
Research Trends, Enabling Technologies and Application Areas for Big Data


Abstract
1. Introduction
2. Methodology
- 1.
- Identifying the major application areas and the major enabling technologies for Big Data;
- 2.
- Using bibliometrics to quantify how the research interest for each of the identified application areas and enabling technologies for Big Data have developed during the last decade. In this step, we also quantify how the total number of research publications in Big Data from different geographical regions has developed during the last decade.
2.1. Identifying Important Application Areas and Enabling Technologies in Big Data
- 1.
- Extensive contacts with experts from the industry and research community in the Big Data domain for more than 8 years;
- 2.
- Systematically reviewing the recent literature in Big Data.
2.1.1. Extensive Contacts with Experts from the Industry and Research Community
2.1.2. Systematically Reviewing the Recent Literature on Big Data
2.2. Bibliometric Study
3. Application Areas for Big Data
4. Enabling Technologies for Big Data
5. Trends in Big Data Research
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marr, B. How Much Data Do We Create Every Day? The Mind-Blowing Stats Everyone Should Read. 2018. Available online: https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/?sh=661e274e60ba (accessed on 5 August 2022).
- Roh, Y.; Heo, G.; Whang, S. A Survey on Data Collection for Machine Learning: A Big Data—AI Integration Perspective. IEEE Trans. Knowl. Data Eng. 2021, 33, 1328–1347. [Google Scholar] [CrossRef]
- Lundberg, L.; Grahn, H.; Cardellini, V.; Polze, A.; Shirinbab, S. Editorial to the Special Issue on Big Data in Industrial and Commercial Applications. Big Data Res. 2021, 26, 100244. [Google Scholar] [CrossRef]
- Vassakis, K.; Petrakis, E.; Kopanakis, I. Big Data Analytics: Applications, Prospects and Challenges. In Mobile Big Data: A Roadmap from Models to Technologies; Skourletopoulos, G., Mastorakis, G., Mavromoustakis, C.X., Dobre, C., Pallis, E., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–20. [Google Scholar] [CrossRef]
- Desai, P.V. A survey on big data applications and challenges. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 737–740. [Google Scholar] [CrossRef]
- Wang, Z.; Wei, G.; Zhan, Y.; Sun, Y. Big Data in Telecommunication Operators: Data, Platform and Practices. J. Commun. Inf. Netw. 2017, 2, 78–91. [Google Scholar] [CrossRef][Green Version]
- Zahid, H.; Mahmood, T.; Morshed, A.; Sellis, T. Big data analytics in telecommunications: Literature review and architecture recommendations. IEEE/CAA J. Autom. Sin. 2020, 7, 18–38. [Google Scholar] [CrossRef]
- Xia, X.; Zeng, L.; Yu, R. HMM of telecommunication big data for consumer churn prediction. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/ IOP/SCI), Guangzhou, China, 8–12 October 2018; pp. 1903–1910. [Google Scholar] [CrossRef]
- Sidorova, J.; Sköld, L.; Rosander, O.; Lundberg, L. Optimizing utilization in cellular radio networks using mobility data. Optim. Eng. 2019, 20, 37–64. [Google Scholar] [CrossRef]
- Sidorova, J.; Rosander, O.; Skold, L.; Grahn, H.; Lundberg, L. Finding a Healthy Equilibrium of Geo-demographic Segments for a Telecom Business: Who Are Malicious Hot-Spotters? In Machine Learning Paradigms: Advances in Data Analytics, Intelligent Systems Reference Library, Volume 149; Tsihrintzis, G.A., Sotiropoulos, D.N., Jain, L.C., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 187–196. [Google Scholar] [CrossRef]
- Niyizamwiyitira, C.; Lundberg, L. Performance evaluation of SQL and NoSQL database management systems in a cluster. Int. J. Database Manag. Syst. 2017, 9, 124. [Google Scholar] [CrossRef]
- Shirinbab, S.; Lundberg, L.; Erman, D. Performance evaluation of distributed storage systems for cloud computing. Int. J. Comput. Their Appl. 2013, 20, 195–207. [Google Scholar]
- Shirinbab, S.; Lundberg, L.; Casalicchio, E. Performance evaluation of containers and virtual machines running Cassandra workload concurrently. Concurr. Comput. Pract. Exp. 2020, 32, e5693. [Google Scholar] [CrossRef]
- Souza, R.P.; dos Santos, L.J.; Coimbra, G.T.; Silva, F.A.; Silva, T.R. A big data-driven hybrid solution to the indoor-outdoor detection problem. Big Data Res. 2021, 24, 100194. [Google Scholar] [CrossRef]
- Dubey, R.; Gunasekaran, A.; Childe, S.; Blome, C.; Papadopoulos, T. Big data and predictive analytics and manufacturing performance: Integrating institutional theory, resource-based view and big data culture. Brit. J. Manag. 2019, 3, 341–361. [Google Scholar] [CrossRef]
- Cui, Y.; Kara, S.; Chan, K.C. Manufacturing big data ecosystem: A systematic literature review. Robot. Comput.-Integr. Manuf. 2020, 62, 101861. [Google Scholar] [CrossRef]
- O’Donovan, P.; Leahy, K.; Bruton, K.; O’Sullivan, D. Big data in manufacturing: A systematic mapping study. J. Big Data 2015, 2, 20. [Google Scholar] [CrossRef]
- Leal, F.; Chis, A.; Caton, S.; González-Vélez, H.; García-Gómez, J.; Durá, M.; Sánchez-García, A.; Sáez, C.; Karageorgos, A.; Gerogiannis, V.; et al. Smart pharmaceutical manufacturing: Ensuring end-to-end traceability and data integrity in medicine production. Big Data Res. 2021, 24, 100172. [Google Scholar] [CrossRef]
- Gupta, A.K.; Goyal, H. Framework for implementing big data analytics in Indian manufacturing: ISM-MICMAC and Fuzzy-AHP approach. Inf. Technol. Manag. 2021, 22, 207–229. [Google Scholar] [CrossRef]
- Hashem, I.; Chang, V.; Anour, N.; Adewole, K.; Yaqoob, I.; Gani, A.; Ahmed, E.; Chiroma, H. The role of big data in smart city. Int. J. Inf. Manag. 2016, 36, 748–758. [Google Scholar] [CrossRef]
- Jara, A.; Genoud, D.; Bocchi, Y. Big data for smart cities with KNIME: A real experience in the SmartSantander testbed. Softw. Pract. Exp. 2015, 45, 1145–1160. [Google Scholar] [CrossRef]
- Popescu, G.; Lazaroiu, G.; Kovacova, M.; Valaskova, K.; Majerova, J. Urban sustainability analytics: Harnessing Big Data for smart city planning and design. Theor. Empir. Res. Urban Manag. 2020, 15, 39–48. [Google Scholar]
- Badidi, E.; Mahrez, Z.; Sabir, E. Fog computing for smart cities’ big data management and analytics: A review. Future Internet 2020, 12, 190. [Google Scholar] [CrossRef]
- Fugini, M.; Finocchi, J.; Locatelli, P. A big data analytics architecture for smart cities and smart companies. Big Data Res. 2021, 24, 100192. [Google Scholar] [CrossRef]
- Koulali, R.; Zaidani, H.; Zaim, M. Image classification approach using machine learning and an industrial Hadoop based data pipeline. Big Data Res. 2021, 24, 100184. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kavukcuoglu, K.; Sermanet, P.; Boureau, Y.; Gregor, K.; Mathieu, M.; LeCun, Y. Learning convolutional feature hierarchies for visual recognition. In Proceedings of the 23rd International Confenerce on Neural Information Processing Systems (NIPS’10), Vancouver, BC, Canada, 6–9 December 2010; pp. 1090–1098. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2nd International Conference on Learning Representations 2014 (ICLR’14), Banff, AB, Canada, 14–16 April 2014. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1 (NIPS’12), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR’15), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Hussain, R.; Raza, A.; Siddiqi, I.; Khurshid, K.; Djeddi, C. A comprehensive survey of handwritten document benchmarks: Structure, usage and evaluation. EURASIP J. Image Video Process. 2015, 2015, 46. [Google Scholar] [CrossRef]
- Westphal, F.; Grahn, H.; Lavesson, N. Efficient document image binarization using heterogeneous computing and parameter tuning. Int. J. Doc. Anal. Recognit. 2018, 21, 41–58. [Google Scholar] [CrossRef]
- Fernández-Mota, D.; Almazán, J.; Cirera, N.; Fornés, A.; Lladós, J. BH2M: The Barcelona historical, handwritten marriages database. In Proceedings of the 22nd International Conference on Pattern Recognition (ICPR’14), Stockholm, Sweden, 24–28 August 2014; pp. 256–261. [Google Scholar] [CrossRef]
- Kusetogullari, H.; Yavariabdi, A.; Cheddad, A.; Grahn, H.; Hall, J. Efficient document image binarization using heterogeneous computing and parameter tuning. Neural Comput. Appl. 2020, 32, 16505–16518. [Google Scholar] [CrossRef]
- Westphal, F.; Lavesson, N.; Grahn, H. Learning character recognition with graph-based privileged information. In Proceedings of the 15th International Conference on Document Analysis and Recognition (ICDAR’19), Sydney, NSW, Australia, 20–25 September 2019; pp. 1163–1168. [Google Scholar] [CrossRef]
- Kusetogullari, H.; Grahn, H.; Lavesson, N. Handwriting image enhancement using local learning windowing, Gaussian mixture model and k-means clustering. In Proceedings of the 16th IEEE International Symposium on Signal Processing and Information Technology (ISSPIT 2016), Limassol, Cyprus, 12–14 December 2016; pp. 305–310. [Google Scholar] [CrossRef]
- Kusetogullari, H.; Yavariabdi, A.; Hall, J.; Lavesson, N. Diginet: A deep handwritten digit detection and recognition method using a new historical handwritten digit dataset. Big Data Res. 2021, 23, 100182. [Google Scholar] [CrossRef]
- Liang, X.; Cheddad, A.; Hall, J. Comparative study of layout analysis of tabulated historical documents. Big Data Res. 2021, 24, 100195. [Google Scholar] [CrossRef]
- Ghani, N.A.; Hamid, S.; Targio Hashem, I.A.; Ahmed, E. Social media big data analytics: A survey. Comput. Hum. Behav. 2019, 101, 417–428. [Google Scholar] [CrossRef]
- Jiang, M.; Fu, K. Chinese social media and big data: Big data, big brother, big profit? Policy Internet 2018, 10, 372–392. [Google Scholar] [CrossRef]
- Yang, M.; Kiang, M.; Shang, W. Filtering big data from social media – Building an early warning system for adverse drug reactions. J. Biomed. Inform. 2015, 54, 230–240. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.J.; Marsch, L.A.; Hancock, J.T.; Das, A.K. Scaling up research on drug abuse and addiction through social media big data. J. Med. Internet Res. 2017, 19, e353. [Google Scholar] [CrossRef] [PubMed]
- Arrigo, E.; Liberati, C.; Mariani, P. Social media data and users’ preferences: A statistical analysis to support marketing communication. Big Data Res. 2021, 24, 100189. [Google Scholar] [CrossRef]
- Rossit, D.; Olivera, A.; Cespedes, V.; Broz, D. A Big Data approach to forestry harvesting productivity. Comput. Electron. Agric. 2019, 161, 29–52. [Google Scholar] [CrossRef]
- Zou, W.; Jing, W.; Chen, G.; Lu, Y.; Song, H. A Survey of Big Data Analytics for Smart Forestry. IEEE Access 2019, 7, 46621–46636. [Google Scholar] [CrossRef]
- Osinga, S.; Paudel, D.; Mouzakitis, S.; Athanasiadis, I. Big data in agriculture: Between opportunity and solution. Agric. Syst. 2022, 195, 103298. [Google Scholar] [CrossRef]
- Morota, G.; Ventura, R.; Silva, F.; Koyama, M.; Fernando, S. Big Data analytics and Precision animal agriculture symposium: Machine learning and data mining advance predictive big data analysis in precision animal agriculture. J. Anim. Sci. 2018, 96, 1540–1550. [Google Scholar] [CrossRef] [PubMed]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldu, F. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Hasan, M.; Popp, J.; Olah, J. Current landscape and influence of big data on finance. J. Big Data 2020, 7, 21. [Google Scholar] [CrossRef]
- Nobanee, H. A Bibliometric Review of Big Data in Finance. Big Data 2021, 9, 73–78. [Google Scholar] [CrossRef] [PubMed]
- Goldstein, I.; Spatt, C.; Ye, M. Big Data in Finance. Rev. Financ. Stud. 2021, 34, 3213–3225. [Google Scholar] [CrossRef]
- Cockcroft, S.; Russell, M. Big Data Opportunities for Accounting and Finance Practice and Research. Aust. Account. Rev. 2018, 28, 323–333. [Google Scholar] [CrossRef]
- Alani, M.; Tawfik, H.; Saeed, M.; Anya, O. Applications of Big Data Analytics: Trends, Issues, and Challenges; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-3-319-76471-9. [Google Scholar]
- Grandinetti, L.; Mirtaheri, S.; Shahbazian, R. (Eds.) Communications in Computer and Information Science-High-Performance Computing and Big Data Analysis; Springer: Berlin/Heidelberg, Germany, 2019; Volume 891. [Google Scholar]
- Mirtaheri, S.; Grandinetti, L. Optimized load balancing in high-performance computing for big data analytics. Concurr. Comput. Pract. Exp. 2021, 33, e6265. [Google Scholar] [CrossRef]
- Kumar, D.; Kumar Jha, V. An efficient query optimization technique in big data using σ-ANFIS load balancer and CaM-BW optimizer. J. Supercomput. 2021, 77, 13018–13045. [Google Scholar] [CrossRef]
- Chen, C.; Li, K.; Ouyang, A.; Li, K. FlinkCL: An OpenCL-Based In-Memory Computing Architecture on Heterogeneous CPU-GPU Clusters for Big Data. IEEE Trans. Comput. 2018, 67, 1765–1779. [Google Scholar] [CrossRef]
- Jurczuk, K.; Czajkowski, M.; Kretowski, M. Multi-GPU approach to global induction of classification trees for large-scale data mining. Appl. Intell. 2021, 51, 5683–5700. [Google Scholar] [CrossRef]
- Ahmad, A.; Paul, A.; Din, S.; Rathore, M.; Choi, G.; Jeon, G. Multilevel Data Processing Using Parallel Algorithms for Analyzing Big Data in High-Performance Computing. Int. J. Parallel Program. 2018, 46, 508–527. [Google Scholar] [CrossRef]
- Dolev, S.; Florissi, P.; Gudes, E.; Sharma, S.; Singer, I. A Survey on Geographically Distributed Big-Data Processing Using MapReduce. IEEE Trans. Big Data 2019, 5, 60–80. [Google Scholar] [CrossRef]
- Wang, Y.; Hao, H.; Zhang, J.; Jiang, J.; He, J.; Ma, Y. Performance optimization and evaluation for parallel processing of big data in earth systems models. Clust. Comput. 2019, 22, 2371–2381. [Google Scholar] [CrossRef]
- Chen, D.; Hu, Y.; Cai, C.; Zeng, K.; Li, X. Brain big data processing with massively parallel computing technology: Challenges and opportunities. Softw. Pract. Exp. 2017, 47, 405–420. [Google Scholar] [CrossRef]
- Zhang, Y.; Cao, T.; Li, S.; Tian, X.; Yuan, L.; Jia, H.; Vasilakos, A. Parallel Processing Systems for Big Data: A Survey. Proc. IEEE 2016, 104, 2114–2136. [Google Scholar] [CrossRef]
- Xu, G.; Tan, Z.; Feng, D.; Yang, L.; Zhou, W.; Zhang, X.; Zhang, Y.; Xu, J. FvRS: Efficiently identifying performance-critical data for improving performance of big data processing. Future Gener. Comput. Syst. 2019, 91, 157–166. [Google Scholar] [CrossRef]
- Lee, C.G.; Cho, J.Y.; Kim, J.; Jin, H.W. Transparent many-core partitioning for high-performance big data I/O. Concurr. Comput. Pract. Exp. 2020, 33, e6017. [Google Scholar] [CrossRef]
- Lu, J.; Chen, Y.; Herodotou, H.; Babu, S. Speedup Your Analytics: Automatic Parameter Tuning for Databases and Big Data Systems. Proc. Vldb Endow. 2019, 12, 1970–1973. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Y.; Zhang, R.; Qian, W.; Zhou, A. Benchmarking for Transaction Processing Database Systems in Big Data Era. In Lecture Notes in Computer Science, Proceedings of the Benchmarking, Measuring, and Optimizing: First BenchCouncil International Symposium, Seattle, WA, USA, 10–13 December 2018; Revised Selected Papers; Springer: Cham, Switzerland, 2018; pp. 147–158. [Google Scholar] [CrossRef]
- Bauer, D.; Froese, F.; Garcés-Erice, L.; Giblin, C.; Labbi, A.; Nagy, Z.; Pardon, N.; Rooney, S.; Urbanetz, P.; Vetsch, P.; et al. Building and operating a large-scale enterprise data analytics platform. Big Data Res. 2021, 23, 100181. [Google Scholar] [CrossRef]
- Naiouf, M.; Rucci, E.; Chichizola, F.; De Giusti, L. (Eds.) Communications in Computer and Information Science-Cloud Computing, Big Data & Emerging Topics; Springer: Berlin/Heidelberg, Germany, 2021; Volume 1444. [Google Scholar]
- Cai, Z.; Angryk, R.; Song, W.Z.; Li, Y.; Cao, X.; Bourgeois, A.; Luo, G.; Cheng, L.; Krishnamachari, B. (Eds.) IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom), BDCloud-SocialCom-SustainCom; IEEE Computer Society: Washington, DC, USA, 2016; ISBN 978-1-5090-3936-4. [Google Scholar]
- Aceto, G.; Persico, V.; Pescape, A. Industry 4.0 and Health: Internet of Things, Big Data, and Cloud Computing for Healthcare 4.0. J. Ind. Inf. Integr. 2020, 18, 100129. [Google Scholar] [CrossRef]
- Hashem, I.; Yaqoob, I.; Anuar, N.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Zbakh, M.; Bakhouya, M.; Essaaidi, M.; Manneback, P. Cloud computing and big data: Technologies and applications. Concurr. Comput. Pract. Exp. 2018, 30, e4517. [Google Scholar] [CrossRef]
- Sing, S.; Nayyar, A.; Kumar, R.; Sharma, A. Fog computing: From architecture to edge computing and big data processing. J. Supercomput. 2018, 75, 2070–2105. [Google Scholar] [CrossRef]
- Sanchez-Gallegos, D.; Carrizales-Espinoza, D.; Reyes-Anastacio, H.; Gonzalez-Compean, J.; Carretero, J.; Morales-Sandoval, M.; Galaviz-Mosqueda, A. From the edge to the cloud: A continuous delivery and preparation model for processing big IoT data. Simul. Model. Pract. Theory 2020, 105, 102136. [Google Scholar] [CrossRef]
- Barik, R.; Dubey, H.; Mankodiya, K. SOA-FOG: Secure Service-Oriented Edge Computing Architecture for Smart Health Big Data Analytics. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Montreal, QC, Canada, 4–16 November 2017; pp. 477–481. [Google Scholar] [CrossRef]
- Du, M.; Wang, K.; Xia, Z.; Zhang, Y. Differential Privacy Preserving of Training Model in Wireless Big Data with Edge Computing. IEEE Trans. Big Data 2020, 6, 283–295. [Google Scholar] [CrossRef]
- Lai, C.F.; Chien, W.C.; Yang, L.; Qiang, W. LSTM and Edge Computing for Big Data Feature Recognition of Industrial Electrical Equipment. IEEE Trans. Ind. Inform. 2019, 15, 2469–2477. [Google Scholar] [CrossRef]
- Hassanien, A.; Darwish, A. (Eds.) Machine Learning and Big Data Analytics Paradigms: Analysis, Applications and Challenges; Studies in Big Data; Springer: Berlin/Heidelberg, Germany, 2021; Volume 77, ISBN 978-3-030-59337-7. [Google Scholar]
- Hossain, M.; Muhammad, G. Emotion recognition using deep learning approach from audio-visual emotional big data. Inf. Fusion 2019, 49, 69–78. [Google Scholar] [CrossRef]
- Sohangir, S.; Wang, D.; Pomeranets, A.; Khoshgoftaar, T. Big Data: Deep Learning for financial sentiment analysis. J. Big Data 2018, 5, 3. [Google Scholar] [CrossRef]
- Dekhtiar, J.; Durupt, A.; Bricogne, M.; Eynard, B.; Rowson, H.; Kiritsis, D. Deep learning for big data applications in CAD and PLM-Research review, opportunities and case study. Comput. Ind. 2018, 100, 227–243. [Google Scholar] [CrossRef]
- Dargazany, A.; Stegagno, P.; Mankodiya, K. WearableDL: Wearable Internet-of-Things and Deep Learning for Big Data Analytics—Concept, Literature, and Future. Mob. Inf. Syst. 2018, 2018, 8125126. [Google Scholar] [CrossRef]
- Khan, M.; Jan, B.; Farman, H. Deep Learning: Convergence to Big Data Analytics; SpringerBriefs in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; ISBN 978-981-13-3458-0. [Google Scholar]
- Sakr, S. Big Data 2.0 Processing Systems—A Survey; Springer Briefs in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; ISBN 978-3-030-44186-9. [Google Scholar] [CrossRef]
- Misale, C.; Drocco, M.; Tremblay, G.; Martinelli, A.; Aldinucci, M. PiCo: High-performance data analytics in modern C++. Future Gener. Comput. Syst. 2018, 87, 392–403. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
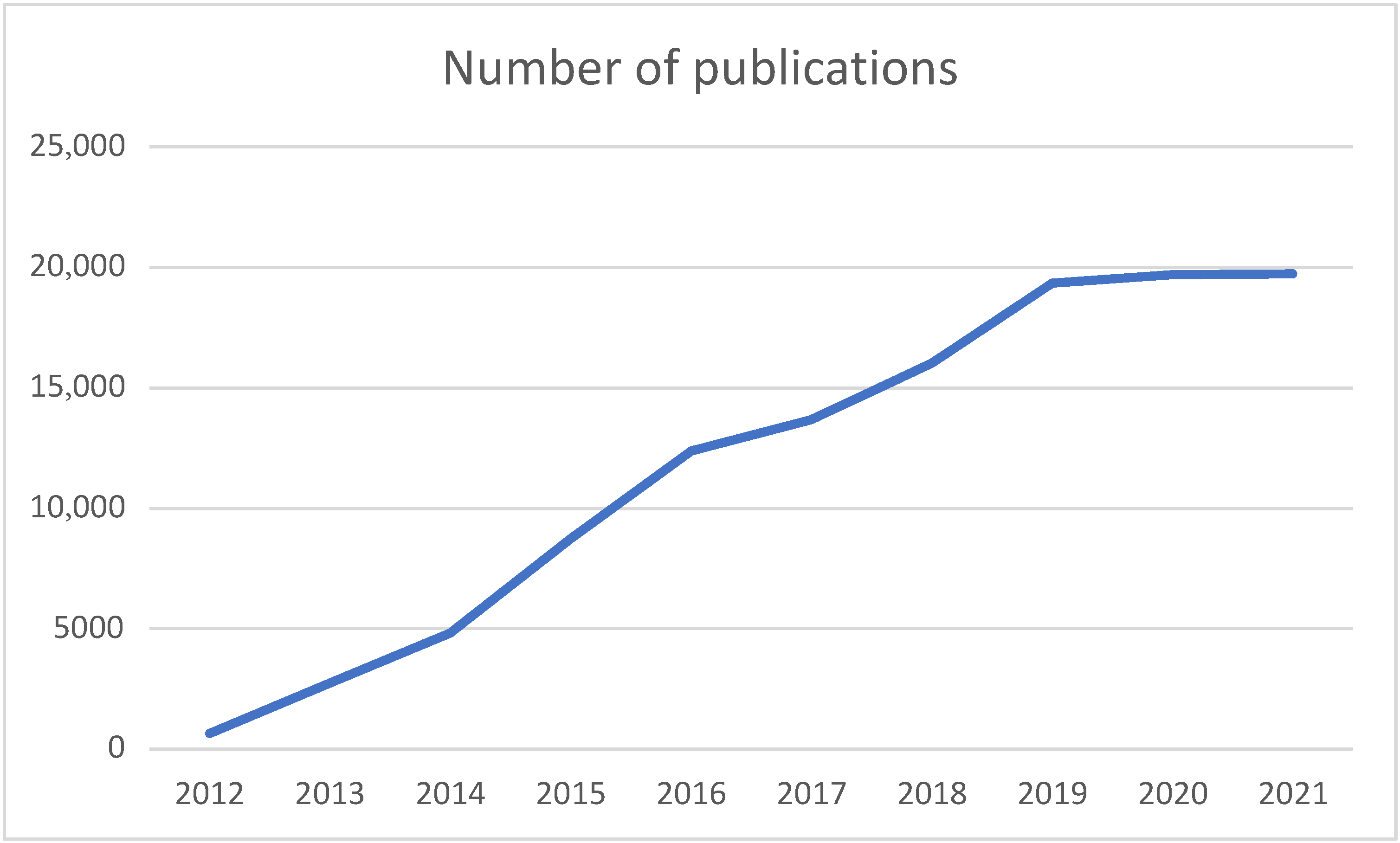
| Year | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|
| No. of Publications | 663 | 2766 | 4817 | 8751 | 12,389 | 13,679 | 16,020 | 19,366 | 19,693 | 19,758 |
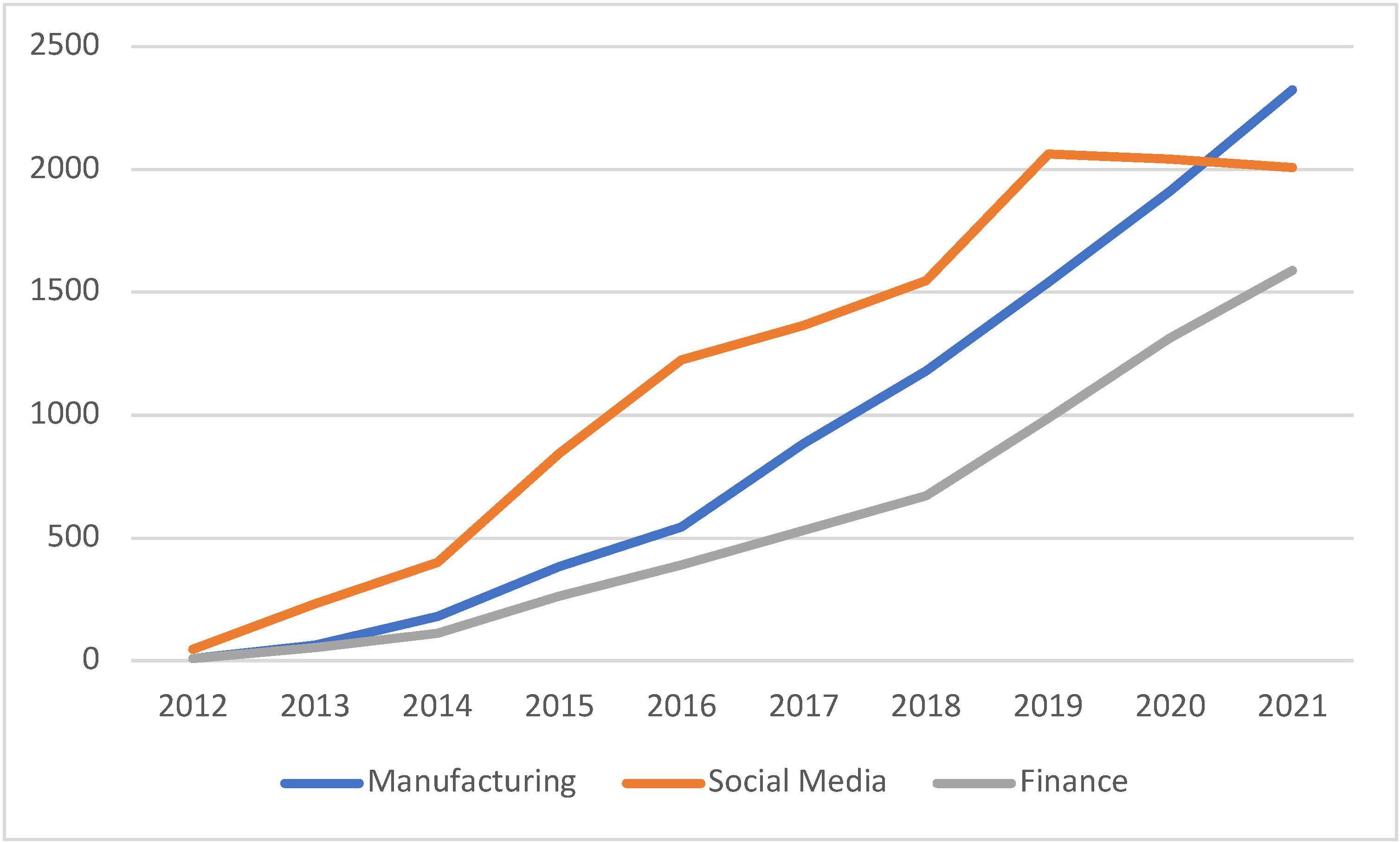
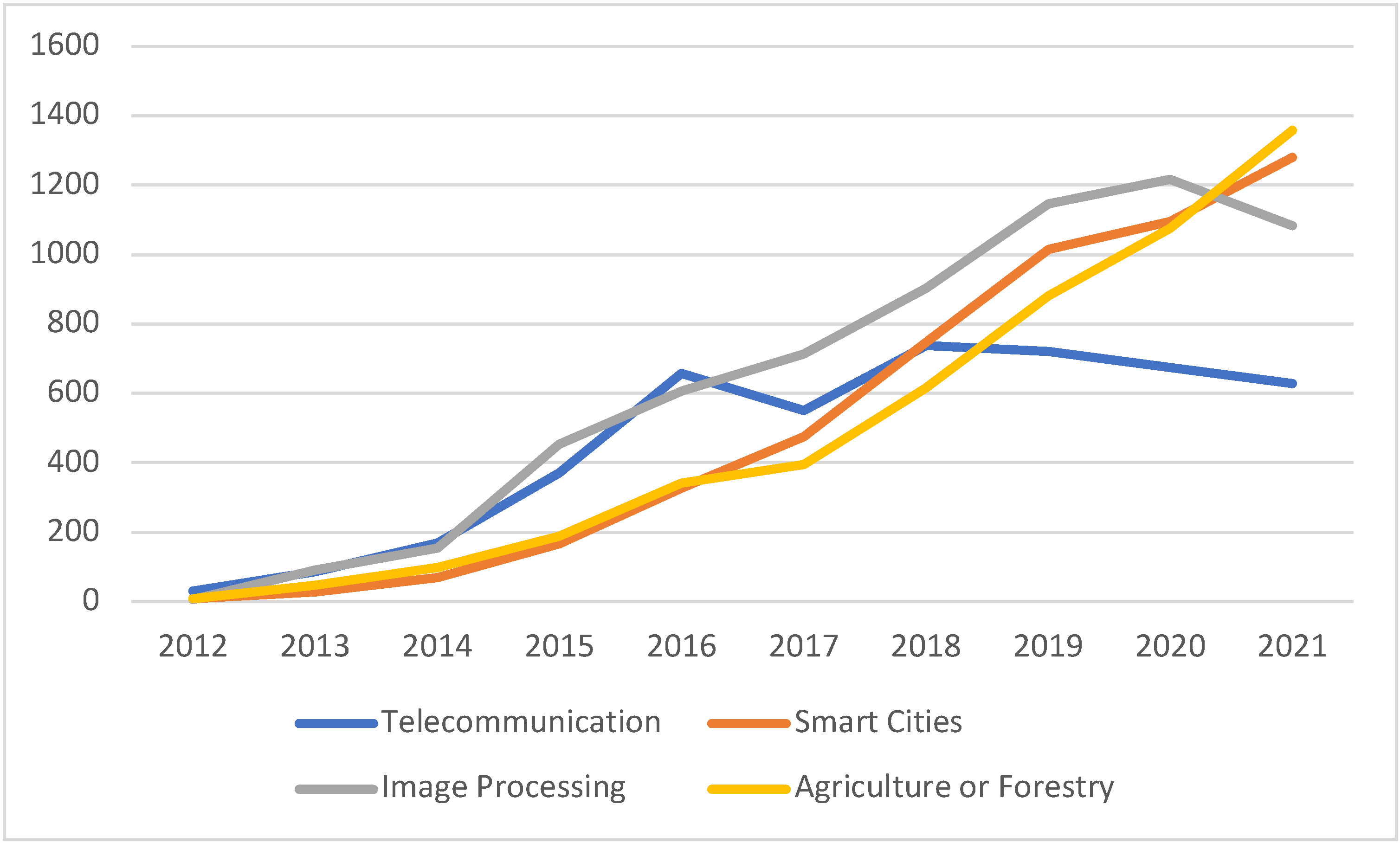
| Application Area∖Year | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|
| Telecommunication | 29 | 85 | 169 | 370 | 658 | 550 | 737 | 720 | 675 | 628 |
| Manufacturing | 11 | 63 | 180 | 384 | 546 | 886 | 1180 | 1540 | 1912 | 2323 |
| Smart Cities | 8 | 28 | 69 | 166 | 327 | 476 | 747 | 1014 | 1096 | 1281 |
| Image Processing | 6 | 92 | 154 | 452 | 606 | 714 | 903 | 1147 | 1218 | 1083 |
| Social Media | 46 | 232 | 402 | 844 | 1223 | 1367 | 1548 | 2063 | 2040 | 2008 |
| Agriculture or Forestry | 7 | 47 | 97 | 188 | 341 | 396 | 615 | 882 | 1076 | 1359 |
| Finance | 10 | 54 | 111 | 265 | 390 | 531 | 672 | 987 | 1313 | 1588 |
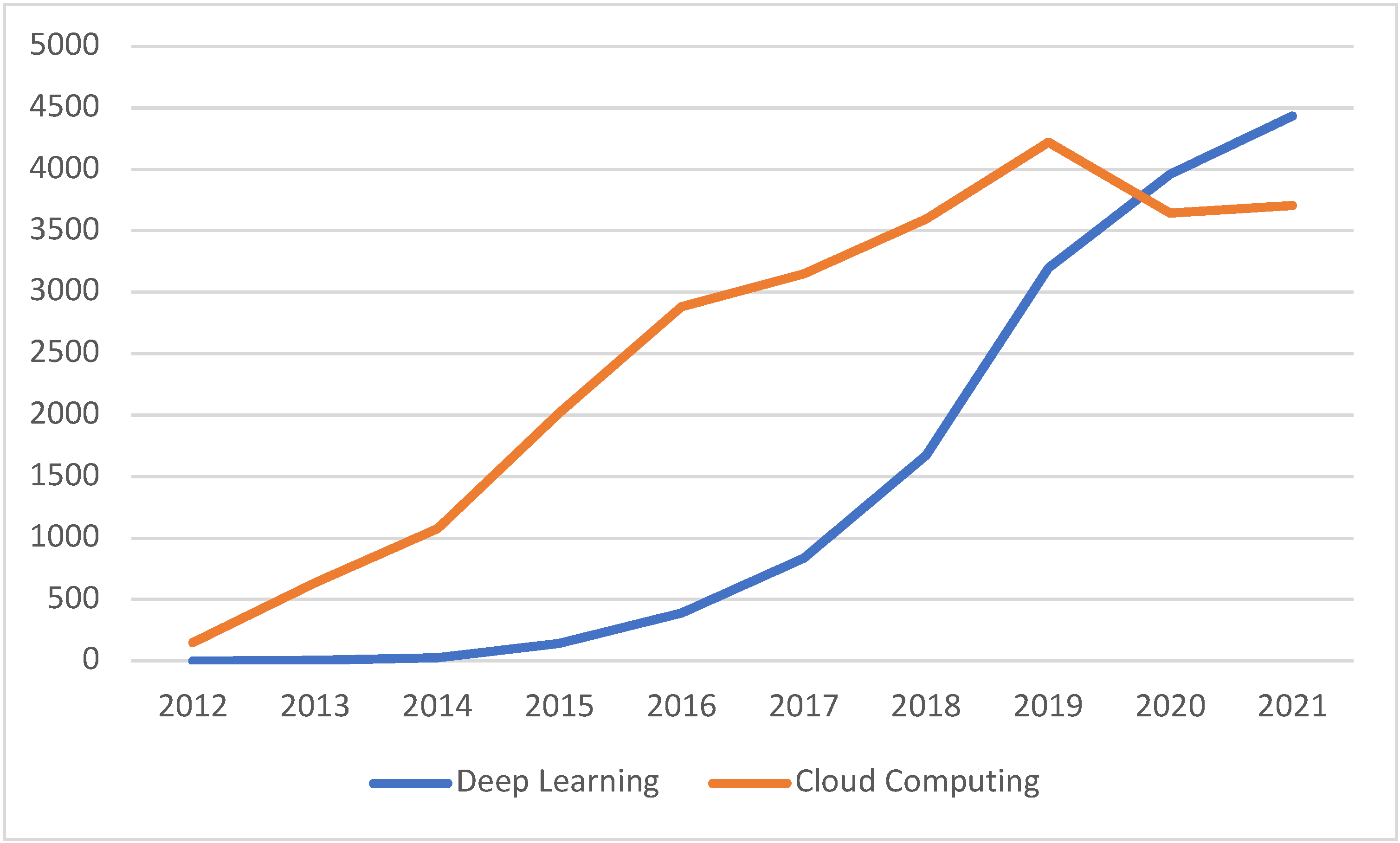
| Enabling Tech.∖Year | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|
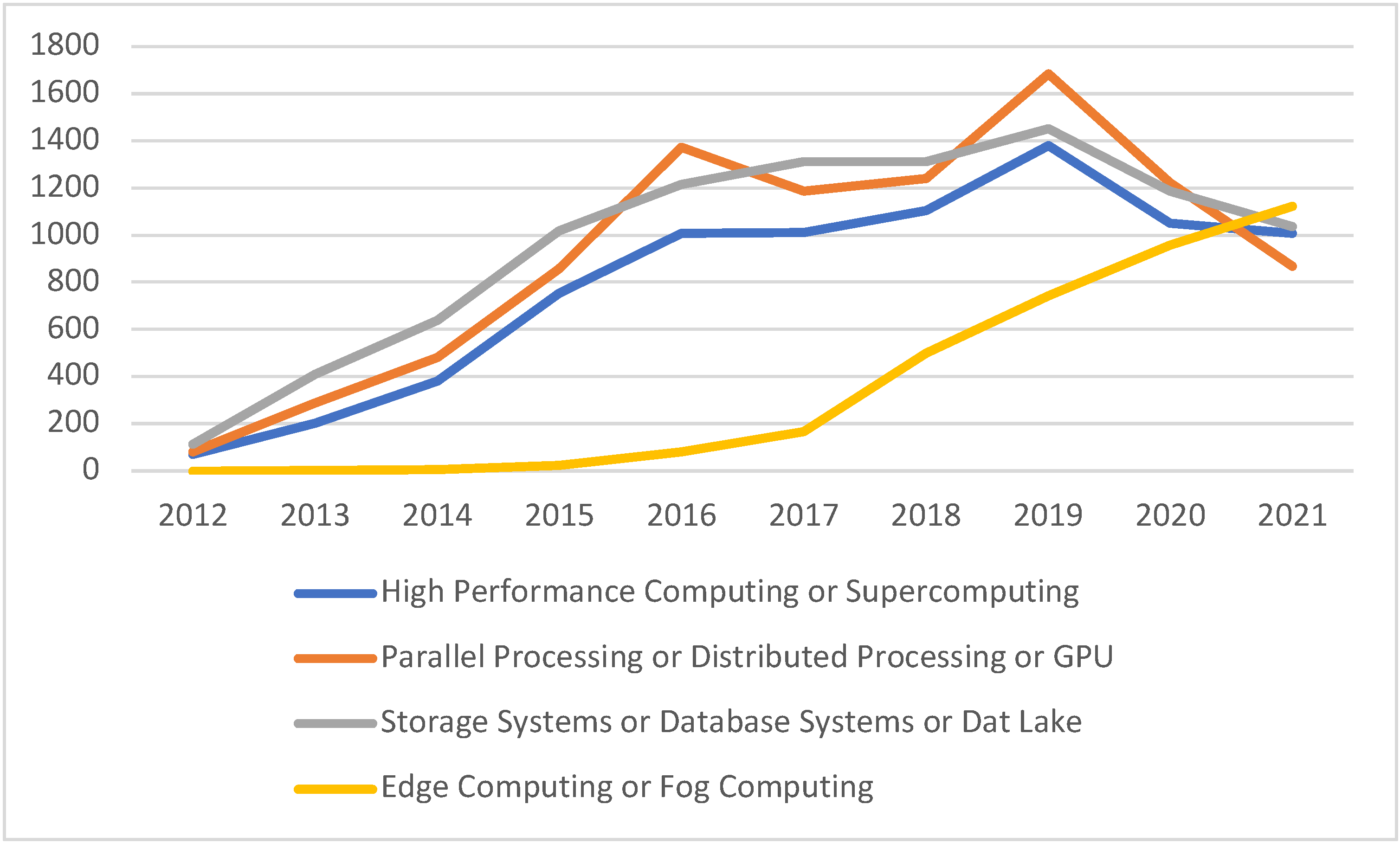
| High-Performance Computing or Supercomputing | 69 | 203 | 382 | 753 | 1009 | 1012 | 1105 | 1378 | 1051 | 1008 |
| Deep Learning | 0 | 7 | 29 | 143 | 388 | 835 | 1674 | 3195 | 3958 | 4434 |
| Cloud Computing | 147 | 635 | 1078 | 2020 | 2880 | 3149 | 3594 | 4223 | 3644 | 3704 |
| Parallel Processing, Distributed Processing or GPU | 81 | 289 | 480 | 858 | 1373 | 1187 | 1239 | 1685 | 1221 | 867 |
| Storage Systems or Database Systems or Data Lakes | 115 | 411 | 639 | 1017 | 1214 | 1312 | 1313 | 1452 | 1187 | 1035 |
| Edge Computing or Fog Computing | 0 | 3 | 5 | 25 | 81 | 167 | 501 | 744 | 957 | 1123 |
| Countries∖Year | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|
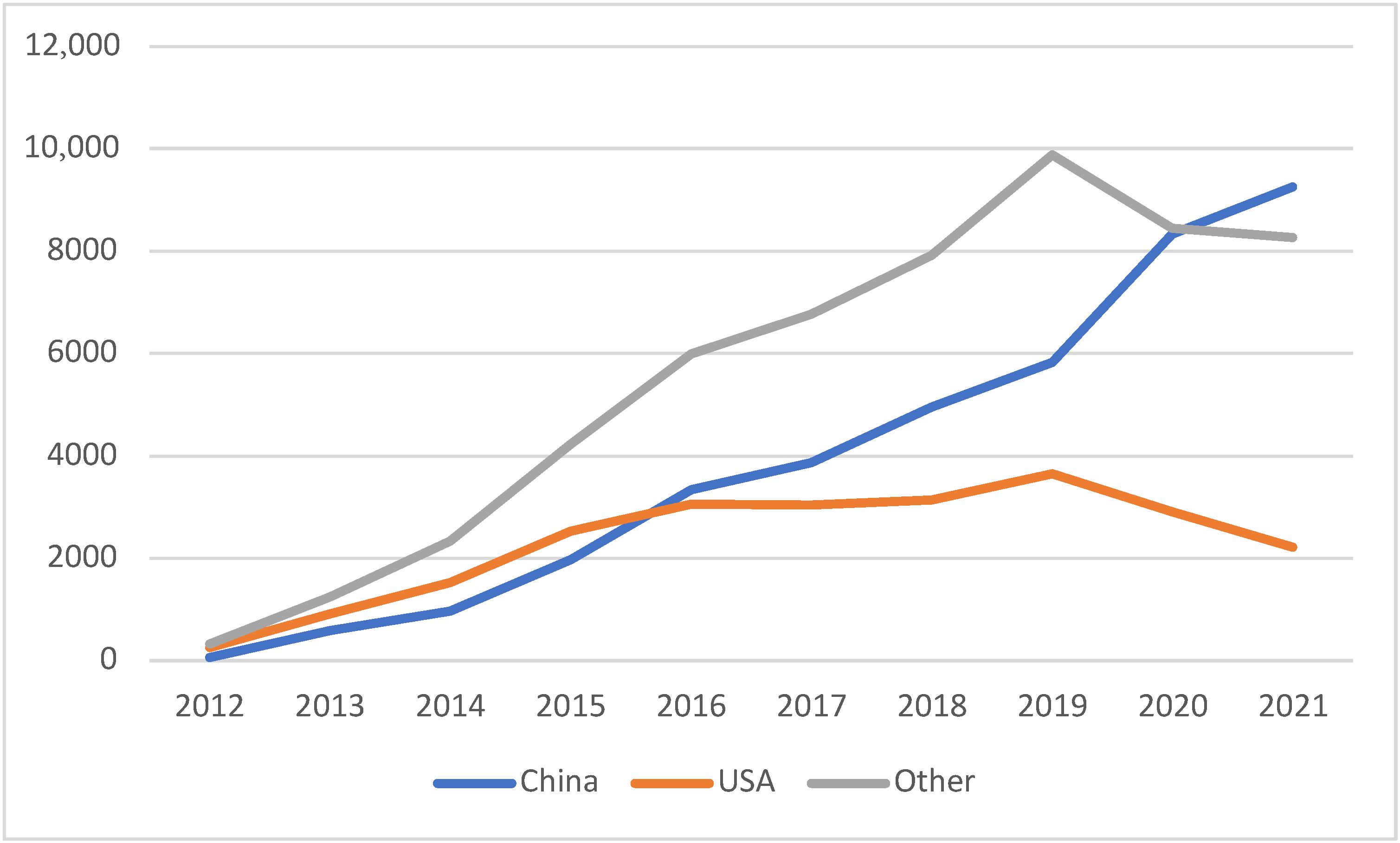
| China | 69 | 588 | 962 | 1970 | 3340 | 3862 | 4960 | 5831 | 8330 | 9263 |
| USA | 268 | 921 | 1523 | 2542 | 3063 | 3052 | 3139 | 3656 | 2917 | 2227 |
| Other | 326 | 1257 | 2332 | 4239 | 5986 | 6765 | 7921 | 9879 | 8446 | 8268 |
| Concept∖Year | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|
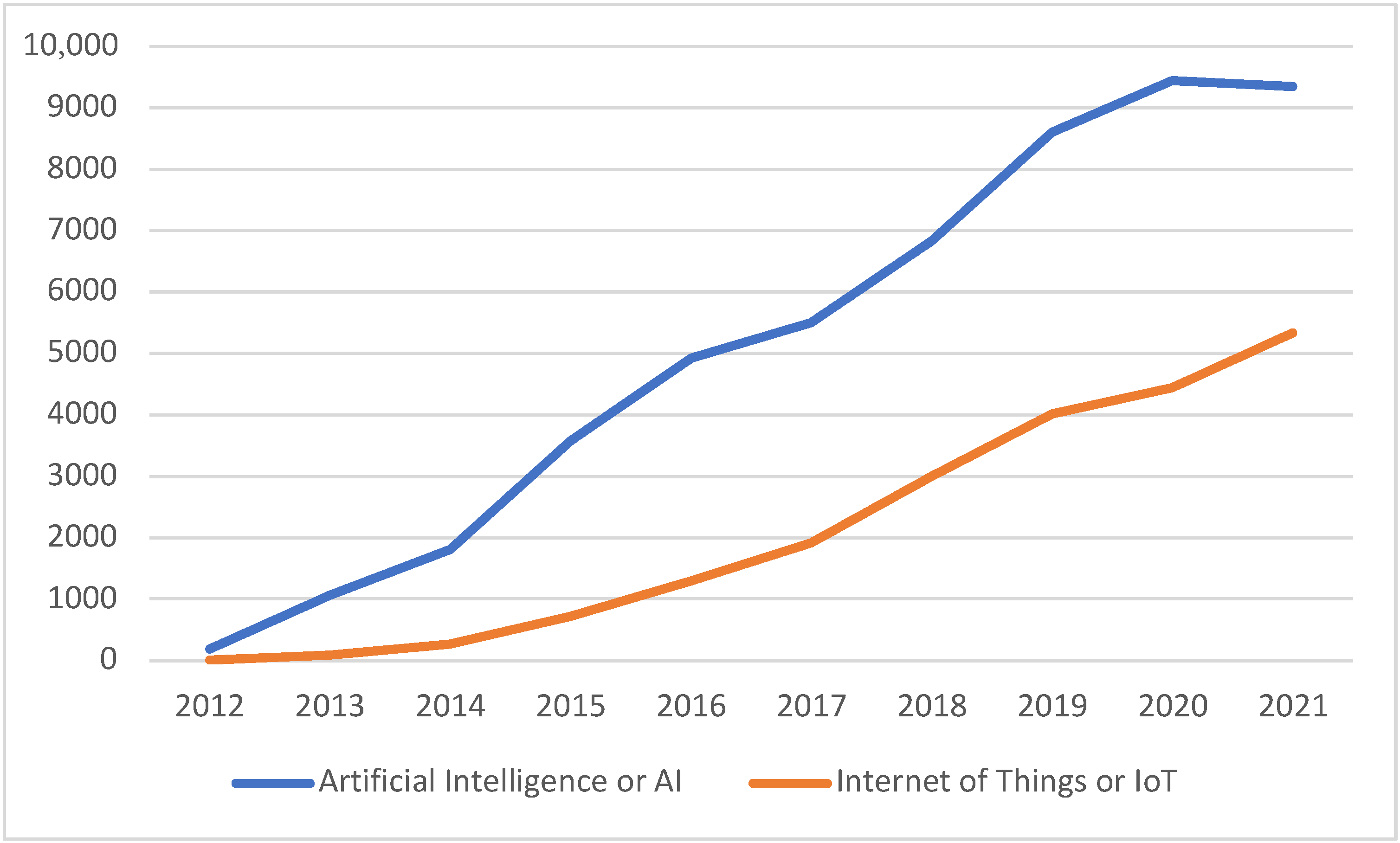
| Artificial Intelligence or AI | 192 | 1068 | 1804 | 3580 | 4930 | 5497 | 6830 | 8605 | 9436 | 9353 |
| Internet of Things or IoT | 13 | 91 | 270 | 727 | 1307 | 1924 | 2999 | 4026 | 4442 | 5341 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lundberg, L.; Grahn, H. Research Trends, Enabling Technologies and Application Areas for Big Data. Algorithms 2022, 15, 280. https://doi.org/10.3390/a15080280
Lundberg L, Grahn H. Research Trends, Enabling Technologies and Application Areas for Big Data. Algorithms. 2022; 15(8):280. https://doi.org/10.3390/a15080280
Chicago/Turabian StyleLundberg, Lars, and Håkan Grahn. 2022. "Research Trends, Enabling Technologies and Application Areas for Big Data" Algorithms 15, no. 8: 280. https://doi.org/10.3390/a15080280
APA StyleLundberg, L., & Grahn, H. (2022). Research Trends, Enabling Technologies and Application Areas for Big Data. Algorithms, 15(8), 280. https://doi.org/10.3390/a15080280