
A Statistical Framework for Automatic Leakage Detection in Smart Water and Gas Grids




Abstract
:
1. Introduction
1.1. State of the Art
1.2. Literature Review
1.3. Innovative Contribution
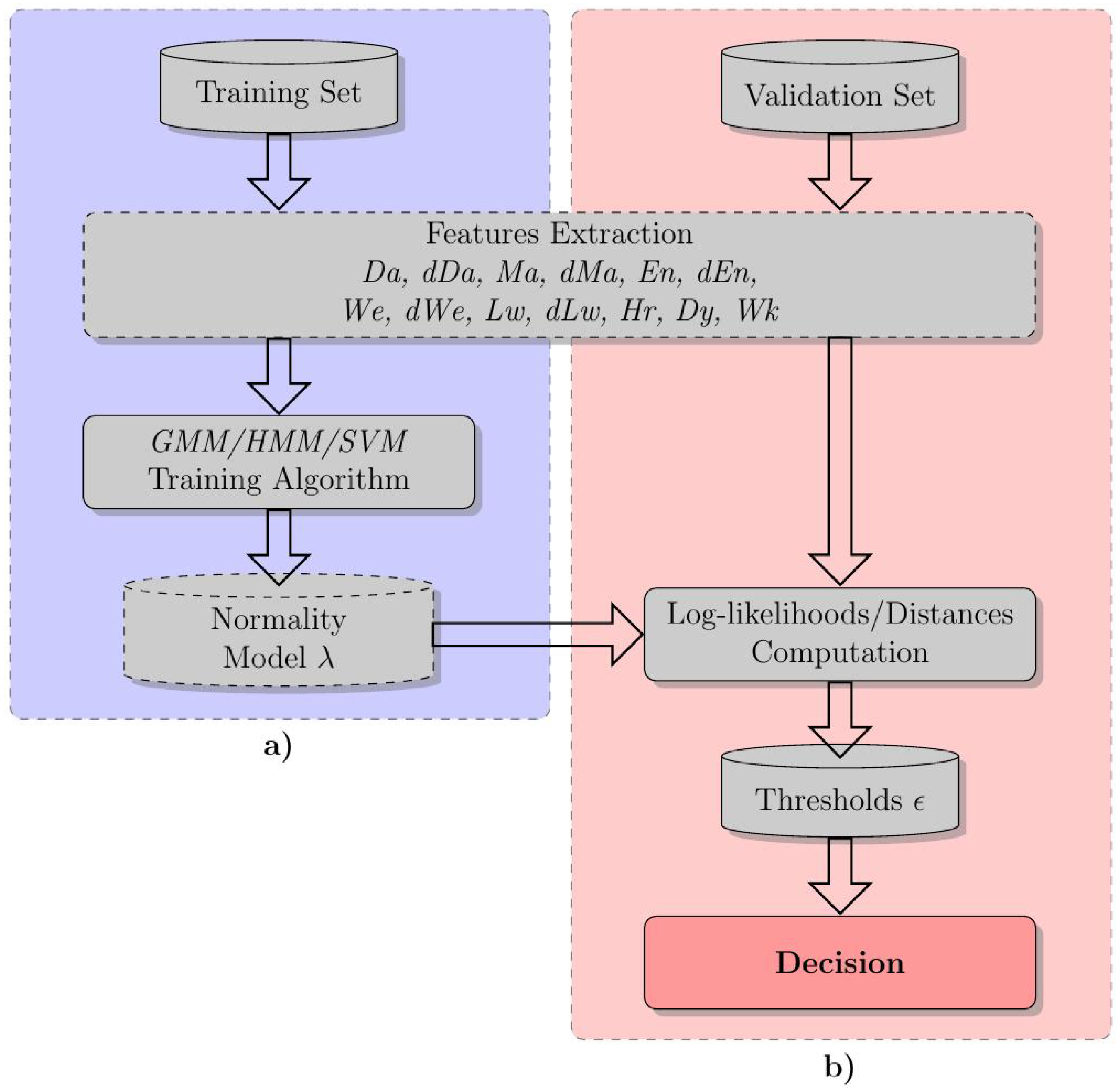
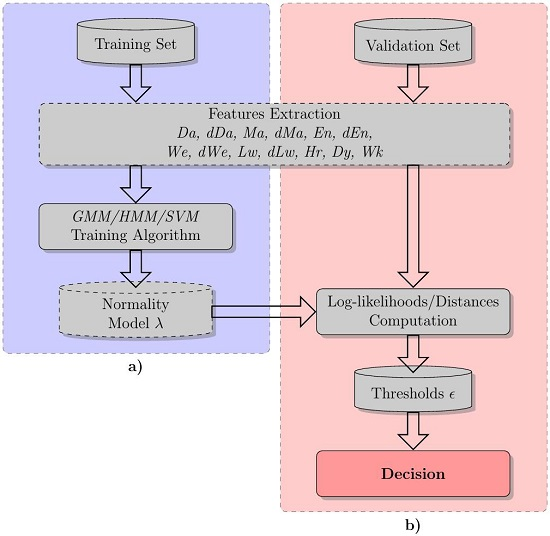
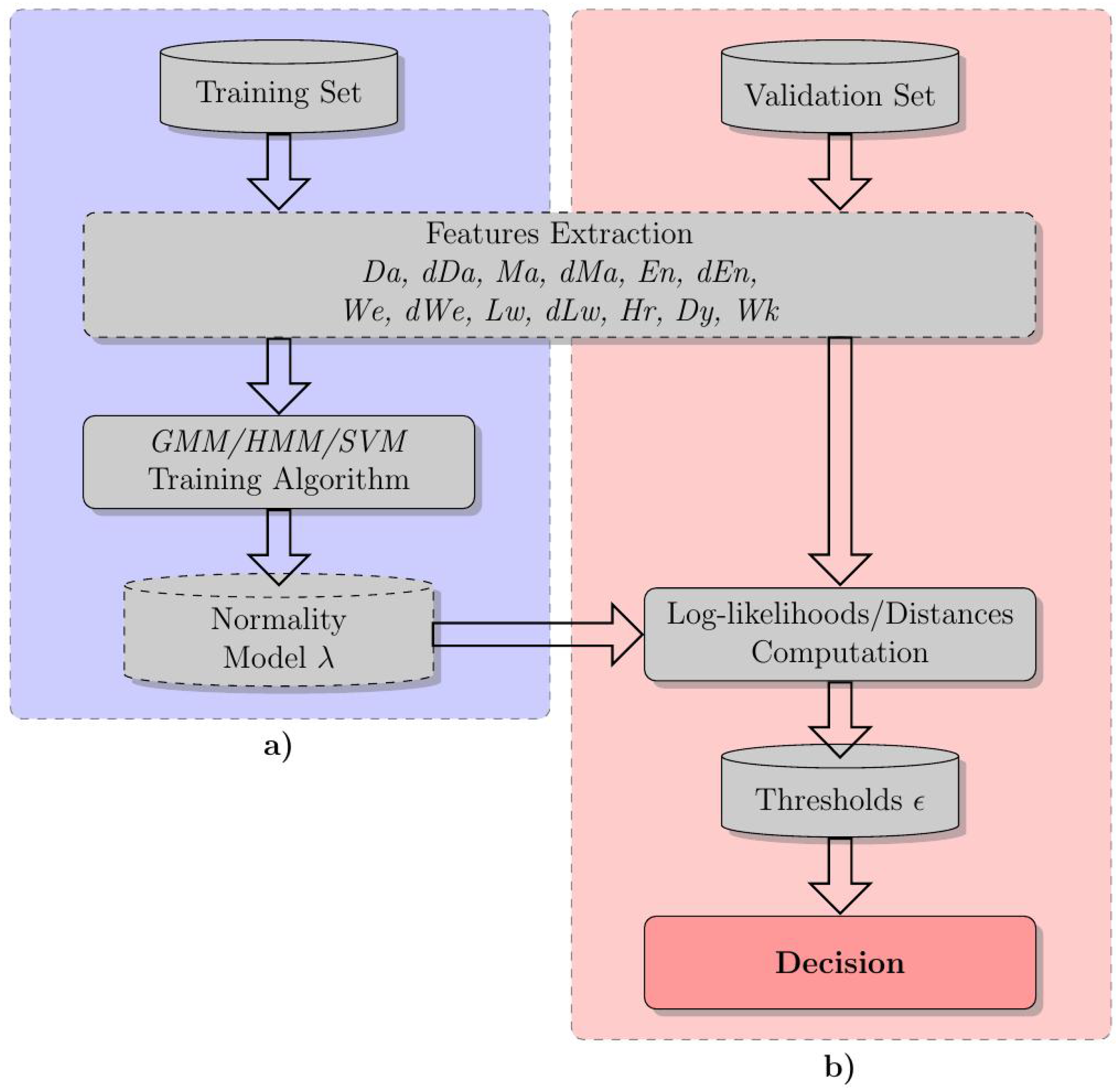
2. The Proposed Statistical Framework
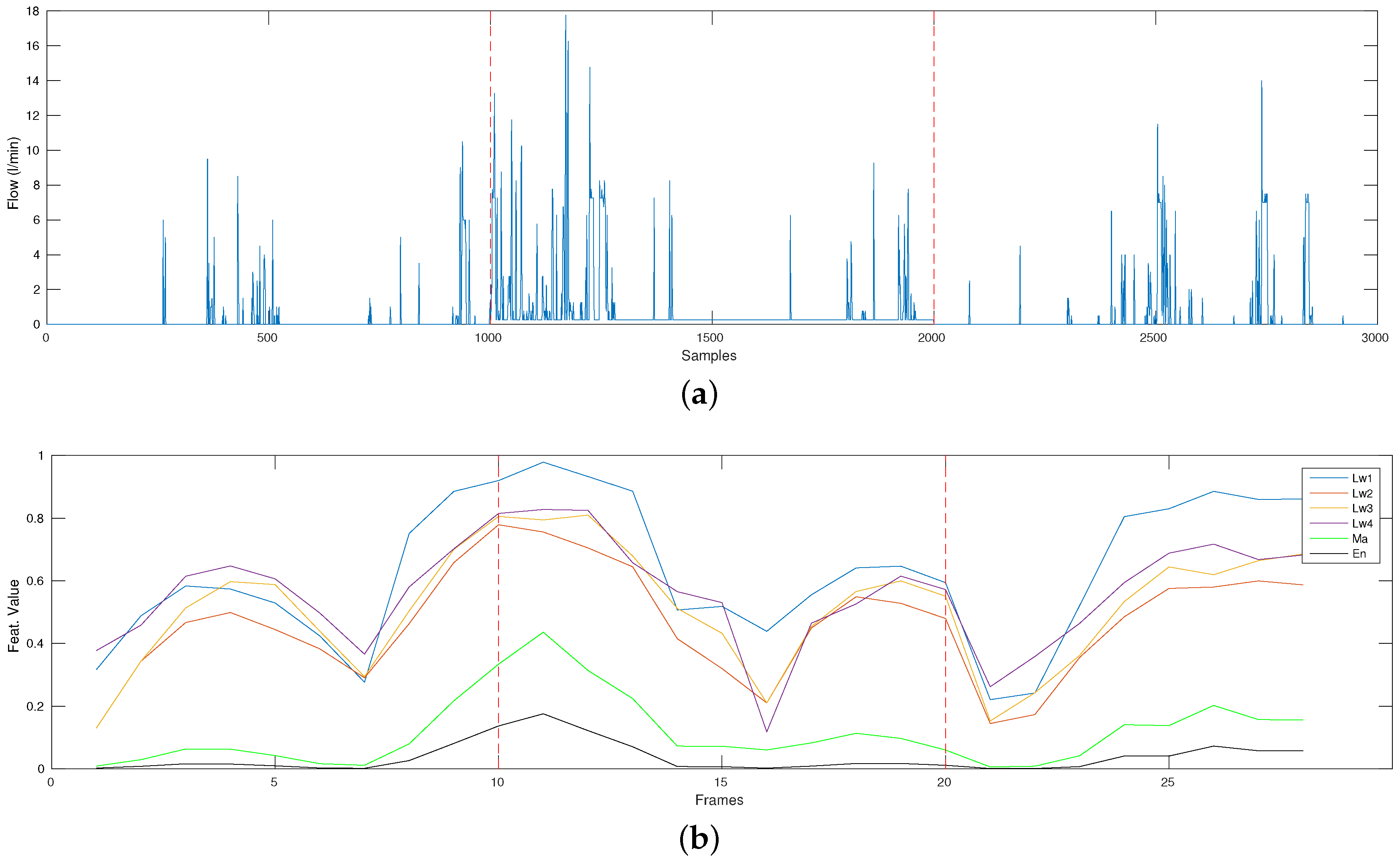
2.1. Features
2.2. GMM and HMM
2.3. One-Class Support Vector Machine
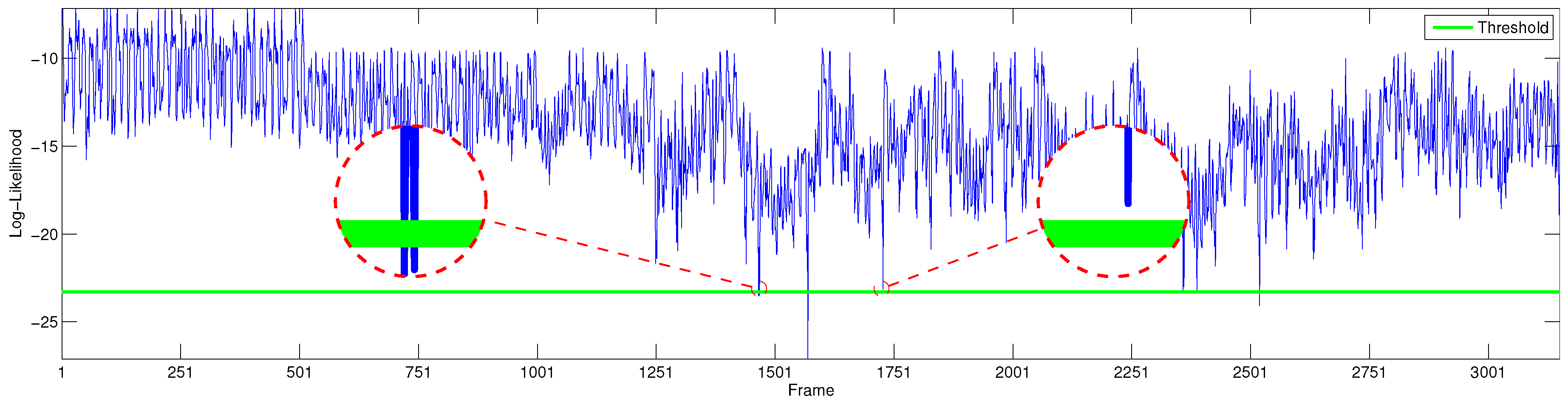
2.4. Novelty Detection
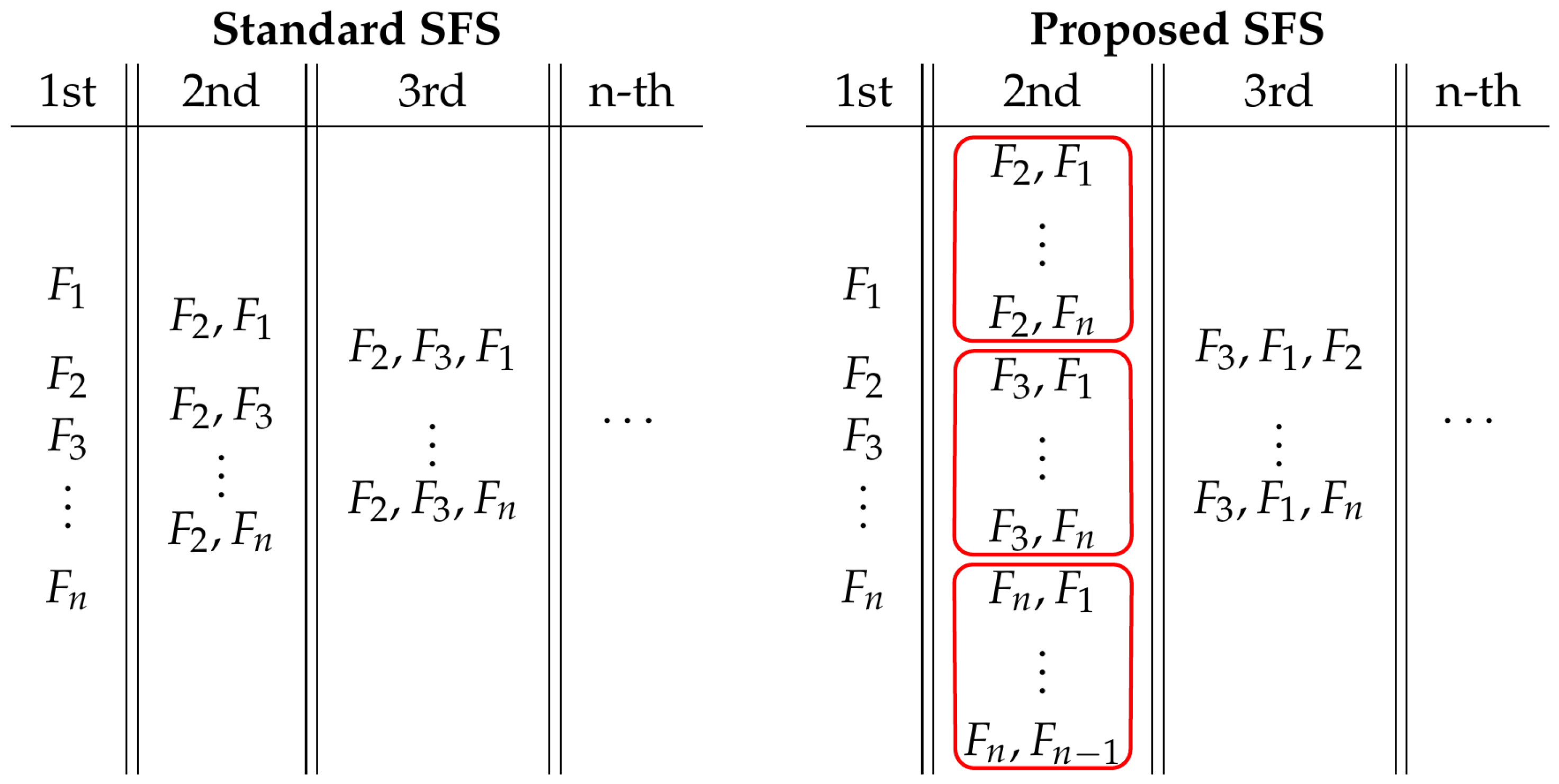
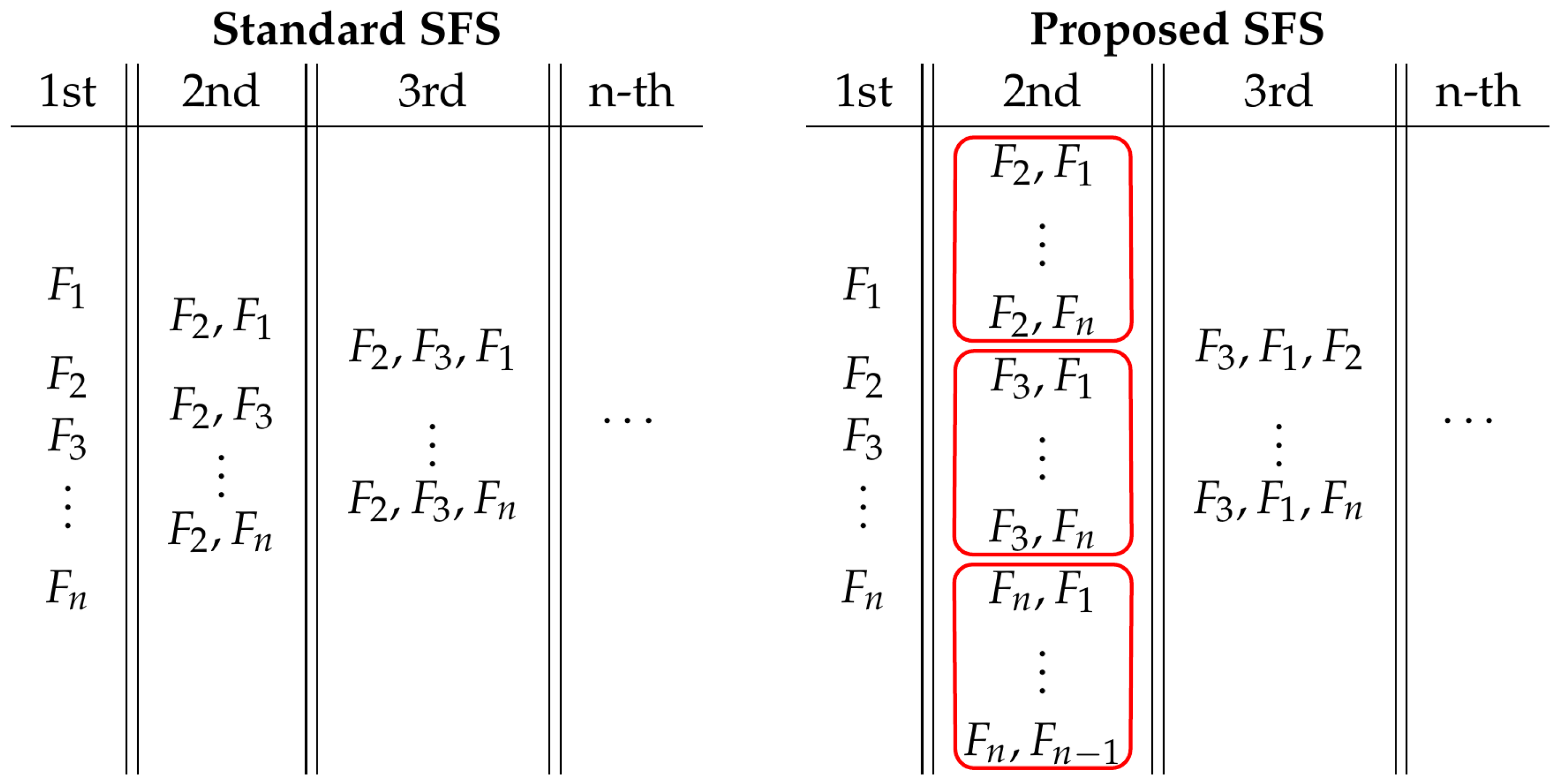
2.5. Feature Selection
| Algorithm 1 Sequential forward selection. |
|
3. Experiments
3.1. Datasets
3.2. Computer Simulation Setup
3.3. Leakage Creation
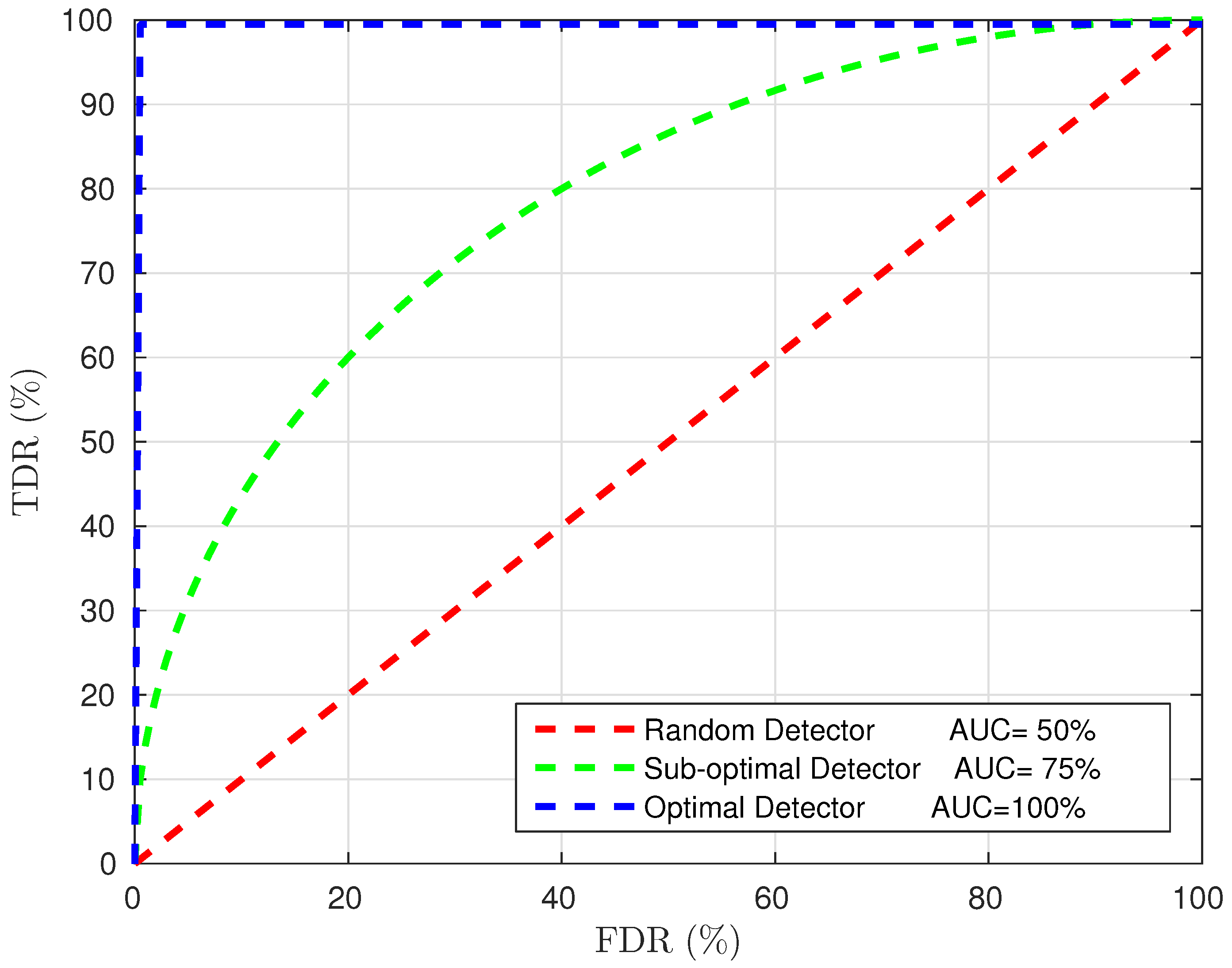
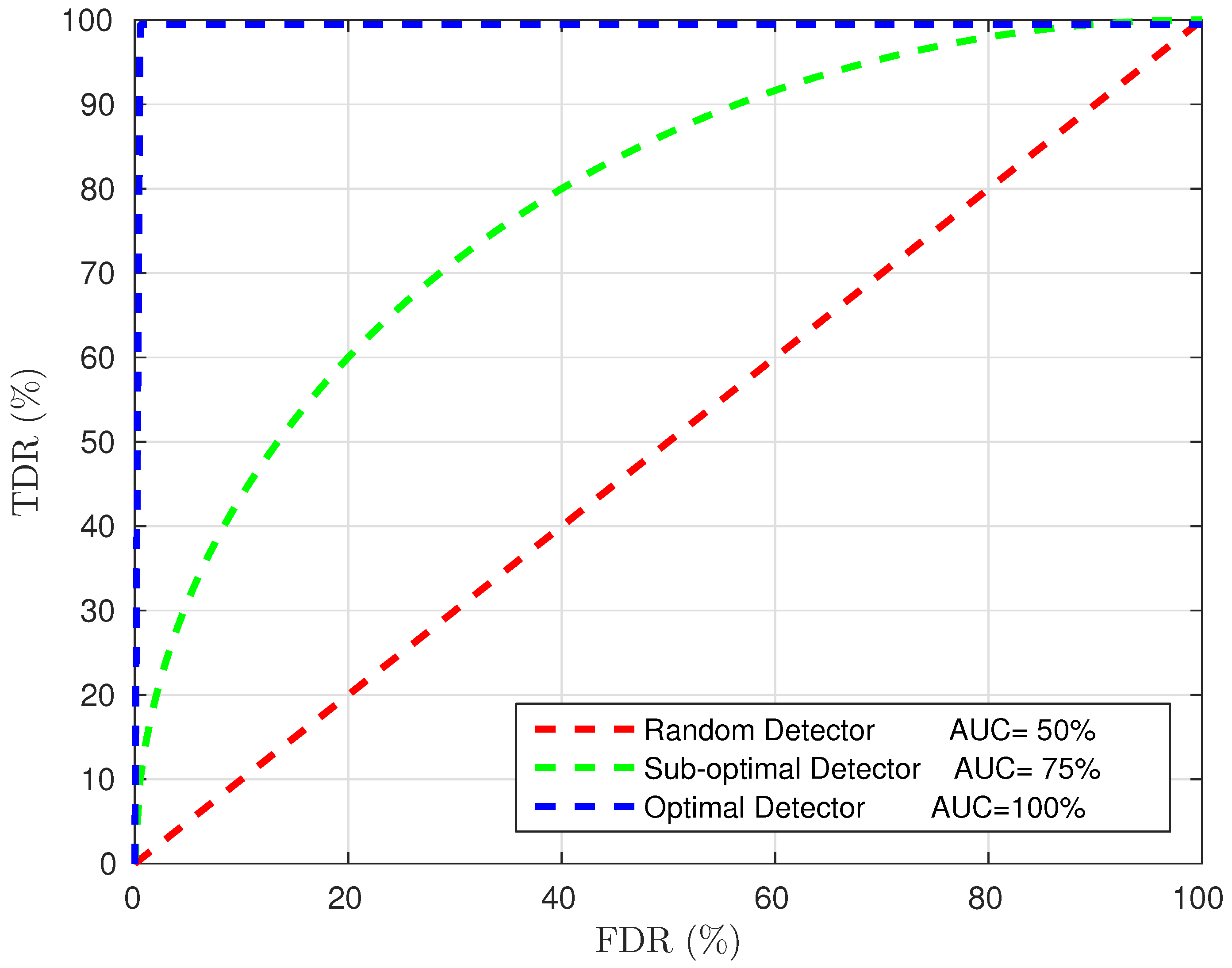
3.4. Evaluation Method
4. Results
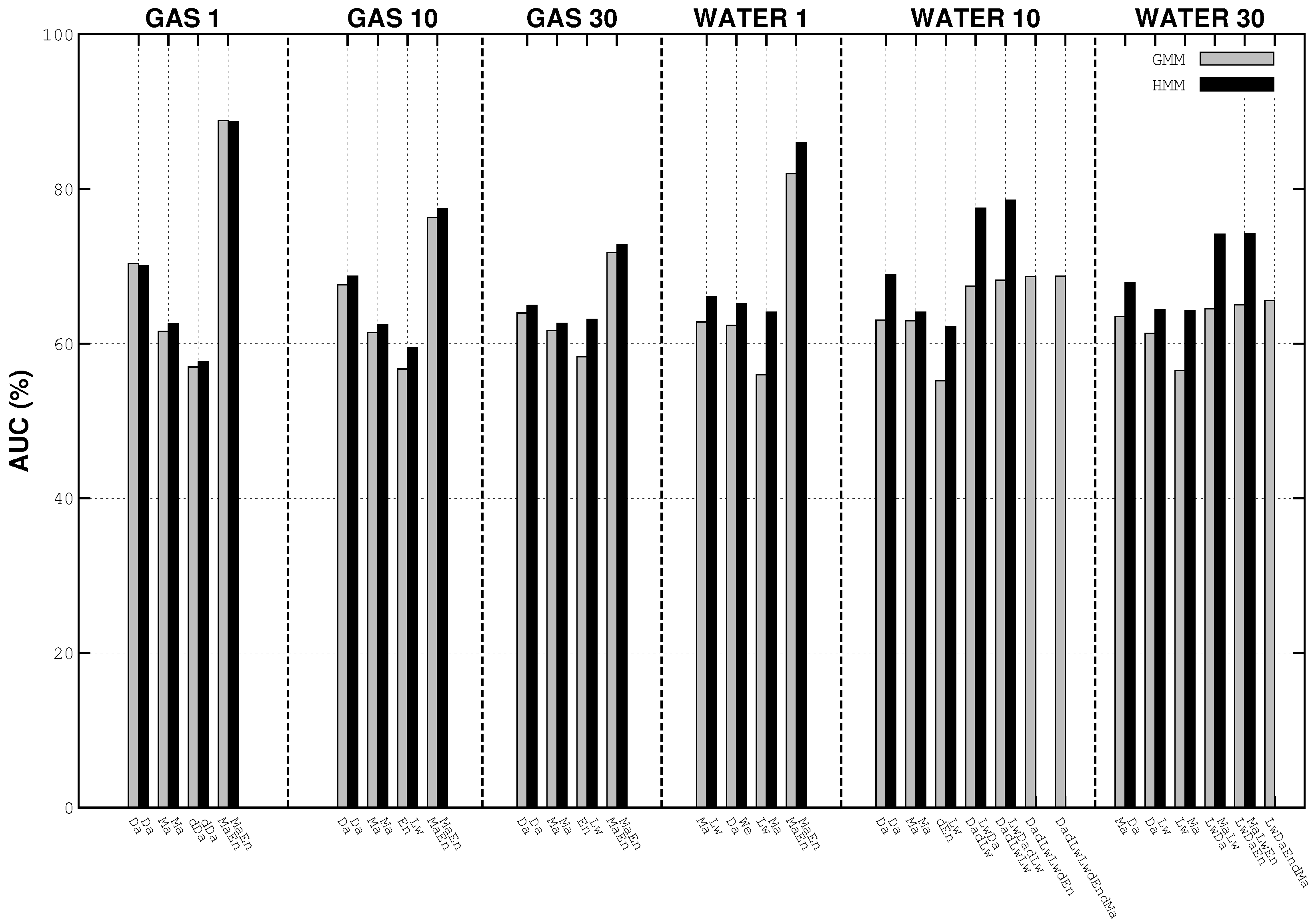
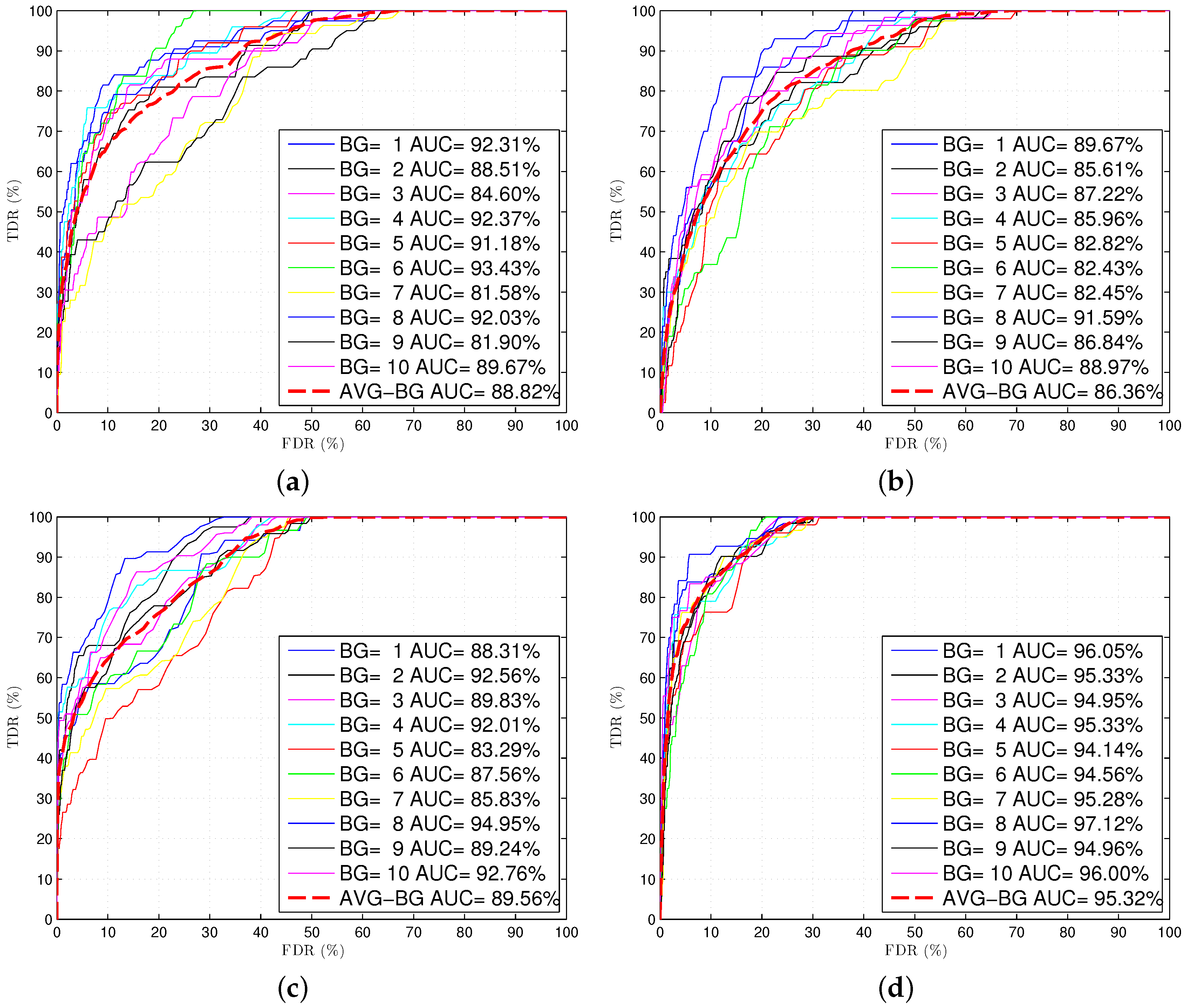
4.1. Residential Consumption
4.2. Building Consumption
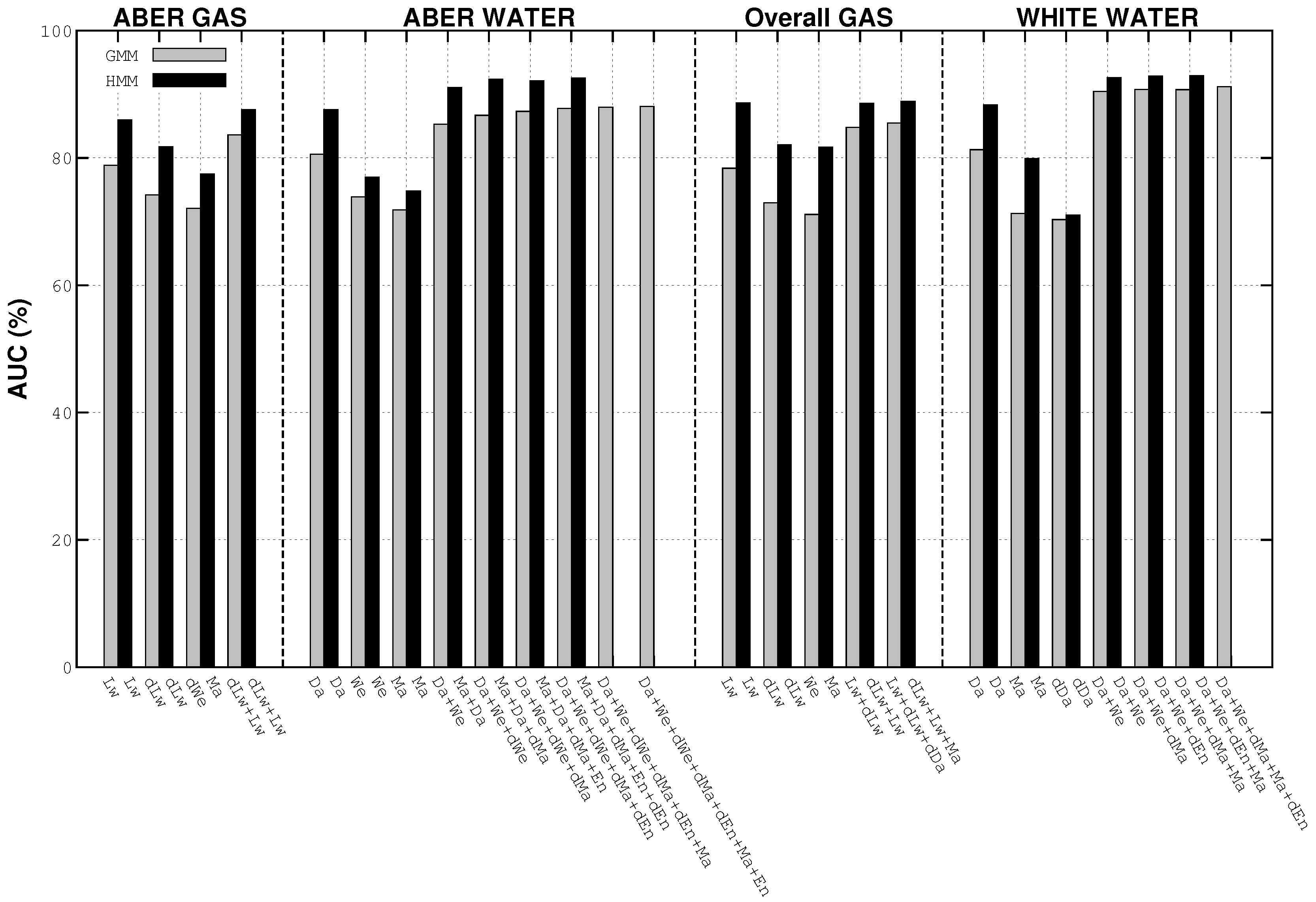
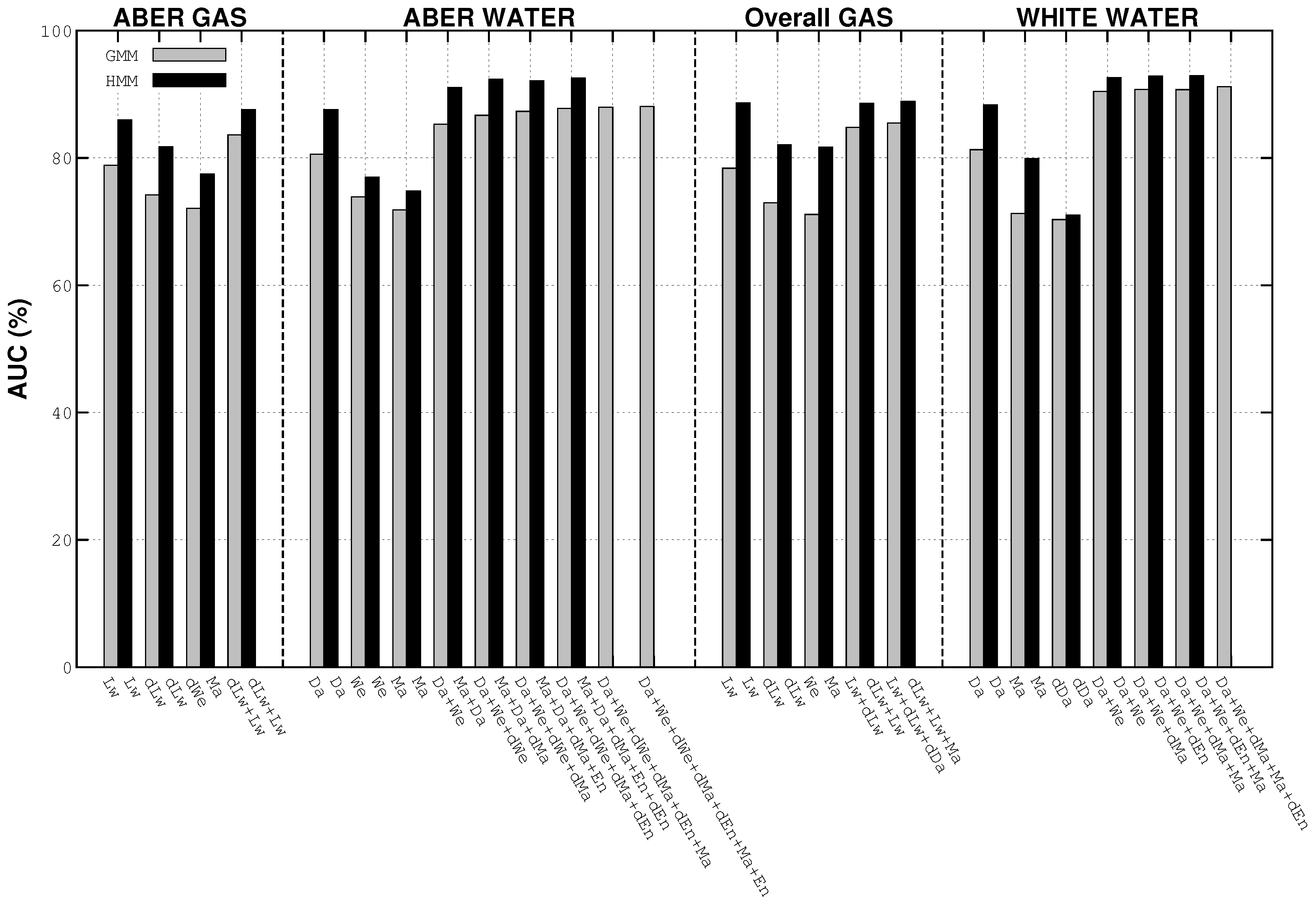
4.3. Best Results’ Details
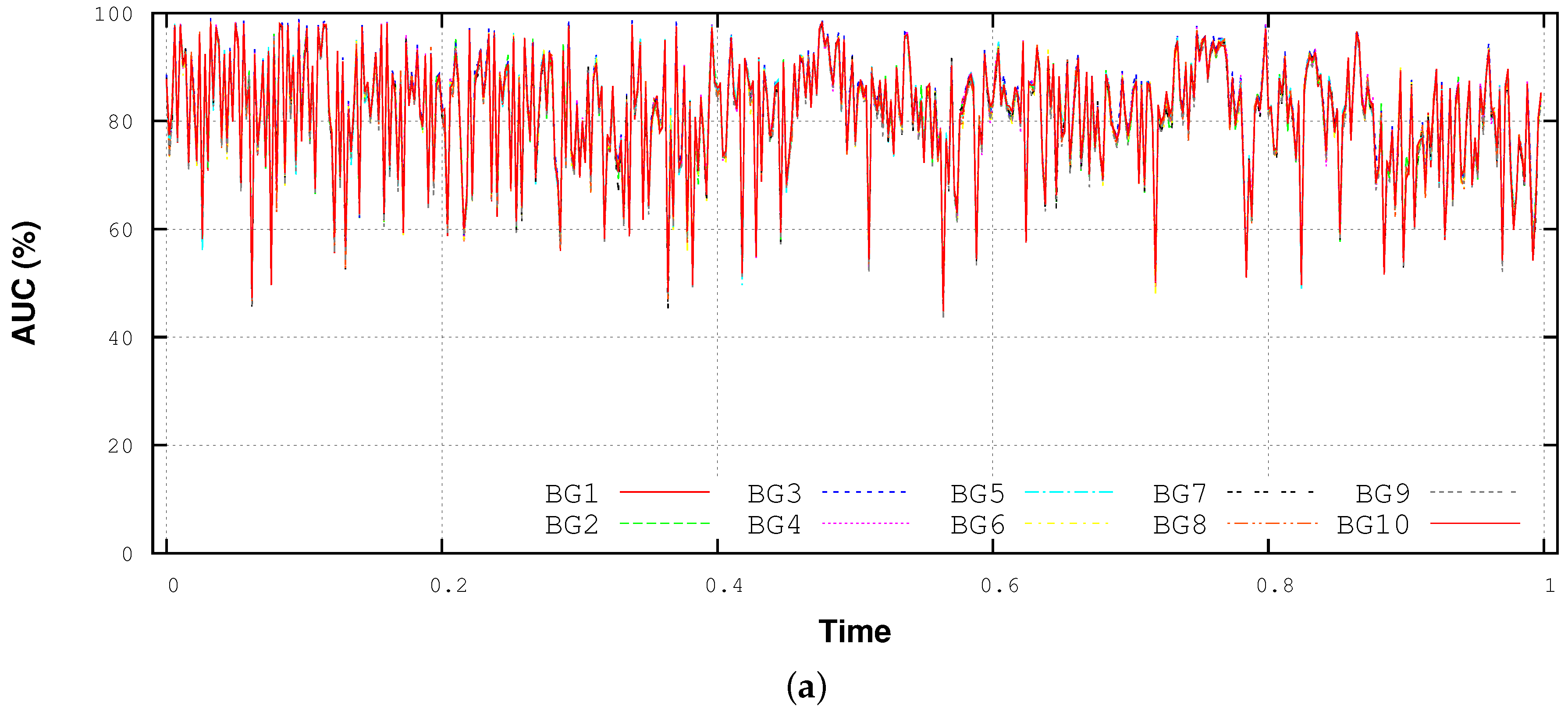
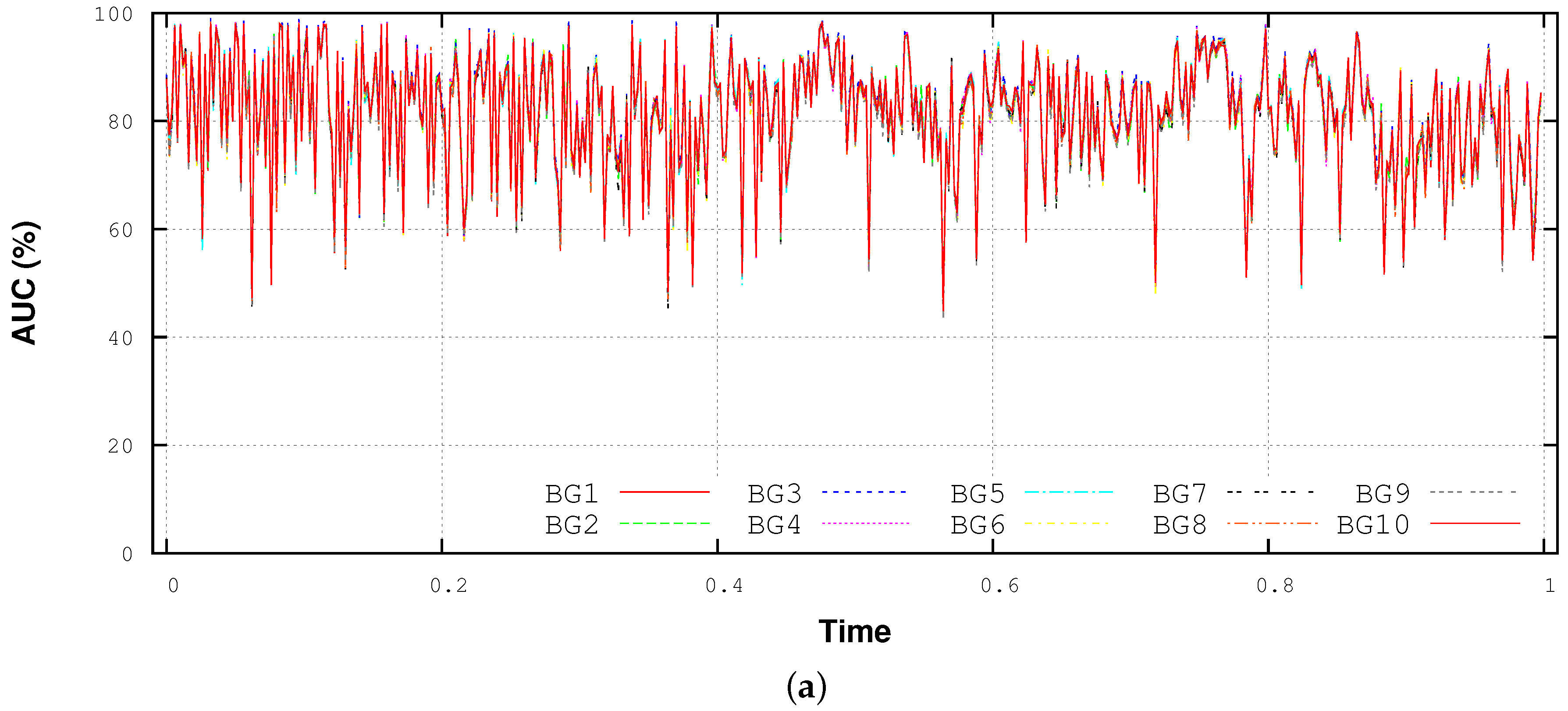
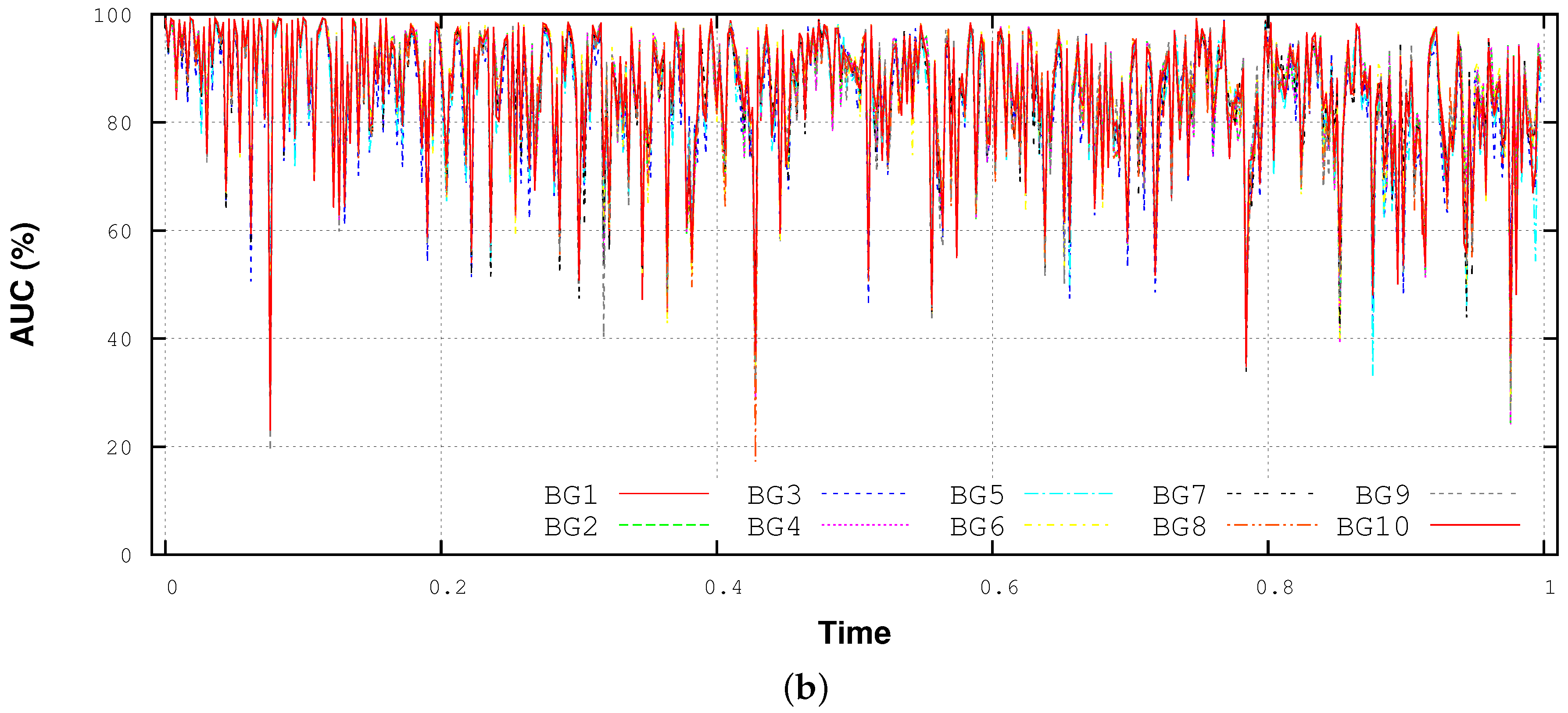
4.4. Performance Variability Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| Indexes | |
| i | Sample number. |
| Sample number within the validation set. | |
| j | Wavelet decomposition sequence. |
| n | Frame number. |
| g | Gaussian number. |
| t | Observation number. |
| State number. | |
| Parameters | |
| Value of the i-th sample of the frame. | |
| N | Number of samples in the frame. |
| Number of frames in the dataset. | |
| L | Number of feature components in the vector . |
| Number of Gaussian components. | |
| Weight value of the g-th Gaussian component. | |
| n-th state of the HMM. | |
| t-th observation of the HMM. | |
| T | Number of observations. |
| Number of states. | |
| m | Number of available features. |
| l | Number of features for each vector combination. |
| Average consumption computed from the training sequence. | |
| β | Leakage size. |
| Sets | |
| X | Samples within the frame. |
| Detail sequence of the wavelet decomposition of order k. | |
| Approximation sequence of the wavelet decomposition of order k. | |
| C | Energies of the wavelet decomposition sequences. |
| Vector of features. | |
| Vector of normalized features. | |
| Maximum values of the feature/s components. | |
| Minimum values of the feature/s components. | |
| Mean vector of the g-th Gaussian component. | |
| Covariance matrix of the g-th Gaussian component. | |
| λ | Set of μ, Σ, and w of the Gaussian components. |
| Emission probabilities of the HMM states. | |
| Observation likelihoods of the HMM states. | |
| Set of state of the HMM. | |
| Observation sequence. | |
| v | Validation dataset. |
| Features | |
| Value of the samples within the frame. | |
| Average value of the samples within the frame. | |
| Energy of the samples within the frame. | |
| Percentage of energy distribution among the wavelet sequences. | |
| Logarithmic energy of the wavelet sequences. | |
| Hourly window. | |
| Daily window. | |
| Weekly window. | |
| F | Generic set of feature, or features combination, extracted from the whole dataset. |
References
- WaterSense. Leak Facts. Available online: http://www3.epa.gov/watersense/pubs/fixleak.html (accessed on 30 October 2015).
- Fagiani, M.; Squartini, S.; Gabrielli, L.; Spinsante, S.; Piazza, F. A Review of Datasets and Load Forecasting Techniques for Smart Natural Gas and Water Grids: Analysis and Experiments. Neurocomputing 2015, 170, 448–465. [Google Scholar] [CrossRef]
- Spinsante, S.; Pizzichini, M.; Mencarelli, M.; Squartini, S.; Gambi, E. Evaluation of the Wireless M-Bus Standard for Future Smart Water Grids. In Proceedings of the Wireless Communications and Mobile Computing Conference, 9th International, Cagliari, Sardinia, Italy, 1–5 July 2013; pp. 1382–1387.
- Spinsante, S.; Squartini, S.; Gabrielli, L.; Pizzichini, M.; Gambi, E.; Piazza, F. Wireless M-Bus sensor networks for smart water grids: Analysis and results. Int. J. Distrib. Sens. Netw. 2014, 10. [Google Scholar] [CrossRef]
- Hao, W.S.; Garcia, R. Development of a Digital and Battery-Free Smart Flowmeter. Energies 2014, 7, 3695–3705. [Google Scholar] [CrossRef]
- Quevedo, J.; Chen, H.; Cugueró, M.; Tino, P.; Puig, V.; García, D.; Sarrate, R.; Yao, X. Combining Learning in Model Space Fault Diagnosis with Data Validation/Reconstruction: Application to the Barcelona Water Network. Eng. Appl. Artif. Intell. 2014, 30, 18–29. [Google Scholar] [CrossRef]
- Sadeghioon, A.M.; Metje, N.; Chapman, D.N.; Anthony, C.J. SmartPipes: Smart Wireless Sensor Networks for Leak Detection in Water Pipelines. J. Sens. Actuator Netw. 2014, 3, 64–78. [Google Scholar] [CrossRef]
- Lobaccaro, G.; Carlucci, S.; Löfström, E. A Review of Systems and Technologies for Smart Homes and Smart Grids. Energies 2016, 9, 348. [Google Scholar] [CrossRef]
- Hajebi, S.; Song, H.; Barrett, S.; Clarke, A.; Clarke, S. Towards a reference model for water smart grid. Int. J. Adv. Eng. Sci. Technol. 2013, 2, 310–317. [Google Scholar]
- Siano, P.; Graditi, G.; Atrigna, M.; Piccolo, A. Designing and testing decision support and energy management systems for smart homes. J. Ambient Intell. Humanized Comput. 2013, 4, 651–661. [Google Scholar] [CrossRef]
- Somma, M.D.; Yan, B.; Bianco, N.; Graditi, G.; Luh, P.; Mongibello, L.; Naso, V. Operation optimization of a distributed energy system considering energy costs and exergy efficiency. Energy Convers. Manag. 2015, 103, 739–751. [Google Scholar] [CrossRef]
- Fagiani, M.; Squartini, S.; Bonfigli, R.; Piazza, F. Short-term Load Forecasting for Smart Water and Gas Grids: A Comparative Evaluation. In Proceedings of the 2015 IEEE 15th International Conference on Environment and Electrical Engineering (EEEIC), Rome, Italy, 10–13 June 2015; pp. 1198–1203.
- Fagiani, M.; Squartini, S.; Severini, M.; Piazza, F. A Novelty Detection Approach to Identify the Occurrence of Leakage in Smart Gas and Water Grid. In Proceedings of the 2015 International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015; pp. 1309–1316.
- Markou, M.; Singh, S. Novelty Detection: A Review-Part 1: Statistical Approaches. Signal Process. 2003, 83, 2481–2497. [Google Scholar] [CrossRef]
- Markou, M.; Singh, S. Novelty Detection: A Review-Part 2: Neural Network Based Approaches. Signal Process. 2003, 83, 2499–2521. [Google Scholar] [CrossRef]
- Pimentel, M.A.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A Review of Novelty Detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Chis, T. Pipeline Leak Detection Techniques. CoRR, 2009; arXiv:0903.4283. [Google Scholar]
- Murvay, P.S.; Silea, I. A Survey on Gas Leak Detection and Localization Techniques. J. Loss Prev. Process Ind. 2012, 25, 966–973. [Google Scholar] [CrossRef]
- Mounce, S.R.; Mounce, R.B.; Boxall, J.B. Novelty Detection for Time Series Data Analysis in Water Distribution Systems using Support Vector Machines. J. Hydroinform. 2011, 13, 672–686. [Google Scholar] [CrossRef]
- Nasir, M.; Mysorewala, M.; Cheded, L.; Siddiqui, B.; Sabih, M. Measurement Error Sensitivity Analysis for Detecting and Locating Leak in Pipeline using ANN and SVM. In Proceedings of the 2014 11th International Multi-Conference on Systems, Signals Devices (SSD), Castelldefels, Barcelona, Spain, 11–14 February 2014; pp. 1–4.
- Rossman, L.A. The EPANET Water Quality Model; Coulbeck, B., Ed.; Research Studies Press Ltd.: Somerset, UK, 1993; Volume 2. [Google Scholar]
- Gamboa-Medina, M.; Reis, L.R.; Guido, R.C. Feature Extraction in Pressure Signals for Leak Detection in Water Networks. Procedia Eng. 2014, 70, 688–697. [Google Scholar] [CrossRef]
- Sanz, G.; Perez, R.; Escobet, A. Leakage Localization in Water Networks using Fuzzy Logic. In Proceedings of the 20th Mediterranean Conference on Control Automation (MED), Barcelona, Spain, 3–6 July 2012; pp. 646–651.
- Alkasseh, J.; Adlan, M.; Abustan, I.; Aziz, H.; Hanif, A. Applying Minimum Night Flow to Estimate Water Loss Using Statistical Modeling: A Case Study in Kinta Valley, Malaysia. Water Resour. Manag. 2013, 27, 1439–1455. [Google Scholar] [CrossRef]
- Oren, G.; Stroh, N.Y. Mathematical Model for Detection of Leakage in Domestic Water Supply Systems by Reading Consumption from an Analogue Water Meter. Int. J. Environ. Sci. Dev. 2013, 4, 386–389. [Google Scholar] [CrossRef]
- Wan, J.; Yu, Y.; Wu, Y.; Feng, R.; Yu, N. Hierarchical Leak Detection and Localization Method in Natural Gas Pipeline Monitoring Sensor Networks. Sensors 2012, 12, 189–214. [Google Scholar] [CrossRef] [PubMed]
- Vapnik, V.N. Statistical Learning Theory; Wiley-Interscience: New York, NY, USA, 1998. [Google Scholar]
- Perner, P. Concepts for Novelty Detection and Handling Based on a Case-based Reasoning Process Scheme. Eng. Appl. Artif. Intell. 2009, 22, 86–91. [Google Scholar] [CrossRef]
- Makonin, S.; Popowich, F.; Bartram, L.; Gill, B.; Bajic, I. AMPds: A Public Dataset for Load Disaggregation and Eco-Feedback Research. In Proceedings of the 2013 IEEE Electrical Power Energy Conference (EPEC), Halifax, NS, Canada, 21–23 August 2013; pp. 1–6.
- Department for International Development. Live Data Page for Energy and Water Consumption. Available online: http://data.gov.uk/dataset/dfid-energy-and-water-consumption (accessed on 30 October 2015).
- Principi, E.; Squartini, S.; Bonfigli, R.; Ferroni, G.; Piazza, F. An Integrated System for Voice Command Recognition and Emergency Detection Based on Audio Signals. Expert Syst. Appl. 2015, 42, 5668–5683. [Google Scholar] [CrossRef]
- Kuncheva, L.I. Change Detection in Streaming Multivariate Data Using Likelihood Detectors. IEEE Trans. Knowl. Data Eng. 2013, 25, 1175–1180. [Google Scholar] [CrossRef]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition, 4th ed.; Academic Press: Burlington, VT, USA, 2008. [Google Scholar]
- Britton, T.C.; Stewart, R.A.; O’Halloran, K.R. Smart Metering: Enabler for Rapid and Effective Post Meter Leakage Identification and Water Loss Management. J. Clean. Prod. 2013, 54, 166–176. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Secaucus, NJ, USA, 2006. [Google Scholar]
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker Verification Using Adapted Gaussian Mixture Models. Digit. Signal Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Rabiner, L. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Baum, L. An inequality and associated Maximization Technique in Statistical Estimation for Probabilistic Functions of Markov Processes. Inequalities 1972, 3, 1–8. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Collobert, R.; Bengio, S.; Marithoz, J. Torch: A Modular Machine Learning Software Library. Available online: https://infoscience.epfl.ch/record/82802/files/rr02-46.pdf (accessed on 1 June 2015).
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Probabilistic Novelty Detection for Acoustic Surveillance Under Real-World Conditions. IEEE Trans. Multimed. 2011, 13, 713–719. [Google Scholar] [CrossRef]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Contribution | Target | Data | Resource | Technique | Main Issues |
|---|---|---|---|---|---|
| Alkasseh et al. [24] | D | F and P | W | MNF-MLR | Indirect detection 2 sensors No novelty approach |
| Gamboa-Medina et al. [22] | - | P | W | C4.5 | Laboratory circuit 15 sensors No novelty approach |
| Mounce et al. [19] | D | F and P | W | SVR | Anomalies detection |
| Nasir et al. [20] | R | F and P | W | SVM and ANN | No real data 6 sensors No novelty approach |
| Oren and Stroh [25] | R | F | W | Heuristic | Ad hoc constraints No validation |
| Sanz et al. [23] | D | F | W | Fuzzy logic | 2 sensors No novelty approach |
| Wan et al. [26] | - | F and P | G | SVM | 5 acoustic and pressure sensors High-pressure pipe No novelty approach |
| Index | Name | Feature Size | Acronym |
|---|---|---|---|
| 1 | Data | Number of samples | Da |
| 2 | Energy | 1 | En |
| 3 | Moving Average | 1 | Ma |
| 4 | Wavelet Decomposition Energy | 4 | We |
| 5 | Logarithmic Wavelet Energy | 4 | Lw |
| 6 | Hourly Window | 1 | Hr |
| 7 | Daily Window | 1 | Dy |
| 8 | Weekly Window | 1 | Wk |
| Resource | Res. | AUC (%) | SD | Model | Parameters | Features Combination |
|---|---|---|---|---|---|---|
| Without Temporal Features | ||||||
| Gas | 1 | GMM | 256 | Ma + En | ||
| Gas | 1 | HMM | 1–256 | Ma + En | ||
| Gas | 1 | OC-SVM | dWe + We | |||
| Gas | 10 | GMM | 128 | Ma + En | ||
| Gas | 10 | HMM | 3–256 | Ma + En | ||
| Gas | 10 | OC-SVM | 2 | dWe + dLw | ||
| Gas | 30 | GMM | 128 | Ma + En | ||
| Gas | 30 | HMM | 3–256 | Ma + En | ||
| Gas | 30 | OC-SVM | 2 | dWe + dLw | ||
| With Temporal Features | ||||||
| Gas | 1 | GMM | 256 | Ma + En | ||
| Gas | 1 | HMM | 3–256 | Ma + En | ||
| Gas | 1 | OC-SVM | dWe + We | |||
| Gas | 10 | GMM | 256 | Ma + En | ||
| Gas | 10 | HMM | 3–256 | Ma + En | ||
| Gas | 10 | OC-SVM | 2 | dWe + dLw | ||
| Gas | 30 | GMM | 256 | En + Ma | ||
| Gas | 30 | HMM | 3–256 | Ma + En | ||
| Gas | 30 | OC-SVM | 2 | dWe + dLw | ||
| Resource | Res. | AUC (%) | SD | Model | Parameters | Features Combination |
|---|---|---|---|---|---|---|
| Without Temporal Features | ||||||
| Water | 1 | GMM | 128 | Ma + En | ||
| Water | 1 | HMM | 4–64 | Ma + En | ||
| Water | 1 | OC-SVM | dWe + dEn | |||
| Water | 10 | GMM | 256 | Da + dLw + Lw + dEn + dMa | ||
| Water | 10 | HMM | 4–256 | Lw + Da + dLw | ||
| Water | 10 | OC-SVM | dWe + dEn | |||
| Water | 30 | GMM | 256 | Lw + Ma + En + dMa + dLw + Da + dEn | ||
| Water | 30 | HMM | 4–256 | Ma + Lw + En | ||
| Water | 30 | OC-SVM | We + dEn | |||
| With Temporal Features | ||||||
| Water | 1 | GMM | 128 | Ma + En | ||
| Water | 1 | HMM | 4–64 | Ma + En | ||
| Water | 1 | OC-SVM | dWe + dEn | |||
| Water | 10 | GMM | 256 | Ma + Hr + dMa | ||
| Water | 10 | HMM | 4–256 | Lw + Da + Hr + dLw + Wk + Ma + dEn | ||
| Water | 10 | OC-SVM | dWe + dEn | |||
| Water | 30 | GMM | 256 | Da + Hr + dEn + dMa + En + Ma | ||
| Water | 30 | HMM | 4–256 | Da + Hr | ||
| Water | 30 | OC-SVM | dWe + dEn | |||
| Resource | Res. | AUC (%) | SD | Model | Parameters | Features Combination |
|---|---|---|---|---|---|---|
| Without Temporal Features | ||||||
| Aber. Gas | 30 | GMM | 256 | dLw + Lw | ||
| Aber. Gas | 30 | HMM | 4–64 | dLw + Lw | ||
| Aber. Gas | 30 | OC-SVM | Da + dMa + Ma + En | |||
| Aber. Water | 30 | GMM | 256 | Da + We + dWe + dMa + dEn | ||
| Aber. Water | 30 | HMM | 3–256 | Ma + Da + dMa + En + dEn | ||
| Aber. Water | 30 | OC-SVM | Da + Ma + En | |||
| Overall Gas | 30 | GMM | 256 | Lw + dLw + dMa | ||
| Overall Gas | 30 | HMM | 4–256 | dLw + Lw + Ma | ||
| Overall Gas | 30 | OC-SVM | Da + dDa + dMa + dEn | |||
| White. Water | 30 | GMM | 256 | Da + We + dMa + Ma + dEn | ||
| White. Water | 30 | HMM | 4–128 | Da + We + dEn + Ma | ||
| White. Water | 30 | OC-SVM | Da + Ma | |||
| With Temporal Features | ||||||
| Aber. Gas | 30 | GMM | 256 | Lw + dLw + Hr + Ma | ||
| Aber. Gas | 30 | HMM | 4-256 | dLw + Lw + Hr + Wk + Ma | ||
| Aber. Gas | 30 | OC-SVM | Da + dMa + Ma + En | |||
| Aber. Water | 30 | GMM | 256 | Da + Hr + We + dWe + Ma + dEn + dMa | ||
| Aber. Water | 30 | HMM | 4–256 | Da + Hr + Ma + dMa | ||
| Aber. Water | 30 | OC-SVM | Da + Ma + En | |||
| Overall Gas | 30 | GMM | 256 | dLw + Lw + Hr + dMa + Ma | ||
| Overall Gas | 30 | HMM | 4–32 | Lw + dLw + dMa + Wk + Dy + Ma | ||
| Overall Gas | 30 | OC-SVM | Da + Ma + En | |||
| White. Water | 30 | GMM | 256 | Da + Hr + Dy | ||
| White. Water | 30 | HMM | 2–256 | Da + Hr + Dy + dEn | ||
| White. Water | 30 | OC-SVM | Da + Ma | |||
| Resource | AUC (%) | TDR (%) | FDR (%) | ||||
|---|---|---|---|---|---|---|---|
| AVG | BEST BG | BEST | AVG | BEST BG | BEST | ||
| AMPds Gas | 100 | ||||||
| AMPds Water | 100 | ||||||
| Overall Gas | 100 | ||||||
| White. Water | 100 | ||||||
| Resource | Model | Leakage Starting Point | Leakage Size | Leakage Duration | |||
|---|---|---|---|---|---|---|---|
| AUC (%) | SD | AUC (%) | SD | AUC (%) | SD | ||
| AMPds Gas | GMM | ||||||
| AMPds Gas | HMM | ||||||
| AMPds Gas | SVM | ||||||
| AMPds Water | GMM | ||||||
| AMPds Water | HMM | ||||||
| AMPds Water | SVM | ||||||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fagiani, M.; Squartini, S.; Gabrielli, L.; Severini, M.; Piazza, F. A Statistical Framework for Automatic Leakage Detection in Smart Water and Gas Grids. Energies 2016, 9, 665. https://doi.org/10.3390/en9090665
Fagiani M, Squartini S, Gabrielli L, Severini M, Piazza F. A Statistical Framework for Automatic Leakage Detection in Smart Water and Gas Grids. Energies. 2016; 9(9):665. https://doi.org/10.3390/en9090665
Chicago/Turabian StyleFagiani, Marco, Stefano Squartini, Leonardo Gabrielli, Marco Severini, and Francesco Piazza. 2016. "A Statistical Framework for Automatic Leakage Detection in Smart Water and Gas Grids" Energies 9, no. 9: 665. https://doi.org/10.3390/en9090665
APA StyleFagiani, M., Squartini, S., Gabrielli, L., Severini, M., & Piazza, F. (2016). A Statistical Framework for Automatic Leakage Detection in Smart Water and Gas Grids. Energies, 9(9), 665. https://doi.org/10.3390/en9090665