


Analyzing Meta-Heuristic Algorithms for Task Scheduling in a Fog-Based IoT Application


Abstract
1. Introduction
- Edge computing enables data processing at the network edge. It provides fast responses to computational service requests. Additionally, it does not associate IaaS, PaaS, SaaS, and other cloud-based services spontaneously and concentrates more on the end-device side.
- MEC is an evolution of cellular base stations. It can be connected or not connected to distant cloud data centers. MEC uses radio network information in distributed applications [3].
- Cloud computing is used to manage and control the massive amount of data produced by objects. Many applications, such as health monitoring, intelligent traffic control, and games, may need to get feedback in a short amount of time, and the latency caused by sending data to the cloud and then returning the response from the cloud to the operator of these programs has adverse effects. Further, the massive amount of data generated by some of these applications may impose heavy burdens on the network. Sending this volume of data to the cloud and then returning it is not desirable [4]. Cloud data centers are centralized, so it is difficult to service distributed applications. Using cloud computing for these applications increases latency and network congestion and decreases quality of service (QoS) [3].
- MCC provides necessary computational resources to support remote execution of offloaded mobile applications in closer proximity to end-users based on a three-tier hierarchical architecture. MCC combines cloud computing and mobile computing [3].
- Fog computing is a type of distributed computing and is located between objects and the cloud. FC extends clouds to the edge of the network and presents a solution to overcome its limitations. FC can also provide MEC, MCC, and edge computing [5].
2. Related Work
2.1. Traditional Algorithms
2.2. Heuristic Algorithms
2.3. Meta-Heuristic Algorithms
2.3.1. GA-Based Meta-Heuristic Algorithms
2.3.2. ACO-Based Meta-Heuristic Algorithms
2.3.3. PSO-Based Meta-Heuristic Algorithms
2.3.4. Other Evolutionary Meta-Heuristic Algorithms
2.4. Hybrid Heuristic Algorithms
2.5. Hyper Heuristic Algorithms
3. The Proposed Approach
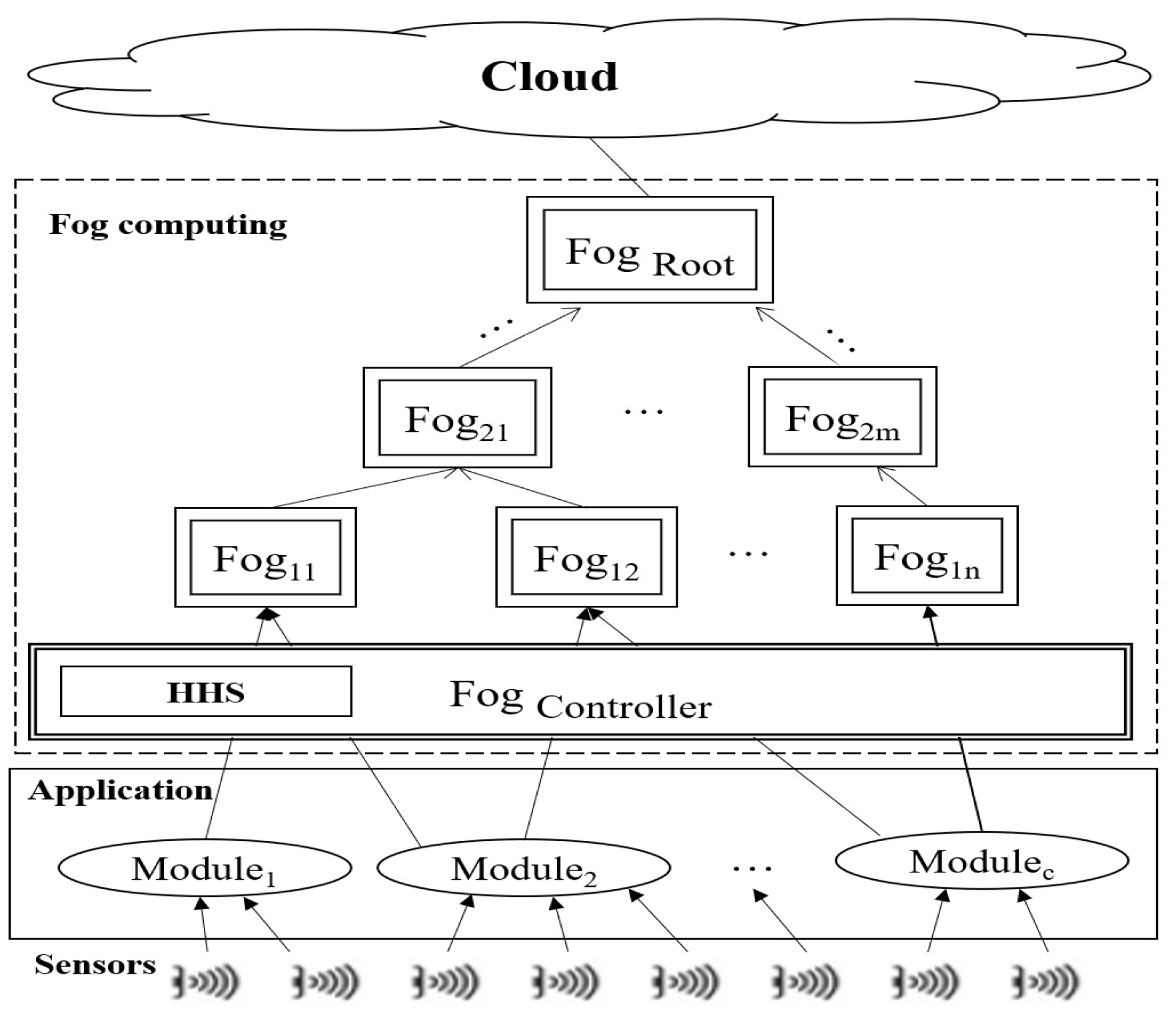
3.1. System Model and Case Study
3.1.1. FD
3.1.2. Application
- Application module: This module is a type of VM. The module’s properties include MIPS, size, bandwidth, and the number of PEs. The number of modules in each FD is more than the number of PEs , where C is the total number of modules, and K is the total number of FDs. The application modules of the considered case study include an object detector, motion detector, object tracker, and user interface.
- Application edge: The application modules are connected by edges. Each application edge is between two modules. In fact, tuples are transferred between modules by edges. Each edge has two important features: CPU length and data size. In fact, , and . This means the total CPU length and the data size of all input tuples to a module must be less than or equal to the MIPS and RAM capacity of that module. is the total CPU length, and is the data size of the tuple. M is the total number of tuples. is the module’s MIPS.
- Application tuple mapping: The tuple is the input/output relationships of the application modules that send data from one module to another module ( to ; ).
- Application loop: Each workflow of modules is an application loop. Each application has some workflow that connects modules by edges.
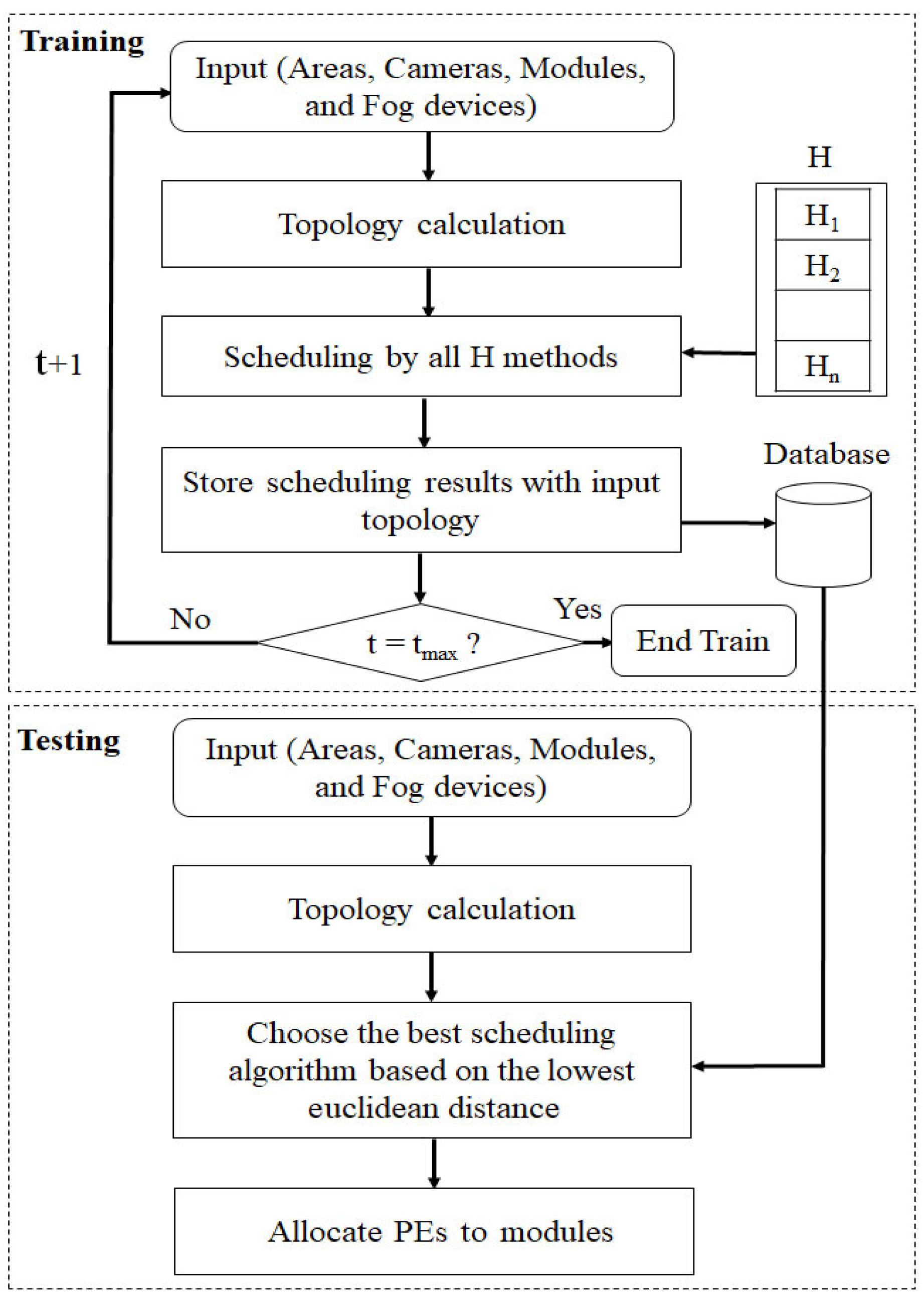
3.2. HHS
3.2.1. Encoding Individual
3.2.2. Fitness Function
3.2.3. Total Execution Cost
3.2.4. Total Network Usage
3.2.5. Energy Consumption
3.2.6. Application Loop Delay
| Algorithm 1 HHS. |
Input: number of areas, number of cameras, scheduling methods.
|
- Training phase: Initially, 64 different workflows enter the system. The proposed algorithm includes GA [22], PSO [30], ACO [26], and SA [53] and is implemented to allocate PEs to modules in all workflows and for the intelligent monitoring system that comes along with the modules. The energy consumption, network usage, and total execution cost of each algorithm are achieved for each workflow. Then, the results are stored in the database, and for each workflow, the best algorithm is selected.
- Testing phase: A new workflow enters the system. Then, the Euclidean distance between the new workflow and examples inside the database is obtained. The best algorithm is chosen. Then, the energy consumption, network usage, and total execution cost of the new workflow are calculated. Finally, the results are returned.
3.2.7. Data Mining
3.2.8. Algorithm Parameters and Complexity Analysis
- In GA, the fitness calculates in so that n is the number of individuals with size m. The crossover and mutation operators calculate in . The elitism order is . The computational complexity of GA is .
- In PSO, the algorithm gets the position and velocity of all particles calculated in . The fitness value for each particle calculates in , and m is the particle size. The computational complexity of PSO is .
- In ACO, the pheromones update in . Since the upper bound of is , the computational complexity is . The computational complexity of ACO is .
- In SA, the fitness of each particle and a new particle calculate in . The computational complexity of GA is .
- In HHS, k is the size of topology samples in the database. Additionally, the computational complexity of HHS depends on the algorithm selected based on Euclidean distance.
4. Evaluation
4.1. Experimental Environment
4.2. Simulation Configuration
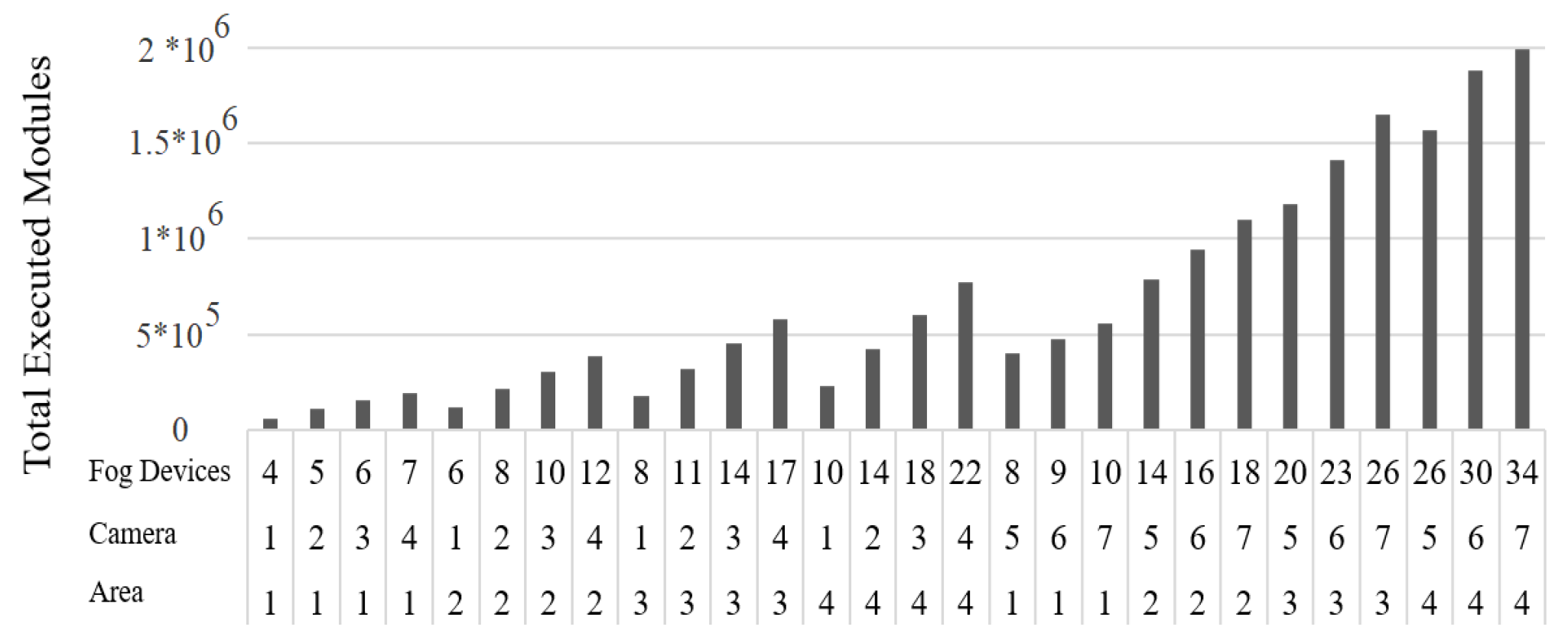
4.3. Statistical Analysis of Fog-Based Case Study
4.4. Analysis Based on the Number of Users
4.5. Analysis Based on the Number of Devices
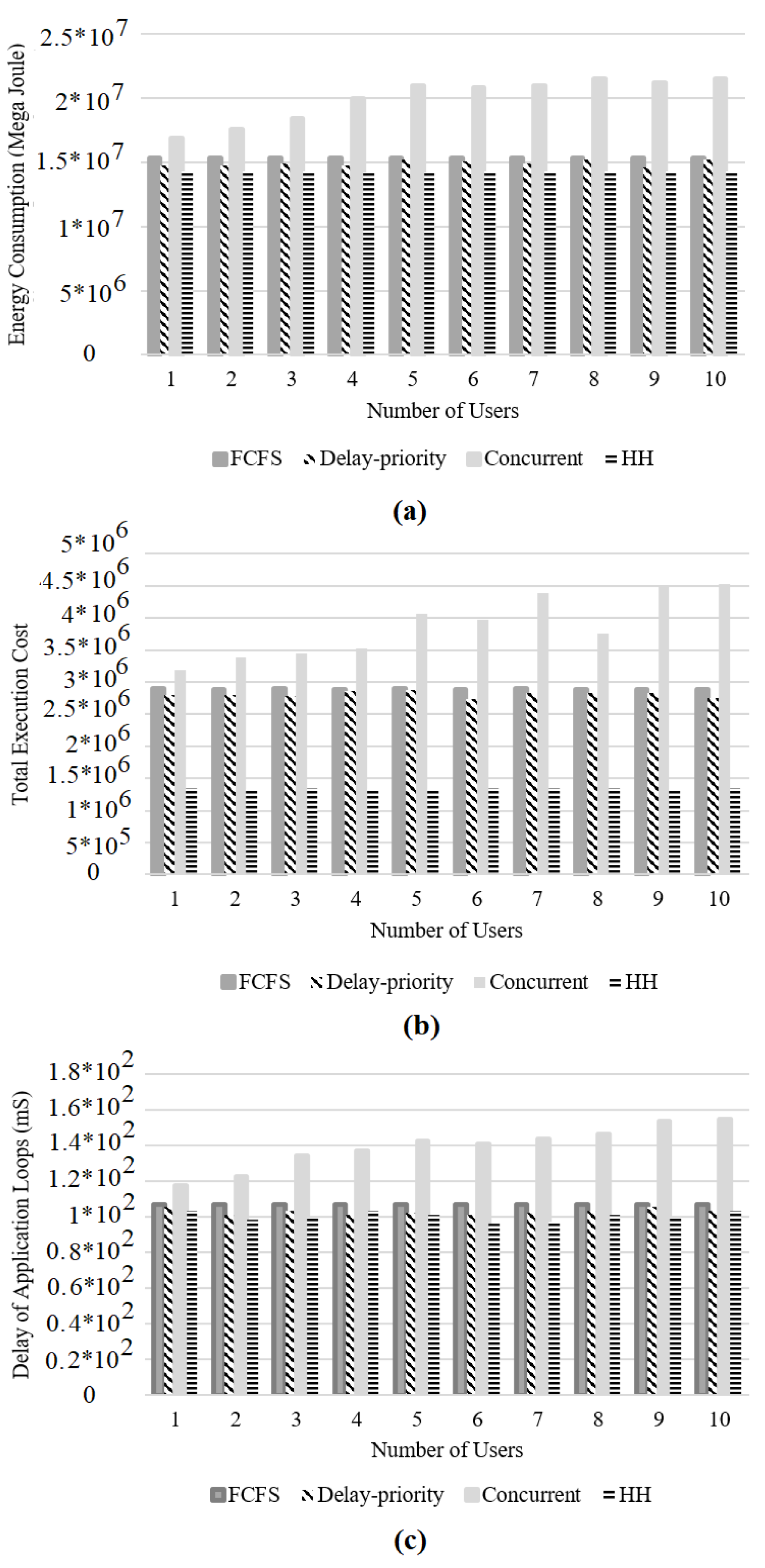
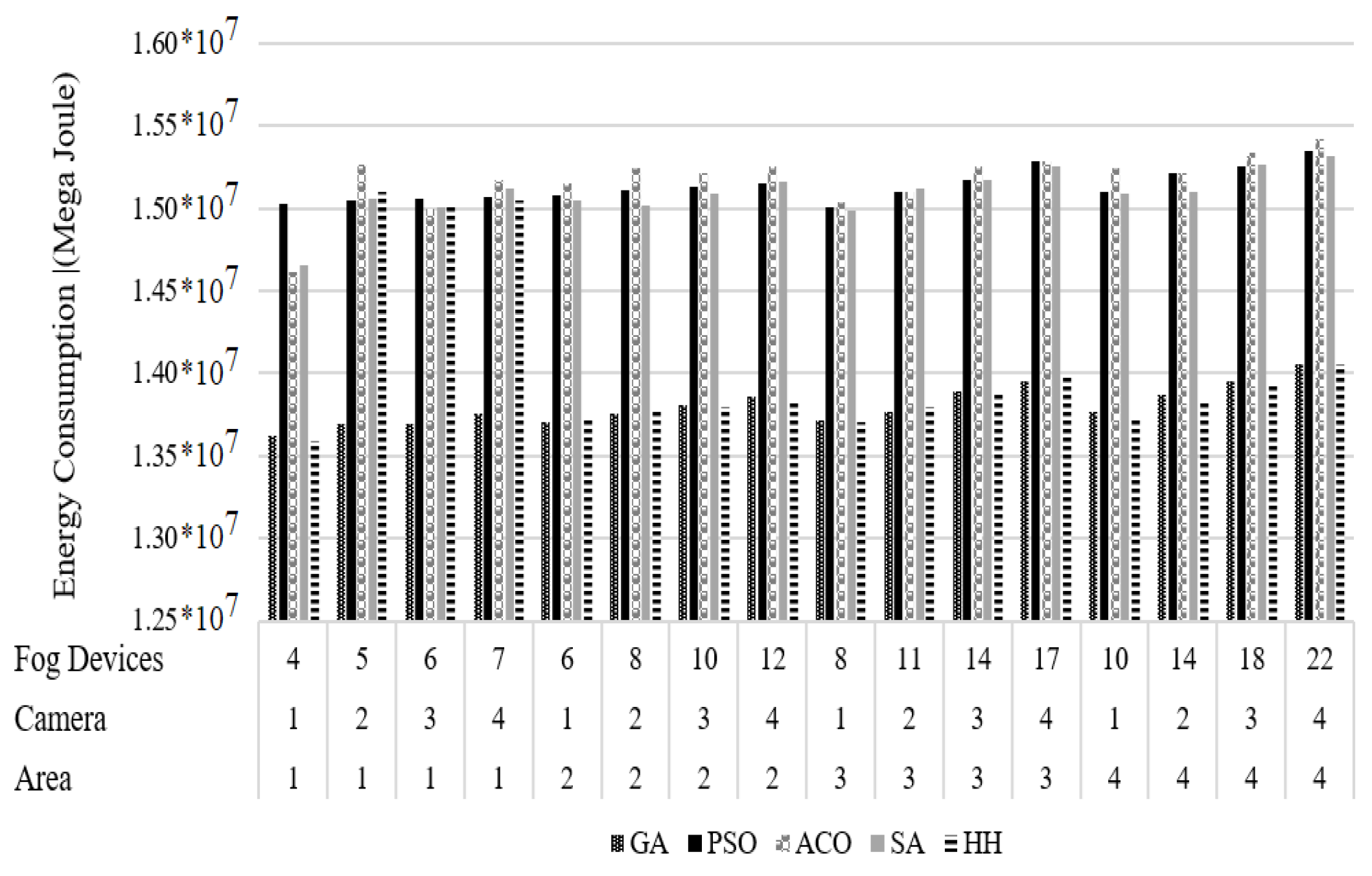
4.5.1. Energy Consumption
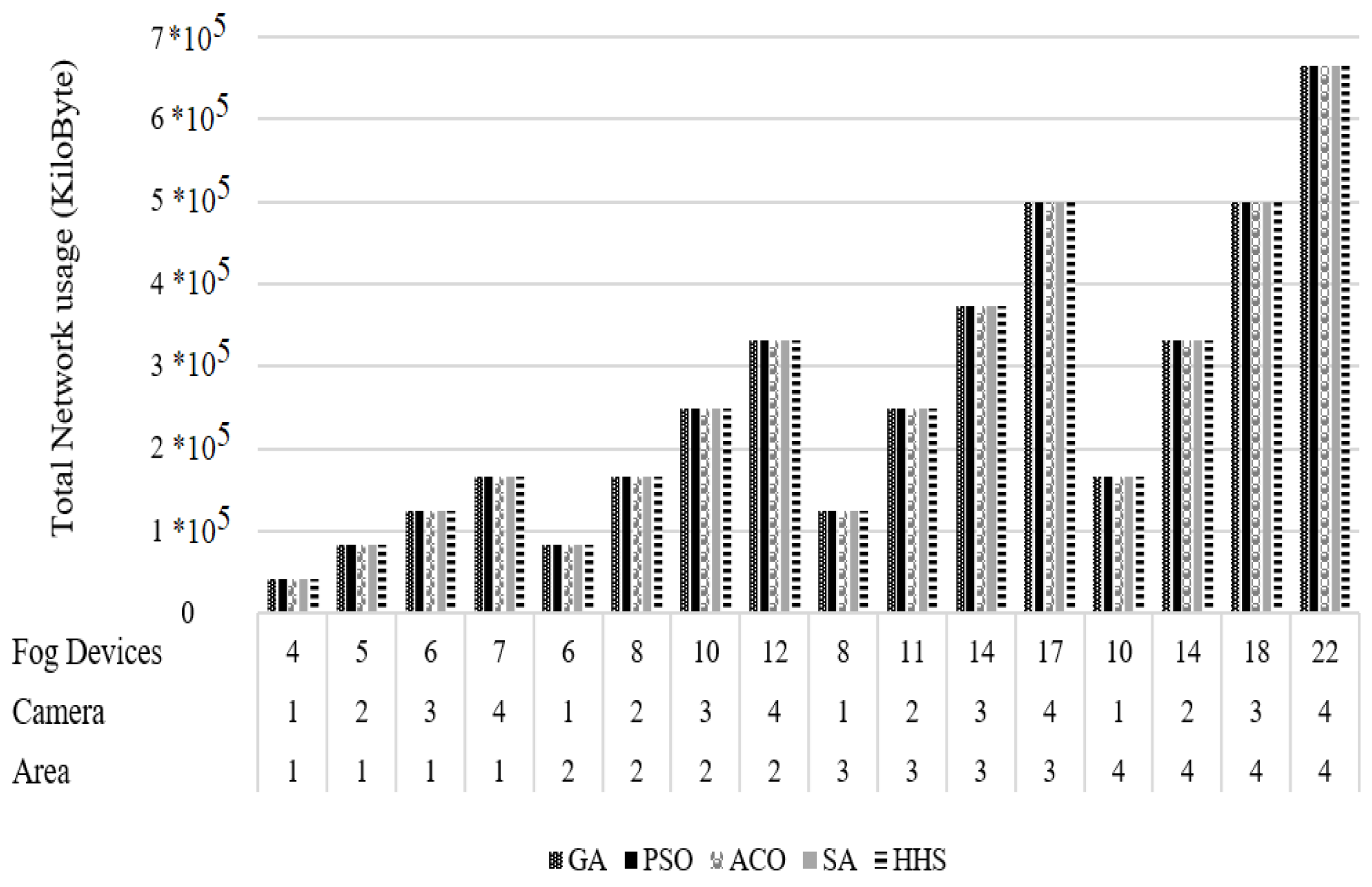
4.5.2. Total Network Usage
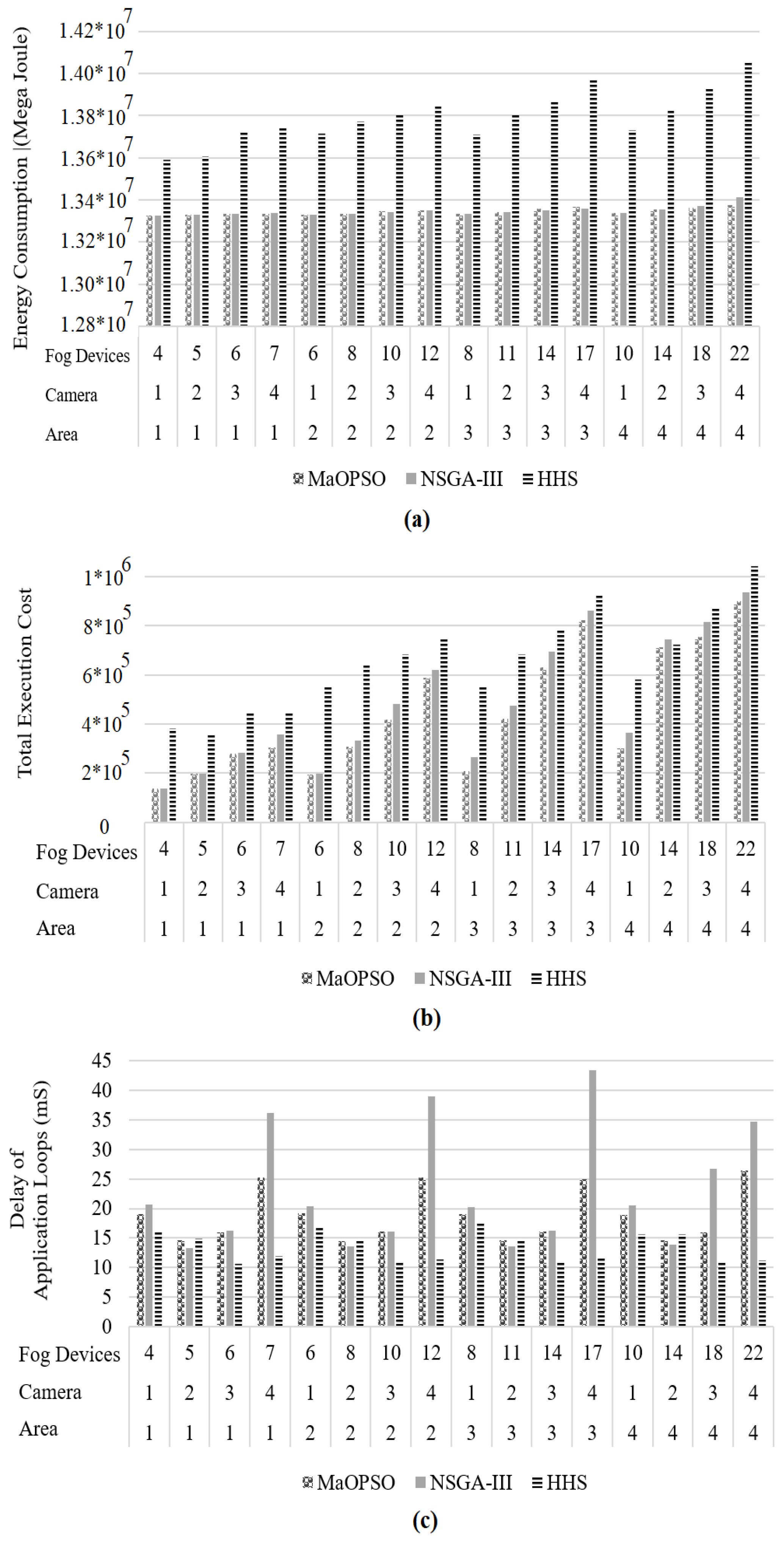
4.5.3. Comparison with Meta-Heuristic Methods
- NSGA-III: population size = 100, crossover probability = 0.9, mutation probability = 0.5, and max iterations = 50.
- MaOPSO: swarm size = 100, archive size = 100, mutation probability = 0.5, and max iterations = 50.
4.5.4. Execution Time
5. Conclusions and Future Work
Funding
Data Availability Statement
Conflicts of Interest
References
- Jamshed, M.A.; Ali, K.; Abbasi, Q.H.; Imran, M.A.; Ur-Rehman, M. Challenges, applications and future of wireless sensors in Internet of Things: A review. IEEE Sens. J. 2022, 22, 5482–5494. [Google Scholar] [CrossRef]
- Bansal, S.; Aggarwal, H.; Aggarwal, M. A systematic review of task scheduling approaches in fog computing. Trans. Emerg. Telecommun. Technol. 2022, 33, e4523. [Google Scholar] [CrossRef]
- Mahmud, R.; Kotagiri, R.; Buyya, R. Fog computing: A taxonomy, survey and future directions. In Internet of Everything; Springer: Berlin/Heidelberg, Germany, 2018; pp. 103–130. [Google Scholar]
- Ni, L.; Zhang, J.; Jiang, C.; Yan, C.; Yu, K. Resource allocation strategy in fog computing based on priced timed petri nets. IEEE Internet Things J. 2017, 4, 1216–1228. [Google Scholar] [CrossRef]
- Bitam, S.; Zeadally, S.; Mellouk, A. Fog computing job scheduling optimization based on bees swarm. Enterp. Inf. Syst. 2017, 12, 373–397. [Google Scholar] [CrossRef]
- Jamil, B.; Ijaz, H.; Shojafar, M.; Munir, K.; Buyya, R. Resource Allocation and Task Scheduling in Fog Computing and Internet of Everything Environments: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2022, 54, 115. [Google Scholar] [CrossRef]
- Mathew, T.; Sekaran, K.C.; Jose, J. Study and analysis of various task scheduling algorithms in the cloud computing environment. In Proceedings of the Advances in Computing, Communications and Informatics (ICACCI, International Conference on IEEE, Delhi, India, 24–27 September 2014; pp. 658–664. [Google Scholar]
- Tsai, C.-W.; Huang, W.-C.; Chiang, M.-H.; Chiang, M.-C.; Yang, C.-S. A hyper-heuristic scheduling algorithm for cloud. IEEE Trans. Cloud Comput. 2014, 2, 236–250. [Google Scholar] [CrossRef]
- Gasmi, K.; Dilek, S.; Tosun, S.; Ozdemir, S. A survey on computation offloading and service placement in fog computing-based IoT. J. Supercomput. 2022, 78, 1983–2014. [Google Scholar] [CrossRef]
- Singh, P.; Dutta, M.; Aggarwal, N. A review of task scheduling based on meta-heuristics approach in cloud computing. Knowl. Inf. Syst. 2017, 52, 1–51. [Google Scholar] [CrossRef]
- Kabirzadeh, S.; Rahbari, D.; Nickray, M. A hyper heuristic algorithm for scheduling of fog networks. In Proceedings of the 2017 21st Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 6–10 November 2017; pp. 148–155. [Google Scholar]
- Bittencourt, L.F.; Diaz-Montes, J.; Buyya, R.; Rana, O.F.; Parashar, M. Mobility-aware application scheduling in fog computing. IEEE Cloud Comput. 2017, 4, 26–35. [Google Scholar] [CrossRef]
- Jain, H.; Deb, K. An evolutionary many-objective optimization algorithm using reference-point based nondominated sorting approach, part ii: Handling constraints and extending to an adaptive approach. IEEE Trans. Evol. Comput. 2014, 18, 602–622. [Google Scholar] [CrossRef]
- Figueiredo, E.M.; Ludermir, T.B.; Bastos-Filho, C.J. Many objective particle swarm optimization. Inf. Sci. 2016, 374, 115–134. [Google Scholar] [CrossRef]
- Deng, R.; Lu, R.; Lai, C.; Luan, T.H.; Liang, H. Optimal workload allocation in fog-cloud computing toward balanced delay and power consumption. IEEE Internet Things J. 2016, 3, 1171–1181. [Google Scholar] [CrossRef]
- Intharawijitr, K.; Iida, K.; Koga, H. Analysis of fog model considering computing and communication latency in 5g cellular networks. In Pervasive Computing and Communication Workshops (PerCom Workshops); IEEE International Conference on IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Wu, X.; Deng, M.; Zhang, R.; Zeng, B.; Zhou, S. A task scheduling algorithm based on qos-driven in cloud computing. Procedia Comput. Sci. 2013, 17, 1162–1169. [Google Scholar] [CrossRef]
- Zeng, L.; Veeravalli, B.; Li, X. Saba: A security-aware and budget-aware workflow scheduling strategy in clouds. J. Parallel Distrib. Comput. 2015, 75, 141–151. [Google Scholar] [CrossRef]
- Durillo, J.J.; Prodan, R. Multi-objective workflow scheduling in amazon ec2. Clust. Comput. 2014, 17, 169–189. [Google Scholar] [CrossRef]
- Calheiros, R.N.; Buyya, R. Meeting deadlines of scientific workflows in public clouds with tasks replication. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 1787–1796. [Google Scholar] [CrossRef]
- Pham, X.-Q.; Huh, E.-N. Towards task scheduling in a cloud-fog computing system. In Proceedings of the Network Operations and Management Symposium (APNOMS), 18th Asia-Pacific, Kanazawa, Japan, 5–7 October 2016; pp. 1–4. [Google Scholar]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Z.; Chen, Y.; Xu, Y.; Dai, X. Load balancing task scheduling based on genetic algorithm in cloud computing. In Proceedings of the Dependable, Autonomic and Secure Computing (DASC), IEEE 12th International Conference on IEEE, Dalian, China, 24–27 August 2014; pp. 146–152. [Google Scholar]
- Szabo, C.; Sheng, Q.Z.; Kroeger, T.; Zhang, Y.; Yu, J. Science in the cloud: Allocation and execution of data-intensive scientific workflows. J. Grid Comput. 2014, 12, 245–264. [Google Scholar] [CrossRef]
- Sun, Y.; Lin, F.; Xu, H. Multi-objective optimization of resource scheduling in fog computing using an improved nsga-ii. Wirel. Pers. Commun. 2018, 102, 1369–1385. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Liu, X.-F.; Zhan, Z.-H.; Du, K.-J.; Chen, W.-N. Energy aware virtual machine placement scheduling in cloud computing based on ant colony optimization approach. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, 12–16 July 2014; pp. 41–48. [Google Scholar]
- Tawfeek, M.A.; El-Sisi, A.; Keshk, A.E.; Torkey, F.A. Cloud task scheduling based on ant colony optimization. In Proceedings of the Computer Engineering and Systems (ICCES), 8th International Conference on IEEE, Cairo, Egypt, 26–28 November 2013; pp. 64–69. [Google Scholar]
- Wang, T.; Wei, X.; Tang, C.; Fan, J. Efficient multi-tasks scheduling algorithm in mobile cloud computing with time constraints. Peer-Peer Netw. Appl. 2017, 11, 793–807. [Google Scholar] [CrossRef]
- Kennedy, J. Particle swarm optimization. In Encyclopedia of Machine Learning; Springer: Berlin/Heidelberg, Germany, 2011; pp. 760–766. [Google Scholar]
- Masdari, M.; Salehi, F.; Jalali, M.; Bidaki, M. A survey of pso-based scheduling algorithms in cloud computing. J. Netw. Syst. Manag. 2017, 25, 122–158. [Google Scholar] [CrossRef]
- Yassa, S.; Chelouah, R.; Kadima, H.; Granado, B. Multi-objective approach for energy-aware workflow scheduling in cloud computing environments. Sci. World J. 2013, 2013, 350934. [Google Scholar] [CrossRef] [PubMed]
- Abdel-Basset, M.; Fakhry, A.E.; El-Henawy, I.; Qiu, T.; Sangaiah, A.K. Feature and intensity based medical image registration using particle swarm optimization. J. Med. Syst. 2017, 41, 197. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.-G.; Guo, L.; Gandomi, A.H.; Hao, G.-S.; Wang, H. Chaotic krill herd algorithm. Inf. Sci. 2014, 274, 17–34. [Google Scholar] [CrossRef]
- Wang, G.-G.; Gandomi, A.H.; Alavi, A.H.; Gong, D. A comprehensive review of krill herd algorithm: Variants hybrids and applications. Artif. Intell. Rev. 2017, 51, 119–148. [Google Scholar] [CrossRef]
- Srikanth, K.; Panwar, L.K.; Panigrahi, B.; Herrera-Viedma, E.; Sangaiah, A.K.; Wang, G.-G. Meta-heuristic framework: Quantum inspired binary grey wolf optimizer for unit commitment problem. Comput. Electr. Eng. 2018, 70, 243–260. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Shawky, L.A.; Sangaiah, A.K. A comparative study of cuckoo search and flower pollination algorithm on solving global optimization problems. Libr. Tech 2017, 35, 595–608. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, M.; Hussien, A.-N.; Sangaiah, A.K. A novel group decision-making model based on triangular neutrosophic numbers. Soft Comput. 2018, 22, 6629–6643. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; El-Shahat, D.; Sangaiah, A.K. A modified nature inspired meta-heuristic whale optimization algorithm for solving 0–1 knapsack problem. Int. J. Mach. Learn. Cybern. 2019, 10, 495–514. [Google Scholar] [CrossRef]
- Wang, G.-G.; Cai, X.; Cui, Z.; Min, G.; Chen, J. High performance computing for cyber physical social systems by using evolutionary multi-objective optimization algorithm. IEEE Trans. Emerg. Top. Comput. 2017, 8, 20–23. [Google Scholar] [CrossRef]
- Zade, B.M.H.; Mansouri, N.; Javidi, M.M. Multi-objective scheduling technique based on hybrid hitchcock bird algorithm and fuzzy signature in cloud computing. Eng. Appl. Artif. Intell. 2021, 104, 104372. [Google Scholar] [CrossRef]
- Agarwal, M.; Srivastava, G.M.S. Opposition-based learning inspired particle swarm optimization (OPSO) scheme for task scheduling problem in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9855–9875. [Google Scholar] [CrossRef]
- Guddeti, R.M.; Buyya, R. A hybrid bio-inspired algorithm for scheduling and resource management in cloud environment. IEEE Trans. Serv. Comput. 2017, 17, 3–15. [Google Scholar]
- Delavar, A.G.; Aryan, Y. Hsga: A hybrid heuristic algorithm for workflow scheduling in cloud systems. Clust. Comput. 2014, 17, 129–137. [Google Scholar] [CrossRef]
- Kaur, R.; Ghumman, N. Hybrid improved max min ant algorithm for load balancing in cloud. In Proceedings of the International Conference On Communication, Computing and Systems (ICCCS–2014), Shanghai, China, 4–7 August 2014. [Google Scholar]
- Hussain, S.M.; Begh, G.R. Hybrid heuristic algorithm for cost-efficient QoS aware task scheduling in fog–cloud environment. J. Comput. Sci. 2022, 64, 101828. [Google Scholar] [CrossRef]
- Talha, A.; Bouayad, A.; Malki, M.O.C. Improved Pathfinder Algorithm using Opposition-based Learning for tasks scheduling in cloud environement. J. Comput. Sci. 2022, 64, 101873. [Google Scholar] [CrossRef]
- Chen, Z.; Wei, P.; Li, Y. Combining neural network-based method with heuristic policy for optimal task scheduling in hierarchical edge cloud. Digit. Commun. Networks, 2022; in press. [Google Scholar] [CrossRef]
- Gomez, J.C.; Terashima-Mar, H. Evolutionary hyper-heuristics for tackling bi-objective 2d bin packing problems. Genet. Program. Evolvable Mach. 2018, 19, 151–181. [Google Scholar] [CrossRef]
- Chen, S.; Li, Z.; Yang, B.; Rudolph, G. Quantum-inspired hyper-heuristics for energy-aware scheduling on heterogeneous computing systems. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1796–1810. [Google Scholar] [CrossRef]
- Zade, B.M.H.; Mansouri, N.; Javidi, M.M. A two-stage scheduler based on New Caledonian Crow Learning Algorithm and reinforcement learning strategy for cloud environment. J. Netw. Comput. Appl. 2022, 202, 103385. [Google Scholar] [CrossRef]
- Gupta, H.; Dastjerdi, A.V.; Ghosh, S.K.; Buyya, R. Ifogsim: A toolkit for modeling and simulation of resource management techniques in internet of things, edge and fog computing environments. Software: Pract. Exp. 2017, 47, 1275–1296. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J. A task scheduling based on simulated annealing algorithm in cloud computing. Int. J. Hybrid Inf. Technol. 2016, 9, 403–412. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Strategy | Scheduling Objectives | Environment | Pros and Cons |
|---|---|---|---|---|
| SABA [18] | Heuristic | Makespan, security, and budget | Cloud/Real environment | Improves response time. Ignores energy consumption. |
| MOHEFT [19] | Heuristic | Makespan and cost | Cloud/Real environment | Trade-off between cost and makespan. |
| EIPR [20] | Heuristic | Deadlines, total execution time, and budget | Cloud/Real environment | Improves performance. Ignores energy consumption. |
| Heuristic [21] | Heuristic | Makespan and execution cost | Cloud–Fog/CloudSim | Cost efficient. No scalability. |
| JLGA [23] | Meta-heuristic | Makespan and load balancing. | Cloud/MATLAB | Energy efficient. |
| RSS-IN [25] | Meta-heuristic | Latency and stability | Fog/MATLAB | Decreases latency. Ignores energy consumption. |
| ACO [28] | Meta-heuristic | Makespan | Cloud/CloudSim | Local optimum problem. |
| CMSACO [29] | Meta-heuristic | Delay, complete time, and energy consumption | Fog/Simulation | Ignores time complexity. |
| BLA [5] | Meta-heuristic | Execution time and memory size | Fog/C++ | Better performance than basic evolutionary algorithms. |
| MOHFHB [41] | Meta-heuristic | Makespan, resource utilization, energy consumption, latency, and degree load balance | Cloud/Simulation | Optimizes energy consumption and latency. |
| OPSO [42] | Meta-heuristic | Energy consumption and makespan | Cloud/CloudSim | Convergence of standard PSO, energy consumption, and makespan. |
| DVFS-MODPSO [32] | Hybrid-heuristic | Makespan, cost, and energy | Cloud/Real environment | Optimizes performance. |
| BIA [43] | Hybrid-heuristic | Response time and optimum usage of resources | Cloud/PySim | Resource efficient. Ignores energy consumption. |
| HSGA [44] | Hybrid-heuristic | Makespan and load balancing | Cloud/Real environment | Ignores time complexity. |
| MMACO [45] | Hybrid-heuristic | Makespan and load balancing | Cloud/CloudSim | Improves performance. |
| HFSGA [46] | Hybrid-heuristic | Makespan and cost | Fog–Cloud/MATLAB | Optimized for deadline-satisfied tasks. |
| OBLPFA [47] | Hybrid-heuristic | Execution time, cost, and resource utilization | Cloud/CloudSim | Improved time complexity. |
| JNNHSP [48] | Hybrid-heuristic | Service latency | Edge–Cloud/Real | Improves scheduling error ratio, average service latency, and execution efficiency. |
| HHSA [8] | Hyper-heuristic | Makespan and computation Time | Cloud/CloudSim and Hadoop | Realistic environment. Time efficient. |
| Algorithm | Parameters | Complexity |
|---|---|---|
| GA | Mutation rate = 0.5 Crossover rate = 0.9 Elitism = 10% | |
| PSO | Swarm size = 10 Acceleration rate = 2 | |
| ACO | Ant count = 10 Pheromone updating rate = 0.1 Choosing probability = 0.85 Influence weights = 0.95 | |
| SA | Mutation rate = 0.3 Starting temperature = 1 Cooling rate = 0.05 | |
| HHS | Training samples = 64 Testing samples = 16 | = |
| Name | MIPS | RAM | UpBw | DownBw | Level | RatePerMips | Busy Power | Idle Power |
|---|---|---|---|---|---|---|---|---|
| FD | 44,800 | 40,000 | 100 | 10,000 | 0 | 0.01 | 16 ∗ 103 | 16 ∗ 83.25 |
| Area’s FD | 2800 | 4000 | 10,000 | 10,000 | 1 | 0 | 107.339 | 83.4333 |
| Camera’s FD | 500 | 1000 | 10,000 | 10,000 | 3 | 0 | 87.53 | 82.44 |
| Application module | 1000 | 10 | 1000 | - | - | - | - | - |
| Value | FCFS | Concurrent | DP | HHS |
|---|---|---|---|---|
| Avg | 1.54 | 2.00 | 1.49 | 1.43 |
| Max | 1.54 | 2.15 | 1.52 | 1.43 |
| Min | 1.54 | 1.69 | 1.46 | 1.43 |
| SD | 1.97 | 1630 | 216 | 4.90 |
| Value | FCFS | Concurrent | DP | HHS |
|---|---|---|---|---|
| Avg | 2.89 | 3.87 | 2.81 | 1.34 |
| Max | 2.90 | 4.53 | 2.87 | 1.35 |
| Min | 2.89 | 3.18 | 2.74 | 1.33 |
| SD | 2.79 | 463 | 41.7 | 6.95 |
| Value | FCFS | Concurrent | DP | HHS |
|---|---|---|---|---|
| Avg | 107 | 139 | 103 | 100 |
| Max | 107 | 155 | 106 | 103 |
| Min | 107 | 117 | 101 | 96 |
| SD | 16.8 | 11.4 | 1.52 | 2.61 |
| A | C | GA | PSO | ACO | SA | MO | NSGA-III | Con. | FCFS | DP | HHS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 10.04 | 2.09 | 10.01 | 1.15 | 16.04 | 16.48 | 2.57 | 2.38 | 1.28 | 1.36 |
| 1 | 2 | 19.05 | 6.17 | 42.47 | 4.08 | 31.02 | 34.01 | 7.19 | 5.39 | 4.12 | 4.39 |
| 1 | 3 | 75.98 | 23.42 | 157.03 | 14.55 | 80.27 | 84.37 | 24.90 | 20.74 | 18.71 | 14.86 |
| 1 | 4 | 115.20 | 32.19 | 180.72 | 25.61 | 90.18 | 105.39 | 53.38 | 47.01 | 40.75 | 25.93 |
| 2 | 1 | 17.20 | 5.13 | 36.28 | 3.53 | 25.83 | 28.10 | 5.72 | 4.01 | 3.81 | 3.84 |
| 2 | 2 | 66.13 | 26.03 | 130.39 | 10.11 | 70.28 | 75.43 | 26.53 | 25.01 | 20.19 | 15.49 |
| 2 | 3 | 81.02 | 30.69 | 160.03 | 30.66 | 84.93 | 87.20 | 50.16 | 41.02 | 38.02 | 30.97 |
| 2 | 4 | 90.02 | 43.75 | 198.26 | 45.03 | 91.05 | 98.35 | 62.93 | 54.07 | 48.30 | 41.61 |
| 3 | 1 | 70.29 | 21.14 | 120.39 | 12.94 | 74.09 | 78.10 | 22.73 | 20.15 | 18.13 | 12.05 |
| 3 | 2 | 85.39 | 34.28 | 178.20 | 34.01 | 90.12 | 94.42 | 55.01 | 44.20 | 39.14 | 34.32 |
| 3 | 3 | 82.59 | 37.05 | 181.33 | 41.50 | 85.53 | 90.10 | 55.42 | 47.01 | 36.18 | 41.81 |
| 3 | 4 | 90.44 | 43.01 | 192.85 | 52.39 | 93.30 | 101.24 | 74.02 | 65.40 | 60.13 | 52.88 |
| 4 | 1 | 120.29 | 35.70 | 184.22 | 28.10 | 93.38 | 97.01 | 44.02 | 36.51 | 30.11 | 38.31 |
| 4 | 2 | 81.20 | 40.77 | 170.41 | 40.01 | 84.30 | 89.02 | 56.39 | 49.31 | 42.02 | 40.31 |
| 4 | 3 | 92.10 | 44.58 | 195.01 | 55.09 | 95.33 | 97.05 | 72.29 | 66.20 | 59.02 | 55.40 |
| 4 | 4 | 96.22 | 47.06 | 200.74 | 72.03 | 91.44 | 98.05 | 92.39 | 88.04 | 79.06 | 72.34 |
| 2 | 6 | 103.92 | 53.02 | 227.30 | 86.22 | 108.34 | 115.73 | 105.40 | 93.84 | 80.11 | 86.33 |
| 2 | 7 | 130.88 | 69.32 | 244.07 | 93.21 | 142.01 | 155.20 | 110.36 | 101.55 | 98.22 | 93.33 |
| 3 | 6 | 122.04 | 59.20 | 231.40 | 90.11 | 114.19 | 125.03 | 113.92 | 105.35 | 95.04 | 90.34 |
| 3 | 7 | 140.59 | 64.27 | 255.38 | 112.19 | 140.20 | 149.01 | 150.44 | 134.06 | 127.47 | 112.40 |
| 4 | 6 | 163.41 | 75.99 | 280.31 | 130.27 | 173.93 | 180.55 | 161.30 | 140.25 | 139.90 | 130.58 |
| 4 | 7 | 171.48 | 153.59 | 306.10 | 150.31 | 217.20 | 222.09 | 180.77 | 166.02 | 160.05 | 150.62 |
| Avg. | 92.07 | 43.11 | 176.50 | 51.50 | 95.13 | 101.00 | 69.45 | 61.71 | 56.35 | 52.25 | |
| Max | 171.48 | 153.59 | 306.1 | 150.31 | 217.20 | 222.09 | 180.77 | 166.02 | 160.05 | 150.62 | |
| Min | 10.04 | 2.09 | 10.01 | 1.15 | 16.04 | 16.48 | 2.57 | 2.38 | 1.28 | 1.36 | |
| SD | 41.06 | 30.82 | 72.94 | 41.78 | 44.07 | 45.72 | 49.18 | 44.89 | 43.74 | 41.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahbari, D. Analyzing Meta-Heuristic Algorithms for Task Scheduling in a Fog-Based IoT Application. Algorithms 2022, 15, 397. https://doi.org/10.3390/a15110397
Rahbari D. Analyzing Meta-Heuristic Algorithms for Task Scheduling in a Fog-Based IoT Application. Algorithms. 2022; 15(11):397. https://doi.org/10.3390/a15110397
Chicago/Turabian StyleRahbari, Dadmehr. 2022. "Analyzing Meta-Heuristic Algorithms for Task Scheduling in a Fog-Based IoT Application" Algorithms 15, no. 11: 397. https://doi.org/10.3390/a15110397
APA StyleRahbari, D. (2022). Analyzing Meta-Heuristic Algorithms for Task Scheduling in a Fog-Based IoT Application. Algorithms, 15(11), 397. https://doi.org/10.3390/a15110397