Solon: A Holistic Approach for Modelling, Managing and Mining Legal Sources



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Architecture
2.1. General Characteristics
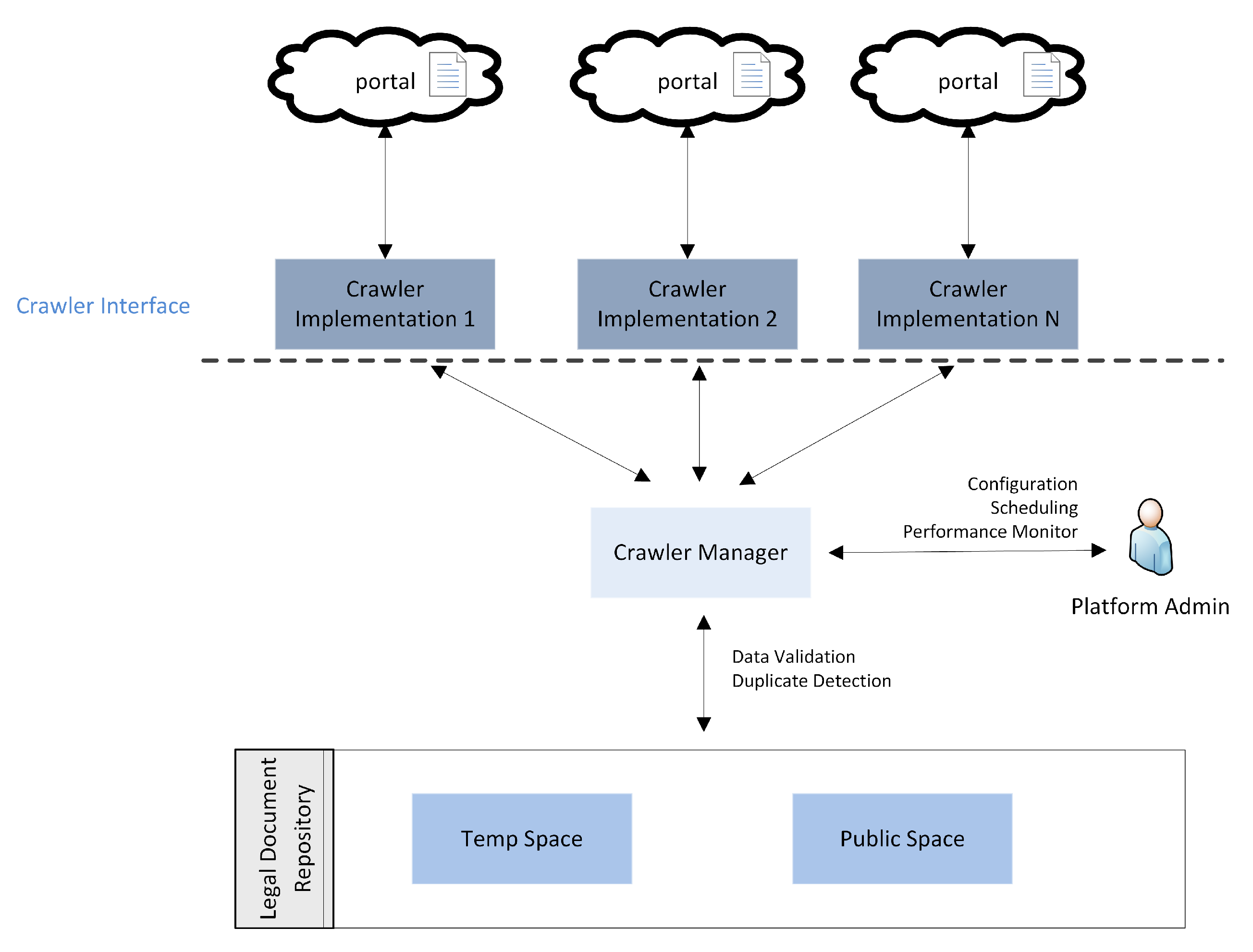
- Support for automatic and manual import of unstructured documents from predefined legal sources.Legal sources, i.e., regulations, case law and administrative acts, are usually authored by government agencies and disseminated through authoritative government websites. Therefore a reliable mechanism should provide input data to the platform on a scheduled basis.
- Automatic structural analysis and semantic representation of textual data and metadata.Input legal sources are usually distributed in unstructured text, often proprietary, formats, thus, it is preferable to transform them to a suitable for modelling legal sources format, capturing the legal semantics.
- Automatic discovery and resolution of legal citations, for each respective structural unit.Typically, legal documents refer to authoritative documents and sources, thus forming a network of interconnected legal documents. A precondition for the inter-linkage of legal documents and the Legal Linked Open Data formulation is the discovery and resolution of legal citations.
- Automatic classification of legal sources based on custom rules.Since the amount of legal sources available will always outweigh the time one actually has to read them, a popular approach to manage the information overload is to assign legal sources to one or more classes or categories, either manually or algorithmically.
- Support for manual curation of the automatically discovered, structured and semantically enriched content.While information extraction processes may achieve high levels of accuracy as to replace manual curation, the later is an importance step towards the completeness of the resulting legal knowledge base. Apart from that, there is also a zero tolerance for errors regarding the provision of legal documents.
- Support for multi criteria and multi faceted search using all metadata identified in documents.The aim of any information retrieval system is to deliver content that can precisely match and satisfy the users information need. With the plethora of intended users categories, ranging from novices to legal experts, distinctive information retrieval techniques, utilizing heterogeneous dimensions over the legal information sources, should be supported, so as to precisely match information requests.
- Support for structured content retrieval.A Legal Document cannot be processed as a general purpose text document; instead it exhibits strict semantics for each part of it, having a hierarchical structure of nested elements (e.g., articles that contain paragraphs, etc.) and covering multiple legal topics. Thus, a more precise approach than simply indexing and retrieving documents as single units, is needed, in order to provide more accurate and relevant results.
- Support for user-defined collections of legal resources around a topic.Integrating end users knowledge into the legal sources, is expected to assist them organize and explore legal sources in various meaningful ways.
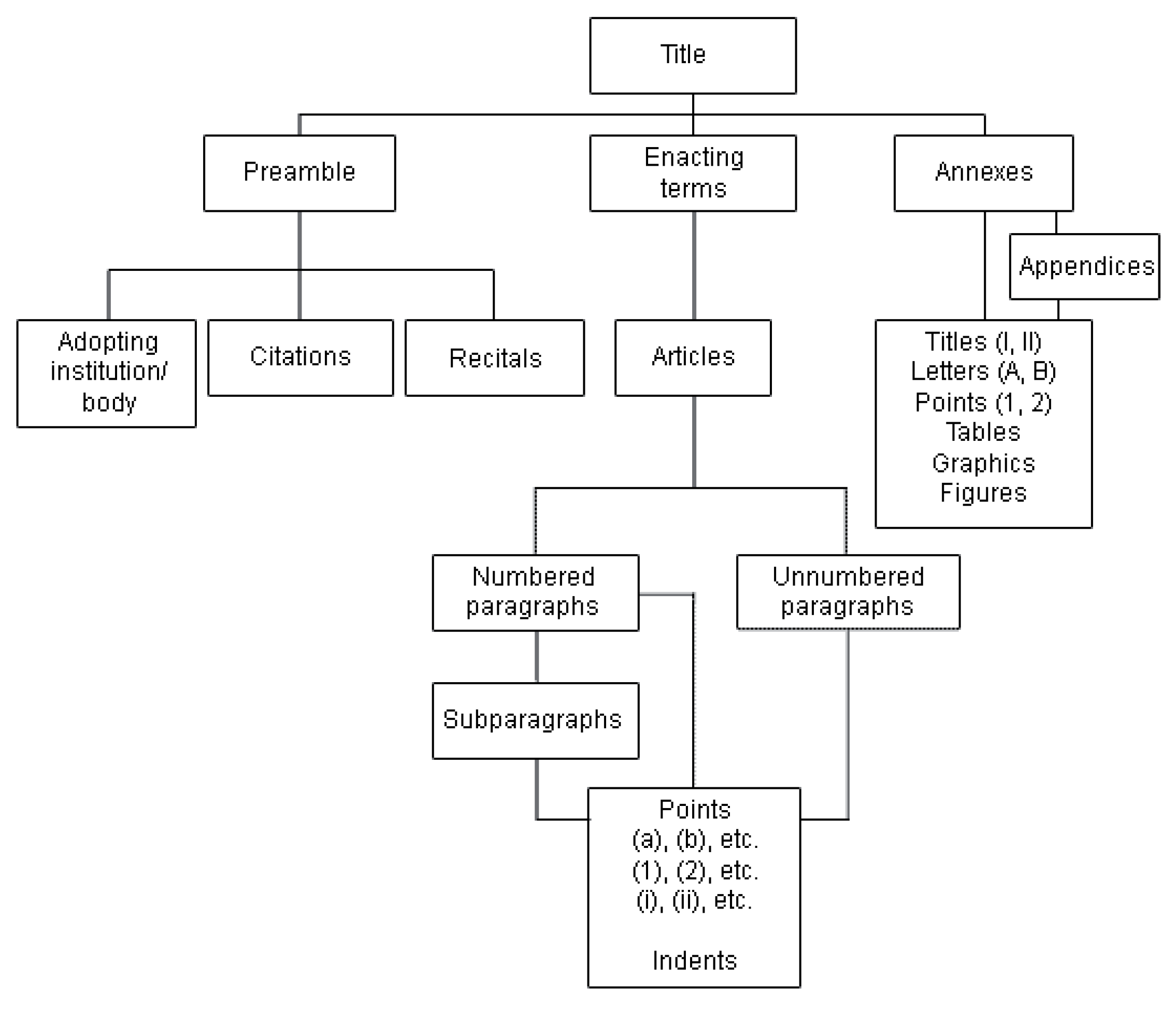
2.2. Data Model
- Introductory part. The introductory part contains information enabling us to identify the type of document as well as most of its publication and manifestation metadata, e.g., title, number, issuing authority, etc.
- Text body. The text body is the main part of the document and it may be structured differently depending on the legal document type. It usually follows a well-defined hierarchical layout of text blocks (legal blocks), where high level parts of a document, such as the chapter of a law, contain other blocks, such as articles and paragraphs.
- End part. The end part contains closing formulas, the date, and the signatures.
2.3. Architecture
3. Solon in Depth
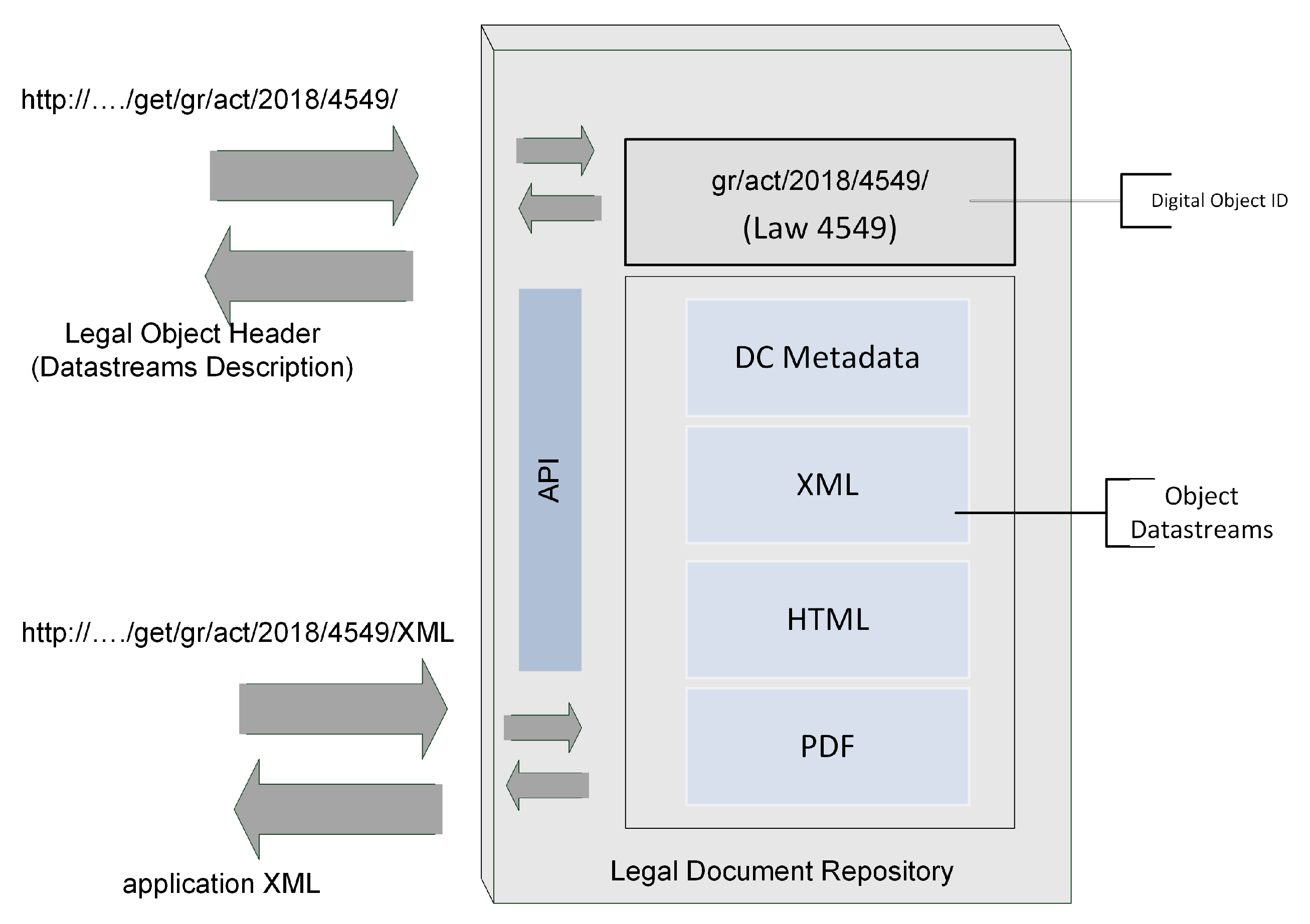
3.1. Legal Document Repository
3.2. Crawler—Harvester
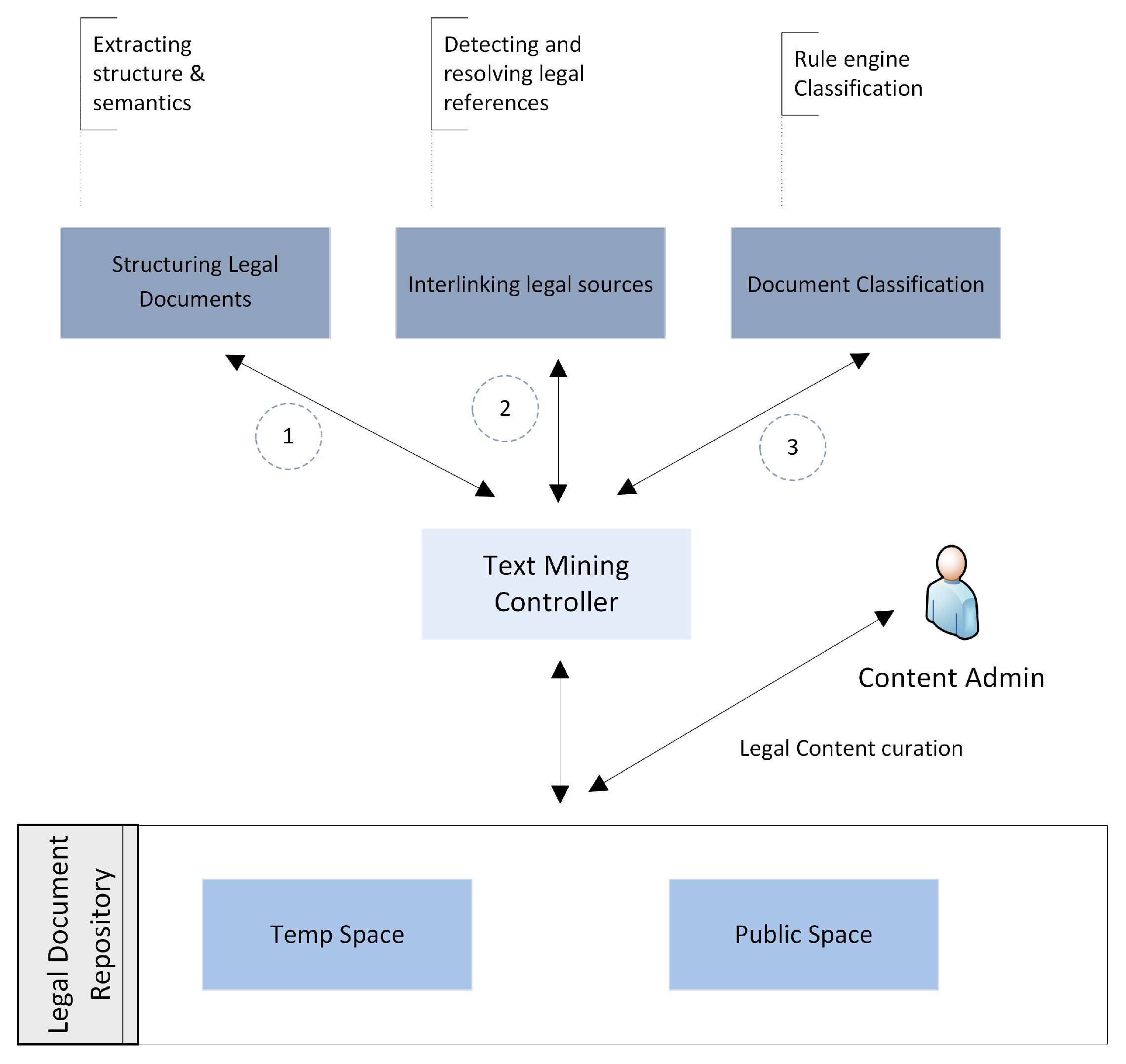
3.3. Text Mining
3.3.1. Structuring Legal Documents
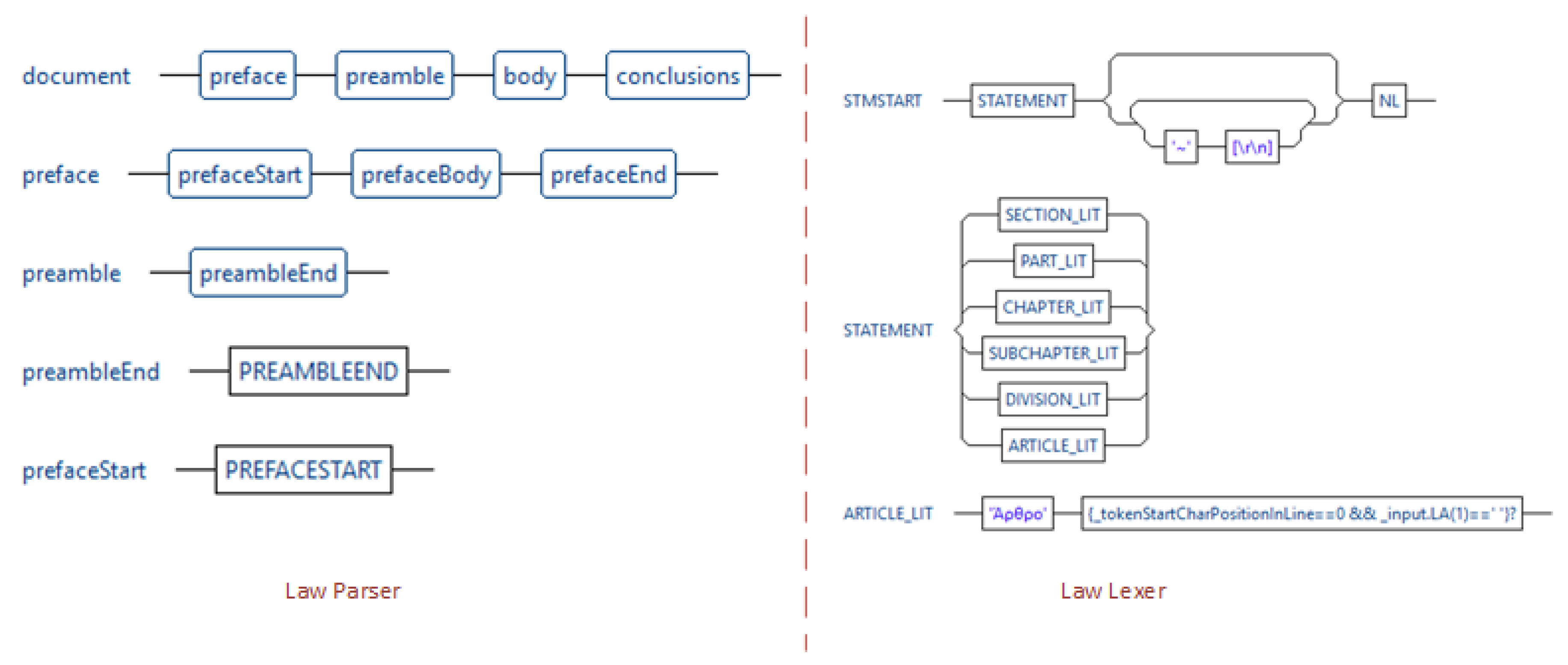
A DSL Languange for Legal Documents
- V is the (finite) set of variables (or nonterminals or syntactic categories). Each variable represents a language, i.e., a set of strings
- T is a finite set of terminals, i.e., the symbols that form the strings of the language being defined
- P is a set of production rules that represent the recursive definition of the language.
- S is the start symbol that represents the language being defined. Other variables represent auxiliary classes of strings that are used to help define the language of the start symbol.
- we use a powerful abstraction that seperates programming from legal domain knowledge
- we can easily extend our grammars to provide for more legal documents e.g., judgements
- it is easier to maintain/evolve the procedure
- our layered implementation allows to easily adopt to new schemas/standards.
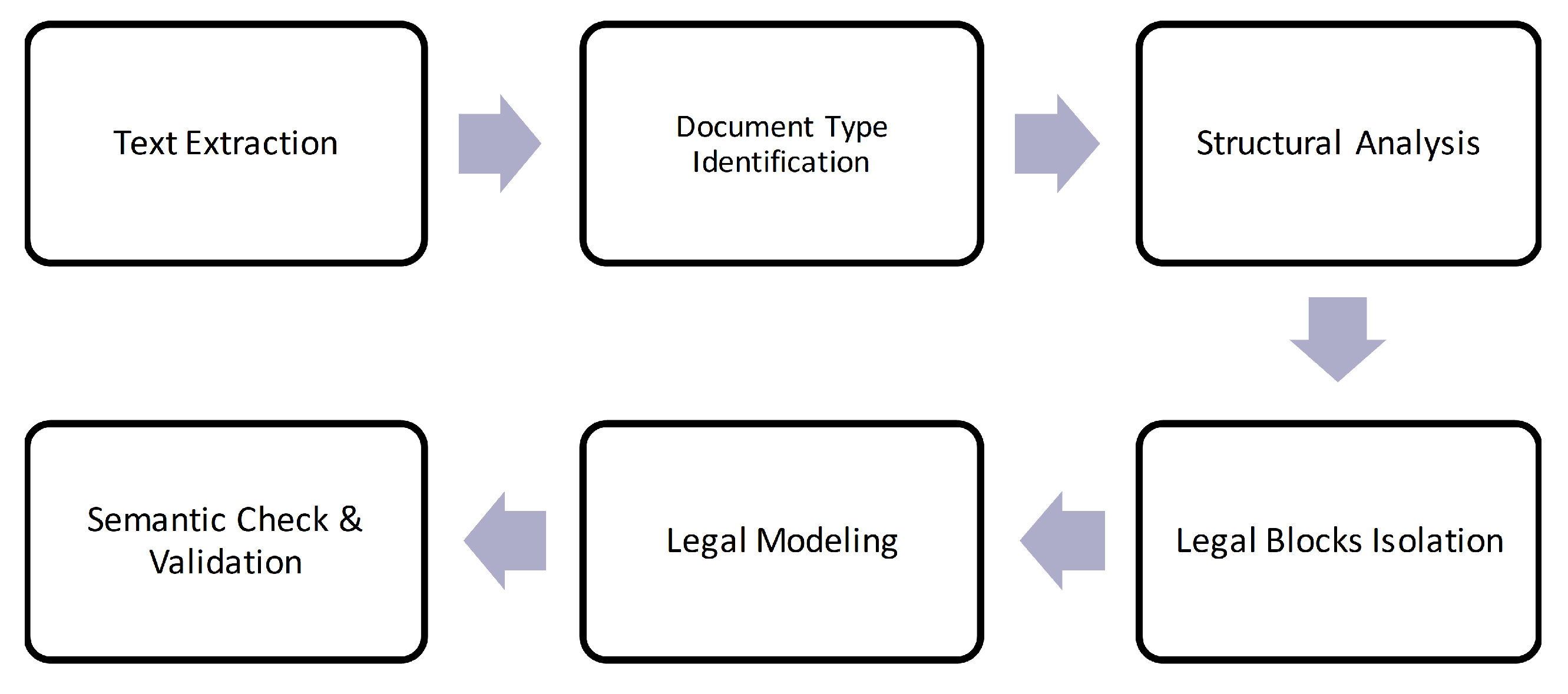
Parsing Process
- (a)
- Document Type Identification. A first step in our methodology is to properly identify the type of legal document, since the type of the document defines both the document structure, available metadata and the internal semantic organization of the resulting document. Thus, identifying the type of legal document is a fundamental task to effectively model legal documents. This is achieved by scanning the beginning of the text for several predefined keywords that effectively distinguish document types.
- (b)
- Structural Analysis. Having identified the type of legal document, we distinguish legal blocks in the document (e.g., front matter, body, conclusions, annexes). Structural Analysis differs between various document types as predefined in the corresponding grammar and implemented in the appropriate parser.
- (c)
- Legal Blocks Isolation. Legal blocks, previously identified in the structural analysis step, are iteratively broken down, into distinct elements, according to the corresponding grammar. Within this step, we try to identify and describe the structure of the legal documents; this includes identification and mark-up of each structural unit of the document (title, articles, sections, chapters, paragraphs, annexes, etc.). In that way, the structural units can be later precisely referred by linking tools where there is a legal citation quoting the respective structural unit. In this step, we also identify document metadata values. Our parser follows an eager approach as to identify as many metadata values as possible, as we assume by design we assume that no metadata is available to the parser. If content metadata is available to our parser, it is parametrically defined whether supplied metadata should prevail over discovered metadata, in cases of conflict, or as an override mechanism.
- (d)
- Legal Modelling. In this step, an in-memory model of the document is iteratively constructed as new elements are identified in the text source. Also, this step assigns permanent URI to legal resources based on the technical specifications of the chosen data model and schema (Section 2.2).
- (e)
- Semantic check and validation. As a final step semantic check and validation detects any inconsistencies the text may contain from the legal point of view or any discrepancies with the chosen legal meta model. Our data model follows the LegalDocML schema, a schema where certain elements form a hierarchy of containment. A hierarchy is a set of arbitrarily deep nested sections with title and numbering. Each level of the nesting can contain either more nested sections or blocks and no text is allowed directly inside the hierarchy, but only within the appropriate block element. As a first process in our semantic check and validation step, we perform a schema validation i.e., validate the resulting XML file against the LegalDocML schema. Furthermore, LegalDocML uses only one hierarchy, with predefined names and no constraints on their order or systematic layering. However, legal documents follow constraints on the order or sequence of such hierarchical nested elements e.g., a sub-chapter should be nested inside a chapter or paragraph numbered ‘4’ should precede paragraph numbered ‘5’. Thus, a second process is needed, verifying that the resulting XML files adhere to the constraints of legal documents. Potential errors identified are logged so that the content administrator can access whether they are based on inconsistencies of input text or a system malfunction.
3.3.2. Interlinking Legal Sources
3.3.3. Document Classification
3.4. Collaborative Semantic Interlinking
3.5. Search
4. Digital Library System
5. Related Work
5.1. Legal Resources Meta Models
5.2. Legal Document Management Systems
5.3. Legal Document Structuring
5.4. Legal Citations
5.5. Legal Text Retrieval
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Dataset
References
- World Legal Information Institute. Declaration on Free Access to Law. 2012. Available online: http://www.worldlii.org/worldlii/declaration/ (accessed on 2 December 2018).
- Boer, A.; Winkels, R.; Vitali, F. Metalex xml and the legal knowledge interchange format. In Computable Models of the Law; Springer: Berlin, Germany, 2008; pp. 21–41. [Google Scholar]
- Marchetti, A.; Megale, F.; Seta, E.; Vitali, F. Using XML as a means to access legislative documents: Italian and foreign experiences. ACM SIGAPP Appl. Comput. Rev. 2002, 10, 54–62. [Google Scholar] [CrossRef]
- Barabucci, G.; Cervone, L.; Palmirani, M.; Peroni, S.; Vitali, F. Multi-layer markup and ontological structures in Akoma Ntoso. In AI Approaches to the Complexity of Legal Systems. Complex Systems, the Semantic Web, Ontologies, Argumentation, and Dialogue; Springer: Berlin, Germany, 2010; pp. 133–149. [Google Scholar]
- Inter-Parliamentary Union. World e-Parliament Report 2016. Available online: http://www.ipu.org/pdf/publications/eparl16-en.pdf (accessed on 2 December 2018).
- Tillett, B. A Conceptual Model for the Bibliographic Universe. Technicalities 2003, 25, 5. [Google Scholar] [CrossRef]
- Francesconi, E. On the Future of Legal Publishing Services in the Semantic Web. Future Internet 2018, 10, 48. [Google Scholar] [CrossRef]
- Koniaris, M.; Papastefanatos, G.; Vassiliou, Y. Towards Automatic Structuring and Semantic Indexing of Legal Documents. In Proceedings of the 20th Pan-Hellenic Conference on Informatics, Patras, Greece, 10–12 November 2016. [Google Scholar]
- Koniaris, M.; Papastefanatos, G.; Meimaris, M.; Alexiou, G. Introducing Solon: A Semantic Platform for Managing Legal Sources. In International Conference on Theory and Practice of Digital Libraries; Springer: Cham, Switzerland, 2017; pp. 603–607. [Google Scholar]
- Publications Office of the European Union. Interinstitutional Style Guide: 2012; EU Publications: Luxembourg, 2012. [Google Scholar] [CrossRef]
- Organization for the Advancement of Structured Information Standards (OASIS). Advancing Worldwide Best Practices for the Use of XML in Legal Documents, OASIS LegalDocumentML (LegalDocML) TC. 2016. Available online: https://www.oasis-open.org/committees/legaldocml/ (accessed on 2 December 2018).
- Official Journal of the European Union. Council Conclusions of 6 November 2017 on the European Legislation Identifier (2017/C 441/05), OJ C 441, 22.12.2017. 2017, pp. 8–12. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52017XG1222%2802%29 (accessed on 2 December 2018).
- The future of Research Communications and e-Scholarship, FORCE11. The FAIR Data Principles. 2018. Available online: https://www.force11.org/group/fairgroup/fairprinciples (accessed on 2 December 2018).
- Lagoze, C.; Payette, S.; Shin, E.; Wilper, C. Fedora: An architecture for complex objects and their relationships. Int. J. Digit. Libr. 2006, 6, 124–138. [Google Scholar] [CrossRef]
- World Wide Web Consortium (W3C). Linked Data Platform 1.0. Available online: http://www.w3.org/TR/ldp/ (accessed on 2 December 2018).
- Evans, E. Domain-Driven Design: Tackling Complexity in the Heart of Software; Addison-Wesley: Boston, MA, USA, 2004. [Google Scholar]
- Parr, T. Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages, 1st ed.; The Pragmatic Programmers: Raleigh, NC, USA, 2009. [Google Scholar]
- Fowler, M. Domain Specific Languages; Addison-Wesley Professional: Boston, MA, USA, 2010. [Google Scholar]
- Parr, T.; Harwell, S.; Fisher, K. Adaptive LL (*) Parsing: The Power of Dynamic Analysis. ACM SIGPLAN Notices 2014, 49, 579–598. [Google Scholar] [CrossRef]
- De Maat, E.; Winkels, R.; van Engers, T. Automated Detection of Reference Structures in Law. In Proceedings of JURIX 2006; IOS Press: Amsterdam, The Netherlands, 2006; pp. 41–50. [Google Scholar]
- Meimaris, M.; Alexiou, G.; Papastefanatos, G. LinkZoo: A linked data platform for collaborative management of heterogeneous resources. In European Semantic Web Conference; Springer: Cham, Switzerland, 2014; pp. 407–412. [Google Scholar]
- Hand, D.J.; Mannila, H.; Smyth, P. Principles of Data Mining; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Amer-Yahia, S.; Lalmas, M. XML Search: Languages, INEX and Scoring. SIGMOD Rec. 2006, 35, 16–23. [Google Scholar] [CrossRef]
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Diversifying the Legal Order. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Cham, Switzerland, 2016; pp. 499–509. [Google Scholar]
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Multi-dimension Diversification in Legal Information Retrieval. In International Conference on Web Information Systems Engineering; Springer: Cham, Switzerland, 2016; pp. 174–189. [Google Scholar]
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Evaluation of Diversification Techniques for Legal Information Retrieval. Algorithms 2017, 10, 22. [Google Scholar] [CrossRef]
- Independent Authority for Public Revenue. Business Plan. 2016. Available online: https://www.aade.gr/sites/default/files/2016-12/epixirisiako_sxedio_ggde_2016_v5.pdf (accessed on 2 December 2018). (In Greek).
- Lima Jao, C.F. LexML Brasil, Parte 3—LexML XML Schema. Version 1.0; 2016. Available online: http://projeto.lexml.gov.br/documentacao/Parte-3-XML-Schema.pdf (accessed on 2 December 2018).
- Lupo, C.; Vitali, F.; Francesconi, E.; Palmirani, M.; Winkels, R.; de Maat, E.; Boer, A.; Mascellani, P. ESTRELLA Project, Deliverable D3.1—General XML Format(s) for Legal Sources. Version 1.0. Available online: https://pdfs.semanticscholar.org/a5ee/a8dfc5bad0e9d368cd60fffe1e885c237fe8.pdf (accessed on 2 December 2018).
- Leith, P. The rise and fall of the legal expert system. Eur. J. Law Technol. 2010, 1, 1. [Google Scholar] [CrossRef]
- Boella, G.; Humphreys, L.; Martin, M.; Rossi, P.; van der Torre, L. Eunomos, a legal document and knowledge management system to build legal services. In International Workshop on AI Approaches to the Complexity of Legal Systems; Springer: Cham, Switzerland, 2011; pp. 131–146. [Google Scholar]
- Hoekstra, R. The MetaLex Document Server. In Proceedings of the 10th International Semantic Web Conference; Springer: Berlin/Heidelberg, Germany, 2011; pp. 128–143. [Google Scholar]
- Frosterus, M.; Tuominen, J.; Hyvönen, E. Facilitating Re-use of Legal Data in Applications—Finnish Law as a Linked Open Data Service. In Legal Knowledge and Information Systems; IOS Press: Amsterdam, The Netherlands, 2014; pp. 115–124. [Google Scholar]
- Van De Ven, S.; Hoekstra, R.; Winkels, R.; de Maat, E.; Kollár, Á. MetaVex: Regulation drafting meets the semantic web. In Computable Models of the Law; Springer: Berlin, Germany, 2008; pp. 42–55. [Google Scholar]
- Agnoloni, T.; Francesconi, E.; Spinosa, P. xmLegesEditor: An Opensource Visual XML Editor for Supporting Legal National Standards. Available online: http://www.xmleges.org/ita/images/articoli/art17.pdf (accessed on 2 December 2018).
- Igari, H.; Shimazu, A.; Ochimizu, K. Document structure analysis with syntactic model and parsers: Application to legal judgments. JSAI Int. Symp. Artif. Intell. 2011, 7258, 126–140. [Google Scholar]
- Ford, B. Parsing expression grammars: A recognition-based syntactic foundation. ACM SIGPLAN Notices 2004, 39, 111–122. [Google Scholar] [CrossRef]
- Opijnen, M.V.; Verwer, N.; Meijer, J. Beyond the Experiment: The eXtendable Legal Link eXtractor. Workshop on Automated Detection, Extraction and Analysis of Semantic Information in Legal Texts. 2015. Available online: https://ssrn.com/abstract=2626521 (accessed on 2 December 2018).
- Agnoloni, T.; Bacci, L.; Peruginelli, G.; van Opijnen, M.; van den Oever, J.; Palmirani, M.; Cervone, L.; Bujor, O.; Lecuona, A.A.; García, A.B.; et al. Linking European Case Law: BO-ECLI Parser, an Open Framework for the Automatic Extraction of Legal Links. Legal Knowl. Inf. Syst. 2017. [Google Scholar] [CrossRef]
- Marx, S.M. Citation networks in the law. Jurimetrics J. 1970, 10, 121–137. [Google Scholar]
- Fowler, J.H.; Johnson, T.R.; Spriggs, J.F.; Jeon, S.; Wahlbeck, P.J. Network Analysis and the Law: Measuring the Legal Importance of Precedents at the U.S. Supreme Court. Political Anal. 2006, 15, 324–346. [Google Scholar] [CrossRef]
- Galgani, F.; Compton, P.; Hoffmann, A. Citation based summarisation of legal texts. In PRICAI 2012: Trends in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 40–52. [Google Scholar]
- Koniaris, M.; Anagnostopoulos, I.; Vassiliou, Y. Network analysis in the legal domain: A complex model for European Union legal sources. J. Complex Netw. 2018, 6, 243–268. [Google Scholar] [CrossRef]
- Van Opijnen, M.; Santos, C. On the concept of relevance in legal information retrieval. Artif. Intell. Law 2017, 25, 65–87. [Google Scholar] [CrossRef]
- Moens, M. Innovative techniques for legal text retrieval. Artif. Intell. Law 2001, 9, 29–57. [Google Scholar] [CrossRef]












© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koniaris, M.; Papastefanatos, G.; Anagnostopoulos, I. Solon: A Holistic Approach for Modelling, Managing and Mining Legal Sources. Algorithms 2018, 11, 196. https://doi.org/10.3390/a11120196
Koniaris M, Papastefanatos G, Anagnostopoulos I. Solon: A Holistic Approach for Modelling, Managing and Mining Legal Sources. Algorithms. 2018; 11(12):196. https://doi.org/10.3390/a11120196
Chicago/Turabian StyleKoniaris, Marios, George Papastefanatos, and Ioannis Anagnostopoulos. 2018. "Solon: A Holistic Approach for Modelling, Managing and Mining Legal Sources" Algorithms 11, no. 12: 196. https://doi.org/10.3390/a11120196
APA StyleKoniaris, M., Papastefanatos, G., & Anagnostopoulos, I. (2018). Solon: A Holistic Approach for Modelling, Managing and Mining Legal Sources. Algorithms, 11(12), 196. https://doi.org/10.3390/a11120196