
Performance Evaluation of Open-Source Serverless Platforms for Kubernetes


Abstract
:1. Introduction
1.1. Background
1.2. Related Work
1.3. Contributions
- A comparative assessment of two open-source Kubernetes-based serverless platforms. Initially, it was planned to evaluate additional platforms; however, due to issues that prevented meaningful benchmarking and assessment of these platforms, they were left out, further demonstrating the need to evaluate performance systematically. For instance, with respect to Fission (https://fission.io/ accessed on 27 May 2022), we submitted an issue (https://github.com/fission/environments/issues/157 accessed on 27 May 2022) that was later fixed by the community.
- Two serverless workloads designed with practical use cases in mind that can be configured to systematically test individual system components, and can easily be ported to additional platforms.
- A discussion of the implications that can be drawn from our benchmark results on the performance capabilities of serverless platforms and how these can be improved.
1.4. Outline
2. Materials and Methods
2.1. Methods Outline
2.2. Experiment Setup
2.3. Workload Design
2.4. Test and Benchmark
- Setting up the correct number of function instances
- Preparing the test data
- Starting the benchmark and timer
- Submitting the test data as a function invocations until all test data had been processed
- Stopping the timer
- Saving the results
- Ubuntu Server version 20.04.3
- OpenStack Queens release (Feb. 2018)
- Kubernetes version 1.20.8
- Docker version 20.10
- OpenFaaS version 0.21.1
- Nuclio version 1.6.18
- ImageMagick version 7.10-3 Q16
- OpenMP version 4.5
3. Results
3.1. Image Processing
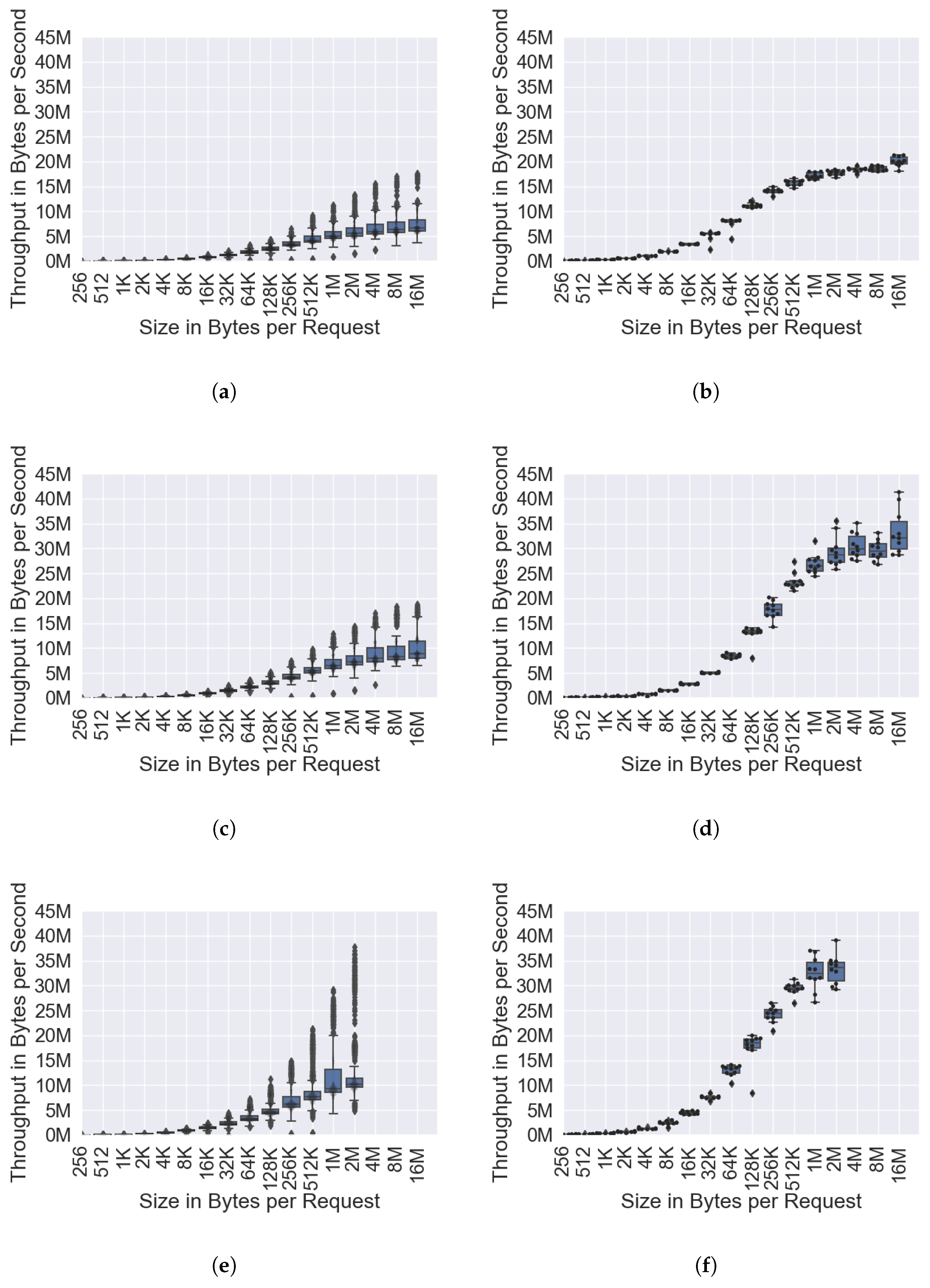
3.2. Byte Reversal
4. Discussion
4.1. Implications
4.2. Error Analysis
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| AWS | Amazon Web Services |
| FaaS | Function-as-a-Service |
| FD | Function Director |
| HPC | High-Performance Computing |
| MDPI | Multidisciplinary Digital Publishing Institute |
| MPI | Message Passing Interface |
| NP | Null Processing |
| RDMA | Remote Direct Memory Access |
| SDK | Software Development Kit |
| VM | Virtual Machine |
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}

Appendix A.2

Appendix A.3

References
- Schleier-Smith, J.; Sreekanti, V.; Khandelwal, A.; Carreira, J.; Yadwadkar, N.J.; Popa, R.A.; Gonzalez, J.E.; Stoica, I.; Patterson, D.A. What Serverless Computing Is and Should Become: The next Phase of Cloud Computing. Commun. ACM 2021, 64, 76–84. [Google Scholar] [CrossRef]
- Jonas, E.; Schleier-Smith, J.; Sreekanti, V.; Tsai, C.C.; Khandelwal, A.; Pu, Q.; Shankar, V.; Carreira, J.; Krauth, K.; Yadwadkar, N.; et al. Cloud Programming Simplified: A Berkeley View on Serverless Computing. arXiv 2019, arXiv:cs/1902.03383. [Google Scholar]
- Spillner, J.; Mateos, C.; Monge, D.A. FaaSter, Better, Cheaper: The Prospect of Serverless Scientific Computing and HPC. In Proceedings of the High Performance Computing, Dresden, Germany, 11–12 September 2017; Mocskos, E., Nesmachnow, S., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 154–168. [Google Scholar] [CrossRef] [Green Version]
- Scheuner, J.; Leitner, P. Function-as-a-Service Performance Evaluation: A Multivocal Literature Review. J. Syst. Softw. 2020, 170, 110708. [Google Scholar] [CrossRef]
- Van Eyk, E.; Scheuner, J.; Eismann, S.; Abad, C.L.; Iosup, A. Beyond Microbenchmarks: The SPEC-RG Vision for a Comprehensive Serverless Benchmark. In Proceedings of the Companion of the ACM/SPEC International Conference on Performance Engineering (ICPE ’20), Edmonton, AB, Canada, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 26–31. [Google Scholar] [CrossRef]
- Beltre, A.M.; Saha, P.; Govindaraju, M.; Younge, A.; Grant, R.E. Enabling HPC Workloads on Cloud Infrastructure Using Kubernetes Container Orchestration Mechanisms. In Proceedings of the 2019 IEEE/ACM International Workshop on Containers and New Orchestration Paradigms for Isolated Environments in HPC (CANOPIE-HPC), Denver, CO, USA, 18 November 2019; pp. 11–20. [Google Scholar] [CrossRef]
- Kuhlenkamp, J.; Werner, S. Benchmarking FaaS Platforms: Call for Community Participation. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018; pp. 189–194. [Google Scholar] [CrossRef]
- Van Eyk, E.; Grohmann, J.; Eismann, S.; Bauer, A.; Versluis, L.; Toader, L.; Schmitt, N.; Herbst, N.; Abad, C.L.; Iosup, A. The SPEC-RG Reference Architecture for FaaS: From Microservices and Containers to Serverless Platforms. IEEE Internet Comput. 2019, 23, 7–18. [Google Scholar] [CrossRef]
- Eismann, S.; Scheuner, J.; van Eyk, E.; Schwinger, M.; Grohmann, J.; Herbst, N.; Abad, C.L.; Iosup, A. Serverless Applications: Why, When, and How? IEEE Softw. 2021, 38, 32–39. [Google Scholar] [CrossRef]
- Jain, P.; Munjal, Y.; Gera, J.; Gupta, P. Performance Analysis of Various Server Hosting Techniques. Procedia Comput. Sci. 2020, 173, 70–77. [Google Scholar] [CrossRef]
- Malla, S.; Christensen, K. HPC in the Cloud: Performance Comparison of Function as a Service (FaaS) vs Infrastructure as a Service (IaaS). Internet Technol. Lett. 2020, 3, e137. [Google Scholar] [CrossRef]
- Zhou, N.; Georgiou, Y.; Pospieszny, M.; Zhong, L.; Zhou, H.; Niethammer, C.; Pejak, B.; Marko, O.; Hoppe, D. Container Orchestration on HPC Systems through Kubernetes. J. Cloud Comput. 2021, 10, 16. [Google Scholar] [CrossRef]
- Decker, J. The Potential of Serverless Kubernetes-Based FaaS Platforms for Scientific Computing Workloads; Göttingen Research Online/Data 2022; Available online: https://data.goettingen-research-online.de/dataset.xhtml?persistentId=doi:10.25625/6GSJSE (accessed on 17 June 2022).
- Cheney, D. Cgo | The Acme of Foolishness; 2016; Available online: https://dave.cheney.net/2016/01/18/cgo-is-not-go (accessed on 17 June 2022).
- Asuni, N.; Giachetti, A. TESTIMAGES: A Large Data Archive For Display and Algorithm Testing. J. Graph. Tools 2013, 17, 113–125. [Google Scholar] [CrossRef]
- Van Eyk, E.; Iosup, A.; Abad, C.L.; Grohmann, J.; Eismann, S. A SPEC RG Cloud Group’s Vision on the Performance Challenges of FaaS Cloud Architectures. In Proceedings of the Companion of the 2018 ACM/SPEC International Conference on Performance Engineering (ICPE ’18), Berlin, Germany, 9–13 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 21–24. [Google Scholar] [CrossRef] [Green Version]
- Copik, M.; Kwasniewski, G.; Besta, M.; Podstawski, M.; Hoefler, T. SeBS: A Serverless Benchmark Suite for Function-as-a-Service Computing. In Proceedings of the 22nd International Middleware Conference (Middleware ’21), Québec, QC, Canada, 6–10 December 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 64–78. [Google Scholar] [CrossRef]
- Satzke, K.; Akkus, I.E.; Chen, R.; Rimac, I.; Stein, M.; Beck, A.; Aditya, P.; Vanga, M.; Hilt, V. Efficient GPU Sharing for Serverless Workflows. In Proceedings of the 1st Workshop on High Performance Serverless Computing (HiPS ’21), Stockholm, Sweden, 23–26 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 17–24. [Google Scholar] [CrossRef]
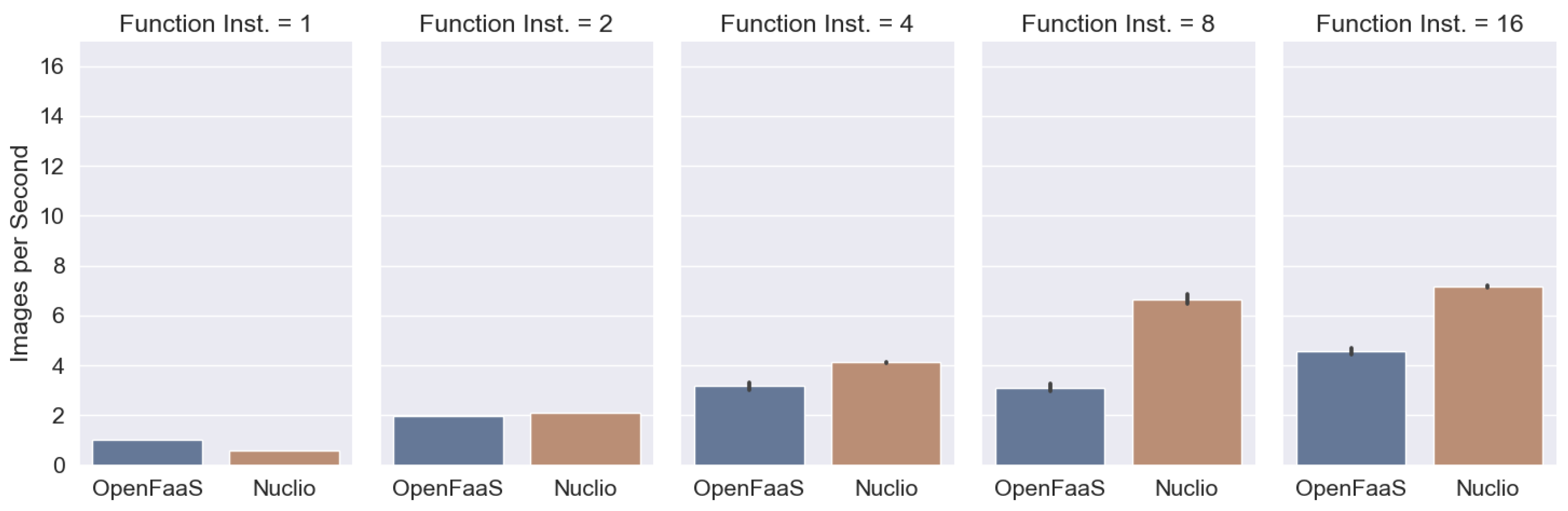
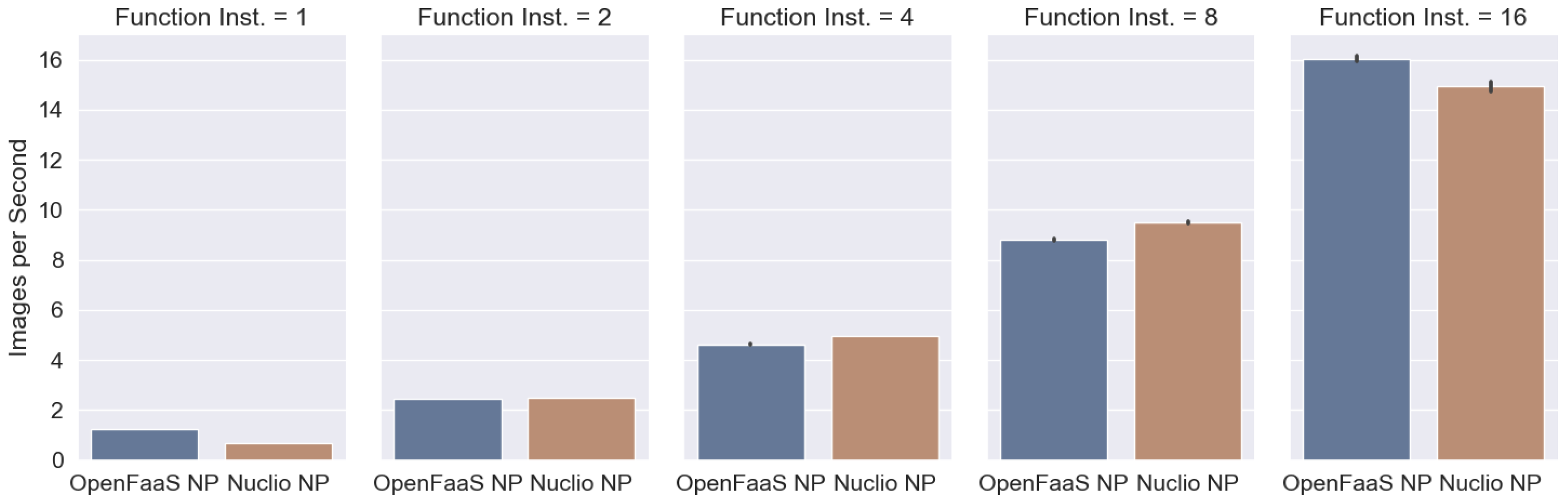
| Unit | Baseline | OpenFaaS | Nuclio | OpenFaaS NP | Nuclio NP |
|---|---|---|---|---|---|
| Images/s | 12.58 | 4.58 | 7.17 | 16.04 | 14.93 |
| MiB/s | 37.74 | 13.74 | 21.51 | 48.12 | 44.79 |
| Variant | OpenFaaS | Nuclio | Nuclio Go | |||
|---|---|---|---|---|---|---|
| Throughput | Instances | Throughput | Instances | Throughput | Instances | |
| Single | 7.47 | 4 | 9.64 | 4 | 12.71 | 1 |
| Parallel | 20.00 | 4 | 33.27 | 8 | 33.25 | 8 |
| OpenFaaS | Nuclio | Nuclio Go | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | GMean | Hmean | Mean | Gmean | Hmean | Mean | Gmean | Hmean |
| 7.47 | 7.22 | 7.02 | 9.64 | 9.40 | 9.20 | 12.71 | 11.63 | 11.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Decker, J.; Kasprzak, P.; Kunkel, J.M. Performance Evaluation of Open-Source Serverless Platforms for Kubernetes. Algorithms 2022, 15, 234. https://doi.org/10.3390/a15070234
Decker J, Kasprzak P, Kunkel JM. Performance Evaluation of Open-Source Serverless Platforms for Kubernetes. Algorithms. 2022; 15(7):234. https://doi.org/10.3390/a15070234
Chicago/Turabian StyleDecker, Jonathan, Piotr Kasprzak, and Julian Martin Kunkel. 2022. "Performance Evaluation of Open-Source Serverless Platforms for Kubernetes" Algorithms 15, no. 7: 234. https://doi.org/10.3390/a15070234
APA StyleDecker, J., Kasprzak, P., & Kunkel, J. M. (2022). Performance Evaluation of Open-Source Serverless Platforms for Kubernetes. Algorithms, 15(7), 234. https://doi.org/10.3390/a15070234