1. Introduction
Traditional evolutionary algorithms are successfully used for solving black-box optimization problems [
1]. Cooperative coevolution (CC) was proposed by Potter and De Jong, in [
2], to increase the performance of the standard genetic algorithm (GA) [
1] when solving continuous optimization problems. The authors proposed two versions of CC-based algorithms, CCGA-1 and CCGA-2. The main idea behind CC is to decompose a problem into parts (subcomponents) and optimize them independently. The authors noted that any evolutionary algorithm (EA) can be used to evolve subcomponents. The first algorithm merges the current solution with subcomponents from the best solutions. The second algorithm merges the current solution with randomly selected individuals from other subcomponents. As has been shown in numerical experiments, CCGA-1 and CCGA-2 outperform the standard GA. This study marked the beginning of a new branch of methods for solving large-scale global optimization problems [
3]. The pseudo-code of a CC-based EA is presented in Algorithm 1. The termination criterion is the predefined number of function evaluations (FEs). It should be clarified that CC has two main control parameters: the population size and the number of subcomponents.
| Algorithm 1 The classic CC-based EA |
| Set the number of individuals (pop_size), the number of subcomponents (m) |
| 1: | Generate an initial population randomly; |
| 2: | Decompose an optimization vector into m independent subcomponents; |
| 3: | while (FEs > 0) do |
| 4: | for i = 1 to m |
| 5: | Evaluate the i-th subcomponent using pop_size individuals; |
| 6: | Construct a solution by merging the best-found solutions from all subcomponents; |
| 7: | end for |
| 8: | end while |
| 9: | return the best-found solution; |
In general, an LSGO problem can be stated as a continuous optimization problem (1):
where
is a fitness function to be minimized,
,
is an n-dimensional vector of continuous variables,
is the search space defined by box constraints
,
and
are the lower and upper borders of the
i-th variable, respectively, and
is a global optimum. It is assumed that the fitness function is continuous. The satisfaction of the Lipschitz condition is not assumed; therefore, no operations are performed to estimate the Lipschitz constant. In this case, the convergence of an algorithm to the global optimum cannot be guaranteed. In the case of a huge number of decision variables, it is not possible to adequately explore the high-dimensional search space using a limited fitness budget. Additionally, we can clarify the goal of the stated problem as proposed in [
4]: “the goal of global optimization methods is often to obtain a better estimate of
and
given a fixed limited budget of evaluations of
”.
In the last two decades, many researchers and applied specialists have successfully applied CC-based approaches to the increase of performance of metaheuristics when solving real-world LSGO problems [
5,
6,
7,
8,
9,
10]. According to the generally accepted classification [
11,
12], CC-based approaches can be divided into three groups: static, random, and learning-based variable groupings.
In case of static grouping (decomposition), one needs to set a fixed number of subcomponents and how the variables will be assigned to these subcomponents during the optimization process. It is appropriate to apply the static decomposition provided that the relationship between an optimized variables is known. However, many hard LSGO problems are represented by a black-box or gray-box model. The relationship between optimized variables is unknown, and it is risky to choose the number of subcomponents randomly. For example, two interacting variables can be placed in different groups and as a result the performance of this approach will be worse on average than the performance in a case in which the variables are placed in the same group. Nevertheless, the static decomposition performs well on fully separable optimization problems.
Random grouping is a kind of static grouping, but variables can be placed in different subcomponents in different steps of the optimization process. The size of the subcomponents can be fixed or dynamically changed. The main purpose of applying random grouping is to increase the probability of placing interacted variables in the same subcomponents. Furthermore, after a random mixing of variables and the creation of new groups, an optimizer solves a slightly or totally different problem in terms of task features. As a result, the regrouping of variables acts as a reorganization for an optimizer.
Learning grouping is based on experiments that aim to find the original interaction between decision variables. In most cases, these approaches are based on permutations, statistical models, and distribution models. Permutation techniques perturb variables and measure the change in the fitness function. Based on the changes, variables are grouped into subcomponents. In general, permutation-based techniques require a huge number of fitness evaluations. For example, the DGCC [
13] algorithm requires
fitness evaluations (FEs) to detect variable interactions. A modification of DGCC, titled DG2 [
14], requires
FEs. In the first iteration, a statistical analysis is performed. In the second iteration, a grouping of decision variables is performed using a statistical metric, for example, a correlation between variables based on fitness function values or a distribution of variable values. In distribution models, the first iteration is based on the estimation of variable distributions and an interaction between variables in the set of the best solutions. After that, new candidate solutions are generated on the basis of the learned variable distributions and variable interactions.
In practice, the determination of the appropriate group size is a hard task, because of unknown optimization problem properties. In static and random grouping, setting an arbitrary group size can lead to low performance. On the other hand, learning grouping needs a large amount of FEs to determine true connections between variables, and there is no guarantee that an EA will perform better using the discovered true connection between variables. Usually, the small group size performs better in the beginning of the optimization process, and the large group size performs better in the last stages [
15]. Thereby, there is the need to develop a self-adaptive mechanism for the automatic selection of the number of subcomponents and the population size.
The paper is organized as follows.
Section 2 outlines the proposed approach. In
Section 3, we discuss our experimental results. We considered how the population size and the number of subcomponents affect the performance of static CC-based approaches. We evaluated the performance of the proposed self-adaptive CC-based algorithm and have compared it with the performance of CC-based approaches with a static number of subcomponents and a static population size. Additionally, we investigated a selective pressure parameter when choosing the number of subcomponents and the population size. All numerical experiments were confirmed by the Wilcoxon rank-sum test.
Section 4 concludes the paper and outlines possible future work.
2. Proposed Approach
In this section, the proposed approach is described in detail. The approach combines cooperative coevolution, the multilevel self-adaptive approach for selecting the number of subcomponents and the number of individuals, and SHADE. This approach is titled CC-SHADE-ML. This study was inspired by the MLCC algorithm [
16] proposed by Z. Yang, K. Tang, and X. Yao. MLCC is based on the multilevel cooperative coevolution framework for solving continuous LSGO problems. Before the optimization process, there is a need to determine a set of integer values
corresponding to the number of subcomponents. The optimization process is divided into a predefined number of cycles. In each cycle, the number of subcomponents is selected according to the performance of decomposition in the previous cycles. Variables are divided in subcomponents randomly in each cycle. The Equation (2) is used to evaluate the performance of the selected number of subcomponents after each cycle.
is the best-found fitness value before the optimization cycle, and
is the best-found fitness value after the optimization cycle. If the calculated value is less than 1E-4, then it is set to 1E-4. If this condition is not applied, the selection probability for the applied decomposition size is set to 0 after a cycle without improving. This means that the algorithm will never select this parameter in the future. Before starting the optimization process, all values of the
vector are set to 1.0.
When the performance of the selected parameter is calculated, it is necessary to recalculate the selection probability for all parameters. In MLCC, the authors propose to use Equation (3), where
k is a control parameter and it is set to 7. In the original study, the authors note that 7 is an empirical value. In
Section 3, we investigate the influence of this parameter on the algorithm’s performance.
In the next optimization cycle, the decomposition size will be selected based on the new probability distribution. MLCC uses SaNSDE as a subcomponent optimizer. In the original article, the population size is fixed and is set to 50. At the same time, the population size is one of the most important parameters in population- and swarm-based algorithms. The choice of a good number of individuals can significantly increase the performance of an algorithm. In the proposed approach, for selecting the population size we apply the same idea as in selecting the number of subcomponents.
In this study, we use a recent variant of differential evolution (DE) [
17] as a subcomponent optimizer. DE is a kind of EA that solves an optimization problem in the continuous search space but does not require a gradient calculation of the optimized problem. DE applies an iterative procedure for the crossing of individuals to generate new best solutions.
F and
CR are the main parameters in DE, a scale factor, and a crossover rate, respectively. Many researchers have tried to find good values for these parameters [
18], however, these parameters are good only for specific functions. Numerous varieties of the classic DE with self-tuning parameters have been proposed, for example, self-adaptive DE (SaDE) [
19], ensemble of parameters and mutation strategies (EPSDE) [
20], adaptive DE with optional external archive (JADE) [
21], and success-history based parameter adaptation for DE (SHADE) [
22]. We use SHADE as an optimizer of subcomponents in the proposed CC-based metaheuristic because it is the self-adaptive and high-performing modification of the classic DE algorithm. SHADE uses a historical memory that stores well-performed values of
F and
CR. New values of
CR and
F are generated randomly but close to values of stored pairs of values. An external archive stores previously replaced individuals and is used for maintaining the population diversity. Usually, the external archive size is 2–3 times larger than the population size. The proposed CC-SHADE-ML algorithm differs from MLCC in the following. We use SHADE instead of SaNSDE and extend MLCC by applying a self-adaptation multilevel (ML) approach for the population size. The proposed algorithm can be described by the pseudocode in Algorithm 2.
| Algorithm 2 CC-SHADE-ML |
| Set the set of individuals, the set of subcomponents, optimizer, cycles_number |
| 1: | Generate an initial population randomly; |
| 2: | Initialize performance vectors, CC_performance and pop_performance; |
| 3: | FEs_cycle_init = FEs_total/cycles_number; |
| 4: | while (FEs_total > 0) do |
| 5: | FEs_cycle = FEs_cycle_init; |
| 6: | Randomly shuffle indices; |
| 7: | Randomly select CC_size and pop_size from CC_performance and pop_performance; |
| 8: | while (FEs_cycle > 0) do |
| 9: | Find the best fitness value before the optimization cycle f_best_before; |
| 10: | for i = 1 to CC_size |
| 11: | Evaluate the i-th subcomponent using the SHADE algorithm; |
| 12: | end for |
| 13: | Find the best fitness value after the optimization cycle f_best_after; |
| 14: | Evaluate performance of CC_size and pop_size using Equation (2); |
| 15: | Update CC_performance and pop_performance; |
| 16: | end while |
| 17: | end while |
| 18: | return the best-found solution |
3. Numerical Experiments and Analysis
There are some variants of LSGO benchmarks. The first version was proposed in the CEC’08 special session on LSGO [
23]. This benchmark set has seven high-dimensional optimization problems,
. Test problems are divided into two classes: unimodal and multimodal. Later, the LSGO CEC’10 benchmark set was proposed [
24] as an improved version of LSGO CEC’08. The number of problems was increased to 20 by adding partially separable functions to increase the complexity of the benchmark. In this study, we use a recent version of the benchmark, namely the LSGO CEC’13 benchmark set [
25]. This set consists of 15 high-dimensional continuous optimization problems, which are divided into five classes: fully separable (C1), partially additively separable (functions with a separable subcomponent (C2) and functions with no separable subcomponents (C3), overlapping (C4), and non-separable functions (C5). The number of variables of each problem is equal to 1000. The maximum number of fitness evaluations is 3.0×10
6 in each independent run. The comparison of algorithms is based on the mean of the best-found values, which are obtained in 25 independent runs.
The software implementation of CC-SHADE and CC-SHADE-ML was undertaken using the C++ programming language. We used the MPICH2 framework to parallel numerical experiments because the problems are computational complex. We built a computational cluster of 8 PCs based on AMD Ryzen CPUs. Each CPU has eight cores and sixteen threads (8C/16T). Thus, the total number of computational threads is 128. The operating system was Ubuntu 20.04.3 LTS.
3.1. CC-Based EA
In this subsection we investigate the effect of CC-SHADE’s main parameters on its performance. The population size was set to 25, 50, 100, 150, and 200. The number of subcomponents was set to 1, 2, 5, 10, 20, 50, 100, 200, 500, and 1000.
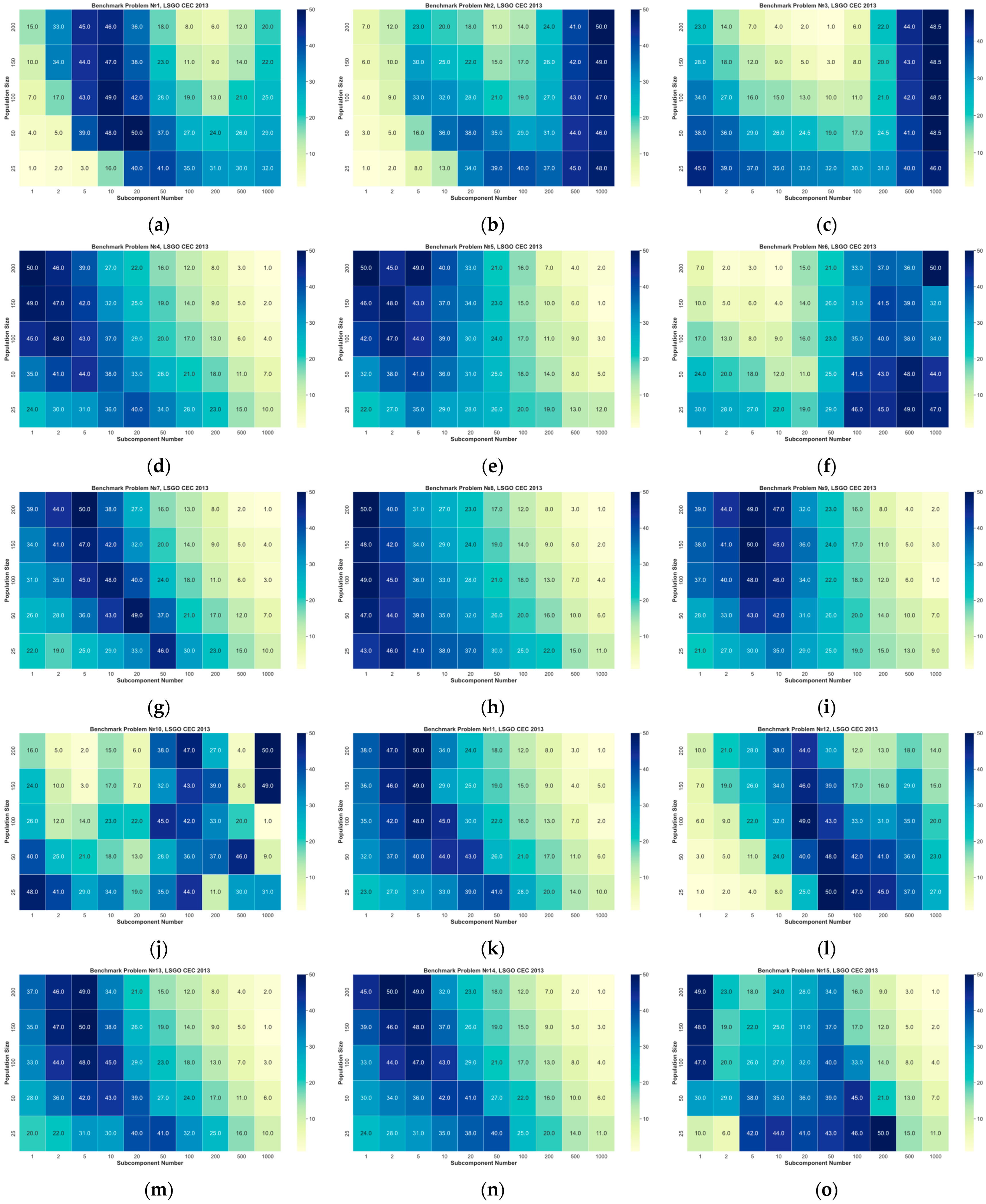
Figure 1 presents heatmaps for each benchmark problem and each combination of the parameters. The
x-axis denotes the number of subcomponents, the
y-axis denotes the population size. The total number of combinations is equal to 50 for each benchmark problem. The performance of each parameters’ combination is presented as a rank. The biggest number denotes the best average fitness value obtained in 25 independent runs. If two or more combinations of parameters have the same averaged fitness value, then their ranks are averaged. The ranks are colored in heatmaps from white (light) for the worst combination to dark blue (dark) for the best combination. The rank distributions are different in heatmaps for different optimization problems.
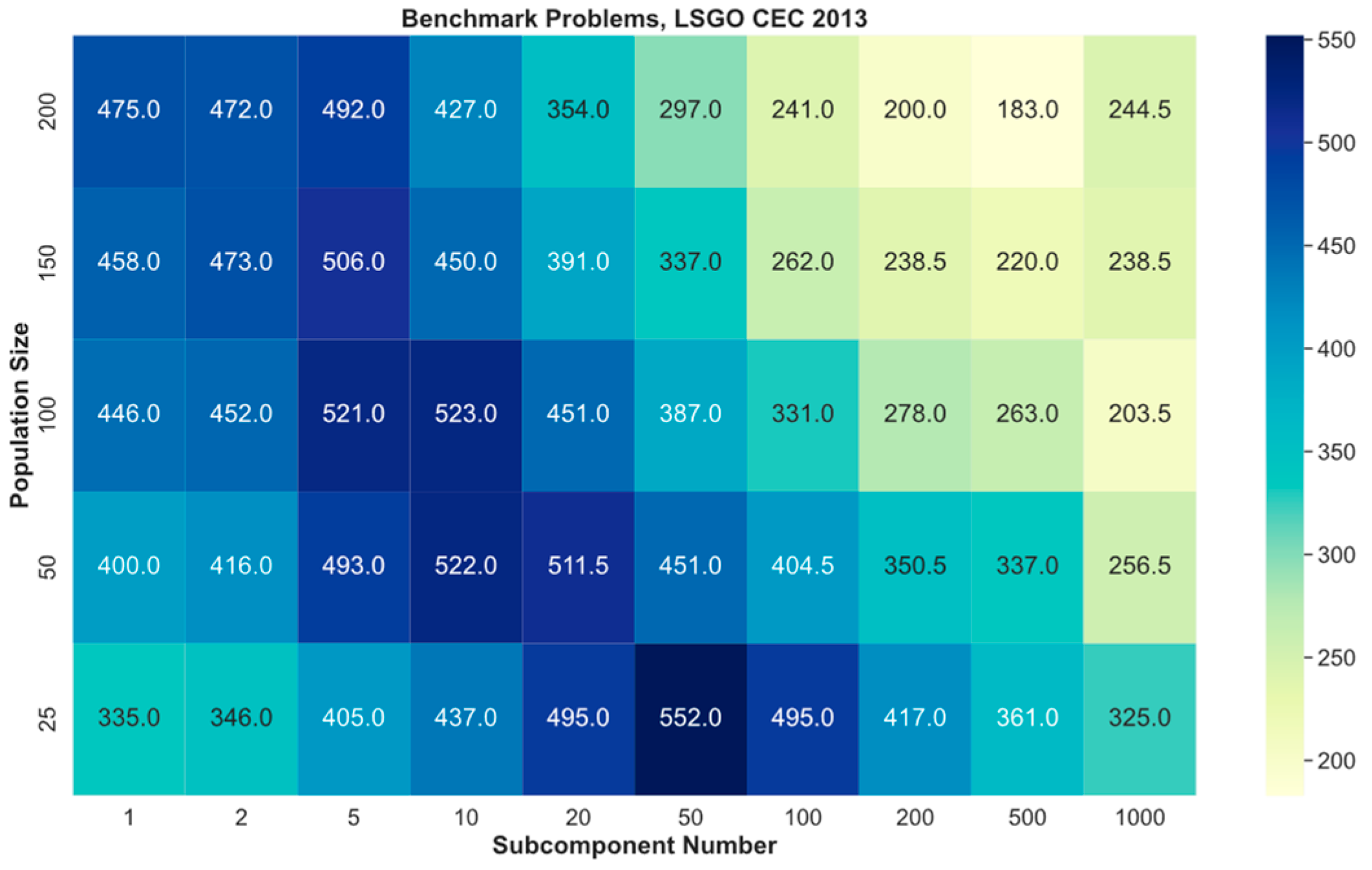
Figure 2 shows the ranks sum for the algorithm’s parameters for all benchmark problems. The
x-axis denotes the number of subcomponents, the
y-axis denotes the number of individuals using the results from
Figure 1. The highest sum of ranks is the best achieved result. Dark color denotes the best average combination of parameters. The best average combination of parameters for CC-SHADE are 50 subcomponents and 25 individuals.
Table 1 shows the best combination(s) of parameters for each benchmark problem. The first column denotes the problem number, the second column denotes the best combination using the following notation, “CC × pop_size”, where CC is the best subcomponent size, and pop_size is the best population size. The last column denotes the class of a benchmark problem. As we can see from the results in
Table 1, we cannot define the best combination of parameter combination for all problems. Additionally, we cannot find any pattern of the best parameters for each class of LSGO problems.
3.2. CC-SHADE-ML
We evaluated the performance of CC-SHADE-ML and compared it with CC-SHADE with a fixed number of subcomponents and a fixed number of individuals. The proposed CC-SHADE-ML algorithm has the following parameters. The set of subcomponents is equal to The set of the population size is equal to . The number of cycles is set to 50. According to our numerical experiments, this value for the number of cycles performs better than other tested values. Thus, in each cycle, CC-SHADE-ML evaluates 6.0 × 104 FEs.
We use “CC” and “CC-k(v)” notations to save space in
Table 2, where CC is all variants of CC-SHADE parameters, and CC-k(v) is the proposed approach, where the parameter
k is set to
v (3), and
v is the power of the exponent in Equation (3). We investigated
equal to
.
Table 2 proves the statistical difference in the results of the rank comparison using the Wilcoxon rank-sum test with the
p-value equal to 0.05. The first column denotes better (+), worse (-), and equal performance (≈). Other columns contain the settings of the proposed algorithm. The cells contain the total number of benchmark problems where CC demonstrates better, worse, or equal performance in comparison with CC-k(v). As we can see, each version of the proposed algorithm has scores larger than CC. As we can see from
Table 2, the proposed algorithm with all values of the power (3) always demonstrates better performance in comparison with the CC with a fixed number of subcomponents and individuals. Based on the results of the numerical experiments and the results of the statistical test, it is preferable on average to choose the proposed approach than the CC algorithm with an arbitrary set of parameters.
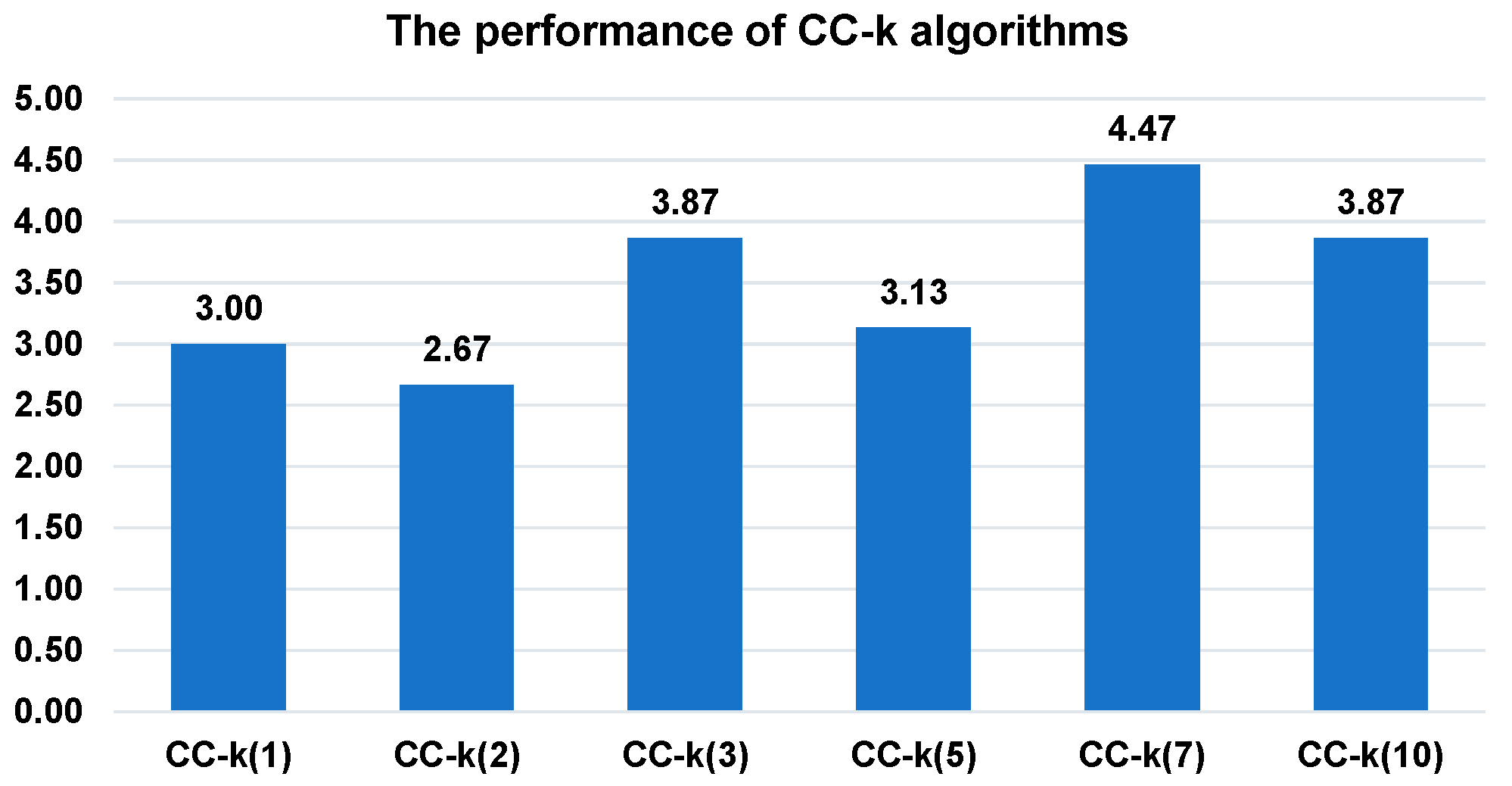
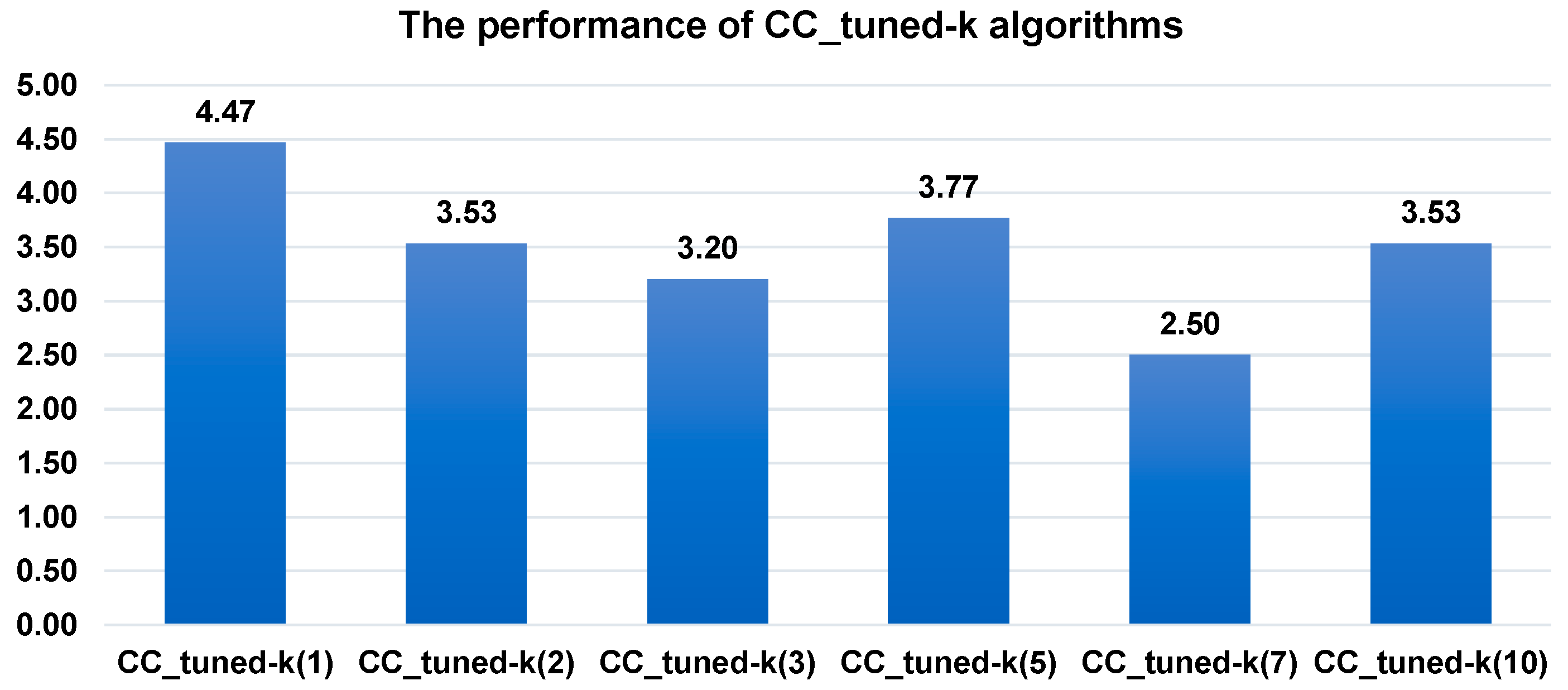
Figure 3 shows the ranking of CC-SHADE-ML algorithms with different values of power (3). The ranking is based on the obtained mean values in 25 independent runs. The ranking is averaged on 15 benchmark problems. The highest rank corresponds to the best algorithm.
We have compared the performance estimations of all CC-k algorithms. The statistical experimental results are placed in
Table 3. The first column denotes indexes of the algorithm. The second column denotes the title of the algorithm. The next columns denote the compared algorithms corresponding to the index value. Values in each cell are based on the following notation. We compare algorithms from a row and column, if the algorithm from the row demonstrates statistically better, worse of equal performance we add points to the corresponding criterion.
Table 3 contains the sum of (
better/worse/equal) points of all algorithms.
The results in
Table 4 are based on the results from
Table 3. Algorithms are sorted according to their statistical performance and their averaged rank. As we can see, CC-k(7) has taken first place. It outperforms the other algorithms 10 times, loses only once and demonstrates the same performance 64 times. It can be noted that the second last column contains large values. This means that the majority of considered algorithms demonstrate an equal performance on benchmark problems that can be explained by the introduced self-adaptiveness.
Based on the ranking and the statistical tests, we can conclude that CC-k(7) performs the other variants of CC-k(v). In the original paper [
16], the authors also found that MLCC demonstrates better results with the power value (3) equal to 7.
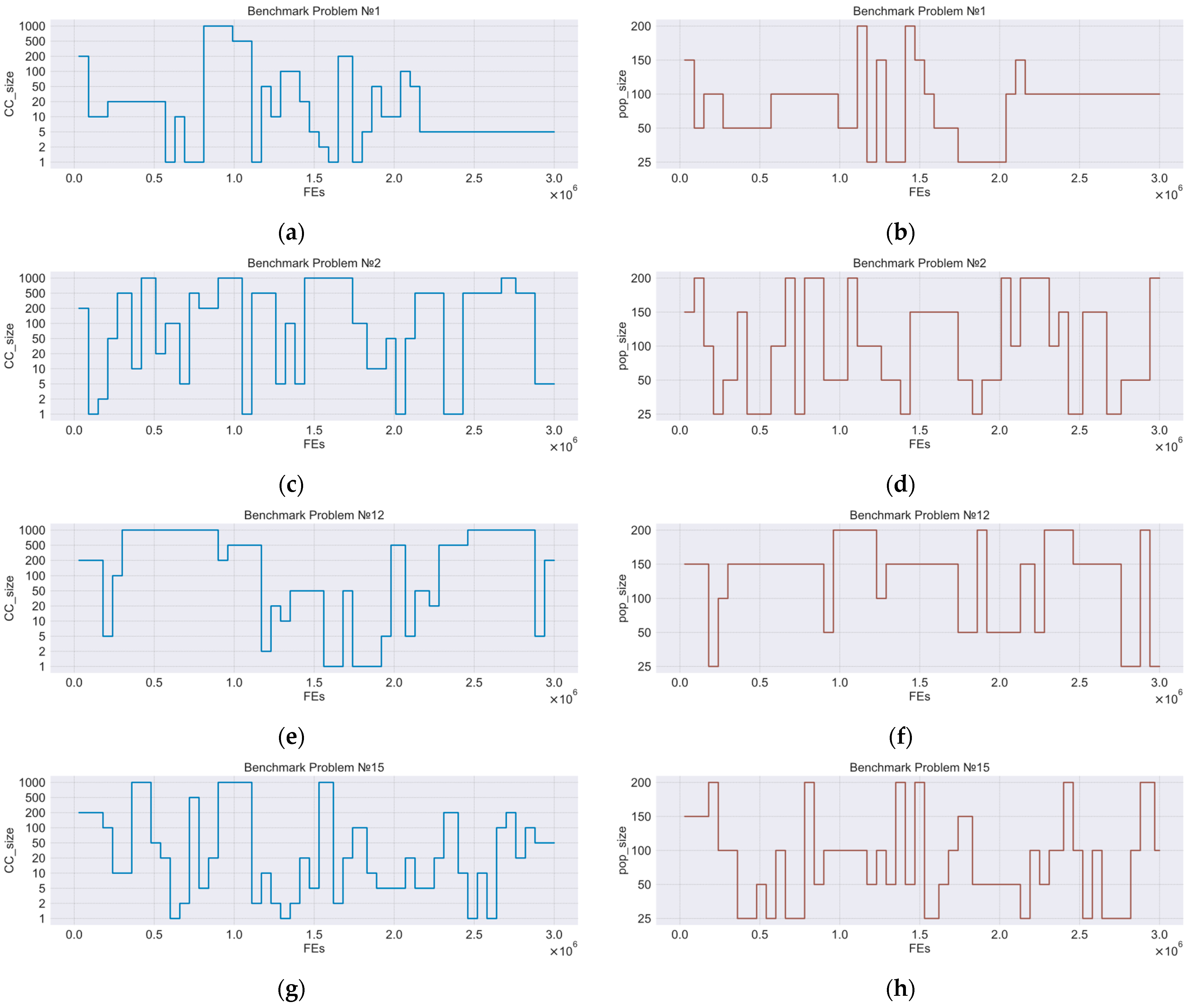
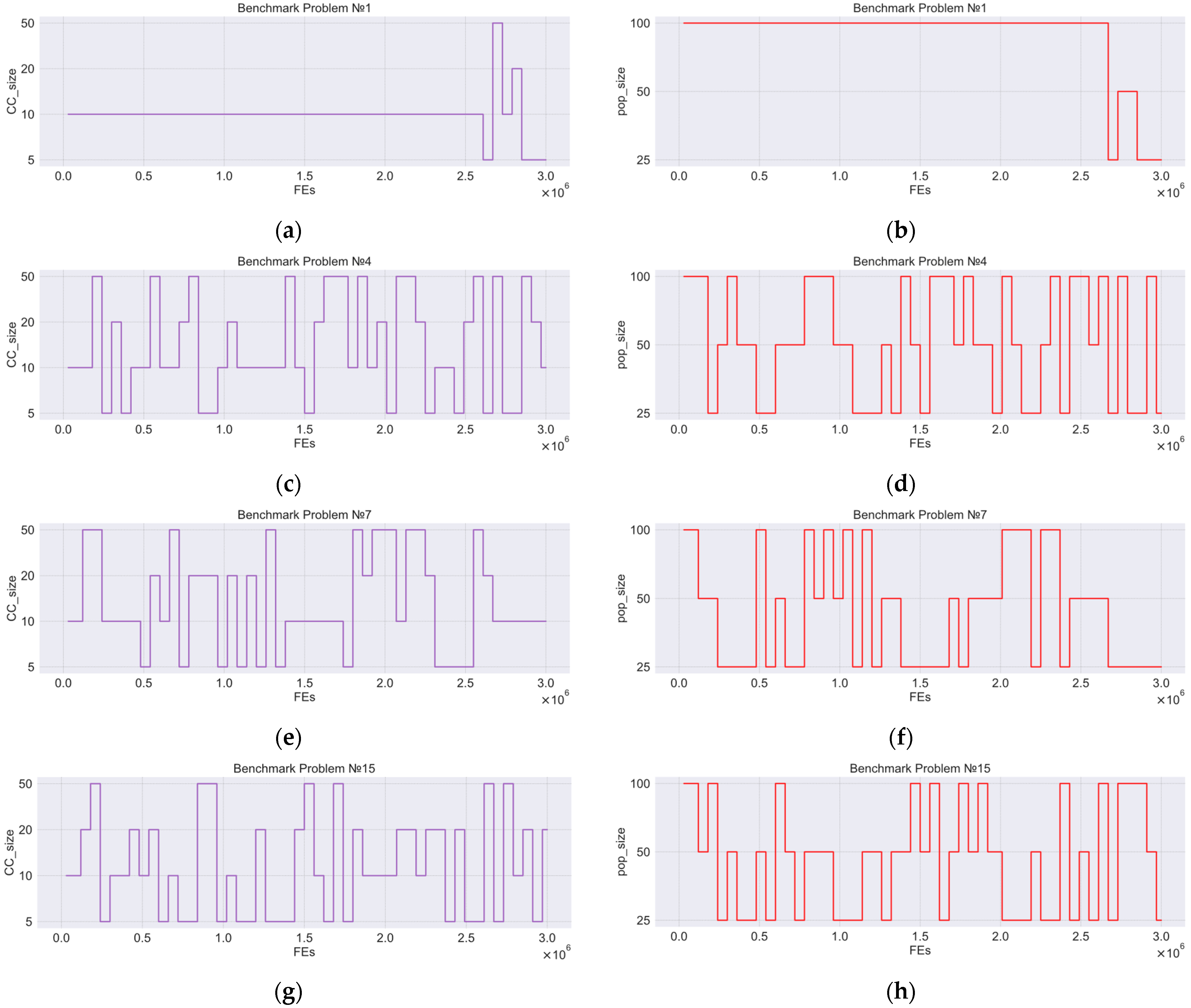
In
Figure 4, we show an example of curves which demonstrate the dynamic adaptation of the number of subcomponents and the population size in one independent run of CC-k(7). The
x-axis denotes the FEs, the
y-axis denotes the selected level of parameters. The pictures show graphs for
,
,
, and
benchmark problems.
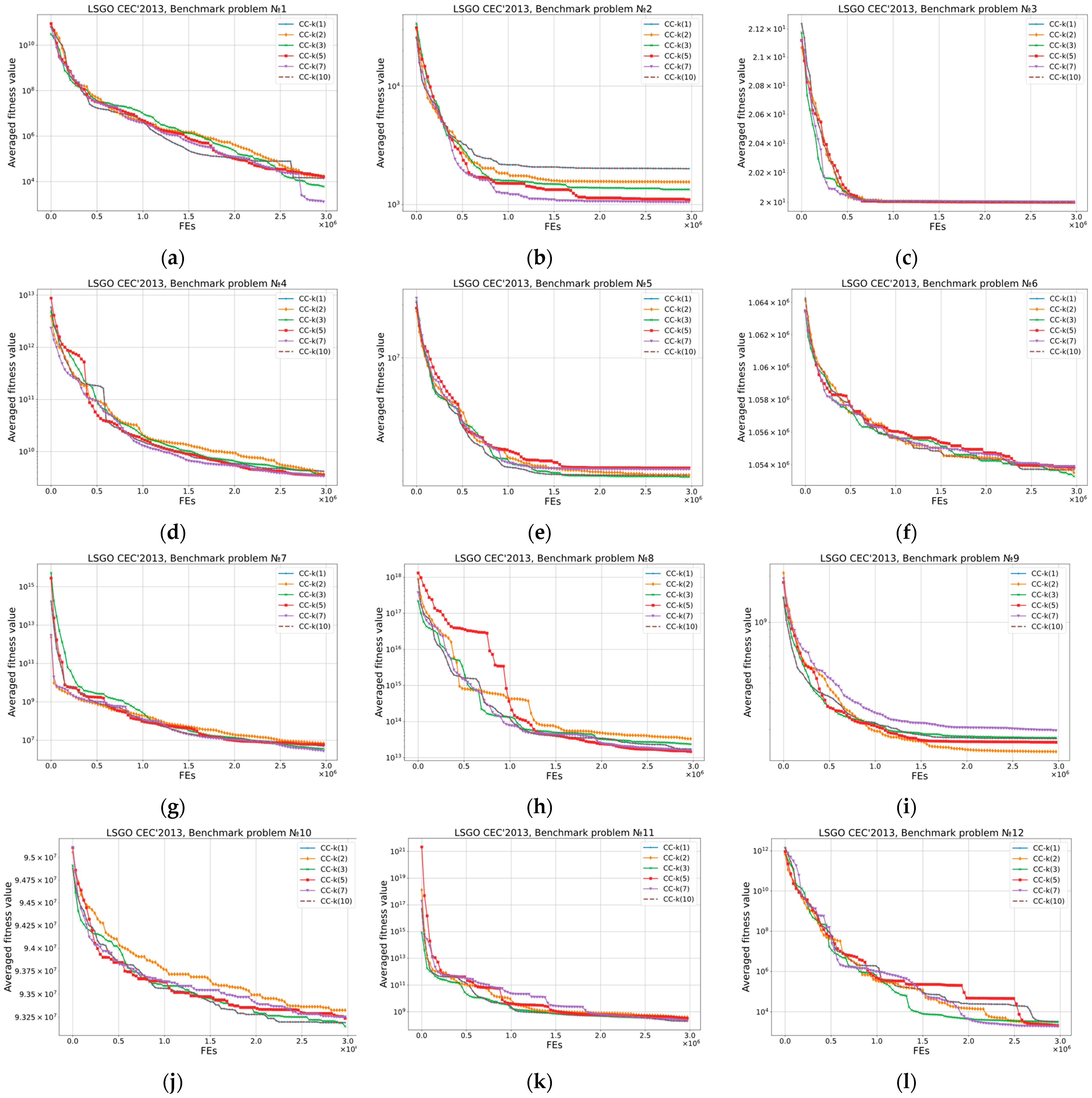
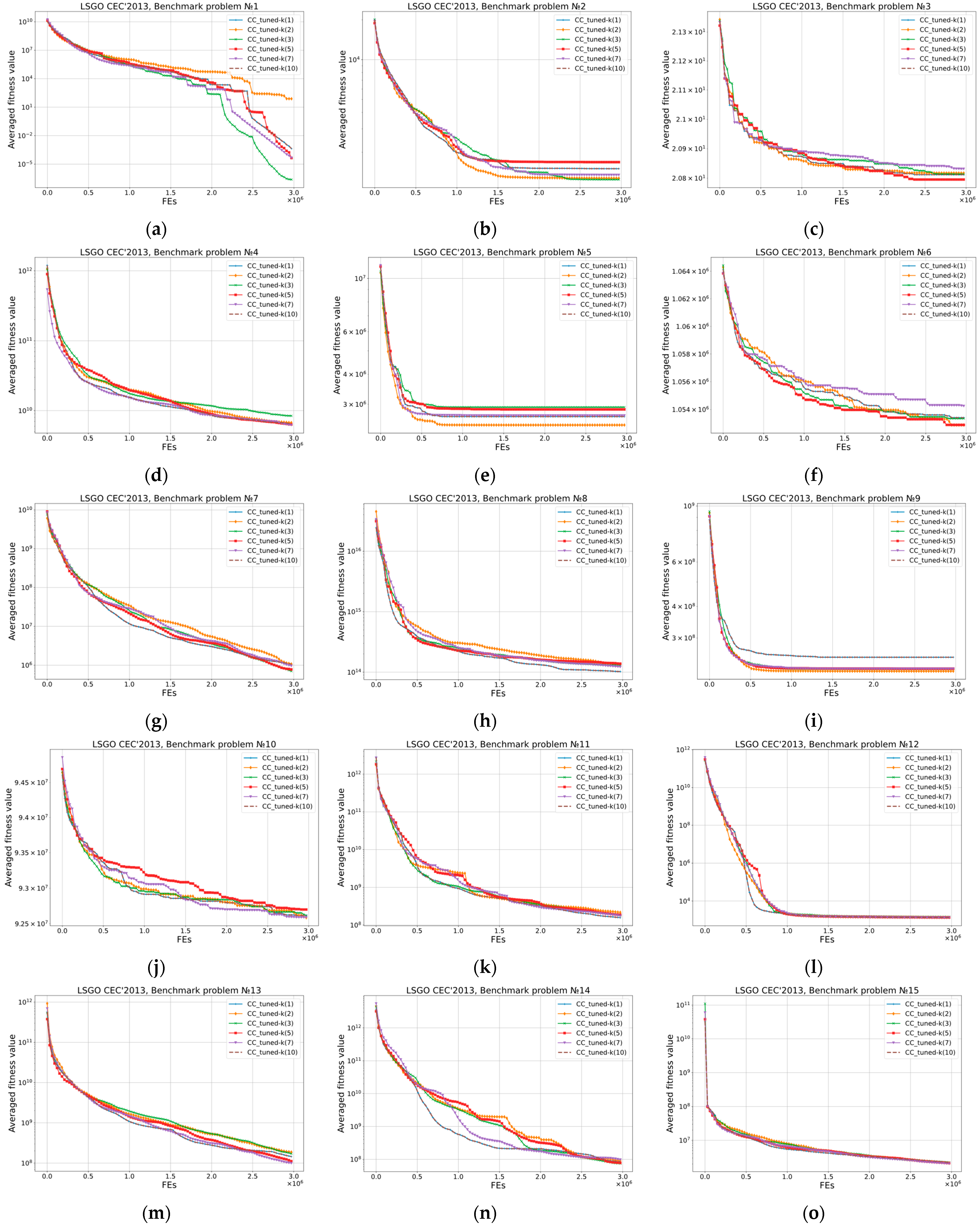
Figure 5 shows convergence graphs for CC-k(v) algorithms. The
x-axis denotes the FEs number, the
y-axis denotes the averaged fitness value obtained in 25 independent runs. As we can see, the convergence plots are almost similar for all CC-k algorithms. In most cases, the value of the power in (3) does not critically affect the behavior of the CC-SHADE-ML algorithm. As we have noted, according to the results from
Table 4, the algorithms’ performance is the same on the majority of problems.
3.3. The Tuned CC-SHADE-ML
In this subsection, we evaluate the performance of the tuned CC-SHADE-ML. As we can see in
Figure 2, the region with the best-ranked solutions covers the set of subcomponents equal to
and the set of the population size equal to
. The tuned CC-SHADE-ML will use these parameters.
Figure 6 has the same structure as
Figure 3. Based on the ranking, CC_tuned-k(1) demonstrates the best performance.
Table 5 has the same structure as
Table 2.
Table 2 compares the performance of CC and CC_tuned-k algorithms. According to the results of the Wilcoxon test, we can conclude that any power value of tuned CC-k demonstrates better performance than CC with the fixed number of subcomponents and individuals.
Table 6 and
Table 7 have the same structure as
Table 3 and
Table 4, respectively. We placed CC_tuned-k(7) on the first place because it has no loss point. Although, if we take into account only the averaged rank, we then need to place CC_tuned-k(7) in last place. Additionally, CC_tuned-k(1) has the highest rank, however, it does not significantly outperform any of compared algorithms.
We compared the performance of CC-k(7) and CC_tuned-k between each other using the Wilcoxon test. The statistical difference analysis is presented in
Table 8. Columns denote the number of benchmark problems. The (+/-/≈) symbols mean better, worse, and equal performance of CC-k in comparison with CC_tuned-k. Algorithms demonstrate the same performance for six problems. CC-k outperforms CC_tuned-k on four problems and loses on five problems.
Figure 7 has the same structure as
Figure 4. As we can see, on the
F1 benchmark problem, the algorithm has chosen a good combination of parameters and does not change the certain number of cycles because this combination demonstrates the high performance. On other benchmark problems, we can see more rapid switching between values of parameters.
Figure 8 has the same structure as
Figure 5. It shows convergence graphs for CC_tuned algorithms.
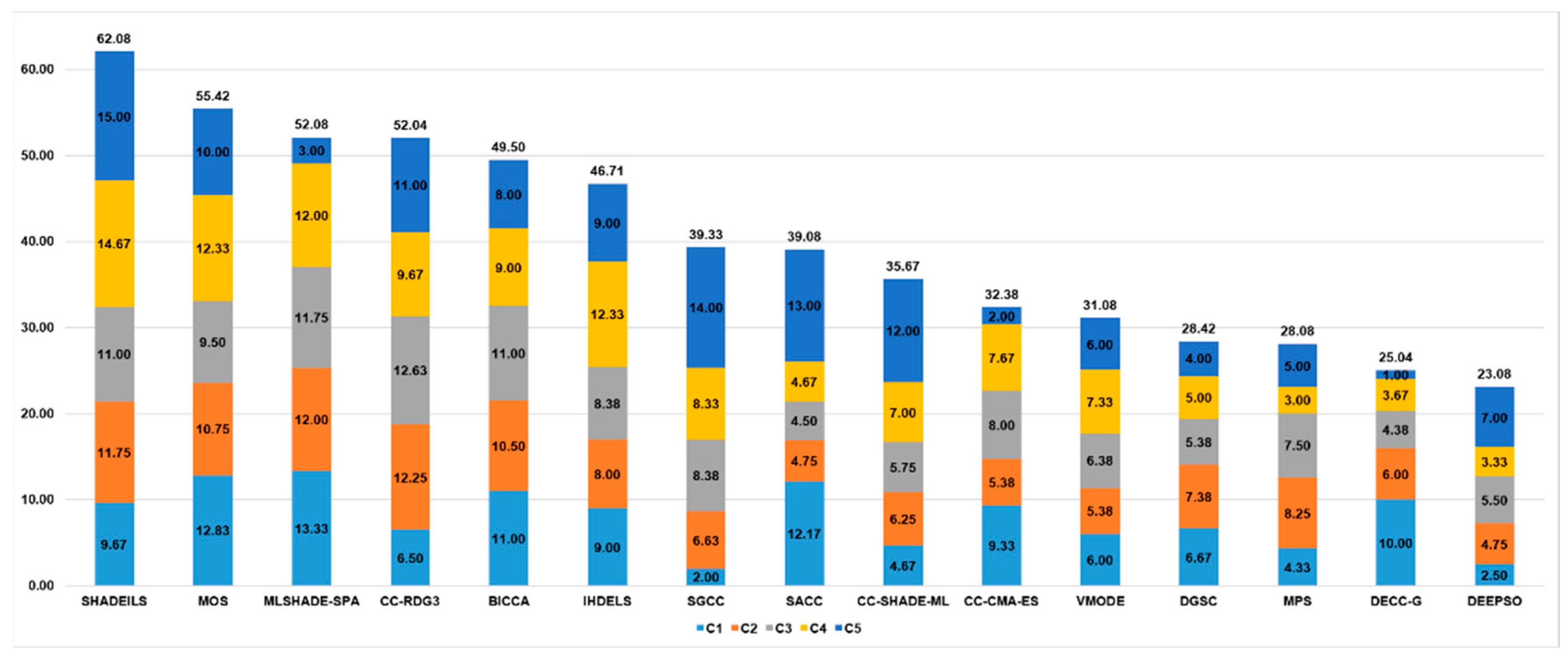
We have compared the performance of CC_tuned-k(7) with other state-of-the-art LSGO metaheuristics. These metaheuristics were specially created and tuned to solve the LSGO CEC’2013 benchmark set. We selected high-performed metaheuristics from the TACOlab database [
26]: SHADEILS [
27], MOS [
28], MLSHADE-SPA [
29], CC-RDG3 [
30], BICCA [
31], IHDELS [
32], SGCC [
33], SACC [
34], CC-CMA-ES [
35], VMODE [
36], DGSC [
37], MPS [
38], DECC-G [
39], and DEEPSO [
40].
Figure 9 shows the ranking of the compared metaheuristics.
Table 9 consists of the ranking values of state-of-the-art algorithms depending on the class of benchmark problems. Ranks are averaged in each class. The proposed algorithm takes ninth place out of 15. We should note that the majority of metaheuristics in the comparison use special local search techniques adapted for the CEC’13 LSGO benchmark and their control parameters are also fine-tuned to the given problem set. Thus, there is no guarantee that these algorithms will demonstrate the same high performance with other LSGO problems. At the same time, the proposed approach automatically adapts to the given problem, so we conclude that it can also perform well when solving new LSGO problems. In
Section 3.3, we propose a hybrid algorithm which is a combination of CC-SHADE-ML and MTS-LS1 [
41].
Table 10 contains the detailed results for the fine-tuned CC-SHADE-ML algorithm. The first column contains three checkpoints, 1.2 × 10
5, 6.0 × 10
5, and 3.0 × 10
6. The remaining columns show the number of a benchmark problem. Each cell contains five numbers: the best-found value, the median value, the worst value, the mean value, and the standard deviation value. The authors of the LSGO CEC’2013 benchmark set recommend the inclusion of this information for the convenient further comparison of the proposed algorithm with others. Usually, the comparison is based on values after 3.0 × 10
6 FEs.
3.4. Hybrid Algorithm Based on CC-SHADE-ML and MTS-LS1
In the CC-SHADE-ML algorithm, MTS-LS1 [
41] performs after the optimization cycle and uses 25,000 FEs (this value has been defined by numerical experiments). MTS-LS1 tries to improve each
i-th coordinate using the search range SR[i]. In this study, the initialization value of each SR[i] is equal to
.
and
are low and high bounds for the
i-th variable. If MTS-LS1 does not improve a solution using the current value of SR[i], it should be reduced by two times (SR[i] = SR[i]/2). If SR[i] is less than 10
−18 (in [
41], the original threshold is 10
−15), the value is reinitialized. As we can see from the numerical experiments, usually, MTS-LS1 finds a new best solution that is so far from other individuals in the population. Thus, CC-SHADE-ML is not able to improve the best-found solution after applying MTS-LS1, but it does improve the median fitness value in the population. In this case, Formula (2) will be inappropriate for the evaluation of the performance of selected parameters. We use Formula (4) to overcome this difficulty, the formula is based on the median fitness value before and after the CC-SHADE-ML cycle.
Different mutation schemes have been evaluated and we determined that the best performance of CC-SHADE-ML-LS1 has been reached using the following Formula (5).
here,
is a mutant vector,
is a solution from the population,
is a scale factor,
is a solution from the population chosen from the
p best solutions,
is a solution from the population chosen using the tournament selection (in this study, the tournament size is equal to 2),
is a randomly chosen solution from the population or from the archive. To perform Formula (5), the following condition must be met:
.
Control parameters of CC-SHADE-ML-LS1 are the following: the set of subcomponents equal to
; the set of the population size equal to
; FEs_LS1 equal to 25,000; the mutation scheme, in SHADE, is (5); and the tournament size is 2.
is equal to 1.5 × 10
5. The complete pseudocode of the hybrid is presented in Algorithm 3. Additionally, the CC-SHADE-ML-LS1 performance has been evaluated and compared with state-of-the-art metaheuristics. Comparison rules and algorithms for comparison are the same as in
Section 3.2.
Table 11 and
Table 12 have the same structure as
Table 9 and
Table 10, respectively.
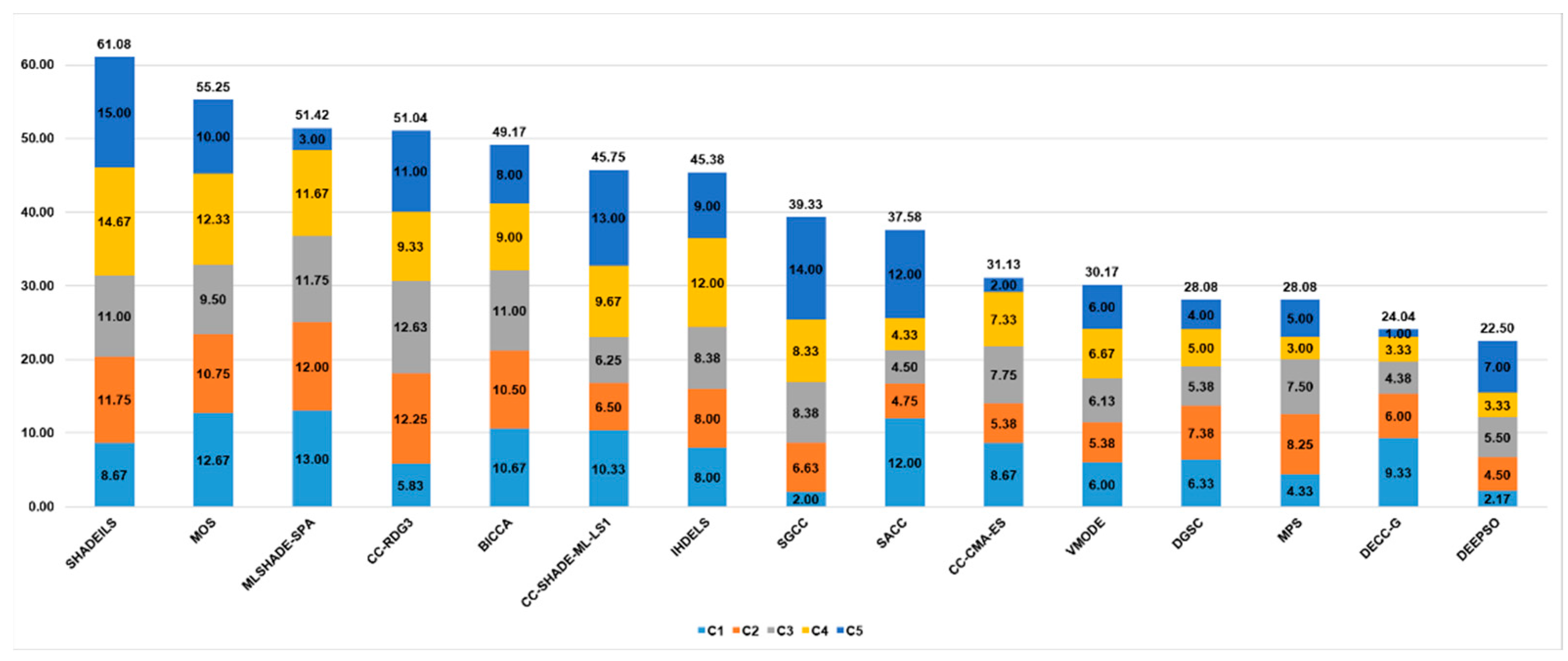
Table 11 shows the ranking of CC-SHADE-ML-LS1.
Table 12 contains the detailed results of the tuned CC-SHADE-LS1 algorithm.
Figure 10 has the same structure as
Figure 9.
| Algorithm 3 CC-SHADE-ML-LS1 |
| Set the set of individuals, the set of subcomponents, optimizer, cycles_number |
| 1: | Generate an initial population randomly; |
| 2: | Initialize performance vectors, CC_performance and pop_performance; |
| 3: | FEs_cycle_init = FEs_total/cycles_number; |
| 4: | while (FEs_total > 0) do |
| 5: | FEs_cycle = FEs_cycle_init; |
| 6: | Randomly shuffle indices; |
| 7: | Randomly select CC_size and pop_size from CC_performance and pop_performance; |
| 8: | while (FEs_cycle > 0) do |
| 9: | Find the median fitness value before the optimization cycle ; |
| 10: | for i = 1 to CC_size |
| 11: | Evaluate the i-th subcomponent using the SHADE algorithm; |
| 12: | end for |
| 13: | Find the median fitness value after the optimization cycle ; |
| 14: | Evaluate performance of CC_size and pop_size using Equation (4); |
| 15: | pdate CC_performance and pop_performance; |
| 16: | end while |
| 17: | while (FEs_LS1 > 0) do |
| 18: | Apply MTS-LS1(best_fould_solution); |
| 19: | end while |
| 20: | end while |
| 21: | return the best-found solution |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}