
Learning Agent for a Heat-Pump Thermostat with a Set-Back Strategy Using Model-Free Reinforcement Learning

Abstract
:1. Introduction
2. Literature Review
3. Problem Statement
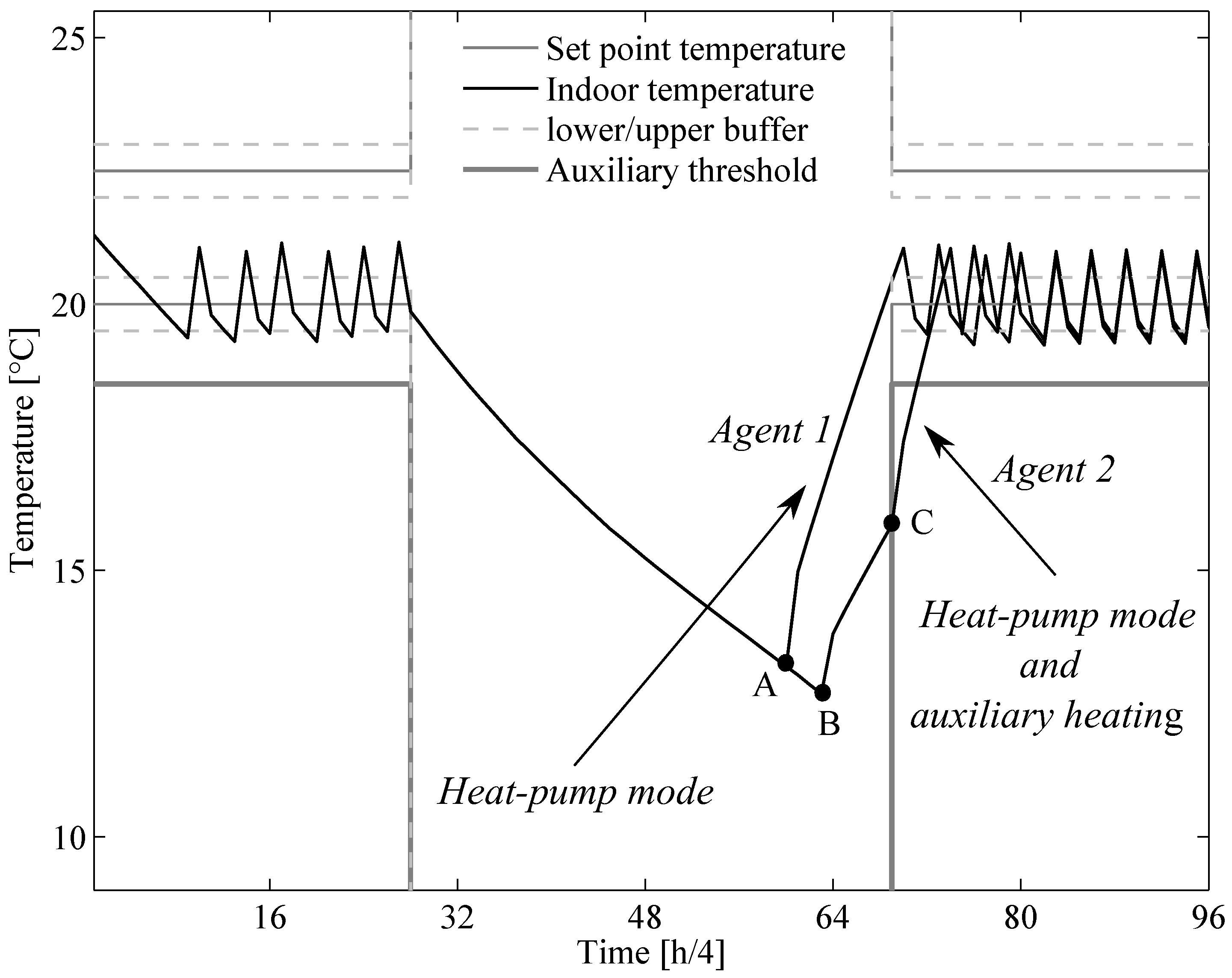
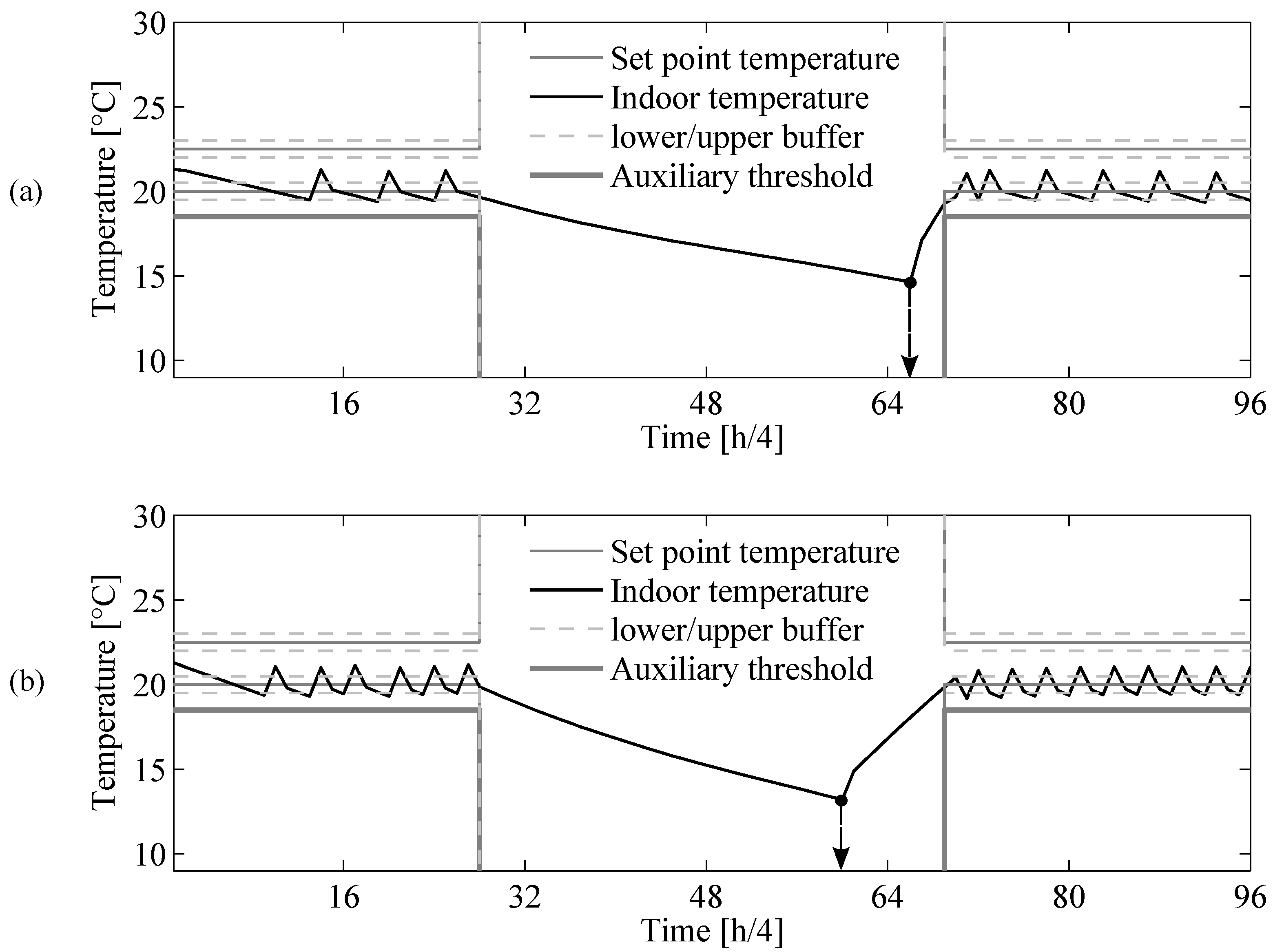
4. Markov Decision Process
4.1. Observable State
4.2. Thermostat Function
4.3. Augmented State
4.4. Transition Function
4.5. Cost Function
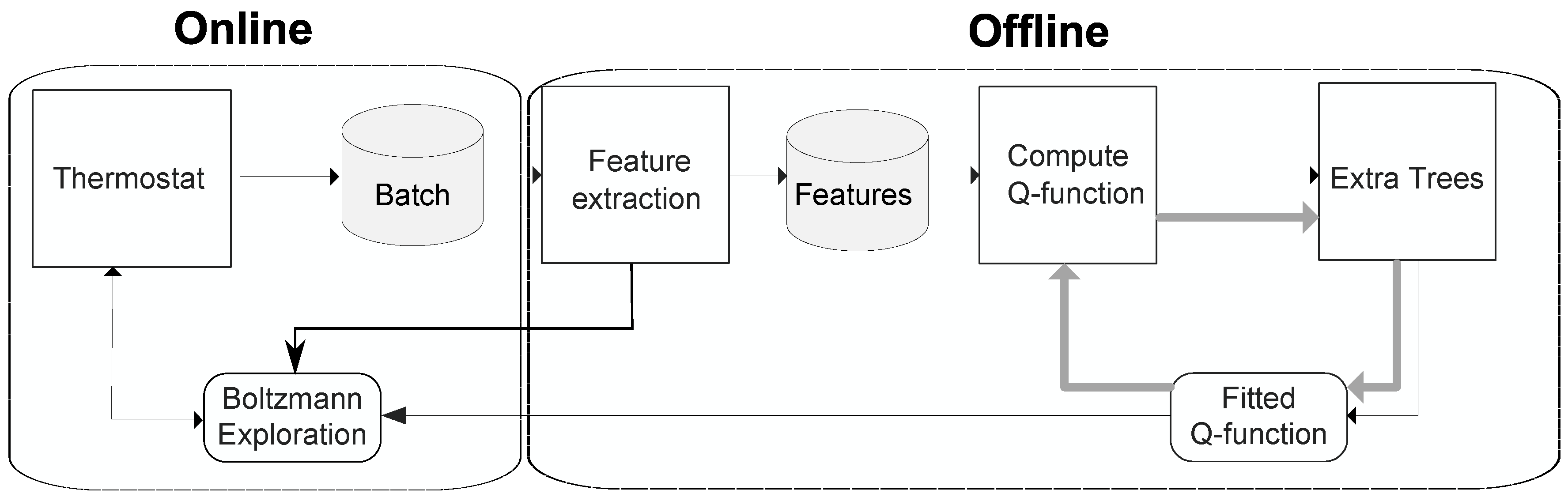
5. Model-Free Batch Reinforcement Learning Approach
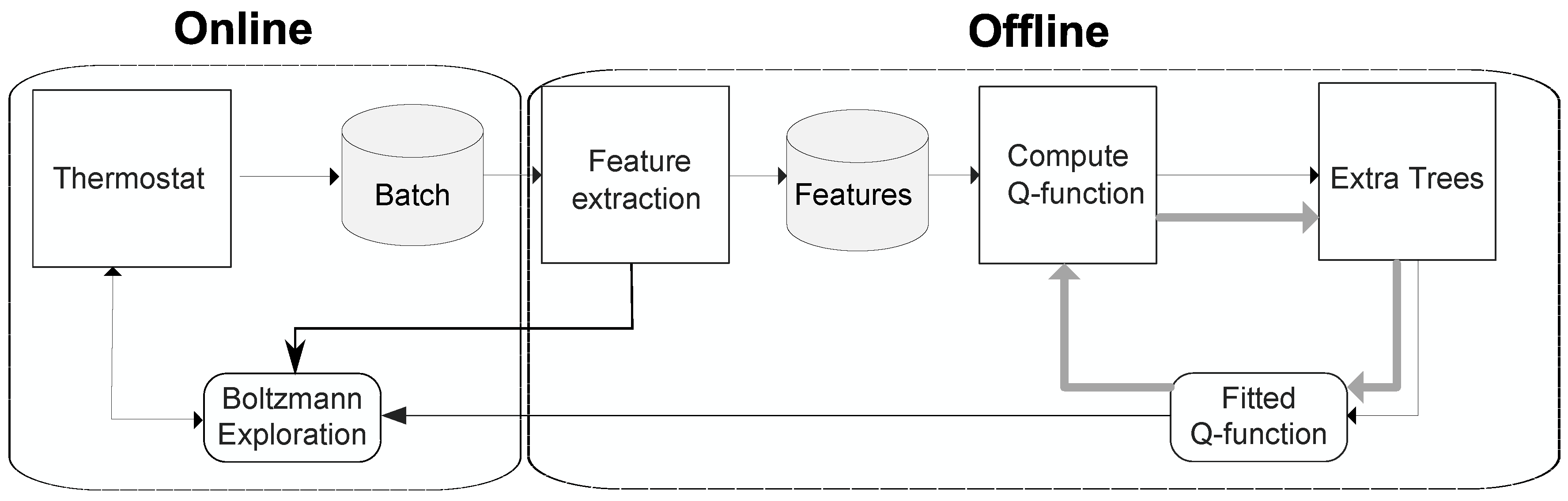
5.1. Offline Loop
5.1.1. Feature Extraction
5.1.2. Fitted Q-Iteration
| Algorithm 1 Fitted Q-iteration [24] |
| Input: |
| 1: Initialize to zero |
| 2: for do |
| 3: for do |
| 4: |
| 5: |
| 6: end for |
| 7: use regression to obtain from |
| 8: end for |
| Output: |
5.2. Online Loop
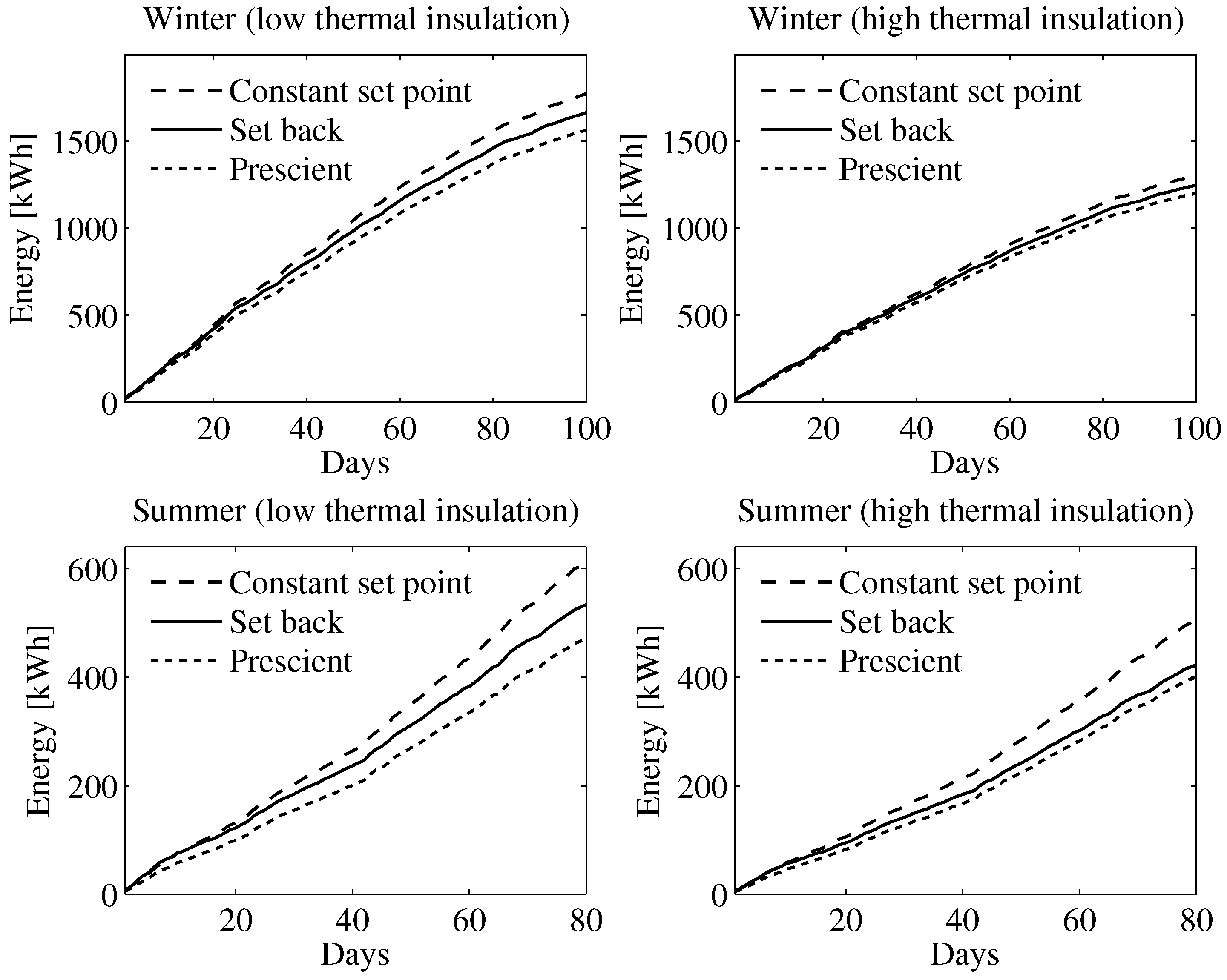
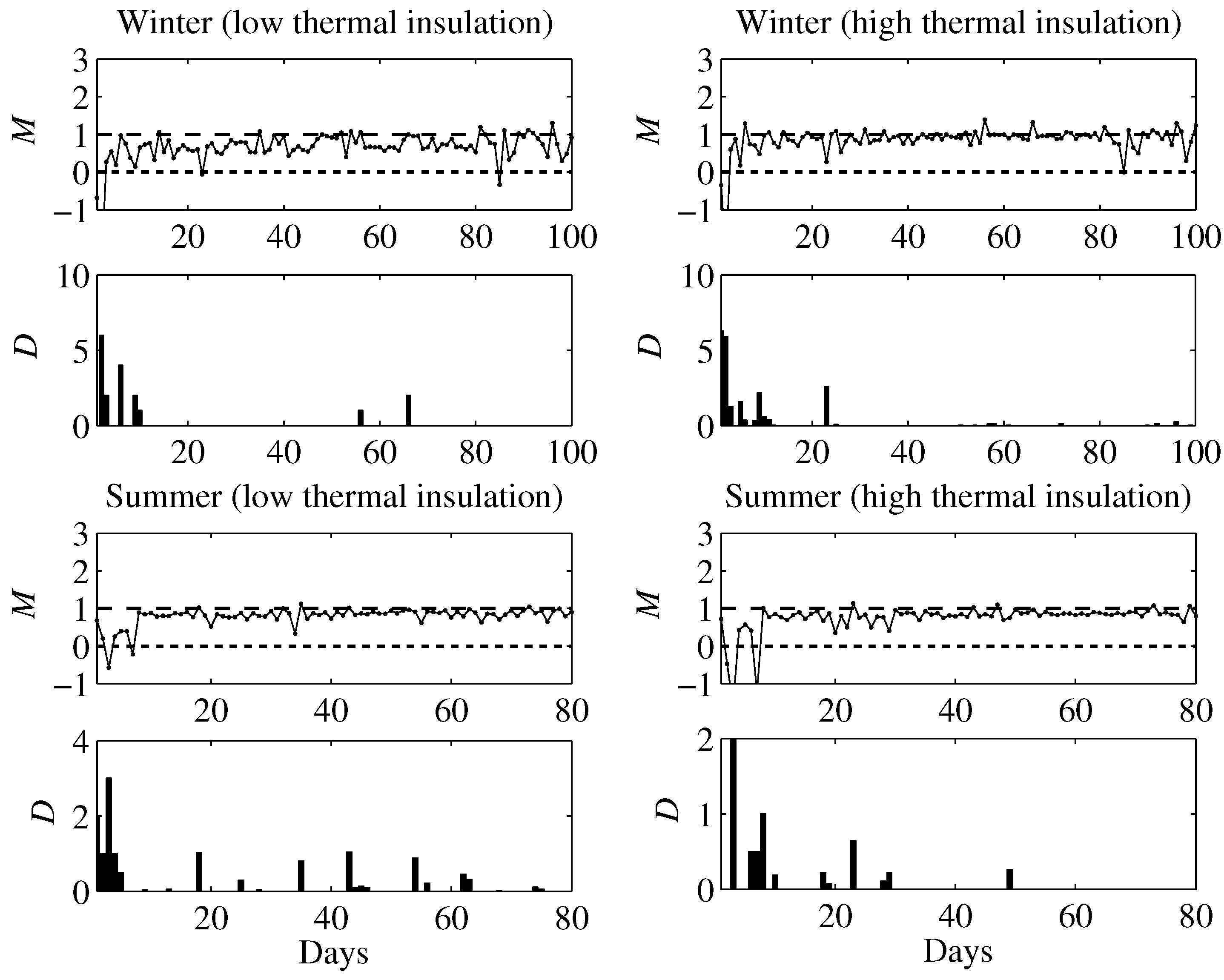
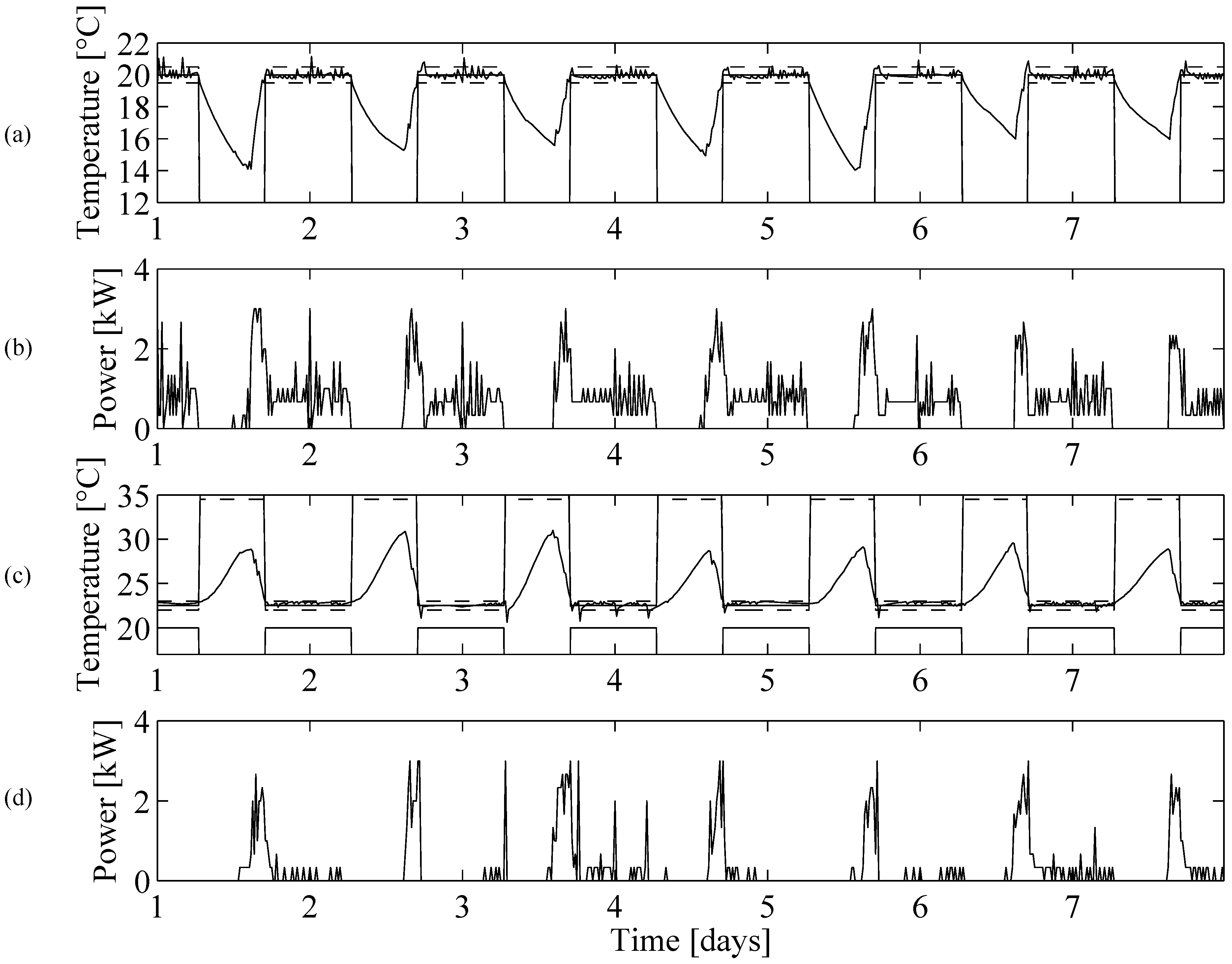
6. Simulation Results
6.1. Simulation Setup
6.2. Learning Agent
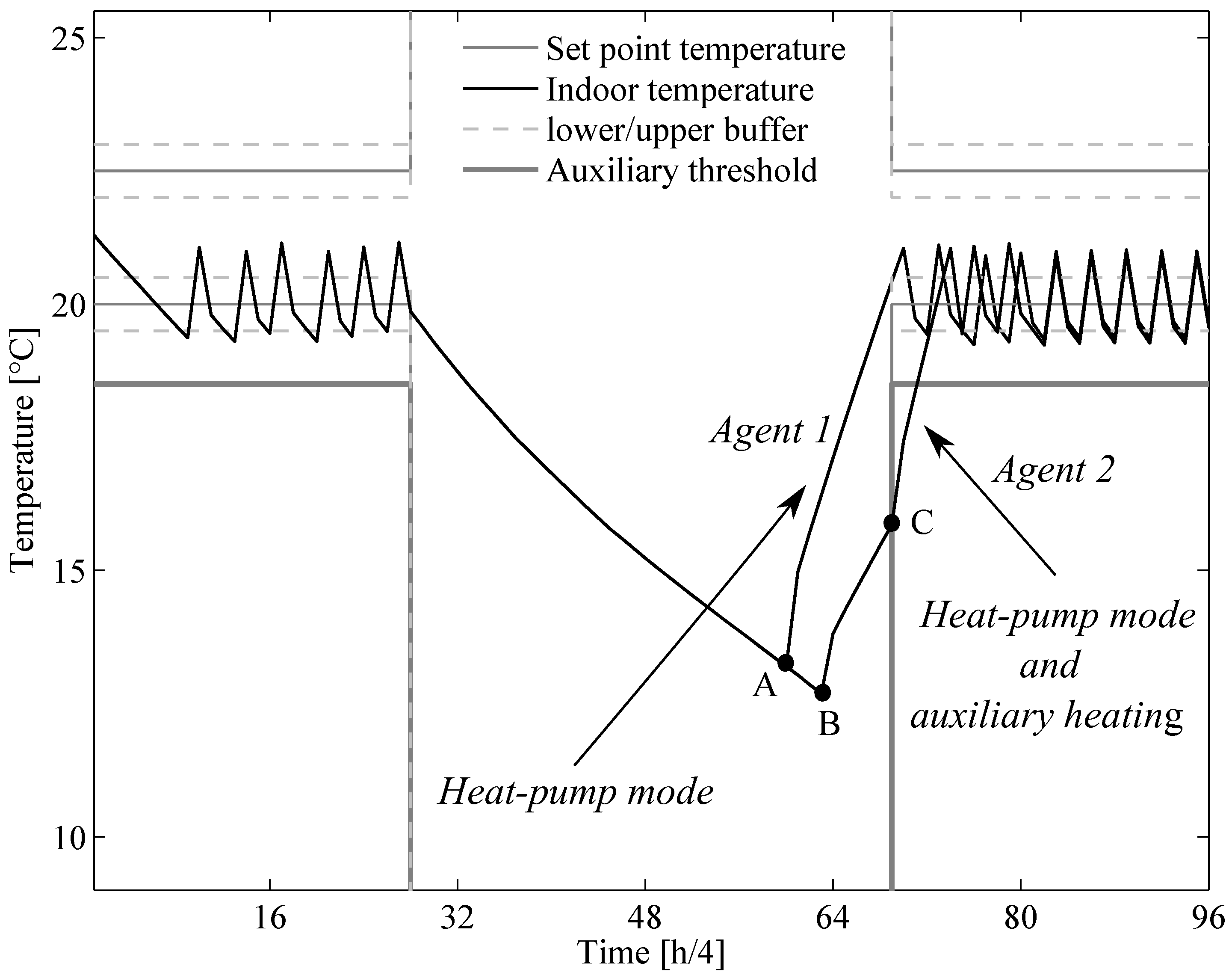
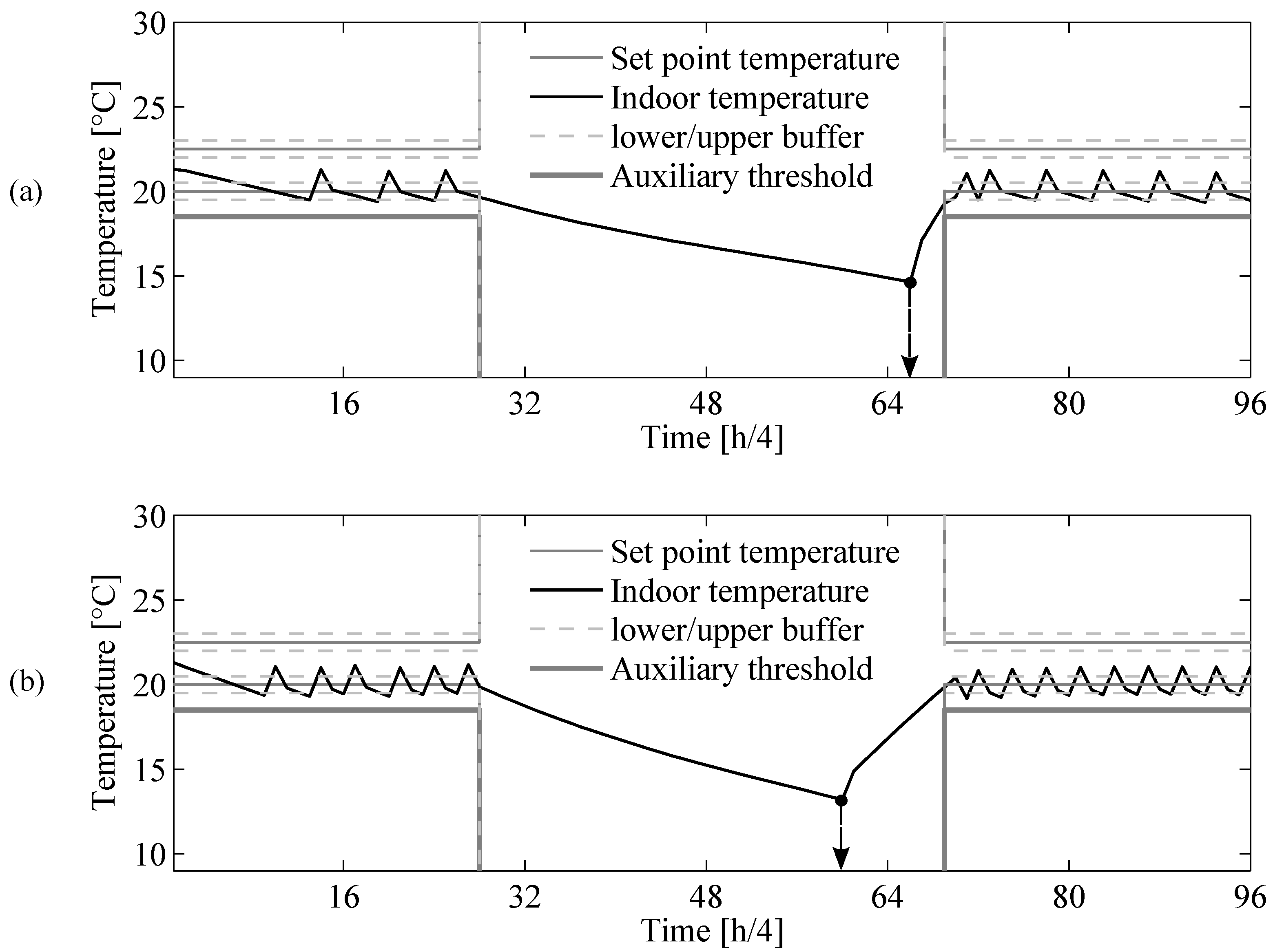
6.3. Prescient Method
6.4. Simulation Results
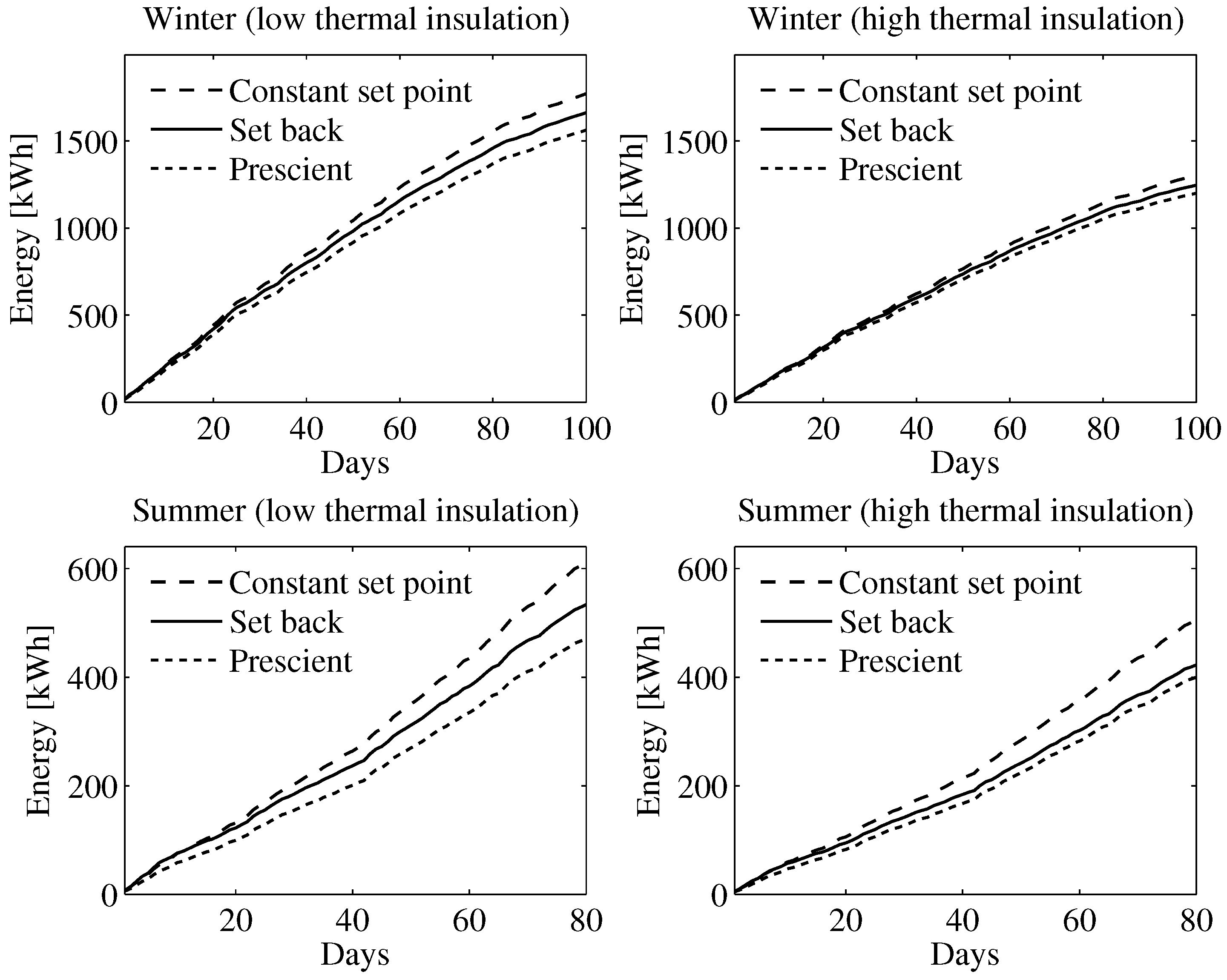
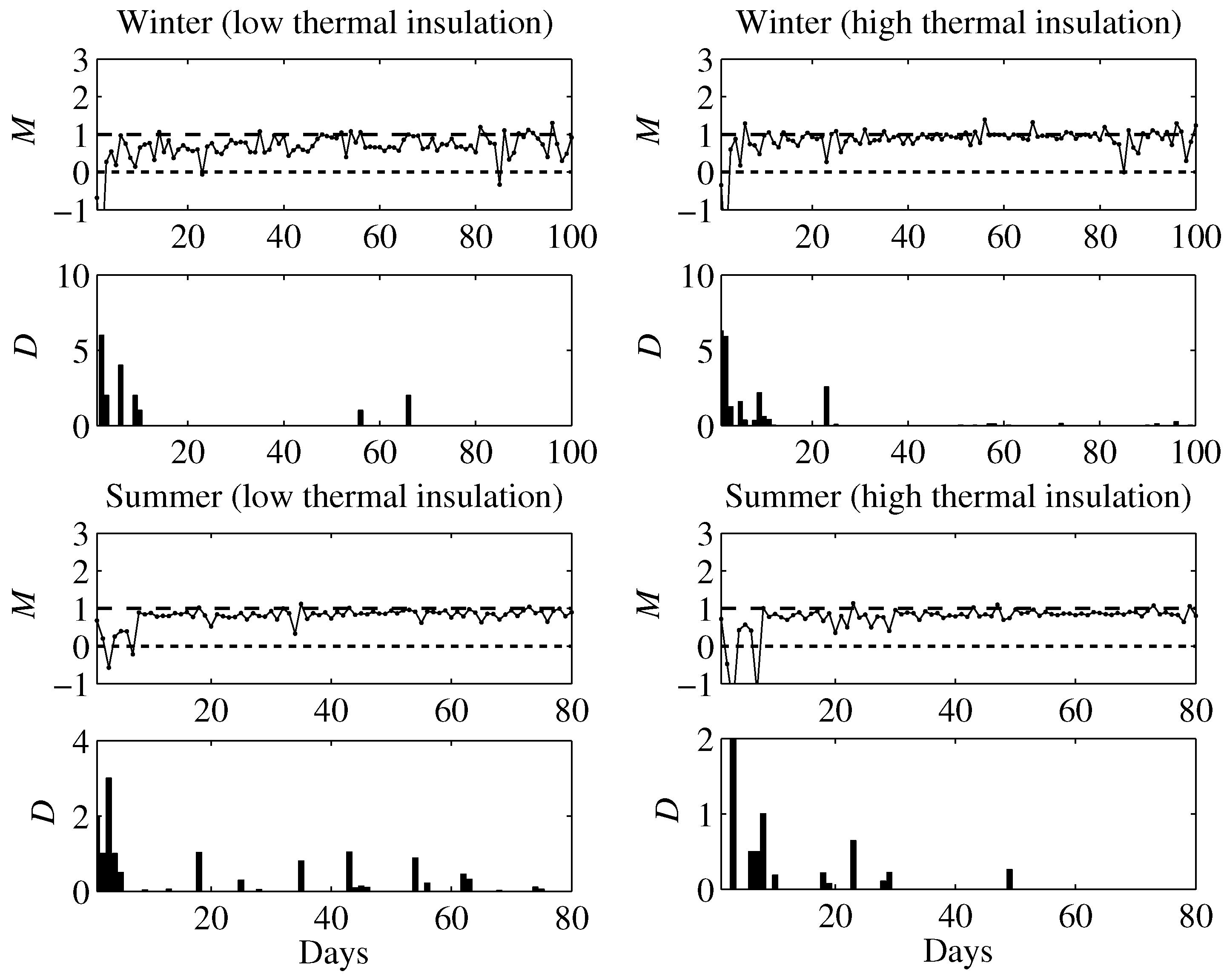
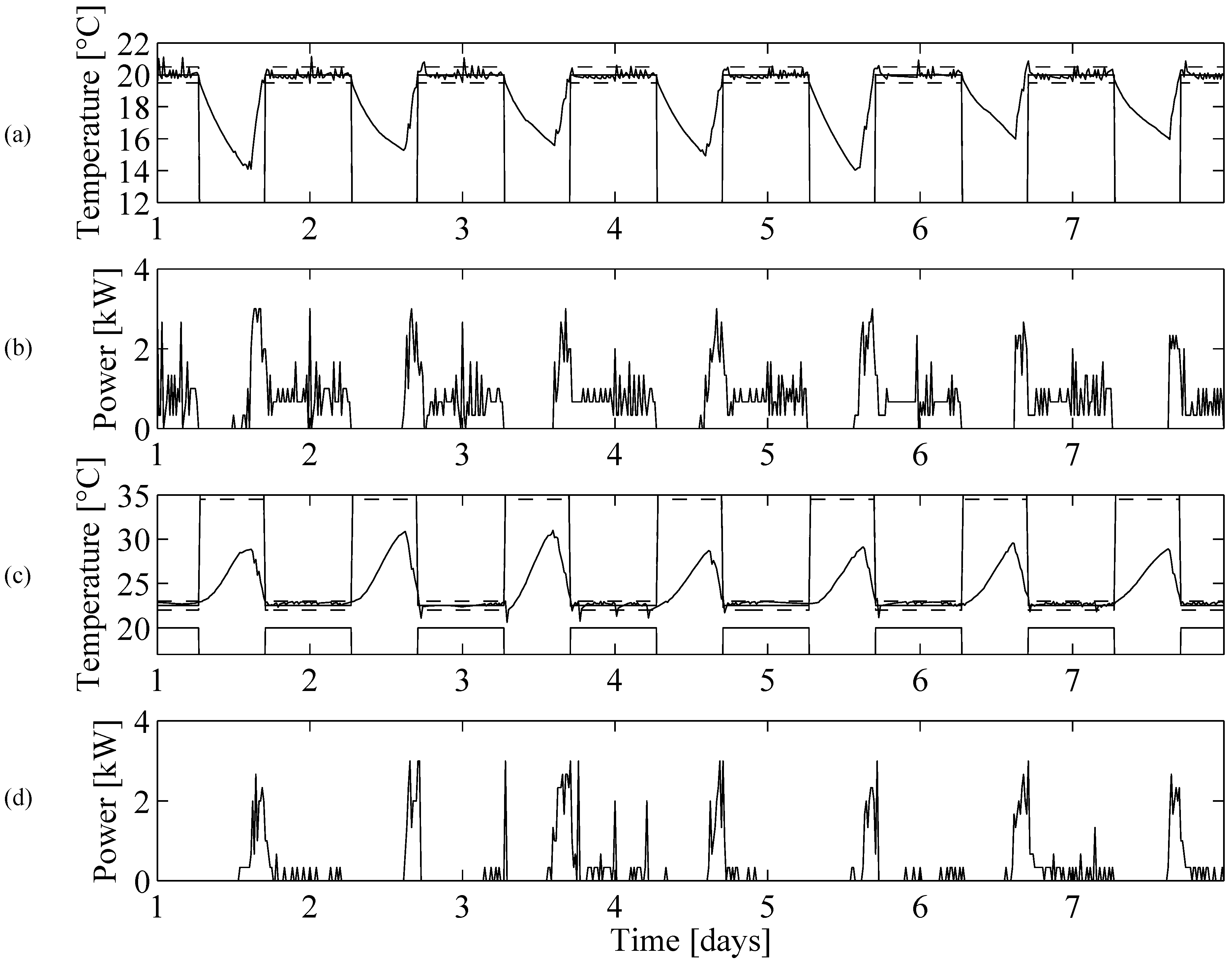
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A: Thermostat Logic
| Algorithm 2 Thermostat of a heat pump with auxiliary heating. |
| 1: Measure |
| 2: Initialize |
| 3: if |
| until |
| 4: elseif |
| 5: elseif |
| 6: elseif |
| until |
| 7: end if |
Appendix B: Model Equations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Low Thermal | High Thermal | Unit |
|---|---|---|---|
| 1154 | 272 | W/° C | |
| 6863 | 6863 | W/° C | |
| 2.441 | 2.441 | MJ/° C | |
| 9.896 | 9.896 | MJ/° C |
| Parameters | Value |
|---|---|
| 2500 W | |
| 3000 W | |
| 20 °C | |
| 22.5 °C | |
| 0.5 °C | |
| 1.5 °C |
Appendix C: Prescient Method
References
- U.S. Energy Information Administration (EIA). EIA Online Statistics. Available online: http://www.iea.org/topics/electricity/ (accessed on 21 May 2015).
- Moretti, E.; Bonamente, E.; Buratti, C.; Cotana, F. Development of Innovative Heating and Cooling Systems Using Renewable Energy Sources for Non-Residential Buildings. Energies 2013, 6, 5114–5129. [Google Scholar] [CrossRef]
- Luickx, P.J.; Peeters, L.F.; Helsen, L.M.; D’haeseleer, W.D. Influence of massive heat-pump introduction on the electricity-generation mix and the GHG effect: Belgian case study. Int. J. Energy Res. 2008, 32, 57–67. [Google Scholar] [CrossRef]
- Forsén, M.; Boeswarth, R.; Dubuisson, X.; Sandström, B. Heat Pumps: Technology and Environmental Impact. 2005. Available online: http://ec.europa.eu/environment/ecolabel/about_ecolabel/reports/hp_tech_env_impact_aug2005.pdf (accessed on 31 July 2015).
- Bayer, P.; Saner, D.; Bolay, S.; Rybach, L.; Blum, P. Greenhouse gas emission savings of ground source heat pump systems in Europe: A review. Renew. Sustain. Energy Rev. 2012, 16, 1256–1267. [Google Scholar] [CrossRef]
- U.S. Department of Energy. Limitations for Homes with Heat Pumps, Electric Resistance Heating, Steam Heat, and Radiant Floor Heating. Available online: http://energy.gov/energysaver/articles/thermostats (accessed on 21 March 2015).
- Michaud, N.; Megdal, L.; Baillargeon, P.; Acocella, C. Billing Analysis & Environment that “Re-Set” Savings for Programmable Thermostats in New Homes. 2009. Available online: http://www.anevaluation.com/pubs/090604_econoler_iepec_paper-lm.pdf (accessed on 31 July 2015).
- Urieli, D.; Stone, P. A Learning Agent for Heat-pump Thermostat Control. In Proceedings of the 12th International Conference on Autonomous Agents and Multi-agent Systems (AAMAS), Saint Paul, MN, USA, 6–10 May 2013; pp. 1093–1100.
- Rogers, A.; Maleki, S.; Ghosh, S.; Nicholas, R.J. Adaptive Home Heating Control Through Gaussian Process Prediction and Mathematical Programming. In Proceedings of the 2nd International Workshop on Agent Technology for Energy Systems (ATES), Taipei, Taiwan, 2–3 May 2011; pp. 71–78.
- Nest Labs. The Nest Learning Thermostat. Available online: https://nest.com/ (accessed on 21 March 2015).
- Honneywell. Programmable Thermostats. Available online: http://yourhome.honeywell.com/home/products/thermostats/ (accessed on 21 March 2015).
- BuildingIQ. BuildingIQ, a Leading Energy Management Software Company. Available online: https://www.buildingiq.com/ (accessed on 21 March 2015).
- Neurobat. Neurobat Interior Climate Technologies. Available online: http://www.neurobat.net/de/home/ (accessed on 21 March 2015).
- Plugwise. Smart thermostat Anna. Available online: http://www.whoisanna.com/ (accessed on 21 March 2015).
- Treado, S.; Chen, Y. Saving Building Energy through Advanced Control Strategies. Energies 2013, 6, 4769–4785. [Google Scholar] [CrossRef]
- Cigler, J.; Gyalistras, D.; Širokỳ, J.; Tiet, V.; Ferkl, L. Beyond theory: The challenge of implementing Model Predictive Control in buildings. In Proceedings of the 11th REHVA World Congress (CLIMA), Prague, Czech Republic, 16–19 June 2013.
- Powell, W. Approximate Dynamic Programming: Solving The Curses of Dimensionality, 2nd ed.; Wiley-Blackwell: Hoboken, NJ, USA, 2011. [Google Scholar]
- Bertsekas, D. Dynamic Programming and Optimal Control; Athena Scientific: Belmont, MA, USA, 1995. [Google Scholar]
- Morel, N.; Bauer, M.; El-Khoury, M.; Krauss, J. Neurobat, a predictive and adaptive heating control system using artificial neural networks. Int. J. Solar Energy 2001, 21, 161–201. [Google Scholar] [CrossRef]
- Collotta, M.; Messineo, A.; Nicolosi, G.; Pau, G. A Dynamic Fuzzy Controller to Meet Thermal Comfort by Using Neural Network Forecasted Parameters as the Input. Energies 2014, 7, 4727–4756. [Google Scholar] [CrossRef]
- Moon, J.W.; Chang, J.D.; Kim, S. Determining adaptability performance of artificial neural network-based thermal control logics for envelope conditions in residential buildings. Energies 2013, 6, 3548–3570. [Google Scholar] [CrossRef]
- Henze, G.P.; Schoenmann, J. Evaluation of reinforcement learning control for thermal energy storage systems. HVACR Res. 2003, 9, 259–275. [Google Scholar] [CrossRef]
- Wen, Z.; O Neill, D.; Maei, H. Optimal Demand Response Using Device-Based Reinforcement Learning. Available online: http://web.stanford.edu/class/ee292k/reports/ZhengWen.pdf (accessed on 27 July 2015).
- Ernst, D.; Geurts, P.; Wehenkel, L. Tree-based batch mode reinforcement learning. J. Mach. Learn. Res. 2005, 6, 503–556. [Google Scholar]
- Ernst, D.; Glavic, M.; Capitanescu, F.; Wehenkel, L. Reinforcement learning versus model predictive control: A comparison on a power system problem. IEEE Trans. Syst. Man Cybern. Syst. 2009, 39, 517–529. [Google Scholar] [CrossRef] [PubMed]
- Lange, S.; Gabel, T.; Riedmiller, M. Batch Reinforcement Learning. In Reinforcement Learning: State-of-the-Art; Wiering, M., van Otterlo, M., Eds.; Springer: New York, NY, USA, 2012; pp. 45–73. [Google Scholar]
- Claessens, B.; Vandael, S.; Ruelens, F.; de Craemer, K.; Beusen, B. Peak shaving of a heterogeneous cluster of residential flexibility carriers using reinforcement learning. In Proceedings of the 2nd IEEE Innovative Smart Grid Technologies Conference (ISGT Europe), Lyngby, Danish, 6–9 October 2013; pp. 1–5.
- Ruelens, F.; Claessens, B.; Vandael, S.; Iacovella, S.; Vingerhoets, P.; Belmans, R. Demand Response of a Heterogeneous Cluster of Electric Water Heaters Using Batch Reinforcement learning. In Proceedings of the 18th IEEE Power System Computation Conference (PSCC), Wroclaw, Poland, 18–22 August 2014; pp. 1–8.
- Lange, S.; Riedmiller, M. Deep auto-encoder neural networks in reinforcement learning. In Proceedings of the IEEE 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8.
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with deep reinforcement learning. Available online: http://arxiv.org/pdf/1312.5602v1.pdf (accessed on 27 July 2015).
- Riedmiller, M.; Gabel, T.; Hafner, R.; Lange, S. Reinforcement learning for robot soccer. Auton. Robots 2009, 27, 55–73. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Bellman, R. Dynamic Programming; Dover Publications, Inc.: New York, NY, USA, 2003. [Google Scholar]
- Bertsekas, D.; Tsitsiklis, J. Neuro-Dynamic Programming; Athena Scientific: Nashua, NH, USA, 1996. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Riedmiller, M.; Braun, H. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In Proceedings of the 1993 IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 586–591.
- Hestenes, M.R.; Stiefel, E. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bureau Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Scholz, M.; Vigário, R. Nonlinear PCA: A New Hierarchical Approach; ESANN: Bruges, Belgium, 2002; pp. 439–444. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar]
- Chassin, D.; Schneider, K.; Gerkensmeyer, C. GridLAB-D: An open-source power systems modeling and simulation environment. In Proceedings of the IEEE Transmission and Distribution Conference and Exposition, Chicago, IL, USA, 21–24 April 2008; pp. 1–5.
- Crawley, D.B.; Lawrie, L.K.; Winkelmann, F.C.; Buhl, W.F.; Huang, Y.J.; Pedersen, C.O.; Strand, R.K.; Liesen, R.J.; Fisher, D.E.; Witte, M.J.; et al. EnergyPlus: Creating a new-generation building energy simulation program. Energy Build. 2001, 33, 319–331. [Google Scholar] [CrossRef]
- Dupont, B.; Vingerhoets, P.; Tant, P.; Vanthournout, K.; Cardinaels, W.; de Rybel, T.; Peeters, E.; Belmans, R. LINEAR breakthrough project: Large-scale implementation of smart grid technologies in distribution grids. In Proceedings of the 3rd IEEE PES Innovative Smart Grid Technologies Conference, (ISGT Europe), Berlin, Germany, 14–17 October 2012; pp. 1–8.
- Sonderegger, R.C. Dynamic Models of House Heating Based on Equivalent Thermal Parameters. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 1978. [Google Scholar]
- Klein, S.A. TRNSYS, a Transient System Simulation Program; Solar Energy Laboratory, University of Wisconsin: Madison, WI, USA, 1979. [Google Scholar]
- Gurobi Optimization. Gurobi optimizer reference manual. Available online: http://www.gurobi. com (accessed on 21 March 2015).
- Löfberg, J. YALMIP: A toolbox for modeling and optimization in MATLAB. In Proceedings of the IEEE 2004 International Symposium on Computer Aided Control Systems Design, Taipei, Taiwan, 2–4 September 2004; pp. 284–289.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruelens, F.; Iacovella, S.; Claessens, B.J.; Belmans, R. Learning Agent for a Heat-Pump Thermostat with a Set-Back Strategy Using Model-Free Reinforcement Learning. Energies 2015, 8, 8300-8318. https://doi.org/10.3390/en8088300
Ruelens F, Iacovella S, Claessens BJ, Belmans R. Learning Agent for a Heat-Pump Thermostat with a Set-Back Strategy Using Model-Free Reinforcement Learning. Energies. 2015; 8(8):8300-8318. https://doi.org/10.3390/en8088300
Chicago/Turabian StyleRuelens, Frederik, Sandro Iacovella, Bert J. Claessens, and Ronnie Belmans. 2015. "Learning Agent for a Heat-Pump Thermostat with a Set-Back Strategy Using Model-Free Reinforcement Learning" Energies 8, no. 8: 8300-8318. https://doi.org/10.3390/en8088300
APA StyleRuelens, F., Iacovella, S., Claessens, B. J., & Belmans, R. (2015). Learning Agent for a Heat-Pump Thermostat with a Set-Back Strategy Using Model-Free Reinforcement Learning. Energies, 8(8), 8300-8318. https://doi.org/10.3390/en8088300