3.1. Parametric Based Train Dynamic Model
To facilitate understanding, in this subsection, we briefly introduce a classical single-point train dynamic model. Other types of dynamic models (such as multi-point models) can be considered as optimized or expanded versions of this model. By ignoring the in-train force and assuming continuous control rates, the model can be formulated as [
44]
where
x,
v and
t denote the train displacement, velocity and time, respectively.
represents the total mass of the train, where
is the mass of the
ith carriage.
is the train traction force while
denotes the train braking force.
and
represent the relative accelerating and braking coefficients, respectively. Given a certain train position
x,
describes the impacts of the gradient resistances and curve resistances.
is the Davis formula, which expresses the relationship between the train speed and the aerodynamic drag, where
,
and
indicate the resistance parameters.
In this model, let
denote the set of train positions in a certain operation area. The location data can be obtained by locating devices, i.e., balises, which are extensively deployed in the European Train Control System and the Chinese Train Control System [
45]. With low time delay, a balise transmits the position data to the passing train. The velocity of the train can be similarly captured by track-side and on-board devices. Given the fixed parameters of the dynamic model (
,
,
,
,
and
), the inputs and the outputs of the model are shown in
Figure 1. As can be seen in
Figure 1, when a certain train passes
, the inputs of the dynamic model are
,
,
and
. Using Equations (
1) and (
2), the model output
can be calculated.
Since some of the model parameters are difficult to acquire in real-world scenarios, their values are arbitrarily assigned, resulting in a poor performance of this parametric approach. Furthermore, the velocity of the train varies in a wide range during the operation process. By adjusting the control commands, the operation process can be divided into four phases: train acceleration, train coasting, train cruising and train braking. At different operation phases, the parameters and disturbance factors have different influences of the model outputs. Thus, Equations (
1) and (
2) may change into various complicated multivariate nonlinear functions, which increases the difficulty of system modeling.
3.2. LSTM Based Train Dynamic Model: Problem Statement
To overcome the aforementioned disadvantages of the parametric approach, we propose a data-driven approach to address the issue of train dynamic model construction, where the LSTM network is applied. Besides, by deliberately designing the lagged features and statistical features, we extend the proposed LSTM based algorithm to predict train speed for multi-step ahead. To be more specific, the train dynamic model can be considered as an approach to get the train speed of the next time step. Since LSTM networks have the capacity to model long-term dependencies, our proposed model can obtain the train speeds for next n time steps.
For clarity, in this subsection, we review the problem of the train dynamic model. Note that the model inputs are exactly the same as the aforementioned parametric approach. Formally, let
and
denote the sets of observable features and target outputs, respectively. Similar to
Section 3.1, all features (model inputs) can be instantly seized at any time step.
represents the set of previous time steps, which can be written as
. For
and
, we express the feature vector
as the values of features seized at
th previous time step, where
n denotes the number of features. The feature matrix can be formulated as
where
means the
jth feature captured at
ith time step.
In addition, we denote
. For
and
,
is defined as the value of model output at
qth time step in the future.
is defined as the output vector. Using a deep learning method, a regression function
h is trained, which can be written as
where
represents the set of algorithm parameters.
With the purpose of reducing the gap between the predicted outputs and the actual values, the loss function
should be minimized
where
l represents the number of samples.
denotes the vector of actual values. In our scenario, according to
Figure 1, using feature matrix
generated by
,
,
and
, the proposed approach is capable of getting the predicted train speeds
.
3.3. LSTM Network Structure
The LSTM network is a variant of deep neural networks, which was first introduced by Hochreiter [
20]. Distinguished from traditional neural networks, there exists an internal hidden state in the units that constitutes the LSTM network. Generally, an LSTM network is made up of one input layer, one recurrent hidden layer and one output layer. The unit in the recurrent hidden layer is termed as the memory block, which consists of memory cells and adaptive, multiplicative gating units. In the memory cell, the state vector is saved to aggregate the previous input data. By tuning the parameters of gating units, the input data, the output data and the state data are mixed to update the current state. The control mechanism is summarized as follows. Note that all the symbol definitions can be found in
Table 1.
Without ambiguity, at each time iteration
t, let
denote the hidden layer input feature which is directly fed to the LSTM cell through the input gate. The input gate can be written as [
46]
Assuming the dimensions of and are and , respectively, the dimension of is . is defined as the dimension of the state vector. , and are decided to control the effects of the layer input and the layer output of previous time step on the output of input gate .
To deal with the gradient diffusion and the gradient explosion problems [
47], in LSTM networks, the forget gate is deliberately designed
According to Equation (
8), once the contents of the LSTM cell are out of date, the forget gate helps to update parameters by resetting the memory block. Similarly, the dimension of
is
.
The output gate is defined as
The definitions of
,
,
and
are listed in
Table 1.
To update the cell statement,
is defined as the state update vector ,which is calculated as
In Equation (
10),
represents the hyperbolic tangent function. The reason for using this particular function is that other activation functions (e.g., the rectified linear unit) may have very large outputs and cause the gradient explosion problem [
48]. The hyperbolic tangent function can be written as
Based on the results of Equations (
7) and (
11), at a certain time step
t, the current cell state is updated by
where ∘ represents the scalar product of two vectors. By observing Equation (
12), thanks to the control of the input gate and the forget gate, one can find that the current input and long-term memories are combined to form a new cell state.
At last, the hidden layer output is decided by the output of the output gate and the current cell state
The internal structure of an LSTM cell is shown in
Figure 2.
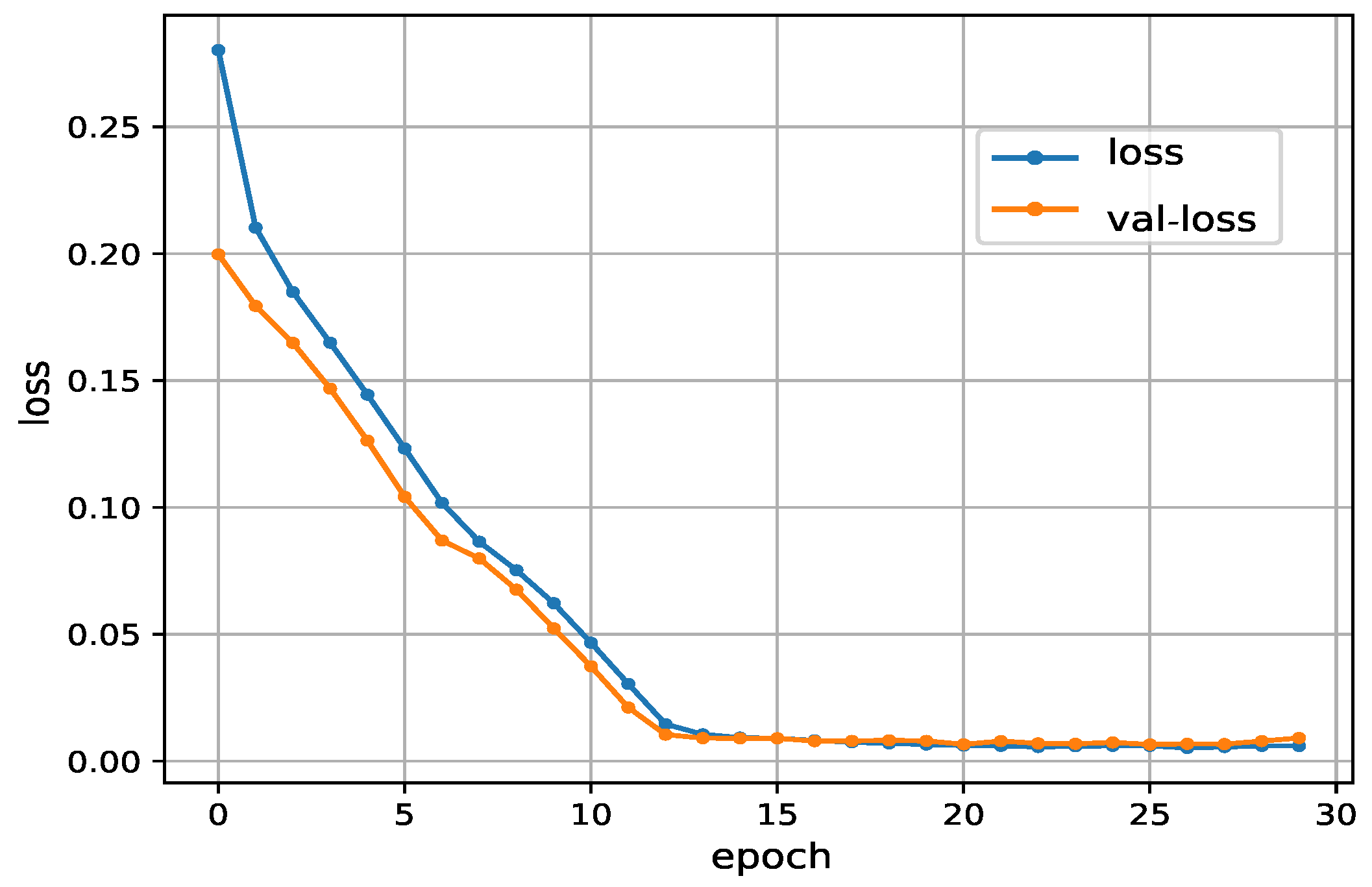
The training process can be regarded as a supervised learning process and many objective functions are designed to minimize the average differences between the outputs of the LSTM network and the actual values. In the training process, the parameters (such as the weight matrices and the biases vectors) are optimized. Errors are intercepted at the LSTM cells and are vanished thanks to the forget gate. The gradient descent optimization algorithm is adopted to obtain the gradient of the objective function, and then the Back Propagation Through Time (BPTT) [
49] algorithm is used to train and update all the parameters to increase the prediction accuracy. The derivations of the training process are not covered in this paper due to space restrictions. One can refer to the work in [
46] for detailed execution steps.
Through multiple iterations, ideally, the parameters will gradually converge to the global optimum while the training process is finished. However, due to the substantial number of hyperparameters and the deep network structure, the gradient descent algorithm may be trapped to the local optimum, resulting in the degradation of output accuracy and the prolongation of training time. To cope with this problem, in this paper, the Adaptive Moment estimation (Adam) optimization algorithm [
50] is employed to avoid low efficiency and local optimum.
Note that, even though only one hidden layer exits in the network, the LSTM network is considered as a deep learning algorithm due to the recurrent nature. Similar to convolutional neural networks, more hidden layers can be stacked to seize high-dimensional characteristics. However, previous studies show that adding hidden layers may not significantly improve the algorithm performance over a single layer [
51,
52]. Thus, in this paper, the aforementioned standard LSTM network structure is adopted where one hidden layer is deployed to save storage and computing resource.
3.4. Algorithm Implementation
3.4.1. Data Preparation
In this study, to prove the practicality of the proposed LSTM network based algorithm, we used actual runtime data as the network inputs. The actual in-field data were gathered by the Vehicle On Board Controller (VOBC) from Shenzhen Metro Line No. 7 in China and Beijing Yanfang Metro Line in China. The dataset of Shenzhen Metro Line consists of three subsets, which separately record the train operation data of a certain train on three days, i.e., 7 April 2018, 8 April 2018 and 11 July 2018. The dataset of Beijing Yanfang Metro Line includes the operation data collected on 13 May 2019. For example, the subset on 7 April 2018 contains 381,637 records which describe the driving process through the whole day. The relevant information of one record is listed in
Table 2.
As can be seen in
Table 2, the information of the train operation state was meticulously recorded. The vast amounts of data offer the advantageous support to apply data-driven algorithms. To keep consistent with the inputs of the traditional dynamic model presented in
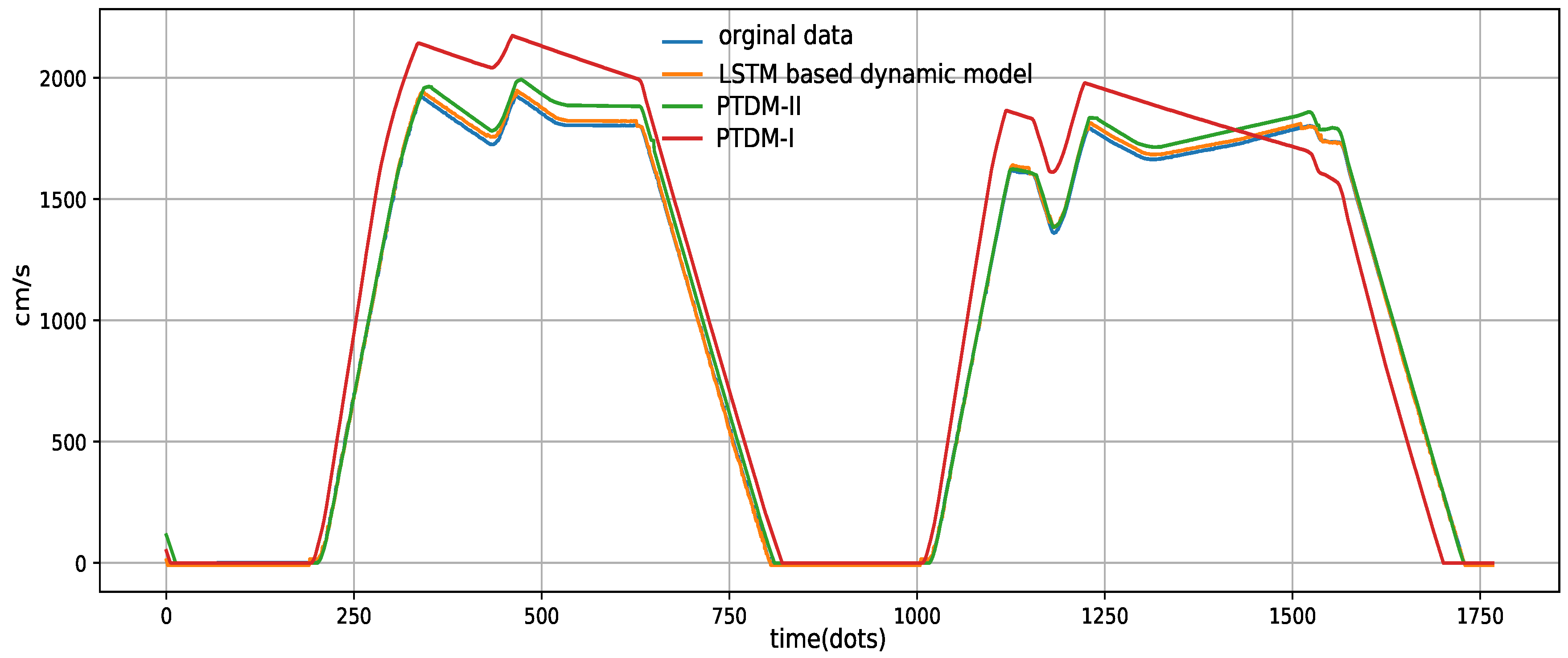
Section 3.1, we chose four raw features as the inputs of the proposed algorithm: analog output, traction brake, train speed and slope. These four features for a certain operation process are shown in
Figure 3.
Analog output: Analog output is a continuous variable, which is outputted by electric motors. This feature is used to control the train to accelerate or decelerate. It reflects the absolute value of the train braking force and the train traction force .
Traction brake: Traction brake is a categorical variable, which implies the direction of analog output and gives the signs of and .
Train speed: At each time iteration t, the train speed is accurately recorded by VOBC.
Slope: Slope represents the track gradient which impacts the gradient resistances.
One can find that extra information is not added to our algorithm compared to the traditional method. The purpose is to prove that the performance improvement of the proposed approach depends on the algorithm itself rather than the extension of inputs.
3.4.2. Data Preprocessing
In reality, operation data are collected by many on-board sensors and trackside equipments. Considering the practical working environment, the sensors and actuators may fail to generate data due to line fault, equipment failure, communication quality, etc. This situation further leads to the problem of missing values. Missing values of the dataset reduce the fitting effect and increase the model bias, resulting in a poor performance of regression and prediction. For LSTM based algorithms, the effect of missing values is more serious. LSTM networks fail to run since null values cannot be calculated during the error propagation process. The missing values can be arbitrarily set to zero or other statistical values (such as the most frequent non-missing value). However, this treatment causes a great disturbance when handling time series problems. In this paper, similar to Cui [
43], a masking mechanism is proposed to solve the problem of missing values.
In the masking mechanism, we predefine a mask value and the missing values are directly set as . At each iteration t, if one of the raw features is invalid, all the raw features, i.e., , , and , are set to . In this paper, the mask value is assigned as null. For a feature matrix , if there exists a missing element in , the element equals and the training process at the kth step will be skipped. Thus, the state vector is directly fed to the ()th time step. Note that the issue of continuous missing values can also be solved using this masking mechanism.
3.4.3. Feature Engineering
Feature engineering is a vital part of data analysis. The quality of results of deep learning algorithms heavily relies on the quality of the input features. For the traditional train dynamic model, as can be seen in
Figure 1, with the inputs of
,
and
, the current speed
can be calculated. To be consistent with the previous model, in the proposed dynamic model, the raw features, i.e.,
,
,
and
, are directly fed into the LSTM cells after removing the missing values. To facilitate understanding, in this paper, we do not use abbreviations for these features.
Considering the problem of train speed prediction, since we expect to obtain the train speeds for next n time steps, more delicate descriptions of the features should be made to capture more information from previous data. For this reason, we establish a different set of features as inputs for train speed prediction. The set contains three types of features, i.e., lagged features, crossed features and statistical features. All features are produced by , , and slope, which are listed above.
The lagged features imply the instantaneous values of the previous time steps, which are defined as:
At time iteration t, the train speed of kth step earlier: , where .
At time iteration t, the analog output of kth step earlier: , where .
The statistical features capture the changes of the input values in the previous period:
The average value of train speed of past k steps: , where .
The standard deviation of train speed of past k steps: , where .
The difference of train speed between the previous kth step and the current step: , where .
The average value of analog output of past k steps: , where .
The standard deviation of analog output of past k steps: , where .
The difference of analog output between the previous kth step and the current step: , where .
Since recent data play a more important role for a time series problem, the crossed features are designed as:
The product of train speed of past k steps: , where . For example, .
In total, 43 features are extracted for the train speed prediction task.
3.4.4. Offline Training and Online Predicting
When the feature engineering process is done, the features are fed to the input layer. To eliminate the effect of index dimension and quantity of data, all features are normalized using the Min-Max Normalization method shown in Equation (
14).
where
and
represent the minimum and maximum of a certain feature, respectively.
Each neuron in the input layer is connected to each LSTM cell in the hidden layer. Note that its number should match the dimension of the input data. In this paper, the activation functions of the input gate, the output gate and the forget gate are selected as the standard logistics sigmoid function shown in Equation (
15)
In the recurrent hidden layer, as described in
Section 3.3, the “meaningful parts” are abstracted from the input time series. The parameters are updated using the Adam optimization algorithm and the BPTT algorithm. These “higher-level features” are then combined in the output layer. The output layer is also termed as the dense layer to produce the predicted train speeds of future time steps. As a regression problem, the output layer has only one neuron. In this paper, the optimization of the dense layer can be considered as a linear regression problem, i.e., the activation function of the output layer is set as a linear function. The loss function in this paper adopts the Mean Absolute Error (MAE) loss
The offline training phase ends when the error of the algorithm outputs meets the preset threshold. The set of parameters (such as the weight matrices and the biases vectors) can be obtained, which approximately describes the regression function
in Equation (
5).
In the online predicting phase, the actual data gathered by VOBC are fed to the trained LSTM network. After extracting the raw features, the proposed data-driven algorithm can output the prediction of the next time step, whose functionality can serve as the train dynamic model. In addition, with the feature engineering process, the train speeds for next n time steps can be obtained.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}