1. Introduction
Currently, the
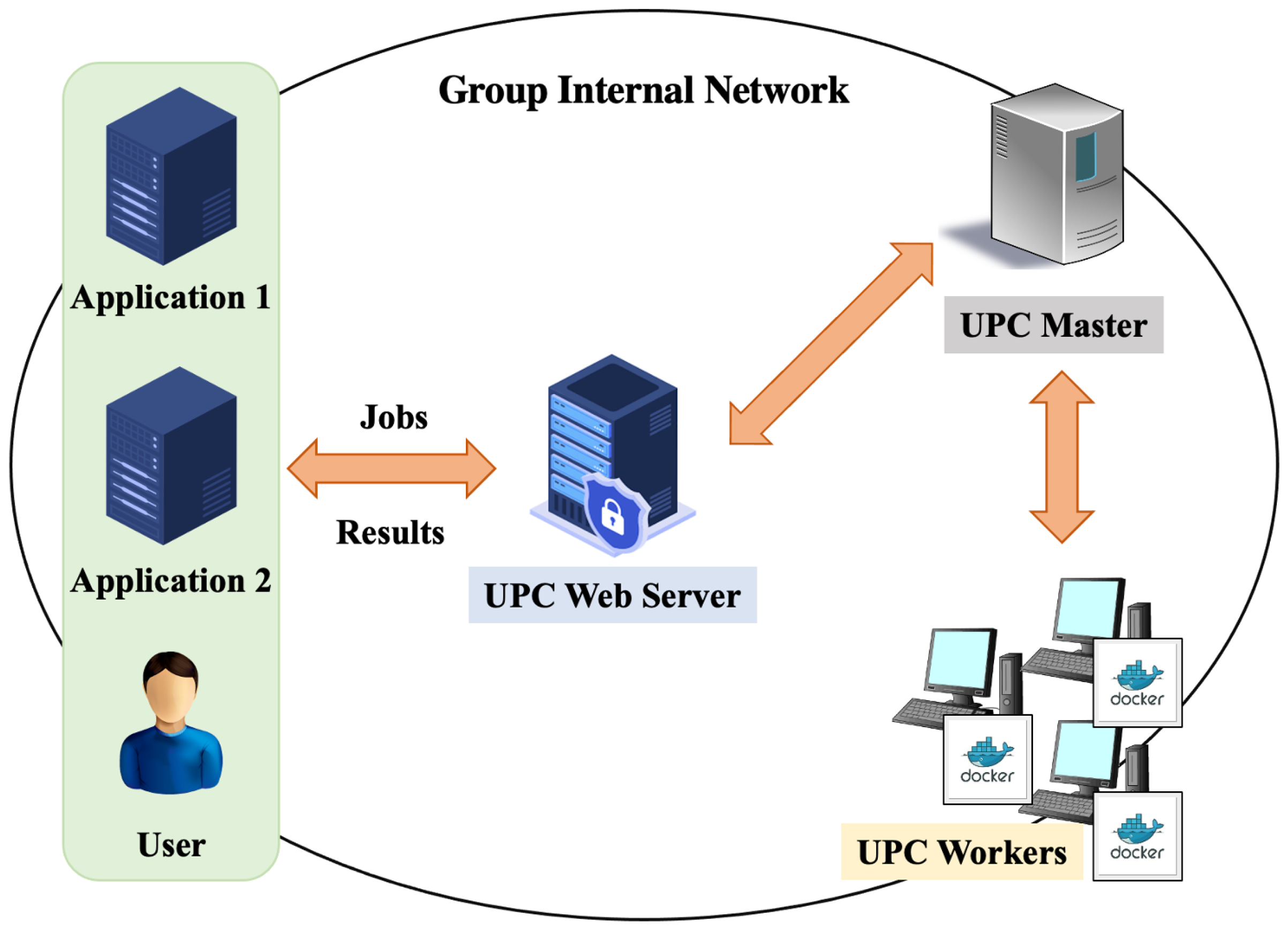
User-PC computing (UPC) system has been studied as a low-cost and high-performance distributed computing platform [
1]. The UPC system uses idling resources of personal computers (PCs) in a group to handle a number of various computing jobs from users. Then, the proper assignment of incoming jobs to workers is very important to effectively deal with them by using computational resources properly. As a result, the job assignment algorithm is critical to achieve the minimization for
makespan to complete all the demanded jobs in the UPC system.
Previously, we proposed the algorithm of assigning
non-uniform jobs to workers in the UPC system [
2]. In
non-uniform jobs, the programs are much different from each other, including the developed programming languages, the number of threads, and the requiring data. The execution time for each
non-uniform job is highly different from the others. The previous algorithm can find the job-worker assignment through two stages sequentially, of which are heuristic due to the nature of the
NP-hardness and cannot guarantee the optimality of the solution.
Some applications need to execute a lot of uniform jobs that use the identical program but with slightly different data/files, where they take a similar CPU time on a PC. The applications include deep learning (machine learning), physics simulations, software testing, computer network simulations, mathematical modeling, and mechanics modeling. These jobs have the common feature of a similar CPU time when they run on a specific PC. The uniform jobs often need a long CPU time. For example, in physics or network simulations, it can take several days to run one job. Nevertheless, it will be necessary to find the best result of all the input data by repeating them to slightly change some parameter values for the program and running them. This work can be common in research activities using computer simulations.
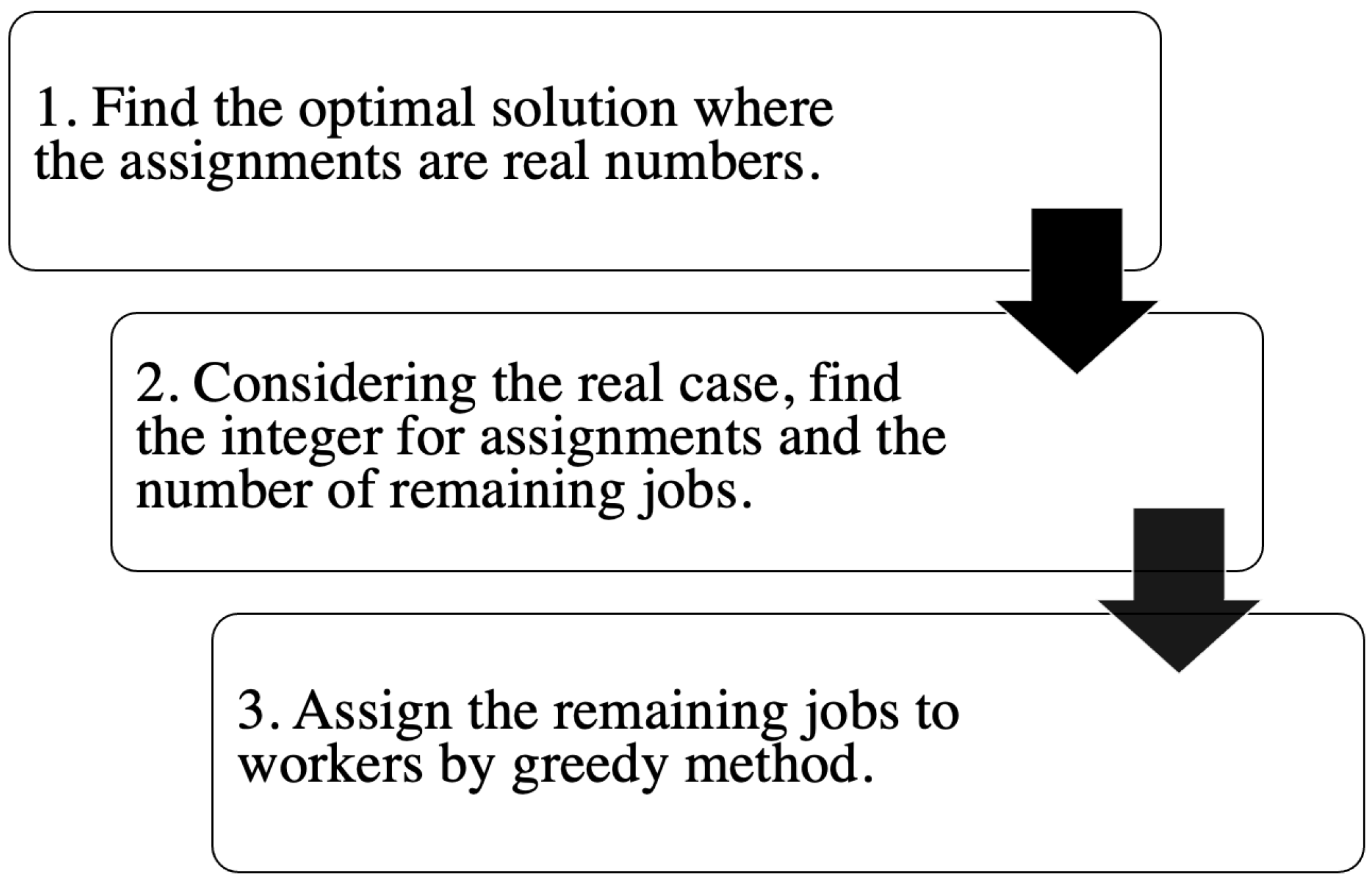
In this paper, we propose a static assignment algorithm of uniform jobs to workers in the UPC system, using simultaneous linear equations to find the lower bound on makespan, where every worker requires the same CPU time to complete the assigned jobs. The simultaneous linear equations describe the equality of the estimated CPU time among the workers, and the equality of the total number of assigned jobs to workers with the number of given jobs. The estimated CPU time considers simultaneous executions of multiple jobs on one worker by using its multiple cores. Since solutions of simultaneous linear equations become real numbers in general, the integer number of jobs assigned to each worker is introduced to them in a greedy way.
For evaluations of the proposal, we consider
uniform jobs in the three applications for the UPC system, namely,
OpenPose [
3],
OpenFOAM [
4], and
code testing [
5,
6]. For
OpenPose, the CNN-based program runs with 41 images of human bodies. For
OpenFOAM, the physics simulation program runs with 32 parameter sets. For
unit testing, the open-source programs run with 578 source codes that were submitted from students to the server in the
Android programming learning assistance system (APLAS). These jobs were applied to the proposed algorithm and were assigned to six workers in the testbed UPC system by following the results. Then, the CPU time was measured by running them. For comparisons, two simple algorithms were also implemented where the jobs were applied, and the CPU time was measured. The evaluation results show that the difference between the longest CPU time and the shortest one among the six workers became 92 s, and
makespan of the UPC system was reduced by
on average from the results by comparative algorithms. Thus, the effectiveness of the proposal was confirmed.
The proposed algorithm limits the application to the jobs where the CPU time is nearly equal to a worker. This limitation can simplify the job scheduling algorithm to only considering the number of jobs assigned to each worker, while neglecting the differences between individual jobs. Fortunately, it is possible to alleviate this limitation to a certain degree by considering the granularity of the CPU time on a worker. The CPU time of a job that is applicable to the proposal is often proportional to the number of iteration steps before the termination, or to the number of elements in the computational model. For example, in computer network simulations, the number of iteration steps need to be selected with the unit time before simulations, where the CPU time is usually proportional to it. By considering a multiple of a constant number of iteration steps, such as 100, the CPU time can be estimated even if the number of iteration steps is widely changed with this granularity. In future works, we will study this extension of the proposed algorithm to increase its applicable applications.
The rest of this paper is organized as follows:
Section 2 discusses related works.
Section 3 reviews the UPC system,
OpenPose,
OpenFOAM, and
code testing in
APLAS.
Section 4 presents the
static assignment algorithm of
uniform jobs to workers in the UPC system.
Section 5 evaluates the proposal through experiments.
Section 6 extends the proposal to multiple job-type assignments. Finally,
Section 7 concludes this paper with future works.
2. Related Works in the Literature
In this section, we discuss some related works in the literature.
In [
7], Lin proposed several linear programming models and algorithms for identical jobs (
uniform jobs) on parallel uniform machines for individual minimizations of several different performance measures. The proposed linear programming models provide structured insights of the studied problems and provide an easy way to tackle the scheduling problems.
In [
8], Mallek et al. addressed the problem of scheduling identical jobs (
uniform jobs) on a set of parallel uniform machines. The jobs are subjected to conflicting constraints modeled by an undirected graph
G, in which adjacent jobs are not allowed to be processed on the same machine. The minimization of the maximum
makespan in the schedule is known to be
NP-hard. To solve the general case of this problem, they proposed mixed-integer linear programming formulations alongside lower bounds and heuristic approaches.
In [
9], Bansal et al. proposed the two-stage
Efficient Refinery Scheduling Algorithm (ERSA) for distributed computing systems. In the first stage, it assigns a task according to the min–max heuristic. In the second stage, it improves the scheduling by using the refinery scheduling heuristic that balances the loads across the machines and reduces
makespan.
In [
10], Murugesan et al. proposed a multi-source task scheduler to map the tasks to the distributed resources in a cloud. The scheduler has three phases: the task aggregation, the task selection, and the task sequencing. By using the ILP formulation, this scheduler minimizes
makespan while satisfying the budget allotted by the cloud user based on the divisible load theory.
In [
11], Garg et al. proposed the
adaptive workflow scheduling (AWS) for grid computing using the dynamic resources based on the rescheduling method. The AWS has three stages of the initial static scheduling, the resource monitoring, and the rescheduling, to minimize
makespan using the directed acyclic graph workflow model for grid computing. It deals with the heterogeneous dynamic grid environment, where the availability of computing nodes and link bandwidths are inevitable due to existences of loads.
In [
12], Gawali et al. proposed the two-stage
Standard Deviation-Based Modified Cuckoo Optimization Algorithm (SDMCOA) for the scheduling of distributed computing systems. In the first stage, it calculates the sample initial population among all the available number of task populations. In the second stage, the modified COA immigrates and lays the tasks.
In [
13], Bittencourt et al. reviewed existing scheduling problems in cloud computing and distributed systems. The emergence of distributed systems brought new challenges on scheduling in computer systems, including clusters, grids, and clouds. They defined a taxonomy for task scheduling in cloud computing, namely, pre-cloud schedulers and cloud schedulers, and classified existing scheduling algorithms in the taxonomy. They introduced future directions for scheduling research in cloud computing.
In [
14], Attiya et al. presented a modified
Harris hawks optimization (HHO) algorithm based on the
simulated annealing (SA) for scheduling the jobs in a cloud environment. In this approach, SA is employed as a local search algorithm to improve the convergence rate and the solution quality generated by the standard HHO algorithm. HHO is a novel population-based, nature-inspired optimization paradigm proposed by Heidari et al. [
15]. The main inspiration of HHO is the cooperative behavior and the chasing style of Harris’ hawks in nature. In the HHO model, several hawks explore prey, respectively, and simultaneously after attacking the target from different directions to surprise it.
In [
16], Al-Maytami et al. presented a novel scheduling algorithm using
Directed Acyclic Graph (DAG) based on the
Prediction of Tasks Computation Time algorithm (PTCT) to estimate the preeminent scheduling algorithm for prominent cloud data. The proposed algorithm provides a significant improvement with respect to
makespan and reduces the computational complexity via employing
Principal Components Analysis (PCA) and reducing the
Expected-Time-to-Compute (ETC) matrix.
In [
17], Panda et al. proposed an
energy-efficient task scheduling algorithm (ETSA) to address the demerits associated with the task consolidation and scheduling. The proposed algorithm
ETSA takes into account the completion time and the total utilization of a task on the resources, and follows a normalization procedure to make a scheduling decision. The
ETSA provides an elegant trade-off between energy efficiency and
makespan, more so than the existing algorithms.
5. Evaluation
In this section, we evaluate the proposal through extensive experiments which are running jobs in three applications on the testbed UPC system.
5.1. Testbed UPC System
Table 1 shows the PC specifications in the testbed UPC system. One master and six workers are used here.
5.2. Jobs
Table 2 shows the specifications of the jobs for the eight job types in our experiments. For the
code testing application in
APLAS, six job types are prepared, where each job type represents one assignment to students in
APLAS. These job types run the same programs of
JUnit and
Robolectric, but accept many different data of answer source codes and test codes. For the other applications, only one job type is considered.
5.3. CPU Time
Table 3 shows the constant CPU time required to start running the jobs on each worker for each of the six job types.
Table 4,
Table 5 and
Table 6 show the increasing CPU time when the number of jobs is increased by one until the number for the best throughput for each type.
Through preliminary experiments, we found the number of simultaneously running jobs for the highest throughput for each worker. For code testing in APLAS, PC1, PC2, and PC3 can run only one job in parallel due to the low specifications. This number is two for PC4, five for PC5, and six for PC6. For OpenPose, any worker can only execute one job because it uses a lot of threads to compute CNN. For OpenFOAM, for each worker, the CPU time is constant at any number of simultaneously running jobs until it reaches the number of cores in the worker.
5.4. Comparative Algorithms
For performance comparisons, we implemented two simple algorithms to assign non-uniform jobs to workers.
The first one is the First-Come-First-Serve (FCFS) algorithm. It assigns each job to the first available worker, starting from the worker with the highest specification until the one with the lowest. It limits the worker to executing only one job at a time.
The second is the best throughput-based FCFS (T-FCFS) algorithm. The difference between T-FCFS and FCFS is that each worker may execute multiple jobs simultaneously until the best throughput.
5.5. Total Makespan Results
Table 7 compares the maximum
makespan results for each job type when the testbed UPC system runs the jobs by following the assignments found by the algorithms. Furthermore, it shows the
lower bound (LB) on the maximum
makespan found at
First Step of the proposed algorithm for the reference of them.
The results indicate that for any job type, the maximum makespan result by the proposal is better than the results by the two compared algorithms and is close to the lower bound. Thus, the effectiveness of the proposal is confirmed. It is noted that the results by FCFS are far larger than the ones by the others because FCFS does not consider simultaneous multiple job executions for a worker.
5.6. Individual Makespan Results
For reference,
Table 8,
Table 9 and
Table 10 show
makespan or the total CPU time of each worker and the largest CPU time difference between the workers and the three algorithms. For
OpenFOAM, no job was assigned to
PC1–
PC4, because all of the 32 jobs can be executed simultaneously at
PC5 and
PC6. The largest CPU time difference by the proposal is smaller than the ones by the others, except for
ColorGame,
SoccerMatch,
AnimalTour, and
MyLibrary, where in
Table 4, the increasing CPU time of
PC1 is much larger than other workers, and the far smaller number of jobs was assigned. Therefore, the proposal can balance well the job assignments among the workers.
5.7. Discussions
The results in
Table 7 show improvements of maximum
makespan results by the proposed algorithm if compared with
T-FCFS. However, some differences can be observed against the
lower bound.
The current algorithm can find the assignment of some remaining jobs to workers, and assign an integer number of jobs to any worker in a greedy way, after the real number solutions are obtained by solving the simultaneous linear equations. A greedy method is usually difficult to give a near-optimum solution, since it only considers the local optimality under the current assignment.
To improve the solution quality, a local search method using iterations has often been adopted for solving combinatorial optimization problems, including this study. Therefore, we will study the use of a local search method for the remaining job assignment in the proposed algorithm.
6. Extension to Multiple Job Types Assignment
In this section, we extend the proposed algorithm to the case when jobs for multiple job types are assigned together.
6.1. Algorithm Extension
In
First Step of the proposed algorithm, the linear equations are modified in this extension to consider the CPU time to complete all the jobs for the plural job types assigned to each worker:
The number of variables to be solved is , where represents the number of workers and represents the number of job types, respectively. Thus, linear equations are necessary to solve them. In the original algorithm, for each job type, linear equations are derived for the CPU time equality and one equation is for the job number. Thus, equations can be introduced.
However, in this extension, the total number of linear equations for the CPU time equality is reduced to
because all the job types need to be considered together here. Therefore, to solve the linear equations uniquely, the following
linear equations will be introduced by considering the total CPU time for
job types together for
combinations of
job types, in addition to the total CPU time for
job types together in (
13):
where
represents the set of the job types in
T except for job type
u.
The
combinations of
job types are selected by excluding the combination where the following estimated total CPU time to execute all the jobs in the remaining job types on
PC6 is smallest:
Then, in Second Step and Third Step, the estimated makespan for each worker and the maximum estimated makespan among the workers are modified to consider all the given job types together.
6.2. Total Makespan Results
Table 11 shows the maximum
makespan results when the testbed UPC system runs the jobs by following the assignments by the extended algorithm. When compared with the result by the original algorithm, it is reduced by
, and becomes closer to the
lower bound. The difference between our result and the lower bound is very small. Thus, this extension is effective when plural job types are requested at the UPC system together.
6.3. Discussions
The result in
Table 11 confirms some reduction in the total
makespan result by the extended algorithm. However, there is still a difference when compared to the
lower bound. Thus, it is necessary to further improve the algorithm.
One idea for this improvement in the extended algorithm will not be to limit the exclusion of one job type combination—where the estimated total CPU time to execute all jobs in the remaining job types on PC6 is the smallest—and to generate the linear equations for the CPU time equality. Instead, every combination will be excluded one by one to obtain the result for each combination exclusion. Then, the best one will be selected among them.
7. Conclusions
This paper proposed the static uniform job assignment algorithm to workers in the UPC system. The simultaneous linear equations have been derived to find the optimal assignment of minimizing the maximum makespan among the workers, where the CPU time to complete the assigned jobs becomes equal among all the workers.
For an evaluation, the 651 uniform jobs in three applications, OpenPose, OpenFOAM, and code testing in APLAS, were considered to run on six workers in the testbed UPC system, and the makespan was compared with the results by two simple algorithms and the lower bounds. The comparisons confirmed the effectiveness of the proposal.
The novelty of the proposal is that with a very simple formula, it is able to provide the near-optimal solutions to NP-complete problems in the User-PC computing (UPC) system, a typical distributed system. The current algorithm limits the jobs whereby the computing time for a worker is nearly equal. This limitation can simplify our approach of considering the simple assignment of the number of jobs for each worker without considering the differences among individual jobs.
Fortunately, it is possible to alleviate this limitation by considering the granularity of the CPU time for a worker. The CPU time of a job in suitable applications to the proposal is often proportional to the number of iteration steps before the termination or the number of elements in the model. By considering a multiple of a constant number of iteration steps, the CPU time can be estimated even if the number of iteration steps is widely changed with this granularity; this finding will be in future studies.
In future studies, we will also improve the algorithm for remaining job assignments and simultaneous job assignments of multiple job types, and we will study the combination of uniform jobs and non-uniform jobs in the job-worker assignment algorithm for the UPC system.







{kind=link}
{kind=link}