In this case study, we demonstrate the use of PCS principles in designing an RL algorithm for Oralytics. Two main challenges are (1) we do not have timely access to many features and the reward is relatively noisy and (2) we have sparse, partially informative data to inform the construction of our simulation environment test bed. In addition, there are several study constraints.
We highlight how we handle these challenges by using the PCS framework, despite being in a highly constrained setting. The case study is organized as follows. In
Section 5.1, we give background context and motivation for the Oralytics study. In
Section 5.2, we explain the Oralytics sequential decision-making problem. In
Section 5.3, we describe our process for designing RL algorithm candidates that can stably learn despite having a severely constrained features space and noisy rewards. Finally, in
Section 5.4, we describe how we designed the simulation environment variants to evaluate the RL algorithm candidates; throughout, we offer recommendations for designing realistic environment variants and for constructing such environments using data for only a subset of actions.
5.2. The Oralytics Sequential Decision-Making Problem
We now discuss how we designed the state space and rewards for our RL problem in collaboration with domain experts and the software team while considering various constraints. These decisions must be communicated and agreed upon with the software development team because they build the systems that provide the RL algorithm with the necessary data at decision and update times and execute actions selected by the RL algorithm.
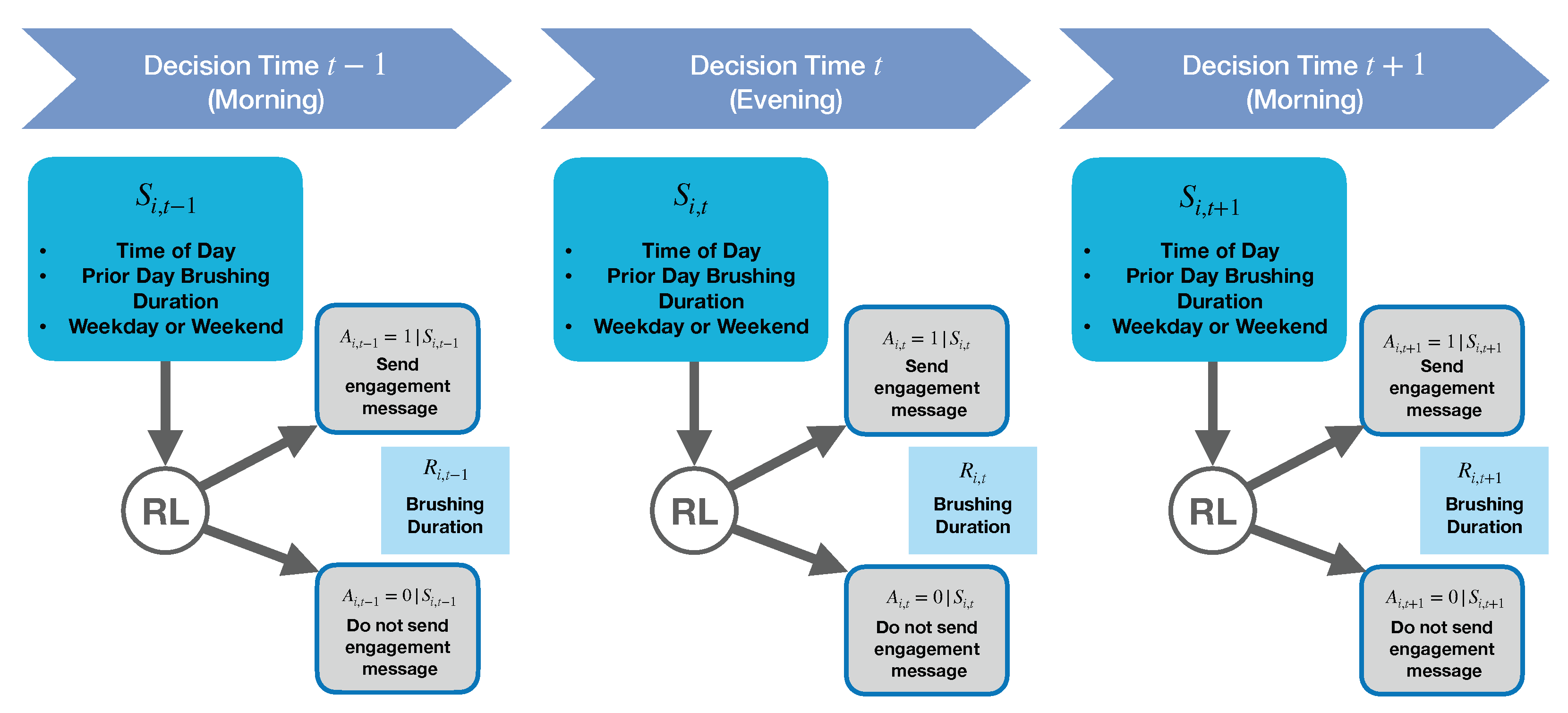
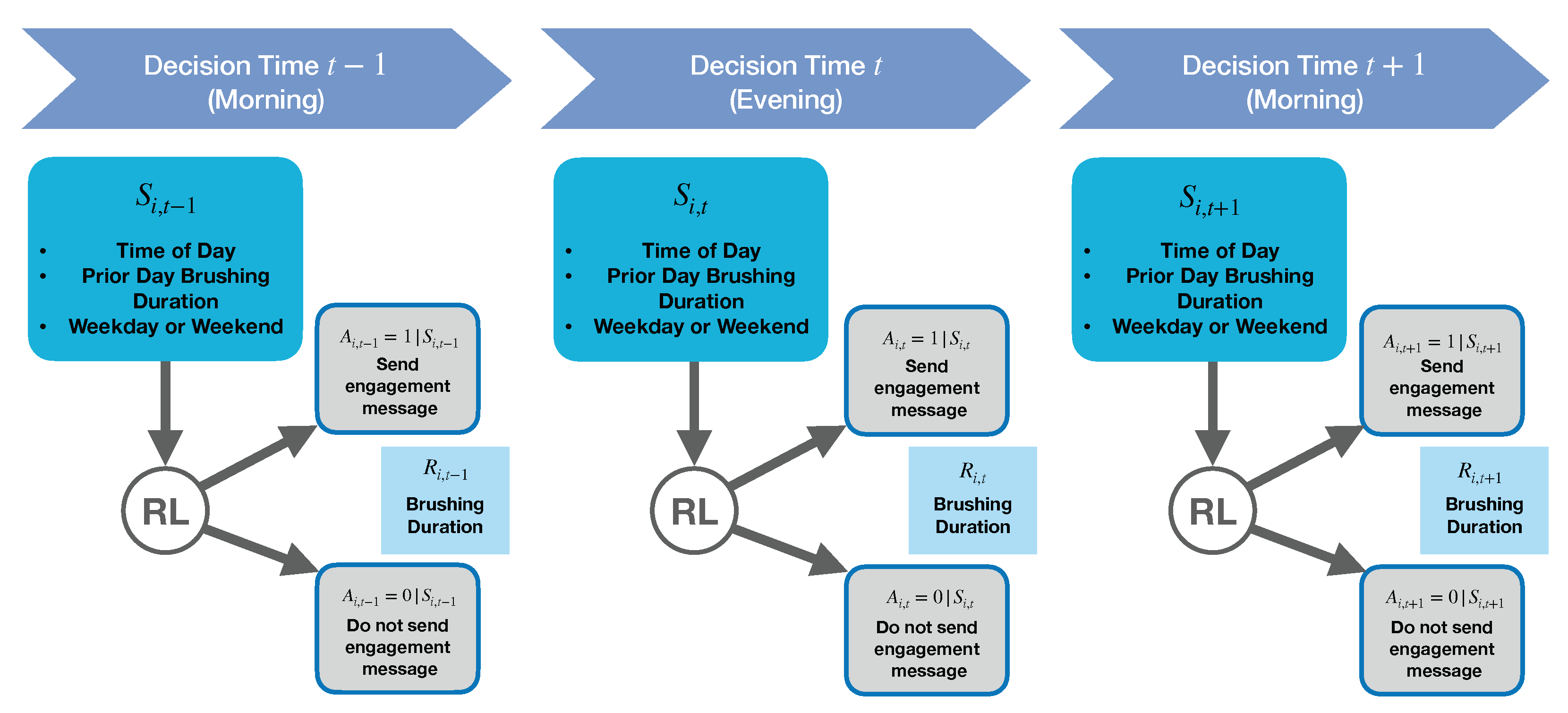
1. Choice of Decision Times: We chose the decision times to be prior to each user’s specified morning and evening brushing windows, as the scientific team thought this would be the best time to influence users’ brushing behavior.
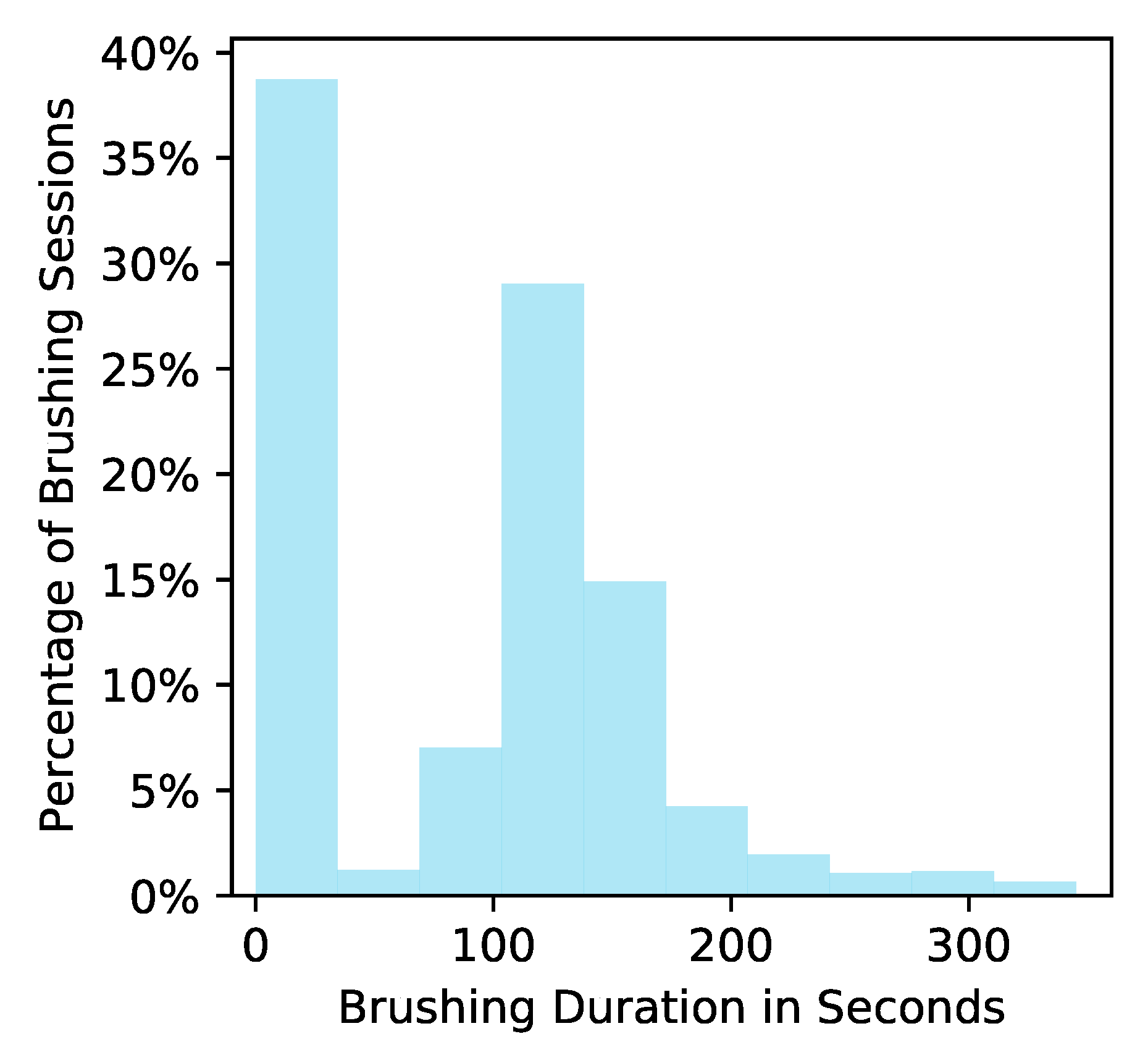
2. Choice of Reward: The research team’s first choice of reward was a measure of brushing quality derived from the toothbrush sensor data from each brushing episode. However, the brushing quality outcome is often not reliably obtainable because it requires (1) that the toothbrush dock be plugged in and (2) that the user be standing within a few feet of the toothbrush dock when brushing their teeth. Users may fail to meet these two requirements for a variety of reasons, e.g., the user brushes their teeth in a shared bathroom where they cannot conveniently leave the dock plugged in. Thus, we selected brushing duration in seconds as the reward (personalization) since 120 s is the dentist-recommended brushing duration and brushing duration is a necessary factor in calculating the brushing quality score. Additionally, brushing duration is expected to be reliably obtainable even when the user is far from the toothbrush dock when brushing (computability). Note that in
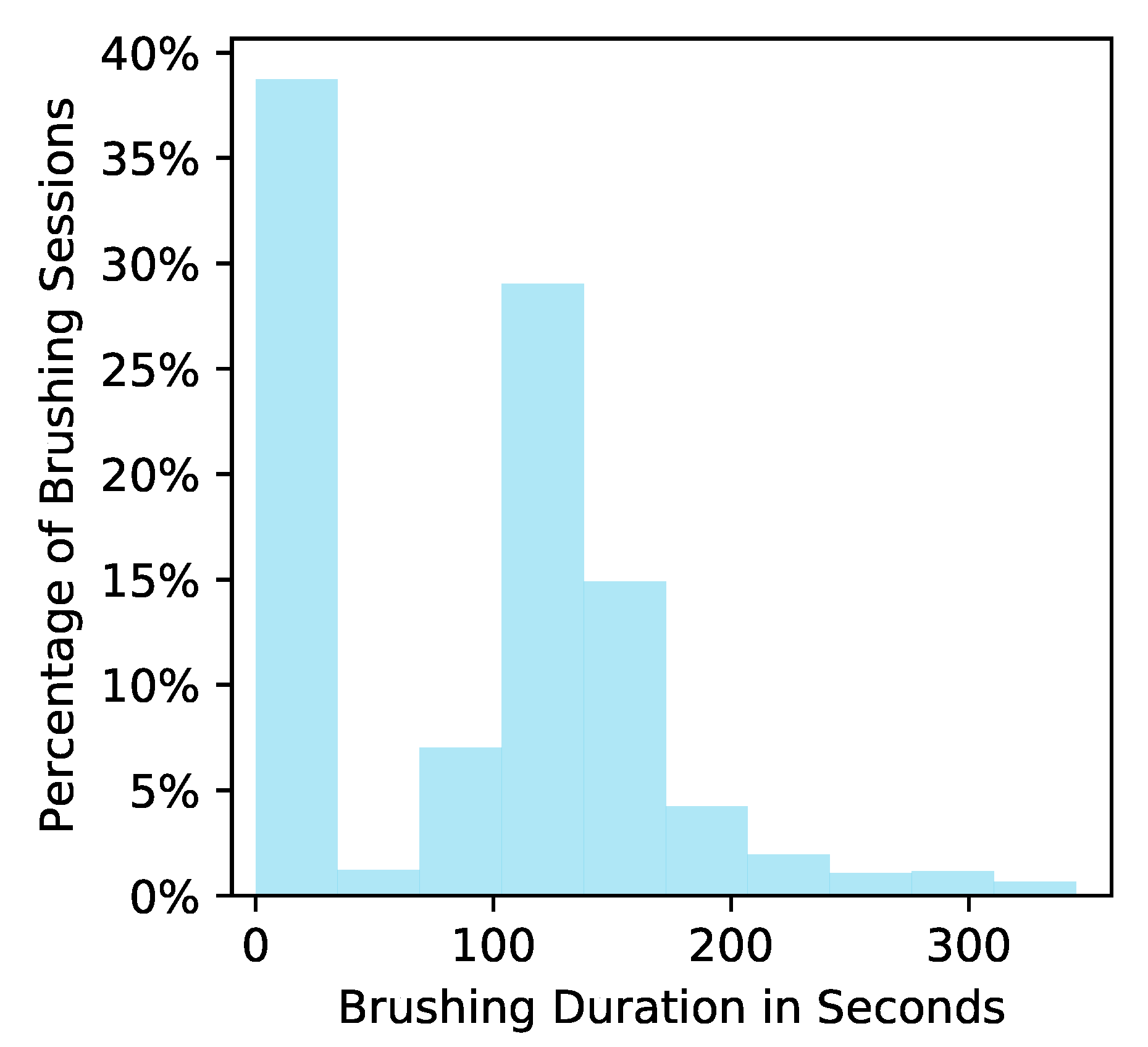
Figure 2, a small number of user-brushing episodes have durations over the recommended 120 s. Hence, we truncate the brushing time to avoid optimizing for overbrushing. Let
denote the user’s brushing duration. The reward is defined as
.
3. Choice of State Features At Decision Time: To provide the best personalization, an RL algorithm ideally has access to as many relevant state features as possible to inform a decision, e.g., recent brushing, location, user’s schedule, etc. However, our choice of the state space is constrained by the need to get features reliably before decision and update times, as well as by our limited engineering budget. For example, we originally wanted a feature for the evening decision time to be the morning’s brushing outcome; however, this feature may not be accessible in a timely manner. This is because in order for the algorithm to receive the morning brushing data, the Oralytics smartphone app requires the user to open the app and we do not expect most users to reliably open the app after every morning brush time before the evening brushing window. Further discussion of our choice of decision time state features can be found in
Appendix B.1.
4. Choice of Algorithm Update Times: In our simulations, we update the algorithm weekly. In terms of speed of learning (at least in idealized settings), it is best to update the algorithm after each decision time. However, due to computability considerations, we chose a slower update cadence. Specifically, for the Oralytics app, the consideration was that we can only update the policy used to select actions when the user opens the app. If the user did not open the app for many days, we would be unable to update the app after each decision time. Users may well fail to open the app for a few days at a time, so we chose weekly updates. In the future, we will explore other update cadences as well, e.g., once a day.
5.3. Designing the RL Algorithm Candidates
Here, we discuss our use of the PCS framework to guide and evaluate the following design decisions for the RL algorithm candidates. There are some decisions that we have already made and other decisions that we encode as axes for our algorithm candidates to test in the simulation environment. See
Appendix B for further details regarding the RL algorithm candidates.
1. Choice of using a Contextual Bandit Algorithm Framework: We understand that actions will likely affect a user’s future states and rewards, e.g., sending an intervention message the previous day may affect how receptive a user is to an intervention message today. This suggests that an RL algorithm that models a full Markov decision process (MDP) may be more suitable than a contextual bandit algorithm. However, the highly noisy environment and the limited data to learn from (140 decision times per user total) make it difficult for the RL algorithm to accurately model state transitions. Due to errors in the state transition model, the estimates of the delayed effects of actions used in MDP-based RL algorithms can often be highly noisy or inaccurate. This issue is exacerbated by our severely constrained state space (i.e., we have few features and the features we get are relatively noisy). As a result, an RL algorithm that fits a full MDP model may not learn much during the study, which could compromise personalization and offer a poor user experience. To mitigate these issues, we use contextual bandit algorithms, which fit a simpler model of the environment. Using a lower discount factor (a form of regularization) has been shown to lead to learning a better policy than using the true discount factor, especially in data-scarce settings [
37]. Thus, a contextual bandit algorithm can be interpreted as an extreme form of this regularization where the discount factor is zero. Finally, contextual bandits are the simplest algorithm for sequential decision making (computability) and have been used to personalize digital interventions in a variety of areas [
1,
2,
5,
23].
2. Choice of a Bayesian Framework: We consider contextual bandit algorithms that use a Bayesian framework, specifically posterior (Thompson) sampling algorithms [
38]. Posterior sampling involves placing a prior on the parameters of the reward approximating function and updating the posterior distribution of the reward function parameters at each algorithm update time. This allows us to incorporate prior data and domain expertise into the initialization of the algorithm parameters. In addition, Thompson sampling algorithms are stochastic (action selections are a not deterministic function of the data), which better facilitate causal inference analyses later on using the data collected in the study.
3. Choice of Constrained Action Selection Probabilities: We constrain the action selection probabilities to be bounded away from zero and one in order to facilitate off-policy and causal inference analyses once the study is over (computability). With help from the domain experts, we decided to constrain the action selection probabilities of the algorithm to be in the interval .
The following are decisions we will test using the simulation environment.
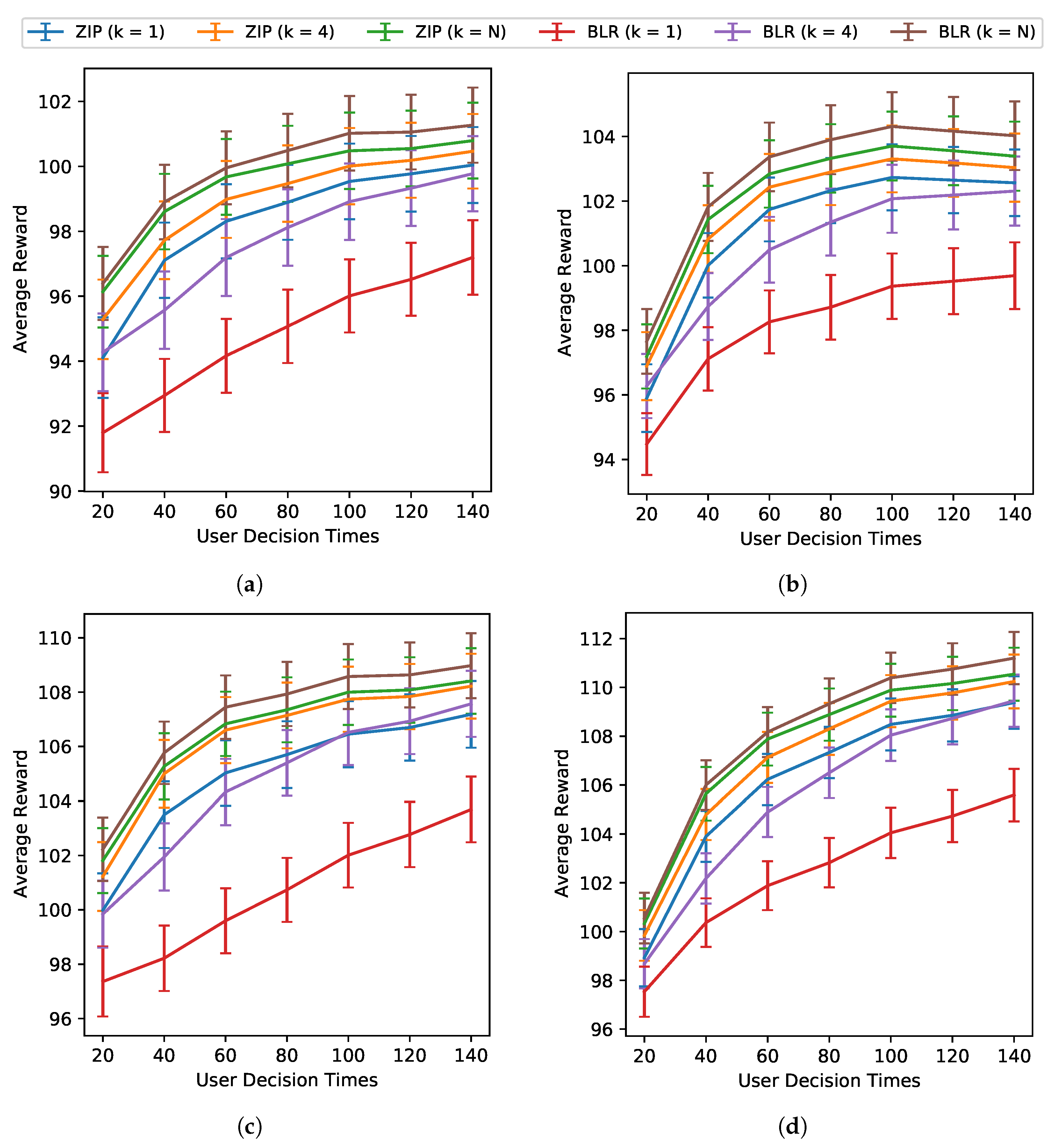
4. Choice of the Reward Approximating Function: An important decision in designing the contextual bandit algorithm is how to approximate the reward function. We consider two types of approximations, a Bayesian linear regression model (BLR) and a Bayesian zero-inflated Poisson regression model (ZIP), which are both relatively simple, well studied, and well understood. For BLR, we implement action centering in the linear model [
1]. The linear model for the reward function is easily interpretable by domain experts and allows them to critique and inform the model. We consider the ZIP because of the zero-inflated nature of brushing durations in our existing dataset ROBAS 2; see
Figure 2. We expect the ZIP to provide a better fit to the reward function by the contextual bandit and thus lead to increased average rewards. Formal specifications for BLR and ZIP as reward functions can be found in
Appendix B.2.1 and
Appendix B.2.2, respectively.
To perform posterior sampling, both the BLR and ZIP models are Bayesian with uninformative priors. From the perspective of computability and stability, the posterior for the BLR has a closed form, which makes it easier to write software that performs efficient and stable updates. In contrast, for the ZIP, the posterior distribution must be approximated and the approach used to approximate the posterior is another aspect of the algorithm design that the scientific team needs to consider. See
Appendix C for further discussion on how to update the RL algorithm candidates.
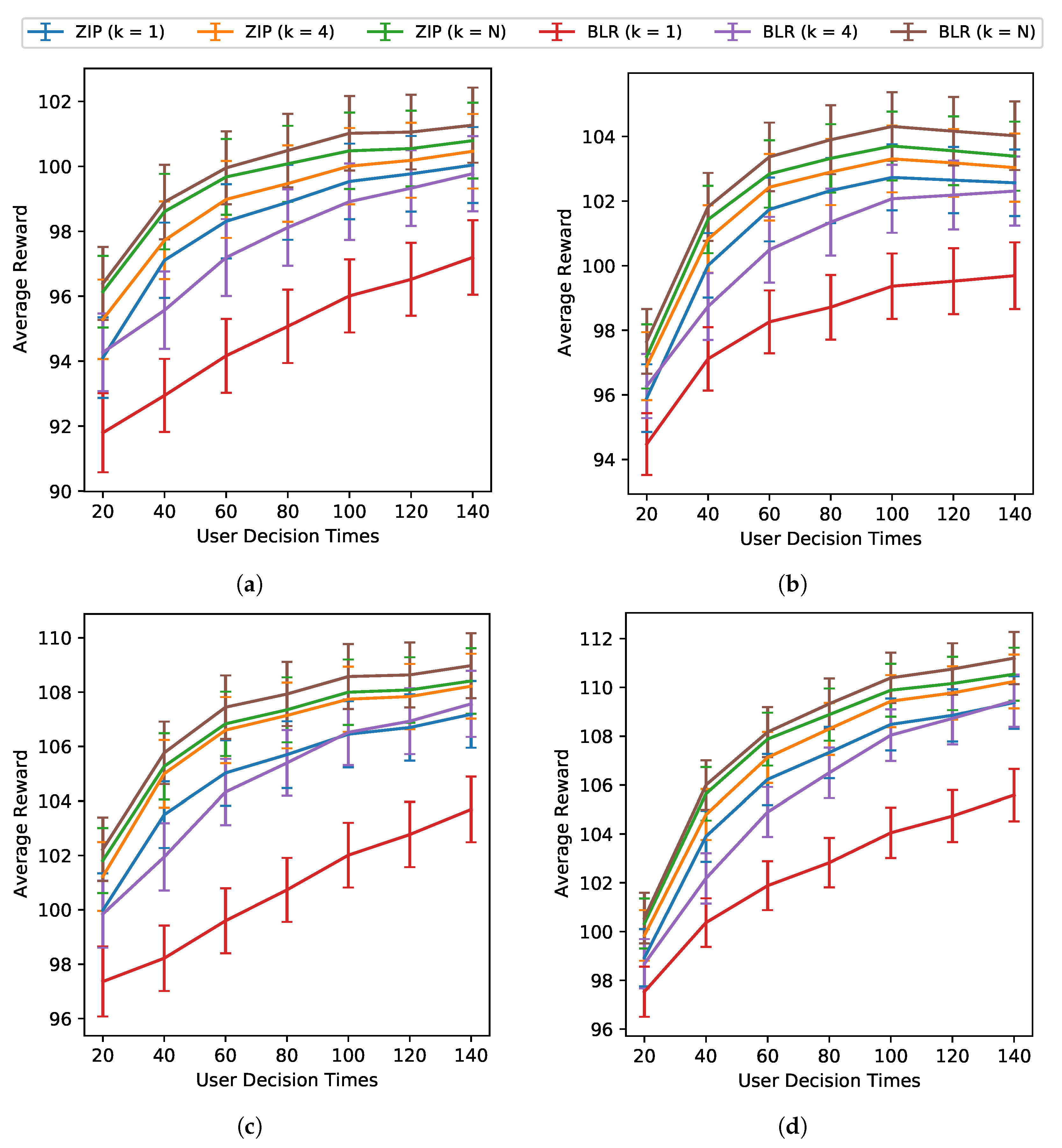
5. Choice of Cluster Size: We consider clustering users with cluster sizes
K = 1 (no pooling),
K = 4 (partial pooling), and
(full pooling) to determine whether clustering in our setting will lead to higher sums of rewards (personalization). Note that 72 is the approximate expected sample size for the Oralytics study. Clustering-based algorithms pool data from multiple users to learn an algorithm per cluster (i.e., at update times, the algorithm uses
for all users
i in the same cluster, and at decision times, the same algorithm is used to select actions for all users in the cluster). Clustering-based algorithms have been empirically shown to perform well when users within a cluster are similar [
39,
40]. In addition, we believe that clustering will facilitate learning within environments that have noisy within-user rewards [
41,
42]. There is a trade-off between no pooling and full pooling. No pooling may learn a policy more specific to the user later on in the study but may not learn as well earlier in the study when there is not a lot of data for that user. Full pooling may learn well earlier in the study because it can take advantage of all users’ data but may not personalize as well as a no-pooling algorithm, especially if users are heterogeneous. We consider
for the balance partial pooling offers between the advantages and disadvantages between no pooling and full pooling. Moreover, four is the study’s expected weekly recruitment rate and the update cadence is also weekly. We consider the two extremes and partial pooling as a way to explore this trade-off. A further discussion on choices of cluster size can be found in
Appendix B.3.
5.4. Designing the Simulation Environment
We build a simulator that considers multiple variants for the environment, each encoding a concern by the research team. The simulator allows us to evaluate the stability of results for each RL algorithm across the environmental variants (stability).
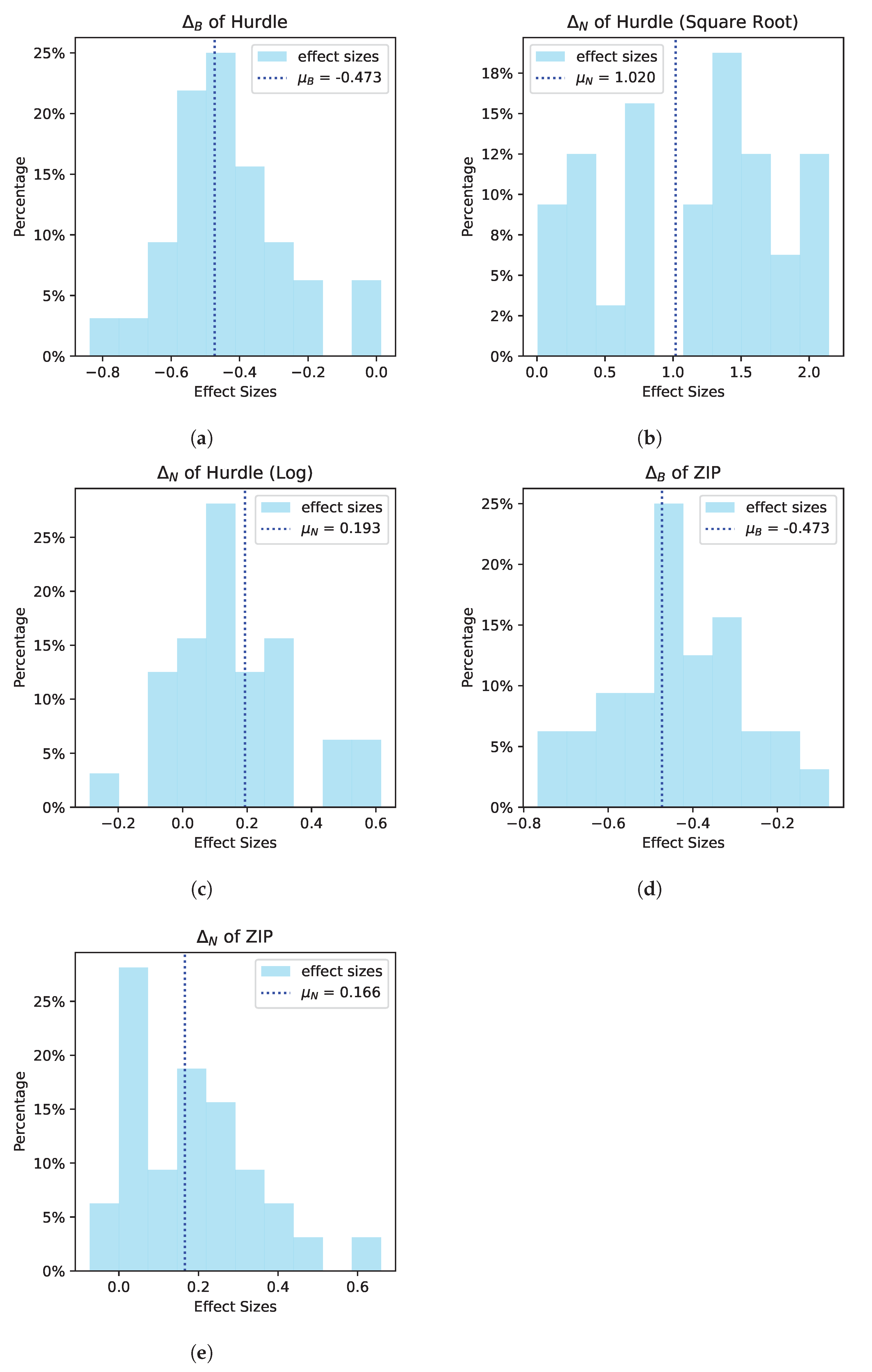
Fitting Base Models: Recall that the ROBAS 2 study did not involve intervention messages. However, we can still use the ROBAS 2 dataset to fit the base model for the simulation environment, i.e., a model for the reward (brushing duration in seconds) under no action. Two main approaches for fitting zero-inflated data are the zero-inflated model and the hurdle model [
43]. Both the zero-inflated model and the hurdle model have (i) a Bernoulli component and (ii) a nonzero component. The zero-inflated model’s Bernoulli component is latent and represents the user’s intention to brush, while the hurdle model’s Bernoulli component is observed and represents whether the user brushed or not. Therefore, the zero-inflated model’s nonzero component models the user’s brushing duration when the user intends to brush, and the hurdle model’s nonzero component models the user’s brushing duration conditional on whether the user brushed or not. Throughout the model fitting process, we performed various checks on the quality of the model to determine whether the fitted model was sufficient (
Appendix A.4). This included checking whether the percentage of zero brush times simulated by our model was comparable to that of the original ROBAS 2 dataset. Additionally, we checked whether the model accurately captured the mean and variance of the nonzero brushing durations across users.
The first approach we took was to choose one model class (zero-inflated Poisson) and fit a single population-level model for all users in the ROBAS 2 study. However, a single population-level model was insufficient for fitting all users due to the high level of user heterogeneity (i.e., the between-user and within-user variance of the simulated brushing durations from the fitted model was smaller than the between-user and within-user variance of brushing durations in the ROBAS 2 data). Thus, next, we decided to maintain one model class, but fit one model per user for all users. However, when we fit a zero-inflated Poisson to each user, we found that the model provided an adequate fit for some users but not for users who showed more variability in their brushing durations. The within-user variance simulated rewards from the model fit on those users was still lower than the within-user variance of the ROBAS 2 user data used to fit the model. Therefore, we considered a hurdle model [
43] because it is more flexible than the zero-inflated Poisson. For Poisson distributions, the mean and variance are equal, whereas the hurdle model does not conflate the mean and variance.
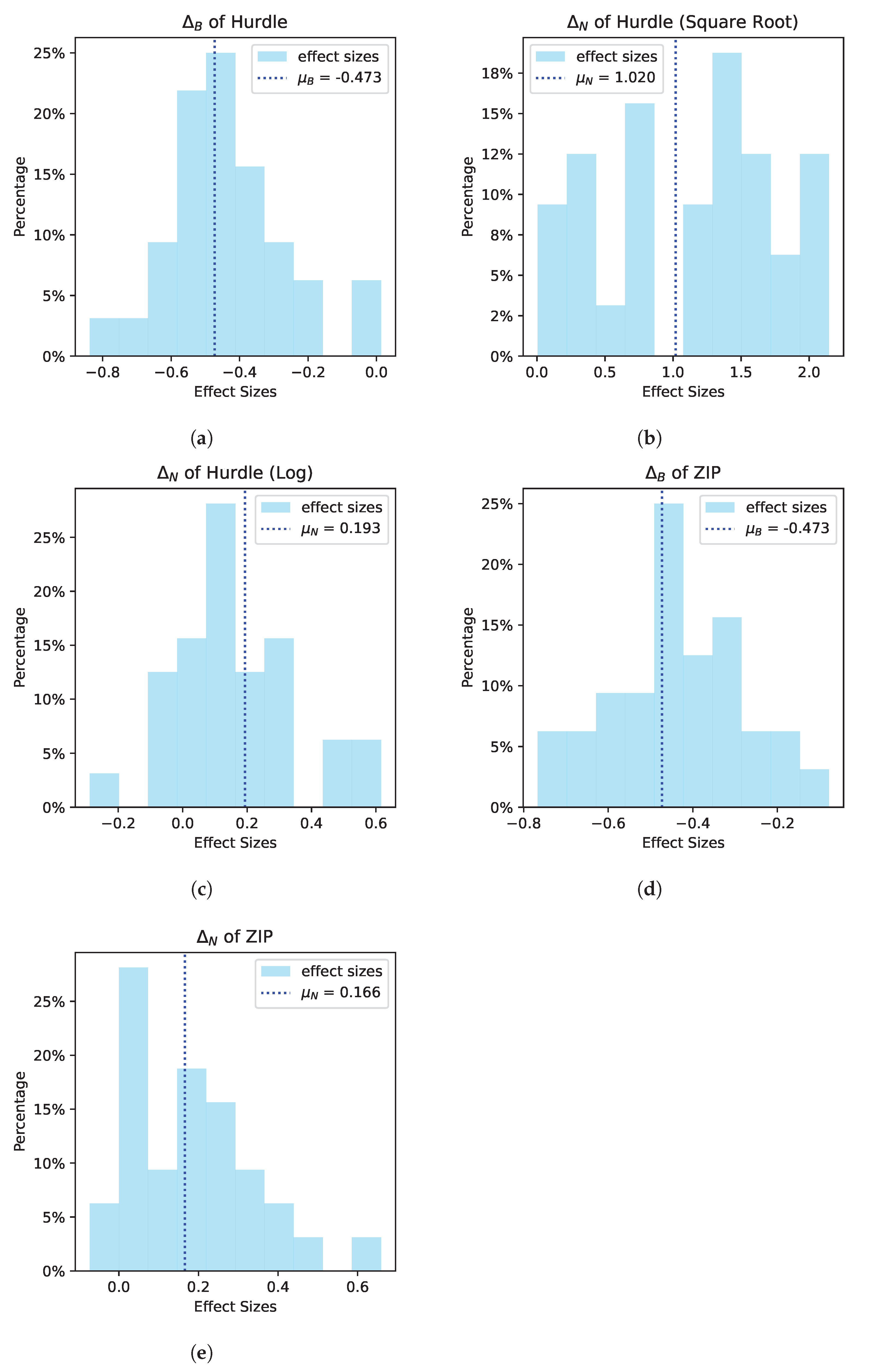
Ultimately, for each user, we considered three model classes: (1) a zero-inflated Poisson, (2) a hurdle model with a square root transform, and (3) a hurdle model with a log transform, and chose one of these model classes for each user (
Appendix A.2). Specifically, to select the model class for user
i, we fit all three model classes using each user’s data from ROBAS 2. Then, we chose the model class that had the lowest root mean squared error (RMSE) (
Appendix A.3). Additionally, along with the base model that generates stationary rewards, we include an environmental variant with a nonstationary reward function; here, “day in study” is used as a feature in the environment’s reward generating model (
Appendix A.1).
Imputing Treatment Effect Sizes: To construct a model of rewards for when an intervention message is sent (a case for which we have no data), we impute plausible treatment effects with the interdisciplinary team and modify the fitted base model with these effects. Specifically, we impute treatment effects on the Bernoulli component and the nonzero component. We impute both types of treatment effects because the investigative team’s intervention messages were developed to encourage users to brush more frequently and to brush for the recommended duration. Furthermore, because the research team believes that the users may respond differently to the engagement messages depending on the context and depending on the user, we included context-aware, population-level, and user-heterogeneous effects of the engagement messages as environmental variants (
Appendix A.5).
We use the following guidelines to guide the design of the effect sizes:
Following guideline 1 above, to set the population level effect size, we take the absolute value of the weights (excluding that for the intercept term) of the base models fitted for each ROBAS 2 user and the average across users and features (e.g., the average absolute value of weight for time of day and previous day brushing duration). For the heterogeneous (user-specific) effect sizes, for each user, we draw a value from a normal centered at the population effect sizes. Following guideline 2, the variance of the normal distributions is found by again taking the absolute value of the weights of the base models fitted for each user, averaging the weights across features, and taking the empirical variance across users. In total, there are eight environment variants, which are summarized in
Table 1. See
Appendix A for further details regarding the development of the simulation environments.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}