1. Introduction
The traffic conditions on road segments in a network are usually described by macroscopic traffic state variables, such as flow rate, vehicle speed, and vehicle density as traffic streams. Transport planners identify congestion levels and traffic demands, as well as bottlenecks on roadways, through these indicators [
1]. However, these important measurements are not available for all locations or times due to physical and budget constraints of the measurements; even if the availability issue is not a concern, undesired noises in the measurements have been making ITS traffic management operations difficult [
2]. Combining factors such as the cost of sensor installation, the accuracy of vehicle detection techniques, and restrictions on data storage and transmission can often lead to partial observations of traffic state variables [
3]. To deliver effective traffic management, it is vital to estimate traffic state variables at locations without sensor data.
Traffic state estimation (TSE) refers to the prediction of traffic state variables such as flow, density, and speed of road segments using partially observed traffic data [
4]. Approaches to TSE can be roughly categorized into two groups based on the a priori knowledge they depend on: model-driven and data-driven. In model-driven approaches, traffic flow state predictions are based on prior knowledge of the flow, usually embodied in physics-based models such as the Lighthill–Whitham–Richards (LWR) model or the Aw–Rascle–Zhang (ARZ) model [
5,
6]. Physical processes play a key role in how these models work, such as the way the state variable changes across space and time. These models are much less limited by data availability and can make predictions without the training data. A model-based approach assumes that the physics-based models are representative of traffic dynamics and can be utilized to determine unobserved values based on partially observed data. Despite the independence from data requirements, the physics-based models suffer from a few challenges that may lead to low-quality estimates. Some of these challenges include: (i) they can only capture a limited set of traffic dynamics in real-world situations; (ii) they are derived under ideal conditions, entail large effort for parameter calibrations; and (iii) they are difficult to apply with noisy/fluctuating traffic data. The other group of TSE methods is the data-driven models based on machine learning. Data-driven models employ statistical relationships in data and are model-free so that formulating specific underlying physics is not necessary. Data-driven methods have been intensively studied recently due to the increasing availability of data, as they do not require specific theoretical assumptions and have a remarkably low computing cost during the testing phase. However, the data-driven nature of those machine learning (ML) models leaves them vulnerable to the following situations: (i) insufficient training data to learn the system’s complexity, (ii) training samples with misleading information, and (iii) test samples that are not representative of the training samples. Dramatic performance drops alongside large and/or biased estimations are not rare in these scenarios, which unfortunately are very common in the real world. In addition, the machine learning models are difficult to interpret because of their ‘black-box’ nature.
Very recent studies on the hybrid approaches integrate physics knowledge from traffic flow models and machine learning models, in order to mitigate the limitations of the above-mentioned approaches. For instance, Yuan et al. (2021) presented the physics regularized Gaussian process (PRGP) method for TSE by integrating macroscopic traffic flow models with Gaussian process (GP) [
7]. Raissi et al. were the first ones to propose implementations of fully connected neural networks that incorporate residuals from partial differential equations (PDEs) into their loss function as regularizers, which restrains the feasible solution space [
8]. The major advantage of physics-informed learning (PIL) is that an effective loss function can be implemented using a modest amount of data. However, there is a major limitation to using PIL: their high training costs can cause adverse effects on their performance, which is especially of concern when dealing with real-world applications. Using the domain decomposition approach, Jagtap and Karniadakis (2020) accelerated the convergence of these models without compromising their performance by partitioning the computational domain into more than one subdomain, and then defining boundaries between these subdomains that are subject to some continuity conditions [
9]. The presented numerical experiments were, however, limited to the partitioning of a single solution space, which is not representative of the network’s links in a true sense. In a traffic network, the state variables are correlated with the physical characteristics of the links for example number of lanes, road geometry, etc. The existing PIL studies consider the training data from the exact solution space of the governing partial differential equation. The macroscopic traffic state variables, on the other hand, are estimated through sensors and are subject to various measurement biases and approximations. Therefore, the real or simulated traffic data does not strictly follow the traffic governing physics model.
Another limitation of the existing hybrid studies for training neural networks is that they mainly consider the exact solution of the traffic flow model over a spatiotemporal space subject to relevant initial and boundary conditions. Such an approach with the exact analytical solution may lead to two potential shortcomings: (1) the analytical solution of PDE contains negative traffic state variables, which is not realistic; (2) the data generated from a continuous road segment cannot have any merging or diverging points. Such deficiency is critical for a real-world traffic network, as the traffic dynamics with and without the network consideration are significantly different. The state-of-art of the hybrid models are only applicable to one road segment or a sequence of segments without merges or divergences, which greatly limits their applications. It is therefore imperative that such studies be extended to realistic road networks.
This study aims to fill the above research gaps by extending physics-informed neural network application to simulated traffic network data following the domain decomposition approach. In a domain decomposition approach, we divide the whole traffic network into individual links. Afterwards, the individual links are joined together (stitching process) corresponding to their connectivity in the network. The flow conservation condition is applied at the joints (merge/diverge sections) while stitching the link. The domain decomposition in the framework is very useful in three major aspects. First, different physical properties on different links in a traffic network can be properly modeled. Second, the decomposition of a large network into individual links may help to reduce the requirement on the structural complexity of the neural network for each link to facilitate the training. Third, given the finite number of links, a massively parallel computation can be performed. Moreover, large-scale problems can be effectively handled by such domain decomposition method.
To the best of our knowledge, this is the first article to introduce PINNs for a traffic network. This study seeks to fuse traffic flow models and ML techniques in a traffic network setting with the physics-informed neural networks for network TSE. We present a novel and extensive study of the PINNs for the network TSE in this paper. The paper contributes in the following ways. First, it introduces a specific setup and training methodology to support a traffic network consisting of links. Sparse data grids within each link are unified into a regular grid. Links are processed in the neural networks and are stitched together. Second, the link connectivity matrix that contains information about the network structure is utilized in the PINNs to facilitate the stitching process by utilizing flow conservation constraints at merge and diverge points. Third, this study demonstrates a single sparse data source is sufficient for training PINNs, even in the absence of the complete dataset or an enhanced dataset augmented by micro-simulation.
The rest of the paper is organized as follows:
Section 2 ‘Related Work’ briefly reviews related work. The architecture of the proposed framework and data description are presented in
Section 3 ‘Methodology’ and
Section 4 ‘Data’, respectively. In
Section 5 ‘Experimental setup and discussion’, we present numerical experiment and discussions. Conclusions summarize the findings and suggest future research.
3. Methodology
This section introduces the PINNs framework in terms of traffic state estimation. Here we describe the basic terminology used in the follow-up presentation. The notations are majorly inherited from [
9,
23].
Link: The road links Ωq, q = 1… N refer to the non-overlapping links of the whole transport network Ω such that Ω = ⋃q = 1…N (Ωq) and Ωi ∩ Ωj = ∂Ωij, i ≠ j. N represents the total number of road links in the network. The links interact only at the intersection points i.e., merge or diverge point ∂Ωij.
Link-Net: The link-net refers to the individual PINN with its own set of optimized hyper parameters, λ described later in the article, employed in each link.
Intersection: The intersection is the common point between two or more links, where the corresponding Link-Nets communicate with each other.
Intersection Condition: These conditions are used to stitch the decomposed links together to obtain a solution for the governing PDEs over the complete network. We employ flow conservation conditions at diverge and merge points.
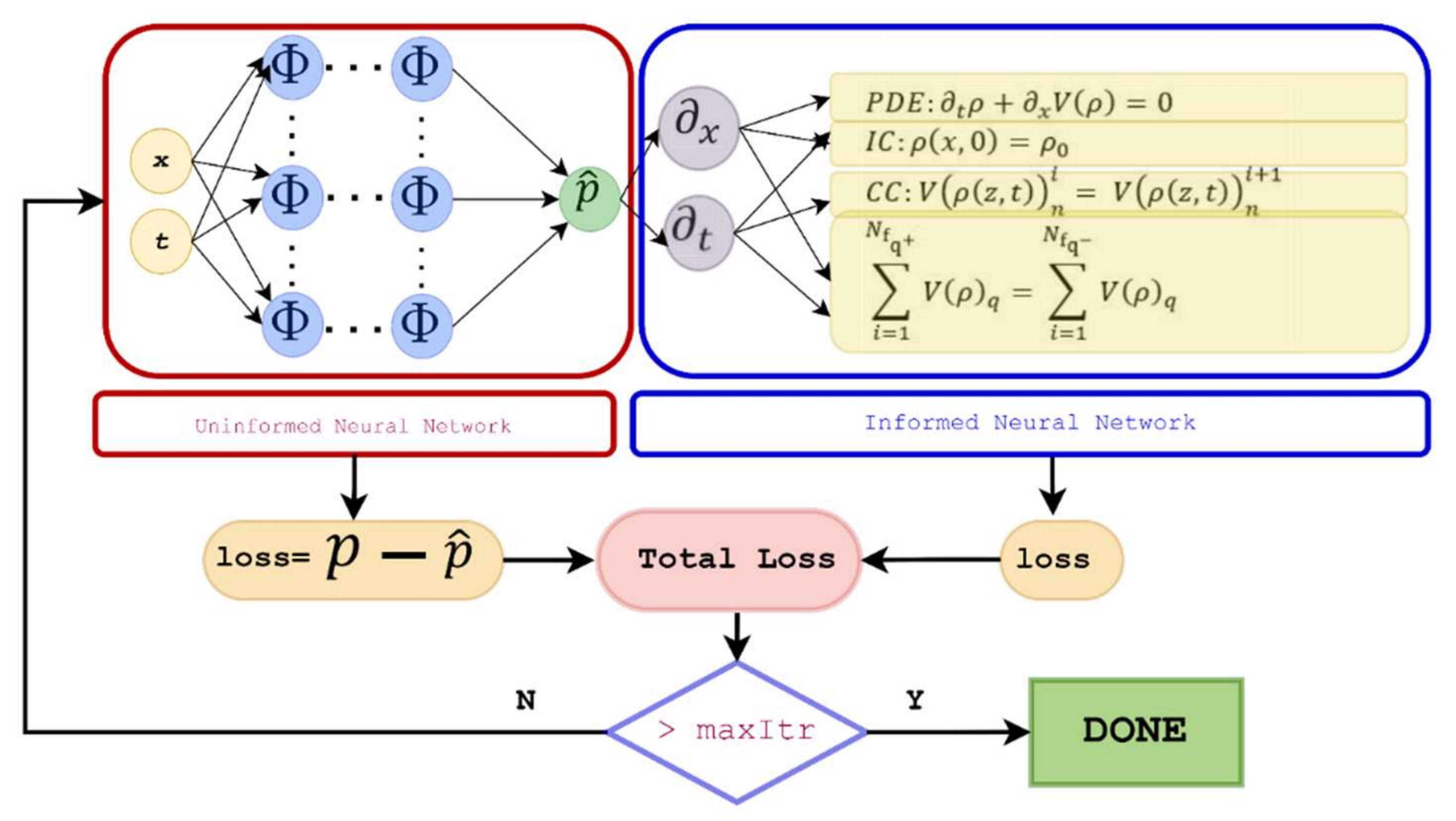
Figure 1 presents the architecture of the PINN Link-Net. The proposed framework consists of parts, i.e., physics-uninformed neural network (PUNN) and physics-informed neural network (PINN). The PUNN and PINN parts are described in detail in the following subsections.
3.1. PUNN
The physics-uninformed neural network corresponds to purely the data part. The growing amount of scientific data and rapid advances in machine learning have made data-driven approaches increasingly popular. Instead of using an existing theory, a machine learning algorithm can be employed to analyze a complex problem based solely on data. The scientific challenge is to find a model that can accurately predict new experimental measurements given existing experimental data points resulting from an unknown physical phenomenon. Input data points can be used to train neural networks, which can predict the response variable based on the set of input variables. This is usually achieved by minimizing the mean-squared error between its predictions and the given training points. In the proposed framework, the data-dependent part is the physics-uninformed neural network, owing to its black-box nature and lack of understanding of the underlying physical system. Fulari et al., 2017 developed an artificial neural network (ANN) model for traffic state estimation using erroneous data [
49]. He et al., 2016 estimated freeway speeds using neural network-based fusion modules designed to combine traffic information from cellular handoff probe systems and microwave sensors [
50].
3.2. PINN
Many scientific fields have adopted machine learning algorithms, but do these algorithms understand the underlying physical systems they are attempting to solve? For neural network models to understand the underlying physical system, prior scientific knowledge is incorporated into the network through governing differential equations. PINN algorithms combine the contribution of the neural network with residual terms from the governing equations, which are used as penalties to constrain the space of acceptable solutions. A PINN algorithm for the LWR Model is shown in
Figure 1 with the neural network along with a physics-informed component. In addition to the contribution from the neural network, the loss function is evaluated based on the residual of the governing equation. In PINN part, the loss function consists of errors from governing PDE, initial condition, and intersection conditions. The intersection conditions include the traffic flow continuity and flow conservation at the intersection points. In order to minimize the loss function, weights (w) and biases (b) are determined such that the loss function is minimized below a specified threshold or until a maximum number of iterations is reached. The following studies have focused on PINNs in transportation related studies.
Using SUMO simulated data, Agarwal and Huang validated Greenshields-based LWR models for loop detector scenarios using the PIL algorithm [
29]. Based on the data collected from probe vehicles, Barreau et al. developed a PINNs model for trajectory reconstruction [
30]. Shi et al. (2020) integrated second-order ARZ model for TSE by using loop detectors and probe vehicle data [
31]. They also expanded their study to estimate fundamental diagrams (FDs) and determine model parameters [
32].
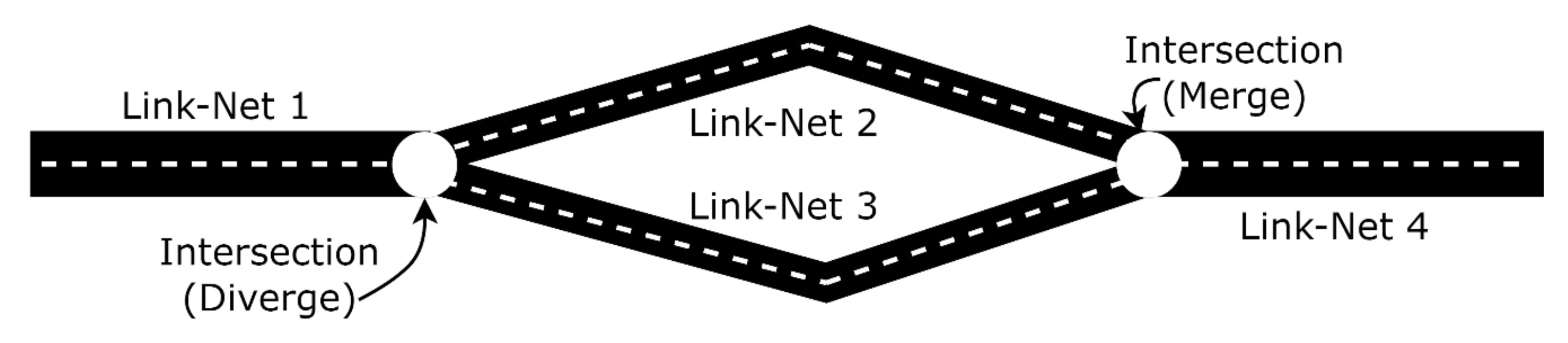
To illustrate the method in an example network,
Figure 2 presents a small traffic flow network, which is composed of four links. Link-Nets are employed in each link with the different architecture of the neural networks to solve the integrated traffic flow model. The Link-Nets offer better computational efficiency through parallelization of the network. Moreover, shallow and deep networks could be employed for various links depending upon the complexity of traffic on the links.
On the traffic flow model, the general form of the partial differential equation of the Lighthill–Whitham–Richards (LWR) model of traffic flow is given by:
where
: ℝ
+ → [0, 1] is the traffic density, i.e., the number of vehicles per unit length
v is the traffic speed, and
V (
) is the flux which is a speed-density function.
Consider a traffic flow network consisting of N number of non-overlapping links. Let
D[⋅] be a general differential operator and Ω
q be a subset of the computational domain Ω. The traffic state
at each point
in a continuous domain is determined such that the following traffic flow model PDE could be satisfied:
The output of the PINNs for the
qth link is given by
Let
,
, and
be the set of randomly drawn training, residual and intersection points in the
qth link, respectively. In a
qth link, the number training, residual, and intersection points are respectively represented by
,
, and
. On the ML part, under the PINN algorithm, the loss from PUNN and PINN for TSE is respectively given by
and
. Then, a generalized form is to solve the following optimization problem:
where
The following flow conservation equation helps to combine the individual links and thus to find the traffic state over the entire network;
Q represents the link flow which is a speed density function, and i, j ∈ Ω are the inward and outward traffic flow links, respectively, represented by q+ and q−, at any intersection I.
Using the above set of Equation (6), the proposed neural network framework aims to predict the traffic state over the entire traffic network. The link-wise defined loss functions are extended for the whole network by connecting individual links using a connectivity matrix subject to the relevant flow continuity and conservation equations. Thus, the loss function for a
qth link is given by:
where
,
, and
represent the weights assigned to errors related to the training data, residual, and intersection points, respectively. At this stage, the weights are assigned manually, though they can be chosen dynamically for faster convergence, this will increase the computational load. The mean-squared errors (MSEs) are given by Equation (8).
The term
MSEu and
MSEf are the
MSE for data discrepancy (PUNN part) and physics discrepancy (PINN part) for the link
q, respectively. In addition, the following flow continuity condition could be integrated into the loss function:
The
MSEc corresponds to the residual continuity condition at a common point of two connected links given by two different neural networks. The continuity condition is a special case of flow conservation where there is only one inward flow and one outward flow link. The continuity condition can be useful where the physical characteristics of the road change like the number of lanes, etc., and it is desired to split the link to separately model their traffic flow. The
MSEI is the residual flux conservation condition at the intersection given by different neural networks of the links
q+ and
q−. The superscript + over
q represents the inward flow links and − over
q represents the outward flow links at the intersections. The flow conservation ensures that the flow information from the incoming links is propagating to the outward flow links at the intersection. The term
represents the residual of the governing PDE of the
qth link which is given by Equation (10).
We find
to minimize the loss function
for each link. A good solution can be obtained for the whole network by wisely designing the network’s architecture and providing sufficient training data points. Several optimization algorithms can be used to minimize the loss function. Stochastic gradient descent is an extensively used method. In SGD, a small set of points is randomly selected in each iteration to determine the direction of the gradient. Under the condition of single-point convexity, the SGD algorithm can avoid local minima during PUNN training. Particularly, we use the Adam optimizer, which is a version of SGD. The basic form to update the parameters in the
qth link, given the initial value of parameter
, is given by Equation (11).
where
r is the learning rate. As explained above, the traffic flux
Q is described by a speed-density function with some parameters λ that best describe the data. It is difficult to obtain fine-tuned parameters, with a modest amount of data, which best explain the unknown hidden state of the system.
3.3. Activation Function (AF)
The activation function transforms the weighted summed input from the node into an output value, which is then fed to the next hidden layer or used as output. It is the activation function that decides whether or not a neuron should be activated. The activation function determines whether a neuron should be activated, i.e., whether the neuron’s input to the network is important in predicting the future. In the absence of an activation function, neurons simply perform linear transformations on inputs using weights and biases. Moreover, a neuron’s activation function adds nonlinearity to its output, enabling it to solve complex problems. Different activation functions may be used in different portions of a model, and they affect the capabilities and performances of the neural network. A neural network is usually trained with a backpropagation algorithm that requires the derivative of prediction error to update the weights of the model, which requires differentiable activation functions. There are a variety of activation functions available in the literature, including sigmoid, tanh functions, ReLUs, ELU, swish, softmax, etc. [
51,
52].
In addition to predefined functions, Jagtap et al. introduced adaptive activation functions by integrating a trainable hyper-parameter that accelerates PINN convergence. In their study, they showed that the adaptive activation function could be used to solve a range of forward and inverse problems more quickly and accurately [
53]. For layer-wise and neuron-wise activation functions, they introduced an activation slope-based slope recovery term in the loss function to further reduce the training cost [
54]. Researchers also employed physical activation functions (PAFs) derived from physical laws governing the phenomena under study [
55]. They validated the performance of PAFs integrated with neurons of hidden layers in combination with other AFs by solving harmonic oscillations equation, Burger’s equation, Advection–Convection equation, etc.
Jagtap et al., 2022 proposed a Rowdy-Net with Rowdy activation functions based on Kronecker neural networks (KNNs) [
56]. In KNN, Kronecker’s product made the network wide while keeping the number of trainable parameters low, thereby enabling faster convergence whereas the Rowdy activation removed the saturation zone from every layer in the network, allowing it to explore more and learn faster.
In this study, we chose the tanh activation function. In addition, we used adaptive activation, following the approach presented in [
53].
4. Data
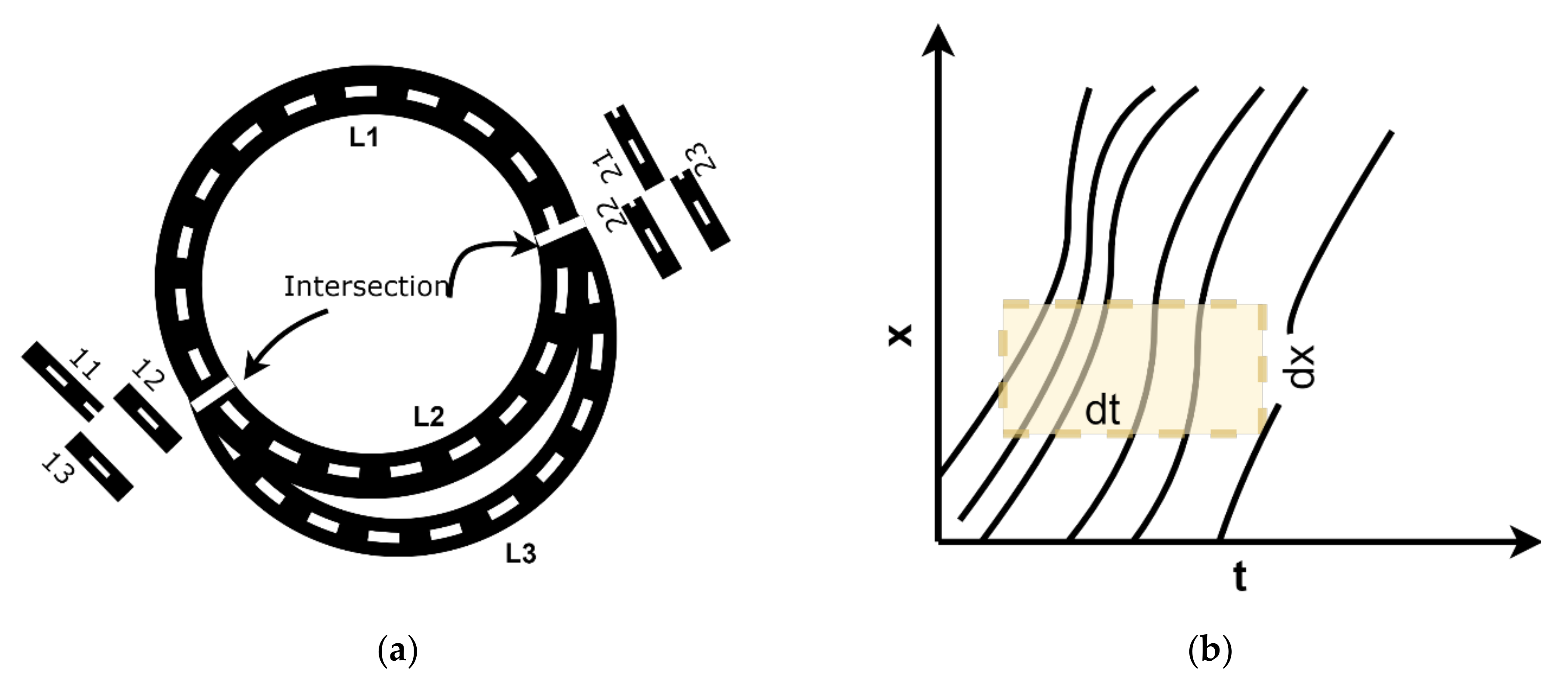
In this study, we use VISSIM simulation to generate traffic trajectory data for the circular network presented in
Figure 3a, which is not on scale and it is for illustration purpose only. The traffic network consists of three links, and the length of link is set to
L meters. Note that there is diverge point and a merge point in
Figure 3a denoted by 1 and 2, respectively. We use connectors to join the road links in VISSIM. The traffic state data of the connectors obtained from the VISSIM were not very accurate due to the following dilemma. Connectors in VISSIM (and also in other similar simulation environments) are not dimensionless points but rather a small segment with physical length. The traffic characteristics of the short connectors are then presented by VISSIM as the average along the short distance. To achieve a higher accuracy for the average value, in theory, the connectors should be as short as possible to mimic the dimensionless points so that the data at the beginning, the ending, and throughout a short segment should be the same or very close to that. On the other hand, if segments in the simulation are too short, it may lead to computational issues such as frequent zero volume and missing observation regarding speed and density. Such a dilemma shows that there is no easy way to get the instantaneous values of speed, density, and volume of a short connector accurately. Such challenges impact the fulfillment of flow conservation equations at the merge and diverge points. In this study, we balance such challenges by keeping the connectors to be reasonably short and then try to maintain the flow conservation by using the segment data of the links at their beginnings and endings.
The traffic flows are assigned to the starting points of links
L1,
L2, and
L3, and the traffic is let to run in the network. The obtained vehicles’ trajectory data are used to estimate the traffic speed, density, and flow. On a stretch of road with length
L and time interval
T, the time-space is discretized into a uniform grid with cell size
dT × dL. The discrete area to estimate the traffic states is illustrated in
Figure 3b. The total number of cells in the time and space dimensions are
NT and
NL, respectively.
4.1. Speed
The speed is assumed a constant in each cell, which is the average slope of spatiotemporal trajectories in that cell. For cells where no trajectory is detected, the speed of the adjacent cell is used to replace missing values. The average speed of cell
i, j is denoted by
vij where
i = 1… NT,
j = 1 … NL and is given by Equation (12).
ΔLv is the distance l traveled by any vehicle v in time ΔT, and speed is stored in a matrix V ∈ R + (NT × NL).
4.2. Density
The average traffic density
ρij of a cell in a time-space diagram is evaluated by
∑ΔT is the total time traveled by all vehicles in a certain cell and ΔAij = dL × dT is the area of the cell.
4.3. Flow
The average traffic flow
Qij of a cell in a time-space diagram is evaluated by:
∑ΔL is the total distance traveled by all vehicles in a certain cell and ΔAij = dL × dT is the area of the cell.
5. Experimental Setup and Discussion
In this section, we test the performance of the proposed framework to estimate traffic dynamics in a traffic network based on the LWR model. Traffic data are obtained from the circular traffic network shown in
Figure 3 using PTV VISSIM. The length of each link is set to 15,015 m.
In this study, we use synthetic demand to simulate the traffic in VISSIM. The traffic input flows are randomly assigned, for the initial 900 s of a simulation run, to the starting points of Links L1, L2 and L3 are 3000, 1000, and 2000 vehicles per hour, respectively, as presented in
Table 1. In addition, to generate more dynamics in traffic behavior, speed reduction areas are activated for some time during the simulation run as well as activating a stochastic behavior of the vehicles. After the initial 900 s of a simulation run, the traffic is allowed to stabilize in the network for another 300 s, and trajectory data of the following 800 s are used in this study. We considered a closed traffic network in this study to observe the complete shockwave and congestion spillover in the network.
To estimate the macroscopic traffic flow parameters, the cell size in the time-space diagram is set to 5 s along the time dimension, and 5 m along the space dimension. Thus, the size of the obtained uniform grid is 160 × 3003. Five seconds is a common time step length for realistic speed data. For instance, we have real world speed data every five seconds for the major freeways from Alabama Department of Transportation. Some widely used datasets such as PeMS in California also provide speed data every five second. Therefore, we choose 5 s as ΔT. The segment length is on trial basis. It is not too short to have the frequent empty cells with no detected vehicles. It is not too long to have significant heterogeneity on traffic states within each road segment.
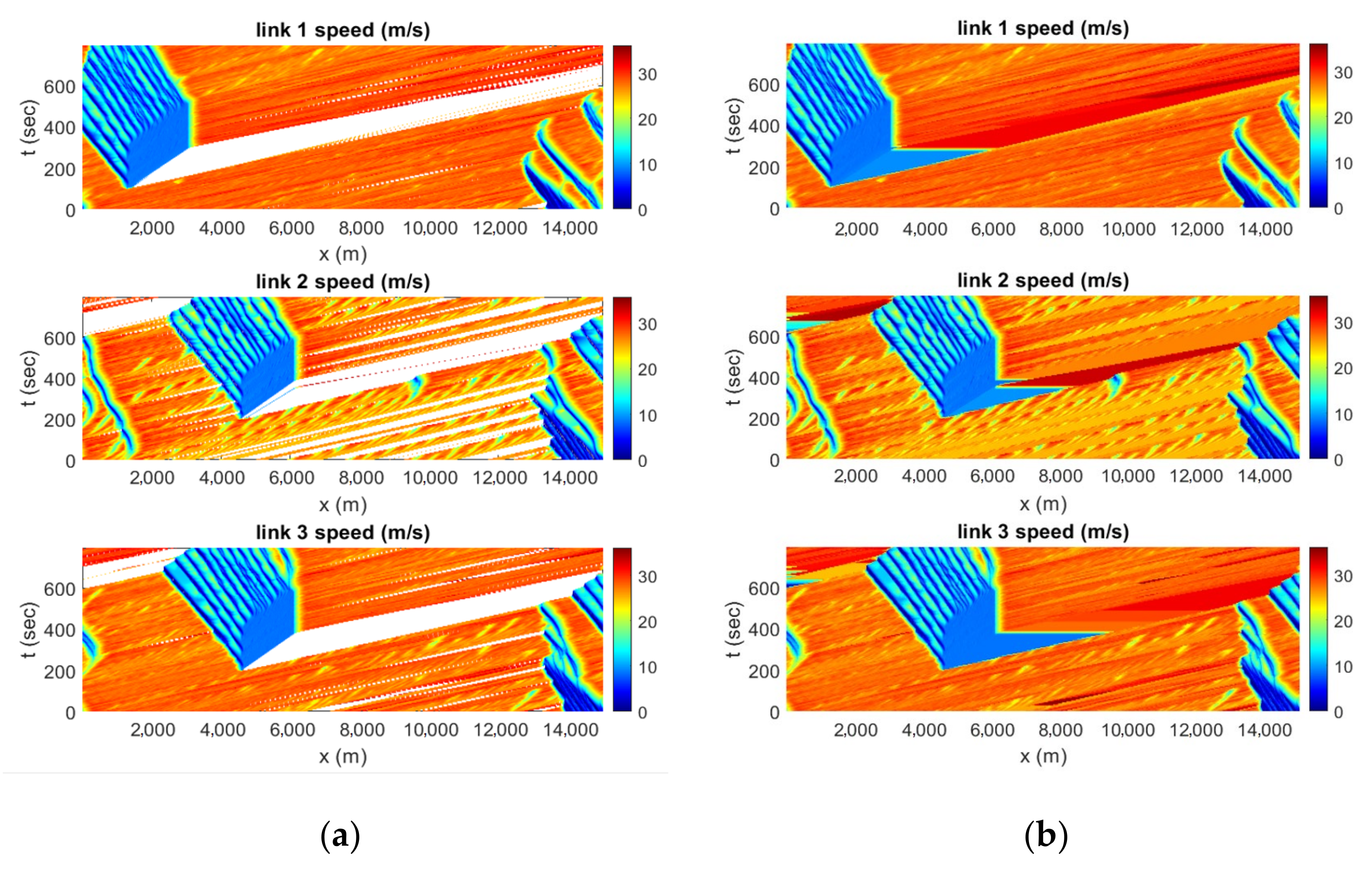
In the obtained data, there are cells, named empty cells, where the vehicles are not detected. The flow and density in the empty cells are zero, but the speed should be either close to free flow or the average speed of nearby cells. For simplicity, the speed in the empty cells is set to constant between two cells. The speed contour plot of all three links before and after filling the empty cells is presented in
Figure 4a,b, respectively.
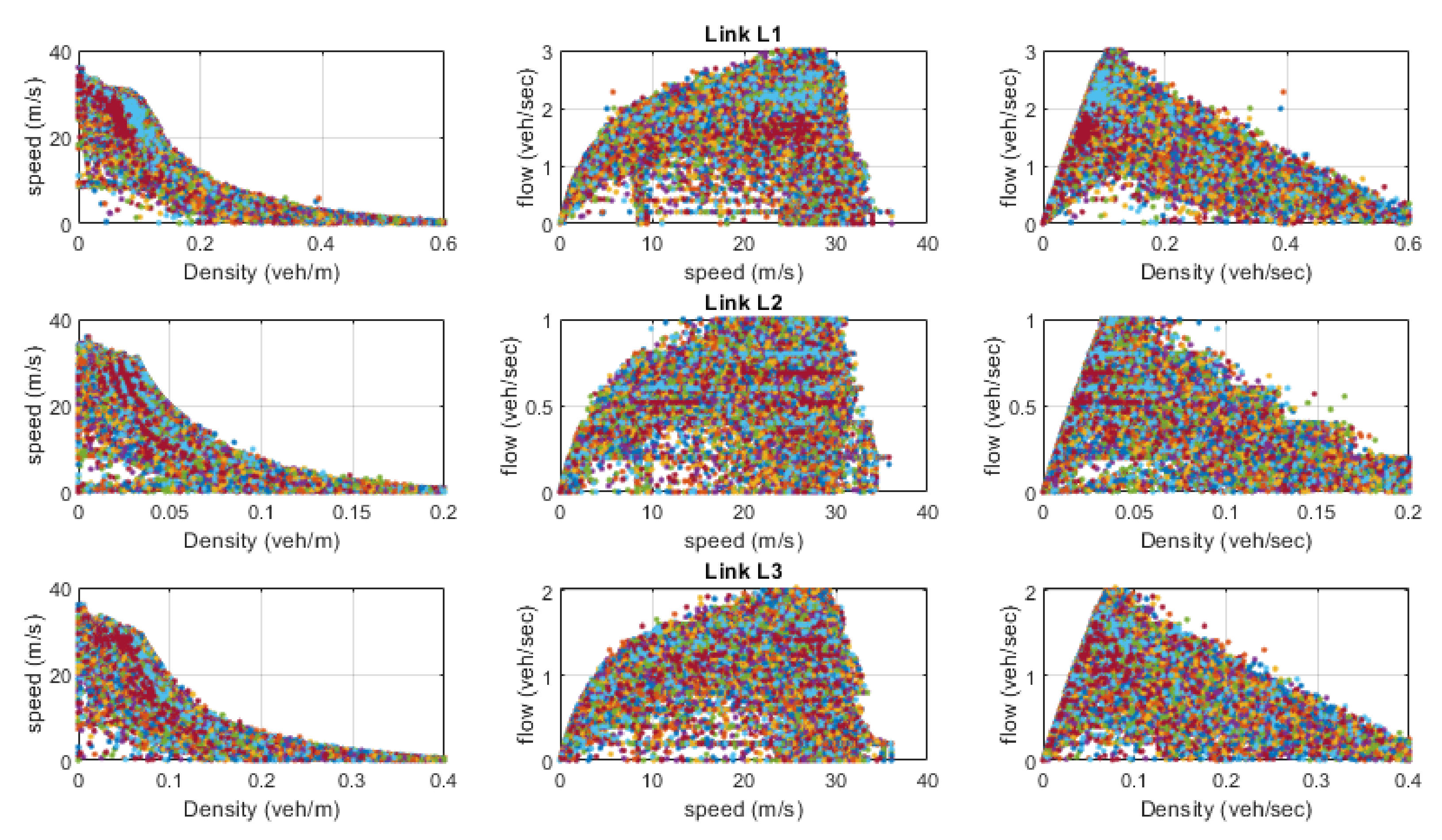
The speed, density, and flow data of the network are explored in
Figure 5. The figure shows that flow-density-speed follows a similar pattern; however, the jam density and peak flows are different in various links of the network. Therefore, we left this part on the framework to estimate the best-fit parameters. The LWR model is given by
. The flux function
V = ρv is described as a speed-density function, and density can also be described as a function of velocity.
Figure 5 shows a nonlinear relationship between speed and density. However, we consider a linear relationship following Greenshield’s Model, i.e.,
ρ = λ1 v + λ2. The flux function is given by
V(v) = v(λ1 v + λ2), and the resulting LWR model would be
λ2⋅vx + 2⋅λ1⋅v⋅vx + λ1⋅vt = 0, where
λ1 and
λ2 are the parameters that define the nature of the relationship between traffic state variables, and these parameters are trained during the training of the neural network.
The individual links are stitched together based on the connectivity matrix in
Table 2. Each row (sub vector) in the matrix represents one link. The first, second, and third elements of a row denote link ID, start point, and end point, respectively. Node 1 or intersection 1 is the diverge point where traffic from link L1 diverges to links L2 and L3. Similarly, Node 2 is a merging point in the network where traffic from links L2 and L3 merges onto L1.
To train the proposed model, 1200 data points are randomly selected from each link of the network. There are 10 layers and 30 neurons in each layer in PINNs architecture and the input training and residual data points are 1200 and 30,000, respectively. The input data show that the model is trained using only about 0.25% of the total data points in the network.
Accuracy and performance are greatly influenced by the framework’s width, depth, and learning rate. In line with the literature, 8 hidden layers are selected for the network and a sensitivity analysis is performed to determine its width and learning rate. Learning rate is crucial when seeking global minima. The studies showed that the computational cost of a small learning rate can increase even though it moves towards global minima gradually, whereas a large learning rate can skip the global minima altogether [
53]. A sensitivity analysis is presented in
Table 3, which compares the relative errors of the various links for the fixed tanh activation function. A model with 8 hidden layers and 30 neurons performs the best with a learning rate of 0.001. Keeping in view the optimal parameters, the PINNs architecture and the input data points are summarized in
Table 4. There are 10 layers, including an input layer, 8 hidden layers, and 1 output layer.
Keeping in view
Figure 3 from the previous section, the conservation conditions
Q11 = Q12 + Q13 and
Q21 = Q22 + Q23 are integrated into the model for diverging and merging points, respectively.
Q represents the flow
V and the first and second digits in subscript refer to node and link, respectively.
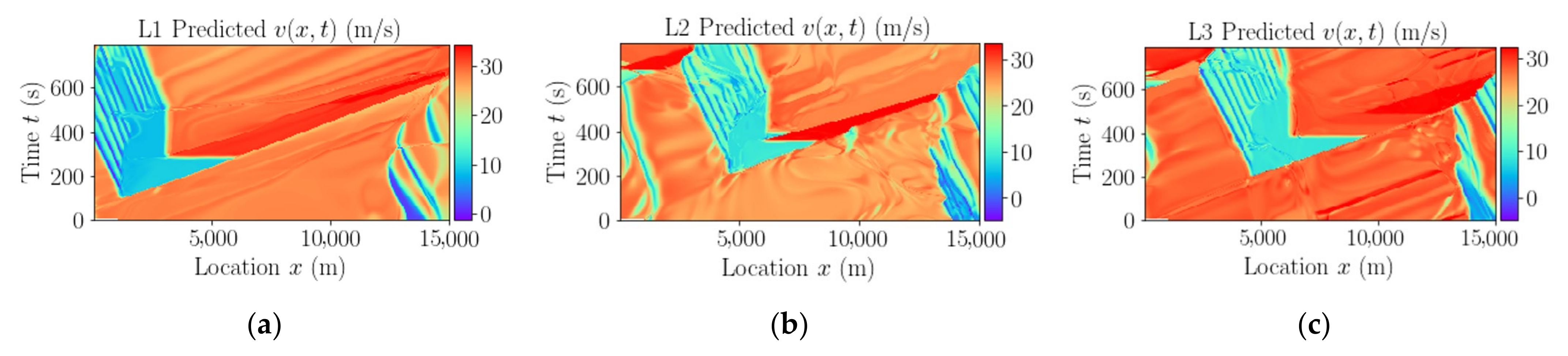
After training the model, the complete dataset of the network is passed to the model to estimate the traffic state. The predicted speeds for the links L1, L2, and L3 are respectively reported in
Figure 6a–c. The predicted speed contours for all the links of the network are pretty similar to the actual speed contours counterparts in
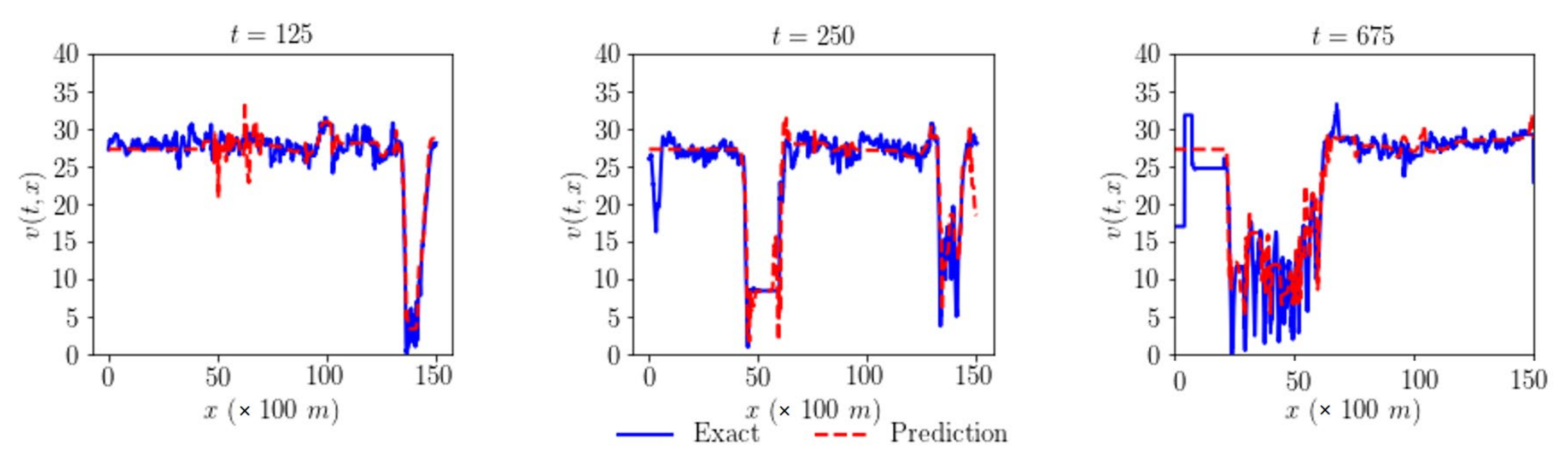
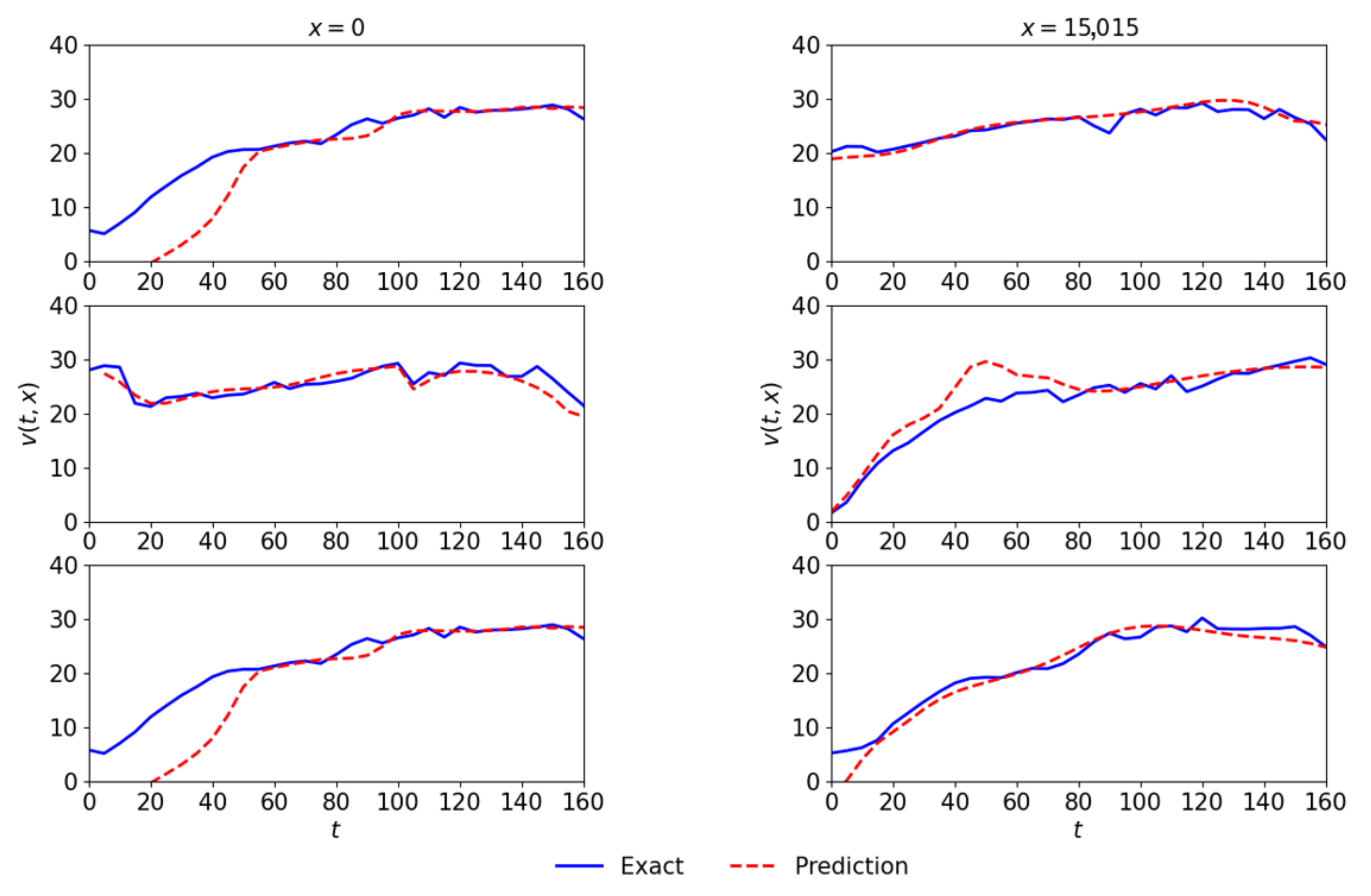
Figure 4b. The model has successfully captured the traffic dynamics of the network. The predicted data are further compared at different fixed locations along time and space dimensions.
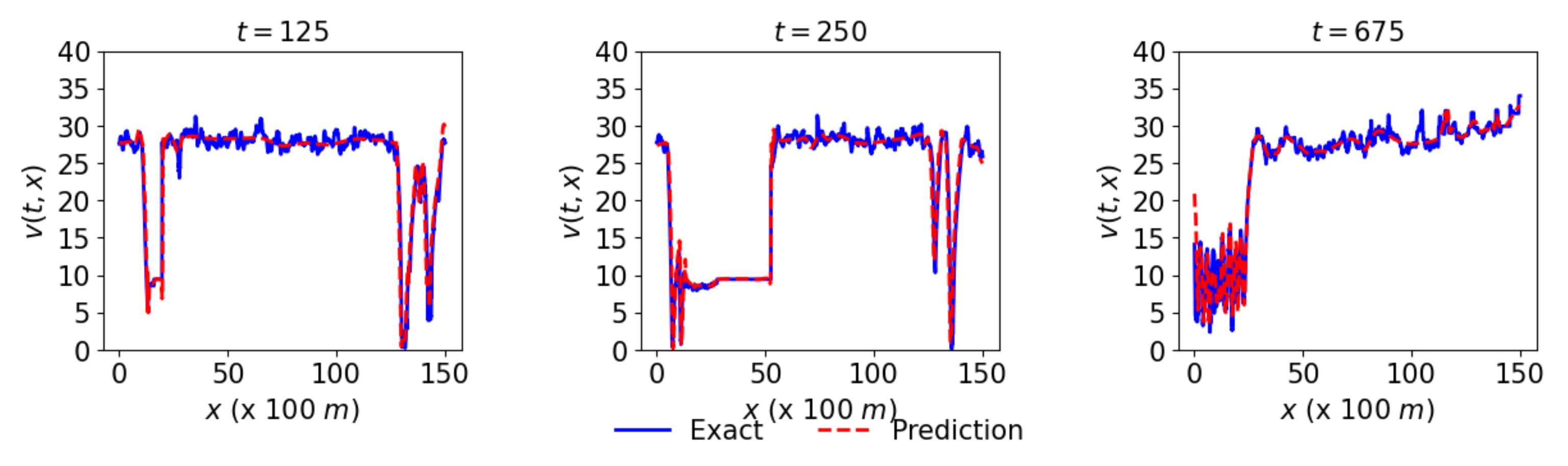
Figure 7 presents actual and predicted speed at three different times 125, 250, and 675 respectively given by the first, second, and third columns. The first, second, and third rows respectively represent the network’s links, L1, L2, and L3, that show the promising results.
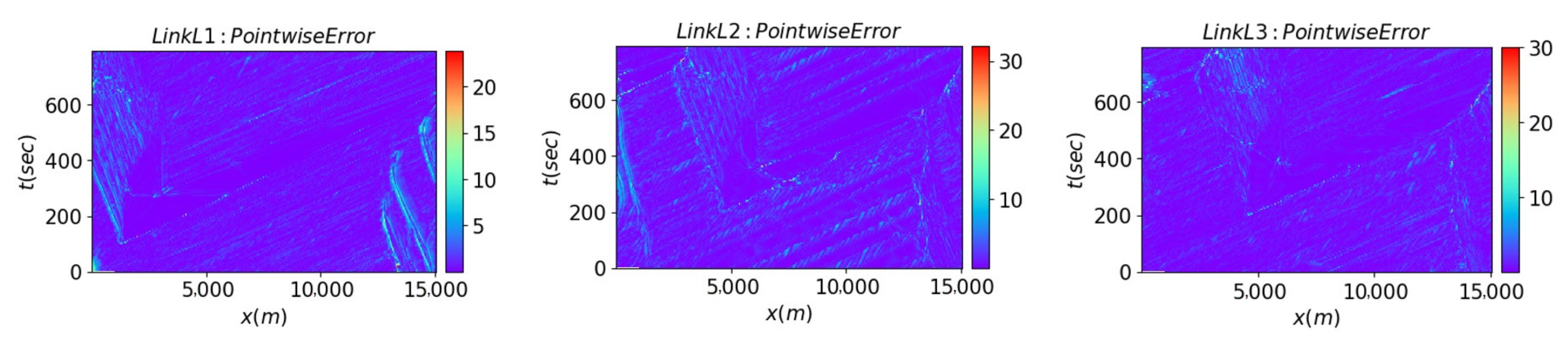
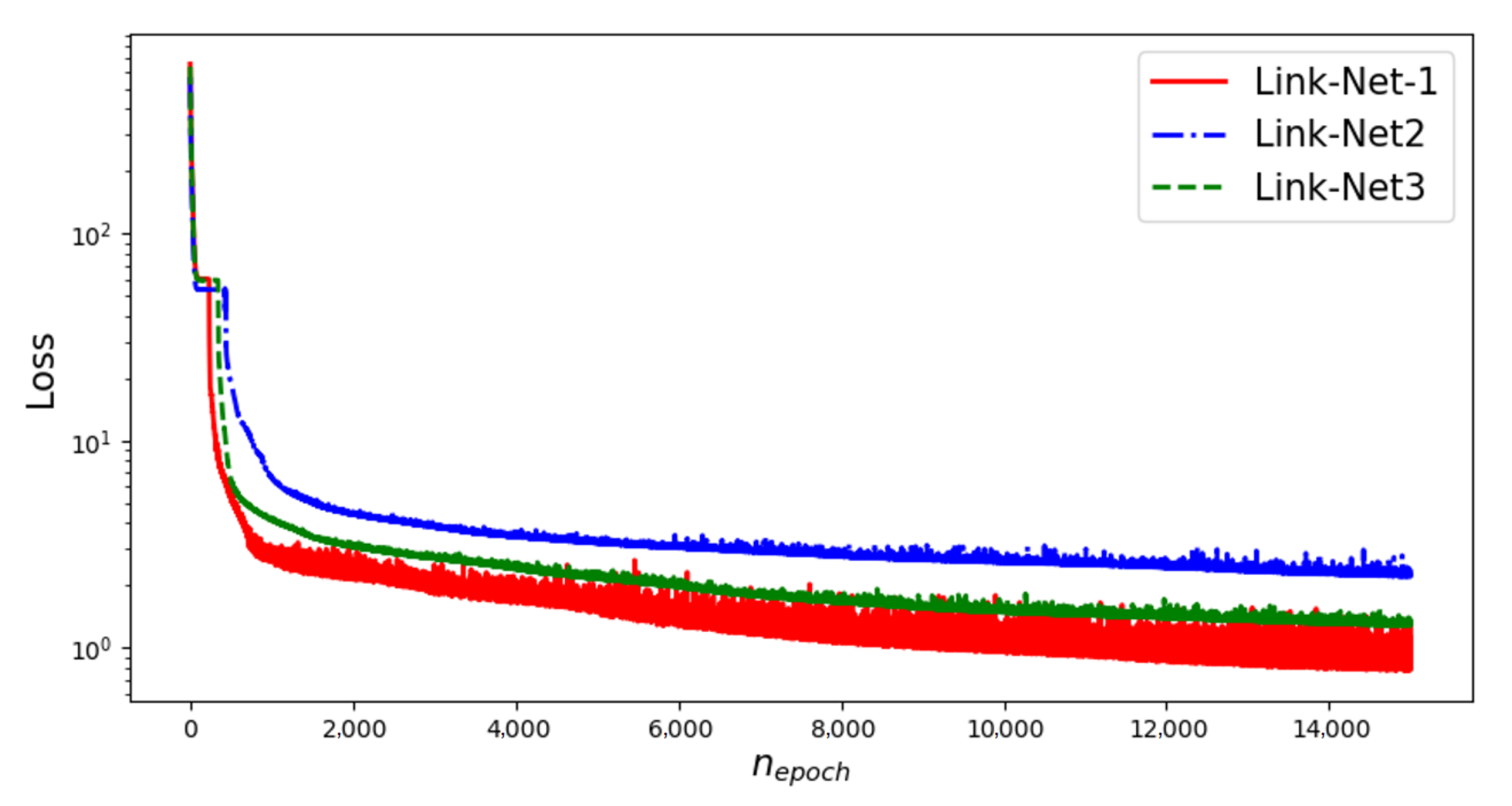
The pointwise error of all three links and the loss convergence history are presented in
Figure 8 and
Figure 9, respectively. Based on
Figure 8, the dominant blue color indicates lower prediction error, which indicates the model effectively captures the general congestion pattern. It is evident from
Figure 9 that even after 15,000 epochs, the loss for all three links remains continuously decreasing.
In our case, we use an adaptive activation function in accordance with Jagtap et al. [
53]. However, the adaptive activation function does not significantly improve the results.
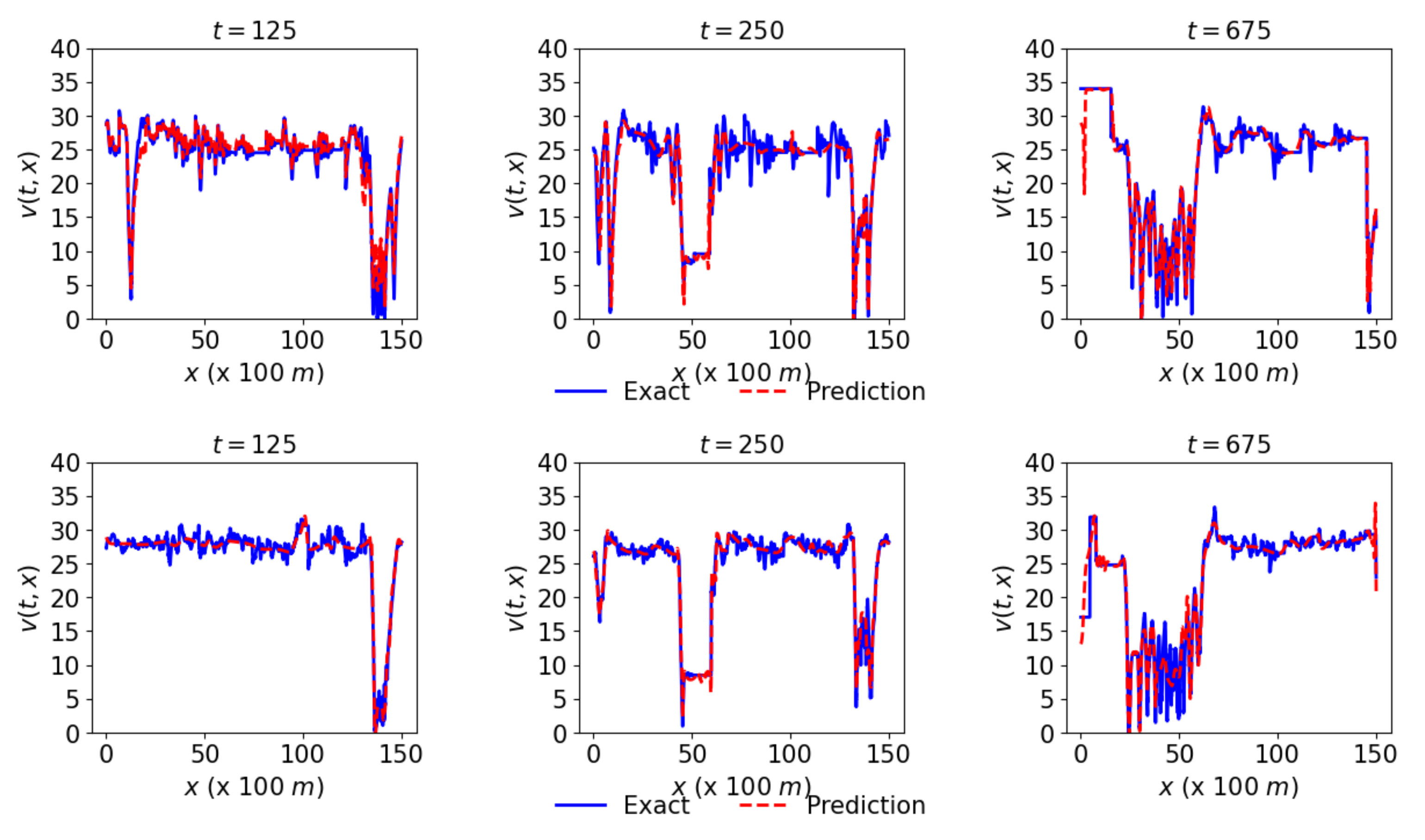
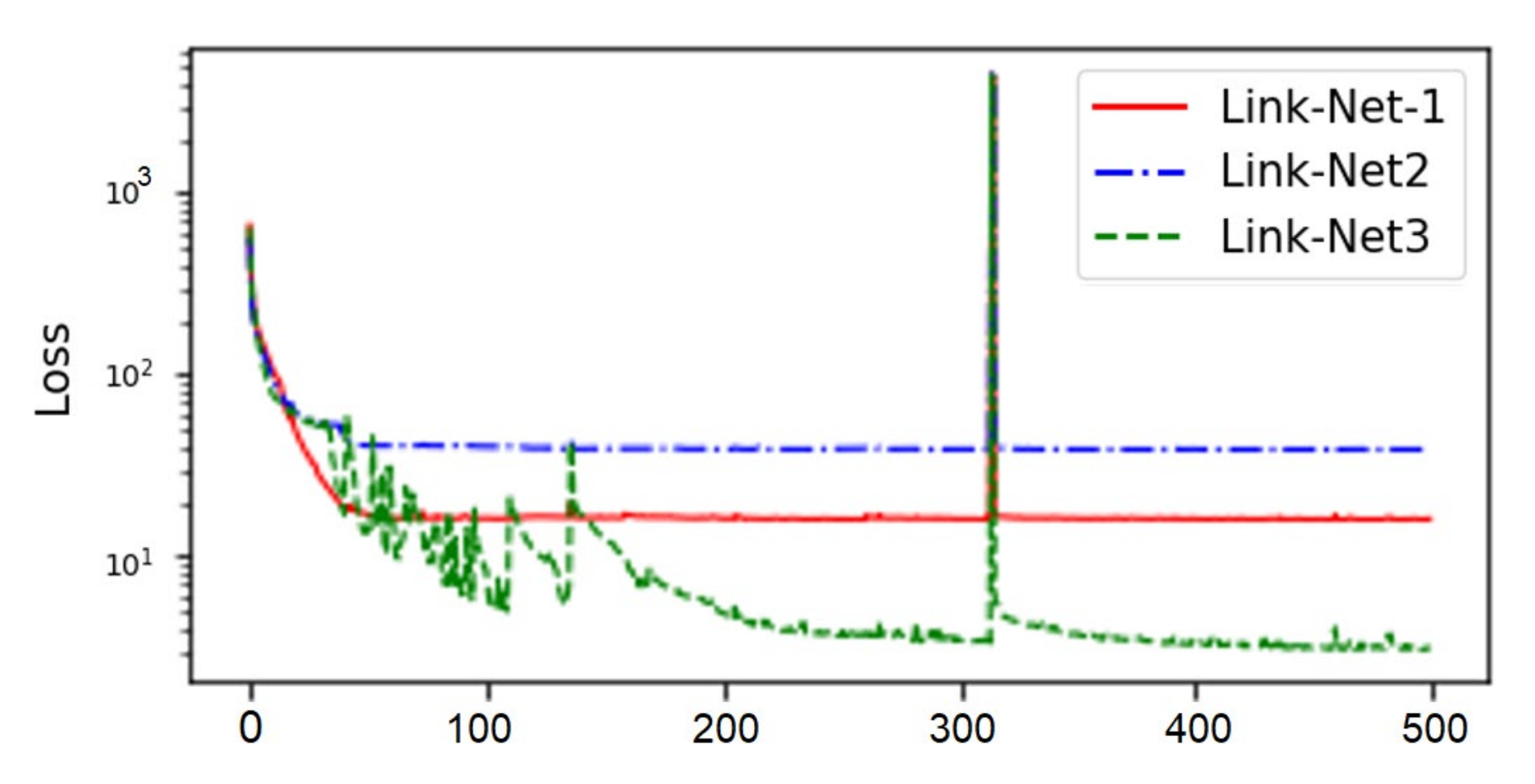
Figure 10 and
Figure 11 present representative results of the framework with adaptive activation. In
Figure 11, the loss of links L1 and L2 does not diminish after about 50 epochs, despite a rapid convergence at the initial epochs.
Although the proposed approach successfully captured the complex traffic behavior in the network, the model needs further improvements and fine tuning to eliminate the large errors. In addition, the lesser accuracy is likely due to ambiguities in the data collection process. For example, the assumption of constant traffic state across a cell may be reasonable from a macroscopic perspective, but it may not necessarily satisfy the partial differential equation that describes traffic flow. Moreover, the data failed to follow the basic flow conservation phenomenon at the intersecting points. We further compare the data and model predictions at the intersection using
Figure 12.
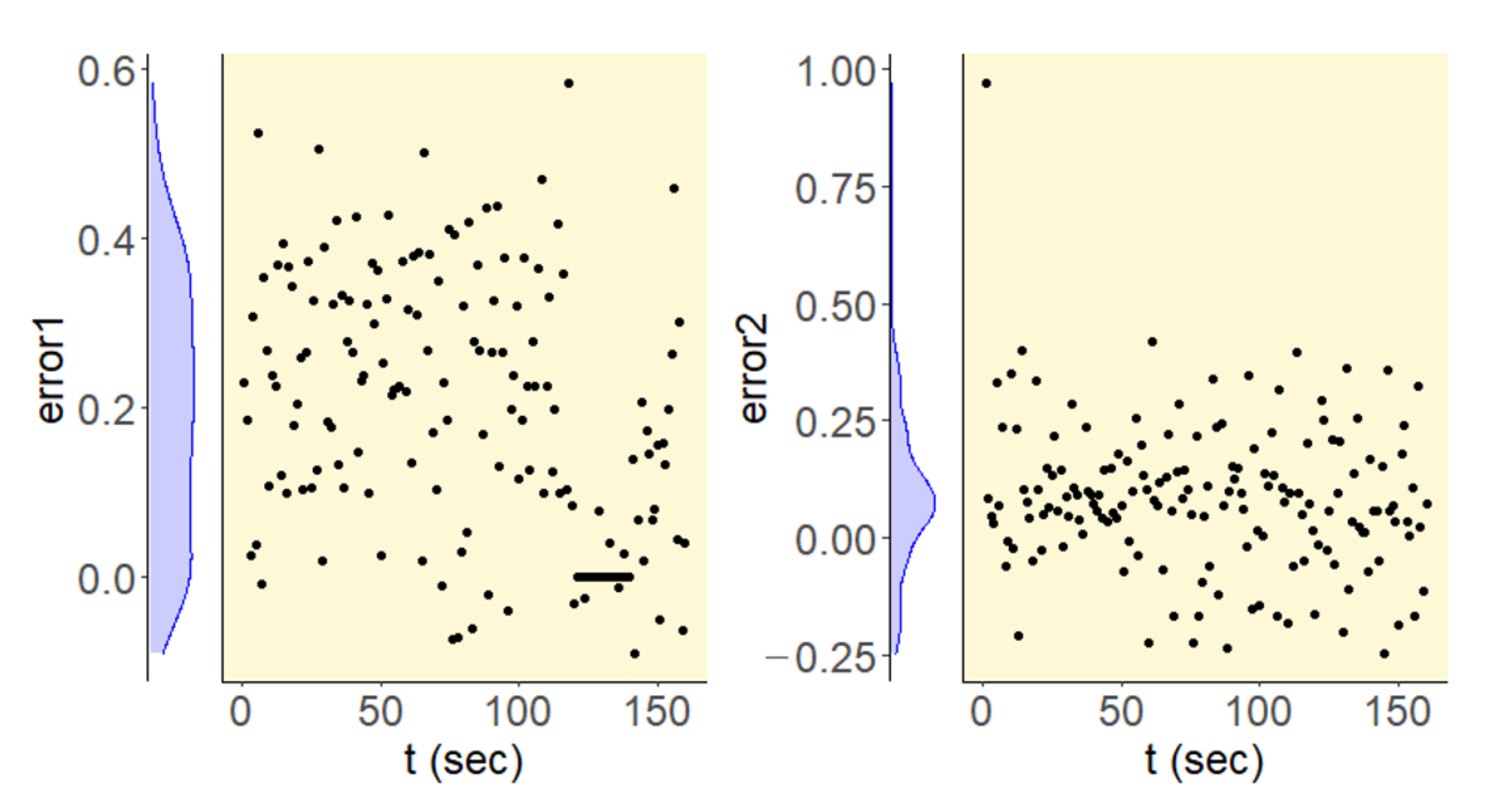
The larger error at the intersection points is due to discrepancies in the actual data. Since the data are estimated as described in the previous section and the data are not preprocessed to strictly satisfy the flow conservation at the intersection points.
Figure 13 shows the flow conservation error1 and error2 at intersections 1 and 2, respectively. The flow conservation error in the observed data is due to the assumption of grid cells while estimating the traffic state variables from the trajectory data. The error could be reduced to zero by assuming a minimally small-sized cell. The time complexity of the algorithm to compute traffic state variables from the space-time diagram is
O(n2), and a too small-sized cell could be computationally expensive. The flow conservation error distribution shows lesser violations at intersection 2 and that the prediction results are better as compared to intersection 1.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}