A Variable Block Insertion Heuristic for Solving Permutation Flow Shop Scheduling Problem with Makespan Criterion


Abstract
:1. Introduction
2. Mathematical Model Formulation
2.1. The MIP Model
2.2. The CP Model
3. Meta-Heuristic Algorithms
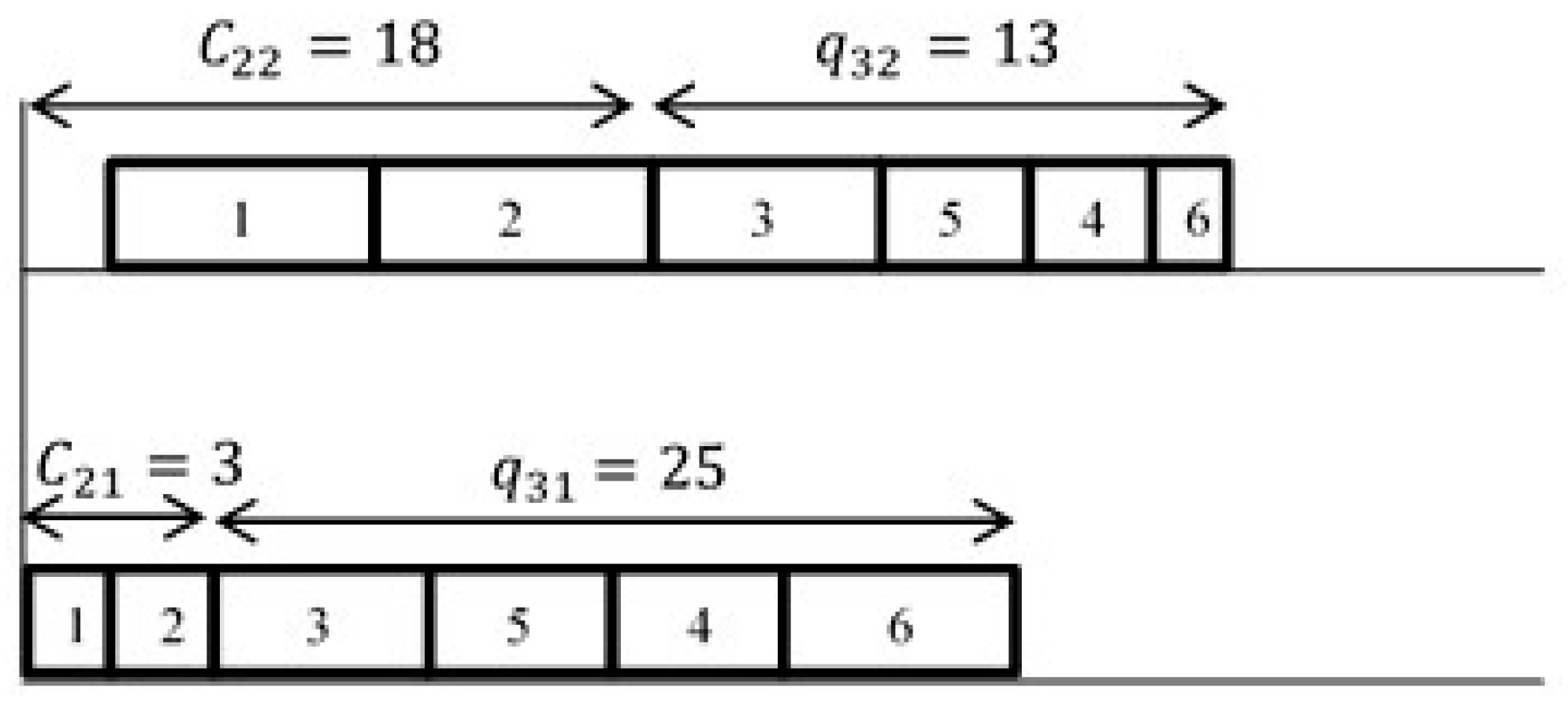
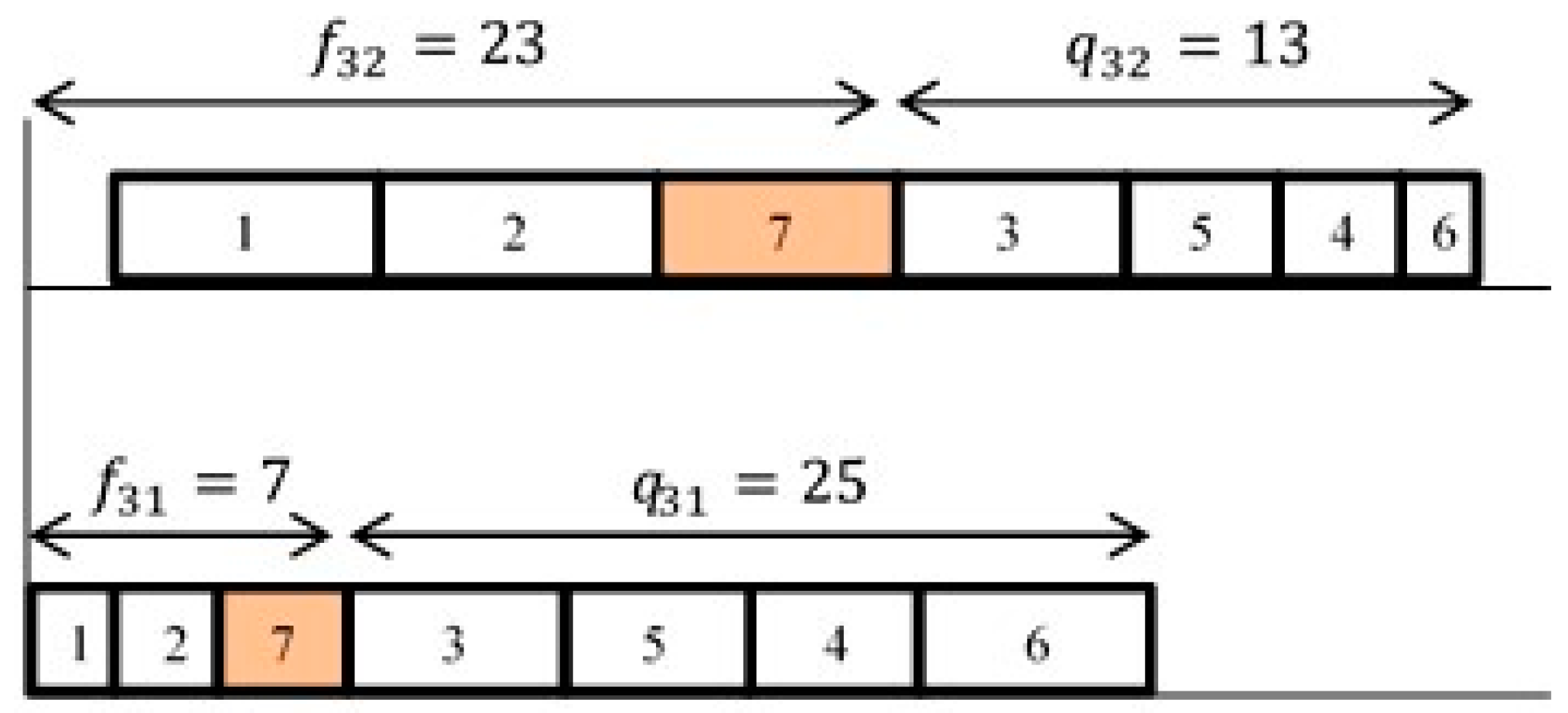
3.1. Taillard’s Speed Up Method for PFSP with Makespan Criterion
- Compute the head, , which is the earliest completion time of each job on each machine. The starting time of the first job on the first machine is 0..
- Compute the tail, , which is the duration between the starting time of each job on each machine and the end of all the operations on each machine.= 0.
- Compute the earliest relative completion time on the lth machine of job inserted at the lth position. Completion time of an inserted job on the first machine is zero.; .
- The value of the makespan when inserting job at the lth position is:; .
- Compute heads:.
- Compute tails:= 0.
- 5.
- Compute the earliest relative completion time;.Speed-up calculation of the complete solution is given in Figure 2.
- 6.
- The value of the makespan when inserting job at the lth position is:;.
3.2. IG Algorithms
| Algorithm 1: Traditional IGRS algorithm |
| Algorithm 2: NEH and FRB5 constructive heuristics |
| Algorithm 3: First improvement insertion neighborhood(π) |
| Algorithm 4: First improvement insertion neighborhood(π) |
| Algorithm 5: IGALL algorithm |
3.3. Variable Block Insertion Algorithm
| Algorithm 6: VBIH algorithm |
| Algorithm 7: Referenced insertion neighborhood(π) |
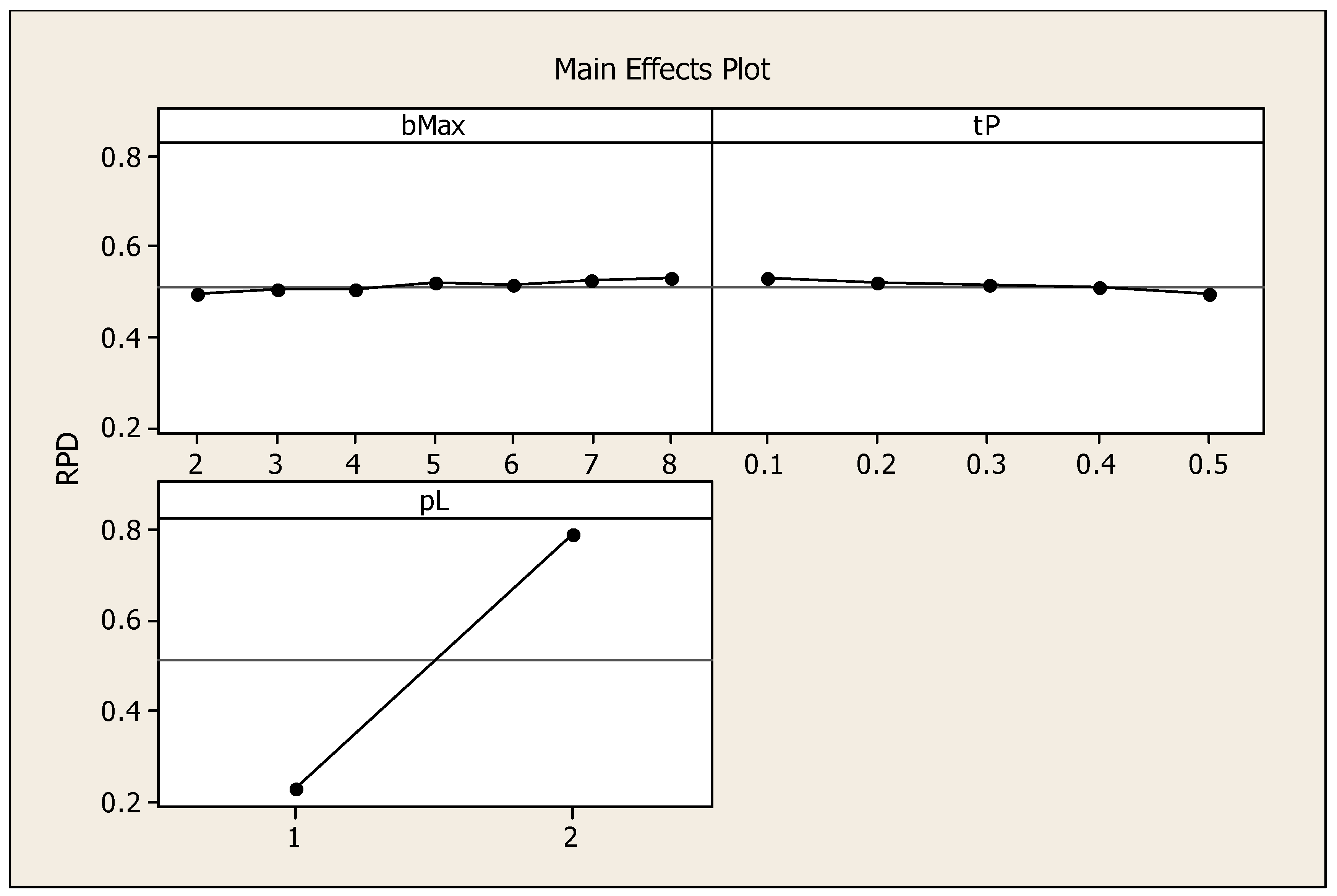
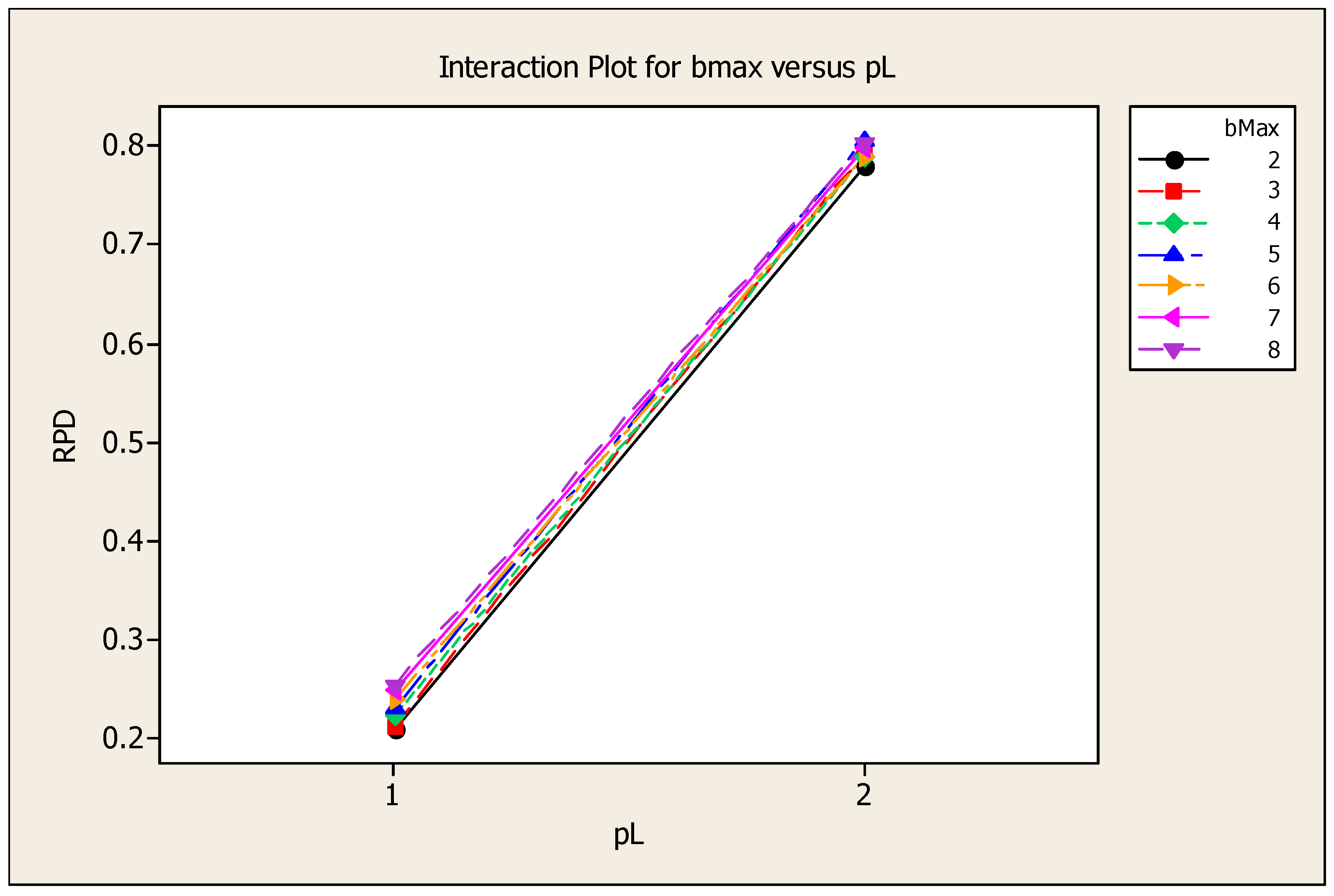
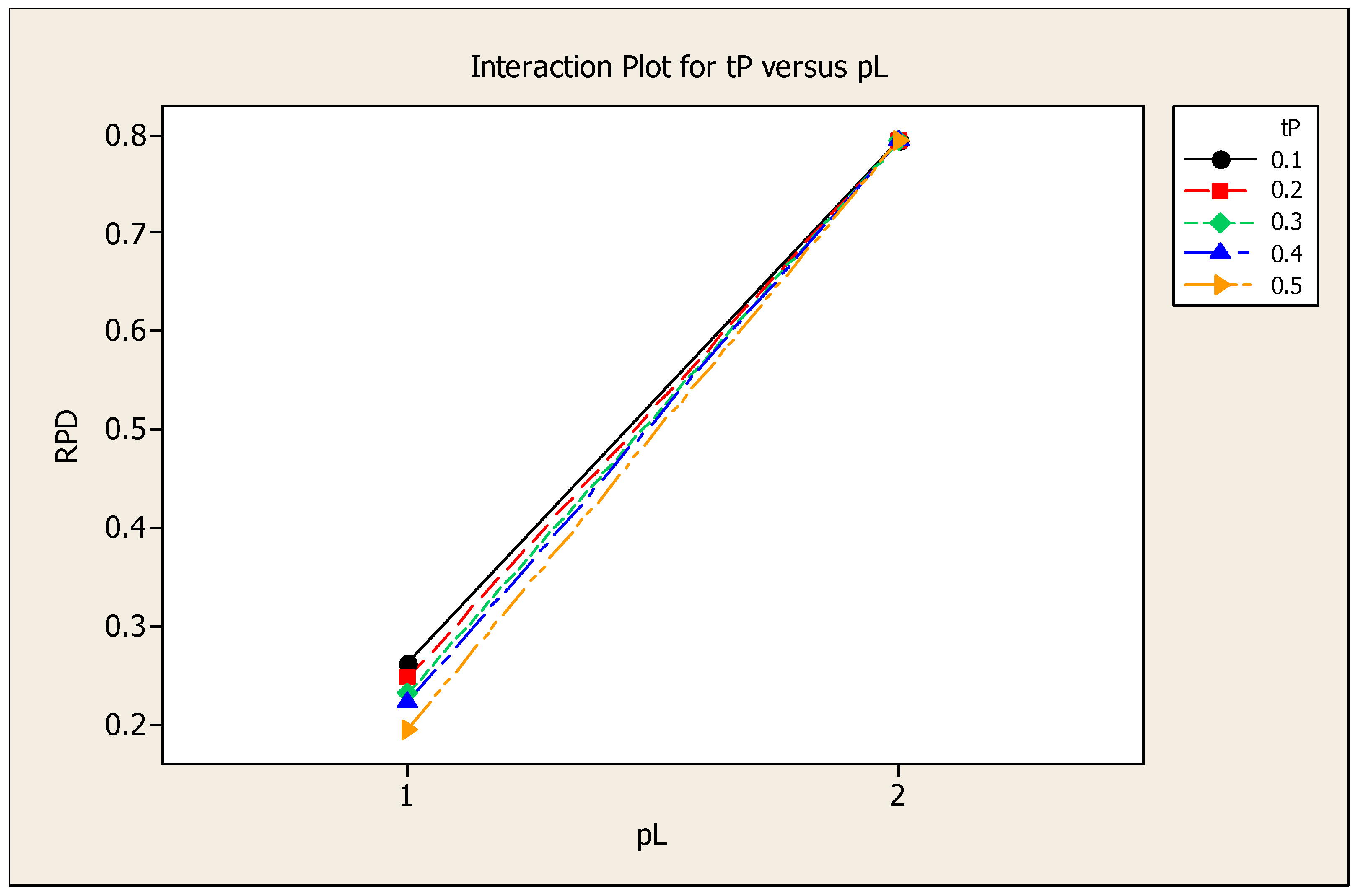
4. Design of Experiment for Parameter Tuning
5. Computational Results
5.1. Small VRF Instances
5.1.1. MIP Versus CP
5.1.2. Comparison of Heuristic Algorithms with Exact Solutions
5.2. Large VRF Instances
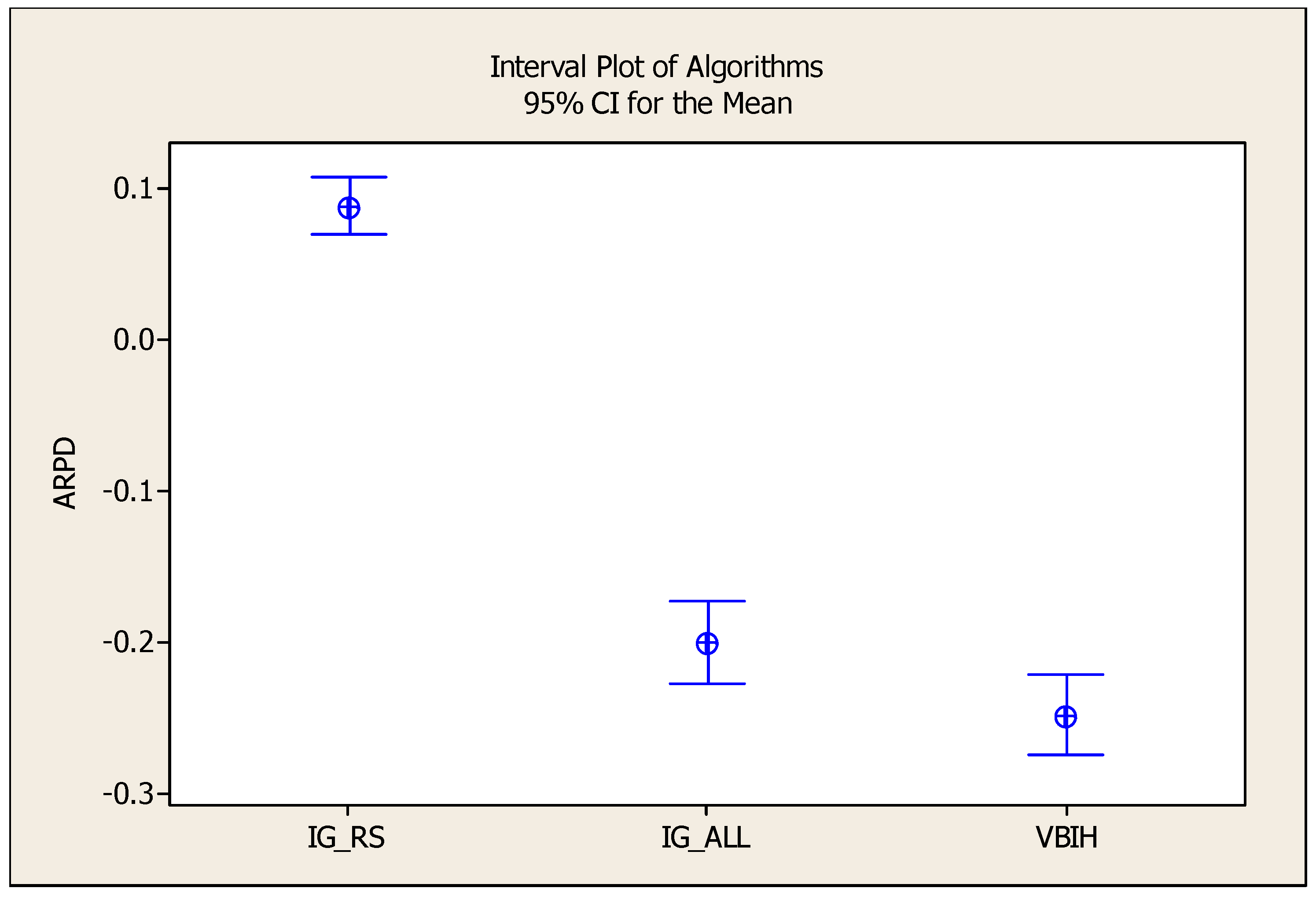
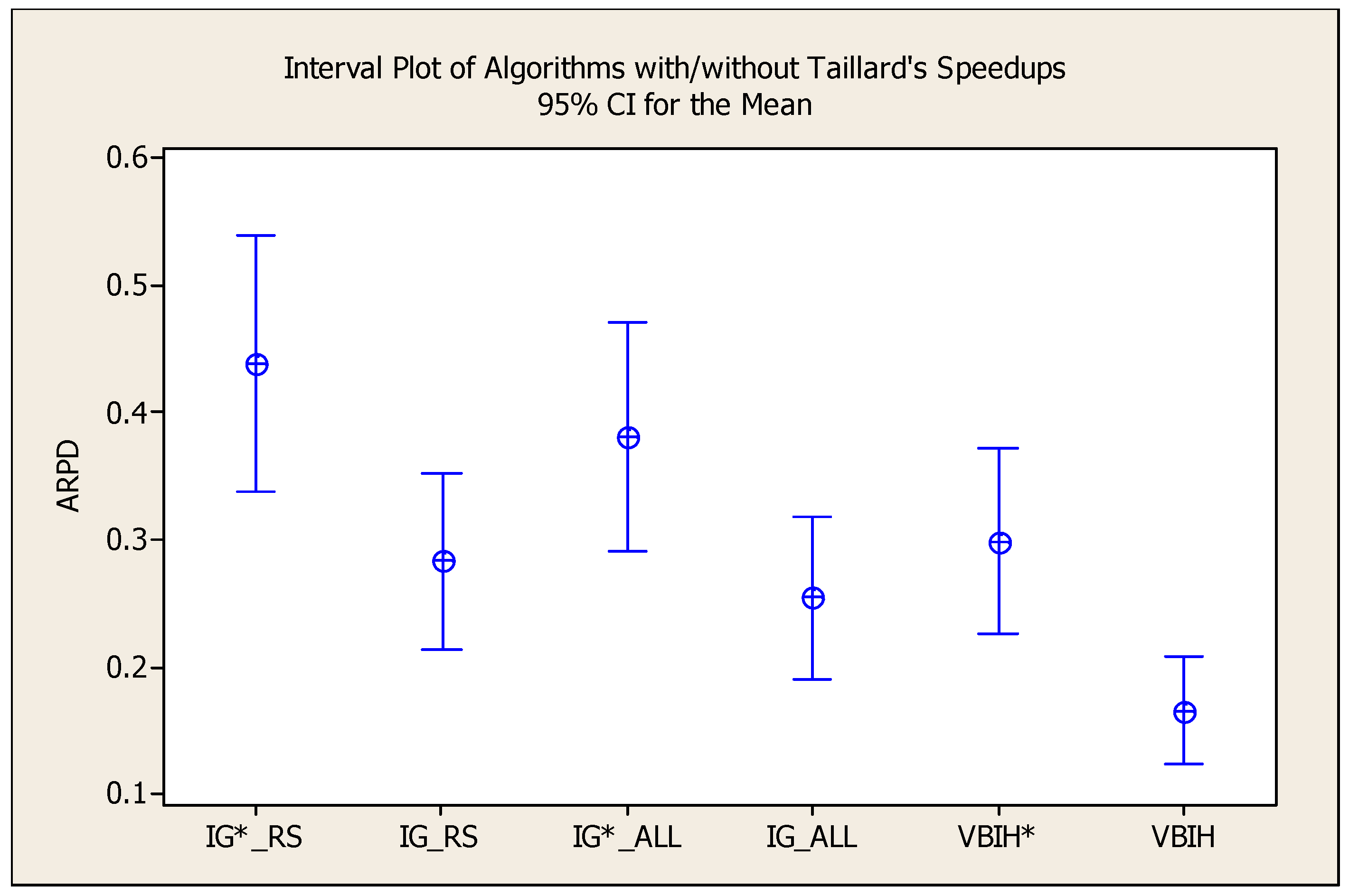
5.3. Computational Results of Metaheuristics
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Jobs | Machines | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 1 | 456 | 654 | 852 | 145 | 632 | 425 | 214 | 654 |
| 2 | 789 | 123 | 369 | 678 | 581 | 396 | 123 | 789 |
| 3 | 654 | 123 | 632 | 965 | 475 | 325 | 456 | 654 |
| 4 | 321 | 456 | 581 | 421 | 32 | 147 | 789 | 123 |
| 5 | 456 | 789 | 472 | 365 | 536 | 852 | 654 | 123 |
| 6 | 789 | 654 | 586 | 824 | 325 | 12 | 321 | 456 |
| 7 | 654 | 321 | 320 | 758 | 863 | 452 | 456 | 789 |
| 8 | 789 | 147 | 120 | 639 | 21 | 863 | 789 | 654 |
| Machines | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Job | Position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 7 | 1 | 654 | 975 | 1295 | 2053 | 2916 | 3368 | 3824 | 4613 |
| 3 | 2 | 1308 | 1431 | 2063 | 3028 | 3503 | 3828 | 4284 | 5267 |
| 8 | 3 | 2097 | 2244 | 2364 | 3667 | 3688 | 4691 | 5480 | 6134 |
| 5 | 4 | 2553 | 3342 | 3814 | 4179 | 4715 | 5567 | 6221 | 6344 |
| 1 | 5 | 3009 | 3996 | 4848 | 4993 | 5625 | 6050 | 6435 | 7089 |
| 6 | 6 | 3798 | 4650 | 5434 | 6258 | 6583 | 6595 | 6916 | 7545 |
| 4 | 7 | 4119 | 5106 | 6015 | 6679 | 6711 | 6858 | 7705 | 7828 |
| Machines | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Job | Position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 7 | 1 | 654 | 975 | 1295 | 2053 | 2916 | 3368 | 3824 | 4613 |
| 3 | 2 | 1308 | 1431 | 2063 | 3028 | 3503 | 3828 | 4284 | 5267 |
| 8 | 3 | 2097 | 2244 | 2364 | 3667 | 3688 | 4691 | 5480 | 6134 |
| 5 | 4 | 2553 | 3342 | 3814 | 4179 | 4715 | 5567 | 6221 | 6344 |
| 2 | 5 | 3342 | 3465 | 4183 | 4861 | 5442 | 5936 | 6344 | 7133 |
| Machines | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Job | Position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | 6 | 4942 | 4486 | 3832 | 2649 | 2504 | 1872 | 1447 | 1233 |
| 6 | 7 | 4423 | 3634 | 2980 | 2394 | 1570 | 1245 | 1233 | 579 |
| 4 | 8 | 2870 | 2549 | 2093 | 1512 | 1091 | 1059 | 912 | 123 |
Appendix B
| Instance | Cmax | Best | Instance | Cmax | Best | Instance | Cmax | Best |
|---|---|---|---|---|---|---|---|---|
| 100_20_1 | 6198 | 6173 | 300_60_1 | 20522 | 20483 | 600_40_1 | 33839 | 33683 |
| 100_20_2 | 6306 | 6267 | 300_60_2 | 20399 | 20249 | 600_40_2 | 33467 | 33405 |
| 100_20_3 | 6238 | 6221 | 300_60_3 | 20434 | 20328 | 600_40_3 | 33866 | 33713 |
| 100_20_4 | 6245 | 6227 | 300_60_4 | 20395 | 20293 | 600_40_4 | 33693 | 33584 |
| 100_20_5 | 6296 | 6264 | 300_60_5 | 20341 | 20200 | 600_40_5 | 33553 | 33401 |
| 100_20_6 | 6321 | 6285 | 300_60_6 | 20388 | 20280 | 600_40_6 | 33809 | 33626 |
| 100_20_7 | 6434 | 6401 | 300_60_7 | 20457 | 20358 | 600_40_7 | 33686 | 33545 |
| 100_20_8 | 6104 | 6074 | 300_60_8 | 20410 | 20319 | 600_40_8 | 33482 | 33298 |
| 100_20_9 | 6354 | 6328 | 300_60_9 | 20549 | 20405 | 600_40_9 | 33697 | 33567 |
| 100_20_10 | 6145 | 6125 | 300_60_10 | 20472 | 20385 | 600_40_10 | 33642 | 33473 |
| 100_40_1 | 7881 | 7846 | 400_20_1 | 21120 | 21042 | 600_60_1 | 36198 | 35976 |
| 100_40_2 | 8007 | 7976 | 400_20_2 | 21457 | 21411 | 600_60_2 | 36184 | 35923 |
| 100_40_3 | 7935 | 7894 | 400_20_3 | 21441 | 21428 | 600_60_3 | 36201 | 35917 |
| 100_40_4 | 7932 | 7913 | 400_20_4 | 21247 | 21237 | 600_60_4 | 36136 | 36000 |
| 100_40_5 | 8011 | 7997 | 400_20_5 | 21553 | 21528 | 600_60_5 | 36153 | 36004 |
| 100_40_6 | 8023 | 7993 | 400_20_6 | 21214 | 21188 | 600_60_6 | 36116 | 35943 |
| 100_40_7 | 8006 | 7980 | 400_20_7 | 21625 | 21599 | 600_60_7 | 36179 | 35965 |
| 100_40_8 | 7979 | 7957 | 400_20_8 | 21277 | 21264 | 600_60_8 | 36185 | 35894 |
| 100_40_9 | 7931 | 7888 | 400_20_9 | 21346 | 21293 | 600_60_9 | 36195 | 35987 |
| 100_40_10 | 7952 | 7917 | 400_20_10 | 21538 | 21526 | 600_60_10 | 36163 | 35943 |
| 100_60_1 | 9395 | 9353 | 400_40_1 | 23578 | 23393 | 700_20_1 | 36394 | 36388 |
| 100_60_2 | 9596 | 9567 | 400_40_2 | 23456 | 23380 | 700_20_2 | 36337 | 36316 |
| 100_60_3 | 9349 | 9349 | 400_40_3 | 23575 | 23467 | 700_20_3 | 36568 | 36519 |
| 100_60_4 | 9426 | 9403 | 400_40_4 | 23409 | 23269 | 700_20_4 | 36452 | 36380 |
| 100_60_5 | 9465 | 9431 | 400_40_5 | 23339 | 23213 | 700_20_5 | 36584 | 36556 |
| 100_60_6 | 9667 | 9630 | 400_40_6 | 23444 | 23298 | 700_20_6 | 36671 | 36645 |
| 100_60_7 | 9391 | 9346 | 400_40_7 | 23556 | 23415 | 700_20_7 | 36624 | 36597 |
| 100_60_8 | 9534 | 9523 | 400_40_8 | 23411 | 23290 | 700_20_8 | 36522 | 36492 |
| 100_60_9 | 9527 | 9488 | 400_40_9 | 23637 | 23424 | 700_20_9 | 36329 | 36315 |
| 100_60_10 | 9598 | 9572 | 400_40_10 | 23720 | 23606 | 700_20_10 | 36417 | 36386 |
| 200_20_1 | 11305 | 11272 | 400_60_1 | 25607 | 25395 | 700_40_1 | 38964 | 38767 |
| 200_20_2 | 11265 | 11240 | 400_60_2 | 25656 | 25549 | 700_40_2 | 38775 | 38560 |
| 200_20_3 | 11327 | 11294 | 400_60_3 | 25821 | 25707 | 700_40_3 | 38621 | 38460 |
| 200_20_4 | 11208 | 11188 | 400_60_4 | 25837 | 25638 | 700_40_4 | 38785 | 38597 |
| 200_20_5 | 11208 | 11143 | 400_60_5 | 25877 | 25669 | 700_40_5 | 38671 | 38490 |
| 200_20_6 | 11367 | 11310 | 400_60_6 | 25536 | 25407 | 700_40_6 | 38710 | 38440 |
| 200_20_7 | 11380 | 11365 | 400_60_7 | 25600 | 25415 | 700_40_7 | 38585 | 38355 |
| 200_20_8 | 11141 | 11128 | 400_60_8 | 25800 | 25603 | 700_40_8 | 39059 | 38817 |
| 200_20_9 | 11123 | 11091 | 400_60_9 | 25882 | 25673 | 700_40_9 | 38814 | 38569 |
| 200_20_10 | 11310 | 11294 | 400_60_10 | 25767 | 25658 | 700_40_10 | 38850 | 38712 |
| 200_40_1 | 13132 | 13124 | 500_20_1 | 26411 | 26374 | 700_60_1 | 41436 | 41192 |
| 200_40_2 | 13102 | 13049 | 500_20_2 | 26681 | 26641 | 700_60_2 | 41375 | 41002 |
| 200_40_3 | 13264 | 13222 | 500_20_3 | 26409 | 26359 | 700_60_3 | 41317 | 41173 |
| 200_40_4 | 13232 | 13163 | 500_20_4 | 26124 | 26080 | 700_60_4 | 41401 | 41120 |
| 200_40_5 | 13043 | 12974 | 500_20_5 | 26781 | 26759 | 700_60_5 | 41262 | 41167 |
| 200_40_6 | 13124 | 13061 | 500_20_6 | 26443 | 26411 | 700_60_6 | 41340 | 41159 |
| 200_40_7 | 13299 | 13220 | 500_20_7 | 26433 | 26409 | 700_60_7 | 40876 | 40734 |
| 200_40_8 | 13238 | 13132 | 500_20_8 | 26318 | 26305 | 700_60_8 | 41474 | 41305 |
| 200_40_9 | 13166 | 13033 | 500_20_9 | 26442 | 26430 | 700_60_9 | 41291 | 41111 |
| 200_40_10 | 13228 | 13146 | 500_20_10 | 26072 | 26034 | 700_60_10 | 41377 | 41186 |
| 200_60_1 | 14990 | 14906 | 500_40_1 | 28548 | 28402 | 800_20_1 | 41558 | 41479 |
| 200_60_2 | 14954 | 14909 | 500_40_2 | 28793 | 28613 | 800_20_2 | 41407 | 41345 |
| 200_60_3 | 15200 | 15134 | 500_40_3 | 28607 | 28526 | 800_20_3 | 41425 | 41399 |
| 200_60_4 | 15044 | 14968 | 500_40_4 | 28828 | 28615 | 800_20_4 | 41426 | 41426 |
| 200_60_5 | 15130 | 15042 | 500_40_5 | 28683 | 28579 | 800_20_5 | 41710 | 41705 |
| 200_60_6 | 15035 | 14996 | 500_40_6 | 28524 | 28432 | 800_20_6 | 42010 | 41961 |
| 200_60_7 | 15040 | 15006 | 500_40_7 | 28760 | 28553 | 800_20_7 | 41425 | 41395 |
| 200_60_8 | 14968 | 14894 | 500_40_8 | 28698 | 28488 | 800_20_8 | 41492 | 41435 |
| 200_60_9 | 15022 | 14925 | 500_40_9 | 28870 | 28640 | 800_20_9 | 41796 | 41783 |
| 200_60_10 | 15000 | 14908 | 500_40_10 | 28758 | 28644 | 800_20_10 | 41574 | 41568 |
| 300_20_1 | 16149 | 16089 | 500_60_1 | 30861 | 30682 | 800_40_1 | 43671 | 43466 |
| 300_20_2 | 16512 | 16483 | 500_60_2 | 30828 | 30664 | 800_40_2 | 43746 | 43575 |
| 300_20_3 | 16173 | 16129 | 500_60_3 | 31125 | 30852 | 800_40_3 | 43749 | 43596 |
| 300_20_4 | 16181 | 16168 | 500_60_4 | 30928 | 30793 | 800_40_4 | 43892 | 43743 |
| 300_20_5 | 16342 | 16307 | 500_60_5 | 30935 | 30763 | 800_40_5 | 43905 | 43794 |
| 300_20_6 | 16137 | 16095 | 500_60_6 | 31027 | 30788 | 800_40_6 | 43811 | 43638 |
| 300_20_7 | 16266 | 16244 | 500_60_7 | 30928 | 30826 | 800_40_7 | 43766 | 43484 |
| 300_20_8 | 16416 | 16369 | 500_60_8 | 30988 | 30837 | 800_40_8 | 43839 | 43666 |
| 300_20_9 | 16376 | 16324 | 500_60_9 | 30978 | 30805 | 800_40_9 | 43879 | 43643 |
| 300_20_10 | 16899 | 16798 | 500_60_10 | 31050 | 30866 | 800_40_10 | 43861 | 43630 |
| 300_40_1 | 18298 | 18199 | 600_20_1 | 31433 | 31372 | 800_60_1 | 46470 | 46279 |
| 300_40_2 | 18454 | 18373 | 600_20_2 | 31418 | 31397 | 800_60_2 | 46493 | 46232 |
| 300_40_3 | 18457 | 18348 | 600_20_3 | 31429 | 31429 | 800_60_3 | 46389 | 46258 |
| 300_40_4 | 18351 | 18227 | 600_20_4 | 31547 | 31487 | 800_60_4 | 46457 | 46261 |
| 300_40_5 | 18484 | 18343 | 600_20_5 | 31448 | 31407 | 800_60_5 | 46401 | 46164 |
| 300_40_6 | 18449 | 18340 | 600_20_6 | 31717 | 31696 | 800_60_6 | 46421 | 46288 |
| 300_40_7 | 18419 | 18396 | 600_20_7 | 31527 | 31527 | 800_60_7 | 46319 | 46061 |
| 300_40_8 | 18392 | 18290 | 600_20_8 | 31564 | 31523 | 800_60_8 | 46474 | 46257 |
| 300_40_9 | 18394 | 18261 | 600_20_9 | 31577 | 31532 | 800_60_9 | 46538 | 46279 |
| 300_40_10 | 18401 | 18286 | 600_20_10 | 31130 | 31107 | 800_60_10 | 46244 | 46211 |
References
- Fernandez-Viagas, V.; Ruiz, R.; Framinan, J.M. A new vision of approximate methods for the permutation flowshop to minimise makespan: State-of-the-art and computational evaluation. Eur. J. Oper. Res. 2017, 257, 707–721. [Google Scholar] [CrossRef]
- Pinedo, M.L. Scheduling: Theory, Algorithms, and Systems; Springer: New York, NY, USA, 2008. [Google Scholar]
- Garey, M.R.; Johnson, D.S.; Sethi, R. The Complexity of Flowshop and Jobshop Scheduling. Math. Oper. Res. 1976, 1, 117–129. [Google Scholar] [CrossRef]
- Ruiz, R.; Stützle, T. A simple and effective iterated greedy algorithm for the permutation flowshop scheduling problem. Eur. J. Oper. Res. 2007, 177, 2033–2049. [Google Scholar] [CrossRef]
- Dubois-Lacoste, J.; Pagnozzi, F.; Stützle, T. An iterated greedy algorithm with optimization of partial solutions for the makespan permutation flowshop problem. Comput. Oper. Res. 2017, 81, 160–166. [Google Scholar] [CrossRef]
- Ruiz, R.; Stützle, T. An Iterated Greedy heuristic for the sequence dependent setup times flowshop problem with makespan and weighted tardiness objectives. Eur. J. Oper. Res. 2008, 187, 1143–1159. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Framinan, J. On insertion tie-breaking rules in heuristics for the permutation flowshop scheduling problem. Comput. Oper. Res. 2014, 45, 60–67. [Google Scholar] [CrossRef]
- Pan, Q.-K.; Tasgetiren, M.F.; Liang, Y.-C. A discrete differential evolution algorithm for the permutation flowshop scheduling problem. Comput. Ind. Eng. 2008, 55, 795–816. [Google Scholar] [CrossRef]
- Vallada, E.; Ruiz, R.; Framinan, J.M. New hard benchmark for flowshop scheduling problems minimising makespan. Eur. J. Oper. Res. 2015, 240, 666–677. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Pan, Q.-K.; Kizilay, D.; Velez-Gallego, M.C. A variable block insertion heuristic for permutation flowshops with makespan criterion. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), San Sebastian, Spain, 5–8 June 2017. [Google Scholar]
- Shao, W.; Pi, D.; Shao, Z. Optimization of makespan for the distributed no-wait flow shop scheduling problem with iterated greedy algorithms. Knowl. Based Syst. 2017, 137, 163–181. [Google Scholar] [CrossRef]
- Ding, J.-Y.; Song, S.; Gupta, J.; Zhang, R.; Chiong, R.; Wu, C. An improved iterated greedy algorithm with a Tabu-based reconstruction strategy for the no-wait flowshop scheduling problem. Appl. Soft Comput. 2015, 30, 604–613. [Google Scholar] [CrossRef]
- Li, X.; Yang, Z.; Ruiz, R.; Chen, T.; Sui, S. An iterated greedy heuristic for no-wait flow shops with sequence dependent setup times, learning and forgetting effects. Inf. Sci. 2018, 453, 408–425. [Google Scholar] [CrossRef]
- Ribas, I.; Companys, R.; Tort-Martorell, X. An iterated greedy algorithm for the flowshop scheduling problem with blocking. Omega 2011, 39, 293–301. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Kizilay, D.; Pan, Q.-K.; Suganthan, P.N. Iterated greedy algorithms for the blocking flowshop scheduling problem with makespan criterion. Comput. Oper. Res. 2017, 77, 111–126. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Leisten, R.; Framinan, J. A computational evaluation of constructive and improvement heuristics for the blocking flow shop to minimise total flowtime. Expert Syst. Appl. 2016, 61, 290–301. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Pan, Q.-K.; Kizilay, D.; Suer, G. A populated local search with differential evolution for blocking flowshop scheduling problem. In Proceedings of the 2015 IEEE Congress on Evolutionary Computation (CEC), Sendai, Japan, 25–28 May 2015. [Google Scholar]
- Ying, K.-C.; Lin, S.-W.; Cheng, C.-Y.; He, C.-D. Iterated reference greedy algorithm for solving distributed no-idle permutation flowshop scheduling problems. Comput. Ind. Eng. 2017, 110, 413–423. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Pan, Q.-K.; Suganthan, P.N.; Buyukdagli, O. A variable iterated greedy algorithm with differential evolution for the no-idle permutation flowshop scheduling problem. Comput. Oper. Res. 2013, 40, 1729–1743. [Google Scholar] [CrossRef]
- Pan, Q.-K.; Ruiz, R. An effective iterated greedy algorithm for the mixed no-idle permutation flowshop scheduling problem. Omega 2014, 44, 41–50. [Google Scholar] [CrossRef]
- Ding, J.-Y.; Song, S.; Wu, C. Carbon-efficient scheduling of flow shops by multi-objective optimization. Eur. J. Oper. Res. 2016, 248, 758–771. [Google Scholar] [CrossRef]
- Öztop, H.; Tasgetiren, M.F.; Eliiyi, D.T.; Pan, Q.-K. Green Permutation Flowshop Scheduling: A Trade- off- Between Energy Consumption and Total Flow Time. In Intelligent Computing Methodologies; Springer: Cham, Switzerland, 2018; pp. 753–759. [Google Scholar]
- Minella, G.; Ruiz, R.; Ciavotta, M. Restarted Iterated Pareto Greedy algorithm for multi-objective flowshop scheduling problems. Comput. Oper. Res. 2011, 38, 1521–1533. [Google Scholar] [CrossRef]
- Ciavotta, M.; Minella, G.; Ruiz, R. Multi-objective sequence dependent setup times permutation flowshop: A new algorithm and a comprehensive study. Eur. J. Oper. Res. 2013, 227, 301–312. [Google Scholar] [CrossRef]
- Pan, Q.-K.; Wang, L. Effective heuristics for the blocking flowshop scheduling problem with makespan minimization. Omega 2012, 40, 218–229. [Google Scholar] [CrossRef]
- Karabulut, K. A hybrid iterated greedy algorithm for total tardiness minimization in permutation flowshops. Comput. Ind. Eng. 2016, 98, 300–307. [Google Scholar] [CrossRef]
- Fernandez-Viagas, V.; Valente, J.M.S.; Framinan, J. Iterated-greedy-based algorithms with beam search initialization for the permutation flowshop to minimise total tardiness. Expert Syst. Appl. 2018, 94, 58–69. [Google Scholar] [CrossRef]
- Pan, Q.-K.; Ruiz, R. Local search methods for the flowshop scheduling problem with flowtime minimization. Eur. J. Oper. Res. 2012, 222, 31–43. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Pan, Q.; Ozturkoglu, Y.; Chen, A.H.L. A memetic algorithm with a variable block insertion heuristic for single machine total weighted tardiness problem with sequence dependent setup times. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 2911–2918. [Google Scholar]
- Subramanian, A.; Battarra, M.; Potts, C.N. An Iterated Local Search heuristic for the single machine total weighted tardiness scheduling problem with sequence-dependent setup times. Int. J. Prod. Res. 2014, 52, 2729–2742. [Google Scholar] [CrossRef]
- Xu, H.; Lü, Z.; Cheng, T.C.E. Iterated Local Search for single-machine scheduling with sequence-dependent setup times to minimize total weighted tardiness. J. Sched. 2014, 17, 271–287. [Google Scholar] [CrossRef]
- Fernández, M.Á.G.; Palacios, J.; Vela, C.; Hernández-Arauzo, A. Scatter search for minimizing weighted tardiness in a single machine scheduling with setups. J. Heuristics 2017, 23, 81–110. [Google Scholar]
- Tasgetiren, M.F.; Pan, Q.-K.; Kizilay, D.; Gao, K. A Variable Block Insertion Heuristic for the Blocking Flowshop Scheduling Problem with Total Flowtime Criterion. Algorithms 2016, 9, 71. [Google Scholar] [CrossRef]
- Manne, A.S. On the Job-Shop Scheduling Problem. Oper. Res. 1960, 8, 219–223. [Google Scholar] [CrossRef]
- Taillard, E. Some efficient heuristic methods for the flow shop sequencing problem. Eur. J. Oper. Res. 1990, 47, 65–74. [Google Scholar] [CrossRef]
- Johnson, S.M. Optimal Two and Three Stage Production Schedules with Set-Up Time Included. Nav. Res. Logist. Q. 1954, 1, 61–68. [Google Scholar] [CrossRef]
- Nawaz, M.; Enscore, E.E.; Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar] [CrossRef]
- Osman, I.; Potts, C.N. Simulated Annealing for Permutation Flow-Shop Scheduling. Omega 1989, 17, 551–557. [Google Scholar] [CrossRef]
- Rad, S.F.; Ruiz, R.; Boroojerdian, N. New high performing heuristics for minimizing makespan in permutation flowshops. Omega 2009, 37, 331–345. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Pan, Q.-K.; Suganthan, P.N.; Chua, T.J. A differential evolution algorithm for the no-idle flowshop scheduling problem with total tardiness criterion. Int. J. Prod. Res. 2011, 49, 5033–5050. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments, 2nd ed.; Wiley: New York, NY, USA, 1984. [Google Scholar]
- Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 1993, 64, 278–285. [Google Scholar] [CrossRef]
| Instance | Optimal Solution with | |||||
|---|---|---|---|---|---|---|
| Jobs | M1 | M2 | Jobs | Position | M1 | M2 |
| 1 | 1 | 8 | 1 | 1 | 1 | 8 |
| 2 | 2 | 9 | 2 | 2 | 2 | 9 |
| 3 | 7 | 5 | 7 | 3 | 4 | 5 |
| 4 | 5 | 3 | 3 | 4 | 7 | 5 |
| 5 | 5 | 4 | 5 | 5 | 5 | 4 |
| 6 | 7 | 1 | 4 | 6 | 5 | 3 |
| 7 | 4 | 5 | 6 | 7 | 7 | 1 |
| Source | DF | Seq SS | Adj SS | Adj MS | F | p-Value |
|---|---|---|---|---|---|---|
| 6 | 0.0086 | 0.0086 | 0.0014 | 33.370 | 0.000 | |
| 4 | 0.0090 | 0.0090 | 0.0022 | 52.080 | 0.000 | |
| 1 | 5.5441 | 5.5441 | 5.5441 | 129,096.720 | 0.000 | |
| 24 | 0.0010 | 0.0010 | 0.0000 | 0.990 | 0.505 | |
| 6 | 0.0025 | 0.0025 | 0.0004 | 9.830 | 0.000 | |
| 4 | 0.0090 | 0.0090 | 0.0022 | 52.100 | 0.000 | |
| Error | 24 | 0.0010 | 0.0010 | 0.0000 | ||
| Total | 69 | 5.5752 |
| n × m | CP | MIP | ||||||
|---|---|---|---|---|---|---|---|---|
| nOpt | ARPD | CPU | GAP | nOpt | RPD | CPU | GAP | |
| 10 × 5 | 10 | 0 | 14.03 | 0 | 10 | 0 | 2.68 | 0 |
| 10 × 10 | 10 | 0 | 102.13 | 0 | 10 | 0 | 4.35 | 0 |
| 10 × 15 | 10 | 0 | 256.45 | 0 | 10 | 0 | 5.68 | 0 |
| 10 × 20 | 10 | 0 | 452.79 | 0 | 10 | 0 | 9.59 | 0 |
| 20 × 5 | 10 | 0 | 2.49 | 0 | 0 | 0.58 | 3600.18 | 0.37 |
| 20 × 10 | 6 | 0.11 | 2250.09 | 0.03 | 0 | 2.24 | 3600.51 | 0.32 |
| 20 × 15 | 0 | 0.53 | 3600.05 | 0.13 | 0 | 2.54 | 3600.06 | 0.29 |
| 20 × 20 | 0 | 0.48 | 3600.07 | 0.17 | 40 | 2.61 | 3600.06 | 0.25 |
| 30 × 5 | 10 | 0 | 5.82 | 0 | Na | Na | Na | Na |
| 30 × 10 | 2 | 0.47 | 3191.89 | 0.05 | Na | Na | Na | Na |
| 30 × 15 | 0 | 1.29 | 3600.14 | 0.11 | Na | Na | Na | Na |
| 30 × 20 | 0 | 1.63 | 3600.13 | 0.15 | Na | Na | Na | Na |
| 40 × 5 | 10 | 0 | 15.03 | 0 | Na | Na | Na | Na |
| 40 × 10 | 3 | 0.22 | 3113.36 | 0.03 | Na | Na | Na | Na |
| 40 × 15 | 0 | 2.16 | 3600.10 | 0.10 | Na | Na | Na | Na |
| 40 × 20 | 0 | 2.11 | 3600.16 | 0.13 | Na | Na | Na | Na |
| 50 × 5 | 10 | 0 | 11.64 | 0 | Na | Na | Na | Na |
| 50 × 10 | 3 | 0.19 | 2939.96 | 0.02 | Na | Na | Na | Na |
| 50 × 15 | 0 | 2.28 | 3600.22 | 0.08 | Na | Na | Na | Na |
| 50 × 20 | 0 | 2.73 | 3600.22 | 0.12 | Na | Na | Na | Na |
| 60 × 15 | 10 | 0 | 6.44 | 0 | Na | Na | Na | Na |
| 60 × 10 | 4 | 0.19 | 3158.95 | 0.01 | Na | Na | Na | Na |
| 60 × 15 | 0 | 1.98 | 3600.19 | 0.07 | Na | Na | Na | Na |
| 60 × 20 | 0 | 2.82 | 3600.29 | 0.10 | Na | Na | Na | Na |
| Overall Avg. | 108 | 0.80 | 2146.78 | 0.05 | 40 | 2.61 | 3600.06 | 0.25 |
| Instance | CP | 15 × n × m | 30 × n × m | 45 × n × m | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| IGRS | IGALL | VBIH | IGRS | IGALL | VBIH | IGRS | IGALL | VBIH | ||
| 10 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 10 × 10 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 10 × 15 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | 0.02 |
| 10 × 20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 20 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 20 × 10 | 0.11 | 0.04 | 0.00 | 0.04 | 0.03 | 0.00 | 0.04 | 0.02 | 0.00 | 0.04 |
| 20 × 15 | 0.53 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 20 × 20 | 0.48 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 30 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 30 × 10 | 0.47 | 0.06 | 0.04 | 0.05 | 0.01 | 0.03 | 0.01 | 0.01 | 0.03 | −0.01 |
| 30 × 15 | 1.29 | 0.03 | 0.02 | 0.03 | 0.02 | −0.02 | 0.02 | 0.02 | −0.02 | 0.02 |
| 30 × 20 | 1.63 | 0.02 | 0.00 | 0.03 | 0.02 | 0.00 | 0.02 | 0.02 | 0.00 | 0.02 |
| 40 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 40 × 10 | 0.22 | 0.06 | 0.02 | 0.03 | 0.02 | 0.01 | −0.01 | 0.00 | 0.00 | −0.01 |
| 40 × 15 | 2.16 | 0.09 | 0.05 | 0.04 | 0.04 | 0.02 | −0.02 | −0.01 | −0.05 | −0.05 |
| 40 × 20 | 2.11 | 0.10 | −0.08 | −0.04 | 0.04 | −0.08 | −0.05 | −0.01 | −0.08 | −0.07 |
| 50 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 50 × 10 | 0.19 | 0.16 | 0.14 | 0.04 | 0.11 | 0.11 | 0.00 | 0.08 | 0.08 | −0.03 |
| 50 × 15 | 2.28 | 0.24 | 0.18 | 0.10 | 0.15 | 0.14 | 0.05 | 0.10 | 0.09 | 0.02 |
| 50 × 20 | 2.73 | 0.17 | 0.02 | 0.00 | 0.07 | −0.08 | −0.10 | 0.04 | −0.11 | −0.10 |
| 60 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 60 × 10 | 0.19 | 0.07 | 0.11 | −0.01 | −0.04 | 0.08 | −0.03 | −0.06 | 0.05 | −0.05 |
| 60 × 15 | 1.98 | 0.21 | 0.09 | 0.10 | 0.12 | 0.06 | 0.01 | 0.08 | 0.06 | −0.04 |
| 60 × 20 | 2.81 | 0.20 | 0.01 | 0.00 | 0.03 | −0.07 | −0.12 | −0.03 | −0.08 | −0.17 |
| Avg. | 0.80 | 0.06 | 0.02 | 0.02 | 0.03 | 0.01 | −0.01 | 0.01 | 0.00 | −0.02 |
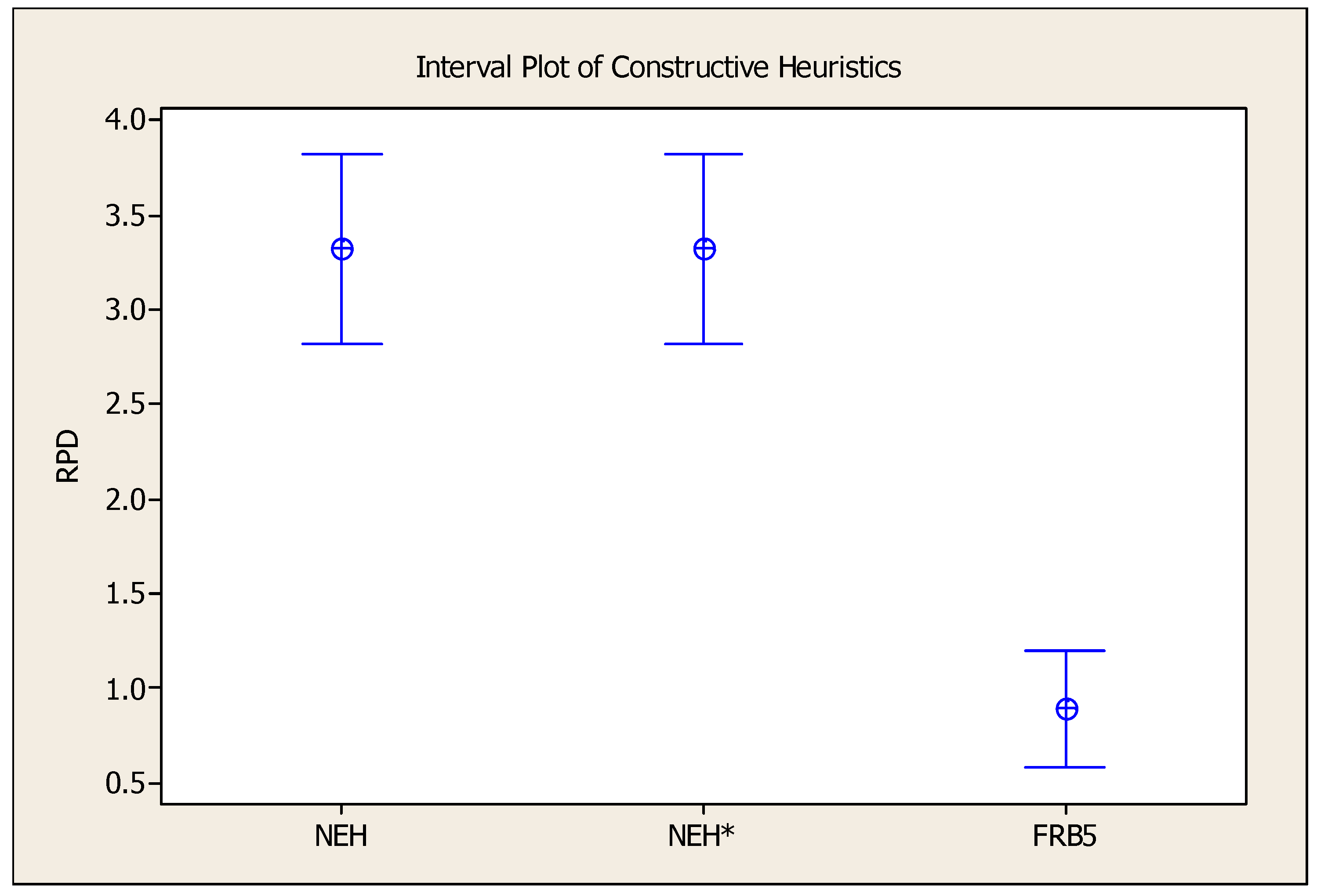
| Instance | NEH | NEH * | FRB5 | |||
|---|---|---|---|---|---|---|
| ARPD | CPU(s) | ARPD | CPU(s) | ARPD | CPU(s) | |
| 100 × 20 | 5.82 | 0.00 | 5.82 | 0.01 | 2.45 | 0.10 |
| 100 × 40 | 5.30 | 0.00 | 5.30 | 0.03 | 2.57 | 0.21 |
| 100 × 60 | 4.89 | 0.00 | 4.89 | 0.05 | 2.19 | 0.32 |
| 200 × 20 | 4.15 | 0.00 | 4.15 | 0.10 | 1.42 | 0.89 |
| 200 × 40 | 4.81 | 0.01 | 4.81 | 0.23 | 1.67 | 1.91 |
| 200 × 60 | 4.48 | 0.01 | 4.48 | 0.39 | 1.56 | 2.73 |
| 300 × 20 | 3.17 | 0.01 | 3.17 | 0.33 | 0.80 | 2.75 |
| 300 × 40 | 4.05 | 0.02 | 4.05 | 0.79 | 1.07 | 6.45 |
| 300 × 60 | 3.94 | 0.03 | 3.94 | 1.31 | 1.23 | 9.85 |
| 400 × 20 | 2.44 | 0.01 | 2.44 | 0.80 | 0.50 | 6.27 |
| 400 × 40 | 3.80 | 0.03 | 3.80 | 1.91 | 0.82 | 15.83 |
| 400 × 60 | 3.42 | 0.04 | 3.42 | 3.14 | 0.75 | 24.39 |
| 500 × 20 | 2.06 | 0.02 | 2.06 | 1.53 | 0.43 | 12.10 |
| 500 × 40 | 3.17 | 0.04 | 3.17 | 3.75 | 0.63 | 31.73 |
| 500 × 60 | 3.27 | 0.06 | 3.27 | 6.05 | 0.57 | 47.97 |
| 600 × 20 | 1.70 | 0.03 | 1.70 | 2.60 | 0.24 | 20.76 |
| 600 × 40 | 2.96 | 0.06 | 2.96 | 6.34 | 0.53 | 54.97 |
| 600 × 60 | 2.97 | 0.09 | 2.97 | 10.31 | 0.37 | 82.27 |
| 700 × 20 | 1.42 | 0.04 | 1.42 | 4.13 | 0.25 | 31.50 |
| 700 × 40 | 2.80 | 0.08 | 2.80 | 10.06 | 0.26 | 84.38 |
| 700 × 60 | 2.66 | 0.13 | 2.66 | 17.22 | 0.32 | 249.99 |
| 800 × 20 | 1.35 | 0.04 | 1.35 | 6.06 | 0.21 | 42.31 |
| 800 × 40 | 2.45 | 0.10 | 2.45 | 15.48 | 0.24 | 125.13 |
| 800 × 60 | 2.74 | 0.16 | 2.74 | 26.17 | 0.31 | 195.41 |
| Avg | 3.33 | 0.04 | 3.33 | 4.95 | 0.89 | 43.76 |
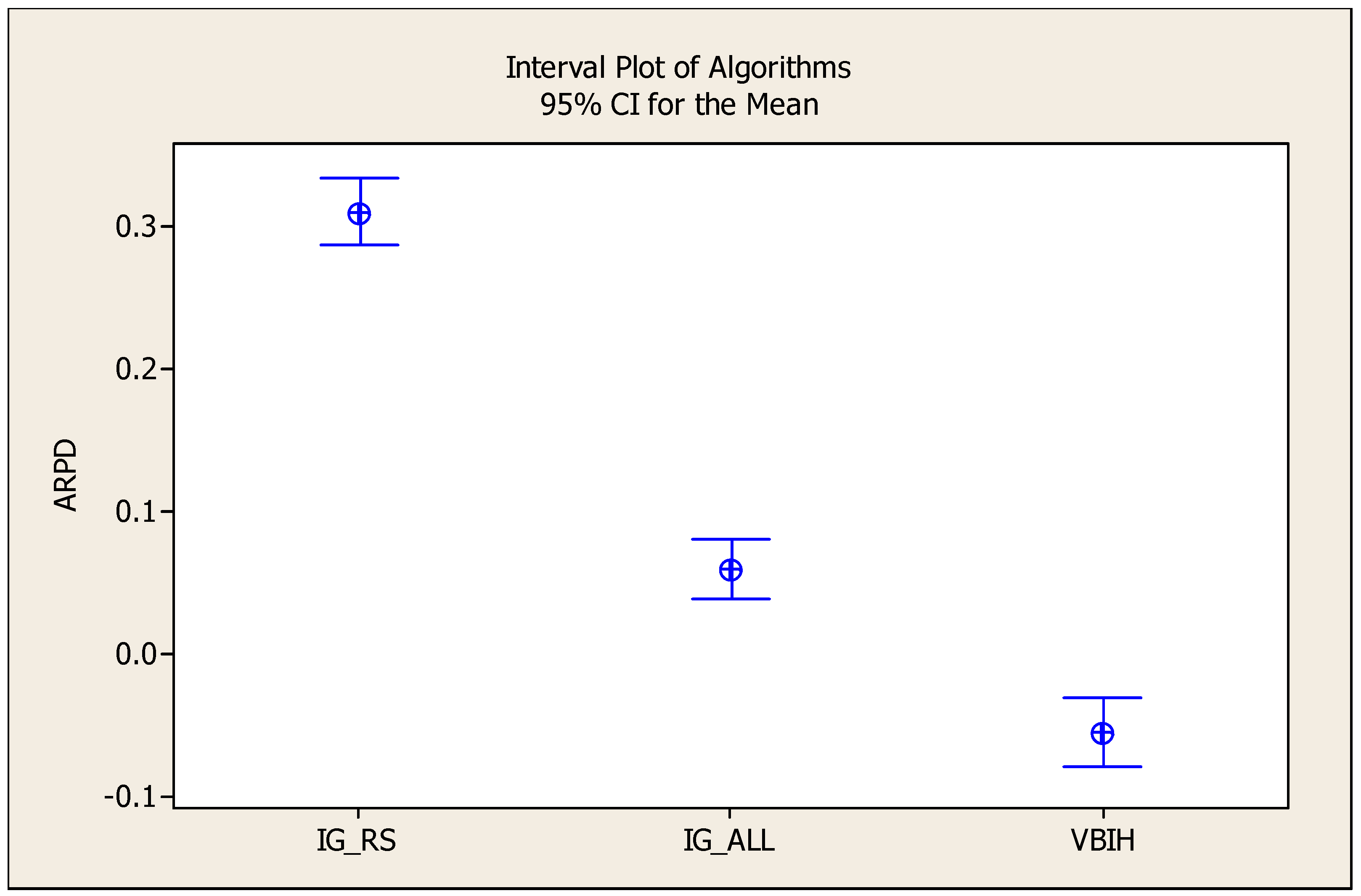
| Instance | IGRS | IGALL | VBIH | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Avg. | Min | Max | Avg. | Min | Max | Avg. | Min | Max | |
| 100 × 20 | 0.45 | 0.13 | 0.74 | 0.12 | −0.07 | 0.33 | 0.00 | −0.21 | 0.23 |
| 100 × 40 | 0.56 | 0.26 | 0.90 | 0.28 | 0.04 | 0.49 | 0.13 | −0.09 | 0.37 |
| 100 × 60 | 0.50 | 0.22 | 0.78 | 0.23 | 0.02 | 0.42 | 0.27 | 0.05 | 0.54 |
| 200 × 20 | 0.42 | 0.24 | 0.61 | 0.19 | 0.04 | 0.35 | 0.03 | −0.14 | 0.17 |
| 200 × 40 | 0.47 | 0.25 | 0.68 | 0.14 | −0.01 | 0.31 | 0.01 | −0.21 | 0.24 |
| 200 × 60 | 0.46 | 0.24 | 0.65 | 0.17 | −0.01 | 0.37 | 0.05 | −0.15 | 0.22 |
| 300 × 20 | 0.22 | 0.06 | 0.35 | 0.10 | −0.03 | 0.21 | −0.03 | −0.17 | 0.11 |
| 300 × 40 | 0.35 | 0.15 | 0.56 | 0.04 | −0.16 | 0.25 | −0.18 | −0.35 | −0.02 |
| 300 × 60 | 0.36 | 0.16 | 0.56 | 0.12 | −0.06 | 0.27 | −0.03 | −0.20 | 0.15 |
| 400 × 20 | 0.20 | 0.11 | 0.33 | 0.09 | 0.01 | 0.18 | 0.03 | −0.03 | 0.10 |
| 400 × 40 | 0.31 | 0.12 | 0.50 | 0.01 | −0.11 | 0.14 | −0.17 | −0.32 | −0.03 |
| 400 × 60 | 0.27 | 0.08 | 0.46 | −0.02 | −0.17 | 0.12 | −0.16 | −0.27 | −0.05 |
| 500 × 20 | 0.15 | 0.06 | 0.26 | 0.12 | 0.07 | 0.18 | 0.03 | −0.05 | 0.12 |
| 500 × 40 | 0.29 | 0.12 | 0.45 | 0.00 | −0.10 | 0.11 | −0.19 | −0.30 | −0.07 |
| 500 × 60 | 0.33 | 0.15 | 0.51 | −0.06 | −0.20 | 0.08 | −0.19 | −0.31 | −0.06 |
| 600 × 20 | 0.11 | 0.03 | 0.18 | 0.02 | −0.03 | 0.07 | 0.01 | −0.05 | 0.06 |
| 600 × 40 | 0.38 | 0.23 | 0.54 | 0.03 | −0.07 | 0.13 | −0.05 | −0.17 | 0.06 |
| 600 × 60 | 0.30 | 0.12 | 0.50 | −0.05 | −0.18 | 0.05 | −0.13 | −0.23 | −0.04 |
| 700 × 20 | 0.11 | 0.05 | 0.18 | 0.04 | −0.01 | 0.08 | 0.03 | −0.03 | 0.08 |
| 700 × 40 | 0.24 | 0.13 | 0.37 | −0.11 | −0.20 | 0.00 | −0.21 | −0.28 | −0.12 |
| 700 × 60 | 0.26 | 0.09 | 0.46 | −0.05 | −0.15 | 0.04 | −0.13 | −0.24 | −0.03 |
| 800 × 20 | 0.07 | 0.02 | 0.14 | 0.06 | 0.02 | 0.12 | 0.01 | −0.04 | 0.05 |
| 800 × 40 | 0.22 | 0.09 | 0.36 | −0.06 | −0.14 | 0.02 | −0.25 | −0.33 | −0.17 |
| 800 × 60 | 0.40 | 0.25 | 0.57 | 0.02 | −0.04 | 0.08 | −0.19 | −0.29 | −0.10 |
| Avg | 0.31 | 0.14 | 0.48 | 0.06 | −0.06 | 0.18 | −0.05 | −0.18 | 0.08 |
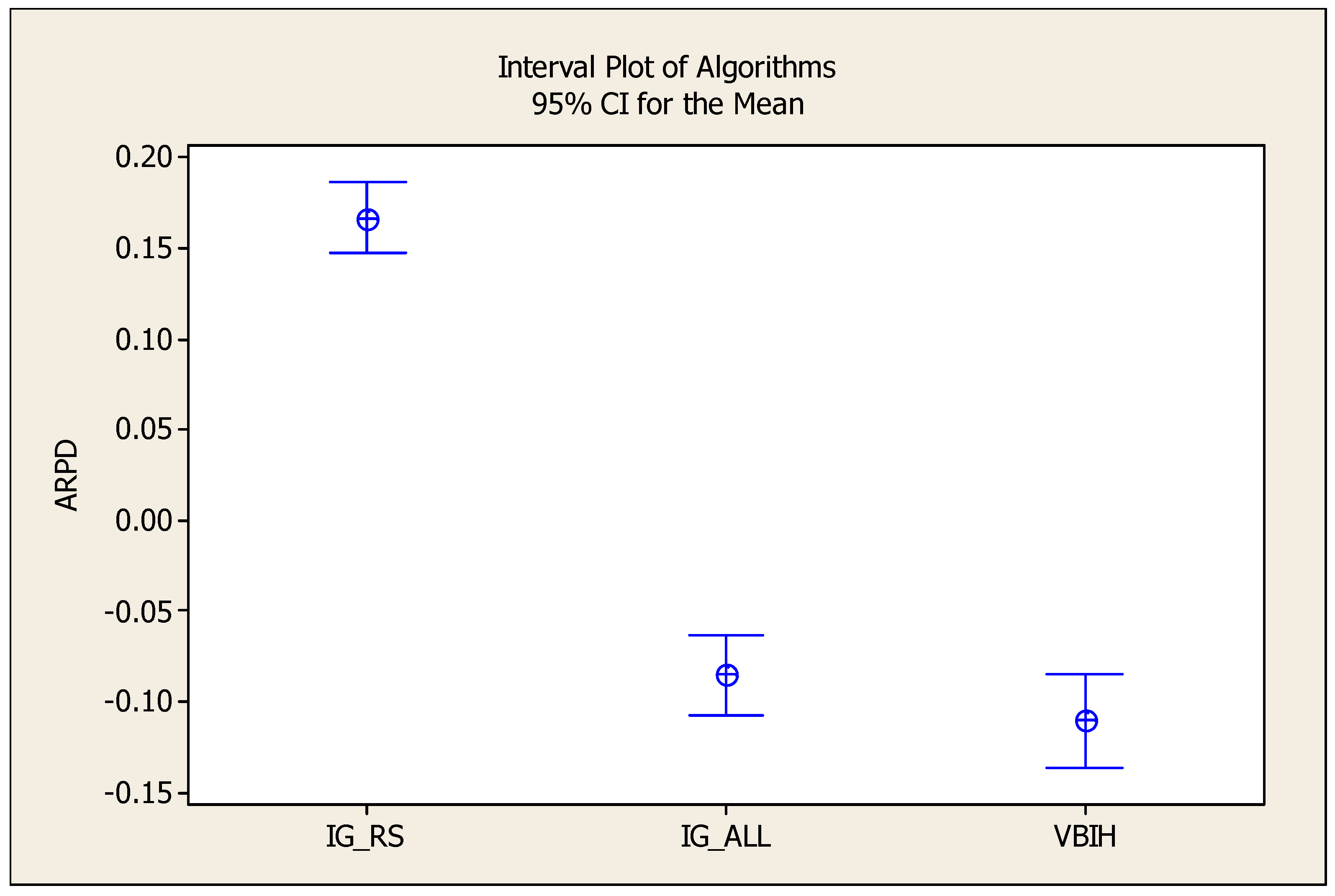
| n × m | IGRS | IGALL | VBIH | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Avg. | Min | Max | Avg. | Min | Max | Avg. | Min | Max | |
| 100 × 20 | 0.25 | −0.02 | 0.54 | 0.03 | −0.11 | 0.16 | −0.05 | −0.25 | 0.16 |
| 100 × 40 | 0.38 | 0.08 | 0.68 | 0.05 | −0.14 | 0.23 | 0.07 | −0.15 | 0.33 |
| 100 × 60 | 0.36 | 0.13 | 0.63 | 0.05 | −0.17 | 0.23 | 0.21 | −0.02 | 0.51 |
| 200 × 20 | 0.28 | 0.12 | 0.45 | 0.07 | −0.05 | 0.22 | 0.00 | −0.16 | 0.14 |
| 200 × 40 | 0.30 | 0.06 | 0.51 | −0.08 | −0.25 | 0.08 | −0.04 | −0.25 | 0.16 |
| 200 × 60 | 0.26 | 0.05 | 0.51 | −0.04 | −0.19 | 0.13 | 0.02 | −0.17 | 0.19 |
| 300 × 20 | 0.12 | −0.01 | 0.23 | 0.01 | −0.10 | 0.14 | −0.06 | −0.21 | 0.08 |
| 300 × 40 | 0.17 | −0.03 | 0.41 | −0.22 | −0.37 | −0.04 | −0.23 | −0.39 | −0.07 |
| 300 × 60 | 0.18 | −0.03 | 0.42 | −0.08 | −0.25 | 0.12 | −0.09 | −0.24 | 0.07 |
| 400 × 20 | 0.12 | 0.04 | 0.19 | 0.03 | −0.04 | 0.09 | 0.01 | −0.06 | 0.09 |
| 400 × 40 | 0.16 | −0.03 | 0.37 | −0.20 | −0.38 | −0.07 | −0.22 | −0.36 | −0.08 |
| 400 × 60 | 0.08 | −0.11 | 0.24 | −0.22 | −0.37 | −0.07 | −0.20 | −0.31 | −0.11 |
| 500 × 20 | 0.11 | 0.02 | 0.20 | 0.07 | 0.01 | 0.13 | 0.02 | −0.06 | 0.10 |
| 500 × 40 | 0.13 | −0.05 | 0.32 | −0.16 | −0.26 | −0.06 | −0.24 | −0.36 | −0.12 |
| 500 × 60 | 0.15 | −0.03 | 0.32 | −0.22 | −0.35 | −0.09 | −0.23 | −0.35 | −0.10 |
| 600 × 20 | 0.07 | −0.02 | 0.15 | −0.01 | −0.06 | 0.04 | −0.02 | −0.07 | 0.03 |
| 600 × 40 | 0.20 | 0.04 | 0.36 | −0.11 | −0.19 | −0.02 | −0.19 | −0.29 | −0.07 |
| 600 × 60 | 0.13 | −0.03 | 0.32 | −0.23 | −0.37 | −0.11 | −0.26 | −0.37 | −0.15 |
| 700 × 20 | 0.08 | 0.01 | 0.16 | 0.02 | −0.03 | 0.06 | −0.01 | −0.07 | 0.03 |
| 700 × 40 | 0.09 | −0.01 | 0.19 | −0.27 | −0.38 | −0.15 | −0.34 | −0.42 | −0.27 |
| 700 × 60 | 0.07 | −0.11 | 0.23 | −0.21 | −0.28 | −0.13 | −0.28 | −0.39 | −0.19 |
| 800 × 20 | 0.04 | −0.01 | 0.09 | 0.02 | −0.01 | 0.05 | 0.00 | −0.04 | 0.04 |
| 800 × 40 | 0.07 | −0.07 | 0.21 | −0.20 | −0.30 | −0.11 | −0.28 | −0.35 | −0.21 |
| 800 × 60 | 0.22 | 0.10 | 0.40 | −0.13 | −0.22 | −0.04 | −0.23 | −0.32 | −0.13 |
| Avg | 0.17 | 0.00 | 0.34 | −0.08 | −0.20 | 0.03 | −0.11 | −0.24 | 0.02 |
| n × m | IGRS | IGALL | VBIH | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Avg. | Min | Max | Avg. | Min | Max | Avg. | Min | Max | |
| 100 × 20 | 0.13 | −0.14 | 0.39 | −0.04 | −0.21 | 0.1 | −0.25 | −0.44 | −0.03 |
| 100 × 40 | 0.29 | 0.02 | 0.59 | −0.05 | −0.25 | 0.13 | −0.18 | −0.35 | −0.01 |
| 100 × 60 | 0.26 | 0.03 | 0.48 | −0.03 | −0.28 | 0.17 | −0.02 | −0.17 | 0.19 |
| 200 × 20 | 0.21 | 0.05 | 0.37 | 0 | −0.14 | 0.12 | −0.12 | −0.27 | 0.03 |
| 200 × 40 | 0.21 | 0.01 | 0.4 | −0.2 | −0.36 | −0.03 | −0.3 | −0.53 | −0.07 |
| 200 × 60 | 0.14 | −0.07 | 0.37 | −0.14 | −0.3 | 0.02 | −0.27 | −0.43 | −0.1 |
| 300 × 20 | 0.07 | −0.06 | 0.17 | −0.04 | −0.18 | 0.1 | −0.15 | −0.26 | −0.05 |
| 300 × 40 | 0.06 | −0.13 | 0.27 | −0.33 | −0.47 | −0.17 | −0.45 | −0.56 | −0.28 |
| 300 × 60 | 0.08 | −0.14 | 0.34 | −0.24 | −0.4 | −0.04 | −0.32 | −0.47 | −0.17 |
| 400 × 20 | 0.09 | 0 | 0.17 | −0.03 | −0.12 | 0.02 | −0.05 | −0.12 | 0.01 |
| 400 × 40 | 0.09 | −0.09 | 0.3 | −0.44 | −0.57 | −0.3 | −0.41 | −0.52 | −0.28 |
| 400 × 60 | −0.03 | −0.23 | 0.16 | −0.48 | −0.64 | −0.31 | −0.41 | −0.52 | −0.32 |
| 500 × 20 | 0.07 | −0.02 | 0.18 | 0.02 | −0.06 | 0.08 | −0.04 | −0.11 | 0.06 |
| 500 × 40 | 0.04 | −0.16 | 0.21 | −0.41 | −0.53 | −0.29 | −0.42 | −0.5 | −0.29 |
| 500 × 60 | 0.02 | −0.14 | 0.17 | −0.44 | −0.56 | −0.3 | −0.41 | −0.54 | −0.29 |
| 600 × 20 | 0.04 | −0.04 | 0.13 | −0.04 | −0.08 | 0.01 | −0.05 | −0.08 | −0.01 |
| 600 × 40 | 0.11 | −0.05 | 0.29 | −0.32 | −0.41 | −0.21 | −0.27 | −0.39 | −0.15 |
| 600 × 60 | 0.03 | −0.12 | 0.22 | −0.45 | −0.6 | −0.33 | −0.35 | −0.44 | −0.23 |
| 700 × 20 | 0.06 | −0.02 | 0.14 | 0 | −0.05 | 0.05 | −0.03 | −0.08 | 0.02 |
| 700 × 40 | 0.01 | −0.11 | 0.13 | −0.36 | −0.48 | −0.24 | −0.42 | −0.5 | −0.35 |
| 700 × 60 | −0.01 | −0.2 | 0.16 | −0.3 | −0.4 | −0.22 | −0.37 | −0.48 | −0.25 |
| 800 × 20 | 0.02 | −0.04 | 0.07 | 0.01 | −0.03 | 0.04 | −0.01 | −0.06 | 0.03 |
| 800 × 40 | −0.01 | −0.15 | 0.12 | −0.27 | −0.36 | −0.17 | −0.36 | −0.43 | −0.29 |
| 800 × 60 | 0.13 | 0 | 0.31 | −0.21 | −0.3 | −0.14 | −0.32 | −0.4 | −0.22 |
| Average | 0.09 | −0.07 | 0.26 | −0.20 | −0.32 | −0.08 | −0.25 | −0.36 | −0.13 |
| IGRS | IGRS * | IGALL | IGALL * | VBIH | VBIH * | |
|---|---|---|---|---|---|---|
| Avg | Avg | Avg | Avg | Avg | Avg | |
| 20 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 20 × 10 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 |
| 20 × 20 | 0.01 | 0.01 | 0.00 | 0.00 | 0.00 | 0.01 |
| 50 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 50 × 10 | 0.34 | 0.43 | 0.40 | 0.43 | 0.26 | 0.31 |
| 50 × 20 | 0.57 | 0.79 | 0.53 | 0.71 | 0.33 | 0.53 |
| 100 × 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 100 × 10 | 0.10 | 0.19 | 0.04 | 0.11 | 0.02 | 0.09 |
| 100 × 20 | 0.82 | 1.33 | 0.89 | 1.23 | 0.54 | 0.94 |
| 200 × 10 | 0.05 | 0.14 | 0.03 | 0.05 | 0.03 | 0.05 |
| 200 × 20 | 1.04 | 1.46 | 0.82 | 1.29 | 0.55 | 1.02 |
| 500 × 20 | 0.47 | 0.92 | 0.35 | 0.75 | 0.26 | 0.64 |
| Overall Avg. | 0.28 | 0.44 | 0.26 | 0.38 | 0.17 | 0.30 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kizilay, D.; Tasgetiren, M.F.; Pan, Q.-K.; Gao, L. A Variable Block Insertion Heuristic for Solving Permutation Flow Shop Scheduling Problem with Makespan Criterion. Algorithms 2019, 12, 100. https://doi.org/10.3390/a12050100
Kizilay D, Tasgetiren MF, Pan Q-K, Gao L. A Variable Block Insertion Heuristic for Solving Permutation Flow Shop Scheduling Problem with Makespan Criterion. Algorithms. 2019; 12(5):100. https://doi.org/10.3390/a12050100
Chicago/Turabian StyleKizilay, Damla, Mehmet Fatih Tasgetiren, Quan-Ke Pan, and Liang Gao. 2019. "A Variable Block Insertion Heuristic for Solving Permutation Flow Shop Scheduling Problem with Makespan Criterion" Algorithms 12, no. 5: 100. https://doi.org/10.3390/a12050100
APA StyleKizilay, D., Tasgetiren, M. F., Pan, Q.-K., & Gao, L. (2019). A Variable Block Insertion Heuristic for Solving Permutation Flow Shop Scheduling Problem with Makespan Criterion. Algorithms, 12(5), 100. https://doi.org/10.3390/a12050100