
The Assignment Problem and Its Relation to Logistics Problems


Abstract
1. Introduction
2. The Assignment Problem Model
3. Routing Problems
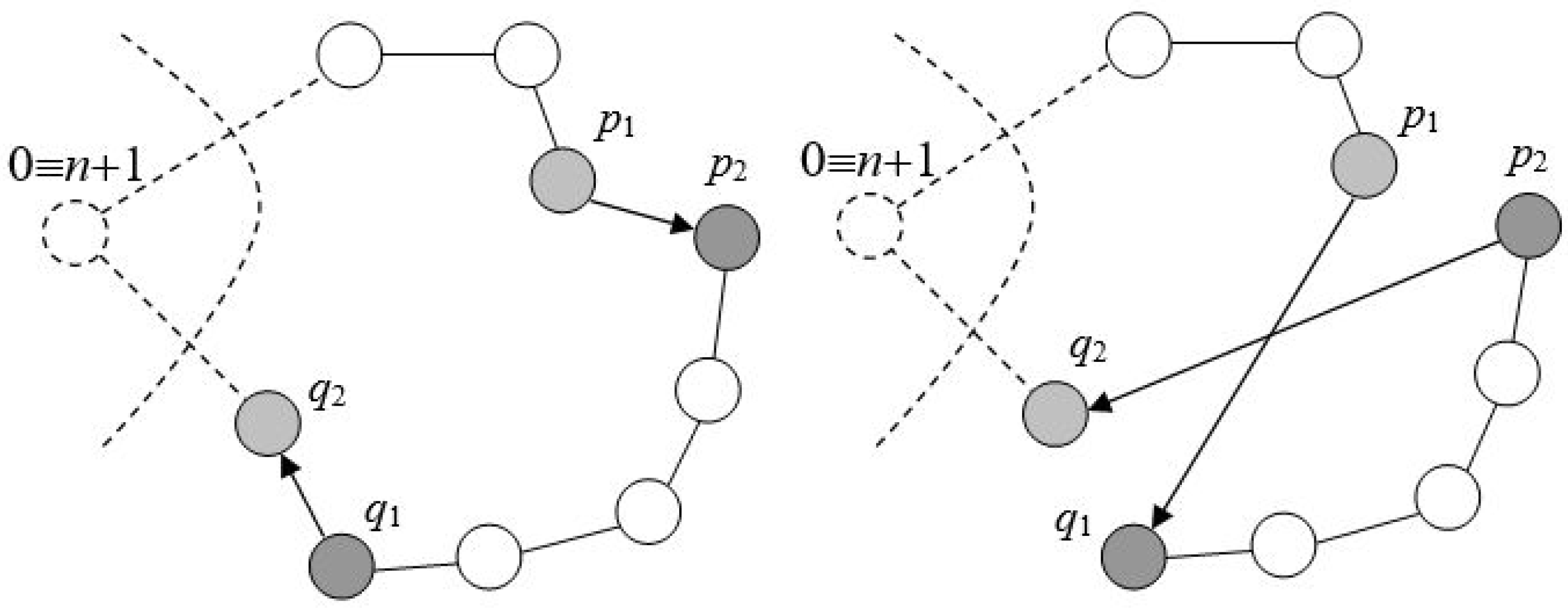
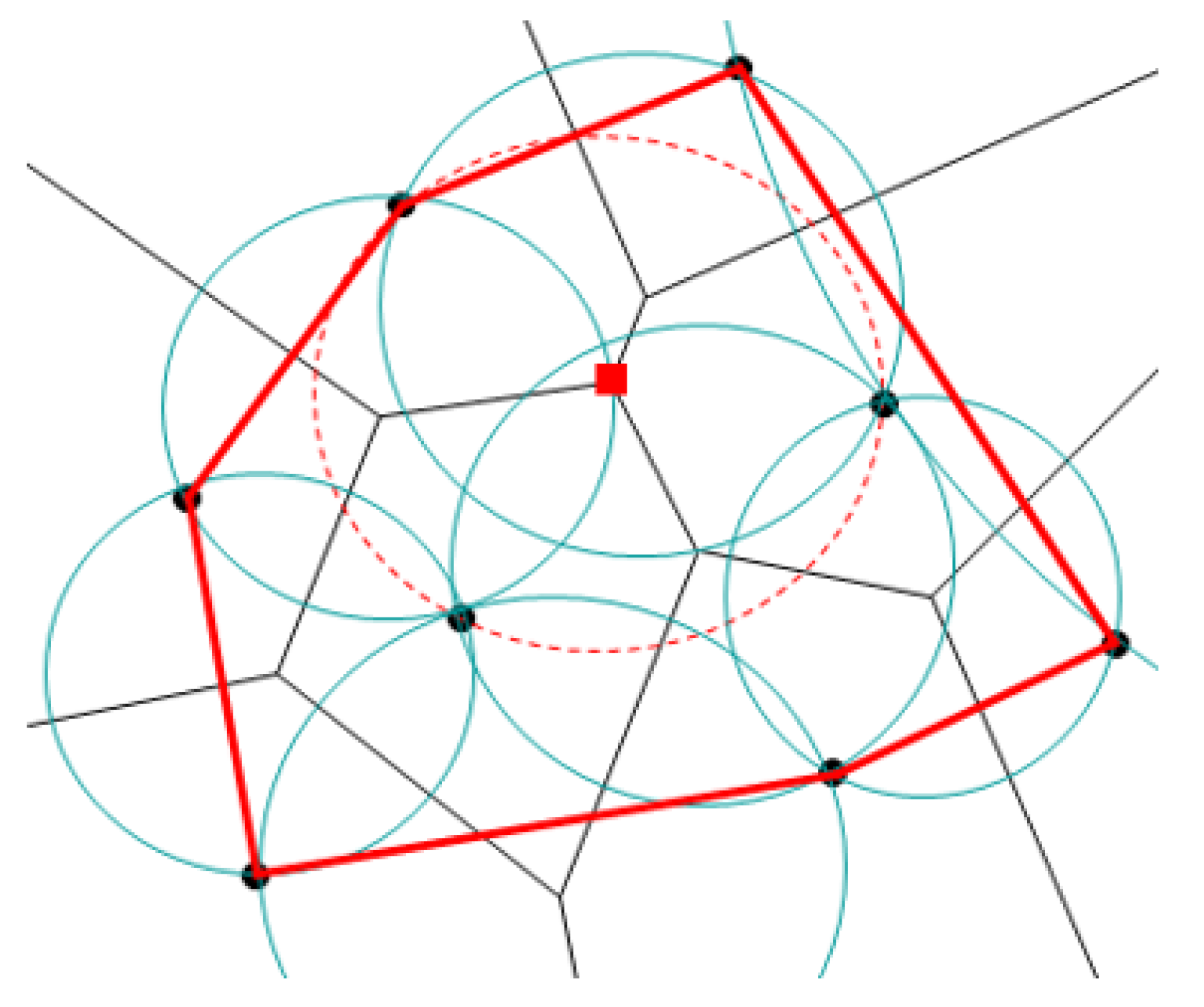
3.1. Travelling Salesman Problem
3.2. Vehicle Routing Problem
4. Distribution Problems
4.1. Container Transportation Problem
4.2. Allocation Problem
4.3. Location Problem
4.4. Capacitated Network Area Coverage
4.5. Transportation Problem with Supply from Primary Source
4.6. Crop Problem
5. Scheduling Problems
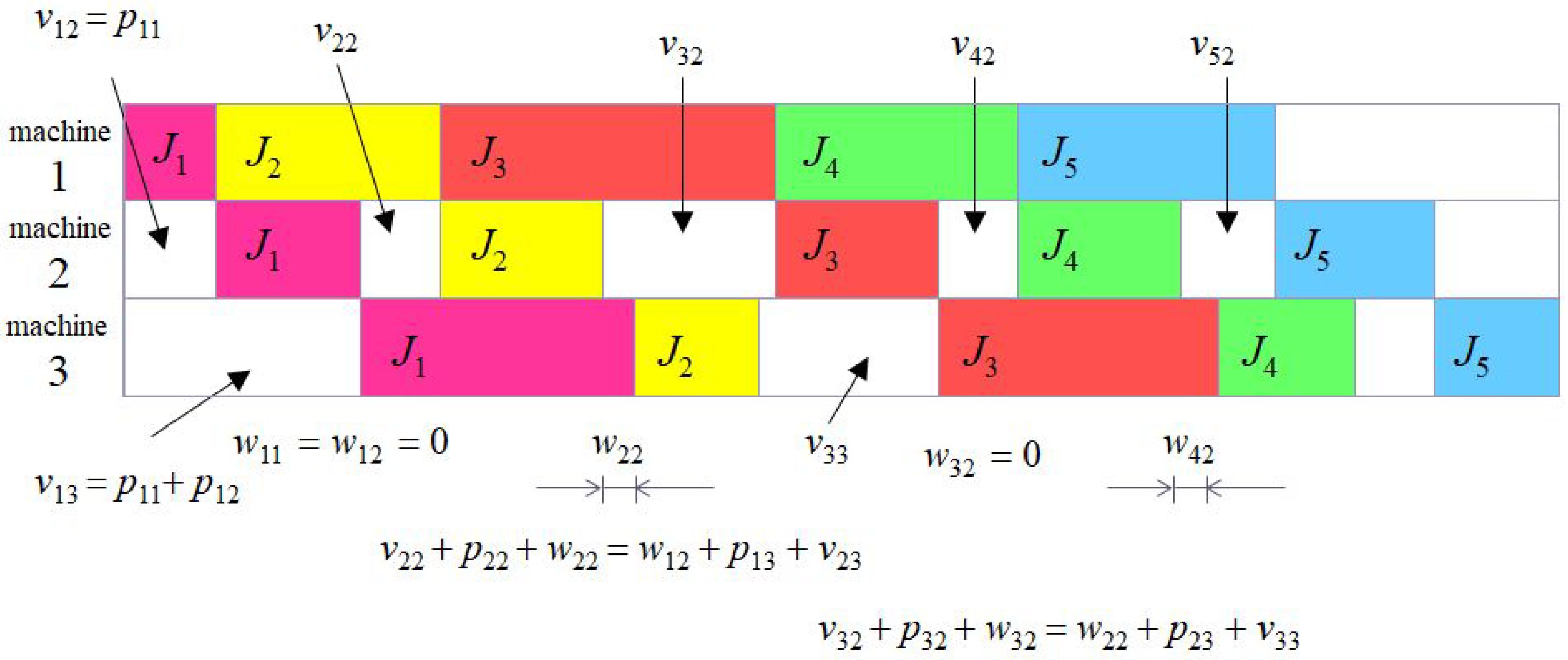
Mathematical Model of PFSSP
- The first task in a permutation can always continue the next operation on the next machine without delay because it does not wait for the completion of any other operation.
- It follows from the previous conclusion that waiting times to start the operation of the first task in the permutation on the second and subsequent machines are given by the sum of the durations of the operations of that task on the previous machines.
- Equalities of 3 addition terms in Figure 1 can be generalized into a Gantt chart between all pairs of neighboring machines.
- The duration of the entire schedule (makespan) is given by the sum of the waiting times for the start of operations on the last machine and the duration of these operations.
6. Computational Results
6.1. PFSSP Computational Results
1 2 3 4 5 6
1 333 991 996 123 145 234
2 333 111 663 456 785 532
3 252 222 222 789 214 586
4 222 204 114 876 752 532
5 255 477 123 543 143 142
6 555 566 456 210 698 573
7 558 899 789 124 532 12
8 888 965 876 537 145 14
9 889 588 543 854 247 527
10 999 889 210 632 451 856;
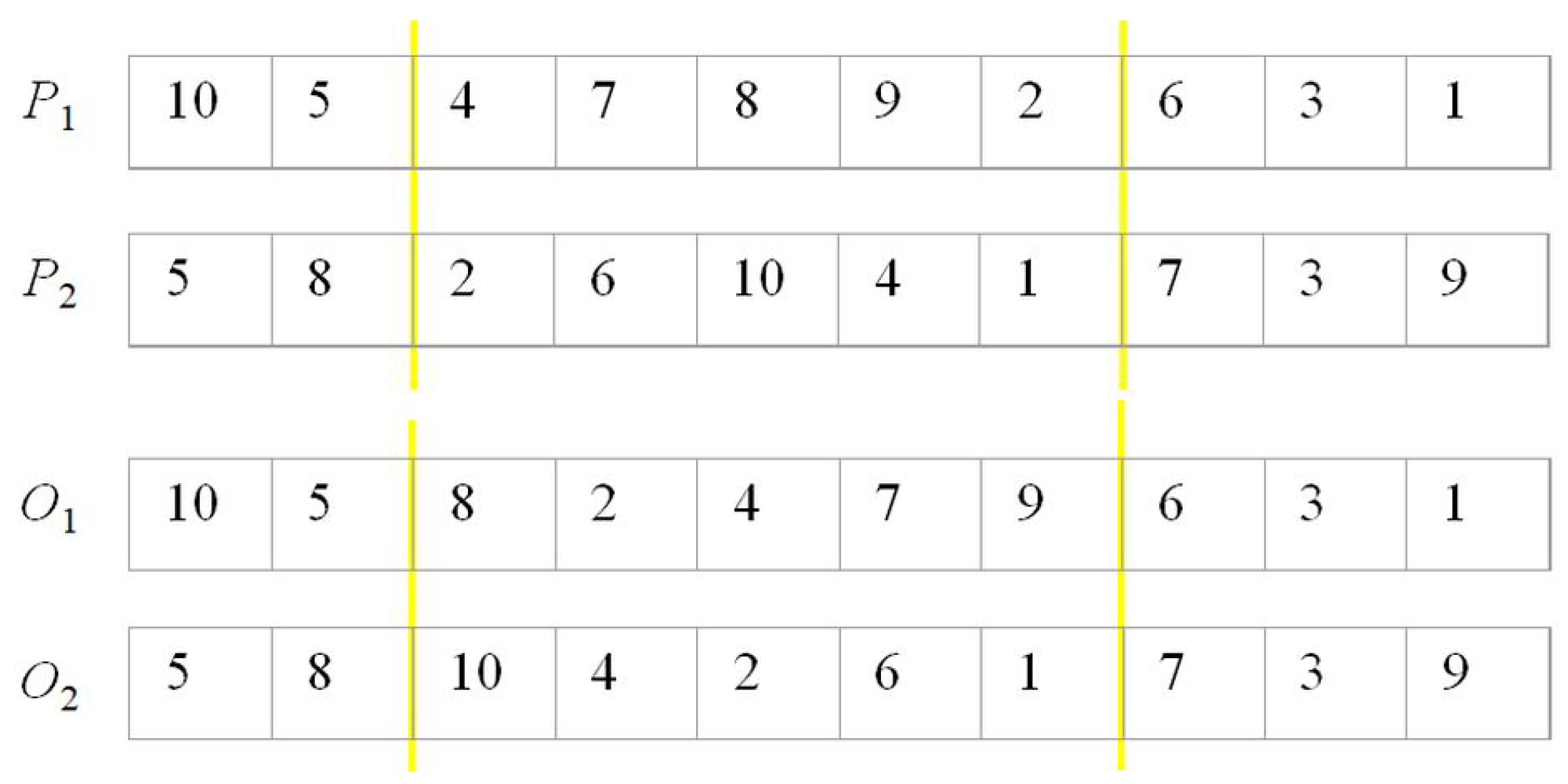
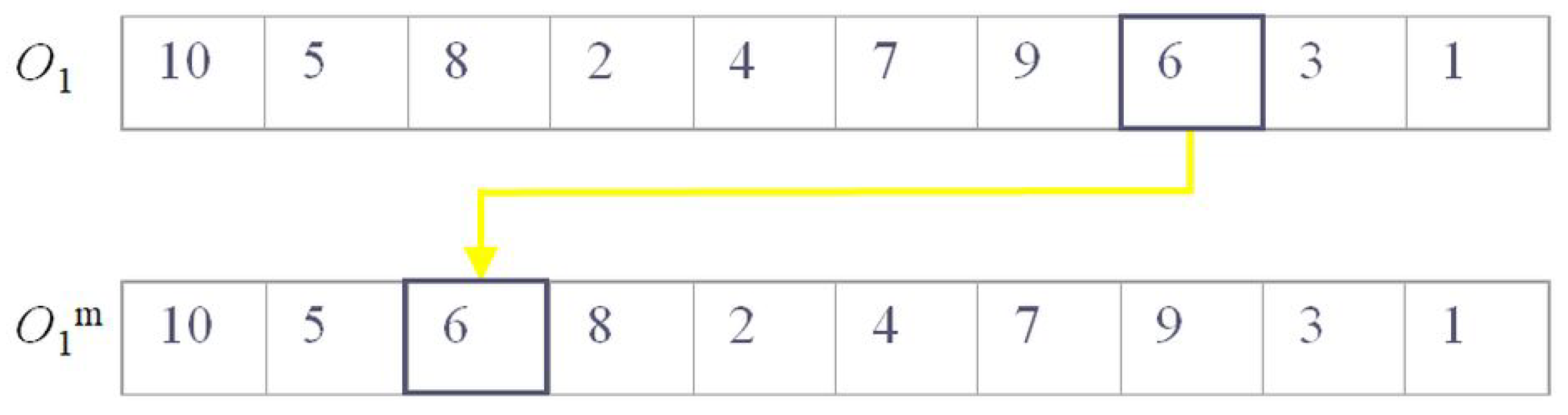
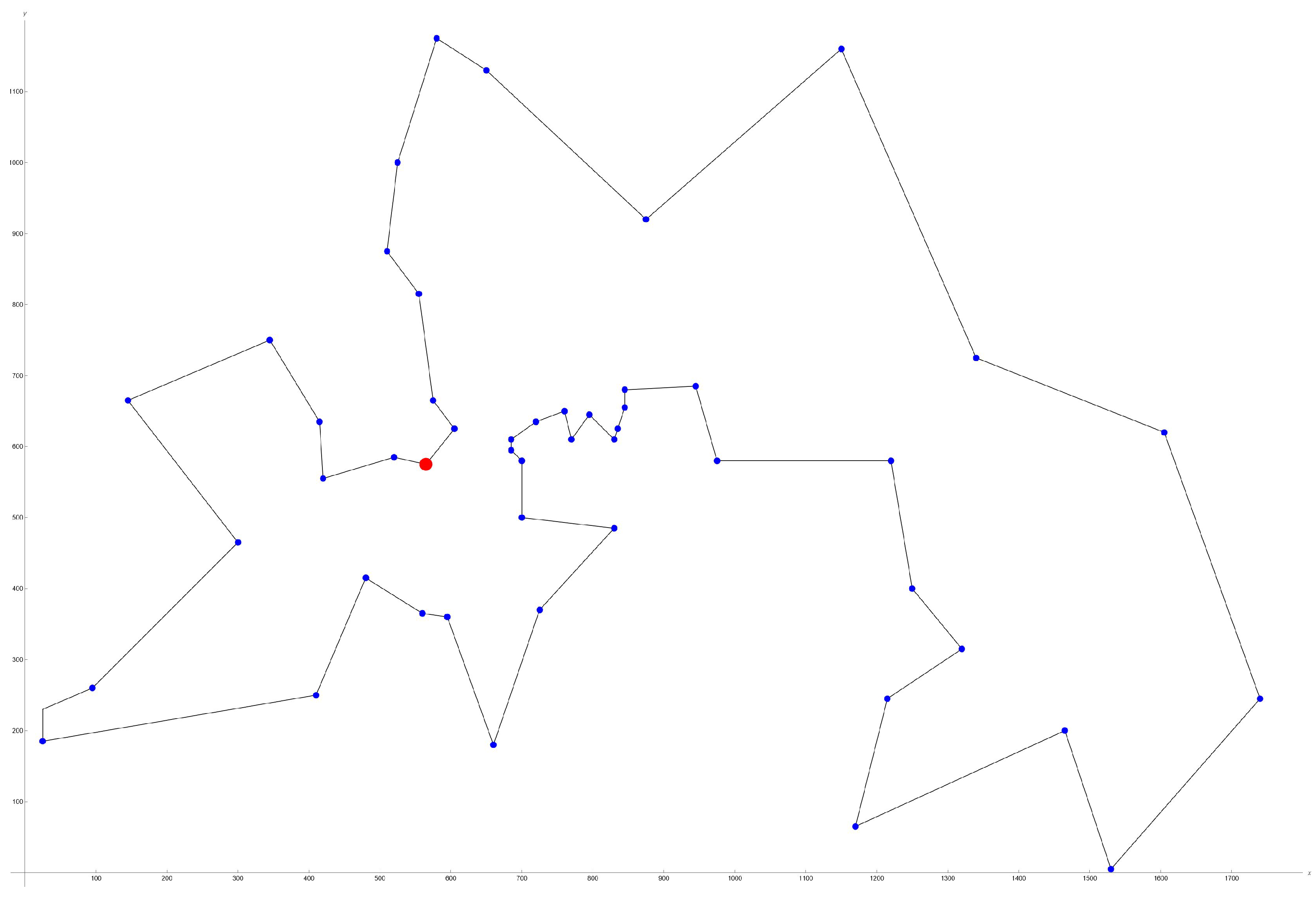
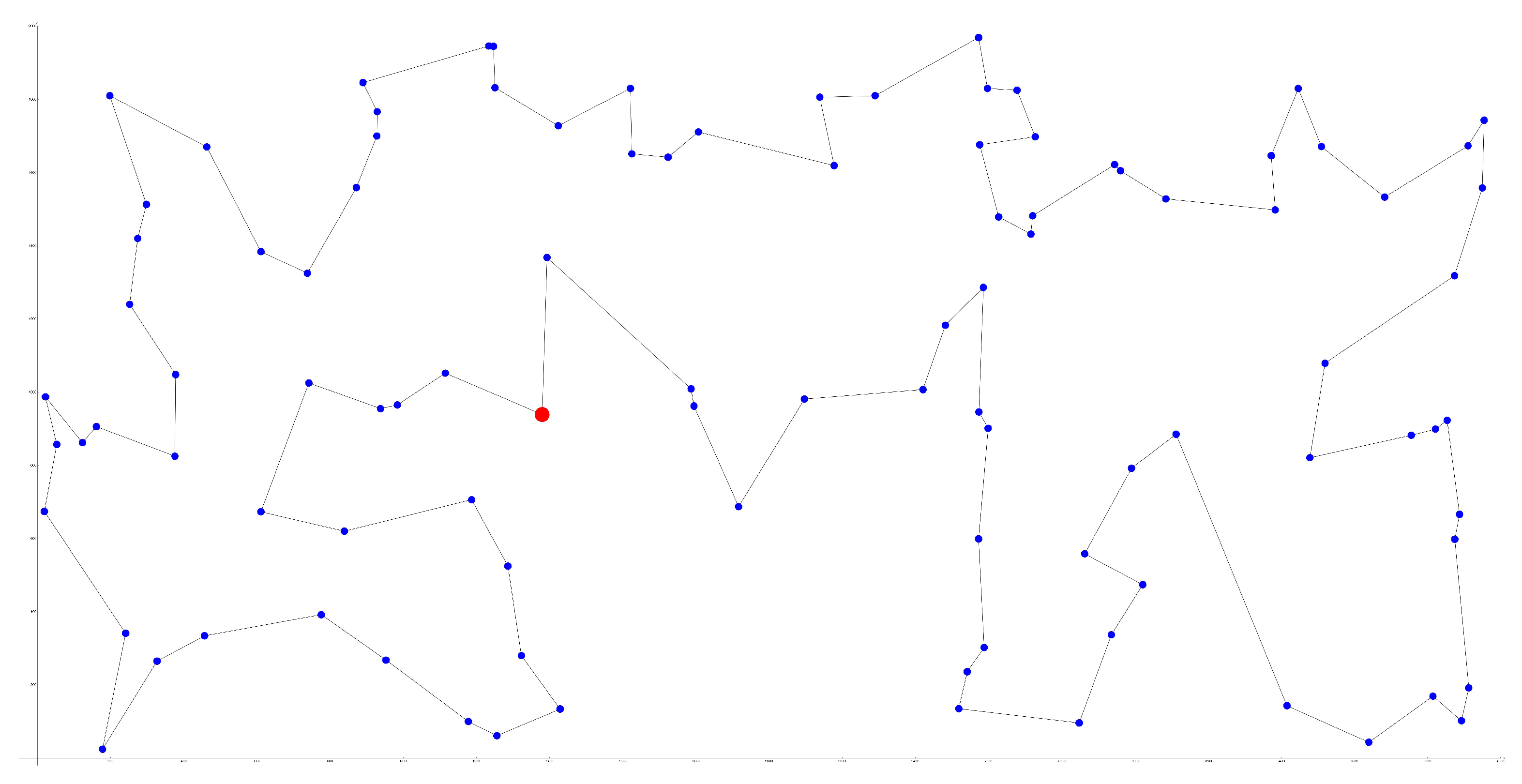
6.2. TSP Implementation in GAMS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
1 0
2 257 0
3 87 196 0
4 91 228 158 0
5 150 112 96 120 0
6 80 196 88 77 63 0
7 130 167 59 101 56 25 0
8 134 154 63 105 34 29 22 0
9 243 209 286 159 190 216 229 225 0
10 185 86 124 156 40 124 95 82 207 0
11 214 223 49 185 123 115 86 90 313 151 0
12 70 191 121 27 83 47 64 68 173 119 148 0
13 272 180 315 188 193 245 258 228 29 159 342 209 0
14 219 83 172 149 79 139 134 112 126 62 199 153 97 0
15 293 50 232 264 148 232 203 190 248 122 259 227 219 134 0
16 54 219 92 82 119 31 43 58 238 147 84 53 267 170 255 0
17 211 74 81 182 105 150 121 108 310 37 160 145 196 99 125 173 0
18 290 139 98 261 144 176 164 136 389 116 147 224 275 178 154 190 79 0
19 268 53 138 239 123 207 178 165 367 86 187 202 227 130 68 230 57 86 0
20 261 43 200 232 98 200 171 131 166 90 227 195 137 69 82 223 90 176 90 0
21 175 128 76 146 32 76 47 30 222 56 103 109 225 104 164 99 57 112 114 134 0
22 250 99 89 221 105 189 160 147 349 76 138 184 235 138 114 212 39 40 46 136 96 0
23 192 228 235 108 119 165 178 154 71 136 262 110 74 96 264 187 182 261 239 165 151 221 0
24 121 142 99 84 35 29 42 36 220 70 126 55 249 104 178 60 96 175 153 146 47 135 169 0;
1 2
1 565.0 575.0
2 25.0 185.0
3 345.0 750.0
4 945.0 685.0
5 845.0 655.0
6 880.0 660.0
7 25.0 230.0
8 525.0 1000.0
9 580.0 1175.0
10 650.0 1130.0
11 1605.0 620.0
12 1220.0 580.0
13 1465.0 200.0
14 1530.0 5.0
15 845.0 680.0
16 725.0 370.0
17 145.0 665.0
18 415.0 635.0
19 510.0 875.0
20 560.0 365.0
21 300.0 465.0
22 520.0 585.0
23 480.0 415.0
24 835.0 625.0
25 975.0 580.0
26 1215.0 245.0
27 1320.0 315.0
28 1250.0 400.0
29 660.0 180.0
30 410.0 250.0
31 420.0 555.0
32 575.0 665.0
33 1150.0 1160.0
34 700.0 580.0
35 685.0 595.0
36 685.0 610.0
37 770.0 610.0
38 795.0 645.0
39 720.0 635.0
40 760.0 650.0
41 475.0 960.0
42 95.0 260.0
43 875.0 920.0
44 700.0 500.0
45 555.0 815.0
46 830.0 485.0
47 1170.0 65.0
48 830.0 610.0
49 605.0 625.0
50 595.0 360.0
51 1340.0 725.0
52 1740.0 245.0;
6.3. Data, Changes in Time, Uncertainty
7. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AP | Assignment Problem |
| TSP | Travelling Salesman Problem |
| VRP | Vehicle Routing Problem |
| PFSSP | Permutation Flow Shop Scheduling Problem |
| GAMS | General Algebraic Modelling System |
| GA | Genetic Algorithm |
| ANN | Artificial Neural Network |
References
- Gass, S.I. Linear Programming. Methods and Applications; Dover Books on Computer Science; Courier Corporation: North Chelmsford, MA, USA, 2010. [Google Scholar]
- Du, D.Z.; Pardalos, P.M. Handbook of Combinatorial Optimization. Volume A; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1999. [Google Scholar]
- Du, D.Z.; Pardalos, P.M. Handbook of Combinatorial Optimization. Volume B; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Kuhn, H.W. The Hungarian Method for the Assignment Problem. Nav. Res. Logist. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Burkard, R.; Dell’Amico, M.; Martello, S. Assignment Problems; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2009. [Google Scholar]
- Diestel, R. Graph Theory; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Burkard, R.E.; Cela, E.; Pardalos, P.M.; Pitsoulis, L.S. The Quadratic Assignment Problem; Report; Graz University of Technology: Graz, Austria, 1998; p. 71. [Google Scholar]
- Gutin, G.; Punnen, A.P. The Traveling Salesman Problem and Its Variations; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Nalepa, J. Smart Delivery Systems. Solving Complex Vehicle Routing Problems; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Ganesh, K.; Malaijaran, R.A.; Mohapatra, S.; Punniyamoorthy, M. Resource Allocation Problems in Supply Chains; Emerald Group Publishing Limited: Bingley, UK, 2015. [Google Scholar]
- Bohle, C.; Maturana, S.; Vera, J. A Robust Optimization Approach to Wine Grape Harvesting Scheduling. Eur. J. Oper. Res. 2010, 200, 245–252. [Google Scholar] [CrossRef]
- Church, R.L.; Murray, A. Location Covering Models; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Seda, P.; Seda, M.; Hosek, J. On Mathematical Modelling of Automated Coverage Optimization in Wireless 5G and beyond Deployments. Appl. Sci. 2020, 10, 8853. [Google Scholar] [CrossRef]
- Błażewicz, J.; Ecker, K.H.; Schmidt, G.; Wȩglarz, J. Scheduling Computer and Manufacturing Processes; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Rossit, D.; Vásquez, Ó.C.; Tohmé, F.; Frutos, M.; Safe, M. A Combinatorial Analysis of the Permutation and Non-Permutation Flow Shop Scheduling Problems. Eur. J. Oper. Res. 2021, 289, 841–854. [Google Scholar] [CrossRef]
- Ali, I.; Essam, D.; Kasmarik, K. A Novel Design of Differential Evolution for Solving Discrete Traveling Salesman Problems. Swarm Evol. Comput. 2020, 52, 100607. [Google Scholar] [CrossRef]
- Dong, X.; Cai, Y. A Novel Genetic Algorithm for Large Scale Colored Balanced Traveling Salesman Problem. Future Gener. Comput. Syst. 2019, 95, 727–742. [Google Scholar] [CrossRef]
- Placido, A.D.; Archetti, C.; Cerrone, C. A Genetic Algorithm for the Close-Enough Traveling Salesman Problem with Application to Solar Panels Diagnostic Reconnaissance. Comput. Oper. Res. 2022, 145, 105831. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, J.; Tian, Z.; Sun, S.; Li, J.; Yang, J. A Genetic Algorithm with Jumping Gene and Heuristic Operators for Traveling Salesman Problem. Appl. Soft Comput. 2022, 127, 109339. [Google Scholar] [CrossRef]
- Mahrach, M.; Miranda, G.; León, C.; Segredo, E. Comparison between Single and Multi-Objective Evolutionary Algorithms to Solve the Knapsack Problem and the Travelling Salesman Problem. Mathematics 2020, 8, 2018. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, Y.; Fu, Z.H. Knowledge-Guided Two-Stage Memetic Search for the Pickup and Delivery Traveling Salesman Problem with FIFO Loading. Knowl.-Based Syst. 2022, 242, 108332. [Google Scholar] [CrossRef]
- Larasati, M.R.; Wang, I.L. An Integrated Integer Programming Model with a Simulated Annealing Heuristic for the Carrier Vehicle Traveling Salesman Problem. Procedia Comput. Sci. 2022, 197, 301–308. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, Y. The Neural Network Methods for Solving Traveling Salesman Problem. Procedia Comput. Sci. 2022, 199, 681–686. [Google Scholar] [CrossRef]
- Karakostas, P.; Sifaleras, A. A Double-Adaptive General Variable Neighborhood Search Algorithm for the Solution of the Traveling Salesman Problem. Appl. Soft Comput. 2022, 121, 108746. [Google Scholar] [CrossRef]
- Schmidt, J.; Irnich, S. New Neighborhoods and an Iterated Local Search Algorithm for the Generalized Traveling Salesman Problem. EURO J. Comput. Optim. 2022, 10, 100029. [Google Scholar] [CrossRef]
- Kanna, S.; Sivakumar, K.; Lingaraj, N. Development of Deer Hunting Linked Earthworm Optimization Algorithm for Solving Large Scale Traveling Salesman Problem. Knowl.-Based Syst. 2021, 227, 107199. [Google Scholar] [CrossRef]
- Akhand, M.; Ayon, S.; Shahriyar, S.; Siddique, N.; Adel, H. Discrete Spider Monkey Optimization for Travelling Salesman Problem. Appl. Soft Comput. 2020, 86, 105887. [Google Scholar] [CrossRef]
- Krishna, M.; Panda, N.; Majhi, S. Solving Traveling Salesman Problem Using Hybridization of Rider Optimization and Spotted Hyena Optimization Algorithm. Expert Syst. Appl. 2021, 183, 115353. [Google Scholar] [CrossRef]
- Panwar, K.; Deep, K. Discrete Grey Wolf Optimizer for Symmetric Travelling Salesman Problem. Appl. Soft Comput. 2021, 105, 107298. [Google Scholar] [CrossRef]
- Reda, M.; Onsy, A.; Elhosseini, M.A.; Haikal, A.Y.; Badawy, M. A Discrete Variant of Cuckoo Search Algorithm to Solve the Travelling Salesman Problem and Path Planning for Autonomous Trolley inside Warehouse. Knowl.-Based Syst. 2022, 252, 109290. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, J. A Discrete Cuckoo Search Algorithm for Traveling Salesman Problem and Its Application in Cutting Path Optimization. Comput. Ind. Eng. 2022, 169, 108157. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, Y. Discrete Sparrow Search Algorithm for Symmetric Traveling Salesman Problem. Appl. Soft Comput. 2022, 118, 108469. [Google Scholar] [CrossRef]
- Huang, Y.; Shen, X.N.; You, X. A Discrete Shuffled Frog-Leaping Algorithm Based on Heuristic Information for Traveling Salesman Problem. Appl. Soft Comput. 2021, 102, 107085. [Google Scholar] [CrossRef]
- Stodola, P.; Otřísal, P.; Hasilová, K. Adaptive Ant Colony Optimization with Node Clustering Applied to the Travelling Salesman Problem. Swarm Evol. Comput. 2022, 70, 101056. [Google Scholar] [CrossRef]
- Land, A. The Solution of Some 100-City Travelling Salesman Problems. EURO J. Comput. Optim. 2021, 9, 100017. [Google Scholar] [CrossRef]
- Dell’Amico, M.; Montemanni, R.; Novellani, S. Algorithms Based on Branch and Bound for the Flying Sidekick Traveling Salesman Problem. Omega 2021, 104, 102493. [Google Scholar] [CrossRef]
- Pereira, A.; Mateus, G.; Urrutia, S. Valid Inequalities and Branch-and-Cut Algorithm for the Pickup and Delivery Traveling Salesman Problem with Multiple Stacks. Eur. J. Oper. Res. 2022, 300, 207–220. [Google Scholar] [CrossRef]
- Yuan, Y.; Cattaruzza, D.; Ogier, M.; Semet, F. A Branch-and-Cut Algorithm for the Generalized Traveling Salesman Problem with Time Windows. Eur. J. Oper. Res. 2020, 286, 849–866. [Google Scholar] [CrossRef]
- Morais, M.; Ribeiro, M.; da Silva, R.; Mariani, V.; Coelho, L. Discrete Differential Evolution Metaheuristics for Permutation Flow Shop Scheduling Problems. Comput. Ind. Eng. 2022, 166, 107956. [Google Scholar] [CrossRef]
- Qiao, Y.; Wu, N.; He, Y.; Li, Z.; Chen, T. Adaptive Genetic Algorithm for Two-Stage Hybrid Flow-Shop Scheduling with Sequence-Independent Setup Time and No-Interruption Requirement. Expert Syst. Appl. 2022, 208, 118068. [Google Scholar] [CrossRef]
- Wu, X.; Cao, Z. An Improved Multi-Objective Evolutionary Algorithm Based on Decomposition for Solving Re-Entrant Hybrid Flow Shop Scheduling Problem with Batch Processing Machines. Comput. Ind. Eng. 2022, 169, 108236. [Google Scholar] [CrossRef]
- Song, H.B.; Lin, J. A Genetic Programming Hyper-Heuristic for the Distributed Assembly Permutation Flow-Shop Scheduling Problem with Sequence Dependent Setup Times. Swarm Evol. Comput. 2021, 60, 100807. [Google Scholar] [CrossRef]
- Wang, J.J.; Wang, L. A Cooperative Memetic Algorithm with Feedback for the Energy-Aware Distributed Flow-Shops with Flexible Assembly Scheduling. Comput. Ind. Eng. 2022, 168, 108126. [Google Scholar] [CrossRef]
- Harbaoui, H.; Khalfallah, S. Tabu-Search Optimization Approach for No-Wait Hybrid Flow-Shop Scheduling with Dedicated Machines. Procedia Comput. Sci. 2020, 176, 706–712. [Google Scholar] [CrossRef]
- Doush, I.; Al-Betar, M.; Awadallah, M.; Alyasseri, Z.; Makhadmeh, S.; El-Abd, M. Island Neighboring Heuristics Harmony Search Algorithm for Flow Shop Scheduling with Blocking. Swarm Evol. Comput. 2022, 74, 101127. [Google Scholar] [CrossRef]
- Brum, A.; Ruiz, R.; Ritt, M. Automatic Generation of Iterated Greedy Algorithms for the Non-Permutation Flow Shop Scheduling Problem with Total Completion Time Minimization. Comput. Ind. Eng. 2022, 163, 107843. [Google Scholar] [CrossRef]
- Miyata, H.; Nagano, M. An Iterated Greedy Algorithm for Distributed Blocking Flow Shop with Setup Times and Maintenance Operations to Minimize Makespan. Comput. Ind. Eng. 2022, 171, 108366. [Google Scholar] [CrossRef]
- Schulz, S.; Neufeld, J.; Buscher, U. Multi-Objective Iterated Local Search Algorithm for Comprehensive Energy-Aware Hybrid Flow Shop Scheduling. J. Clean. Prod. 2019, 224, 421–434. [Google Scholar] [CrossRef]
- Shao, W.; Shao, Z.; Pi, D. Multi-Local Search-Based General Variable Neighborhood Search for Distributed Flow Shop Scheduling in Heterogeneous Multi-Factories. Appl. Soft Comput. 2022, 125, 109138. [Google Scholar] [CrossRef]
- Pereira, M.; Nagano, M. Hybrid Metaheuristics for the Integrated and Detailed Scheduling of Production and Delivery Operations in No-Wait Flow Shop Systems. Comput. Ind. Eng. 2022, 170, 108255. [Google Scholar] [CrossRef]
- Umam, M.; Mustafid, M.; Suryono, S. A Hybrid Genetic Algorithm and Tabu Search for Minimizing Makespan in Flow Shop Scheduling Problem. J. King Saud Univ. Comput. Inf. Sci. 2022, in press. [Google Scholar] [CrossRef]
- Brammer, J.; Lutz, B.; Neumann, D. Permutation Flow Shop Scheduling with Multiple Lines and Demand Plans Using Reinforcement Learning. Eur. J. Oper. Res. 2022, 299, 75–86. [Google Scholar] [CrossRef]
- Pang, X.; Xue, H.; Tseng, M.L.; Lim, M.; Liu, K. Hybrid Flow Shop Scheduling Problems Using Improved Fireworks Algorithm for Permutation. Appl. Sci. 2020, 10, 1174. [Google Scholar] [CrossRef]
- Engin, O.; Güclü, A. A New Hybrid Ant Colony Optimization Algorithm for Solving the No-Wait Flow Shop Scheduling Problems. Appl. Soft Comput. 2018, 72, 166–176. [Google Scholar] [CrossRef]
- Gümüsçü, A.; Kaya, S.; Tenekeci, M.; Karaçizmeli, I.; Aydilek, I. The Impact of Local Search Strategies on Chaotic Hybrid Firefly Particle Swarm Optimization Algorithm in Flow-Shop Scheduling. J. King Saud Univ. Comput. Inf. Sci. 2022, in press. [Google Scholar] [CrossRef]
- Deng, G.; Xu, M.; Zhang, S.; Jiang, T.; Su, Q. Migrating Birds Optimization with a Diversified Mechanism for Blocking Flow Shops to Minimize Idle and Blocking Time. Appl. Soft Comput. 2022, 114, 107834. [Google Scholar] [CrossRef]
- Zhang, C.; Tan, J.; Peng, K.; Gao, L.; Shen, W.; Lian, K. A Discrete Whale Swarm Algorithm for Hybrid Flow-Shop Scheduling Problem with Limited Buffers. Robot. Comput.-Integr. Manuf. 2021, 68, 102081. [Google Scholar] [CrossRef]
- Croce, F.; Salassa, F.; T’Kindt, V. Exact Solution of the Two-Machine Flow Shop Problem with Three Operations. Comput. Oper. Res. 2022, 138, 105595. [Google Scholar] [CrossRef]
- Ho, M.; Hnaien, F.; Dugardin, F. Exact Method to Optimize the Total Electricity Cost in Two-Machine Permutation Flow Shop Scheduling Problem under Time-of-Use Tariff. Comput. Oper. Res. 2022, 144, 10578. [Google Scholar] [CrossRef]
- Oujana, S.; Yalaoui, F.; Amodeo, L. A Linear Programming Approach for Hybrid Flexible Flow Shop with Sequence-Dependent Setup Times to Minimise Total Tardiness. IFAC PapersOnLine 2021, 54-1, 1162–1167. [Google Scholar] [CrossRef]
- Schaller, J.; Valente, J. Branch-and-Bound Algorithms for Minimizing Total Eearliness and Tardiness in a Two-Machine Permutation Flow Shop with Unforced Idle Allowed. Comput. Oper. Res. 2019, 109, 1–11. [Google Scholar] [CrossRef]
- Liu, M.; Li, Y.; Huo, Q.; Li, A.; Zhu, M.; Qu, N.; Chen, L.; Xia, M. A Two-Way Parallel Slime Mold Algorithm by Flow and Distance for the Travelling Salesman Problem. Appl. Sci. 2020, 10, 6180. [Google Scholar] [CrossRef]
- Golden, B.; Raghavan, S.; Wasil, E. The Vehicle Routing Problem: Latest Advances and New Challenges; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Toth, P.; Vigo, D. The Vehicle Routing Problem; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2002. [Google Scholar]
- Soto-Mendoza, V.; García-Calvillo, I.; Ruiz-y Ruiz, E.; Pérez-Terrazas, J. Comparison between Single and Multi-Objective Evolutionary Algorithms to Solve the Knapsack Problem and the Travelling Salesman Problem. Algorithms 2020, 13, 96. [Google Scholar] [CrossRef]
- Ochelska-Mierzejewska, J.; Poniszewska-Marańda, A.; Marańda, W. Selected Genetic Algorithms for Vehicle Routing Problem Solving. Electronics 2021, 10, 3147. [Google Scholar] [CrossRef]
- Desrochers, M.; Laporte, G. Improvements and Extensions to the Miller-Tucker-Zemlin Subtour Elimination Constraints. Oper. Res. Lett. 1991, 10, 27–36. [Google Scholar] [CrossRef]
- Stroh, M.B. A Practical Guide to Transportation and Logistics; Logistics Network: Burr Ridge, IL, USA, 2006. [Google Scholar]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness, 19th ed.; W.H. Freeman and Company: New York, NY, USA, 1997. [Google Scholar]
- Ausiello, G.; Crescenzi, P.; Gambosi, G.; Kann, V.; Marchetti-Spaccamela, A.; Protasi, M. Complexity and Approximation: Combinatorial Optimization Problems and their Approximability Properties; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Reeves, C.R. Modern Heuristic Techniques for Combinatorial Problems; Blackwell Scientific Publications: Oxford, UK, 1993. [Google Scholar]
- Michalewicz, Z.; Fogel, D.B. How to Solve It: Modern Heuristics; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Onwubolu, G.; Davendra, D. Differential Evolution. A Handbook for Global Permutation-Based Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Wolpert, D.H.; McReady, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef]
- Wolpert, D.H.; McReady, W.G. Coevolutionary Free Lunches. IEEE Trans. Evol. Comput. 2005, 9, 721–735. [Google Scholar] [CrossRef]
- Brooke, A.; Kendrick, D.; Meeraus, A. GAMS Release 2.25. A User’s Guide; The Scientific Press. Boyd & Fraser Publishing Company: Boston, MA, USA, 1992. [Google Scholar]
- Rosenthal, R.E. GAMS—A User’s Guide; GAMS Development Corporation: Washington, DC, USA, 2016. [Google Scholar]
- GAMS. Solver Manuals. Report, GAMS Development Corporation. Available online: https://www.gams.com/latest/docs/S_MAIN.html (accessed on 6 September 2022).
- Seda, P.; Mark, M.; Su, K.W.; Seda, M.; Hosek, J.; Leu, J. The Minimization of Public Facilities With Enhanced Genetic Algorithms Using War Elimination. IEEE Access 2019, 7, 9395–9405. [Google Scholar] [CrossRef]
- Beasley, J.E. OR-Library. Report, Brunel University London. 2018. Available online: http://people.brunel.ac.uk/~mastjjb/jeb/info.html (accessed on 6 September 2022).
- Beasley, J.E. OR-Library: Distributing Test Problems by Electronic Mail. J. Oper. Res. Soc. 1990, 41, 1069–1072. [Google Scholar] [CrossRef]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Reinelt, G. MP-TESTDATA—The TSPLIB Symmetric Traveling Salesman Problem Instances; Report; Heidelberg University: Heidelberg, Germany, 2013; Available online: http://elib.zib.de/pub/mp-testdata/tsp/tsplib/tsp (accessed on 6 September 2022).
- Alkaya, A.F.; Yildirim, S.; Aksakalli, V. Heuristics for the Canadian Traveler Problem with Neutralizations. Comput. Ind. Eng. 2019, 159, 107488. [Google Scholar] [CrossRef]
- Liao, C.S.; Huang, Y. The Covering Canadian Traveller Problem. Theor. Comput. Sci. 2014, 530, 80–88. [Google Scholar] [CrossRef]
- Aurenhammer, F. Voronoi Diagrams. A Survey of a Fundamental Geometric Data Structure. ACM Comput. Surv. 1991, 23, 345–405. [Google Scholar] [CrossRef]
- de Berg, M.; Cheong, O.; van Kreveld, M.; Overmars, M. Computational Geometry: Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Becerra, P.; Mula, J.; Sanchis, R. Green Supply Chain Quantitative Models for Sustainable Inventory Management: A Review. J. Clean. Prod. 2021, 328, 129544. [Google Scholar] [CrossRef]
- Forkan, M.; Rizvi, M.M.; Chowdhury, M.A.M. Multiobjective Reverse Logistics Model for Inventory Management with Eenvironmental Impacts: An Application in Industry. Intell. Syst. Appl. 2022, 14, 200078. [Google Scholar]
- Teerasoponpong, S.; Sopadang, A. Decision Support System for Adaptive Sourcing and Inventory Management in Small- and Medium-Sized Enterprises. Robot. Comput.-Integr. Manuf. 2022, 73, 102226. [Google Scholar] [CrossRef]
- Xiong, X.; Li, Y.; Yang, W.; Shen, H. Data-Driven Robust Dual-Sourcing Inventory Management under Purchase Price and Demand Uncertainties. Transp. Res. Part E 2022, 160, 102671. [Google Scholar] [CrossRef]
- Sarkar, B.; Kar, S.; Basu, K.; Guchhait, R. A Sustainable Managerial Decision-Making Problem for a Substitutable Product in a Dual-Channel under Carbon Tax Policy. Comput. Ind. Eng. 2022, 172, 108635. [Google Scholar] [CrossRef]
- Sarkar, A.; Guchhait, R.; Sarkar, B. Application of the Artificial Neural Network with Multithreading within an Inventory Model under Uncertainty and Inflation. Int. J. Fuzzy Syst. 2022, 24, 2318–2332. [Google Scholar] [CrossRef]
- Guchhait, R.; Sarkar, B. Economic and Environmental Assessment of an Unreliable Supply Chain Management. RAIRO Oper. Res. 2021, 55, 3153–3170. [Google Scholar] [CrossRef]
- Seda, M. Steiner Tree Problem in Graphs and Mixed Integer Linear Programming-Based Approach in GAMS. WSEAS Trans. Comput. 2022, 21, 257–262. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark | Result/Optimum/Early End | Time [S] | Iterations |
|---|---|---|---|
| 7720/7720/no | 0.75 | 31,535 | |
| 7038/7038/no | 0.13 | 243 | |
| 7312/7312/no | 0.42 | 13,095 | |
| 7166/7166/no | 0.20 | 650 | |
| 8003/8003/no | 0.13 | 262 | |
| 1566/1566/no | 164.45 | 2,619,405 | |
| 2120/2093/t-l-e | 1000.02 | 6,398,821 | |
| 2692/2513/t-l-e | 1000.02 | 4,886,367 | |
| 3190/3045/t-l-e | 1000.03 | 3,164,599 | |
| 5372/in [4890, 4951]/t-l-e | 1000.03 | 2,145,971 |
| Benchmark | Average Result/the Best Result | Optimum |
|---|---|---|
| 2126/2099 | 2093 | |
| 2570/2525 | 2513 | |
| 3132/3090 | 3045 | |
| 5261/5203 | between 4890 and 4951 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seda, M. The Assignment Problem and Its Relation to Logistics Problems. Algorithms 2022, 15, 377. https://doi.org/10.3390/a15100377
Seda M. The Assignment Problem and Its Relation to Logistics Problems. Algorithms. 2022; 15(10):377. https://doi.org/10.3390/a15100377
Chicago/Turabian StyleSeda, Milos. 2022. "The Assignment Problem and Its Relation to Logistics Problems" Algorithms 15, no. 10: 377. https://doi.org/10.3390/a15100377
APA StyleSeda, M. (2022). The Assignment Problem and Its Relation to Logistics Problems. Algorithms, 15(10), 377. https://doi.org/10.3390/a15100377