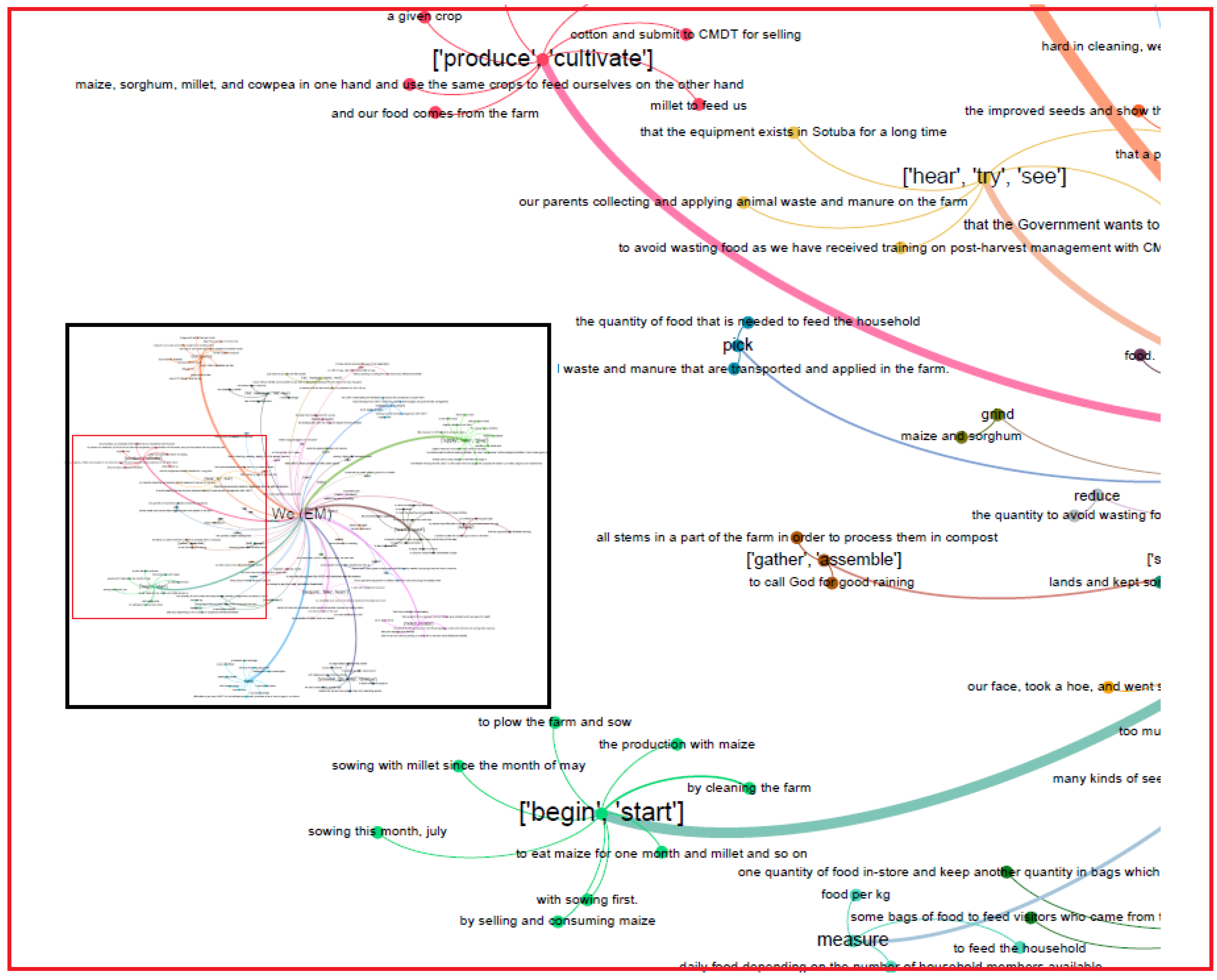
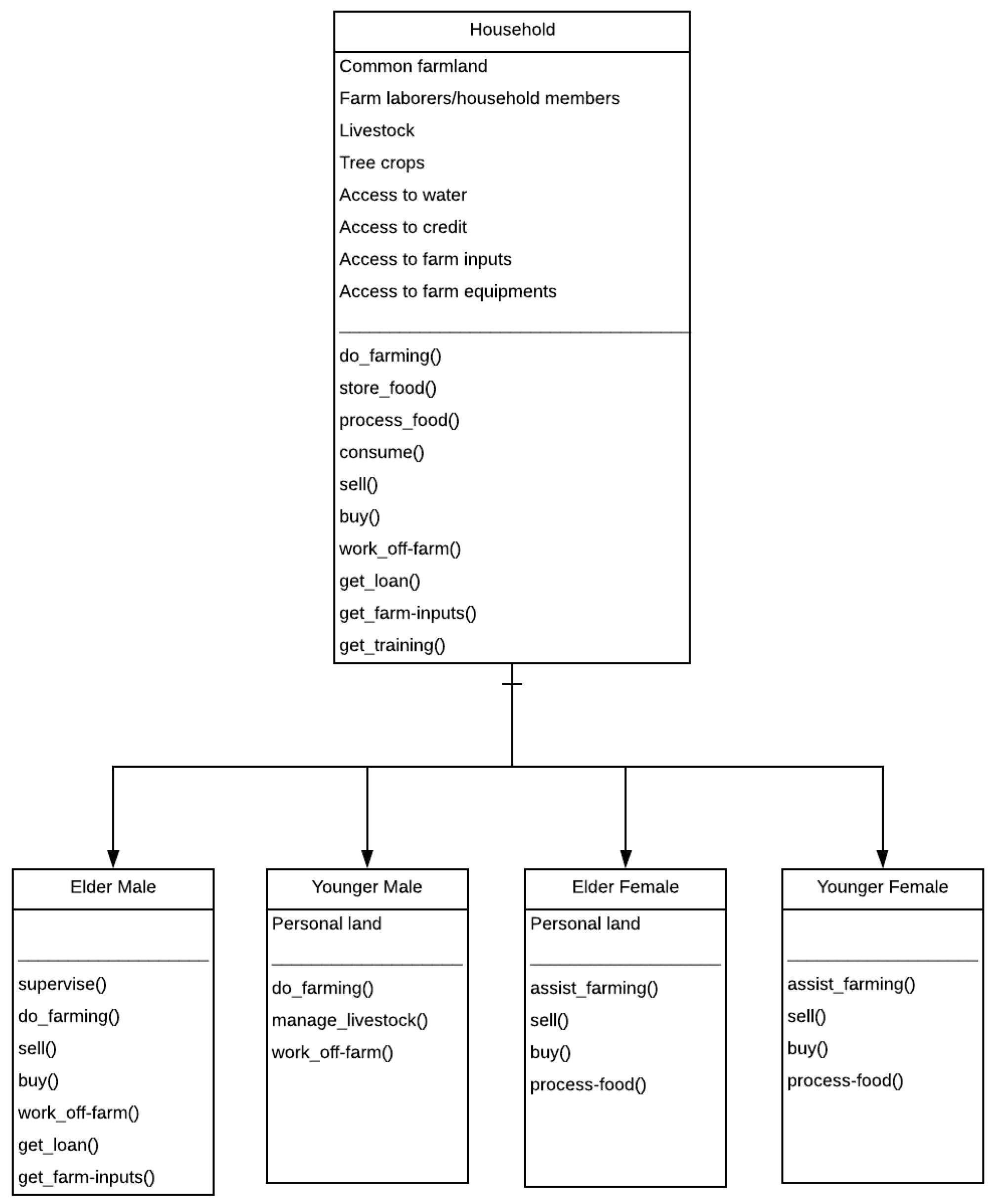
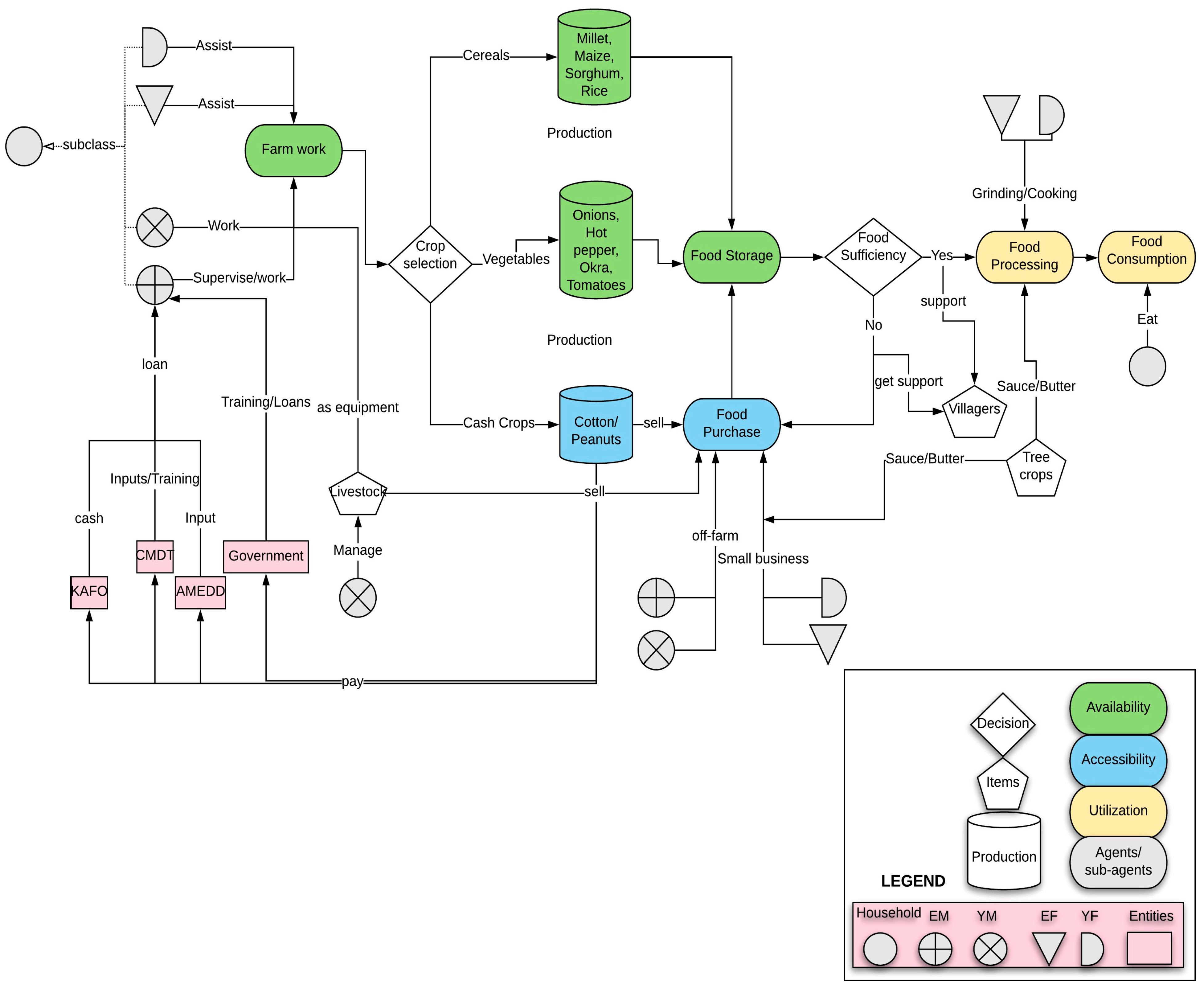
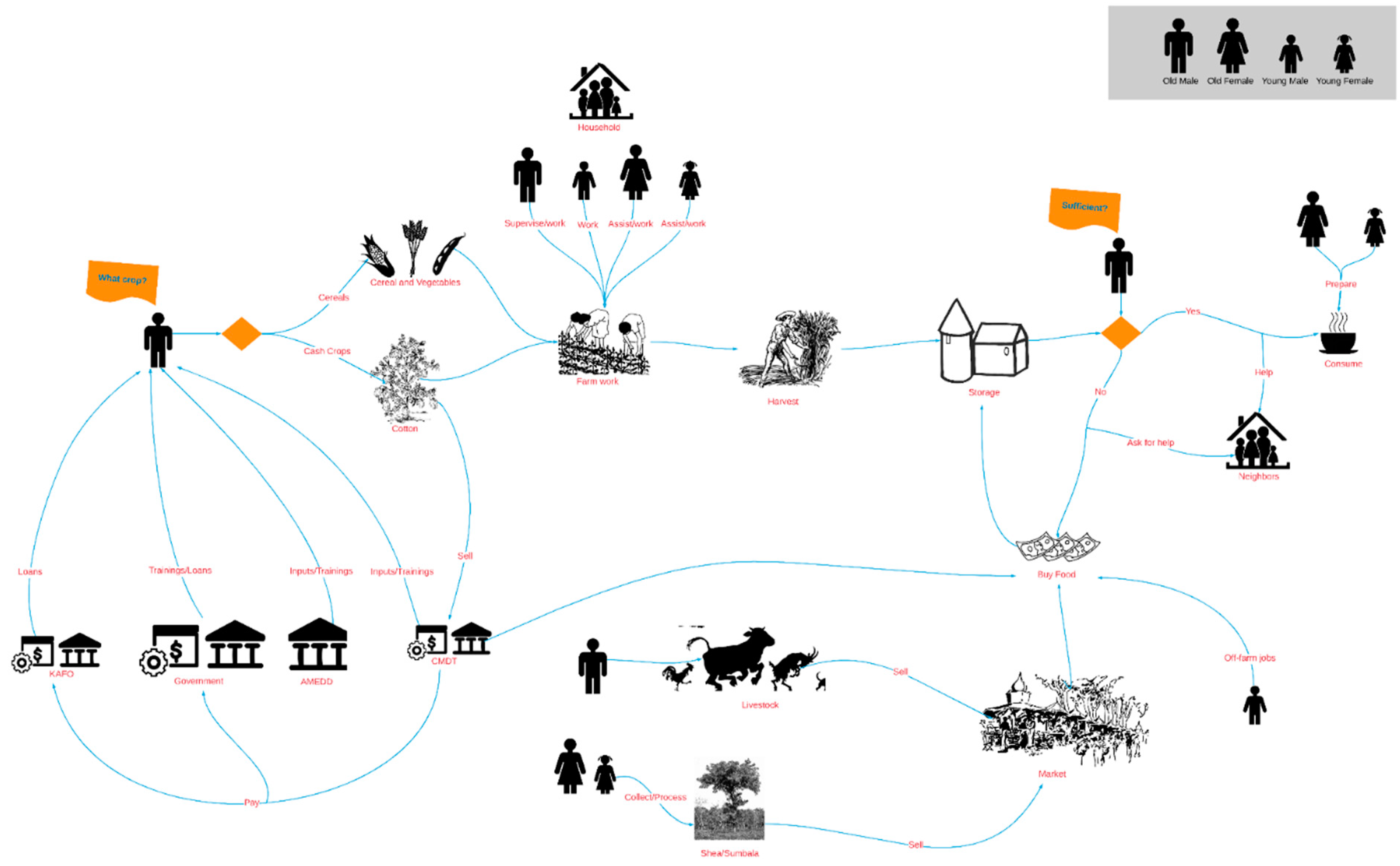
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Miles, M.B. Qualitative data as an attractive nuisance: The problem of analysis. Adm. Sci. Q. 1979, 24, 590–601. [Google Scholar] [CrossRef]
- Mortelmans, D. Analyzing qualitative data using NVivo. In The Palgrave Handbook of Methods for Media Policy Research; Palgrave Macmillan: London, UK, 2019; pp. 435–450. [Google Scholar]
- Rich, M.; Ginsburg, K.R. The reason and rhyme of qualitative research: Why, when, and how to use qualitative methods in the study of adolescent health. J. Adolesc. Health 1999, 25, 371–378. [Google Scholar] [CrossRef] [PubMed]
- Watkins, D.C. Qualitative research: The importance of conducting research that doesn’t “count”. Health Promot. Pract. 2012, 13, 153–158. [Google Scholar] [CrossRef]
- Kemp-Benedict, E. From Narrative to Number: A Role for Quantitative Models in Scenario analysis. In Proceedings of the International Congress on Environmental Modelling and Software, Osnabrück, Germany, 1 July 2004. [Google Scholar]
- Ackermann, F.; Eden, C.; Williams, T. Modeling for litigation: Mixing qualitative and quantitative approaches. Interfaces 1997, 27, 48–65. [Google Scholar] [CrossRef]
- Coyle, G. Qualitative and quantitative modelling in system dynamics: Some research questions. Syst. Dyn. Rev. J. Syst. Dyn. Soc. 2000, 16, 225–244. [Google Scholar] [CrossRef]
- Forbus, K.D.; Falkenhainer, B. Self-Explanatory Simulations: An Integration of Qualitative and Quantitative Knowledge. In Proceedings of the AAAI, Boston, MA, USA, 29 July–3 August 1990; pp. 380–387. [Google Scholar]
- Jo, H.I.; Jeon, J.Y. Compatibility of quantitative and qualitative data-collection protocols for urban soundscape evaluation. Sustain. Cities Soc. 2021, 74, 103259. [Google Scholar] [CrossRef]
- Wolstenholme, E.F. Qualitative vs quantitative modelling: The evolving balance. J. Oper. Res. Soc. 1999, 50, 422–428. [Google Scholar] [CrossRef]
- Djenontin, I.N.S.; Zulu, L.C.; Ligmann-Zielinska, A. Improving representation of decision rules in LUCC-ABM: An example with an elicitation of farmers’ decision making for landscape restoration in central Malawi. Sustainability 2020, 12, 5380. [Google Scholar] [CrossRef]
- Polhill, J.G.; Sutherland, L.-A.; Gotts, N.M. Using qualitative evidence to enhance an agent-based modelling system for studying land use change. J. Artif. Soc. Soc. Simul. 2010, 13, 10. [Google Scholar] [CrossRef]
- Landrum, B.; Garza, G. Mending fences: Defining the domains and approaches of quantitative and qualitative research. Qual. Psychol. 2015, 2, 199. [Google Scholar] [CrossRef]
- Runck, B. GeoComputational Approaches to Evaluate the Impacts of Communication on Decision-Making in Agriculture. Ph.D. Thesis, University of Minnesota, Minneapolis, MN, USA, 2018. [Google Scholar]
- Du, J.; Ligmann-Zielinska, A. The Volatility of Data Space: Topology Oriented Sensitivity Analysis. PLoS ONE 2015, 10, e0137591. [Google Scholar] [CrossRef] [PubMed]
- Grimm, V.; Augusiak, J.; Focks, A.; Frank, B.M.; Gabsi, F.; Johnston, A.S.; Liu, C.; Martin, B.T.; Meli, M.; Radchuk, V. Towards better modelling and decision support: Documenting model development, testing, and analysis using TRACE. Ecol. Model. 2014, 280, 129–139. [Google Scholar] [CrossRef]
- Ligmann-Zielinska, A.; Siebers, P.-O.; Magliocca, N.; Parker, D.C.; Grimm, V.; Du, J.; Cenek, M.; Radchuk, V.; Arbab, N.N.; Li, S. ‘One size does not fit all’: A roadmap of purpose-driven mixed-method pathways for sensitivity analysis of agent-based models. J. Artif. Soc. Soc. Simul. 2020, 23. [Google Scholar] [CrossRef]
- An, L.; Linderman, M.; Qi, J.; Shortridge, A.; Liu, J. Exploring Complexity in a Human–Environment System: An Agent-Based Spatial Model for Multidisciplinary and Multiscale Integration. Ann. Assoc. Am. Geogr. 2005, 95, 54–79. [Google Scholar] [CrossRef]
- Railsback, S.F.; Grimm, V. Agent-Based and Individual-Based Modeling: A Practical Introduction; Princeton University Press: Princeton, NJ, USA, 2019. [Google Scholar]
- Wilensky, U.; Rand, W. An Introduction to Agent-Based Modeling: Modeling Natural, Social, and Engineered Complex Systems with NetLogo; Mit Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Janssen, M.; Ostrom, E. Empirically based, agent-based models. Ecol. Soc. 2006, 11. [Google Scholar] [CrossRef]
- O’Sullivan, D.; Evans, T.; Manson, S.; Metcalf, S.; Ligmann-Zielinska, A.; Bone, C. Strategic directions for agent-based modeling: Avoiding the YAAWN syndrome. J. Land. Use Sci. 2016, 11, 177–187. [Google Scholar] [CrossRef] [PubMed]
- Robinson, D.T.; Brown, D.G.; Parker, D.C.; Schreinemachers, P.; Janssen, M.A.; Huigen, M.; Wittmer, H.; Gotts, N.; Promburom, P.; Irwin, E.; et al. Comparison of empirical methods for building agent-based models in land use science. J. Land. Use Sci. 2007, 2, 31–55. [Google Scholar] [CrossRef]
- Smajgl, A.; Barreteau, O. Empirical Agent-Based Modelling-Challenges and Solutions; Springer: Berlin/Heidelberg, Germany, 2014; Volume 1. [Google Scholar]
- Seidl, R. Social scientists, qualitative data, and agent-based modeling. In Proceedings of the Social Simulation Conference, Barcelona, Spain, 1–5 September 2014. [Google Scholar]
- Grimm, V.; Berger, U.; DeAngelis, D.L.; Polhill, J.G.; Giske, J.; Railsback, S.F. The ODD protocol: A review and first update. Ecol. Model. 2010, 221, 2760–2768. [Google Scholar] [CrossRef]
- Müller, B.; Balbi, S.; Buchmann, C.M.; De Sousa, L.; Dressler, G.; Groeneveld, J.; Klassert, C.J.; Le, Q.B.; Millington, J.D.A.; Nolzen, H. Standardised and transparent model descriptions for agent-based models: Current status and prospects. Environ. Model. Softw. 2014, 55, 156–163. [Google Scholar] [CrossRef]
- Ford, A.; Ford, F.A. Modeling the Environment: An Introduction to System Dynamics Models of Environmental Systems; Island press: Washington, DC, USA, 1999. [Google Scholar]
- Heath, B.L.; Ciarallo, F.W.; Hill, R.R. Validation in the agent-based modelling paradigm: Problems and a solution. Int. J. Simul. Process Model. 2012, 7, 229–239. [Google Scholar] [CrossRef]
- An, L.; Grimm, V.; Bai, Y.; Sullivan, A.; Turner II, B.; Malleson, N.; Heppenstall, A.; Vincenot, C.; Robinson, D.; Ye, X. Modeling agent decision and behavior in the light of data science and artificial intelligence. Environ. Model. Softw. 2023, 166, 105713. [Google Scholar] [CrossRef]
- Balke, T.; Gilbert, N. How Do Agents Make Decisions? A Survey. J. Artif. Soc. Soc. Simul. 2014, 17, 13. [Google Scholar] [CrossRef]
- Doscher, C.; Moore, K.; Smallman, C.; Wilson, J.; Simmons, D. An Agent-Based Model of Tourist Movements in New Zealand. In Empirical Agent-Based Modelling-Challenges and Solutions: Volume 1, The Characterisation and Parameterisation of Empirical Agent-Based Models; Springer: Berlin/Heidelberg, Germany, 2014; pp. 39–51. [Google Scholar]
- Edwards-Jones, G. Modelling farmer decision-making: Concepts, progress and challenges. Anim. Sci. 2006, 82, 783–790. [Google Scholar] [CrossRef]
- Janssen, M.; Jager, W. An integrated approach to simulating behavioural processes: A case study of the lock-in of consumption patterns. J. Artif. Soc. Soc. Simul. 1999, 2, 21–35. [Google Scholar]
- Becu, N.; Barreteau, O.; Perez, P.; Saising, J.; Sungted, S. A methodology for identifying and for-malizing farmers’ representations of watershed management: A case study from northern Thailand. In Companion Modeling and Multi-Agent Systems for Integrated Natural Resource Management in Asia; International Rice Research Institute: Manila, Philippines, 2005; p. 41. [Google Scholar]
- Voinov, A.; Bousquet, F. Modelling with stakeholders. Environ. Model. Softw. 2010, 25, 1268–1281. [Google Scholar] [CrossRef]
- Bharwani, S. Understanding complex behavior and decision making using ethnographic knowledge elicitation tools (KnETs). Soc. Sci. Comput. Rev. 2006, 24, 78–105. [Google Scholar] [CrossRef]
- Edmonds, B. A context-and scope-sensitive analysis of narrative data to aid the specification of agent behaviour. J. Artif. Soc. Soc. Simul. 2015, 18, 17. [Google Scholar] [CrossRef]
- Ghorbani, A.; Schrauwen, N.; Dijkema, G.P.J. Using Ethnographic Information to Conceptualize Agent-based Models. In Proceedings of the European Social Simulation Association Conference, Warsaw, Poland, 16–20 September 2013. [Google Scholar]
- Gilbert, N.; Terna, P. How to build and use agent-based models in social science. Mind Soc. 2000, 1, 57–72. [Google Scholar] [CrossRef]
- Huigen, M.G. First principles of the MameLuke multi-actor modelling framework for land use change, illustrated with a Philippine case study. J. Environ. Manag. 2004, 72, 5–21. [Google Scholar] [CrossRef]
- Clark, M.; Kim, Y.; Kruschwitz, U.; Song, D.; Albakour, D.; Dignum, S.; Beresi, U.C.; Fasli, M.; De Roeck, A. Automatically structuring domain knowledge from text: An overview of current research. Inf. Process. Manag. 2012, 48, 552–568. [Google Scholar] [CrossRef]
- Al-Safadi, L.A.E. Natural Language Processing for Conceptual Modeling. JDCTA 2009, 3, 47–59. [Google Scholar]
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. (CSUR) 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Husain, M.S.; Khanum, M.A. Word Sense Disambiguation in Software Requirement Specifications Using WordNet and Association Mining Rule. In Proceedings of the Second International Conference on Information and Communication Technology for Competitive Strategies, Udaipur, India, 4–5 March 2016; pp. 1–4. [Google Scholar]
- Orkphol, K.; Yang, W. Word sense disambiguation using cosine similarity collaborates with Word2vec and WordNet. Future Internet 2019, 11, 114. [Google Scholar] [CrossRef]
- Fraga, A.; Moreno, V.; Parra, E.; Garcia, J. Extraction of Patterns Using NLP: Genetic Deafness. In Proceedings of the SEKE, Pittsburgh, PA, USA, 5–7 July 2017; pp. 428–431. [Google Scholar]
- Liddy, E.D. Natural Language Processing. 2001. Available online: https://surface.syr.edu/cgi/viewcontent.cgi?article=1043&context=istpub (accessed on 28 June 2023).
- Loper, E.; Bird, S. NLTK: The natural language toolkit. In Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics, Philadelphia, PA, USA, 7 July 2002; pp. 63–70. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd annual meeting of the association for computational linguistics: System demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Salloum, S.A.; Al-Emran, M.; Monem, A.A.; Shaalan, K. Using text mining techniques for extracting information from research articles. In Intelligent Natural Language Processing: Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 373–397. [Google Scholar]
- Sun, S.; Luo, C.; Chen, J. A review of natural language processing techniques for opinion mining systems. Inf. Fusion. 2017, 36, 10–25. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural language processing with Python: Analyzing text with the natural language toolkit; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Nasukawa, T.; Yi, J. Sentiment analysis: Capturing favorability using natural language processing. In Proceedings of the 2nd International Conference on Knowledge Capture, Sanibel Island, FL, USA, 23–25 October 2003; pp. 70–77. [Google Scholar]
- Harris, L.R. The ROBOT System: Natural language processing applied to data base query. In Proceedings of the 1978 Annual Conference, Washington, DC, USA, 4–6 December 1978; pp. 165–172. [Google Scholar]
- Lees, B. Artificial Intelligence Education for Software Engineers. In WIT Transactions on Information and Communication Technologies; 1970; Volume 12, Available online: https://www.witpress.com/elibrary/wit-transactions-on-information-and-communication-technologies/12/10537 (accessed on 28 June 2023).
- Runck, B.C.; Manson, S.; Shook, E.; Gini, M.; Jordan, N. Using word embeddings to generate data-driven human agent decision-making from natural language. GeoInformatica 2019, 23, 221–242. [Google Scholar] [CrossRef]
- Padilla, J.J.; Shuttleworth, D.; O’Brien, K. Agent-Based Model Characterization Using Natural Language Processing. In Proceedings of the 2019 Winter Simulation Conference (WSC), National Harbor, MD, USA, 8–11 December 2019; pp. 560–571. [Google Scholar]
- Heppenstall, A.; Crooks, A.; Malleson, N.; Manley, E.; Ge, J.; Batty, M. Future Developments in Geographical Agent-Based Models: Challenges and Opportunities. Geogr. Anal. 2021, 53, 76–91. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Luo, L.; Hu, S.; Li, Y. Mapping the knowledge frontiers and evolution of decision making based on agent-based modeling. Knowl.-Based Syst. 2022, 250, 108982. [Google Scholar] [CrossRef]
- Harmain, H.M.; Gaizauskas, R. CM-Builder: An automated NL-based CASE tool. In Proceedings of the ASE 2000 Fifteenth IEEE International Conference on Automated Software Engineering, Grenoble, France, 11–15 September 2000; pp. 45–53. [Google Scholar]
- Bersini, H. UML for ABM. J. Artif. Soc. Soc. Simul. 2012, 15, 9. [Google Scholar] [CrossRef]
- Collins, A.; Petty, M.; Vernon-Bido, D.; Sherfey, S. A Call to Arms: Standards for Agent-Based Modeling and Simulation. J. Artif. Soc. Soc. Simul. 2015, 18, 12. [Google Scholar] [CrossRef]
- Bakam, I.; Kordon, F.; Le Page, C.; Bousquet, F. Formalization of a spatialized multiagent model using coloured petri nets for the study of an hunting management system. In Proceedings of the International Workshop on Formal Approaches to Agent-Based Systems, Greenbelt, MD, USA, 5–7 April 2000; pp. 123–132. [Google Scholar]
- Gilbert, N. Agent-based social simulation: Dealing with complexity. Complex. Syst. Netw. Excell. 2004, 9, 1–14. [Google Scholar]
- Miller, J.H.; Page, S.E. Complex Adaptive Systems: An Introduction to Computational Models of Social Life; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Manning, C.; Raghavan, P.; Schütze, H. Introduction to information retrieval. Nat. Lang. Eng. 2010, 16, 100–103. [Google Scholar]
- Namey, E.; Guest, G.; Thairu, L.; Johnson, L. Data reduction techniques for large qualitative data sets. Handb. Team-Based Qual. Res. 2008, 2, 137–161. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Piscataway, NJ, USA, 3–8 December 2003; pp. 133–142. [Google Scholar]
- Rivers III, L.; Sanga, U.; Sidibe, A.; Wood, A.; Paudel, R.; Marquart-Pyatt, S.T.; Ligmann-Zielinska, A.; Olabisi, L.S.; Du, E.J.; Liverpool-Tasie, S. Mental models of food security in rural Mali. Environ. Syst. Decis. 2017, 38, 33–51. [Google Scholar] [CrossRef]
- Ligmann-Zielinska, A.; Sun, L. Applying time-dependent variance-based global sensitivity analysis to represent the dynamics of an agent-based model of land use change. Int. J. Geogr. Inf. Sci. 2010, 24, 1829–1850. [Google Scholar] [CrossRef]
- Xiang, X.; Kennedy, R.; Madey, G.; Cabaniss, S. Verification and validation of agent-based scientific simulation models. In Proceedings of the Agent-Directed Simulation Conference, San Diego, CA, USA, 3 April 2005; p. 55. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision Verbs | Action Verbs |
|---|---|
| adhere | abandon |
| advise | accelerate |
| approve | accept |
| assess | access |
| choose | accompany |
| comply | accord |
| consult | achieve |
| decide | acquaint |
| determine | acquire |
| discourage | add |
| educate | adjust |
| encourage | adopt |
| expect | advertise |
| favor | affect |
| guide | afford |
| instruct | aim |
| learn | allow |
| obey | analyze |
| oblige | apply |
| plan | argue |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paudel, R.; Ligmann-Zielinska, A. A Largely Unsupervised Domain-Independent Qualitative Data Extraction Approach for Empirical Agent-Based Model Development. Algorithms 2023, 16, 338. https://doi.org/10.3390/a16070338
Paudel R, Ligmann-Zielinska A. A Largely Unsupervised Domain-Independent Qualitative Data Extraction Approach for Empirical Agent-Based Model Development. Algorithms. 2023; 16(7):338. https://doi.org/10.3390/a16070338
Chicago/Turabian StylePaudel, Rajiv, and Arika Ligmann-Zielinska. 2023. "A Largely Unsupervised Domain-Independent Qualitative Data Extraction Approach for Empirical Agent-Based Model Development" Algorithms 16, no. 7: 338. https://doi.org/10.3390/a16070338
APA StylePaudel, R., & Ligmann-Zielinska, A. (2023). A Largely Unsupervised Domain-Independent Qualitative Data Extraction Approach for Empirical Agent-Based Model Development. Algorithms, 16(7), 338. https://doi.org/10.3390/a16070338