1. Introduction
In [
1], Larsen and Skou proposed the notion of probabilistic bisimulation. Although described for deterministic transition systems, the same notion is also very suitable for probabilistic transition systems with nondeterminism [
2,
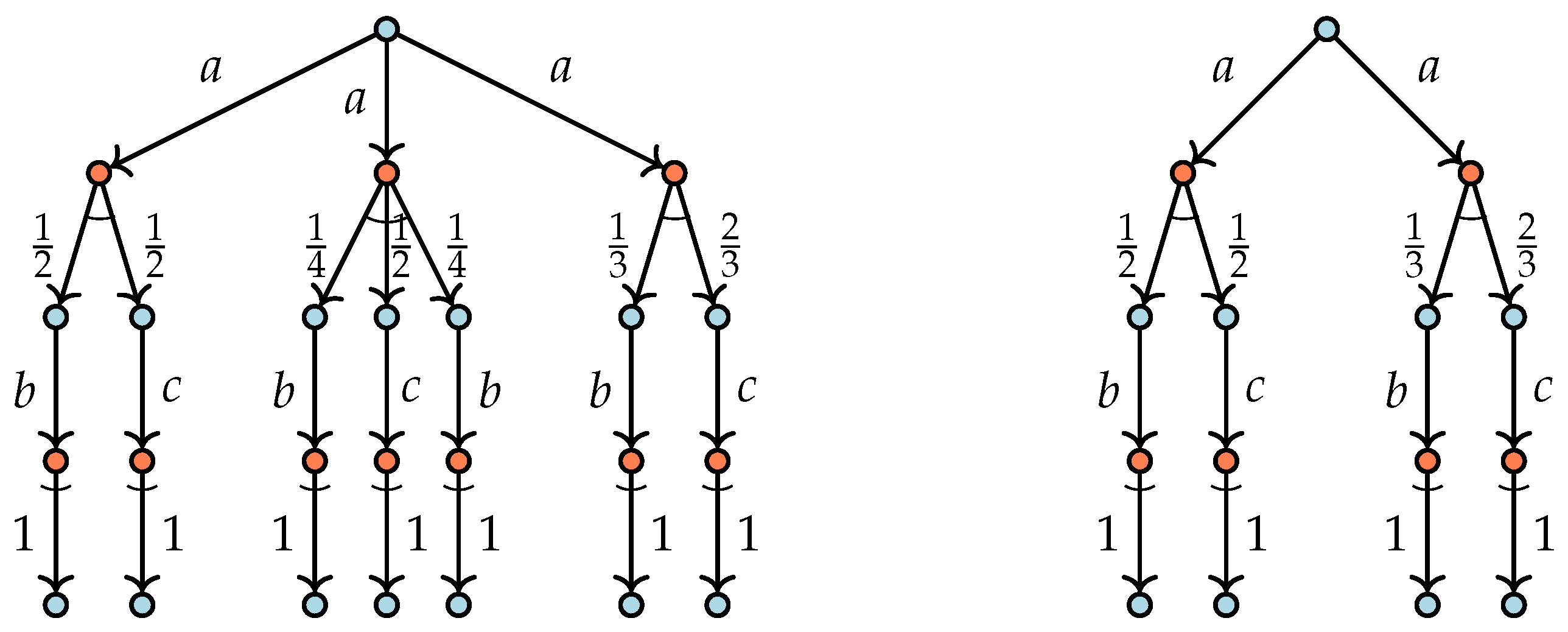
3], i.e. so-called PLTSs. It expresses that two states are equivalent exactly when the following condition holds: if one state can perform an action ending up in a set of states, each with a certain probability, and then the other state can do the same step ending up in an equivalent set of states with the same distribution of probabilities. Two characteristic nondeterministic transition systems of which the initial states are probabilistically bisimilar are given in
Figure 1.
In [
4], Baier et al. gave an algorithm for probabilistic bisimulation for PLTSs, thus dealing both with probabilistic and nondeterministic choice, of time complexity
and space complexity
, where
n is the number of states and
m is the number of transitions (from states to distributions over states; there is no separate measure for the size of the distributions). As far as we know, it is the only practical algorithm for bisimulation à la Larsen-Skou for PLTSs. In essence, other algorithms for probabilistic systems typically target Markov chains without nondeterminism. The algorithm in [
4] performs an iterative refinement of a partition of states and a partition of transitions per action label. The crucial point is splitting the groups of states based on probabilities. For this, a specific data structure is used, called augmented ordered balanced trees, to support efficient storage, retrieval and ordering of states indexed by probabilities.
In this paper, we provide a new algorithm for probabilistic bisimulation for PLTSs of time complexity
and space complexity
, where
is the number of states,
the number of transitions labelled with actions,
the number of distributions and
the cumulative support of the distributions. Our
coincides with the
n of Baier et al. We prefer to use
,
, and
over
m as the former support a more refined analysis. A detailed comparison between the algorithms reveals that, if the distributions have a positive probability for all states, the complexities of the algorithms are similar. However, when distributions only touch a limited number of states, as is often the common situation, the implementation of our algorithm outperforms our implementation of the algorithm in [
4], both in time as well as in space complexity.
Similar to the algorithm of Baier et al., our algorithm keeps track of a partition of states and of distributions (referred to as action states and probabilistic states below) but in line with the classical Paige–Tarjan approach [
5] it also maintains a courser partition of so-called constellations. The treatment of distributions in our algorithm is strongly inspired by the work for Markov Chain lumping by Valmari and Franceschinis, but our algorithm applies to the richer setting of non-deterministic labelled probabilistic transition systems. Using a brilliant, yet simple argument, taken from [
6], the number of times a probabilistic transition is sorted can be limited by the fan-out of the source state of the transition. This leads to the observation that we can use straightforward sorting without the need of any tailored data structure such as augmented ordered balanced trees or similar as in [
4,
7]. Actually, our algorithm uses a simplification of the algorithm in [
6] since the calculation of so-called
majority candidates can be avoided, too.
We implemented both the new algorithm and the algorithm from [
4]. We spent quite some effort to establish that both implementations are free from programming flaws. To this end, we ran them side-by-side and compared the outcomes on a vast amount of randomly generated probabilistic transition systems (in the order of millions). Furthermore, we took a number of examples from the field, among others from the
Prism toolset [
8], and ran both implementations on the probabilistic transition systems that were obtained in this way. Time-wise, all benchmarks indicated better results for our algorithm compared to the algorithm from [
4]. Even for rather small transition systems of about 100,000 states, performance gains of a factor 10,000 can be achieved. Memory-wise the implementation of our algorithm also outperforms the implementation in [
4] when the sizes of the probabilistic state space are larger. Both findings are in line with the theoretical complexity analyses of both algorithms. Both implementations have been incorporated in the open source mCRL2 toolset [
9,
10].
1.1. Related Work
Probabilistic bisimulation preserves logic equivalence for PCTL [
11]. In [
12], Katoen c.s. reported up to logarithmic state space reduction obtained by probabilistic bisimulation minimisation for DTMCs. Quotienting modulo probabilistic bisimulation is based on the algorithm in [
7]. In the same vein, Dehnert et al. proposed symbolic probabilistic bisimulation minimisation to reduce computation time for model checking PCTL in a setting for DTMCs [
13], where an SMT solver is exploited to do the splitting of blocks. Partition reduction modulo probabilistic bisimulation is also used as an ingredient in a counter-example guided abstraction refinement approach (CEGAR) for model checking for PCTL by Lei Song et al. in [
14].
For CTMCs, Hillston et al. proposed the notion of contextual lumpability based on lumpable bisimulation in [
15]. Their reduction technique uses the Valmari–Franceschinis algorithm for Markov chain lumping mentioned earlier. Crafa and Renzato [
16] characterised probabilistic bisimulation of PLTSs as a partition shell in the setting of abstract interpretation. The algorithm for probabilistic bisimulation that comes with such a characterisation turns out to coincide with that in [
4]. A similar result applies to the coalgebraic approach to partition refinement in [
17] that yields a general bisimulation decision procedure, which can be instantiated with probabilistic system types.
Probabilistic simulation for PLTSs has been treated in [
4], too. In [
18], maximum flow techniques are proposed to improve the complexity. Zhang and Jansen [
19] presented a space-efficient algorithm based on partition refinement for simulation between probabilistic automata, which improves upon the algorithm for simulation by Crafa and Renzato [
16] for concrete experiments taken from the PRISM benchmark suite. A polynomial algorithm, essentially cubic, for deciding weak and branching probabilistic bisimulation by Turrini and Hermanns, recasting the algorithm in [
20], is presented in [
21].
1.2. Synopsis
The structure of this article is as follows. In
Section 2, we provide the notions of a probabilistic transition system as well as that of probabilistic bisimulation. In
Section 3, the outline of our algorithm is provided and it is proven that it correctly calculates probabilistic bisimulation. This section ends with an elaborate example. In
Section 4 we provide a detailed version the algorithm with a focus on the implementation details necessary to achieve the complexity. In
Section 5, we provide some benchmarking results and a few concluding remarks are made in
Section 6.
2. Preliminaries
Let S be a finite set. A distribution f over S is a function such that . For each distribution f, its support is the set . The size of f is defined as the number of elements in its support, written as . The set of all distributions over a set S is denoted by . Distributions are lifted to act on subsets by .
For an equivalence relation R on S, we use to denote the set of equivalence classes of R. We define and, for a subset T of S, we define . A partition is a set of non-empty subsets such that for all and . Each is called a block of the partition. Slightly ambiguously, we use to denote the set of equivalence classes of R with respect to S. Clearly, the set of equivalence classes of R forms a partition of S. Reversely, a partition of S induces an equivalence relation on S, by iff for some block B of . A partition is called a refinement of a partition iff each block of is a subset of a block of . Hence, each block in is a disjoint union of blocks from .
We use probabilistic labeled transition systems as the canonical way to represent the behaviour of systems.
Definition 1. (Probabilistic Labeled Transition System). A probabilistic labeled transition system (PLTS) for a set of actions is a pair where
S is a finite set of states, and
is a finite transition relation relating states and actions to distributions.
It is common to write for . For , , and a set of distributions, we write if for some . Similarly, we write if there is no distribution such that . For the presentation below, we associate a so-called probabilistic state with each distribution f provided there is some transition of . We write U for , with typical element u. Note that, since is finite, U is also finite. We also use the notation if for some . As a matter of notation, we write for if probabilistic state corresponds to the distribution f. We sometimes use a so-called probabilistic transition for and iff . To stress , we refer to states as action states.
Below, in particular in the complexity analysis, we use as the number of action states, as the number of probabilistic states, as the number of action transitions and as the cumulative size of the support of the distributions corresponding to all probabilistic states. Note that as every distribution has support of at least size 1.
The following definition for probabilistic bisimulation stems from [
1].
Definition 2. (Probabilistic Bisimulation). Consider a PLTS . An equivalence relation is called aprobabilistic bisimulationfor iff for all states such that and , for some action and distribution , it holds that for some distribution , and for each .
Two states are probabilistically bisimilar iff a probabilistic bisimulation R for exists such that , which we write as . Two distributions , and similarly two probabilistic states , areprobabilistically bisimilariff for all it holds that , which we also denote by and , respectively.
By definition, probabilistic bisimilarity is the union of all probabilistic bisimulations. To be able to speak of probabilistically bisimilar distributions (or of probabilistically bisimilar probabilistic states), probabilistic bisimilarity needs to be an equivalence relation. In fact, probabilistic bisimilarity is a probabilistic bisimulation. See [
22] for a proof.
3. A Partition Refinement Algorithm for Probabilistic Bisimulation (Outline)
Many efficient algorithms for standard bisimulation calculate partitions of states [
5,
23,
24]. Here, we consider the construction of a partition
of the sets of action states
S and of probabilistic states
U for some fixed PLTS
over a set of actions
. Below blocks of the partition always contain either action states or probabilistic states.
3.1. Stability of Blocks and Partitions
An important notion underlying the algorithm introduced below is that of the stability of a block of a partition. If a block is not stable, it contains states that are not bisimilar. These states either have different transitions or different distributions. We first define the notion of stability more generically on sets instead of on blocks. Then, we lift it to partitions.
Definition 3. (Stable Sets and Partitions). - 1.
A set of action states is called stable under a set of probabilistic states with respect to an action iff whenever and vice versa for all . The set B is called stable under C iff B is stable under C with respect to all actions .
- 2.
A set of probabilistic states is called stable under a set of action states iff for all .
- 3.
A set of states B with , respectively , is called stable under a partition of , with or for all , iff B is stable under each with , respectively .
- 4.
A partition is called stable under a partition iff all blocks B of are stable under .
There are two simple but important properties stating that stability is preserved when splitting sets. The first one says that subsets of stable sets are also stable.
Lemma 1. Let be a set of action states and a set of probabilistic states. If B is stable under C, then any is also stable under C. Similarly, if C is stable under B, then any is also stable under B.
Proof. We only prove the first part as the argument for the second part is essentially the same. If , then also . As B is stable under C, it holds that for every action either both satisfy and , or neither does. Thus, is stable under C. ☐
The second property says that splitting a set in two parts can only influence the stability of an other set if there is a transition or a positive probability from this other set to one of the parts of the split set.
Lemma 2. Let be a set of action states and a set of probabilistic states.
- 1.
Suppose B is stable under C with respect to an action a, , and there is no such that . Then, B is stable under and with respect to a.
- 2.
Suppose C is stable under B, , and for all . Then, C is stable under and .
Proof. We only provide the proof for the first part of this lemma. If , then both and by assumption. Thus, B is stable under with respect to a. Furthermore, B is stable under : Suppose and . Thus, . As B is stable under C, , and by assumption . Therefore, . Suppose . Then, also . As B is stable under C, and hence, . ☐
The following property, called the stability property, says that a partition stable under itself induces a probabilistic bisimulation. In general, partition based algorithms for bisimulation search for such a stable partition.
Lemma 3. Stability Property. Let be a PLTS. If a partition for is stable under itself, then the corresponding equivalence relation on S is a probabilistic bisimulation.
Proof. By the first condition of Definition 3 and stability of all blocks in we have that either or , for each block . We write iff for some . Note that used in this way is an equivalence relation on S.
Suppose for some and . Let correspond to f. Say and for some blocks . Then, . By stability of B for , it follows that . Hence, and exist such that v corresponds to g and . Therefore, for any block we have since the block of u and v is stable under each block of .
Thus, the stable partition induces an equivalence relation that satisfies the conditions for a probabilistic bisimulation of Definition 2, as was to be shown. ☐
3.2. Outline of the Algorithm
We present our algorithm in two stages. An abstract description of the algorithm is presented as Algorithm 1; the detailed algorithm is provided as Algorithm 2. The set-up of Algorithm 1 is a fairly standard, iterative refinement of a partition
, in this particular case containing both action states and probabilistic states, which are treated differently. In addition, following the approach of Paige and Tarjan [
5], we maintain a coarser partition
, which we call the set of
constellations. Each constellation in partition
is a union of one or more blocks of
, thus
is a refinement of
. A constellation
that consists of exactly one block in
is called
trivial. We refine partitions
and
until
only contains trivial constellations (see Line 5 of Algorithm 1).
| Algorithm 1 Abstract Partition Refinement Algorithm for Probabilistic Bisimulation. |
- 1:
functionpartition-refinement - 2:
- 3:
- 4:
where - 5:
while contains a non-trivial constellation C do - 6:
choose block from in C - 7:
replace in constellation C by and - 8:
if C contains probabilistic states then - 9:
for all blocks B of action states in unstable under or do - 10:
refine by splitting B into blocks of states with the same actions into and - 11:
end for - 12:
else - 13:
for all blocks B of probabilistic states in unstable under do - 14:
refine by splitting B into blocks of states with equal probabilities into - 15:
end for - 16:
end if - 17:
end while - 18:
return
|
| Algorithm 2 Partition Refinement Algorithm for Probabilistic Bisimulation |
 |
Among others, we preserve the invariant that the blocks in partition are always stable under partition . If all constellations in are trivial, then the partitions and coincide. Hence, the blocks in are stable under itself, and according to Lemma 3 we have found a probabilistic bisimulation. Our algorithm works by iteratively refining the set of constellations . When refining , we must also refine to preserve the above mentioned invariant.
Since the set of states of a PLTS is finite (cf. Definition 1) refinement of the partitions and cannot be repeated indefinitely. Thus, termination of the algorithm is guaranteed. The partition consisting of singletons of action states and of probabilistic states is the finest that can be obtained, but this is only possible if all states are not bisimilar. In practice, the main loop of the algorithm stops well before reaching that point.
The algorithm maintains the following three invariants:
- Invariant 1.
Probabilistic bisimilarity is a refinement of .
- Invariant 2.
Partition is a refinement of partition .
- Invariant 3.
Partition is stable under the set of constellations (mentioned already above).
Invariant 1 states that if two action states or two probabilistic states are probabilistically bisimilar, then they are in the same block of partition . Thus, the partition-refinement algorithm will not separate states if they are bisimilar. By Invariant 2, we have that, at the end and at the start of each iteration, each constellation in is a union of blocks in . Invariant 3 says that blocks in partition cannot be split by blocks in constellation .
In Lines 2 and 3 of Algorithm 1, the set of constellation and the initial partition are set such that the invariants hold. All probabilistic states are put in one block, and all action states with exactly the same actions labelling outgoing transitions are also put together in blocks. (Note the universal quantification over all actions a in A for the set comprehension at Line 4 to ensure that only maximal blocks are included in for it being a partition indeed.) The set of constellations contains two constellations namely one with all action states, and one with all probabilistic states. It is straightforward to see that Invariants 1 and 2 hold. Invariant 3 is valid because all transitions from action states go to probabilistic states and vice versa.
Invariants 1–3 guarantee correctness of Algorithm 1. That is, from the invariants, it follows that, upon termination, when all constellations have become trivial, the computed partition identifies probabilistically bisimilar action states and probabilistically bisimilar probabilistic states.
Theorem 1. Consider the partition resulting from Algorithm 1. We find that (i) two action states are in the same block of iff they are probabilistically bisimilar, and (ii) two probabilistic states are in the same block of iff they are probabilistically bisimilar.
Proof. Upon termination, because of the while loop of Algorithm 1, all constellations of are trivial, i.e. each constellation in consists of exactly one block of . Hence, by Invariant 2, the partitions and coincide. Thus, by Invariant 3, each block of is stable under each block in . In other words, partition is stable under itself.
By the Stability Property of Lemma 3, we have that is a probabilistic bisimulation on S. It follows that two action states in the same block of are probabilistically bisimilar. Reversely, by Invariant 1, probabilistically bisimilar action states are in the same block of . Thus, and coincide on S. In other words, two action states are in the same block of iff they are probabilistically bisimilar.
To compare and the relation on U, choose probabilistic states such that . Thus, u and v are in the same block of . By stability of block B for it follows that , for each block . Since and coincide on S this implies for all . Thus, we have . Reversely, if , we have for some block B of by Invariant 1. Thus, two probabilistic states are in the same block of iff they are probabilistically bisimilar. ☐
It is worth noting that in Line 5 of Algorithm 1 an arbitrary non-trivial constellation is chosen and in Line 6 an arbitrary block
is selected from
C (we later put a constraint on the choice of
). In general, there are many possible choices and this influences the way the final partition is calculated. The previous theorem indicates that the final partition is not affected by this choice, neither is the complexity upper-bound, see
Section 4.6. However, it is conceivable that practical runtimes can be improved by choosing the non-trivial constellation
C and the block
optimally.
3.3. Refining the Set of Constellations and Restoring the Invariants
As we see from the high-level description of the partition refinement Algorithm 1, a non-trivial constellation C and a constituent block are chosen (Lines 5 and 6) and C is replaced in by the smaller constellations and (Line 7). This preserves Invariants 1 and 2, but Invariant 3 may be violated as stability under or (or both) may be lost: On the one hand, it may be the case that two actions states s and t both have an a-transition into C, but s may have one to but t to only or vice versa. On the other hand, it may be the case that two probabilistic states u and v yield the same value for C as a whole, i.e. , but by no means this needs to hold for or , i.e. and . Therefore, in the remainder of the body of Algorithm 1, the blocks that are unstable under and are split such that Invariant 3 is restored, both for blocks of actions states (Lines 9 and 10) and for blocks of probabilistic states (Lines 13 and 14). In the next section, the detailed Algorithm 2 describes how this is done precisely.
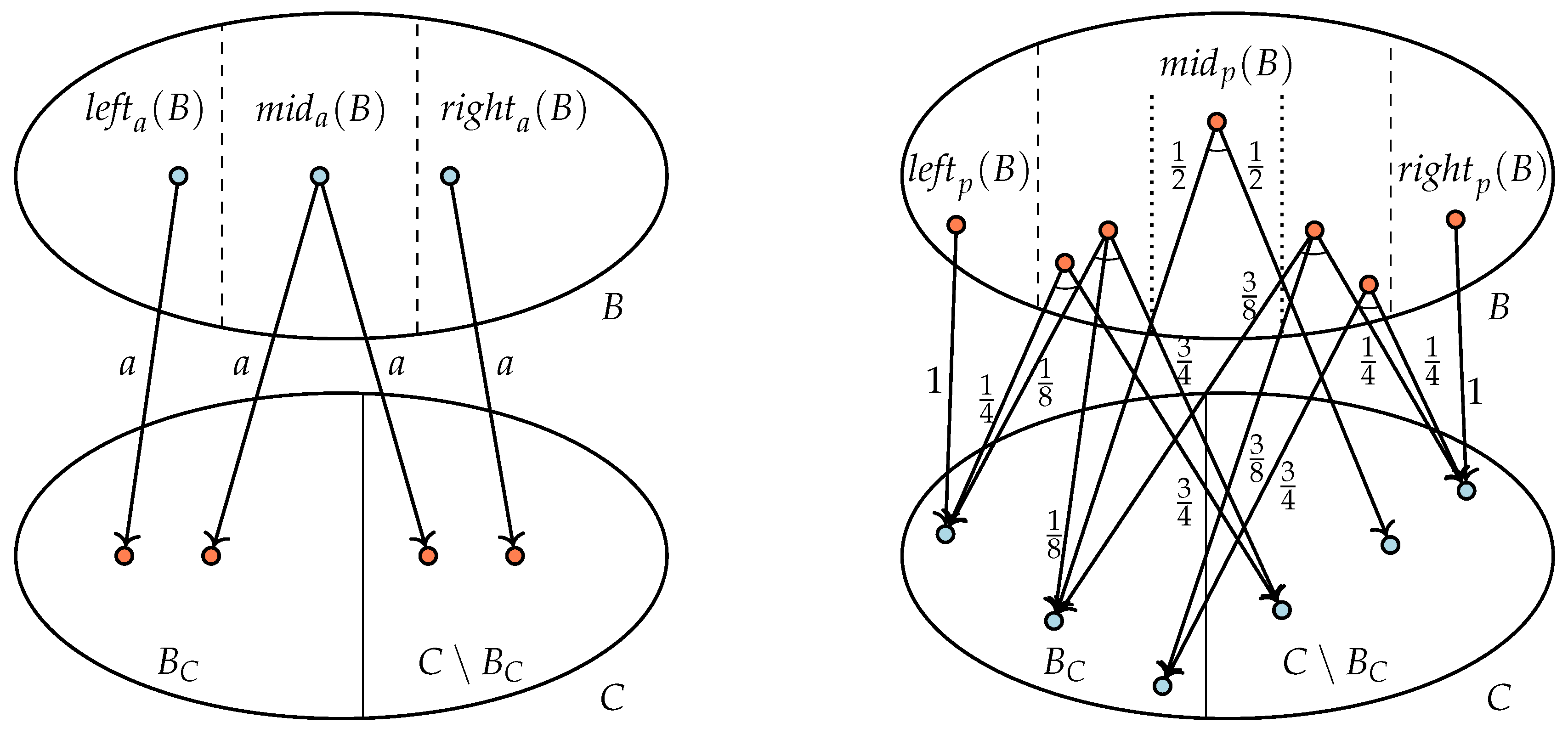
The general situation when splitting a block
B for a constellation
C containing a block
is depicted in
Figure 2, at the left where
B contains action states and at the right where
B consists of probabilistic states. We first consider the case at the left.
In this case, block is stable under constellation and C is non-trivial. Thus, C properly contains a block of , and we distinguish two non-empty subsets of C, the block on its own and the remaining blocks together in . As B is stable under C, the block B can only be unstable under or if there is an action and a state such that (Lemma 2.1). Thus, we only investigate and split blocks, for which such a transition exists.
We can restore stability by splitting
B into the following three subsets:
Note that the remaining set must be empty; if not, this would imply that there is some action state t such that . However, due to the existence of state s such that , this would mean that block B is unstable under C, contradicting Invariant 3.
Checking that the sets , , are stable under C is immediate. As subsets of stable sets are also stable (Lemma 1) and B is stable all other configurations of , the sets , , and are stable under all other configurations of too.
Note that, due to the existence of state s with , it is not possible that both and are equal to the empty set. It is however possible that or , leaving the other two sets empty.
Lines 9 and 10 can now be read as follows. For all , investigate all blocks B such that there is an action state with as these blocks are the only candidates to be unstable. Replace each such block B in by to restore stability under and .
Invariants 1 and 2 are preserved by splitting B. For Invariant 2, this is trivial by construction. For Invariant 1, note that the states in different blocks among cannot be probabilistically bisimilar as they have unique transitions to states and and these target states cannot be bisimilar by Invariant 1. Thus, if two states of B are probabilistically bisimilar then both are in the same subset , , or of B.
We next turn to the case of a set of probabilistic states
B, see the right-side of
Figure 2. Again, we assume that the non-trivial constellation
C is replaced by its two non-empty subsets
and
. As in the previous case, although the block
B is stable under the constellation
C, this may not be the case under the subsets
and
.
To restore stability, we now consider for all
q,
, the sets
Note that, for finitely many , we have . Observe that each set is stable under as by construction for any . The set is also stable under . To see this consider two states . As block is stable under constellation , . Hence, . By Lemma 1, the new blocks are also stable under the other constellations in .
According to Lemma 2.2, only those blocks B that contain a probabilistic state such that can be unstable under and . Thus, at Line 13 of Algorithm 1 we consider all those blocks B and replace each of them by the non-empty subsets , at Line 14 in . This makes the partition stable again under all constellations in , in particular under the new constellations and .
Again, it is straightforward to see that Invariants 1 and 2 are not violated by replacing the block B by the blocks . For Invariant 1, if states are probabilistically bisimilar in B, they remain in the same block . For Invariant 2, as B is refined, partition remains a refinement of partition .
For the detailed algorithm in
Section 4, it is required to group the sets
as follows:
,
, and
. This does not play a role here, but
,
, and
are already indicated in
Figure 2, in particular
.
3.4. An Example
We provide an example to illustrate how Algorithm 1 calculates partitions.
Example 1. Consider the PLTS given in Figure 3. We provide a detailed account of the partitions that are obtained when calculating probabilistic bisimulation. The obtained partitions are listed in Table 1. In the lower table, nine partitions together with their constellations are listed that are generated for a run of Algorithm 1. In the upper table the blocks that occur in these partitions are defined. Observe that we put the blocks and constellations with action states and probabilistic states in different columns. This is only for clarity, as in the current partition and the current set of constellations they are joined. Algorithm 1 starts with four blocks of action states,
to
, which contain the action states with no outgoing transitions and those with an outgoing transition labelled with
a, with
b, and with
c, respectively. In the algorithm, all probabilistic states are initially collected in block
. There are two constellations, viz.
and
. These initial partitions are listed in R0w 0 of the lower part of
Table 1.
Since the constellation with action states is non-trivial we split it, rather arbitrarily, in
and
. The block
is not stable under
and
and is split in
,
and
. This is because we have
for
u equal to
,
, and
to
; we have
for
u equal to
and
; we have
and
. The resulting partitions are listed at Row 1 in
Table 1.
For the second iteration, we consider the non-trivial constellation and split it into and . Note, the action states to in do not have incoming transitions. Consequently, for all , we have ; for all we have ; for all we have . Thus, all blocks of probabilistic states are stable under and . Hence, no block is split.
In the third iteration, we split the non-trivial constellation into and . For all, we have . Thus, is stable under and . For , the probabilistic states and agree on the value for , hence for too. Thus, is stable as well. However, for and in we have and . Therefore, needs to be split in and .
At this point, all constellations with actions states are trivial, so at iteration 4 we turn to the non-trivial constellation of probabilistic states and split it into and . Block is stable since each of its states has no transitions at all. Block is not stable: and , but and . Thus, needs to be split into and . Block is stable since its states have only b-transitions into . Block is a singleton and therefore cannot be split.
The following iteration, Iteration 5, sets and apart as constellations. Again, in absence of transitions, block is stable under and . The same holds for that has only b-transitions into . Block can be ignored. For , both and have an a-transition into as their only transition. Hence, block is stable. Similarly, is stable, as its states and both have an a-transition into and no other transitions. Overall, in this iteration, no blocks require splitting to restore Invariant 3.
Next, at Iteration 6, we split non-trivial constellation into and . For , , and we conclude stability in the same way as in the previous iteration. However, now we have for on the one hand and , but on the other hand and . Hence, needs to be split, yielding the singletons and .
Returning to constellations of actions states, at Iteration 7, we split over and . All probabilistic states have value 0 for both and , hence no split of probabilistic blocks is needed.
This is similar in Iteration 8, where the non-trivial constellation is split, and none of the blocks become unstable. Now, all constellations are trivial and the algorithm terminates. According to the Stability Property, Lemma 3, the corresponding equivalence relation is a probabilistic bisimulation. Thus, the final partition is . Moreover, the deadlock states and to are probabilistically bisimilar, the states that have only a b-transition into a Dirac distribution to deadlock are probabilistically bisimilar, the states and are probabilistically bisimilar (which is clear when identifying states and ), whereas the remaining action states , and have no probabilistically bisimilar counterpart. For the probabilistic states the states , and to are identified by probabilistic bisimulation. This also holds for the probabilistic states and . Probabilistic states and each have no probabilistically bisimilar counterpart.
4. A Partition-Refinement Algorithm for Probabilistic Bisimulation (Detailed)
Algorithm 1 gives an outline but leaves many details implicit. The detailed refinement-partition algorithm is presented in this section as Algorithm 2. It has the same structure as Algorithm 1, but in this section we focus on how to efficiently calculate whether and how blocks must be split, and how this split is actually carried out. We first explain grouping of action transitions per action, next we introduce various data structures that are used by the algorithm, subsequently we explain how the algorithm is working line-by-line, and finally we give an account of its complexity.
4.1. Grouping Action Transitions per Action Label
To obtain the complexity bound of our algorithm, it is essential that we can group action transitions by actions linearly in the number of transitions. Grouping means that the action transitions with the same action occur consecutively in this ordering. It is not necessary that the transitions are ordered according to some overall ordering.
We assume that and that the actions in are consecutively numbered. Recall, denotes the number of transitions . These assumptions are easily satisfied, by removing those actions in that are not used in transitions and by sorting and numbering the remaining action labels. Sorting these actions adds a negligible .
Grouping transitions is performed by an array of buckets indexed with actions. All transitions are put in the appropriate bucket in constant time exploiting actions being numbered. Furthermore, all buckets that contain transitions are linked together. When all transitions are in the buckets, a straightforward traversal of all linked buckets provides the transitions in a grouped order. This requires time linear in the number of considered action transitions. Note that the number of buckets is equal to and, therefore, the buckets do not require more than linear memory.
4.2. Data Structures
We give a concise overview of the concrete data structures in the algorithm for states, transitions, blocks, and constellations. We list the names of the fields in these data structures in a programming vein to keep a close link with the actual implementation.
The chosen data structures are not particularly optimised. Exploiting ideas from [
6,
24,
25] to store states, blocks, and constellations, usage of time and memory can be further reduced. All data structures come in two flavours, one related to actions and the other related to probabilities. We treat them simultaneously and only mention their differences when appropriate.
4.2.1. Global
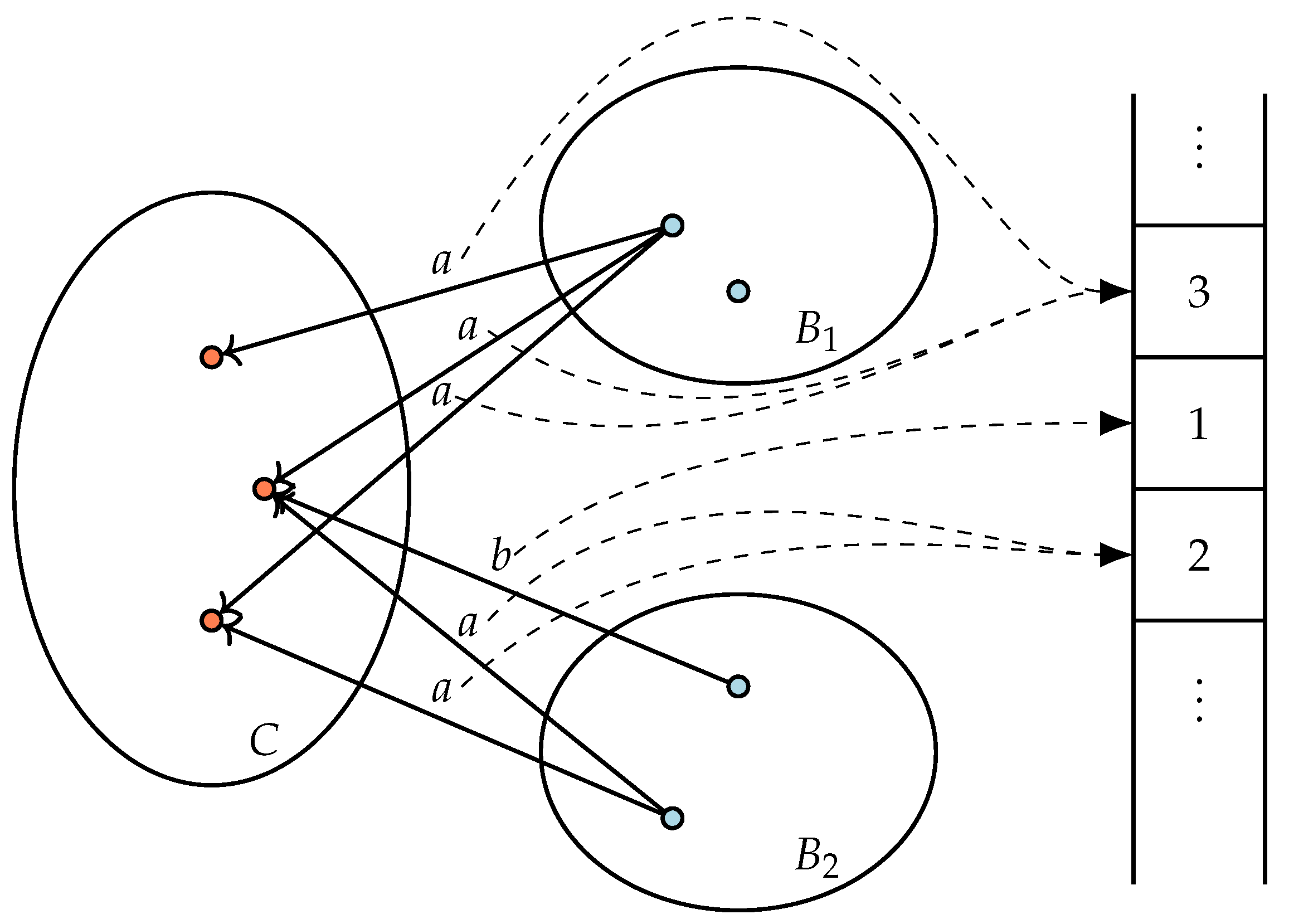
In the detailed algorithm, there are arrays containing transitions, actions, blocks and constellations. There is a stack of non-trivial constellations to identify in constant time which constellation must be investigated in the main loop. Furthermore, there is an array containing the variables , which are explained below.
For all action transitions
, it is maintained how many action transitions there are labelled with the same action
a, and that go from
s to the constellation
C containing
u. This value is called
for this transition. The value is required to efficiently split probabilistic blocks (the idea of using such variables stems from [
5]). For each state
s, constellation
C, and action
a there is one instance of
stored in a global array. Each transition
contains a reference called
to the appropriate value in this array. See
Figure 3 for a graphical illustration with a constellation
C of probabilistic states and blocks
and
of action states. The purpose of this construction is that
can be changed by one operation for all transitions from the same state with the same action to the same constellation, simultaneously.
4.2.2. Transition
Each transition consists of the fields , and . Here, and refer to an action/probabilistic state, and is the action label or probabilistic label of the transition. The action labels are consecutive numbers; the probabilistic labels are exact fractions. Action transitions also contain a reference to the variable as indicated above.
4.2.3. State
Each action state and probabilistic state contains a list of incoming transitions and a reference to the block in which the state resides. For intermediate calculations, each state contains a boolean which is used to indicate that a state has been marked. Each action state also contains two more variables for temporary use. When deciding whether blocks need to be split, the variable indicates how many residual transitions there are to blocks when splitting takes place by a block . The variable is used to let the variable for an action transition point to a new instance of when this transitions is moved to a new block. In probabilistic states, there is the temporary variable used to calculate the total probability to reach a block under splitting.
4.2.4. Block
Blocks contain an indication of the constellation in which it occurs, a list of the states contained in the block including the size of this list, and a list of transitions ending in this block. For blocks of action states, this list of transitions is grouped by action label, i.e., transitions with the same action label are a consecutive sublist. For temporary use, there is also a variable to indicate that the block is marked. This marking contains exactly the information that the functions and , discussed below, provide for blocks of action states and blocks of probabilistic states, respectively.
4.2.5. Constellation
Finally, constellations contain a list of the blocks in the constellation as well as the cumulative number of states contained in all blocks in this constellation.
4.3. Explanation of the Detailed Algorithm
Algorithm 1 focuses on how, by refining partitions and sets of constellations, probabilistic bisimulation can be calculated. In Algorithm 2, we stress the details of carrying out concrete refinement steps to realise the required time bound. As already indicated, the overall structure of both algorithms is the same.
The initial Lines 2 and 3 of Algorithm 2 are the same as those of Algorithm 1. In Line 3, the partition
is set to contain one block with all probabilistic states and a number of blocks of action states, grouped per common outgoing action labels. Thus, two action states are in the same block initially if their menu, i.e., the set of actions for which there is a transition, is identical. This initial partition
is calculated using a simple partition refinement algorithm on outgoing transitions of states. This operation is linear in the number of outgoing action transitions when using grouping of transitions as explained in
Section 4.1.
At Line 4, the incoming transitions are ordered on actions as indicated in
Section 4.1. At Line 5, an array with one instance of
for each action label is made where each instance contains the number of action transitions that contain that action label. The reference
for each action transition is set to refer to the appropriate instance in this array. This is done by simply traversing all transitions
grouped by action labels and incrementing the appropriate entry in the array containing all
variables. The appropriate entry can be found using the temporary variable
associated to state
s. If no entry for
exists yet, the variable
belonging to
s is
null and an appropriate entry must be created.
In Line 6, selecting a non-trivial constellation is straightforward, as a stack of non-trivial constellations is maintained. Initially, this stack contains . To obtain the required time complexity, we select such that in Line 8. This is done in constant time as we know the number of states in C. Hence, either the first or second block B of constellation C satisfies that (for if the first block contains more than half the states the second one cannot). We replace the constellation C by and in , see Line 8, and put the constellation on the stack of non-trivial constellations if it is non-trivial.
From Line 9 to Line 19, the partition is refined to restore the invariants, especially Invariant 3. This is done by first marking the blocks (Line 11 and Line 16) such that it is clear how they must be split, and by subsequently splitting the blocks (Lines 12–14, and Lines 17–19). Both operations are described in the next two subsections.
4.4. Marking
Given a constellation C that contains a block and in the case of an action transition, an action a, we need to know which blocks need to be split in what way. This is calculated using the functions and . The first one is for marking blocks with respect to action transitions, the second for marking blocks with respect to probabilities.
Both functions yield a five-tuple . Here, is a set of blocks that may have to be split and , , and are functions that together for each block provide the sets into which B must be partitioned. The set is the largest set among them. For every set in which B must be partitioned, except for , it holds that . To obtain the complexity bound, we only move such small blocks out of B, i.e., those blocks not equal to .
We note that sets in , and can be empty. Such sets can be ignored. It is also possible that there is only one non-empty set being equal to B itself. In this case, B is stable under and . Furthermore, it is equal to and therefore B is kept intact.
We now concentrate on the function
with a partition
, a constellation
C, a block
contained in
C, and an action
a. In this situation,
C is a non-trivial constellation of probabilistic states. Since
C contains probabilistic states only, incoming transitions for states in
are action transitions. The situation is depicted in
Figure 2, at the left. The call
returns the tuple
defined as follows.
We calculate by traversing the list of all transitions with action a going into and adding each block containing any source state of these transitions to . The blocks in are the only blocks that may be unstable under and with respect to a (Lemma 2).
The for loop at Line 10 iterates over all actions. As the incoming transitions into block are grouped per action, all incoming transitions with the same action can easily be processed together, while the total processing time is linear in the number of incoming transitions. However, note that calculating is based on partition , while is refined at Line 14. Thus, the calculation of for different actions a can be based on repeatedly refined partitions .
Next, we discuss how to construct the blocks , , and . While traversing a-labelled transitions into , all action states in a block B with an a-transition into are marked and (temporarily) moved into . The remaining states in block B form the subset . We keep track of the number of states in a block. Thus, we can easily maintain the size of .
To find out which states now in must be transferred to , the variables are used. Recall that these variables record for each transition , with , how many transitions there are to states . These variables are initialised in Line 5 of Algorithm 2. When the first state is moved to , we copy the value of of transition to the variable belonging to state s of the transition, subtracted by one. The number indicates how many unvisited a-transitions are left from the state s into C. Every time an a-transition is visited of which the source state is already in , we decrease of the source state by one again. If all a-transitions into have been visited, the number of a state s indicates how many transitions labelled a go from s into .
Subsequently, we traverse the states in . If a state s has a non-zero , we know that there are a-transitions from s to both and . Therefore, we move state s into . Otherwise, all transitions from s with action a go to and s must remain in .
While moving states into and , we also keep track of the sizes of these sets. Hence, it is easy to indicate in which set is the largest.
We calculate
in a slightly different manner than
. In particular, we have
, i.e.,
is a set of blocks. This indicates that the block
B can be partitioned in many sets, contrary to the situation with action blocks where
B could be split in at most three blocks. The situation is depicted in
Figure 2 at the right. The five-tuple that
returns has the following components:
The above is obtained by traversing through all incoming probabilistic transitions in
. Whenever there is a state
u in a block
B such that
, one of the following cases applies:
If B is not in yet, it is added now. The variable in state u is set to p, and u is (temporarily) moved from B to .
If B is already in , then the probability p is added to of state u.
After the traversal of all incoming probabilistic transitions into , the variable of u contains , i.e., the probability to reach from the state u.
Those states that are left in
B form the set
. We know the number of states in
by keeping track how many states were moved to
. Next, the states temporarily stored in
must be distributed over
and
. First, all states with
are moved into some set
M such that
contains exactly the states with
. Then, the states in
M are sorted on their value for
such that it is easy to move all states with the same
into separate sets in
. In
Figure 2, at the right, the set
consists of three sets, corresponding to the probabilities
,
and
to reach
. Note that all processing steps mentioned require time proportional to the number of incoming probabilistic transitions in
, except for the time to sort. In the complexity analysis below, it is explained that the cumulative sorting time is bounded by
.
By traversing the sets of states in and once more, we can determine which set among , , and the set of sets contains the largest number of probabilistic states. This set is reported in .
4.5. Splitting
In Lines 14 and 19 of Algorithm 2, a block is moved out of the existing block B. By the marking procedure, either or , the states involved are already put in separate lists and are moved in constant time to the new block B’.
Blocks contain lists of incoming transitions. When moving the states to a new block, the incoming transitions are moved by traversing the incoming transitions of each moved state, removing them from the list of incoming transitions of the old block and inserting them in the same list for the new block. There is a complication, namely that incoming action transitions must be grouped by action labels. This is done separately for the transitions moved to
as explained in
Section 4.1 and this is linear in the number of transitions being moved. When removing incoming action transitions from the old block
B, the ordering of the transitions is maintained. Thus, the grouping of incoming action transitions into
B remains intact without requiring extra work.
When moving action states to a new block we also need to adapt the variable for each action transition with state . Observe that this only needs to be done if there are some a-transitions to and some to , which means that . In that case for state s is larger than 0.
This is accomplished by traversing all incoming transitions into one extra time. If for s is larger than 0 we need to replace the for this transition by the value of of s. For all non-visited transitions where , the value of must be set to of s.
This is where we use that
is actually referred to by the pointer
(see
Figure 3). When traversing the first transition of the form
with
such that
for
s is larger than 0, a new entry in the array containing the variables
is constructed containing the value
and the auxiliary variable
is used to point to this entry. At the same time, the value in old entry in this array for
is replaced by the value
of state
s. In this way, the values of
of all transitions labelled with
a from
s to
are updated in constant time, i.e., without visiting the transitions that are not moved. For all transitions
with
, the variable
is made to refer the new entry in the array.
4.6. Complexity Analysis
The complexity of the algorithm is determined below. Recall that and are the number of action states and probabilistic states, respectively, while is the number of action transitions and is the cumulative size of the supports of the distributions.
Theorem 2. The total time complexity of the algorithm is and the space complexity is .
Proof. In Algorithm 2, the cost of each computation step is indicated. The initialisation of the algorithm at Lines 2–5 is linear in
,
and
. At Line 3, calculating
can be done by iteratively splitting
S using the outgoing transitions grouped per action label. This is linear in the number of action transitions. At Line 4, grouping the incoming transitions per action is also linear as argued in
Section 4.1.
The while loop at Line 6 is executed for each where . As becomes a constellation itself, each state can only be part of this splitting step times and times, respectively. The steps in Lines 10–13 and Lines 16–18 require steps proportional to the number of incoming action transitions and probabilistic transitions, respectively, in , apart from a sorting penalty which we treat separately below. The cumulative complexity of this part is therefore .
At Lines 14 and 19, the states in are moved to a new block. This requires to group the incoming action transitions in a block per action, which can be done in time linear in the number of these transitions. Block is not the largest block of B considered and therefore . Hence, each state can only be or times be involved in the operation to move to a new block. Hence, the total time to be attributed to moving is .
While marking, probabilistic states in
need to be sorted. An ingenious argument by Valmari and Franceschinis [
6] shows that this will at most contribute
to the total complexity: Let
K be the total number of times sorting takes place. Assume, for
, that the total number of distributions in
when sorting it for the
i-th time is
. Clearly,
. Each time a distribution in
is involved in sorting, the number of reachable constellations with non-zero probability from this distribution is increased by one. Before sorting it could reach
C, and after sorting it can reach both new constellations
and
with non-zero probability. Note that this does not hold for the states in
and
, and this is the reason why we have to treat them separately. In particular, to obtain complexity
, it is not allowed to involve the states in
and
in the sorting process as shown by an example in [
6]. Due to the increased number of reachable constellations, the total number of times a probabilistic state can be involved in sorting is bounded by the size of the distribution. In other words,
. Hence, the total time that is required by sorting is bounded as follows:
Adding up the complexities leads to the conclusion that the total complexity of the algorithm is
. As
, the stated time complexity in the theorem follows.
The space complexity follows as all data structures are linear in the number of transitions and states. As , this complexity can be stated as . ☐
Note that it is reasonable that the number of probabilistic transitions is at least equal to the number of action states as otherwise there are unreachable action states. This allows formulating our complexity more compactly.
Corollary 1. Algorithm 2 has time complexity and space complexity if all action states are reachable.
The only other algorithm to determine probabilistic bisimilarity for PLTS is by Baier, Engelen and Majster-Cederbaum [
4]. The algorithm uses extended ordered binary trees and is claimed to have a complexity of
where
m is the number of transitions (including distributions) and
n the number of action states. For a fair comparison, we reconstructed their complexity in terms of
,
,
and
. Their space complexity is
and the time complexity is
. The last part
is not mentioned in the analysis in [
4]. It is due to taking the time into account for “inserting
into
” (see page 208 of [
4]) for the version of ordered balanced trees used, and we believe it to be forgotten [
26].
This complexity is not easily comparable to ours. We make two reasonable assumptions to facilitate comparison. The first assumption is that the number of action transitions is equal to the number of distributions: . As second assumption, we use that and only differ by a constant.
In the rare case that the support of distributions is large, i.e., if all or nearly all action states have a positive probability in each distribution, then
is equal or close to
. In this case our space complexity becomes
and our time complexity is
, which is comparable
mutatis mutandis to the complexity in [
4]. However, in the more common case where the support of distributions is limited by some constant
c, i.e.,
, we can simplify the space and time complexities to those in the following
Table 2.
In the table the underlined part stems from the extra time needed for insertions. It is clear tha,t if the assumptions mentioned are satisfied, the complexity of the present algorithm stands out well. This is confirmed in the next section where we report on the performance on a number of benchmarks of implementations of both algorithms.
5. Benchmarks
Both our algorithm, below referred to as GRV, and the reference algorithm by Baier, Engelen and Majster-Cederbaum [
4], for which we use the abbreviation BEM, have been implemented in C++ as part of the mCRL2 toolset [
9,
10] (
www.mcrl2.org). This toolset is available under a Boost license which means that the source code is open and available without restriction to be inspected or used. In the implementation of BEM, some of the operations are not carried out exactly as prescribed in [
4] for reasons of practicality.
We have extensively tested the correctness of the implementation of the new algorithm by applying it to millions of randomly generated PLTSs, and comparing the results to those of the implementation of the BEM algorithm. This is not done because we doubt the correctness of the algorithm, but because we want to be sure that all the details of our implementation are right.
We experimentally compared the performance of both implementations. All experiments have been performed on a relatively dated machine running Fedora 12 with INTEL XEON E5520 2.27 GHz CPUs and 1TB RAM. For the probabilities exact rational number arithmetic is used which is much more time consuming than floating point arithmetic. The reported runtimes do not include the time to read the input PLTS and write the output.
Our first experimental question regards the growth of the practical complexity of the BEM and GRV algorithm when concrete probabilistic transition systems grow in size. To get an impression of this, we considered the so-called “ant on a grid” puzzle published in the New York Times [
27,
28]. In this puzzle, an ant sits on a square grid. When it reaches the leftmost or rightmost position on the grid it dies. When it reaches the upper or lower position of the grid it is free and lives happily ever after. On any remaining position, the ant chooses with equal probability to go to a neighbouring position on the grid. The question is what the probabilities for the ant are to die and stay alive, given an initial position on the grid.
The specification in probabilistic mCRL2 of the ant-on-a-grid is given in
Figure 4, where the dimensions of the grid are
and
, and the initial position is given by
and
.
The actions , and indicate that the ant is dead, stays alive and makes a step. The process expression stands for sequential composition and represents the choice in behaviour. The notations and are the if-then and if-then-else of mCRL2. The curly equal sign (≈) in conditions stands for equality applied to data expressions. The expression means that each direction d is chosen with probability . From this description, PLTSs are generated that are used as input for the probabilistic bisimulation reduction tools.
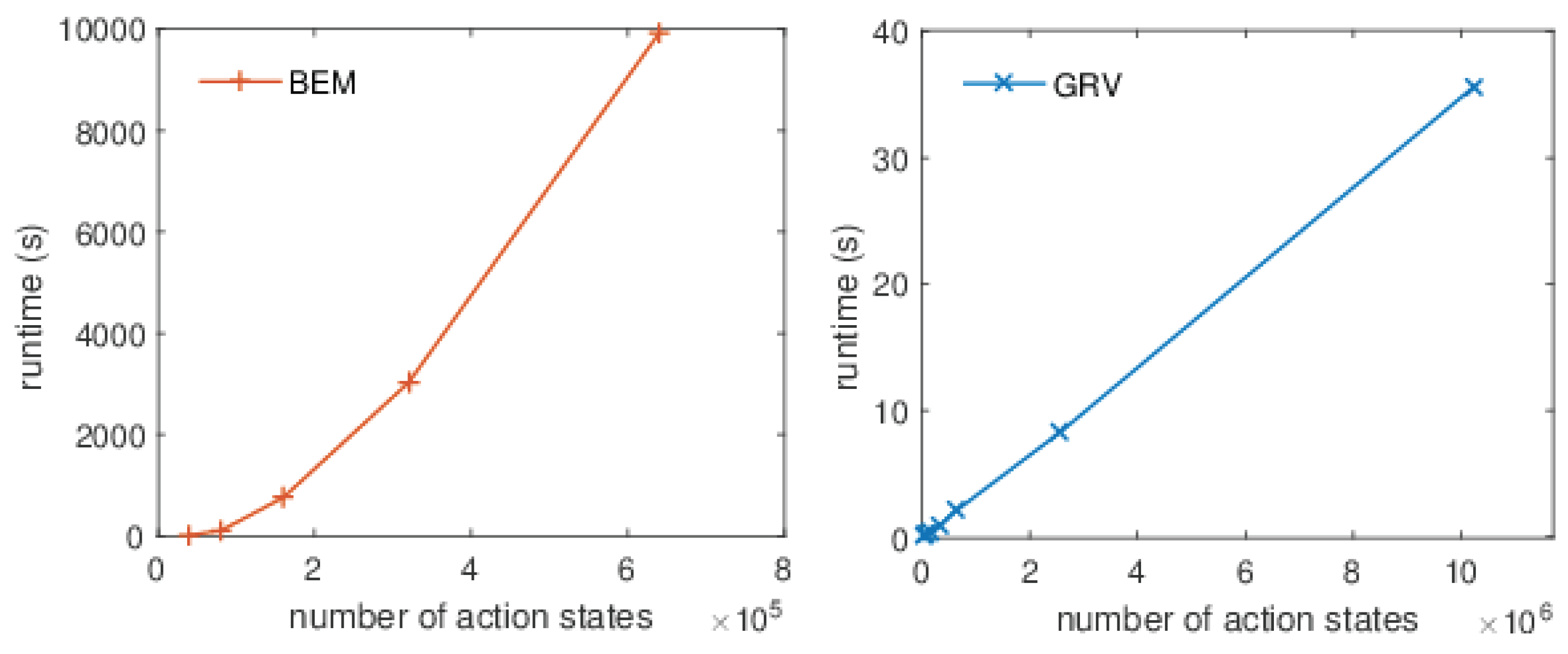
Figure 5 depicts the runtime results of a set of experiments when increasing the total number of states of the ant on the grid model. At the left are the results when running the BEM algorithm, whereas the results for the GRV algorithm are shown at the right. Note that the
x-axis only depicts the number of action states. This figure indicates that the practical running times of both algorithms are pretty much in line with the theoretical complexity. This is in agreement with our findings on other examples as well. Furthermore, it should be noted that the difference in performance is dramatic. The largest example that our implementation of the BEM algorithm can handle within a timeout of 5 h requires approximately 10,000 s compared to 2 s for GRV. The particular example regards a PLTS of
action states. The graphs clearly indicate that the difference grows when the probabilistic transition systems get larger.
To further understand the practical usability of the GRV algorithm, we applied it to a number of benchmarks taken from the PRISM Benchmark Suite (
www.prismmodelchecker.org/benchmarks/) and the mCRL2 toolset (
www.mcrl2.org/). The tests taken from PRISM were first translated into mCRL2 code to generate the corresponding PLTSs.
Table 3 collects the results for the experiments conducted. The
ant_N_M_grid examples refer to the ant-on-a-grid puzzle for an
N by
M grid with the ant initially placed at the approximate center of the grid. The models
airplane_N are instances of an airplane ticket problem using
N seats. In the airplane ticket problem,
N passengers enter a plane. The first passenger lost his boarding pass and therefore takes a random seat. Each subsequent passenger will take his own seat unless it is already taken, in which case he randomly selects an empty seat as well. The intriguing question is to determine the probability that the last passenger will have his or her own seat (see [
28] for a more detailed account).
The following three benchmarks stem from PRISM: The brp_N_MAX models are instances of the bounded retransmission protocol when transmitting N packages and bounding the number of retransmissions to . The self_stab_N and shared_coin_N_K are extensions of the self stabilisation protocol and the shared coin protocol, respectively. For the self stabilisation protocol, N processes are involved in the protocol, each holding a token initially. The shared coin protocol is modelled using N processes and setting the threshold to decide head or tail to K.
Finally, the random_N tests are randomly generated PLTSs with N action states. All the models are available in the mCRL2 toolset.
At the left of
Table 3, the characteristics for each PLTS are given: the number of action states (
), the number of action transitions (
), the number of distributions (
), and the cumulative support of the distributions (
). The symbol “K” is an indicator for 1000 states. The same characteristics for the minimised PLTS are also provided. Furthermore, the runtime for minimising the probabilistic transition system in seconds as well as the required memory in megabytes are indicated for both algorithms. As mentioned earlier, we limited the runtime to 5 h.
The experiments show that the GRV algorithm outperforms the reference algorithm quite substantially in all studied cases. In the case of “
random_100” the difference is four orders of magnitude, despite the fact that this state space has only 100 K action states. The second last column of
Table 3 lists the relative speed-up, i.e. the quotient of the time needed by BEM over the time needed by GRV, when applicable. Memory usage is comparable for both algorithms for small cases, whereas for larger examples the BEM algorithm requires up to one order of magnitude more memory than the GRV algorithm. The right-most column of
Table 3 contains the relative efficiency in memory, i.e. the quotient of the memory used by BEM over the memory used by GRV, for the cases where BEM terminated before the deadline.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}