
LTU Attacker for Membership Inference

 , ,
, ,
Abstract
:1. Introduction
2. Related Work
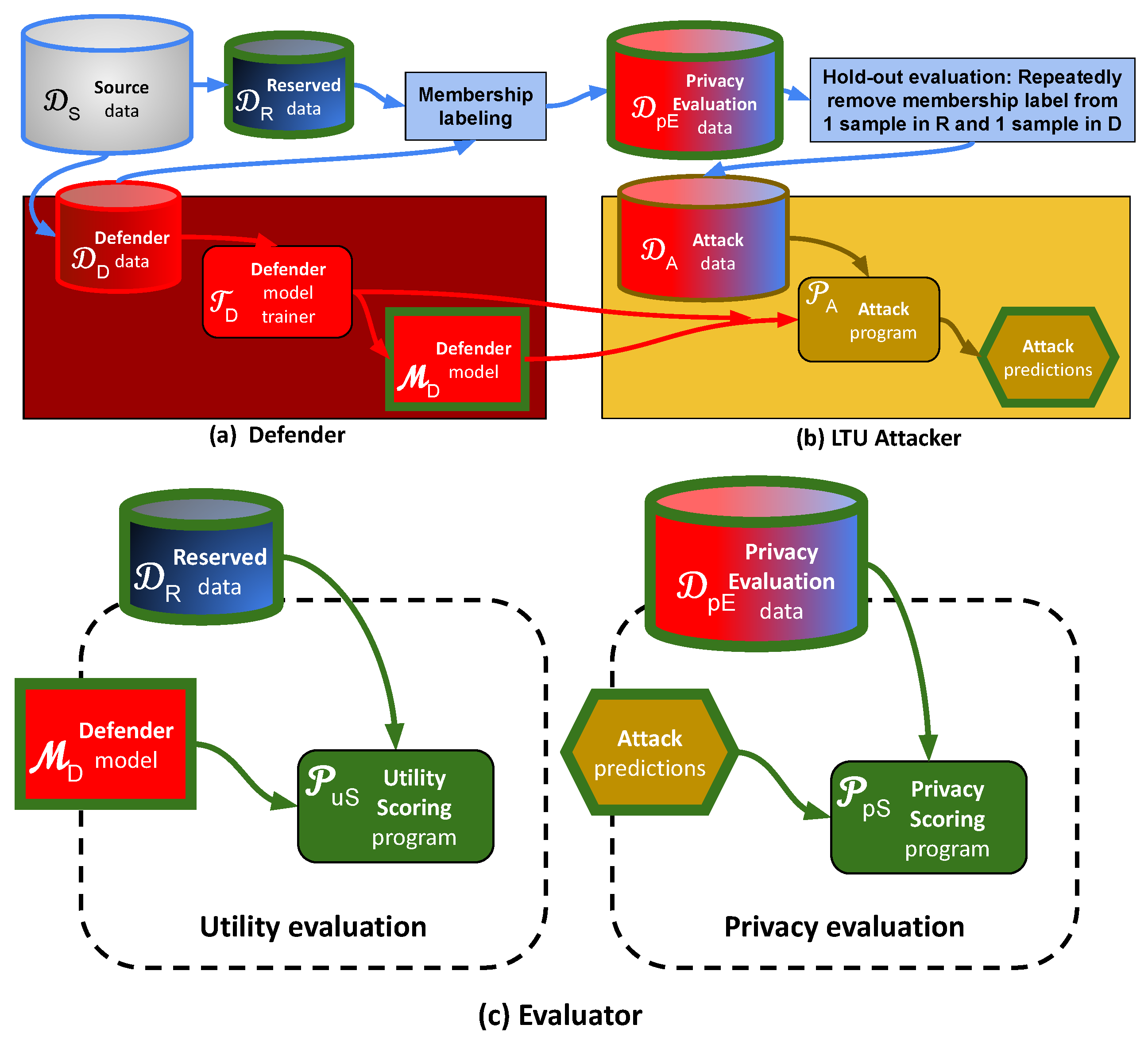
3. Problem Statement and Methodology
- Attack on alone: (1) Simply use a generalization Gap-attacker, which classifies as belonging to if the loss function of is smaller than that of (works well if overfits ); (2) Train a -attacker to predict membership, using as input any internal state or the output of , and using as training data. Then use to predict the labels of and .
- Attack on and : Depending on whether the Defender trainer is a white-box from which gradients can be computed, define by: (3) Training two mock Defender models and , one using and the other using , with the trainer . If is deterministic and independent of sample ordering, either or should be identical to , and otherwise one of them should be “closer” to . The sample corresponding to the model closest to is classified as being a member of . (4) Performing one gradient learning step with either or using , starting from the trained model , and compare the gradient norms.
- Applying over-fitting prevention (regularization) to ;
- Applying Differential Privacy algorithms to ;
- Training in a semi-supervised way (with transfer learning) or using synthetic data (generated with a simulator trained with a subset of );
- Modifying to optimize both utility and privacy.
4. Theoretical Analysis of Naïve Attackers
5. Data and Experimental Setting
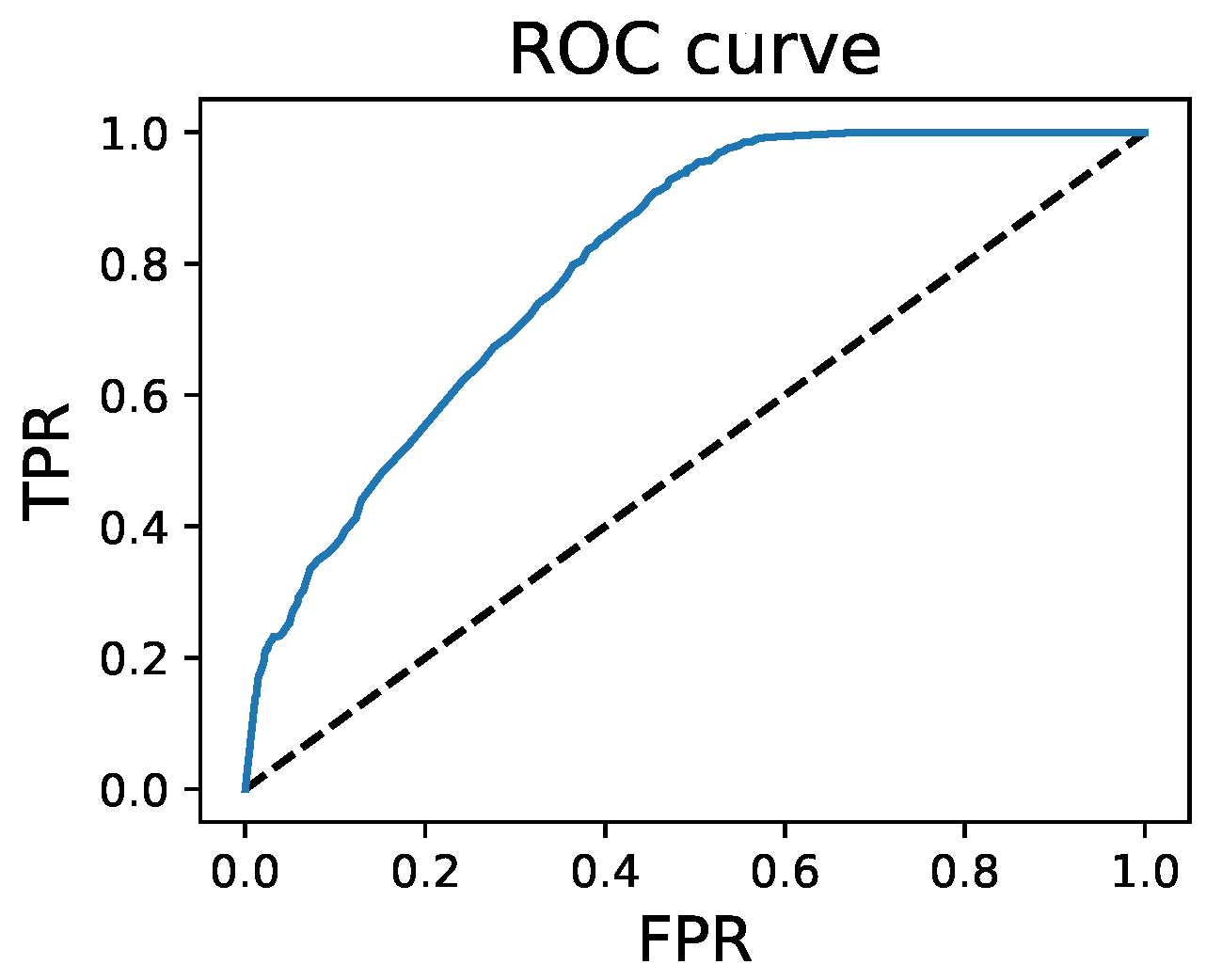
6. Results
6.1. Black-Box Attacker
6.2. White-Box Attacker
7. Discussion and Further Work
8. Conclusions
- Avoid storing examples (a weakness of example-based method, such as Nearest Neighbors);
- Ensure that for all f, following Theorem 1 ( is the probability that discriminant function f “favors” Reserved data while is the probability with which it favors the Defender data);
- Ensure that , following Theorem 2 ( is the expected value of the loss on Reserved data and on Defender data);
- Include some randomness in the Defender trainer algorithm, after Theorem 3.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Derivation of the Proof of Theorem 2
Appendix B. Non-Dominance of Either Strategy in Theorem 1 or Theorem 2

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | 1/2 | 1 | Row Sum | |
|---|---|---|---|---|
| 0.24 | 0.24 | 0.12 | 0.6 | |
| 0.12 | 0.12 | 0.06 | 0.3 | |
| 0.04 | 0.04 | 0.02 | 0.1 | |
| column sum | 0.4 | 0.4 | 0.2 |
Appendix C. LTU Global and Individual Privacy Scores
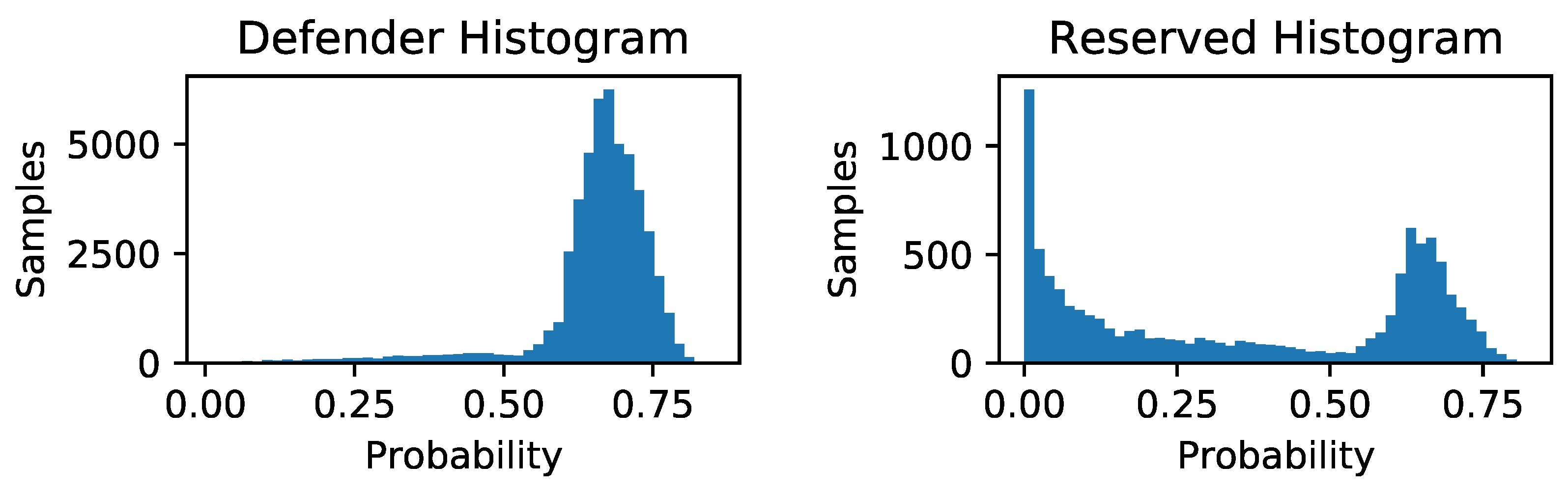
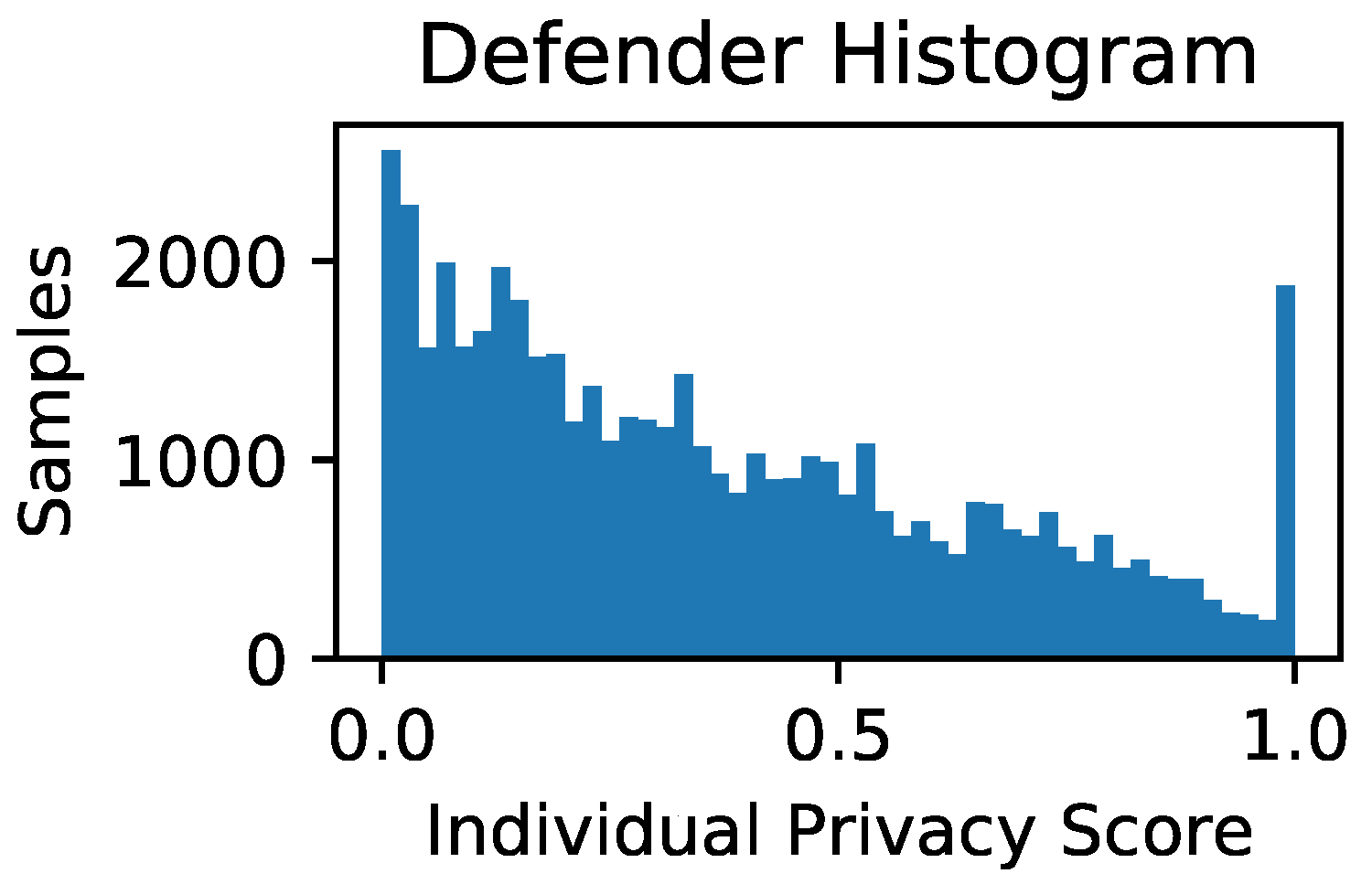
References
- Nasr, M.; Shokri, R.; Houmansadr, A. Comprehensive privacy analysis of deep learning: Passive and active white-box inference attacks against centralized and federated learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 739–753. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 3–18. [Google Scholar]
- Li, N.; Qardaji, W.; Su, D.; Wu, Y.; Yang, W. Membership privacy: A unifying framework for privacy definitions. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 889–900. [Google Scholar]
- Long, Y.; Bindschaedler, V.; Gunter, C.A. Towards measuring membership privacy. arXiv 2017, arXiv:1712.09136. [Google Scholar]
- Thudi, A.; Shumailov, I.; Boenisch, F.; Papernot, N. Bounding Membership Inference. arXiv 2022, arXiv:2202.12232. [Google Scholar] [CrossRef]
- Song, L.; Mittal, P. Systematic evaluation of privacy risks of machine learning models. In Proceedings of the 30th {USENIX} Security Symposium ({USENIX} Security 21), Virtual Event, 11–13 August 2021; pp. 2615–2632. [Google Scholar]
- Jayaraman, B.; Wang, L.; Knipmeyer, K.; Gu, Q.; Evans, D. Revisiting membership inference under realistic assumptions. arXiv 2020, arXiv:2005.10881. [Google Scholar] [CrossRef]
- Yeom, S.; Giacomelli, I.; Fredrikson, M.; Jha, S. Privacy risk in machine learning: Analyzing the connection to overfitting. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; pp. 268–282. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Demystifying membership inference attacks in machine learning as a service. IEEE Trans. Serv. Comput. 2019, 14, 2073–2089. [Google Scholar] [CrossRef]
- Hayes, J.; Melis, L.; Danezis, G.; Cristofaro, E.D. LOGAN: Membership Inference Attacks Against Generative Models. arXiv 2018, arXiv:1705.07663. [Google Scholar] [CrossRef] [Green Version]
- Hilprecht, B.; Härterich, M.; Bernau, D. Reconstruction and Membership Inference Attacks against Generative Models. arXiv 2019, arXiv:1906.03006. [Google Scholar]
- Chen, D.; Yu, N.; Zhang, Y.; Fritz, M. Gan-leaks: A taxonomy of membership inference attacks against generative models. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 343–362. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Theory of Cryptography Conference; Springer: Berlin, Germany, 2006; pp. 265–284. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Xie, L.; Lin, K.; Wang, S.; Wang, F.; Zhou, J. Differentially private generative adversarial network. arXiv 2018, arXiv:1802.06739. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2030–2096. [Google Scholar]
- Nasr, M.; Shokri, R.; Houmansadr, A. Machine learning with membership privacy using adversarial regularization. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 634–646. [Google Scholar]
- Huang, H.; Luo, W.; Zeng, G.; Weng, J.; Zhang, Y.; Yang, A. DAMIA: Leveraging Domain Adaptation as a Defense against Membership Inference Attacks. IEEE Trans. Dependable Secur. Comput. 2021. [Google Scholar] [CrossRef]
- Nasr, M.; Song, S.; Thakurta, A.; Papernot, N.; Carlini, N. Adversary Instantiation: Lower Bounds for Differentially Private Machine Learning. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021. [Google Scholar] [CrossRef]
- Sablayrolles, A.; Douze, M.; Schmid, C.; Ollivier, Y.; Jégou, H. White-box vs black-box: Bayes optimal strategies for membership inference. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5558–5567. [Google Scholar]
- Liu, X.; Xu, Y.; Tople, S.; Mukherjee, S.; Ferres, J.L. Mace: A flexible framework for membership privacy estimation in generative models. arXiv 2020, arXiv:2009.05683. [Google Scholar]
- Guyon, I.; Makhoul, J.; Schwartz, R.; Vapnik, V. What size test set gives good error rate estimates? IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 52–64. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. J. Priv. Confidentiality 2017, 7, 17–51. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report TR-2009; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Yadav, C.; Bottou, L. Cold Case: The Lost MNIST Digits. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Rahman, M.A.; Rahman, T.; Laganière, R.; Mohammed, N.; Wang, Y. Membership Inference Attack against Differentially Private Deep Learning Model. Trans. Data Priv. 2018, 11, 61–79. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnetv2: Smaller models and faster training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Jia, J.; Salem, A.; Backes, M.; Zhang, Y.; Gong, N.Z. MemGuard: Defending against Black-Box Membership Inference Attacks via Adversarial Examples; CCS’19; Association for Computing Machinery: New York, NY, USA, 2019; pp. 259–274. [Google Scholar] [CrossRef]
- Wang, J.; Hou, W. DeepDA: Deep Domain Adaptation Toolkit. Available online: https://github.com/jindongwang/transferlearning/tree/master/code/DeepDA (accessed on 4 May 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sun, H.; Tu, W.W.; Guyon, I.M. OmniPrint: A Configurable Printed Character Synthesizer. arXiv 2022, arXiv:2201.06648. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep Subdomain Adaptation Network for Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]

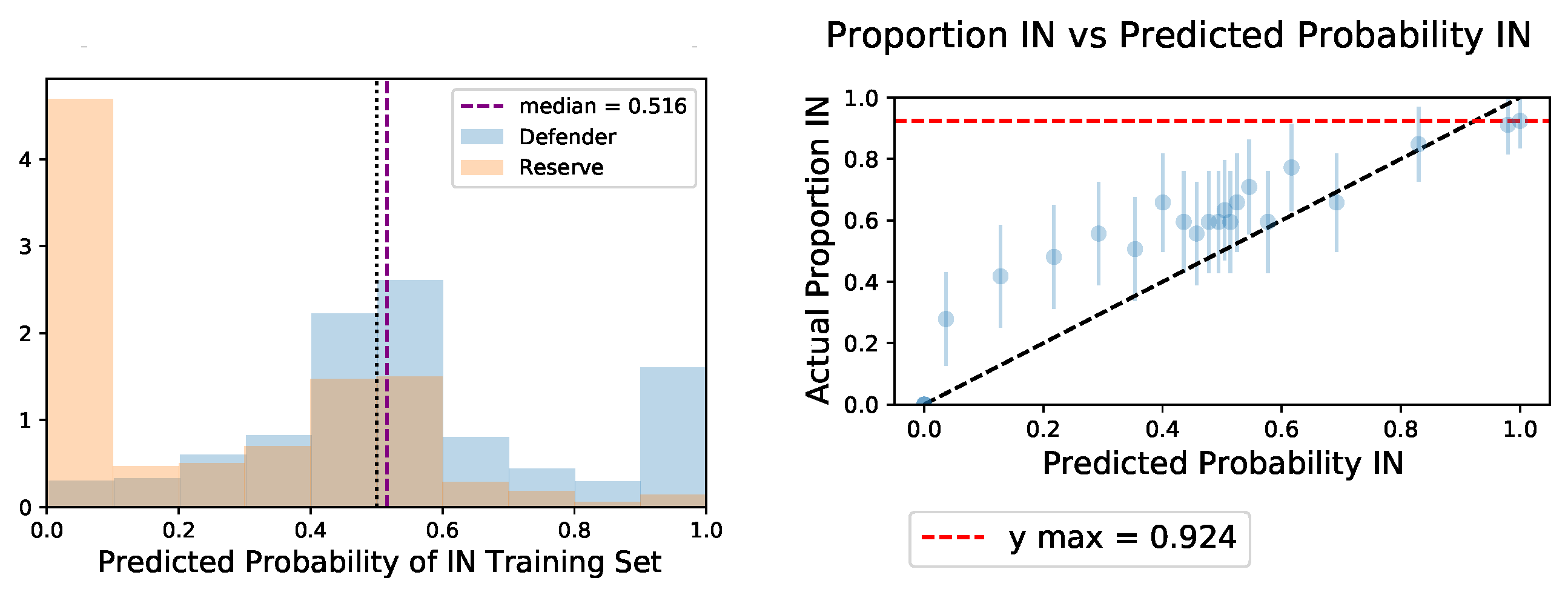
| QMNIST Utility | Privacy | Orig. order + Seeded | Rand. order + Seeded | Not Seeded |
| Logistic lbfgs | 0.92|0.00 | 0.91|0.00 | 0.91|0.00 |
| Bayesian ridge | 0.92|0.00 | 0.92|0.00 | 0.89|0.00 |
| Naive Bayes | 0.70|0.00 | 0.70|0.00 | 0.70|0.00 |
| SVC | 0.91|0.00 | 0.91|0.00 | 0.88|0.00 |
| KNN* | 0.86|0.27 | 0.86|0.27 | 0.83|0.18 |
| LinearSVC | 0.92|0.00 | 0.92|0.69 | 0.91|0.63 |
| SGD SVC | 0.90|0.03 | 0.92|1.00 | 0.89|1.00 |
| MLP | 0.90|0.00 | 0.90|0.97 | 0.88|0.93 |
| Perceptron | 0.90|0.04 | 0.91|1.00 | 0.92|1.00 |
| Random Forest | 0.88|0.00 | 0.88|0.99 | 0.85|1.00 |
| CIFAR-10 Utility | Privacy | Orig. order + Seeded | Rand. order + Seeded | Not Seeded |
| Logistic lbfgs | 0.95|0.00 | 0.95|0.00 | 0.95|0.00 |
| Bayesian ridge | 0.91|0.00 | 0.90|0.00 | 0.90|0.00 |
| Naive Bayes | 0.89|0.00 | 0.89|0.01 | 0.89|0.00 |
| SVC | 0.95|0.00 | 0.94|0.00 | 0.95|0.00 |
| KNN* | 0.92|0.44 | 0.91|0.49 | 0.92|0.49 |
| LinearSVC | 0.95|0.00 | 0.95|0.26 | 0.95|0.22 |
| SGD SVC | 0.94|0.32 | 0.94|0.98 | 0.93|0.99 |
| MLP | 0.95|0.00 | 0.94|0.98 | 0.95|0.97 |
| Perceptron | 0.94|0.26 | 0.94|1.00 | 0.93|0.96 |
| Random Forest | 0.92|0.00 | 0.93|0.99 | 0.91|0.92 |
| Defender Model | Utility | Privacy |
|---|---|---|
| Supervised | ||
| Unsupervised Domain Adaptation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pedersen, J.; Muñoz-Gómez, R.; Huang, J.; Sun, H.; Tu, W.-W.; Guyon, I. LTU Attacker for Membership Inference. Algorithms 2022, 15, 254. https://doi.org/10.3390/a15070254
Pedersen J, Muñoz-Gómez R, Huang J, Sun H, Tu W-W, Guyon I. LTU Attacker for Membership Inference. Algorithms. 2022; 15(7):254. https://doi.org/10.3390/a15070254
Chicago/Turabian StylePedersen, Joseph, Rafael Muñoz-Gómez, Jiangnan Huang, Haozhe Sun, Wei-Wei Tu, and Isabelle Guyon. 2022. "LTU Attacker for Membership Inference" Algorithms 15, no. 7: 254. https://doi.org/10.3390/a15070254
APA StylePedersen, J., Muñoz-Gómez, R., Huang, J., Sun, H., Tu, W.-W., & Guyon, I. (2022). LTU Attacker for Membership Inference. Algorithms, 15(7), 254. https://doi.org/10.3390/a15070254