Multi-Level Joint Feature Learning for Person Re-Identification


Abstract
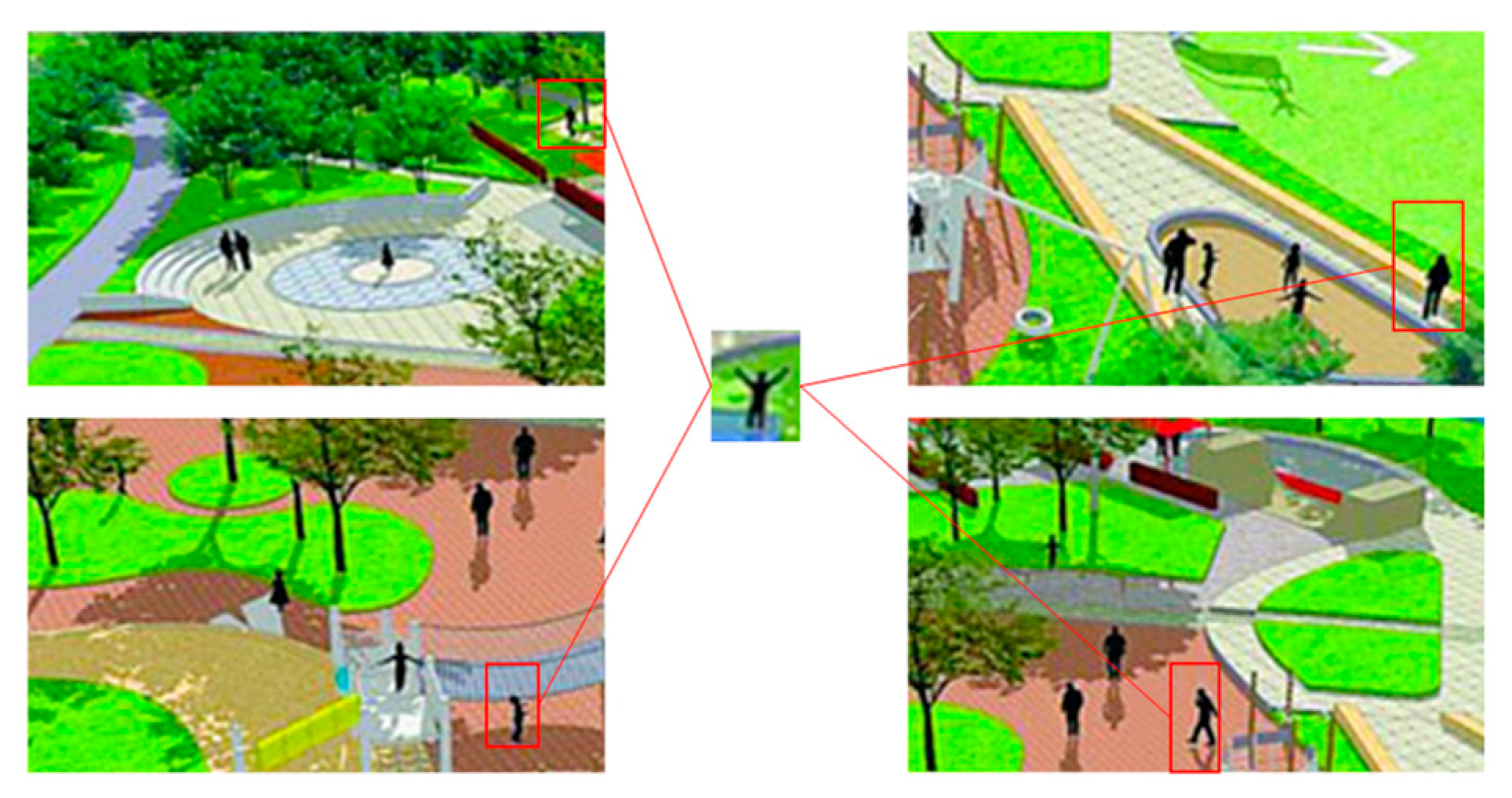
1. Introduction
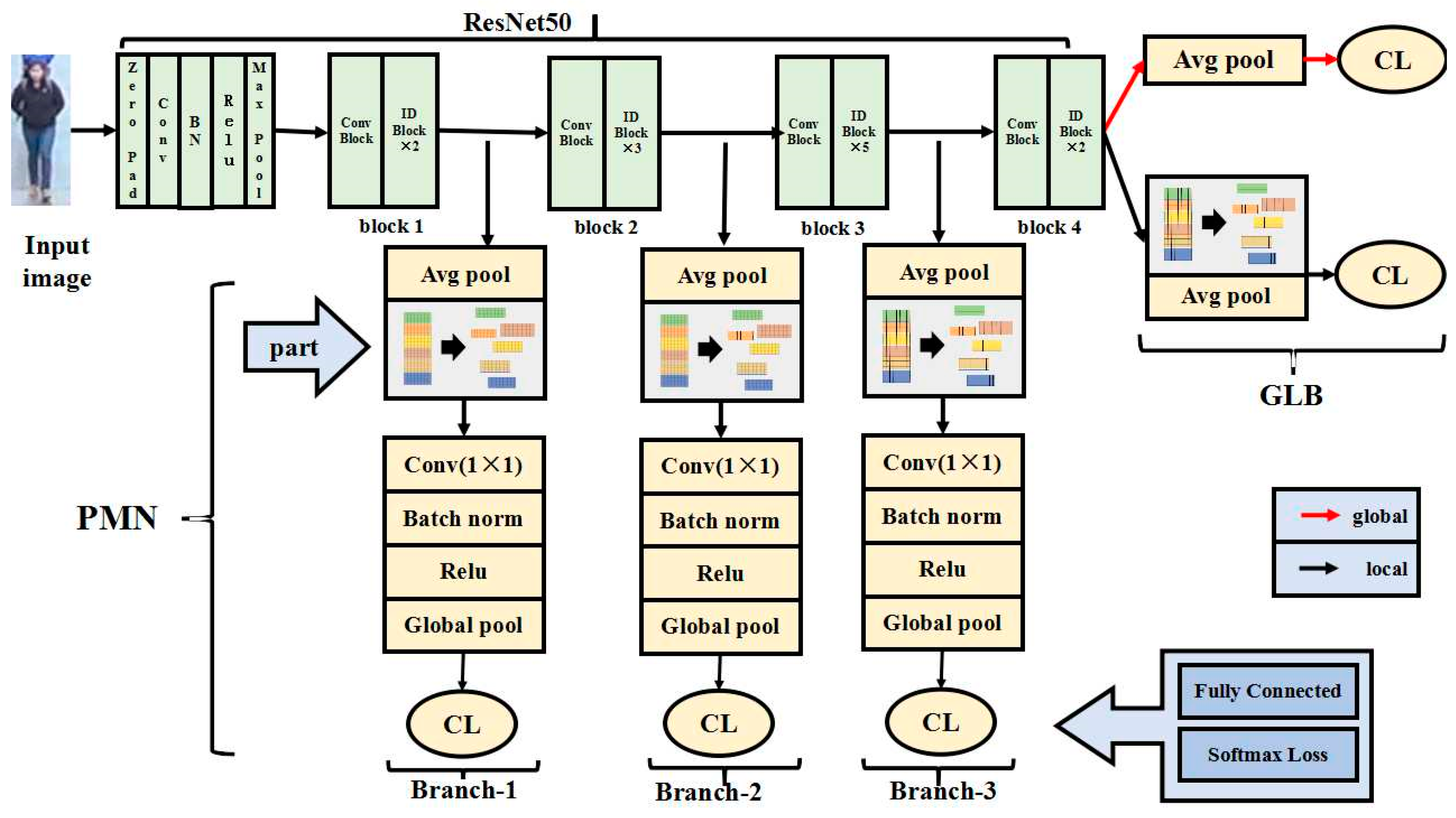
- We add Part-based Multi-level Net (PMN) to extract local features more comprehensively from lower to higher layers of the network. Compared with other traditional feature extraction methods, PMN can learn more local detailed features from different network layers.
- We join to learn global features and local features. The robustness of the MFF model can be improved by joint learning features. We use multi-class loss functions to classify the features extracted from different network branches separately, which enhances the accuracy of MFF.
- We implement extensive experiments on three challenging person re-identification datasets. Experiments show that our method is superior to existing person re-identification methods.
2. Related Work
3. Materials and Methods
3.1. Change of Backbone Network
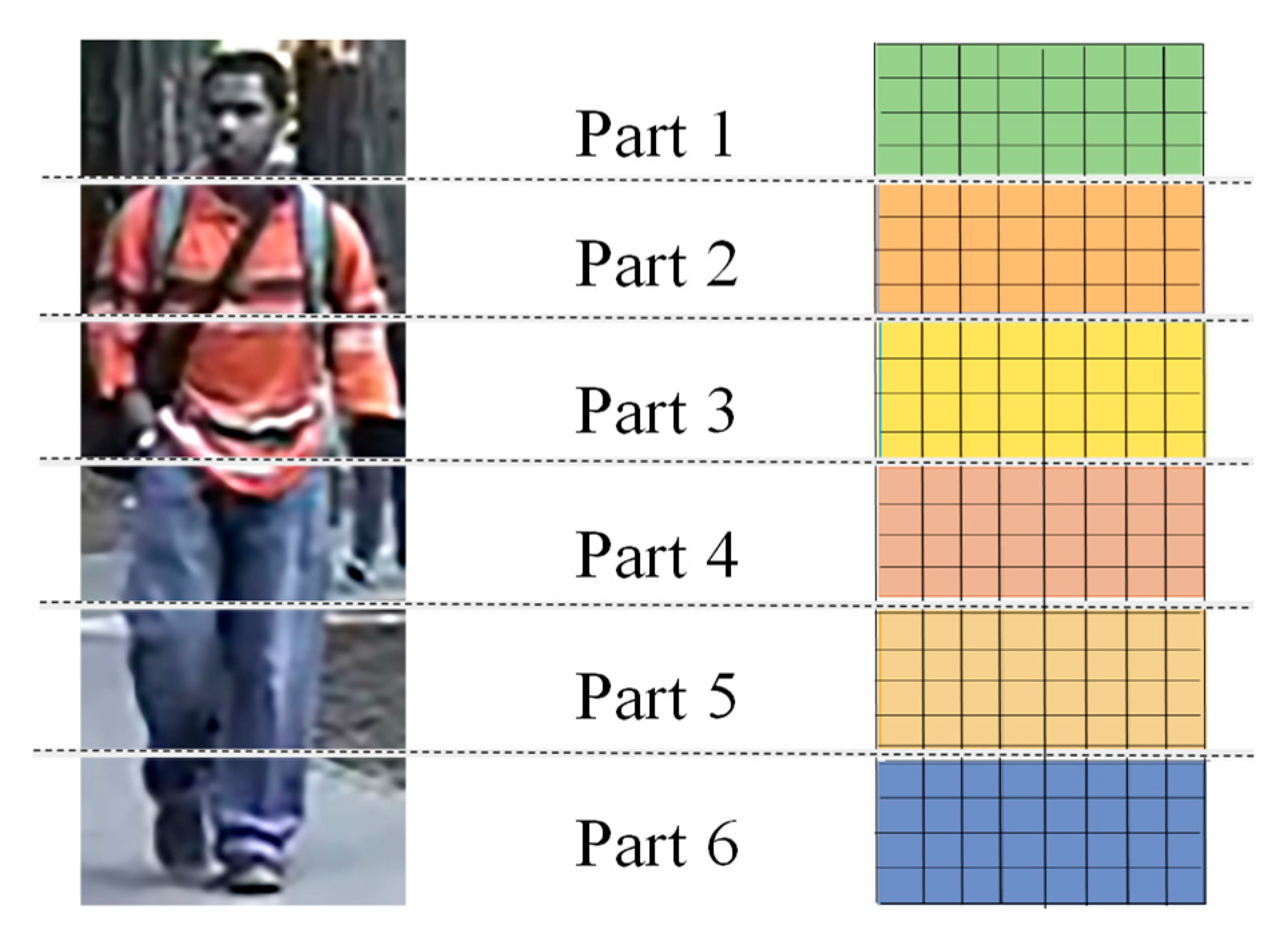
3.2. Structure of Multi-Level Feature Fusion (MFF)
3.3. Loss Function
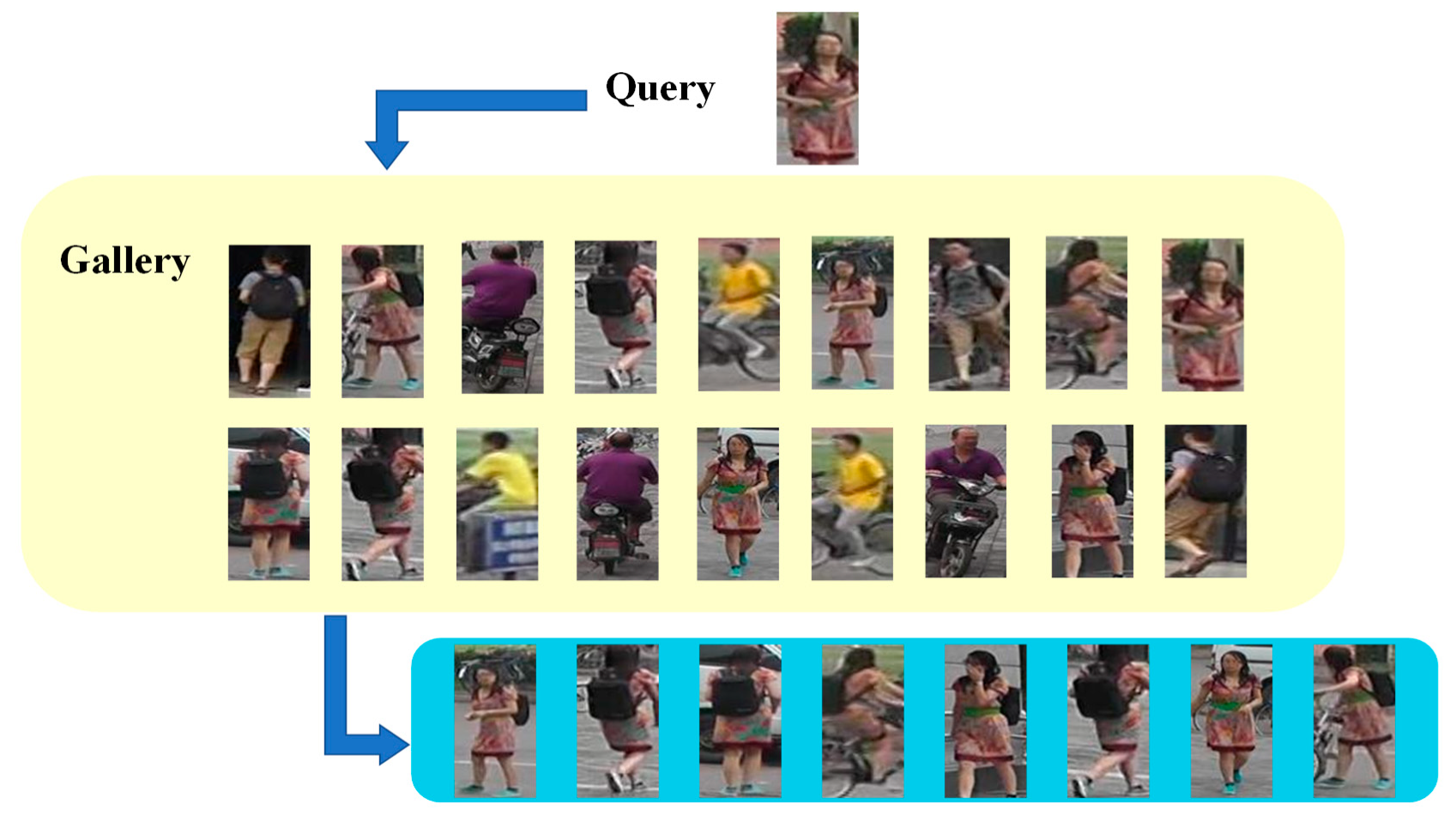
4. Results
4.1. Datasets
4.2. Implementation Details
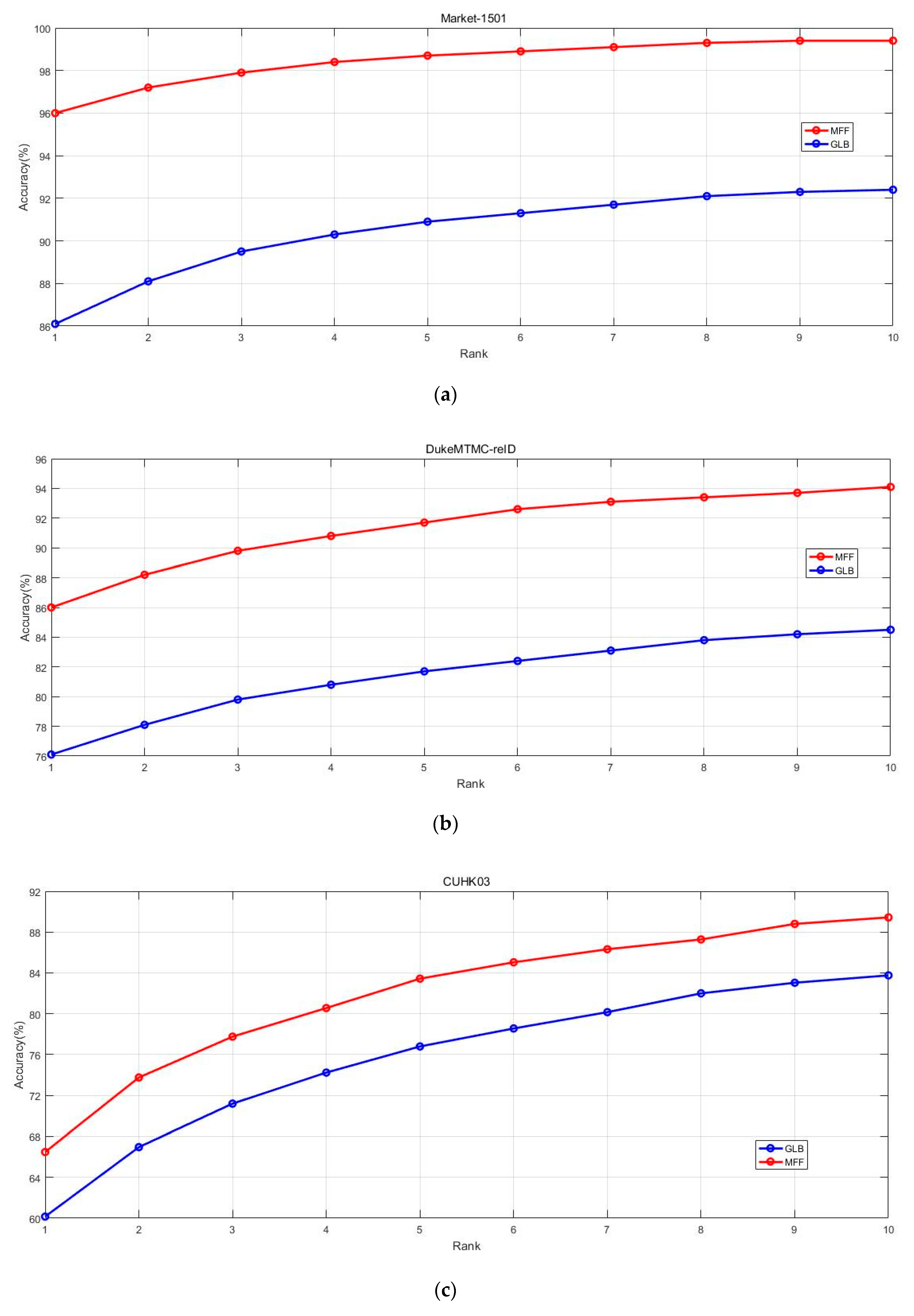
4.3. Comparison with Market1501
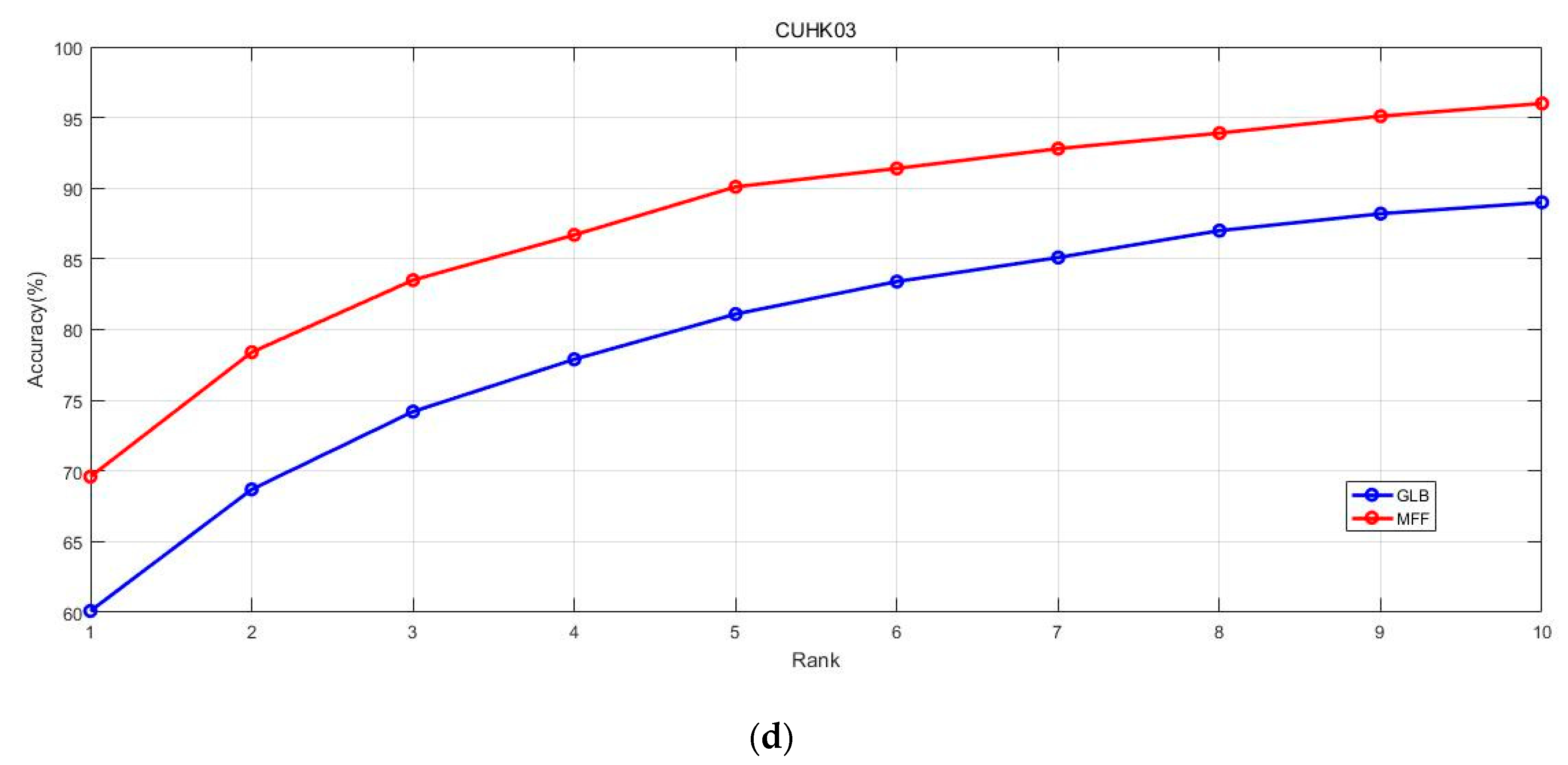
4.4. Comparison with CUHK03
4.5. Comparison with DukeMTMC-reID
4.6. Effectiveness of PMN
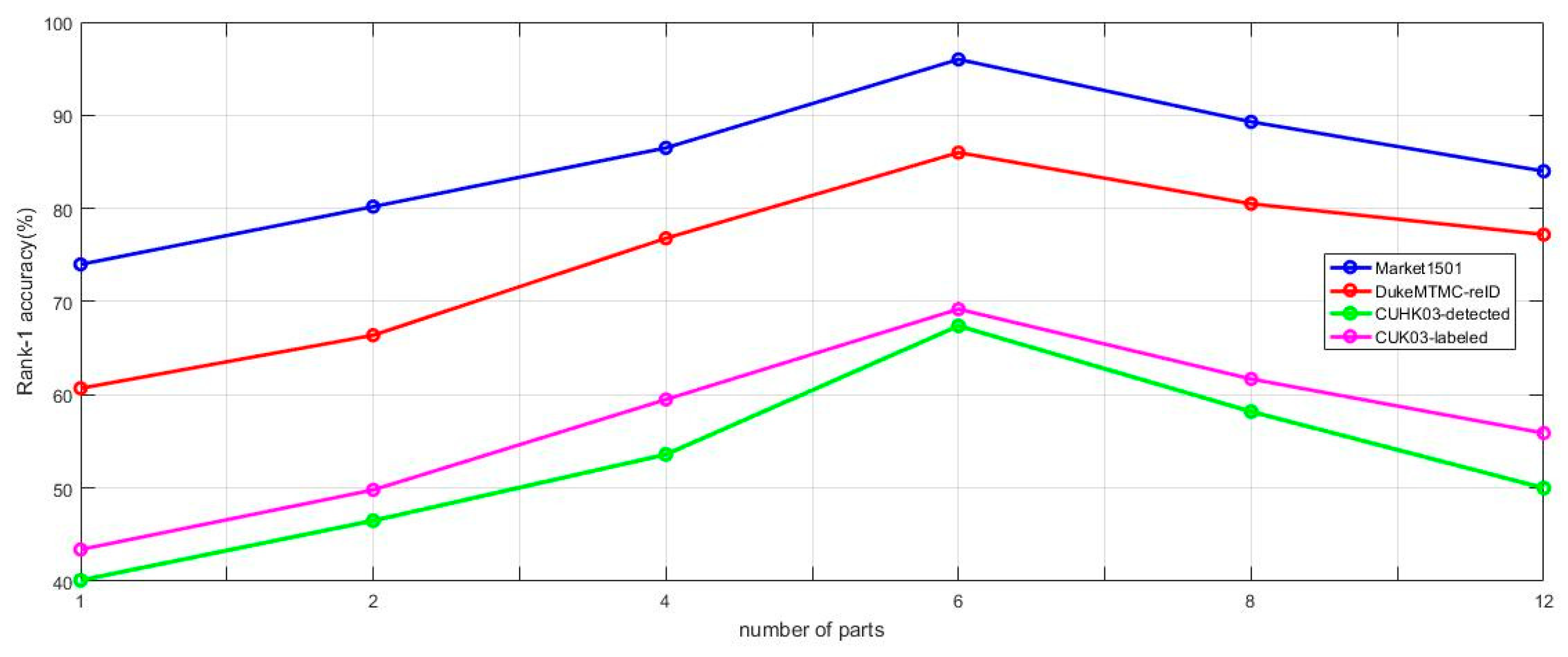
4.7. Influence of the Number of Parts
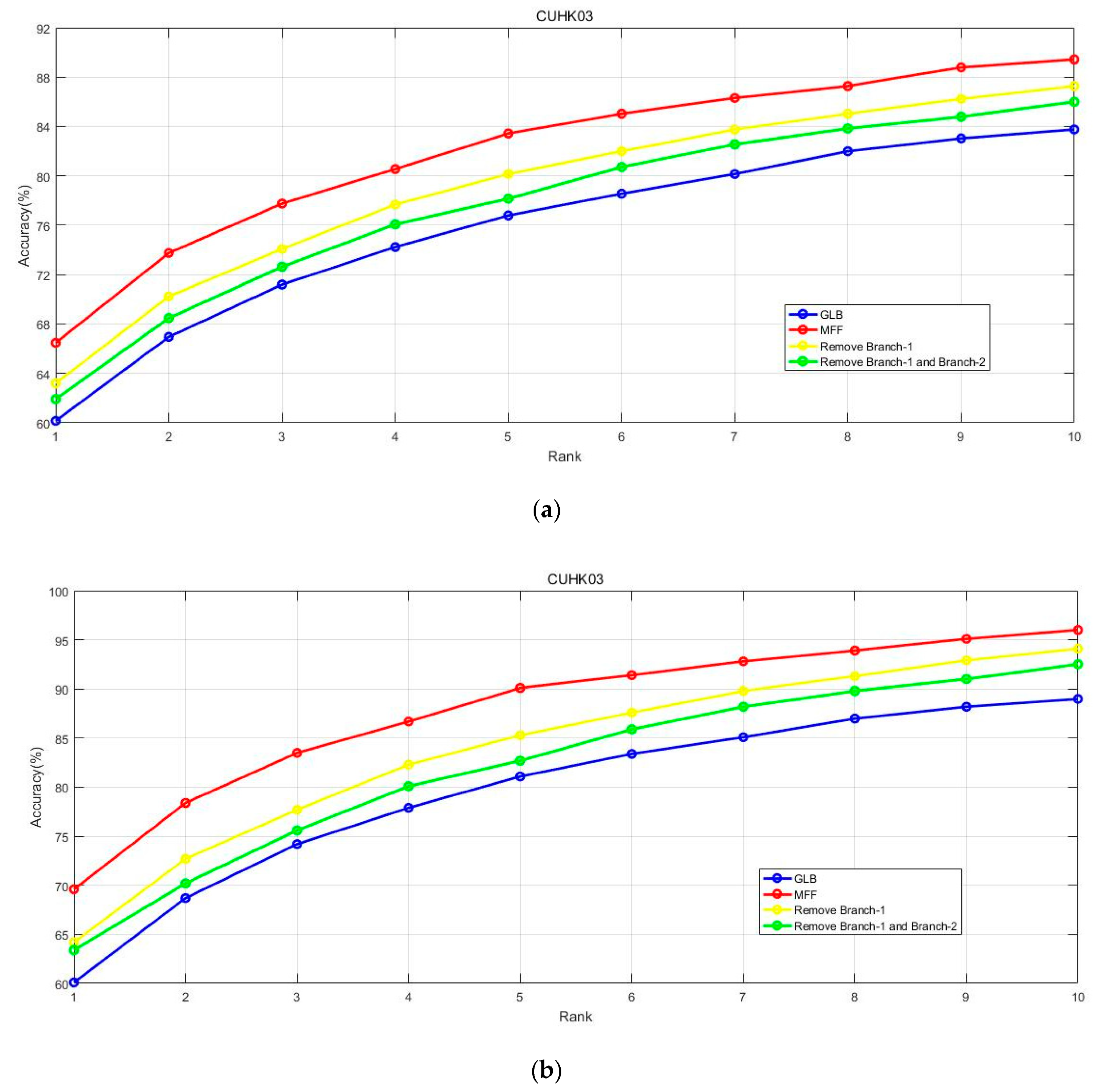
4.8. Influence of the PMN Branches
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ristani, E.; Tomasi, C. Features for Multi-Target Multi-Camera Tracking and Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 28 June 2018; pp. 6036–6046. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A Multi-task Attentional Network with Curriculum Sampling for Person Re-Identification. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 6 September 2018; pp. 365–381. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 24 July 2017; pp. 7291–7299. [Google Scholar]
- Gong, K.; Liang, X.; Zhang, D.; Shen, X.; Lin, L. Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 16 July 2017; pp. 932–940. [Google Scholar]
- Wei, L.; Zhang, S.; Yao, H.W.; Gao, W.; Tian, Q. GLAD: Global-local-alignment descriptor for pedestrian retrieval. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 13 October 2017; pp. 420–428. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 20 June 2015; pp. 2197–2206. [Google Scholar]
- Xiao, Q.; Luo, H.; Zhang, C. Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 7 July 2017. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Person re-identification by deep joint learning of multi-loss classification. In Proceedings of the International Joint Conferences on Artificial Intelligence, Melbourne, Australia, 1 May 2017; pp. 2194–2200. [Google Scholar]
- Yao, H.; Zhang, S.; Zhang, Y.; Li, J.; Tian, Q. Deep representation learning with part loss for person re-identification. IEEE Trans. Image Process. 2019, 28, 2860–2871. [Google Scholar] [CrossRef] [PubMed]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 14 June 2016; pp. 1335–1344. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 6 September 2018; pp. 480–496. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z. Learning deep context-aware features over body and latent parts for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 25 July 2017; pp. 384–393. [Google Scholar]
- Zhao, L.; Li, X.; Wang, J.; Zhuang, Y. Deeply-learned part-aligned representations for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 23 October 2017; pp. 3219–3228. [Google Scholar]
- Kalayeh, M.M.; Basaran, E.; Gökmen, M.; Kamasak, M.E.; Shah, M. Human Semantic Parsing for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 20 June 2018; pp. 1062–1071. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-Aligned Bilinear Representations for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 9 June 2018; pp. 402–419. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 18 June 2014; pp. 152–159. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 24 October 2016; pp. 791–808. [Google Scholar]
- Xiao, T.; Li, H.; Ouyang, W.; Wang, X. Learning deep feature representations with domain guided dropout for person reidentification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, Las Vegas, NV, USA, 26 June 2016; pp. 1249–1258. [Google Scholar]
- Yang, Y.; Liu, X.; Ye, Q.; Tao, D. Ensemble Learning-Based Person Re-identification with Multiple Feature Representations. Complexity 2018, 2018. [Google Scholar] [CrossRef]
- Wang, H.; Zhu, X.; Gong, S.; Xiang, T. Person re-identification in identity regression space. Int. J. Comput. Vis. 2018, 126, 1288–1310. [Google Scholar] [CrossRef] [PubMed]
- Paolanti, M.; Romeo, L.; Liciotti, D.; Pietrini, R.; Cenci, A.; Frontoni, E.; Zingaretti, P. Person Re-Identification with RGB-D Camera in Top-View configuration through Multiple Nearest Neighbor Classifiers and Neighborhood Component Features Selection. Sensors 2018, 18, 3471. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 18 October 2017; pp. 350–359. [Google Scholar]
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-Person: Learning Discriminative Deep Features for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 20 November 2017. [Google Scholar]
- Liu, H.; Feng, J.; Qi, M.; Jiang, J.; Yan, S. End-to-End Comparative Attention Networks for Person Re-Identification. IEEE Trans. Image Process. 2017, 3492–3506. [Google Scholar] [CrossRef] [PubMed]
- Lei, W.; Zhu, X.; Gong, S. Harmonious Attention Network for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 6 June 2018; pp. 2285–2294. [Google Scholar]
- Chen, D.; Yuan, Z.; Hua, G.; Zheng, N.; Wang, J. Similarity learning on an explicit polynomial kernel feature map for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 1 June 2015; pp. 1565–1573. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. arXiv 2016, arXiv:1612.02295. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep hypersphere embedding for face recognition. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar]
- Ahmed, E.; Jones, M.; Marks, T.K. An improved deep learning architecture for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 10 June 2015; pp. 3908–3916. [Google Scholar]
- Zhang, X.; Luo, H.; Fan, X.; Xiang, W.; Sun, Y.; Xiao, Q.; Jiang, W.; Zhang, C.; Sun, J. Alignedreid: Surpassing human-level performance in person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 8 November 2017. [Google Scholar]
- Chen, W.; Chen, X.; Zhang, J.; Huang, K. Beyond Triplet Loss: A Deep Quadruplet Network for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 6 July 2017; pp. 403–412. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 20 December 2015. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person reidentification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 9 December 2015; pp. 1116–1124. [Google Scholar]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 16 October 2017; pp. 3800–3808. [Google Scholar]
- Engel, C.; Baumgartner, P.; Holzmann, M.; Nutzel, J.F. Person re-identification by support vector ranking. In Proceedings of the British Machine Vision Conference, Aberystwyth, UK, 1 August 2010. [Google Scholar]
- Jose, C.; Fleuret, F. Scalable metric learning via weighted approximate rank component analysis. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 1 October 2016; pp. 875–890. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 7 June 2009. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 25 October 2017; pp. 3960–3969. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person reidentification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 17 March 2017. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 1 June 2018; pp. 4320–4328. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Person Alignment Network for Large-scale Person Re-identification. IEEE Trans. Image Process. 2018. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Feature. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 10 October 2016. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 15 September 2017; pp. 2590–2600. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-Level Factorisation Net for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 24 March 2018; pp. 2109–2118. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Disriminative Features with Multiple Granularities for Person Re-Identification. arXiv 2018, arXiv:1804.01438. [Google Scholar]
- Zheng, Z.; Zheng, L.Y.; Yang, Y. A Discriminatively Learned Cnn Embedding for Person Re-identification. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 13. [Google Scholar] [CrossRef]
- Schumann, A.; Stiefelhagen, R. Person Re-identification by Deep Learning Attribute-Complementary Information. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 8 October 2017; pp. 20–28. [Google Scholar]
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-Person: Learning Discriminative Deep Features for Person Re-Identification. arXiv 2017, arXiv:1711.10658. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch | Dimension |
|---|---|
| Branch-1 | 256 × 6 |
| Branch-2 | 256 × 6 |
| Branch-3 | 256 × 6 |
| GLB-1 | 256 |
| GLB-2 | 256 × 6 |
| Dataset | Release Tine | Identities | Cameras | Crop Size | Label Method |
|---|---|---|---|---|---|
| Market-1501 | 2015 | 1501 | 6 | Vary | Hand/DPM |
| DukeMTMC-reID | 2017 | 1812 | 8 | 128 64 | Hand |
| CUHK03 | 2014 | 1467 | 10 | Vary | Hand/DPM |
| Method | Market1501 | |||
|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-10 | mAP | |
| BoW + KISSME [33] | 44.4 | 63.9 | 72.2 | 20.8 |
| WARCA [36] | 45.2 | 68.1 | 76.0 | - |
| SVDNet [34] | 82.3 | 92.3 | 95.2 | 62.1 |
| PDC [38] | 84.4 | 92.7 | 94.9 | 63.4 |
| Triplet Loss [39] | 84.9 | 94.2 | - | 69.1 |
| DML [40] | 87.7 | - | - | 68.8 |
| PAR [13] | 81.0 | 92.0 | 94.7 | 63.4 |
| MFF (Ours) | 96.0 | 98.7 | 99.3 | 87.9 |
| Method | CUHK03-Detected | |
|---|---|---|
| Rank-1 | mAP | |
| BoW + KISSME [33] | 6.4 | 6.4 |
| LOMO + KISSME [6] | 12.8 | 11.5 |
| IDE [42] | 21.3 | 19.7 |
| PAN [41] | 36.3 | 34.0 |
| DPFL [43] | 40.7 | 37.0 |
| SVDNet [34] | 41.5 | 37.3 |
| HA-CNN [25] | 41.7 | 38.6 |
| MLFN [44] | 52.8 | 47.8 |
| PCB+RPP [11] | 63.7 | 57.5 |
| MGN [45] | 66.8 | 66.0 |
| MFF (Ours) | 67.4 | 66.7 |
| Method | CUHK03-Labeled | |
|---|---|---|
| Rank-1 | mAP | |
| BoW + KISSME [31] | 7.9 | 6.4 |
| LOMO + KISSME [6] | 14.8 | 11.5 |
| IDE [42] | 22.2 | 19.7 |
| PAN [41] | 36.9 | 34.0 |
| DPFL [43] | 43.0 | 37.0 |
| SVDNet [34] | 40.9 | 37.3 |
| HA-CNN [25] | 44.4 | 38.6 |
| MLFN [44] | 54.7 | 49.2 |
| MGN [45] | 68.0 | 67.4 |
| MFF (Ours) | 69.6 | 68.8 |
| Method | DukeMTMC-reID | |
|---|---|---|
| Rank-1 | mAP | |
| BoW + KISSME [33] | 25.1 | 12.2 |
| LOMO + KISSME [6] | 30.8 | 17.0 |
| Verif + Identif [46] | 68.9 | 49.3 |
| ACRN [47] | 72.6 | 52.0 |
| PAN [41] | 71.6 | 51.5 |
| SVDNet [34] | 76.7 | 56.8 |
| DPFL [43] | 79.2 | 60.6 |
| HA-CNN [25] | 80.5 | 63.8 |
| Deep-Person [48] | 80.9 | 64.8 |
| PCB+RPP [11] | 83.3 | 69.2 |
| MFF (Ours) | 86.0 | 76.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Gao, L. Multi-Level Joint Feature Learning for Person Re-Identification. Algorithms 2020, 13, 111. https://doi.org/10.3390/a13050111
Wu S, Gao L. Multi-Level Joint Feature Learning for Person Re-Identification. Algorithms. 2020; 13(5):111. https://doi.org/10.3390/a13050111
Chicago/Turabian StyleWu, Shaojun, and Ling Gao. 2020. "Multi-Level Joint Feature Learning for Person Re-Identification" Algorithms 13, no. 5: 111. https://doi.org/10.3390/a13050111
APA StyleWu, S., & Gao, L. (2020). Multi-Level Joint Feature Learning for Person Re-Identification. Algorithms, 13(5), 111. https://doi.org/10.3390/a13050111