1. Introduction
Recent years have witnessed the increasing attention to distributed machine learning algorithms [
1,
2,
3,
4]. The motivation to train machine-learning models in a distributed manner arises from the rapid growth of the sizes of machine-learning models and datasets, the increase in the diversity of the datasets, and the privacy concerns of centralized training alternatives. On one hand, we can use multiple GPU devices to accelerate the training with more computation power. On the other hand, training machine-learning models on the local private data on the massive edge devices makes the models more informative and representative. However, in both cases, the communication overhead between the devices is the potential bottleneck of the performance. To make things worse, larger learning systems with more devices are also more vulnerable to software/hardware failures, as well as malicious (Byzantine) attacks.
In practice, different scenarios require different solutions. For example, when conducting training tasks in a traditional datacenter, we do not require too much reduction of the communication overhead, or too much asynchrony, since the communication is relatively fast. In such a scenario, the requirement of privacy preservation and Byzantine tolerance is lower. However, when there are remote devices that are geographically far away from each other, the system should still work well with more limited communication. Additionally, the system should also support an asynchronous mode, in case there are stragglers. Furthermore, for edge devices, the system has to prepare for unreliable or malicious entities and provide guarantees in preserving privacy for users of remote devices (e.g., local differential privacy in sending messages to the central servers). The upshot of this is that any system must be flexible enough in order to fulfill the requirements of different scenarios.
Besides the system-level concerns, a machine-learning system also needs to guarantee the performance of model training. However, there are always trade-offs. Reducing the communication overhead usually causes performance regression due to the inaccuracy in training. Robustness or fault tolerance also causes additional noise in training. It is essential to develop algorithms that satisfy the system requirements while guarantee training performance by providing theoretical analysis to show the trade-offs.
An efficient, secure, and privacy-preserving distributed learning system benefits a wide range of real-world applications. For example, communication compression can reduce the time cost by training [
5,
6] for large-scale deep-learning models such as BERT [
7] and GPT-2 [
8]. Federated learning [
9] (FL) is another application that potentially benefits from our proposed distributed learning system. FL is designed to train machine-learning models on a collection of remote agents with their local private datasets, where the communication is extremely slow or unreliable, thus requiring compression [
10] and protection [
11]. For example, next-word prediction is a widely used feature on virtual keyboards for touchscreen mobile devices, which is commonly supported by FL due to the privacy concerns. However, the mobile devices are not always connected to high-speed and free WiFi. To make things worse, nefarious users can easily feed poisoned data with abnormal behaviors to attack the learning system. In that case, a distributed learning system that integrates both communication efficiency and security is very useful. Industrial machine-learning applications such as the ML-embedded energy sector [
12,
13] can also use distributed learning systems to train a global model on the data placed on multiple sites that are remote to each other, without transmitting the local training data, which are potentially confidential. In such cases, the communication efficiency and robustness are substantial due to the slow and unreliable networking of the remote sites located in suburban or even offshore areas [
14]. However, combining communication efficiency, security, and privacy preservation is challenging in both theory and practice.
In this paper, we study distributed stochastic gradient descent (SGD) and its variants, which are commonly used for training large-scale deep neural networks. We present a distributed learning system that trains machine-learning models with variants of distributed SGD, which integrates several techniques in (1) communication reduction, (2) asynchronous training, and (3) tolerance to Byzantine faults.
In contrast to previous works that focus on one of the aspects in communication reduction [
15], asynchronous training [
16], and Byzantine tolerance [
17,
18,
19], this paper presents a distributed learning system, ZenoPS, with the following characteristics:
Communication efficiency and security in a single system: In contrast to the previous works that focus on either communication efficiency or security in distributed SGD, this paper presents algorithms that achieve communication reduction with both message compression and infrequent synchronization, asynchronous training, and Byzantine tolerance, simultaneously.
Detached validation from the servers: In this paper, we present a new system architecture with an additional component called the Validator, which decouples the Byzantine tolerance from the server side. By doing so, the servers can focus on maintaining the global model parameters, which requires less computation resources, while the validators, which are more computation-intensive, are tasked with defending the servers by verifying the anonymous updates.
Local differential privacy: In this paper, we propose to randomly insert Byzantine failures on the workers intentionally to produce noisy updates for the protection of the private local data on the workers. Combined with the validators, the system achieves both local differential privacy with limited regression in training convergence and accuracy.
The contributions of this paper are as follows:
We present a distributed learning system, ZenoPS, that integrates the techniques of communication compression, different synchronization modes, and Byzantine tolerance.
We present a novel system design with implementation details of ZenoPS.
We establish the theoretical guarantees for the convergence, Byzantine tolerance, and local differential privacy of the proposed system.
We show that the integrated system can achieve both communication efficiency and security in the experiments.
The rest of this paper is organized as follows. In
Section 2, we briefly discuss the previous research related to our work.
Section 3 formalizes the distributed optimization problem solved in this paper, with the detailed definition of the parameter-server architecture, Byzantine failures in distributed SGD, and local differential privacy. In
Section 4, we present the algorithm and the system design of ZenoPS. The theoretical analysis of the convergence, Byzantine tolerance, and privacy preservation can be found in
Section 5, with detailed proofs in
Appendix A. We present the empirical results in
Section 6. Finally, we conclude the paper in
Section 7.
2. Related Work
This paper leverages previous works providing communication reduction with error reset [
15], asynchronous federated optimization [
16], and Byzantine tolerance [
17,
18,
19,
20,
21]. The authors of [
15] presented a technique called
error reset, which adapts arbitrary compressors to distributed SGD and corrects for local residual errors, but the proposed algorithm and the corresponding theoretical analysis are limited to the classic synchronous SGD rather than the federated optimization. The authors of [
16] presented a combination of asynchronous training and federated optimization or local SGD, but it lacked guarantees in security and privacy. For the security, we focus on the Byzantine failures [
22] in this paper. The authors of [
17,
20,
21] presented Byzantine-tolerant SGD algorithms based on robust statistics such as the trimmed mean. However, it is argued in [
18] that these previous approaches are not specially designed for gradient descent algorithms, which results in the potential vulnerability to several specific types of attacks. To resolve the potential issues of the previous approaches based on robust statistics, the authors of [
19] presented score-based approaches, which validated the updates with a standalone validation dataset, but they used a definition of Byzantine tolerance similar to that in [
21]. There are also other approaches to Byzantine-tolerant SGD. For example, DRACO [
23] uses redundant workers as pivots to distinguish Byzantine workers, which provides strong guarantees for Byzantine tolerance, at the cost of additional computation resources for the redundant workers. To make things worse, adding redundant workers is infeasible in federated learning scenarios. While there are many different kinds of differential privacy (DP) [
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35], we focus on local differential privacy when releasing the individual updates from the workers to the servers, which is more important in the federated learning scenarios.
3. Preliminaries
In this paper, we focus on distributed SGD with a parameter aerver (PS) architecture, and unreliable workers. In this section, we formally introduce the optimization problem, distributed SGD, PS architecture, and the threat model of Byzantine failures.
3.1. Notations
First, in
Table 1, we define some important notations and terminologies that are used throughout this paper.
3.2. Problem Formulation
We consider the following optimization problem with
n workers:
where
,
,
are the set of model parameters, and
is a mini-batch of data sampled from the local data
on the
ith device. Each device can be a GPU, a machine with multiple GPUs, or an edge device such as a smart phone, depending on the scenario and application.
3.3. Distributed SGD
In this paper, we use distributed SGD to solve the optimization problem (
1). In each iteration, a random mini-batch of data
is sampled from the training dataset of any worker
i, which is used to compute the local stochastic gradient
. We then rescale
with the learning rate
and update the model parameters
x.
There are typically two strategies to execute distributed training with SGD: synchronous and asynchronous. In synchronous training, the combination of the updates aggregated from all workers are applied to the global model parameters in every step. In contrast, for asynchronous training, the global model parameters are immediately updated by any single worker without waiting for the other workers [
36,
37,
38]. Typically, synchronous training is more stable with less noise, but it is also slower due to the global barrier across all workers. Asynchronous training is faster, but any asynchronous training technique needs to address instability and noisiness due to staleness.
The detailed distributed synchronous SGD algorithm is shown in Algorithm 1. In each iteration, every worker computes the stochastic gradient on a random mini-batch of data and then takes the average over the gradients from all workers. The averaged gradient is used to update the global model parameters in the same way as vanilla SGD. The global averaging incurs communication overhead.
| Algorithm 1 Distributed synchronous stochastic gradient descent (DS-SGD). |
- 1:
Initialize - 2:
for all iteration do - 3:
for all workers in parallel do - 4:
- 5:
end for - 6:
Synchronization: - 7:
- 8:
end for
|
The detailed distributed asynchronous SGD algorithm is shown in Algorithm 2. In each iteration, the global model parameters are updated by the stochastic gradient from an arbitrary worker. Note that such a stochastic gradient is based on the model parameters from any previous iteration instead of the last iteration. There is a central node that maintains the latest version of the global model parameters. Pushing the stochastic gradient from any worker to the central node and pulling the model parameters from the central node to any worker incur communication overhead.
In brief, if the same number of stochastic gradients are applied to the global model parameters, then synchronous SGD and asynchronous SGD have the same communication overhead. The main difference is that the global updates are blocked until all gradients are collected for synchronous training, while for asynchronous training, the global updates are executed whenever the stochastic gradients arrive. Furthermore, since the stochastic gradients are potentially based on the model parameters previous to the latest version, such staleness incurs additional noise to the convergence.
| Algorithm 2 Distributed asynchronous stochastic gradient descent (DA-SGD). |
- 1:
Initialize - 2:
for all iteration do - 3:
arbitrary worker : - 4:
- 5:
- 6:
end for
|
3.4. Parameter-Server Architecture
For distributed SGD, there are various strategies and infrastructures that support the communication and synchronization between the workers. In this research, we focus on the parameter-server (PS) architecture [
39,
40,
41,
42,
43], which is one of the most popular strategies to enable distributed training.
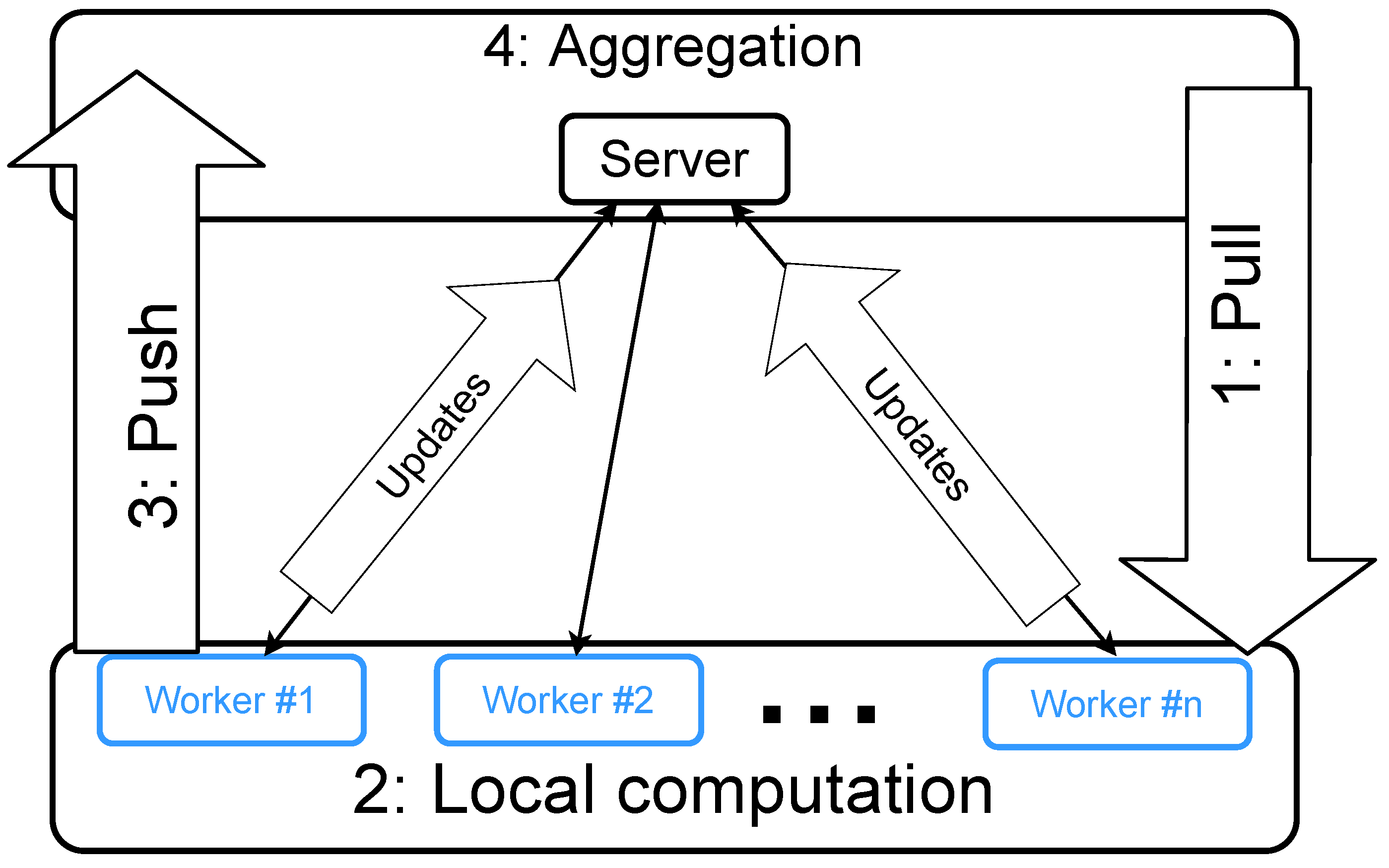
The system is composed of the server nodes and the worker nodes, as illustrated in
Figure 1. Typically, the training data and the major workload of computation are distributed onto the worker nodes. For cloud computing, the worker nodes are placed on the cloud, where more worker nodes accelerate the training. For edge computing, the worker nodes are placed on the edge devices, where more worker nodes bring more training data. The server nodes, located on the cloud, are used for synchronization among the worker nodes. In summary, the workers conduct computation on their local data, and the resulting updates are then merged by the server. Such merge/synchronization operations cause the communication overhead. Different algorithms send different types of updates to the server, e.g., gradients or updated model parameters. Thus, the same PS architecture could be used in different algorithms and scenarios.
3.5. Byzantine Failures
Byzantine failure, first introduced in [
22], is a well-studied problem in the field of distributed systems. In general, Byzantine failures assume a threat model where the failed agents behave arbitrarily in a traditional distributed system. Such a threat model assumes the worse cases of failures and attacks in the distributed systems.
Many failures and attacks can be viewed as special cases of Byzantine failures. For example, the authors of [
44] describe the vulnerability to bit-flipping attacks in the wireless transmission technology, where the servers can receive data via such vulnerable communication media, even if the messages are encrypted. As a result, an arbitrary fraction of the received values are corrupted. Furthermore, federated learning can be vulnerable to data poisoning attacks, where the users feed compromised or fabricated data such as fake reviews [
45] to the learning systems. A recent work [
46] argues that data poisoning attacks are equivalent to Byzantine failures under certain assumptions.
The authors of [
47] introduced Byzantine failures to distributed synchronous SGD, with some modifications to make the threat model fit the machine-learning scenario, in which the Byzantine failures only happen on the worker nodes. In summary, workers with Byzantine failures send arbitrary messages to other processes. We define the threat model as follows.
Definition 1 (Threat Model). Additional to the n honest workers, there are q Byzantine workers that send out arbitrary messages during communication. Furthermore, we assume that the workers are anonymous to the other processes.
The existence of Byzantine workers prevents the distributed SGD from converging or decreasing the loss value on the training data. We formally define the Byzantine failures for synchronous training and asynchronous training as follows.
Definition 2 (Threat model for synchronous SGD).
We assume that there are n honest workers and q Byzantine workers. When the server receives a gradient estimator from the ith worker in the iteration, it is either correct or Byzantine. If sent by a Byzantine worker, is assigned arbitrary values. If sent by an honest worker, the correct gradient is . Thus, we have Definition 3 (Threat model for asynchronous SGD).
We assume that there are n honest workers and q Byzantine workers. When the server receives a gradient estimator from the ith worker in the iteration, it is either correct or Byzantine. If sent by a Byzantine worker, is assigned arbitrary values. If sent by an honest worker, the correct gradient is . Thus, we have Based on the definition of Byzantine failures above, we formally define the general Byzantine tolerance for both synchronous and asynchronous SGD in the IID settings.
Definition 4 (SGD Byzantine Tolerance).
Without a loss of generality, suppose that, in any iteration t on the server, the global model parameters are updated by , where is the update vector (gradient estimator) produced by different approaches. An algorithm is said to be SGD-Byzantine-tolerant if the following condition is satisfied where there are Byzantine workers in the IID settings:where for synchronous training, and for asynchronous training. In brief, an SGD-Byzantine-tolerant algorithm must have a positive inner product with the correct gradient. Note that SGD-Byzantine tolerance is a necessary condition of SGD convergence under Byzantine attacks. To guarantee the convergence sufficiently, other conditions such as smoothness, bounded variance, and
-norm of gradients, as well as sufficiently small learning rates are required, as we have shown in
Section 5.3.
3.6. Design Objectives
The goal of this research is to design an integrated system resolving the critical problems in distributed machine learning: heavy communication overhead, system security, and client privacy. To be more specific, we solve the distributed optimization problem defined in (
1) based on the parameter server architecture with the following additional features.
Communication reduction: Optionally, the workers can reduce the communication overhead via both infrequent synchronization and message compression. To be more specific, every worker sends updates to the central server after every H local iterations, and compresses the update with the error reset technique and an arbitrary compressor that satisfies -approximation: , where v is the message vector sent to the server.
Synchronization mode: The system supports both synchronous and asynchronous training.
Byzantine tolerance: The system supports Byzantine tolerance on the server side, with multiple choices of defense methods, including a coordinate-wise trimmed mean and score-based validation approaches.
Local differential privacy: We show the theoretical guarantees that the local differential privacy of releasing updates from the workers to the servers can be achieved by randomly replacing the correct values with arbitrary (Byzantine) values. To be more specific, we use the following definition for local differential privacy (LDP).
Definition 5 (
-LDP [
48]).
Given the domain of the datasets and a query function , a mechanism with domain is ξ-LDP if, for any and two arbitrary datasets , In the case of distributed SGD, the queries are the gradients or updates released by the workers. Note here that the result does not refer to differential privacy of the full training pipeline, but only to differential privacy of a single step with the following threat model: We assume that the attackers are the curious servers, from which we want to protect the workers and of which we want to avoid the servers recovering the private updates from individual workers. There are various mechanisms or protocols that achieve LDP [
49,
50,
51,
52,
53,
54,
55,
56]. Furthermore, some LDP mechanisms can also provide
-DP guarantees [
48,
57] for the full training process, at the expense of increased
for LDP.
4. Methodology
In this section, we present ZenoPS, which is a distributed learning system based on the PS architecture. Our implementation is based on the cutting-edge PS implementation called BytePS [
42,
43]. In the ZenoPS architecture, the processes are categorized into three roles: servers, workers, and validators. Note that, compared to the original PS architecture, ZenoPS has an additional role of nodes:
validators, which read the update cached on the servers and filter out the potentially malicious ones. The responsibilities of the three roles are described as follows:
Server: The server nodes maintain the global model parameters. ZenoPS also supports multiple server nodes, where the model parameters are partitioned into several blocks and are uniquely assigned to different server nodes via some hash functions. The servers communicate to both the workers and the validators. On one hand, the servers send the latest model parameters to the workers on request and cache the updates sent from the workers. On the other hand, the servers send the cached updates to the validators and collect the verified updates from the validators. Once verified, the updates are supposed to be benign and safe for the servers to update the global model parameters. In the synchronous mode, the servers will wait for all validators to respond, take the average of the verified updates from all validators, and then apply the averaged updates to the global model parameters. In the asynchronous mode, the servers update the global model parameters whenever a verified update arrives.
Worker: The worker nodes take the main workload of computation in the ZenoPS system. Periodically, the workers pull the latest model parameters from the servers, run SGD locally for H steps to update the local models, and then send the accumulated updates to the server. Optionally, the workers can compress the updates sent to the servers and use error reset for biased compressors. Optionally, the workers can randomly replace the updates sent to the servers with arbitrary noise, which helps provide privacy preservation. We show that the adverse effects of adding noise are managed by the robust aggregation.
Validator: The validators are used for filtering out the potentially malicious updates. Any update sent from the workers will be cached and rallied to a validator. The users of ZenoPS can choose various algorithms for validation. In the synchronous mode, the validators can use the coordinate-wise trimmed mean, Phocas [
17], or score-based approaches such as Zeno [
19], or they can simply take the average. In the asynchronous mode, the validators have two options: score-based approaches or no validation at all (approving any received updates). Future robust training approaches can be implemented using the same framework. Typically, we assume fast communication between the servers and validators. A reasonable configuration is to co-locate the servers and the validators. For example, when using the score-based approaches, a validator node should have the computation power similar to a worker node. In that case, we could put the server node and the validator node in the same machine, where the server is assigned to the CPU, and the validator is assigned to the GPU.
The detailed algorithm is shown in Algorithm 3, where we only use the score-based validation approach defined in Definition 6 for Byzantine tolerance.
The workers pull the model parameters from the servers and add the local residual errors to the pulled model. After H steps of local updates, the workers obtain the accumulated local update, which is the difference between the current version of local models and the previously pulled models. The workers will then compress the local updates, update the local residual errors, and send the compressed updates to the servers. To protect privacy, the workers can randomly replace the messages with arbitrary values, which inserts some noise in the released data, in order to achieve differential privacy.
The servers simply relay all updates sent from the workers to the validators and respond to any pulling request from the workers and the validators. In the synchronous mode, the servers will wait until the approved updates are received from all validators. In the asynchronous mode, the servers will update the global model parameters whenever an approved update is received from any validator. Note that the validators can send vectors of all 0 values to the server, as a notification that an update fails the validation. The servers will not move on to the next iteration until a non-zero approved update is received.
The validator uses the criterion defined in Definition 6 to validate the candidate updates sent from the servers. If a candidate update passes the validation procedure, it will be sent to the servers; otherwise the validator will send a vector of all 0 values to the server. Periodically, the validators will pull the model parameters from the servers and update the validator vector. Note that, in the synchronous mode, the validators always pull the latest version of the global model; in the asynchronous mode, the pulled model can have some delay.
| Algorithm 3 ZenoPS with score-based validation. |
- 1:
Server - 2:
Initialize - 3:
for all server step do - 4:
- 5:
while do - 6:
Send to workers on request - 7:
Receive updates from workers, and relay to validators - 8:
if Synchronous then - 9:
, after all validators respond - 10:
else - 11:
, after receiving from a validator - 12:
end if - 13:
Update the parameters - 14:
end while - 15:
end for
- 1:
Worker (honest) - 2:
Initialize - 3:
while until terminated do - 4:
Receive from the server, and initialize - 5:
for all local iteration do - 6:
- 7:
end for - 8:
Compute the accumulated update - 9:
Compress , and update the local residual error - 10:
Replace by arbitrary value with probability (optional) - 11:
Send to the server - 12:
end while
- 1:
Validator - 2:
Initialize - 3:
while until terminated do - 4:
if then - 5:
Pull from server, update for H SGD steps, and obtain - 6:
Update the validation vector - 7:
end if - 8:
- 9:
Wait until any update arrives - 10:
if the validation defined in Definition 6 is passed, else - 11:
Send u to the server - 12:
end while
|
To make the system design and the relationship between the three groups of nodes clearer, we illustrate the ZenoPS architecture in
Figure 2.
In the remainder of this section, we present more details of the optional features provided by ZenoPS.
4.1. Communication Reduction
When sending updates to the servers, the workers can choose to compress the message using an arbitrary compressor
and use the technique of error reset to handle the residual error of the compression. In the algorithm, we compress the locally accumulated update
and maintain the local residual error
of worker
i, in Line 9 in Algorithm 3 (in the worker process). The local residual error will then be applied to the model parameters pulled from the servers in the next time. Similar to CSER in [
15], we assume
-approximate compressors:
, where
. The choice of the expected compression ratio
depends on the sensitivity of the deep neural network and the networking environment. When the number of workers increases, the network tends to become congested and requires a larger compression ratio to maintain the efficiency of training. However, larger compression ratios usually incur larger noise. Thus, case-by-case hyperparameter tuning is typically required to find the optimal trade-offs.
4.2. Synchronization Modes
Besides the synchronous mode, ZenoPS also provides the asynchronous mode, where the workers and validators can check in and send updates to the server at any time. The servers launch multiple threads to handle the pushing and pulling request sent by the workers and validators. In the synchronous mode, any pulling request from the workers or the validators will be blocked until the global model parameters are updated. In the asynchronous mode, the servers respond to the pulling requests immediately without any barrier.
If the workers have almost identical computation power and networking environments, the synchronous mode is recommended, which is more efficient and stable. However, there are also cases where the workers have heterogeneous capabilities and communication speeds, especially in the federated learning scenario. The heterogeneity results in stragglers in the system, which then causes noisy or slow updates sent to the servers. In that case, the asynchronous mode is recommended for efficiency. The noise caused by the stragglers can be mitigated by tuning the mixing hyperparameter and using the validators to automatically filter out the extremely outdated updates.
4.3. Byzantine Tolerance
In ZenoPS, we use the following score-based approach for Byzantine tolerance.
Definition 6 (ZenoPS validation).
Assume that, in the tth iteration, based on the model parameters (with latency) on the server, where ( in the synchronous mode), the validator locally updates the model parameters for H steps using the validation data and obtains the accumulated update for validation: ∼, where ∼, and . An update u from any worker will be approved and sent back to the server for updating the global model parameters if the following two conditions are satisfied:where are some hyperparameters for the thresholds. The above validation mechanism allows both the candidate update and the validation vector to be the accumulation of multiple steps of SGD updates. Thus, such a validation mechanism can be used for distributed SGD with infrequent synchronization, such as federated optimization or local SGD.
4.4. Byzantine Mechanism and Privacy Preservation
In our implementation, we add a simulator on the worker side to simulate Byzantine failures and send malicious values to the servers. It turns out that such a simulator can also be used to generate random noises for privacy preservation. On the server side, the random noises will then be treated as values from Byzantine workers. Formally, we introduce the Byzantine mechanism as follows.
Definition 7. In the Byzantine mechanism denoted as , the ith worker sends the vectorwhere is the correct vector. In other words, with probability , the worker sends the value , which is randomly drawn from the distribution instead of the correct value , to the server. 5. Theoretical Analysis
In this section, we show the theoretical guarantees of ZenoPS using the score-based approach in the validators. We theoretically analyze the Byzantine tolerance, the convergence, and the differential privacy of the proposed system. The detailed proofs of the theorems are in
Appendix A.
5.1. Assumptions
Assumption 1 (Smoothness).
and are L-smooth:and Assumption 2 (Variance). For any stochastic gradient ∼, we assume bounded intra-worker variance: where is the variance of the gradient of a single data sample, and s is the mini-batch size per worker.
Assumption 3 (Bounded gradients). For any stochastic gradient , we assume bounded expectation: In some cases, we directly assume the upper bound of the stochastic gradients:
Assumption 4 (Global minimum). There is at least one global minimum , where
5.2. Byzantine Tolerance
In the following theorem, we show the Byzantine tolerance of score-based validation approach defined in Definition 6.
Theorem 1 (SGD-Byzantine tolerance of ZenoPS).
Assume that the validation data is close to the training data where and (the expectation is taken with respect to z), and ϵ is large enough. Under Assumptions 2 and 3 (bounded gradients and variance, which is also applied to the validation gradients), for a verified update u sent from the validators, there is a such that we have the positive inner-product:where , and . 5.3. Convergence
Now we prove the convergence of the proposed algorithm in the synchronous mode. For simplicity, we take in the synchronous mode.
Theorem 2 (Error bound of ZenoPS in the synchronous mode without compression).
In addition to Assumption 1 (smoothness), Assumption 2 (bounded variance), Assumption 3 (bounded gradients), and Assumption 4 (global minimum), we assume that the compressors are disabled and that the validation data is close to the training data where and (the expectation is taken with respect to z). Taking , we have the following error bound for ZenoPS in the synchronous mode: Taking , , we have The error bound of ZenoPS is composed of four parts: the gap to the initial value , the error caused and the infrequent synchronization that is proportional to H, the noise caused by variance , and the validation error caused by Byzantine tolerance . A better validation dataset that is closer to the training dataset with a smaller r decreases the validation error. Increasing c and or decreasing decreases the validation error, but also potentially decreases the chances that benign updates pass the validation procedure, which can slow down the optimization progress. In short, stronger security guarantees smaller validation error, but also slower convergence.
When the compressors are enabled, there is an additional error term with the approximation factor .
Theorem 3 (Error bound of ZenoPS in the synchronous mode with compression).
In addition to Assumption 1 (smoothness), Assumption 3 (bounded gradients), and Assumption 4 (global minimum), we assume that the compressors are disabled and the validation data is close to the training data where and (the expectation is taken with respect to z). Taking and , we have the following error bound for ZenoPS in the synchronous mode: Finally, we prove the convergence of the proposed algorithm in the asynchronous mode.
Theorem 4 (Error bound of ZenoPS in the asynchronous model with compression).
In addition to Assumption 1 (smoothness), Assumption 2 (bounded variance), Assumption 3 (bounded gradients), and Assumption 4 (global minimum), we assume that the validation data is close to the training data where and (the expectation is taken with respect to z). Furthermore, we assume that, in any server step t, the approved update is based on the global model parameters in the server step , where has bounded delay . Taking , we have the following error bound for ZenoPS in the asynchronous mode:Taking , , we have 5.4. Local Differential Privacy
Finally, we present the theoretical guarantee of the Byzantine mechanism in local differential privacy. Denote as the probability density function of the random variable . We show that the Byzantine mechanism is LDP in the following theorem.
Theorem 5 (LDP of Byzantine mechanism).
Assume that the noise distribution has the support , and , where is the PDF of the noise distribution (e.g., uniform distribution with support ). The Byzantine mechanism is then ξ-LDP, where Thus, a larger makes the mechanism more differentially private, at the cost of replacing more correct values with the random noise as well as a slowdown of the overall optimization progress on the servers.
6. Experiments
In this section, we empirically evaluate the proposed ZenoPS system in various simulated settings. We test the performance of ZenoPS in both the synchronous and asynchronous mode, where the asynchronous experimental setting represents edge computing with flexible workers, and the synchronous experimental setting represents a traditional datacenter. Furthermore, we test the robustness of ZenoPS under various attacks in both synchronous and asynchronous modes.
6.1. Evaluation Setup
We trained ResNet-20 on the CIFAR-10 [
58] dataset. The mini-batch size was 32. In this section, our experiments were conducted in real distributed environments with CPU workers. We used
in the synchronous mode and
in the asynchronous mode. In the epochs 100 and 150, the learning rate decayed by
in the synchronous mode and
in the asynchronous mode. We used a constant
in the synchronous mode. In the asynchronous mode, we used an initial value
, which decayed by
in the epochs 100 and 150.
The communication overhead was reduced by both message compression and infrequent synchronization. We used random block-wise sparsification to compress the communication. Whenever a worker sent an update of a block of parameters to the server, with the probability of , it ignored the communication and put the update into the local residual error. Furthermore, the number of local steps H was 8.
For the validators, we set for both the trimmed mean and Phocas. We set , , for Zeno validation in the synchronous mode. In the asynchronous mode, we set (with clipping), , for Zeno validation.
We randomly and evenly partitioned the training data into the number of workers plus one parts and assigned the additional part to every validator.
We evaluated ZenoPS in both the synchronous mode and the asynchronous mode. In the synchronous mode, we used
Mean,
Trimmed mean,
Phocas [
17], and
Zeno (the score-based validation defined in Definition 6) as the validators. In the asynchronous mode, we used
FedAsync (no validation) and
Zeno as the validators.
In the experiments, we used the following two types of attacks:
Sign-flipping attack: The worker multiplies the original updates by
, i.e., flips the sign and rescales the updates by
. We call this type of attack a “sign-flipping attack rescaled by
”. The same type of attacks have also been used in previous work [
20,
23].
Random attack: The worker uses Gaussian random values with a 0 mean to replace the original values. If we use Gaussian random values with variance
, then we call this type of attack a “random attack rescaled to
”. On the other hand, if we use Gaussian random values and rescale the Byzantine vector, so that the
norm of the Byzantine vector is
times the original one, then we call this type of attack a “random attack rescaled by
”. The same type of attacks have also been used in previous work [
47].
We simulated the Byzantine attacks by randomly replacing the vectors sent from the workers to the servers with a probability of .
6.2. Empirical Results
The result of ZenoPS in the synchronous mode is shown in
Figure 3. We can see that, when there are no Byzantine attacks, all algorithms have similar performance. When there are Byzantine attacks, using a Zeno validator, ZenoPS converged almost as well as using averaging without any attack. However, the trimmed mean had relatively bad results under sign-flipping attacks, and both the trimmed mean and Phocas failed under the random attacks rescaled to 1. In some cases, where the attacks were relatively weak, such as the sign-flipping attacks rescaled by 6 and the random attacks rescaled by 8, Phocas also had good convergence, which is an option that is cheaper than Zeno. However, in general, using Zeno as the validator provided the best performance under all kinds of attacks.
Furthermore, we show that ZenoPS is capable of using multiple servers and validators. Different servers are responsible for different blocks of the model parameters. The updates sent to the servers will be evenly hashed to the validators, so that different validators are assigned a similar workload.
Figure 4 shows that, by using multiple validators, ZenoPS has a similar performance compared to the case of using a single validator. Note that the multiple validators send updates to the server independently and asynchronously. Such asynchronicity causes additional noise compared to the case where there is only 1 Zeno validator. Furthermore, without changing the hyperparameter
for the trimmed mean and Phocas validators, adding more validators results in more potentially harmful updates being dropped. Hence, the trimmed mean and Phocas validators have slightly better results in
Figure 4b than those in
Figure 3c.
The result of ZenoPS in the asynchronous mode is shown in
Figure 5. When there are no Byzantine attacks, using Zeno as the validator provides good convergence similar to FedAsync. Adding Byzantine attacks makes FedAsync performs much worse. Using Zeno as the validator, ZenoPS converges as well as the cases where there are no attacks. We also show the results where two servers and two validators are used in
Figure 6.
As shown in
Figure 7, we tested the sensitivity to the hyperparameter
, with fixed
. We varied
in
. In most cases, the Zeno validator was insensitive to
and converged to the same value. The only exception was the case of
, where the threshold was too large and made the convergence extremely slow. Thus, while a grid search needs to be performed for hyperparameter tuning in practice, for
we recommend using a negative value close to 0. Although the convergence analysis shows that a larger
yields smaller error bounds, it will also decrease the number of approved updates. As shown in
Figure 7, when
, only
of the updates passed the validation. By decreasing the threshold, the approval rate approached the ideal value of
(
of the updates are Byzantine). We also show the result of training the model only using the validation data, which is referred to as “validation only.” Note that, in this case, the training was not affected by the attacks. It is shown that, if we only use the validation data, the testing accuracy will be very low. Thus, when using Zeno as the validator, the models learn from the training data. However, if the threshold
is too large, the approved updates will be extremely biased to the validation data, which causes the performance to be close to the case of “validation only.” Another interesting observation is that “validation only” has a slightly higher testing accuracy at the very beginning of the training. Thus, the validation dataset is useful for training the model for several epochs as initialization.
7. Conclusions
We propose a prototype of a distributed learning system, ZenoPS, that integrates message compression, infrequent synchronization, both asynchronous and synchronous training, and score-based validation. The proposed system provides communication reduction, asynchronous training, Byzantine tolerance, and local differential privacy, with theoretical guarantees, and was evaluated on an open benchmark.
This work also raises some open problems to be solved in future work. One limitation of ZenoPS is the relatively high computation overhead of the score-based validation algorithm, which gives improved protection from attacks at the cost of consuming more computation resources. How the score-based validation can be more efficient remains to be explored. The learning system could also be made to automatically and adaptively choose the compression ratio and validation methods for different training tasks, to make the system more user-friendly in practice. For theoretical analysis, it will be interesting to establish theories for optimal values of hyperparameters such as in score-based validation, and to study how hyperparameters such as the learning rate affect the optimal value of .










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}