
Multi-Fidelity Sparse Polynomial Chaos and Kriging Surrogate Models Applied to Analytical Benchmark Problems

Abstract
1. Introduction
2. Methodology
2.1. Single-Fidelity Universal Kriging
2.2. Multi-Fidelity Kriging
- 1.
- Using lowest fidelity training points construct a kriging model, .
- 2.
- Construct another kriging model for the additive bridge function, , where in training points. Compute an optimal (and ) during the maximum likelihood estimation updates for , which means training point values will change constantly, but once converged one can evaluate .
- 3.
- Repeat step 2 until reaching the highest fidelity level (this is analogous to a multi-grid strategy).
2.3. Multi-Fidelity Sparse Polynomial Chaos Expansions
2.4. Multi-Fidelity SPCE-Kriging
- 1.
- Choose PCE orthogonal bases associated with the probability distributions of the (random) inputs;
- 2.
- Solve for the PCE coefficients using the LASSO algorithm as described in Section 2.3 to determine which bases are most important;
- 3.
3. Numerical Experiments Setup
3.1. Assessment Metric
3.2. Benchmark Problems
3.2.1. Forrester Function
3.2.2. Rosenbrock Function
3.2.3. Shifted-Rotated Rastrigin Function
3.2.4. ALOS Function
3.2.5. Coupled Spring-Mass-System
| Spring Constants | The springs obey Hooke’s law with constants and the mass of each spring is negligible. |
| Fixed Ends | The first and last spring are attached to fixed walls and have the same spring constant. |
| Mass Constants | , , are point masses. |
| Position Variables | The variables , , represent the mass positions measured from their equilibrium positions (negative is left and positive is right). |
Proposed Benchmark Problem
4. Results
4.1. Forrester
4.2. Rosenbrock
4.3. Rastrigin
4.4. ALOS
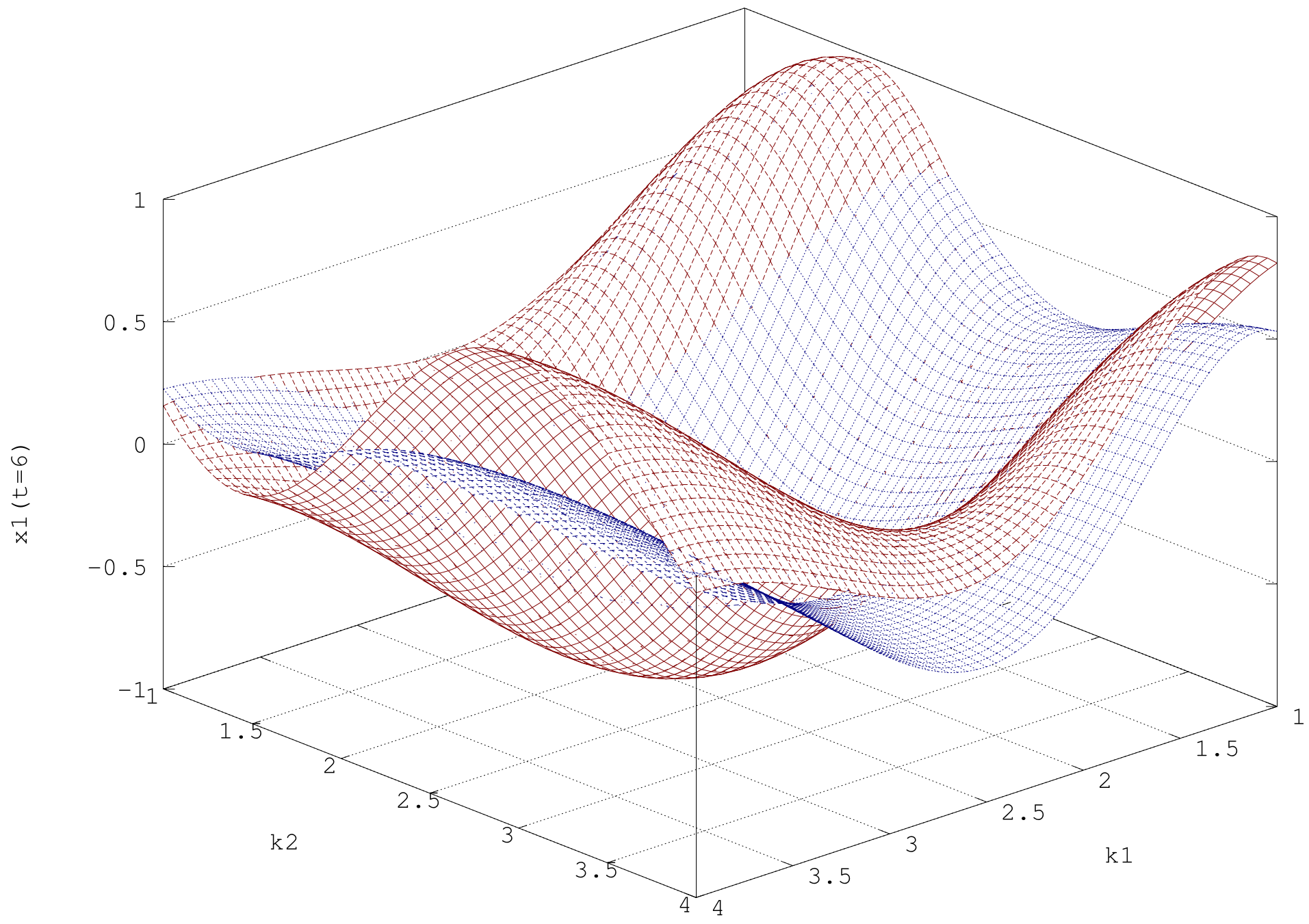
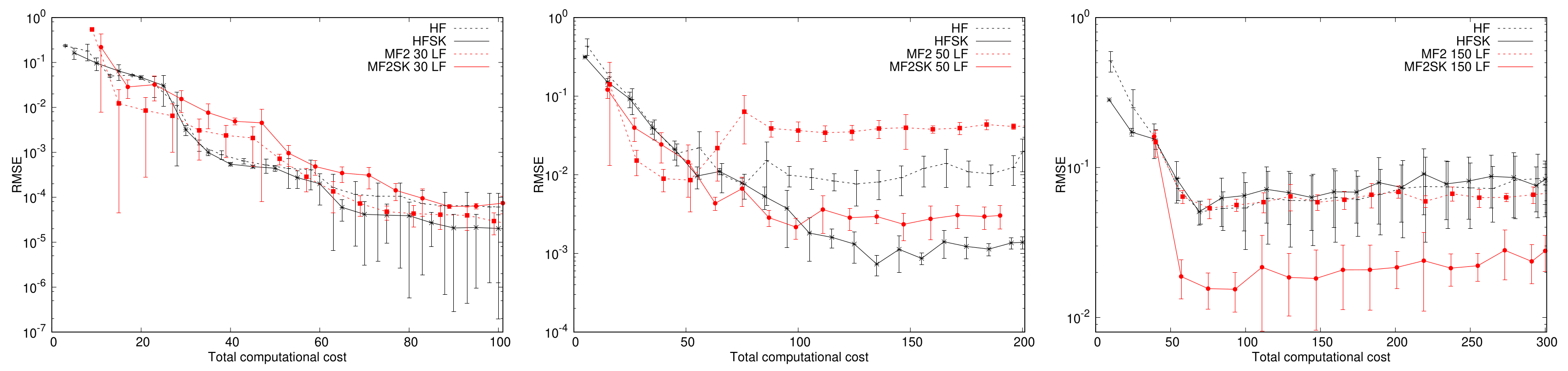
4.5. Coupled Spring-Mass-System
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Beran, P.; Bryson, D.; Thelen, A.; Diez, M.; Serani, A. Comparison of Multi-Fidelity Approaches for Military Vehicle Design. In Proceedings of the AIAA AVIATION 2020 FORUM, Virtual Event, 15–19 June 2020. [Google Scholar]
- Isukapalli, S.; Roy, A.; Georgopoulos, P. Efficient sensitivity/uncertainty analysis using the combined stochastic response surface method and automated differentiation: Application to environmental and biological systems. Risk Anal. 2000, 20, 591–602. [Google Scholar] [CrossRef] [PubMed]
- Kim, N.; Wang, H.; Queipo, N. Adaptive reduction of random variables using global sensitivity in reliability-based optimisation. Int. J. Reliab. Saf. 2006, 1, 102–119. [Google Scholar] [CrossRef]
- Roderick, O.; Anitescu, M.; Fischer, P. Polynomial regression approaches using derivative information for uncertainty quantification. Nucl. Sci. Eng. 2010, 164, 122–139. [Google Scholar] [CrossRef]
- Krige, D.G. A statistical approach to some basic mine valuations problems on the Witwatersrand. J. Chem. Metall. Min. Eng. Soc. South Afr. 1951, 52, 119–139. [Google Scholar]
- Cressie, N. The Origins of Kriging. Math. Geol. 1990, 22, 239–252. [Google Scholar] [CrossRef]
- Koehler, J.R.; Owen, A.B. Computer Experiments. In Handbook of Statistics; Ghosh, S., Rao, C.R., Eds.; Elsevier: Amsterdam, The Netherlands, 1996; Volume 13, pp. 261–308. [Google Scholar]
- Yamazaki, W.; Mouton, S.; Carrier, G. Efficient Design Optimization by Physics-Based Direct Manipulation Free-Form Deformation. In Proceedings of the 12th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Victoria, BC, Canada, 10–12 September 2008; p. 5953. [Google Scholar]
- Boopathy, K.; Rumpfkeil, M.P. A Unified Framework for Training Point Selection and Error Estimation for Surrogate Models. AIAA J. 2015, 53, 215–234. [Google Scholar] [CrossRef]
- Gano, S.; Renaud, J.E.; Sanders, B. Variable Fidelity Optimization Using a Kriging Based Scaling Function. In Proceedings of the 10th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Albany, NY, USA, 30 August–1 September 2004. [Google Scholar] [CrossRef]
- Eldred, M.S.; Giunta, A.A.; Collis, S.S.; Alexandrov, N.A.; Lewis, R. Second-Order Corrections for Surrogate-Based Optimization with Model Hierarchies. In Proceedings of the 10th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Albany, NY, USA, 30 August–1 September 2004. [Google Scholar] [CrossRef]
- Ng, L.W.T.; Eldred, M.S. Multifidelity Uncertainty Quantification Using Non-Intrusive Polynomial Chaos and Stochastic Collocation. In Proceedings of the 53rd AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference, Honolulu, HI, USA, 23–26 April 2012. [Google Scholar]
- Bryson, D.E.; Rumpfkeil, M.P. All-at-Once Approach to Multifidelity Polynomial Chaos Expansion Surrogate Modeling. Aerosp. Sci. Technol. 2017, 70C, 121–136. [Google Scholar] [CrossRef]
- Han, Z.H.; Zimmermann, R.; Goertz, S. On Improving Efficiency and Accuracy of Variable-Fidelity Surrogate Modeling in Aero-data for Loads Context. In Proceedings of the CEAS 2009 European Air and Space Conference, Manchester, UK, 26–29 October 2009. [Google Scholar]
- Han, Z.H.; Zimmermann, R.; Goertz, S. A New Cokriging Method for Variable-Fidelity Surrogate Modeling of Aerodynamic Data. In Proceedings of the 48th AIAA Aerospace Sciences Meeting Including the New Horizons Forum and Aerospace Exposition, Orlando, FL, USA, 4–7 January 2010. [Google Scholar]
- Yamazaki, W.; Rumpfkeil, M.P.; Mavriplis, D.J. Design Optimization Utilizing Gradient/Hessian Enhanced Surrogate Model. In Proceedings of the 28th AIAA Applied Aerodynamics Conference, Chicago, IL, USA, 28 June–1 July 2010. [Google Scholar]
- Yamazaki, W.; Mavriplis, D.J. Derivative-Enhanced Variable Fidelity Surrogate Modeling for Aerodynamic Functions. AIAA J. 2013, 51, 126–137. [Google Scholar] [CrossRef]
- Han, Z.H.; Goertz, S.; Zimmermann, R. Improving variable-fidelity surrogate modeling via gradient-enhanced kriging and a generalized hybrid bridge function. Aerosp. Sci. Technol. 2013, 25, 177–189. [Google Scholar] [CrossRef]
- Choi, S.; Alonso, J.J.; Kroo, I.M.; Wintzer, M. Multi-Fidelity Design Optimization of Low-Boom Supersonic Business Jets. In Proceedings of the 10th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Albany, NY, USA, 30 August–1 September 2004. [Google Scholar] [CrossRef]
- Lewis, R.; Nash, S. A Multigrid Approach to the Optimization of Systems Governed by Differential Equations. In Proceedings of the 8th Symposium on Multidisciplinary Analysis and Optimization, Long Beach, CA, USA, 6–8 September 2000. [Google Scholar] [CrossRef]
- Alexandrov, N.M.; Lewis, R.M.; Gumbert, C.R.; Green, L.L.; Newman, P.A. Approximation and Model Management in Aerodynamic Optimization with Variable-Fidelity Models. J. Aircr. 2001, 38, 1093–1101. [Google Scholar] [CrossRef]
- Candes, E.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inform. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Donoho, D. Compressed sensing. IEEE Trans. Inform. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Blatman, G.; Sudret, B. Adaptive sparse polynomial chaos expansion based on least angle regression. J. Comput. Phys. 2011, 230, 2345–2367. [Google Scholar] [CrossRef]
- Doostan, A.; Owhadi, H. A non-adapted sparse approximation of PDEs with stochastic inputs. J. Comput. Phys. 2011, 230, 3015–3034. [Google Scholar] [CrossRef]
- Davenport, M.A.; Duarte, M.F.; Eldar, Y.; Kutyniok, G. Introduction to compressed sensing. In Compressed Sensing: Theory and Applications; Eldar, Y.C., Kutyniok, G., Eds.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Jakeman, J.D.; Eldred, M.S.; Sargsyan, K. Enhancing l1-minimization estimates of polynomial chaos expansions using basis selection. J. Comput. Phys. 2015, 289, 18–34. [Google Scholar] [CrossRef]
- Kougioumtzoglou, I.; Petromichelakis, I.; Psaros, A. Sparse representations and compressive sampling approaches in engineering mechanics: A review of theoretical concepts and diverse applications. Probabilistic Eng. Mech. 2020, 61, 103082. [Google Scholar] [CrossRef]
- Luethen, N.; Marelli, S.; Sudret, B. Sparse Polynomial Chaos Expansions: Literature Survey and Benchmark. SIAM/ASA J. Uncertain. Quantif. 2021, 9, 593–649. [Google Scholar] [CrossRef]
- Rumpfkeil, M.P.; Beran, P. Multi-Fidelity Sparse Polynomial Chaos Surrogate Models Applied to Flutter Databases. AIAA J. 2020, 58, 1292–1303. [Google Scholar] [CrossRef]
- Salehi, S.; Raisee, M.; Cervantes, M.J.; Nourbakhsh, A. Efficient Uncertainty Quantification of Stochastic CFD Problems Using Sparse Polynomial Chaos and Compressed Sensing. Comput. Fluids 2017, 154, 296–321. [Google Scholar] [CrossRef]
- Schobi, R.; Sudret, B.; Wiart, J. Polynomial-chaos–based Kriging. Int. J. UQ 2015, 5, 171–193. [Google Scholar] [CrossRef]
- Leifsson, L.; Du, X.; Koziel, S. Efficient yield estimation of multiband patch antennas by polynomial chaos-based Kriging. Int. J. Numer. Model. 2020, 33, e2722. [Google Scholar] [CrossRef]
- Rumpfkeil, M.P.; Beran, P. Multi-Fidelity Surrogate Models for Flutter Database Generation. Comput. Fluids 2020, 197, 104372. [Google Scholar] [CrossRef]
- Rumpfkeil, M.P.; Beran, P. Multi-Fidelity, Gradient-enhanced, and Locally Optimized Sparse Polynomial Chaos and Kriging Surrogate Models Applied to Benchmark Problems. In Proceedings of the AIAA Scitech 2020 Forum, Orlando, FL, USA, 6–10 January 2020. [Google Scholar]
- Wendland, H. Scattered Data Approximation, 1st ed.; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Rumpfkeil, M.P.; Beran, P. Construction of Multi-Fidelity Surrogate Models for Aerodynamic Databases. In Proceedings of the Ninth International Conference on Computational Fluid Dynamics, ICCFD9, Istanbul, Turkey, 11–15 July 2016. [Google Scholar]
- Burkardt, J. SGMGA: Sparse Grid Mixed Growth Anisotropic Rules. Available online: https://people.math.sc.edu/Burkardt/f_src/sgmga/sgmga.html (accessed on 1 March 2020).
- Curtin, R.R.; Cline, J.R.; Slagle, N.P.; March, W.B.; Ram, P.; Mehta, N.A.; Gray, A.G. MLPACK: A Scalable C++ Machine Learning Library. J. Mach. Learn. Res. 2013, 14, 801–805. [Google Scholar]
- Allen, D.M. The relationship between variable selection and data agumentation and a method for prediction. Technometrics 1974, 16, 125–127. [Google Scholar] [CrossRef]
- Forrester, A.I.; Sóbester, A.; Keane, A.J. Multi-fidelity optimization via surrogate modelling. Proc. R. Soc. A Math. Phys. Eng. Sci. 2007, 463, 3251–3269. [Google Scholar] [CrossRef]
- Aguilera, A.; Pérez-Aguila, R. General n-dimensional rotations. In Proceedings of the WSCG’2004, Plzen, Czech Republic, 2–6 February 2004. [Google Scholar]
- Wang, H.; Jin, Y.; Doherty, J. A generic test suite for evolutionary multifidelity optimization. IEEE Trans. Evol. Comput. 2017, 22, 836–850. [Google Scholar] [CrossRef]
- Clark, D.L.; Bae, H.R.; Gobal, K.; Penmetsa, R. Engineering Design Exploration utilizing Locally Optimized Covariance Kriging. AIAA J. 2016, 54, 3160–3175. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D | 1 | 2 | 3 | 4 | 5 | 10 |
|---|---|---|---|---|---|---|
| 1001 | 101 | 31 | 21 | 11 | 3 |
| Function | Dimension, D | Comp. Budget | Cost per Fidelity Level | |||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| Forrester | 1 | 100 | 1 | 0.5 | 0.1 | 0.05 |
| Rosenbrock | 2 | 200 | 1 | 0.5 | 0.1 | - |
| 5 | 500 | 1 | 0.5 | 0.1 | - | |
| 10 | 1000 | 1 | 0.5 | 0.1 | - | |
| Rastrigin | 2 | 200 | 1 | 0.0625 | 0.00390625 | - |
| 5 | 500 | 1 | 0.0625 | 0.00390625 | - | |
| 10 | 1000 | 1 | 0.0625 | 0.00390625 | - | |
| ALOS | 1 | 100 | 1 | 0.2 | - | - |
| 2 | 200 | 1 | 0.2 | - | - | |
| 3 | 300 | 1 | 0.2 | - | - | |
| Spring-Mass | 2 (springs) | 200 | 1 | 1/60 | - | - |
| 4 (springs + masses) | 400 | 1 | 1/60 | - | - | |
| # of HF Points | # of LF3 Points | λ | Order, P | Additive, R | Multiplicative, Q |
|---|---|---|---|---|---|
| 3 | 0 | 6 | – | – | |
| 7 | 0 | 9 | – | – | |
| 15 | 0 | 20 | – | – | |
| 31 | 0 | 22 | – | – | |
| 63 | 0 | 22 | – | – | |
| 127 | 0 | 23 | – | – | |
| 3 | 63 | 11 | 1 | 4 | |
| 7 | 63 | 12 | 1 | 3 | |
| 15 | 63 | 21 | 11 | 12 | |
| 31 | 63 | 22 | 12 | 13 | |
| 31 | 127 | 22 | 12 | 13 | |
| 63 | 127 | 22 | 14 | 14 |
| # of HF Points | # of LF2 Points | Order, P | Additive, R | Multiplicative, Q | |
|---|---|---|---|---|---|
| 5 | 0 | 6 | – | – | |
| 9 | 0 | 6 | – | – | |
| 17 | 0 | 8 | – | – | |
| 33 | 0 | 9 | – | – | |
| 65 | 0 | 7 | – | – | |
| 97 | 0 | 10 | – | – | |
| 161 | 0 | 17 | – | – | |
| 257 | 0 | 18 | – | – | |
| 5 | 33 | 10 | 1 | 1 | |
| 9 | 65 | 9 | 1 | 1 | |
| 17 | 97 | 12 | 6 | 4 | |
| 33 | 97 | 12 | 6 | 2 | |
| 33 | 161 | 12 | 6 | 3 | |
| 65 | 161 | 10 | 6 | 5 | |
| 97 | 161 | 15 | 10 | 10 | |
| 161 | 321 | 15 | 9 | 10 | |
| 257 | 449 | 17 | 10 | 10 |
| # of HF Points | # of LF2 Points | Order, P | Additive, R | Multiplicative, Q | |
|---|---|---|---|---|---|
| 5 | 0 | 6 | – | – | |
| 9 | 0 | 6 | – | – | |
| 17 | 0 | 6 | – | – | |
| 33 | 0 | 6 | – | – | |
| 65 | 0 | 11 | – | – | |
| 97 | 0 | 12 | – | – | |
| 161 | 0 | 12 | – | – | |
| 257 | 0 | 11 | – | – | |
| 5 | 33 | 6 | 1 | 1 | |
| 9 | 65 | 11 | 1 | 1 | |
| 17 | 97 | 12 | 1 | 1 | |
| 33 | 97 | 12 | 1 | 1 | |
| 33 | 161 | 12 | 1 | 1 | |
| 65 | 161 | 12 | 1 | 1 | |
| 97 | 161 | 12 | 3 | 1 | |
| 161 | 321 | 12 | 3 | 1 |
| # of HF Points | # of LF Points | Order, P | Additive, R | Multiplicative, Q | |
|---|---|---|---|---|---|
| 5 | 0 | 6 | – | – | |
| 9 | 0 | 9 | – | – | |
| 17 | 0 | 9 | – | – | |
| 33 | 0 | 6 | – | – | |
| 65 | 0 | 7 | – | – | |
| 97 | 0 | 12 | – | – | |
| 161 | 0 | 11 | – | – | |
| 257 | 0 | 11 | – | – | |
| 5 | 33 | 6 | 1 | 1 | |
| 9 | 65 | 12 | 2 | 4 | |
| 17 | 97 | 10 | 4 | 3 | |
| 33 | 97 | 12 | 6 | 1 | |
| 33 | 161 | 12 | 6 | 1 | |
| 65 | 161 | 12 | 6 | 4 | |
| 97 | 161 | 12 | 6 | 6 | |
| 161 | 321 | 11 | 6 | 6 |
| # of HF Points | # of LF Points | Order, P | Additive, R | Multiplicative, Q | |
|---|---|---|---|---|---|
| 9 | 0 | 6 | – | – | |
| 33 | 0 | 10 | – | – | |
| 81 | 0 | 10 | – | – | |
| 193 | 0 | 7 | – | – | |
| 385 | 0 | 7 | – | – | |
| 641 | 0 | 8 | – | – |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rumpfkeil, M.P.; Bryson, D.; Beran, P. Multi-Fidelity Sparse Polynomial Chaos and Kriging Surrogate Models Applied to Analytical Benchmark Problems. Algorithms 2022, 15, 101. https://doi.org/10.3390/a15030101
Rumpfkeil MP, Bryson D, Beran P. Multi-Fidelity Sparse Polynomial Chaos and Kriging Surrogate Models Applied to Analytical Benchmark Problems. Algorithms. 2022; 15(3):101. https://doi.org/10.3390/a15030101
Chicago/Turabian StyleRumpfkeil, Markus P., Dean Bryson, and Phil Beran. 2022. "Multi-Fidelity Sparse Polynomial Chaos and Kriging Surrogate Models Applied to Analytical Benchmark Problems" Algorithms 15, no. 3: 101. https://doi.org/10.3390/a15030101
APA StyleRumpfkeil, M. P., Bryson, D., & Beran, P. (2022). Multi-Fidelity Sparse Polynomial Chaos and Kriging Surrogate Models Applied to Analytical Benchmark Problems. Algorithms, 15(3), 101. https://doi.org/10.3390/a15030101