
BAG-DSM: A Method for Generating Alternatives for Hierarchical Multi-Attribute Decision Models Using Bayesian Optimization



Abstract
:1. Introduction
2. Related Work
3. Problem Description
3.1. Multi-Criteria Modeling
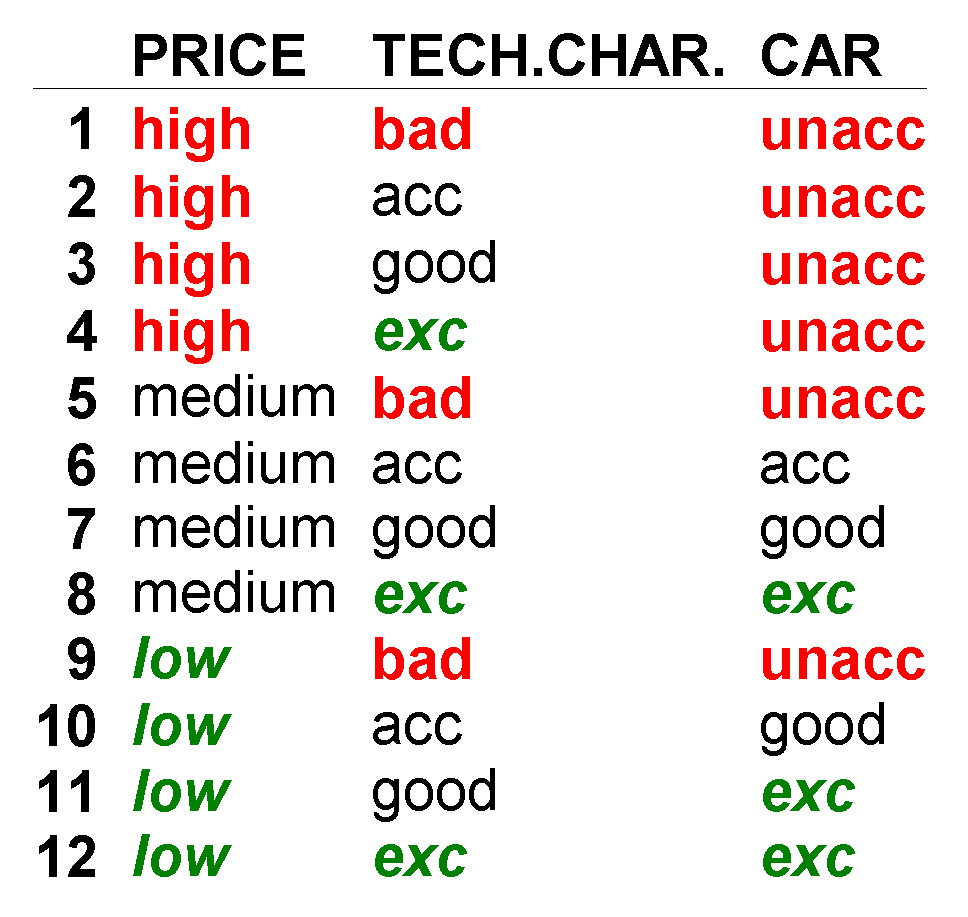
3.2. Method DEX
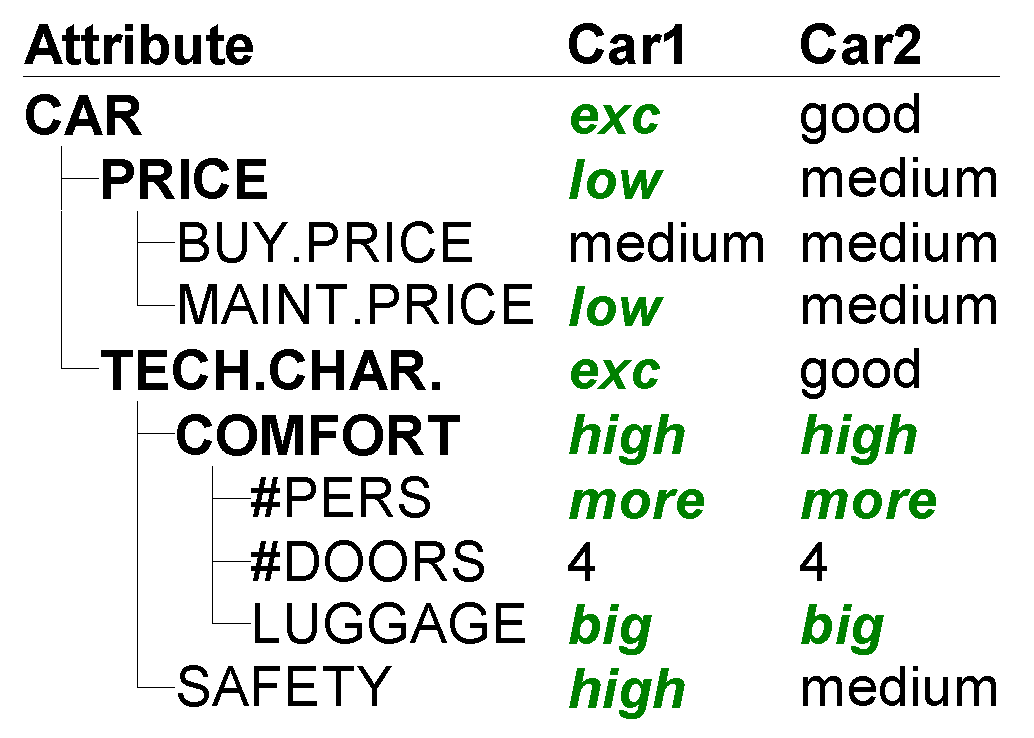
3.3. DEX Models and Their Properties
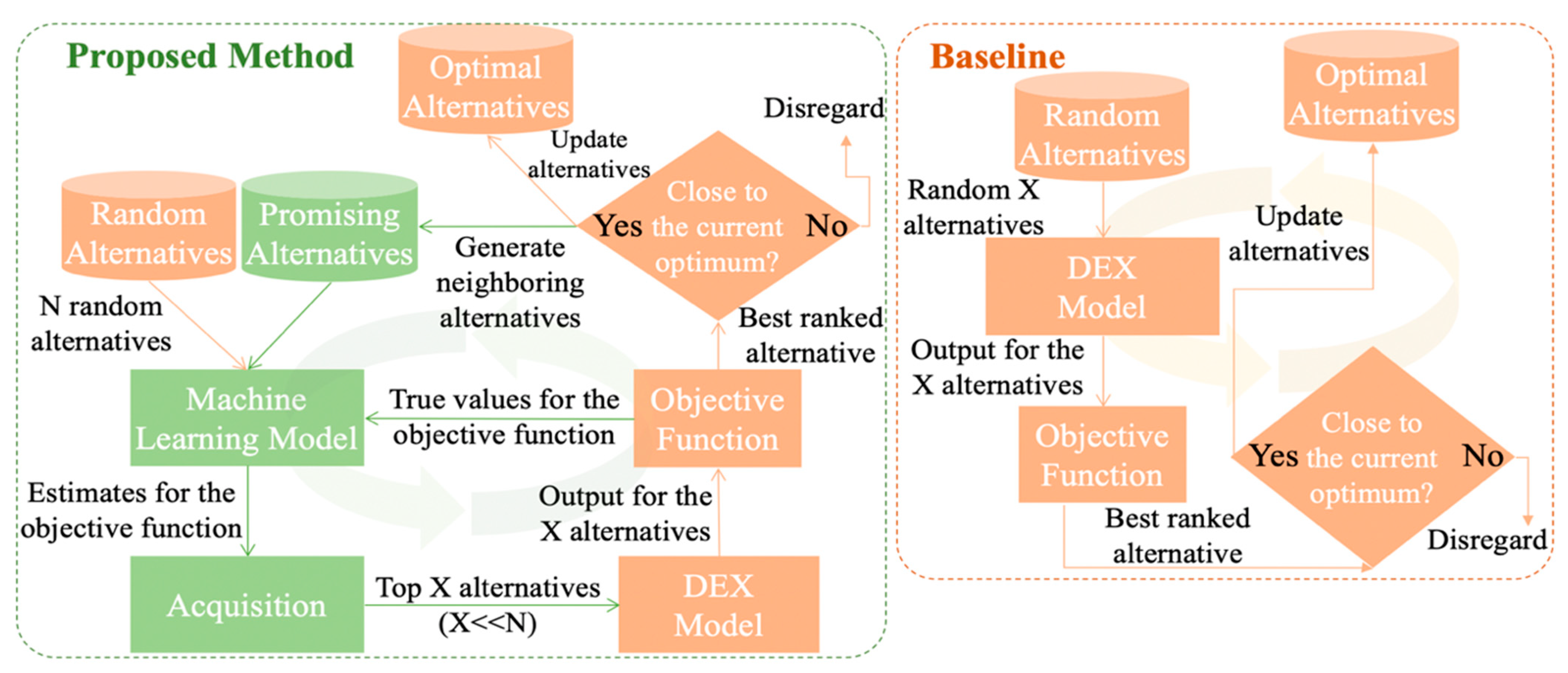
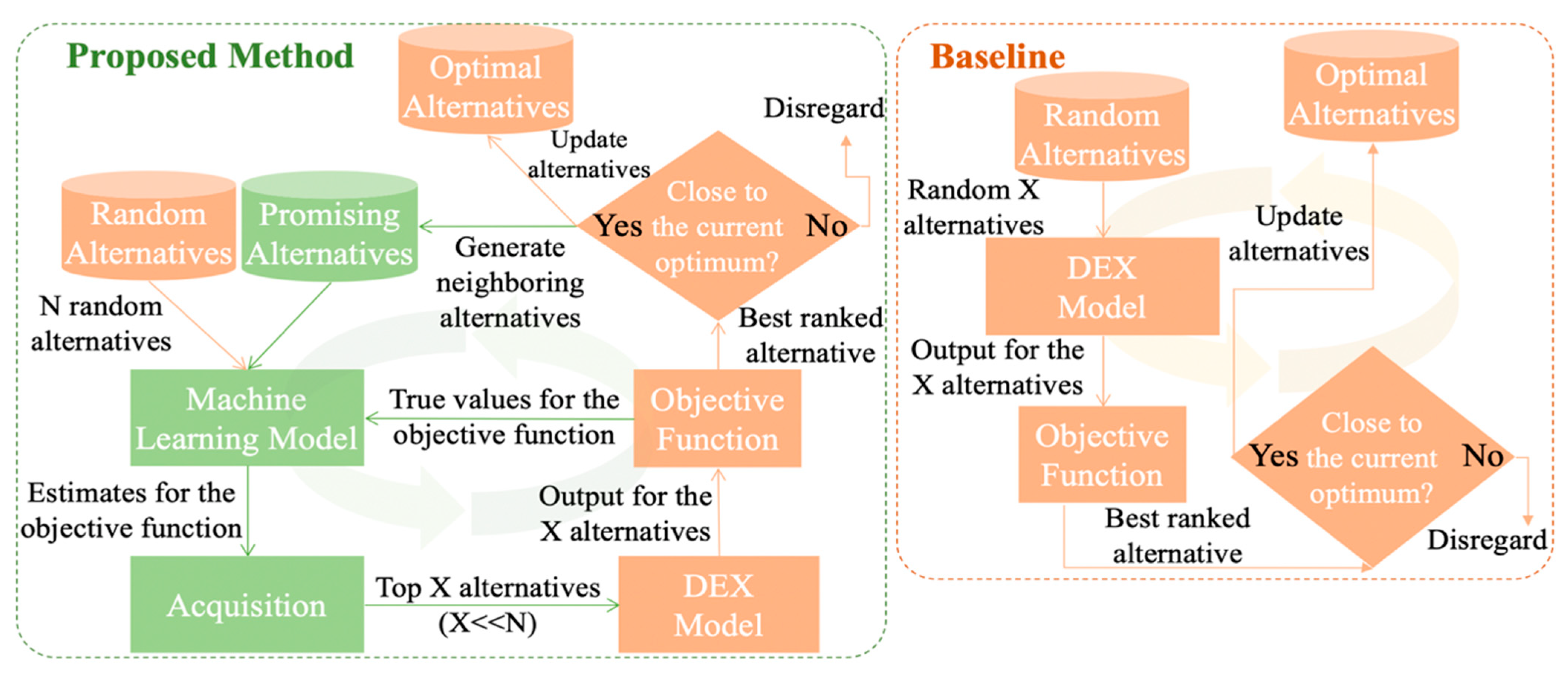
4. Bayesian Alternative Generator for Decision Support Models (BAG-DSM)
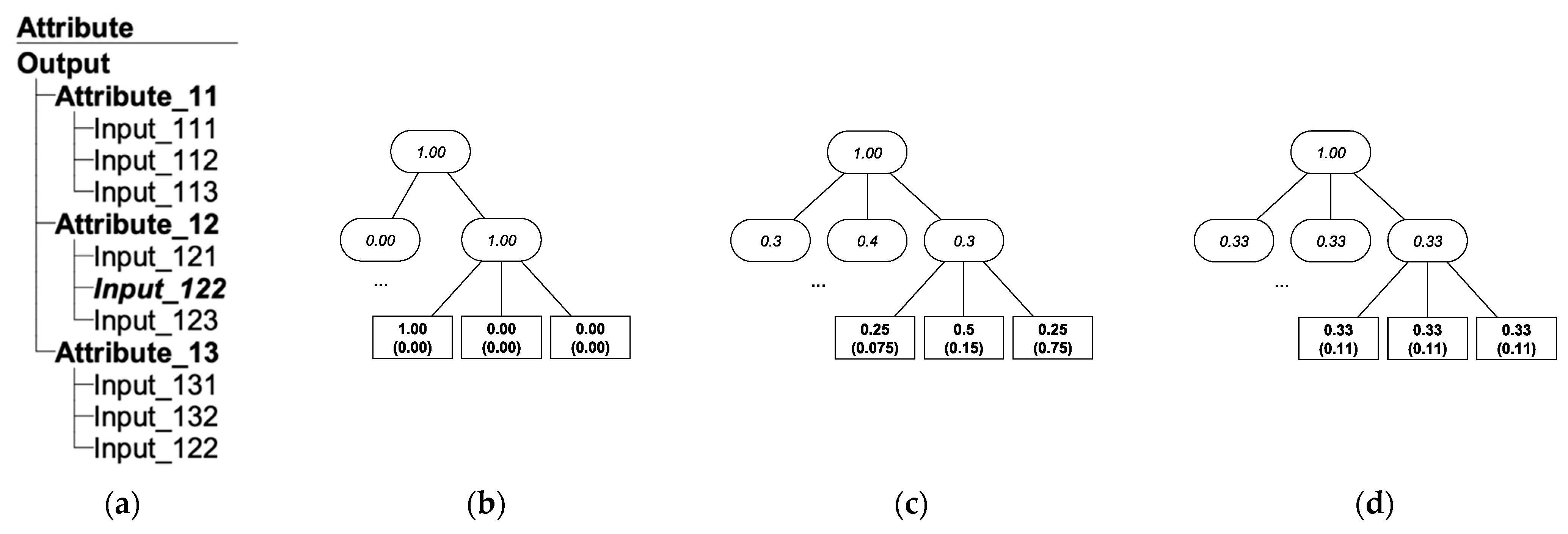
4.1. Problem Formulation
4.2. Implementation
| Algorithm 1: Input: Decision model F and current alternative CA; Output: best_alternatives |
| # parameters and initialization max_e = 150 # maximum number of epochs n_candidates = 10 # number of candidates per iteration objective_jitter = 0.8 # if an alternative is close to the current best (e.g, 80% as good as the current best, the alternative’s neighbors should be checked) random_sample_size = 10,000 #number of randomly generated alternatives best_alternatives = [] surrogate_model = new Random_Forest() promising_alternatives_pool = [] #initial values candidate_alternatives = generate_random_alternatives (10) real_objective_values = objective_function (F, CA, alternatives) surrogate_model.fit (candidate_alternatives, real_objective_values) known_alternatives.add (candidate_alternatives, real_objective_values) best_alternative, best_score = max (candidate_alternatives, real_objective_values) neighboring_alternatives= generate_neighborhood (best_alternative) while counter < max_e do: |
| If size (neighboring_alternatives) > 0: alternatives_pool = neighboring_alternatives else: alternatives_pool = gen_rand_alternatives (best_alternative, random_sample_size) # get top ranked (e.g., 10) candidates using the acquisition function candidate_alternatives, candidate_scores = perform_acquisition (alternatives_pool, n_candidates) #evaluation of candidate alternatives real_objective_values = objective_function (F, CA, alternatives) known_alternatives.add (candidate_alternatives, real_objective_values) #update current best and promising alternatives i = 0 while i < size (candidate_scores) do: if best_score*objective_jitter <= candidate_scores[i] do: neighboring_alternatives = generate_ neighbourhood (candidate_alternatives[i]) promising_alternatives_pool.add (neighboring_alternatives) if best_score < candidate_scores[i] do: best_alternatives = [] best_alternatives.add (candidate_alternatives[i]) if best_score==candidate_scores[i] do: best_alternatives.add (candidate_alternatives[i]) i++ #update the surrogate model surrogate_model.fit (candidate_alternatives, real_objective_values) counter++ |
| end #peform final check of the promising alternatives best_alternatives = check_promising_values(promising_alternatives_pool,best_alternatives) return best_alternatives |
5. Experiments
5.1. Experimental Setup
- starting with output attribute value “low”, generate alternatives that would improve the final attribute value to “medium” (positive change),
- starting with output attribute value “low”, generate alternatives that would improve the final attribute value to “high” (positive change),
- starting with output attribute value ‘medium’, generate alternatives that would improve the final attribute value to ‘high (positive change),
- starting with output attribute value “medium”, generate alternatives that would change the final attribute value to “low” (negative change),
- starting with output attribute value “high”, generate alternatives that would change the final attribute value to “medium” (negative change),
- starting with output attribute value “high”, generate alternatives that would change the final attribute value to “low” (negative change).
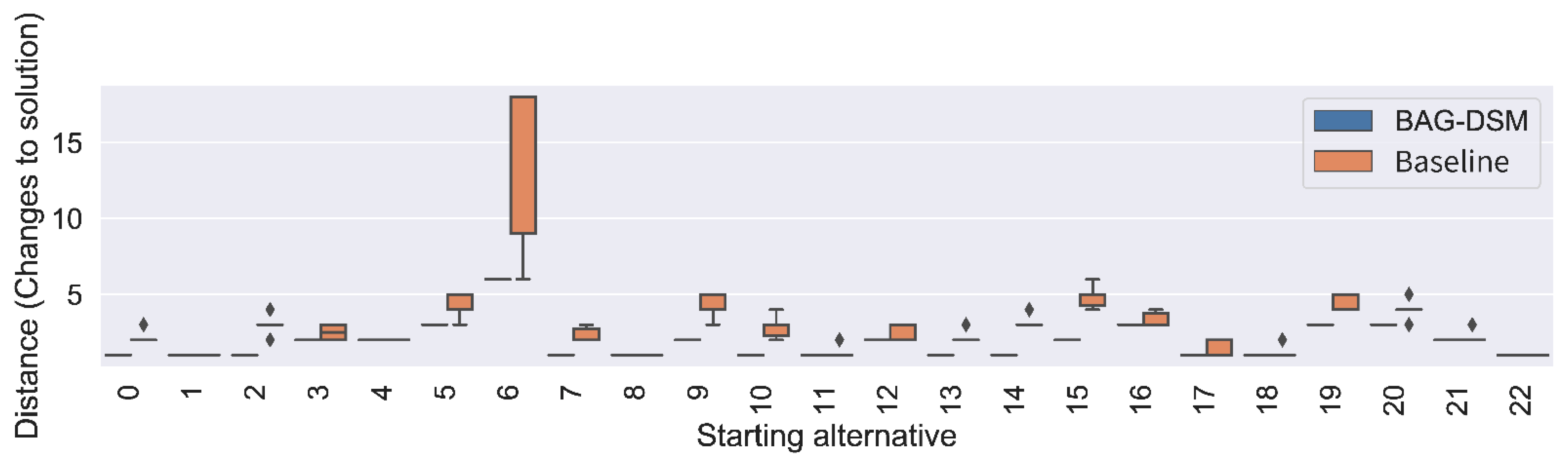
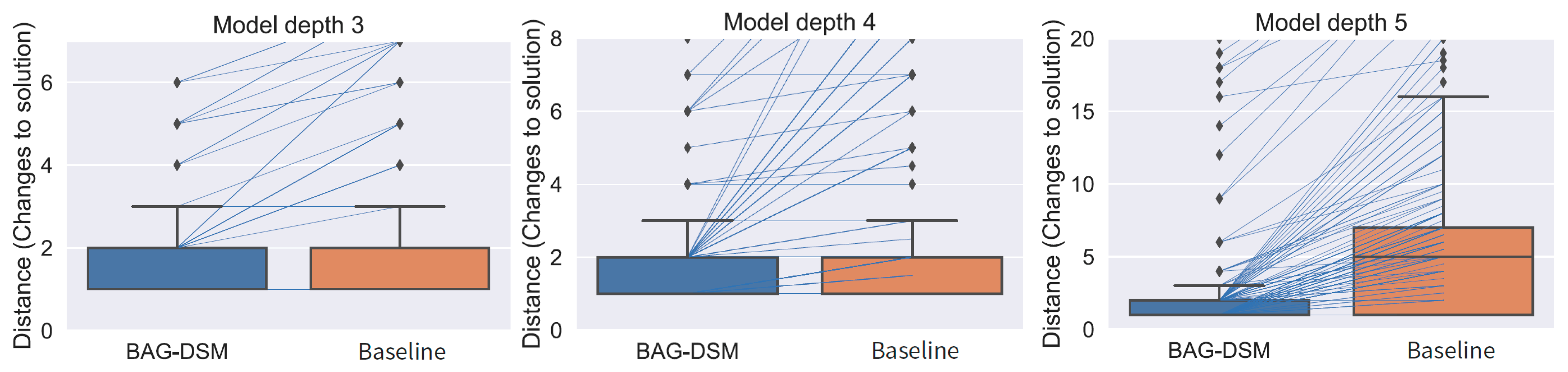
- distance—as defined in Equation (3). The shorter the distance is, the better the solutions are;
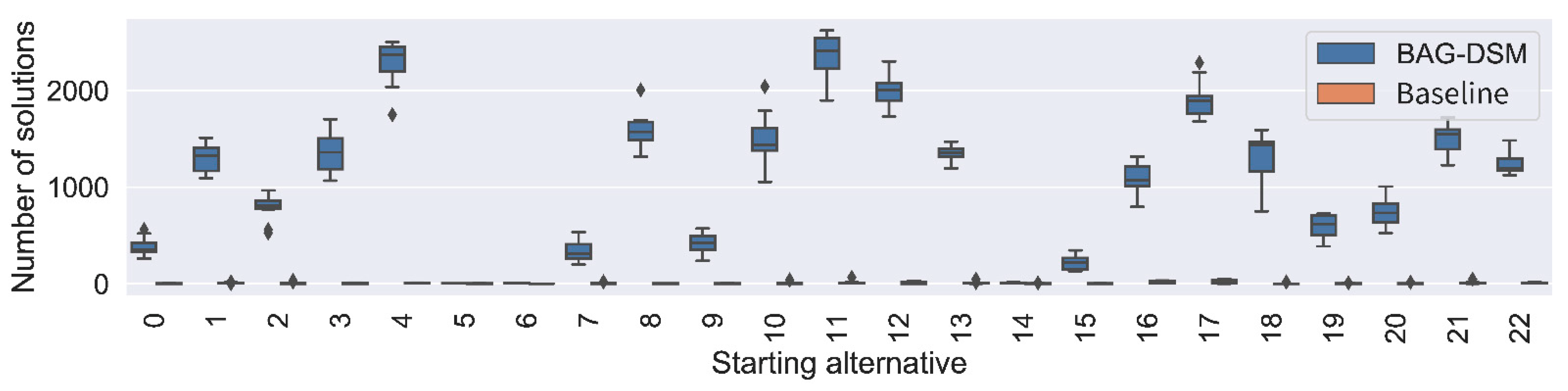
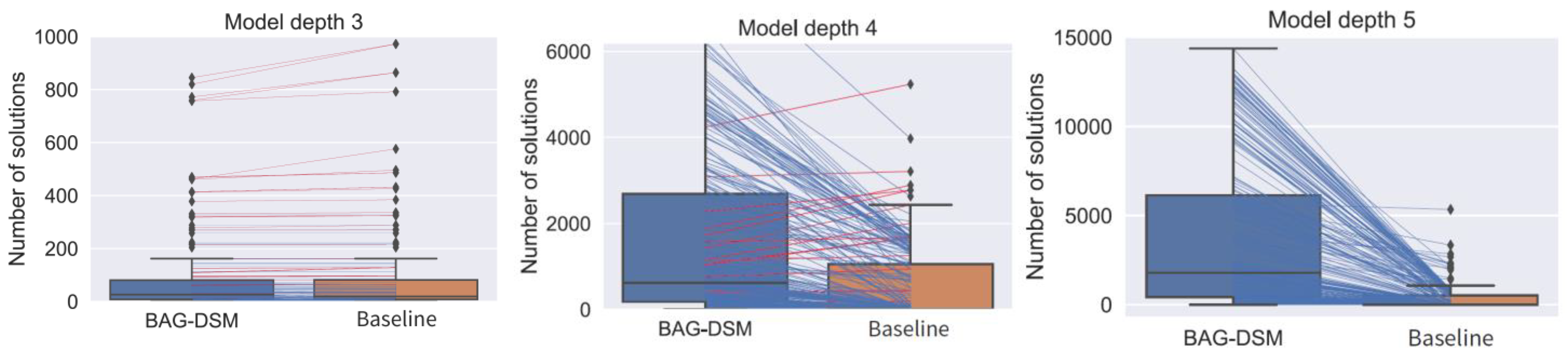
- optimal solution set size—the method outputs a set of optimal alternatives that have an equal score with respect to the objective function (defined in Equation (5)). The bigger the solution set is, the more options to choose from for the user;
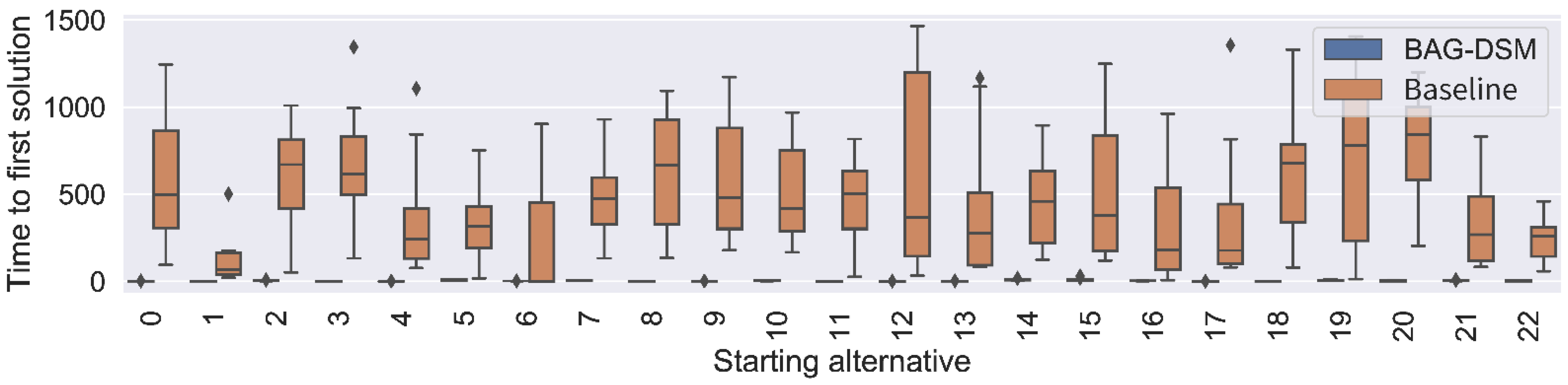
- time to first optimal solution—i.e., the time required to generate the first solution in the optimal solution set.
5.2. Experimental Results
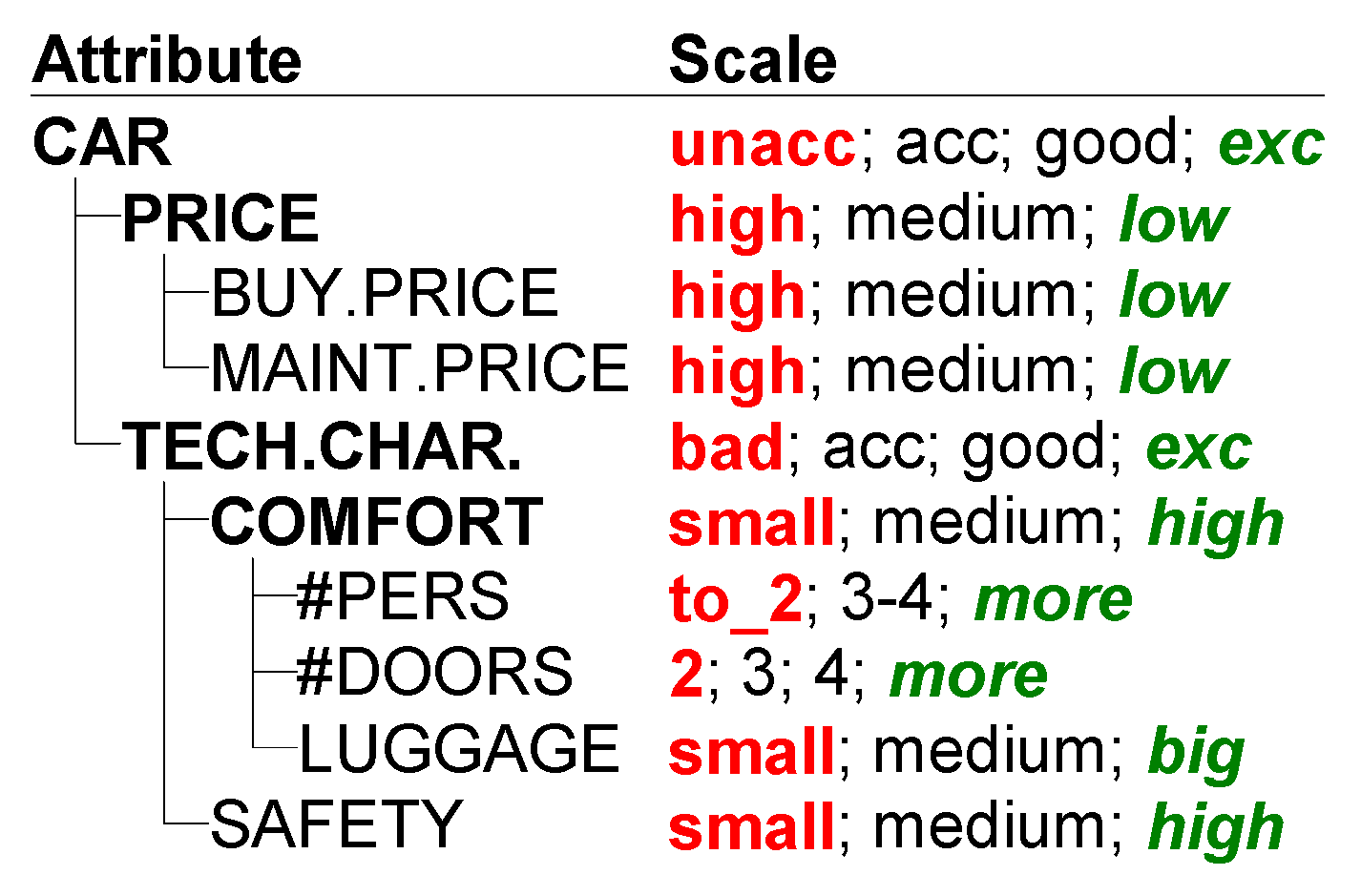
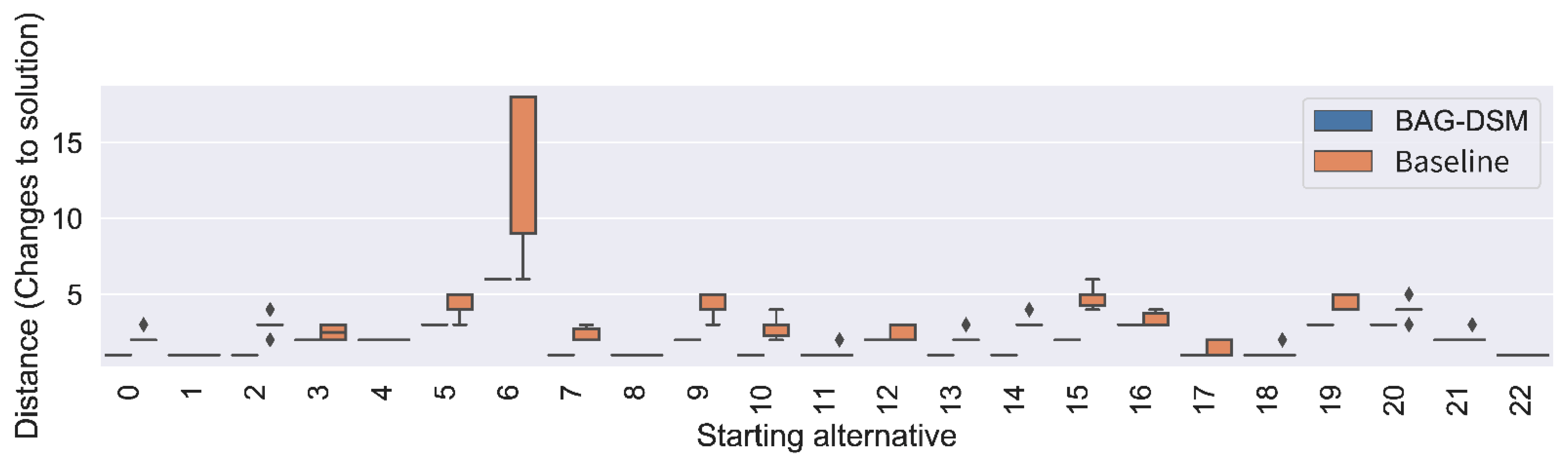
5.2.1. Landmark Use Case
5.2.2. Benchmark Models
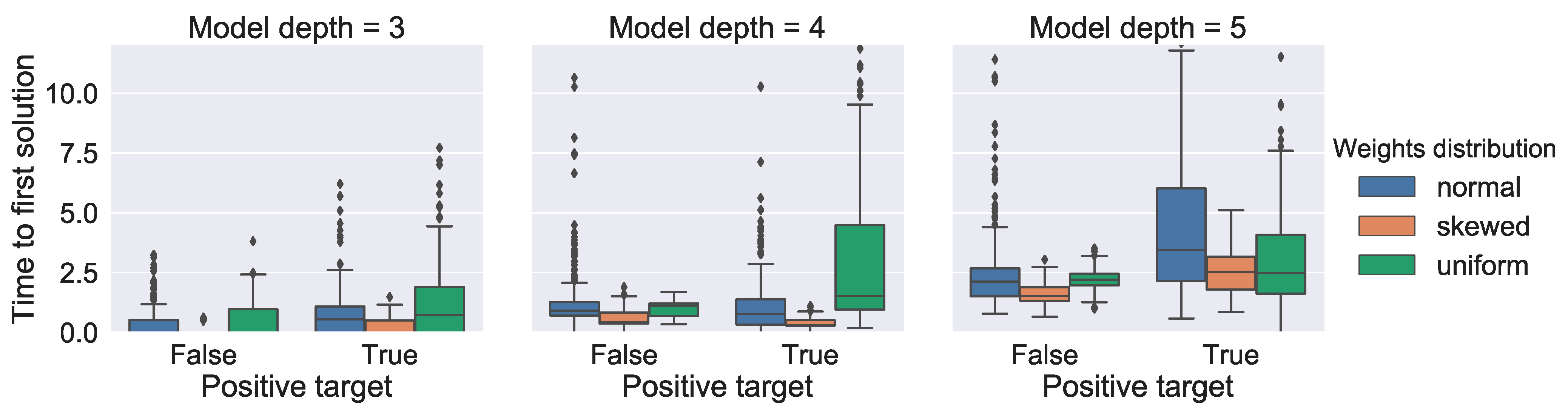
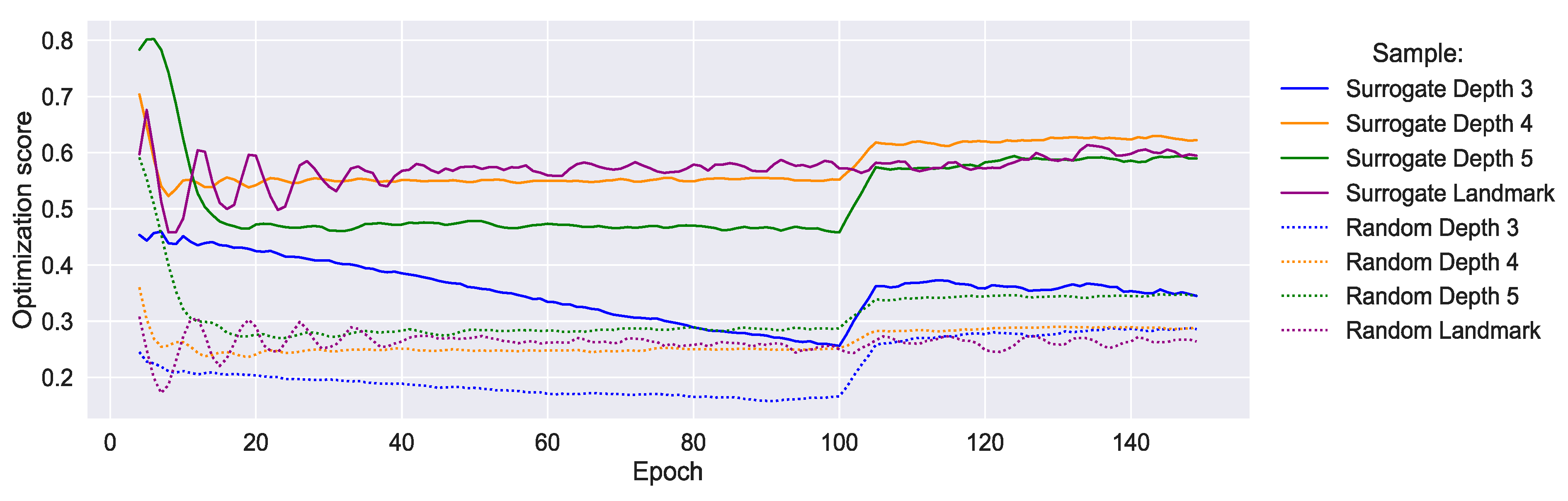
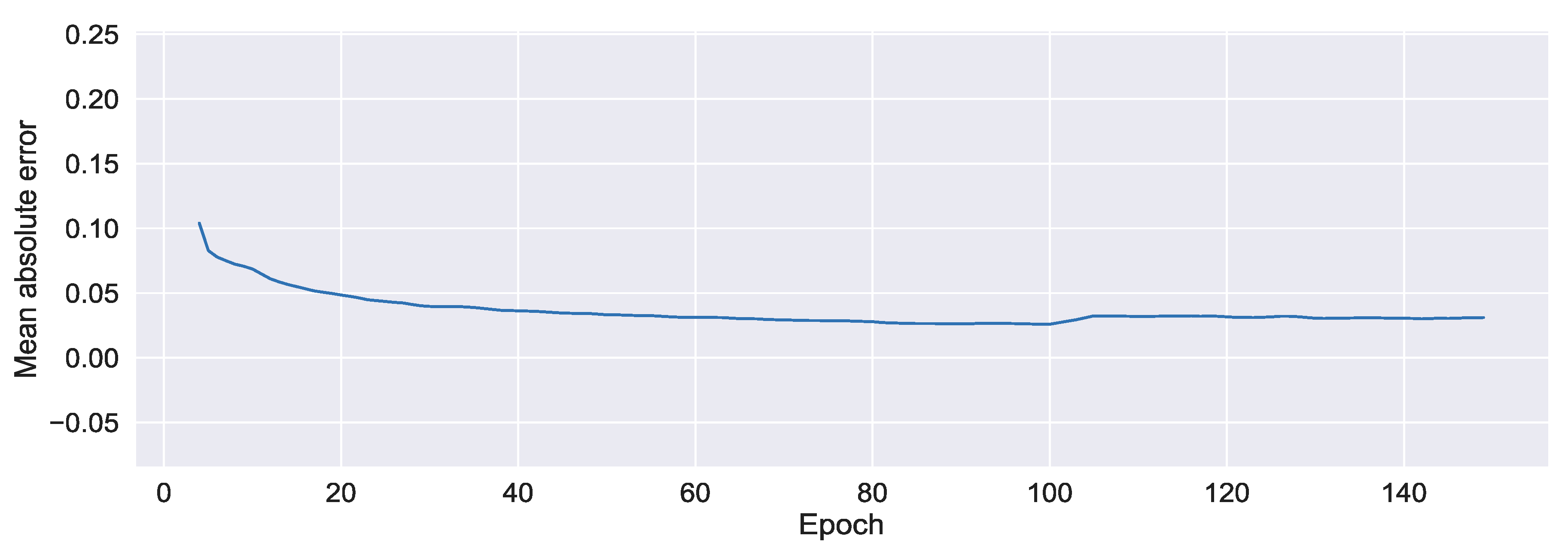
5.2.3. Performance Analysis
6. Discussion
6.1. Results Discussion
6.2. Limitations and Future Work
6.3. Implications
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Power, D.J. Decision Support Systems: Concepts and Resources for Managers; Quorum Books: Westport, CT, USA, 2002. [Google Scholar]
- Turban, E.; Aronson, J.E.; Liang, T.-P. Decision Support Systems and Intelligent Systems; Prentice-Hall: Hoboken, NJ, USA, 2005. [Google Scholar]
- Mallach, E. Decision Support and Data Warehouse Systems; Irwin Profesional Publishing: Burr Ridge, IL, USA, 2000. [Google Scholar]
- Sadok, W.; Angevin, F.; Bergez, J.-É.; Bockstaller, C.; Colomb, B.; Guichard, L.; Reau, R.; Doré, T. Ex ante assessment of the sustainability of alternative cropping systems: Implications for using multi-criteria decision-aid methods. A review. Agron. Sustain. Dev. 2008, 28, 163–174. [Google Scholar] [CrossRef] [Green Version]
- Sadok, W.; Angevin, F.; Bergez, J.-É.; Bockstaller, C.; Colomb, B.; Guichard, L.; Reau, R.; Messean, A.; Doré, T. MASC, a qual-itative multi-attribute decision model for ex ante assessment of the sustainability of cropping systems. Agron. Sustain. Dev. 2009, 29, 447–461. [Google Scholar] [CrossRef] [Green Version]
- Martel, J.-M.; Matarazzo, B. Multiple Criteria Decision Analysis: State of the Art Surveys; Springer: New York, NY, USA, 2016. [Google Scholar]
- Dogliotti, S.; Rossing, W.; van Ittersum, M. Systematic design and evaluation of crop rotations enhancing soil conservation, soil fertility and farm income: A case study for vegetable farms in South Uruguay. Agric. Syst. 2004, 80, 277–302. [Google Scholar] [CrossRef]
- Bohanec, M. DEX (Decision EXpert): A Qualitative Hierarchical Multi-Criteria Method; Kulkarni, A.J., Ed.; Multiple Criteria Decision Making, Studies in Systems, Decision and Control 407; Springer: Singapore, 2022. [Google Scholar]
- Kontić, B.; Bohanec, M.; Kontić, D.; Trdin, N.; Matko, M. Improving appraisal of sustainability of energy options—A view from Slovenia. Energy Policy 2016, 90, 154–171. [Google Scholar] [CrossRef]
- Erdogan, G.; Refsdal, A. A Method for Developing Qualitative Security Risk Assessment Algorithms. In Risks and Security of Internet and Systems; Springer International Publishing: Dinard, France, 2018; pp. 244–259. [Google Scholar]
- Prevolšek, B.; Maksimović, A.; Puška, A.; Pažek, K.; Žibert, M.; Rozman, Č. Sustainable Development of Ethno-Villages in Bosnia and Herzegovina—A Multi Criteria Assessment. Sustainability 2020, 12, 1399. [Google Scholar] [CrossRef] [Green Version]
- Bampa, F.; O’Sullivan, L.; Madena, K.; Sanden, T.; Spiegel, H.; Henriksen, C.B.; Ghaley, B.B.; Jones, A.; Staes, J.; Sturel, S.; et al. Harvesting European knowledge on soil functions and land manage-ment using multi-criteria decision analysis. Soil Use Manag. 2019, 35, 6–20. [Google Scholar] [CrossRef] [Green Version]
- Lotfi, F.H.; Rostamy-Malkhalifeh, M.; Aghayi, N.; Beigi, Z.G.; Gholami, K. An improved method for ranking alternatives in multiple criteria decision analysis. Appl. Math. Model. 2013, 37, 25–33. [Google Scholar] [CrossRef] [Green Version]
- Contreras, I. A DEA-inspired procedure for the aggregation of preferences. Expert Syst. Appl. 2011, 38, 564–570. [Google Scholar] [CrossRef]
- Bergez, J.-E. Using a genetic algorithm to define worst-best and best-worst options of a DEXi-type model: Application to the MASC model of cropping-system sustainability. Comput. Electron. Agric. 2012, 90, 93–98. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual Explanations Without Opening The Black Box: Automated Decisions And The Gdpr. Harv. J. Law Technol. 2018, 31, 842–887. [Google Scholar] [CrossRef] [Green Version]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Joshi, S.; Koyejo, O.; Vijitbenjaronk, W.; Kim, B.; Ghosh, J. Towards Realistic Individual Recourse and Actionable Explanations in Black-Box Decision Making Systems. 24 July 2019. Available online: https://arxiv.org/abs/1907.09615 (accessed on 4 May 2022).
- Karimi, A.-H.; Barthe, G.; Balle, B.; Valera, I. Model-Agnostic Counterfactual Explanations for Consequential Decisions. 27 May 2019. Available online: https://arxiv.org/abs/1905.11190 (accessed on 4 May 2022).
- Wexler, J.; Pushkarna, M.; Bolukbasi, T.; Wattenberg, M.; Viegas, F.; Wilson, J. The What-If Tool: Interactive Probing of Machine Learning Models. IEEE Trans. Vis. Comput. Graph. 2019, 26, 56–65. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tolomei, G.; Silvestri, F.; Haines, A.; Lalmas, M. Interpretable Predictions of Tree-based Ensembles via Actionable Feature Tweaking. 20 June 2017. Available online: https://arxiv.org/abs/1706.06691 (accessed on 4 May 2022).
- Ustun, B.; Spangher, A.; Liu, Y. Actionable Recourse in Linear Classification. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 10–19. [Google Scholar] [CrossRef] [Green Version]
- Roy, B. The Optimisation Problem Formulation: Criticism and Overstepping. J. Oper. Res. Soc. 1981, 32, 427. [Google Scholar] [CrossRef]
- Sanden, T.; Trajanov, A.; Spiegel, H.; Kuzmanovski, V.; Saby, N.P.A.; Picaud, C.; Henriksen, C.B.; Debeljak, M. Development of an Agricultural Primary Productivity Decision Support Model: A Case Study in France. Front. Environ. Sci. 2019, 58. [Google Scholar] [CrossRef] [Green Version]
- Kuzmanovski, V.; Trajanov, A.; Džeroski, S.; Debeljak, M. Cascading constructive heuristic for optimization problems over hierarchically decomposed qualitative decision space. 2021; submitted. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic Back-Propagation and Variational Inference in Deep Latent Gaussian Models. 16 January 2014. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.753.7469&rep=rep1&type=pdf (accessed on 4 May 2022).
- Brochu, E.; Cora, V.M.; de Freitas, N. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning. 14 December 2010. Available online: https://arxiv.org/abs/1012.2599 (accessed on 4 May 2022).
- Snoek, J.; Rippel, O.; Swersky, K.; Kiros, R.; Satish, N.; Sundaram, N.; Patwary, M.; Prabhat, M.; Adams, R. Scalable Bayesian Optimization Using Deep Neural Networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- de Freitas, J.F.G. Bayesian Methods for Neural Networks. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2003. [Google Scholar]
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Sequential Model-Based Optimization for General Algorithm Configuration. In International Conference on Learning and Intelligent Optimization; Springer: Berlin/Heidelberg, Germany, 2011; pp. 507–523. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Sequential Model-Based Optimization for General Algorithm Configuration (Extended Version); Technical Report TR-2010–10; University of British Columbia, Computer Science: Endowment Lands, BC, Canada, 2010. [Google Scholar]
- Močkus, J. On bayesian methods for seeking the extremum. In Proceedings of the IFIP Technical Conference on Optimization Techniques, Novosibirsk, Ruassia, 1–7 July 1974. [Google Scholar]
- Kushner, H.J. A New Method of Locating the Maximum Point of an Arbitrary Multipeak Curve in the Presence of Noise. J. Basic Eng. 1964, 86, 97–106. [Google Scholar] [CrossRef]
- Srinivas, N.; Krause, A.; Kakade, S.; Seeger, M. Gaussian process optimization in the bandit setting: No regret and exper-imental design. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Lizotte, D.J. Practical Bayesian Optimization. Ph.D. Thesis, University of Albert, Edmonton, AB, Canada, 2008. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Leaves | Depth | Weights’ Distribution | Links | Model Variations per Weights’ Distribution | ||
|---|---|---|---|---|---|---|
| 8 | 3 | skewed, | normal, | uniform | yes | 3, 3, 1 |
| 9 | 3 | skewed, | normal, | uniform | no | 3, 3, 1 |
| 19 | 4 | skewed, | normal, | uniform | yes | 3, 3, 1 |
| 20 | 4 | skewed, | normal, | uniform | no | 3, 3, 1 |
| 38 | 5 | skewed, | normal, | uniform | yes | 3, 3, 1 |
| 39 | 5 | skewed, | normal, | uniform | no | 3, 3, 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gjoreski, M.; Kuzmanovski, V.; Bohanec, M. BAG-DSM: A Method for Generating Alternatives for Hierarchical Multi-Attribute Decision Models Using Bayesian Optimization. Algorithms 2022, 15, 197. https://doi.org/10.3390/a15060197
Gjoreski M, Kuzmanovski V, Bohanec M. BAG-DSM: A Method for Generating Alternatives for Hierarchical Multi-Attribute Decision Models Using Bayesian Optimization. Algorithms. 2022; 15(6):197. https://doi.org/10.3390/a15060197
Chicago/Turabian StyleGjoreski, Martin, Vladimir Kuzmanovski, and Marko Bohanec. 2022. "BAG-DSM: A Method for Generating Alternatives for Hierarchical Multi-Attribute Decision Models Using Bayesian Optimization" Algorithms 15, no. 6: 197. https://doi.org/10.3390/a15060197
APA StyleGjoreski, M., Kuzmanovski, V., & Bohanec, M. (2022). BAG-DSM: A Method for Generating Alternatives for Hierarchical Multi-Attribute Decision Models Using Bayesian Optimization. Algorithms, 15(6), 197. https://doi.org/10.3390/a15060197