1. Introduction
The CSP is an optimisation problem that basically consists of cutting larger parts (objects) available in stock in order to produce smaller parts (items) to meet a given demand, optimising a certain objective function, for example, the loss of material or the cost of the objects to be cut. This problem belongs to the NP-Hard class [
1], that is, there is no deterministic algorithm that can solve it in polynomial time with certificate of optimality, unless P = NP. Thus, for large sized instances of the problem to be tackled efficiently, it is necessary to resort to approximation algorithms, such as heuristics and metaheuristics, and, therefore, the guarantee of optimality is lost in order to obtain good solutions in a reasonable time.
Applications of this problem are commonly found in a wide variety of industries in which the waste of materials is a major concern, such as in manufacturing processes of steel, textile, paper, and glass. It is important to note that, in real world applications, different constraints may be considered due to the particularities of the manufacturing processes involved in each scenario. Given its wide applicability, in addition to its theoretical relevance, the search for increasingly promising solutions to this problem is still very relevant [
2].
In this work, we propose a procedure for generating cutting patterns for the 1D-CSP and a strategy for reducing the number of patterns generated, in order to deal with large scale instances of the problem, even if the guarantee of obtaining an optimal solution is lost. Using benchmark instances from the literature [
3], computational experiments were performed for two ILP models, an implementation of the classical CG technique [
4,
5,
6], and an application of the G&S framework [
7,
8,
9,
10].
We employed CPLEX [
11] for solving the ILP models. We resorted to Coluna [
12] for running the CG technique and Java Concert for implementing the G&S method to tackle the problem. The exact method was able to solve only small and medium sized instances. None of the CG and G&S algorithms stood out from the other for all instances. In fact, the effectiveness varied according to the characteristics of the instances, such as the number of item types, the size of the items in relation to the size of the object, and the demand for each item type. Roughly, G&S performed well for all classes, obtaining quasi-optimal solutions for the majority of the instances.
The remainder of this article is structured as it follows: in
Section 2, we formally state the 1D-CSP, discuss the approaches commonly used to solve it, and introduce the G&S framework. In
Section 3, we present a procedure for generating cutting patterns for the 1D-CSP and propose a strategy for artificially reducing the number of patterns to be considered into the formulation. In addition, we explain in detail the application of this methodology to the 1D-CSP.
Section 4 is dedicated to present and analyse the computational results obtained from the different approaches. In
Section 5, final remarks and perspectives on future work conclude the article.
3. Materials and Methods
In this section, we first propose a procedure to generate a subset of cutting patterns and then propose an application of the G&S approach for tackling the problem.
3.1. Generation of Cutting Patterns
The task of generating all cutting patterns is computationally expensive, since the quantity
n of patterns can be extremely large. The greater the variability of the length of the items and the smaller these items are in relation to the object size, the greater is the complexity of this task. In what follows, we resort to a procedure for generating cutting patterns proposed by Suliman [
31] and propose a strategy employed to artificially reduce the amount of patterns considered into the ILP formulation.
Consider an example in which the identical objects of length
and a set of
different types of items are given. The procedure starts by sorting the items in descending order of length
,
. In the running example, assume
,
, and
. An
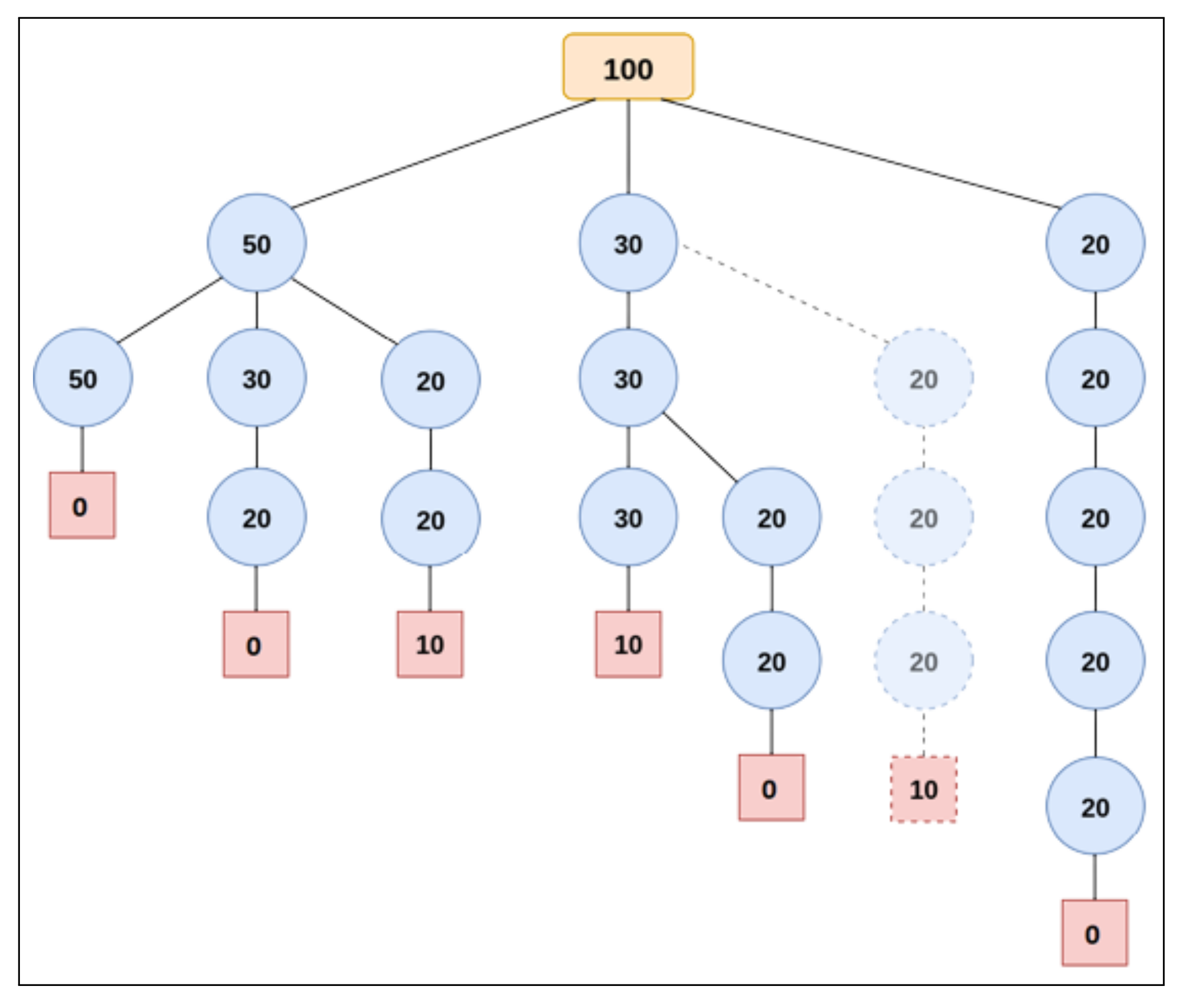
m-ary search tree is used to illustrate the pattern generation procedure, as presented in
Figure 2. The root node (in orange) represents the length of the large object, the internal nodes (in blue) represent the length of the items, and the leaf nodes (in red) indicate a cut loss. Any path from the root node down to a leaf represents a cutting pattern.
Starting from the root node, the procedure recursively includes as a new branch every item that can be obtained from the residual length of the object. If it is no longer possible to include any of the items as a new branch of a given node, the leaf node is created, indicating the cut loss of the cutting pattern defined. The implementation, however, is optimised as in [
31] so that the height of the search tree is limited to the number
m of different types of items. In addition, in every cutting pattern, we limit the number of items of each type to their corresponding demand, because this reduces the search space of the continuous relaxation in instances where the demands are small.
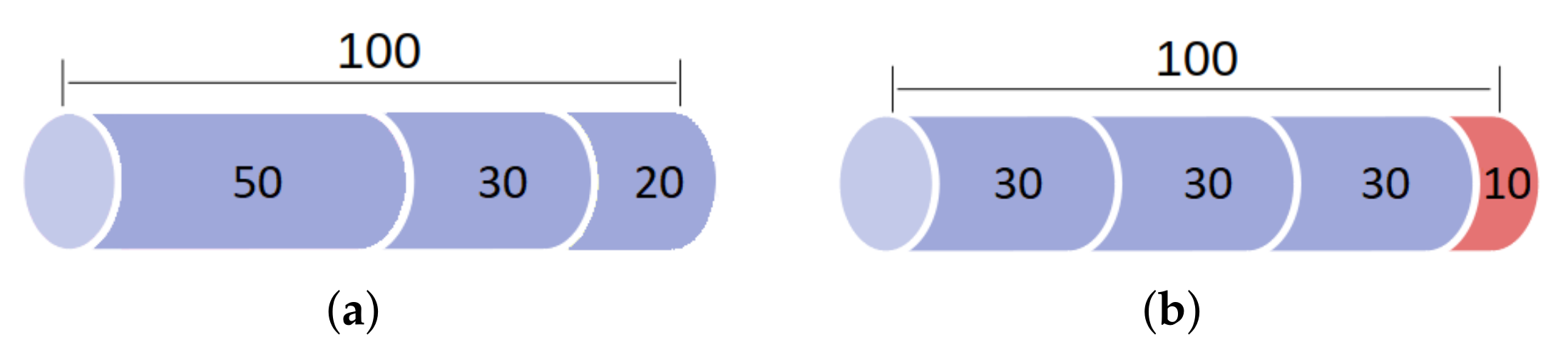
In the running example, there exist
cutting patterns, depicted in the search tree, from left to right:
,
,
,
,
,
e
. The patterns
and
are illustrated in
Figure 3a,b, respectively.
The number
n of cutting patterns can grow exponentially according to the number
m of item types, and, therefore, the large number of cutting patterns generally makes computation infeasible. To cope with this issue, we propose to limit the generation to a maximum number
M of cutting patterns. More precisely, a maximum number
of cutting patterns beginning with a given type of item
i is computed as follows:
The recursive procedure to construct the search tree follows a depth-first strategy and includes the branches of a given node according to the ordering of the items. A new branch is added only if the limit has not been reached for patterns beginning with type of item i.
In the running example, consider the value of
. As we have
,
. In
Figure 2, only the cutting patterns represented in solid lines are actually generated in the search tree. The branch represented in dashed lines is, in turn, pruned down. In this example, the cutting patterns
is discarded.
3.2. Application of the Generate-and-Solve
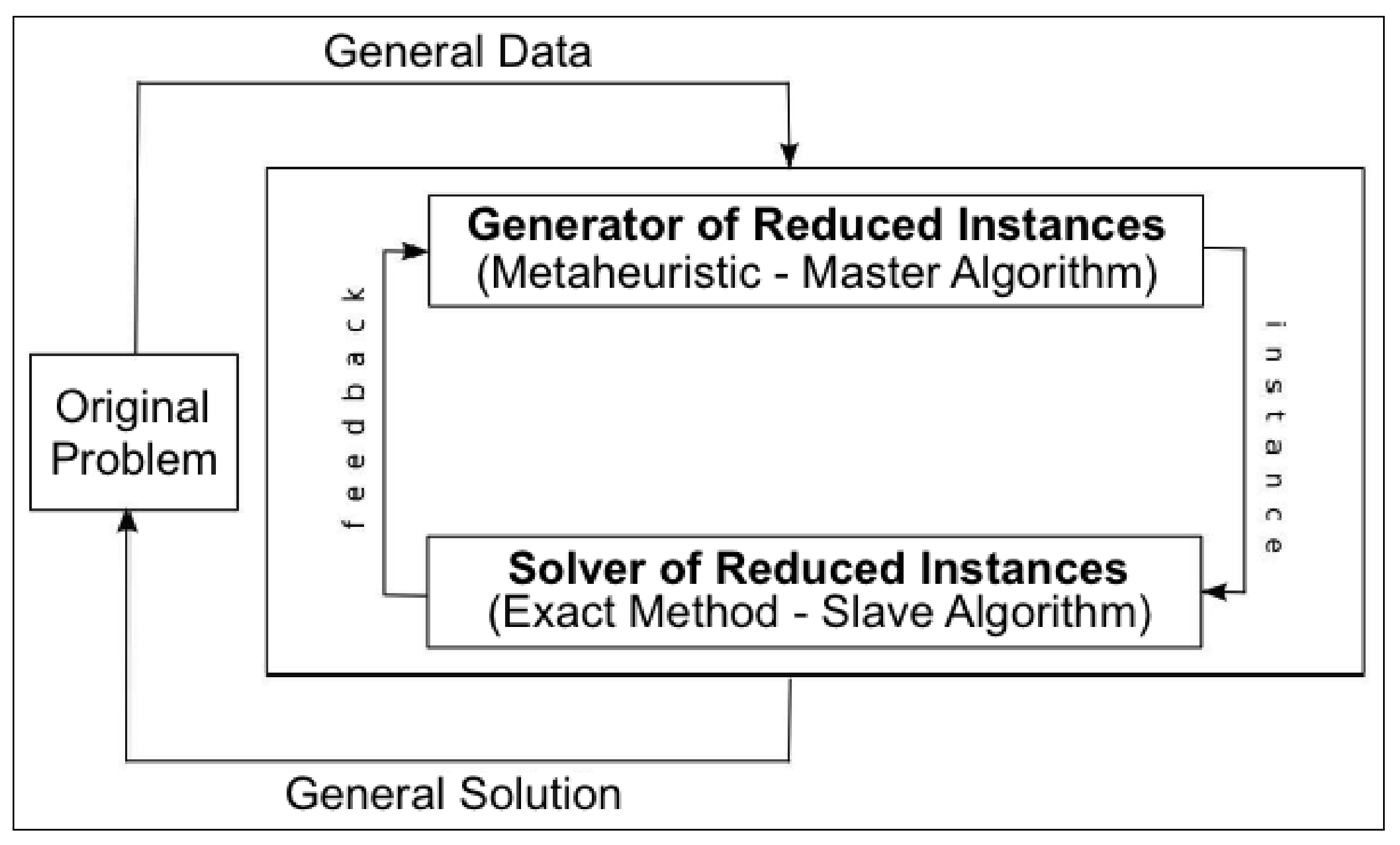
Reduced instances of the 1D-CSP can be obtained by considering only a subset of the decision variables of the original problem instance, that is, only a subset of the feasible cutting patterns. The reduced instance is, therefore, an ILP model containing all the constraints present in the problem formulation, but only a subset of the cutting patterns, as in the CG technique. The choice of the subset of cutting patterns, however, is performed through a metaheuristic engine.
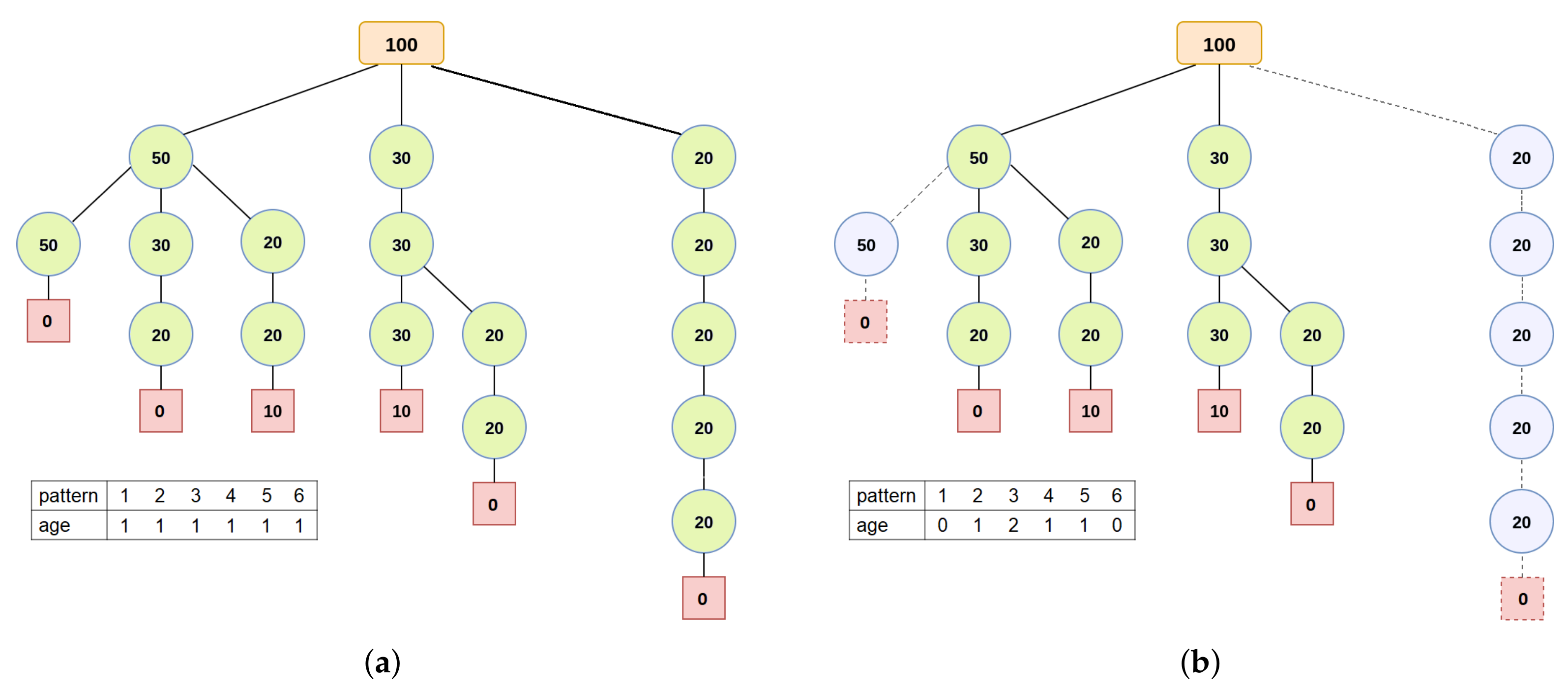
To explain the representation of a reduced instance, we refer to the running example discussed previously. Recall that, in order to deal with large sized instances of the problem, we employ a strategy for reducing the number of patterns. Thus, in
Figure 4, we represent only the cutting patterns that were not discarded when applying this strategy.
The representation of a reduced instance of the problem is performed using an array of integers. Each position in the array is associated with a cutting pattern in the search tree. In this representation, a value greater than or equal to 1 (one) indicates that the associated cutting pattern (decision variable) is considered in the reduced instance (ILP model). Conversely, a value of 0 (zero) indicates that the associated cutting pattern is not taken into account in the reduced instance.
In addition, the value is used as an aging mechanism [
25] to control the growth of reduced instances. Whenever a new cutting pattern is incorporated into the reduced instance, its age is set to 1 (one) and, at each iteration of the G&S method, the age of every cutting pattern that is part of the reduced instance is increased by 1 (one). If the age of a cutting pattern reaches a maximum age value
, the value is reset to 0 (zero), that is, the pattern is removed from the reduced instance to prevent unpromising cutting patterns from unnecessarily impacting the efficiency of the ILP solver. However, whenever a cutting pattern is effectively used in the solution returned by the ILP solver, its age is reset to 1 (one) to ensure that this pattern is considered in the next
iterations of the G&S method.
In order to obtain an initial reduced instance that produces a feasible solution when submitted to the ILP solver, the following greedy strategy was adopted to select the cutting patterns. Considering the cutting pattern search tree from left to right, the current cutting pattern is added to the instance under construction if it contains an item that has not yet been covered by any other pattern. The process continues until all items have been covered by the patterns added to the instance. Then, the reduced instance is submitted to the SRI to obtain an initial solution. From then on, the aging mechanism guarantees the existence of a feasible solution in all reduced instances submitted to the SIR. In addition, at each iteration of the G&S method, the current instance contains a solution that is at least as good as the previous ones.
For the GRI, a simple hill climbing algorithm was implemented, as illustrated in Algorithm 1. A neighbour instance is obtained from the application of a mutation operator. Considering a mutation rate
, the mutation operator, when effectively applied to a position of the array, modifies the value to 1 (one) whenever the original value is 0 (zero), and, conversely, modifies the value to 0 (zero) whenever the original value is greater than 1 (one). Note that, when the original value is 1 (one), the value remains unchanged in order to ensure that the neighbour instance preserves the current feasible solution.
| Algorithm 1: Pseudocode of the generate-and-solve method implemented. |
- parameters:
G&S time limit , solver time limit , maximum age value , and mutation rate . - input:
Set of cutting patterns and demands of each type of item. - output:
The number of objects cut according to each cutting pattern.
 |
At each iteration of the G&S method, a new reduced instance is generated and submitted to the SRI to obtain a new best solution. For each reduced instance, we adopt a time limit of computation of the ILP solver. Furthermore, we consider an execution time limit as a stopping criterion for the G&S method.
4. Results
We employed IBM ILOG CPLEX 22.1 [
11] to solve the ILP models and used Coluna 0.4.2 (JuMP 1.1.0 and Julia 1.8) [
12] to run the CG technique. Coluna implements a default CG procedure and provides dual and primal bounds for each iteration of the method. We set CPLEX as underlying ILP solver to handle master and subproblem. For the search tree, we considered a maximum number
of cutting patterns. The hill climbing algorithm was implemented in Java language and, after preliminary tests, the values of the parameters of the G&S method were chosen:
s,
s,
, and
. The computational experiments were performed on Intel Core i7 7500U CPU 2.70 GHz 8 GB RAM machines. Benchmark instances from the literature [
3], divided into 5 classes, were used to carry out a comparative analysis of the performance of the different methods. We set an execution timeout of 600 s for all methods.
The comparative results are presented in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5. Along with the characterisation of the instances, we present the computational results for the different methods. Since G&S is stochastic, we provide the best and average values over 10 (ten) executions of this method, besides the average time to best (
), i.e., the elapsed time until finding the best solution of an execution. For the CG algorithm, we provide the dual lower bound
and the primal upper bound
. Note that, when the CG algorithm stops before convergence due to the time limit of 600 s, the dual bound may not represent the object value of the linear relaxation of the original ILP formulation. For each instance, we mark the proven optimal solutions with the symbol
and highlight in boldface the best solutions found among those obtained by the competitive approaches. Particularly, in
Table 1, we present as well computational results for the ILP formulations proposed by Gilmore and Gomory [
5,
6] (GG-ILP) and Delorme and Iori [
18] (REFLECT-ILP), in an attempt to investigate the scalability of the exact approach. In this table,
and
define, respectively, a primal lower bound and a primal upper bound for the ILP models.
The computational results for the set of instances of class
U are presented in
Table 1. The characteristics of these instances are as follows: the number of types of items ranges from 15 to 1005; the length of each item is between 31.66% and 35.01% of the length of the object; and the demand multiplicity (i.e., the average demand per item type), calculated as the average value among all instances of the class, is unitary. CPLEX was able to obtain feasible solutions to the GG-ILP formulation only for the instances with up to 495 item types. For the small sized instances, GG-ILP obtained proven optimal solutions very fast. The REFLECT-ILP, in turn, obtained feasible solutions for the instances with up to 675 item types. Despite the fact that REFLECT-ILP proved to be more time consuming for small sized instances compared to GG-ILP, CPLEX scaled better with this formulation. CG and G&S methods were able to find feasible solutions for all instances of this class. CG proved to be the most effective and time efficient for small sized instances (with up to 405 item types). It is important to remark that, for medium sized instances, CG outperforms the G&S approach. G&S obtained optimal solutions for instances with up to 285 item types. In addition, for large sized instances, G&S provided the best feasible solutions, and, therefore, the strategy of artificially limiting the number of cutting patterns proved to be very effective.
The set of instances of class
hard28, presented in
Table 2, has between 136 to 189 types of items. In these instances, the length of each item is between 0.1% and 80.0% of the length of the object and the demand multiplicity is of 1.1221. The demands vary from 1 (one) to 3 (three). The wide variety of the length of the items in relation to the length of the object stands out. CG method obtained the proven optimal solution for 15 out of 28 instances. This method, however, was not able to provide a feasible solution for the instance
BPP195, which does not have any particular characteristic that justifies this behavior. Conversely, G&S obtained a better solution for 13 out of 28 instances of this class. For the other instances (but instance
BPP900), the difference in the quality of the solution obtained by the G&S approach and the proven optimal solution was limited to 1 (one) additional object. It is also important to remark that the elapsed time until finding the best solution is relatively small, suggesting that convergence was reached very fast.
In
Table 3, the computational results for the set of instances of class
7hard are presented. These instances are characterised by: number of types of items ranging from 85 to 143; length of each item is between 1.7% and 80.0% of the length of the object; and demand multiplicity is of 1.1027 units per item (varying from 1 to 4). As in the set of instances of class
hard28, there is a wide variety of the length of the items, although the ratio for the smallest length is a little larger. Note, also, that the number of types of items is smaller here. For these instances, CG method provided the proven optimal solution for 5 instances. G&S obtained a better solution for 2 out of 7 instances of this class. Again, for the other 5 instances, the quality of the solution obtained by the G&S approach and the proven optimal solution differs by 1 (one) additional object. The convergence of both algorithms is very fast.
The set of instances of class
hard10, presented in
Table 4, has between 197 and 200 types of items. In these instances, the length of each item is between 20% and 35% of the length of the object and the demand multiplicity is of 1.0050 units per item (varying from 1 to 3). The number of types of items is greater than in the two previous classes, but there is a significantly smaller variation in the length of the items. For all instances of this class, G&S overachieved the CG method and the solutions differed by 1 (one) additional object considering the dual lower bound provided by the CG algorithm (but for instance
HARD7). It was also noticed that CG was not able to obtain a feasible solution for the instance
HARD4.
Finally, the computational results for the set of instances of class
wae_gau1 are presented in
Table 5. These instances are characterised by: the number of types of items ranges from 33 to 64; the length of each item is between 0.02% and 73.32% of the length of the object; and the demand multiplicity is of 2.5974 (varying from 1 to 38). The number of items is lower in relation to the other classes of instances, but with a large demand multiplicity. In addition, the variation in the length of the items is huge. For these instances, G&S significantly outperformed CG. The solutions obtained by the G&S method differed at most by 1 (one) from the lower bound provided by the CG algorithm (but, for instance,
WAE_GAU1_TEST0055_2). In fact, the CG method was only able to handle 4 out 17 instances of this class. Again, the strategy of artificially limiting the number of cutting patterns proved to be effective.
5. Conclusions
The computational effort for solving the 1D-CSP is largely affected by the number of the cutting patterns. In order to cope with large instances of the problem, we proposed a strategy to restrict the number of patterns to be generated while applying a pattern generating procedure. Using benchmark instances, computational experiments were performed for ILP models, an implementation of the CG technique, and an application of the G&S framework. We begin the conclusions on our experimental analysis, stating that the exact approach was only able to cope well with small and medium-sized instances. In addition, none of the CG and G&S algorithms stood out from the other for all instances. In fact, the effectiveness of these methods varied according to the characteristics of the instances, such as the number of item types, the size of the items in relation to the size of the object, and the demand multiplicity. Nonetheless, G&S performed well for all classes, obtaining quasi-optimal solutions for the majority of the instances. In addition, the strategy of artificially reducing the number of cutting patterns proved to be very effective.
It is important to remark, however, that G&S does not present any sort of guarantee of convergence and the optimality gap cannot be estimated by the G&S method alone. On the other hand, CG was able to produce strong lower bounds fast. Therefore, G&S could be integrated to CG to speed up the convergence of branch-and price algorithms, especially when CG fails to produce good-quality integer feasible solutions. Future research is also envisaged to adapt the proposed framework using arc-flow formulations, which have shown to be appealing in branch-and-price algorithms.










{kind=link}
{kind=link}
{kind=link}
{kind=link}