
A Review of Parallel Heterogeneous Computing Algorithms in Power Systems


Abstract
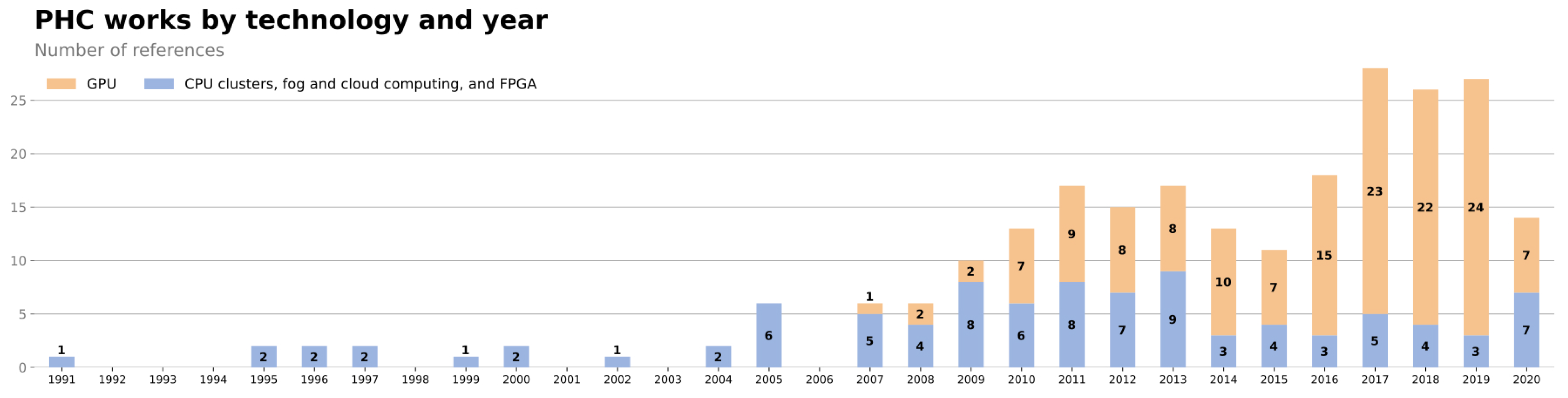
1. Introduction
2. Parallel Heterogeneous Computing
2.1. Central Processing Unit
2.2. Fog and Cloud Computing
2.3. Field-Programmable Gate Array
2.4. Graphics Processing Unit
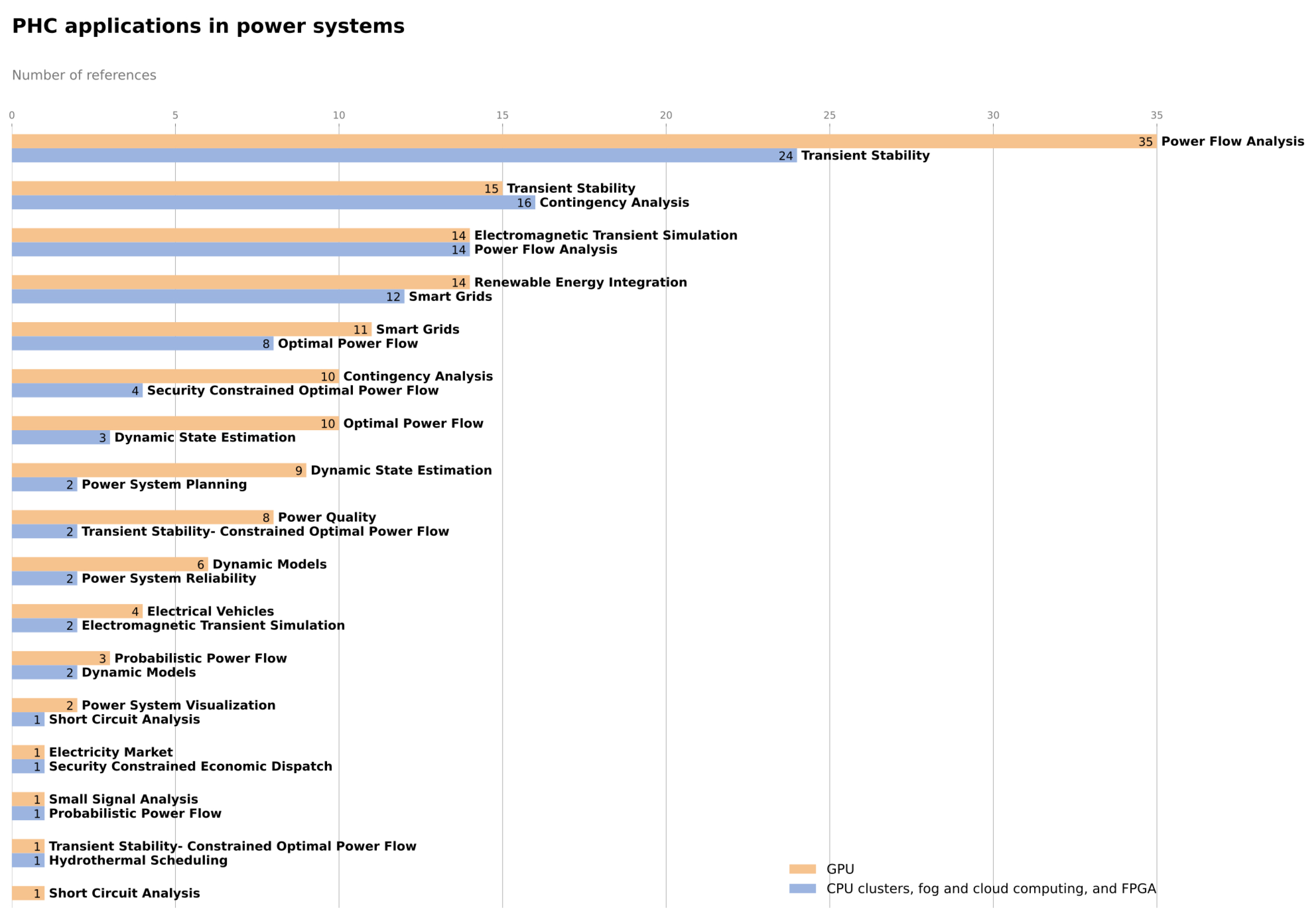
3. PHC in Power Systems
3.1. GPU
3.1.1. Power Flow Analysis
3.1.2. Transient Stability
3.1.3. Electromagnetic Transient Simulation
3.1.4. Renewable Energy Integration
3.1.5. Smart Grids
3.1.6. Contingency Analysis
3.1.7. Optimal Power Flow
3.1.8. Dynamic State Estimation, Power Quality, and Dynamic Models
3.1.9. Other Applications
3.2. CPU Clusters, Fog and Cloud Computing, and FPGA
3.2.1. Transient Stability
3.2.2. Contingency Analysis
3.2.3. Power Flow Analysis
3.2.4. Smart Grids
3.2.5. Optimal Power Flow and Security Constrained Optimal Power Flow
3.2.6. Other Applications
4. Conclusions
5. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, S.; Dinavahi, V. Fast Batched Solution for Real-Time Optimal Power Flow With Penetration of Renewable Energy. IEEE Access 2018, 6, 13898–13910. [Google Scholar] [CrossRef]
- Mojlish, S.; Erdogan, N.; Levine, D.; Davoudi, A. Review of Hardware Platforms for Real-Time Simulation of Electric Machines. IEEE Trans. Transp. Electrif. 2017, 3, 130–146. [Google Scholar] [CrossRef]
- Marin, M. GPU-Enhanced Power Flow Analysis. Ph.D. Thesis, Universite de Perpignan Via Domitia-University College Dublin, Dublin, Ireland, 2016. [Google Scholar]
- Li, Y.; Zhang, Z. Parallel Computing: Review and Perspective. In Proceedings of the 2018 5th International Conference on Information Science and Control Engineering, ICISCE 2018, Zhengzhou, China, 20–22 July 2018; pp. 365–369. [Google Scholar] [CrossRef]
- Kyaw, L.Y.; Phyu, S. Scheduling Methods in HPC System: Review. In Proceedings of the 2020 IEEE Conference on Computer Applications, ICCA 2020, Yangon, Myanmar, 27–28 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yoon, D.H.; Han, Y. Parallel power flow computation trends and applications: A review focusing on GPU. Energies 2020, 13, 2147. [Google Scholar] [CrossRef]
- Duan, P.; Xu, S.; Chen, H.; Yang, X.; Wang, S.; Hu, E. High Performance Computing (HPC)for Advanced Power System Studies. In Proceedings of the 2nd IEEE Conference on Energy Internet and Energy System Integration, EI2 2018-Proceedings, Beijing, China, 20–22 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Thijssen, J. Computational Physics; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Marksteiner, P. High-performance computing—An overview. Comput. Phys. Commun. 1996, 97, 16–35. [Google Scholar] [CrossRef]
- Andrade, H.; Crnkovic, I. A Review on Software Architectures for Heterogeneous Platforms. In Proceedings of the Asia-Pacific Software Engineering Conference, Nara, Japan, 4–7 December 2018; pp. 209–218. [Google Scholar] [CrossRef]
- Glaskowsky, P.N. NVIDIA’s Fermi: The First Complete GPU Computing Architecture. Available online: https://slideplayer.com/slide/8599949/ (accessed on 23 September 2021).
- Page, D. A Practical Introduction to Computer Architecture; Springer: Berlin/Heidelberg, Germany, 2009; p. 823. [Google Scholar] [CrossRef]
- Feng, Z.; Li, P. Multigrid on GPU: Tackling Power Grid Analysis on parallel SIMT platforms. In Proceedings of the 2008 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 10–13 November 2008; pp. 647–654. [Google Scholar] [CrossRef]
- Shi, J.; Cai, Y.; Hou, W.; Ma, L.; Tan, S.X.D.; Ho, P.H.; Wang, X. GPU friendly Fast Poisson Solver for structured power grid network analysis. In Proceedings of the 2009 46th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 26–31 July 2009; pp. 178–183. [Google Scholar]
- Dzafic, I.; Neisius, H.-T. Real-time power flow algorithm for shared memory multiprocessors for European distribution network types. In Proceedings of the 2010 Conference Proceedings IPEC, Singapore, 27–29 October 2010; pp. 152–158. [Google Scholar] [CrossRef]
- Garcia, N. Parallel power flow solutions using a biconjugate gradient algorithm and a Newton method: A GPU-based approach. In Proceedings of the IEEE PES General Meeting, Minneapolis, MN, USA, 25–29 July 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Singh, J.; Aruni, I. Accelerating Power Flow studies on Graphics Processing Unit. In Proceedings of the 2010 Annual IEEE India Conference (INDICON), Kolkata, India, 17–19 December 2010; pp. 1–5. [Google Scholar] [CrossRef]
- Feng, Z.; Zhao, X.; Zeng, Z. Robust Parallel Preconditioned Power Grid Simulation on GPU With Adaptive Runtime Performance Modeling and Optimization. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2011, 30, 562–573. [Google Scholar] [CrossRef]
- Li, Z.; Donde, V.D.; Tournier, J.-C.; Yang, F. On limitations of traditional multi-core and potential of many-core processing architectures for sparse linear solvers used in large-scale power system applications. In Proceedings of the 2011 IEEE Power and Energy Society General Meeting, Detroit, MI, USA, 24–28 July 2011; pp. 1–8. [Google Scholar] [CrossRef]
- Tournier, J.C.; Donde, V.; Li, Z. Comparison of direct and iterative sparse linear solvers for power system applications on parallel computing platforms. In Proceedings of the 17th Power Systems Computation Conference, PSCC 2011, Stockholm, Sweden, 22–26 August 2011. [Google Scholar]
- Vilachá, C.; Moreira, J.C.; Míguez, E.; Otero, A.F. Massive Jacobi power flow based on SIMD-processor. In Proceedings of the 2011 10th International Conference on Environment and Electrical Engineering, Rome, Italy, 8–11 May 2011; pp. 1–4. [Google Scholar] [CrossRef]
- Ablakovic, D.; Dzafic, I.; Kecici, S. Parallelization of radial three-phase distribution power flow using GPU. In Proceedings of the 2012 3rd IEEE PES Innovative Smart Grid Technologies Europe (ISGT Europe), Berlin, Germany, 14–17 October 2012; pp. 1–7. [Google Scholar] [CrossRef]
- Guo, C.; Jiang, B.; Yuan, H.; Yang, Z.; Wang, L.; Ren, S. Performance Comparisons of Parallel Power Flow Solvers on GPU System. In Proceedings of the 2012 IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Seoul, Korea, 19–22 August 2012; pp. 232–239. [Google Scholar] [CrossRef]
- Wigington, A.; Min, L.; Li, C.; Murray, W.; Narayan, A. Advancing the adoption of advanced computing methods and technologies for real-time control center operations. In Proceedings of the 2012 IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 22–26 July 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Yang, M.; Sun, C.; Li, Z.; Cao, D. An improved sparse matrix-vector multiplication kernel for solving modified equation in large scale power flow calculation on CUDA. In Proceedings of the 7th International Power Electronics and Motion Control Conference, Harbin, China, 2–5 June 2012; Volume 3, pp. 2028–2031. [Google Scholar] [CrossRef]
- Kamiabad, A.A.; Tate, J.E. Polynomial Preconditioning of Power System Matrices with Graphics Processing Units. In High Performance Computing in Power and Energy Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 229–246. [Google Scholar] [CrossRef]
- Li, X.; Li, F.; Clark, J.M. Exploration of multifrontal method with GPU in power flow computation. In Proceedings of the 2013 IEEE Power Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Li, X.; Li, F. GPU-based power flow analysis with Chebyshev preconditioner and conjugate gradient method. Electr. Power Syst. Res. 2014, 116, 87–93. [Google Scholar] [CrossRef]
- Blaskiewicz, P.; Zawada, M.; Balcerek, P.; Dawidowski, P. An Application of GPU Parallel Computing to Power Flow Calculation in HVDC Networks. In Proceedings of the 2015 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turku, Finland, 4–6 March 2015; pp. 635–641. [Google Scholar] [CrossRef]
- Li, X.; Li, F. GPU-based two-step preconditioning for conjugate gradient method in power flow. In Proceedings of the 2015 IEEE Power Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Magaña-Lemus, E.; Medina, A.; Ramos-Paz, A. Periodic steady state solution of power systems by selective transition matrix identification, LU decomposition and graphic processing units. In Proceedings of the 2015 IEEE Power Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Jiang, H.; Chen, D.; Li, Y.; Zheng, R. A Fine-Grained Parallel Power Flow Method for Large Scale Grid Based on Lightweight GPU Threads. In Proceedings of the 2016 IEEE 22nd International Conference on Parallel and Distributed Systems (ICPADS), Wuhan, China, 13–16 December 2016; pp. 785–790. [Google Scholar] [CrossRef]
- Araujo, M.H.D.; Rios, A.M.; Lemus, E.M. Periodic Steady State of Power Networks Using Limit Cycle Extrapolation, Spline Interpolation and Parallel Processing Based on GPUs. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 1606–1611. [Google Scholar] [CrossRef]
- Huang, S.; Dinavahi, V. Performance analysis of GPU-accelerated fast decoupled power flow using direct linear solver. In Proceedings of the 2017 IEEE Electrical Power and Energy Conference (EPEC), Saskatoon, SK, Canada, 22–25 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Li, X.; Li, F.; Yuan, H.; Cui, H.; Hu, Q. GPU-Based Fast Decoupled Power Flow With Preconditioned Iterative Solver and Inexact Newton Method. IEEE Trans. Power Syst. 2017, 32, 2695–2703. [Google Scholar] [CrossRef]
- Marin, M.; Defour, D.; Milano, F. Asynchronous Power Flow on Graphic Processing Units. In Proceedings of the 2017 25th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), St. Petersburg, Russia, 6–8 March 2017; pp. 255–261. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Okou, F. Parallel Power Flow on Graphics Processing Units for Concurrent Evaluation of Many Networks. IEEE Trans. Smart Grid 2017, 8, 1639–1648. [Google Scholar] [CrossRef]
- Wang, M.; Xia, Y.; Chen, Y.; Huang, S. GPU-based power flow analysis with continuous Newton’s method. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, G.; Bo, R.; Chien, L.; Zhang, X.; Shi, F.; Xu, C.; Feng, Y. GPU-Based Batch LU-Factorization Solver for Concurrent Analysis of Massive Power Flows. IEEE Trans. Power Syst. 2017, 32, 4975–4977. [Google Scholar] [CrossRef]
- Liu, Z.; Song, Y.; Chen, Y.; Huang, S.; Wang, M. Batched Fast Decoupled Load Flow for Large-Scale Power System on GPU. In Proceedings of the 2018 International Conference on Power System Technology (POWERCON), Guangzhou, China, 6–8 November 2018; pp. 1775–1780. [Google Scholar] [CrossRef]
- Gnanavignesh, R.; Shenoy, U.J. GPU-Accelerated Sparse LU Factorization for Power System Simulation. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), 29 September–2 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Gnanavignesh, R.; Shenoy, U.J. Parallel Sparse LU Factorization of Power Flow Jacobian using GPU. In Proceedings of the TENCON 2019-2019 IEEE Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 1857–1862. [Google Scholar] [CrossRef]
- Qi, S.; Li, G.; Bie, Z. Hybrid Energy Flow Calculation for Electric-Thermal Coupling System Based on Inexact Newton Method. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (iSPEC), Beijing, China, 21–23 November 2019; pp. 2443–2449. [Google Scholar] [CrossRef]
- Tang, K.; Fang, R.; Wang, X.; Dong, S.; Song, Y. Mass Expression Evaluation Parallel Algorithm Based on ‘Expression Forest’ and Its Application in Power System Calculation. In Proceedings of the 2019 IEEE Power Energy Society General Meeting (PESGM), Atlanta, GA, USA, 4–8 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, G.; Feng, Y.; Bo, R.; Zhang, T. GPU-accelerated sparse matrices parallel inversion algorithm for large-scale power systems. Int. J. Electr. Power Energy Syst. 2019, 111, 34. [Google Scholar] [CrossRef]
- Su, X.; He, C.; Liu, T.; Wu, L. Full Parallel Power Flow Solution: A GPU-CPU-Based Vectorization Parallelization and Sparse Techniques for Newton–Raphson Implementation. IEEE Trans. Smart Grid 2020, 11, 1833–1844. [Google Scholar] [CrossRef]
- Wu, J.Q.; Bose, A. Parallel solution of large sparse matrix equations and parallel power flow. IEEE Trans. Power Syst. 1995, 10, 1343–1349. [Google Scholar] [CrossRef]
- Feng, T.; Flueck, A.J. A message-passing distributed-memory Newton-GMRES parallel power flow algorithm. In Proceedings of the IEEE Power Engineering Society Summer Meeting, Chicago, IL, USA, 21–25 July 2002; Volume 3, pp. 1477–1482. [Google Scholar] [CrossRef]
- Foertsch, J.; Johnson, J.; Nagvajara, P. Jacobi load flow accelerator using FPGA. In Proceedings of the 37th Annual North American Power Symposium, Ames, IA, USA, 25–25 October 2005; pp. 448–454. [Google Scholar] [CrossRef]
- Johnson, J.; Vachranukunkiet, P.; Tiwari, S.; Nagvajara, P.; Nwankpa, C. Performance analysis of load flow computation using FPGA. In Proceedings of the 15th Power Systems Computation Conference, Liège, Belgium, 22–26 August 2005. [Google Scholar]
- Yang, F.; He, M.; Tang, Y.; Rao, M. Inexact block Newton methods for solving nonlinear equations. Appl. Math. Comput. 2005, 162, 1207–1218. [Google Scholar] [CrossRef]
- Wang, X.; Ziavras, S.G.; Nwankpa, C.; Johnson, J.; Nagvajara, P. Parallel solution of Newton’s power flow equations on configurable chips. Int. J. Electr. Power Energy Syst. 2007, 29, 422–431. [Google Scholar] [CrossRef]
- Li, Y.; Li, F.; Li, W. Parallel power flow calculation based on multi-port inversed matrix method. In Proceedings of the 2010 International Conference on Power System Technology: Technological Innovations Making Power Grid Smarter, Hangzhou, China, 24–28 October 2010. [Google Scholar] [CrossRef]
- Nechma, T.; Zwoliński, M.; Reeve, J. Parallel sparse matrix solver for direct circuit simulations on FPGAs. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; pp. 2358–2361. [Google Scholar] [CrossRef]
- Cui, T.; Franchetti, F. A multi-core high performance computing framework for distribution power flow. In Proceedings of the 2011 North American Power Symposium, Boston, TX, USA, 14–16 November 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Dağ, H.; Soykan, G. Power flow using thread programming. In Proceedings of the 2011 IEEE Trondheim PowerTech, Trondheim, Norway, 19–23 June 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Cui, T.; Franchetti, F. Optimized parallel distribution load flow solver on commodity multi-core CPU. In Proceedings of the 2012 IEEE Conference on High Performance Extreme Computing, Waltham, MA, USA, 10–12 September 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Ge, X.; Zhu, H.; Yang, F.; Wang, L.; Zeng, X. Parallel sparse LU decomposition using FPGA with an efficient cache architecture. In Proceedings of the 2017 IEEE 12th International Conference on ASIC (ASICON), Guiyang, China, 25–28 October 2017; pp. 259–262. [Google Scholar] [CrossRef]
- Ahmadi, A.; Jin, S.; Smith, M.C.; Collins, E.R.; Goudarzi, A. Parallel Power Flow based on OpenMP. In Proceedings of the 2018 North American Power Symposium (NAPS), Fargo, ND, USA, 9–11 September 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Yoon, D.H.; Kang, S.K.; Kim, M.; Han, Y. Exploiting coarse-grained parallelism using cloud computing in massive power flow computation. Energies 2018, 11, 2268. [Google Scholar] [CrossRef]
- Jalili-Marandi, V.; Dinavahi, V. Large-scale transient stability simulation on graphics processing units. In Proceedings of the 2009 IEEE Power Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Jalili-Marandi, V.; Dinavahi, V. SIMD-Based Large-Scale Transient Stability Simulation on the Graphics Processing Unit. IEEE Trans. Power Syst. 2010, 25, 1589–1599. [Google Scholar] [CrossRef]
- Baijian, W.; Guo, W.X.; Hu, J.Y.; Wang, F.Z.; Ye, J. GPU based parallel simulation of transient stability using symplectic Gauss algorithm and preconditioned GMRES method. In Proceedings of the 2012 Power Engineering and Automation Conference, Wuhan, China, 18–20 September 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Jalili-Marandi, V.; Zhou, Z.; Dinavahi, V. Large-Scale Transient Stability Simulation of Electrical Power Systems on Parallel GPUs. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1255–1266. [Google Scholar] [CrossRef]
- Qin, Z.; Hou, Y. A GPU-Based Transient Stability Simulation Using Runge-Kutta Integration Algorithm. Int. J. Smart Grid Clean Energy 2013, 2, 32–39. [Google Scholar] [CrossRef]
- Yu, Z.; Huang, S.; Shi, L.; Chen, Y. GPU-based JFNG method for power system transient dynamic simulation. In Proceedings of the 2014 International Conference on Power System Technology, Chengdu, China, 20–22 October 2014; pp. 969–975. [Google Scholar] [CrossRef]
- He, K.; Tan, S.X.; Zhao, H.; Liu, X.X.; Wang, H.; Shi, G. Parallel GMRES solver for fast analysis of large linear dynamic systems on GPU platforms. Integration 2016, 52, 10–22. [Google Scholar] [CrossRef]
- Liao, X.; Wang, F. Parallel computation of transient stability using symplectic Gauss method and GPU. IET Gener. Transm. Distrib. 2016, 10, 3727–3735. [Google Scholar] [CrossRef]
- Yu, Z.; Chen, Y.; Song, Y.; Huang, S. Comparison of parallel implementations of controls on GPU for transient simulation of power system. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 9996–10001. [Google Scholar] [CrossRef]
- Liu, K.; Liao, X.; Li, Y. Parallel Simulation of Power Systems Transient Stability Based on Implicit Runge–Kutta Methods and W-transformation. Electr. Power Compon. Syst. 2017, 45, 2246–2256. [Google Scholar] [CrossRef]
- Vasquez, A.D.; Sousa, T. A Parallel Processing Approach to Stability Analysis Considering Transmission and Distribution Systems. In Proceedings of the 2019 IEEE Milan PowerTech, Milan, Italy, 23–27 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Z.; Chakrabortty, A.; Kelley, C.T.; Feng, X.; Franzon, P. Improved Numerical Methodologies on Power System Dynamic Simulation Using GPU Implementation. In Proceedings of the 2019 IEEE Power Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 18–21 February 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, Y.; Guo, Q.; Sun, H.; Yu, Z.; Wu, J.; Hao, L. A novel data-driven approach for transient stability prediction of power systems considering the operational variability. Int. J. Electr. Power Energy Syst. 2019, 107, 379–394. [Google Scholar] [CrossRef]
- Yang, H.; Qiu, R.C.; Shi, X.; He, X. Unsupervised feature learning for online voltage stability evaluation and monitoring based on variational autoencoder. Electr. Power Syst. Res. 2020, 182, 106253. [Google Scholar] [CrossRef]
- Chai, J.S.; Zhu, N.; Bose, A.; Tylavsky, D.J. Parallel Newton type methods for power system stability analysis using local and shared memory multiprocessors. IEEE Trans. Power Syst. 1991, 6, 1539–1545. [Google Scholar] [CrossRef]
- Ten Bruggencate, M.; Chalasani, S. Parallel Implementations of the Power System Transient Stability Problem on Clusters of Workstations. In Proceedings of the 1995 ACM/IEEE Conference on Supercomputing, San Diego, CA, USA, 3–8 December 1995; p. 34. [Google Scholar] [CrossRef]
- La Scala, M.; Sblendorio, G.; Bose, A.; Wu, J.Q. Comparison of algorithms for transient stability simulations on shared and distributed memory multiprocessors. IEEE Trans. Power Syst. 1996, 11, 2045–2050. [Google Scholar] [CrossRef]
- Aloisio, G.; Bochicchio, M.A.; La Scala, M.; Sbrizzai, R. A distributed computing approach for real-time transient stability analysis. IEEE Trans. Power Syst. 1997, 12, 981–987. [Google Scholar] [CrossRef]
- Hong, C.; Shen, C.M. Parallel transient stability analysis on distributed memory message passing multiprocessors. In Proceedings of the 1997 Fourth International Conference on Advances in Power System Control, Operation and Management, Hong Kong, China, 11–14 November 1997; Volume 1, pp. 304–309. [Google Scholar] [CrossRef]
- Hong, C.; Shen, C.M. Implementation of parallel algorithms for transient stability analysis on a message passing multicomputer. In Proceedings of the 2000 IEEE Power Engineering Society Winter Meeting, Singapore, 23–27 January 2000; Volume 2, pp. 1410–1415. [Google Scholar] [CrossRef]
- Lu, J.; Yu, L.; Zhu, Y.L. Application in Electric Power System Transient Stability Analysis with PC Cluster System. In Proceedings of the 2005 IEEE/PES Transmission Distribution Conference Exposition: Asia and Pacific, Dalian, China, 18 August 2005; pp. 1–3. [Google Scholar] [CrossRef]
- Shu, J.; Xue, W.; Zheng, W. A parallel transient stability simulation for power systems. IEEE Trans. Power Syst. 2005, 20, 1709–1717. [Google Scholar] [CrossRef]
- Wei, X.; Shu, J.; Wu, Y.; Zheng, W. Parallel algorithm and implementation for realtime dynamic simulation of power system. In Proceedings of the 2005 International Conference on Parallel Processing (ICPP’05), Oslo, Norway, 14–17 June 2005; pp. 137–144. [Google Scholar] [CrossRef]
- Xue, W.; Qi, S. Multilevel Task Partition Algorithm for Parallel Simulation of Power System Dynamics. In Computational Science–ICCS 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 529–537. [Google Scholar]
- Ye, J.; Liu, Z.; Zhu, L. The Implementation of a Spatial Parallel Algorithm for Transient Stability Simulation on PC Cluster. In Proceedings of the 2007 2nd IEEE Conference on Industrial Electronics and Applications, Harbin, China, 23–25 May 2007; pp. 1489–1492. [Google Scholar] [CrossRef]
- Lin, J.; Tong, X.Y.; Wang, X.D.; Wang, W.C. Parallel simulation for the transient stability of power system. In Proceedings of the 2008 Third International Conference on Electric Utility Deregulation and Restructuring and Power Technologies, Nanjing, China, 6–9 April 2008; pp. 1325–1329. [Google Scholar] [CrossRef]
- Wang, X.Z.; Yan, Z.; Xue, W. An adaptive clustering algorithm with high performance computing application to power system transient stability simulation. In Proceedings of the 2008 Third International Conference on Electric Utility Deregulation and Restructuring and Power Technologies, Nanjing, China, 6–9 April 2008; pp. 1137–1140. [Google Scholar] [CrossRef]
- Lin, J.; Wang, X.D.; Tong, X.Y. Asynchronous parallel simulation of transient stability based on equivalence. In Proceedings of the 2009 International Conference on Sustainable Power Generation and Supply, Nanjing, China, 6–7 April 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Meng, K.; Dong, Z.Y.; Wong, K.P.; Xu, Y.; Luo, F.J. Speed-up the computing efficiency of power system simulator for engineering-based power system transient stability simulations. IET Gener. Transm. Distrib. 2010, 4, 652–661. [Google Scholar] [CrossRef]
- Robbins, B.A.; Zavala, V.M. Convergence Analysis of a Parallel Newton Scheme for Dynamic Power Grid Simulations. In Proceedings of the First International Workshop on High Performance Computing, Networking and Analytics for the Power Grid, HiPCNA-PG ’11, Seattle, WA, USA, 13 November 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 3–10. [Google Scholar] [CrossRef]
- Dufour, C.; Jalili-Marandi, V.; Bélanger, J.; Snider, L. Power system simulation algorithms for parallel computer architectures. In Proceedings of the 2012 IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 22–26 July 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Dufour, C.; Jalili-Marandi, V.; Belanger, J. Real-Time Simulation Using Transient Stability, ElectroMagnetic Transient and FPGA-Based High-Resolution Solvers. In Proceedings of the 2012 SC Companion: High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 283–288. [Google Scholar] [CrossRef]
- Jiang, Q.; Jiang, H. OpenMP-based parallel transient stability simulation for large-scale power systems. Sci. China Technol. Sci. 2012, 55, 2837–2846. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, Y.; Chavarría-Miranda, D. High-Performance Computing for Real-Time Grid Analysis and Operation. In High Performance Computing in Power and Energy Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 151–188. [Google Scholar] [CrossRef]
- Khaitan, S.K.; McCalley, J.D. High Performance Computing for Power System Dynamic Simulation. In High Performance Computing in Power and Energy Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 43–69. [Google Scholar] [CrossRef]
- Aristidou, P.; Fabozzi, D.; Van Cutsem, T. Dynamic Simulation of Large-Scale Power Systems Using a Parallel Schur-Complement-Based Decomposition Method. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2561–2570. [Google Scholar] [CrossRef]
- Jin, S.; Huang, Z.; Diao, R.; Wu, D.; Chen, Y. Comparative Implementation of High Performance Computing for Power System Dynamic Simulations. IEEE Trans. Smart Grid 2017, 8, 1387–1395. [Google Scholar] [CrossRef]
- Sullivan, B.; Shi, J.; Mazzola, M.; Saravi, B. Faster-than-real-time power system transient stability simulation using Parallel General Norton with Multiport Equivalent (PGNME). In Proceedings of the 2017 IEEE Power Energy Society General Meeting, Chicago, IL, USA, 16–20 July 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Gopal, A.; Dagmar, N.; Suresh, V. DC Power Flow Based Contingency Analysis Using Graphics Processing Units. In Proceedings of the 2007 IEEE Lausanne Power Tech, Lausanne, Switzerland, 1–5 July 2007; pp. 731–736. [Google Scholar] [CrossRef]
- Chen, Y.; Jin, H.; Jiang, H.; Xu, D.; Zheng, R.; Liu, H. GPU-based Static State Security Analysis in Power Systems. In Advances in Services Computing; Springer International Publishing: Cham, Switzerland, 2015; pp. 258–267. [Google Scholar]
- Li, X.; Balasubramanian, P.; Sahraei-Ardakani, M.; Abdi-Khorsand, M.; Hedman, K.W.; Podmore, R. Real-Time Contingency Analysis With Corrective Transmission Switching. IEEE Trans. Power Syst. 2017, 32, 2604–2617. [Google Scholar] [CrossRef]
- Zhou, G.; Zhang, X.; Lang, Y.; Bo, R.; Jia, Y.; Lin, J.; Feng, Y. A novel GPU-accelerated strategy for contingency screening of static security analysis. Int. J. Electr. Power Energy Syst. 2016, 83, 33–39. [Google Scholar] [CrossRef]
- Chen, D.; Jiang, H.; Li, Y.; Xu, D. A Two-Layered Parallel Static Security Assessment for Large-Scale Grids Based on GPU. IEEE Trans. Smart Grid 2017, 8, 1396–1405. [Google Scholar] [CrossRef]
- Zhou, G.; Feng, Y.; Bo, R.; Chien, L.; Zhang, X.; Lang, Y.; Jia, Y.; Chen, Z. GPU-Accelerated Batch-ACPF Solution for N-1 Static Security Analysis. IEEE Trans. Smart Grid 2017, 8, 1406–1416. [Google Scholar] [CrossRef]
- Huang, S.; Dinavahi, V. Real-Time Contingency Analysis on Massively Parallel Architectures With Compensation Method. IEEE Access 2018, 6, 44519–44530. [Google Scholar] [CrossRef]
- Sommer, S.; Aabrandt, A.; Jóhannsson, H. Reduce–factor–solve for fast Thevenin impedance computation and network reduction. IET Gener. Transm. Distrib. 2019, 13, 288–295. [Google Scholar] [CrossRef]
- Tang, K.; Dong, S.; Zhu, B.; Ni, Q.; Song, Y. GPU-Based Real-time N-1 AC Power Flow Algorithm With Preconditioned Iterative Method. In Proceedings of the 2018 IEEE Power Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, Y.; Chen, Y.; Liu, Z.; Liu, S.; Su, D.; Wu, H. Batch Computing Method for Sensitivity Analysis of Large Power Grids Based on GPU Acceleration. In Proceedings of the 2019 IEEE 3rd International Electrical and Energy Conference (CIEEC), Beijing, China, 7–9 September 2019; pp. 1792–1797. [Google Scholar] [CrossRef]
- Balduino, L.; Alves, A.C.B. Parallel processing in a cluster of microcomputers with application in contingency analysis. In Proceedings of the 2004 IEEE/PES Transmision and Distribution Conference and Exposition: Latin America (IEEE Cat. No. 04EX956), Sao Paulo, Brazil, 8–11 November 2004; pp. 285–290. [Google Scholar] [CrossRef]
- Angeline Ezhilarasi, G.; Swarup, K.S. Parallel contingency analysis in a high performance computing environment. In Proceedings of the 2009 International Conference on Power Systems, Kharagpur, India, 27–29 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Gao, W.; Chen, X. Distributed Generation Placement Design and Contingency Analysis with Parallel Computing Technology. J. Comput. 2009, 4, 347–354. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, Y.; Nieplocha, J. Massive contingency analysis with high performance computing. In Proceedings of the 2009 IEEE Power Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–8. [Google Scholar] [CrossRef]
- Shi, L.; Guo, Z.; Ni, Y.; Yao, L.; Bazargan, M. Implementation of a distributed parallel computing architecture for transient stability constrained ttc evaluation. In Proceedings of the 2009 IEEE Power Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, Y.; Huang, Z.; Chavarría-Miranda, D. Performance evaluation of counter-based dynamic load balancing schemes for massive contingency analysis with different computing environments. In Proceedings of the IEEE PES General Meeting, Minneapolis, MN, USA, 25–29 July 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Jin, S.; Huang, Z.; Chen, Y.; Chavarría-Miranda, D.; Feo, J.; Wong, P.C. A novel application of parallel betweenness centrality to power grid contingency analysis. In Proceedings of the 2010 IEEE International Symposium on Parallel Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010; pp. 1–7. [Google Scholar] [CrossRef]
- Mittal, A.; Hazra, J.; Jain, N.; Goyal, V.; Seetharam, D.P.; Sabharwal, Y. Real Time Contingency Analysis for Power Grids. In Euro-Par 2011 Parallel Processing; Jeannot, E., Namyst, R., Roman, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 303–315. [Google Scholar]
- Khaitan, S.K.; McCalley, J.D. Achieving Load-Balancing in Power System Parallel Contingency Analysis Using X10 Programming Language. In Proceedings of the Third ACM SIGPLAN X10 Workshop, X10 ’13, Seattle, WA, USA, 20 June 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 20–28. [Google Scholar] [CrossRef]
- Khaitan, S.K.; McCalley, J.D. Dynamic Load Balancing and Scheduling for Parallel Power System Dynamic Contingency Analysis. In High Performance Computing in Power and Energy Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 189–209. [Google Scholar] [CrossRef]
- Khaitan, S.K.; McCalley, J.D. Parallelizing power system contingency analysis using D programming language. In Proceedings of the 2013 IEEE Power Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Khaitan, S.K.; McCalley, J.D.; Somani, A. Proactive task scheduling and stealing in master-slave based load balancing for parallel contingency analysis. Electr. Power Syst. Res. 2013, 103, 9–15. [Google Scholar] [CrossRef]
- Khaitan, S.K.; McCalley, J.D. SCALE: A hybrid MPI and multithreading based work stealing approach for massive contingency analysis in power systems. Electr. Power Syst. Res. 2014, 114, 118–125. [Google Scholar] [CrossRef]
- Zhou, G.; Zhao, D.; Zou, K.; Xu, W.; Lv, X.; Wang, Q.; Yin, W. The static security analysis in power system based on Spark Cloud Computing platform. In Proceedings of the 2015 IEEE Innovative Smart Grid Technologies-Asia (ISGT ASIA), Bangkok, Thailand, 3–6 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Tuyet-Doan, V.N.; Nguyen, T.T.; Nguyen, M.T.; Lee, J.H.; Kim, Y.H. Self-attention network for partial-discharge diagnosis in gas-insulated switchgear. Energies 2020, 13, 2102. [Google Scholar] [CrossRef]
- Tournier, J.; Donde, V.; Li, Z. Potential of General Purpose Graphic Processing Unit for Energy Management System. In Proceedings of the 2011 Sixth International Symposium on Parallel Computing in Electrical Engineering, Luton, UK, 3–7 April 2011; pp. 50–55. [Google Scholar] [CrossRef]
- Green, R.C.; Wang, L.; Alam, M. Applications and Trends of High Performance Computing for Electric Power Systems: Focusing on Smart Grid. IEEE Trans. Smart Grid 2013, 4, 922–931. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, J.; Yang, F. How far is the GPU technology from practical power system applications? In Proceedings of the 2014 IEEE PES General Meeting | Conference Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Sooknanan, D.J.; Joshi, A. GPU computing using CUDA in the deployment of smart grids. In Proceedings of the 2016 SAI Computing Conference (SAI), London, UK, 13–15 July 2016; pp. 1260–1266. [Google Scholar] [CrossRef]
- Zheng, C.; Li, D.; Xi, Y.; Wang, X. Hybrid modeling and optimization for Energy Management System of MicroGrid. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; pp. 10013–10018. [Google Scholar] [CrossRef]
- Celik, B.; Suryanarayanan, S.; Maciejewski, A.A.; Siegel, H.J.; Sharma, S.; Roche, R. A comparison of three parallel processing methods for a resource allocation problem in the smart grid. In Proceedings of the 2017 North American Power Symposium (NAPS), Morgantown, WV, USA, 17–19 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Karimipour, H.; Dinavahi, V. On false data injection attack against dynamic state estimation on smart power grids. In Proceedings of the 2017 IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 14–17 August 2017; pp. 388–393. [Google Scholar] [CrossRef]
- Capizzi, G.; Sciuto, G.L.; Napoli, C.; Tramontana, E. Advanced and Adaptive Dispatch for Smart Grids by Means of Predictive Models. IEEE Trans. Smart Grid 2018, 9, 6684–6691. [Google Scholar] [CrossRef]
- Li, Z.; Yang, F. Advanced Metering Infrastructure and Graphics Processing Unit Technologies in Electric Distribution Networks. In Electric Distribution Network Management and Control; Springer: Singapore, 2018; pp. 309–345. [Google Scholar] [CrossRef]
- Liao, C.L.; Lee, S.J.; Chiou, Y.S.; Lee, C.R.; Lee, C.H. Power consumption minimization by distributive particle swarm optimization for luminance control and its parallel implementations. Expert Syst. Appl. 2018, 96, 479–491. [Google Scholar] [CrossRef]
- Çavdar, I.; Faryad, V. New design of a supervised energy disaggregation model based on the deep neural network for a smart grid. Energies 2019, 12, 1217. [Google Scholar] [CrossRef]
- Perumalla, K.S.; Nutaro, J.J.; Yoginath, S.B. Towards High Performance Discrete-Event Simulations of Smart Electric Grids. In Proceedings of the First International Workshop on High Performance Computing, Networking and Analytics for the Power Grid, HiPCNA-PG ’11, Seattle, WA, USA, 13 November 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 51–58. [Google Scholar] [CrossRef]
- Baek, J.; Vu, Q.H.; Liu, J.K.; Huang, X.; Xiang, Y. A Secure Cloud Computing Based Framework for Big Data Information Management of Smart Grid. IEEE Trans. Cloud Comput. 2015, 3, 233–244. [Google Scholar] [CrossRef]
- Feng, M.; Luo, X.; Frankie, Q.; Zhang, Q.; Litvinov, E. Cloud computing: An innovative IT paradigm to facilitate power system operations. In Proceedings of the 2015 IEEE Power Energy Society General Meeting, Denver, CO, USA, 26–30 July 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Soares, J.; Ghazvini, M.A.F.; Vale, Z.; de Moura Oliveira, P.B. A multi-objective model for the day-ahead energy resource scheduling of a smart grid with high penetration of sensitive loads. Appl. Energy 2016, 162, 1074–1088. [Google Scholar] [CrossRef]
- Hashemi-Dezaki, H.; Hariri, A.M.; Hejazi, M.A. Impacts of load modeling on generalized analytical reliability assessment of smart grid under various penetration levels of wind/solar/non-renewable distributed generations. Sustain. Energy Grids Netw. 2019, 20, 100246. [Google Scholar] [CrossRef]
- Ramanan, P.; Yildirim, M.; Chow, E.; Gebraeel, N. An Asynchronous, Decentralized Solution Framework for the Large Scale Unit Commitment Problem. IEEE Trans. Power Syst. 2019, 34, 3677–3686. [Google Scholar] [CrossRef]
- Zhao, L.; Matsuo, I.B.M.; Zhou, Y.; Lee, W.J. Design of an Industrial IoT-Based Monitoring System for Power Substations. IEEE Trans. Ind. Appl. 2019, 55, 5666–5674. [Google Scholar] [CrossRef]
- Dileep, G. A survey on smart grid technologies and applications. Renew. Energy 2020, 146, 2589–2625. [Google Scholar] [CrossRef]
- Elgamal, M.; Korovkin, N.; Elmitwally, A.; Chen, Z. Robust multi-agent system for efficient online energy management and security enforcement in a grid-connected microgrid with hybrid resources. IET Gener. Transm. Distrib. 2020, 14, 1726–1737. [Google Scholar] [CrossRef]
- Na, U.; Lee, E.K. Fog BEMS: An agent-based hierarchical fog layer architecture for improving scalability in a building energy management system. Sustainability 2020, 12, 2831. [Google Scholar] [CrossRef]
- Wang, L.; Zheng, J.H.; Jing, Z.X.; Wu, Q.H. Individual-based distributed parallel optimization for operation of integrated energy systems considering heterogeneous structure. Int. J. Electr. Power Energy Syst. 2020, 118, 105777. [Google Scholar] [CrossRef]
- Zahmatkesh, H.; Al-Turjman, F. Fog computing for sustainable smart cities in the IoT era: Caching techniques and enabling technologies-an overview. Sustain. Cities Soc. 2020, 59, 102139. [Google Scholar] [CrossRef]
- Papadakis, S.E.; Bakrtzis, A.G. A GPU accelerated PSO with application to Economic Dispatch problem. In Proceedings of the 2011 16th International Conference on Intelligent System Applications to Power Systems, Hersonissos, Greece, 25–28 September 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Rakai, L.; Rosehart, W. GPU-Accelerated Solutions to Optimal Power Flow Problems. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 2511–2516. [Google Scholar] [CrossRef]
- de Oliveira, L.B.; Marcelino, C.G.; Milanés, A.; Almeida, P.E.; Carvalho, L.M. A successful parallel implementation of NSGA-II on GPU for the energy dispatch problem on hydroelectric power plants. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 4305–4312. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Okou, F. Optimal power flow based on parallel metaheuristics for graphics processing units. Electr. Power Syst. Res. 2016, 140, 344–353. [Google Scholar] [CrossRef]
- Yahyaoui, H.; Dekdouk, A.; Krichen, S. Graphic-based optimal network reconfiguration in CPU/GPU architectures using AGA-LS metaheuristics. In Proceedings of the 2016 IEEE International Conference on Power System Technology (POWERCON), Melaka, Malaysia, 28–29 November 2016. [Google Scholar]
- Belič, E.; Lukač, N.; Deželak, K.; Žalik, B.; Štumberger, G. GPU-Based Online Optimization of Low Voltage Distribution Network Operation. IEEE Trans. Smart Grid 2017, 8, 1460–1468. [Google Scholar] [CrossRef]
- Fioretto, F.; Yeoh, W.; Pontelli, E.; Ma, Y.; Ranade, S.J. A Distributed Constraint Optimization (DCOP) Approach to the Economic Dispatch with Demand Response. In Proceedings of the 16th Conference on Autonomous Agents and MultiAgent Systems, São Paulo, Brazil, 8–12 May 2017. [Google Scholar]
- Huang, S.; Dinavahi, V. GPU-based parallel real-time volt/var optimisation for distribution network considering distributed generators. IET Gener. Transm. Distrib. 2018, 12, 4472–4481. [Google Scholar] [CrossRef]
- Araújo, I.; Tadaiesky, V.; Cardoso, D.; Fukuyama, Y.; Santana, Á. Simultaneous parallel power flow calculations using hybrid CPU-GPU approach. Int. J. Electr. Power Energy Syst. 2019, 105, 229–236. [Google Scholar] [CrossRef]
- Baldick, R.; Kim, B.H.; Chase, C.; Luo, Y. A fast distributed implementation of optimal power flow. IEEE Trans. Power Syst. 1999, 14, 858–864. [Google Scholar] [CrossRef]
- Lo, C.H.; Chung, C.Y.; Nguyen, D.H.M.; Wong, K.P. Parallel evolutionary programming for optimal power flow. In Proceedings of the 2004 IEEE International Conference on Electric Utility Deregulation, Hong Kong, China, 5–8 April 2004. [Google Scholar]
- Kim, J.; Jeong, H.M.; Lee, H.S.; Park, J.H. PC Cluster based Parallel PSO Algorithm for Optimal Power Flow. In Proceedings of the 2007 International Conference on Intelligent Systems Applications to Power Systems, Kaohsiung, Taiwan, 4–8 November 2007. [Google Scholar]
- Liu, K.; Li, Y.; Sheng, W. The decomposition and computation method for distributed optimal power flow based on message passing interface (MPI). Int. J. Electr. Power Energy Syst. 2011, 33, 1185–1193. [Google Scholar] [CrossRef]
- Kraning, M.; Chu, E.; Lavaei, J.; Boyd, S.P. Dynamic Network Energy Management via Proximal Message Passing. Found. Trends Optim. 2014, 1, 73–126. [Google Scholar] [CrossRef]
- Ye, C.; Huang, M.X. Multi-Objective Optimal Power Flow Considering Transient Stability Based on Parallel NSGA-II. IEEE Trans. Power Syst. 2015, 30, 857–866. [Google Scholar] [CrossRef]
- Grisales-Noreña, L.; Gonzalez Montoya, D.; Ramos-Paja, C.A. Optimal sizing and location of distributed generators based on PBIL and PSO techniques. Energies 2018, 11, 1018. [Google Scholar] [CrossRef]
- Grisales-Noreña, L.; Montoya, O.D.; Ramos-Paja, C.A. An energy management system for optimal operation of BSS in DC distributed generation environments based on a parallel PSO algorithm. J. Energy Storage 2020, 29, 101488. [Google Scholar] [CrossRef]
- Ujaldon, M. Using GPUs for accelerating electromagnetic simulations. Appl. Comput. Electromagn. Soc. J. 2010, 25, 294–302. [Google Scholar]
- Debnath, J.K.; Fung, W.K.; Gole, A.M.; Filizadeh, S. Simulation of large-scale electrical power networks on graphics processing units. In Proceedings of the 2011 IEEE Electrical Power and Energy Conference, Detroit, MA, USA, 24–28 July 2011. [Google Scholar]
- Kumar Debnath, J.; Fung, W.K.; Gole, A.M.; Filizadeh, S. Electromagnetic transient simulation of large-scale electrical power networks using graphics processing units. In Proceedings of the 2012 25th IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Montreal, QC, Canada, 29 April–2 May 2012. [Google Scholar]
- Song, Y.; Chen, Y.; Yu, Z.; Huang, S.; Chen, L. A fine-grained parallel EMTP algorithm compatible to graphic processing units. In Proceedings of the 2014 IEEE PES General Meeting | Conference Exposition, National Harbor, MD, USA, 27–31 July 2014. [Google Scholar]
- Zhou, Z.; Dinavahi, V. Parallel Massive-Thread Electromagnetic Transient Simulation on GPU. IEEE Trans. Power Deliv. 2014, 29, 1045–1053. [Google Scholar] [CrossRef]
- Debnath, J.K.; Gole, A.M.; Fung, W.K. Graphics-Processing-Unit-Based Acceleration of Electromagnetic Transients Simulation. IEEE Trans. Power Deliv. 2016, 31, 2036–2044. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, J.; Li, P.; Fu, X.; Song, G.; Wang, C. GPU based parallel matrix exponential algorithm for large scale power system electromagnetic transient simulation. In Proceedings of the 2016 IEEE Innovative Smart Grid Technologies-Asia (ISGT-Asia), Melbourne, Australia, 28 November–1 December 2016. [Google Scholar]
- Song, Y.; Chen, Y.; Huang, S.; Xu, Y.; Yu, Z.; Marti, J.R. Fully GPU-based electromagnetic transient simulation considering large-scale control systems for system-level studies. IET Gener. Transm. Distrib. 2017, 11, 2840–2851. [Google Scholar] [CrossRef]
- Zhou, Z.; Dinavahi, V. Fine-Grained Network Decomposition for Massively Parallel Electromagnetic Transient Simulation of Large Power Systems. IEEE Power Energy Technol. Syst. J. 2017, 4, 51–64. [Google Scholar] [CrossRef]
- Song, Y.; Chen, Y.; Huang, S.; Xu, Y.; Yu, Z.; Xue, W. Efficient GPU-Based Electromagnetic Transient Simulation for Power Systems With Thread-Oriented Transformation and Automatic Code Generation. IEEE Access 2018, 6, 25724–25736. [Google Scholar] [CrossRef]
- Lin, N.; Dinavahi, V. Parallel High-Fidelity Electromagnetic Transient Simulation of Large-Scale Multi-Terminal DC Grids. IEEE Power Energy Technol. Syst. J. 2019, 6, 59–70. [Google Scholar] [CrossRef]
- Lin, N.; Dinavahi, V. Variable Time-Stepping Modular Multilevel Converter Model for Fast and Parallel Transient Simulation of Multiterminal DC Grid. IEEE Trans. Ind. Electron. 2019, 66, 6661–6670. [Google Scholar] [CrossRef]
- Yao, S.; Zhang, S.; Guo, W. Electromagnetic transient parallel simulation optimisation based on GPU. J. Eng. 2019, 2019, 1737–1742. [Google Scholar] [CrossRef]
- Shu, D.; Wei, Y.; Dinavahi, V.; Wang, K.; Yan, Z.; Li, X. Cosimulation of Shifted-Frequency/Dynamic Phasor and Electromagnetic Transient Models of Hybrid LCC-MMC DC Grids on Integrated CPU–GPUs. IEEE Trans. Ind. Electron. 2020, 67, 6517–6530. [Google Scholar] [CrossRef]
- DeLeon, R.; Felzien, K.; Senocak, I. Toward a gpu-accelerated immersed boundary method for wind forecasting over complex terrain. In Fluids Engineering Division (Publication); American Society of Mechanical Engineers: New York, NY, USA, 2012; Volume 1, pp. 1385–1394. [Google Scholar] [CrossRef]
- Lukač, N.; Žalik, B. GPU-based roofs’ solar potential estimation using LiDAR data. Comput. Geosci. 2013, 52, 34–41. [Google Scholar] [CrossRef]
- Bonanno, F.; Sciuto, G.L.; Napoli, C.; Pappalardo, G.; Tramontana, E. A novel cloud-distributed toolbox for optimal energy dispatch management from renewables in IGSs by using WRNN predictors and GPU parallel solutions. In Proceedings of the 2014 International Symposium on Power Electronics, Electrical Drives, Automation and Motion, Ischia, Italy, 18–20 June 2014; pp. 1077–1084. [Google Scholar] [CrossRef]
- Gao, H.; Chen, Y.; Xu, Y.; Yu, Z.; Chen, L. A GPU-based parallel simulation platform for large-scale wind farm integration. In Proceedings of the 2014 IEEE PES T D Conference and Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Morales-Aguilar, E.; Ramirez, A.; Matar, M. Multi-frequency sweeping method for periodic steady-state computations on the graphics processor unit. Electr. Power Syst. Res. 2015, 121, 295–301. [Google Scholar] [CrossRef]
- Liu, M.; Liu, G.; Zhao, G.; Li, Z.; Zhao, S.; Guo, C.; Chu, Z. A GPU-Based Lagrange Multiplier Optimization for Dynamic Economic Dispatch Aiming to Reduce Wind Power Curtailment. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018. [Google Scholar]
- Perera, A.T.D.; Wickramasinghe, P.U.; Scartezzini, J.L.; Nik, V.M. Integrating Renewable Energy Technologies into Distributed Energy Systems Maintaining System Flexibility. In Proceedings of the 2018 5th International Symposium on Environment-Friendly Energies and Applications (EFEA), Rome, Italy, 24–26 September 2018. [Google Scholar] [CrossRef]
- Abdelaziz, M.; Moradzadeh, M. Monte-Carlo simulation based multi-objective optimum allocation of renewable distributed generation using OpenCL. Electr. Power Syst. Res. 2019, 170, 81–91. [Google Scholar] [CrossRef]
- Kang, D.; Youn, C.H. Real-Time Control for Power Cost Efficient Deep Learning Processing With Renewable Generation. IEEE Access 2019, 7, 114909–114922. [Google Scholar] [CrossRef]
- Liang, L.; Hou, Y.; Hill, D.J. GPU-Based Enumeration Model Predictive Control of Pumped Storage to Enhance Operational Flexibility. IEEE Trans. Smart Grid 2019, 10, 5223–5233. [Google Scholar] [CrossRef]
- Lin, N.; Dinavahi, V. Exact Nonlinear Micromodeling for Fine-Grained Parallel EMT Simulation of MTDC Grid Interaction With Wind Farm. IEEE Trans. Ind. Electron. 2019, 66, 6427–6436. [Google Scholar] [CrossRef]
- Hu, T.; Wu, W.; Guo, Q.; Sun, H.; Shi, L.; Shen, X. Very short-term spatial and temporal wind power forecasting: A deep learning approach. CSEE J. Power Energy Syst. 2020, 6, 434–443. [Google Scholar] [CrossRef]
- Lin, N.; Cao, S.; Dinavahi, V. Comprehensive Modeling of Large Photovoltaic Systems for Heterogeneous Parallel Transient Simulation of Integrated AC/DC Grid. IEEE Trans. Energy Convers. 2020, 35, 917–927. [Google Scholar] [CrossRef]
- Cisneros-Magaña, R.; Medina, A.; Dinavahi, V. Parallel Kalman filter based time-domain harmonic state estimation. In Proceedings of the 2013 North American Power Symposium (NAPS), Manhattan, NY, USA, 22–24 September 2013. [Google Scholar] [CrossRef]
- Karimipour, H.; Dinavahi, V. Accelerated parallel WLS state estimation for large-scale power systems on GPU. In Proceedings of the 2013 North American Power Symposium (NAPS), Manhattan, NY, USA, 22–24 September 2013. [Google Scholar] [CrossRef]
- Karimipour, H.; Dinavahi, V. On detailed synchronous generator modeling for massively parallel dynamic state estimation. In Proceedings of the 2014 North American Power Symposium (NAPS), Pullman, WA, USA, 7–9 September 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Karimipour, H.; Dinavahi, V. Extended Kalman Filter-Based Parallel Dynamic State Estimation. IEEE Trans. Smart Grid 2015, 6, 1539–1549. [Google Scholar] [CrossRef]
- Rahman, M.A.; Venayagamoorthy, G.K. Dishonest Gauss Newton method based power system state estimation on a GPU. In Proceedings of the 2016 Clemson University Power Systems Conference (PSC), Clemson, SC, USA, 8–11 March 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Rahman, M.A.; Venayagamoorthy, G.K. Convergence of the Fast State Estimation for Power Systems. SAIEE Afr. Res. J. 2017, 108, 117–127. [Google Scholar] [CrossRef][Green Version]
- Xia, Y.; Chen, Y.; Ren, Z.; Huang, S.; Wang, M.; L, M. State estimation for large-scale power systems based on hybrid CPU-GPU platform. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017. [Google Scholar] [CrossRef]
- Cisneros-Magaña, R.; Medina, A.; Dinavahi, V.; Ramos-Paz, A. Time-Domain Power Quality State Estimation Based on Kalman Filter Using Parallel Computing on Graphics Processing Units. IEEE Access 2018, 6, 21152–21163. [Google Scholar] [CrossRef]
- Cao, Z.; Wang, Y.; Chu, C.C.; Gadh, R. Robust pseudo-measurement modeling for three-phase distribution systems state estimation. Electr. Power Syst. Res. 2020, 180, 106138. [Google Scholar] [CrossRef]
- Jeong, H.; Lee, H.S.; Park, J.H. Application of parallel particle swarm optimization on power system state estimation. In Proceedings of the 2009 Transmission Distribution Conference Exposition: Asia and Pacific, Seoul, Korea, 26–30 October 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Korres, G.N.; Tzavellas, A.; Galinas, E. A distributed implementation of multi-area power system state estimation on a cluster of computers. Electr. Power Syst. Res. 2013, 102, 20–32. [Google Scholar] [CrossRef]
- Garcia, N.; Olmos, R.C. GPU-accelerated Poincaré map method for harmonic-oriented analyses of power systems. In Proceedings of the 2013 IEEE Power Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, K.; Li, H.; Huang, Y.; Zhang, Q.; Zhao, G. GPU-accelerated particle swarm optimization for selective harmonic elimination in multilevel converters with unequal DC levels. In Proceedings of the IECON 2017-43rd Annual Conference of the IEEE Industrial Electronics Society, Beijing, China, 29 October–1 November 2017; pp. 1186–1191. [Google Scholar] [CrossRef]
- Balouji, E.; Salor, Ö.; Ermis, M. Exponential Smoothing of Multiple Reference Frame Components With GPUs for Real-Time Detection of Time-Varying Harmonics and Interharmonics of EAF Currents. IEEE Trans. Ind. Appl. 2018, 54, 6566–6575. [Google Scholar] [CrossRef]
- Severoğlu, N.; Salor, Ö. Harmonic analysis in power systems using convolutional neural networks. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Balouji, E.; Bäckström, K.; McKelvey, T.; Salor, Ö. Deep Learning Based Harmonics and Interharmonics Pre-Detection Designed for Compensating Significantly Time-varying EAF Currents. IEEE Trans. Ind. Appl. 2020, 56, 3250–3260. [Google Scholar] [CrossRef]
- Uz-Logoglu, E.; Salor, Ö.; Ermis, M. Real-Time Detection of Interharmonics and Harmonics of AC Electric Arc Furnaces on GPU Framework. IEEE Trans. Ind. Appl. 2019, 55, 6613–6623. [Google Scholar] [CrossRef]
- Qiu, W.; Tang, Q.; Liu, J.; Teng, Z.; Yao, W. Power Quality Disturbances Recognition Using Modified S Transform and Parallel Stack Sparse Auto-encoder. Electr. Power Syst. Res. 2019, 174, 105876. [Google Scholar] [CrossRef]
- Solis-Munoz, F.; Osornio-Rios, R.A.; Romero-Troncoso, R.J.; Jaen-Cuellar, A.Y. Differential evolution implementation for Power Quality Disturbances monitoring using OpenCL. Adv. Electr. Comput. Eng. 2019, 19, 13–22. [Google Scholar] [CrossRef]
- Ma, J.; Man, K.L.; Ting, T.O.; Zhang, N.; Guan, S.U.; Wong, P.W.H. Accelerating Parameter Estimation for Photovoltaic Models via Parallel Particle Swarm Optimization. In Proceedings of the 2014 International Symposium on Computer, Consumer and Control, Taichung, Taiwan, 10–12 June 2014; pp. 175–178. [Google Scholar] [CrossRef]
- Liu, Z.; Li, X.; Wu, L.; Zhou, S.; Liu, K. GPU-Accelerated Parallel Coevolutionary Algorithm for Parameters Identification and Temperature Monitoring in Permanent Magnet Synchronous Machines. IEEE Trans. Ind. Inform. 2015, 11, 1220–1230. [Google Scholar] [CrossRef]
- Liu, Z.; Wei, H.; Zhong, Q.; Liu, K.; Li, X. GPU Implementation of DPSO-RE Algorithm for Parameters Identification of Surface PMSM Considering VSI Nonlinearity. IEEE J. Emerg. Sel. Top. Power Electron. 2017, 5, 1334–1345. [Google Scholar] [CrossRef]
- Klimeš, L.; Mauder, T.; Charvát, P.; Štětina, J. Front tracking in modelling of latent heat thermal energy storage: Assessment of accuracy and efficiency, benchmarking and GPU-based acceleration. Energy 2018, 155, 297–311. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Huang, C.; Tsui, K.L. A GPU-accelerated parallel Jaya algorithm for efficiently estimating Li-ion battery model parameters. Appl. Soft Comput. 2018, 65, 12–20. [Google Scholar] [CrossRef]
- Yüzügüler, A.C.; Moga, A.; Franke, C. Towards Commoditizing Simulations of System Models Using Recurrent Neural Networks. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ma, J.; Man, K.L.; Guan, S.U.; Ting, T.O.; Wong, P.W.H. Parameter estimation of photovoltaic model via parallel particle swarm optimization algorithm. Int. J. Energy Res. 2016, 40, 343–352. [Google Scholar] [CrossRef]
- Schwarzer, V.; Ghorbani, R. New opportunities for large-scale design optimization of electric vehicles using GPU technology. In Proceedings of the 2011 IEEE Vehicle Power and Propulsion Conference, Chicago, IL, USA, 6–9 September 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Sánchez, L.; Otero, J.; Couso, I.; Blanco, C. Battery diagnosis for electrical vehicles through semi-physical fuzzy models. In Proceedings of the 2016 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Vancouver, BC, Canada, 24–29 July 2016; pp. 416–423. [Google Scholar] [CrossRef]
- Schambers, A.; Eavis-O’Quinn, M.; Roberge, V.; Tarbouchi, M. Route planning for electric vehicle efficiency using the Bellman-Ford algorithm on an embedded GPU. In Proceedings of the 2018 4th International Conference on Optimization and Applications (ICOA), Mohammedia, Morocco, 26–27 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Roberge, V.; Tarbouchi, M.; Noureldin, A. Integrated Motor Optimization and Route Planning for Electric Vehicle using Embedded GPU System. In Proceedings of the 2019 5th International Conference on Optimization and Applications (ICOA), Kenitra, Morocco, 25–26 April 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Abdelaziz, M. GPU-OpenCL accelerated probabilistic power flow analysis using Monte-Carlo simulation. Electr. Power Syst. Res. 2017, 147, 70–72. [Google Scholar] [CrossRef]
- Abdelaziz, M.M.A. OpenCL-Accelerated Probabilistic Power Flow for Active Distribution Networks. IEEE Trans. Sustain. Energy 2018, 9, 1255–1264. [Google Scholar] [CrossRef]
- Zhou, G.; Bo, R.; Chien, L.; Zhang, X.; Yang, S.; Su, D. GPU-Accelerated Algorithm for Online Probabilistic Power Flow. IEEE Trans. Power Syst. 2018, 33, 1132–1135. [Google Scholar] [CrossRef]
- Cui, T.; Franchetti, F. A multi-core high performance computing framework for probabilistic solutions of distribution systems. In Proceedings of the 2012 IEEE Power and Energy Society General Meeting, San Diego, CA, USA, 22–26 July 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Borges, C.L.T.; Alves, J.M. Power System Real Time Operation based on Security Constrained Optimal Power Flow and Distributed Processing. In Proceedings of the 2007 IEEE Lausanne Power Tech, Lausanne, Switzerland, 1–5 July 2007; pp. 960–965. [Google Scholar] [CrossRef]
- Thitithamrongchai, C.; Eua-Arporn, B. Security-constrained Optimal Power Flow: A Parallel Self-adaptive Differential Evolution Approach. Electr. Power Compon. Syst. 2008, 36, 280–298. [Google Scholar] [CrossRef]
- Li, Y.; McCalley, J.D. Decomposed SCOPF for Improving Efficiency. IEEE Trans. Power Syst. 2009, 24, 494–495. [Google Scholar] [CrossRef]
- Kim, M.; Park, J.K.; Nam, Y.W. Market-clearing for pricing system security based on voltage stability criteria. Energy 2011, 36, 1255–1264. [Google Scholar] [CrossRef]
- Geng, G.; Jiang, Q.; Sun, Y. Parallel Transient Stability-Constrained Optimal Power Flow Using GPU as Coprocessor. IEEE Trans. Smart Grid 2017, 8, 1436–1445. [Google Scholar] [CrossRef]
- Cai, H.R.; Chung, C.Y.; Wong, K.P. Application of Differential Evolution Algorithm for Transient Stability Constrained Optimal Power Flow. IEEE Trans. Power Syst. 2008, 23, 719–728. [Google Scholar] [CrossRef]
- Tian, F.; Zhang, X.; Yu, Z.; Qiu, W.; Shi, D.; Qiu, J.; Liu, M.; Li, Y.; Zhou, X. Online decision-making and control of power system stability based on super-real-time simulation. CSEE J. Power Energy Syst. 2016, 2, 95–103. [Google Scholar] [CrossRef]
- Tate, J.E.; Overbye, T.J. Contouring for Power Systems Using Graphical Processing Units. In Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS 2008), Waikoloa, HI, USA, 7–10 January 2008; p. 168. [Google Scholar] [CrossRef]
- Chen, Z.; Shen, L.; Zhao, Y.; Yang, C. Parallel algorithm for real-time contouring from grid DEM on modern GPUs. Sci. China Technol. Sci. 2010, 53, 33–37. [Google Scholar] [CrossRef]
- Shang, B.; Xu, Y.; Zhang, C.; Chen, Y.; Liu, Z.; Lin, L.; Xu, C.; Yu, J. GPU-Accelerated Batch Solution for Short-Circuit Current Calculation of Large-scale Power Systems. In Proceedings of the 2019 IEEE 3rd International Electrical and Energy Conference (CIEEC), Beijing, China, 7–9 September 2019; pp. 1743–1748. [Google Scholar] [CrossRef]
- Sato, F.; Garcia, A.V.; Monticelli, A.; Alves, A.B. Distributed short-circuit analysis in heterogeneous computer networks. Int. J. Electr. Power Energy Syst. 2000, 22, 129–136. [Google Scholar] [CrossRef]
- Fukuyama, Y.; Chiang, H.D. A parallel genetic algorithm for generation expansion planning. IEEE Trans. Power Syst. 1996, 11, 955–961. [Google Scholar] [CrossRef]
- Ye, C.; Ding, Y.; Song, Y.; Lin, Z.; Wang, L. A data driven multi-state model for distribution system flexible planning utilizing hierarchical parallel computing. Appl. Energy 2018, 232, 9–25. [Google Scholar] [CrossRef]
- Rami, A.; Zeblah, A.; Hamdaoui, H.; Massim, Y.; Harrou, F. An efficient artificial immune algorithm for power system reliability optimisation. Int. J. Power Energy Convers. 2009, 1, 178–197. [Google Scholar] [CrossRef]
- Green, R.C.; Wang, L.; Alam, M.; Singh, C. Intelligent and parallel state space pruning for power system reliability analysis using MPI on a multicore platform. In Proceedings of the ISGT 2011, Anaheim, CA, USA, 17–19 January 2011; pp. 1–8. [Google Scholar] [CrossRef]
- He, T.; Meng, K.; Dong, Z.Y.; Oh, Y.T.; Xu, Y. Use of High-performance Graphics Processing Units for Power System Demand Forecasting. J. Electr. Eng. Technol. 2010, 5, 363–370. [Google Scholar] [CrossRef]
- Milano, F. Small-Signal Stability Analysis of Large Power Systems With Inclusion of Multiple Delays. IEEE Trans. Power Syst. 2016, 31, 3257–3266. [Google Scholar] [CrossRef]
- Zadeh, A.K.; Nor, K.M.; Zeynal, H. Multi-thread security constraint economic dispatch with exact loss formulation. In Proceedings of the 2010 IEEE International Conference on Power and Energy, Kuala Lumpur, Malaysia, 29 November–1 December 2010; pp. 864–869. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, S.; Liu, H.; Chen, Y.; Zhu, M.; Xu, Y. A small-population based parallel differential evolution algorithm for short-term hydrothermal scheduling problem considering power flow constraints. Energy 2017, 123, 538–554. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Application | GPU | CPU Clusters, Fog and Cloud | Total |
|---|---|---|---|
| Computing, and FPGA | |||
| Power Flow Analysis | [6,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46] | [47,48,49,50,51,52,53,54,55,56,57,58,59,60] | 49 |
| Transient Stability | [18,61,62,63,64,65,66,67,68,69,70,71,72,73,74] | [75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98] | 39 |
| Contingency Analysis | [99,100,101,102,103,104,105,106,107,108] | [94,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123] | 26 |
| Smart Grids | [124,125,126,127,128,129,130,131,132,133,134] | [135,136,137,138,139,140,141,142,143,144,145,146] | 23 |
| Optimal Power Flow | [1,147,148,149,150,151,152,153,154,155] | [156,157,158,159,160,161,162,163] | 18 |
| Electromagnetic Transient Simulation | [164,165,166,167,168,169,170,171,172,173,174,175,176,177] | [91,92] | 16 |
| Renewable Energy Integration | [1,178,179,180,181,182,183,184,185,186,187,188,189,190] | - | 14 |
| Dynamic State Estimation | [191,192,193,194,195,196,197,198,199] | [94,200,201] | 12 |
| Power Quality | [202,203,204,205,206,207,208,209] | - | 8 |
| Dynamic Models | [210,211,212,213,214,215] | [2,216] | 8 |
| Electrical Vehicles | [217,218,219,220] | - | 4 |
| Probabilistic Power Flow | [221,222,223] | [224] | 4 |
| Security Constrained Optimal Power Flow | - | [225,226,227,228] | 4 |
| Transient Stability-Constrained Optimal Power Flow | [229] | [230,231] | 3 |
| Power System Visualization | [232,233] | - | 2 |
| Short Circuit Analysis | [234] | [235] | 2 |
| Power System Planning | - | [236,237] | 2 |
| Power System Reliability | - | [238,239] | 2 |
| Electricity Market | [240] | - | 1 |
| Small Signal Analysis | [241] | - | 1 |
| Security Constrained Economic Dispatch | - | [242] | 1 |
| Hydrothermal Scheduling | - | [243] | 1 |
| Total | 145 | 95 | 240 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez, D.; Gomez, D.; Alvarez, D.; Rivera, S. A Review of Parallel Heterogeneous Computing Algorithms in Power Systems. Algorithms 2021, 14, 275. https://doi.org/10.3390/a14100275
Rodriguez D, Gomez D, Alvarez D, Rivera S. A Review of Parallel Heterogeneous Computing Algorithms in Power Systems. Algorithms. 2021; 14(10):275. https://doi.org/10.3390/a14100275
Chicago/Turabian StyleRodriguez, Diego, Diego Gomez, David Alvarez, and Sergio Rivera. 2021. "A Review of Parallel Heterogeneous Computing Algorithms in Power Systems" Algorithms 14, no. 10: 275. https://doi.org/10.3390/a14100275
APA StyleRodriguez, D., Gomez, D., Alvarez, D., & Rivera, S. (2021). A Review of Parallel Heterogeneous Computing Algorithms in Power Systems. Algorithms, 14(10), 275. https://doi.org/10.3390/a14100275