



Detecting and Processing Unsuspected Sensitive Variables for Robust Machine Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- In Section 2, we rigorously define which types of algorithmic biases are commonly observed in machine learning applications based on images, and what their causes are.
- In Section 3, Section 4 and Section 5, we then give a comprehensive overview of various methods to measure, to detect and to mitigate algorithmic biases. Note that Section 4 distinguishes the cases where the potential algorithmic biases are either due to suspected or to unsuspected sensitive variables, the second case being of particular interest in our paper.
2. Algorithmic Biases in Machine Learning
2.1. Definitions
2.2. Potential Causes of Bias in Computer Vision
2.2.1. Improperly Sampled Training Data
2.2.2. Spurious Correlations and External Factors
2.2.3. Unreliable Labels
2.3. From Determined Bias to Unknown Bias in Image Analysis
- Full information: images, targets, metadata and sensitive variables, i.e., are available. The bias may then come from the meta-observations , the image itself, the labels or all three.
- Partial information: the sensitive variable is not observed, so we only observe . The sensitive variable may be included in the meta variables , or may be estimated using the meta-variables .
- Scarce information: only the images are observed along with their target, i.e., we only observe . The sensitive variable A is, therefore, hidden. The bias it induces is contained inside the images and has to be inferred from the available data X and used to estimate A.
2.4. Current Regulation of AI
3. Measuring Algorithmic Biases
- -
- Statistical Parity One of the most standard measures of algorithmic bias is the so-called Statistical Parity. Balanced decisions in the sense of Statistical Parity are then reached when the model outputs are not influenced by the sensitive variable value—i.e., . For a binary decision, it is often quantified using the Disparate Impact (DI) metric. Introduced in the US legislation in 1971 (https://www.govinfo.gov/content/pkg/CFR-2017-title29-vol4/xml/CFR-2017-title29-vol4-part1607.xml, accessed on 30 October 2023) it measures how the outcome of the algorithm depends on A.It is computed for a binary decision aswhere represents the group which may be discriminated (also called minority group) with respect to the algorithm. Thus, the smaller the value, the stronger the discrimination against the minority group; while a score means that Statistical Parity is reached. A threshold is commonly used to judge whether the discrimination level of an algorithm is acceptable [68,69,70].
- -
- Equal performance metrics familyTaking into account the input observations X or the prediction errors can be more proper in various applications than imposing the same decisions for all. To address this, the notions of equal performance, status-quo preserving, or error parity measure whether a model is equally accurate for individuals in the sensitive and non-sensitive groups. As discussed in [27], it is often measured by using three common metrics: equal sensitivity or equal opportunity [64], equal sensitivity and specificity or equalised odds, and equal positive predictive value or predictive parity [71]. In the case of a binary decision, common metrics usually compute the difference between True Positive Rate and/or False Positive Rate for majority and minority groups. Therefore, algorithmically unbiased decisions in the sense of equal performance are reached when this difference is zero. Specifically, an equal opportunity metric is given bywhile an equality of odds metric is provided byNote finally that, predictive parity refers to Equal accuracy (or error) in the two groups also corresponds to refered by.
- -
- Calibration Previous notions can be written using the notion of calibration in fair machine learning. When the algorithm’s decision is based on a score , as in [72], a calibration metric is defined asCalibration measures the proportion of individuals that experience a situation compared to the proportion of individuals forecast to experience this outcome. It is a measure of efficiency of the algorithm and of the validity of its outcome. Yet, studying the difference between the groups enables one to point out a difference in behaviours that would let the user trust the outcome of an algorithm less for one group than another. This definition extends in this sense previous notions to the multivalued settings as pointed in [73]. Calibration is similar to the definition of fairness using quantiles, as shown in in [74]. Note that previous definitions can also easily be extended to the case where the variables are not binary but discrete.
- -
- Advanced metrics First, for algorithms with continuous values, previous metrics can be understood as quantification of the variability of a mean characteristic of the algorithm, with respect to the sensitive value. So natural metrics as in [75,76] are given byNote that, as pointed out in [75], these two metrics are not normalised Sobol indices. Hence, sensitivity analysis metrics can also be used to measure bias of algorithmic decisions. As a natural extension, sensitivity analysis tools provide new ways to describe the dependency relationships between a well-chosen function of the algorithm, focusing on particular features of the algorithm. They are well-adapted to studying bias in image analysis.Previous measures focus on computing a measure of dependency. Yet, many authors used different ways to compute covariance-like operators, directly as in [69], or based on information theory [77], or using more advanced notions of covariance based on embedding, possibly with kernels. We refer, for instance, to [66] for a review. Each method chooses a measure of dependency and computes an algorithmic bias measure of either the outcome of the algorithmic model or its residuals (or any appropriate transformation) with the sensitive parameter.Other measures of algorithmic biases do not focus on the mean behaviour of the algorithm, but other properties that may be the quantiles or the whole distribution. Hence, algorithmic bias measures can compare the distance between the conditional distribution for two different values of the sensitive attribute of either the decisionsor their lossDifferent distances between probability distributions can be used. We refer for instance to [78] and references therein, where Monge–Kantorovich distance (or Wasserstein distance) is used. Embedding of distributions using kernels can also be used, as pointed out in [79], together with well adapted notions of dependency in this setting.
4. Detecting Algorithmic Biases
4.1. With Suspected Sensitive Variables
4.2. Without Suspected Sensitive Variables
5. Algorithmic Bias Mitigation
- Firstly, it is critical to obtain robust algorithms that generalise to the test domain with a certified level of performance, and that do not depend on specific working conditions or types of sensors to work as intended. The property which is expected is the robustness of the algorithm.
- Secondly, the second goal is to learn representations independent of non-informative variables that can correlate with actual predictive information and play the role of confounding variables. The link between algorithmic biases and these representations constitutes an open challenge. In many cases, representations are affected by spurious correlations between subjects and backgrounds (Waterbirds, Benchmarking Attribution Methods), or gender and occupation (Athletes and health professionals, political person) that influence too much the selection of the features, and hence, the algorithmic decision. One way to study it is through disentangled representations [55], i.e., by isolating each factor of variation into a specific dimension of the latent space, it is possible to ensure the independence with respect to sensitive variables.
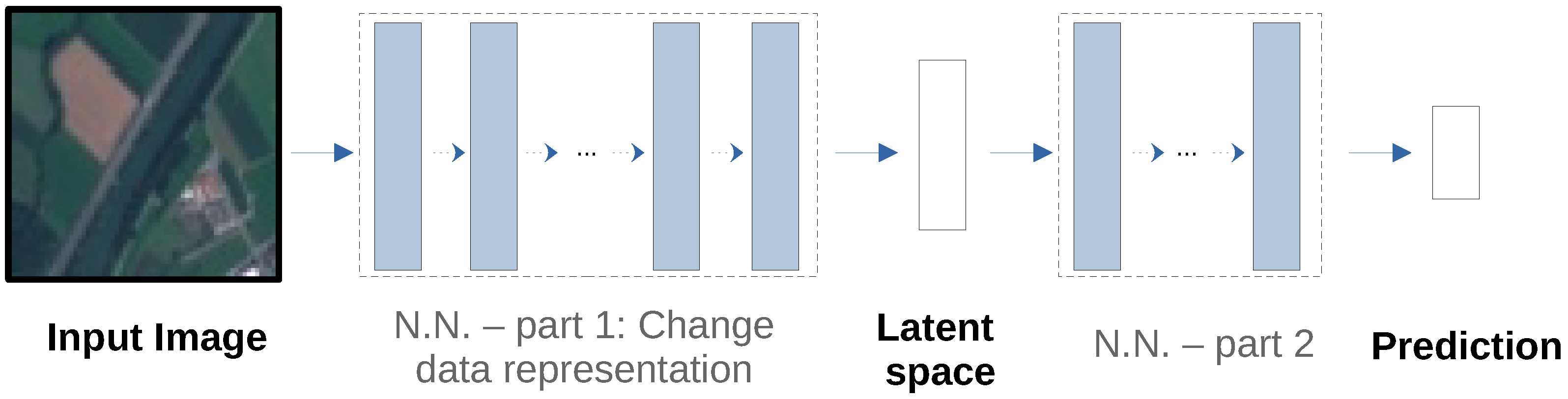
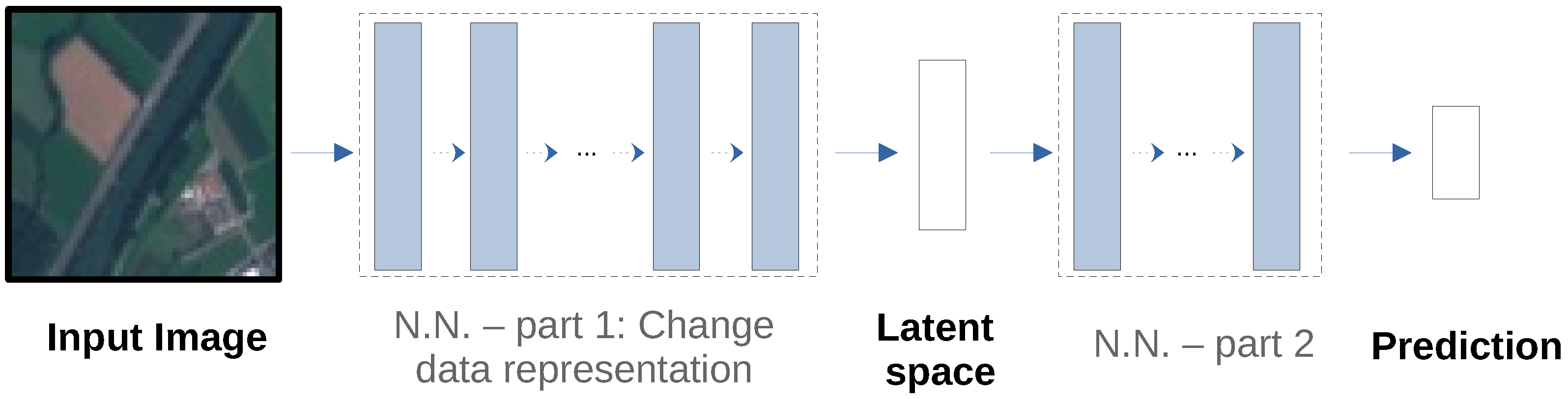
6. A Generic Pipeline to Detect and to Treat Unsuspected Sensitive Variables
| Algorithm 1 Pipeline to detect unsuspected sensitive variables and to mitigate their biases |
|
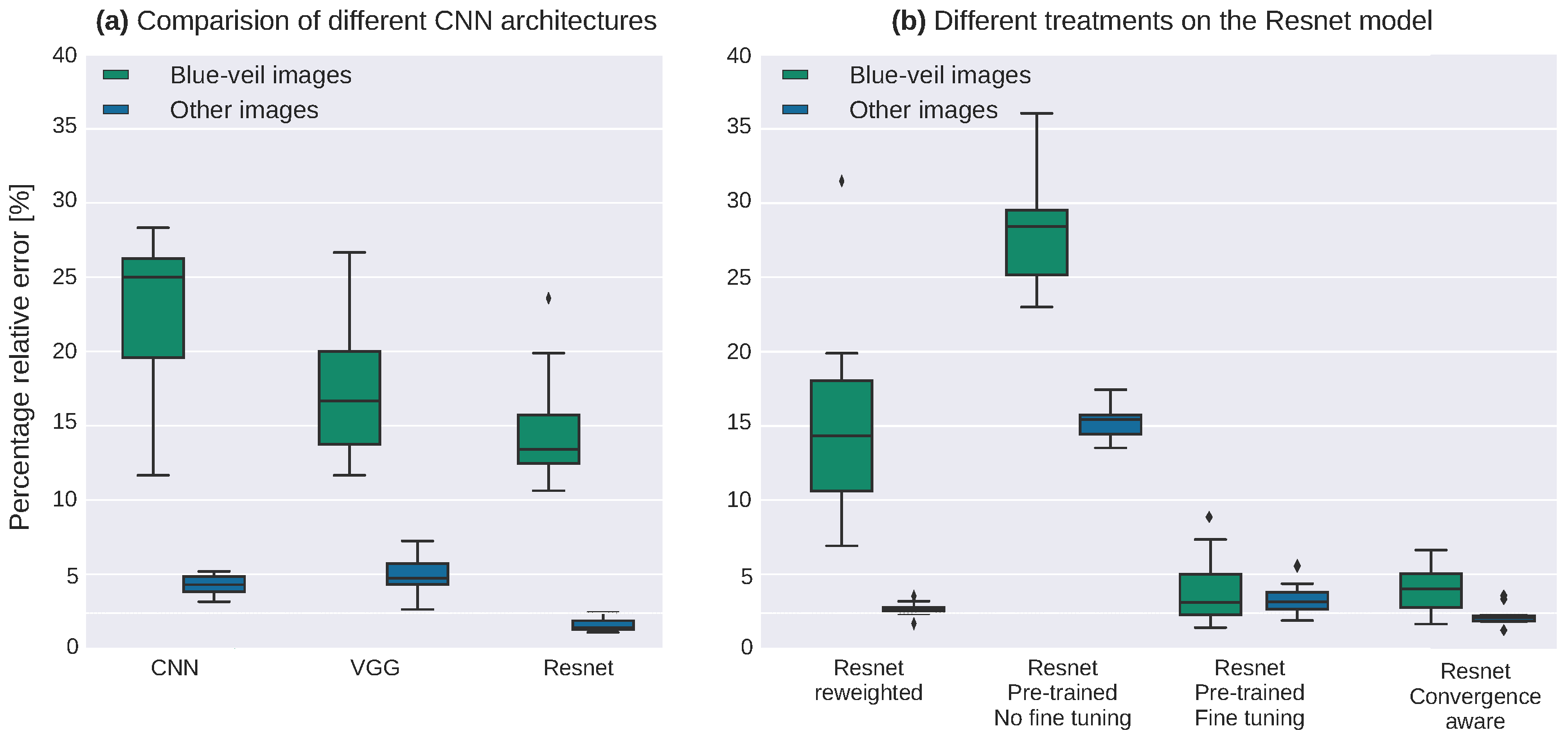
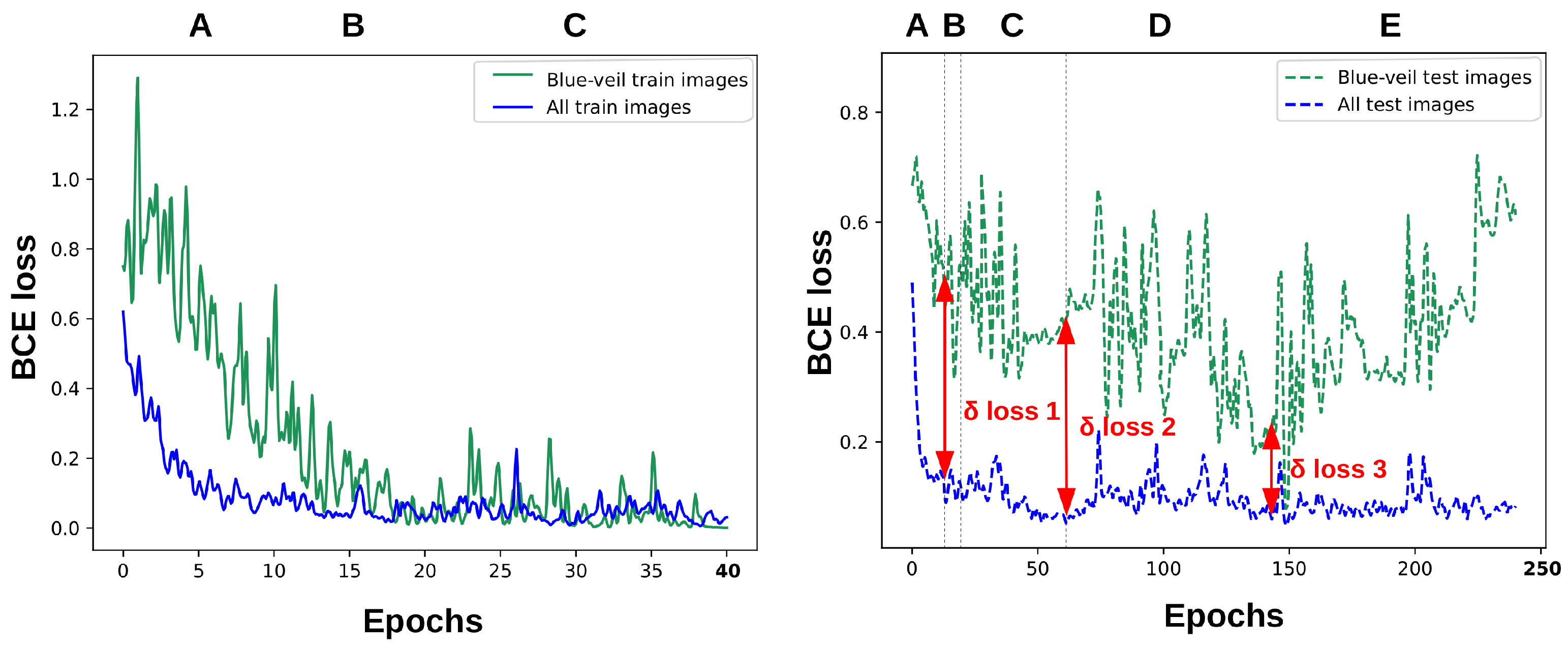
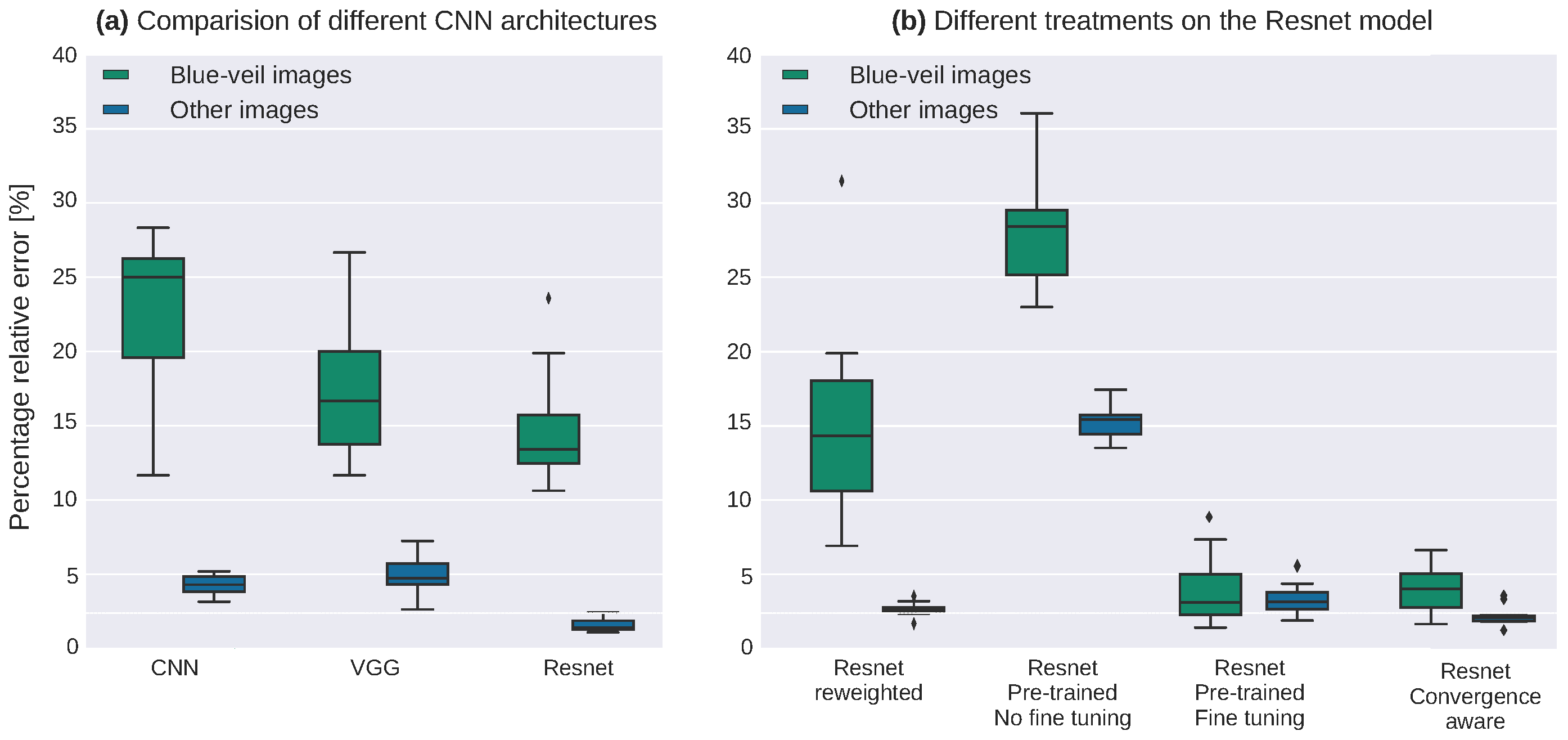
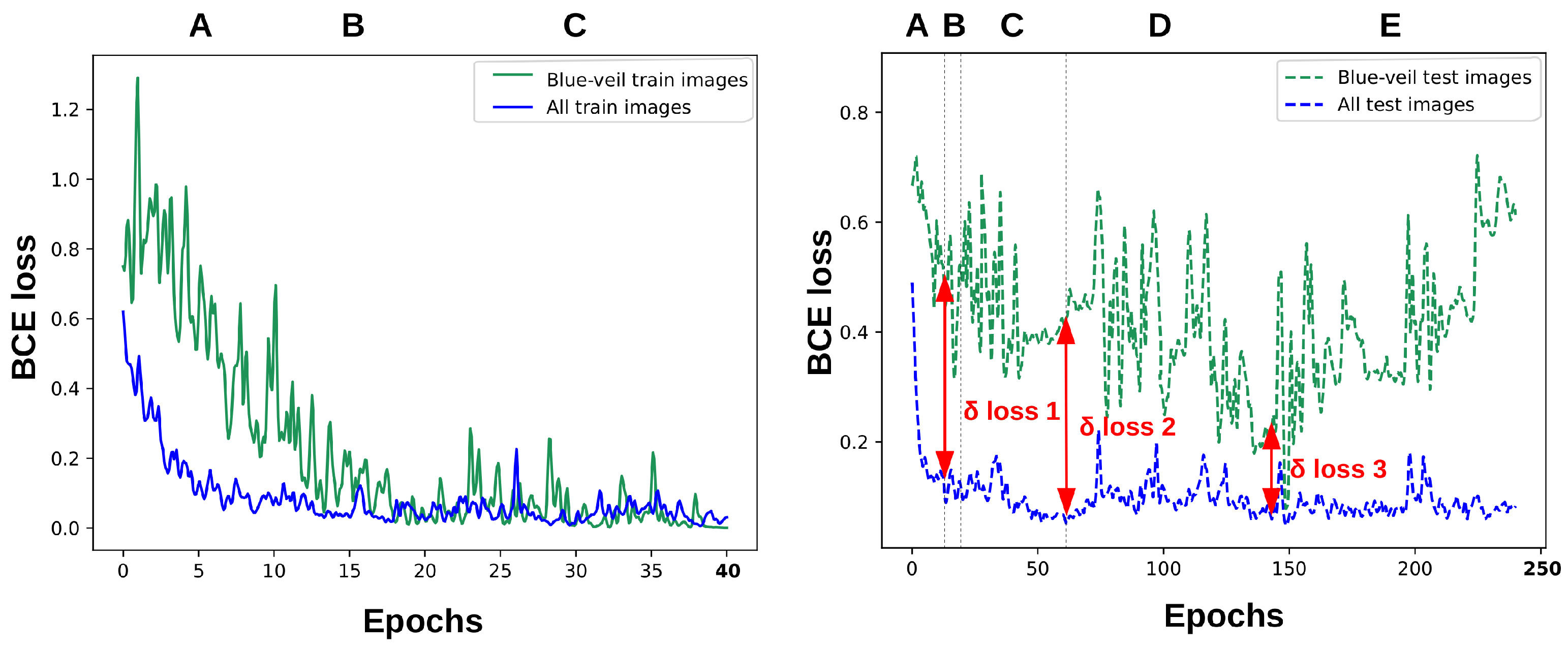
7. A Use-Case for EuroSAT
7.1. The Blue Veil Effect in the EuroSAT Dataset
7.2. Detecting Sensitive Variables without Additional Metadata
7.3. Measuring the Effect of the Sensitive Variable
7.4. Bias Mitigation
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vermeulen, A.F. Industrial Machine Learning, 1st ed.; Apress: Berkeley, CA, USA, 2020. [Google Scholar]
- Bertolini, M.; Mezzogori, D.; Neroni, M.; Zammori, F. Machine Learning for industrial applications: A comprehensive literature review. Expert Syst. Appl. 2021, 175, 114820. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. ATT Labs. Available online: http://yann.lecun.com/exdb/mnist (accessed on 30 October 2023).
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Koehn, P. Europarl: A Parallel Corpus for Statistical Machine Translation. In Proceedings of the MTSUMMIT, Phuket, Thailand, 6–12 September 2005. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 27–30 June 2011; pp. 142–150. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 12. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 27–30 June 2017; Volume 30. [Google Scholar]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient BackProp. In Neural Networks: Tricks of the Trade: Second Edition; Montavon, G., Orr, G.B., Muller, K.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Arora, R.; Basu, A.; Mianjy, P.; Mukherjee, A. Understanding Deep Neural Networks with Rectified Linear Units. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Fel, T.; Cadène, R.; Chalvidal, M.; Cord, M.; Vigouroux, D.; Serre, T. Look at the Variance! Efficient Black-box Explanations with Sobol-based Sensitivity Analysis. Adv. Neural Inf. Process. Syst. 2021, 34, 21. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should i trust you? Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 July 2016; pp. 1135–1144. [Google Scholar]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. Distill 2017, 2017, 7. [Google Scholar] [CrossRef]
- Jourdan, F.; Picard, A.; Fel, T.; Risser, L.; Loubes, J.M.; Asher, N. COCKATIEL: COntinuous Concept ranKed ATtribution with Interpretable ELements for explaining neural net classifiers on NLP tasks. arXiv 2023, arXiv:2305.06754. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Adv. Neural Inf. Process. Syst. 2018, 31, 18. [Google Scholar]
- Nalisnick, E.; Matsukawa, A.; Teh, Y.W.; Gorur, D.; Lakshminarayanan, B. Do deep generative models know what they don’t know? arXiv 2018, arXiv:1810.09136. [Google Scholar]
- Castelnovo, A.; Crupi, R.; Greco, G.; Regoli, D.; Penco, I.G.; Cosentini, A.C. A clarification of the nuances in the fairness metrics landscape. Nat. Sci. Rep. 2022, 12, 22. [Google Scholar] [CrossRef]
- Pessach, D.; Shmueli, E. A Review on Fairness in Machine Learning. ACM Comput. Surv. 2022, 55, 23. [Google Scholar] [CrossRef]
- Kusner, M.; Loftus, J.; Russell, C.; Silva, R. Counterfactual Fairness. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4069–4079. [Google Scholar]
- De Lara, L.; González-Sanz, A.; Asher, N.; Loubes, J.M. Transport-based counterfactual models. arXiv 2021, arXiv:2108.13025. [Google Scholar]
- Garvie, C.; Frankle, J. Facial-recognition software might have a racial bias problem. The Atlantic 2016, 7, 16. [Google Scholar]
- Castelvecchi, D. Is facial recognition too biased to be let loose? Nature 2020, 587, 347–350. [Google Scholar] [CrossRef] [PubMed]
- Conti, J.R.; Noiry, N.; Clemencon, S.; Despiegel, V.; Gentric, S. Mitigating Gender Bias in Face Recognition using the von Mises-Fisher Mixture Model. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MA, USA, 17–23 July 2022; pp. 4344–4369. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–4 December 2015. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Fabris, A.; Messina, S.; Silvello, G.; Susto, G.A. Algorithmic Fairness Datasets: The Story so Far. arXiv 2022, arXiv:2202.01711. [Google Scholar] [CrossRef]
- Shankar, S.; Halpern, Y.; Breck, E.; Atwood, J.; Wilson, J.; Sculley, D. No classification without representation: Assessing geodiversity issues in open data sets for the developing world. arXiv 2017, arXiv:1711.08536. [Google Scholar]
- Riccio, P.; Oliver, N. Racial Bias in the Beautyverse. arXiv 2022, arXiv:2209.13939. [Google Scholar]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, PMLR, Baltimore, MA, USA, 17–23 June 2018; pp. 77–91. [Google Scholar]
- Merler, M.; Ratha, N.; Feris, R.S.; Smith, J.R. Diversity in faces. arXiv 2019, arXiv:1901.10436. [Google Scholar]
- Karkkainen, K.; Joo, J. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 July 2021; pp. 1548–1558. [Google Scholar]
- Johnson, A.E.; Pollard, T.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.Y.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. Proc. AAAI Conf. Artif. Intell. 2019, 33, 590–597. [Google Scholar] [CrossRef]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 2018, 5, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.N.; Lee, M.S.; Kassamali, B.; Mita, C.; Nambudiri, V.E. Bias in, bias out: Underreporting and underrepresentation of diverse skin types in machine learning research for skin cancer detection—A scoping review. J. Am. Acad. Dermatol. 2021, 87, 157–159. [Google Scholar] [CrossRef] [PubMed]
- Bevan, P.J.; Atapour-Abarghouei, A. Skin Deep Unlearning: Artefact and Instrument Debiasing in the Context of Melanoma Classification. arXiv 2021, arXiv:2109.09818. [Google Scholar]
- Huang, J.; Galal, G.; Etemadi, M.; Vaidyanathan, M. Evaluation and Mitigation of Racial Bias in Clinical Machine Learning Models: Scoping Review. JMIR Med. Inform. 2022, 10, e36388. [Google Scholar] [CrossRef]
- Ross, C.; Katz, B.; Barbu, A. Measuring social biases in grounded vision and language embeddings. In Proceedings of the NAACL, Mexico City, Mexico, 6–11 June 2021. [Google Scholar]
- Singh, K.K.; Mahajan, D.; Grauman, K.; Lee, Y.J.; Feiszli, M.; Ghadiyaram, D. Don’t judge an object by its context: Learning to overcome contextual bias. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11070–11078. [Google Scholar]
- Saffarian, S.; Elson, E. Statistical analysis of fluorescence correlation spectroscopy: The standard deviation and bias. Biophys. J. 2003, 84, 2030–2042. [Google Scholar] [CrossRef] [PubMed]
- Tschandl, P. Risk of Bias and Error From Data Sets Used for Dermatologic Artificial Intelligence. JAMA Dermatol. 2021, 157, 1271–1273. [Google Scholar] [CrossRef]
- Pawlowski, N.; Coelho de Castro, D.; Glocker, B. Deep structural causal models for tractable counterfactual inference. Adv. Neural Inf. Process. Syst. 2020, 33, 857–869. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:cs.CL/2005.14165. [Google Scholar]
- Lucy, L.; Bamman, D. Gender and representation bias in GPT-3 generated stories. In Proceedings of the Third Workshop on Narrative Understanding, San Francisco, CA, USA, 15 June 2021; pp. 48–55. [Google Scholar]
- Locatello, F.; Abbati, G.; Rainforth, T.; Bauer, S.; Scholkopf, B.; Bachem, O. On the Fairness of Disentangled Representations. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2019. [Google Scholar]
- Fjeld, J.; Achten, N.; Hilligoss, H.; Nagy, A.; Srikumar, M. Principled Artificial Intelligence: Mapping Consensus in Ethical and Rights-based Approaches to Principles for AI. Berkman Klein Cent. Internet Soc. 2022, 2022, 1. [Google Scholar] [CrossRef]
- Banerjee, I.; Bhimireddy, A.R.; Burns, J.L.; Celi, L.A.; Chen, L.; Correa, R.; Dullerud, N.; Ghassemi, M.; Huang, S.; Kuo, P.; et al. Reading Race: AI Recognises Patient’s Racial Identity In Medical Images. arXiv 2021, arXiv:abs/2107.10356. [Google Scholar]
- Durán, J.M.; Jongsma, K.R. Who is afraid of black box algorithms? On the epistemological and ethical basis of trust in medical AI. J. Med. Ethics 2021, 47, 329–335. [Google Scholar] [CrossRef] [PubMed]
- Muehlematter, U.J.; Daniore, P.; Vokinger, K.N. Approval of artificial intelligence and machine learning-based medical devices in the USA and Europe (2015–20): A comparative analysis. Lancet Digit. Health 2021, 3, e195–e203. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Biemann, C.; Pattichis, C.S.; Kell, D.B. What do we need to build explainable AI systems for the medical domain? arXiv 2017, arXiv:abs/1712.09923. [Google Scholar]
- Raji, I.D.; Gebru, T.; Mitchell, M.; Buolamwini, J.; Lee, J.; Denton, E. Saving Face: Investigating the Ethical Concerns of Facial Recognition Auditing. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 6–12 July 2020; pp. 145–151. [Google Scholar] [CrossRef]
- Xu, T.; White, J.; Kalkan, S.; Gunes, H. Investigating Bias and Fairness in Facial Expression Recognition. arXiv 2020, arXiv:abs/2007.10075. [Google Scholar]
- Atzori, A.; Fenu, G.; Marras, M. Explaining Bias in Deep Face Recognition via Image Characteristics. IJCB 2022, 2022, 110099. [Google Scholar] [CrossRef]
- Hardt, M.; Price, E.; Srebro, N. Equality of opportunity in supervised learning. In Proceedings of the Advances in Neural Information Processing Systems, New York, NY, USA, 6–12 July 2016; pp. 3315–3323. [Google Scholar]
- Oneto, L.; Chiappa, S. Fairness in Machine Learning. In Recent Trends in Learning From Data; Springer: Berlin/Heidelberg, Germany, 2020; pp. 155–196. [Google Scholar]
- Del Barrio, E.; Gordaliza, P.; Loubes, J.M. Review of Mathematical frameworks for Fairness in Machine Learning. arXiv 2020, arXiv:2005.13755. [Google Scholar]
- Chouldechova, A.; Roth, A. A snapshot of the frontiers of fairness in machine learning. Commun. ACM 2020, 63, 82–89. [Google Scholar] [CrossRef]
- Feldman, M.; Friedler, S.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and removing disparate impact. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015. [Google Scholar]
- Zafar, M.B.; Valera, I.; Gomez Rodriguez, M.; Gummadi, K.P. Fairness beyond disparate treatment & disparate impact: Learning classification without disparate mistreatment. In Proceedings of the 26th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, Perth, Australia, 3–7 April 2017; pp. 1171–1180. [Google Scholar]
- Gordaliza, P.; Del Barrio, E.; Gamboa, F.; Loubes, J.M. Obtaining Fairness using Optimal Transport Theory. In Proceedings of the International Conference on Machine Learning (ICML), Virtual Event, 13–18 July 2019; pp. 2357–2365. [Google Scholar]
- Chouldechova, A. Fair Prediction with Disparate Impact: A Study of Bias in Recidivism Prediction Instruments. Big Data 2017, 5, 17. [Google Scholar] [CrossRef]
- Pleiss, G.; Raghavan, M.; Wu, F.; Kleinberg, J.; Weinberger, K.Q. On Fairness and Calibration. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Barocas, S.; Hardt, M.; Narayanan, A. Fairness in machine learning. Nips Tutor. 2017, 1, 2. [Google Scholar]
- Yang, D.; Lafferty, J.; Pollard, D. Fair quantile regression. arXiv 2019, arXiv:1907.08646. [Google Scholar]
- Bénesse, C.; Gamboa, F.; Loubes, J.M.; Boissin, T. Fairness seen as global sensitivity analysis. Mach. Learn. 2022, 2022, 1–28. [Google Scholar] [CrossRef]
- Ghosh, B.; Basu, D.; Meel, K.S. How Biased is Your Feature? Computing Fairness Influence Functions with Global Sensitivity Analysis. arXiv 2022, arXiv:2206.00667. [Google Scholar]
- Kamishima, T.; Akaho, S.; Sakuma, J. Fairness-aware learning through regularization approach. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 643–650. [Google Scholar]
- Risser, L.; Sanz, A.G.; Vincenot, Q.; Loubes, J.M. Tackling Algorithmic Bias in Neural-Network Classifiers Using Wasserstein-2 Regularization. J. Math. Imaging Vis. 2022, 64, 672–689. [Google Scholar] [CrossRef]
- Oneto, L.; Donini, M.; Luise, G.; Ciliberto, C.; Maurer, A.; Pontil, M. Exploiting MMD and Sinkhorn Divergences for Fair and Transferable Representation Learning. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 14 December 2020. [Google Scholar]
- Serna, I.; Pena, A.; Morales, A.; Fierrez, J. InsideBias: Measuring bias in deep networks and application to face gender biometrics. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 3720–3727. [Google Scholar]
- Serna, I.; Morales, A.; Fierrez, J.; Ortega-Garcia, J. IFBiD: Inference-free bias detection. arXiv 2021, arXiv:2109.04374. [Google Scholar]
- Creager, E.; Jacobsen, J.; Zemel, R.S. Exchanging Lessons Between Algorithmic Fairness and Domain Generalization. arXiv 2020, arXiv:abs/2010.07249. [Google Scholar]
- Sohoni, N.S.; Dunnmon, J.A.; Angus, G.; Gu, A.; Ré, C. No Subclass Left Behind: Fine-Grained Robustness in Coarse-Grained Classification Problems. arXiv 2020, arXiv:abs/2011.12945. [Google Scholar]
- Matsuura, T.; Harada, T. Domain Generalization Using a Mixture of Multiple Latent Domains. arXiv 2019, arXiv:abs/1911.07661. [Google Scholar] [CrossRef]
- Ahmed, F.; Bengio, Y.; van Seijen, H.; Courville, A.C. Systematic generalisation with group invariant predictions. In Proceedings of the ICLR, Virtual Event, 3–7 May 2021. [Google Scholar]
- Denton, E.; Hutchinson, B.; Mitchell, M.; Gebru, T. Detecting bias with generative counterfactual face attribute augmentation. arXiv 2019, arXiv:1906.06439. [Google Scholar]
- Li, Z.; Xu, C. Discover the Unknown Biased Attribute of an Image Classifier. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14970–14979. [Google Scholar]
- Paul, W.; Burlina, P. Generalizing Fairness: Discovery and Mitigation of Unknown Sensitive Attributes. arXiv 2021, arXiv:abs/2107.13625. [Google Scholar]
- Tong, S.; Kagal, L. Investigating bias in image classification using model explanations. arXiv 2020, arXiv:2012.05463. [Google Scholar]
- Schaaf, N.; Mitri, O.D.; Kim, H.B.; Windberger, A.; Huber, M.F. Towards measuring bias in image classification. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 433–445. [Google Scholar]
- Sirotkin, K.; Carballeira, P.; Escudero-Viñolo, M. A study on the distribution of social biases in self-supervised learning visual models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10442–10451. [Google Scholar]
- Bao, Y.; Barzilay, R. Learning to Split for Automatic Bias Detection. arXiv 2022, arXiv:abs/2204.13749. [Google Scholar]
- Picard, A.M.; Vigouroux, D.; Zamolodtchikov, P.; Vincenot, Q.; Loubes, J.M.; Pauwels, E. Leveraging Influence Functions for Dataset Exploration and Cleaning. In Proceedings of the 11th European Congress Embedded Real Time Systems (ERTS 2022), Toulouse, France, 13 April 2022; pp. 1–8. [Google Scholar]
- Mohler, G.; Raje, R.; Carter, J.; Valasik, M.; Brantingham, J. A penalized likelihood method for balancing accuracy and fairness in predictive policing. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Tokyo, Japan, 7–10 October 2018; pp. 2454–2459. [Google Scholar]
- Castets-Renard, C.; Besse, P.; Loubes, J.M.; Perrussel, L. Technical and Legal Risk Management of Predictive Policing Activities; French Ministère de l’intérieur: Paris, France, 2019. [Google Scholar]
- Balagopalan, A.; Zhang, H.; Hamidieh, K.; Hartvigsen, T.; Rudzicz, F.; Ghassemi, M. The Road to Explainability is Paved with Bias: Measuring the Fairness of Explanations. arXiv 2022, arXiv:2205.03295. [Google Scholar]
- Dai, J.; Upadhyay, S.; Aivodji, U.; Bach, S.H.; Lakkaraju, H. Fairness via Explanation Quality: Evaluating Disparities in the Quality of Post hoc Explanations. arXiv 2022, arXiv:2205.07277. [Google Scholar]
- Seo, S.; Lee, J.Y.; Han, B. Unsupervised Learning of Debiased Representations with Pseudo-Attributes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 14–17 July 2022; pp. 16742–16751. [Google Scholar]
- Duchi, J.C.; Namkoong, H. Learning models with uniform performance via distributionally robust optimization. Ann. Stat. 2021, 49, 1378–1406. [Google Scholar] [CrossRef]
- Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 335–340. [Google Scholar]
- Kim, B.; Kim, H.; Kim, K.; Kim, S.; Kim, J. Learning not to learn: Training deep neural networks with biased data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2019; pp. 9012–9020. [Google Scholar]
- Grari, V.; Ruf, B.; Lamprier, S.; Detyniecki, M. Fairness-Aware Neural Rényi Minimization for Continuous Features. IJCAI 2020, 19, 15. [Google Scholar]
- Perez-Suay, A.; Gordaliza, P.; Loubes, J.M.; Sejdinovic, D.; Camps-Valls, G. Fair Kernel Regression through Cross-Covariance Operators. Trans. Mach. Learn. Res. 2023, 13, 23. [Google Scholar]
- Creager, E.; Madras, D.; Jacobsen, J.H.; Weis, M.; Swersky, K.; Pitassi, T.; Zemel, R. Flexibly fair representation learning by disentanglement. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 1436–1445. [Google Scholar]
- Sarhan, M.H.; Navab, N.; Eslami, A.; Albarqouni, S. Fairness by learning orthogonal disentangled representations. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 746–761. [Google Scholar]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2012, 33, 1–33. [Google Scholar] [CrossRef]
- Sagawa, S.; Raghunathan, A.; Koh, P.W.; Liang, P. An investigation of why overparameterization exacerbates spurious correlations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 June 2020; pp. 8346–8356. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Du, M.; Mukherjee, S.; Wang, G.; Tang, R.; Awadallah, A.; Hu, X. Fairness via representation neutralization. Adv. Neural Inf. Process. Syst. 2021, 34, 12091–12103. [Google Scholar]
- Goel, K.; Gu, A.; Li, Y.; Ré, C. Model patching: Closing the subgroup performance gap with data augmentation. In Proceedings of the ICLR, Virtual Event, 3–7 May 2021. [Google Scholar]
- Ramaswamy, V.V.; Kim, S.S.; Russakovsky, O. Fair attribute classification through latent space de-biasing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2021; pp. 9301–9310. [Google Scholar]
- Lee, J.; Kim, E.; Lee, J.; Lee, J.; Choo, J. Learning debiased representation via disentangled feature augmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 25123–25133. [Google Scholar]
- Jeon, M.; Kim, D.; Lee, W.; Kang, M.; Lee, J. A Conservative Approach for Unbiased Learning on Unknown Biases. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16752–16760. [Google Scholar]
- Grari, V.; Lamprier, S.; Detyniecki, M. Fairness without the sensitive attribute via Causal Variational Autoencoder. IJCAI 2022, 2022, 3. [Google Scholar]
- Zhai, R.; Dan, C.; Suggala, A.; Kolter, J.Z.; Ravikumar, P. Boosted CVaR Classification. Adv. Neural Inf. Process. Syst. 2021, 34, 21860–21871. [Google Scholar]
- Sinha, A.; Namkoong, H.; Volpi, R.; Duchi, J. Certifying some distributional robustness with principled adversarial training. arXiv 2017, arXiv:1710.10571. [Google Scholar]
- Michel, P.; Hashimoto, T.; Neubig, G. Modeling the second player in distributionally robust optimization. arXiv 2021, arXiv:2103.10282. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Risser, L.; Picard, A.M.; Hervier, L.; Loubes, J.-M. Detecting and Processing Unsuspected Sensitive Variables for Robust Machine Learning. Algorithms 2023, 16, 510. https://doi.org/10.3390/a16110510
Risser L, Picard AM, Hervier L, Loubes J-M. Detecting and Processing Unsuspected Sensitive Variables for Robust Machine Learning. Algorithms. 2023; 16(11):510. https://doi.org/10.3390/a16110510
Chicago/Turabian StyleRisser, Laurent, Agustin Martin Picard, Lucas Hervier, and Jean-Michel Loubes. 2023. "Detecting and Processing Unsuspected Sensitive Variables for Robust Machine Learning" Algorithms 16, no. 11: 510. https://doi.org/10.3390/a16110510
APA StyleRisser, L., Picard, A. M., Hervier, L., & Loubes, J.-M. (2023). Detecting and Processing Unsuspected Sensitive Variables for Robust Machine Learning. Algorithms, 16(11), 510. https://doi.org/10.3390/a16110510