

Batch Acquisition for Parallel Bayesian Optimization—Application to Hydro-Energy Storage Systems Scheduling †

 , ,
, ,  ,
, 
Abstract
1. Introduction
2. Material and Methods
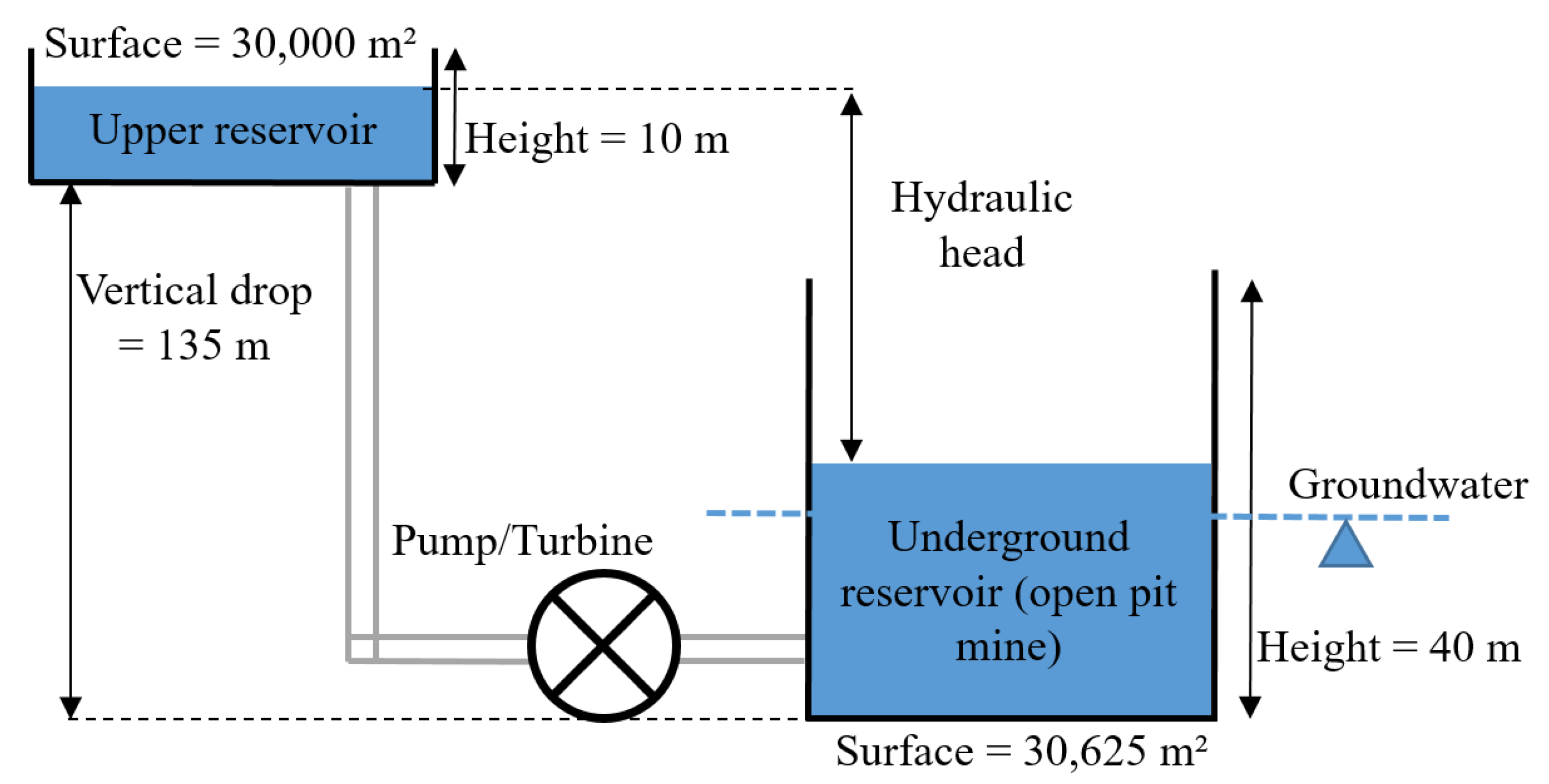
2.1. Underground Pumped Hydro-Energy Storage
2.2. Parallel Bayesian Optimization
2.2.1. Gaussian Process Regression
2.2.2. Acquisition Process for Optimization
| Algorithm 1 Bayesian Optimization |
|
- The KB-q-EGO algorithm refers to the work of Ginsbourger et al. [9,36] where they present heuristics to approximate multi-point criteria which are difficult to exploit when the required number of candidates exceeds (q being the batch size, also denoted as throughout this paper). The idea is to replace the time-consuming simulation with a fast-to-obtain temporary/fantasy value in order to update the surrogate model , which allows the suggestion of a new distinct candidate. In the KB heuristic, it is decided to trust the surrogate model (hence, Kriging Believer) and use its output as fantasy value. The operation can be repeated sequentially until q design points are selected. Then, it is possible to exactly evaluate them in parallel and replace the temporary values with the real costs. However, this strategy has the major drawback of requiring q sequential updates of per cycle. In Ginsbourger et al. [9], inside the heuristic loop, the Kriging model is used without hyperparameter re-estimation. To preserve this aspect and in order to alleviate the fitting cost, the budget allocated to the intermediate fitting of the surrogate model is reduced compared to a full update performed at the beginning of a cycle.
- We propose Multi-infill-criteria q-EGO (mic-q-EGO), an alternative AP that uses multiple IC in the same cycle in order to limit the number of surrogate fitting operations. This approach is a variation of q-EGO using a multi-infill strategy such as in Liu et al. [10] or Wang et al. [11]. Using multiple AFs allows to select different candidate points without updating the surrogate model, assuming that their optimization yields distinct candidate points. Moreover, it has been observed that resorting to different AFs can favorably impact the objective value, especially when the batch size is large. Indeed, repeatedly updating using non-simulated data may degrade the relevance of proposed candidates [8]. Since standard EI, used as the primary criterion, is known to sometimes over-explore the search space, it is decided to rely on the Upper Confidence Bound (UCB) criterion to improve the exploitation. In this paper, two ICs are used with the same number of candidates from each criterion. Therefore, albeit generalizable to more criteria not necessarily evenly distributed, the description of Algorithm 2 considers the previous statement for sake of simplicity. We denote and the two AFs, then for the same model, a candidate can be chosen according to each AF (line 6 and 7). Despite not being implemented yet, the optimizations of could be conducted in parallel. If more candidates are required, a partial model update is necessary (line 11) using the predicted value () as suggested in the KB heuristic. The loop continues until q candidate points are selected.
- BSP-EGO [13] is an algorithm developed by the authors with the objective of tackling time-consuming black-box objective functions for which the execution time does not dominate the acquisition time. It uses a dynamic binary partition of the search space to optimize the AF inside sub-regions. Thereby, a local AP based on a global model is conducted simultaneously in each sub-domain. Candidate points coming from sub-regions are aggregated and sorted according to their infill value in order to choose the most promising ones. By the end of a cycle, the partition evolves in accordance with the performance of each sub-region: the one containing the best candidate in terms of the AF will be split further while the supposedly less valuable sub-regions are merged. At any time, the partition covers the entire search space and involves the same number of sub-regions. The number of sub-regions is chosen to be a multiple of to balance the load between parallel workers. Having avoids sampling into clearly low potential sub-regions by letting the choice of among . Typically in this work, . As the supposed best sub-region is split at each cycle, diversification is imposed at the beginning, while intensification is favored as the budget fades. This considerably reduces the acquisition time compared to q-EGO since it can be conducted in parallel thanks to the spatial decomposition, which is valuable since the optimization must be completed in very restricted time.
- MC-based q-EGO from the BOTorch library, developed by Balandat et al. [12] uses the reparameterization trick from Wilson et al. [43] and (quasi) MC sampling for estimation of multi-points AF - EI in this study. The latter allows to approximate the AF value and time-efficiently optimize the batch of candidates. However, optimizing the multi-points AF still requires optimizing a objective function which can become tricky and, depending on the inner optimization algorithm, time-consuming when increasing .
- TuRBO [14] uses trust regions to progressively reduce the size of the search space with the objective of compensating for the overemphasized exploration resulting from global AP. The trust region takes the form of a hyper-rectangle centered at the best solution found so far. The side length for each dimension of the hyper-rectangle is scaled according to the length scale from the GP model while maintaining a total volume of . Then, an AP is performed in the trust region that yields a batch of candidates. One or several trust regions can be maintained simultaneously. In this work, one trust region is used with multi-point EI (q-EI) evaluated through MC approximation, similarly to MC-based q-EGO. Therefore, the main characteristic of TuRBO is that the search space is re-scaled according to the length scale of the model and evolves according to the following rule: if the current cycle improves the best solution, the trust region is extended, or else it is shrunk. As mentioned in Eriksson et al., running with only one trust region including the whole domain , TuRBO is equivalent to running the standard q-EGO algorithm.
| Algorithm 2 Multi-infill q-EGO acquisition process |
|
2.3. Problem Instances
2.3.1. UPHES Management
2.3.2. Benchmark Functions
2.4. Experimental Protocol
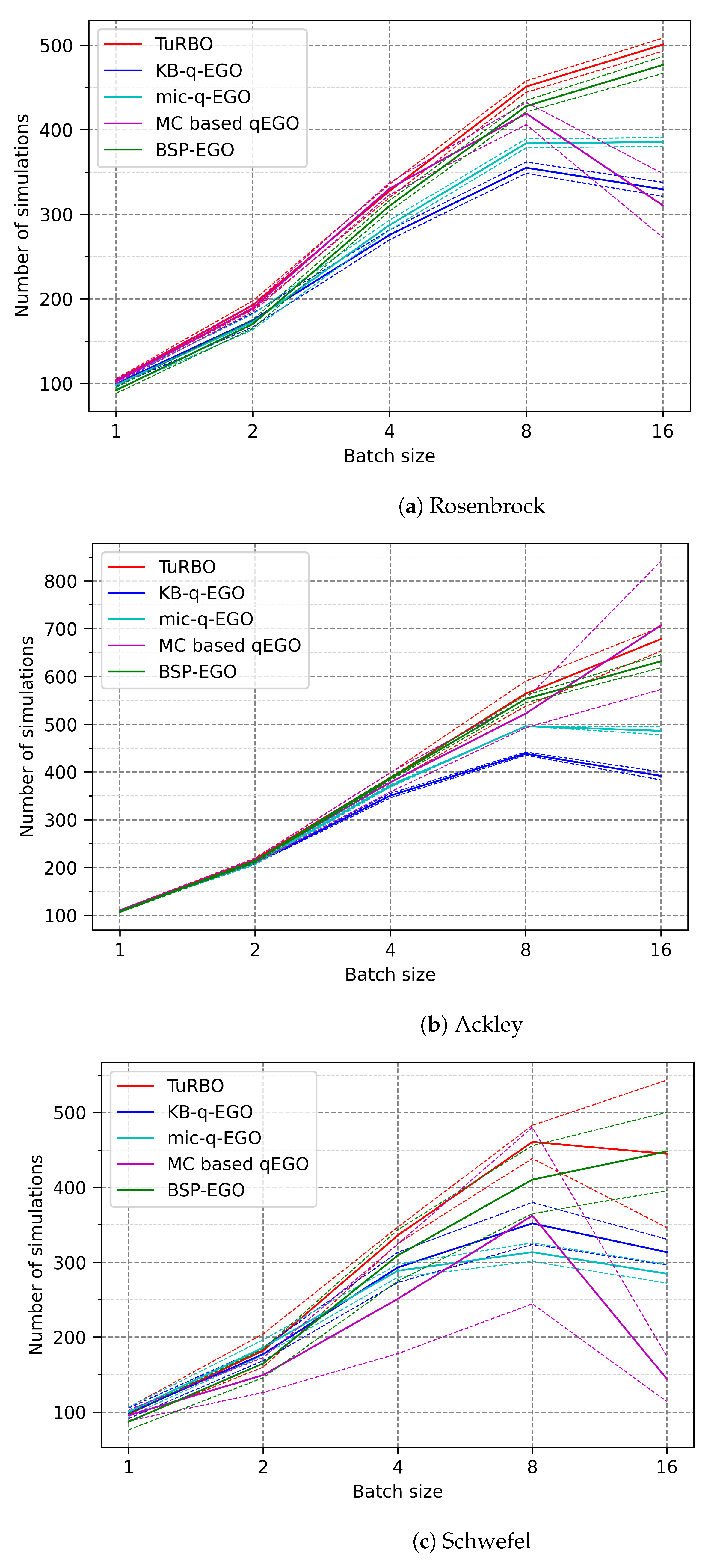
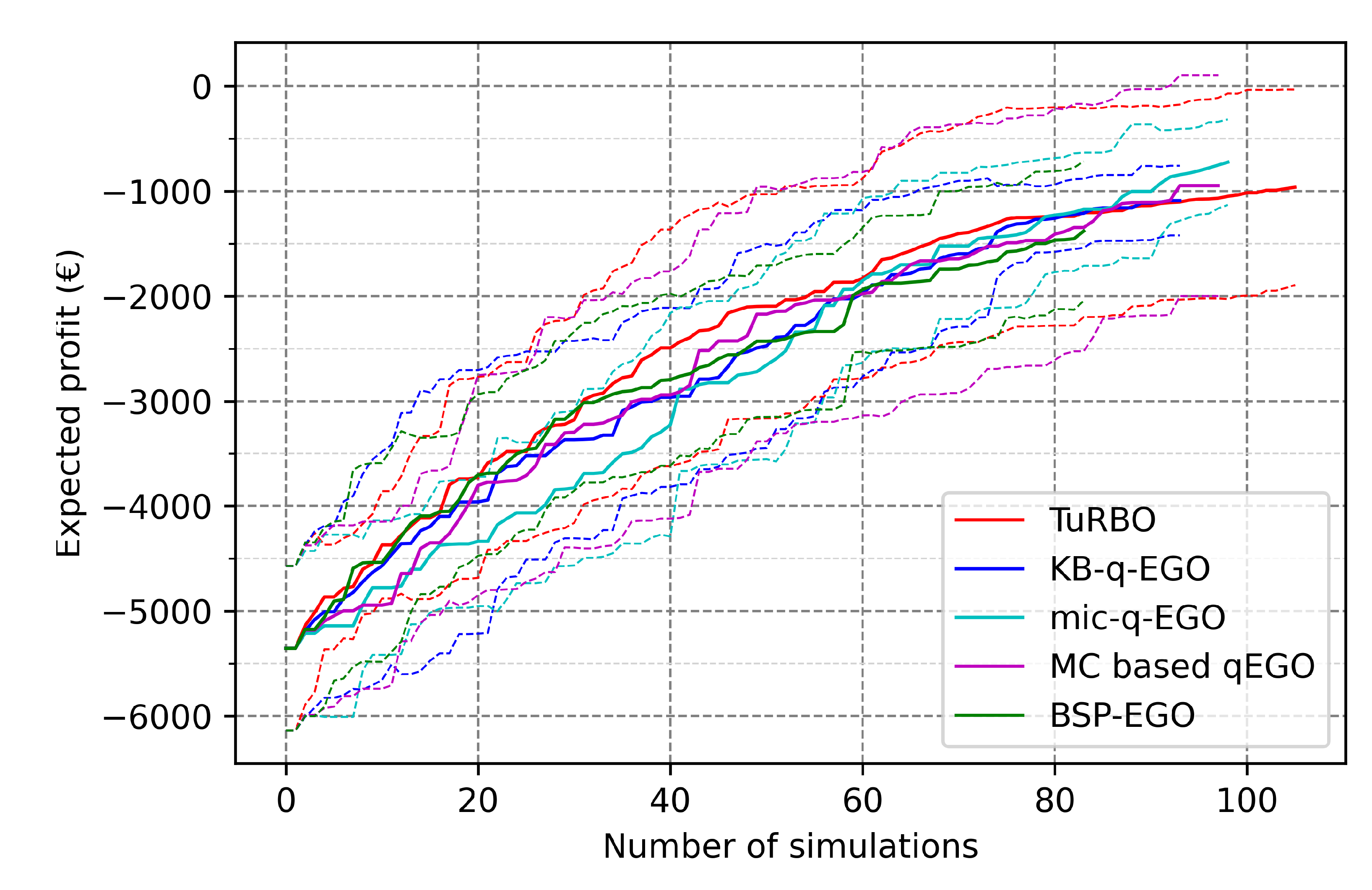
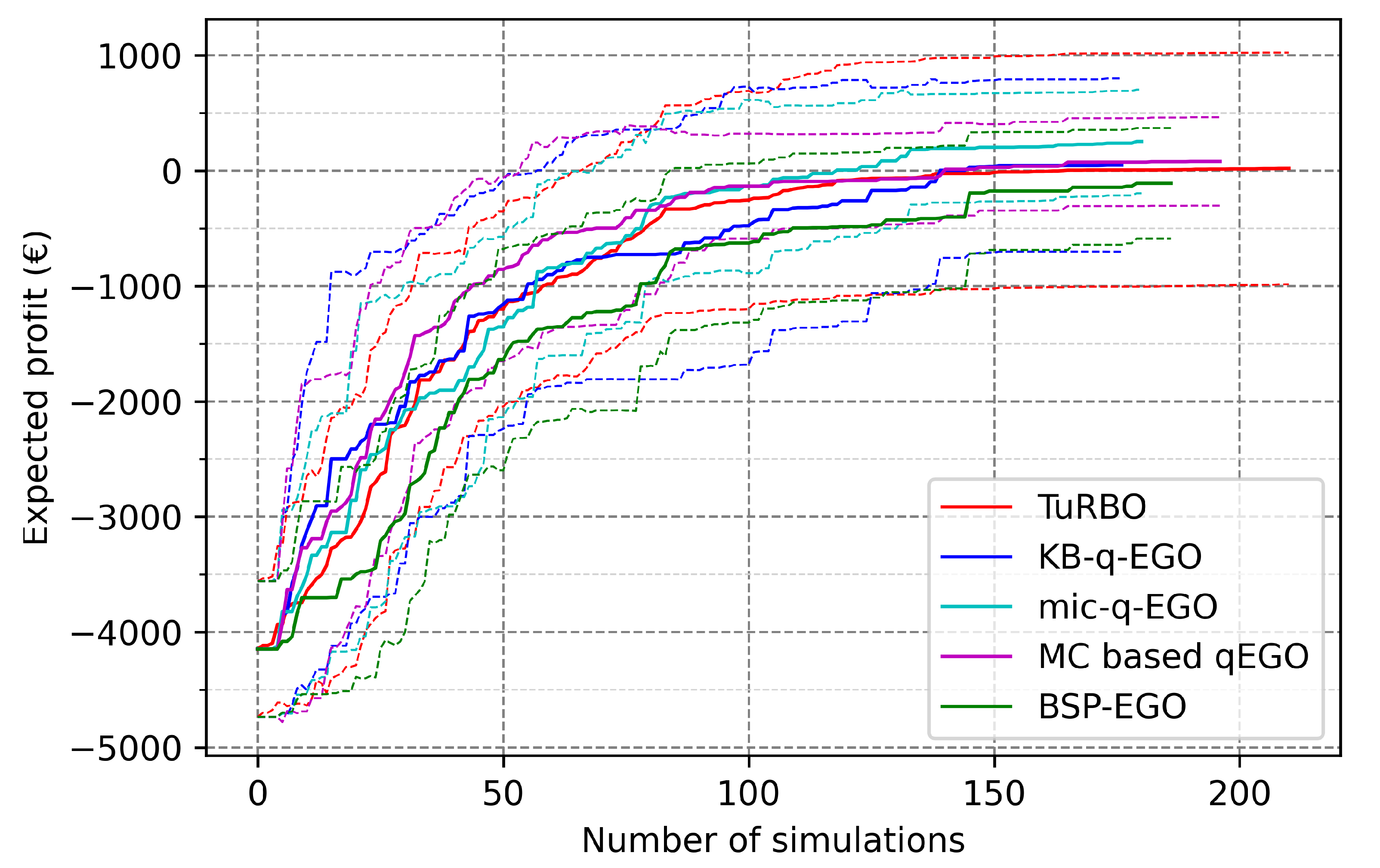
3. Results
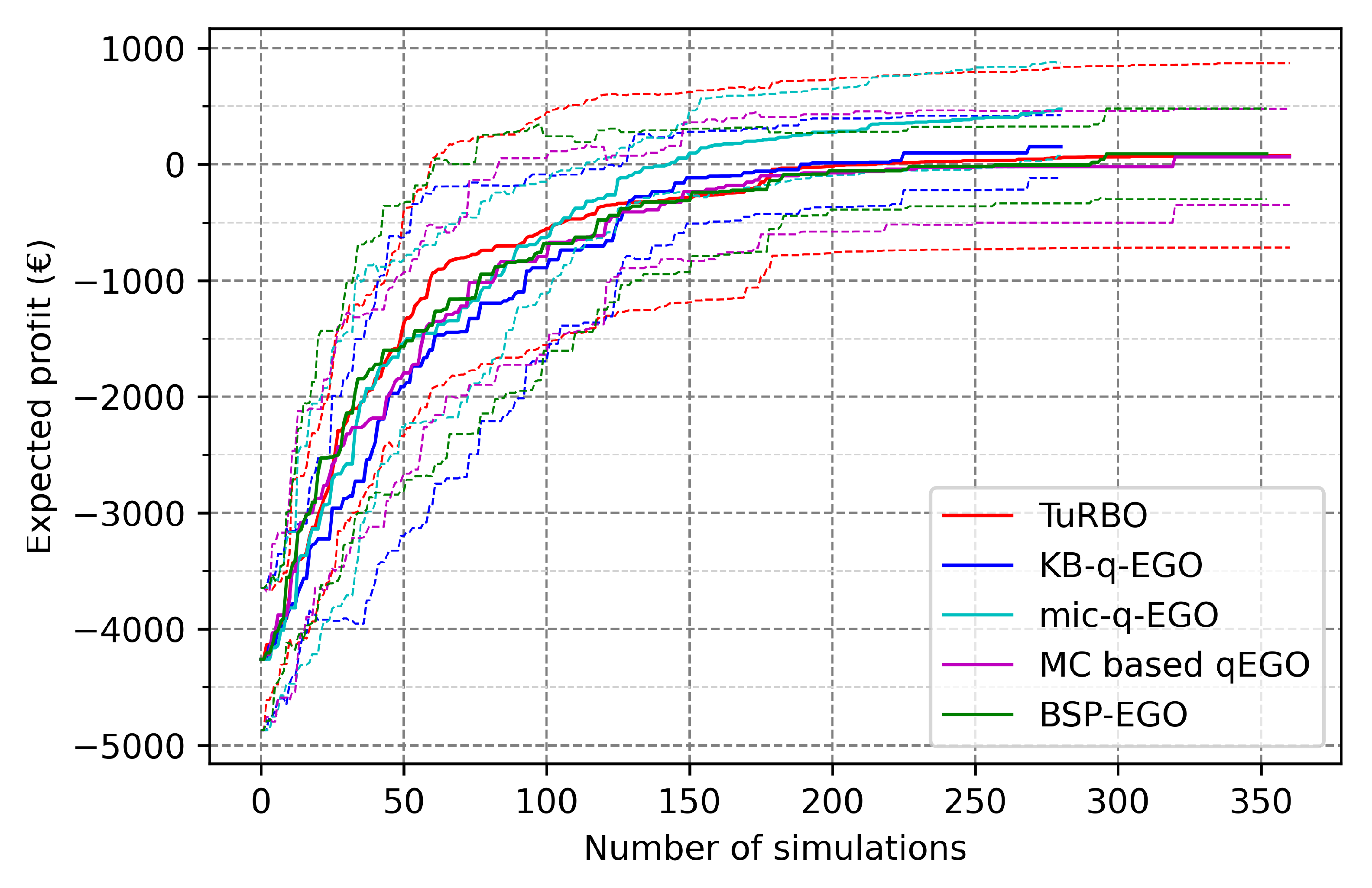
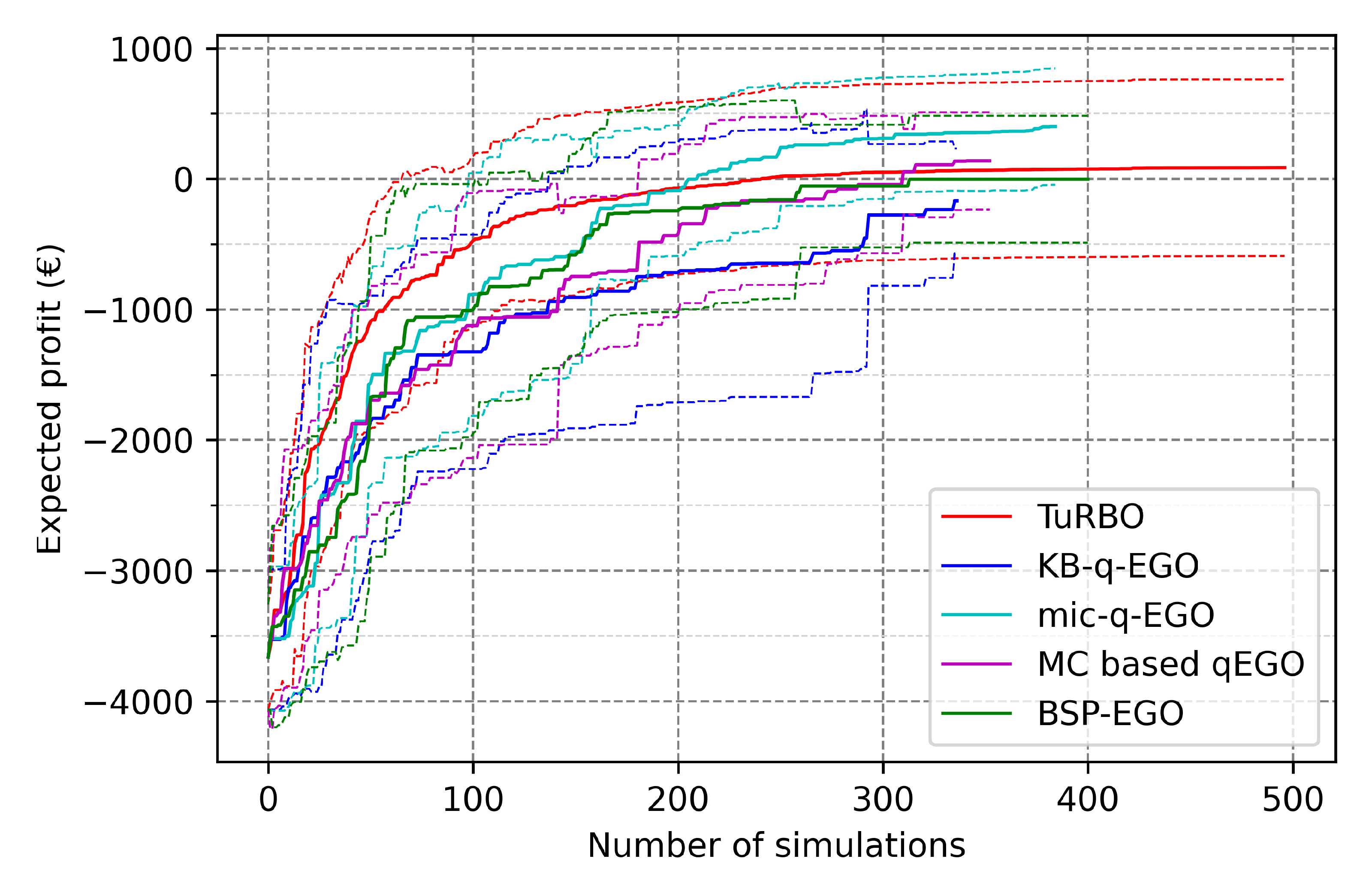
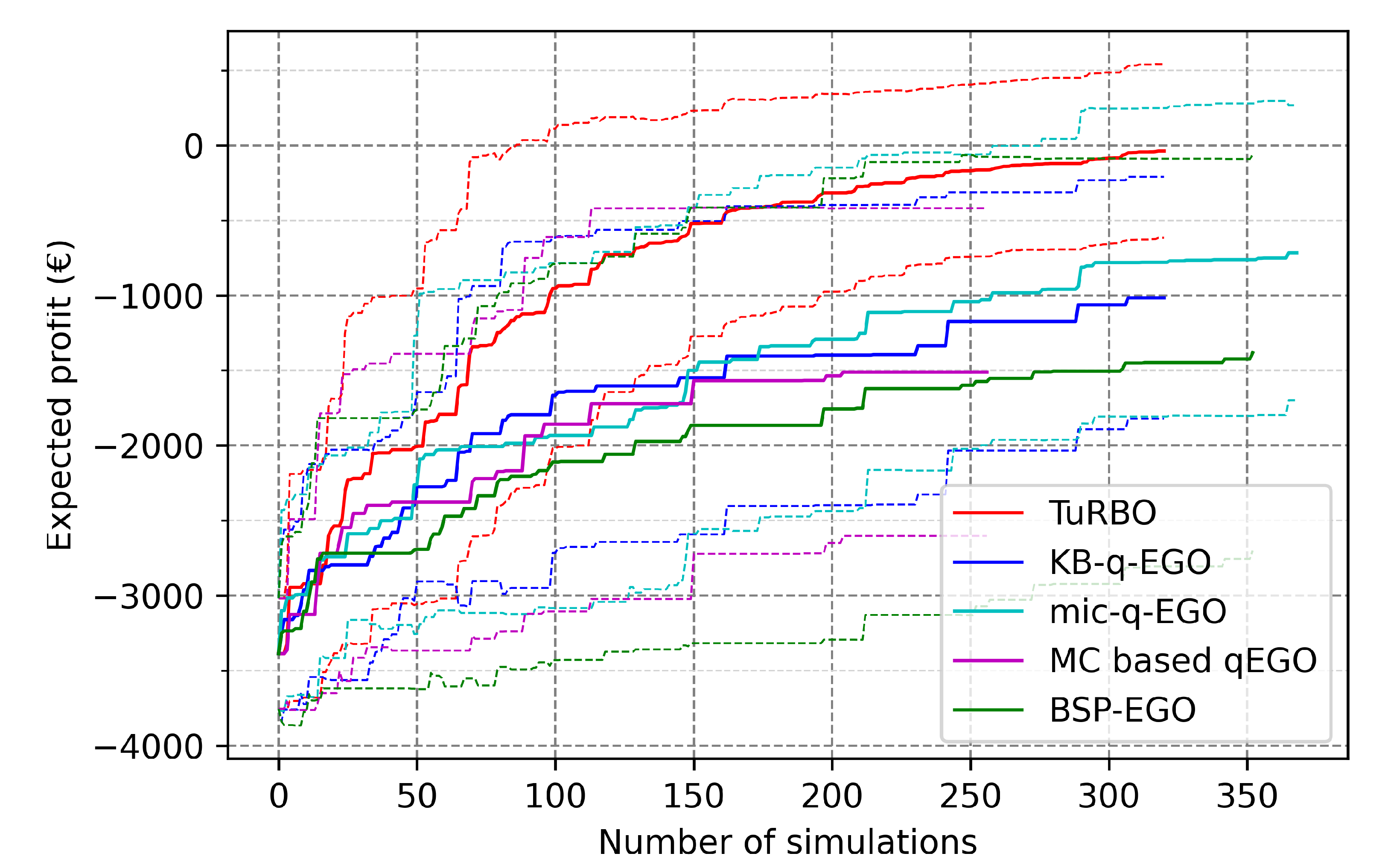
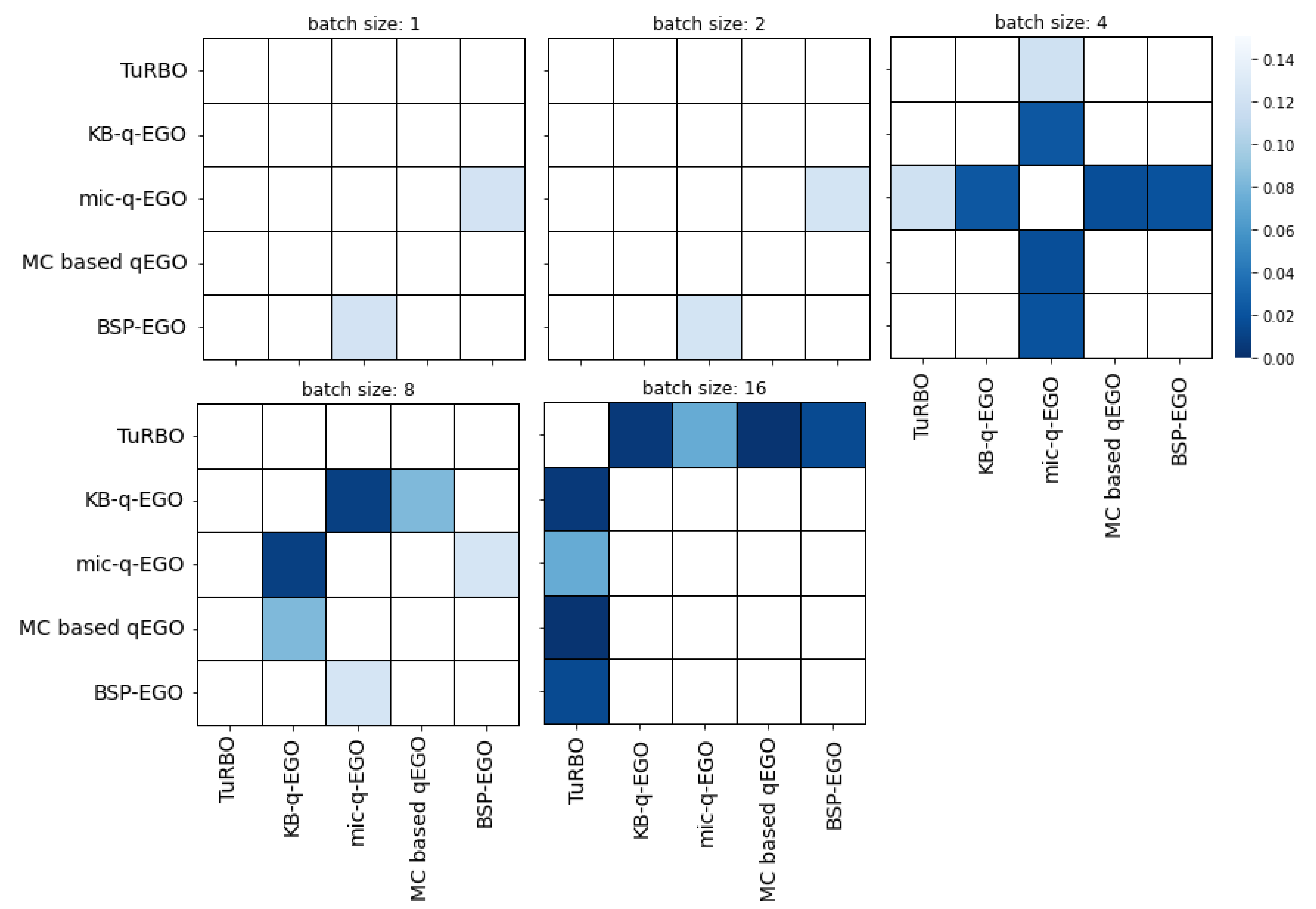
- The performance of a method in terms of the final outcome is compared to its contestants, for a fixed batch size. This is the main objective for the UPHES application: what is the best strategy to optimize the expected profit regarding the given optimization context?
- The performance of the method in terms of the outcome in proportion to the batch size. Ideally, the method obtains equivalent quality of the outcome for an equivalent number of simulations, whatever the batch size. Thus, for a given number of cycles, we achieve better results when increasing the batch size.
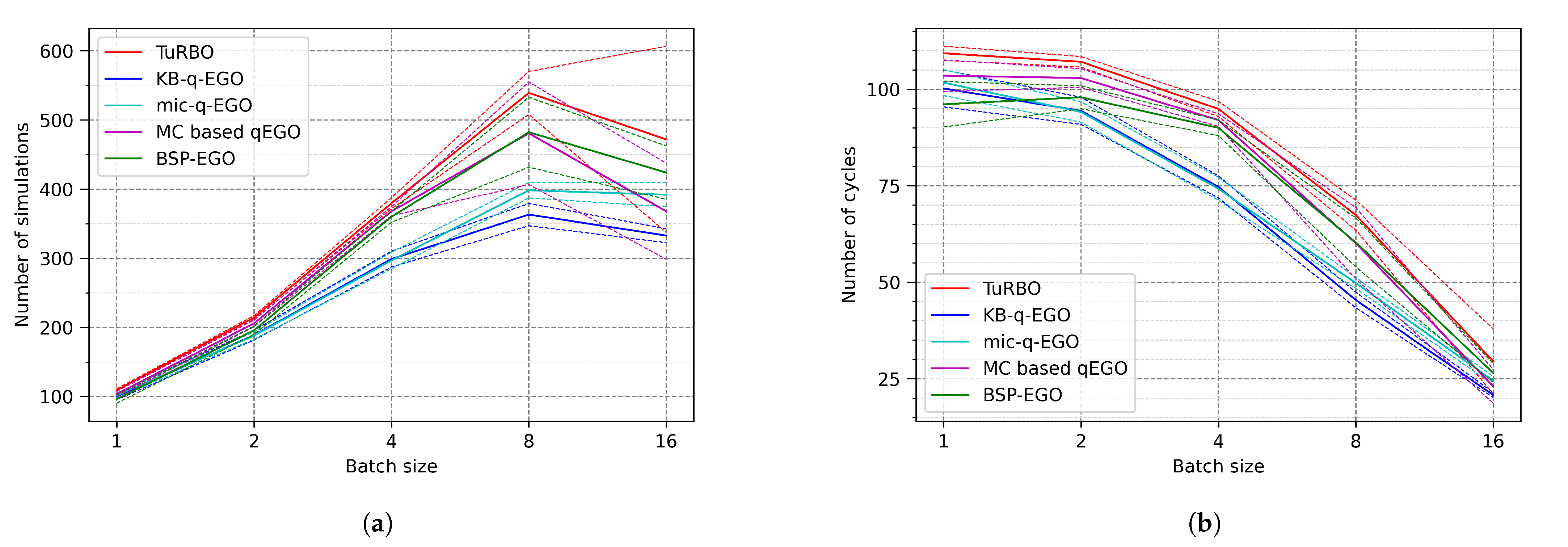
- The scalability of the method, studied with the number of total cycles/simulations performed in the fixed time. The maximum number of cycles is 120 since the budget is 20 min, and a simulation lasts 10 s. Assuming there is no cost for obtaining a batch of candidates, the total number of simulations should be . The expected ideal behavior is that the time cost arising from optimization methods (outside simulation time) remains short enough not to hamper the optimization. Therefore, increasing also increases the number of simulations by the end of the time budget. Additionally, if the previous point is respected, it should also improve the quality of the final result.
3.1. Benchmark Function Analysis
3.2. Application to UPHES Management
4. Discussion
5. Conclusions and Future Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| (U)PHES | (Underground) Pumped Hydro-Energy Storage |
| (P)BO | (Parallel) Bayesian Optimization |
| GP | Gaussian Process |
| AF | Acquisition Function |
| AP | Acquisition Process |
| KB | Kriging Believer |
| EGO | Efficient Global Optimization |
| TuRBO | Trust Region Bayesian Optimization |
| BSP | Binary Space Partitioning |
| IC | Infill Criterion |
| MC | Monte Carlo |
| mic | multi-infill criteria |
| EI | Expected Improvement |
| UCB | Upper Confidence Bound |
References
- Toubeau, J.F.; Bottieau, J.; De Grève, Z.; Vallée, F.; Bruninx, K. Data-Driven Scheduling of Energy Storage in Day-Ahead Energy and Reserve Markets With Probabilistic Guarantees on Real-Time Delivery. IEEE Trans. Power Syst. 2021, 36, 2815–2828. [Google Scholar] [CrossRef]
- Gobert, M.; Gmys, J.; Toubeau, J.F.; Vallée, F.; Melab, N.; Tuyttens, D. Surrogate-Assisted Optimization for Multi-stage Optimal Scheduling of Virtual Power Plants. In Proceedings of the 2019 International Conference on High Performance Computing Simulation (HPCS), Dublin, Ireland, 15–19 July 2019; pp. 113–120. [Google Scholar] [CrossRef]
- Toubeau, J.F.; De Grève, Z.; Goderniaux, P.; Vallée, F.; Bruninx, K. Chance-Constrained Scheduling of Underground Pumped Hydro Energy Storage in Presence of Model Uncertainties. IEEE Trans. Sustain. Energy 2020, 11, 1516–1527. [Google Scholar] [CrossRef]
- Taktak, R.; D’Ambrosio, C. An overview on mathematical programming approaches for the deterministic unit commitment problem in hydro valleys. Energy Syst. 2017, 8, 57–79. [Google Scholar] [CrossRef]
- Steeger, G.; Barroso, L.; Rebennack, S. Optimal Bidding Strategies for Hydro-Electric Producers: A Literature Survey. IEEE Trans. Power Syst. 2014, 29, 1758–1766. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef]
- Haftka, R.; Villanueva, D.; Chaudhuri, A. Parallel surrogate-assisted global optimization with expensive functions—A survey. Struct. Multidiscip. Optim. 2016, 54, 3–13. [Google Scholar] [CrossRef]
- Briffoteaux, G.; Gobert, M.; Ragonnet, R.; Gmys, J.; Mezmaz, M.; Melab, N.; Tuyttens, D. Parallel surrogate-assisted optimization: Batched Bayesian Neural Network-assisted GA versus q-EGO. Swarm Evol. Comput. 2020, 57, 100717. [Google Scholar] [CrossRef]
- Ginsbourger, D.; Le Riche, R.; Carraro, L. A Multi-points Criterion for Deterministic Parallel Global Optimization Based on Gaussian Processes; Technical report; Ecole Nationale Suṕerieure des Mines: Saint-Etienne, France, 2008. [Google Scholar]
- Liu, J.; Song, W.; Han, Z.H.; Zhang, Y. Efficient aerodynamic shape optimization of transonic wings using a parallel infilling strategy and surrogate models. Struct. Multidiscip. Optim. 2017, 55, 925–943. [Google Scholar] [CrossRef]
- Wang, Y.; Han, Z.H.; Zhang, Y.; Song, W. Efficient Global Optimization using Multiple Infill Sampling Criteria and Surrogate Models. In Proceedings of the 2018 AIAA Aerospace Sciences Meeting, Kissimmee, FL, USA, 8–12 January 2018. [Google Scholar] [CrossRef]
- Balandat, M.; Karrer, B.; Jiang, D.R.; Daulton, S.; Letham, B.; Wilson, A.G.; Bakshy, E. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 21524–21538. [Google Scholar]
- Gobert, M.; Gmys, J.; Melab, N.; Tuyttens, D. Adaptive Space Partitioning for Parallel Bayesian Optimization. In Proceedings of the HPCS 2020—The 18th International Conference on High Performance Computing Simulation, Barcelona, Spain, 20–27 March 2021. [Google Scholar]
- Eriksson, D.; Pearce, M.; Gardner, J.R.; Turner, R.; Poloczek, M. Scalable Global Optimization via Local Bayesian Optimization. arXiv 2020, arXiv:cs.LG/1910.01739. [Google Scholar]
- Abreu, L.V.L.; Khodayar, M.E.; Shahidehpour, M.; Wu, L. Risk-Constrained Coordination of Cascaded Hydro Units with Variable Wind Power Generation. IEEE Trans. Sustain. Energy 2012, 3, 359–368. [Google Scholar] [CrossRef]
- Toubeau, J.F.; De Grève, Z.; Vallée, F. Medium-Term Multimarket Optimization for Virtual Power Plants: A Stochastic-Based Decision Environment. IEEE Trans. Power Syst. 2018, 33, 1399–1410. [Google Scholar] [CrossRef]
- Montero, R.; Wortberg, T.; Binias, J.; Niemann, A. Integrated Assessment of Underground Pumped-Storage Facilities Using Existing Coal Mine Infrastructure. In Proceedings of the 4th IAHR Europe Congress, Liege, Belgium, 27–29 July 2016; pp. 953–960. [Google Scholar]
- Pujades, E.; Orban, P.; Bodeux, S.; Archambeau, P.; Erpicum, S.; Dassargues, A. Underground pumped storage hydropower plants using open pit mines: How do groundwater exchanges influence the efficiency? Appl. Energy 2017, 190, 135–146. [Google Scholar] [CrossRef]
- Ponrajah, R.; Witherspoon, J.; Galiana, F. Systems to Optimize Conversion Efficiencies at Ontario Hydro’s Hydroelectric Plants. IEEE Trans. Power Syst. 1998, 13, 1044–1050. [Google Scholar] [CrossRef]
- Pannatier, Y. Optimisation des Stratégies de Réglage d’une Installation de Pompage-Turbinage à Vitesse Variable; EPFL: Lausanne, Switzerland, 2010. [Google Scholar] [CrossRef]
- Toubeau, J.F.; Iassinovski, S.; Jean, E.; Parfait, J.Y.; Bottieau, J.; De Greve, Z.; Vallee, F. A Nonlinear Hybrid Approach for the Scheduling of Merchant Underground Pumped Hydro Energy Storage. IET Gener. Transm. Distrib. 2019, 13, 4798–4808. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, J.; Wu, X. Hydro Unit Commitment With a Head-Sensitive Reservoir and Multiple Vibration Zones Using MILP. IEEE Trans. Power Syst. 2016, 31, 4842–4852. [Google Scholar] [CrossRef]
- Arce, A.; Ohishi, T.; Soares, S. Optimal dispatch of generating units of the Itaipu hydroelectric plant. IEEE Trans. Power Syst. 2002, 17, 154–158. [Google Scholar] [CrossRef]
- Catalao, J.P.S.; Mariano, S.J.P.S.; Mendes, V.M.F.; Ferreira, L.A.F.M. Scheduling of Head-Sensitive Cascaded Hydro Systems: A Nonlinear Approach. IEEE Trans. Power Syst. 2009, 24, 337–346. [Google Scholar] [CrossRef]
- Chen, P.H.; Chang, H.C. Genetic aided scheduling of hydraulically coupled plants in hydro-thermal coordination. IEEE Trans. Power Syst. 1996, 11, 975–981. [Google Scholar] [CrossRef]
- Yu, B.; Yuan, X.; Wang, J. Short-term hydro-thermal scheduling using particle swarm optimization method. Energy Convers. Manag. 2007, 48, 1902–1908. [Google Scholar] [CrossRef]
- Kushner, H.J. A New Method of Locating the Maximum Point of an Arbitrary Multipeak Curve in the Presence of Noise. J. Fluids Eng. 1964, 86, 97–106. [Google Scholar] [CrossRef]
- Mockus, J.; Tiesis, V.; Zilinskas, A. The Application of Bayesian Methods for Seeking the Extremum; Towards Global Optimization: Berlin, Germany, 2014; Volume 2, pp. 117–129. [Google Scholar]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient Global Optimization of Expensive Black-Box Functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Srinivas, N.; Krause, A.; Kakade, S.; Seeger, M. Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. arXiv 2010, arXiv:0912.3995. [Google Scholar]
- Močkus, J. On bayesian methods for seeking the extremum. In Proceedings of the Optimization Techniques IFIP Technical Conference, Novosibirsk, Russia, 1–7 July 1974; Marchuk, G.I., Ed.; Springer: Berlin/Heidelberg, Germany, 1975; pp. 400–404. [Google Scholar]
- Noè, U.; Husmeier, D. On a New Improvement-Based Acquisition Function for Bayesian Optimization. arXiv 2018, arXiv:abs/1808.06918. [Google Scholar]
- Hennig, P.; Schuler, C. Entropy Search for Information-Efficient Global Optimization. J. Mach. Learn. Res. 2011, 13, 1809–1837. [Google Scholar]
- Hernández-Lobato, J.M.; Hoffman, M.W.; Ghahramani, Z. Predictive Entropy Search for Efficient Global Optimization of Black-box Functions. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27, pp. 1–6. [Google Scholar]
- Wang, Z.; Jegelka, S. Max-value Entropy Search for Efficient Bayesian Optimization. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3627–3635. [Google Scholar]
- Ginsbourger, D.; Riche, R.L.; Carraro, L. Kriging Is Well-Suited to Parallelize Optimization; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- González, J.; Dai, Z.; Hennig, P.; Lawrence, N.D. Batch Bayesian Optimization via Local Penalization. arXiv 2015, arXiv:stat.ML/1505.08052. [Google Scholar]
- Zhan, D.; Qian, J.; Cheng, Y. Balancing global and local search in parallel efficient global optimization algorithms. J. Glob. Optim. 2017, 67, 873–892. [Google Scholar] [CrossRef]
- Palma, A.D.; Mendler-Dünner, C.; Parnell, T.; Anghel, A.; Pozidis, H. Sampling Acquisition Functions for Batch Bayesian Optimization. arXiv 2019, arXiv:cs.LG/1903.09434. [Google Scholar]
- Lyu, W.; Yang, F.; Yan, C.; Zhou, D.; Zeng, X. Batch Bayesian Optimization via Multi-objective Acquisition Ensemble for Automated Analog Circuit Design. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Proceedings of Machine Learning Research; PMLR: Stockholm Sweden, 2018; Volume 80, pp. 3306–3314. [Google Scholar]
- Feng, Z.; Zhang, Q.; Zhang, Q.; Tang, Q.; Yang, T.; Ma, Y. A multiobjective optimization based framework to balance the global exploration and local exploitation in expensive optimization. J. Glob. Optim. 2014, 61, 677–694. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Wilson, J.T.; Moriconi, R.; Hutter, F.; Deisenroth, M.P. The reparameterization trick for acquisition functions. arXiv 2017, arXiv:1712.00424. [Google Scholar]
- Artiba, A.; Emelyanov, V.; Iassinovski, S. Introduction to Intelligent Simulation: The RAO Language. J. Oper. Res. Soc. 2000, 51, 395–515. [Google Scholar] [CrossRef]
- Surjanovic, S.; Bingham, D. Virtual Library of Simulation Experiments: Test Functions and Datasets. Available online: http://www.sfu.ca/~ssurjano (accessed on 13 October 2022).
- Dalcin, L.; Fang, Y.L.L. mpi4py: Status Update After 12 Years of Development. Comput. Sci. Eng. 2021, 23, 47–54. [Google Scholar] [CrossRef]
- Lin, X.; Zhen, H.L.; Li, Z.; Zhang, Q.; Kwong, S. A Batched Scalable Multi-Objective Bayesian Optimization Algorithm. arXiv 2018, arXiv:1811.01323. [Google Scholar]
- Leibfried, F.; Dutordoir, V.; John, S.; Durrande, N. A Tutorial on Sparse Gaussian Processes and Variational Inference. arXiv 2020, arXiv:2012.13962. [Google Scholar] [CrossRef]
- Wang, Z.; Gehring, C.; Kohli, P.; Jegelka, S. Batched Large-scale Bayesian Optimization in High-dimensional Spaces. arXiv 2017, arXiv:1706.01445. [Google Scholar]
- Solin, A.; Särkkä, S. Hilbert Space Methods for Reduced-Rank Gaussian Process Regression. Stat. Comput. 2020, 30, 419–446. [Google Scholar] [CrossRef]
- Li, Z.; Ruan, S.; Gu, J.; Wang, X.; Shen, C. Investigation on parallel algorithms in efficient global optimization based on multiple points infill criterion and domain decomposition. Struct. Multidiscip. Optim. 2016, 54, 747–773. [Google Scholar] [CrossRef]
- Villanueva, D.; Le Riche, R.; Picard, G.; Haftka, R. Dynamic Design Space Partitioning for Optimization of an Integrated Thermal Protection System. In Proceedings of the 54th AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics, and Materials Conference, Boston, MA, USA, 8–11 April 2013. [Google Scholar] [CrossRef]
- Wang, G.; Simpson, T. Fuzzy clustering based hierarchical metamodeling for design space reduction and optimization. Eng. Optim. 2004, 36, 313–335. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Expression | ||
|---|---|---|---|
| Rosenbrock | 0 | ||
| Ackley | 0 | ||
| Schwefel | 0 |
| Initial Sample (Simulations) | Simulation Budget (Minutes) | |
|---|---|---|
| 1 | 16 | 20 |
| 2 | 32 | 20 |
| 4 | 64 | 20 |
| 8 | 128 | 20 |
| 16 | 256 | 20 |
| TuRBO | MC-Based q-EGO | KB-q-EGO | mic_q-EGO | BSP-EGO | |
|---|---|---|---|---|---|
| 1 | EI | EI | EI | EI | EI |
| 2 | qEI | qEI | EI | EI/UCB (50%) | EI |
| 4 | qEI | qEI | EI | EI/UCB (50%) | EI |
| 8 | qEI | qEI | EI | EI/UCB (50%) | EI |
| 16 | qEI | qEI | EI | EI/UCB (50%) | EI |
| TuRBO | KB-q-EGO | mic-q-EGO | MC-q-EGO | BSP-EGO | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1108 | 672 | 1538 | 735 | 1584 | 971 | 1362 | 665 | 1336 | 776 |
| 2 | 210 | 174 | 817 | 248 | 708 | 272 | 960 | 387 | 1185 | 509 |
| 4 | 99 | 93 | 461 | 169 | 409 | 217 | 878 | 327 | 497 | 123 |
| 8 | 39 | 34 | 502 | 139 | 371 | 126 | 733 | 454 | 318 | 127 |
| 16 | 14 | 2 | 440 | 213 | 559 | 273 | 318 | 200 | 434 | 205 |
| TuRBO | KB-q-EGO | mic-q-EGO | MC- q-EGO | BSP-EGO | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2.421 | 0.350 | 5.582 | 0.515 | 5.027 | 0.991 | 6.607 | 0.807 | 4.761 | 0.931 |
| 2 | 0.881 | 0.620 | 5.302 | 1.149 | 4.895 | 0.871 | 6.018 | 0.772 | 4.589 | 0.915 |
| 4 | 0.123 | 0.327 | 5.137 | 1.345 | 2.660 | 0.195 | 6.115 | 1.403 | 4.330 | 1.274 |
| 8 | 0.110 | 0.330 | 4.143 | 0.693 | 2.025 | 0.353 | 4.001 | 0.749 | 4.004 | 0.518 |
| 16 | 0.337 | 0.708 | 3.378 | 1.826 | 1.634 | 0.479 | 2.884 | 0.457 | 2.882 | 0.482 |
| TuRBO | KB-q-EGO | mic-q-EGO | MC- q-EGO | BSP-EGO | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2229 | 345 | 2397 | 357 | 2605 | 317 | 2799 | 295 | 2693 | 306 |
| 2 | 1827 | 440 | 2652 | 129 | 2502 | 232 | 2689 | 422 | 2390 | 445 |
| 4 | 1767 | 459 | 2367 | 195 | 1775 | 489 | 2560 | 495 | 2182 | 340 |
| 8 | 1595 | 305 | 2579 | 312 | 2276 | 371 | 2411 | 396 | 2282 | 398 |
| 16 | 1660 | 323 | 2828 | 198 | 2489 | 328 | 2969 | 358 | 2409 | 215 |
| min | mean | max | sd | |
|---|---|---|---|---|
| TuRBO | −2469 | −898 | 368 | 917 |
| KB-q-EGO | −1582 | −765 | −27 | 416 |
| mic-q-EGO | −1511 | −609 | −39 | 487 |
| MC-based q-EGO | −2123 | −690 | 108 | 778 |
| BSP-EGO | −2248 | −1126 | 139 | 883 |
| min | mean | max | sd | |
| TuRBO | −2106 | 19 | 1338 | 1058 |
| KB-q-EGO | −1474 | 167 | 1147 | 773 |
| mic-q-EGO | −429 | 253 | 1369 | 473 |
| MC-based q-EGO | −517 | 79 | 768 | 404 |
| BSP-EGO | −708 | −101 | 723 | 503 |
| min | mean | max | sd | |
| TuRBO | −1766 | 78 | 819 | 837 |
| KB-q-EGO | −344 | 168 | 784 | 287 |
| mic-q-EGO | −96 | 559 | 1097 | 405 |
| MC-based q-EGO | −548 | 65 | 824 | 436 |
| BSP-EGO | −389 | 90 | 746 | 412 |
| min | mean | max | sd | |
| TuRBO | −972 | 86 | 1259 | 713 |
| KB-q-EGO | −703 | −168 | 547 | 423 |
| mic-q-EGO | −568 | 416 | 1184 | 473 |
| MC-based q-EGO | −362 | 163 | 862 | 381 |
| BSP-EGO | −1102 | 78 | 504 | 463 |
| min | mean | max | sd | |
| TuRBO | −827 | 51 | 1162 | 692 |
| KB-q-EGO | −2048 | −963 | 658 | 752 |
| mic-q-EGO | −2383 | −706 | 684 | 1049 |
| MC-based q-EGO | −2475 | −1225 | −14 | 948 |
| BSP-EGO | −3509 | −1183 | 408 | 1275 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gobert, M.; Gmys, J.; Toubeau, J.-F.; Melab, N.; Tuyttens, D.; Vallée, F. Batch Acquisition for Parallel Bayesian Optimization—Application to Hydro-Energy Storage Systems Scheduling. Algorithms 2022, 15, 446. https://doi.org/10.3390/a15120446
Gobert M, Gmys J, Toubeau J-F, Melab N, Tuyttens D, Vallée F. Batch Acquisition for Parallel Bayesian Optimization—Application to Hydro-Energy Storage Systems Scheduling. Algorithms. 2022; 15(12):446. https://doi.org/10.3390/a15120446
Chicago/Turabian StyleGobert, Maxime, Jan Gmys, Jean-François Toubeau, Nouredine Melab, Daniel Tuyttens, and François Vallée. 2022. "Batch Acquisition for Parallel Bayesian Optimization—Application to Hydro-Energy Storage Systems Scheduling" Algorithms 15, no. 12: 446. https://doi.org/10.3390/a15120446
APA StyleGobert, M., Gmys, J., Toubeau, J.-F., Melab, N., Tuyttens, D., & Vallée, F. (2022). Batch Acquisition for Parallel Bayesian Optimization—Application to Hydro-Energy Storage Systems Scheduling. Algorithms, 15(12), 446. https://doi.org/10.3390/a15120446