1. Introduction
The integration of large-scale wind power into modern power systems presents significant operational challenges due to its inherent variability and uncertainty. Wind power generation is influenced by multiple stochastic factors, including wind speed, direction, atmospheric conditions, and complex terrain effects, making it particularly challenging to predict and manage [
1]. Traditional deterministic forecasting approaches, which rely on single-point predictions of wind power output, have proven inadequate for the optimization and uncertainty management of advanced power systems with high wind power penetration [
2]. The scenario analysis method in stochastic programming theory is one of the effective tools for capturing wind power uncertainty [
3,
4]. This approach generates multiple scenarios of wind power output sequences that preserve the essential statistical properties and temporal dynamics of historical patterns. By incorporating these scenarios into power system planning and operations, system operators can develop more robust and flexible strategies that explicitly account for wind power uncertainty. This framework enables enhanced economic efficiency and operational reliability in modern power systems.
According to the time scale, wind power output sequence scenarios can be categorized into three temporal scales: ultra-short-term, short-term, and medium-to-long-term scenarios. Among these, medium-to-long-term scenarios play a crucial role in power system planning, capacity expansion, and long-range power balance optimization [
5,
6]. The inherent chaos in atmospheric dynamics presents fundamental limitations for medium-to-long-term predictions while short-term scenario generation can effectively leverage wind power forecasting and numerical weather prediction (NWP) models. This challenge is compounded by the nonlinear interactions between multiple meteorological variables and their impact on wind power generation. Consequently, the focus in medium-to-long-term scenario generation shifts from achieving precise point-wise predictions to accurately capturing and reproducing the essential statistical characteristics, including temporal fluctuation patterns, spatial correlations among wind farms, and seasonal variations observed in historical data.
Existing approaches to wind power scenario generation can primarily be divided into two methodological frameworks: statistical methods and deep learning techniques. Statistical methods typically employ probabilistic models to characterize the stochastic process of wind power output. Traditional time series approaches, such as the autoregressive moving average (ARMA) model [
7,
8], have been applied to capture temporal dependencies in wind power output sequences. More sophisticated approaches utilize Markov chain Monte Carlo (MCMC) methods [
9,
10] to model state transitions and generate scenarios through sequential sampling. Copula theory has been employed [
11,
12,
13] to model the complex correlation among multiple wind farms, enabling the generation of spatial scenarios through multivariate sampling techniques. However, these statistical methods, while mathematically tractable, often struggle to capture the multiscale characteristics of wind power output, particularly the interaction between different temporal scales and spatial dependencies. In recent years, generative models in deep learning methods have been widely applied in the field of scenario generation, mainly including variational autoencoders (VAE) [
14,
15], generative adversarial networks (GAN) [
16,
17,
18], and normalizing flows (NF) [
19,
20].
Reference [
14] employed an improved VAE to describe the uncertainty of photovoltaic power output and applied the generated scenarios to centralized photovoltaic optimization configuration in multi-energy power systems. However, VAE may introduce reconstruction errors when processing complex wind power data, which limits the accuracy of the generated scenarios. Reference [
15] combined VAE with a bidirectional long short-term memory (Bi-LSTM) network to propose a deep learning framework for large-scale renewable energy demand prediction. Although this method improves the capture of time-series features, the limited ability of Bi-LSTM to model long-term dependencies may result in reduced accuracy in long-term wind power forecasts. Reference [
16] adopted a GAN for model-free renewable energy scenario generation. However, the training process of GAN is prone to mode collapse, which restricts the diversity of generated wind power scenarios and compromises the comprehensiveness of predictions. Reference [
17] proposed a controllable GAN model that allows manual control over the characteristics of generated scenarios. Although this method enhances the controllability of the generated scenarios, the introduction of additional control variables may increase model complexity and training difficulty, thereby impacting the feasibility of practical applications. Reference [
18] employed a style-based generative adversarial network and a sequence encoder to generate day-ahead renewable energy output scenarios through the hierarchical control and blending of scene styles. However, the application of Style-GAN in wind power prediction may be constrained by the quality and quantity of samples, resulting in insufficient representativeness of the generated scenarios. Refs. [
19,
20] indicated that, compared to VAE and GAN, the NF model is more suitable for power system time-series scenario generation. However, NF may face challenges such as high computational complexity and training difficulties when dealing with high-dimensional complex data, limiting its application in large-scale wind power scenario prediction. In summary, existing deep learning methods cannot fully explain the relationship between their model structures and wind power uncertainty, and the model training process is rather cumbersome.
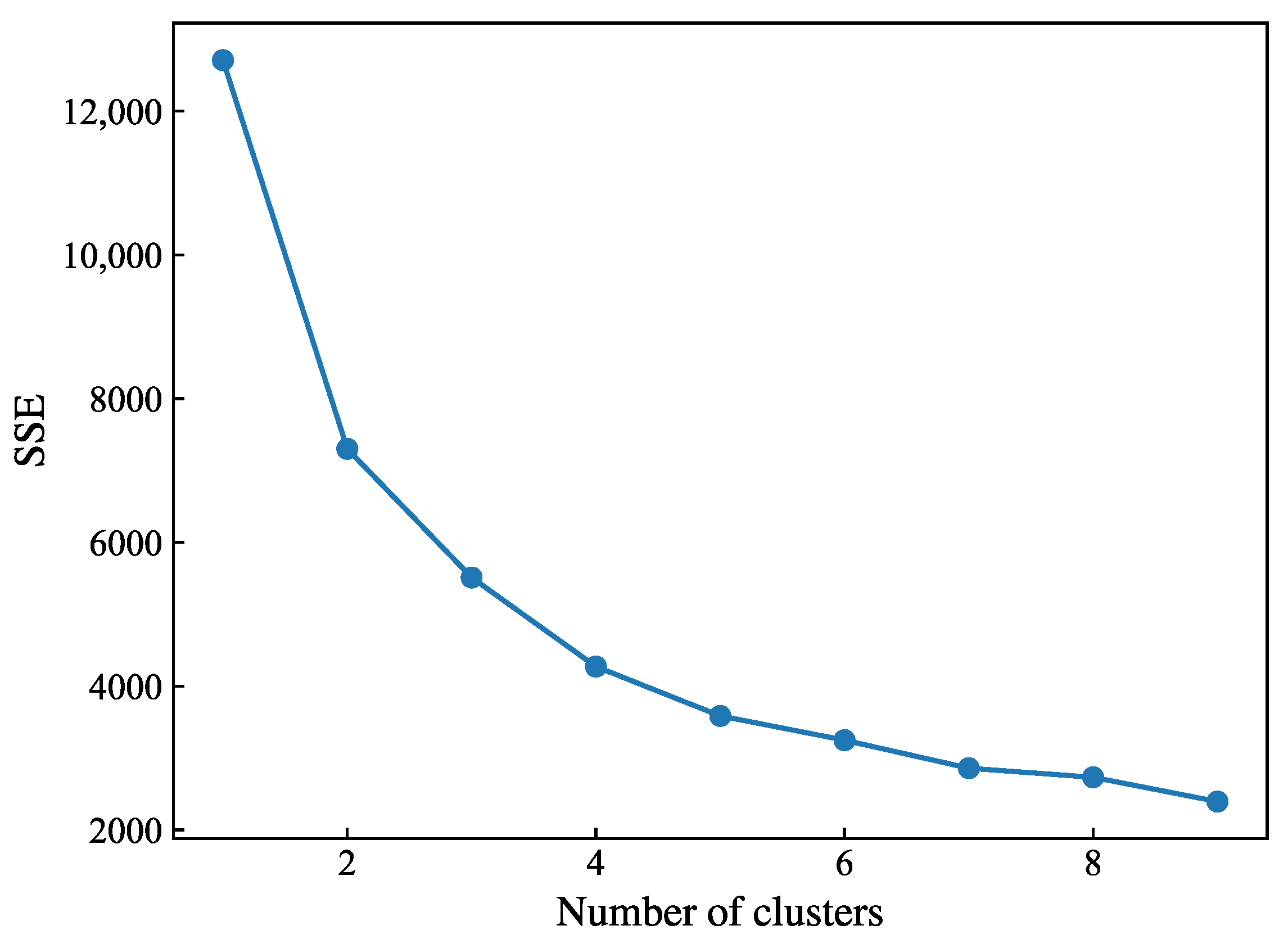
This paper presents a novel methodology for generating medium- to long-term output sequence scenarios across multiple wind farms, with particular attention to both daily pattern variations and intraday output fluctuations. The proposed approach employs a hierarchical framework integrating multiple advanced statistical techniques. First, based on historical data, a feature vector for daily wind power output is constructed. Principal component analysis (PCA) is applied to dimensionality reduction. These reduced-dimension features are then categorized into distinct output patterns using K-means clustering. Secondly, a two-layer temporal modeling framework of multiple wind farms’ output is established. The upper layer implements a discrete hidden Markov model (HMM) to capture transitions between typical daily output patterns, while the lower layer utilizes a Gaussian mixture model–hidden Markov model (GMM–HMM) to characterize intraday output fluctuations within each pattern. Finally, Monte Carlo sampling is employed to simulate and generate sequences of typical output patterns and their corresponding output values, which are subsequently concatenated chronologically to create comprehensive medium- to long-term output sequence scenarios for multiple wind farms while preserving interfarm correlations. The methodology’s efficacy is validated using historical data from two wind farms in southern China, demonstrating robust performance in capturing both temporal dependencies and spatial correlations in wind power generation patterns.
3. Bilevel Model for Multi-Wind Farm Power Output Time Series Simulation
3.1. An Introduction to Hidden Markov Models
Hidden Markov models (HMMs) provide a powerful framework for modeling stochastic processes with unobservable states that generate observable outputs. These models have demonstrated remarkable effectiveness across diverse domains, including time series analysis, speech recognition, and natural language processing [
22]. The theoretical foundation of HMMs relies on two fundamental assumptions:
(1) The Markov property: the probability distribution of future hidden states depends solely on the current hidden state, exhibiting conditional independence from the sequence of past states;
(2) The output independence property: the probability distribution of each observation in the sequence depends only on the current hidden state, independent of both previous observations and states.
These mathematical properties make HMM particularly suitable for modeling sequential data where the underlying generative process is not directly observable but manifests through measurable outputs.
The mathematical model of HMM can be represented as , with its specific components as follows:
(1) The state space
S represents the set of all hidden states, as shown in Equation (5).
where
si represents the
i-th hidden state and
N denotes the number of hidden states.
(2) The observation sequence
O represents the set of all observations, as shown in Equation (6).
where
Oh denotes the
h-th observation value and
M represents the total number of observations.
(3) The initial state probability distribution
describes the probability of the system being in each hidden state at the initial time point, as expressed in Equation (7).
where
represents the probability of the system being in hidden state i at the initial time point.
(4) The state transition probability matrix
A characterizes the transition probabilities between hidden states, as defined in Equation (8).
where
aij denotes the probability of transitioning from hidden state
si to hidden state
sj.
(5) In this formulation, each element of matrix
B represents the probability of observing output when the system is in hidden state, as shown in Equation (9). The matrix captures the complete relationship between hidden states and observable outputs in the discrete case.
where
bi(
ok) represents the probability of observing
Oh given hidden state
si.
When the observation probability follows a continuous distribution,
B can be represented by
N probability distributions, as shown in Equation (10).
where
bi denotes the probability distribution function governing the observation probability for hidden state
si.
3.2. Modeling of Diurnal Typical Power Output Pattern Sequences Based on Discrete Hidden Markov Models
The historical sequence of typical daily wind power output patterns is segmented into four seasonal sequences to capture the distinct characteristics of wind power generation across different quarters. This segmentation acknowledges the fundamental relationship between wind power generation and solar radiation, which exhibits strong seasonal periodicity. The approach also accounts for seasonal variations in power grid loads driven by meteorological conditions and electricity demand patterns.
The historical sequence of typical daily wind power output patterns Ehis is divided into four quarters—spring, summer, fall, and winter—yielding quarterly sequences of typical daily wind power output patterns denoted as Espr, Esum, Efal, and Ewin. For each quarter, a discrete HMM is constructed where:
(1) Hidden states (1 to N) represent unobservable underlying conditions affecting wind power generation.
(2) Observable variables are the typical daily output patterns (q1 to qr) identified through the earlier clustering analysis.
(3) HMM model parameters are estimated separately for each season to capture season-specific transition dynamics.
3.3. Intraday Power Output Numerical Sequence Modeling Based on GMM-HMM
3.3.1. Gaussian Mixture Model
The Gaussian mixture model (GMM) is a probabilistic model that represents complex data distributions as a weighted combination of multiple Gaussian components [
23]. Through appropriate configuration of mixture components and model parameters, GMM can approximate arbitrary probability distributions with high accuracy, making them particularly effective for characterizing the multidimensional distribution properties and inherent correlations of multi-wind farm power outputs.
The model assumes that the observations of a random variable are generated K potential Gaussian distributions, with its probability density function given by Equation (11).
where
represents d-dimensional observation data;
denotes the mixing coefficient of the k-th Gaussian distribution, satisfying
and
; and
represents the multivariate Gaussian distribution with mean matrix
and covariance matrix
, with its probability density function given by:
3.3.2. Multi-Wind Farm Power Output Time Series Model Based on GMM-HMM
Multi-wind farm power output sequences exhibit both temporal and correlative characteristics. The GMM–HMM model, where GMM serves as the observation probability distribution of HMM, can characterize the temporal properties of wind power output through HMM’s hidden state transition mechanism while utilizing GMM to describe the correlations among multiple wind farms.
Building upon the typical power output pattern clustering results from
Section 2.2, intraday power output numerical samples can be categorized into distinct value sets, each corresponding to a specific output pattern given the distinct wind power output characteristics under different typical patterns. To account for the varying wind power output characteristics across different typical patterns and to improve scenario simulation accuracy, this section establishes corresponding GMM–HMMs for each pattern’s intraday power output numerical samples within the typical pattern set
Q. The model framework employs discrete values from 1 to N to represent hidden states and designates power output values as observation variables. The observation variable at time
t can be expressed as
where
pz(
t) represents the power output of wind farm
z at time
t.
3.4. Model Parameter Estimation
Parameter estimation in hidden Markov models (HMMs) comprises three fundamental components derived from the observation sequence O: the initial state probability distribution , the state transition probability matrix A, and the observation probability distribution parameters B. This study employs the expectation maximization (EM) algorithm to estimate these parameters through iterative optimization of the log-likelihood function of the observation sequence. The process consists of the following steps:
(1) Initialize model parameters .
(2) E-step: calculate the expectation of the log-likelihood function of the observation sequence based on current model parameters.
where
represents the initial values of model parameters;
denotes the updated model parameters after iteration; and
represents the expectation operator.
(3) M-step: solve for parameter values that maximize the likelihood expectation produced in the E-step.
(4) Alternate interactively between the E-step and M-step until convergence to the optimal solution.
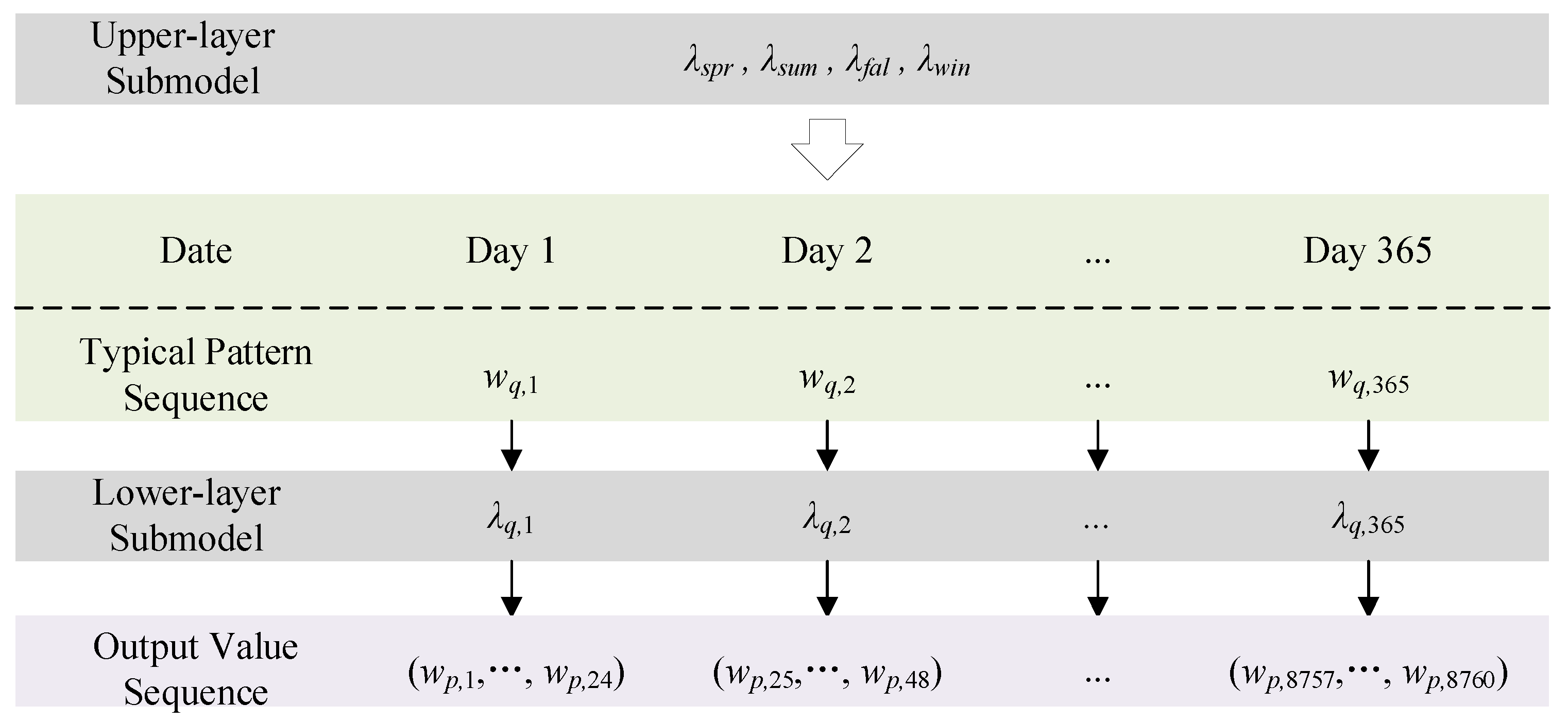
4. Dual-Layer Model for Multi-Wind Farm Power Output Time Series Simulation and Scenario Generation
Based on historical data, four quarterly discrete HMMs and
R GMM–HMMs for power output values under typical output patterns are established, denoted as
, and
, respectively. The simulation process employs Monte Carlo sampling in two stages: first, generating a typical output pattern sequence
Wq for all 365 days using the quarterly discrete HMM, then producing an 8760-h power output sequence
Wp for multiple wind farms throughout the year using the GMM–HMM, where the daily power output in conditioned on the previously generated output pattern sequence. The hierarchical structure of the dual-layer model for simulating multi-wind farm power output time series is shown in
Figure 1, where
,
.
4.1. Scenario Generation for Typical Power Output Pattern Sequences
For a scenario length of Yspr days in spring, the scenario generation process is as follows:
(1) Calculate the cumulative state transition matrix based on the state transition probability matrix of ;
(2) Sample the initial state sspr,1 for day y = 1 based on the initial state probability of ;
(3) For current day y with a hidden state sspr,y = si, sample from row i of the observation probability matrix Bspr to obtain the current day’s output pattern qspr,y;
(4) To determine the hidden state for the next day, generate a random number u from uniform distribution U(0,1). Compare u with the elements in row i of Cspr. If u falls between the element in column j j + 1 of row i, set the hidden state sspr,y+1 for the next day to sj;
(5) Repeat steps 3–4 until y equals Yspr.
These steps are executed sequentially for all four seasons using their respective models. The resulting seasonal scenarios are then concatenated to generate a complete 365-day typical output pattern sequence for the entire year.
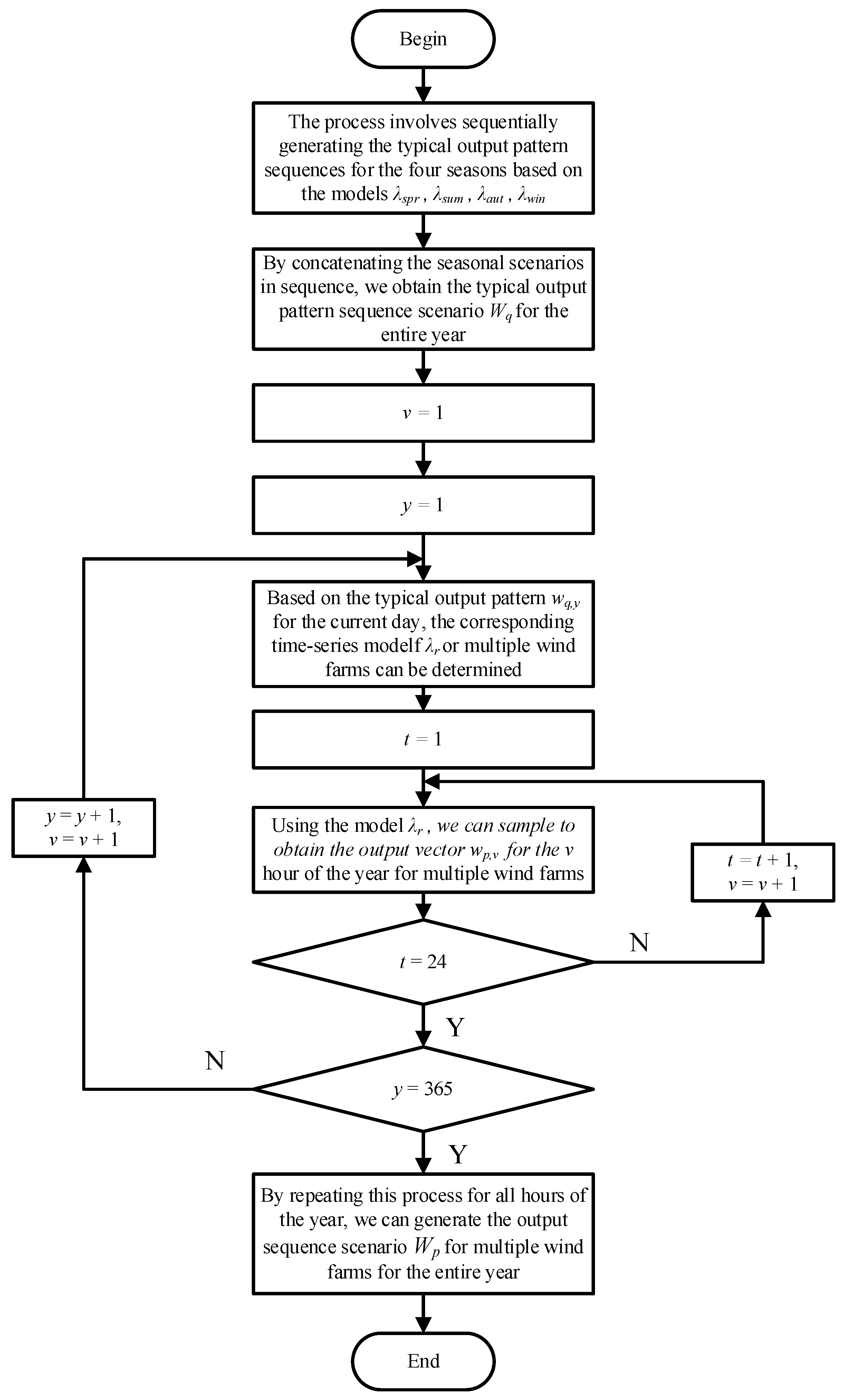
4.2. Generation of Power Output Numerical Sequence Scenarios
The annual wind power output sequence of 8760 h is denoted as , where v represents the hour index. The steps for generating the multi-wind farm output sequence scenario are as follows:
(1) For current day y with typical output pattern wq,y = qr, select the corresponding sequence model for multi-wind farm power output.
(2) Calculate the cumulative state transition matrix from state transition probability matrix associated with .
(3) Sample the initial hidden state for current day using initial state probability distribution of the model.
(4) Sample the Z-dimensional power output vector wp,v of the multi-wind farms at the v-th hour of the year from the observation probability distribution bi corresponding to the hidden state at time t.
(5) To determine the hidden state for the next time step, generate a random number x from the uniform distribution U (0,1). Compare x with the elements of the i-th row of Cr. If x falls between the j-th and the (j + 1)-th element of the i-th row, set the hidden state as for the next moment.
(6) Check whether t ≤ 24. If not, then t = t + 1, v = v + 1, and returns to step 4. If t ≤ 24, then y = y + 1, t = 1, v = v + 1, and returns to step 1. Continue the iterative process until y = 365.
The complete process flowchart is illustrated in
Figure 2.
4.3. Scenario Evaluation Indicators
4.3.1. Randomness Indicators
The root mean square error (RMSE) and mean absolute error (MAE) are employed to quantitatively access the discrepancy between the generated scenarios and actual scenarios. The RMSE is particularly sensitive to large deviations, making it effective for evaluating instances where the generated power values exhibit substantial departures from the actual measurements. The mathematical formulation of RMSE is presented in Equation (16). The MAE provides a measure of the average difference between the generated scenarios and the actual scenarios. The mathematical expression for MAE is given in Equation (17).
Where
wact,v is the actual power output vector of the multi-wind farms at the
v-th hour.
4.3.2. Statistical Characteristics Indicators
The Wasserstein distance between the probability distribution function of the generated and historical power outputs serves as a metric to evaluate the statistical characteristics of the scenarios. The Wasserstein distance measure effectively quantifies the structural discrepancies between two probability distributions. Through computing the Wasserstein distance between the distribution of generated scenarios and historical data, the fitting degree of the generated scenarios to the historical data distribution characteristics is assessed. This assessment validates the capability of the generated scenarios to preserve the essential statistical characteristics inherent in the historical observations.
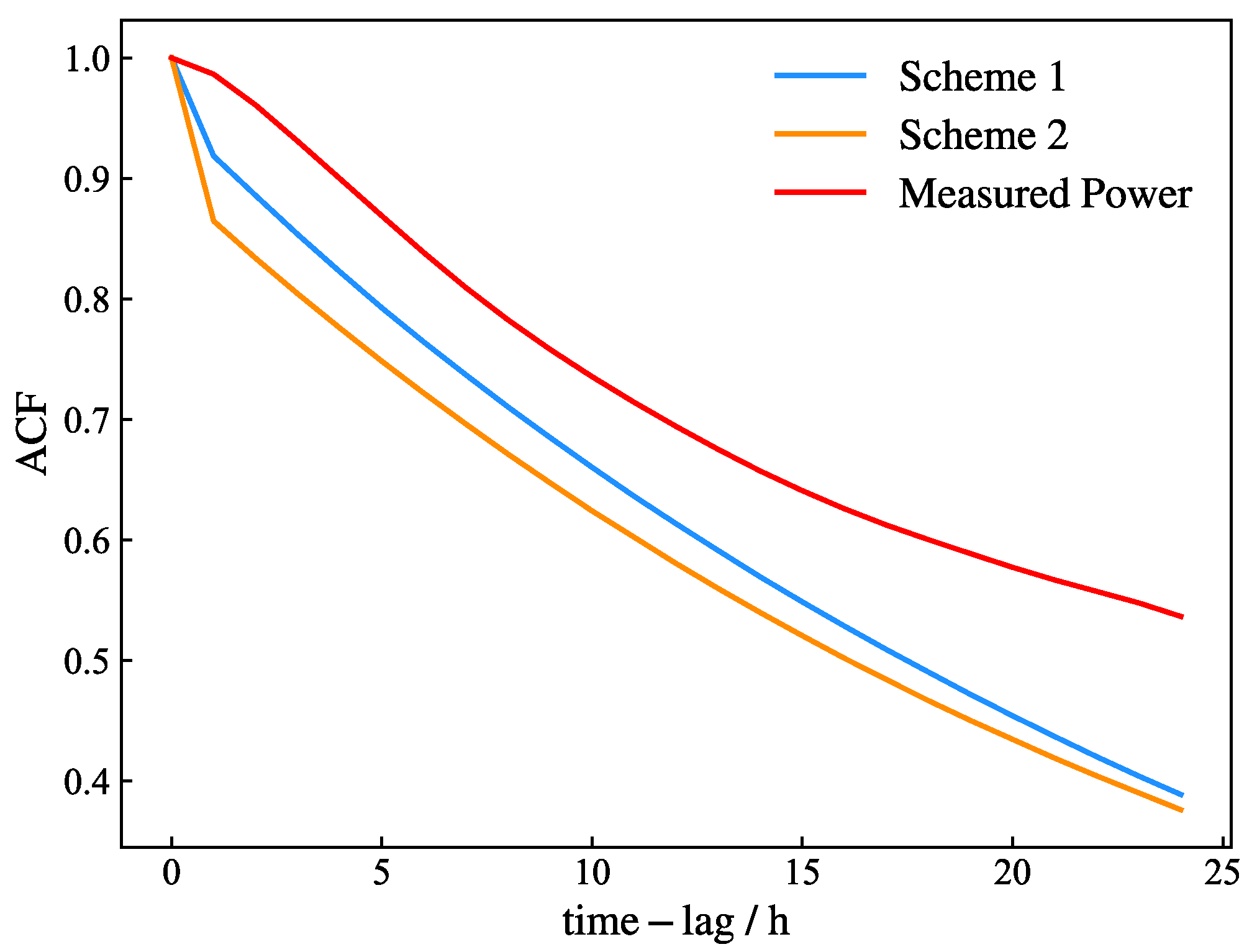
4.3.3. Temporal Characteristics Indicators
The temporal dependency structure of wind power output scenarios can be quantitatively characterized using the autocorrelation function (ACF), which captures the sequential relationships inherent in time series data. For a time series {
u1, …,
ut, …,
un}, the ACF at lag
l is mathematically formulated in Equation (18).
where
denotes the covariance;
denotes the variance.
4.3.4. Correlation Indicators
The cross-correlation function (CCF) characterizes the dynamic correlation structure between two time series as a function of their temporal displacement. The CCF is introduced in this paper to quantify the spatiotemporal dependencies between power output sequence scenarios across multiple wind farms. For two time series {
u1, …,
ut, …,
un} and
, the CCF at lag
l is mathematically expressed in Equation (19)
7. Conclusions
This paper presents a novel scenario generation method for long-term multi-wind farm power output sequences that integrates daily power output patterns with intraday fluctuations. The case studies yield the following conclusions:
(1) The proposed mode-specific modeling approach enhances accuracy by addressing each typical pattern independently, thereby avoiding the sample interference that commonly occurs in aggregate modeling. This targeted approach significantly improves the model’s ability to capture distinct operational characteristics.
(2) The method proposed in this paper adopts a two-layer modeling framework. While considering the spatiotemporal correlation of the power outputs of multiple wind farms, it also takes into account both the short-term stochastic characteristics and long-term changing trends of wind power generation, thus enabling a more accurate description of wind power characteristics.
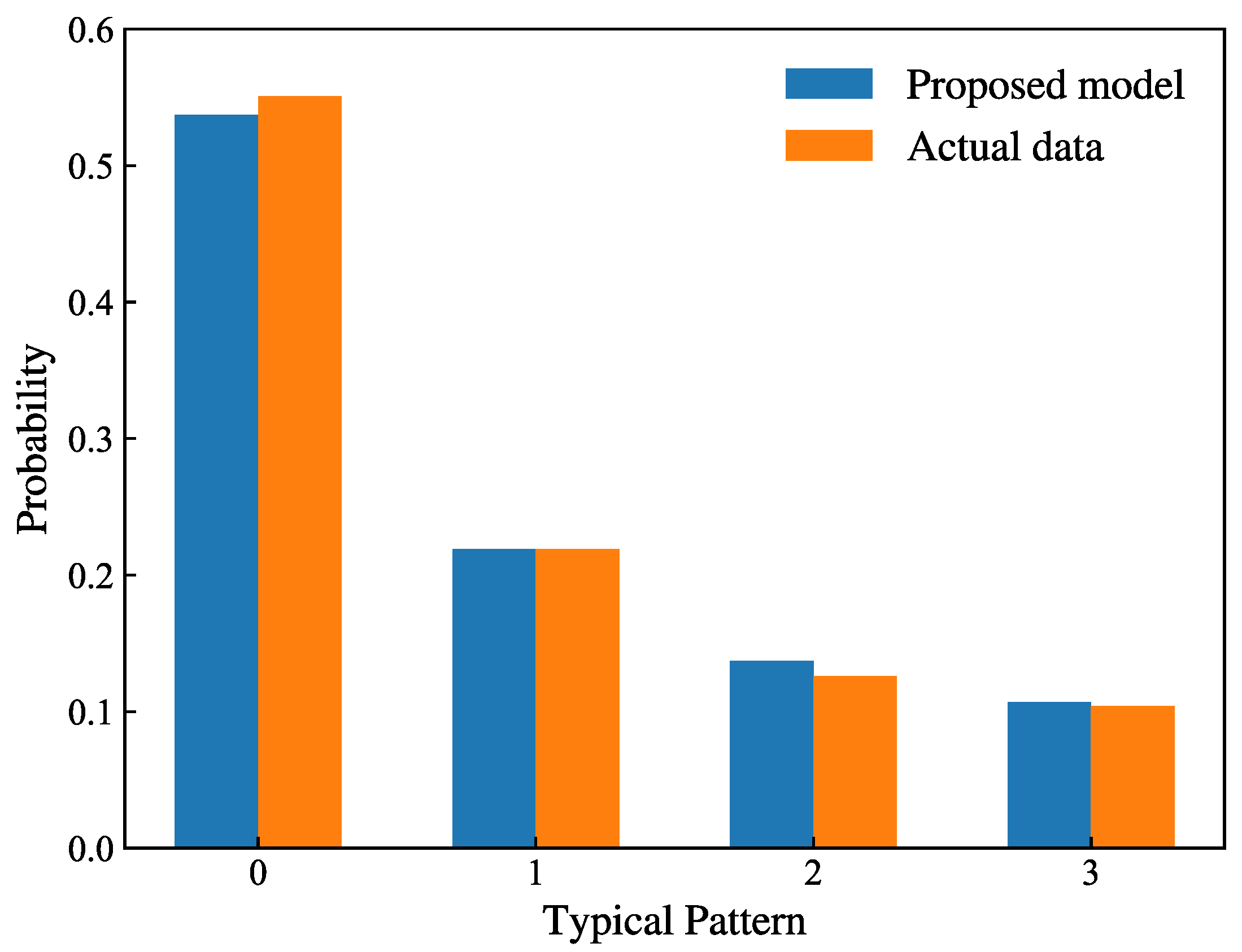
(3) Comparative analysis across multiple performance metrics demonstrates that, compared to the comparison methods, the proposed method reduces the error index by 18% and decreases the Wasserstein distance between the empirical distribution of the scenario set and the historical output distribution by 20%, effectively improving the quality of the scenarios. The case studies show that the proposed method can accurately restore the statistical characteristics, temporal characteristics, sequence correlation, and seasonal characteristics of the output of multiple wind farms. These high-quality scenarios provide valuable insights for power system operation simulation, enabling more robust generation scheduling strategies and enhanced wind power integration capabilities.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}