1. Introduction
Scheduling problems are interesting due to their practical usefulness and hardness. Such problems emerge in various domains, including manufacturing, computing, project management, and many others. Since scheduling problems are typically NP-hard, several approaches compete to attain the often unreached optimal solutions. Metaheuristics, heuristics, constraint programming, and mathematical programming often yield excellent results. The latter two are especially sensitive to problem sizes since their exact nature implies that all solutions must be checked or intelligently pruned.
Scheduling is a thoroughly studied subject that is considered a discipline on its own [
1]. Scheduling problems are classified using the commonly accepted
notation [
2], where
refers to the machine environment,
refers to the constraints, and
refers to the objective function. A valuable asset for appreciating the variety of scheduling problems under the
notation can be found at [
3].
In this work, we study a variation in the one-machine scheduling with time-dependent capacity problem that Mencia et al. introduced in [
4,
5,
6]. The problem emerged in the context of scheduling charge times for a fleet of electric vehicles and is an abstraction of the real problem. It is classified as
, meaning that it involves a single machine with capacity that fluctuates through time, with no other constraints, and the objective is minimizing the accumulated tardiness from all jobs. The problem piqued our interest due to its precise definition, the publicly available datasets, and the excellent results that were already published and which we used for comparisons.
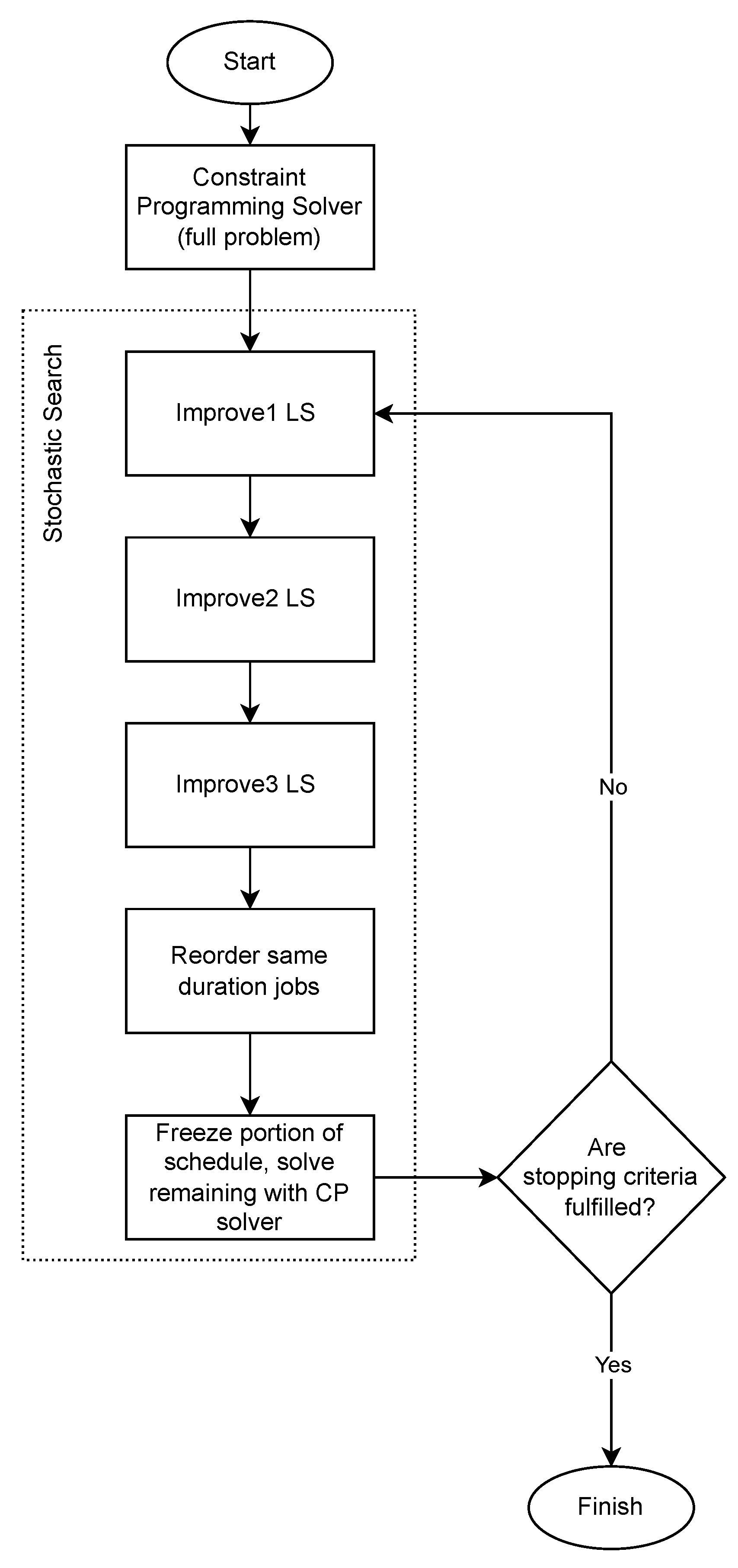
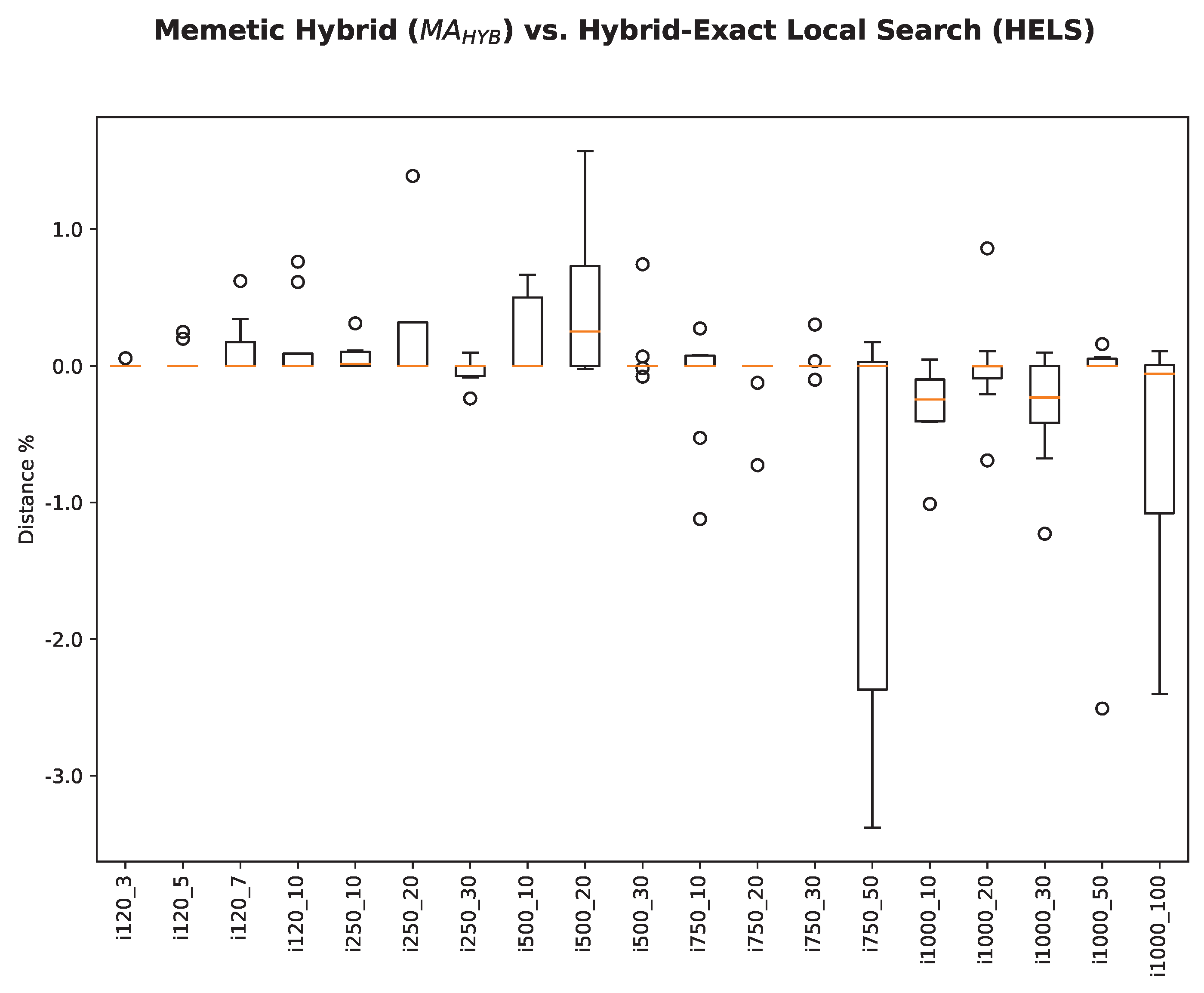
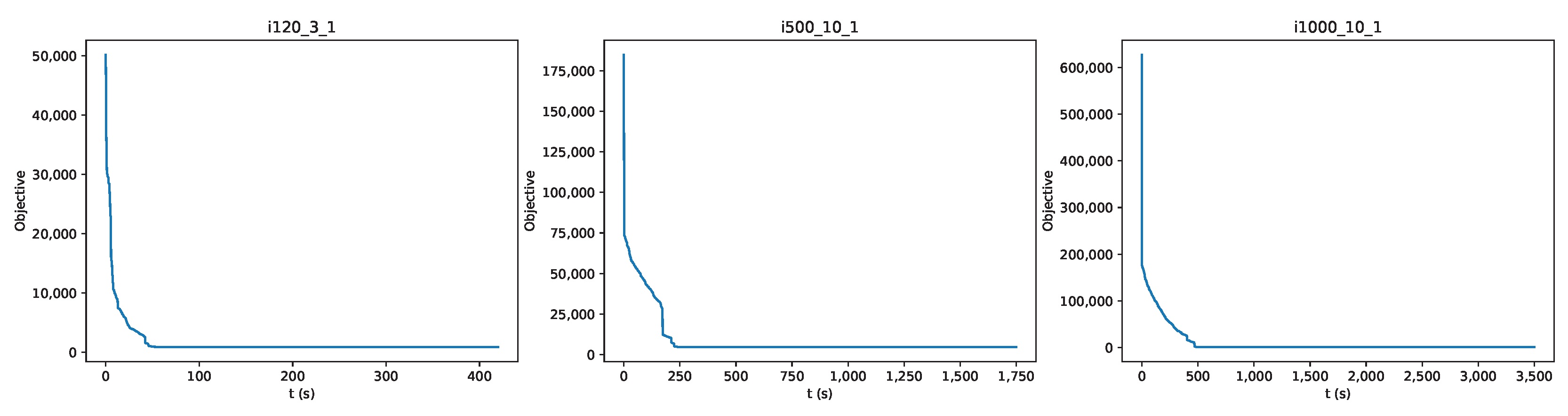
We propose a novel way to approach the problem based on a model with an embedded rule (the due times rule) that helps constraint programming solvers reach good solutions fast. We also propose three improvement procedures that are local search routines. We combine the exact and local search parts in our approach to the problem, and we manage to achieve results equal to or better than the best-known results for 91 and 48 cases, respectively, out of 190 public problem instances.
5. C-Paths
A fundamental concept that was introduced by Mencia et al. in [
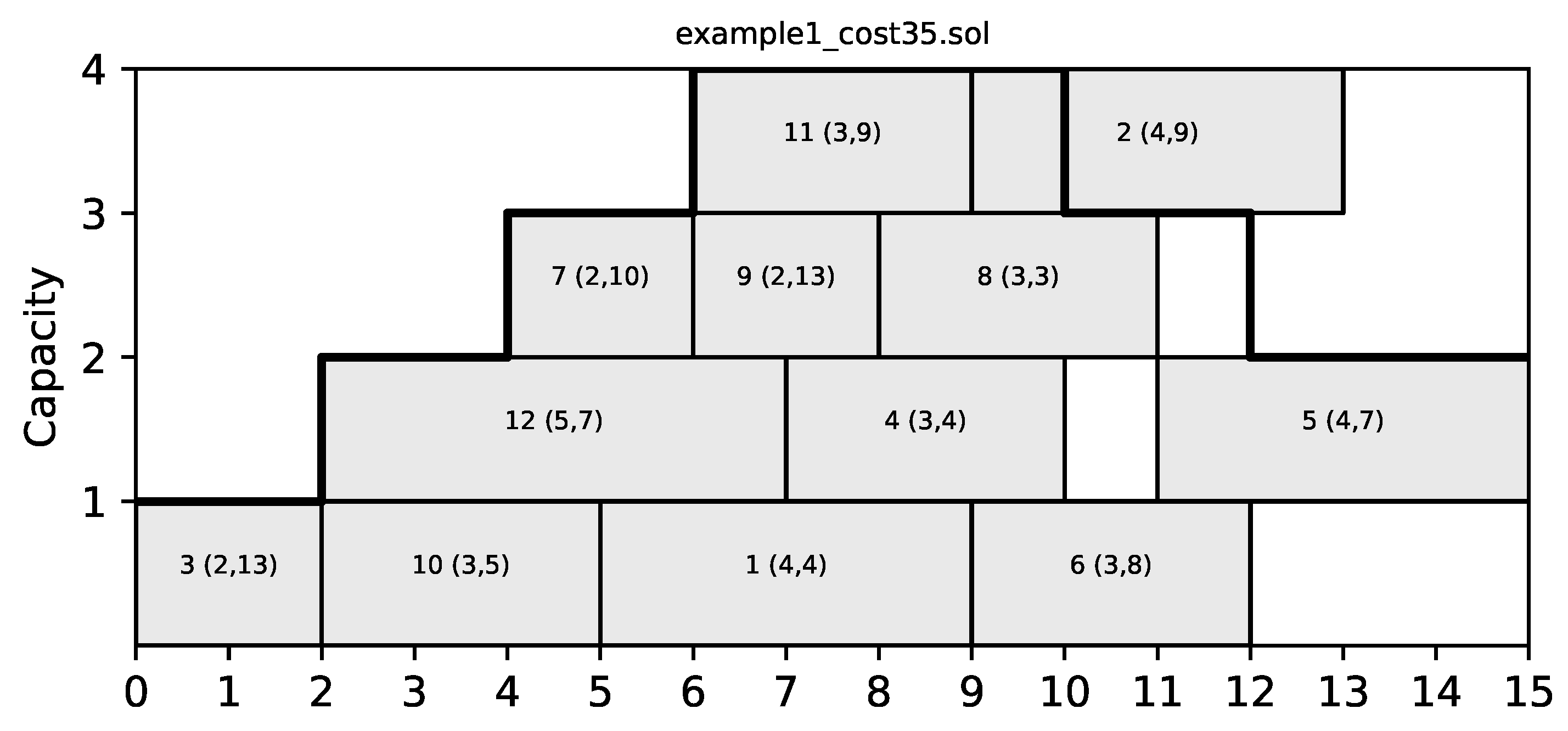
4] is the concept of a C-Path. A C-Path is a sequence of consecutive jobs (i.e., in a C-Path, the finish time of each previous job coincides with the start time of the following job) in a schedule. The importance of C-Paths stems from the fact that jobs in each C-Path can easily swap places and keep the schedule feasible. We can consider a graph view of a schedule, where each job is a node and directed edges connect nodes that correspond to consecutive jobs. Then, each path from a source node of the graph (i.e., a node with no incoming edges) to a sink node (i.e., a node with no outgoing edges) is a C-Path. This is demonstrated in
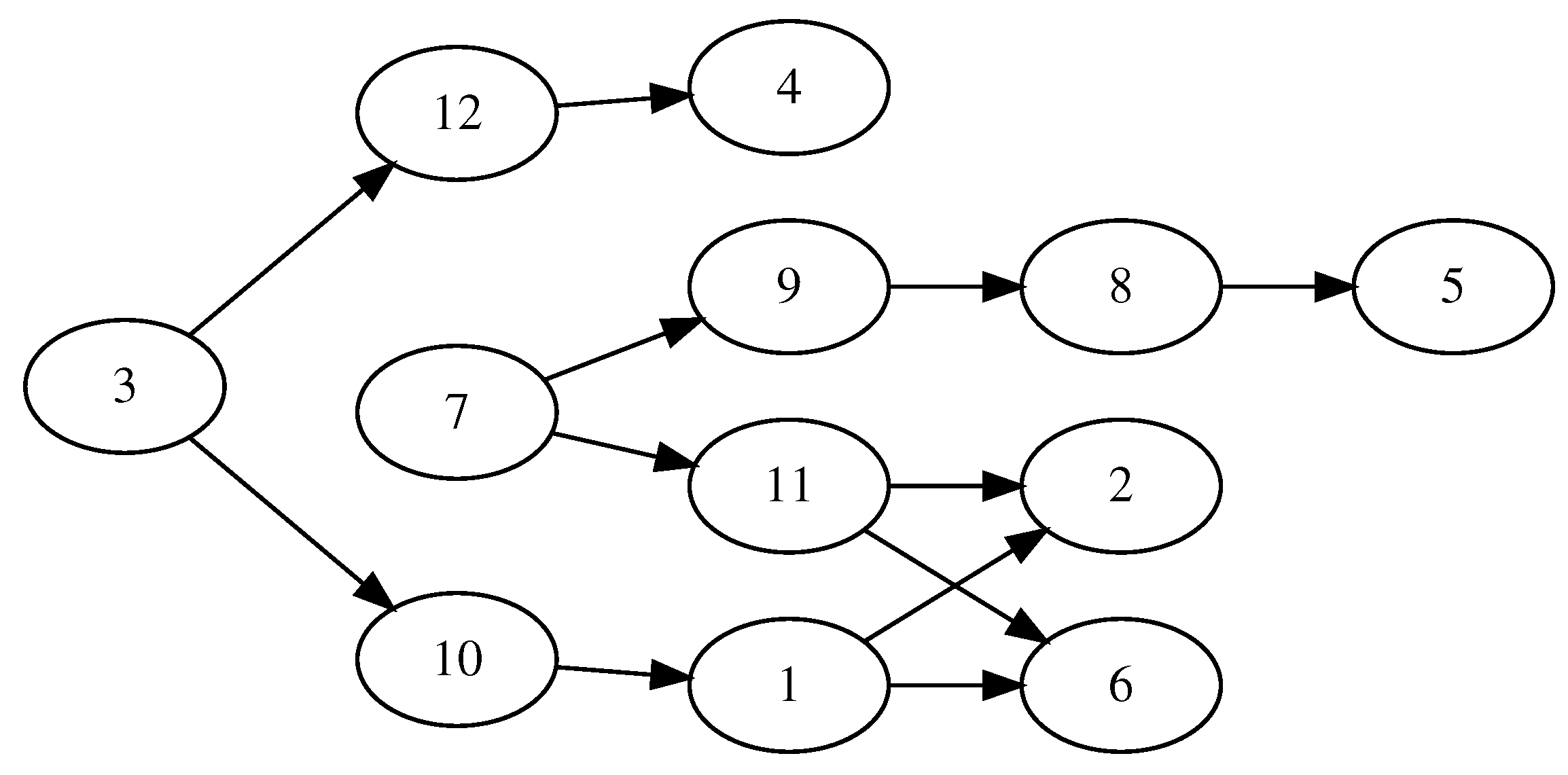
Figure 2 for a sample schedule of cost 35 for the toy problem instance shown in
Table 1 and its corresponding graph in
Figure 3. The list of C-Paths identified in this graph includes the following six: (3,12,4), (3,10,1,6), (3,10,1,2), (7,9,8,5), (7,11,2), and (7,11,6).
The number of C-Paths might be very large, especially for schedules of big-size problems. This is demonstrated in
Table 3, which shows the number of C-Paths for specific schedules of selected problem instances. Note that the number of C-Paths might change dramatically for different schedules of the same problem instance and that larger problem instances might have fewer C-Paths than smaller problem instances for some schedules.
Fast Computation of C-Paths
Since complete enumeration of all C-Paths is out of the question for problems of large sizes, we opted for a faster method of generating a single C-Path each time it is needed. This method starts by picking a random job, followed by two processes that find the right and the left part of a C-Path, having the selected job as a pivot element. The right-side part of the C-path is formed by choosing the next job that starts at the finish time of the current job. If more than one job exists, one of them is randomly selected and becomes the new current job. This process continues until no more subsequent jobs are found. The left side of the C-Path is formed by setting the initially selected job as the current job once again and finding previous jobs that end at the start time of the current job. Similarly, if more than one exists, one is chosen at random and becomes the new current job. The process ends when no more suitable prior jobs can be found.
7. Formulation and Implementation
A formulation of the problem that will be used to construct initial solutions to the problem is presented below. Then, the formulation is slightly modified and used for solving problems involving subsets of tasks in an effort to attain better schedules overall.
Let be the set of jobs.
Let be the duration of each job .
Let be the due date of each job .
Let T be the number of time points. Note that the value of T is not given explicitly by the problem, but such a value can be computed by aggregating the duration of all jobs.
Let be the capacity of the machine at each time point .
We define integer decision variables that denote the start time of each job .
Likewise, we define integer decision variables that denote the finish time of each job .
We also define integer decision variables which denote the tardiness of each job .
Finally, we define binary decision variables
and
. Each one of the former variables assumes the value 1 if job
j starts its execution at time point
t, or else it assumes the value 0. Likewise, each
variable marks the time point at which job
j finishes.
A brief explanation of the above model follows.
The aim of the objective function in Equation (
1) is to minimize the total tardiness of all jobs.
Equation (
2) assigns the proper finish time value to each job given its start time and duration.
Equation (
3) assigns tardiness values to the jobs. In particular, when job
j finishes before its due time, the right side of the inequality is a negative number, and variable
assumes the value 0 since its domain is non-negative integers. When job
j finishes after its due time,
becomes
. This occurs because
is included in the minimized objective function and therefore forced to assume the smallest possible non-negative value.
Equations (
4) and (
5) drive the variables
to proper values based on the
values. This occurs because, when
assumes the value
t,
becomes 1. It should be noted that
M in Equation (
5) represents a big value, and
can be used for it. For the specific time point
t at which a job will be scheduled to begin, the right sides of both equalities will assume the value
t. For all other time points besides
t, the right sides of the former and the latter equations become 0 and
M, respectively.
Equation (
6) enforces that only one among all of the
variables of each job
j will assume the value 1.
Equation (
7) dictates the following association rule: for each job
j, when
becomes 1 or 0, the corresponding
y variable of
j with the time offset
, which is
, will also be 1 or 0, respectively.
Equation (
8) guarantees that for each time point, the capacity of the machine will not be violated. The values that the left side of the equation assumes are the numbers of active jobs at each time point
t. The first double summation counts the jobs that have started no later than
t, while the second double summation counts the jobs that have also finished no later than
t. Their difference is obviously the number of active jobs.
Constraint Programming Formulation
The IBM ILOG constraint programming (CP) solver seems to be a good choice for solving scheduling problems involving jobs that occupy intervals of time and consume some types of resources that have time-varying availability [
27]. The one-machine scheduling problem can be easily formulated in the IBM ILOG CP solver using one fixed-size interval variable per job (
j) and the constraint
always_in, which restricts all of them to assume values that collectively never exceed the maximum available capacity over time. This is possible by using a pulse cumulative function expression that represents the contribution of our fixed interval variables over time. Each job execution requires one capacity unit, which is occupied when the job starts, retained through its execution, and released when the job finishes. In our case, the variable
usage aggregates all pulse requirements by all jobs. The objective function uses a set of integer variables
z[job.id] that are stored in a dictionary that has the identifier of each job as keys. Each
z[job.id] variable assumes the value of the job’s tardiness (i.e., the non-negative difference of the job’s due time (
job.due_time) and its finish time (
end_of(j[job.id])). An additional constraint is added that corresponds to the due times rule mentioned in
Section 6. Jobs are grouped by duration, and a list ordered by due times is prepared for each group. Then, for all jobs in the list, the constraint enforces that the order of the jobs must be respected. This means that each job in the list should have an earlier start time than the start time of the job that follows it in the list. The model implementation using the IBM ILOG CP solver’s python API is presented below.
import docplex.cp.model as cpx
model = cpx.CpoModel()
x_ub = int(problem.ideal_duration() * 1.1)
j = {
job.id: model.interval_var(
start=[0, x_ub - job.duration - 1],
end=[job.duration, x_ub - 1],
size=job.duration
)
for job in problem.jobs
}
z = {
job.id: model.integer_var(lb=0, ub=x_ub - 1)
for job in problem.jobs
}
usage = sum([model.pulse(j[job.id], 1) for job in problem.jobs])
for i in range(problem.nint):
model.add(
model.always_in(
usage,
[problem.capacities[i].start, problem.capacities[i].end],
0,
problem.capacities[i].capacity,
)
)
for job in problem.jobs:
model.add(z[job.id] >= model.end_of(j[job.id]) - job.due_time)
for k in problem.size_jobs: # iterate over discrete job durations
jobs_by_due_time = same_duration_jobs[k]
for i in range(len(jobs_by_due_time)-1):
j1, j2 = jobs_by_due_time[i][1], jobs_by_due_time[i+1][1]
model.add(model.start_of(z[j1]) <= model.start_of(z[j2]))
model.minimize(sum([z[job.id] for job in problem.jobs]))
The object problem is supposed to be an instance of a class that has all relevant information for the problem instance under question (i.e., jobs is the list of all jobs, each job besides id and due_time has also a duration property, nint is the number of capacity intervals, and capacities[i].start and capacities[i].end are the start time and end time of the ith capacity step, respectively). Finally, the problem object has the ideal_duration method that estimates a tight value for the makespan of the schedule, which is incremented by 10% to accommodate possible gaps that hinder the full exploitation of the available capacity. The “ideal duration” is computed by totaling the durations of all jobs and then filling the area under the capacity line from left to right and from bottom to top with blocks of the size until the totaled durations quantity runs out. The rightmost point on the time axis of the filled area becomes the “ideal duration” and is clearly a relaxation of the actual completion time of the optimal solution since each job is decomposed in blocks of the duration one, and no gaps appear in the filled area.
An effort was undertaken to implement the above model using Google’s ORTools CP-SAT Solver [
28]. This solver has a cumulative constraint that can be used in place of
always_in to describe the machine’s varying capacity. A series of
variables were used that transformed the pulse of the capacity to a flat line equal to the maximum capacity. Unfortunately, the solver under this specific model implementation could not approximate good results and was finally not used.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}