1. Introduction
In this article, we study the calculation of the optimal Rice coding parameter. A Rice code is a parameterised Variable-Length Code (VLC)—proposed by Rice in [
1,
2]—that works in the following way.
Rice encoding: For a given parameter
r and source data
, the following two values are calculated:
is the floor function: the function that takes as input a real number and returns as output the greatest integer less than or equal to x. Similarly, we will use for the ceiling function: the function that takes as input a real number and returns as output the smallest integer higher than or equal to x. The function refers to the modulo operation: the remainder after the integer division of a by b.
The Rice encoding for can be constructed in three steps:
append a bit set to one to the output stream, if is a positive number; or a bit set to zero, otherwise,
encode the value of in unary code and append it to the first bit, and finally,
encode the value of as an unsigned integer using only r bits.
The unary code of a value x is a sequence of x bits, all set to the value one plus one additional bit—a delimiter bit—set to zero.
The reader shall note that the encoding operation can be efficiently implemented in CPUs using bit shift and bit masking operations solely, without the need of floating-point operations.
Rice decoding: The decoder must know the Rice coding parameter r that was used for encoding. The following method is used to obtain the values of and from the encoded stream.
read the first bit, and determine the sign of the encoded value: one for a negative sign, zero for a positive sign,
count the number of consecutive bits set to one (let be that number),
discard the delimiter bit (a bit set to zero), and
let the following r bits be the value of .
Once the values of
and
are known, the original value
is calculated as:
The reader shall note that the decoding operation can be efficiently implemented in CPUs using bit shift and addition operations solely, without the need of floating-point operations.
1.1. How the Rice Parameter Affects the Compression Ratio
In Wireless Sensor Networks, transmitted frames do not encode a single measurement value. Instead, in order to minimise the overhead caused by headers of telecommunication protocols, a sequence of measurements is stored, coded, and finally transmitted by the device in a single frame. We initially assume in this article that such a sequence is encoded using a single Rice parameter.
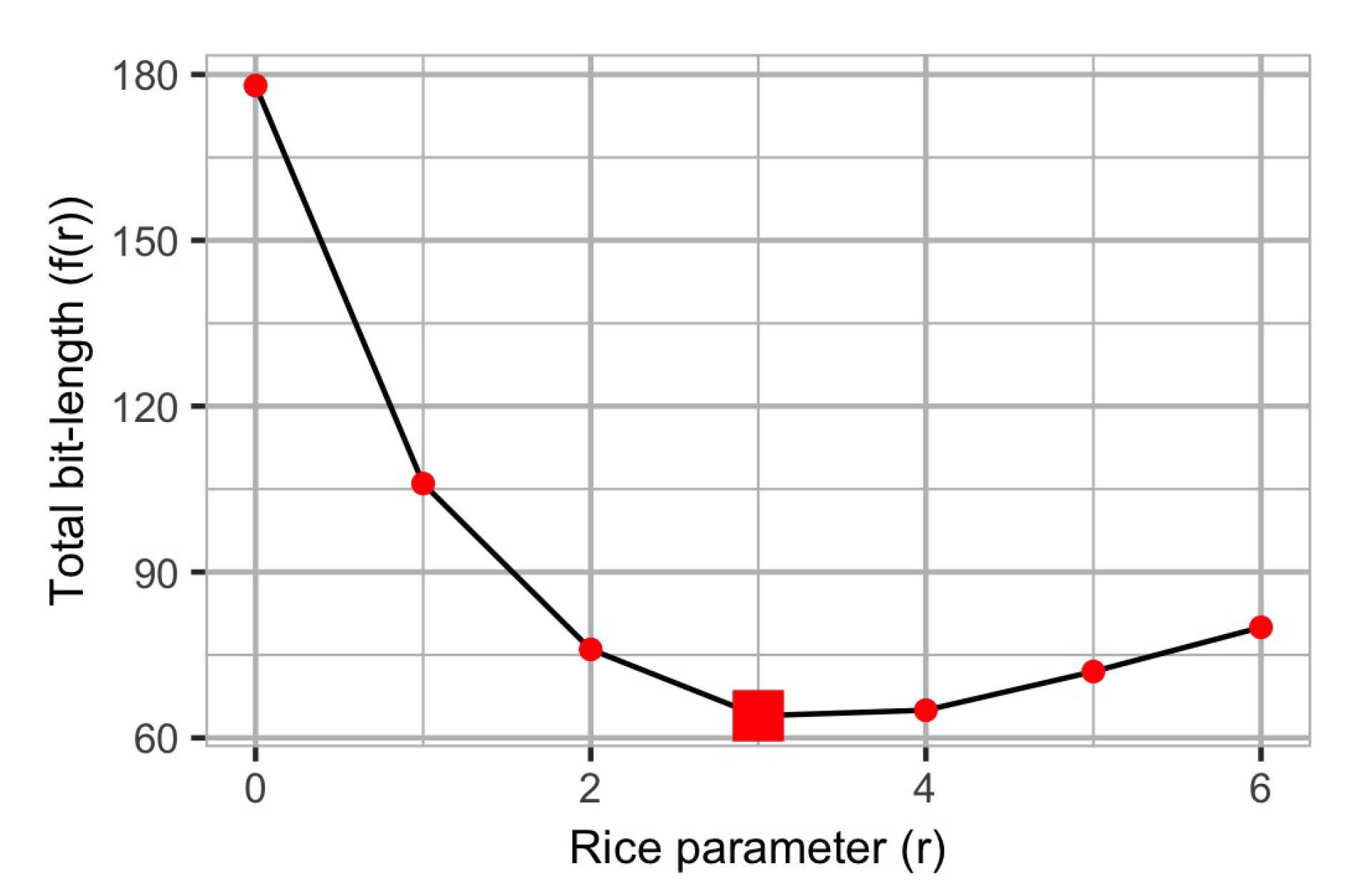
The data sequence presented in
Table 1 is used to illustrate the effects of choosing the Rice parameter,
r, on the total amount of bits encoded.
Figure 1 shows the the total amount of bits encoded for this sequence for different values of the Rice parameter. It can be observed that the total encoding length equals 76 bits when
. If
, the total encoding length decreases to 64 bits. If
, the total encoding length increases again to 65 bits. Therefore, the optimal parameter
r for this dataset is
.
Table 1 will be used in further sections to provide examples of the proposed heuristics, algorithms, and bounds throughout this article.
1.2. Applications
Rice coding has been employed traditionally for data compression of audio [
3], images [
4,
5,
6,
7,
8,
9], video [
10,
11], and electrocardiogram [
12] data. In most cases, the input data is first transformed (using, i.e., a wavelet transform), then the transform coefficients are quantised. The quantised transform coefficients usually follow a two-sided geometric distribution [
13,
14], for which Rice coding can provide short codes close in length to Huffman codes [
15].
In recent years, our research group has developed prototypes of battery-operated resource-constrained Internet of Things (IoT) devices. Such IoT devices usually communicate over low-power lossy wireless networks [
16]. In current IoT telecommunication technologies—such as LoRa [
17,
18,
19]—data rates do not exceed more than 56 kilobits per second, there is no guarantee of successful packet delivery, and the available space for encoding application data in a data frame is no more than 220 bytes [
20]. Such small IoT devices may have up to 32 KB of RAM memory with CPUs running at frequencies below 100 MHz [
21,
22,
23].
In our most recent application, we developed IoT devices for measuring the pH and conductivity of sewage waste water [
24,
25], with the aim of providing information about the presence and localisation of illegal spills of toxic chemicals in sewers. The pH and conductivity values of aggregated sewage waste water are mostly constant in normal conditions. Based on this, we employed Rice codes for coding the difference between consecutive pH and conductivity measurements of sewage wastewater without employing complex CPU operations or using large amounts of memory.
Several other compression methods have been proposed for resource-constrained IoT devices. Most of the proposed data compression methods in the literature for IoT applications—e.g., [
26,
27,
28,
29,
30,
31]—are lossy. Those works propose an estimator method that extracts enough information from a time-sequence and then encodes the minimum set of parameters to recreate, as close as possible, the original information based on the transmitted parameters of the estimator method. Ying et al. [
32] presented a summary of other compression algorithms for IoT prior to the year 2010.
The focus of this work is to evaluate different methods for calculating the Rice parameter. a comparison study of the compression ratio achieved by other different methods is out of the scope of this article, since it would require evaluating the overhead imposed on the network for transmitting frequency tables, volatile memory usage at constrained nodes, and energy used for coding and decoding.
1.3. Contributions
The main contributions of this article are the following:
A closed-form expression for the estimation of the optimal Rice parameter in
time, where
N is the number of input elements to encode. In contrast to previous works, this estimation applies regardless of the probability distribution of the input data (see
Section 3.2);
An algorithm for the calculation of the optimal Rice parameter in
time (see
Section 3.4), where
is the minimum number of bits needed for natural coding of the largest integer;
An algorithm for the partitioning of the
N input elements into sub-sequences yielding a better compression ratio in
(see
Section 5);
Two heuristics for the fast estimation for the partitioning of the input sequence in
(see
Section 5.4).
In order to evaluate the performance of the algorithms, the proposed algorithms are further verified and supported with collected data by a real sensor network in
Section 4 for the first two contributions in the list above, and again later in
Section 6 for the last two contributions in the list above.
2. Related Work
In this section, we summarise to the best of our knowledge the research studies carried out so far on Rice coding.
2.1. Basic Terminology
As far as the terminology in the area of data compression is concerned, we follow the definitions given by Salomon and Motta in [
33].
The terms “source data”, “raw data”, or “sample” refer to original data obtained from a (sensor) system, before their compression, but after its transformation or quantisation. Throughout this article, we use the term “sequence” to denote a list of consecutive samples captured over time. a “sub-sequence” is a list of consecutive samples found within a sequence. In this article, a sequence of samples is represented with and the i-th element of the this sequence by .
The output of a compression algorithm is termed encoded data. Accordingly, a compressor algorithm converts raw data or samples into compressed encoded data of a smaller bit-length.
2.2. Parameter Calculation for Data Following Laplacian Distributions
Yeh et al. in [
15] analysed the optimality of Rice codes to Huffman codes for Laplacian distributions. Following this study, Robinson in [
3] proposed that the optimal Rice parameter for data following a Laplace distribution
be given by:
represents the absolute value of x, is the expected value of x, is the natural logarithm function and is the binary logarithm function. The value of is the weighted sum taken over all possible symbols x, viz., , where the weight corresponds to the probability of occurrence of the symbol x in a sequence.
Merhav et al. extended the study to Two-Sided Geometric Distributions (TSGD) in [
13].
2.3. Derivation for Data Following Geometric Distributions
Rice coding is a special case of Golomb coding as proposed by Golomb in [
34]. It has been shown in [
33] that if the set of numeric data that needs to be encoded is assumed to follow a geometric distribution, i.e., the probability of the number
occurring in the input sequence is:
for some probability
, then the optimal Golomb parameter is given by the integer number
that minimises the following expression:
Therefore, the value of
can be calculated as:
As Rice encoding is the special case of Golomb encoding when the parameter
of the Golomb coder is a power of two, i.e.,
, such an inequality is resolved for Rice encoding to:
Under the same assumptions, viz. of following a geometric probability distribution, Kiely in [
35] proposed the selection of the code parameter considering only the mean value of the distribution as follows:
corresponds to the estimate of the mean value of the data and is the golden ratio constant value .
Previously, other authors considered the case when the input data follow a geometrical distribution and provided a means of calculating the optimal Golomb encoding parameter, hence providing a bound for the Rice encoding parameter. Clearly, these bounds do not apply for all distributions.
In this work, we provide bounds on the value of the Rice encoding parameter regardless of the type of distribution of the data.
2.4. Adaptive Rice Coding
Malvar in [
6] and later improved in [
7] proposed the Run-Length/Golomb–Rice (RLGR) coder. RLGR was designed to work best when the input sequence follows a TSGD. RLGR uses both run-length and Rice coding for encoding an input sequence of measurements. Run-length coding is used for compressing sequences of measurements with a value of zero.
The Rice coding parameter is automatically adapted after a sample is coded: if the encoding process using the previous parameter yields zero on the value of , the Rice coding parameter is increased for coding the next symbol; if the previous parameter yields a value higher than one on , the Rice coding parameter is decreased proportionally. In our opinion, this idea works best if the consecutive values to be encoded are close to each other, but may yield sub-optimal Rice codes in the case that the consecutive values to be encoded are considerably different.
In
Section 5, we propose a way for efficiently using Rice codes in situations where the input sequence of values changes abruptly.
3. General Selection of the Golomb Parameter for Rice Coding
We now focus on the problem of how to find the value of the Rice parameter
r that yields the minimum bit-length of the output stream for any raw data sequence
. The variation in the bit-length due to the choice of this parameter was illustrated above with an example in
Section 1.1.
To simplify notation, we assume that we deal only with the Rice encoding of values with their sign. In such a case, to apply Rice coding to a number , a total of bits are required. Hereinafter, since the sign is encoded in a separate bit, we assume that the samples in the input sequence have been already stripped off its sign; they are all non-negative.
In this section, we are interested in finding the value of
r for which the value of the following function:
is minimum. Note that
is a discontinuous function since its values are only valid for integer values of
r. In this section, an analytical solution is provided to this problem.
Let us define the function
as the number of bits used for representing
:
The values of
can be observed for our example sequence in
Table 1.
It is clear that the optimal value for
r,
, for
is an integer value bounded by:
Hereinafter, we name
and
the left- and right-hand sides expressions of (
11), respectively.
Moreover, note that for each positive number to encode,
, the integer division expression can be bounded as follows:
for certain values of
and
.
We create two derivable continuous functions that will bound the value of
as follows:
and:
for certain values of
and
.
To simplify notation, we drop the parameter (the input data sequence) from the functions f, g, and h since it remains constant in what remains of our analysis.
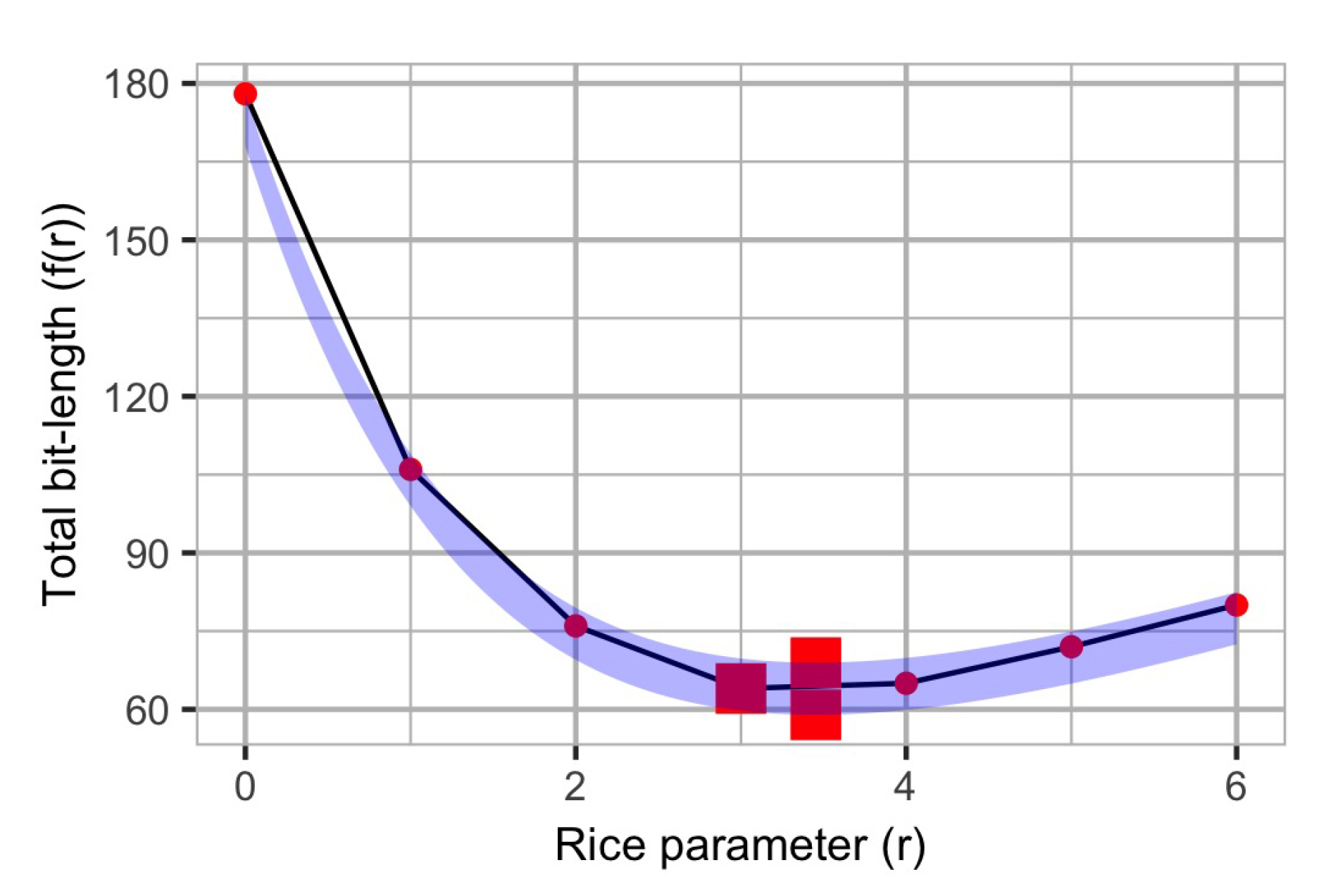
It is not difficult to prove that
and
are both convex functions in
r. As an example, we illustrate in
Figure 2 the two bounding functions for the Rice parameter for the example given in
Section 1.1, together with the optimal values of each function (indicated using a larger squared region).
Therefore, in order to find the solution, the evaluation of the functions for consecutive values of r until the output value starts increasing is not a very time-consuming task. Nonetheless, in further subsections, we will present a faster method for finding the optimal Rice parameter.
3.1. Function Bounds
Since
is a derivable function, its first derivative is:
Since
is convex, we can find the value of
yielding the minimum value of the function by setting the function’s first derivative to zero:
which means that:
Since
is a derivable function, we can proceed with the same approach again to find its optimal value. In fact, its first derivative is the same as the first derivative of
, which means that:
For nomenclature convenience, let us define
as the right-hand side expression of (
18) and (
19):
is the arithmetic mean of the values in
. Please note the similarities of (
20) with (
3), and the different assumptions concerning the probability distributions of the input data for deriving these two expressions.
3.2. Conjecture and Approximation
Since is an irrational number, the quantity is also irrational.
We conjecture that the optimal integer parameter for the Rice code is bounded by:
In our validation results, in
Section 4, we will evaluate how closely the conjectured expression provides the optimal parameter for data compression of real datasets.
3.3. Pre-Calculation of Q
Any non-negative integer value
a is represented in binary by a sequence of bits
such that:
Let us denote by
the function performing the integer division of
x by a power of two—viz. right bit shift. Such an operation can be defined as follows in terms of (
22):
It is not difficult to notice that our definition fulfils the following recursive property of bit shifting:
Considering the encoding problem of this article, we can redefine
as follows:
We are interested in designing an algorithm that efficiently updates the value of
as new samples are added to the set
. Let us denote by
the set of samples
enlarged by a new sample
. The value of
for the new set is therefore defined as:
The next section presents an algorithm that is defined based on (
24) and on (
26).
3.4. Algorithm for Finding the Optimal Parameter
In Algorithm 1, we propose a search heuristic for finding the optimal Rice parameter starting from our approximation values.
It starts by comparing the bit-lengths of the Rice coding of the input sequence when the parameters are and . If the total bit-length resulting from Rice coding using the first parameter () is smaller than when the second value () is used, the search continues using values smaller than until the bit-length starts increasing again. If the total bit-length caused by the first parameter is greater than when the second value is used, the search continues using values greater than until the bit-length starts increasing again. If the total bit-lengths are the same, an optimum has been reached.
The function FindBestRiceParameter—defined between Lines 17 and 37 in Algorithm 1—is our main function in the heuristic. It shall be invoked with the input data sequence, , and the number of elements in the input data sequence, N.
The subroutine PrecalculateRiceQ—defined between Lines 1 and 12 in Algorithm 1—has a complexity of
, since each one of the
input data values is considered, and for each one of them, the value of
is calculated for all potential values of
r, i.e.,
. The operator
is the right-shift-bit operator or, in other words, the integer division by a power of two. The subroutine CalculateF—defined between Lines 13 and 16 in Algorithm 1—has a complexity of
, since it is a mathematical evaluation with no iterative calls on the input data. The loop defined between Lines 30 and 35—within the subroutine FindBestRiceParameter—has only a complexity of
, since the subroutine is evaluating the function
f with all the possibles values of
r in constant time. As a consequence, the complexity of the subroutine FindBestRiceParameter is defined by the invocation of the subroutine PrecalculateRiceQ in Line 18, which has a higher complexity than the aforementioned loop. The subroutine FindBestRiceParameter has a complexity of
.
| Algorithm 1 Online calculation of the Rice-code with complexity . |
- 1:
functionPrecalculateRiceQ() - 2:
- 3:
for do - 4:
- 5:
while do ▹ see ( 10) for - 6:
- 7:
- 8:
- 9:
end while - 10:
end for - 11:
return - 12:
end function - 13:
functionCalculateF(r, Q, N) - 14:
- 15:
return f - 16:
end function - 17:
functionFindBestRiceParameter(, N) - 18:
PrecalculateRiceQ(n) - 19:
- 20:
- 21:
CalculateF(r′, Q, N) - 22:
- 23:
CalculateF(r″, Q, N) - 24:
- 25:
if then - 26:
- 27:
SwapVariables(, ) - 28:
SwapVariables(, ) - 29:
end if - 30:
while do - 31:
- 32:
- 33:
- 34:
CalculateF(r″, Q, N) - 35:
end while - 36:
return - 37:
end function
|
In practice, as will be presented later in
Section 4.4, the approximation described in
Section 3.2 (used as a starting search point in our algorithm) provides the optimal solution. In our experimental results, the loop between Lines 30 and 35 of the algorithm was executed only once or never at all, since either of the values of
and
was yielding the optimal value of
r before the first loop iteration.
Taking advantage of the fixed maximum number of bits that a microcontroller can use for representing an integer number, the author will work on a hardware implementation of the function PrecalculateRiceQ, which will allow decreasing the complexity of the whole procedure to by using hardware counters.
4. Performance on Different Datasets Using Single-Parameter Rice Coding
In this section, a numerical validation of the heuristics and approximations from
Section 3 is presented.
4.1. Datasets and Preprocessing
The datasets used for our numerical analysis are the sets of measurements from the weather stations located at beaches along Chicago’s Lake Michigan lakefront. The weather stations have measured air temperature, wet bulb temperature, humidity, rain intensity, interval rain, total rain, precipitation type, wind direction, wind speed, maximum wind speed, barometric pressure, solar radiation, heading, and the station battery life from three different locations once per hour since the 22nd of June 2015. By considering different sensor types and the different station locations, there are in total 37 datasets. Due to the occasional failure of some sensors or stations, the number of measurements in each dataset ranges from 27,058 to 35,774.
We believe that the way data are preprocessed has an affect on the compression factor of the Rice coding. In this article, we consider three simple methods for data preprocessing.
In the first preprocessing method—referred to as “normalize_dataset_scale”—all measurements are scaled by a constant factor so as to avoid having fractional values. This is needed since Rice coding does not have the possibility to encode non-integer (fractional) values. The scaling factor was calculated for each dataset as the minimum difference between any pair of measurements. All values are then divided by this scaling factor.
In the second preprocessing method—referred to as “normalize_dataset_scale_diff”—all measurements are scaled as previously mentioned, and then, the difference between consecutive scaled measurements is taken. Since we expect that some observed phenomena will change slowly over time, the author believes that the optimal Rice parameter for the difference of consecutive scaled measurements can be smaller, yielding shorter codes on average. This reflects the estimator methods used in some IoT data compression algorithms, such as in [
36].
In the third preprocessing method—referred to as “normalize_dataset_shift_mean”—all measurements are scaled as mentioned in the first preprocessing model, and then, the difference between the scaled measurements and the mean of all scaled values in the batch is taken. This reflects the estimator methods used in some IoT data compression algorithms, such as in [
36].
4.2. Compression Factor of Analysed Codes
As a starting point, the effect of the preprocessing method used before encoding is analysed for Rice coding. Here, we consider only the optimal Rice coding solution.
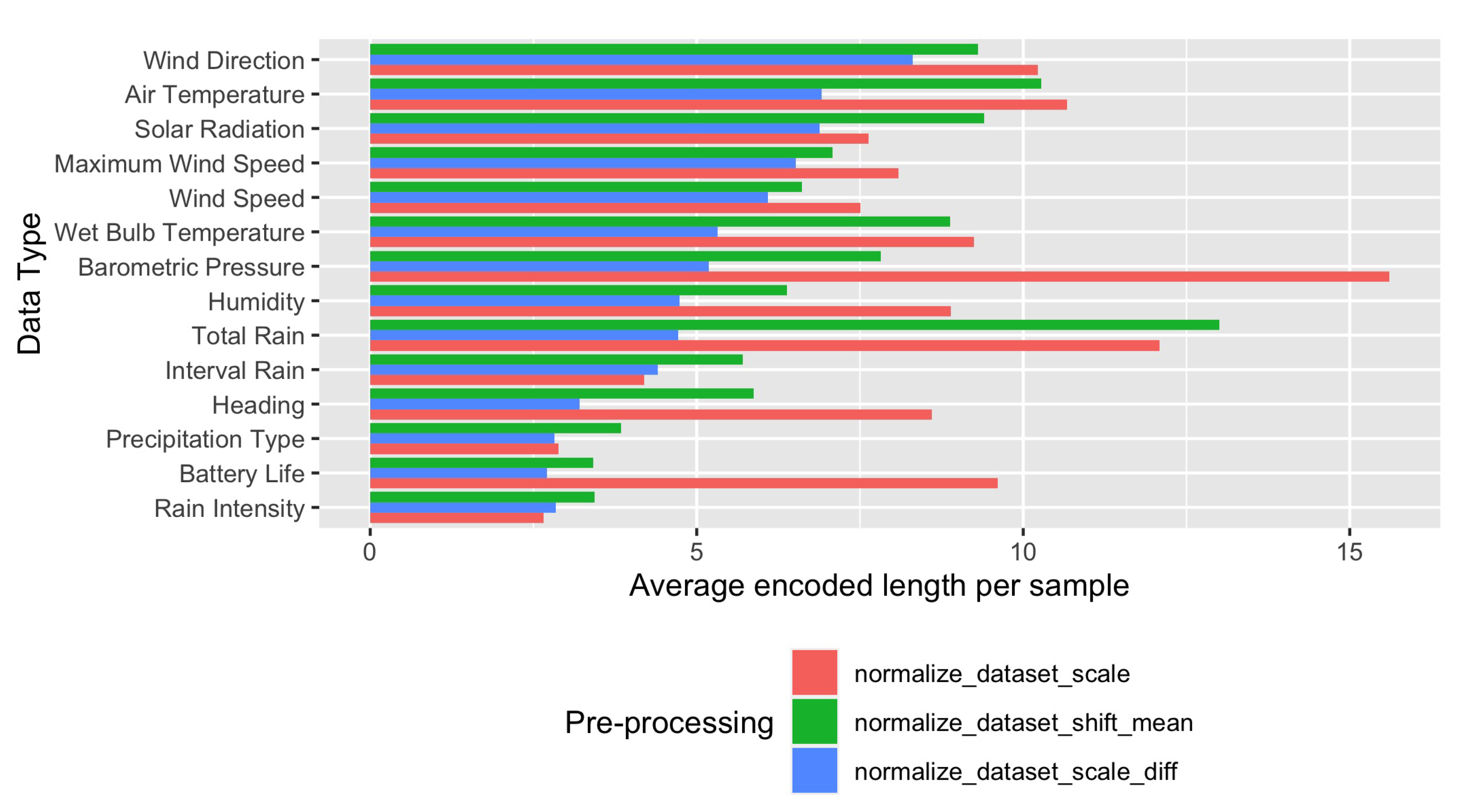
In
Figure 3 is shown the average length needed for encoding a single measurement for each dataset and considering the three preprocessing functions mentioned above. The usage of the second preprocessing function provides shorter codes in all cases, with the exception of the interval rain dataset.
4.3. Estimation of the Output Bit-Length
We conjecture that an estimation of the minimum output bit-length after Rice coding can be derived from (
9), by substituting the value of the Rice parameter given by the value provided in (
20), as follows:
and
are the mean and standard deviation of the samples to be encoded.
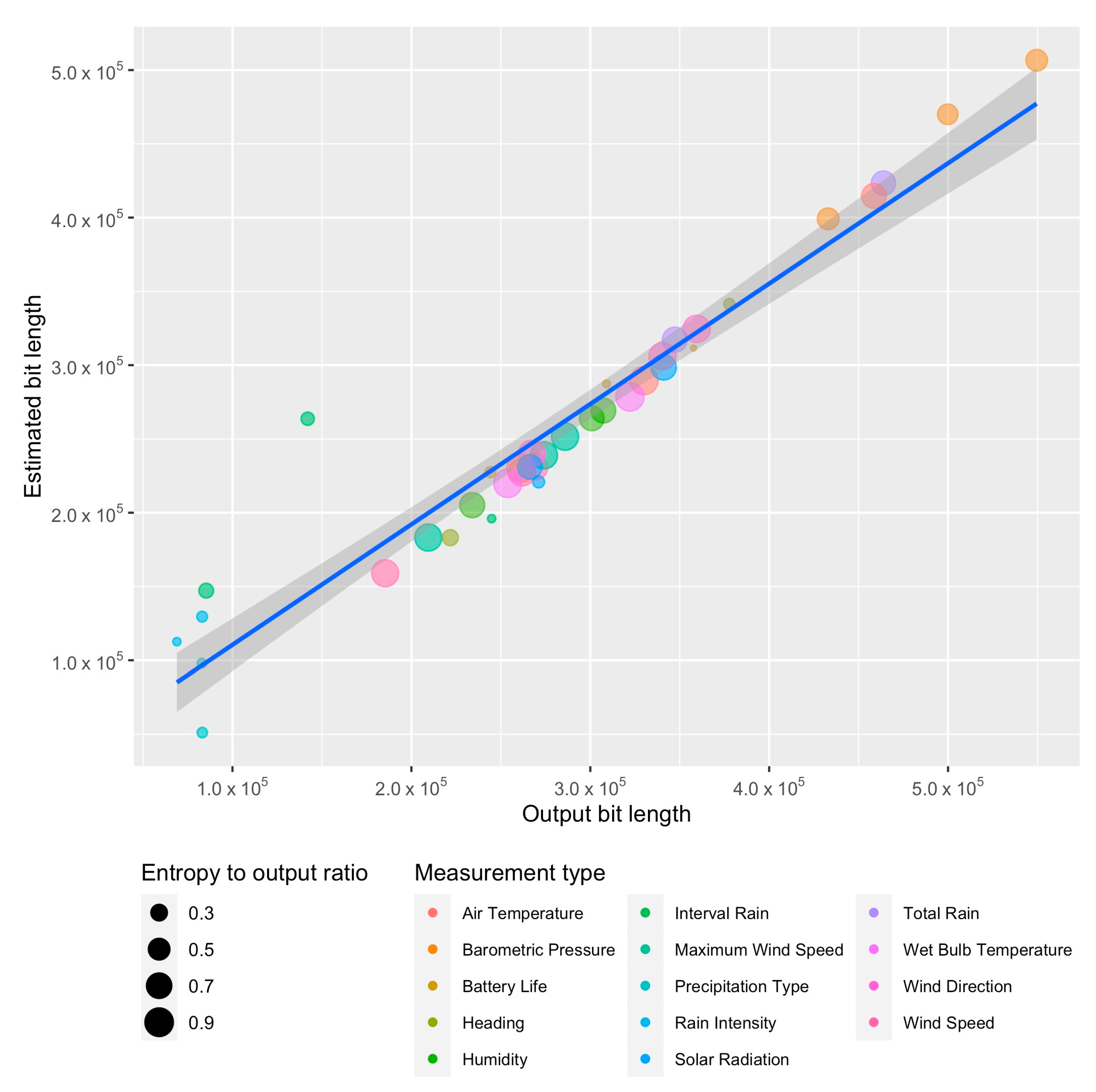
Figure 4 shows the output bit-length found after using the algorithm proposed in this article for finding the minimum output length and the estimated output bit-length based on (
27). The size of the points is proportional to the ratio of the output bit-length based on Shannon theorem and the optimal output bit-length after Rice coding.
A linear approximation was found with the equation , with a standard deviation error of and a t-value of for the estimated slope value, for the input sequences after being preprocessed with the first preprocessing method.
4.4. Approximation Solutions
In this subsection, we illustrate whether the conjecture in (
20) is valid.
Equation (
20) provides three different potential integer values for the optimal Rice coding parameter:
,
, and
. In
Figure 5 is shown the count of solutions found by approximating the Rice coding parameter as mentioned in (
20).
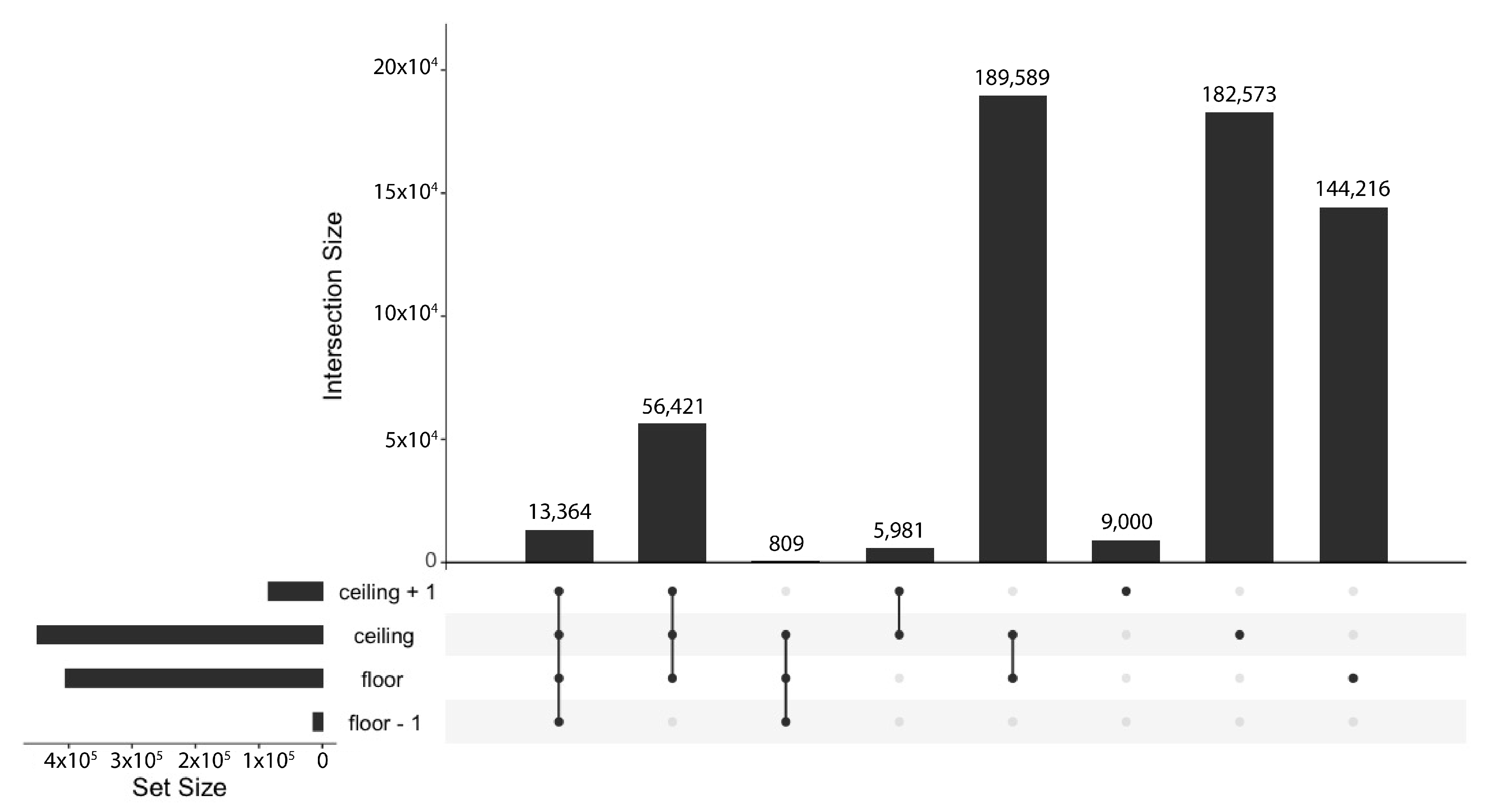
All minimal bit-length solutions were found by approximating the Rice coding parameter: the optimal Rice coding parameter was found using in , in , and in of the 601,953 cases.
4.5. Influence of the Chosen Batch Size
The compression factor
of an encoding method
m for an input dataset
of length
N is defined as follows [
33]:
is the number of bits needed to represent the sample in binary code and is the output bit-length size of the encoding method m when used over .
In
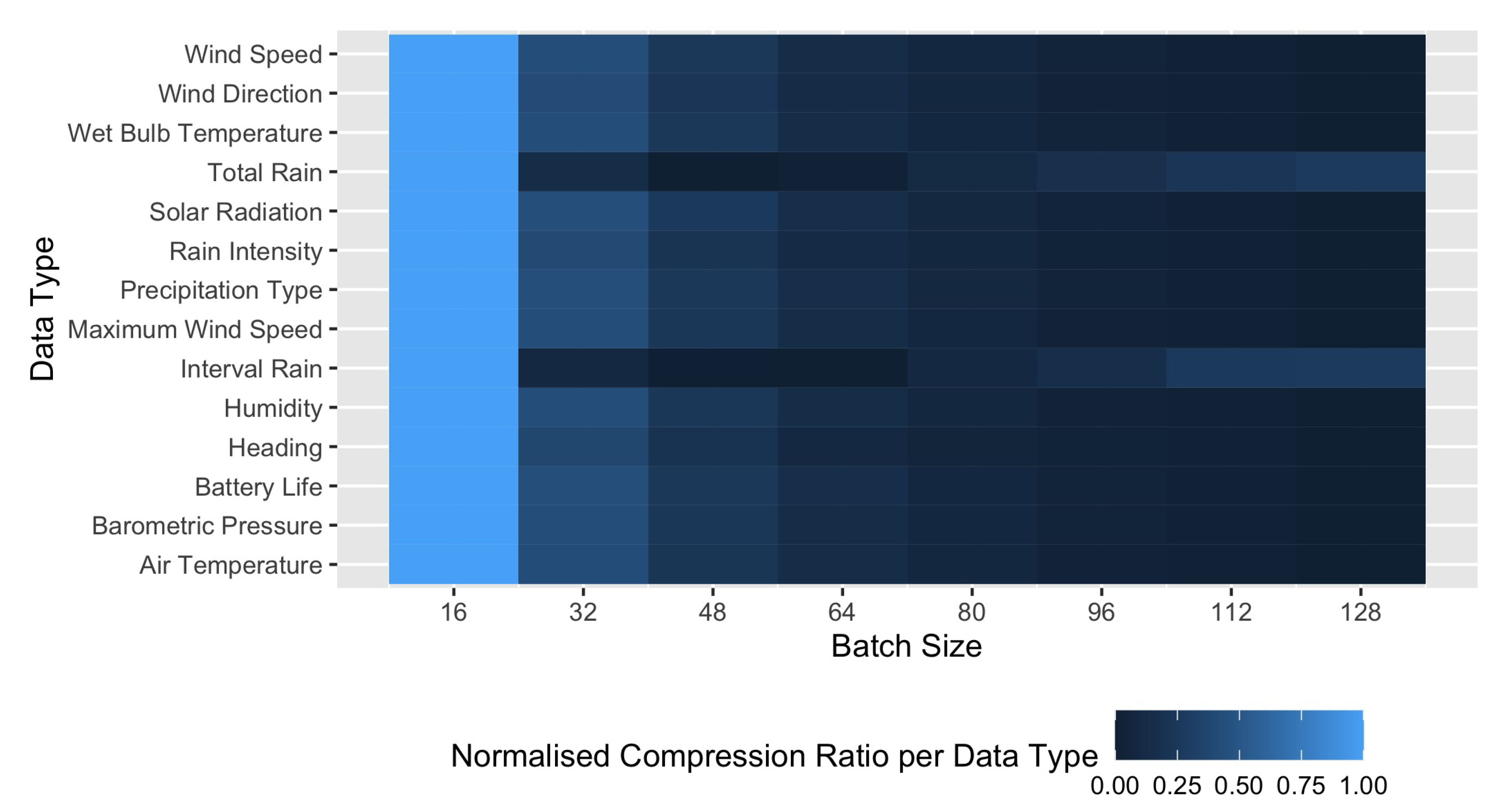
Figure 6, the normalised compression factor for each data type is shown as the batch size varies. The normalised compression factor is calculated as:
As can be observed for most datasets, the compression ratio of Rice coding may decrease for some datasets as the batch size increases, yielding longer codes on average. This is because a single Rice coding parameter cannot fit well to a large sequence of measurements.
For the total rain and interval rain datasets, the compression ratio fluctuates as the batch size varies, indicating that the sequence of measurements largely varies over time.
5. Multi-Parameter Rice Coding
As shown in
Section 4.5, when a large data sequence comprises samples of different orders of magnitude, Rice coding using a single parameter may be inefficient. This is because there is no Rice parameter that can be set efficiently for the whole sequence: a large Rice parameter may aid in the reduction of the bit-length of samples having large values at the expense of increasing the bit-length of small samples, while a small Rice parameter may aid in the reduction of the bit-length of samples having small values at the expense of increasing the bit-length of large samples.
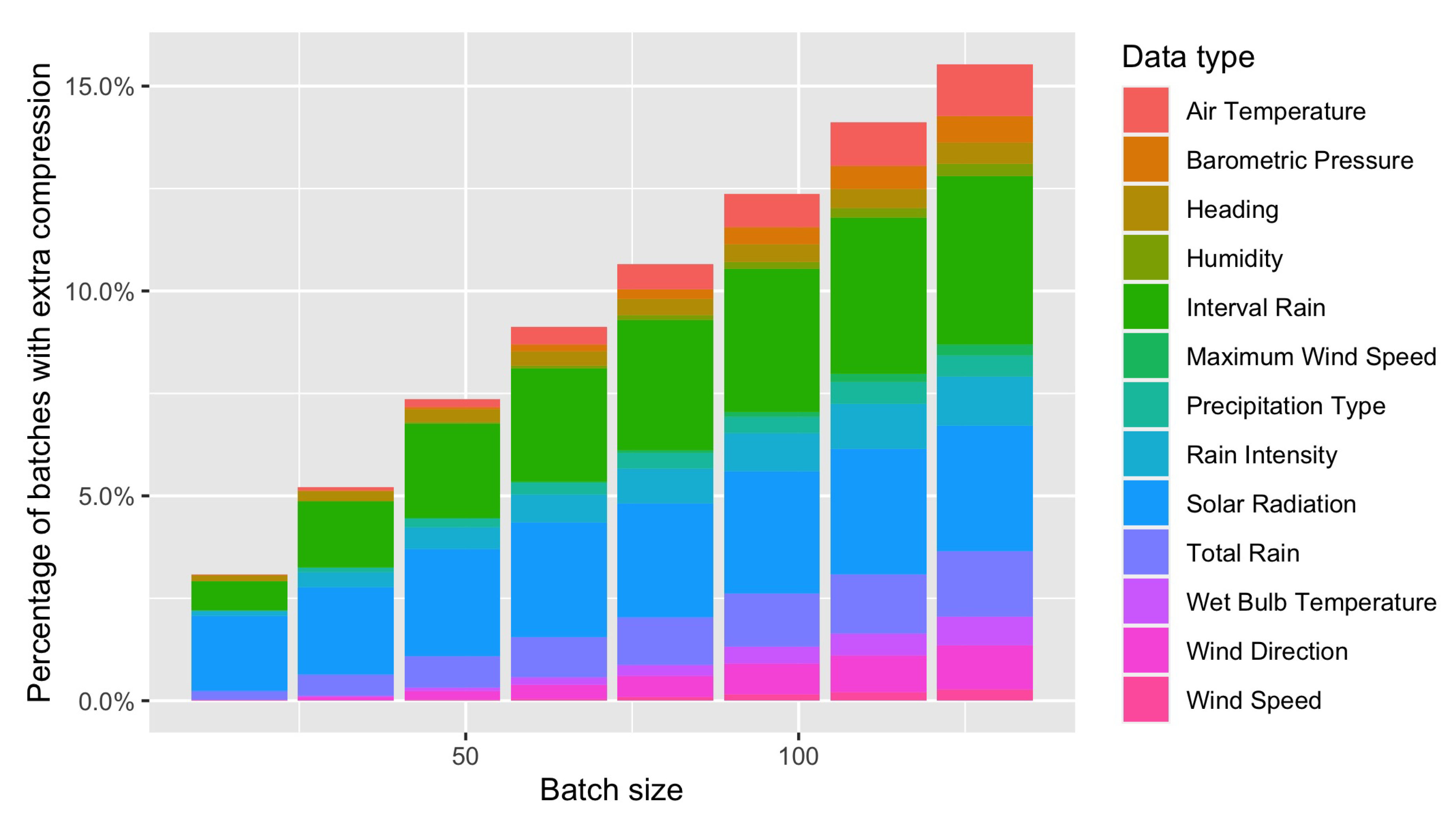
As an example, we show in
Figure 7 a sequence of 128 measurements taken from the interval rain dataset. Most of the values of this sequence are close to zero, but a few peak values are found at the beginning of the sequence. The optimal Rice coding parameter for this particular sequence is
, yielding a code of 987 bits. Instead, if we are allowed to partition the sequence of 128 values into sub-sequences, in such a way that a different Rice coding parameter can be used for each sub-sequence, it could probably yield a shorter code (after taking into account the overhead of encoding the extra parameters). The optimal solution for this instance of the partitioning problem is represented in the same figure with coloured boxes. It consists of partitioning the sequence into four sub-sequences and Rice coding them with parameters 5, 0, 9, and 0, respectively. This solution can encode the same sequence in 359 bits, after considering an overhead of 16 bits for appending to the stream the corresponding value of the Rice parameter for each sub-sequence.
More formally, for a given input sequence of samples, , a more optimal encoding can be achieved if we partition the sequence of input data, , into a set of P consecutive sub-sequences and we allow ourselves to encode each sub-sequence with a different Rice parameter . We would like the reader to notice that these two decision problems—viz. how each sub-sequence is defined and what Rice parameter is to be used for each sub-sequence—are interrelated: the choice of the ranges defining each sub-sequence boundaries has an effect on the value of its optimal parameter for efficient Rice coding and vice versa.
In this section, we present an algorithm for finding the optimal bounds for each sub-sequence and the corresponding Rice parameters so as to minimise the overall total bit-length.
The algorithm is divided into three phases. In the first phase, in
Section 5.1, a set of special sub-sequences is calculated, namely basis. In the second phase (
Section 5.2), the algorithm calculates the costs of all feasible sub-sequences in an efficient manner, by reusing previous calculations of other sub-sequences (including the basis). In the third phase (
Section 5.3), the algorithm constructs an auxiliary Directed Acyclic Graph (DAG) with at most
weighted nodes. The optimal solution to the problem results from finding the shortest path in the auxiliary weighted DAG.
While this approach is generally tedious, simply because it would require the calculation of the costs of all possible sub-sequences, it will help us in setting up the basic concepts for two efficient heuristics suitable for implementation in constrained IoT devices. These efficient heuristics will be presented later in
Section 5.4.
5.1. Basis—Reducing Input Length
Initially, we attempt to reduce the input length of our problem. For this, we partition the input sequence of
N samples into
consecutive sub-sequences of samples, in such a way that the samples in each sub-sequence require the same number of bits for encoding, as given by the value of the function
previously defined in (
10).
In this section, the sub-sequences are defined by the pair of indices of the start and end positions in its original input sequence
. We illustrate the outcomes of this process with the example dataset previously presented in
Table 1. In this case, a total of four sub-sequences—viz.
,
,
and
—shall conform the basis, since the values of
for the samples within these ranges is the same.
In this first step, for each sub-sequence in the basis, we compute and store: the value of
of (
9) for different values of
r, the range index in the sequence, and the sum of the values of that sub-sequence. This information will be used to generate all the other potentially needed sub-sequences in the second step of this algorithm (see
Section 5.2). The function for computing these parameters can be seen in Algorithm 2. For each sub-sequence
, the function returns the index of its starting and last elements in
and
, respectively. Note that
, since no sample is lost in the partitioning, nor repeated. The function also returns in
the encoding length of the each one of the
sub-sequences for different potential values of
r, and also the sum of the values for each sub-sequence
.
| Algorithm 2 Calculation of the basis for the multi-parameter Rice-encoding problem with complexity . |
- 1:
functionMultiParameterBasis(, N) - 2:
- 3:
- 4:
▹ see ( 10) for - 5:
- 6:
- 7:
- 8:
- 9:
for do - 10:
- 11:
for do - 12:
- 13:
end for - 14:
if then - 15:
- 16:
- 17:
- 18:
- 19:
- 20:
end if - 21:
end for - 22:
return - 23:
end function
|
Algorithm 2 has two nested loops. The outer loop—between Lines 9 and 21—iterates over all input values. The inner loop—between Lines 11 and 13—calculates the values for every potential value of r for the input value in consideration. Therefore, this step has a complexity of .
The output of Algorithm 2 for the example data presented in
Table 1 is provided in
Table 2.
In order to better illustrate constant values in the remaining part of this section, we will use and to denote the set of indices of where the sub-sequence k of the basis starts and ends, respectively. These two values correspond to the output values of and of Algorithm 2. In addition, the output value of k becomes the constant : the length of the basis and the output matrix become an array of constants .
5.2. Computing the Cost of All Sub-Sequences Efficiently
The sub-sequences calculated in the first step do not embrace all potential sub-sequences, but only the shortest ones. The second phase of the algorithm calculates the minimum bit-length of all other possible sub-sequences of , by reusing the information generated after the basis calculation by Algorithm 2.
Algorithm 3 receives as input: an index of the basis sub-sequences (
), the values of
of the basis for each potential value of
r (
, the start and end index of the sub-sequence (
and
, respectively), the length of the basis (
), and the range of the values of
(
and
, respectively).
| Algorithm 3 Calculation of the cost for all sub-sequences with complexity . |
- 1:
functionMultiParameterSubSequencesFrom(, , , , , , ) - 2:
- 3:
- 4:
- 5:
for do - 6:
for do ▹ see ( 10) for - 7:
- 8:
if then - 9:
- 10:
- 11:
end if - 12:
end for - 13:
end for - 14:
return - 15:
end function
|
The algorithm returns the minimum bit-length and the best Rice parameter for each one of the sub-sequences in that have as first element .
Algorithm 3 consists of two nested loops. The outer loop—between Lines 5 and 13—considers the creation of a sub-sequence by merging the sub-sequences from until k in . Each time it considers the creation of a sub-sequence, the inner loop—between Lines 6 and 12—calculates the bit-length of encoding such a new sub-sequence with different values of r. As a result, Algorithm 3 has a running complexity of .
Algorithm 3 needs to be called once for each sub-sequence in the basis. Therefore, computing the costs of every possible sub-sequence starting at any index of the input data yields a running time complexity of .
For the example sequence provided in this article, Algorithm 3 is invoked four times (once per sub-sequence in the basis). The values stored in the variable
in the first iteration of each call are shown in
Table 3. These values correspond to the bit-length of the sub-sequences in the basis for different values of the Rice parameter.
Table 4 shows the input values of Algorithm 3 for the example sequences of this article. Each column represents the minimum bit-length and optimal Rice parameter for each one of the 10 possible sub-sequences for the example problem.
5.3. Auxiliary DAG and Optimal Solution
In the third phase, we construct an auxiliary Directed Acyclic Bipartite Graph (DABiG) for finding the best subset of sub-sequences that yield the best multi-parameter solution.
The DABiG is constructed as follows:
for each sub-sequence in the basis k, we add two vertices and , representing the sub-sequence’s start and the , respectively;
we add two special vertices and ;
we add one edge from each vertex to each vertex , where , with the cost given by when Algorithm 3 is invoked with as its first parameter;
we add one edge from each vertex to with cost ; and finally,
we add one edge from to with cost and another edge from to with cost zero.
Therefore, the DABiG consists of
vertices and
directed edges. a graphical representation of the DABiG can be observed in
Figure 8.
The solution to our problem is given by the shortest path from to . The total minimal cost of the encoding is the cost of the shortest path found.
Following with our example,
Figure 9 shows the DABiG based on the found sub-sequences by Algorithm 3, which were previously mentioned in
Table 4.
5.4. Two Simple Heuristics for Constrained IoT Devices
Based on the analysis of the solution to the problem of finding the optimal Rice coding using the partitioning process as described above, in this subsection, we present two parameterized heuristics of reduced complexity in terms of both memory and CPU usage.
The idea behind the design of these parameterized heuristics is to define—in a single iteration through samples—output sub-sequences based on their similarity in terms of the number of bits needed for their encoding, following the concept of the basis presented in
Section 5.1. To do this, we assume that we are given an input parameter, say
, bounded by
, which we name the spread factor. Output sub-sequences are going to be built in such a way that the difference in the bit-length of the raw values—i.e.,
—of each output sub-sequence will not be larger than the parameter
. As a result, if
equals
, the output of these heuristics will be a single sub-sequence comprising all elements. On the other hand, if
is equal to zero, the output of these heuristics will be the set of all the sub-sequences found in the basis (as explained in
Section 5.1).
Our first proposed heuristic for this problem sets the encoding parameter of each sub-sequence as the optimal value as calculated by Algorithm 1. Our second proposed heuristic for this problem sets the encoding parameter of each sub-sequence to its respective value of
, as explained in
Section 3.2.
The pseudo-code of the second heuristic can be observed in Algorithm 4. The function RiceEncode( does only the encoding (no parameter calculation) of the sub-sequence of starting from the i-th element to the j-th element using Rice parameter r. Since each element in is passed through only once and all other calculations are done within the loop itself—between Lines 6 and 20—the running complexity of the second heuristic is .
The pseudo-code for the first heuristic is very similar, with the difference that the estimation
s and its associated summation
are not implemented and, hence, not passed to the function RiceEncode. In such a case, the function RiceEncode should find the optimal parameter for the given sub-sequence using Algorithm 1, before encoding the set of samples. Each element must be passed twice: first by the loop function presented in Algorithm 4 and later for determining the optimal parameter (Algorithm 1) for the sub-sequence. The running complexity of the first heuristic is, therefore,
, i.e., it is defined by the complexity of finding the optimal parameter of a sub-sequence.
| Algorithm 4 Heuristic for Rice encoding with partitioning with complexity . |
- 1:
functionRiceEncodeMultiHeurS(, N, ) - 2:
- 3:
- 4:
- 5:
- 6:
for do - 7:
- 8:
if then - 9:
- 10:
- 11:
- 12:
else - 13:
- 14:
RiceEncode - 15:
- 16:
- 17:
- 18:
- 19:
end if - 20:
end for - 21:
if then - 22:
- 23:
RiceEncode - 24:
end if - 25:
end function
|
5.5. Multi-Parameter Coding and Decoding
In the previous subsection, we defined different algorithms for the calculation of a set of Rice parameters that can be applied to partitions of the input data sequence. In this subsection, we propose a method for encoding the set of Rice parameters and the generated Rice codes of each sub-sequence within a single bit-stream without ambiguity.
The proposed method encodes each sub-sequence separately by providing first a code for its Rice parameter, then the Rice encoded values in the sub-sequence, and finally, a terminating delimiter for the sub-sequence.
In most applications, the Rice parameter is usually a relatively small value. In such cases, the code for the Rice parameter can be the corresponding Elias gamma code, or any other prefix non-parametrizable VLC code (refer to [
33] for a list of some of them). In applications where the Rice parameter is usually large, the author suggests including instead a field of fixed bit-length and using the natural coding for the Rice parameter. In our numerical results in the upcoming
Section 6, we will consider the later case and include an overhead of one single byte per sub-sequence for encoding the Rice parameter.
As for the terminating delimiter, it should be recalled that in
Section 1, an explanation of Rice coding and decoding for all integer values was given. It should be pointed out that, according to the definition of Rice coding presented here (from [
33]), there could be two Rice codes for the input value zero (0), since zero is neither positive nor negative but still Rice coding utilises one bit for coding its sign. In this work, for convention, we propose the usage of negative zero for delimiting the termination of the Rice coding of a sub-sequence and the coding of the Rice parameter of the next sub-sequence. In this way, the delimiter will occupy
additional bits for each sub-sequence. In order to avoid confusion, an input sample with value zero should be always encoded assuming that it is positive.
7. Conclusions
In this article, we designed several methods for the calculation of the optimal Rice coding parameter and then evaluated them using real data.
Our analysis and numerical verification showed that the optimal Rice coding parameter for a data sequence can be quickly bounded as expressed by (
21). In addition, we also observed that the output bit-length of Rice codes can be estimated by (
27) knowing the mean and variance of the dataset.
In around of the experiments, it was observed that partitioning the sequence into sub-sequences, such that each sub-sequence is coded with a different Rice parameter, can be profitable. An algorithm for finding the optimal partitioning solution for Rice codes was proposed, as well as fast heuristics, based on the understanding of the problem trade-offs.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}