1. Introduction
Networks are widely adopted to represent relations between objects in various disciplines. For instance, we leverage networks to study social ties [
1], financial transactions [
2], word co-occurrence [
3], and protein–protein interactions [
4]. When the network is small, traditional algorithms in graph theory can be used to analyze the network. Examples include clustering based on normalized cuts and node classification on the basis of label propagation. However, learning and prediction tasks in real-world networked systems have been incredibly complex, such as recommendations and advertising on large social networks with multifarious user-generated content [
5], the completion of knowledge graphs with millions of entities [
6], and fraud detection in financial transaction networks [
7]. Hence, traditional graph theory cannot directly satisfy the demands of real-world network analysis tasks.
To fill this gap and utilize off-the-shelf machine-learning algorithms in large and sophisticated networks, node representation learning (NRL) [
1,
8] has been extensively investigated. Machine-learning algorithms often make default assumptions that instances are independent of each other, and their features exist in the Euclidean space. However, these are not applicable to networked data, because, usually, networks depict node-to-node dependencies and exist in non-Euclidean space. The goal of NRL is to learn a low-dimensional vector to represent each node, such that actionable patterns in the original networks and side information can be well-preserved in the learned vectors [
9,
10]. Furthermore, these low-dimensional representations can be directly leveraged by common machine-learning algorithms as feature vectors, or hidden layers can perform a wide variety of tasks, such as node classification [
11,
12], anomaly detection [
13], community detection [
14], and link prediction [
15,
16].
In the early 2000s, as illustrated in
Figure 1, NRL was known as graph embedding [
17,
18,
19], which was mainly used to perform dimensionality reduction for feature vectors. Its core idea can be summarized as two steps. First, given a set of instances, such as documents or images of faces, associated with feature vectors, we construct a new graph to connect all instances. Its
edge weight is set as the shortest path distance [
18], reconstruction coefficient [
20,
21], or similarity [
17] between nodes
i and
j in the feature vector space. Second, we apply multidimensional scaling [
18] or eigen decomposition to the adjacency matrix or its variation [
17,
20]. In such a way, the learned node representations can be employed as the latent features of instances. It has been proven that most dimensionality reduction techniques, such as principal component analysis and linear discriminant analysis, could be reformulated as graph-embedding processes with constraints [
19]. Meanwhile, efforts have also been devoted to utilizing NRL as an intermediate process to conduct clustering [
22,
23,
24], known as spectral clustering. Its key idea is similar to graph embedding [
19]. Based on feature vectors, we construct a new network depicting similarities between instances, and then calculate the eigenvectors of the graph Laplacian matrix of this new network. The learned eigenvectors serve as the latent representations of instances. To predict the clusters, a traditional clustering algorithm such as
k-means is applied to the eigenvectors.
Later, since mid 2000s, with the rapid development of the web, especially social-networking sites, there has been an increase in the types and numbers of real-world networks available, such as Facebook, Flickr, and Twitter. NRL has been employed as an intermediate step when performing node classification [
12,
25,
26] and visualizations [
27] in real-world networks, including online social networks such as Flickr [
26] and BlogCatalog [
28], academic networks [
25], molecule structures [
27], and linked web pages [
12]. With the boom in web-based networks and prediction tasks performed on them, node representation learning, also known as network embedding, was formally defined [
1,
10,
29] in 2014 and has attracted intensive attention in recent years [
30,
31]. Since real-world networks are often large, alongside the major goal, i.e., preserving the topological structure information, scalability is another common objective of NRL algorithms [
8,
32]. The availability of networked data boosts the development of various NRL algorithms [
33,
34,
35], because it is significant for different practical scenarios which need distinct and appropriate NRL solutions.
However, it has become challenging to track the state-of-the-art node representation learning algorithms, given that numerous methods are available in the literature. When an NRL algorithm is proposed, only a few baseline methods and datasets are included in the empirical evaluation. Moreover, different NRL studies may use different experimental settings, such as evaluation tasks, hardware environments, and ways of hyperparameter tuning. Therefore, the lack of fair and comprehensive evaluation of state-of-the-art NRL algorithms is preventing researchers and practitioners from tracking the effective NRL algorithms for specific scenarios.
In this paper, we focus on unsupervised node representation learning. There are three major challenges in developing a fair and comprehensive evaluation framework for unsupervised NRL. First, it is difficult to guarantee fair comparisons. The running times of different NRL algorithms vary significantly. These algorithms also have different numbers of hyper-parameters and search spaces. A fair evaluation framework should take the running time and hyperparameter tuning into consideration. Second, tailored evaluation tasks are needed to comprehensively assess each NRL algorithm. Node classification and link prediction are two widely adopted downstream tasks when evaluating NRL algorithms. However, for each task, there are many ways to tune hyperparameters. Third, as different NRL algorithms are originally implemented in distinct systems, it is not easy to integrate them into a unified environment for a fair comparison.
To bridge this gap, in this paper, we develop a fair and comprehensive evaluation framework for unsupervised node representation learning (FURL). Through the development of FURL, we aim to answer two research questions. (1) How can we fairly evaluate state-of-the-art unsupervised NRL algorithms, given that they have different efficiencies and distinct search spaces for hyperparameters? (2) On the basis of a fair evaluation protocol, how can we comprehensively evaluate each unsupervised NRL algorithm? Our contributions can be summarized as follows.
We develop a novel evaluation framework—FURL, which could fairly and comprehensively evaluate unsupervised NRL algorithms.
We enable fair comparisons by performing a random search and allowing a fixed amount of time to fine-tune each algorithm.
We enable comprehensiveness by using three tailored evaluation tasks, i.e., classification fine tuned via a validation set, link prediction fine-tuned in the first run, and classification fine tuned via link prediction.
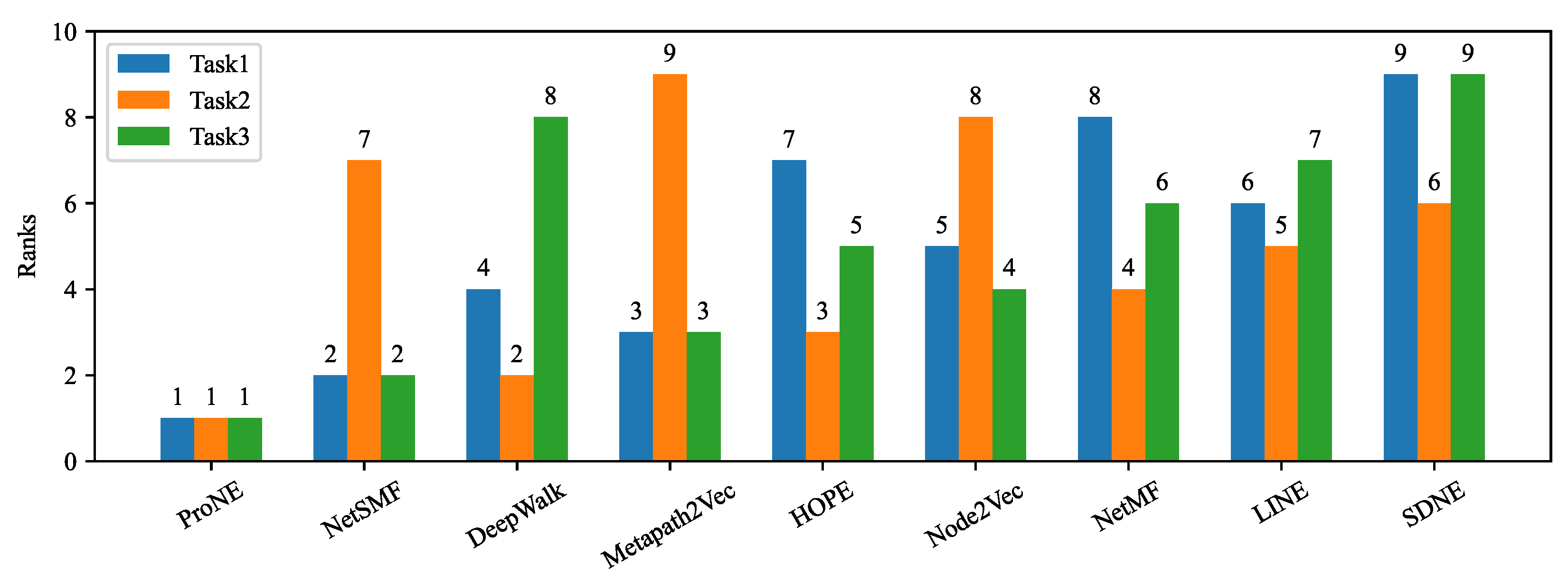
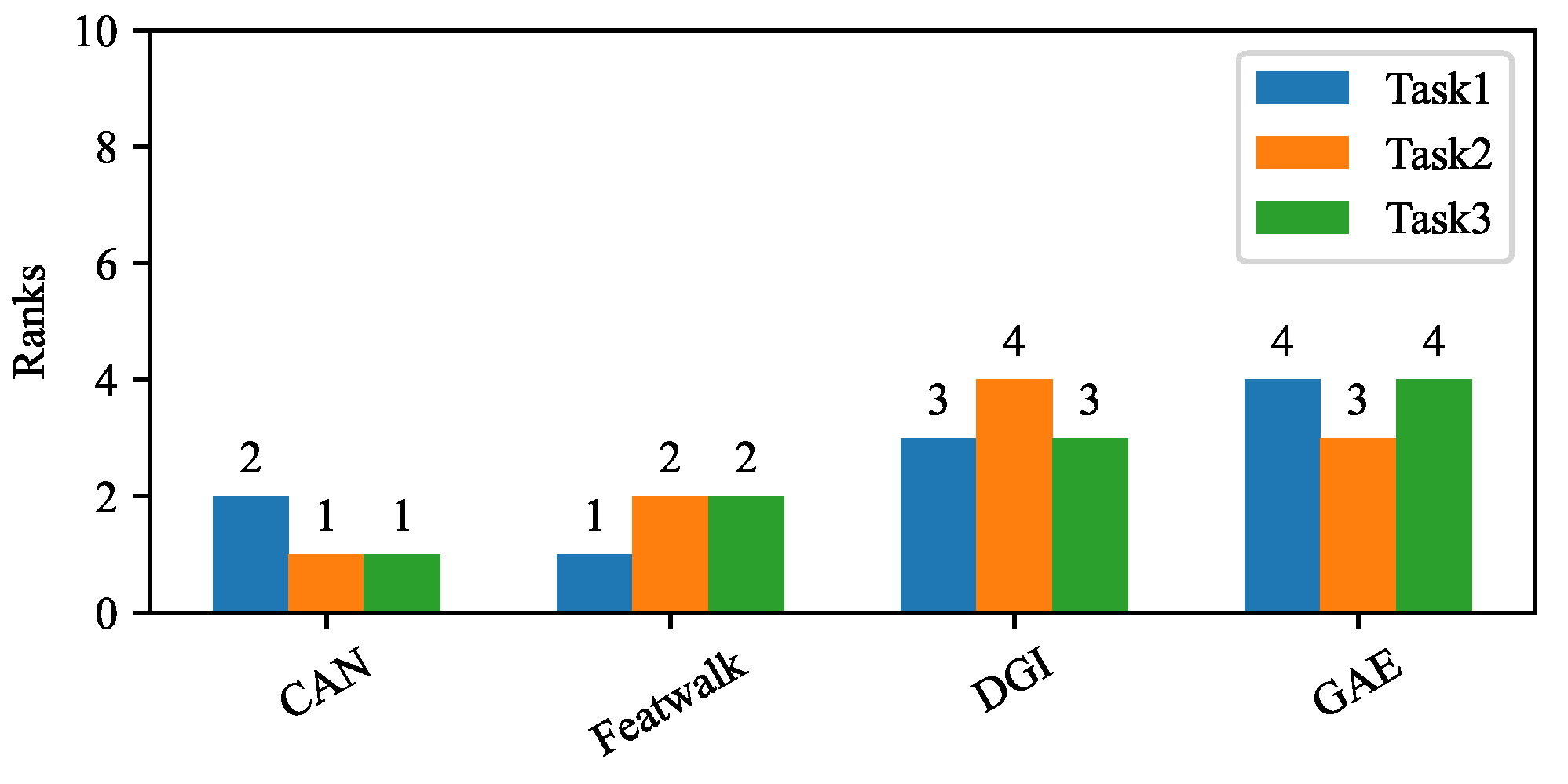
We perform empirical studies by utilizing eight datasets and thirteen state-of-the-art unsupervised NRL algorithms. It is straightforward to extend these to more unsupervised NRL algorithms and datasets. Based on the systematic results from three tasks and eight datasets, we assess the overall rank of all thirteen algorithms.
2. Fair and Comprehensive Evaluation Algorithm—FURL
To help researchers and practitioners track the state-of-the-art unsupervised node representation learning methods, an ideal solution would have two properties. First, fairness. Existing methods are implemented using different experimental settings, including cross-validation settings, hyperparameter tuning methods, and total running time. It is important to design a mechanism to fairly compare these methods under the same setting. Second, comprehensiveness. The learned embedding representations are designed for different downstream tasks in general. It is desirable to evaluate all NRL algorithms comprehensively from multiple aspects. Additionally, when integrating these multiple evaluation results into an overall rank, the integration schema should be in line with human prior experience. For example, it is expected that an NRL algorithm with ranks (evaluated from three aspects) should rank higher than an NRL algorithm with ranks . This is because the former NRL algorithm ranks second in the first aspects, indicating a significant potential.
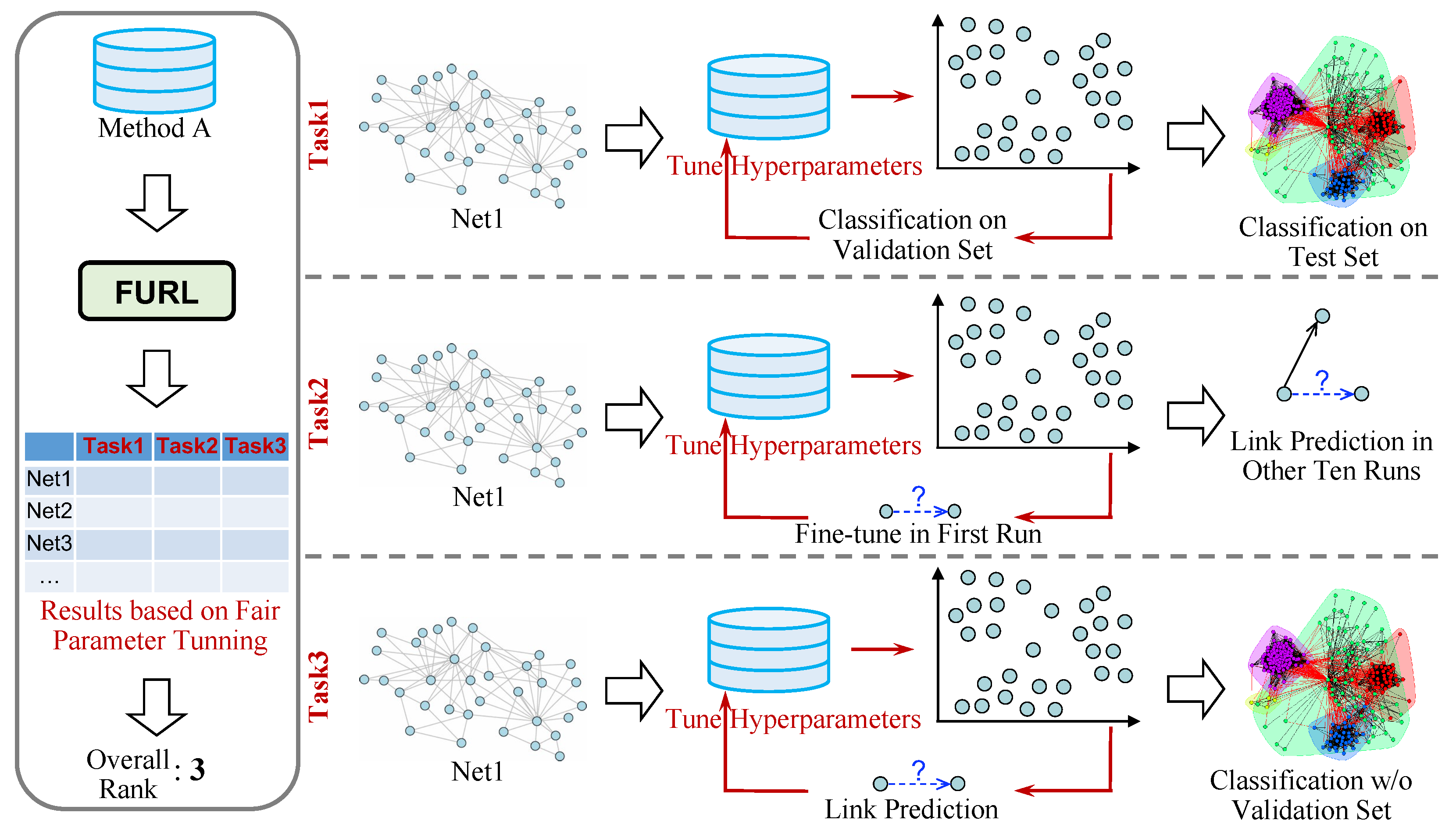
We propose a fair and comprehensive evaluation framework—FURL. Its core idea is illustrated in
Figure 2. To systematically evaluate an NRL method, we apply it to performing three tasks. To make the comparisons fair, on each task, the total amount of hyperparameter tuning time and running time is the same for all methods. We now introduce the three tasks in detail. We design a tailored integration schema to combine evaluation results in three tasks. It would assess a comprehensive rank for each given NRL algorithm. We now introduce the three tasks in detail.
2.1. Task 1—Classification Fine Tuned via a Validation Set
Node classification has been widely used to evaluate embedding models [
36,
37]. As illustrated in
Figure 2, Task 1 consists of three steps. First, given an NRL method, e.g., Method A, we apply it to embed the entire network, e.g., Net1, and learn embedding representations for all nodes. We use
k-fold cross-validation to separate all the nodes into a training set and a test set. Second, we tune the hyperparameters of Method A in the first round (
k rounds in total, corresponding to
k folds), and then fix the hyperparameters for all
k rounds. Specifically, in the first round, we employ
of the training set as a validation set to tune hyperparameters. We leverage the embedding representations of the remaining training nodes (
) and their labels to train support vector machines (SVMs). Then, we use the trained SVMs to predict the classes of nodes in the validation set. Based on the classification performance on the validation set, we select the best hyperparameters for the embedding model, i.e., Method A. Third, after we have selected the best hyperparameters, we add the validation set back into the training set. Given the embedding representations learned by fine tuning model (with the best hyperparameters), we conduct
k-fold cross-validation ten times, named as ten runs. In each run, there are
k rounds. In each round, we use the labels of the training nodes to train SVMs, and use them to predict the classes of test nodes. The average of all
results on the test sets is employed as the final performance of Method A in Task 1.
In summary, we employ a simple process, i.e., using a validation set in the first round, to fine tune the embedding model. This is because efficiency is important for hyperparameter searching. After we have identified the best hyperparameters, we evaluate Method A by performing k-fold cross-validation ten times. This is because comprehensiveness is essential to the final evaluation result. It should be noted that the validation set is generated from the training set in the first round, so test data is not leaked in the hyperparameter tuning. Task 1 is not end-to-end.
2.2. Task 2—Link Prediction Fine Tuned in the First Run
Link prediction has also been widely used to evaluate embedding models. In this task, we evaluate the effectiveness of each NRL algorithm in preserving network patterns by applying the learned representations to recover unseen links. As illustrated in
Figure 2, Task 2 consists of three steps. First, given a network, e.g., Net1, we randomly select
node pairs that are connected as positive samples, and
node pairs that are not connected as negative samples, where B denotes the total number of node pairs to be predicted. We remove the
edges of the
positive samples from the original network. Then, we apply the given NRL model, e.g., Method A, to embed the new network. We will employ the learned node representations to perform link prediction. Second, in the first run, we tune the hyperparameters of Method A. In particular, we mix the
positive samples and
negative samples and obtain a set with
B node pairs. For each pair in the
B node pairs, we denote its two nodes as
i and
j. We compute the inner product of the embedding representations of nodes
i and
j, and employ the inner product to indicate the probability of having a link between nodes
i and
j. After obtaining the inner products of all
B pairs, we rank them and compute the average precision (AP) and area under the receiver operating characteristic curve (ROC AUC), indicating the performance of link prediction. Based on this link-prediction performance, we select the best hyperparameters for the embedding model, i.e., Method A. Third, we employ the selected best hyperparameters to conduct another ten runs. In each run, we randomly select
positive samples and
negative samples from the original network. We remove the
edges of positive samples from the original network, and obtain a new network. We apply Method A with the selected best hyperparameters to embed the new network. We calculate the inner products of all
B pairs, and we compute the AP and ROC AUC. The average of the results of the ten runs is employed as the final performance of Method A in Task 2.
In summary, we fine tune Method A in the first run and obtain the best hyperparameters. We employ the selected hyperparameters to perform another ten runs. In each run, a different set of B samples are utilized to conduct the evaluation, that is, a different network (after removing edges) is used to conduct embedding. Both the hyperparameter tuning and final evaluation are conducted in an unsupervised manner.
2.3. Task 3—Classification Fine Tuned via Link Prediction
One of the core purposes of learning embedding representations is to have low-dimensional representations ready, such that we can directly apply them to downstream tasks if needed. To simulate such a scenario, we propose Task 3, in which we fine tune the NRL model in an unsupervised manner, and then apply the learned unsupervised embedding representations to perform classification. In this task, the hyperparameter-tuning process is the same as the one in Task 2. The final evaluation process is also the same as the one in Task 1. As illustrated in
Figure 2, Task 3 consists of four steps. First, given a network, we randomly select
node pairs that are connected as positive samples, and
node pairs that are not connected as negative samples. We remove the
edges of the
positive samples from the original network. We apply the given NRL model, e.g., Method A, to embed the new network. Second, we tune the hyperparameters of Method A based on link prediction. For each node pair in the
B node pairs (
negative samples and
positive samples), we denote its two nodes as
i and
j. We compute the inner product of the embedding representations of nodes
i and
j, and employ the inner product to indicate the probability of having a link between nodes
i and
j. After obtaining the inner products of all the
B pairs, we compute the AP and ROC AUC. Based on this link-prediction performance, we select the best hyperparameters for the embedding model, i.e., Method A. We apply the fine-tuned model (with the best hyperparameters) to the original network, and learn embedding representations. Third, we use
k-fold cross-validation to separate all nodes into a training set and a test set. We use the representations of training nodes to train SVMs, and use them to predict the classes of test nodes. Fourth, we repeat step three ten times, i.e., conducting
k-fold cross-validation ten times. The average of all
results of the test sets is employed as the final performance of Method A in Task 3.
2.4. Integration Schema for Overall Rank
FURL enables comprehensive evaluations of unsupervised NRL methods. It involves not only two prediction tasks, but also different ways of hyperparameter tuning. Although unsupervised NRL methods are generally trained without labels, the hyperparameter searching can be conducted with or without labeled data. In Task 1, we use labels to tune hyperparameters. In Tasks 2 and 3, we tune hyperparameters without using labels.
We apply each unsupervised NRL algorithm to perform the aforementioned three tasks on all datasets. In each task and each dataset, all algorithms are assigned a fixed amount of time to conduct hyperparameter tuning. They all use random search to tune hyperparameters. Thus, we can perform the evaluation in a fair way.
Let
D denote the total number of datasets used in the evaluation. Let
C denote the total number of unsupervised NRL algorithms that we have included in the experiments. Let
denote the rank of an algorithm, e.g., Method A, among all
C algorithms, based on their performance in the
task on the
dataset. We collect the ranks of Method A as a matrix
. Then, the overall rank of Method A can be calculated by computing the rank product over all datasets and three tasks as follows. The rank product is a widely used approach to combine ranked lists.
which can be simplified as follows,
where
takes the result of Method A as input, compares it with the corresponding results of all other
algorithms, and returns the rank of Method A as output. Equation (
1) is simplified into Equation (
2) by applying a logarithmic function to the output of rank products before computing ranks using
. Since the logarithmic operation is monotonic, this transformation does not affect the final ranks. As illustrated in Equation (
2), our schema integrates the rank matrix
in two steps. First, we sum up the logarithm of the ranks of Method A on all
D datasets. Then,
can help us find the rank of Method A on the
ith task. Second, we sum up the logarithm of the ranks of Method A on all three tasks. Finally,
can return the overall rank of Method A.
In each step, we follow a map-and-aggregate policy. The ranks are first mapped using a logarithmic function, then aggregated by summing up. The mapping function needs to be monotone, aiming to maintain the order of algorithms after mapping. The simplified rank product indicates that an algorithm that ranks 2th, 3th, and 4th in the three tasks has a higher potential than an algorithm that ranks 3th, 3th, and 3th.
5. Discussions
For hardware, it is challenging to ensure absolute fairness because NRL methods may or may not employ GPU. We can roughly categorize NRL methods into two groups, i.e., CPU only and GPU involved. For methods in the first group, the same number of threads is allocated to each method, while different methods will use it in different ways. If a method does not have multiprocessing or multithreading functions, it will only occupy one thread even though we have allocated more resources. For methods in the second group, we can provide the same resources, though they may not make full use of them. There is a gap between the performance of the CPU and GPU. However, it should be considered as an advantage of a method, if it could fully utilize the resources or accelerate computing by GPU.
Another problem is the search space of hyperparameters. For most hyperparameters, the search space is continuous. It is impossible and impractical to fine tune precisely within a constrained time. Meanwhile, the parameter sensitiveness is non-uniform, e.g., learning rate and final task performance do not show a linear correlation. Therefore, for the most frequently used parameters, such as learning rate and dropout, we restrict the search space to a set of discrete values within the commonly used parameter range. In this way, we introduce prior results into hyperparameter searching and significantly improve the searching efficiency. Moreover, when a method runs out of the total given tuning time, we will not interrupt the hyperparameter tuning immediately. Instead, we will wait until the current trial ends.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}