Study of Precipitation Forecast Based on Deep Belief Networks


Abstract
1. Introduction
2. Related Work
3. Material and Methods
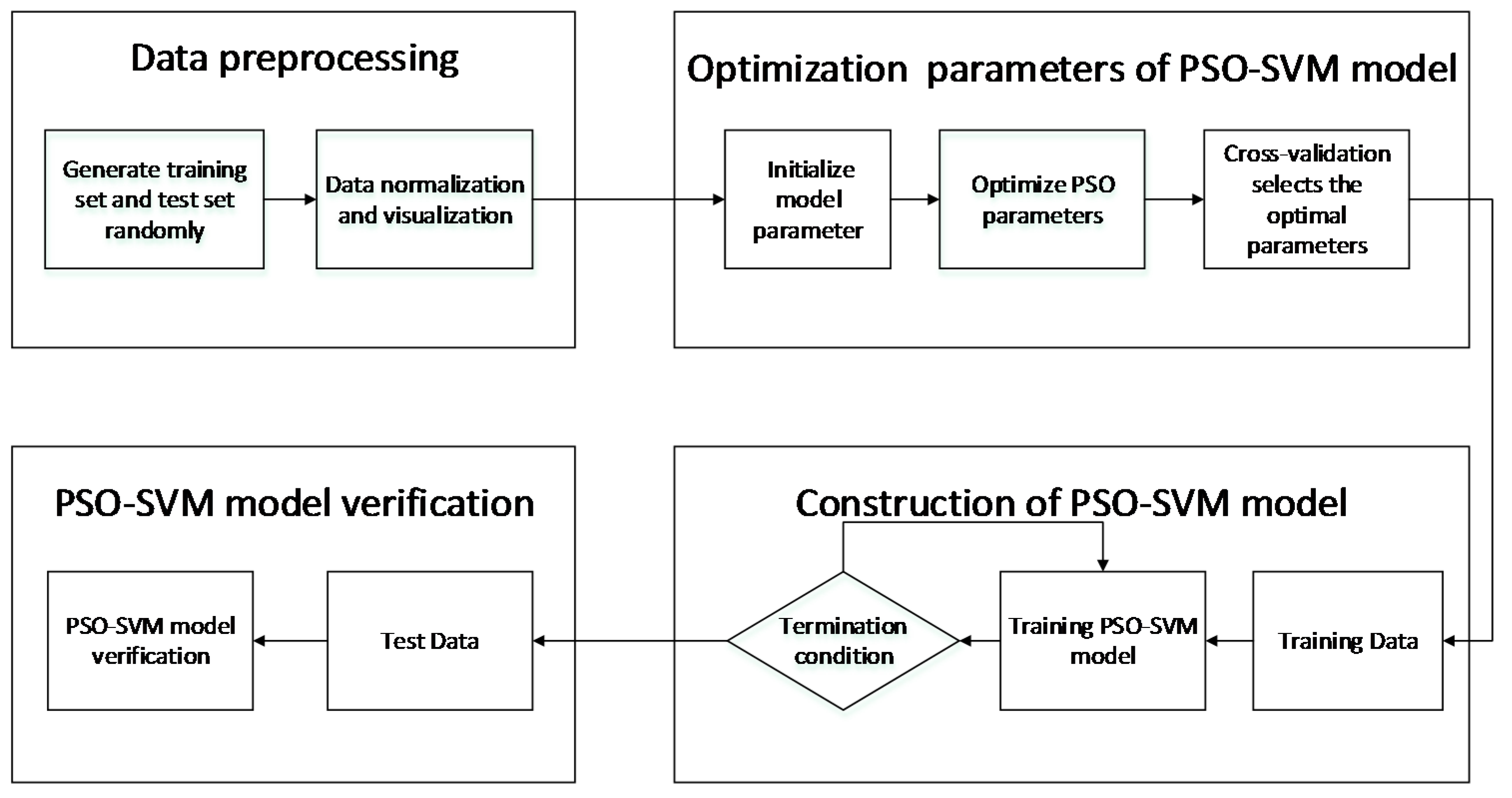
3.1. SVM Based on the PSO
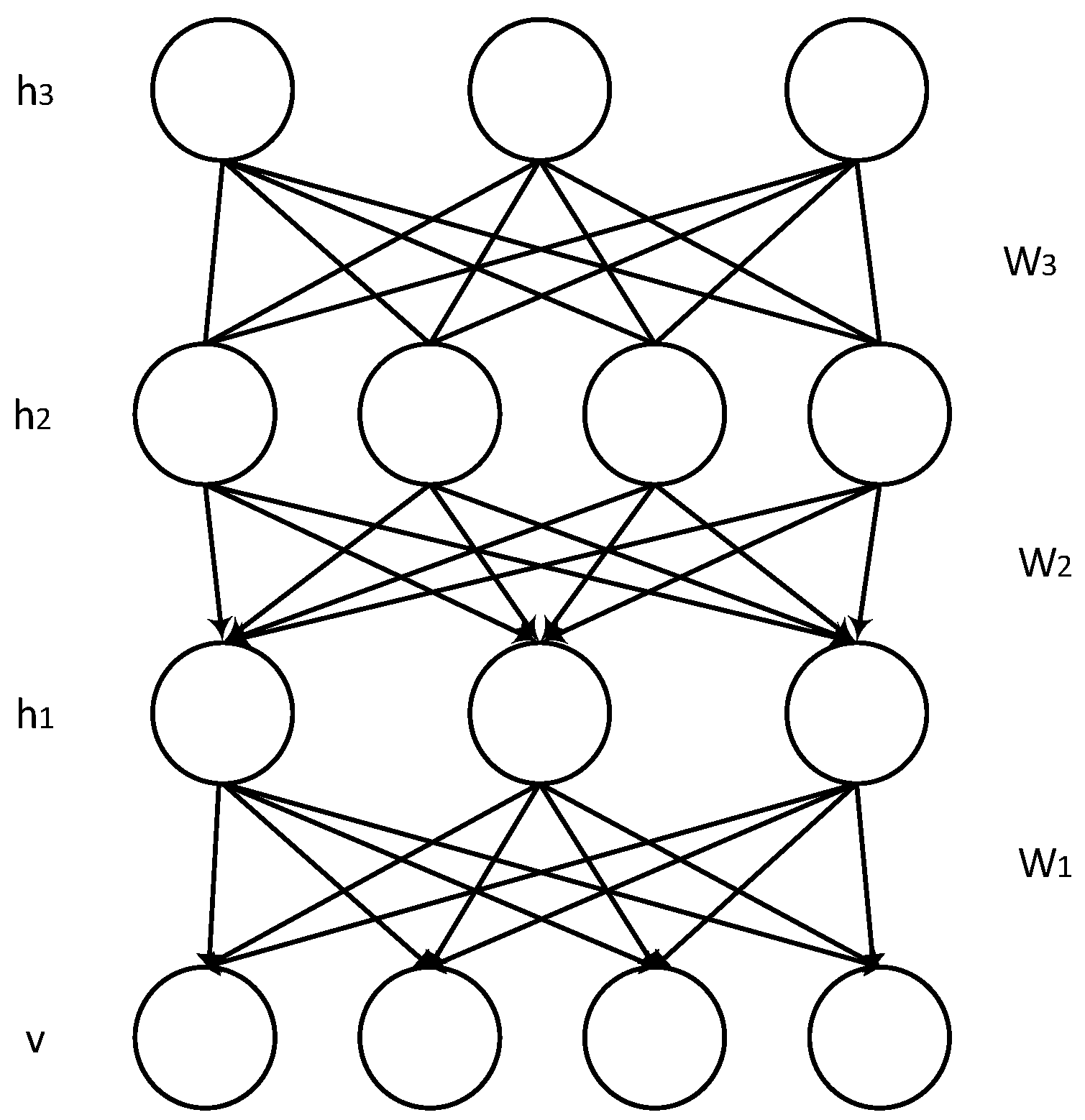
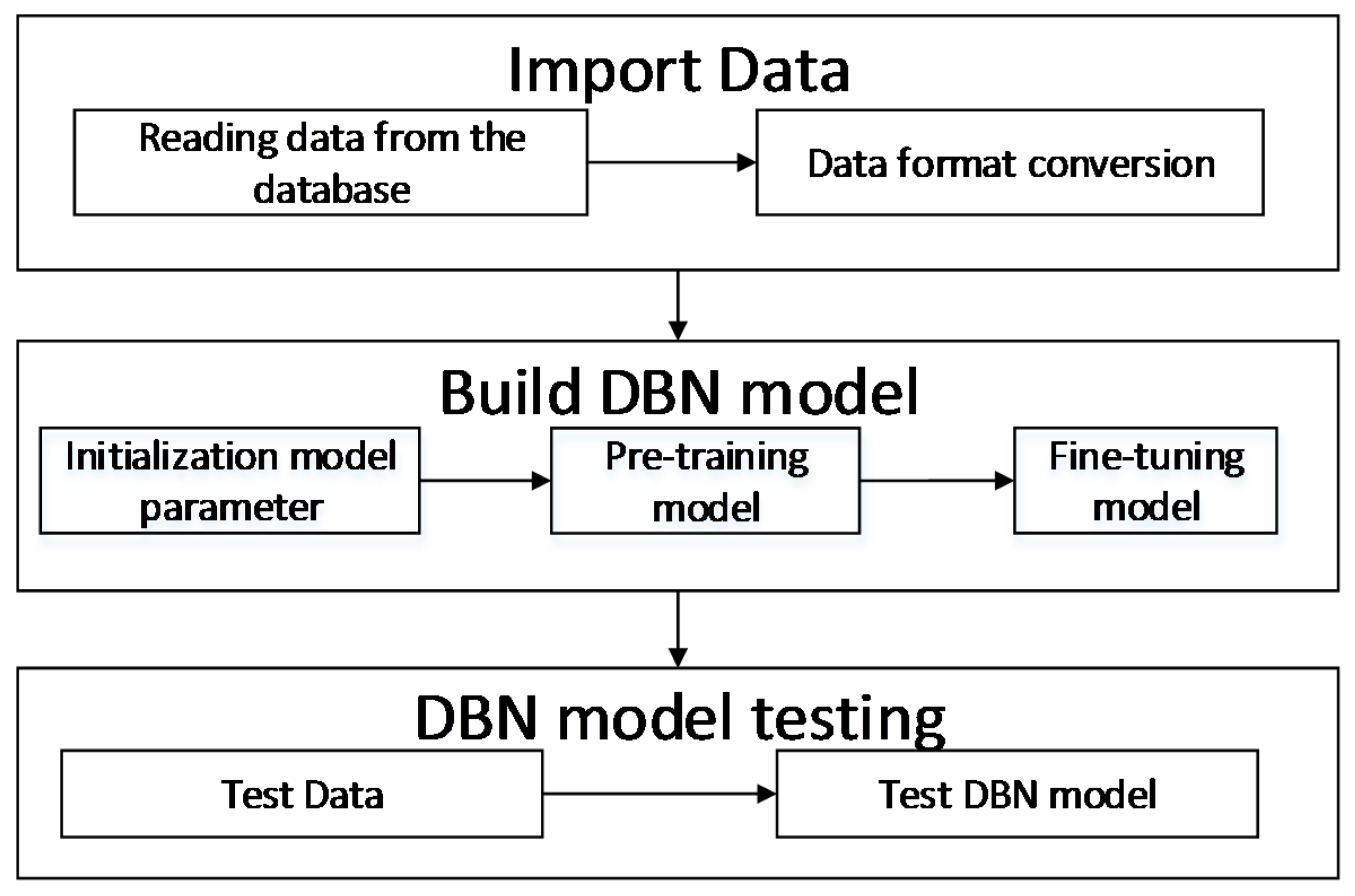
3.2. Deep Belief Network
- Step 1.
- Train the raw input, , as the first RBM layer. The first layer is its visible layer.
- Step 2.
- The hidden layer of the first RBM layer is used as the visual layer of the second RBM layer. The output of the first layer is used as the input of the second layer. This representation can be chosen as being the samples of or mean activations of .
- Step 3.
- Take the transformed samples or mean activations as training examples to train the second layer as an RBM.
- Step 4.
- Repeat Step 2 and Step 3, upward of either samples or mean values each iterate.
- Step 5.
- When the training period is reached, or this satisfies the stop condition, end the iteration.
4. Results and Discussion
4.1. Data Collection and Preprocessing
4.2. Data Normalization
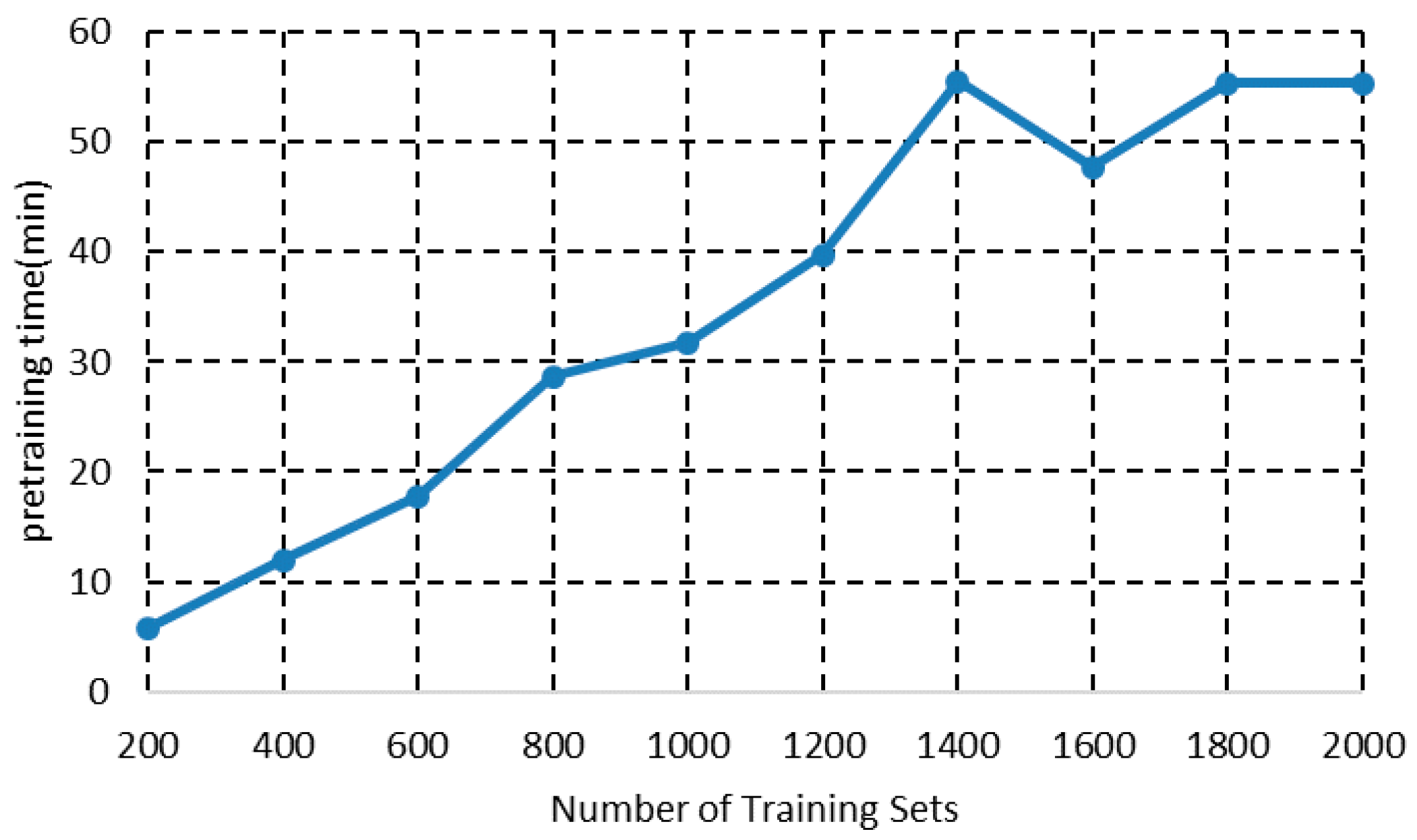
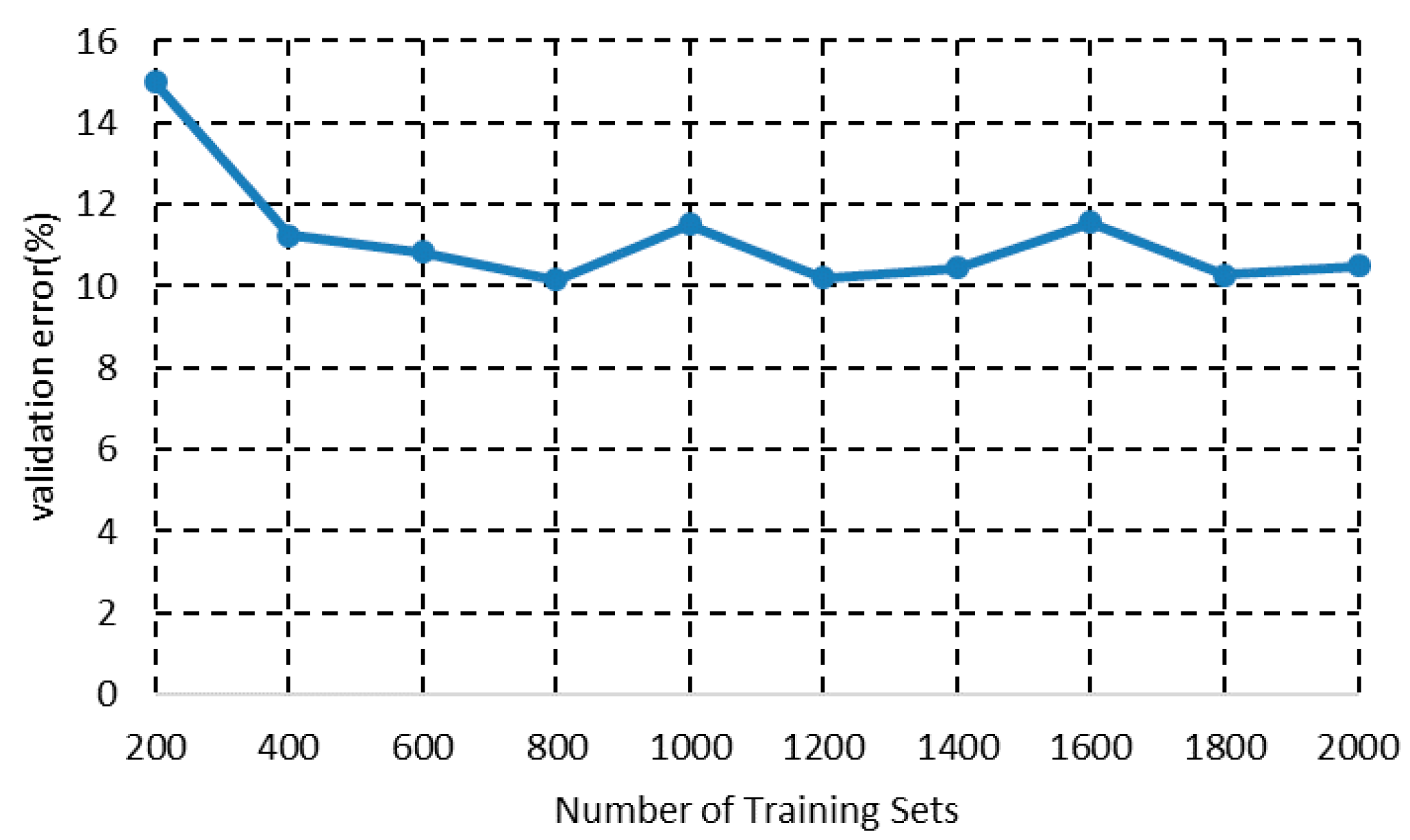
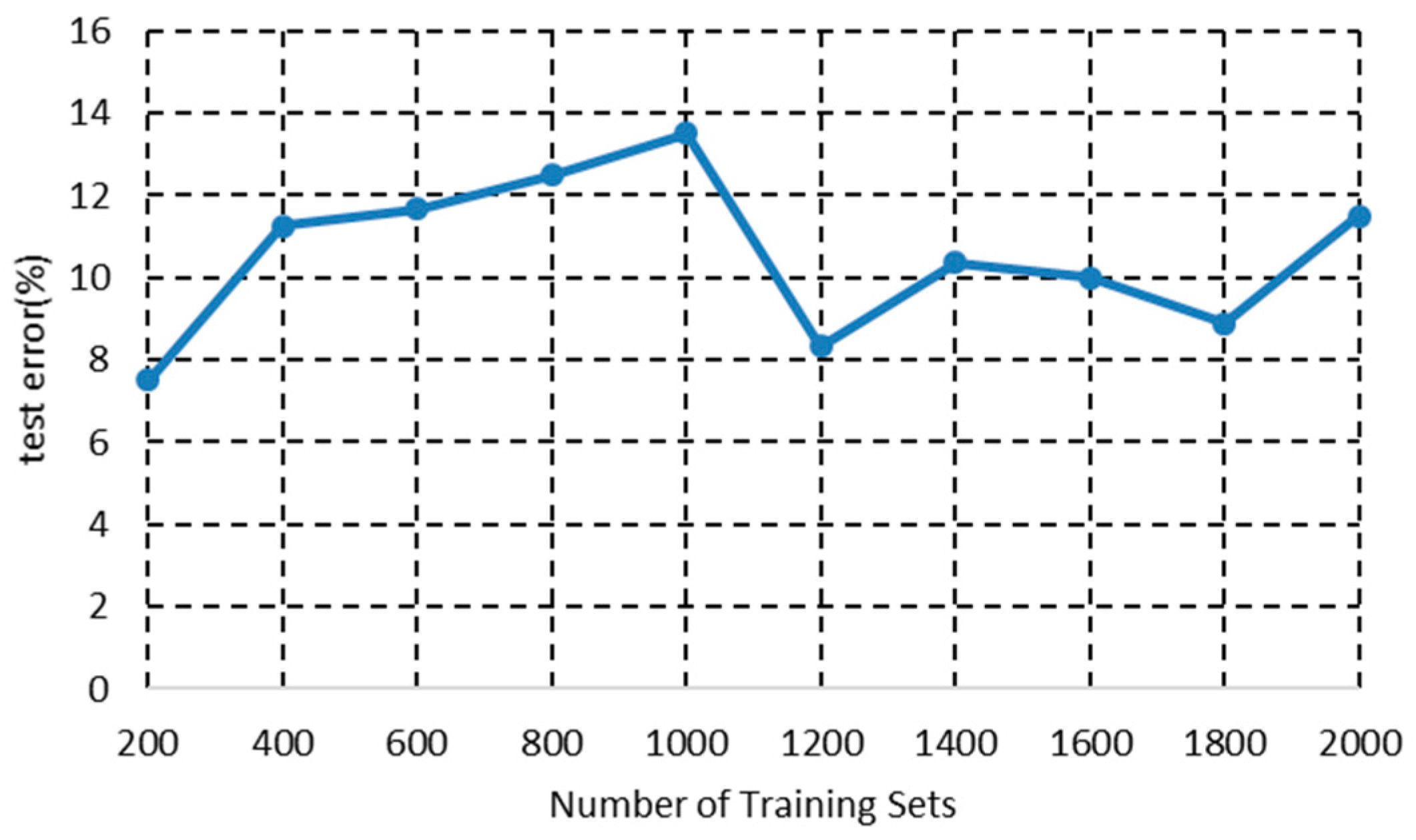
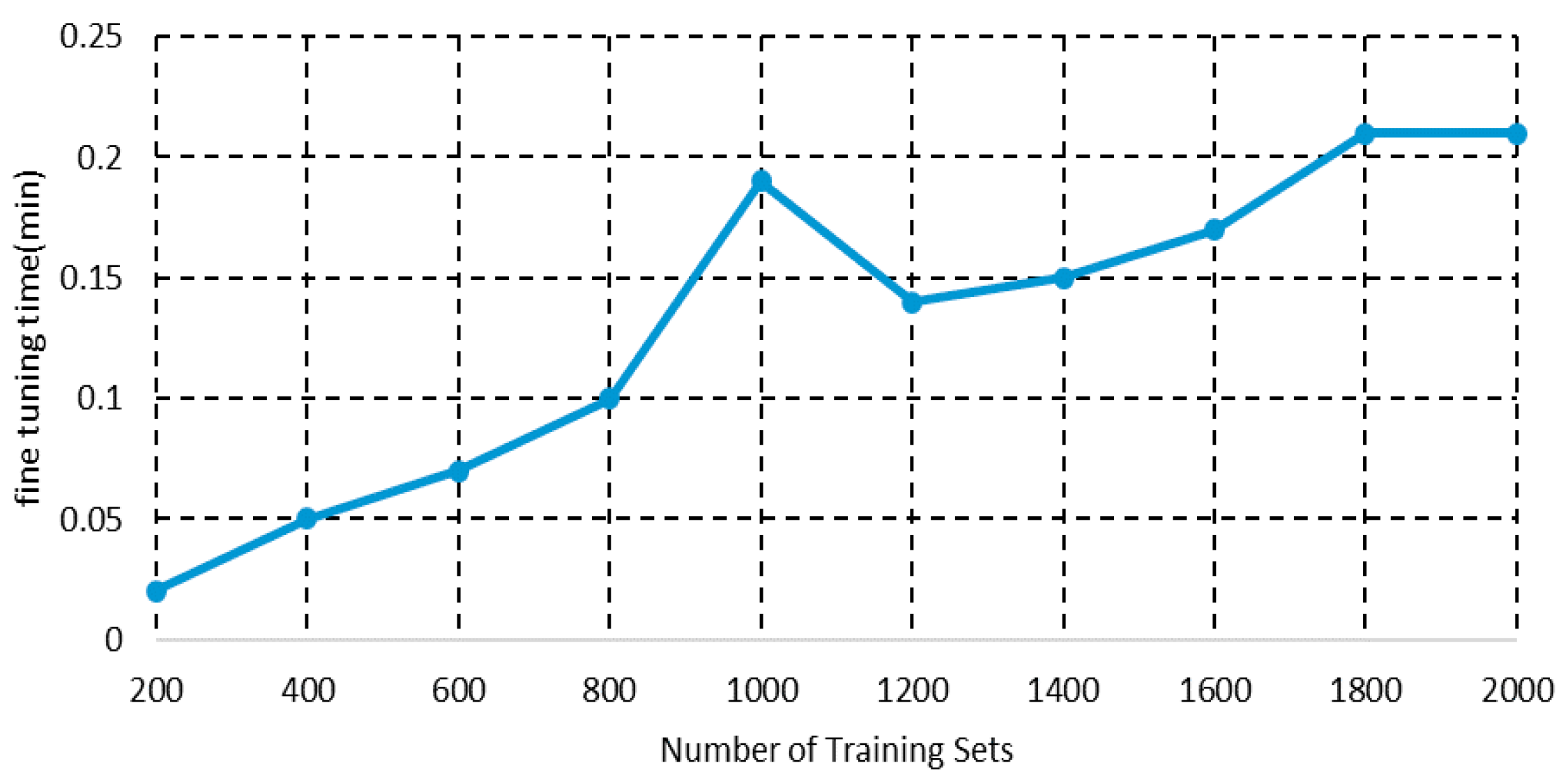
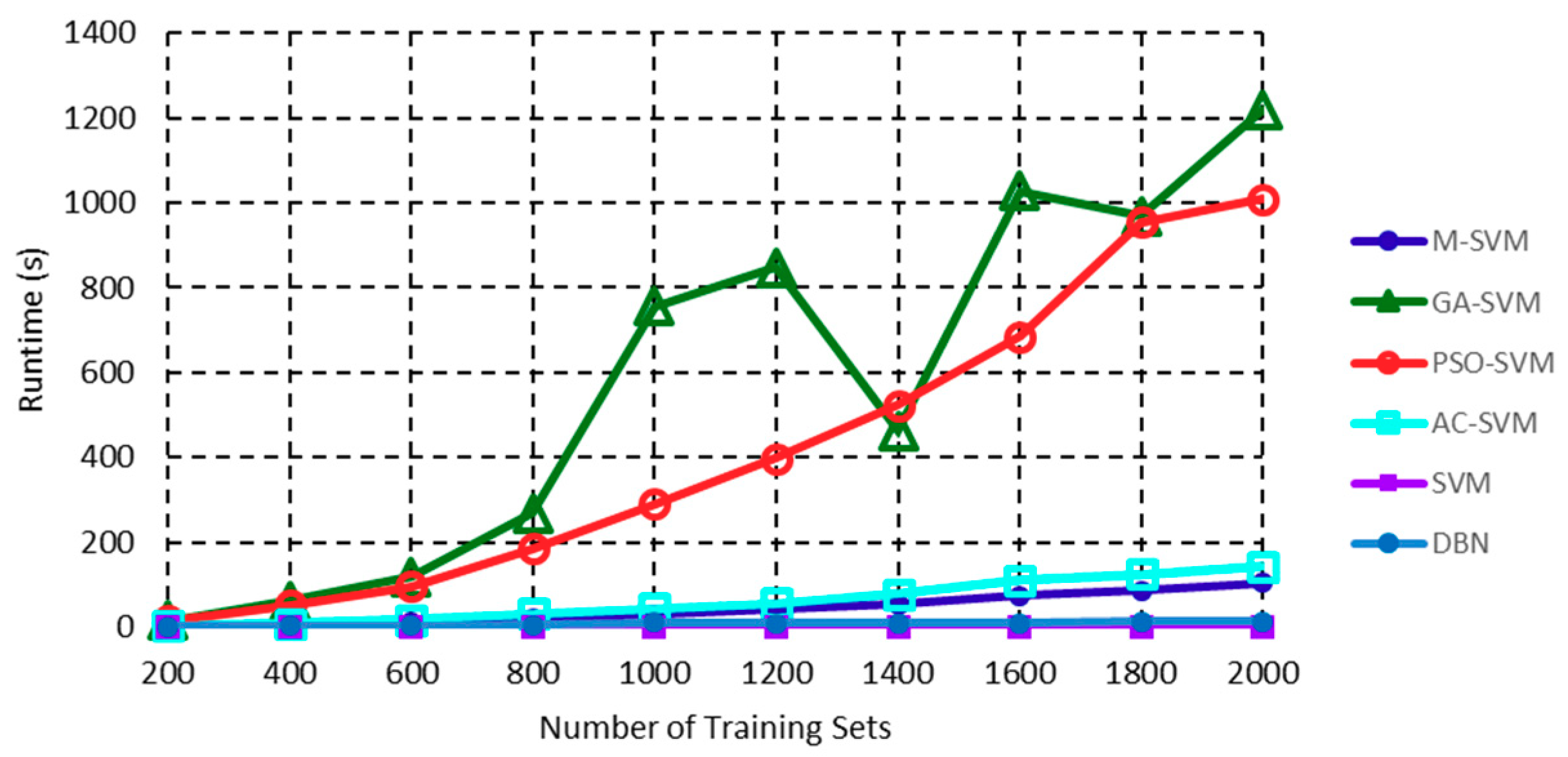
4.3. Algorithm Validation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pan, Y.; Shen, Y.; Yu, J.J.; Xiong, A.Y. An experiment of high-resolution gauge-radar-satellite combined precipitation retrieval based on the Bayesian merging method. J. Meteorol. 2015, 73, 177–186. [Google Scholar] [CrossRef]
- Kondragunta, C.; Seo, D.J. Toward Integration of Satellite Precipitation Estimates into the Multisensor Precipitation Estimator Algorithm. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=2ahUKEwj2jrnJ4Z3dAhUOHXAKHWqoAD8QFjABegQICBAC&url=https%3A%2F%2Fams.confex.com%2Fams%2Fpdfpapers%2F71020.pdf&usg=AOvVaw3O8d6_9aKJB8DEx0731J-P (accessed on 3 September 2004).
- Seo, D.J. Real-time esimation of rainfall fields using radar rainfall and rain gage data. J. Hydrol. 1998, 208, 37–52. [Google Scholar] [CrossRef]
- Lin, F.H.; Liang, L.I.; Chen, L.B. Theoretical Forecast Model of Rainfall and Its Application in Engineering. China Railway Sci. 2002, 23, 62–66. [Google Scholar]
- Qian, H.; Li, P.Y.; Wang, T. Precipitation Predictionon Shizuishan City in Ningxia Province Based on Moving Average and Weighted Markov Chain. J. North China Inst. Water Conserv. Hydroelectr. Power 2010, 31, 6–9. [Google Scholar]
- Cui, L.; Chi, D.C.; Qu, X. Application of Smooth and Steady Time Series Based on Wavelet Denoising in Precipitation Prediction. China Rural Water Hydropower 2010, 34, 30–32, 35. [Google Scholar]
- Cui, D.Y. Application of Combination Model in Rainfall Prediction. Comput. Simul. 2012, 29, 163–166. [Google Scholar]
- Wang, T.; Qian, H.; Li, P.Y. Prediction of Precipitation Based on the Weighted Markov Chain in Yinchuan Area. South-to-North Water Transf. Water Sci. Technol. 2010, 8, 78–81. [Google Scholar] [CrossRef]
- Wang, Y.; Mao, M.Z. Application of Weighted Markov Chain Determined by Optimal Segmentation Method in Rainfall Forecasting. Stat. Decis. 2009, 11, 17–18. [Google Scholar] [CrossRef]
- Zhong, Y.J.; Li, J.; Wang, L. Precipitation Predicting Model Based on Improved Markov Chain. J. Univ. Jinan (Sci. Technol.) 2009, 23, 402–405. [Google Scholar] [CrossRef]
- Ren, Y.; Xu, S.M. Gray neural network combination model Application of Annual Precipitation Forecast in Qingan County. Water Sav. Irrig. 2012, 9, 24–25, 29. [Google Scholar]
- Hsu, K.L.; Gupta, H.V.; Sorooshian, S. Artificial neural network modeling of rainfall-runoff process. Water Resources Res. 1995, 31, 2517–2530. [Google Scholar] [CrossRef]
- Liu, J.N.K.; Hu, Y.; He, Y.; Chan, P.W.; Lai, I. Deep Neural Network Modeling for Big Data Weather Forecasting, Information Granularity, Big Data, and Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2015; pp. 389–408. [Google Scholar]
- Belayneh, A.; Adamowski, J. Standard Precipitation Index Drought Forecasting Using Neural Networks, Wavelet Neural Networks, and Support Vector Regression. In Applied Computational Intelligence and Soft Computing; Article ID 794061; Hindawi Publishing Corporation: New York, NY, USA, 2012; 13p. [Google Scholar]
- Afshin, S. Long Term Rainfall Forecasting by Integrated Artificial, Neural Network-Fuzzy Logic-Wavelet Model in Karoon Basin. Sci. Res. Essay 2011, 6, 1200–1208. [Google Scholar]
- Maqsood, I.; Khan, M.R.; Abraham, A. An ensemble of neural networks for weather forecasting. Neural Comput. Appl. 2004, 13, 112–122. [Google Scholar] [CrossRef]
- Valipour, M. Optimization of neural networks for precipitation analysis in a humid region to detect drought and wet year alarms. Meteorol. Appl. 2016, 23, 91–100. [Google Scholar] [CrossRef]
- Ha, J.H.; Yong, H.L.; Kim, Y.H. Forecasting the Precipitation of the Next Day Using Deep Learning. J. Korean Inst. Intell. Syst. 2016, 26, 93–98. [Google Scholar] [CrossRef]
- Du, J.L.; Liu, Y.Y. A Prediction of Precipitation Data Based on Support Vector Machine and Particle Swarm Optimization (PSO-SVM) Algorithms. Algorithms 2017, 10, 57. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 1st ed.; Springer: New York, NY, USA, 1995; ISBN 978-1-4757-2442-4. [Google Scholar]
- Ahmadi, M.A.; Golshadi, M. Neural network based swarm concept for prediction asphaltene precipitation due to natural depletion. J. Pet. Sci. Eng. 2012, 98–99, 40–49. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Chervonenkis, A. On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities, Theory of Probability and Its Applications; Springer International Publishing: New York, NY, USA, 1971; pp. 264–280. ISBN 978-3-319-21851-9. [Google Scholar]
- Bengio, Y.; Delalleau, O. On the expressive power of deep architectures. In International Conference on Algorithmic Learning Theory; Springer: Berlin/Heidelberg, Germany, 2011; pp. 18–36. [Google Scholar]
- Liu, W.; Wang, Z.; Liu, X. A survey of deep neural network architectures and their applications. Neurocomputing 2016, 234, 11–26. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S.; The, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy Layer-Wise Training of Deep Networks. In Proceedings of the Advances in Neural Information Processing Systems 19 (NIPS 2006), Vancouver, BC, Canada, 4–7 December 2006; pp. 153–160. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Province | Station No. | Station Name | Latitude | Longitude | Air Pressure Sensor Pull Height (m) | Observatory Height (m) |
|---|---|---|---|---|---|---|
| Jiangsu | 58238 | Nanjing | 31.56 | 118.54 | 36.4 | 35.2 |
| PRS (hPa) | PRS_Sea (hPa) | WIN_D (°) | WIN_S (0.1 m/s) | TEM (°C) | RHU (%) | PRE_1h (mm) |
|---|---|---|---|---|---|---|
| 1031.2 | 1035.8 | 89 | 2.5 | 77 | 2 | 0 |
| 1030.8 | 1035.4 | 113 | 2.9 | 61 | 6.4 | 0 |
| 1027.3 | 1031.9 | 153 | 2.1 | 49 | 8.3 | 0 |
| 1026.2 | 1030.8 | 122 | 2 | 55 | 7.1 | 0 |
| 1027.1 | 1031.7 | 121 | 0.7 | 71 | 4.1 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, J.; Liu, Y.; Liu, Z. Study of Precipitation Forecast Based on Deep Belief Networks. Algorithms 2018, 11, 132. https://doi.org/10.3390/a11090132
Du J, Liu Y, Liu Z. Study of Precipitation Forecast Based on Deep Belief Networks. Algorithms. 2018; 11(9):132. https://doi.org/10.3390/a11090132
Chicago/Turabian StyleDu, Jinglin, Yayun Liu, and Zhijun Liu. 2018. "Study of Precipitation Forecast Based on Deep Belief Networks" Algorithms 11, no. 9: 132. https://doi.org/10.3390/a11090132
APA StyleDu, J., Liu, Y., & Liu, Z. (2018). Study of Precipitation Forecast Based on Deep Belief Networks. Algorithms, 11(9), 132. https://doi.org/10.3390/a11090132