




Parkinson’s Disease Classification Framework Using Vocal Dynamics in Connected Speech


Abstract
1. Introduction
- Efforts to establish an analytical framework that can be automated to classify between PD and HC using vocalic dynamics.
- Providing evidence as to the robustness of the framework for the language being spoken.
- Evaluation of PSFs for PD classification.
- Providing evidence for the shortcomings of using MFCCs for PD classification due to their inherent nature of embedding patient identifiable information.
2. Dataset Description
2.1. Database 1
2.2. Database 2
3. Materials and Methods
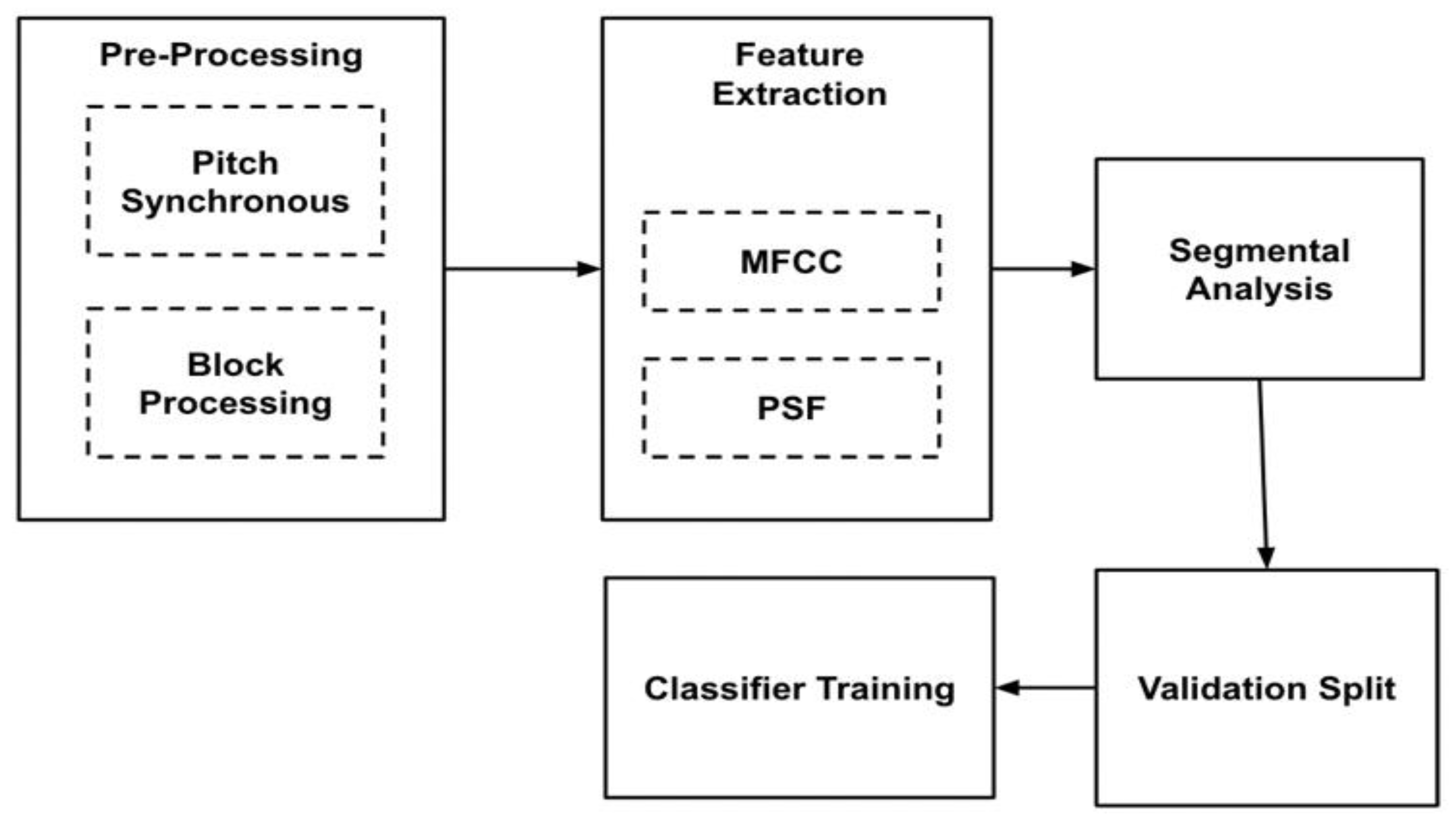
3.1. Methodology Block Description
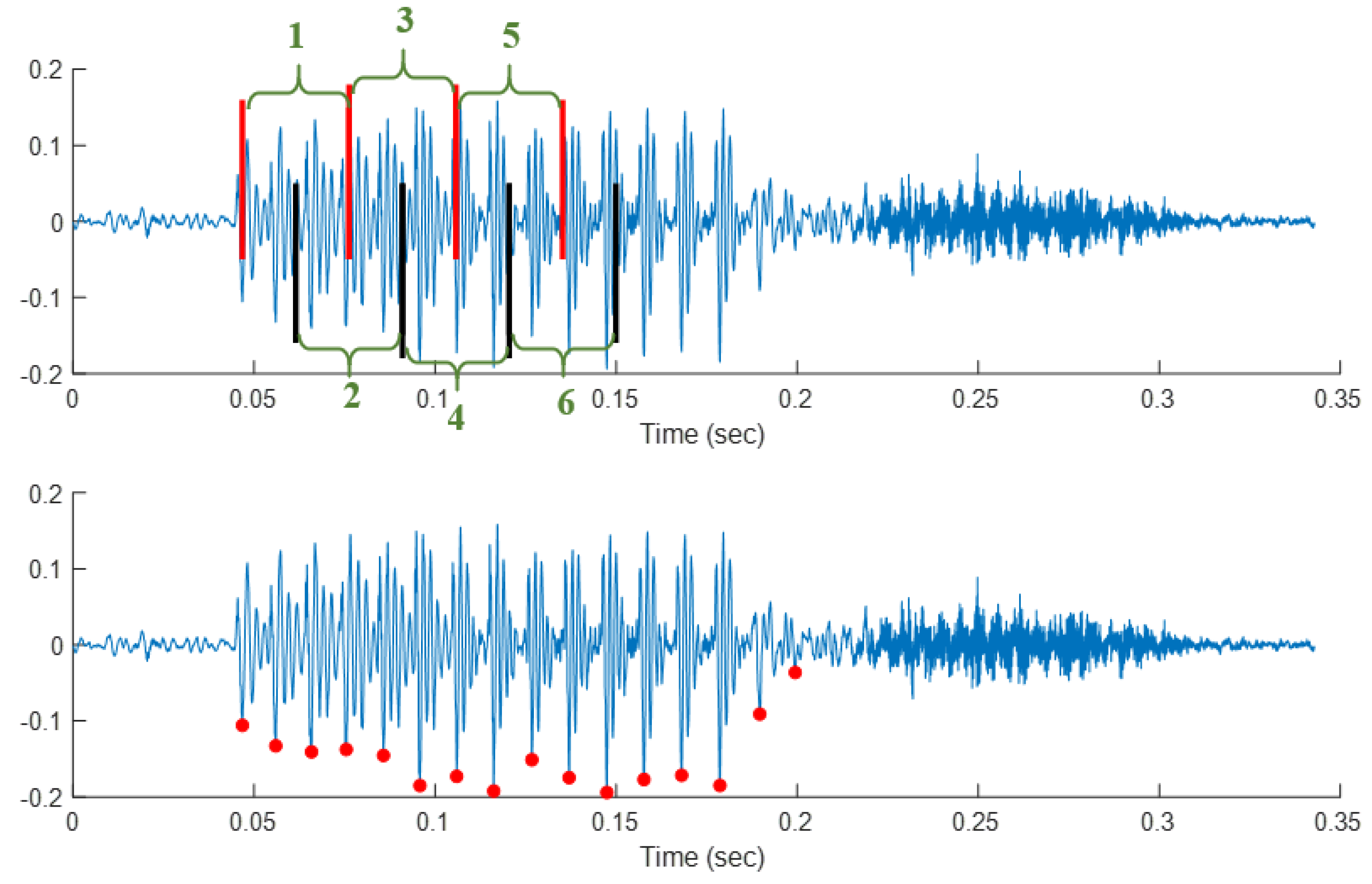
3.1.1. Preprocessing: Block Processing and Pitch Synchronous Segmentation
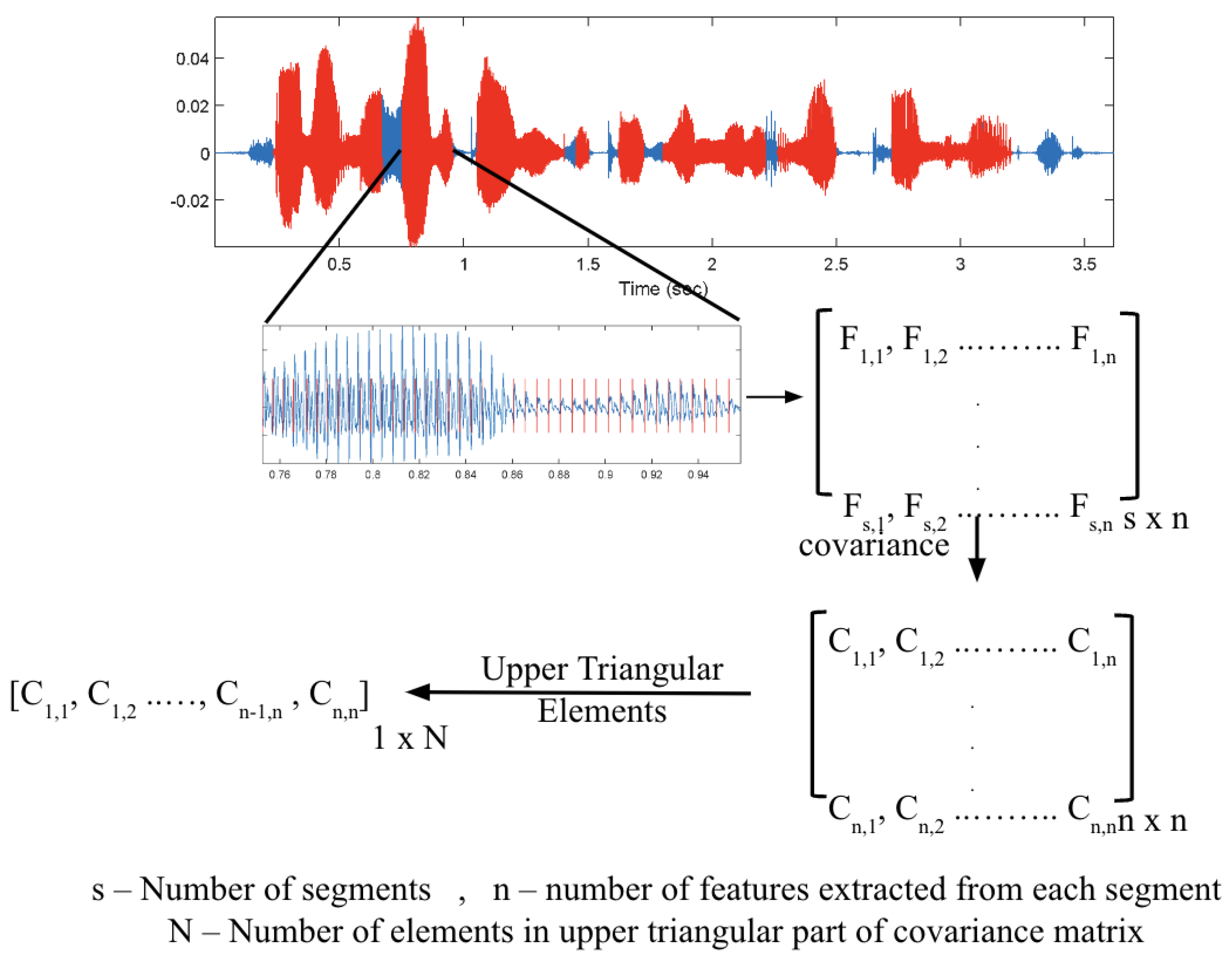
3.1.2. Feature Extraction: MFCCs and PSFs
3.1.3. Feature Preparation
3.1.4. Validation Split: Hold-Out
3.1.5. Classifier Training
3.2. Experimental Design
3.2.1. Importance of Block Size in Conventional Block Processing
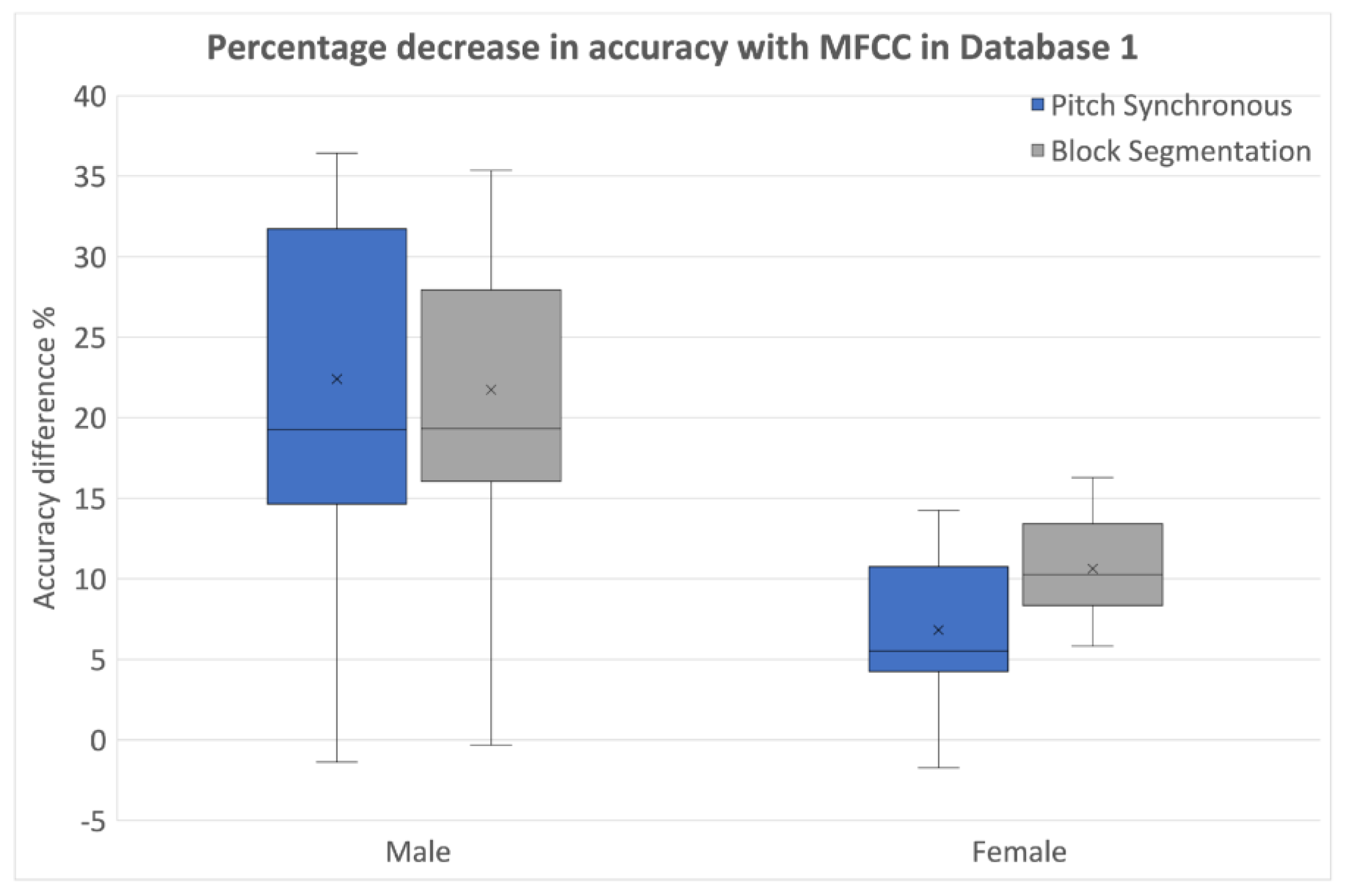
3.2.2. Identification of Optimal Choice for Segmentation Method
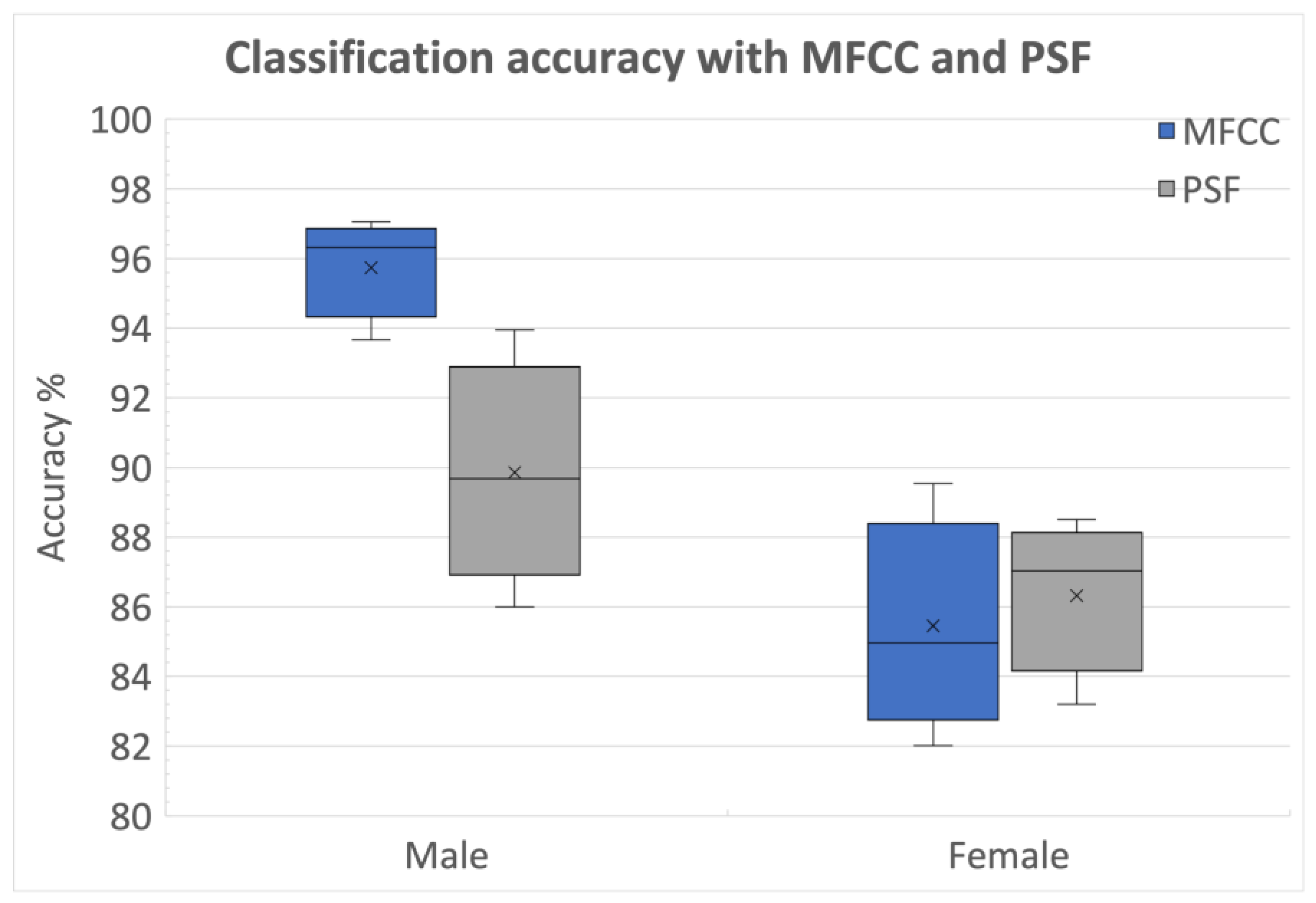
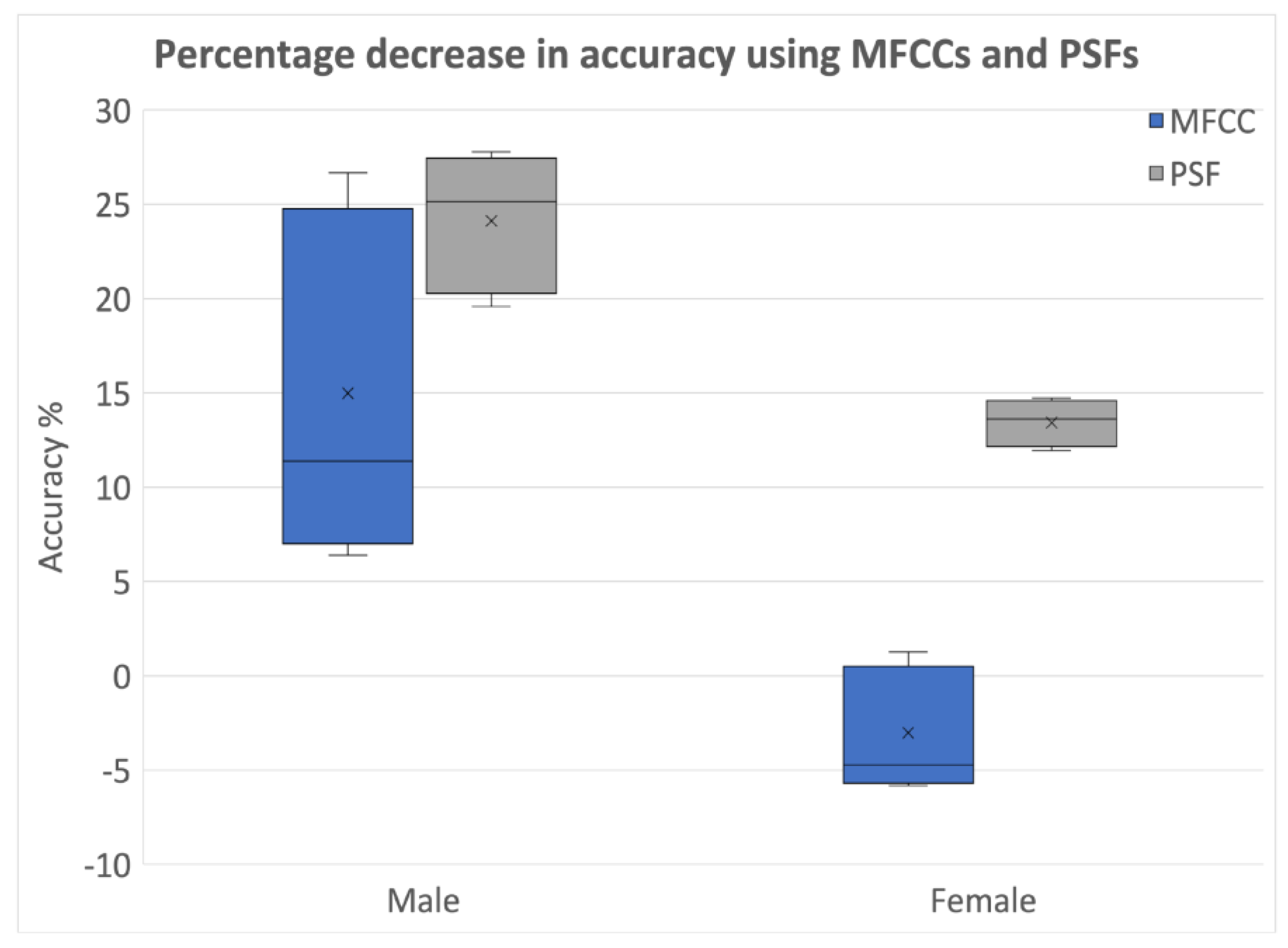
3.2.3. Identification of Optimal Choice for Feature Types
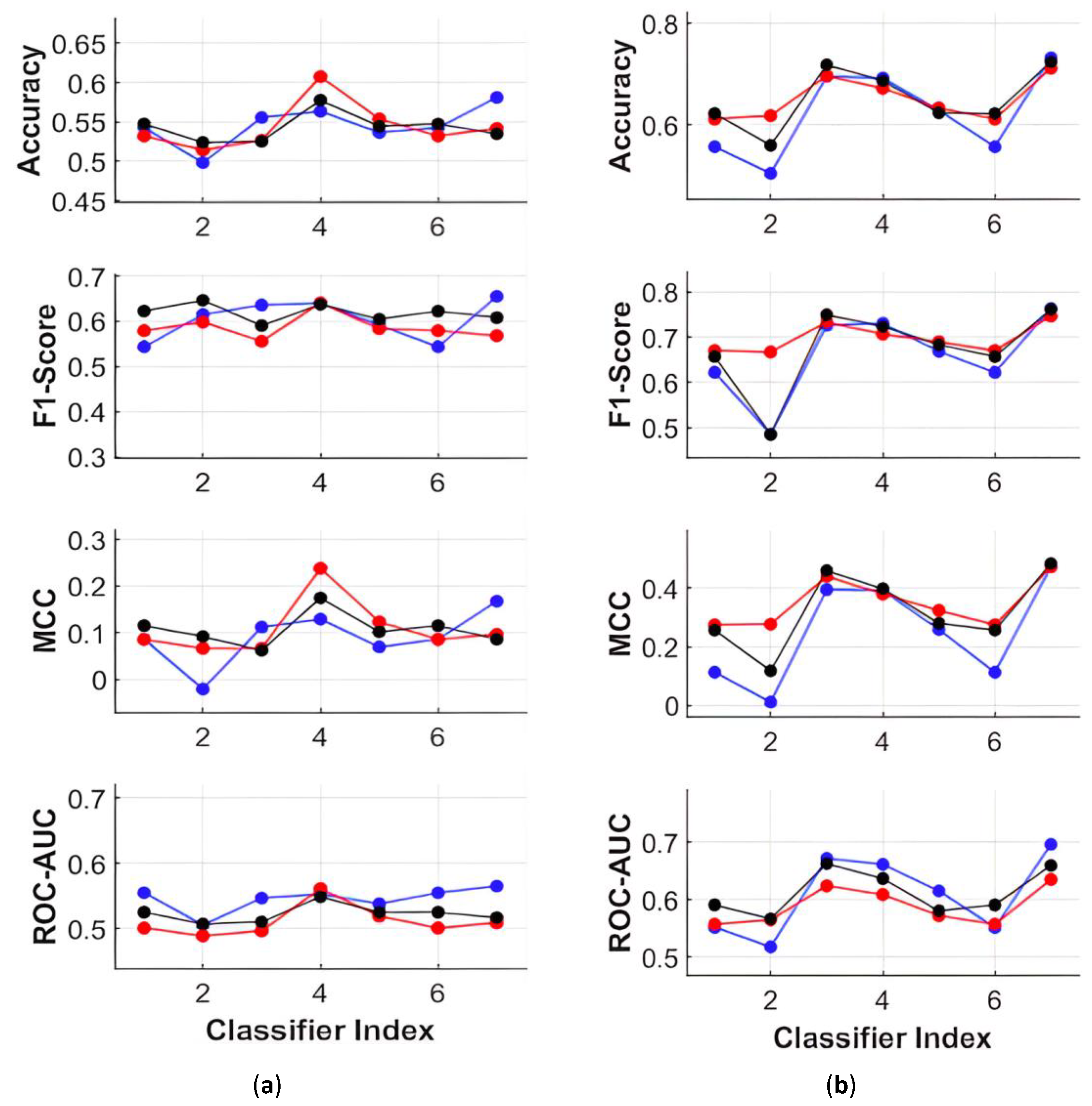
3.2.4. Evaluation of Classifiers
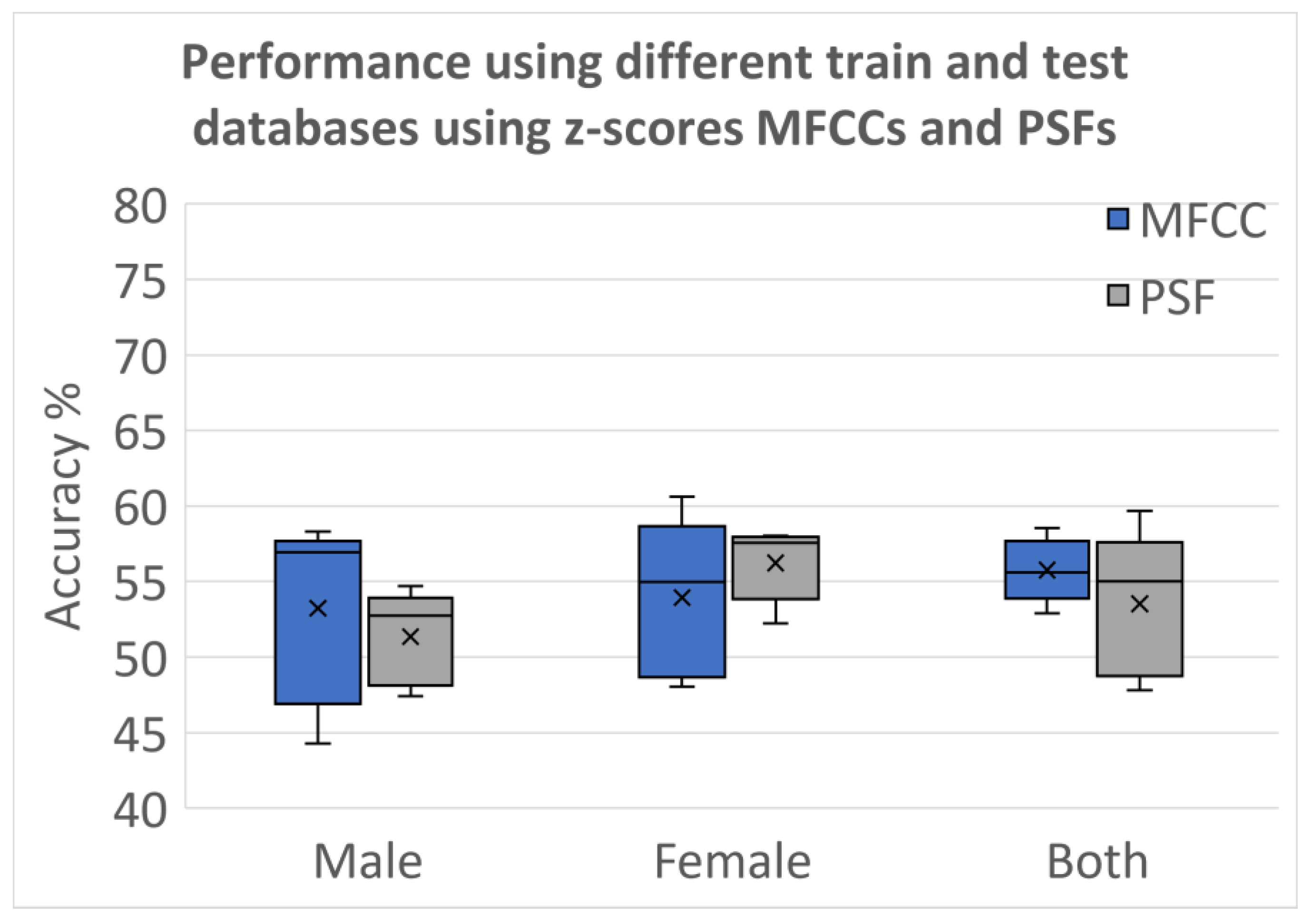
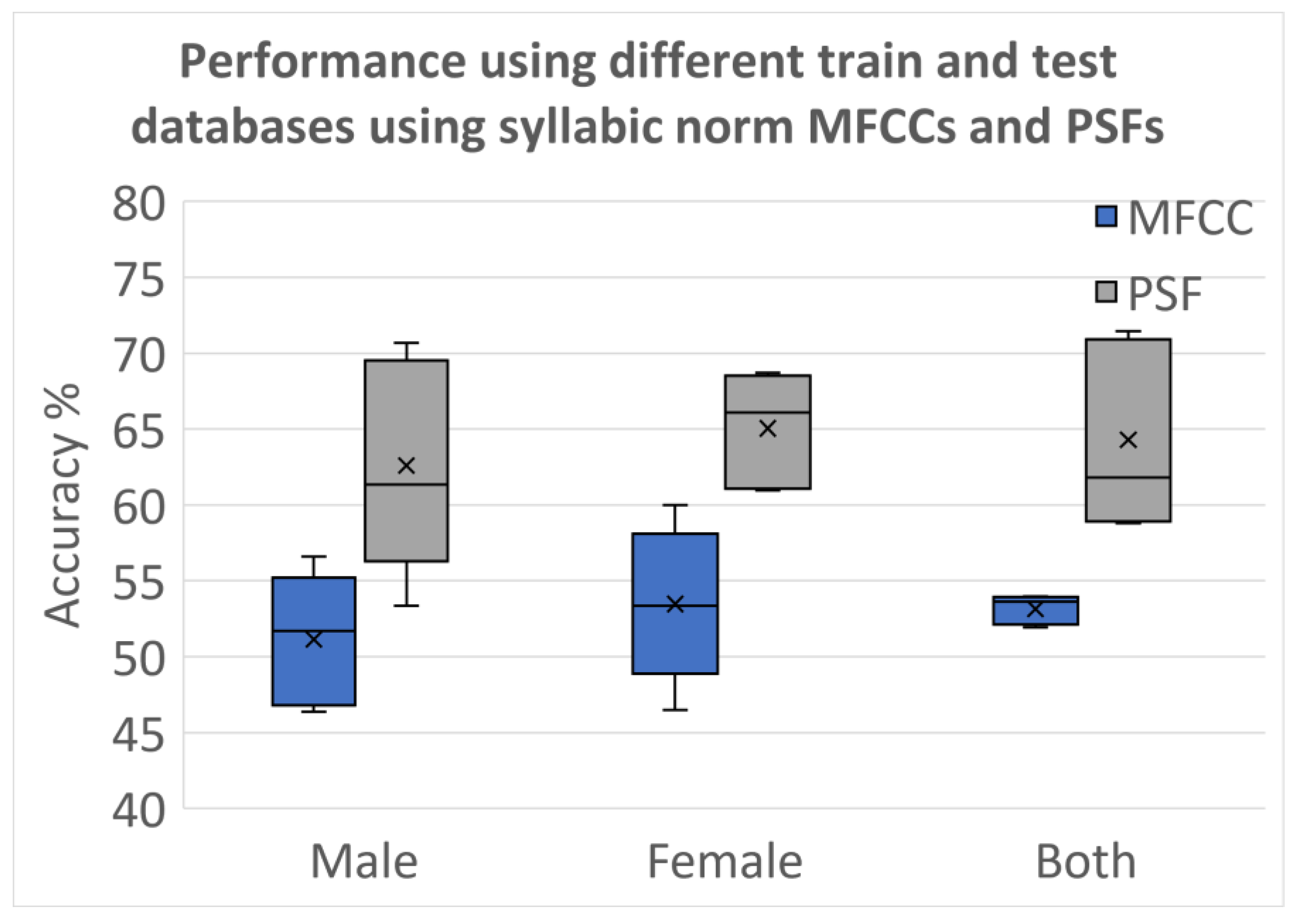
3.2.5. Testing Using Different Databases
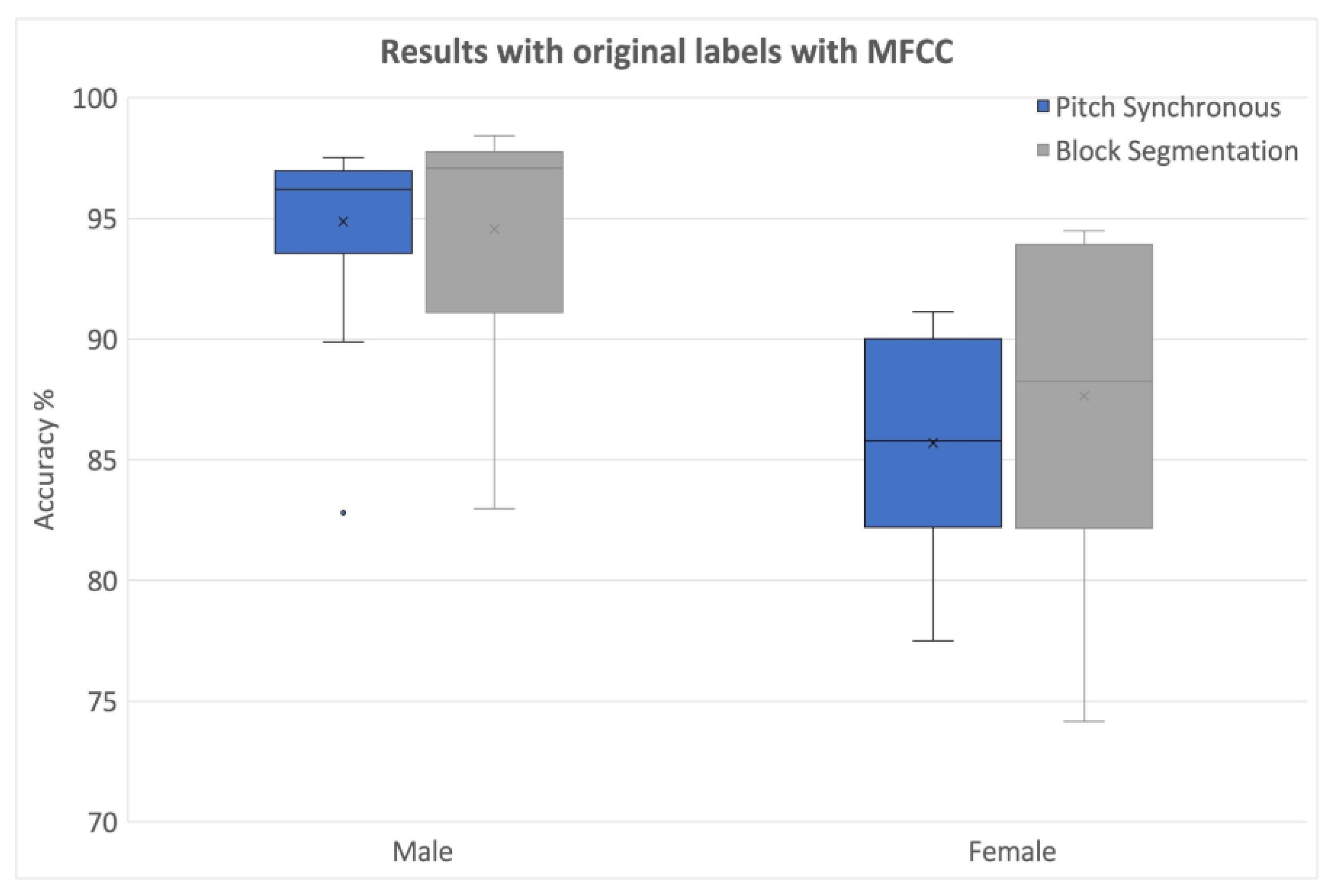
4. Results and Discussion
- True Positives (TP): Number of PD samples predicted as PD.
- True Negatives (TN): Number of HC samples predicted as HC.
- False Positives (FP): Number of HC samples predicted as PD.
- False Negatives (FN): Number of PD samples predicted as HC.
- Accuracy: Proportion of test samples correctly predicted.
- Precision (P): Proportion of PD predictions that were correct.
- Recall (R): Proportion of all PD samples correctly predicted.
- F1-Score: Harmonic mean of precision and recall.
- Matthews Correlation Coefficient (MCC): An improvement over F1-Score as it includes the TN in its computation.
- ROC-AUC: Area under Receiver Operating Characteristic (ROC) curve.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Parkinson, J. An essay on the shaking palsy. J. Neuropsychiatry Clin. Neurosci. 2002, 14, 223–236. [Google Scholar] [CrossRef]
- Tohgi, H.; Abe, T.; Takahashi, S. Parkinson’s disease: Diagnosis, treatment and prognosis. Nihon Ronen Igakkai Zasshi. Jpn. J. Geriatr. 1996, 33, 911–915. [Google Scholar] [CrossRef] [PubMed]
- New Study Shows the Incidence of Parkinson’s Disease in the U.S. Is 50% Higher than Previous Estimates. Available online: https://www.parkinson.org/about-us/news/incidence-2022 (accessed on 3 April 2020).
- Marras, C.; Beck, J.C.; Bower, J.H.; Roberts, E.; Ritz, B.; Ross, G.W.; Abbott, R.D.; Savica, R.; Van Den Eeden, S.K.; Willis, A.W.; et al. Prevalence of Parkinson’s disease across North America. NPJ Park. Dis. 2018, 4, 21. [Google Scholar] [CrossRef]
- Lima, M.S.M.; Martins, E.F.; Marcia Delattre, A.; Proenca, M.B.; Mori, M.A.; Carabelli, B.; Ferraz, A.C. Motor and non-motor features of Parkinson’s disease–A review of clinical and experimental studies. CNS Neurol. Disord. Drug Targets Former. Curr. Drug Targets CNS Neurol. Disord. 2012, 11, 439–449. [Google Scholar]
- Lang, A.E. A critical appraisal of the premotor symptoms of Parkinson’s disease: Potential usefulness in early diagnosis and design of neuroprotective trials. Mov. Disord. 2011, 26, 775–783. [Google Scholar] [CrossRef] [PubMed]
- Schrag, A.; Jahanshahi, M.; Quinn, N. How does Parkinson’s disease affect quality of life? A comparison with quality of life in the general population. Mov. Disord. Off. J. Mov. Disord. Soc. 2000, 15, 1112–1118. [Google Scholar] [CrossRef]
- Lang, A.E.; Obeso, J.A. Time to move beyond nigrostriatal dopamine deficiency in Parkinson’s disease. Ann. Neurol. Off. J. Am. Neurol. Assoc. Child Neurol. Soc. 2004, 55, 761–765. [Google Scholar] [CrossRef]
- Rizzo, G.; Copetti, M.; Arcuti, S.; Martino, D.; Fontana, A.; Logroscino, G. Accuracy of clinical diagnosis of Parkinson disease: A systematic review and meta-analysis. Neurology 2016, 86, 566–576. [Google Scholar] [CrossRef] [PubMed]
- Postuma, R.; Lang, A.; Gagnon, J.; Pelletier, A.; Montplaisir, J. How does parkinsonism start? Prodromal parkinsonism motor changes in idiopathic REM sleep behaviour disorder. Brain 2012, 135, 1860–1870. [Google Scholar] [CrossRef] [PubMed]
- Harel, B.T.; Cannizzaro, M.S.; Cohen, H.; Reilly, N.; Snyder, P.J. Acoustic characteristics of Parkinsonian speech: A potential biomarker of early disease progression and treatment. J. Neurolinguist. 2004, 17, 439–453. [Google Scholar] [CrossRef]
- Ho, A.K.; Iansek, R.; Marigliani, C.; Bradshaw, J.L.; Gates, S. Speech impairment in a large sample of patients with Parkinson’s disease. Behav. Neurol. 1998, 11, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Kent, R.D.; Kent, J.F.; Weismer, G.; Duffy, J.R. What dysarthrias can tell us about the neural control of speech. J. Phon. 2000, 28, 273–302. [Google Scholar] [CrossRef][Green Version]
- Rudzicz, F. Articulatory knowledge in the recognition of dysarthric speech. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 947–960. [Google Scholar] [CrossRef]
- Canter, G.J. Speech characteristics of patients with Parkinson’s disease: III. Articulation, diadochokinesis, and over-all speech adequacy. J. Speech Hear. Disord. 1965, 30, 217–224. [Google Scholar] [CrossRef]
- Darley, F.L.; Aronson, A.E.; Brown, J.R. Motor Speech Disorders; Saunders: Philadelphia, PA, USA, 1975. [Google Scholar]
- Tjaden, K.; Kain, A.; Lam, J. Hybridizing conversational and clear speech to investigate the source of increased intelligibility in speakers with Parkinson’s disease. J. Speech Lang. Hear. Res. 2014, 57, 1191–1205. [Google Scholar] [CrossRef]
- Anand, S.; Stepp, C.E. Listener perception of monopitch, naturalness, and intelligibility for speakers with Parkinson’s disease. J. Speech Lang. Hear. Res. 2015, 58, 1134–1144. [Google Scholar] [CrossRef]
- Chiu, Y.-F.; Neel, A. Predicting Intelligibility Deficits in Parkinson’s Disease With Perceptual Speech Ratings. J. Speech Lang. Hear. Res. 2020, 63, 433–443. [Google Scholar] [CrossRef]
- Miller, N.; Allcock, L.; Jones, D.; Noble, E.; Hildreth, A.J.; Burn, D.J. Prevalence and pattern of perceived intelligibility changes in Parkinson’s disease. J. Neurol. 2007, 78, 1188–1190. [Google Scholar] [CrossRef]
- Cannito, M.P.; Suiter, D.M.; Beverly, D.; Chorna, L.; Wolf, T.; Pfeiffer, R.M. Sentence intelligibility before and after voice treatment in speakers with idiopathic Parkinson’s disease. J. Voice 2012, 26, 214–219. [Google Scholar] [CrossRef]
- Cannito, M.P.; Suiter, D.M.; Chorna, L.; Beverly, D.; Wolf, T.; Watkins, J. Speech intelligibility in a speaker with idiopathic Parkinson’s disease before and after treatment. J. Med. Speech Lang. Pathol. 2008, 16, 207–213. [Google Scholar]
- Goberman, A.M.; Elmer, L.W. Acoustic analysis of clear versus conversational speech in individuals with Parkinson disease. J. Commun. Disord. 2005, 38, 215–230. [Google Scholar] [CrossRef] [PubMed]
- Chenausky, K.; MacAuslan, J.; Goldhor, R. Acoustic analysis of PD speech. Park. Dis. 2011, 2011, 435232. [Google Scholar] [CrossRef] [PubMed]
- Kuo, C.; Tjaden, K. Acoustic variation during passage reading for speakers with dysarthria and healthy controls. J. Commun. Disord. 2016, 62, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Fletcher, A.R.; McAuliffe, M.J.; Lansford, K.L.; Liss, J.M. Assessing vowel centralization in dysarthria: A comparison of methods. J. Speech Lang. Hear. Res. 2017, 60, 341–354. [Google Scholar] [CrossRef]
- Burk, B.R.; Watts, C.R. The effect of Parkinson disease tremor phenotype on cepstral peak prominence and transglottal airflow in vowels and speech. J. Voice 2019, 33, 580.e11–580.e19. [Google Scholar] [CrossRef]
- Orozco-Arroyave, J.R.; Hönig, F.; Arias-Londoño, J.D.; Vargas-Bonilla, J.F.; Skodda, S.; Rusz, J.; Nöth, E. Automatic detection of Parkinson’s disease from words uttered in three different languages. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Orozco-Arroyave, J.; Hönig, F.; Arias-Londoño, J.; Vargas-Bonilla, J.; Daqrouq, K.; Skodda, S.; Rusz, J.; Nöth, E. Automatic detection of Parkinson’s disease in running speech spoken in three different languages. J. Acoust. Soc. Am. 2016, 139, 481–500. [Google Scholar] [CrossRef]
- Rusz, J.; Cmejla, R.; Tykalova, T.; Ruzickova, H.; Klempir, J.; Majerova, V.; Picmausova, J.; Roth, J.; Ruzicka, E. Imprecise vowel articulation as a potential early marker of Parkinson’s disease: Effect of speaking task. J. Acoust. Soc. Am. 2013, 134, 2171–2181. [Google Scholar] [CrossRef]
- Skodda, S.; Grönheit, W.; Schlegel, U. Intonation and speech rate in Parkinson’s disease: General and dynamic aspects and responsiveness to levodopa admission. J. Voice 2011, 25, e199–e205. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Spielman, J.; Ramig, L.O. Novel speech signal processing algorithms for high-accuracy classification of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef]
- Rusz, J.; Cmejla, R.; Ruzickova, H.; Ruzicka, E. Quantitative acoustic measurements for characterization of speech and voice disorders in early untreated Parkinson’s disease. J. Acoust. Soc. Am. 2011, 129, 350–367. [Google Scholar] [CrossRef]
- Little, M.; McSharry, P.; Hunter, E.; Spielman, J.; Ramig, L. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. Nat. Preced. 2008, 1. [Google Scholar] [CrossRef]
- Almeida, J.S.; Rebouças Filho, P.P.; Carneiro, T.; Wei, W.; Damaševičius, R.; Maskeliūnas, R.; de Albuquerque, V.H.C. Detecting Parkinson’s disease with sustained phonation and speech signals using machine learning techniques. Pattern Recognit. Lett. 2019, 125, 55–62. [Google Scholar] [CrossRef]
- Benba, A.; Jilbab, A.; Hammouch, A. Detecting patients with Parkinson’s disease using Mel frequency cepstral coefficients and support vector machines. Int. J. Electr. Eng. Inform. 2015, 7, 297. [Google Scholar]
- Rahn, D.A., III; Chou, M.; Jiang, J.J.; Zhang, Y. Phonatory impairment in Parkinson’s disease: Evidence from nonlinear dynamic analysis and perturbation analysis. J. Voice 2007, 21, 64–71. [Google Scholar] [CrossRef] [PubMed]
- Klingholtz, F. Acoustic recognition of voice disorders: A comparative study of running speech versus sustained vowels. J. Acoust. Soc. Am. 1990, 87, 2218–2224. [Google Scholar] [CrossRef]
- Zraick, R.I.; Dennie, T.M.; Tabbal, S.D.; Hutton, T.J.; Hicks, G.M.; O’Sullivan, P.S. Reliability of speech intelligibility ratings using the Unified Parkinson Disease Rating Scale. J. Med. Speech Lang. Pathol. 2003, 11, 227–241. [Google Scholar]
- Ackermann, H.; Konczak, J.; Hertrich, I. The temporal control of repetitive articulatory movements in Parkinson’s disease. Brain Lang. 1997, 56, 312–319. [Google Scholar] [CrossRef]
- Kumar, S.; Kar, P.; Singh, D.; Sharma, M. Analysis of diadochokinesis in persons with Parkinson’s disease. J. Datta Meghe Inst. Med. Sci. Univ. 2018, 13, 140. [Google Scholar] [CrossRef]
- Hlavnička, J.; Čmejla, R.; Tykalová, T.; Šonka, K.; Růžička, E.; Rusz, J. Automated analysis of connected speech reveals early biomarkers of Parkinson’s disease in patients with rapid eye movement sleep behaviour disorder. Sci. Rep. 2017, 7, 12. [Google Scholar] [CrossRef]
- Rusz, J.; Hlavnička, J.; Tykalová, T.; Novotný, M.; Dušek, P.; Šonka, K.; Růžička, E. Smartphone allows capture of speech abnormalities associated with high risk of developing Parkinson’s disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 1495–1507. [Google Scholar] [CrossRef]
- Whitfield, J.A.; Goberman, A.M. Articulatory–acoustic vowel space: Application to clear speech in individuals with Parkinson’s disease. J. Commun. Disord. 2014, 51, 19–28. [Google Scholar] [CrossRef] [PubMed]
- MacPherson, M.K.; Huber, J.E.; Snow, D.P. The intonation–syntax interface in the speech of individuals with Parkinson’s disease. J. Speech Lang. Hear. Res. 2011, 54, 19–32. [Google Scholar] [CrossRef] [PubMed]
- Forrest, K.; Weismer, G.; Turner, G.S. Kinematic, acoustic, and perceptual analyses of connected speech produced by Parkinsonian and normal geriatric adults. J. Acoust. Soc. Am. 1989, 85, 2608–2622. [Google Scholar] [CrossRef]
- Skodda, S.; Visser, W.; Schlegel, U. Vowel articulation in Parkinson’s disease. J. Voice 2011, 25, 467–472. [Google Scholar] [CrossRef] [PubMed]
- Vizza, P.; Tradigo, G.; Mirarchi, D.; Bossio, R.B.; Lombardo, N.; Arabia, G.; Quattrone, A.; Veltri, P. Methodologies of speech analysis for neurodegenerative diseases evaluation. Int. J. Med. Inform. 2019, 122, 45–54. [Google Scholar] [CrossRef]
- Schultz, B.G.; Tarigoppula, V.S.A.; Noffs, G.; Rojas, S.; van der Walt, A.; Grayden, D.B.; Vogel, A.P. Automatic speech recognition in neurodegenerative disease. Int. J. Speech Technol. 2021, 24, 771–779. [Google Scholar] [CrossRef]
- Shi, X.; Wang, T.; Wang, L.; Liu, H.; Yan, N. Hybrid Convolutional Recurrent Neural Networks Outperform CNN and RNN in Task-state EEG Detection for Parkinson’s Disease. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 939–944. [Google Scholar]
- Quan, C.; Ren, K.; Luo, Z. A Deep Learning Based Method for Parkinson’s Disease Detection Using Dynamic Features of Speech. IEEE Access 2021, 9, 10239–10252. [Google Scholar] [CrossRef]
- Gunduz, H. Deep Learning-Based Parkinson’s Disease Classification Using Vocal Feature Sets. IEEE Access 2019, 7, 115540–115551. [Google Scholar] [CrossRef]
- Nagasubramanian, G.; Sankayya, M. Multi-Variate vocal data analysis for Detection of Parkinson disease using Deep Learning. Neural Comput. Appl. 2020, 33, 4849–4864. [Google Scholar] [CrossRef]
- Karaman, O.; Çakın, H.; Alhudhaif, A.; Polat, K. Robust automated Parkinson disease detection based on voice signals with transfer learning. Expert Syst. Appl. 2021, 178, 115013. [Google Scholar] [CrossRef]
- Ali, L.; Zhu, C.; Zhang, Z.; Liu, Y. Automated Detection of Parkinson’s Disease Based on Multiple Types of Sustained Phonations Using Linear Discriminant Analysis and Genetically Optimized Neural Network. IEEE J. Transl. Eng. Health Med. 2019, 7, 2000410. [Google Scholar] [CrossRef] [PubMed]
- Appakaya, S.B.; Sankar, R. Classification of Parkinson’s disease Using Pitch Synchronous Speech Analysis. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; pp. 1420–1423. [Google Scholar]
- Benba, A.; Jilbab, A.; Hammouch, A. Discriminating between patients with Parkinson’s and neurological diseases using cepstral analysis. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 1100–1108. [Google Scholar] [CrossRef] [PubMed]
- Giovanni, D.; Francesco, G. Italian Parkinson’s Voice and Speech. IEEE Dataport 2019. [Google Scholar] [CrossRef]
- Dimauro, G.; Di Nicola, V.; Bevilacqua, V.; Caivano, D.; Girardi, F. Assessment of speech intelligibility in Parkinson’s disease using a speech-to-text system. IEEE Access 2017, 5, 22199–22208. [Google Scholar] [CrossRef]
- Skowronski, M.D.; Shrivastav, R.; Harnsberger, J.; Anand, S.; Rosenbek, J. Acoustic discrimination of Parkinsonian speech using cepstral measures of articulation. J. Acoust. Soc. Am. 2012, 132, 2089. [Google Scholar] [CrossRef]
- Appakaya, S.B.; Sankar, R. Parkinson’s Disease Classification using Pitch Synchronous Speech Segments and Fine Gaussian Kernels based SVM. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 236–239. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Size |
|---|---|
| Pitch Period | 1 |
| LOC—Length of Curve | 1 |
| Quarter Segment Energy | 4 |
| Total Energy | 1 |
| Correlation Canceller Efficiency | 1 |
| Correlation Canceller MSE | 1 |
| Peak Frequency (Hz) | 1 |
| Quarter Band Magnitude | 4 |
| Spectral Factor | 1 |
| Classifier No. | Classifier Name | Overfit Factor with Original Label | |||
|---|---|---|---|---|---|
| Male | Female | ||||
| MFCC | PSF | MFCC | PSF | ||
| 1 | Medium KNN | −0.003 | 0.021 | 0.023 | 0.022 |
| 2 | Coarse KNN | −0.012 | 0.017 | 0.014 | 0.003 |
| 3 | Cosine KNN | 0.005 | 0.015 | 0.016 | 0.021 |
| 4 | Linear SVM | −0.001 | −0.005 | 0.009 | 0 |
| 5 | Coarse Tree | 0.012 | 0.037 | 0.017 | −0.001 |
| 6 | Coarse Gaussian SVM | −0.002 | 0.006 | 0.013 | 0.001 |
| 7 | Medium Tree | 0.016 | 0.031 | 0.015 | 0.003 |
| 8 | Ensemble Boosted Tree | 0.018 | 0.026 | 0.025 | 0.004 |
| 9 | RUS Boosted Tree | 0.016 | 0.031 | 0,015 | 0.003 |
| 10 | Logistic Regression | 0 | −0.012 | 0.007 | −0.001 |
| 11 | Fine Tree | 0.039 | 0.03 | 0.061 | 0.008 |
| 12 | Medium Gaussian SVM | 0.003 | 0.006 | 0.02 | 0.001 |
| 13 | Fine KNN | 0.035 | 0.057 | 0.109 | 0.111 |
| 14 | Weighted KNN | 0.026 | 0.055 | 0.099 | 0.1 |
| 15 | Ensemble Bagged Trees | 0.046 | 0.051 | 0.1 | 0.051 |
| 16 | Ensemble Subspace KNN | 0.026 | 0.139 | 0.089 | 0.13 |
| 17 | Fine Gaussian SVM | 0.173 | 0.017 | 0.137 | 0.008 |
| Classifier No. | Classifier Name | Median Test Accuracy | |||
|---|---|---|---|---|---|
| Male | Female | ||||
| MFCC | PSF | MFCC | PSF | ||
| 1 | Medium KNN | 90.18 | 75.77 | 93.73 | 78.725 |
| 2 | Coarse KNN | 85.33 | 72.17 | 89.11 | 74.855 |
| 3 | Cosine KNN | 89.46 | 75.965 | 93.14 | 79.31 |
| 4 | Linear SVM | 67.69 | 58.8 | 80.44 | 53.65 |
| 5 | Coarse Tree | 66.52 | 59.52 | 77.01 | 69.605 |
| 6 | Coarse Gaussian SVM | 75.12 | 61.715 | 83.92 | 64.525 |
| 7 | Medium Tree | 68.83 | 63.09 | 76.81 | 72.405 |
| 8 | Ensemble Boosted Tree | 74.04 | 67.96 | 82.76 | 75.415 |
| 9 | RUS Boosted Tree | 68.83 | 63.09 | 76.81 | 72.35 |
| 10 | Logistic Regression | 67.62 | 59.335 | 79.92 | 59.38 |
| 11 | Fine Tree | 72.18 | 66.965 | 80.62 | 75.93 |
| 12 | Medium Gaussian SVM | 86.63 | 70.21 | 90.78 | 75.865 |
| 13 | Fine KNN | 91.27 | 75.32 | 93.91 | 76.43 |
| 14 | Weighted KNN | 91.97 | 77.4 | 94.29 | 78.66 |
| 15 | Ensemble Bagged Trees | 88.67 | 80.98 | 92.39 | 85.26 |
| 16 | Ensemble Subspace KNN | 90.62 | 66.125 | 94.08 | 73.915 |
| 17 | Fine Gaussian SVM | 92.14 | 78.415 | 95.86 | 80.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Appakaya, S.B.; Pratihar, R.; Sankar, R. Parkinson’s Disease Classification Framework Using Vocal Dynamics in Connected Speech. Algorithms 2023, 16, 509. https://doi.org/10.3390/a16110509
Appakaya SB, Pratihar R, Sankar R. Parkinson’s Disease Classification Framework Using Vocal Dynamics in Connected Speech. Algorithms. 2023; 16(11):509. https://doi.org/10.3390/a16110509
Chicago/Turabian StyleAppakaya, Sai Bharadwaj, Ruchira Pratihar, and Ravi Sankar. 2023. "Parkinson’s Disease Classification Framework Using Vocal Dynamics in Connected Speech" Algorithms 16, no. 11: 509. https://doi.org/10.3390/a16110509
APA StyleAppakaya, S. B., Pratihar, R., & Sankar, R. (2023). Parkinson’s Disease Classification Framework Using Vocal Dynamics in Connected Speech. Algorithms, 16(11), 509. https://doi.org/10.3390/a16110509