
Decentralized Identity Authentication with Auditability and Privacy

 and
and 
Abstract
1. Introduction
2. Background and Related Works
2.1. Blockchain
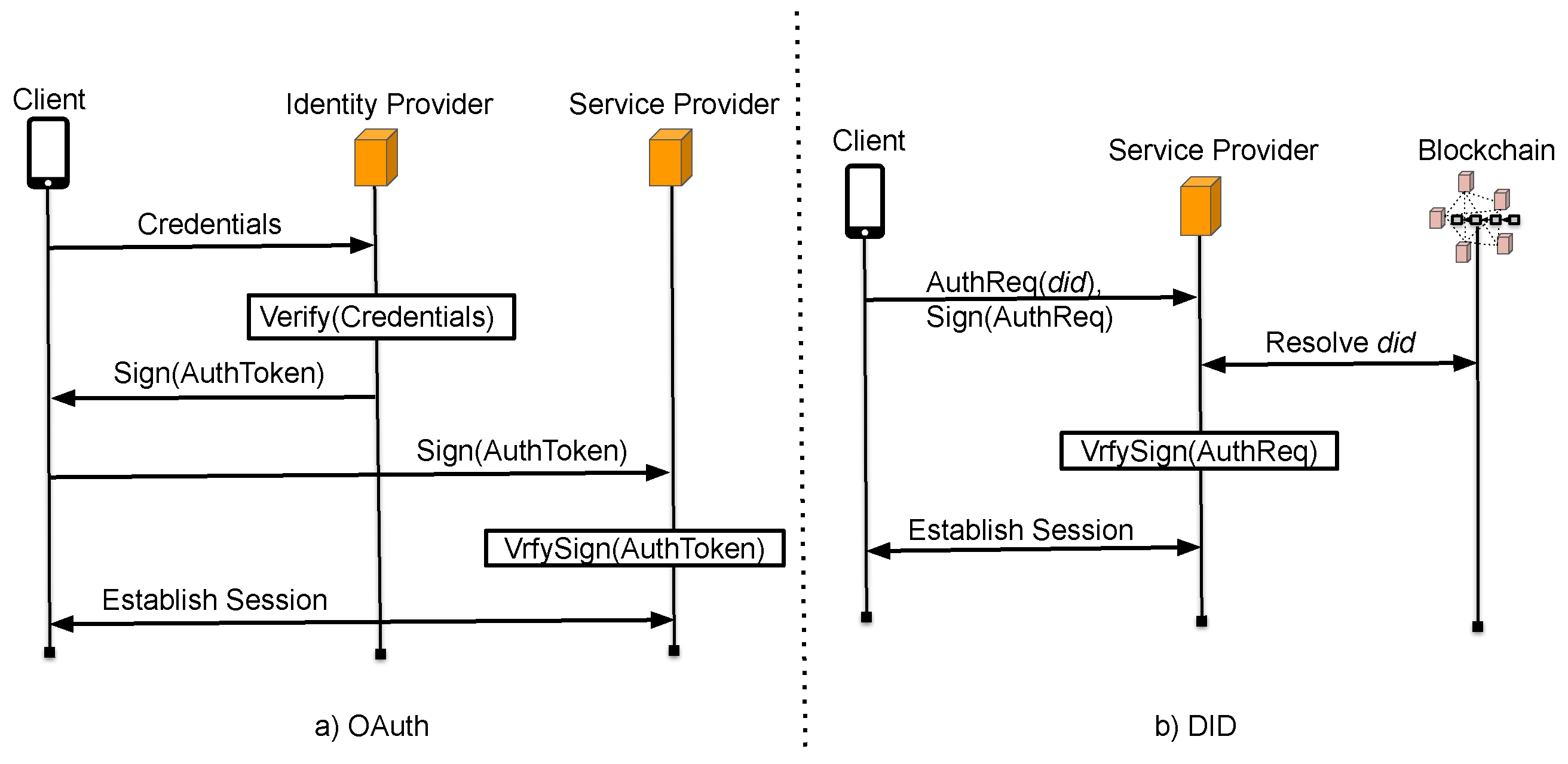
2.2. Decentralized Identity Authentication
2.3. Cryptographic Primitives
- (a)
- is a key generation algorithm that takes a security parameter as input and outputs the (signing) secret key and the verification key .
- (b)
- is a signing algorithm that takes the secret key and a message as inputs, and it outputs a signature .
- (c)
- is a signature verification algorithm that takes a verification key , a message , and a signature as input, and it outputs “True” if the signature matches the key and the message, or “False” otherwise.
- (a)
- is a key generation algorithm that takes a security parameter as input and outputs a keypair, i.e., the secret key and the verification key ( and , respectively).
- (b)
- is an algorithm that takes the secret key and X as inputs and outputs a pseudorandom hash h and a proof (the value h is unique for the inputs and X).
- (c)
- is a verification algorithm that takes the verification key with the values X, h, and ; it returns “True” if proves that h was created for X with the corresponding key , and “False” otherwise.
- (a)
- is a key generation algorithm that takes an arbitrary circuit C and secret parameter as inputs, and it generates a proving key and a verification key . The generation of these keys constitutes a setup phase and is trusted.
- (b)
- is a function that takes public inputs and the private witness w as inputs, and it outputs a succinct-integrity proof of computation .
- (c)
- is a function that takes as input a verification key , a proof , and public inputs , and it returns “True” if the proof is valid, and “False” otherwise.
2.4. Related Work
3. Overview
3.1. Overview
3.2. System and Threat Model
- The blockchain is a blockchain system, such as Hyperledger Fabric or Ethereum, in which users can register their dids and retrieve valid proof that a transaction has been added to the blockchain.
- The client represents the user. It stores secret data, such as private keys associated with the user’s did, and it runs the DID protocol on behalf of the user.
- The service provider (or service) provides resources that the user wants to access. It runs a DID authentication protocol to authenticate the user before giving them access to a resource.
3.3. Properties
- Auditability: The user can detect unauthorized authentication events that use their credentials. More specifically, whenever an adversary uses stolen credentials with an honest server, this fact can be detected later on by the compromised client. Our protocols support “passive” detection, which is when the client detects the misuse while authenticating with an honest server, or “active”, when the client queries the blockchain to find the misuse.
- Privacy: Given an authentication event that is logged in the blockchain, the adversary cannot link it (a) to the identity that is the subject of the authentication event, (b) to the service provider involved, or (c) to any previous authentication events triggered by the identity. We assume that in privacy attacks, the adversary can constantly observe the blockchain’s content, but we leave network-level de-anonymization attacks out of the scope of this submission (i.e., the adversary cannot eavesdrop on the network connections of clients and services).
- Performance: The protocol achieves sufficient throughput to handle realistic authentication workloads.
4. Baseline Protocol
4.1. Registration
4.2. Extended Authentication
| Algorithm 1: Logging authentication events (the baseline protocol). |
incrementCounter (, , σ) 1 assert 2 assert 3 4 assert 5 |
| Algorithm 2: Verification of the inclusion proof of object . |
vrfyInclusion (, ) 1 assert fordo 2 assert 3 assert k is unique 4 assert end |
4.3. Limitations
5. Privacy-Preserving Protocol
5.1. Intermediate Protocol
5.1.1. Registration
5.1.2. Extended Authentication
5.1.3. Discussion
5.2. Final Protocol
5.2.1. New Token and Its Consistency
| Algorithm 3: Circuit for proving that the previous token of the client is in the blockchain. The boxed arguments are secret and are known only to the client (i.e., the prover). |
Token() 1 assert2 assert 3 vrfyInclusion (see Algorithm 2) |
5.2.2. Extended Authentication
| Algorithm 4: Smart contract method for logging authentication events (the final protocol). |
TokenVrfy(π, )
1
assert2 assert 3 |
5.2.3. Discussion
- (a)
- Prior to the registration, the client generates its counter as a large secret number.
- (b)
- For every authentication, a new token and its proof are computed as (the only difference is that the counter is internally hashed).
- (c)
- The service receives —not , as previously—and verifies the token’s authenticity by calling .
- (d)
- The circuit verifies two tokens analogically, thus guaranteeing that the hashes are for the two consecutive values.
6. Security Proofs with Tamarin
6.1. The Tamarin Prover
- denotes the fresh variable x;
- denotes the public variable x;
- denotes the timestamp i;
- denotes a persistent .
Builtins, Functions, and Equations
- Signing: This theory models the signature scheme. The function’s symbols are , , , and , which satisfy the equation .
- Hashing: This theory models a hash function. The function’s symbol is , and there are no equations.
- Multiset: This theory introduces the associative–commutative operator "+", which is usually used to model multisets.
- and with helps to obtain the zero-knowledge proof and verify the proof.
- , , and with, ,help to obtain and verify the VRF output with the token and token proof (gamma).
- and with, .
- with with,.Both t1 and g1 are getter functions. For example, given a pair of tokens, t1 takes the first element of the token.
6.2. Privacy-Preserving DID Authentication Model in Tamarin
6.3. Security Property
- The client sends a registration request to the blockchain.
- The blockchain receives the registration request, verifies the signature, ensures that the token received is unique, and returns the did and token inclusion proof.
- The client generates an authentication request to be sent to the service after deriving a new token and proving its computation.
- The service receives the authentication request, verifies that the token is created with the respective counter and secret key, verifies whether the corresponds to its did inclusion proof, and sends a token request to the blockchain.
- The blockchain receives the token request and verifies it, after which the service establishes a session with the client.
6.4. Privacy with Token Unlinkability
- Anonymity client set . A client with a registered is anonymous with respect to logging a token onto the blockchain if and only if is anonymous within a set of clients defined as the anonymity set.
- Anonymity service set . A service provider is anonymous with respect to logging tokens to the blockchain on behalf of the clients in the set if and only if is anonymous within a set of service providers defined as the service anonymity set.
- Anonymity token set . A token on the blockchain is anonymous if and only if is indistinguishable from other tokens within a set defined as the token anonymity set.
7. Evaluation
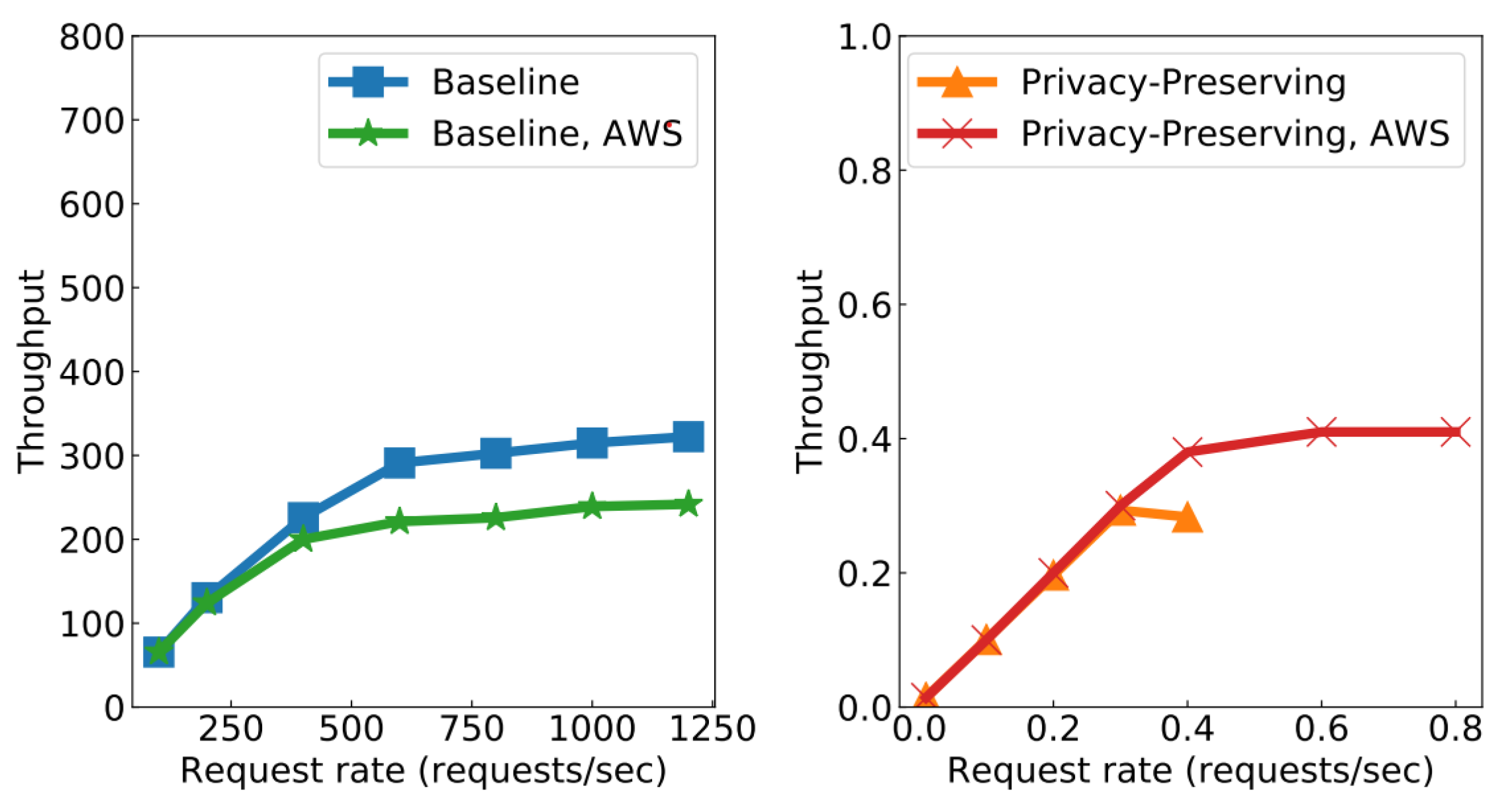
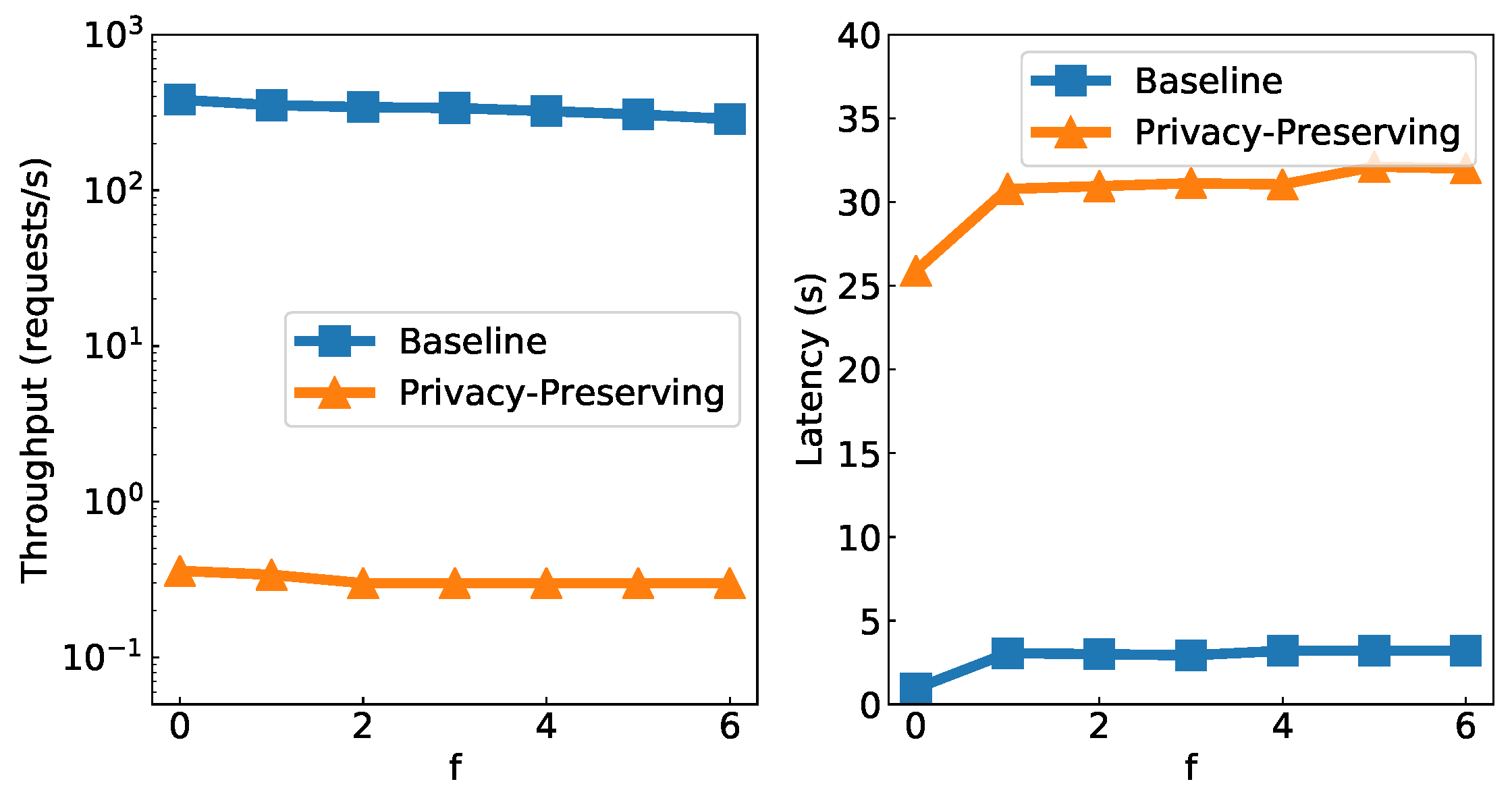
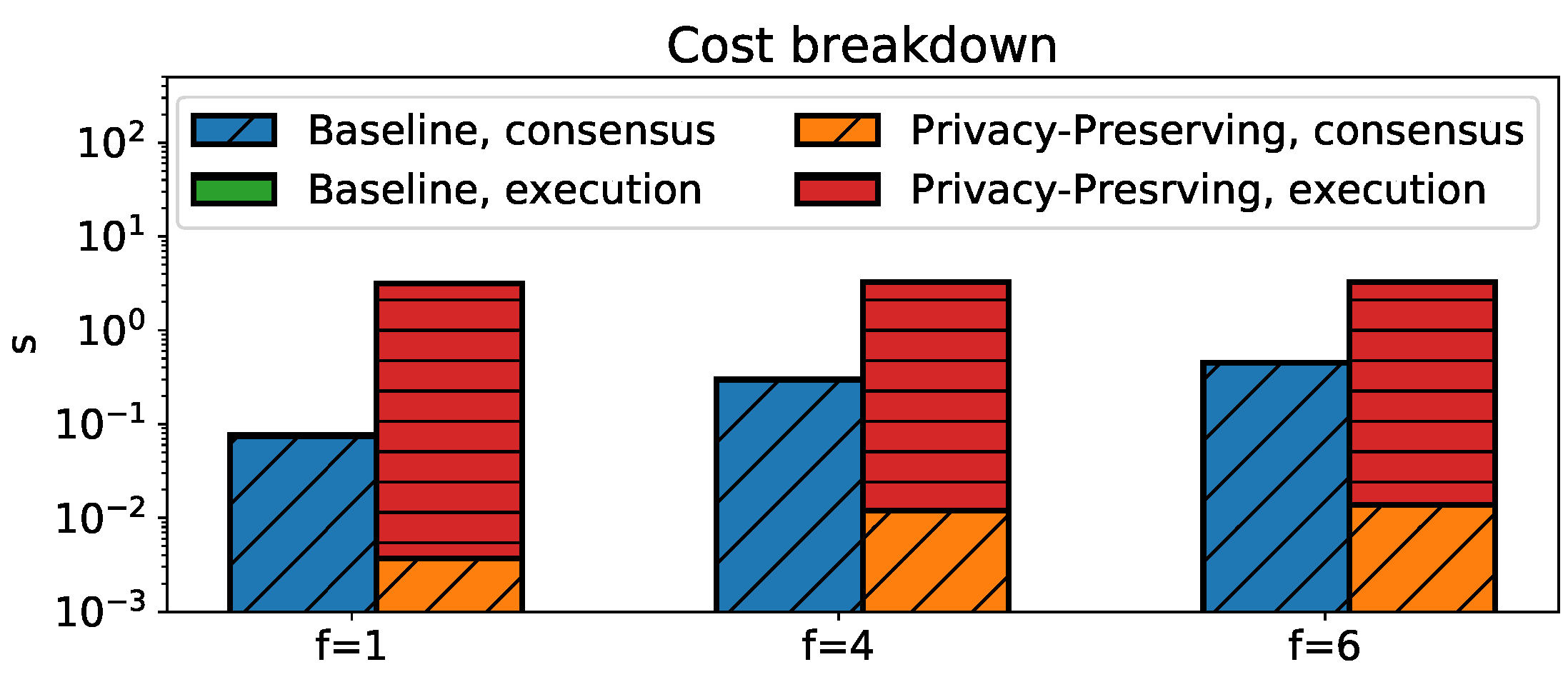
7.1. Performance Evaluation
7.1.1. Methodology
7.1.2. Results
7.2. Discussion
7.3. Integration
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. UC Modeling of the Final Protocol
Appendix A.2. Formalized Final Protocol
References
- Decentralized Identity Foundation. 2018. Available online: https://identity.foundation/ (accessed on 19 October 2020).
- DID Specification. 2020. Available online: https://www.w3.org/TR/did-core/ (accessed on 21 June 2021).
- Hyperledger Indy. 2018. Available online: https://tinyurl.com/yycca4ek (accessed on 19 October 2020).
- Hyperledger Aries. 2019. Available online: https://www.hyperledger.org/projects/aries (accessed on 19 October 2020).
- Evernym. 2018. Available online: https://www.evernym.com (accessed on 19 October 2020).
- Nuggets. 2018. Available online: https://nuggets.life/ (accessed on 19 October 2020).
- Blockstack. 2018. Available online: https://blockstack.org/ (accessed on 19 October 2020).
- Maram, D.; Malvai, H.; Zhang, F.; Jean-Louis, N.; Frolov, A.; Kell, T.; Lobban, T.; Moy, C.; Juels, A.; Miller, A. CanDID: Can-Do Decentralized Identity with Legacy Compatibility, Sybil-Resistance, and Accountability. IACR Cryptol. ePrint Arch. 2020, 2020, 934. [Google Scholar]
- Google Last Login. 2019. Available online: https://tinyurl.com/lqlg2xz (accessed on 21 June 2021).
- Bowe, S.; Gabizon, A.; Miers, I. Scalable Multi-party Computation for zk-SNARK Parameters in the Random Beacon Model. IACR Cryptol. ePrint Arch. 2017, 1050, 1–24. [Google Scholar]
- Dinh, T.T.A.; Liu, R.; Zhang, M.; Chen, G.; Ooi, B.C.; Wang, J. Untangling blockchain: A data processing view of blockchain systems. TKDE 2018, 30, 1366–1385. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decentralized Bus. Rev. 2019, 21260. [Google Scholar]
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Hyperledger Fabric. 2020. Available online: https://tinyurl.com/ydaswf3j (accessed on 21 June 2021).
- Quorum. 2020. Available online: https://www.goquorum.com (accessed on 21 June 2021).
- Castro, M.; Liskov, B. Practical Byzantine fault tolerance. In OSDI; USENIX: Berkeley, CA, USA, 1999; pp. 173–186. [Google Scholar]
- DIDAuth. 2018. Available online: https://tinyurl.com/y89tahad (accessed on 19 October 2020).
- Micali, S.; Rabin, M.; Vadhan, S. Verifiable random functions. In Proceedings of the 40th Annual Symposium on Foundations of Computer Science, Washington, DC, USA, 17–18 October 1999. [Google Scholar]
- Bitansky, N.; Canetti, R.; Chiesa, A.; Tromer, E. From extractable collision resistance to succinct non-interactive arguments of knowledge, and back again. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Berkeley, CA, USA, 31 January–3 February 2022. [Google Scholar]
- Ben-Sasson, E.; Bentov, I.; Horesh, Y.; Riabzev, M. Scalable, transparent, and post-quantum secure computational integrity. IACR Cryptol. ePrint Arch. 2018, 2018, 46. [Google Scholar]
- Ali, M.; Nelson, J.; Shea, R.; Freedman, M.J. Blockstack: A Global Naming and Storage System Secured by Blockchains. In Proceedings of the 2016 USENIX Annual Technical Conference, Denver, Colorado, USA, 22–24 June 2016. [Google Scholar]
- Melara, M.S.; Blankstein, A.; Bonneau, J.; Felten, E.W.; Freedman, M.J. CONIKS: Bringing Key Transparency to End Users. In Proceedings of the 24th USENIX Security Symposium, Washington, DC, USA, 12–14 August 2015. [Google Scholar]
- Key Transparency. 2020. Available online: https://tinyurl.com/ybhedmfs (accessed on 21 June 2021).
- Chu, D.; Lin, J.; Li, F.; Zhang, X.; Wang, Q.; Liu, G. Ticket Transparency: Accountable Single Sign-On with Privacy-Preserving Public Logs. In Proceedings of the International Conference on Security and Privacy in Communication Systems, Orlando, FL, USA, 23–25 October 2019. [Google Scholar]
- Davidson, A.; Goldberg, I.; Sullivan, N.; Tankersley, G.; Valsorda, F. Privacy Pass: Bypassing Internet Challenges Anonymously. Proc. Priv. Enhancing Technol 2018, 3, 164–180. [Google Scholar] [CrossRef]
- Huang, S.; Jeyaraman, S.I.S.; Kushwah, S.; Lee, C.K.; Luo, Z.; Raghunathan, P.M.A.; Shaikh, S.; Sung, Y.C.; Zhang, A. DIT: De-Identified Authenticated Telemetry at Scale. Available online: https://scontent.fsin10-1.fna.fbcdn.net/v/t39.8562-6/246534149_588854725718321_8923613326138589821_n.pdf?_nc_cat=103&ccb=1-7&_nc_sid=ad8a9d&_nc_ohc=sgqd5Qn5r-YAX_F9X4W&_nc_ht=scontent.fsin10-1.fna&oh=00_AfDK48w6piGcXrn2W3zsEvHTqbVqp_6-ugYzHVoZwjNJmQ&oe=63A75882 (accessed on 21 June 2021).
- Sonnino, A.; Al-Bassam, M.; Bano, S.; Meiklejohn, S.; Danezis, G. Coconut: Threshold issuance selective disclosure credentials with applications to distributed ledgers. arXiv 2018, arXiv:1802.07344. [Google Scholar]
- Zhang, Z.; Król, M.; Sonnino, A.; Zhang, L.; Rivière, E. EL PASSO: Privacy-preserving, Asynchronous Single Sign-On. arXiv 2020, arXiv:2002.10289. [Google Scholar]
- Pointcheval, D.; Sanders, O. Short randomizable signatures. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 29 February–4 March 2016; pp. 111–126. [Google Scholar]
- Andersen, M.P.; Kumar, S.; AbdelBaky, M.; Fierro, G.; Kolb, J.; Kim, H.S.; Culler, D.E.; Popa, R.A. WAVE: A Decentralized Authorization Framework with Transitive Delegation. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- Shafagh, H.; Burkhalter, L.; Ratnasamy, S.; Hithnawi, A. Droplet: Decentralized Authorization and Access Control for Encrypted Data Streams. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Google Trillian. 2020. Available online: https://github.com/google/trillian (accessed on 21 June 2021).
- Panwar, G.; Vishwanathan, R.; Misra, S.; Bos, A. SAMPL: Scalable Auditability of Monitoring Processes using Public Ledgers. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019. [Google Scholar]
- Kim, M.; Lee, J.; Oh, J.; Park, K.; Park, Y.; Park, K. Blockchain based energy trading scheme for vehicle-to-vehicle using decentralized identifiers. Appl. Energy 2022, 322, 119445. [Google Scholar] [CrossRef]
- Li, X.; Jing, T.; Li, R.; Li, H.; Wang, X.; Shen, D. BDRA: Blockchain and Decentralized Identifiers Assisted Secure Registration and Authentication for VANETs. IEEE Internet Things J. 2022; Early Access. [Google Scholar] [CrossRef]
- Poolat Parameswarath, R.; Gope, P.; Sikdar, B. Decentralized Identifier-based Privacy-preserving Authenticated Key Exchange Protocol for Electric Vehicle Charging in Smart Grid. arXiv 2022, arXiv:2206.13055. [Google Scholar]
- Cecchetti, E.; Zhang, F.; Ji, Y.; Kosba, A.; Juels, A.; Shi, E. Solidus: Confidential distributed ledger transactions via PVORM. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Narula, N.; Vasquez, W.; Virza, M. zkLedger: Privacy-Preserving Auditing for Distributed Ledgers. In Proceedings of the 5th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18), Boston, MA, USA, 12–14 April 2021. [Google Scholar]
- Crosby, S.A.; Wallach, D.S. Authenticated dictionaries: Real-world costs and trade-offs. ACM Trans. Inf. Syst. Secur. (TISSEC) 2011, 14, 1–30. [Google Scholar] [CrossRef]
- Dingledine, R.; Mathewson, N.; Syverson, P. Tor: The Second-Generation Onion Router; Naval Research Lab: Washington, DC, USA, 2004. [Google Scholar]
- Zcash: Parameter Generation. 2020. Available online: https://z.cash/technology/paramgen/ (accessed on 21 June 2021).
- Meier, S.; Schmidt, B.; Cremers, C.; Basin, D. The TAMARIN prover for the symbolic analysis of security protocols. In Proceedings of the International Conference on Computer Aided Verification, Saint Petersburg, Russia, 13–19 July 2013; pp. 696–701. [Google Scholar]
- DID Authentication Tamarin Model. 2021. Available online: https://github.com/bithinalangot/DIDAuthTamarin (accessed on 18 March 2022).
- Go-Snark. 2020. Available online: https://github.com/arnaucube/go-snark (accessed on 18 March 2022).
- Circom Compiler. 2019. Available online: https://github.com/iden3/circom (accessed on 18 March 2022).
- Babyjub. 2020. Available online: https://tinyurl.com/yc7kmcsj (accessed on 18 March 2022).
- MiMC7. 2020. Available online: https://tinyurl.com/y99c2khj (accessed on 18 March 2022).
- Thomas, K.; Pullman, J.; Yeo, K.; Raghunathan, A.; Kelley, P.G.; Invernizzi, L.; Benko, B.; Pietraszek, T.; Patel, S.; Boneh, D.; et al. Protecting accounts from credential stuffing with password breach alerting. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- Canetti, R. Universally composable security: A new paradigm for cryptographic protocols. In Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science, Las Vegas, NV, USA, 14–17 October 2001. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Auditability | Privacy | Performance | |
|---|---|---|---|
| Existing protocols | ✘ | ✘ | ✔ |
| Baseline | ✔ | ✘ | ✔ |
| Privacy-preserving | ✔ | ✔ | ✘ |
| # sigs in | Setup (min) | Generate Proof (s) |
|---|---|---|
| 2 | 60.53 | 14.44 |
| 3 | 73.41 | 15.35 |
| 4 | 97.81 | 16.79 |
| 5 | 109.60 | 17.88 |
| 6 | 118.86 | 18.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alangot, B.; Szalachowski, P.; Dinh, T.T.A.; Meftah, S.; Gana, J.I.; Aung, K.M.M.; Li, Z. Decentralized Identity Authentication with Auditability and Privacy. Algorithms 2023, 16, 4. https://doi.org/10.3390/a16010004
Alangot B, Szalachowski P, Dinh TTA, Meftah S, Gana JI, Aung KMM, Li Z. Decentralized Identity Authentication with Auditability and Privacy. Algorithms. 2023; 16(1):4. https://doi.org/10.3390/a16010004
Chicago/Turabian StyleAlangot, Bithin, Pawel Szalachowski, Tien Tuan Anh Dinh, Souhail Meftah, Jeff Ivanos Gana, Khin Mi Mi Aung, and Zengpeng Li. 2023. "Decentralized Identity Authentication with Auditability and Privacy" Algorithms 16, no. 1: 4. https://doi.org/10.3390/a16010004
APA StyleAlangot, B., Szalachowski, P., Dinh, T. T. A., Meftah, S., Gana, J. I., Aung, K. M. M., & Li, Z. (2023). Decentralized Identity Authentication with Auditability and Privacy. Algorithms, 16(1), 4. https://doi.org/10.3390/a16010004