
Generating Higher-Fidelity Synthetic Datasets with Privacy Guarantees

Abstract
:1. Introduction
- We use Bayesian DP to enable higher quality GAN samples, while still providing a strong privacy guarantee;
- We demonstrate that this technique can be used to discover finer data errors than has been previously reported;
- We also show that for some tasks synthetic data are of high enough quality to be used for labelling and training.
2. Materials and Methods
2.1. Related Work
2.2. Background
- T1—sanity checking data;
- T2—debugging mistakes;
- T3—debugging unknown labels/classes;
- T4—debugging poor performance on certain classes/slices/users;
- T5—human labelling of examples;
- T6—detecting bias in the training data.
2.3. Our Approach
2.3.1. Formal Overview
2.3.2. Federated Learning Case
2.4. Privacy Analysis
2.5. Experimental Procedures
- 1.
- Train the generative model (teacher) on the original data under privacy guarantees.
- 2.
- Generate an artificial dataset by the obtained model and use it to train ML models (students).
- 3.
- Evaluate students on the held-out real test set.
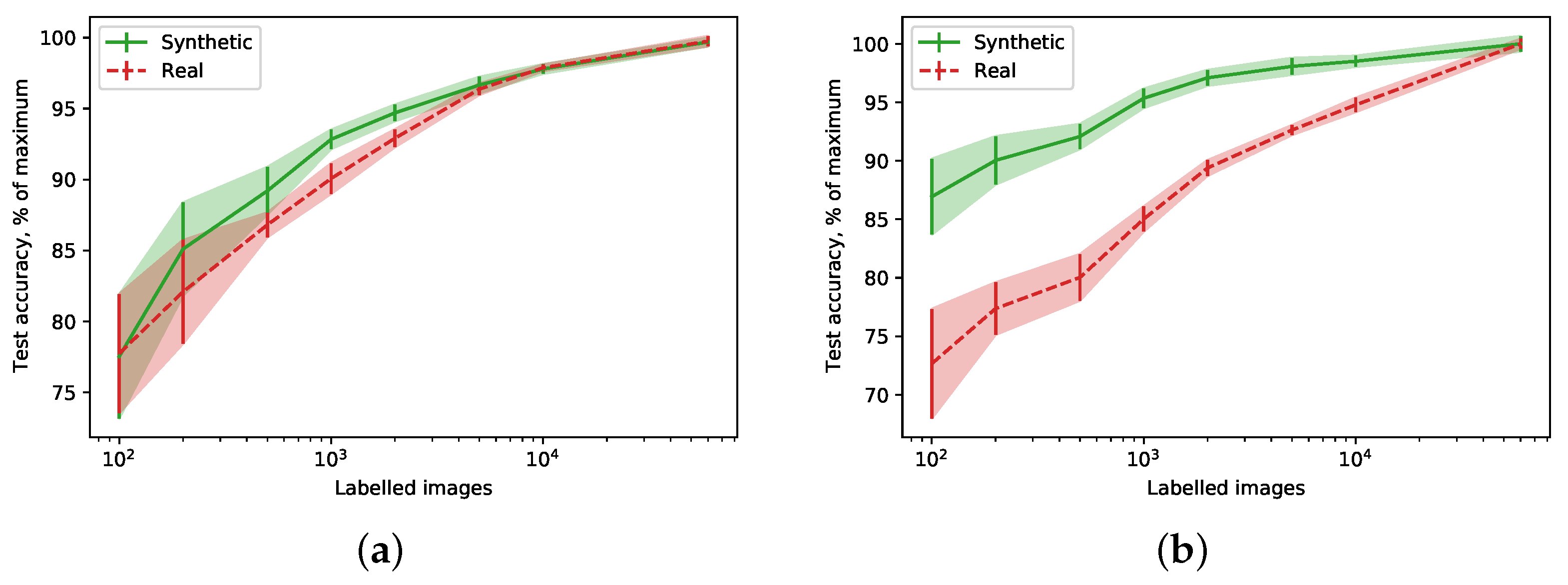
3. Results
3.1. Data Inspection
3.2. Learning Performance
4. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DP | Differential privacy |
| BDP | Bayesian differential privacy |
| FL | Federated learning |
| ML | Machine learning |
| GAN | Generative adversarial network |
| SGD | Stochastic gradient descent |
References
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Hitaj, B.; Ateniese, G.; Pérez-Cruz, F. Deep models under the GAN: Information leakage from collaborative deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 603–618. [Google Scholar]
- Truex, S.; Liu, L.; Gursoy, M.E.; Yu, L.; Wei, W. Towards demystifying membership inference attacks. arXiv 2018, arXiv:1807.09173. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Dwork, C. Differential Privacy. In Proceedings of the 33rd International Colloquium on Automata, Languages and Programming, part II (ICALP 2006), Venice, Italy, 10–14 July 2006; Volume 4052, pp. 1–12. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Augenstein, S.; McMahan, H.B.; Ramage, D.; Ramaswamy, S.; Kairouz, P.; Chen, M.; Mathews, R. Generative Models for Effective ML on Private, Decentralized Datasets. arXiv 2019, arXiv:1911.06679. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Triastcyn, A.; Faltings, B. Bayesian Differential Privacy for Machine Learning. arXiv 2019, arXiv:1901.09697. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Papernot, N.; Abadi, M.; Erlingsson, U.; Goodfellow, I.; Talwar, K. Semi-supervised knowledge transfer for deep learning from private training data. arXiv 2016, arXiv:1610.05755. [Google Scholar]
- Papernot, N.; Song, S.; Mironov, I.; Raghunathan, A.; Talwar, K.; Erlingsson, Ú. Scalable Private Learning with PATE. arXiv 2018, arXiv:1802.08908. [Google Scholar]
- Mironov, I.; Pandey, O.; Reingold, O.; Vadhan, S. Computational differential privacy. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 2009; pp. 126–142. [Google Scholar]
- Mir, D.J. Information-theoretic foundations of differential privacy. In Proceedings of the International Symposium on Foundations and Practice of Security, Montreal, QC, Canada, 25–26 October 2012; pp. 374–381. [Google Scholar]
- Wang, W.; Ying, L.; Zhang, J. On the relation between identifiability, differential privacy, and mutual-information privacy. IEEE Trans. Inf. Theory 2016, 62, 5018–5029. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; Rothblum, G.N. Concentrated differential privacy. arXiv 2016, arXiv:1603.01887. [Google Scholar]
- Bun, M.; Steinke, T. Concentrated differential privacy: Simplifications, extensions, and lower bounds. In Proceedings of the Theory of Cryptography Conference, Tel Aviv, Israel, 10–13 January 2016; pp. 635–658. [Google Scholar]
- Bun, M.; Dwork, C.; Rothblum, G.N.; Steinke, T. Composable and versatile privacy via truncated CDP. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, Los Angeles, CA, USA, 25–29 June 2018; pp. 74–86. [Google Scholar]
- Mironov, I. Renyi differential privacy. In Proceedings of the 2017 IEEE 30th Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar]
- Abowd, J.M.; Schneider, M.J.; Vilhuber, L. Differential privacy applications to Bayesian and linear mixed model estimation. J. Priv. Confidentiality 2013, 5, 4. [Google Scholar] [CrossRef] [Green Version]
- Schneider, M.J.; Abowd, J.M. A new method for protecting interrelated time series with Bayesian prior distributions and synthetic data. J. R. Stat. Soc. Ser. A Stat. Soc. 2015, 178, 963–975. [Google Scholar] [CrossRef] [Green Version]
- Charest, A.S.; Hou, Y. On the Meaning and Limits of Empirical Differential Privacy. J. Priv. Confidentiality 2017, 7, 3. [Google Scholar] [CrossRef] [Green Version]
- Triastcyn, A.; Faltings, B. Federated Generative Privacy. In Proceedings of the IJCAI Workshop on Federated Machine Learning for User Privacy and Data Confidentiality (FML 2019), Macau, China, 12 August 2019. [Google Scholar]
- Beaulieu-Jones, B.K.; Wu, Z.S.; Williams, C.; Greene, C.S. Privacy-preserving generative deep neural networks support clinical data sharing. bioRxiv 2017, 159756. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Lin, K.; Wang, S.; Wang, F.; Zhou, J. Differentially Private Generative Adversarial Network. arXiv 2018, arXiv:1802.06739. [Google Scholar]
- Zhang, X.; Ji, S.; Wang, T. Differentially Private Releasing via Deep Generative Model. arXiv 2018, arXiv:1801.01594. [Google Scholar]
- Jordon, J.; Yoon, J.; van der Schaar, M. PATE-GAN: Generating synthetic data with differential privacy guarantees. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Long, Y.; Lin, S.; Yang, Z.; Gunter, C.A.; Li, B. Scalable Differentially Private Generative Student Model via PATE. arXiv 2019, arXiv:1906.09338. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends® Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Aldous, D.J. Exchangeability and related topics. In École d’Été de Probabilités de Saint-Flour XIII—1983; Springer: Berlin/Heidelberg, Germany, 1985; pp. 1–198. [Google Scholar]
- Triastcyn, A.; Faltings, B. Federated Learning with Bayesian Differential Privacy. arXiv 2019, arXiv:1911.10071. [Google Scholar]
- Triastcyn, A. Data-Aware Privacy-Preserving Machine Learning; Technical Report; École Polytechnique Fédérale de Lausanne—EPFL: Lausanne, Switzerland, 2020. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 972–981. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Dataset | Non-Private | Private Classifier | G-PATE | Our Approach |
|---|---|---|---|---|
| MNIST | ||||
| Fashion-MNIST |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Triastcyn, A.; Faltings, B. Generating Higher-Fidelity Synthetic Datasets with Privacy Guarantees. Algorithms 2022, 15, 232. https://doi.org/10.3390/a15070232
Triastcyn A, Faltings B. Generating Higher-Fidelity Synthetic Datasets with Privacy Guarantees. Algorithms. 2022; 15(7):232. https://doi.org/10.3390/a15070232
Chicago/Turabian StyleTriastcyn, Aleksei, and Boi Faltings. 2022. "Generating Higher-Fidelity Synthetic Datasets with Privacy Guarantees" Algorithms 15, no. 7: 232. https://doi.org/10.3390/a15070232
APA StyleTriastcyn, A., & Faltings, B. (2022). Generating Higher-Fidelity Synthetic Datasets with Privacy Guarantees. Algorithms, 15(7), 232. https://doi.org/10.3390/a15070232