Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer


Abstract
:1. Introduction
- The input value, which is originally changed considerably in a wide range to output within the (0, 1) range, can be squeezed when the sigmoid function is used as an activation function. When the training dataset is large, the sigmoid function easily causes gradient saturation and convergence is slowed.
- In the CNN, the early stop and regularization strategies are often used to mitigate the overfitting problem. The dataset in the early stop strategy is divided into the training and test sets. The training set calculates the gradient and updates the connection and threshold. The test set evaluates the error. The training stop sign reduces the training set error and increases the test set error. In the regularization strategy, the error objective function considers the factors that describe the complexity. When the number of learning layers in the CNN increases, the capability of these layers to solve the overfitting problem is reduced.
- In the training and evaluation phases, the CNN adjusts the cumulative error of the minimum training set of the target gradient through the reverse propagation algorithm and the gradient descent strategy. Not every level of training evaluates the cumulative error but evaluates it after a given interval layer. Although the time lock decreases, the cumulative error increases.
2. Related Works
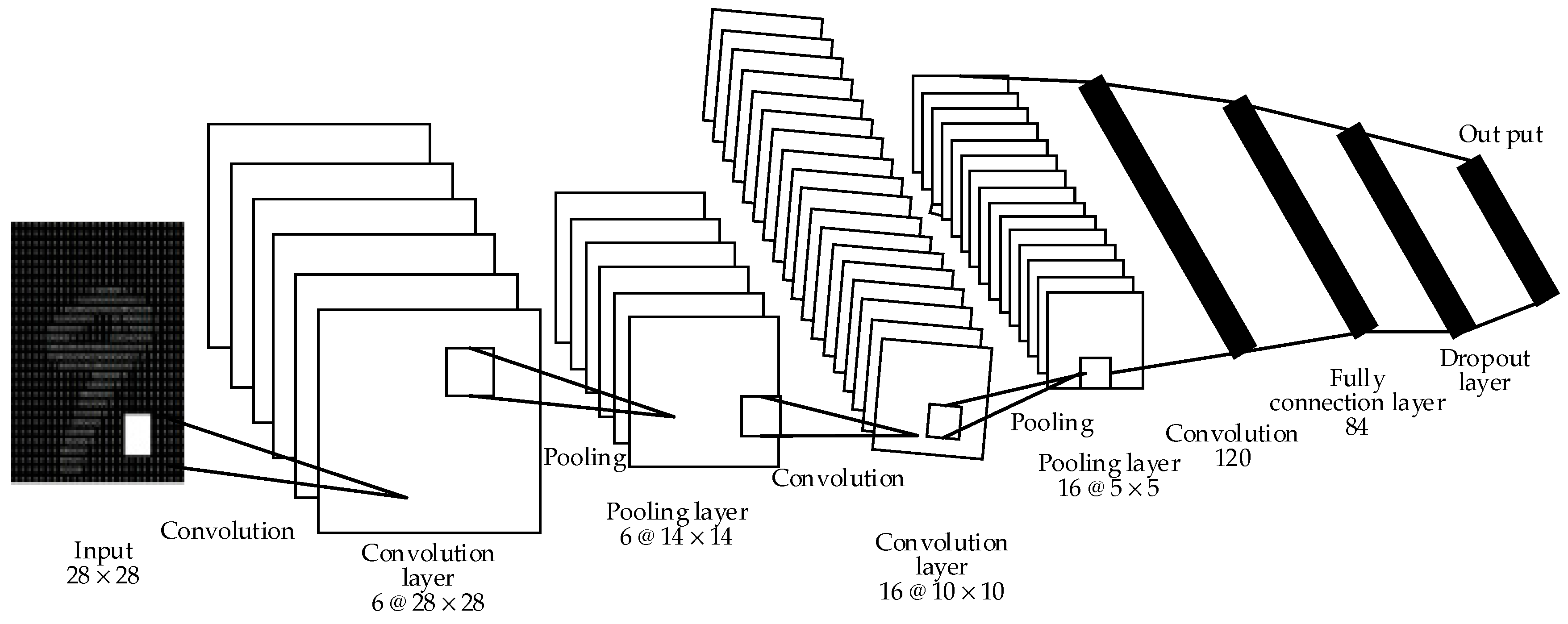
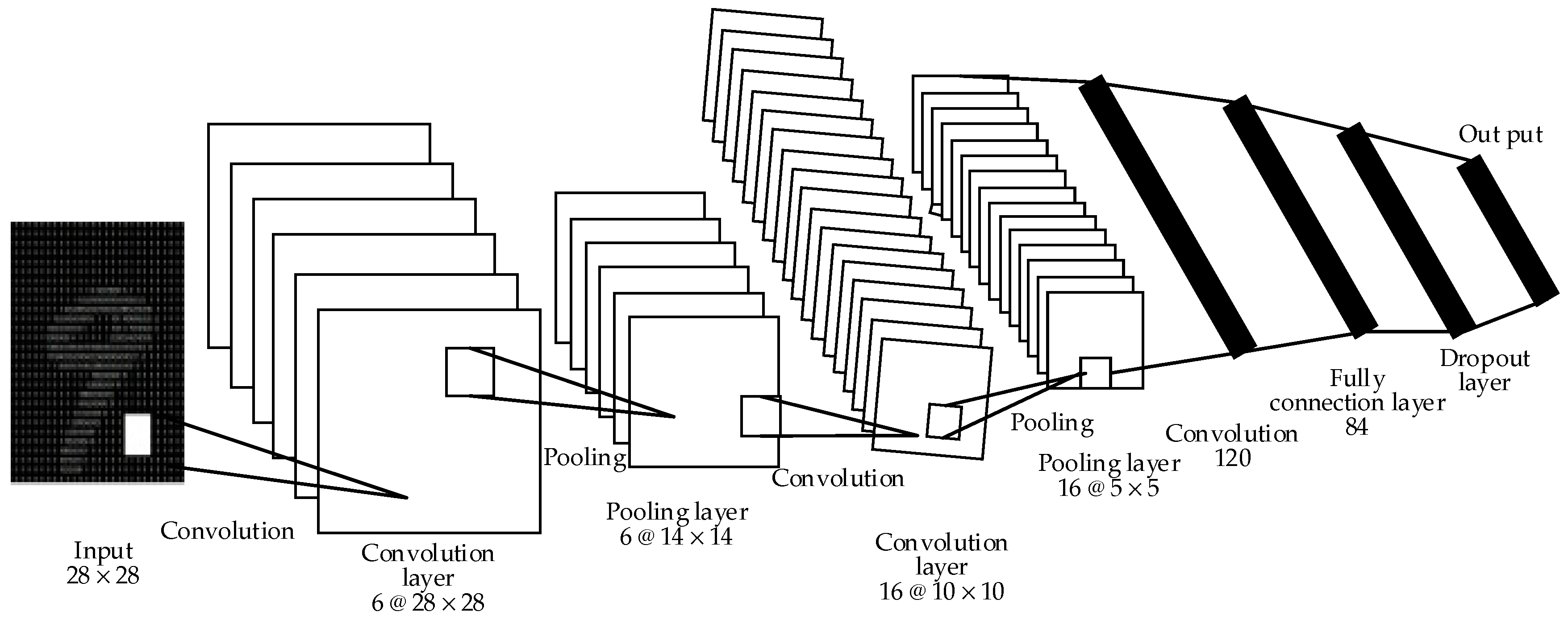
2.1. Typical CNN Model
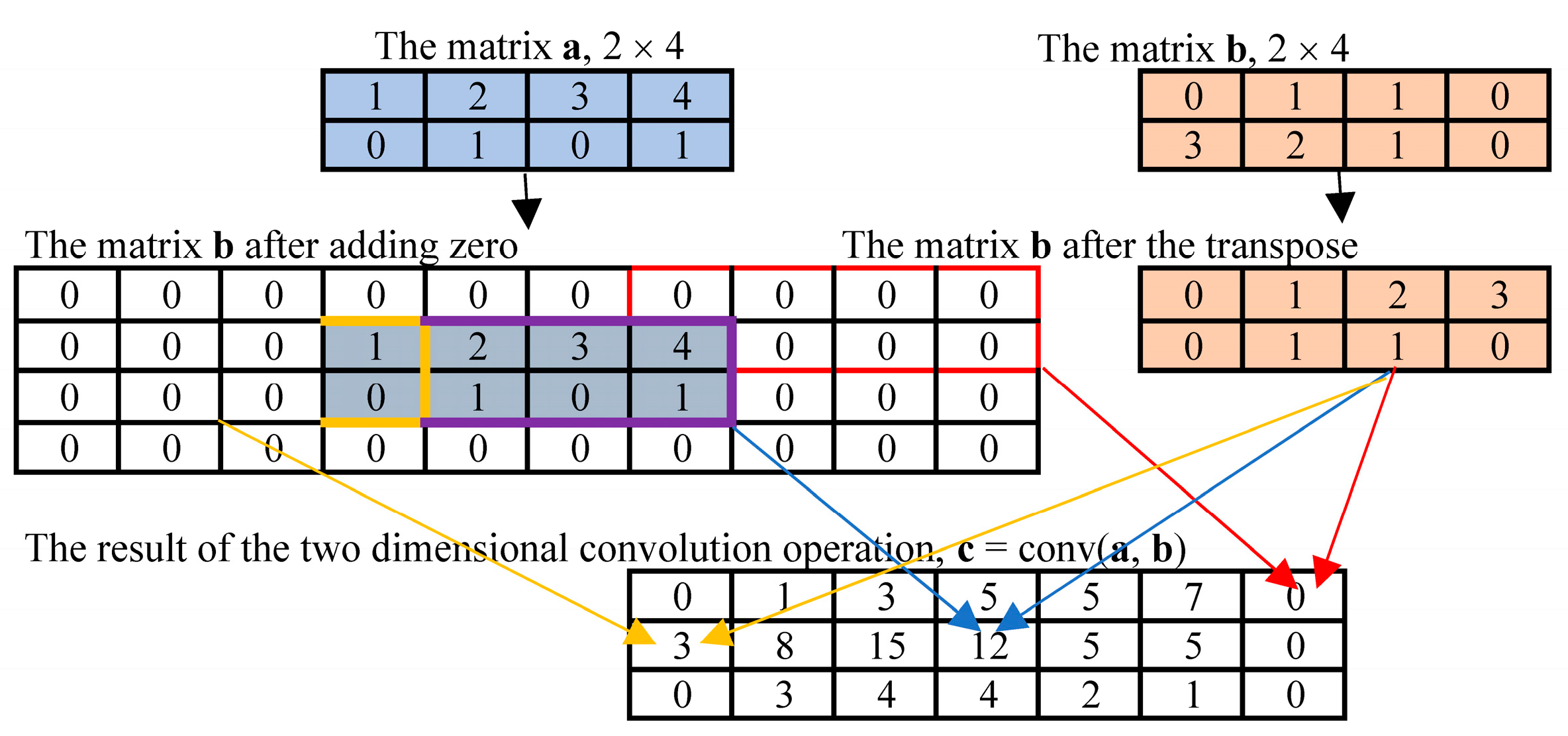
2.2. SGD Optimizer
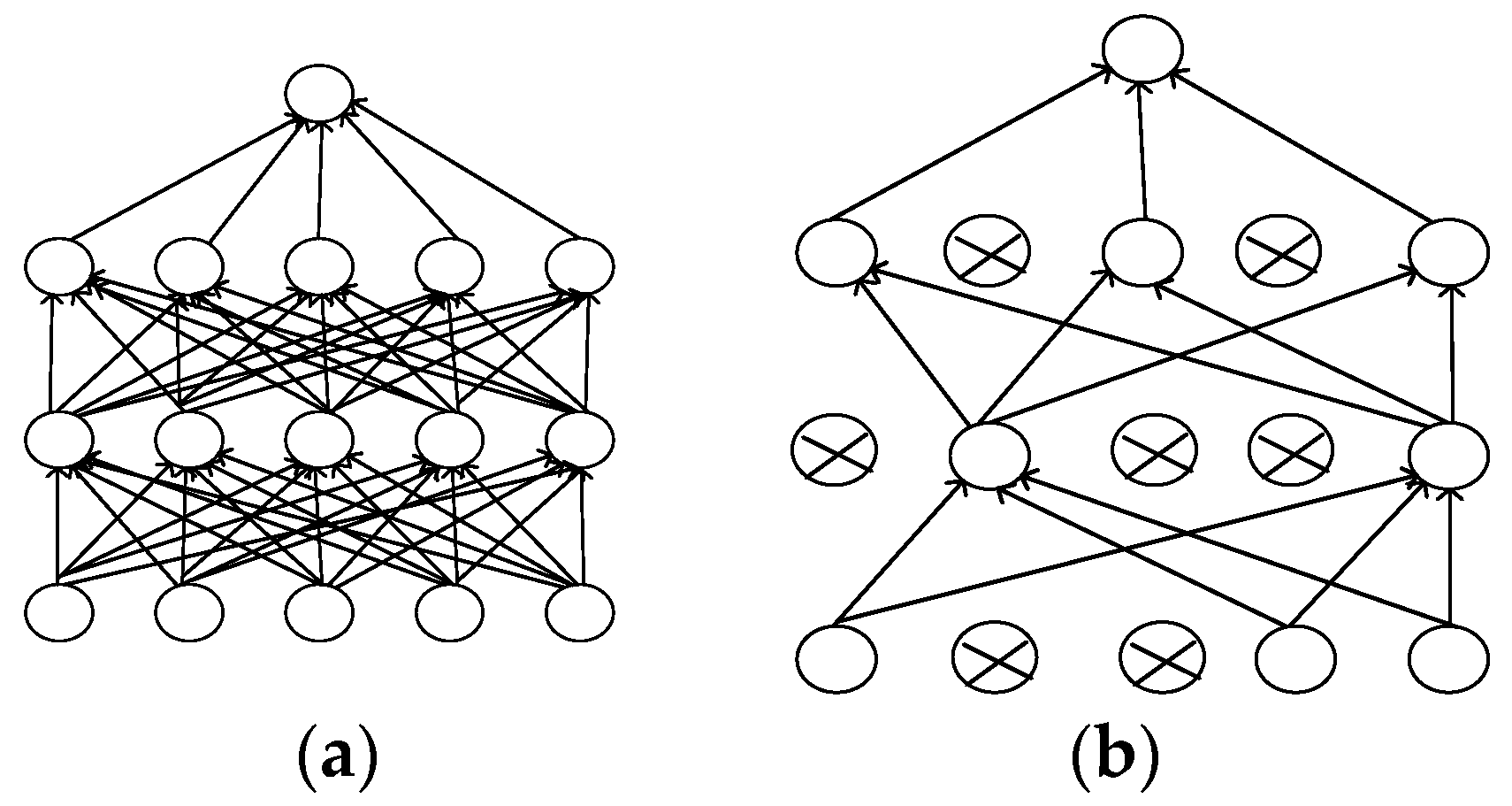
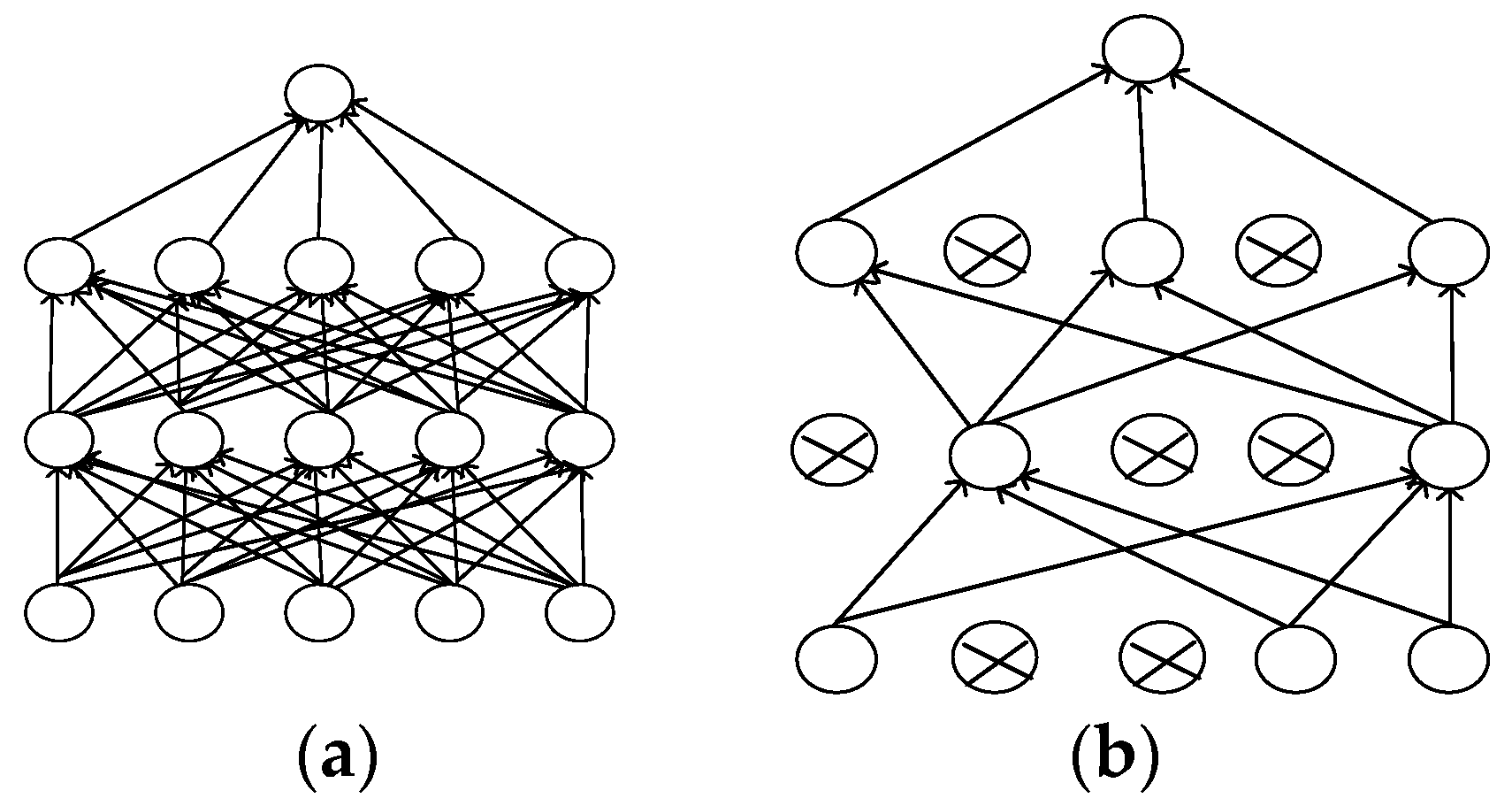
2.3. Dropout Layer
3. Modified CNN Based on Dropout and the SGD Optimizer
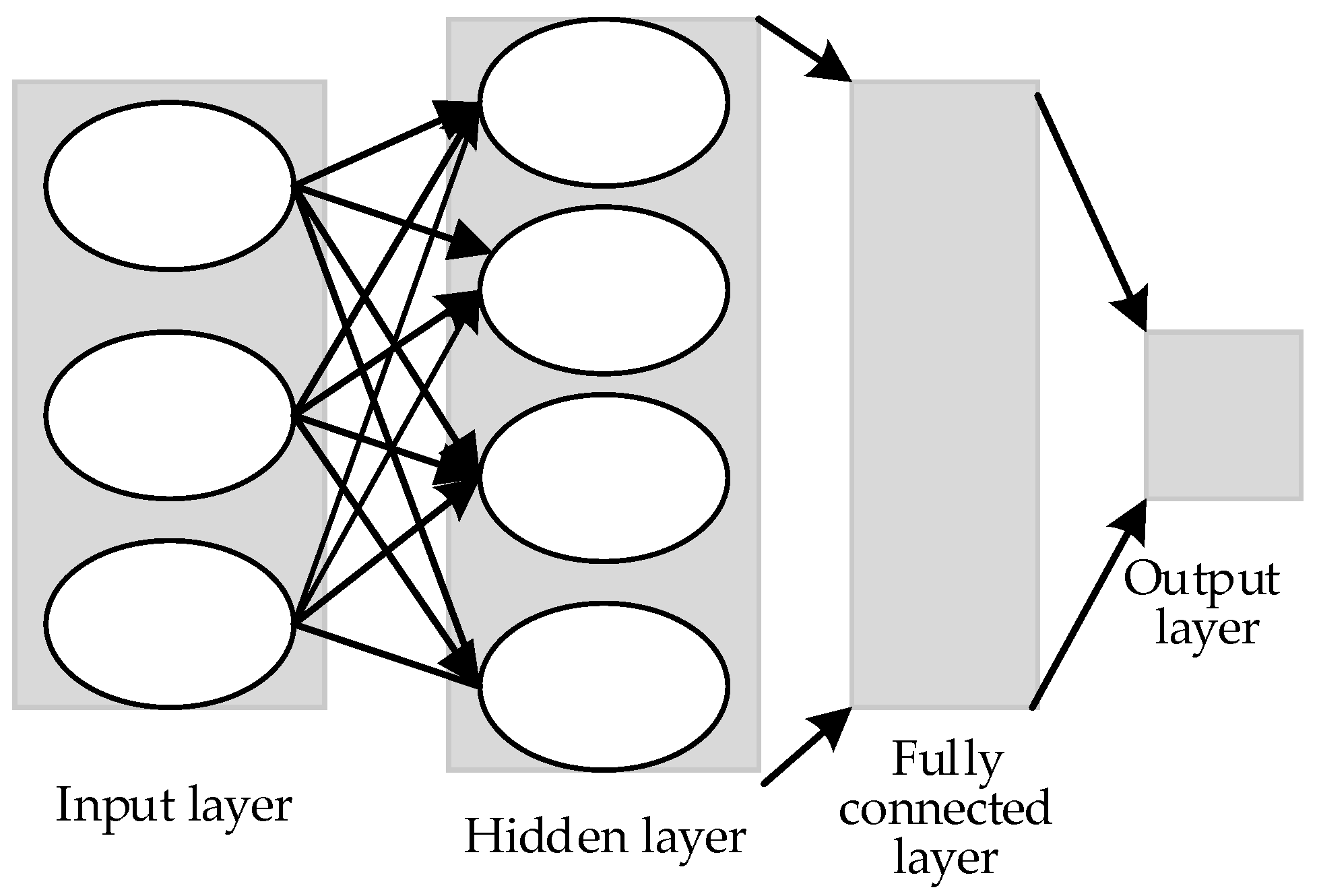
3.1. Quadratic CNN Structure
3.2. Activation Function Based on Leaky ReLU
3.3. Method Based on Dropout and SGD for Preventing Overfitting
3.4. Modified Convolutional Neural Network Based on Dropout and the SGD Optimizer
- Step 1: Pretrain the filter, and initialize the filter size pixel as P1 × P2.
- Step 2: Enter the image dataset for training. Process the image of the training set into the same picture as the filter size, and read the data to form the image data matrix X.
- Step 3: Initialize the weight w(l)i,j and bias bi and invoke the kernel function def Kernel() provided by TensorFlow to initialize parallel operations.
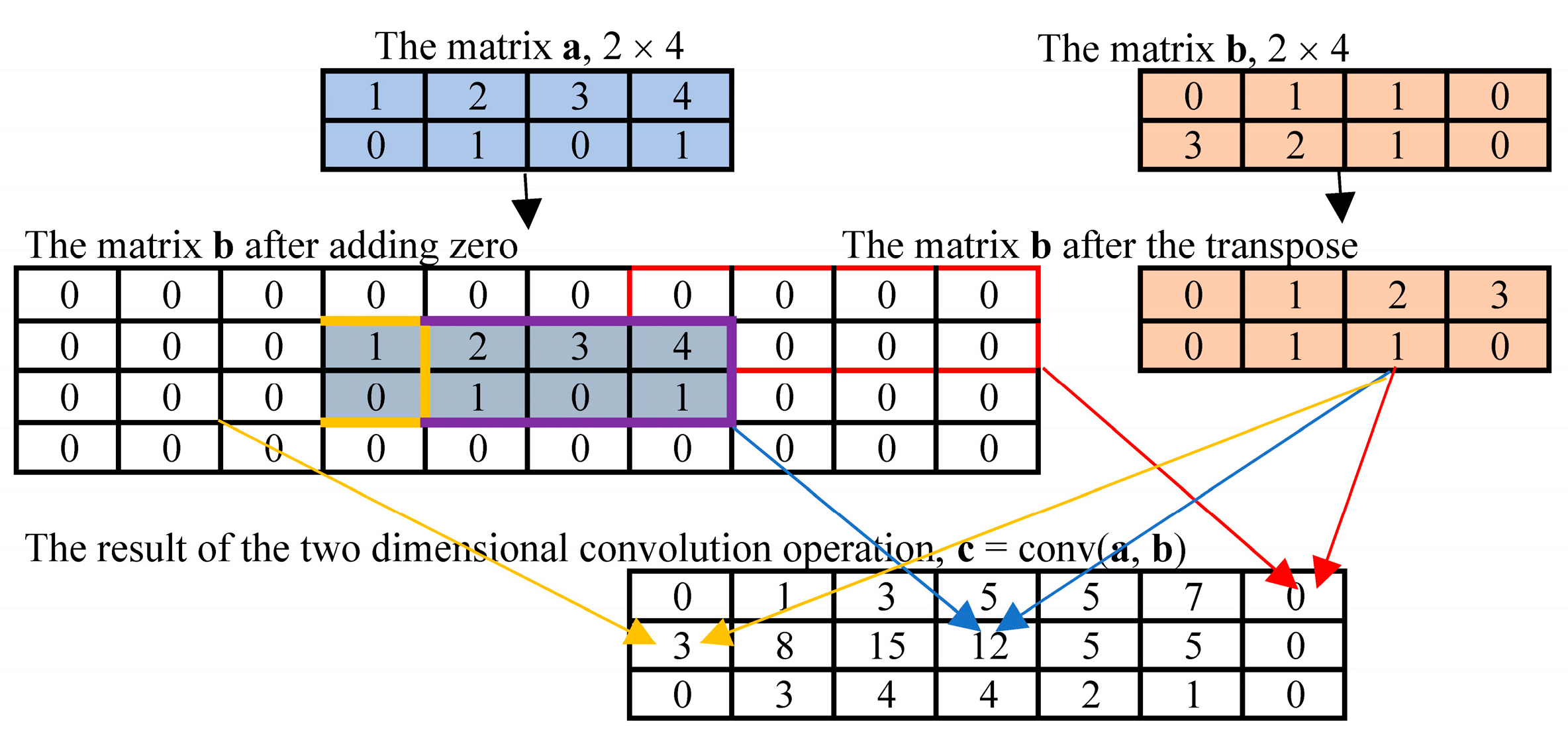
- Step 4: The Conv2d is used for two-dimensional convolution operation to obtain the first layer convolution feature matrix X(1).
- Step 5: The first layer convolution feature matrix X(1) is used as the input data of the pool layer. Use Formula (5) for the pool operation to obtain the feature matrix X(2).
- Step 6: Use the SGD optimizer function expressed in Formula (4) to derive the learning rate of the top-down tuning optimizer, and use the weights in TensorFlow and the update-biased interface to update the weight wi and the bias bi, thus obtaining the feature matrix X(3).
- Step 7: Generate the second convolution following Steps 4, 5, and 6 to derive the feature matrix X(4).
- Step 8: Merge the feature matrix X(4) into a column vector as the input of the neuron at the full-joint layer, multiply it with the weight matrix plus the bias, and then use the Leaky ReLU activation function to obtain the eigenvector b1.
- Step 9: Use the eigenvector of the fully connected stratum as the input of the dropout layer, compute the output probability of the neuron in the dropout layer using Formula (6), and the eigenvector b2 is obtained.
- Step 10: Use the eigenvector b2 as the input and the Softmax classifier [25] output to achieve the results.
4. Experiment and Analysis
4.1. Test Environment
4.2. Comparison Algorithm
- (1)
- Algorithm 1: weighted CNN (WCNN) [11]. This algorithm uses a sigmoid function as the activation function through compounded multiple convolutions and pooling layers to achieve input signal processing. Simultaneously, the mapping relationship between the connection layer and output target is established and the clustering algorithm is used to classify the feature.
- (2)
- Algorithm 2: convolutional neural network with fully connected Multilayer perceptron (MLP) (MLP-CNN) [6]. This algorithm improves model performance by increasing the characteristic number of the neural networks and using the stochastic gradient descent algorithm to optimize the cross entropy.
- (3)
- Algorithm 3: extreme learning machine (ELM) for multi-classification called SVM-ELM(ELM optimized with support vector machine) [27]. This calculation combines the fast learning machine and SVM, reduces the number of hidden nodes as a class number, and optimizes the linear decision function of each node through the SVM.
4.3. Datasets and Settings
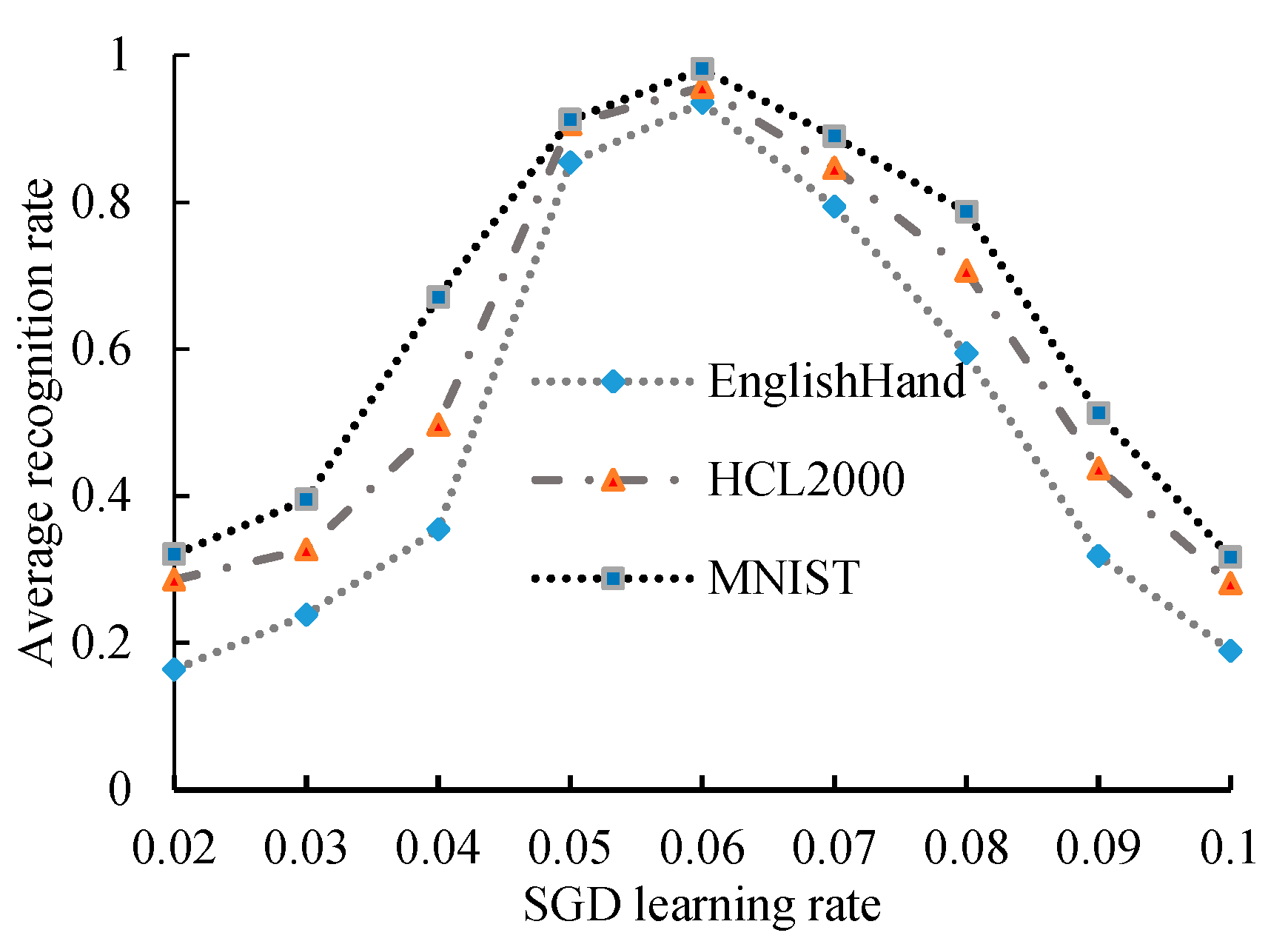
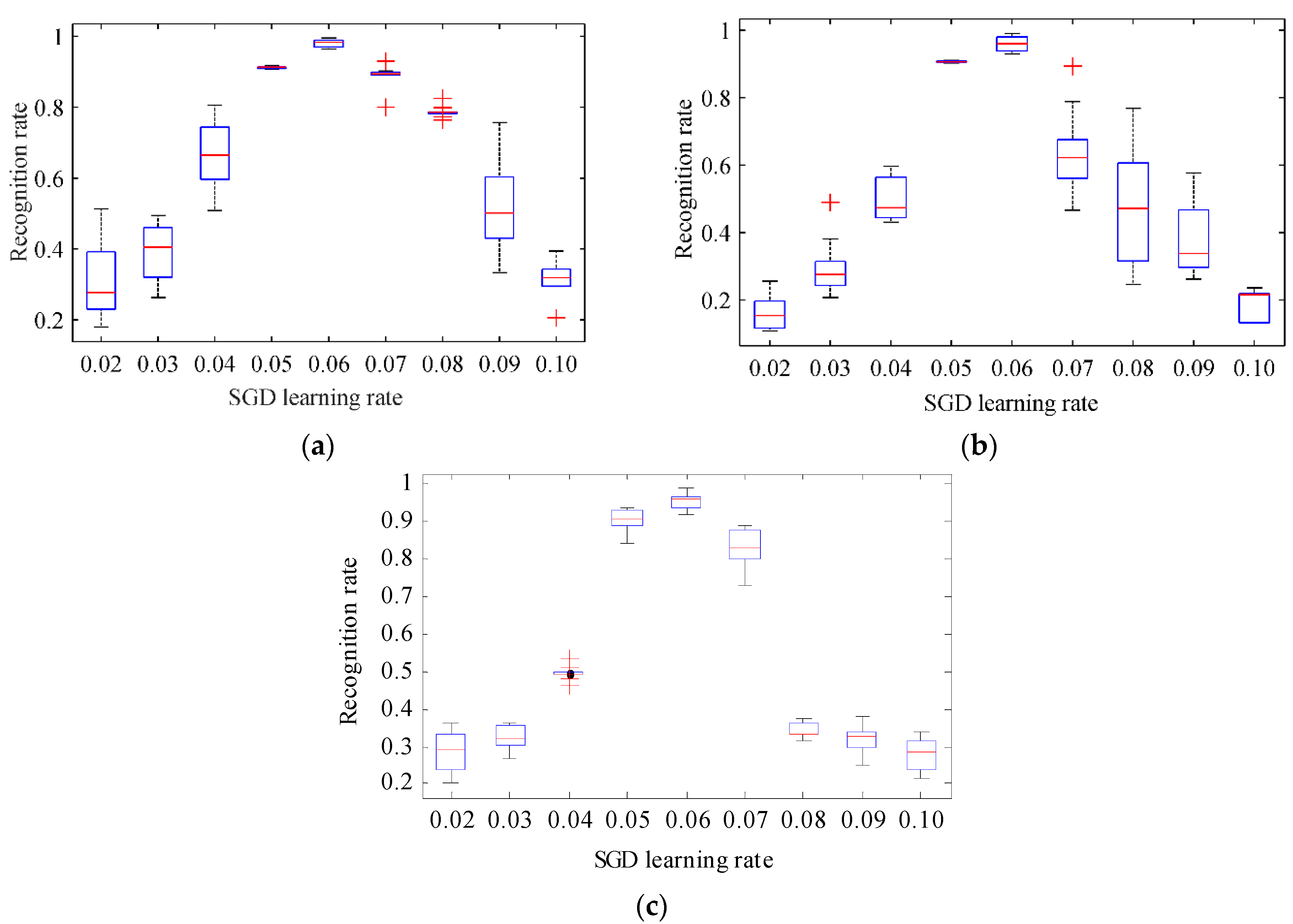
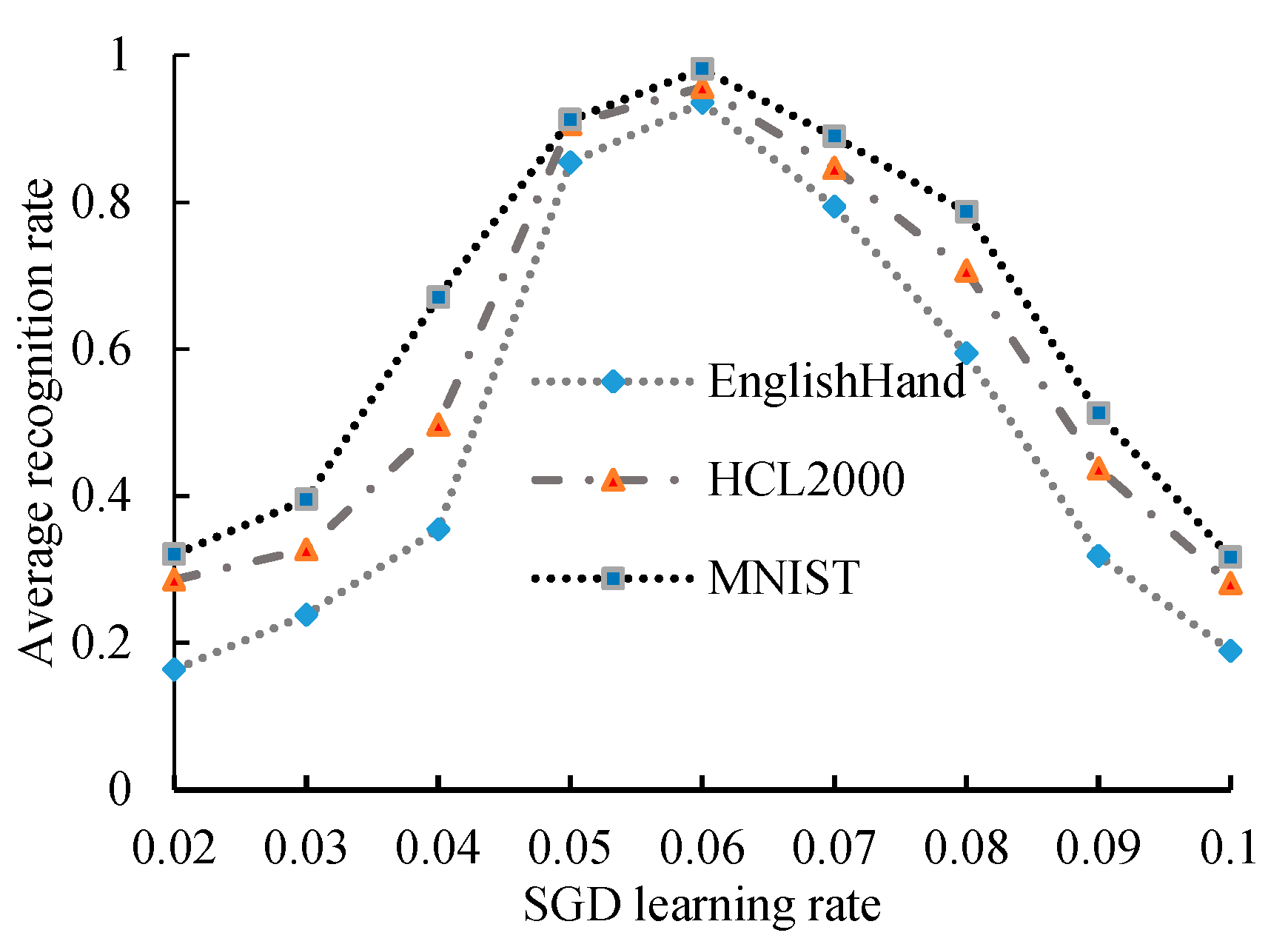
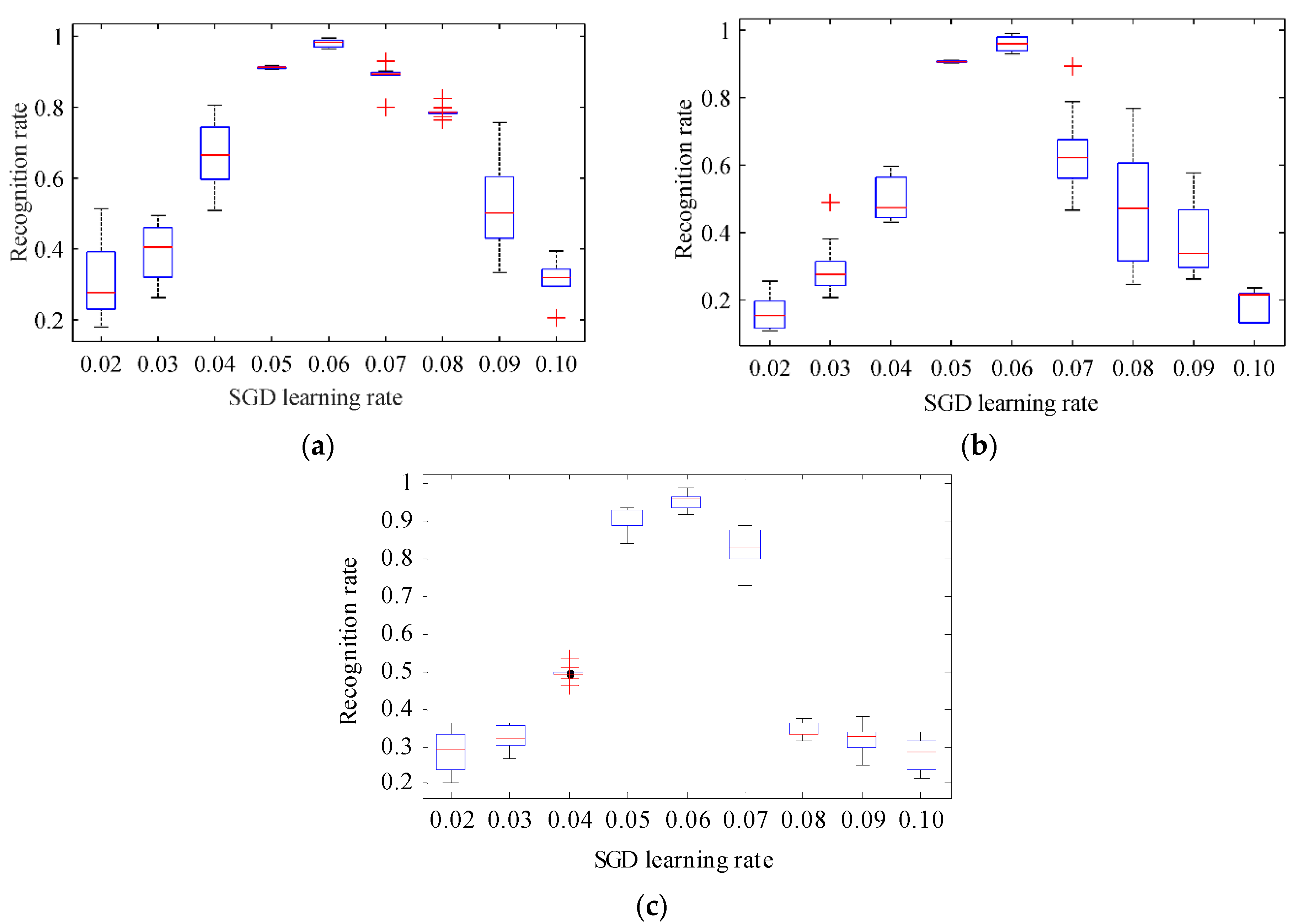
4.4. Experimental Results and Analysis of Recognition Performance under Different Learning Rates
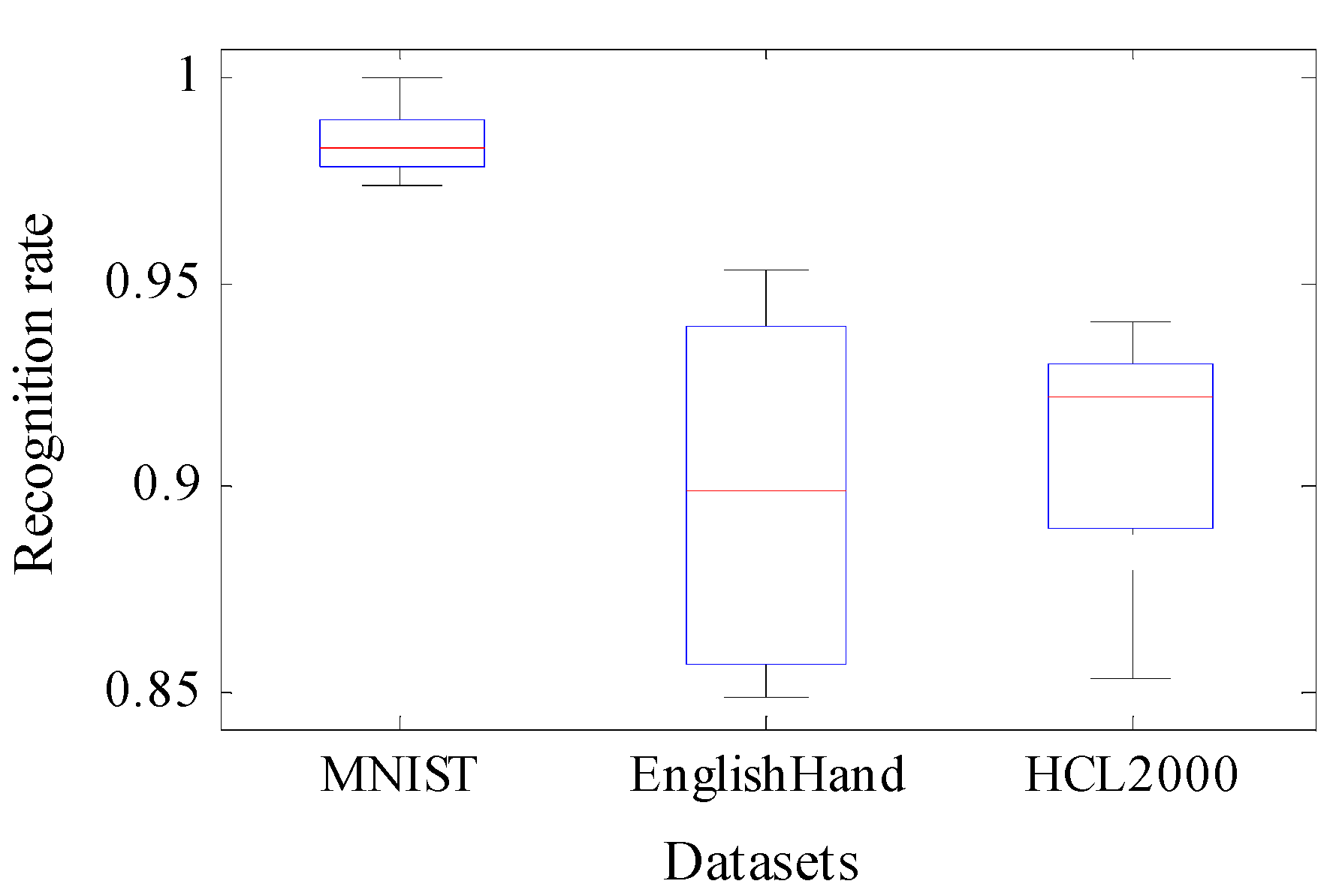
4.5. Comparison and Analysis of the Three Kinds of Algorithms
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Vieira, S.; Pinaya, W.H.L.; Mechelli, A. Using deep learning to investigate the neuroimaging correlates of psychiatric and neurological disorders: Methods and applications. Neurosci. Biobehav. Rev. 2017, 74, 58–75. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Dou, Y.; Niu, X.; Lv, Q.; Wang, Q. A Fast and Memory Saved GPU Acceleration Algorithm of Convolutional Neural Networks for Target Detection. Neurocomputing 2017, 230, 48–59. [Google Scholar] [CrossRef]
- Gong, T.; Fan, T.; Guo, J.; Cai, Z. GPU-based parallel optimization of immune convolutional neural network and embedded system. Eng. Appl. Artif. Intell. 2016, 36, 226–238. [Google Scholar] [CrossRef]
- Zhang, Y.N.; Qu, L.; Chen, J.W.; Liu, J.R.; Guo, D.S. Weights and structure determination method of multiple-input Sigmoid activation function neural network. Appl. Res. Comput. 2012, 29, 4113–4116. [Google Scholar]
- Chen, L.; Wu, C.; Fan, W.; Sun, J.; Naoi, S. Adaptive Local Receptive Field Convolutional Neural Networks for Handwritten Chinese Character Recognition. In Chinese Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2014; pp. 455–463. [Google Scholar]
- Singh, P.; Verma, A.; Chaudhari, N.S. Deep Convolutional Neural Network Classifier for Handwritten Devanagari Character Recognition. In Information Systems Design and Intelligent Applications; Springer: New Delhi, India, 2016. [Google Scholar]
- Sun, W.; Su, F. A novel companion objective function for regularization of deepconvolutional neural networks. Image Vis. Comput. 2016, 56, 110–126. [Google Scholar]
- Wachinger, C.; Reuter, M.; Klein, T. DeepNAT: Deep convolutional neural network for segmenting neuroanatomy. NeuroImage 2017. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Comput. Sci. 2016, 26, 357–361. [Google Scholar]
- Izotov, P.Y.; Kazanskiy, N.L.; Golovashkin, D.L.; Sukhanov, S.V. CUDA-enabled implementation of a neural network algorithm for handwritten digit recognition. Opt. Mem. Neural Netw. 2011, 20, 98–106. [Google Scholar] [CrossRef]
- Hao, H.W.; Jiang, R.R. Training sample selection method for Neural Networks based on Nearest neighbor rule. Acta Autom. Sin. 2007, 33, 1247–1251. [Google Scholar]
- Akeret, J.; Chang, C.; Lucchi, A.; Refregier, A. Radio frequency interference mitigation using deep convolutional neural networks. Astron. Comput. 2017, 18, 35–39. [Google Scholar] [CrossRef]
- Costarelli, D.; Vinti, G. Pointwise and uniform approximation by multivariate neural network operators of the max-product type. Neural Netw. 2016, 81, 81–90. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-supervised nets. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 21 February 2015; pp. 562–570. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Zhou, F.-Y.; Jin, L.-P.; Dong, J. Review of Convolutional Neural Network. Chin. J. Comput. 2017, 40, 1229–1251. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Khoshgoftaar, T.M.; Villanustre, F.; Holt, J. Large-scale distributed L-BFGS. J. Big Data 2017, 4, 22. [Google Scholar] [CrossRef]
- Zinkevich, M.; Weimer, M.; Li, L.; Smola, A.J. Parallelized stochastic gradient descent. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2010; pp. 2595–2603. [Google Scholar]
- Hardt, M.; Recht, B.; Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. arXiv, 2015; arXiv:1509.01240. [Google Scholar]
- Hou, Z.H.; Fang, H.J. Robust fault-tolerant control for networked control system with packet dropout. J. Syst. Eng. Electron. 2007, 18, 76–82. [Google Scholar]
- Luo, P.; Li, H.F. Research on Quantum Neural Network and its Applications Based on Tanh Activation Function. Comput. Digit. Eng. 2012, 16, 33–39. [Google Scholar] [CrossRef]
- Tang, Z.; Luo, L.; Peng, H.; Li, S. A joint residual network with paired ReLUs activation for image super-resolution. Neurocomputing 2018, 273, 37–46. [Google Scholar] [CrossRef]
- Günnemann, N.; Pfeffer, J. Predicting Defective Engines using Convolutional Neural Networks on Temporal Vibration Signals. In Proceedings of the First International Workshop on Learning with Imbalanced Domains: Theory and Applications, Munich, Germany, 11 October 2017; pp. 92–102. [Google Scholar]
- Jin, X.; Xu, C.; Feng, J.; Wei, Y.; Xiong, J.; Yan, S. Deep learning with S-shaped rectified linear activation units. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI Press), Phoenix, AZ, USA, 12–17 February 2016; pp. 1737–1743. [Google Scholar]
- Shi, X.B.; Fang, X.J.; Zhang, D.Y.; Guo, Z.Q. Image Classification Based on Mixed Deep Learning Model Transfer Learning. J. Syst. Simul. 2016, 28, 167–173. [Google Scholar]
- Yang, W.; Jin, L.; Tao, D.; Xie, Z.; Feng, Z. DropSample: A new training method to enhance deep convolutional neural networks for large-scale unconstrained handwritten Chinese character recognition. Pattern Recognit. 2016, 58, 190–203. [Google Scholar] [CrossRef]
- Shen, F.; Wang, L.; Zhang, J. Reduced extreme learning machine employing SVM technique. J. Huazhong Univ. Sci. Technol. 2014, 42, 107–110. [Google Scholar] [CrossRef]
- Yang, G.-C.; Yang, J.; Su, Z.D.; Chen, Z.-J. Improved YOLO feature extraction algorithm and its application to privacy situation detection of social robots. Acta Autom. Sin. 2018, 1–12. [Google Scholar] [CrossRef]

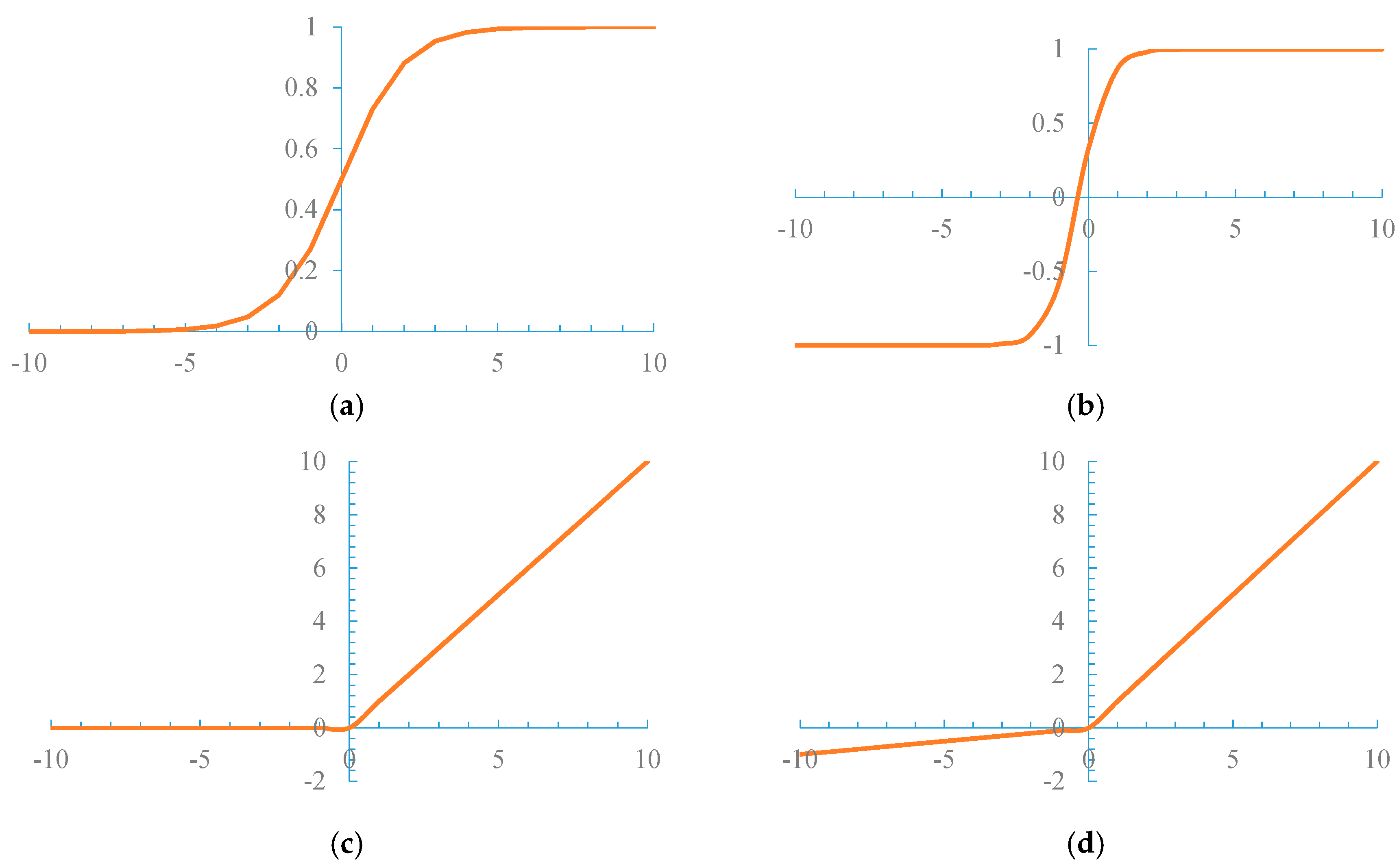



{kind=link}
{kind=link}
{kind=link}
{kind=link}
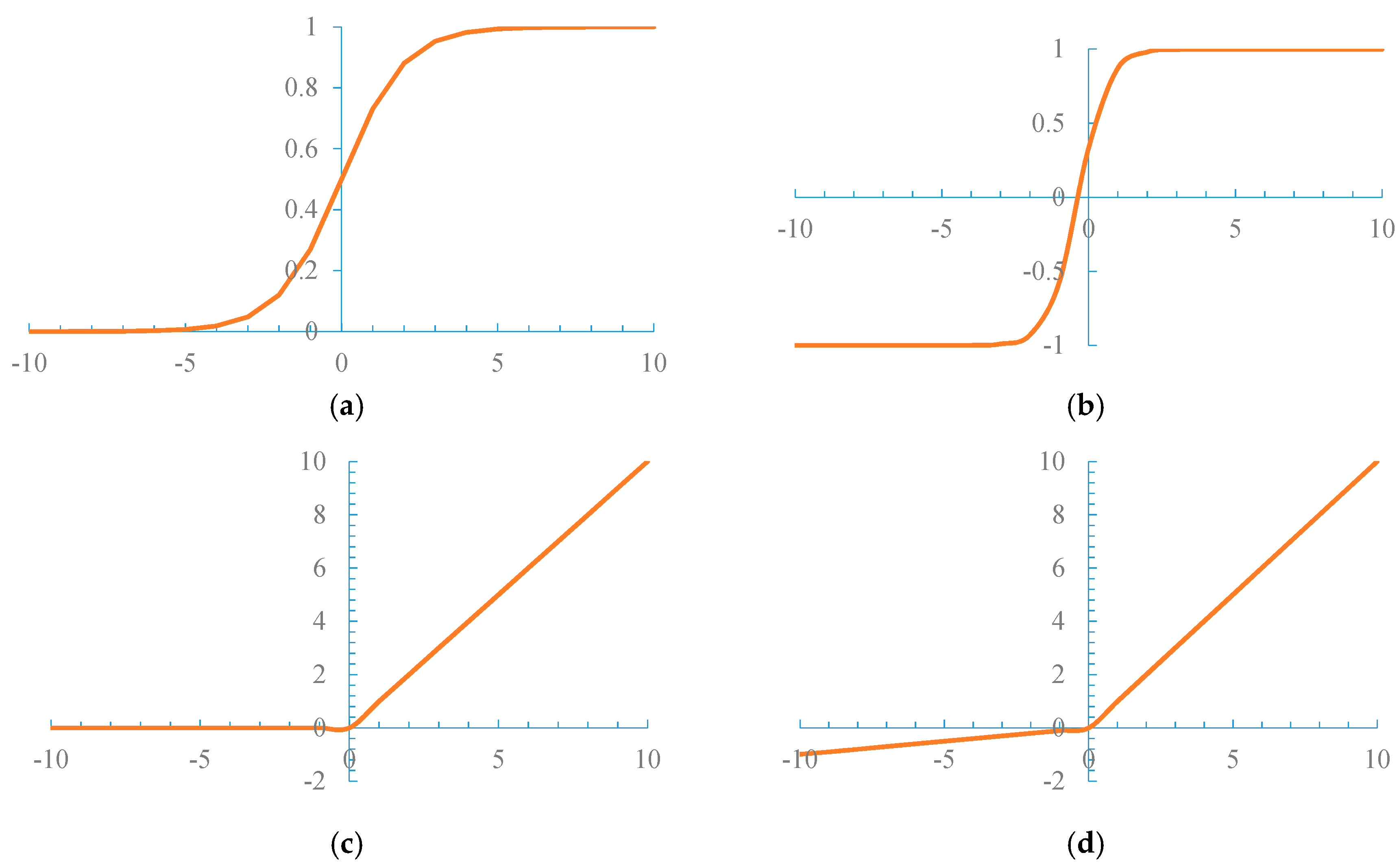{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Size of Training Set | Size of Test Set | Number of Image Category |
|---|---|---|---|
| MNIST | 60,000 | 10,000 | 10 |
| HCL2000 | 2000 | 1000 | 10 |
| EnglishHand | 4200 | 1520 | 26 |
| Dataset | Metric | WCNN [11] | MLP-CNN [6] | SVM-ELM [27] | MCNN-DS |
|---|---|---|---|---|---|
| MNIST | The lowest recognition rate (%) | 95.11 | 97.82 | 89.5 | 97.36 |
| The highest recognition rate (%) | 95.71 | 98.96 | 91.35 | 99.97 | |
| The average recognition rate (%) | 95.36 | 96.32 | 90.26 | 98.43 | |
| Standard deviation of recognition rate | -- | -- | -- | 0.0084 | |
| HCL2000 | The lowest recognition rate (%) | -- | -- | 83.60 | 85.42 |
| The highest recognition rate (%) | -- | -- | 90.00 | 93.99 | |
| The average recognition rate (%) | -- | -- | 88.63 | 90.98 | |
| Standard deviation of recognition rate | -- | -- | -- | 0.0396 | |
| EnglishHand | The lowest recognition rate (%) | -- | -- | -- | 84.93 |
| The highest recognition rate (%) | -- | -- | -- | 95.29 | |
| The average recognition rate (%) | -- | -- | -- | 89.77 | |
| Standard deviation of recognition rate | -- | -- | -- | 0.0280 |
| Algorithms | Time/ms | ||
|---|---|---|---|
| MNIST | HCL2000 | EnglishHand | |
| MLP-CNN | 290,491 | -- | -- |
| SVM-ELM | 132,634 | 316,372 | -- |
| MCNN-DS | 13,236 | 20,531 | 21,617 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Yang, G. Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer. Algorithms 2018, 11, 28. https://doi.org/10.3390/a11030028
Yang J, Yang G. Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer. Algorithms. 2018; 11(3):28. https://doi.org/10.3390/a11030028
Chicago/Turabian StyleYang, Jing, and Guanci Yang. 2018. "Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer" Algorithms 11, no. 3: 28. https://doi.org/10.3390/a11030028
APA StyleYang, J., & Yang, G. (2018). Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer. Algorithms, 11(3), 28. https://doi.org/10.3390/a11030028