3.1. Overall Architecture
As mentioned in the previous section, the existing hybrid mechanisms between meta-heuristics suffer from two pitfalls. First, the information exchange mechanisms are not carefully considered for the factors including the timing, directions, and information of transition. For instance, frequently exchanging the currently best solution of each meta-heuristic branch to the opposite side may prematurely converge to local minima due to the diversification of populations being reduced. Besides, another major pitfall in some cases is that the hybrid frameworks randomly select one of meta-heuristics for every single individual at each iteration. Clearly, this will adversely affect the continuity of search behaviors, and limit the originally nature-inspired search mechanism of each algorithm for which the advantages of evolution may be revealed after keeping the characteristic search for a few iterations. Therefore, to develop an effective transition mechanism while retaining the advantages of special designs of each meta-heuristic algorithm, a simple yet powerful Dynamic Contribution-based State Transition (DCST) scheme is proposed in this work to connect different meta-heuristic algorithms for enhancing the overall search ability. As shown in
Figure 2, the AMPO framework and CSDE approach are linked up by the DCST scheme. In particular, the proposed transition scheme decides when the hybrid framework transmits the information, which direction should be chosen, and what kinds of information should be exchanged. To clearly illustrate the HYPO framework, an example with practical value is how to optimize the capital allocation for different industries as a portfolio usually includes stocks from multiple industries for diversifying the risk. According to the company natures of stocks and the correlation between stocks, the stocks will be allocated to one of the industries (i.e., components). The stocks in the same component have strong correlations while different components may have contrary problems due to different impact factors. However, using a single meta-heuristic mechanism may work on one of the components, and it is difficult to find out the optimal solution for all components at the same time, especially in solving a large-scale portfolio. Thus, integrating different meta-heuristic mechanisms can adapt to more components during the search. For example, a portfolio has several stocks from two industries including real estate and the Internet. The AMPO method may work well on optimizing the capital allocation of stocks in real estate and fail at that of stocks in the Internet, but the CSDE method may fail in real estate and achieve better performance in the Internet. The proposed HYPO framework integrates two meta-heuristic methods and also completely retains their distinctive heuristic mechanism. During the search, those branches obtain some good-performing solutions that implicitly include the locally best allocation schemes of one of the industries, but they trap into local minima as the rest of solutions representing other industries are not optimal. To solve it, the dynamic contribution-based transition scheme in the HYPO framework decides the direction and information of transition by reviewing the contributions of each heuristic branch in the past few generations. Through the dynamic transition scheme, the optimal allocation plan collected by each branch can be shared to help escape from local minima and generate a better solution for the whole portfolio.
Algorithm 2 describes the overall process of the hybrid optimization framework. At the beginning of the search, all user-defined parameters are input to the model. Then, all individuals are initialized and assigned to one of populations in two meta-heuristic algorithms. When starting the evolution process, the algorithm decides whether to transmit the good-performing solutions generated by the CSDE approach to the population of the AMPO framework in terms of the current transition direction. After that, the AMPO algorithm sequentially executes a set of evolutionary operations including transformation, update, recovery, evaluation, and selection on the AMPO population. Furthermore, the DCST scheme allows the information transition from the AMPO framework to the CSDE approach if satisfying the transition conditions. In addition, the CSDE approach conducts the evolution-based DE search on its populations. Also, by evaluating the enhancements of the CSDE approach after introducing the extra information from the AMPO algorithm, the signal of contribution will be given later to support the system state transition. More importantly, to flexibly control the frequency and direction of information exchange between meta-heuristics, a system state transition mechanism in the DCST scheme is presented to update the latest system state and its corresponding transition direction through reviewing the current system state and flow direction. The above optimization processes will be iteratively executed until the maximum iterations are satisfied. Lastly, the globally best individual in all meta-heuristics will be output as the final solution of problems.
| Algorithm 2: The Overall Procedure of the HYPO Approach |
 |
3.2. Dynamic Information Transition
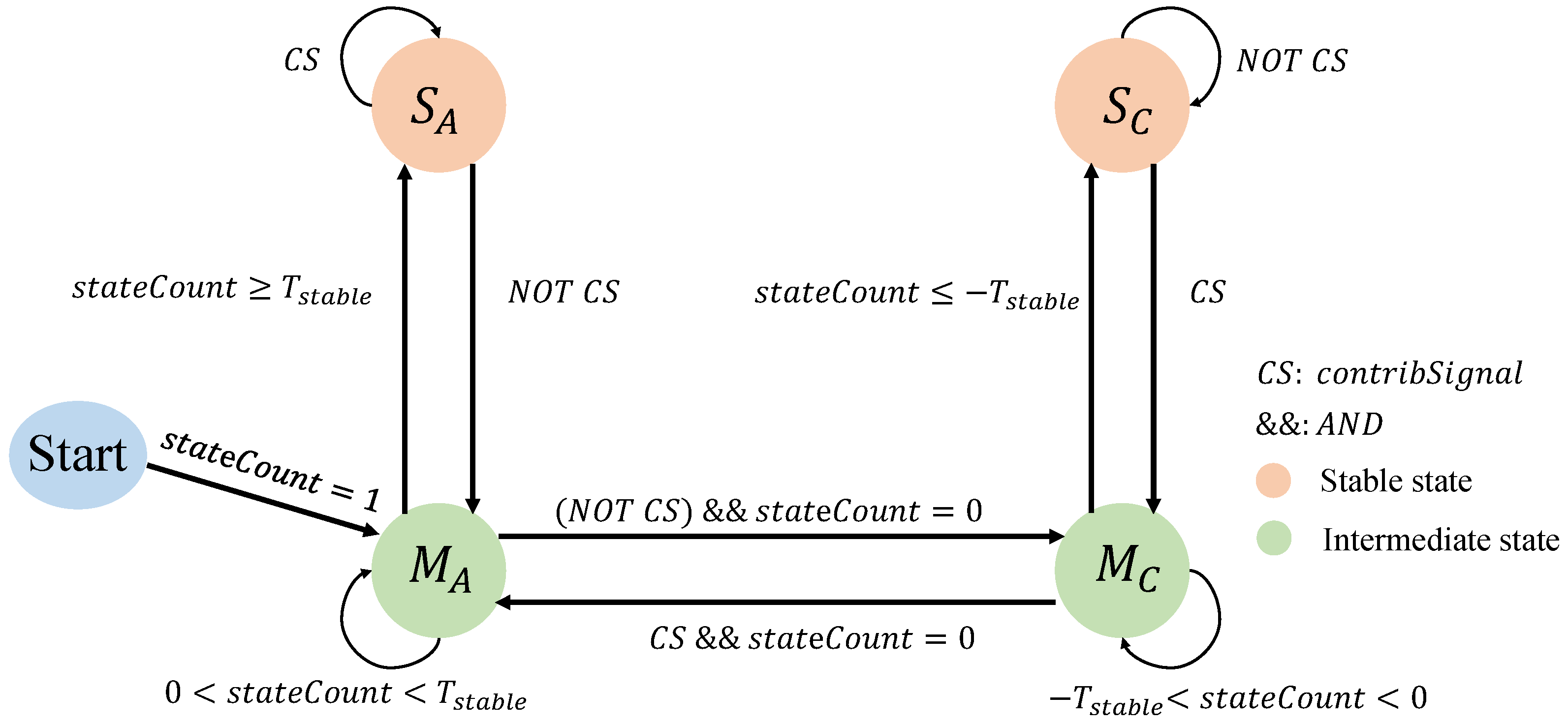
As inspired by the dynamic branch prediction in the computer architecture filed, the decision process of information exchange in the proposed hybrid framework should be quickly responded to with less computing delay according to the historical contributions of meta-heuristics. As aforementioned, the information should not be unconditionally exchanged at each iteration. Accordingly, there are three essential components in the DCST scheme, namely contribution identification, state transition mechanism, and direction update mechanism. Before discussing the details, two new concepts, namely the system state and transition direction, are introduced into the DCST scheme for constructing the branch predictor. Specifically, the system states including the stable state and intermediate state indicate the current position of the transition system. Besides, three transition directions are defined in this work. The bi-directional information transition enables the two meta-heuristic algorithms to share their best solutions with each other, whereas the other two situations are unidirectional transition for two algorithms such that that only one side can send the information to the opposite side. For convenience, the symbol of bi-directional transition is represented by 0 while that of unidirectional transitions are described by 1 or 2 for the transition flow from the AMPO framework to the CSDE approach only or vice versa.
In recent studies, most adaptive mechanisms or cooperative mechanisms in meta-heuristic algorithms adjust search strategies by reviewing the historical contributions of each component. However, in tackling time-sensitive tasks such as online trading and path planning of unmanned driving, calculating the contributions of individuals or populations by using complicated rules is computationally intensive and requires larger memory space for storing historical data. Hence, to trade off the time requirement and contribution calculation on solving large-scale optimization problems, a simple update scheme is presented to identify the current contribution so that it can drive the state transition in the following step. As clearly depicted in Algorithm 3, the scheme will check if any information is being transmitted from the AMPO framework to the CSDE approach at the current iteration. It returns false if no information is being exchanged, otherwise it will further verify if there is an enhancement that is driven by the exchanging information just now. Finally, the value of the contribution signal is assigned true when the transmitted information from the AMPO approach can promote the CSDE search. The intent of the positive signal is to encourage the information transition from the AMPO algorithm to the CSDE approach in the following iterations.
| Algorithm 3: The Update of Contribution Signal |
 |
Furthermore, instead of using memory to store the historical performance of each meta-heuristic algorithm, a state-based transition system is applied in this work in which the system states are utilized to implicitly indicate the current environment of the system with the consideration of historical impacts. As depicted in
Figure 3,
and
are the stable state and intermediate state that indicate the information transition direction from the AMPO to the CSDE. Conversely,
and
are the stable state and intermediate state that show the direction from the CSDE to the AMPO.
records the current position of the system in which the
will increase by 1 when the
is true, otherwise it will decrease by 1 when the
turns false. Specifically, the information is transmitted from the AMPO to the CSDE when the
is greater than 0 (i.e., the system is in
or
) whereas the information flow follows the opposite direction when the
is less than 0 (i.e., the system is in
or
). Furthermore, the state transition depends on the
and
at the current iteration. The
stops increasing and the system moves to the stable state
when the
is equal to the predefined value
and the
remains true. Similarly, the
stops decreasing and the system gets into another stable state
when the
is equal to
and the
remains false. Once entering the stable state, the system will stay here until it receives a false contribution signal at the
or a true contribution signal at the
. More importantly, the information transition direction is reversed when the
increases or decreases to 0. Intrinsically, the chain system drives the state transition based on contributions so that the direction generated by the current state reflects the performance of each branch in the past few iterations, but the preservation of large amounts of historical data is not required for the contribution calculation.
The overall procedure of the system state transition mechanism is described in Algorithm 4. Besides the exchange conditions between two unidirectional transitions discussed above, a bi-directional transition mechanism is introduced to prevent the search from keeping the same direction for a long time. When the continuously accumulated iterations of the same direction exceed the predefined trigger condition, the search enables the bi-directional information exchange for a few iterations to share useful ideas in which it may help to escape from local minima. After that, the search will come back to the unidirectional transition.
For Algorithm 4,
is the current direction of information transition,
is the accumulated number of the same direction,
is the number of iterations running on bi-directional transition, and
is the number of iterations on the same direction to trigger the bi-directional transition. In addition, for the kind of information being transmitted, the whole currently best solution of each meta-heuristic framework will be taken as the most important information being sent to the opposite side. Furthermore, the impact of different kinds of information for transition will be studied in the ablation experiments.
| Algorithm 4: The Mechanism of System State Transition |
 |















{kind=link}
{kind=link}
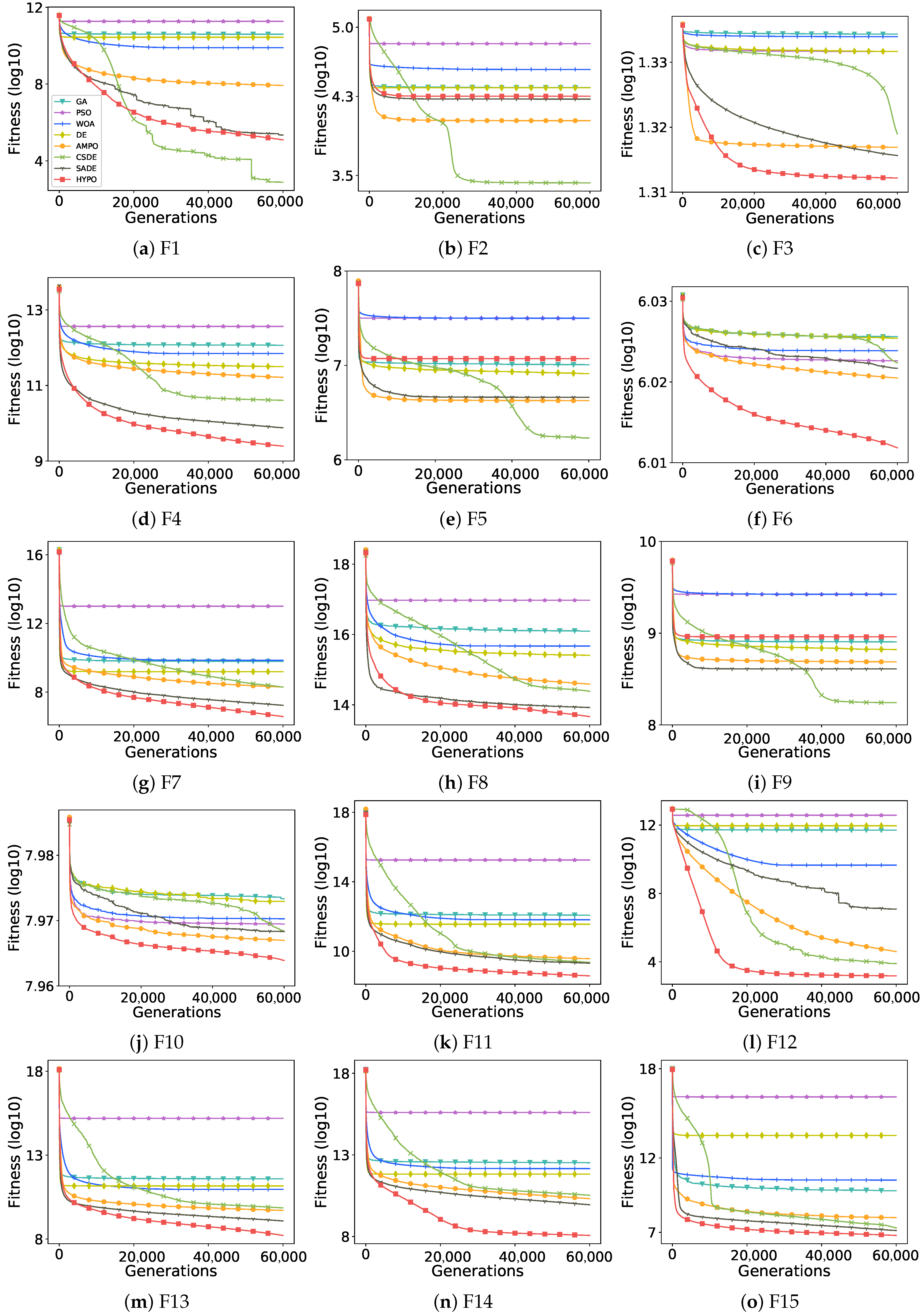
{kind=link}
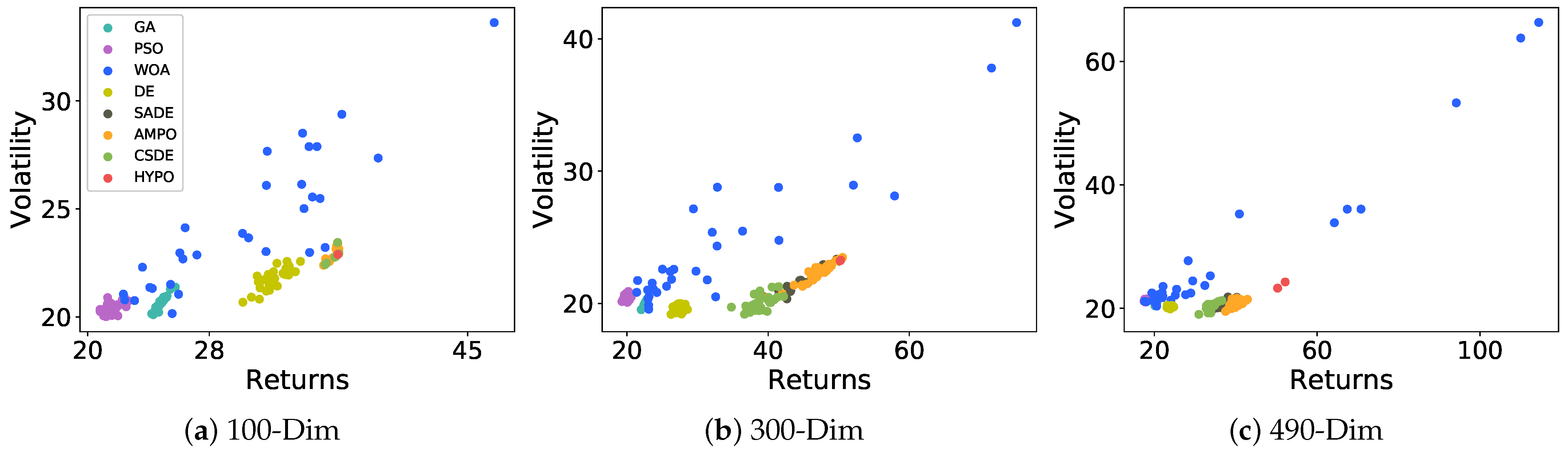
{kind=link}
{kind=link}
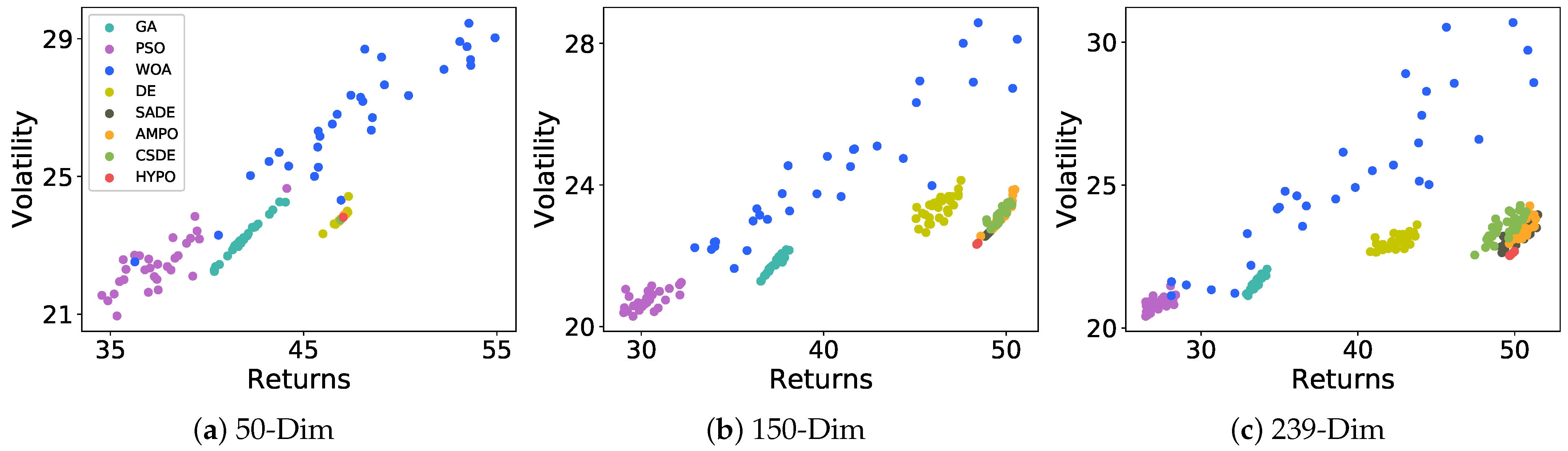
{kind=link}
{kind=link}
{kind=link}